




![Jeff Z. Pan (University of Aberdeen) RDF: Standard for Directed Labelled Graph KBs for the Web • RDF is • a modern version of semantic network, with formal syntax and semantics • a standard model for data interchange on the Web • RDF statements: Subject-property-value triples [my-‐chair colour tan .] [my-‐chair rdf:type chair .] [chair rdfs:subClassOf furniture .] 7](https://image.slidesharecdn.com/kgjist2014-150410070542-conversion-gate01/75/Linked-Data-and-Knowledge-Graphs-Constructing-and-Understanding-Knowledge-Graphs-7-2048.jpg)


















![Jeff Z. Pan (University of Aberdeen) GoodRelaAons GoodRelations is a lightweight ontology for annotating offerings and other aspects of e-commerce on the Web. [Slide credit: MarLn Hepp] 33](https://image.slidesharecdn.com/kgjist2014-150410070542-conversion-gate01/75/Linked-Data-and-Knowledge-Graphs-Constructing-and-Understanding-Knowledge-Graphs-33-2048.jpg)
![Jeff Z. Pan (University of Aberdeen) GoodRelaAons – use cases [Slide credit: MarLn Hepp] 34](https://image.slidesharecdn.com/kgjist2014-150410070542-conversion-gate01/75/Linked-Data-and-Knowledge-Graphs-Constructing-and-Understanding-Knowledge-Graphs-34-2048.jpg)

































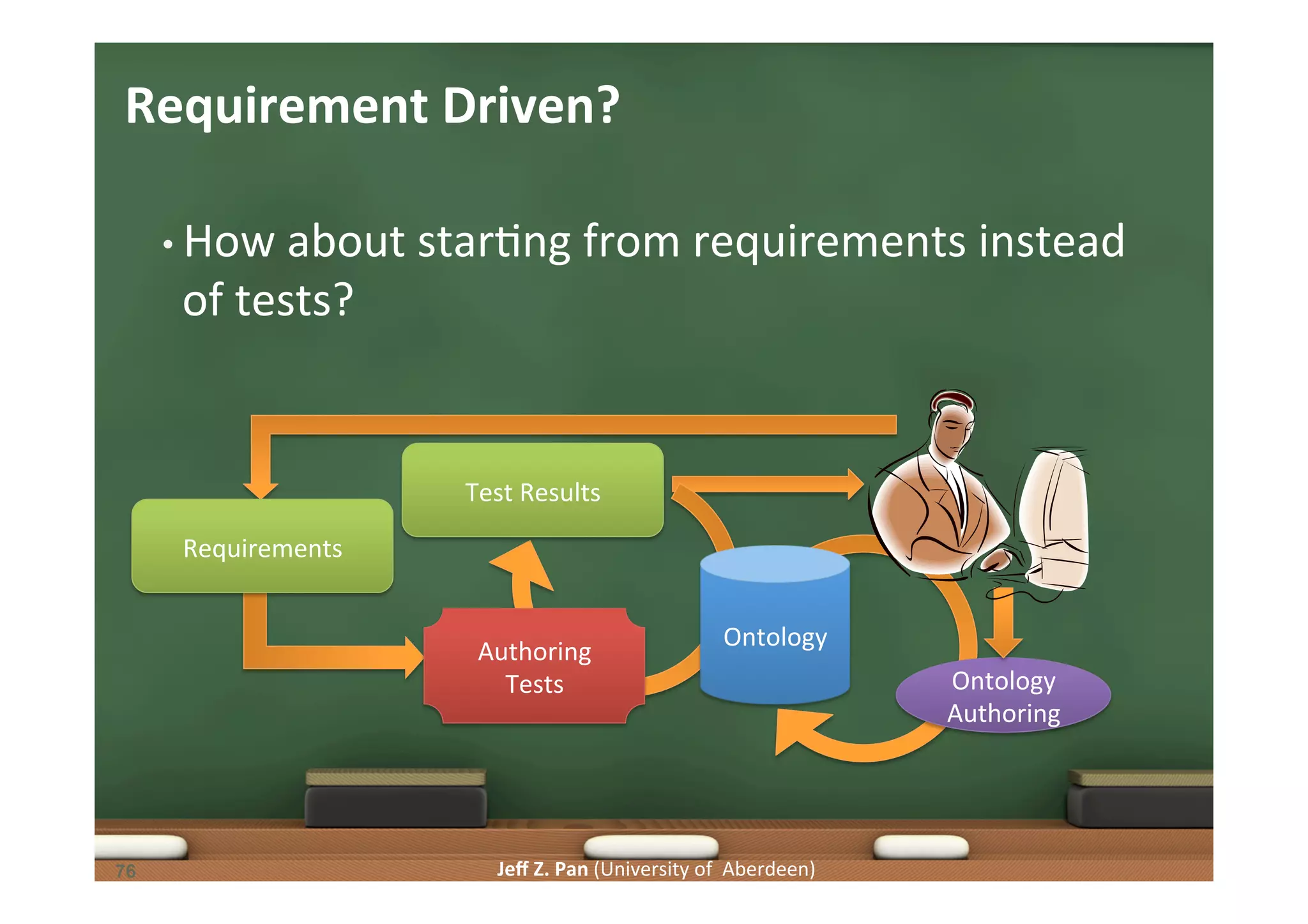
![Jeff Z. Pan (University of Aberdeen) Requirement-‐Driven Ontology Authoring [Ren et. al, 2014] • Key questions • RQ1: what forms of requirements should we consider • RQ2: how to generate authoring tests from requirements 77 77](https://image.slidesharecdn.com/kgjist2014-150410070542-conversion-gate01/75/Linked-Data-and-Knowledge-Graphs-Constructing-and-Understanding-Knowledge-Graphs-77-2048.jpg)


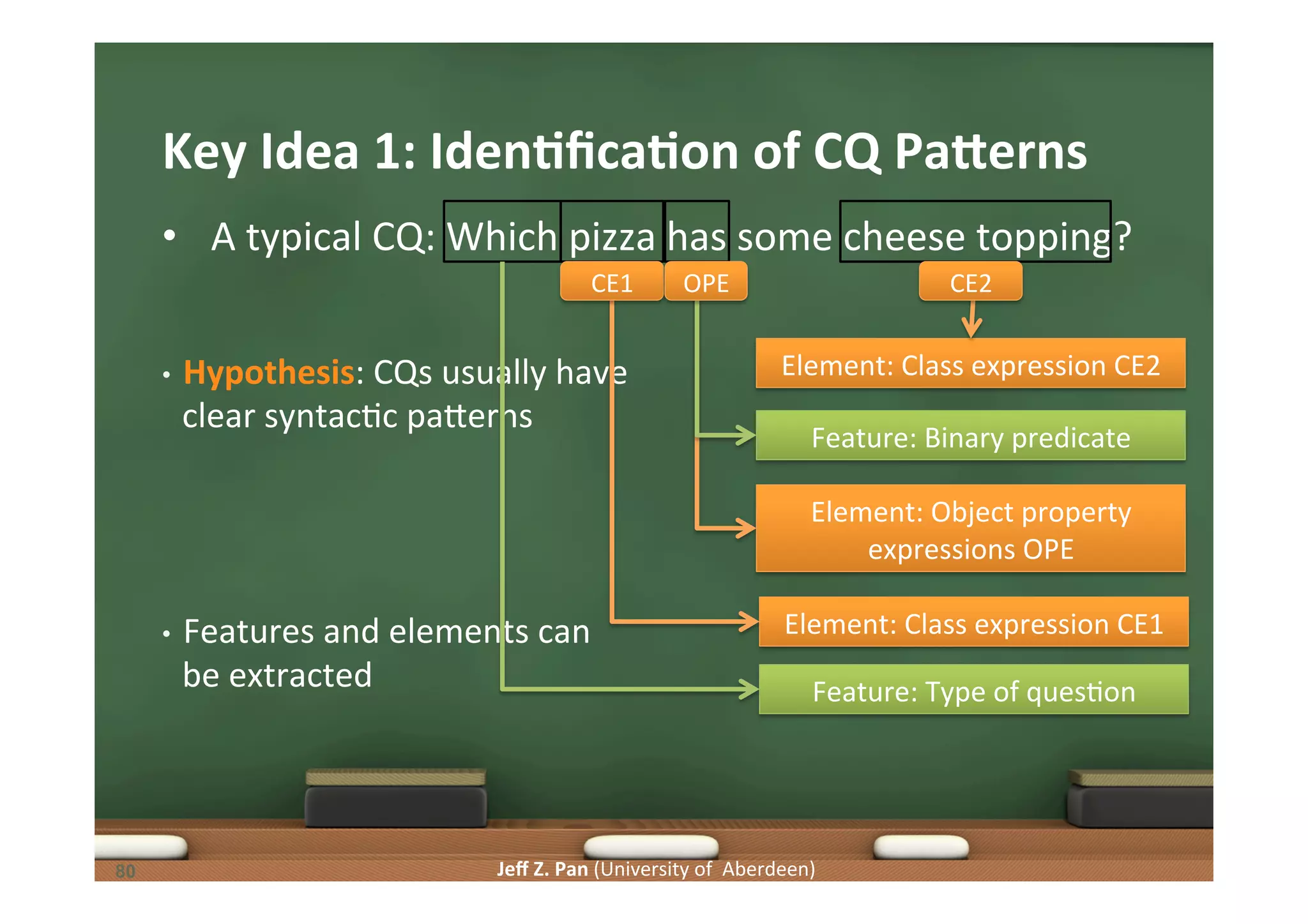
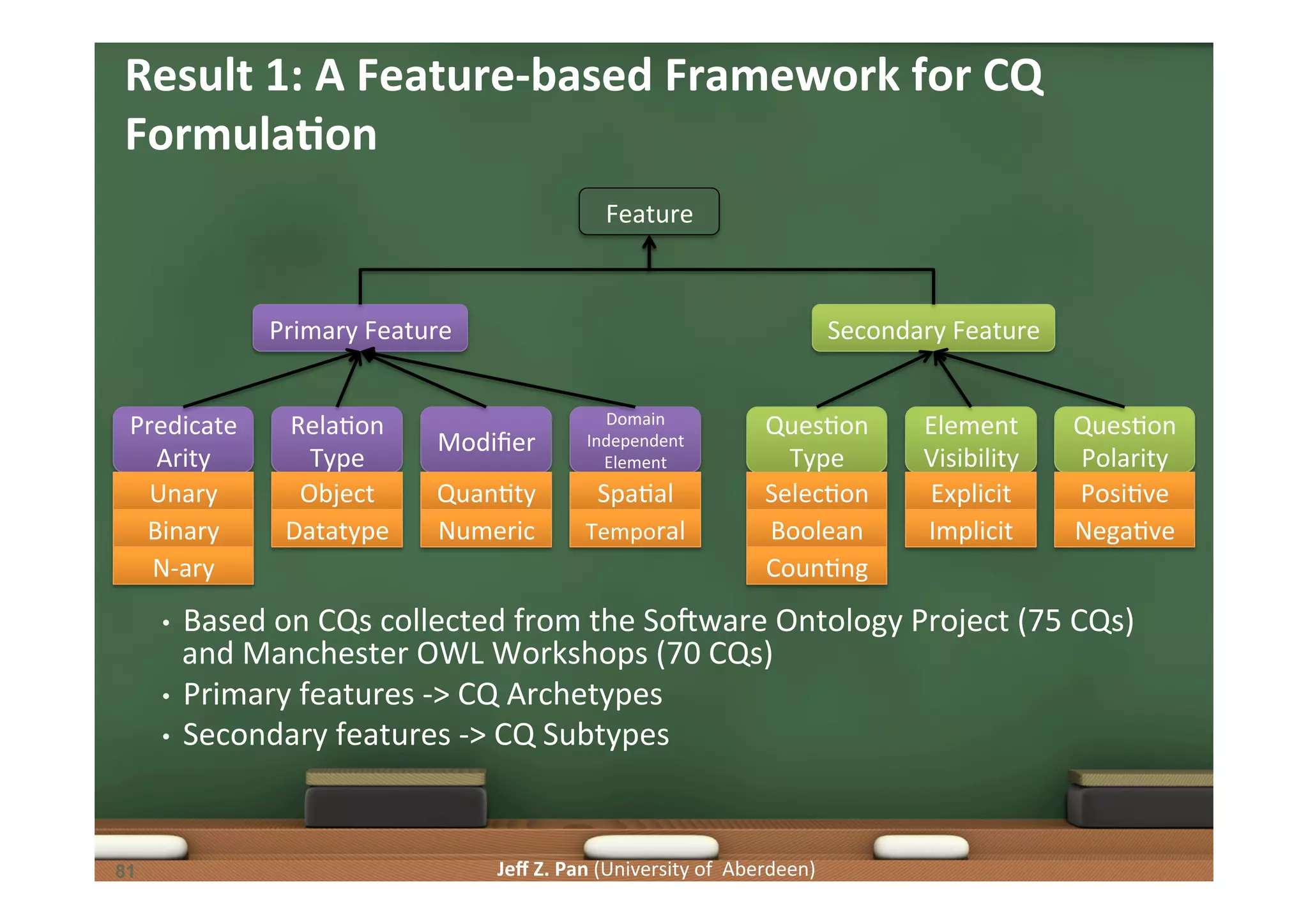
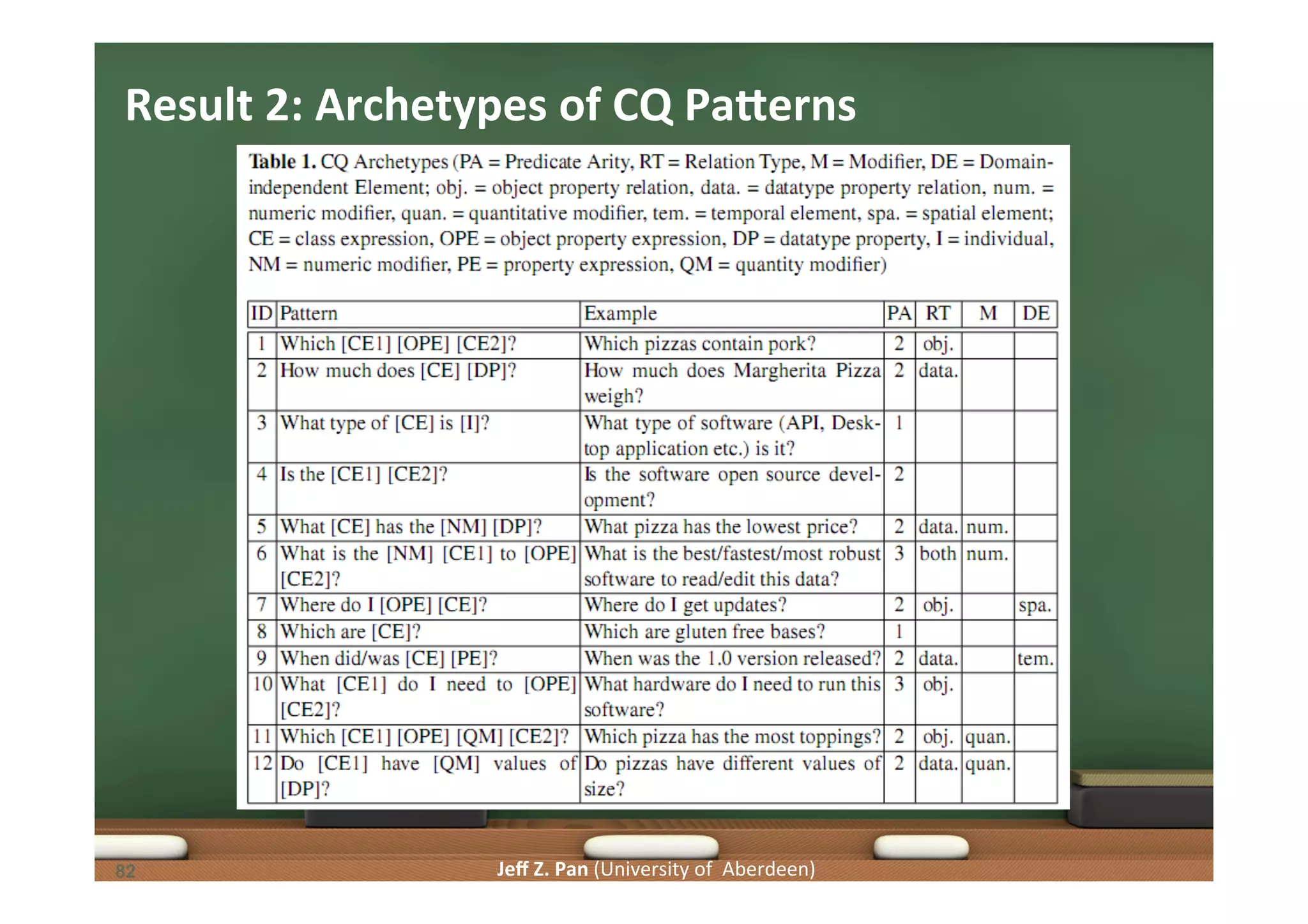



![Jeff Z. Pan (University of Aberdeen) CQs and Authoring Tests • A typical CQ: Which pizza has some cheese topping? • SaLsfiability of CQ presupposiLons can be verified by authoring tests generated based on its features and elements • Classes Pizza, CheeseTopping should occur in the ontology • [CE1], [CE2] should both occur in the class vocabulary • Property has(Topping) should occur in the ontology • [OPE] should occur in the property vocabulry • The ontology should allow Pizza to have CheeseTopping • should be sa6sfiable • The ontology should also allow Pizza to not have CheeseTopping • should be sa6sfiable CE1 OPE CE2 86](https://image.slidesharecdn.com/kgjist2014-150410070542-conversion-gate01/75/Linked-Data-and-Knowledge-Graphs-Constructing-and-Understanding-Knowledge-Graphs-86-2048.jpg)











![Jeff Z. Pan (University of Aberdeen) Understanding Data Redundancy [Wu et. al, 2014] 104](https://image.slidesharecdn.com/kgjist2014-150410070542-conversion-gate01/75/Linked-Data-and-Knowledge-Graphs-Constructing-and-Understanding-Knowledge-Graphs-104-2048.jpg)

![Jeff Z. Pan (University of Aberdeen) Candidate Insighpul Queries [Pan, et al, 2013] • Graph paSerns are summarisaLons that represent many subsets of the RDF graph • PaSern structure • Structured knowledge, which is difficult to express with schema • Such as star, chain, tree, loop • Correspondences between mulLple graph paSerns • Strongly corresponding paSerns (large overlapping) • Weakly corresponding paSerns (liSle overlapping) • ExcepLons 107](https://image.slidesharecdn.com/kgjist2014-150410070542-conversion-gate01/75/Linked-Data-and-Knowledge-Graphs-Constructing-and-Understanding-Knowledge-Graphs-107-2048.jpg)






The document is a tutorial on linked data and knowledge graphs presented by Jeff Z. Pan and others from the University of Aberdeen. It covers topics such as the current status of linked data, methods for constructing and understanding knowledge graphs, and applications, as well as research challenges in the field. Key examples discussed include DBpedia, Wikidata, and GoodRelations as linked data knowledge repositories.
Introduction to JIST2014 tutorial on constructing and understanding knowledge graphs, with an agenda overview.
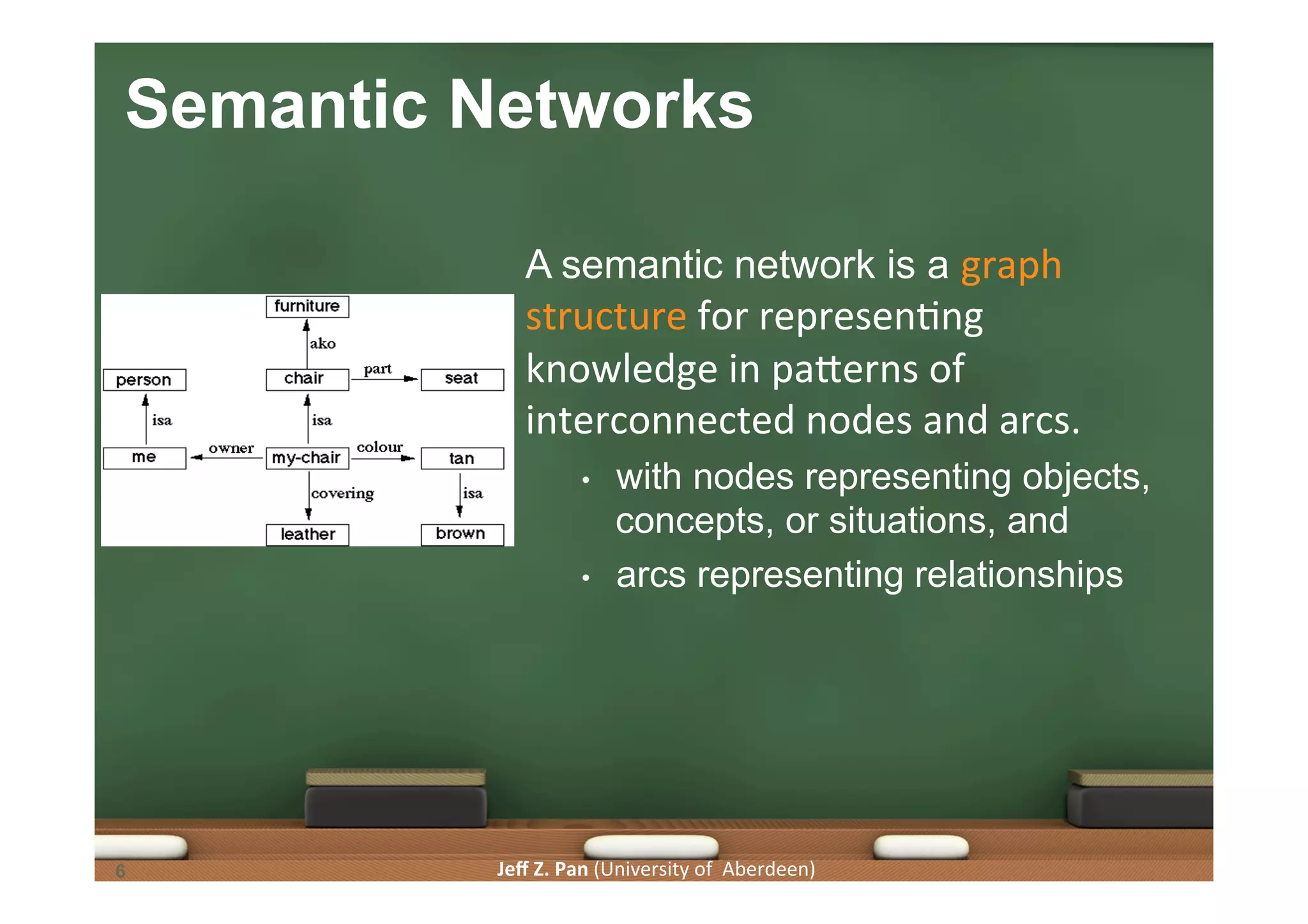
Discussion of knowledge characteristics, semantic networks as graph structures, and RDF as a model for web data interchange.
Overview of knowledge graph services, construction, evaluation challenges, and applications in structured querying.
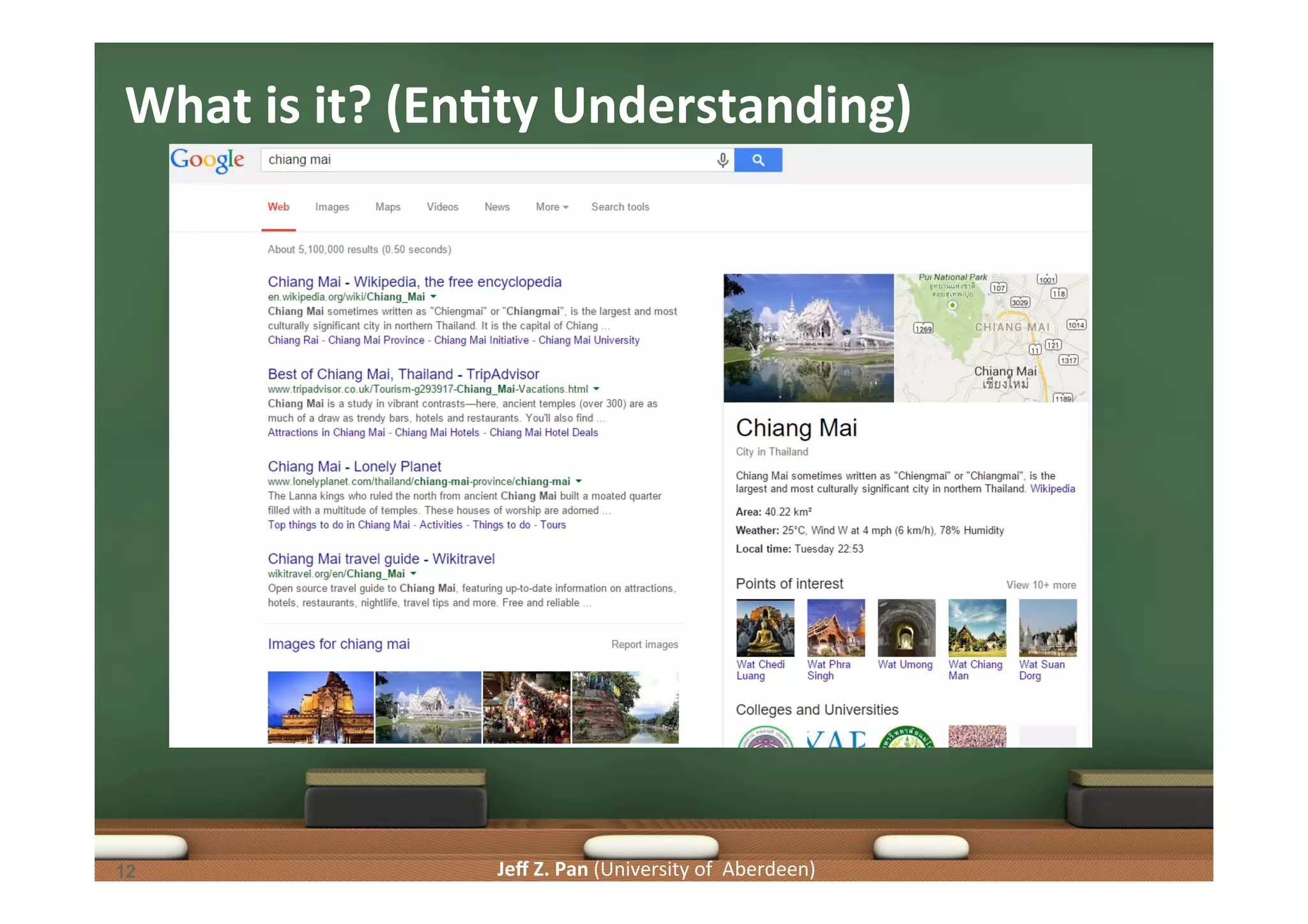
Entities defined in knowledge graphs, querying for attributes, and transforming to structured outputs.
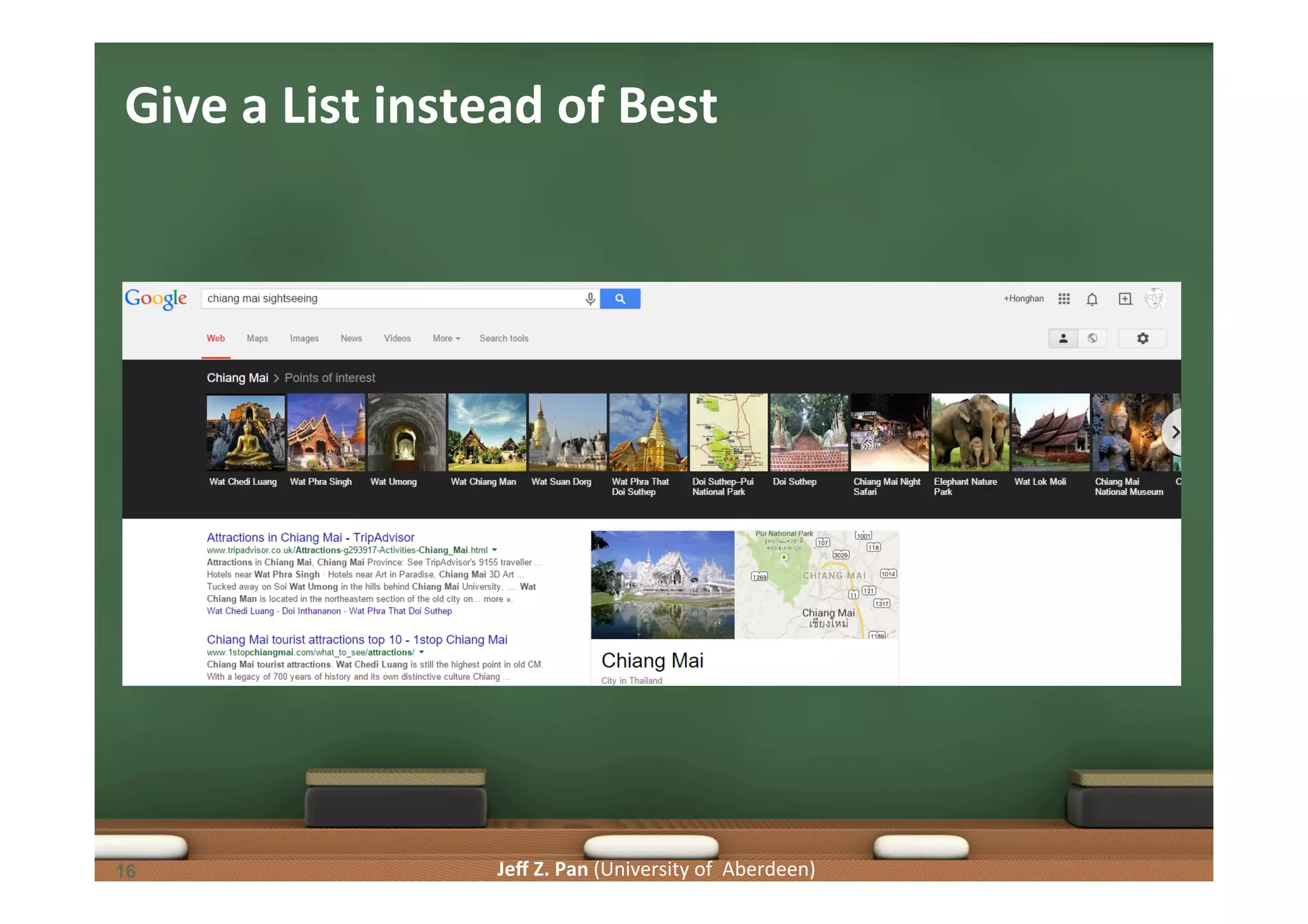
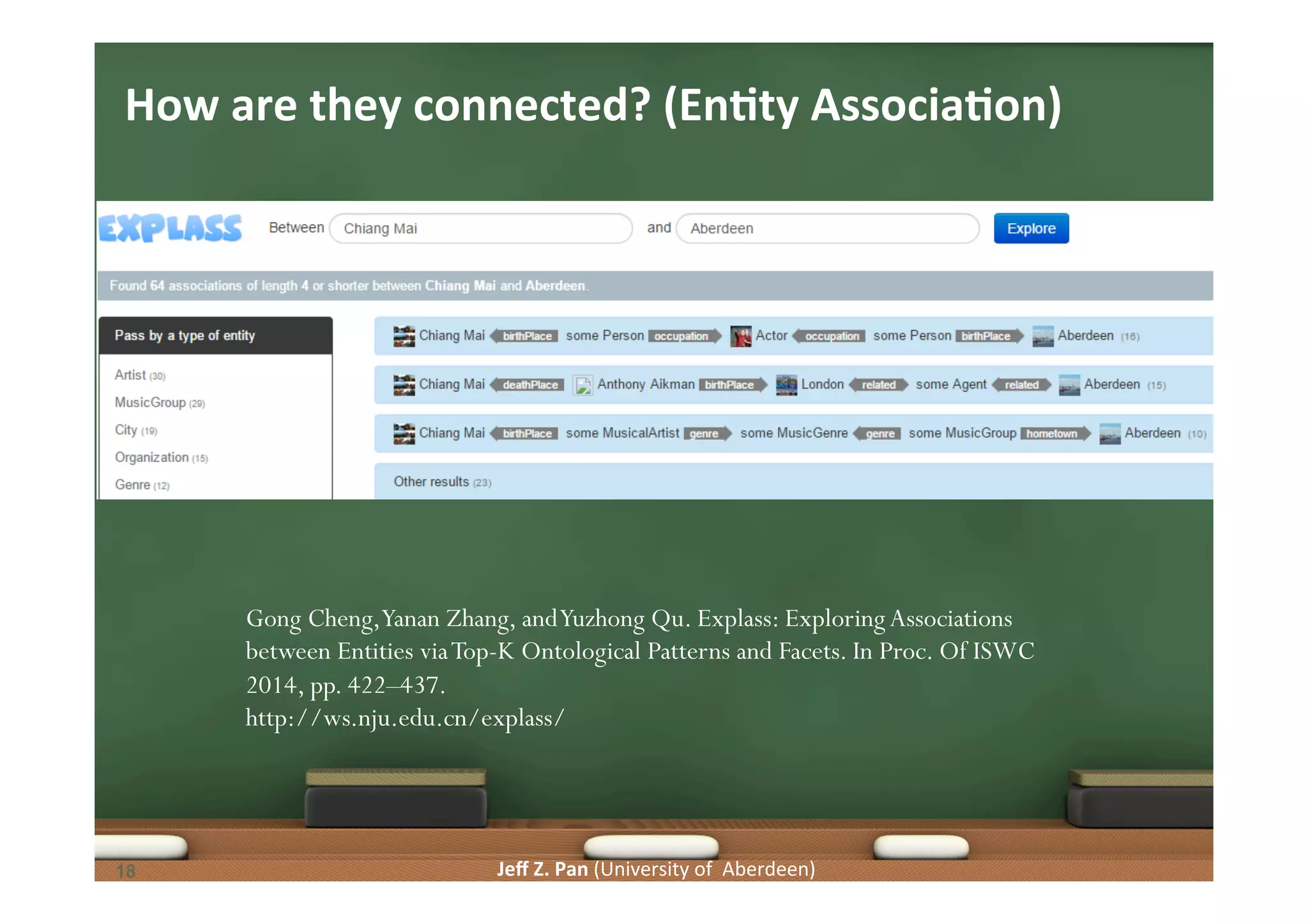
Associating entities, structured queries from keywords, and identifying relationships through knowledge graphs.
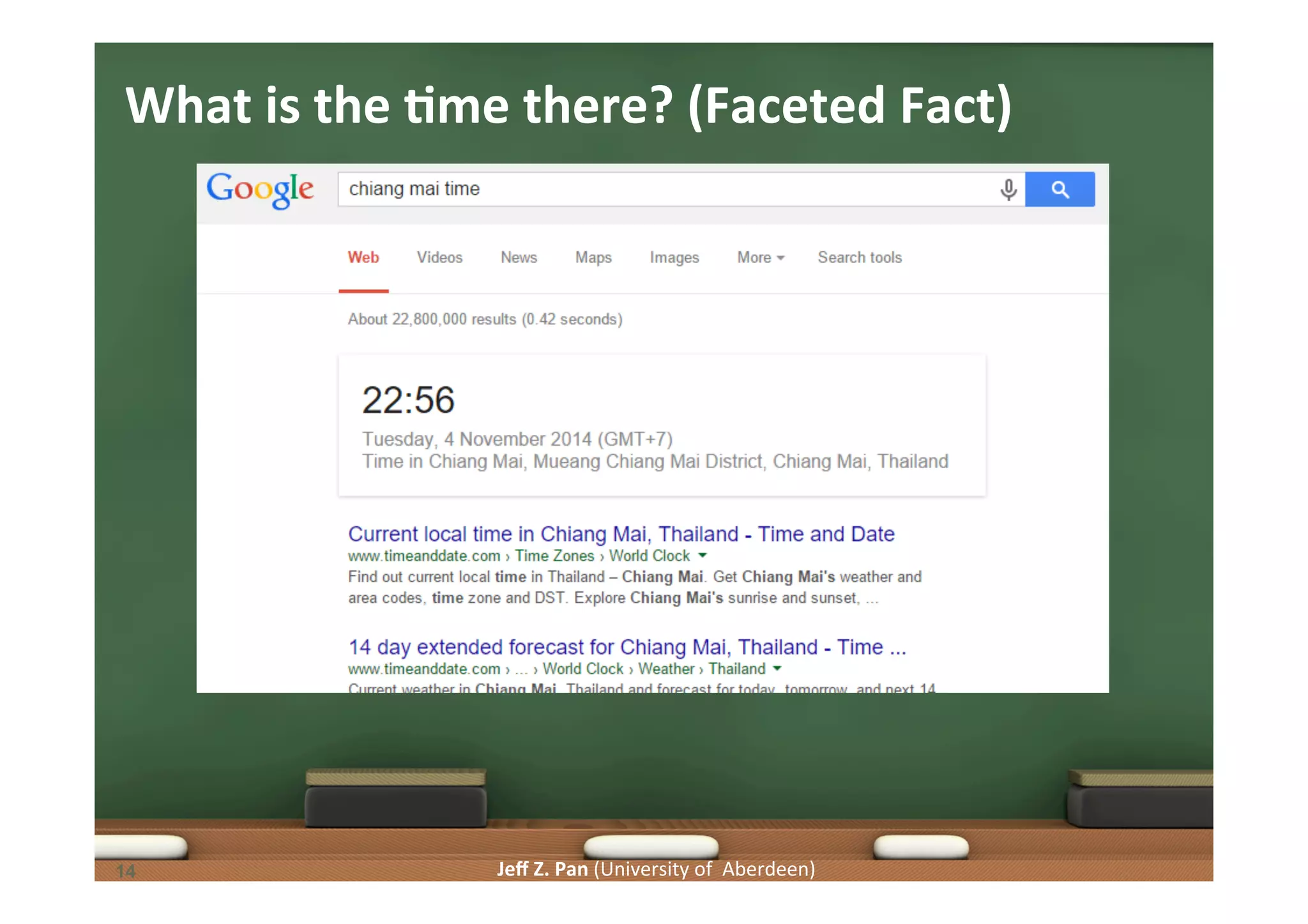
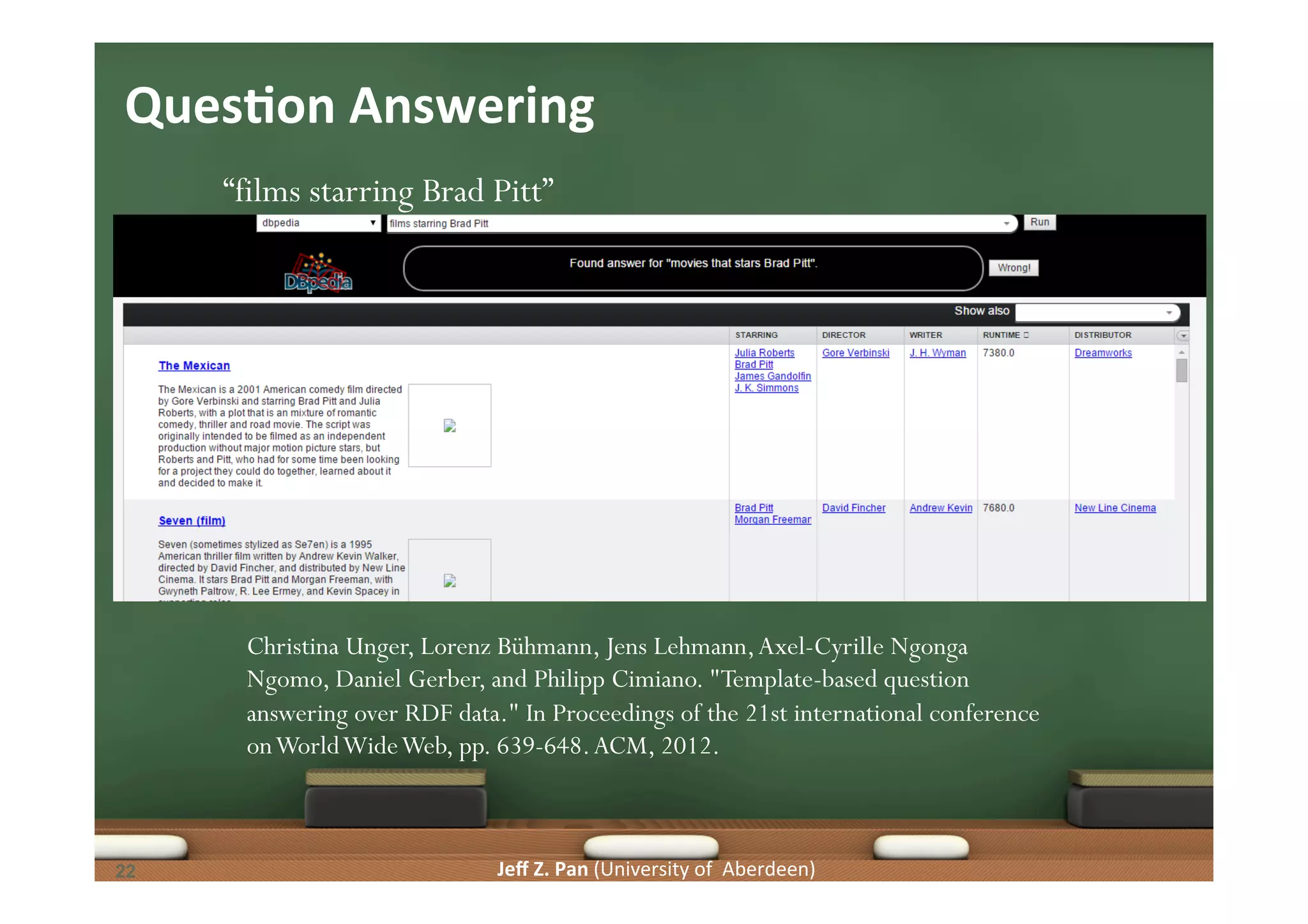
Computing answers using knowledge graphs and the context of queries to improve retrieval effectiveness.
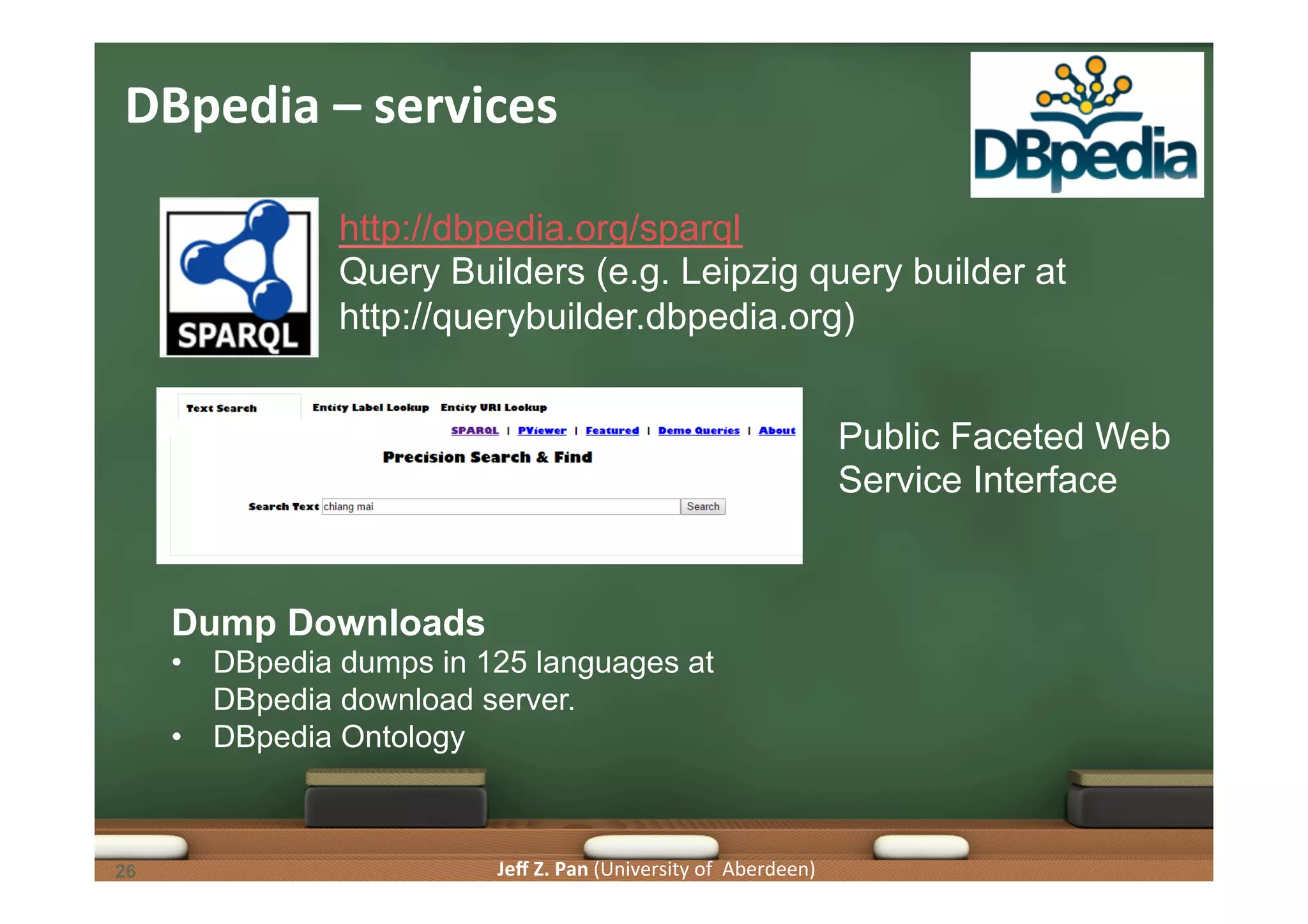
Examples of linked data repositories such as DBpedia and its features, services, and use cases.
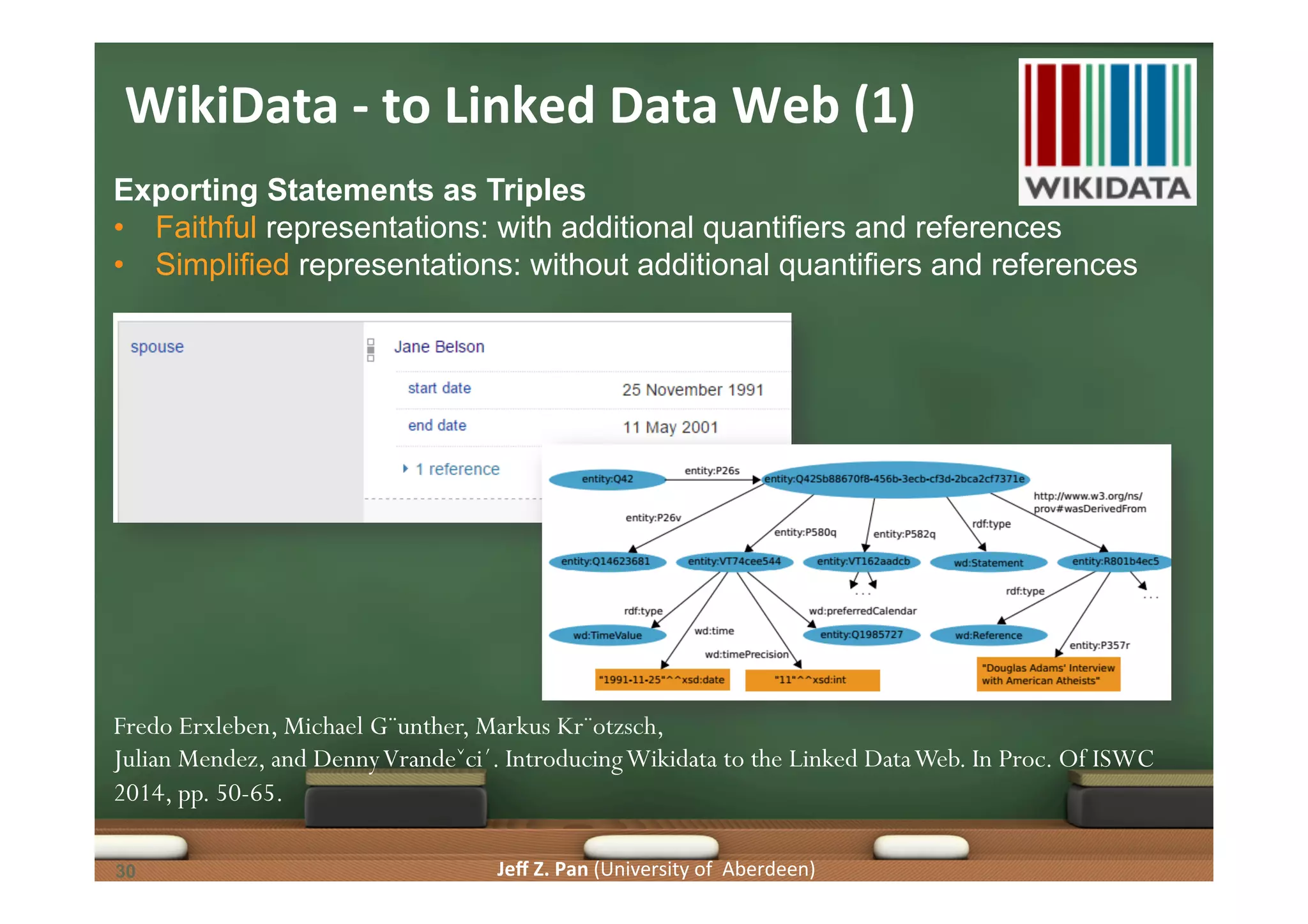
Overview of WikiData's collaborative features, data access methods, and linking with linked data web.
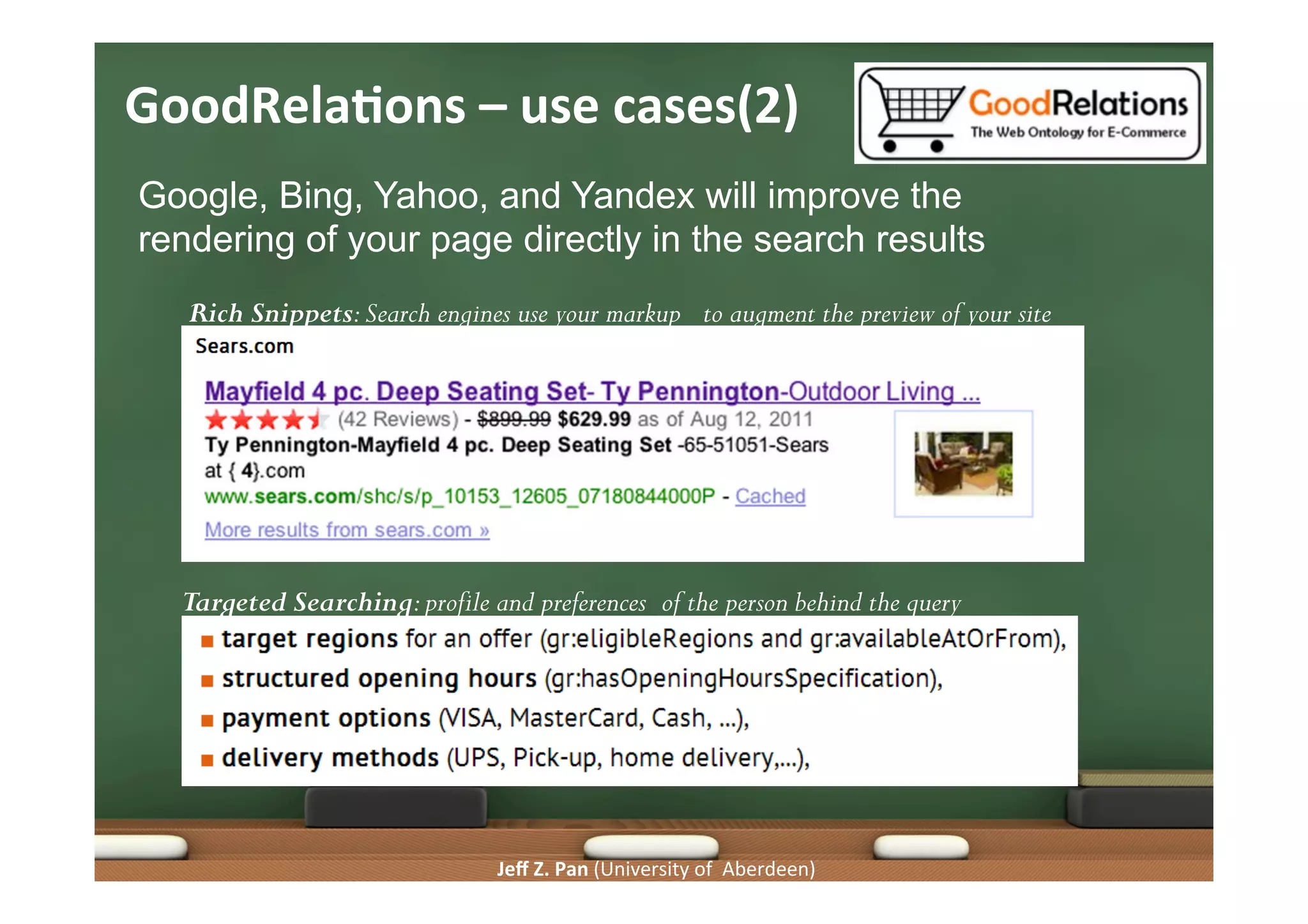
Introduction to GoodRelations ontology for e-commerce data annotation and its significance in improving search.
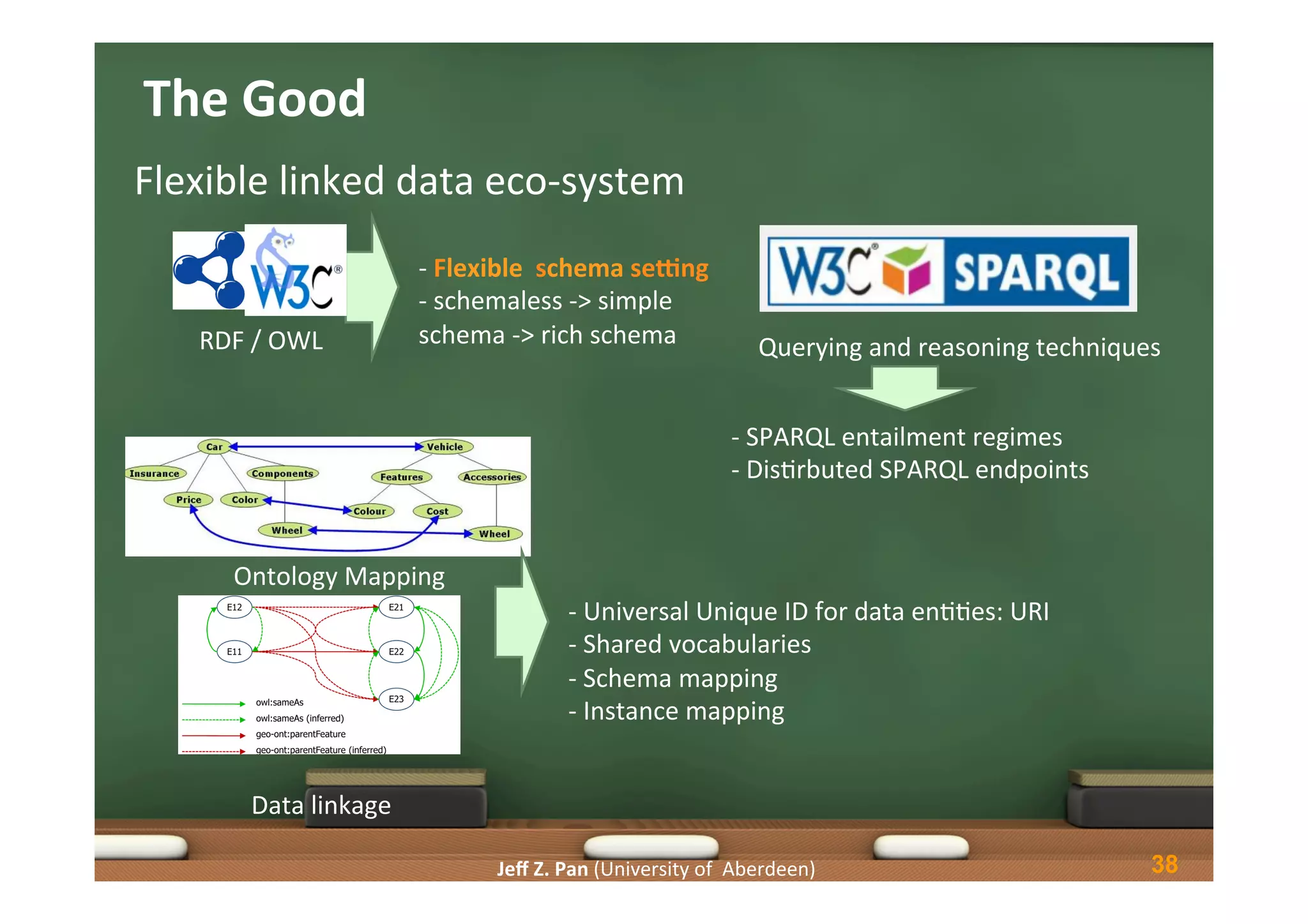
Overview of advantages and disadvantages associated with linked data, including data quality and schema issues.
Identifying key challenges in knowledge graph construction, including quality evaluation and data understanding.
Key challenges in entity identification, data lifting, and user understanding of knowledge graphs.
Dynamic properties of knowledge, real-time access requirements, and the need for efficient services.
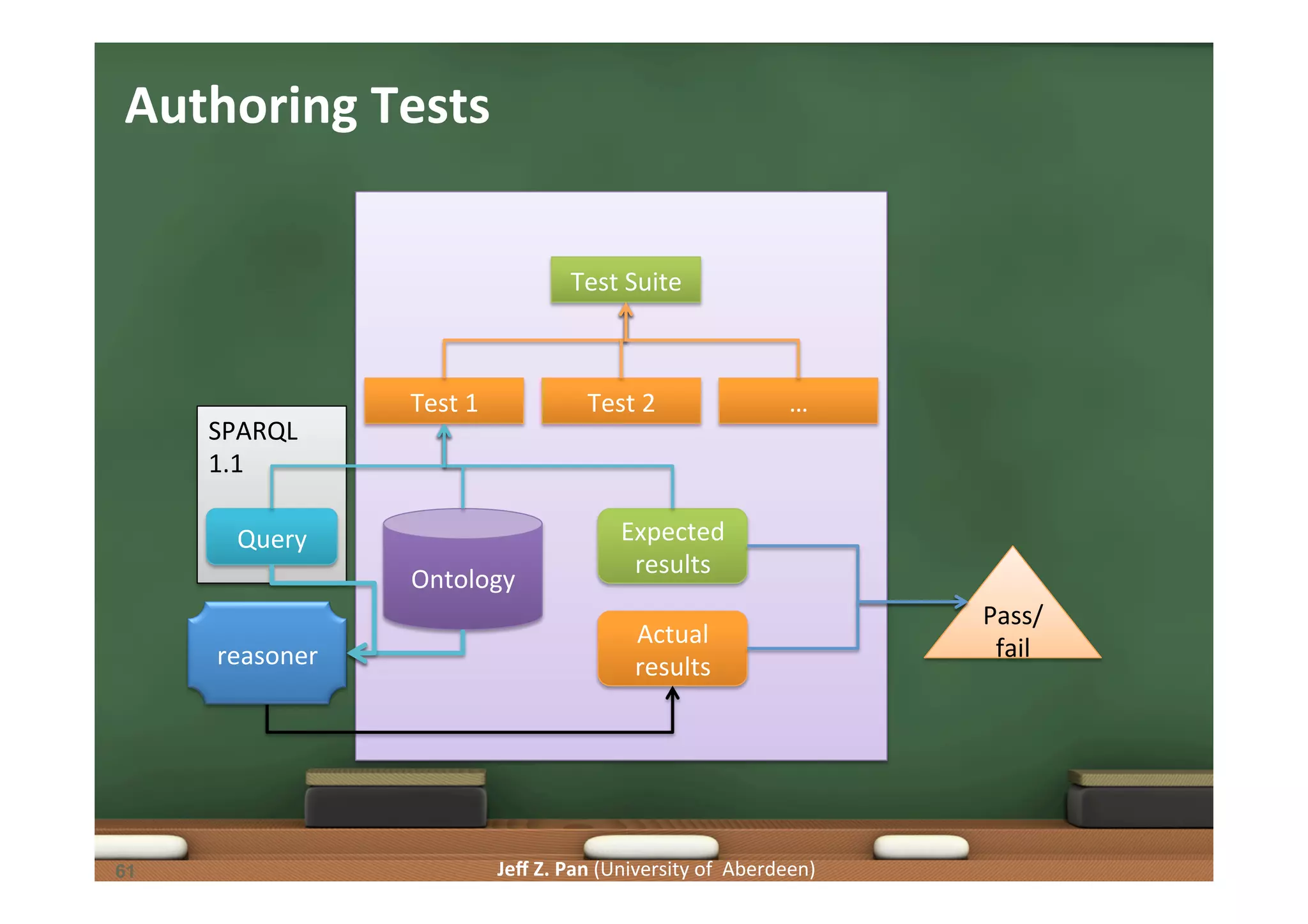
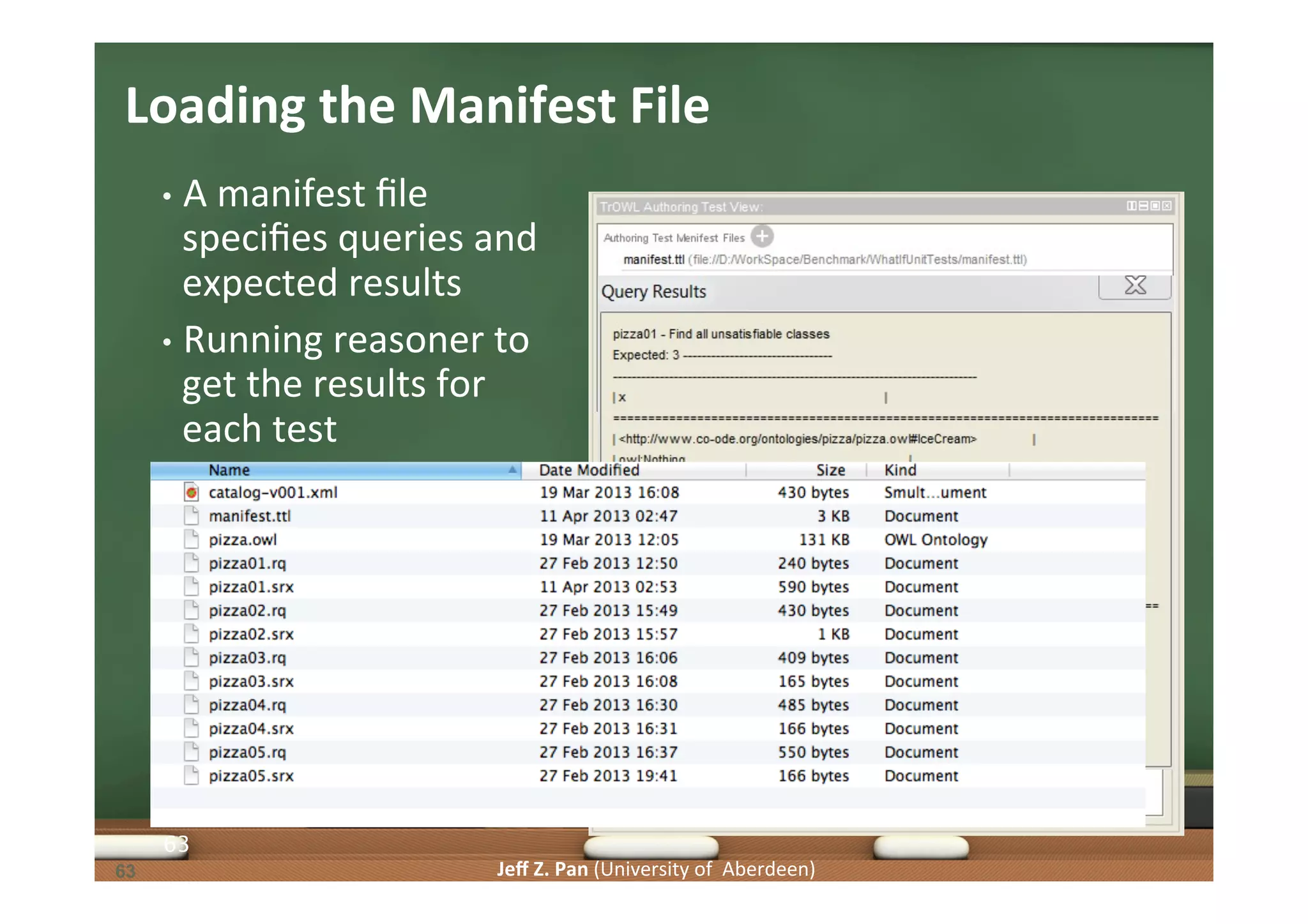
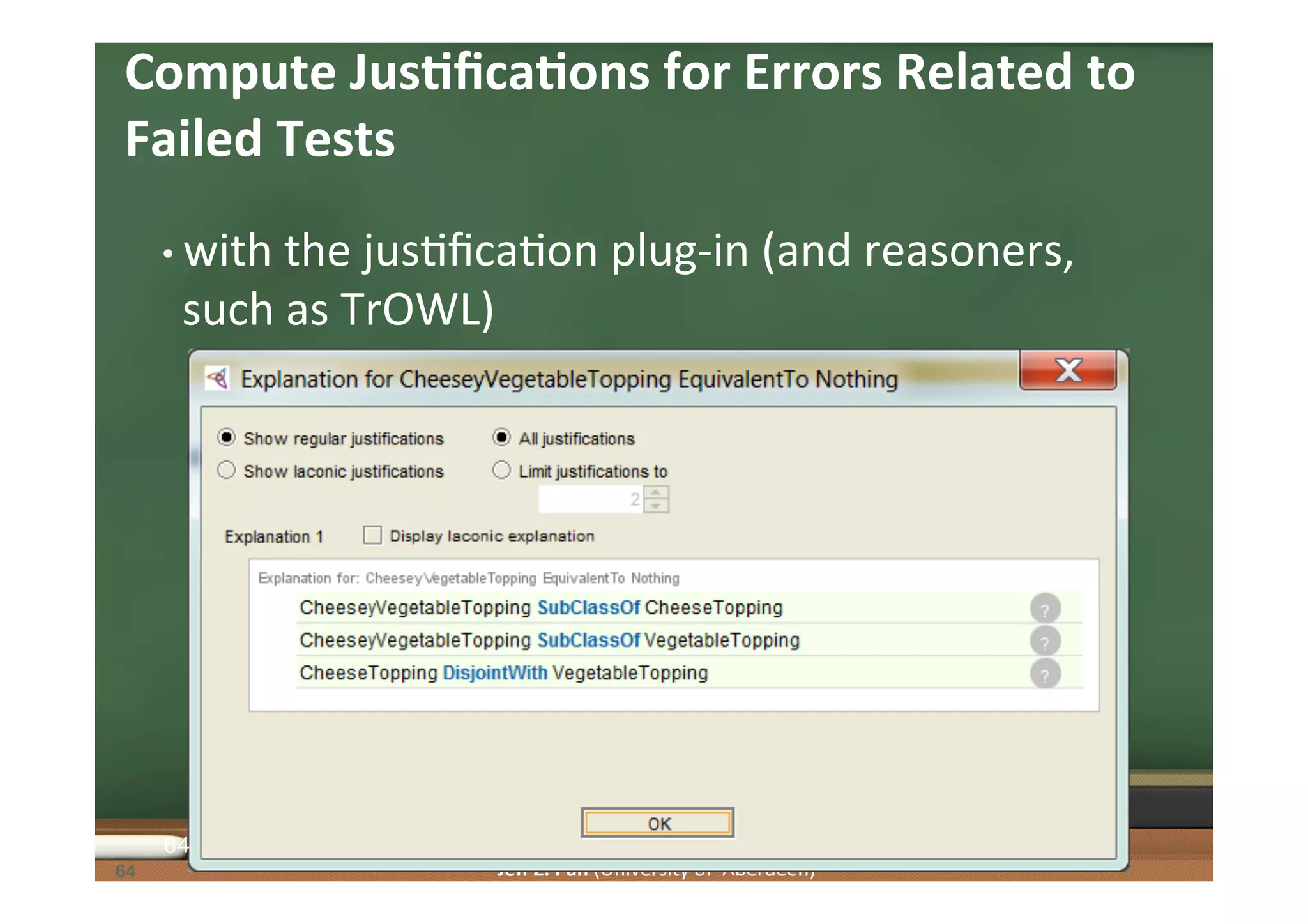
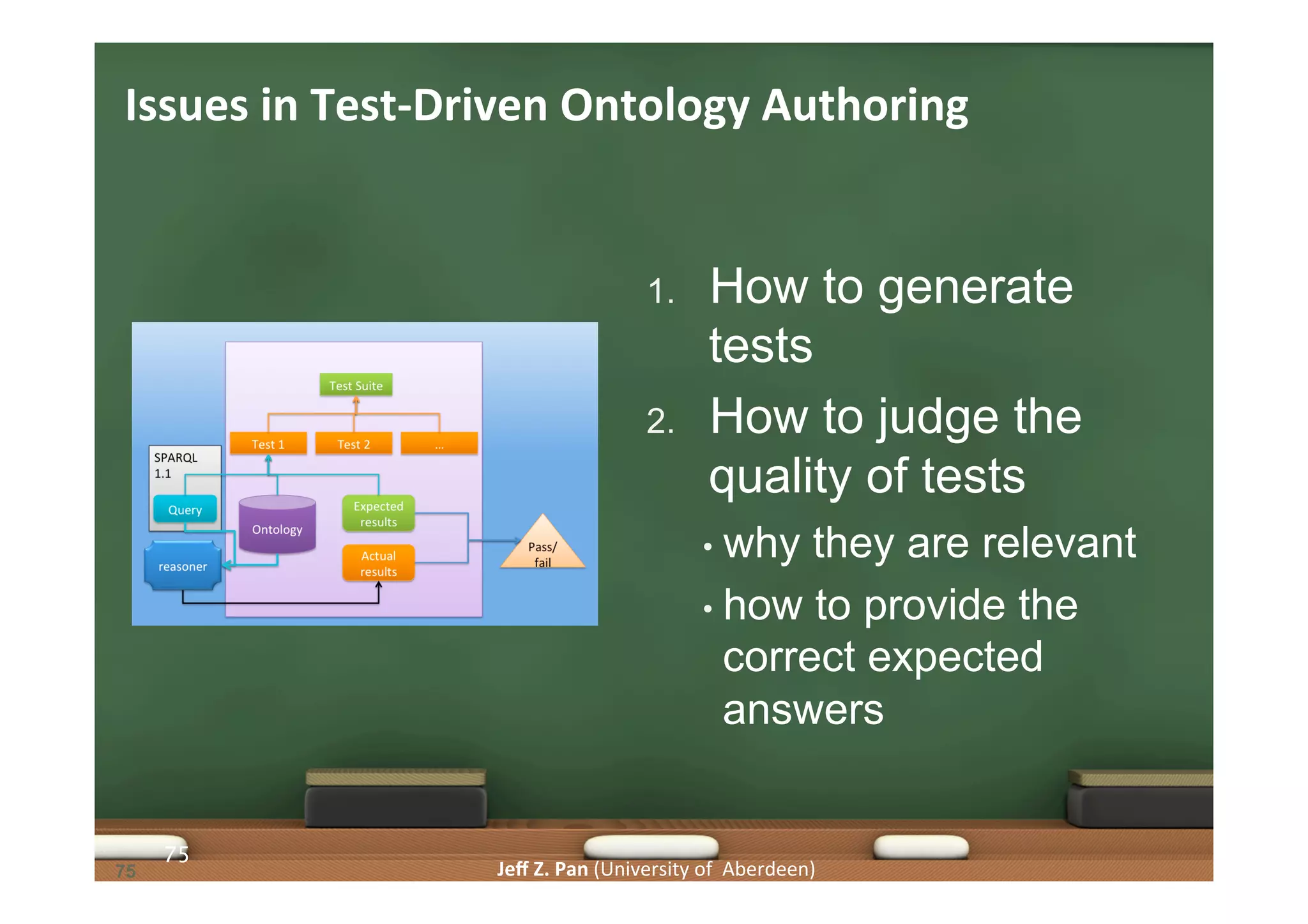
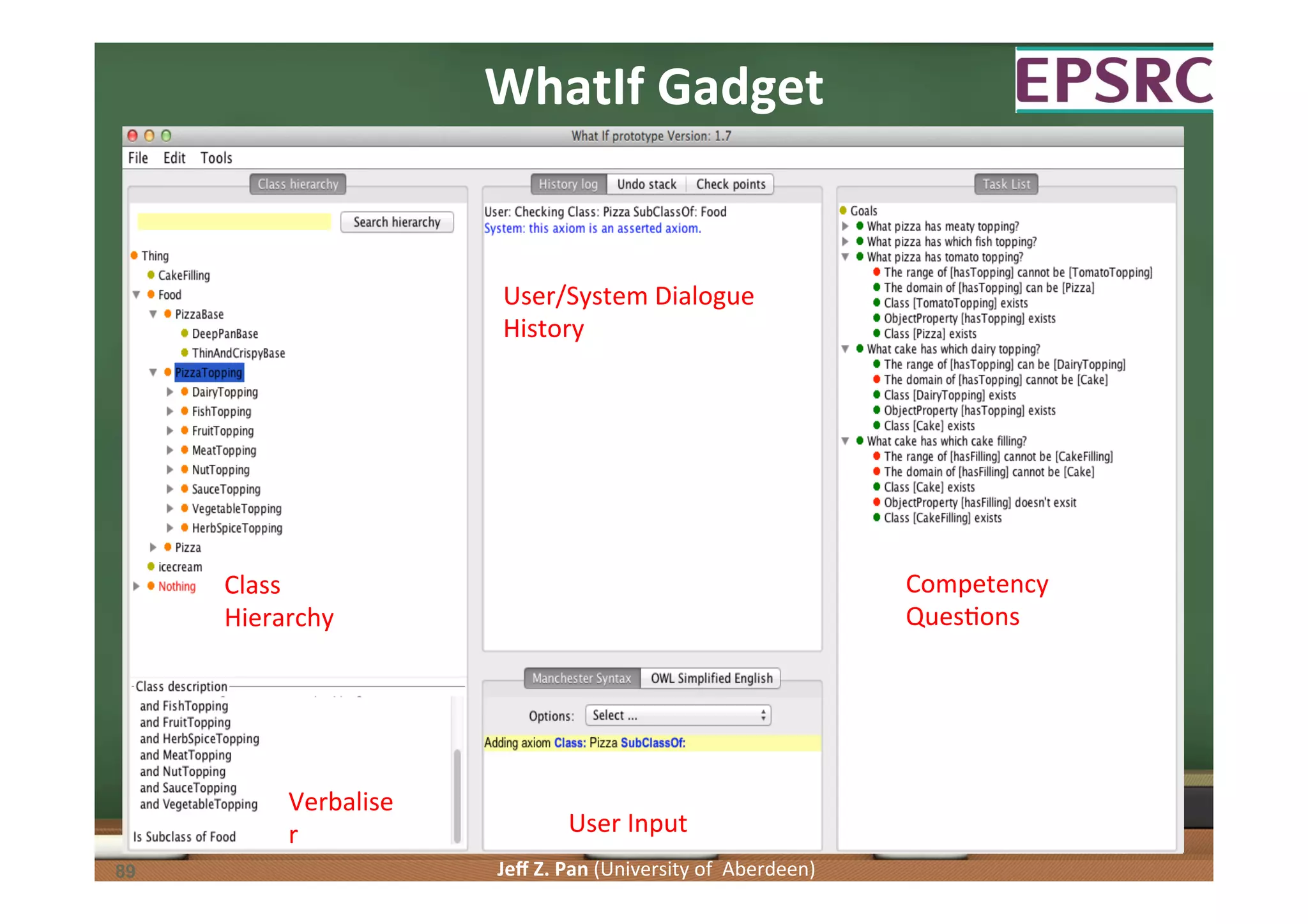
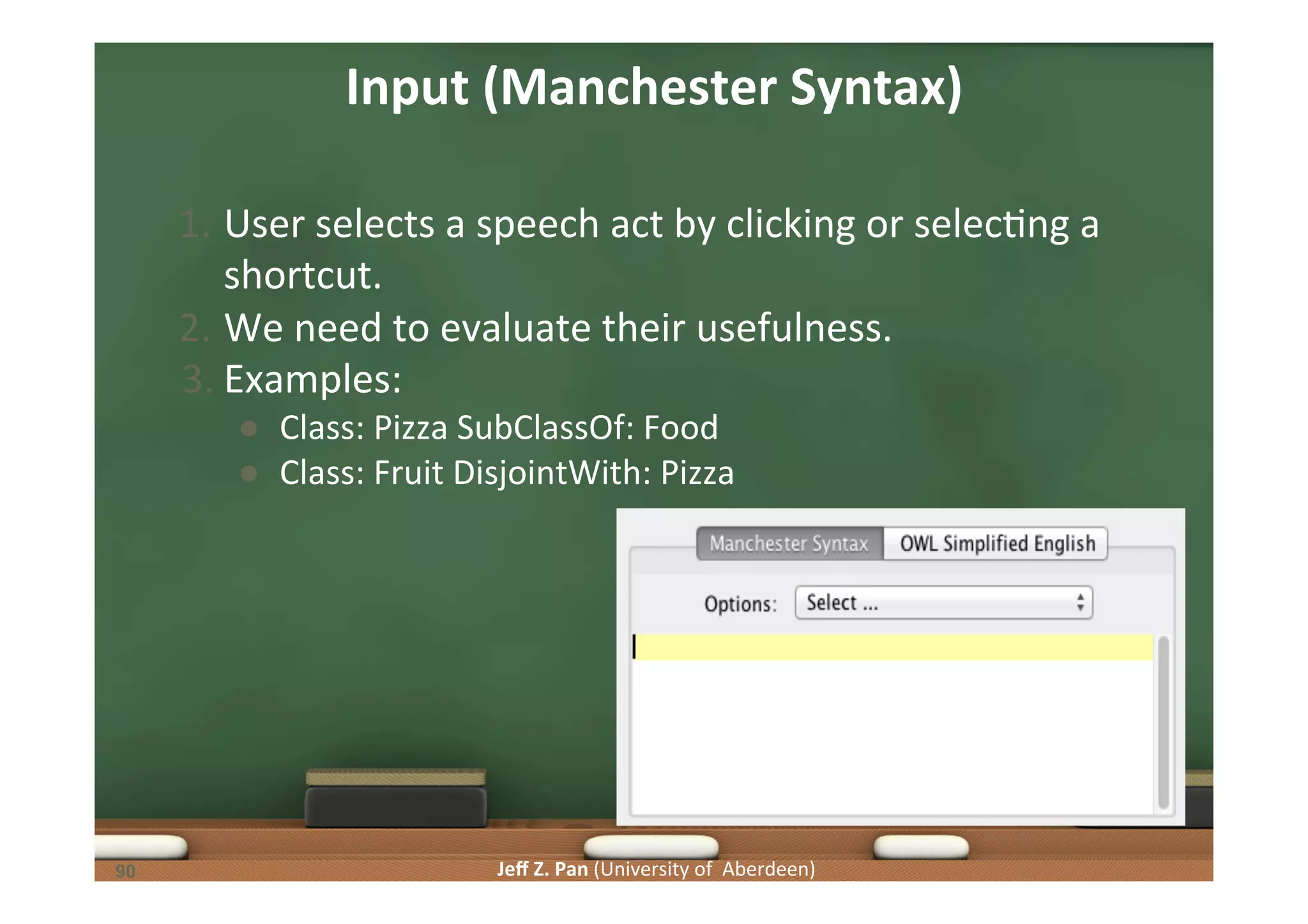
Exploration of methodologies for constructing and evaluating ontologies, emphasizing test-driven approaches.
Understanding competency questions as requirements and their formulation as tests for ontology validation.
Patterns in competency questions and their implications for ontology design and requirement fulfillment.
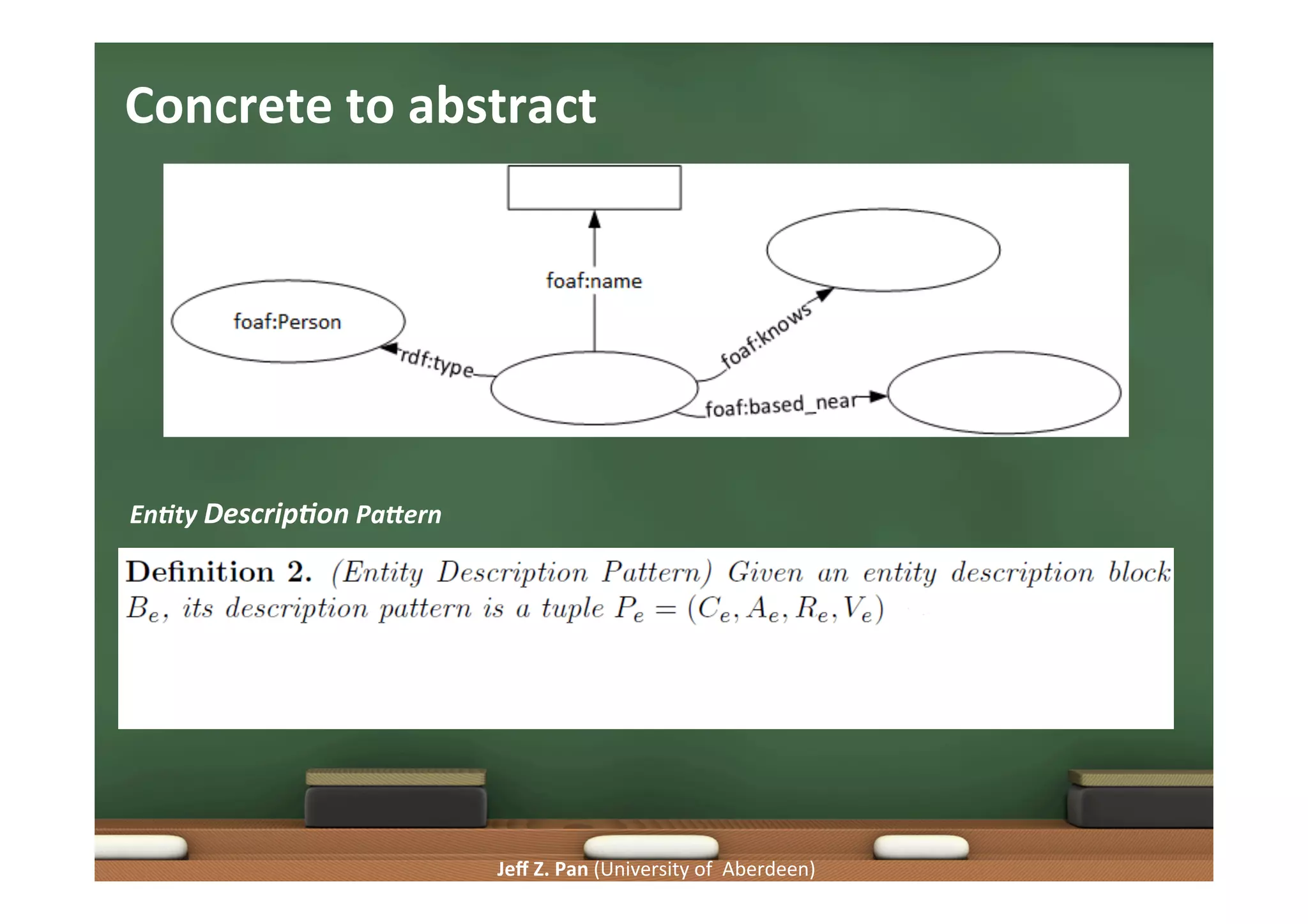
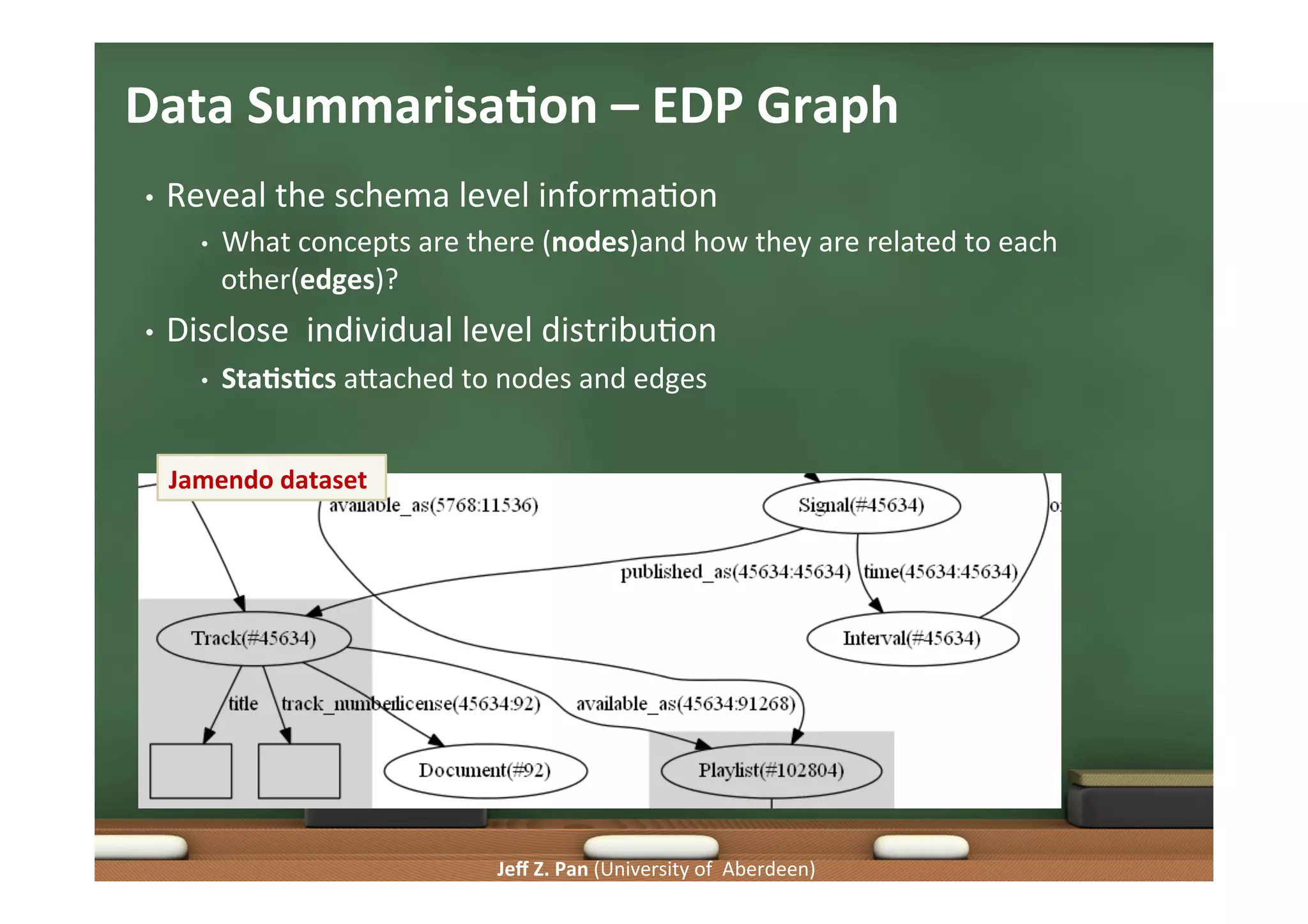
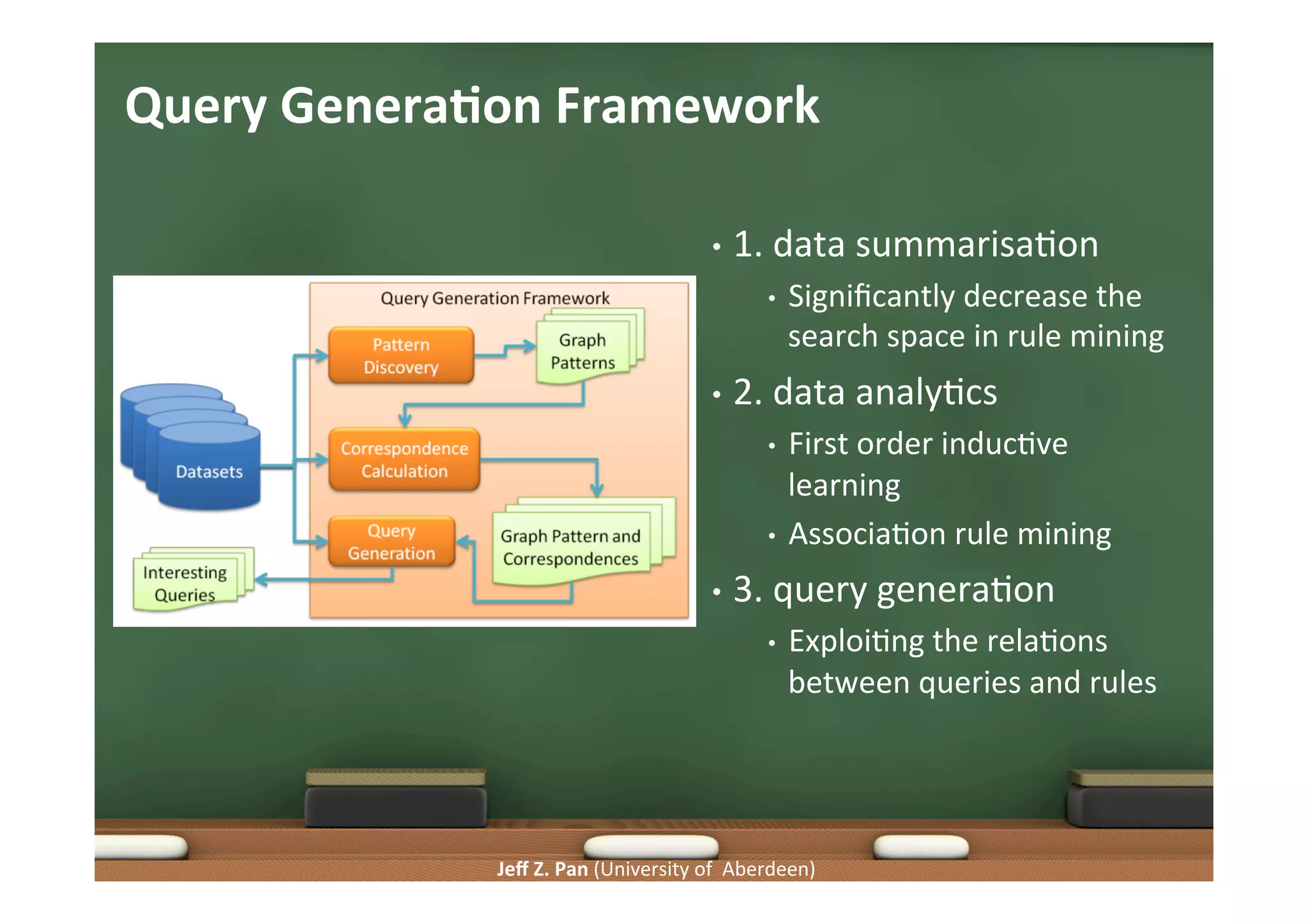
Techniques for generating insightful queries, query generation frameworks, and the role of data summarization.
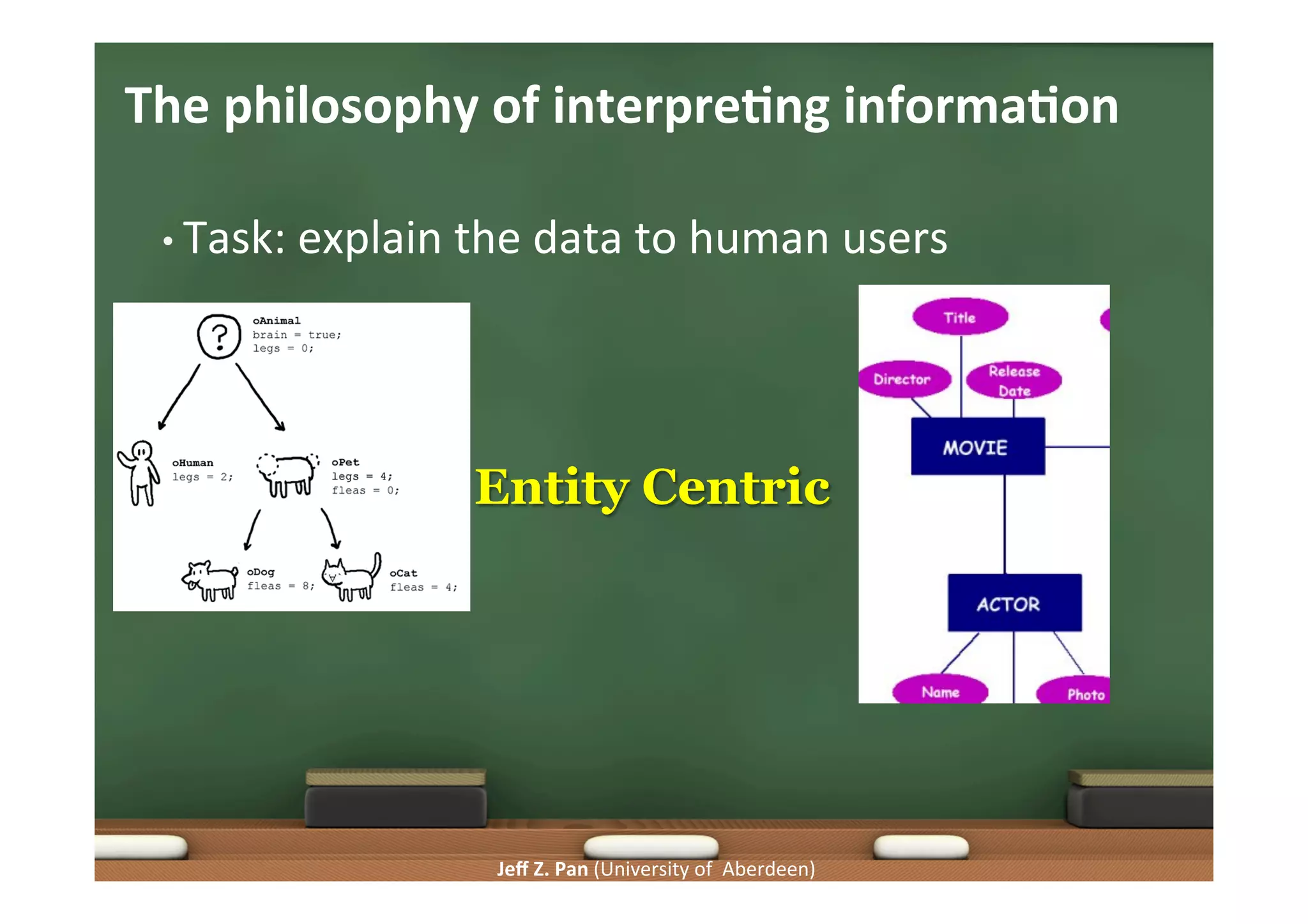
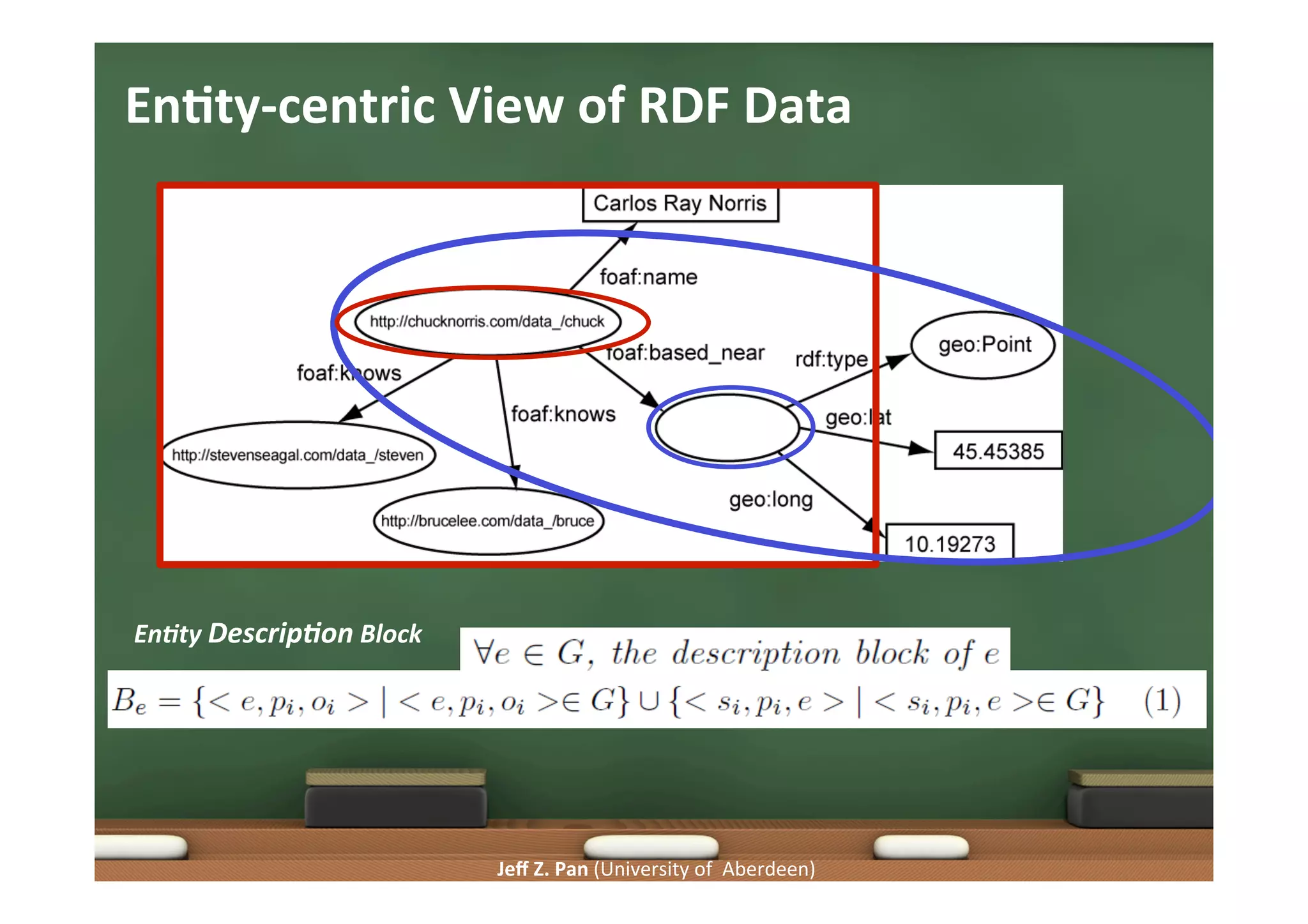
Focus on user interaction, summarizing large datasets, and maintaining meaningful data representations.
Outlook for knowledge graphs, addressing user needs in query formulation and future research directions.