Download to read offline


![SA-‐IS/SA-‐DS アルゴリズム概要 SA-‐IS(S,SA) Scan S to create t Find all LMS-‐substrings to create P1 Induced-‐sort all the LMS-‐substrings using P1 and B Name each LMS-‐substring to create S1 If each char in S1 is unique: SA1[S1[i]] = i for all i Else SA-‐IS(S1, SA1) Induce SA from SA1 SA-‐DS(S,SA) Scan S to create t Find all the d-‐critical substrings to create P1 Radix sort all the d-‐critical substrings in P1 using B Name each d-‐critical substring to create S1 If each char in S1 is unique: SA1[S1[i]] = i for all i Else SA-‐DS(S1, SA1) Induce SA from SA1](https://image.slidesharecdn.com/linearsuffixarraysummary-130618071230-phpapp02/75/Suffix-Array-3-2048.jpg)
![データの説明 (1) • S: 入力文字列 – 長さ n とする – The senMnel $ で終端されていることを仮定. S[i] > $ for all i in [0, n-‐1) • SA: 出力 Suffix Array • t: 長さ n のビット列 – S[i] の L/S-‐type を表す(後述) – t[i] = 1 if S[i] is S-‐type, else 0](https://image.slidesharecdn.com/linearsuffixarraysummary-130618071230-phpapp02/75/Suffix-Array-4-2048.jpg)
![データの説明 (2) • P1: 長さ n1 の整数列 (n1 <= n/2) – SA-‐IS と SA-‐DS で異なる(後述) • K: 文字種の数 – 文字が 1 byte とすると K = 256 – 再帰したときは,n1 以下の値 • B: バケツソート用のデータ – 長さ K + 1 の整数列 – 各整数は [0, n] の範囲](https://image.slidesharecdn.com/linearsuffixarraysummary-130618071230-phpapp02/75/Suffix-Array-5-2048.jpg)
![L/S-‐Type, LMS-‐char/substring • L/S-‐type: – S の各文字は L-‐type か S-‐type のいずれかに分類できる (後述) – $ は S-‐type – S[i] < S[i + 1] à S-‐type – S[i] > S[i + 1] à L-‐type – S[i] == S[i + 1] à type of S[i + 1] • LMS-‐char: – LMS: Leg-‐Most-‐S – S[i] が S-‐type で S[i-‐1] が L-‐type のときの S[i] • LMS-‐substring: S[i..j] – S[i] と S[j] が LMS-‐char かつ S[i+1..j-‐1] は LMS-‐char を含まない](https://image.slidesharecdn.com/linearsuffixarraysummary-130618071230-phpapp02/75/Suffix-Array-6-2048.jpg)

![Induced-‐sort all the LMS-‐substrs • (1) IniMalize tmp where each member is empty • (2) Scan P1 and put to the correct bucket from right to leg • (3) Scan tmp from leg to right and t[tmp[i] – 1] is 0 then put it to the bucket • (4) Scan tmp from right to leg and t[tmp[i] – 1] is 1 then put it to the bucket 0 1 Idx: 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 S: m m i i s s i i s s i i p p i i $ t: 0 0 1 1 0 0 1 1 0 0 1 1 0 0 0 0 1 LMS: * * * * P1: 2 6 10 16 $ i m p s tmp: {16} { _ _ _ _ _ 10 6 2} { _ _} { _ _} { _ _ _ _} tmp: {16} {15 14 _ _ _ 10 6 2} { 1 0} {13 12} { 9 5 8 4} tmp: {16} {15 14 10 6 2 11 7 3} { 1 0} {13 12} { 9 5 8 4}](https://image.slidesharecdn.com/linearsuffixarraysummary-130618071230-phpapp02/75/Suffix-Array-9-2048.jpg)


![Induce SA from SA1 0 1 Idx: 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 S: m m i i s s i i s s i i p p i i $ t: 0 0 1 1 0 0 1 1 0 0 1 1 0 0 0 0 1 LMS: * * * * P1: 2 6 10 16 SA1 : 3 2 1 0 for i from 4-‐1 to 0: put P1[SA1[i]] in the suffix array (tmp) $ i m p s tmp: {16} { _ _ _ _ _ 10 6 2} { _ _} { _ _} { _ _ _ _} tmp: {16} {15 14 _ _ _ 10 6 2} { 1 0} {13 12} { 9 5 8 4} tmp: {16} {15 14 10 6 2 11 7 3} { 1 0} {13 12} { 9 5 8 4}](https://image.slidesharecdn.com/linearsuffixarraysummary-130618071230-phpapp02/75/Suffix-Array-12-2048.jpg)

![d-‐CriMcal char/substring • What is d? – 定数 – 2 <= d • d-‐CriMcal char: – S[i] が LMS-‐char à S[i] は d-‐criMcal char – S[i-‐d] が d-‐criMcal char かつ S[i-‐1] と S[i+1] が LMS-‐char でないとき à S[i] は d-‐criMcal char • d-‐CriMcal substring: S[i..i+d+1] – S[i] が d-‐criMcal char – 後ろの長さが足りないものは S[n-‐1] すなわち $ で埋めたものとする – 長さは d + 2 固定](https://image.slidesharecdn.com/linearsuffixarraysummary-130618071230-phpapp02/75/Suffix-Array-14-2048.jpg)

![ω/γ-‐waited substrs • Sω[i] = 2S[i] + t[i] for all i in [0, n) • ω-‐weighted substring: Sω[i..j] • γ-‐weighted substring: – Sγ[i..j] = S[i..j-‐1]Sω[j] • P1 を radix sort するときに key を w-‐weighted d-‐criMcal substring とする必要あり • Sω[i..j] の代わりに Sγ[i..j] で足りる](https://image.slidesharecdn.com/linearsuffixarraysummary-130618071230-phpapp02/75/Suffix-Array-16-2048.jpg)


![評価データ rithms were implemented in C++ and compiled by g++ with the option of -O3. T d from Sanders’s website [19]. For the KA algorithm, we use an improved versio o’s website [20]) from Yuta Mori. The source code of our algorithm IS is given DS1 and DS2 were embodied in less than 150 and 250 effective lines of code, r on request. Table 1: Data Used in the Experiments Data Characters Σ Description bible.txt 4 047 392 63 King James Bible chr22.dna 34 553 758 4 Human chromosome 22 E.coli 4 638 690 4 Escherichia coli genome etext99 105 277 340 146 Texts from Gutenberg project howto 39 422 105 197 Linux Howto files pic 513 216 159 Black and white fax picture sprot34.dat 109 617 186 66 Swissprot V34 protein database world192.txt 2 473 400 94 CIA world fact book alphabet 100 000 26 Repetitions of the alphabet [a-z] random 100 000 64 Randomly selected from 64 characters ace The time for each algorithm is the mean of 3 runs, and the space is the hea emusage command to fire the running of each program. The total time (in se](https://image.slidesharecdn.com/linearsuffixarraysummary-130618071230-phpapp02/75/Suffix-Array-21-2048.jpg)


The document introduces two algorithms for constructing a suffix array: SA-IS and SA-DS. SA-IS uses induced sorting of longest common prefix substrings, while SA-DS uses radix sorting of fixed-length substrings. The document provides pseudocode for the algorithms and explains various terms and data structures used, including longest minimal suffixes, L-type and S-type characters, and buckets for sorting.
Overview of the presentation on Suffix Arrays by Takashi Hoshino, covering algorithms for construction.
Introduces two algorithms for constructing linear suffix arrays: SA-IS and SA-DS.
Detailed procedure of SA-IS and SA-DS algorithms including induced sorting and substring naming.
Describes input string S, its length, and assumptions about the sentinel '$' character.
Details on different parameters including P1, character types, and bucket sort data.
Explains classification of characters in S as L-type or S-type, and defines LMS characters and substrings.
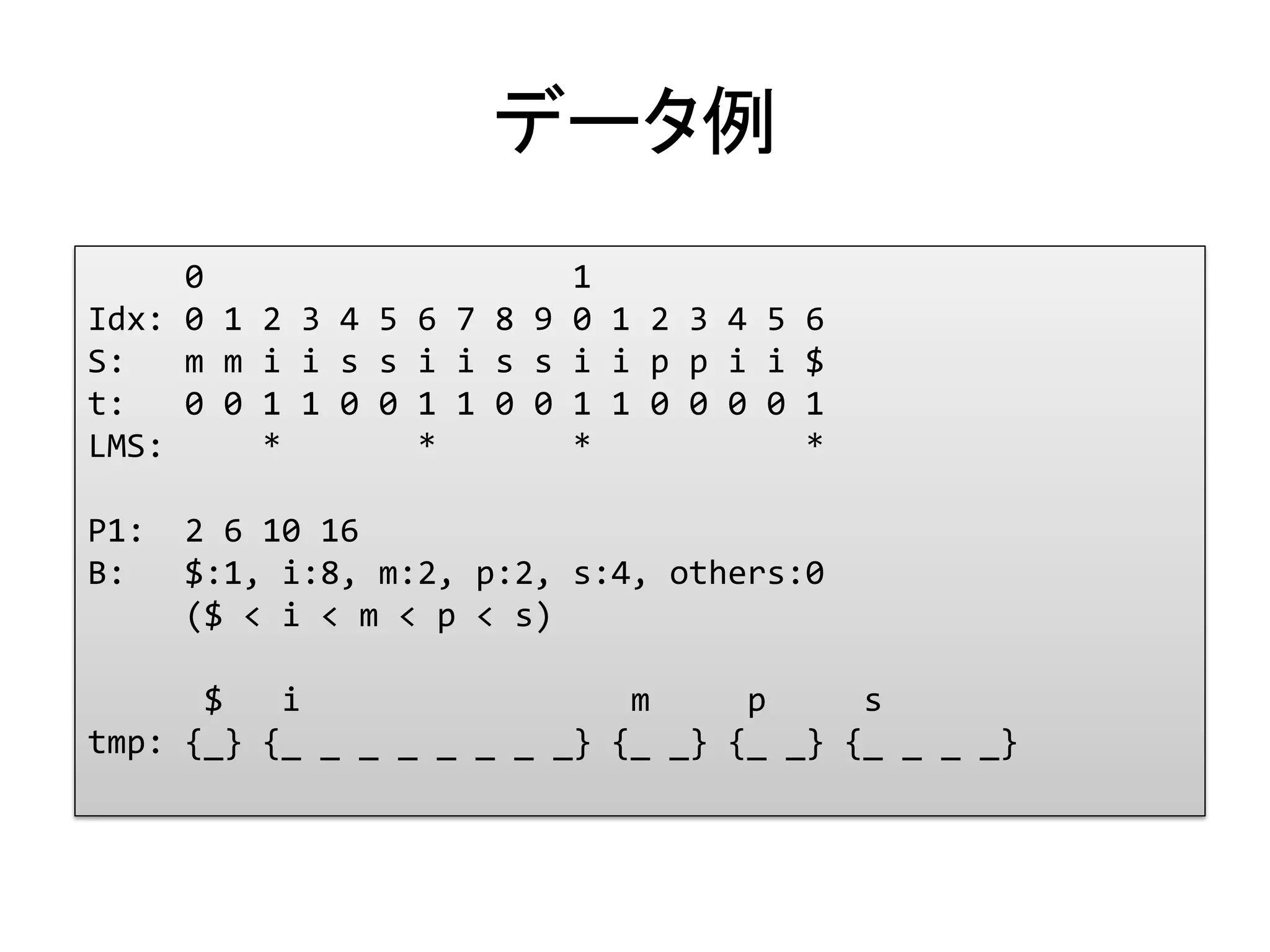
Provides examples of input string S, its L/S-type series, and metrics for substrings in context.
Step by step process of the SA-IS algorithm for substring naming and sorting.
Details on the steps involved in the induced-sort method of LMS substrings.
Additional details on the algorithm execution with recursive calls based on substring order.
Analyzes the results of the recursive process leading to unique suffix array creation.
Step-by-step induction of the suffix array from SA1 utilizing previously defined processes.
Introduces the SA-DS algorithm focused on d-critical substrings and their creation.
Defines what d-critical characters and substrings are in the context of suffix arrays.
Discussion on the characteristics of P1 for both SA-IS and SA-DS algorithms.
Explanation of ω-weighted and γ-weighted substrings and their calculations.
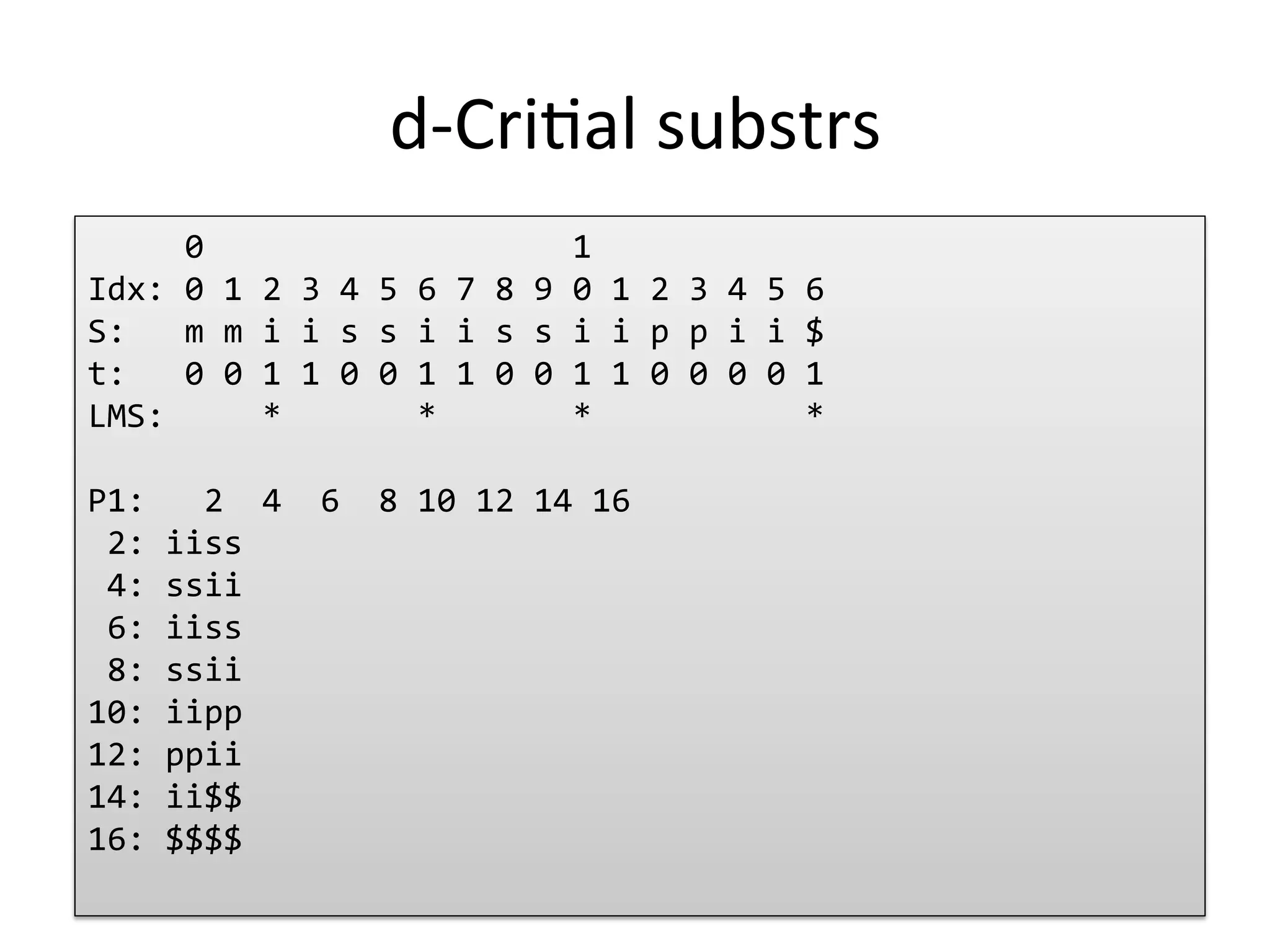
Demonstration of d-critical substrings using example data and their organization.
Overview of executing radix sort on P1 with examples of data progression.
Details on generating lexicographic names for substrings derived from input data.
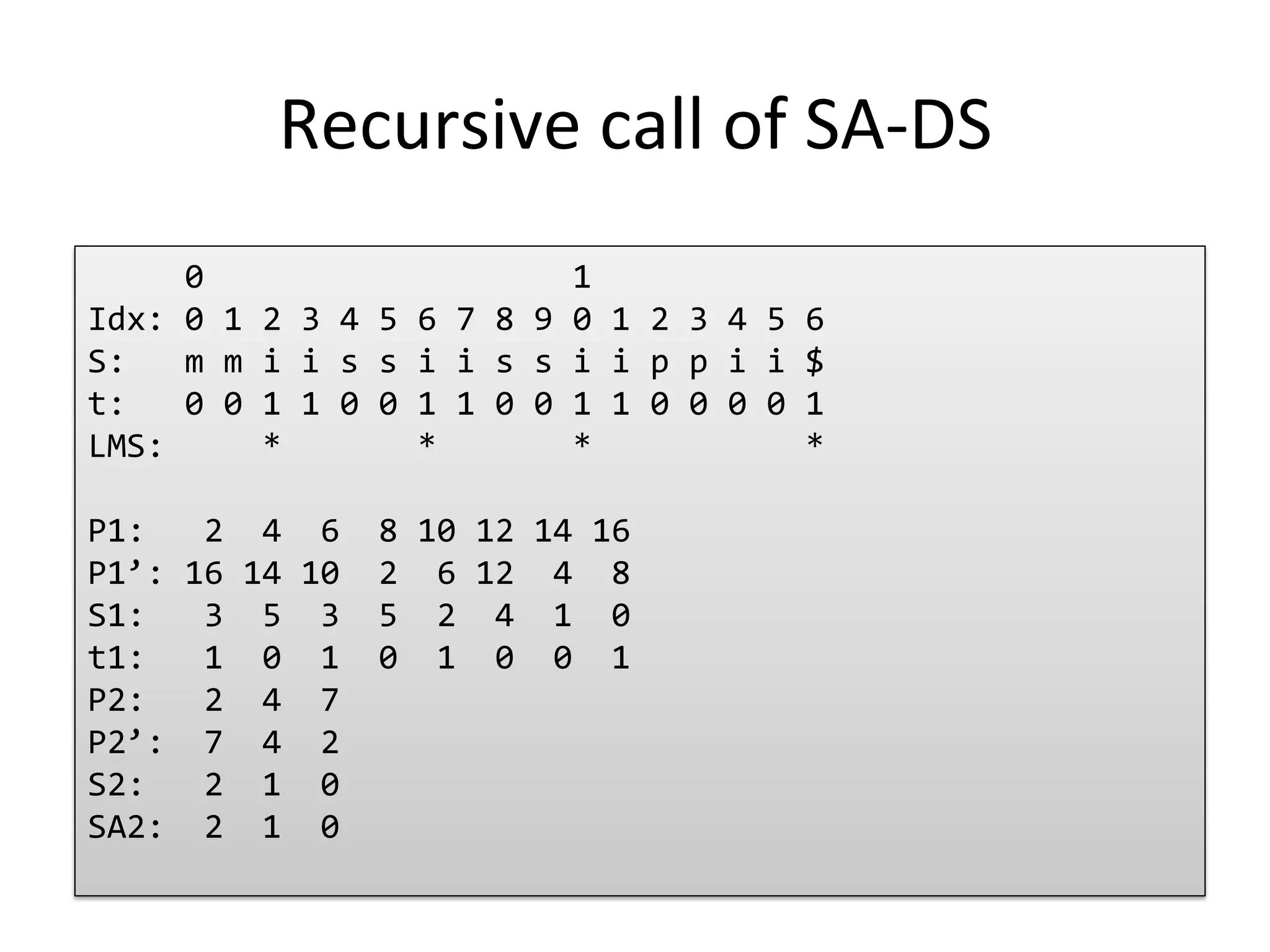
Examines the recursive operations in SA-DS, exploring suffix ordering.
Provides evaluation data for algorithms, showcasing their implementation details.
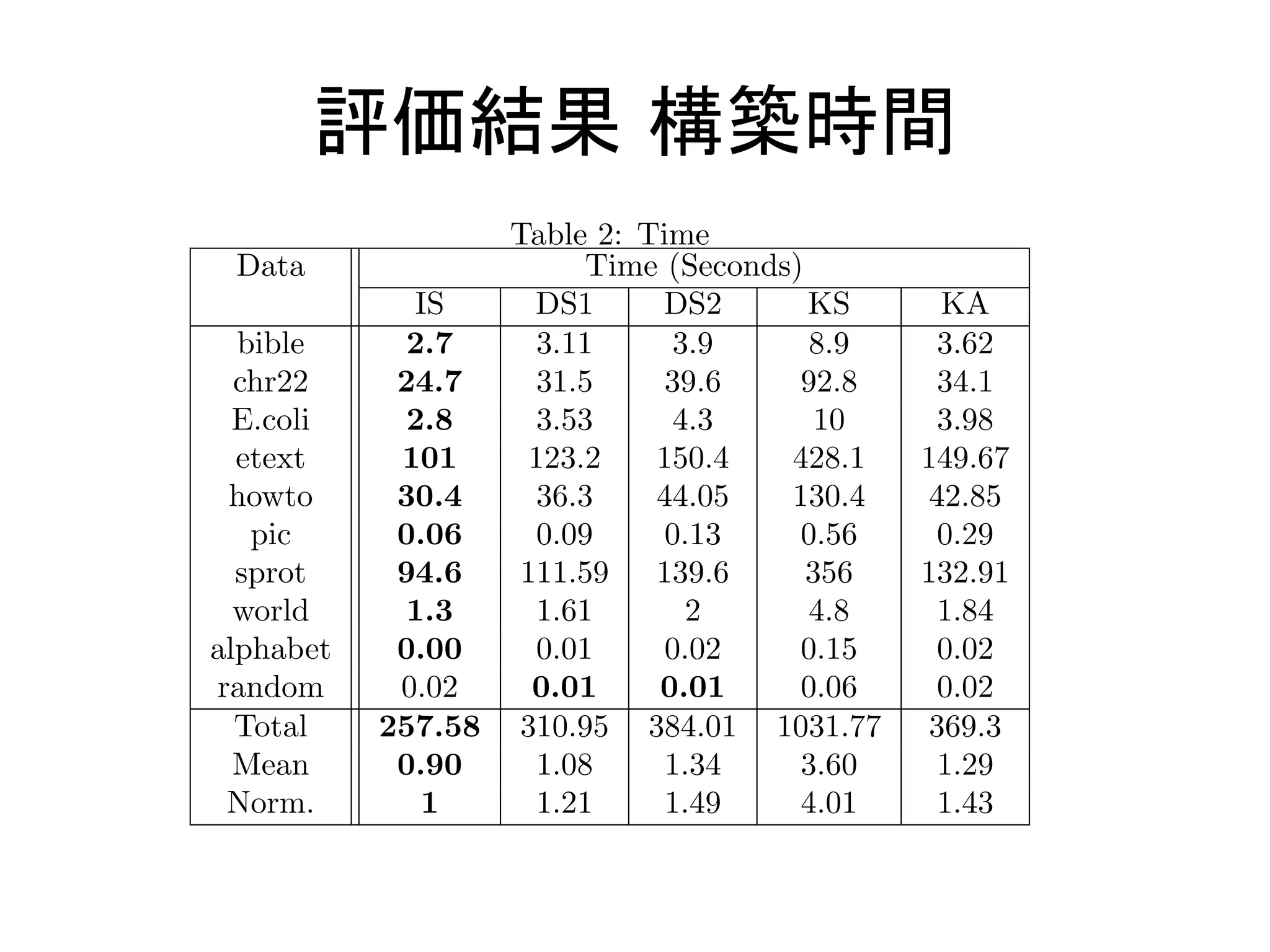
Presents performance metrics in terms of construction time of various algorithms.
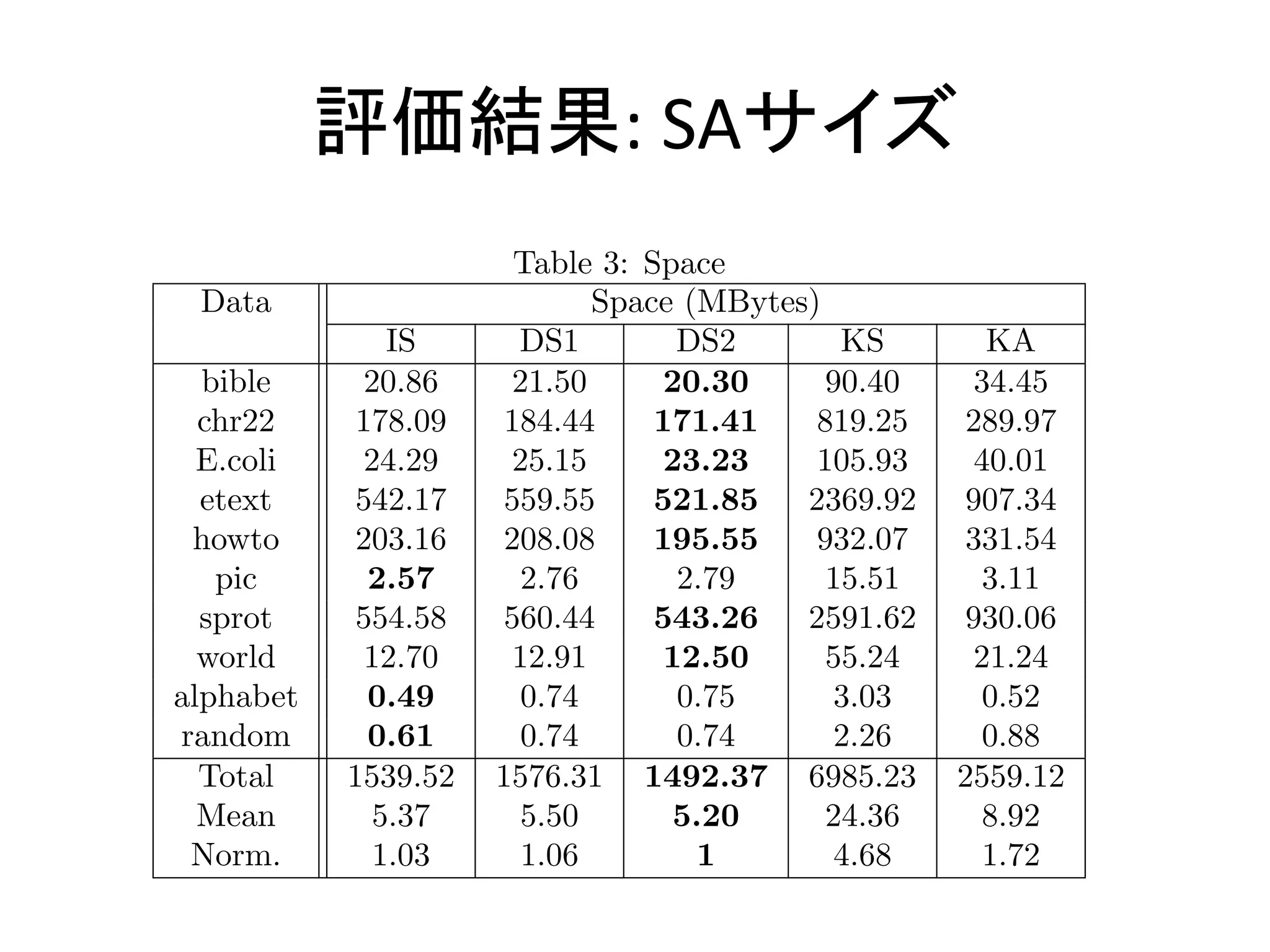
Displays space utilization data for different algorithms in terms of memory usage.
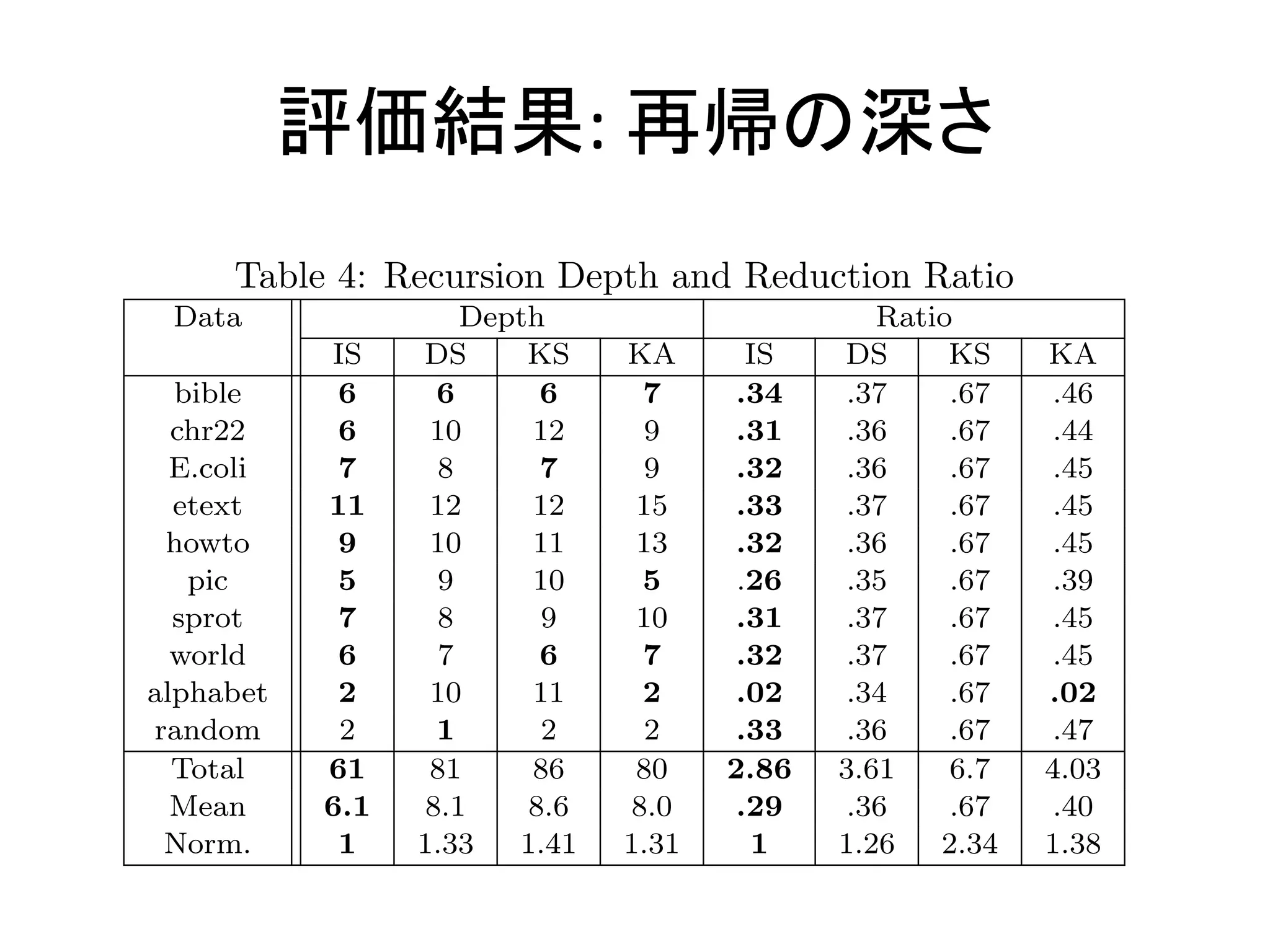
Examines recursion depth and reduction ratios based on algorithm evaluations.
Final thoughts on the effectiveness of SA-IS in implementation and efficiency.