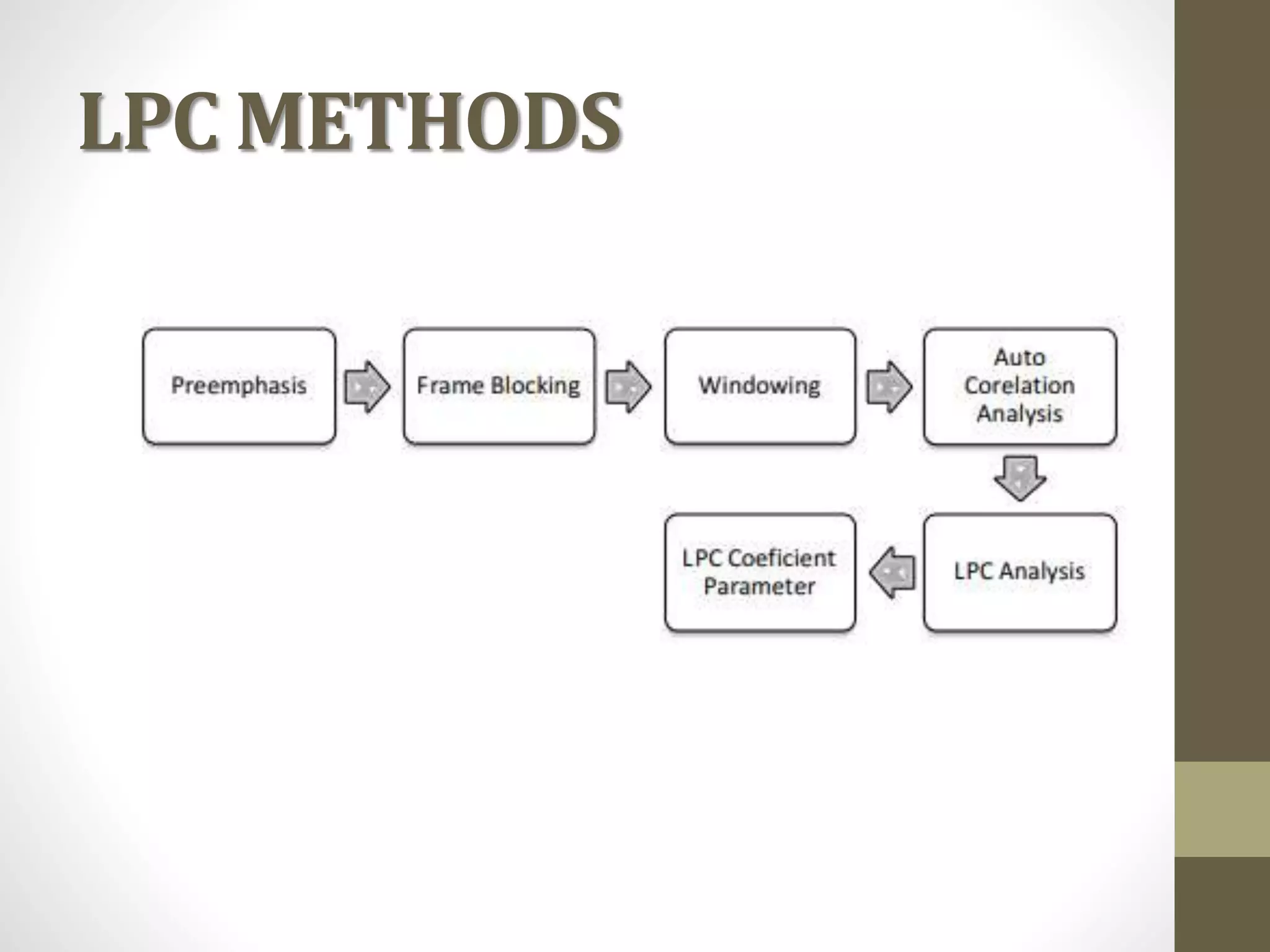
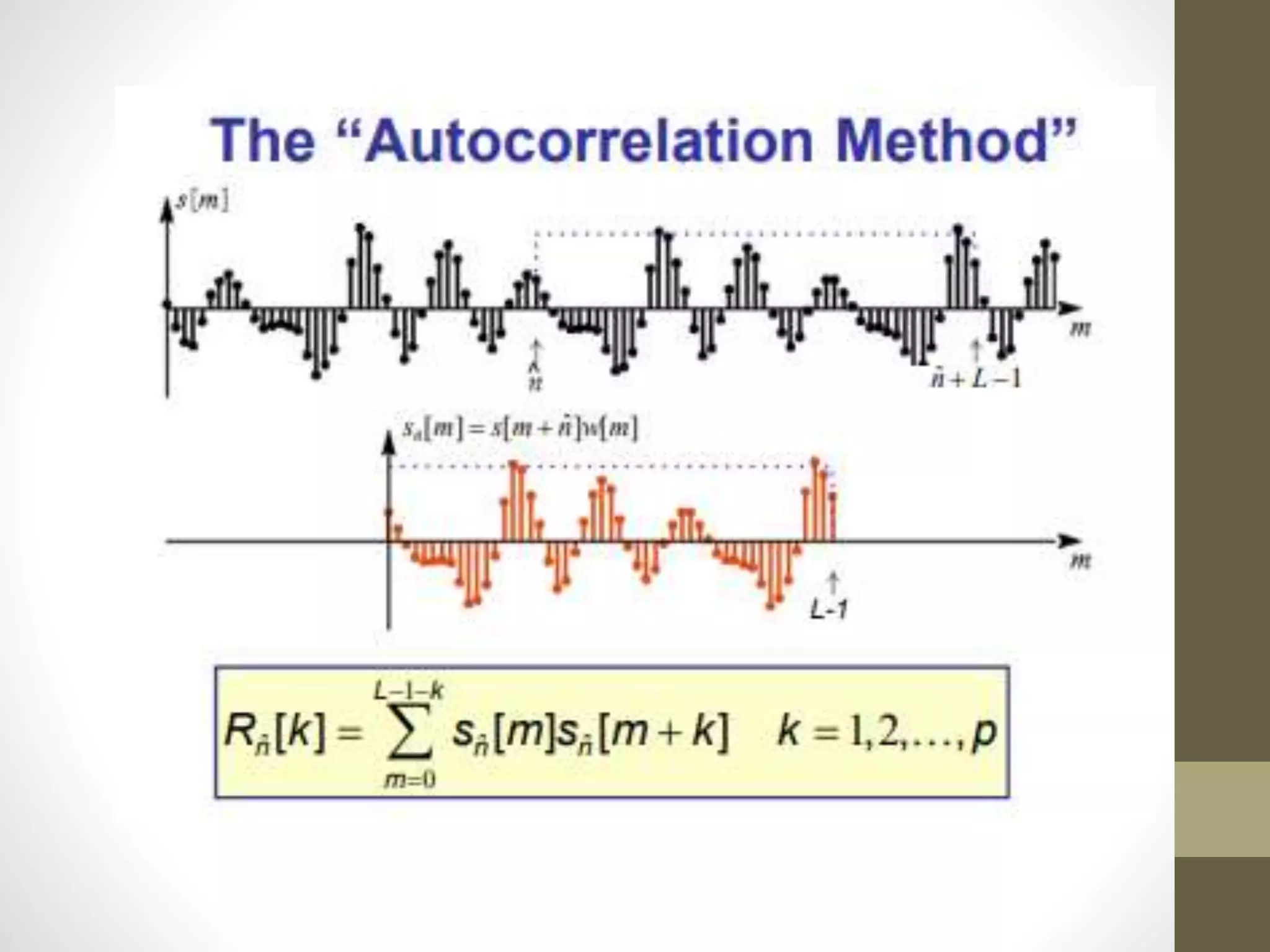
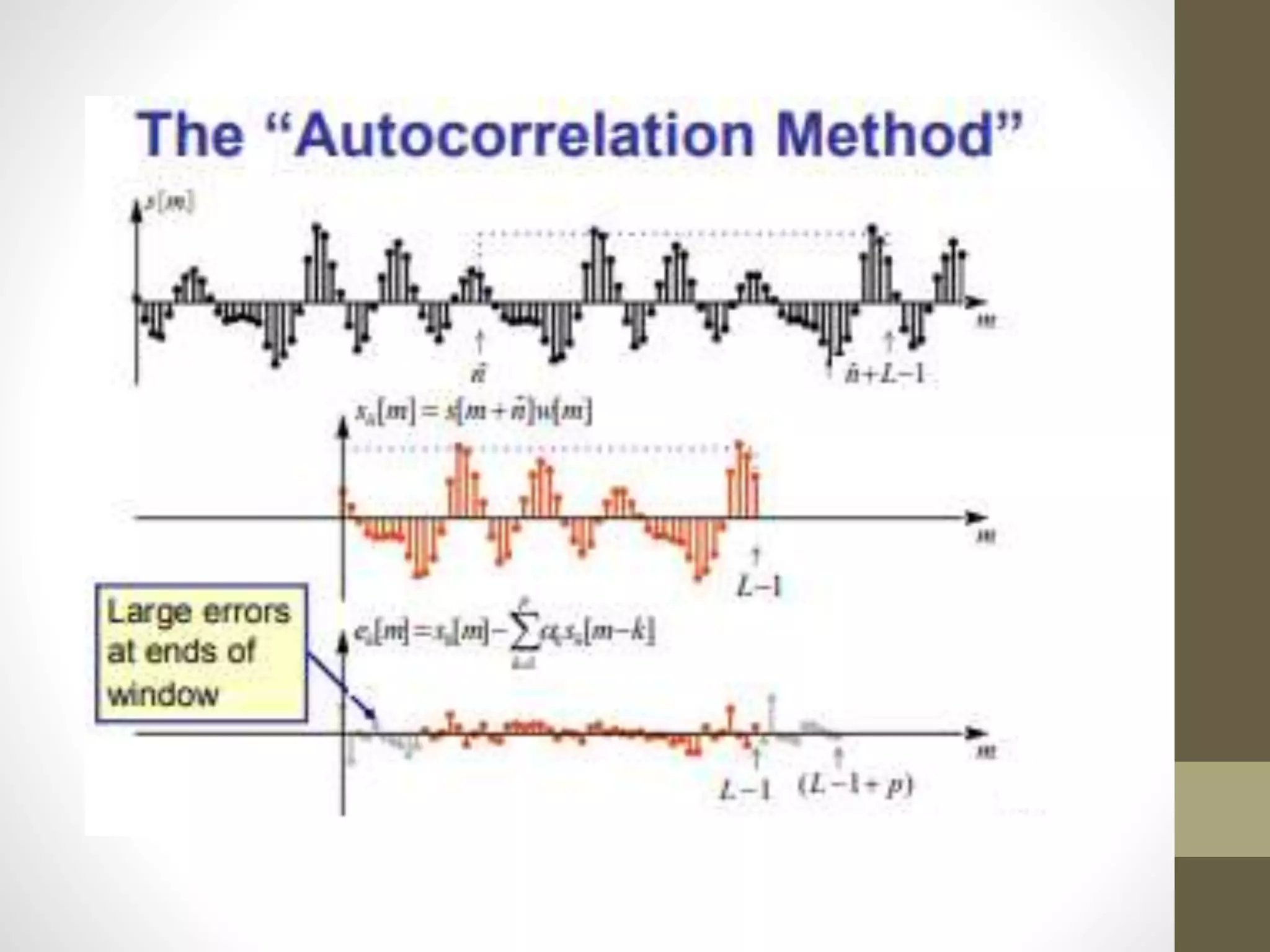
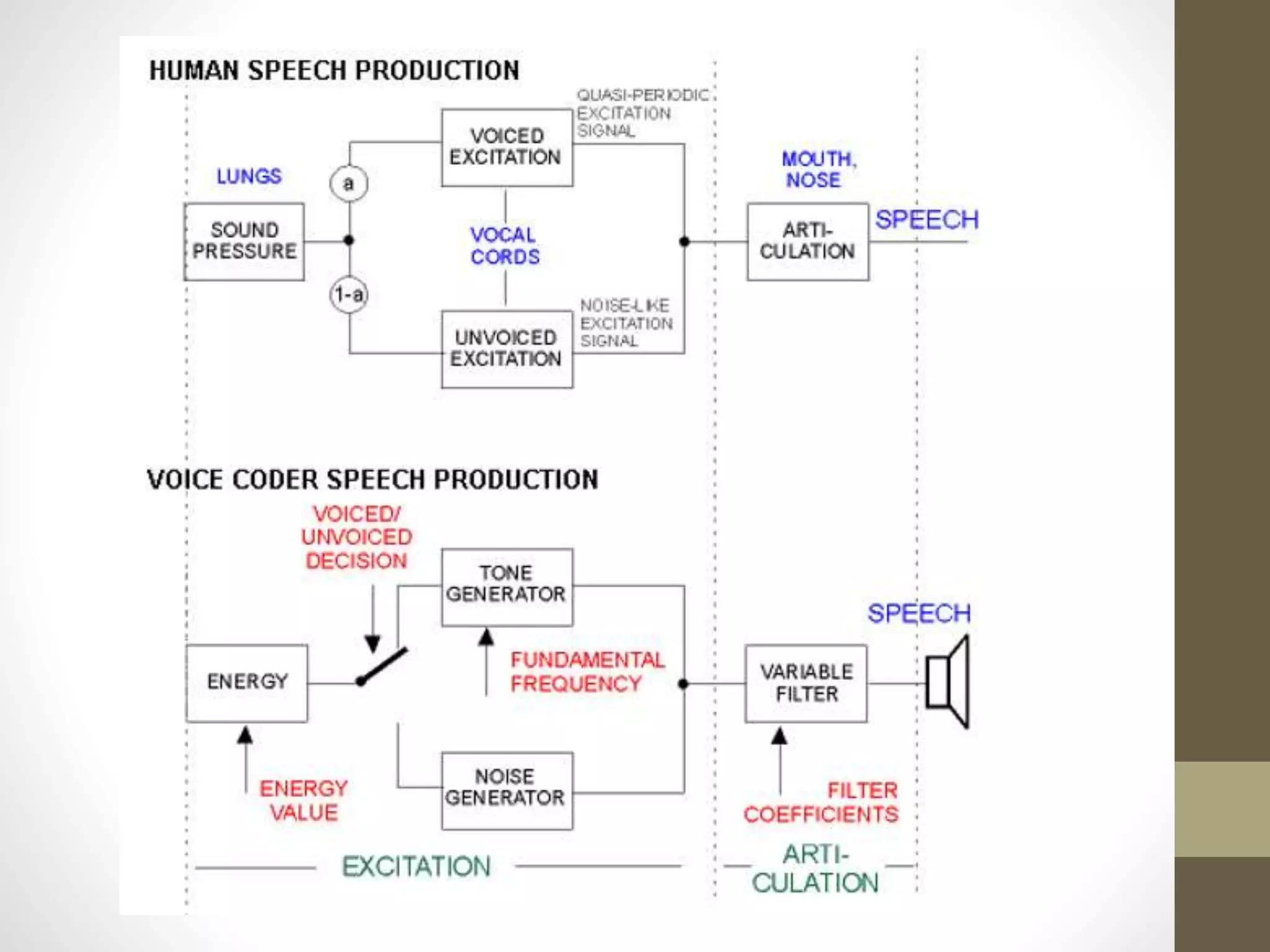
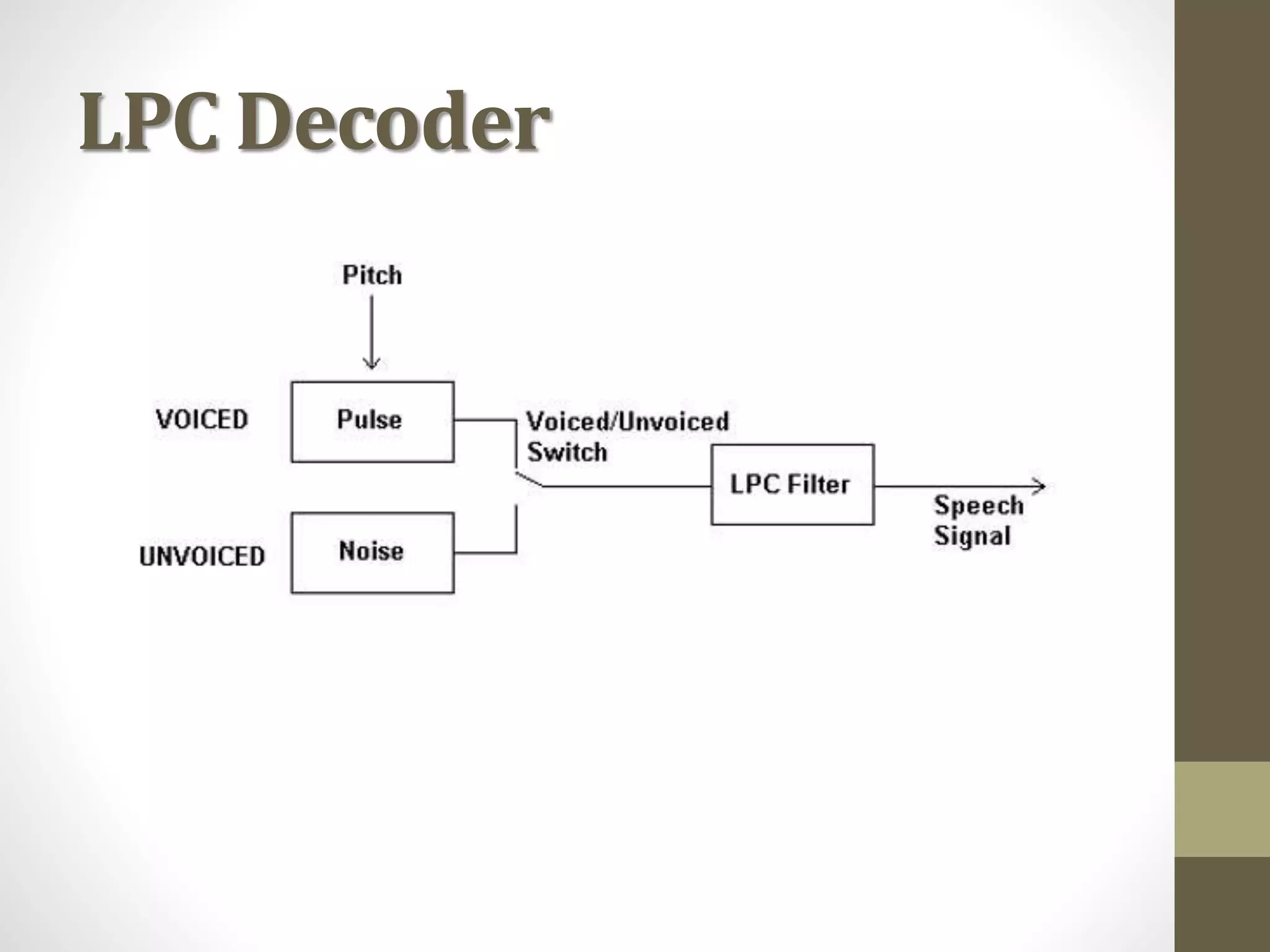
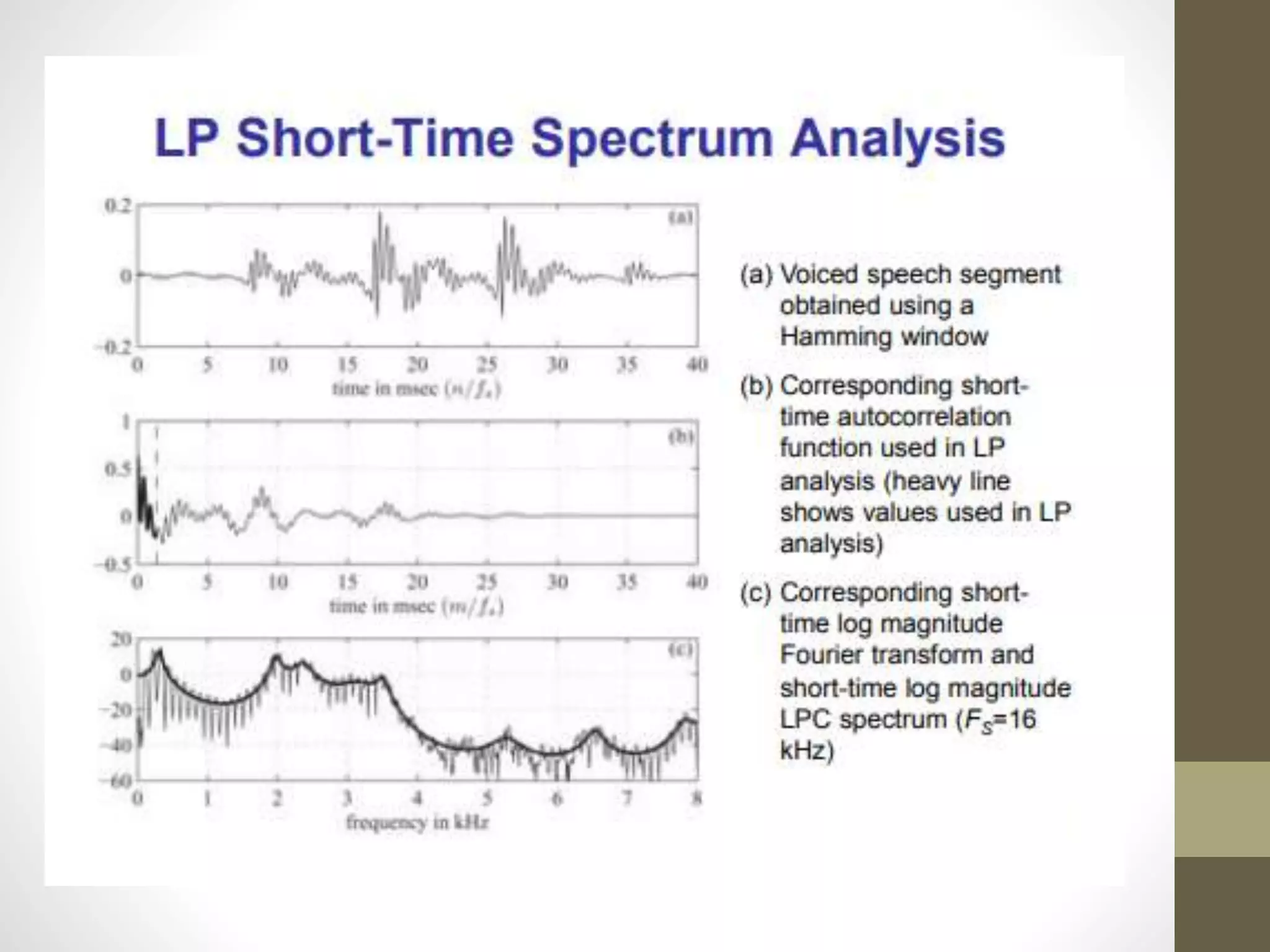
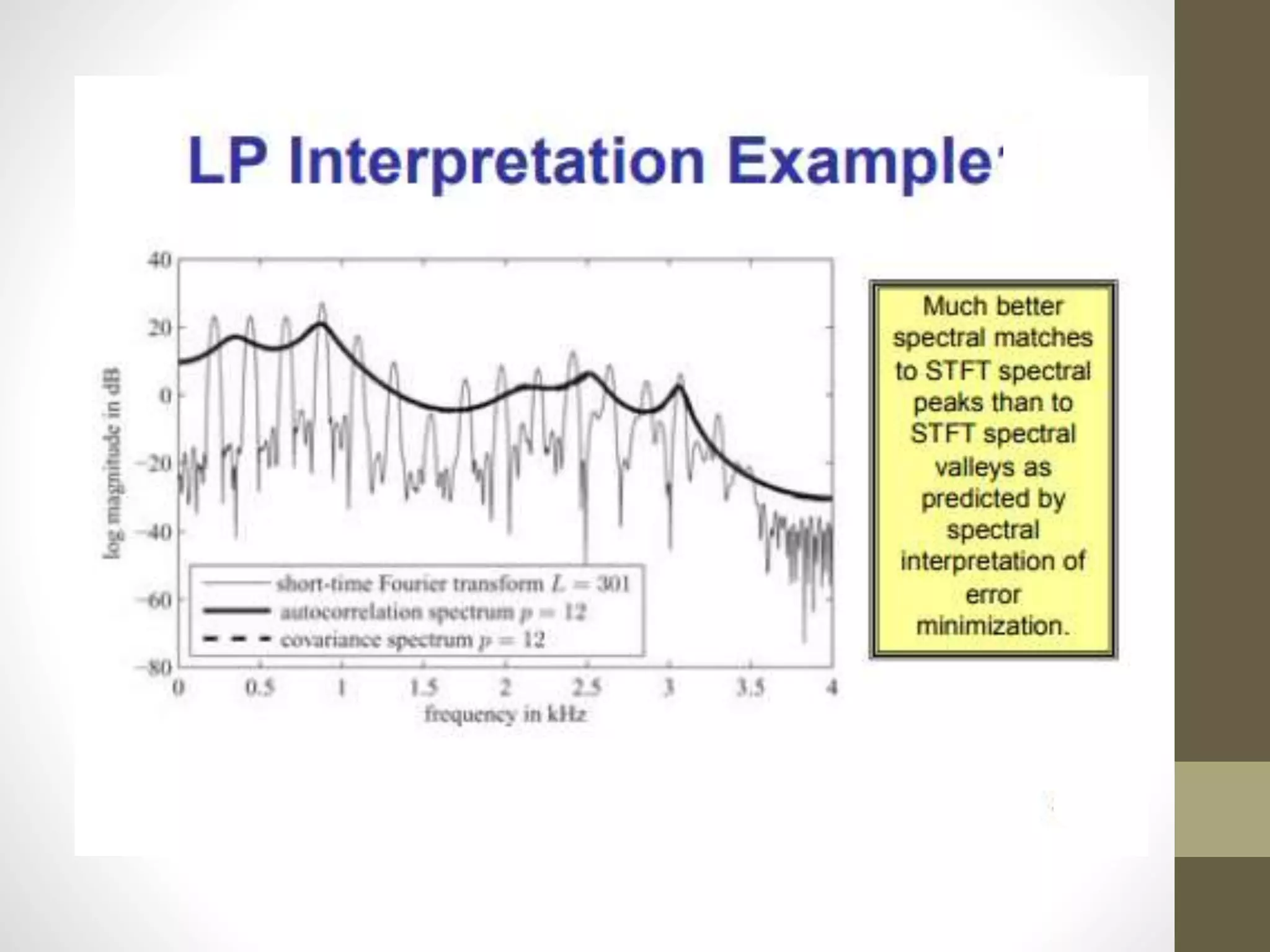
Linear Predictive Coding (LPC) is an effective and efficient speech analysis and encoding technique that compresses speech from 64000 to 2400 bits/second, though with noticeable quality loss. The process includes steps like preemphasis filtering, frame blocking, and autocorrelation analysis, enabling feature extraction and the generation of a synthesized speech signal. LPC involves both analysis for segmenting speech and synthesis using reflection coefficients for creating filters that model vocal tract parameters.