Download to read offline

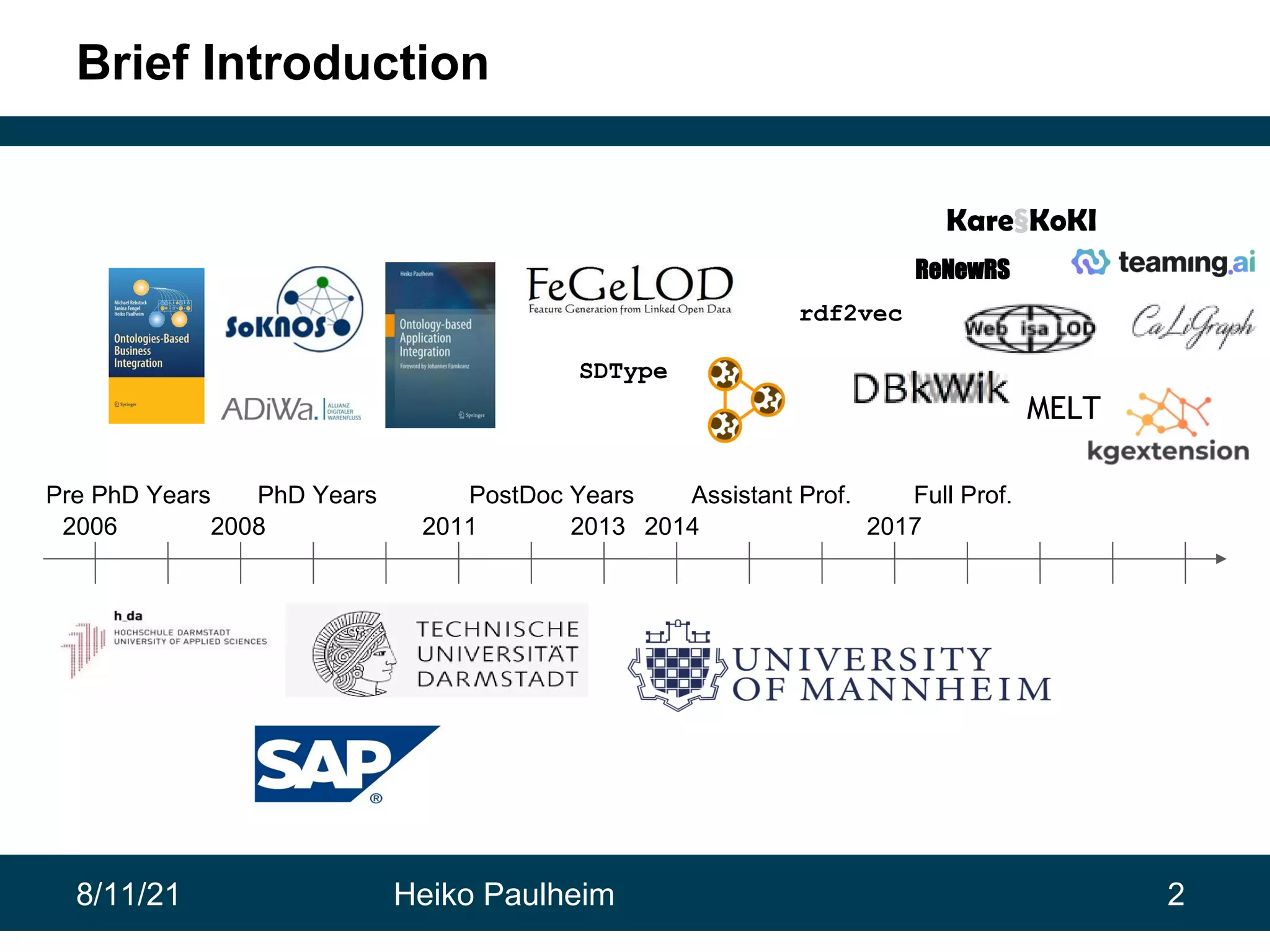
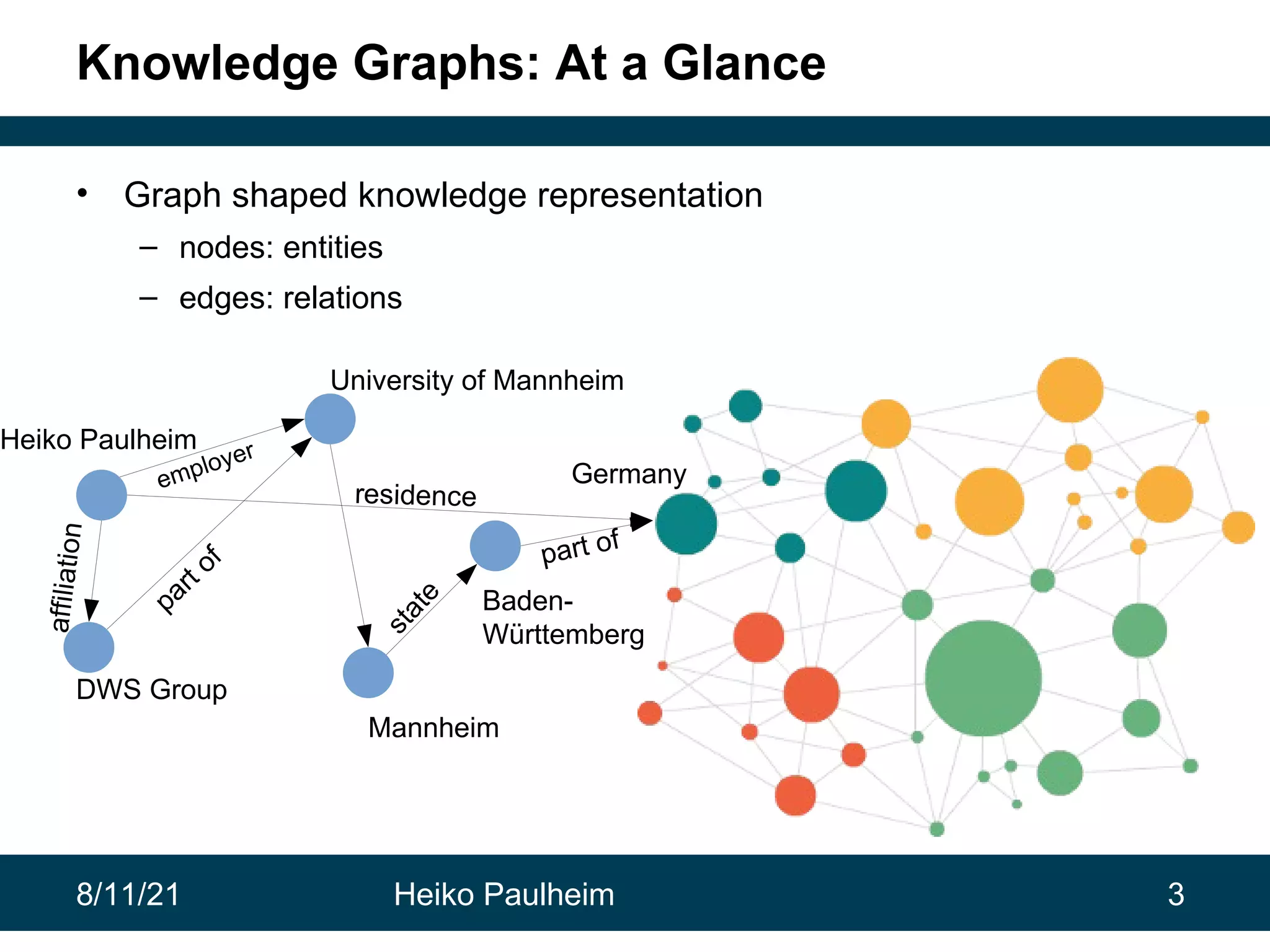
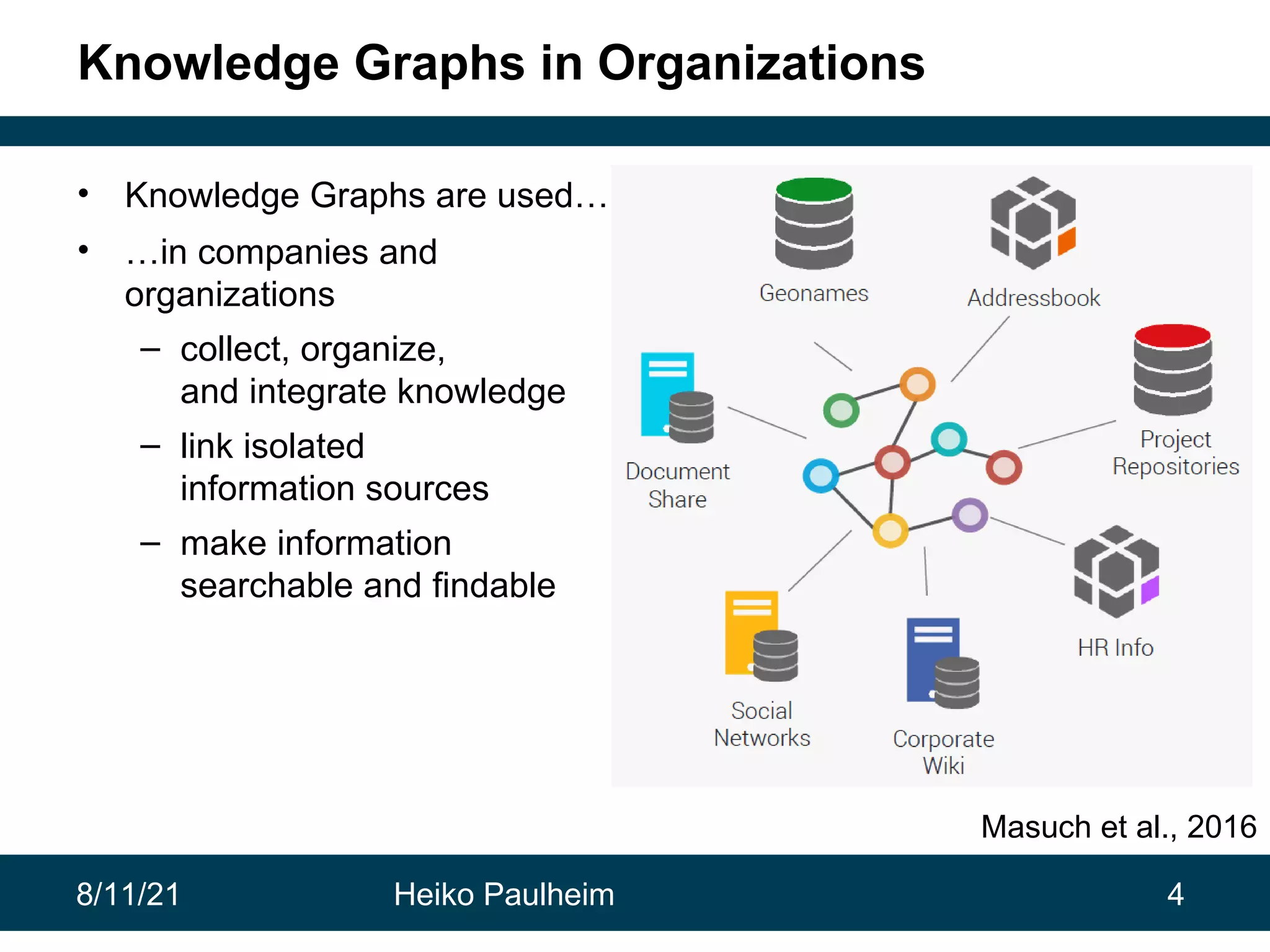


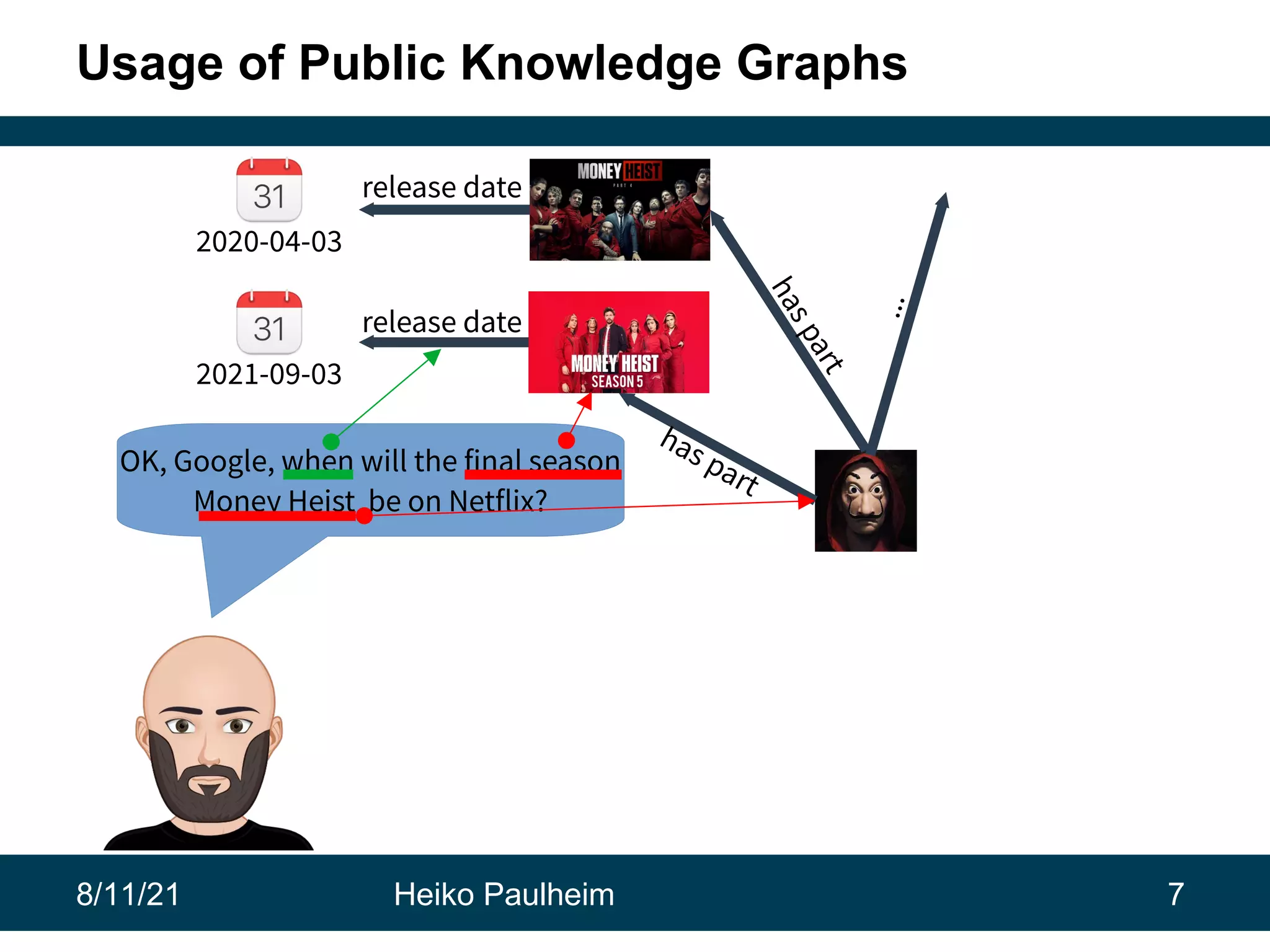
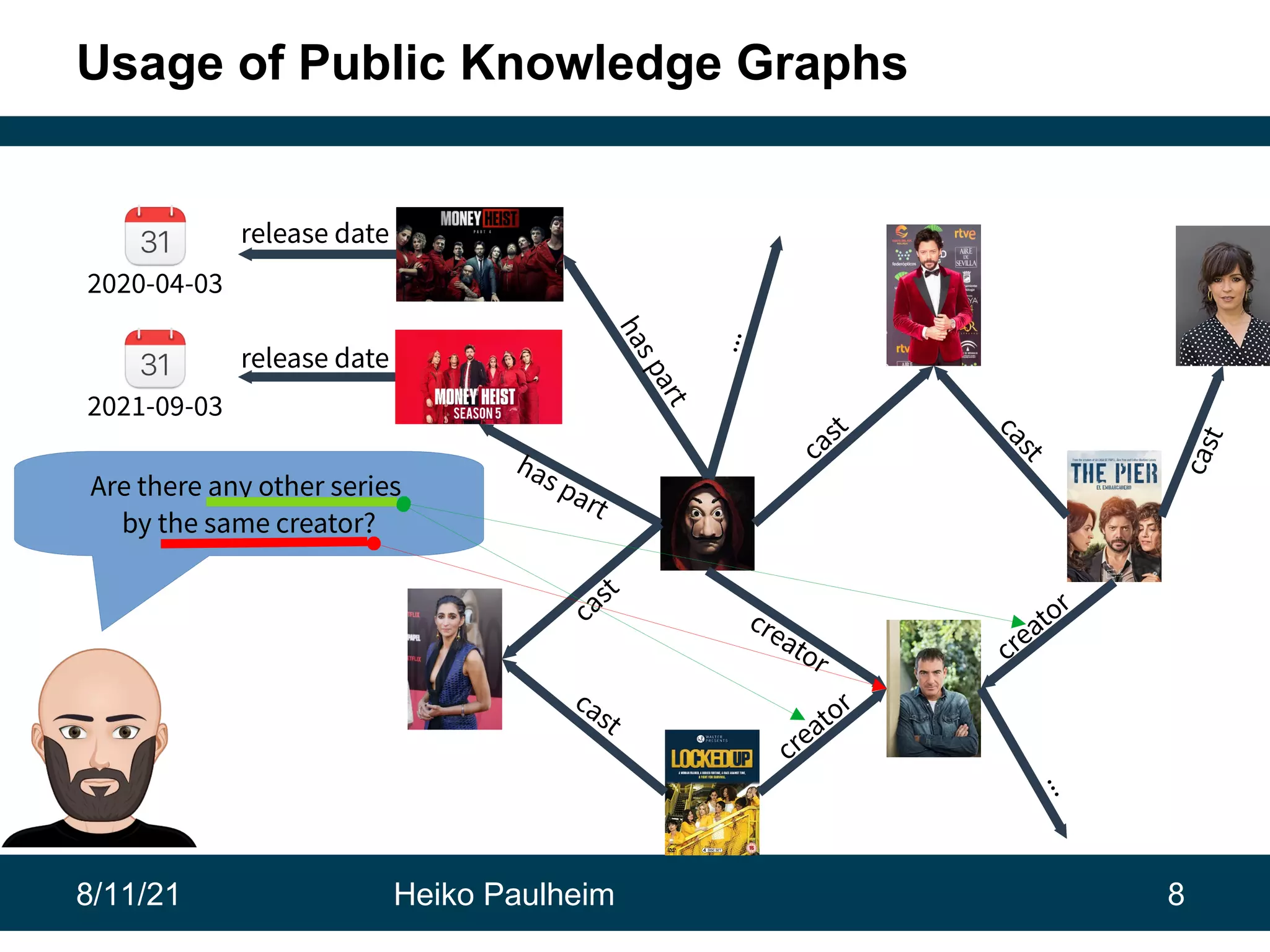






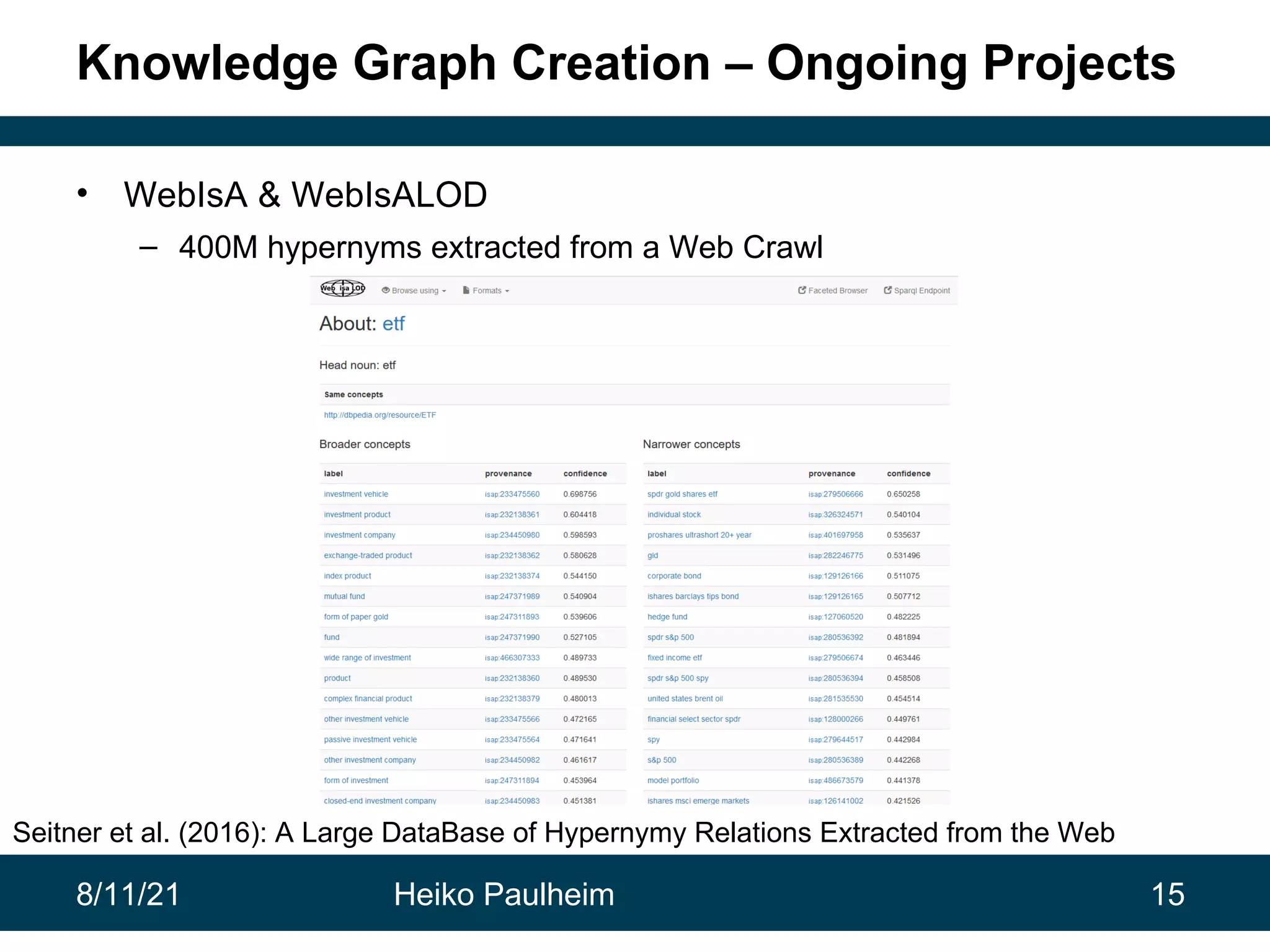
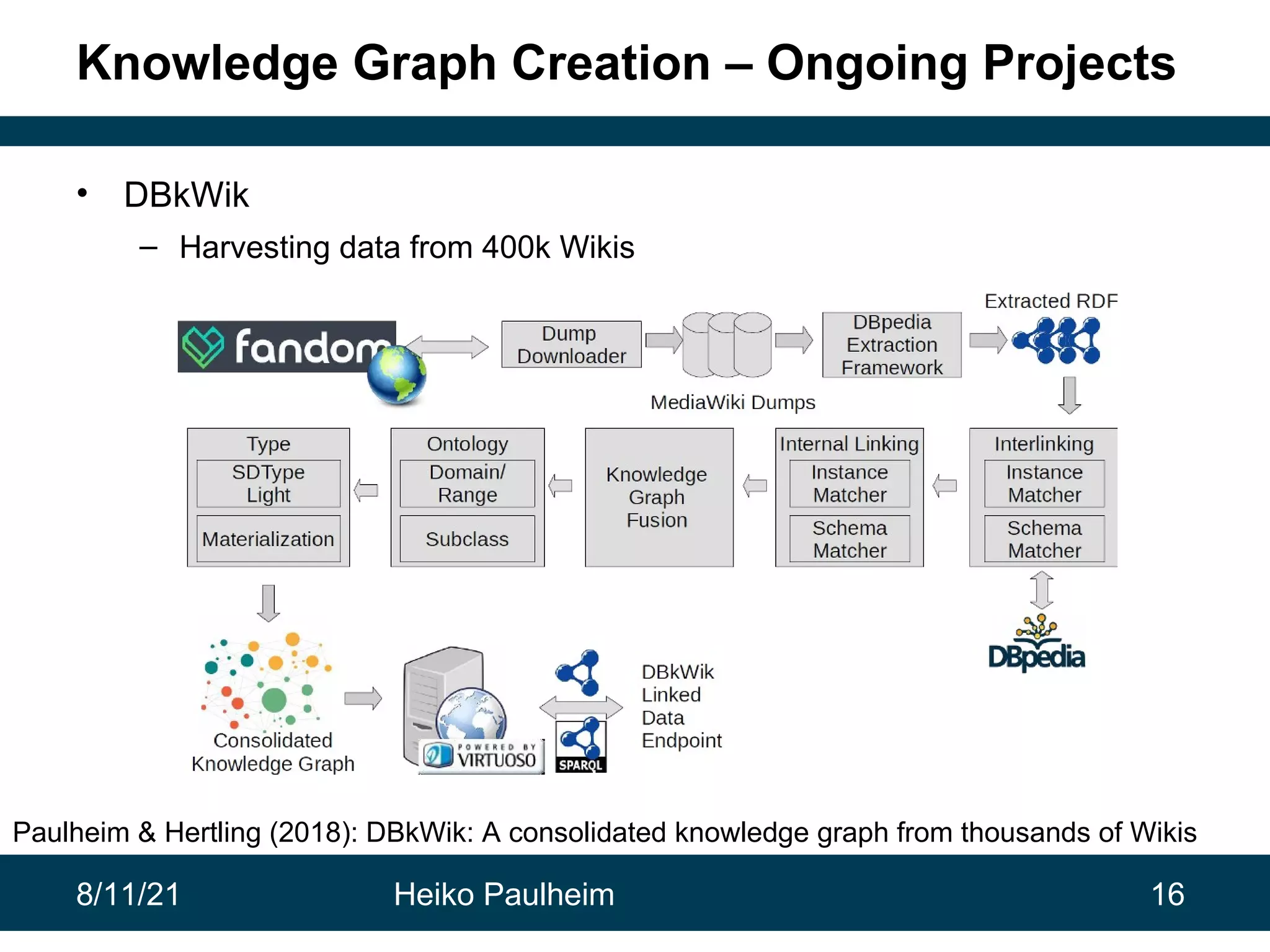
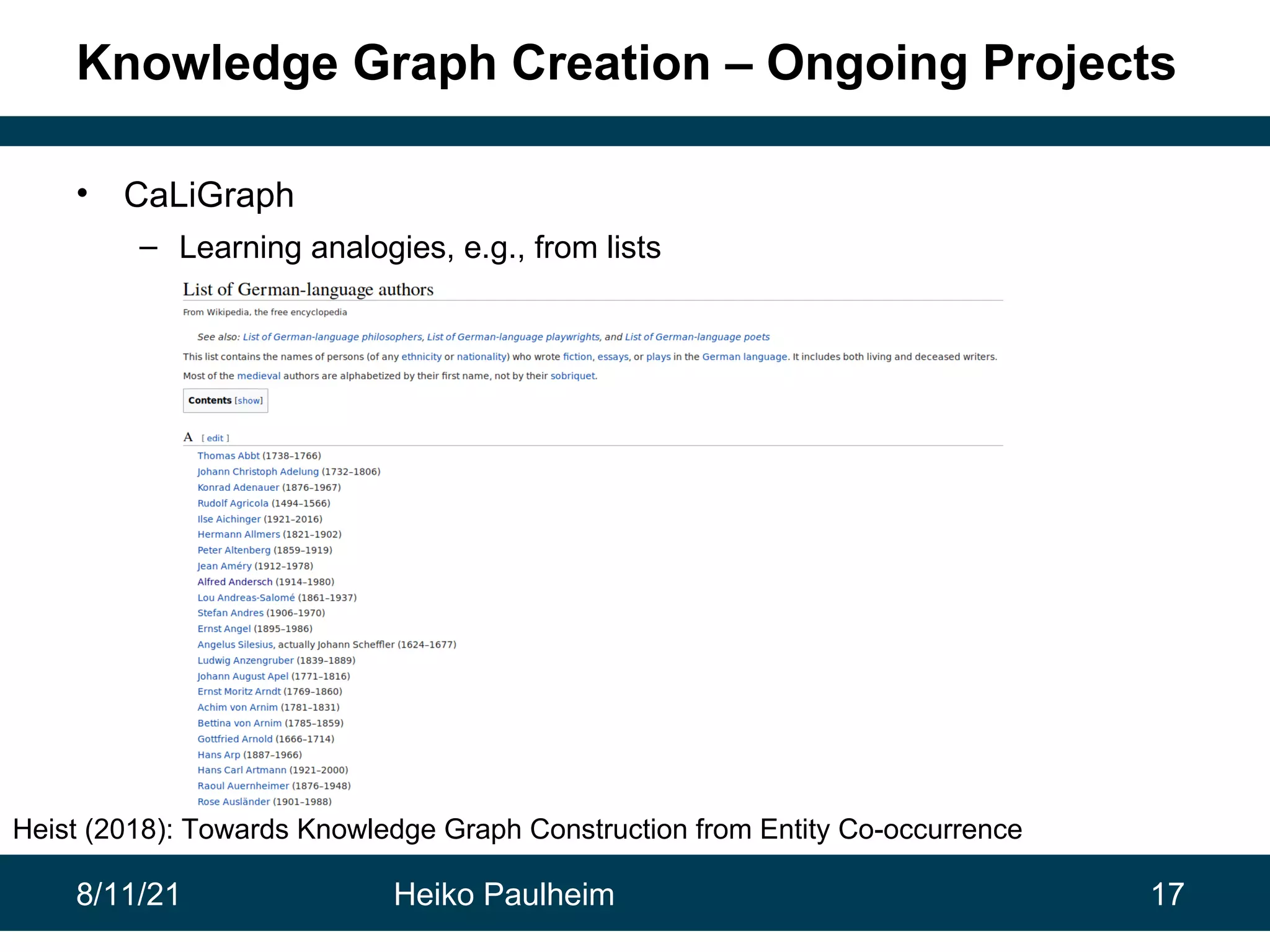



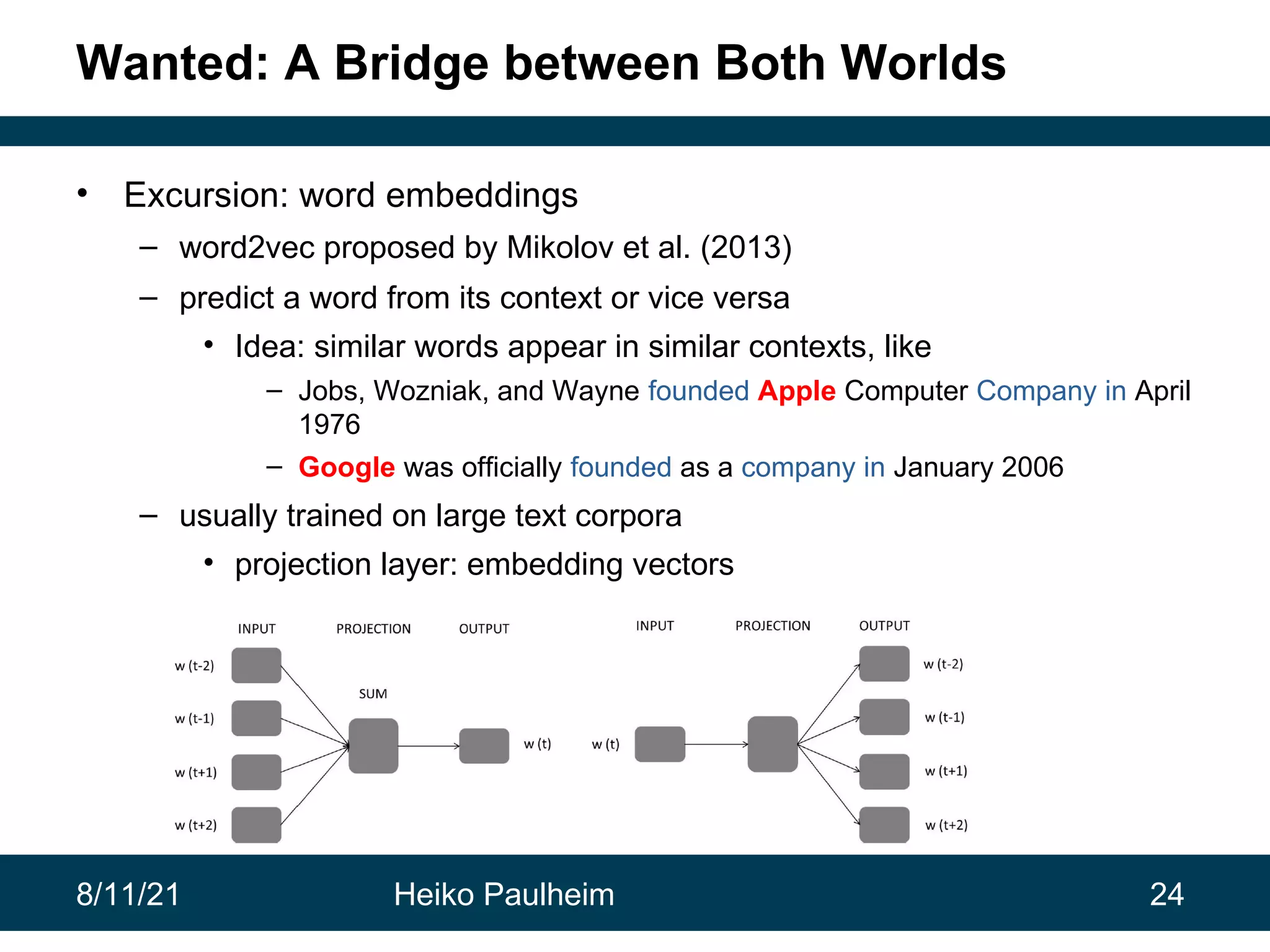

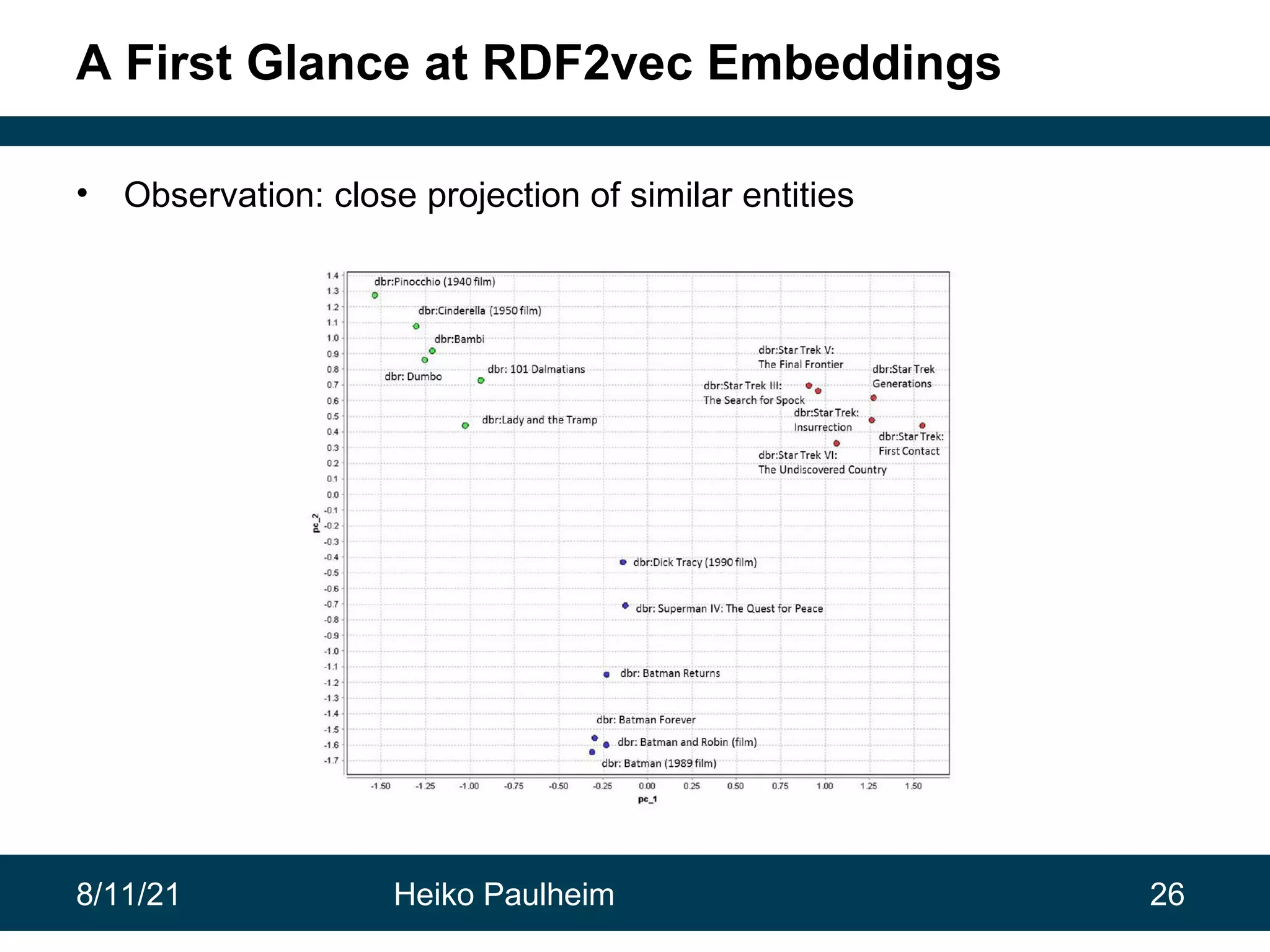



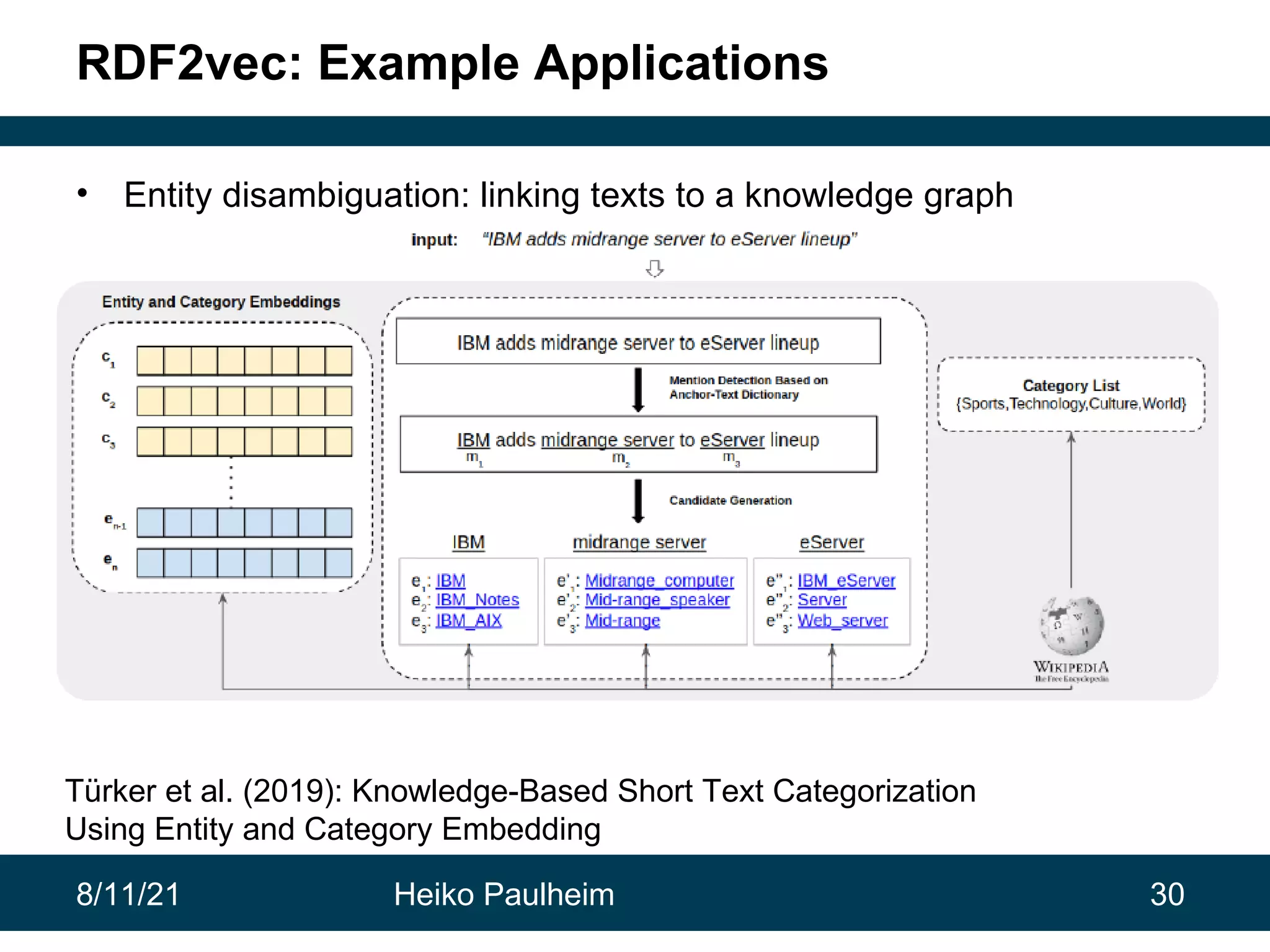


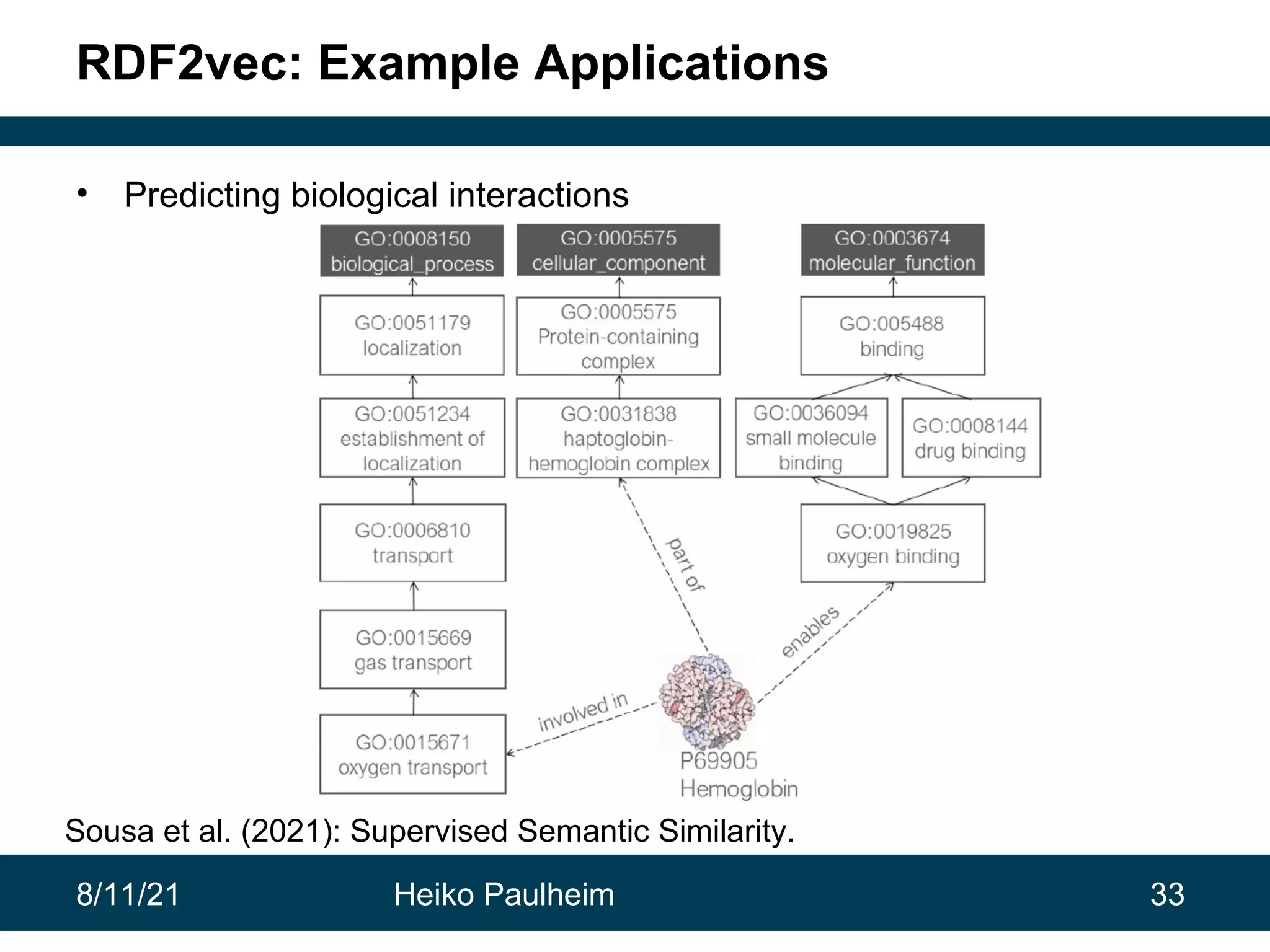

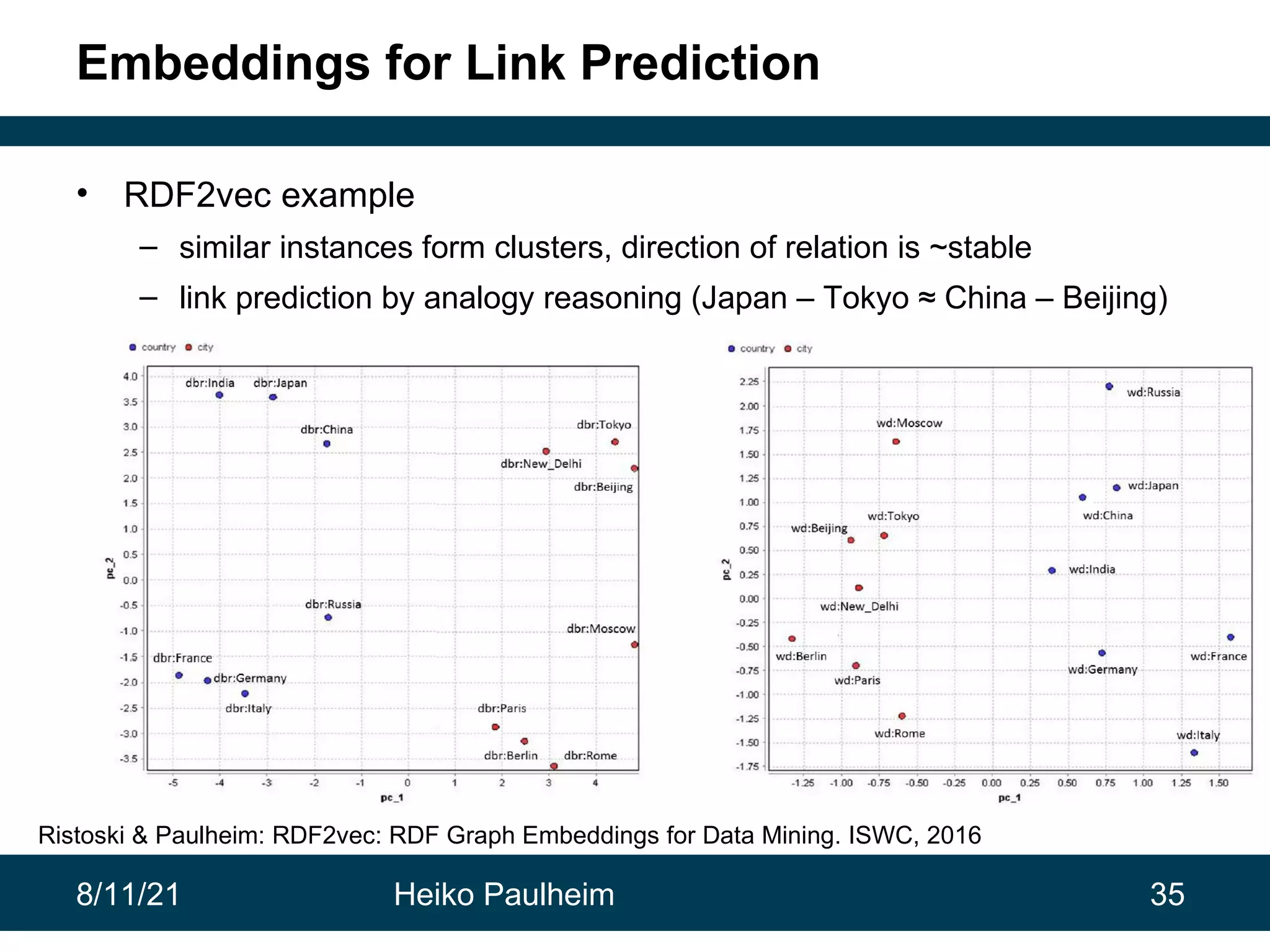


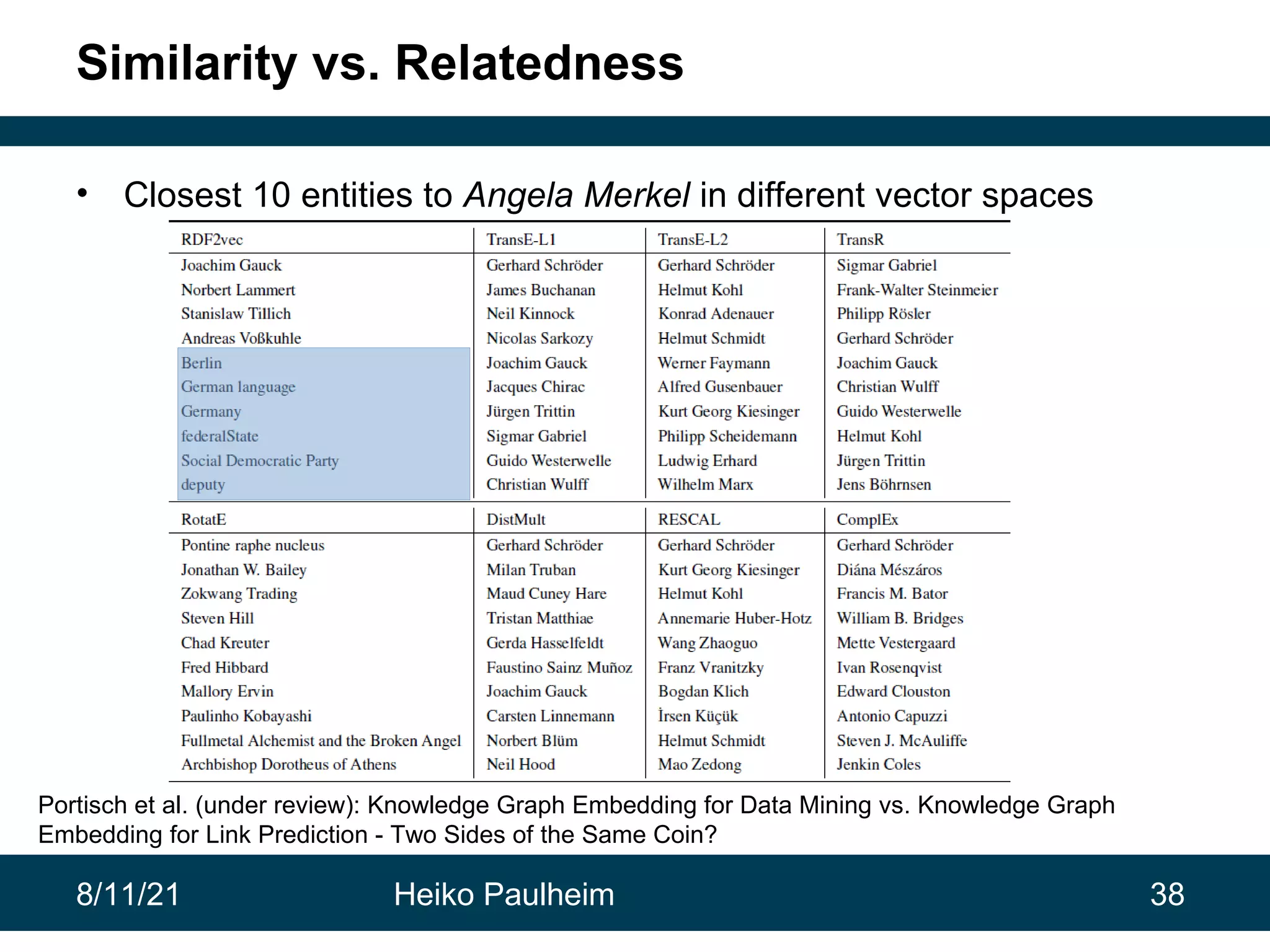
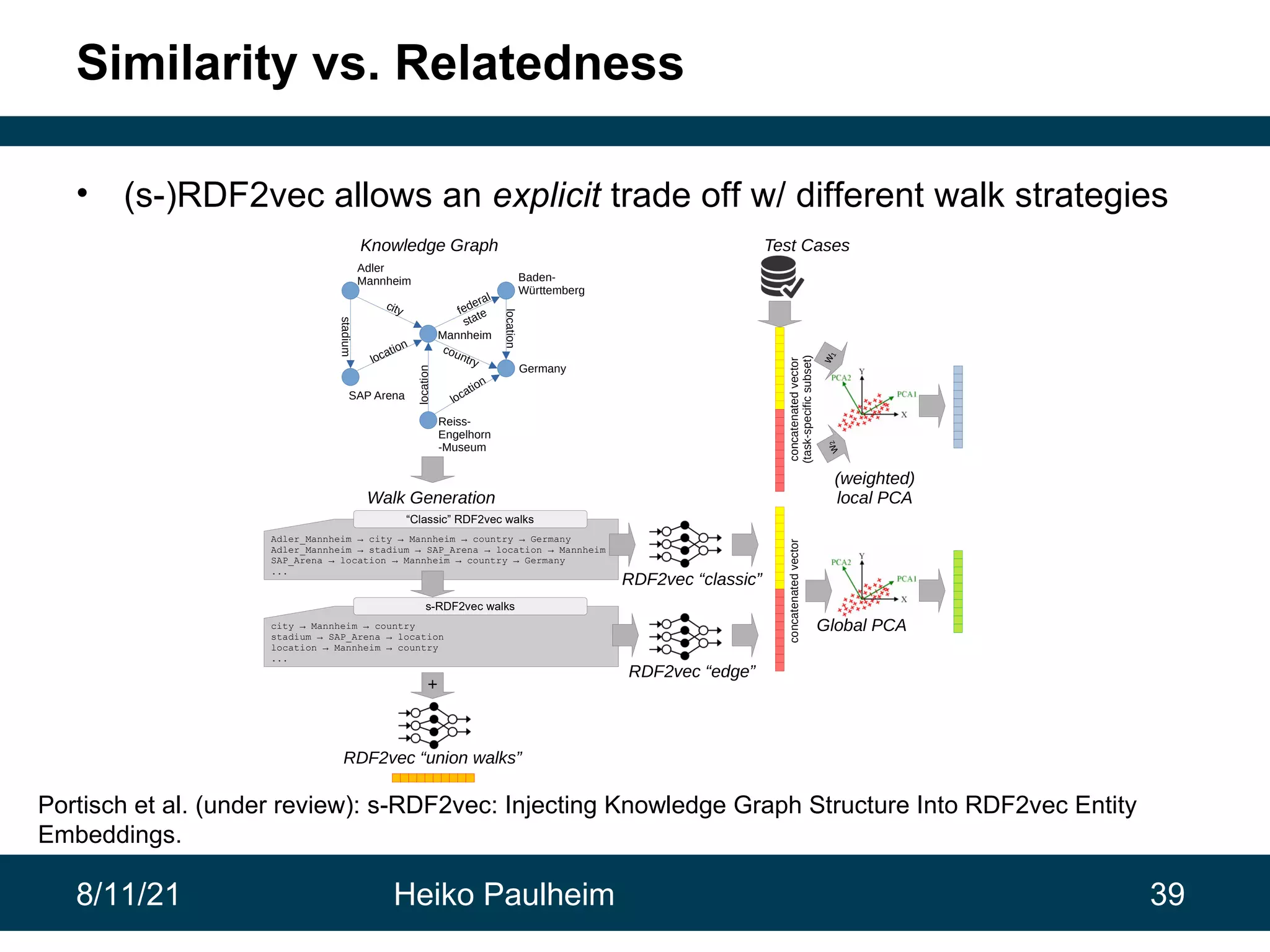
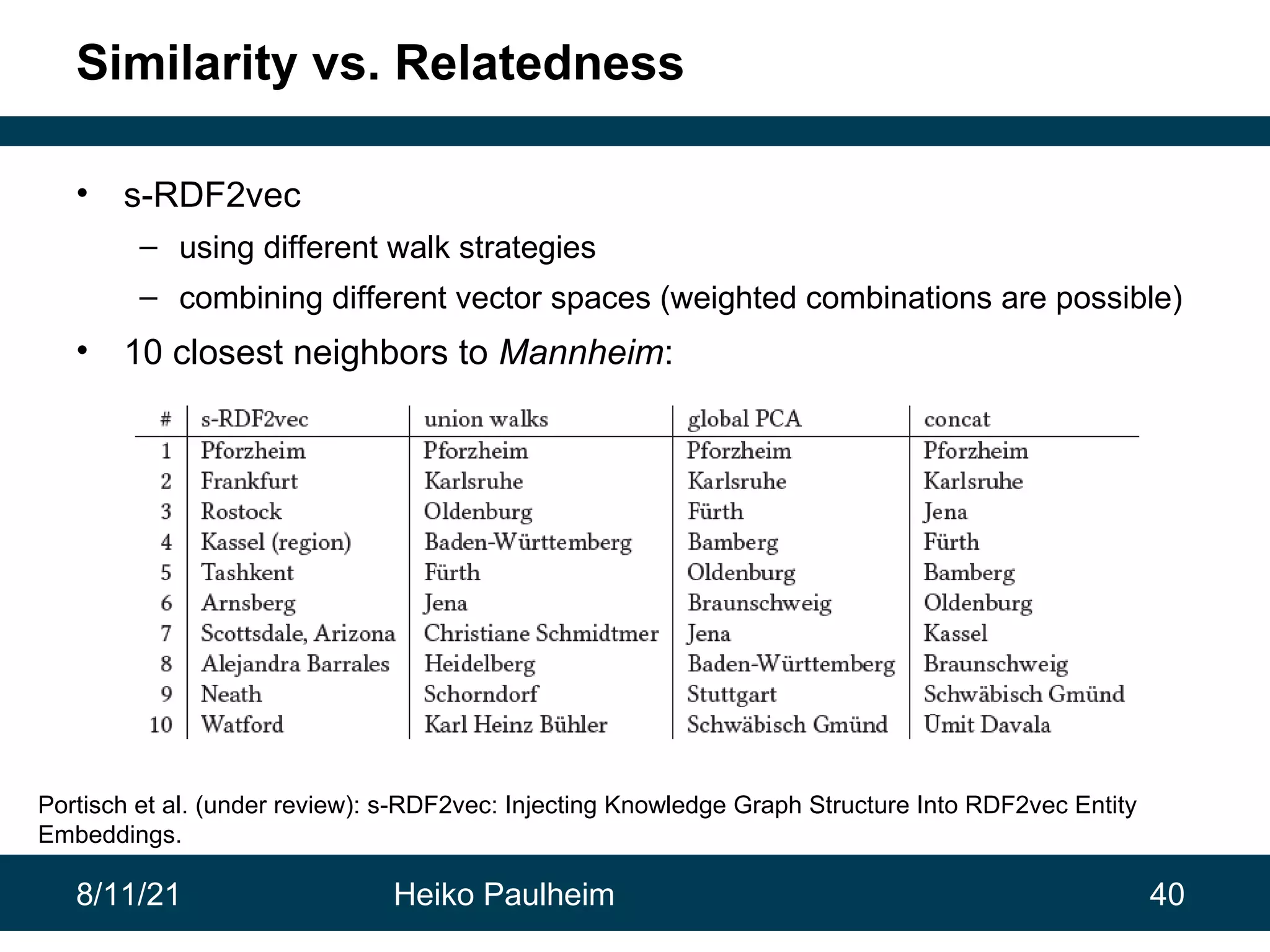
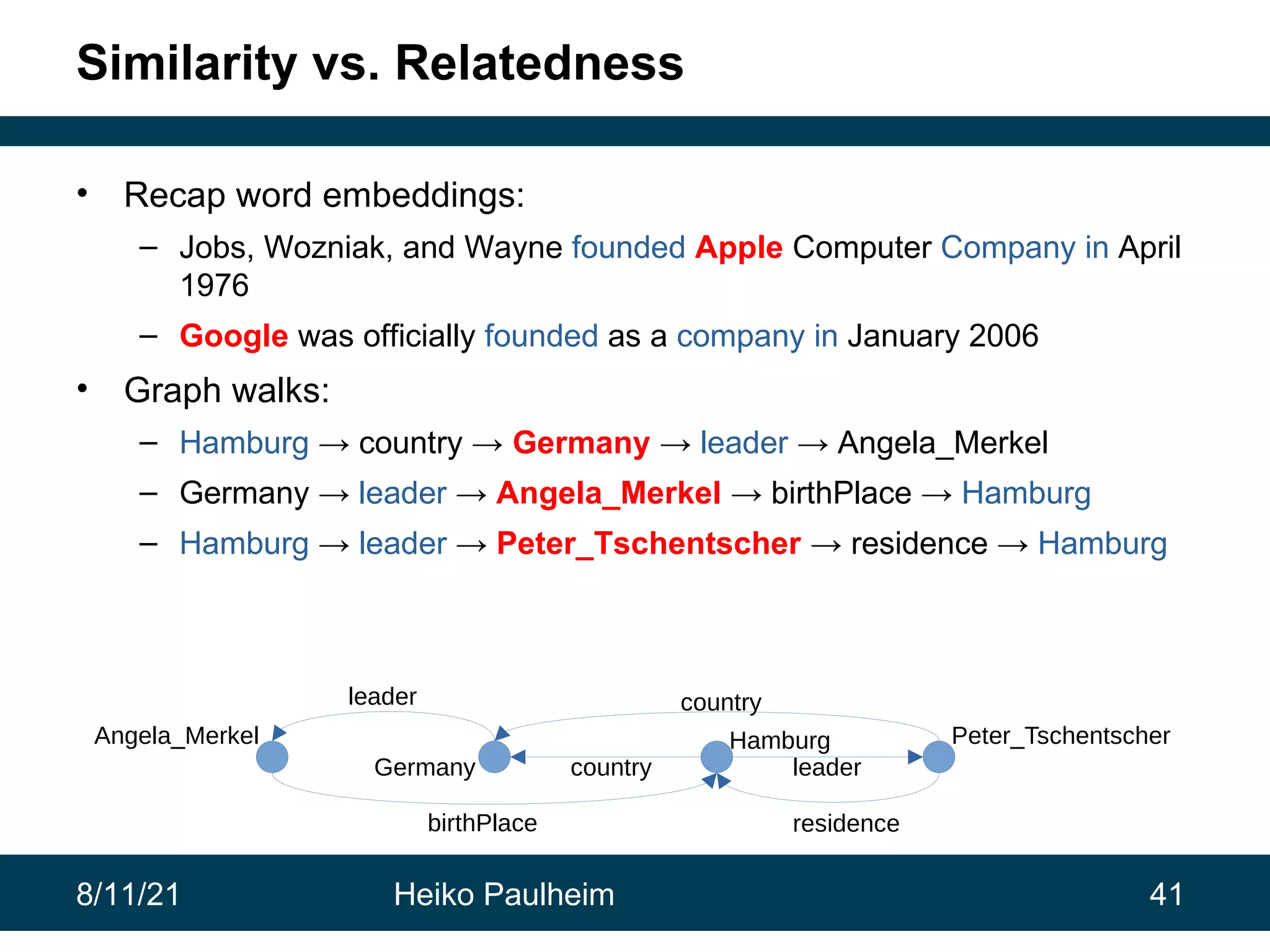

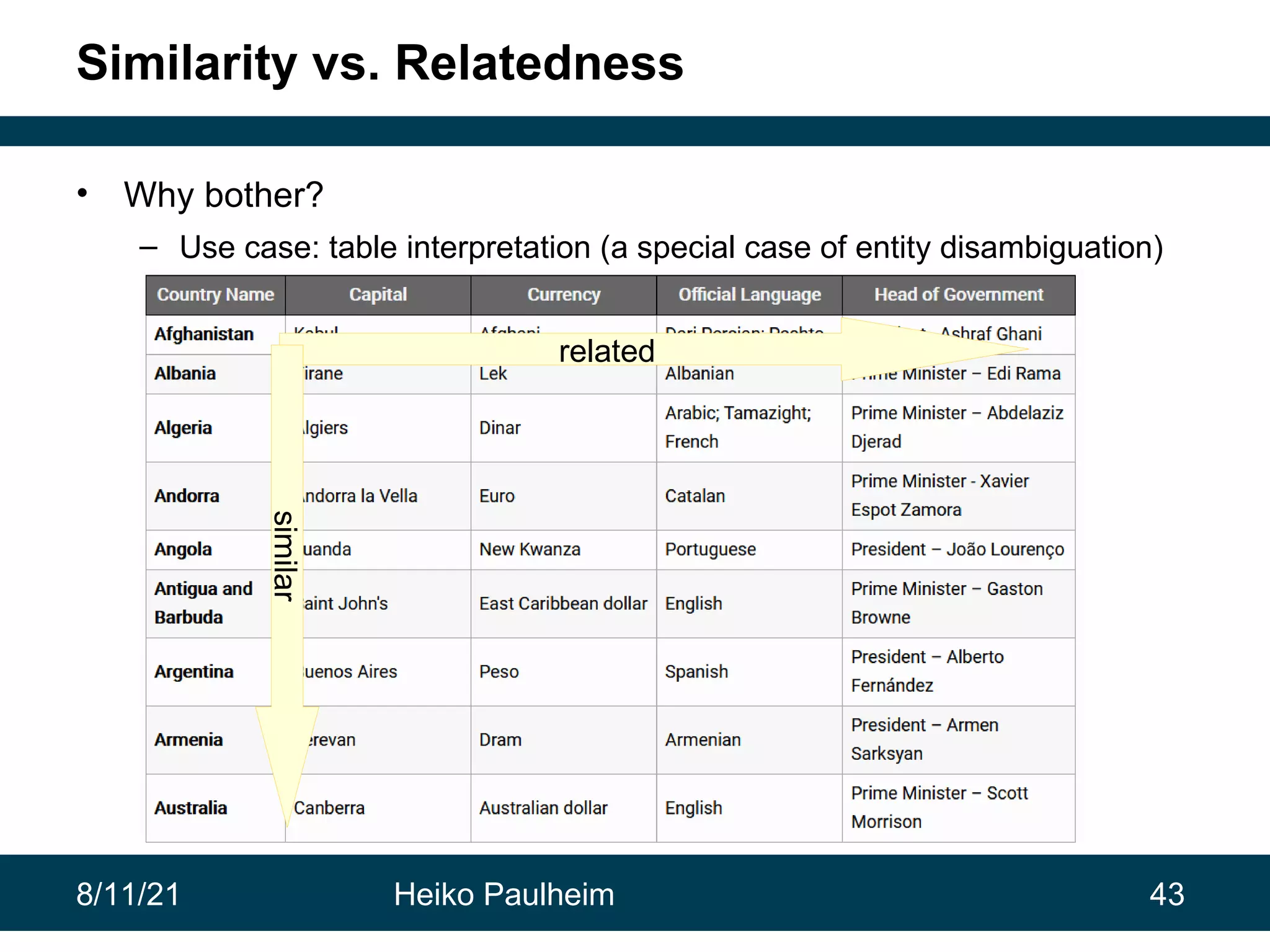

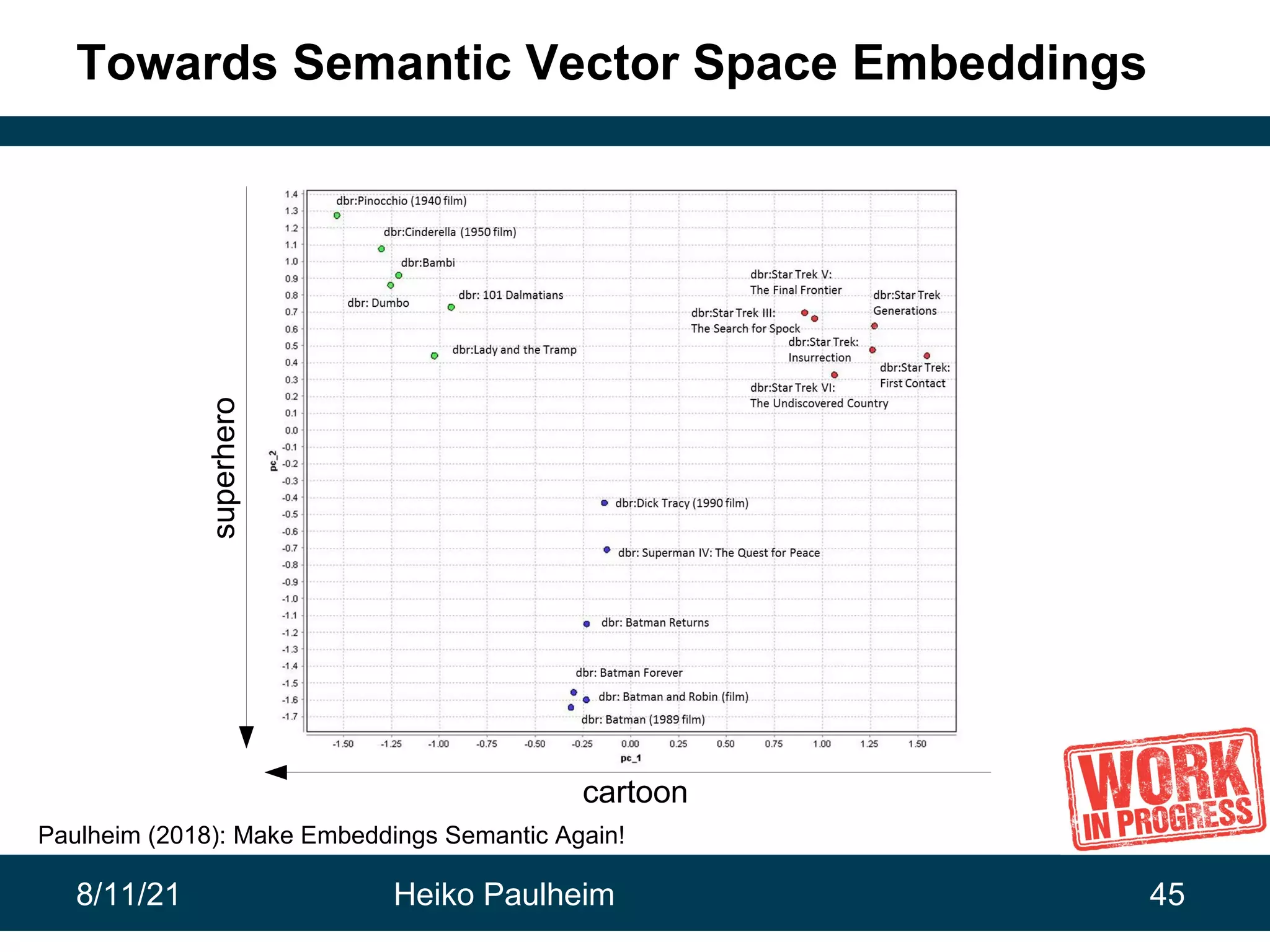








This document discusses the use of knowledge graphs in data science, highlighting their role in organizing and integrating knowledge within organizations and as public resources. It details the history of various knowledge graphs, such as Cyc, Freebase, and Wikidata, along with their applications and the processes of knowledge graph creation. The presentation emphasizes the importance of embedding techniques like rdf2vec for enhancing data interpretation and predictive modeling in AI.