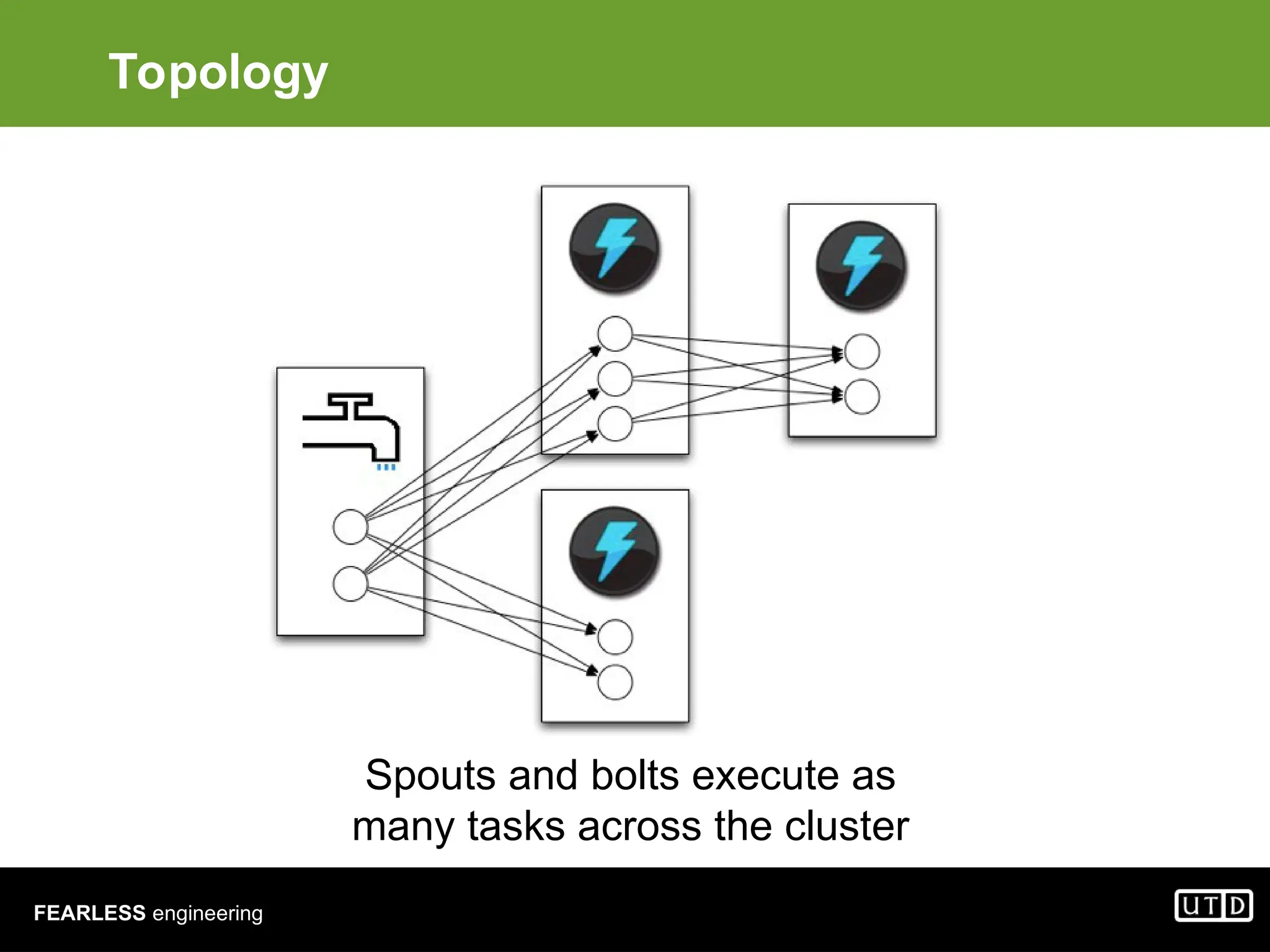
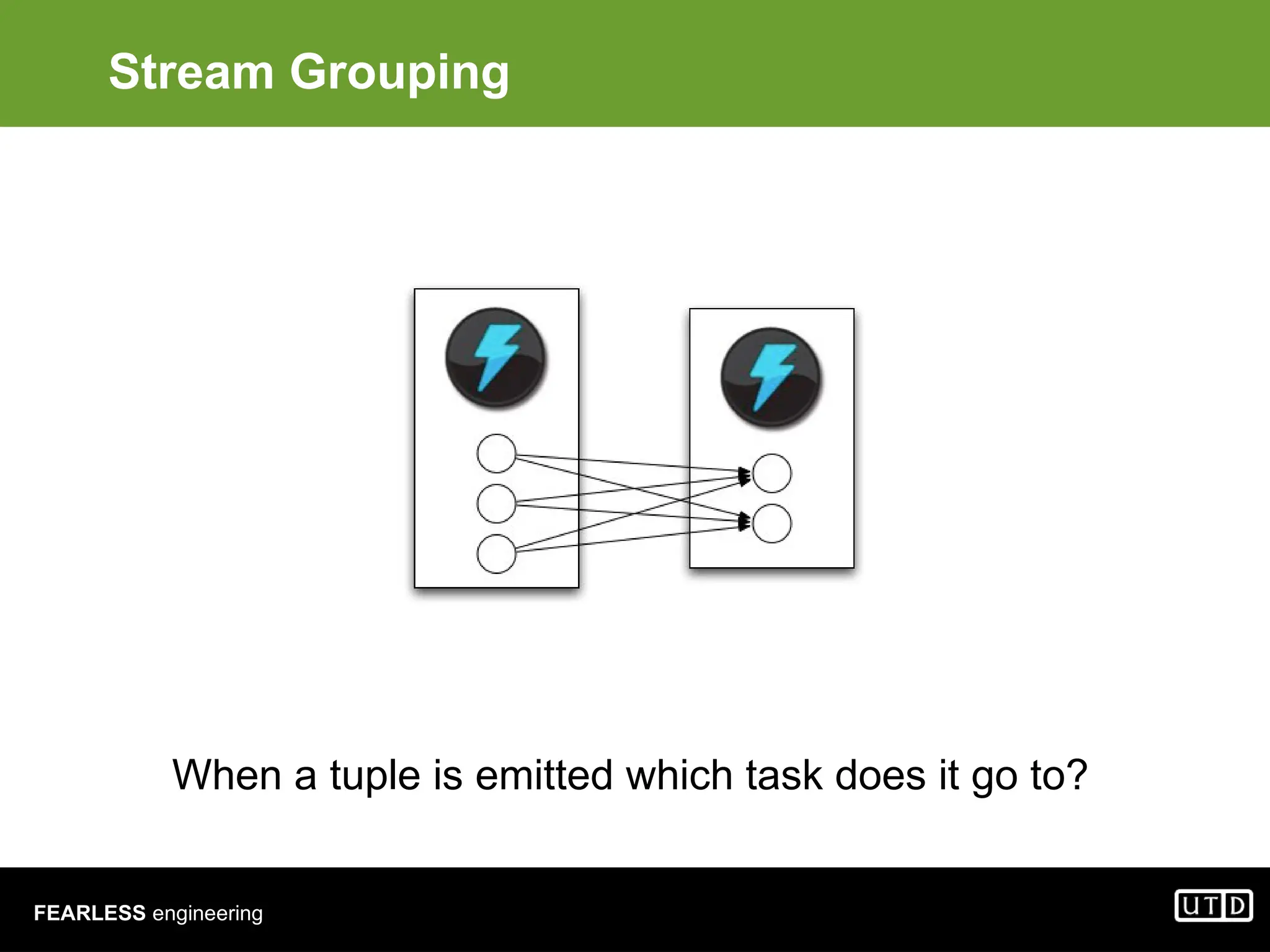
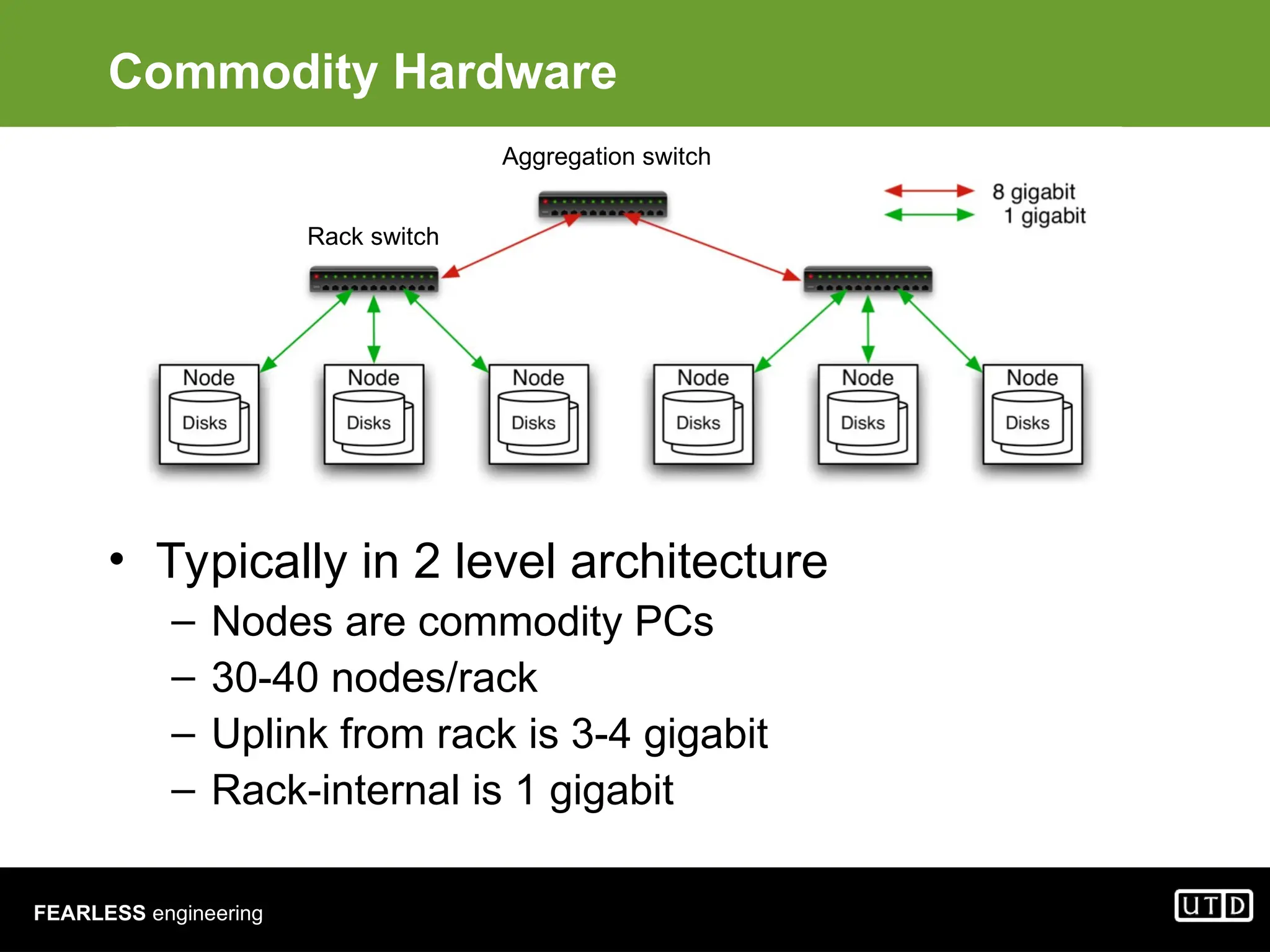
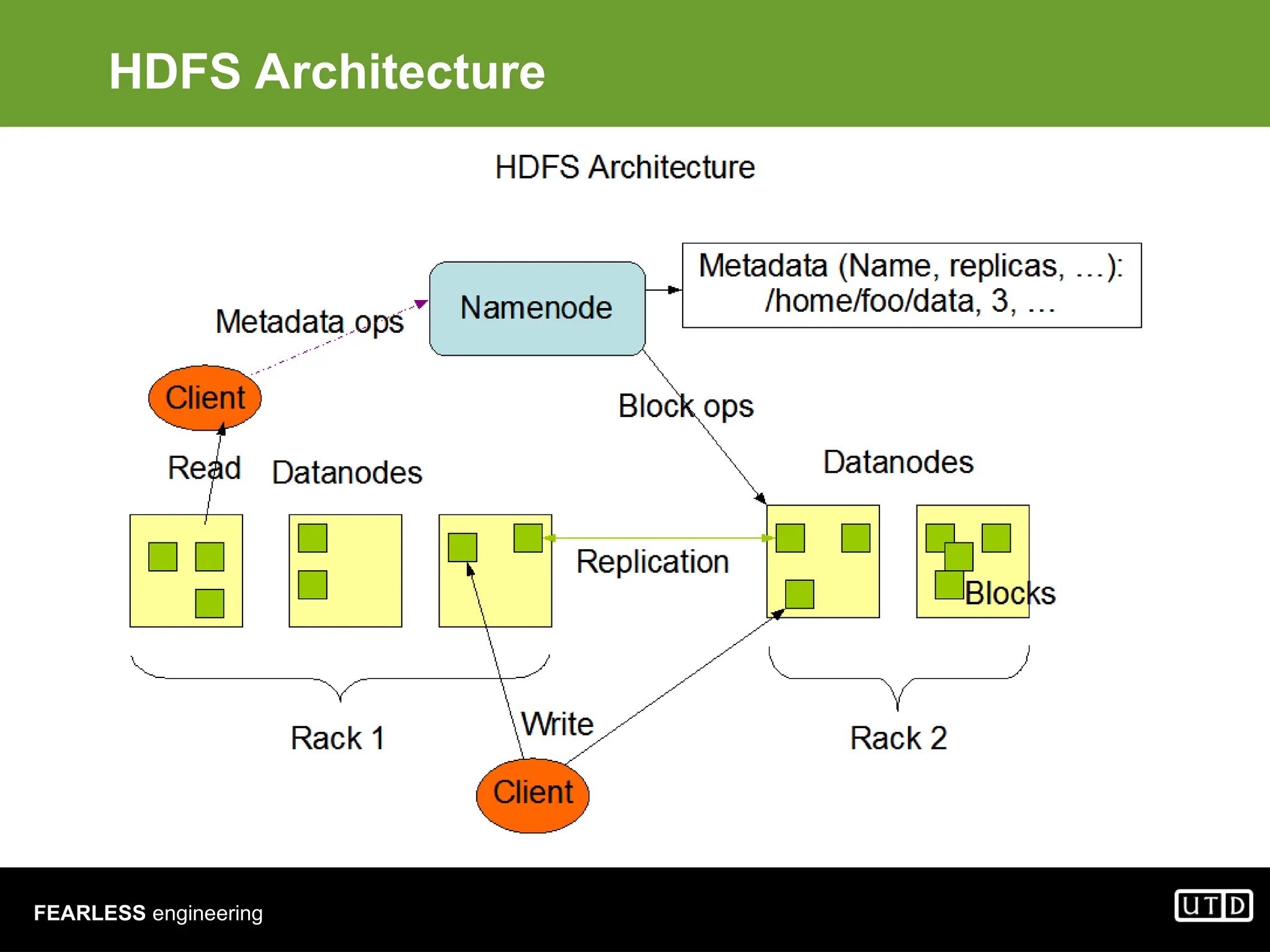
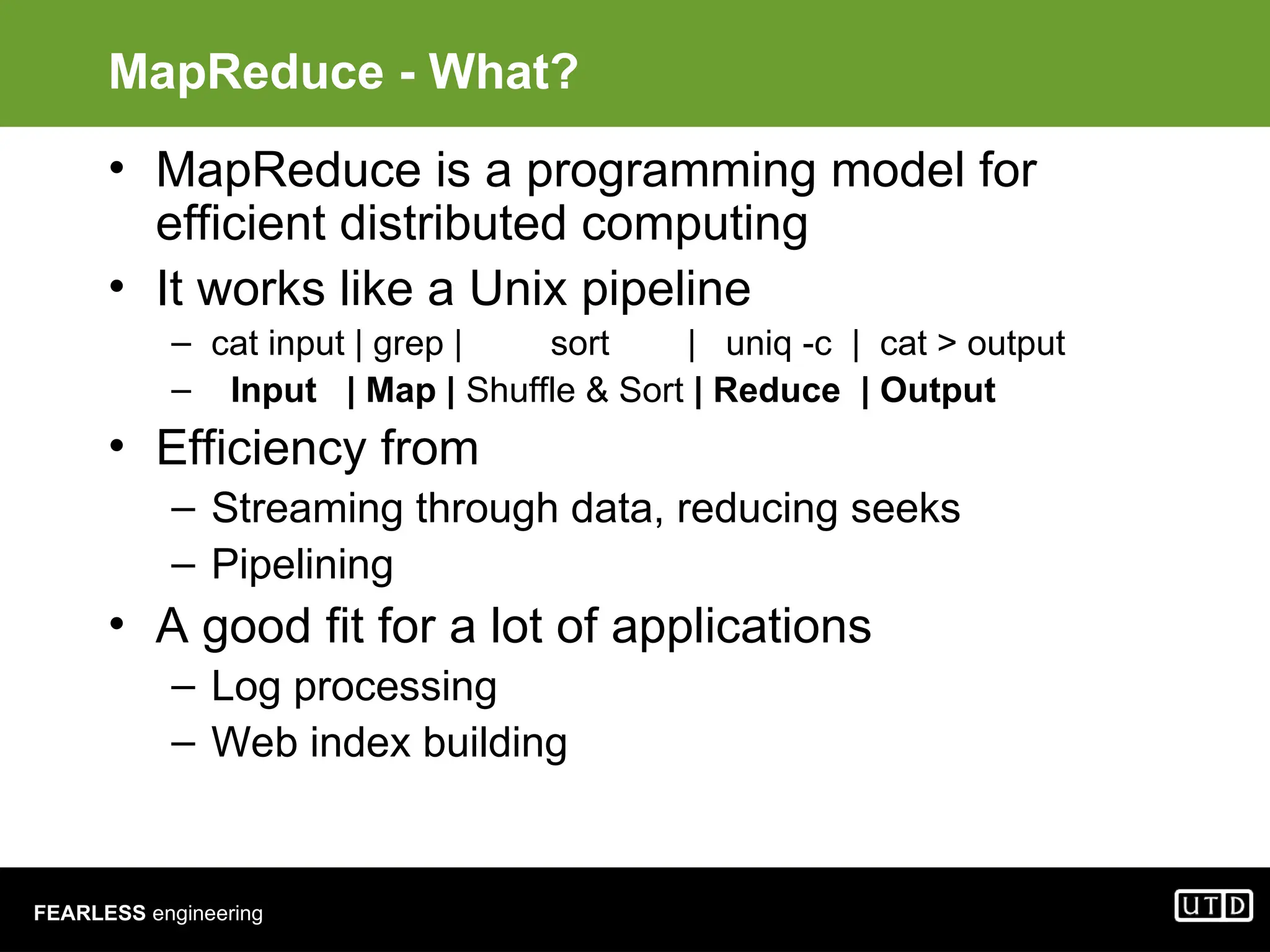
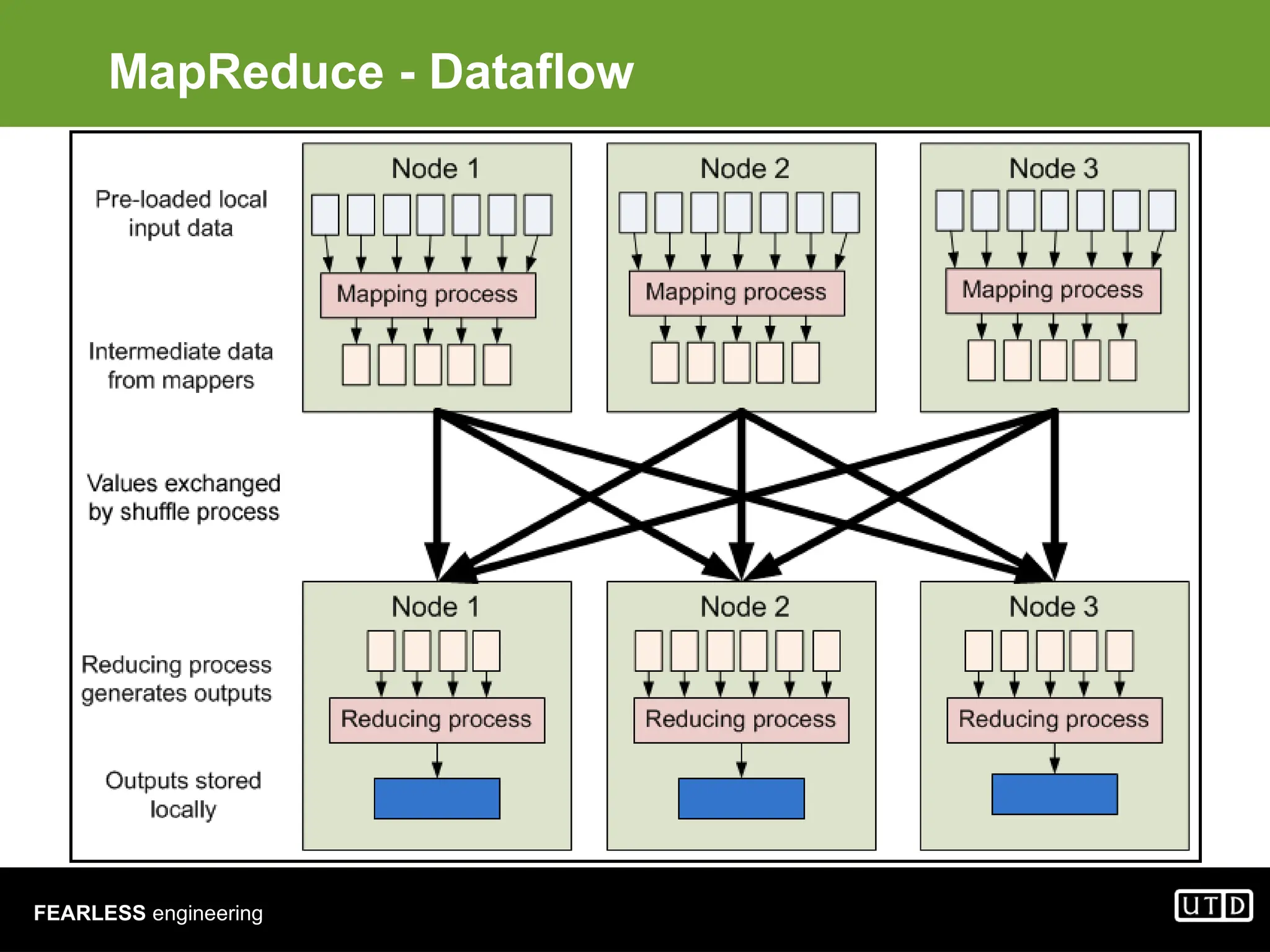
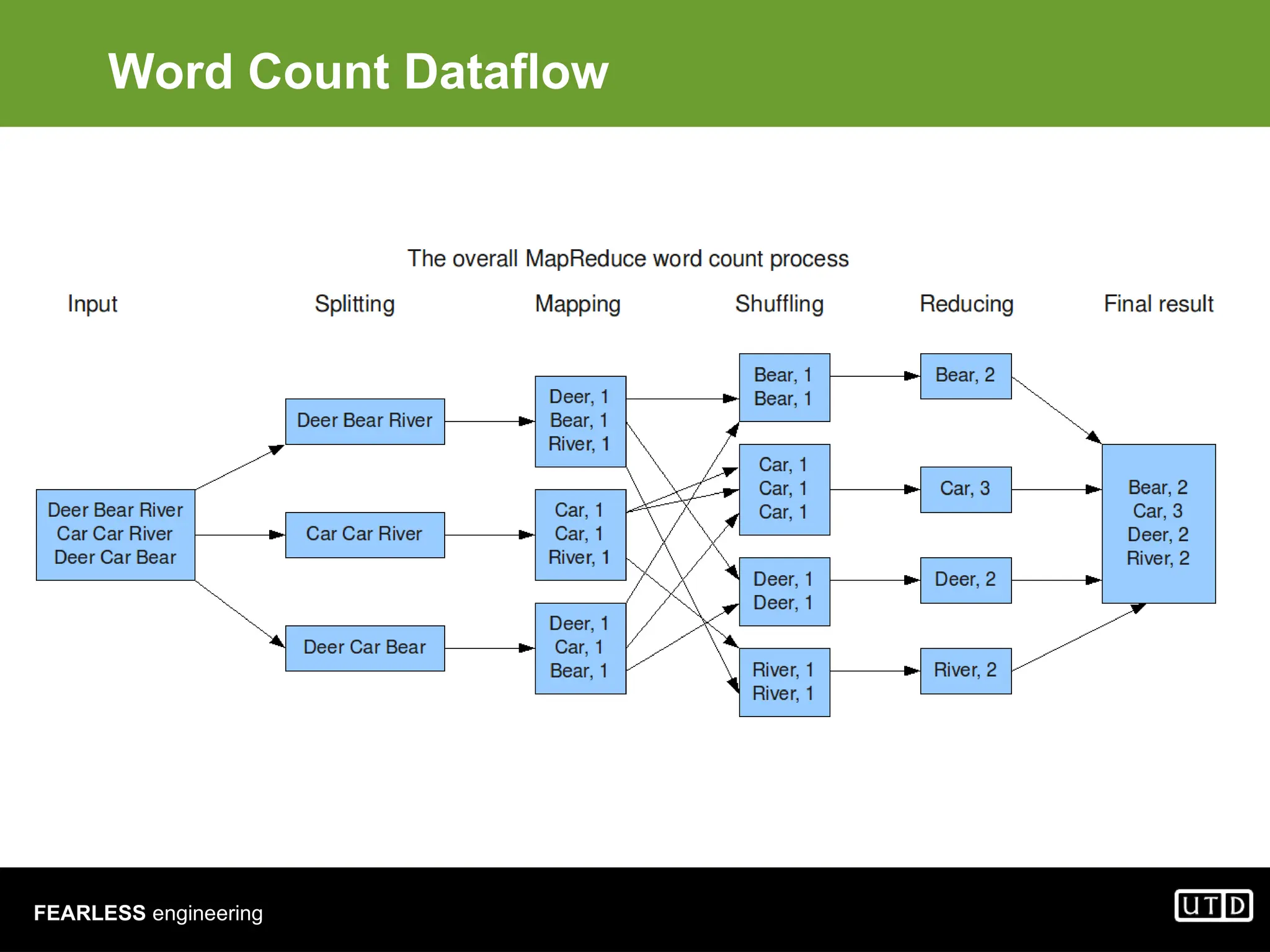
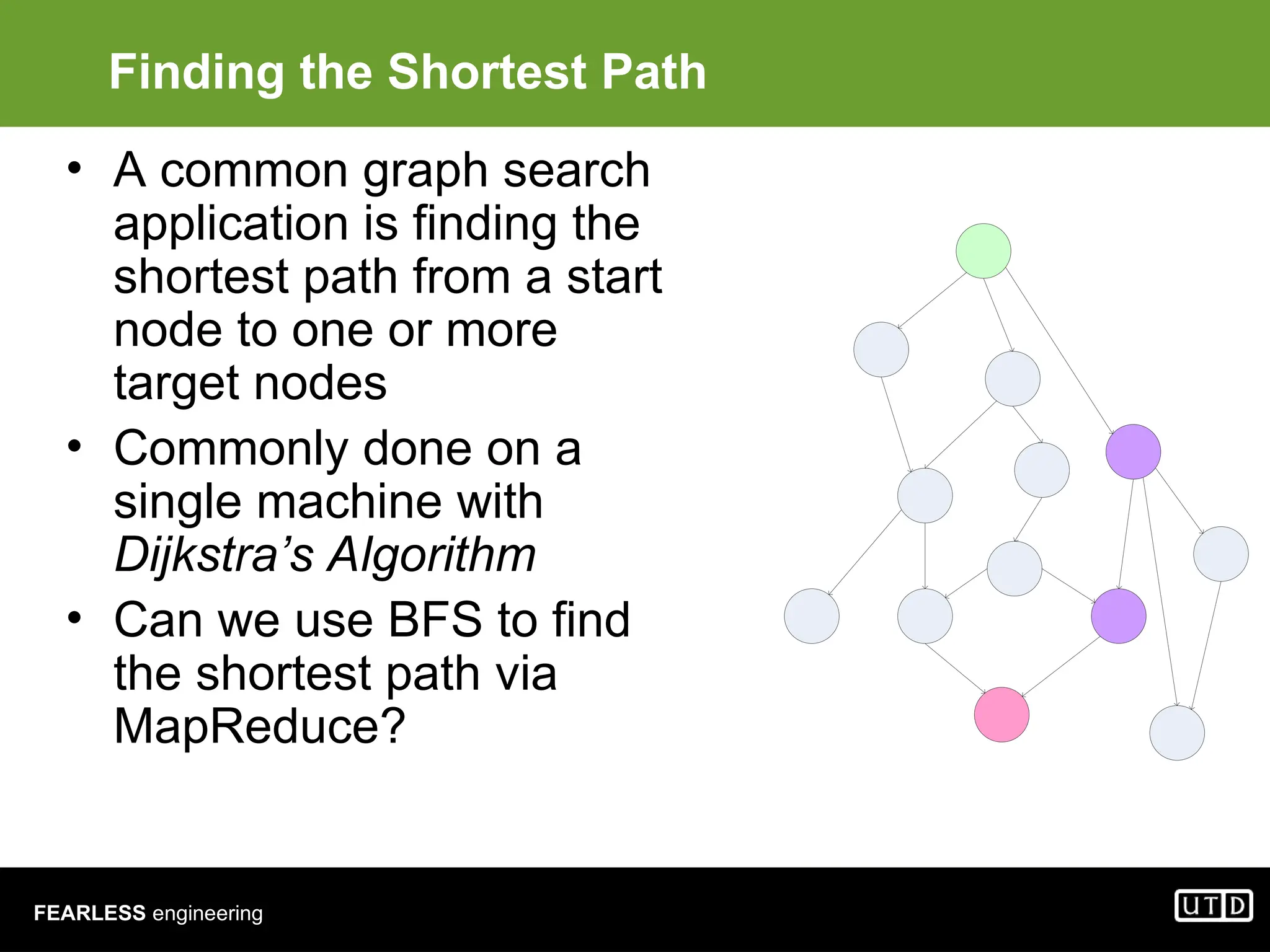
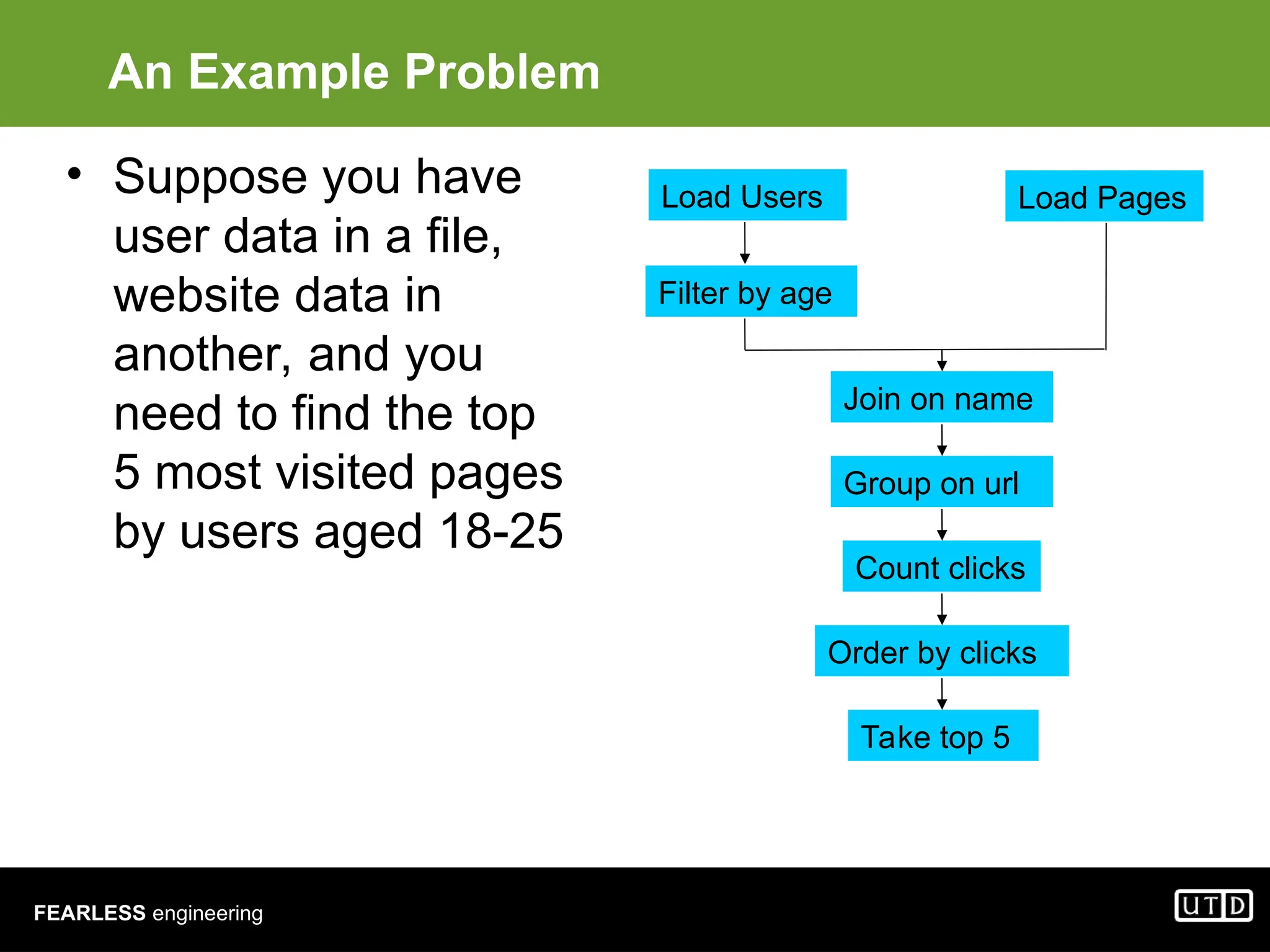
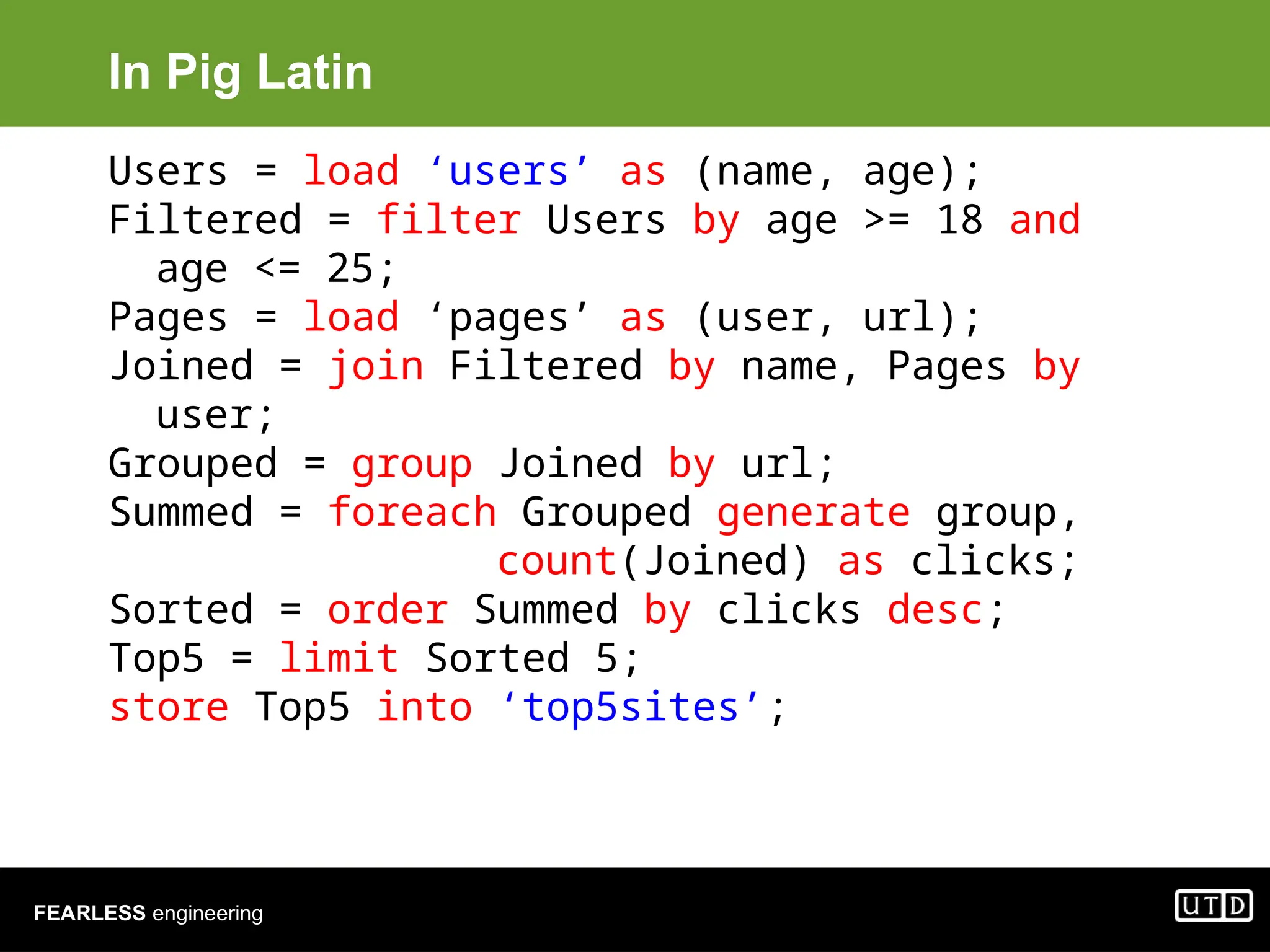
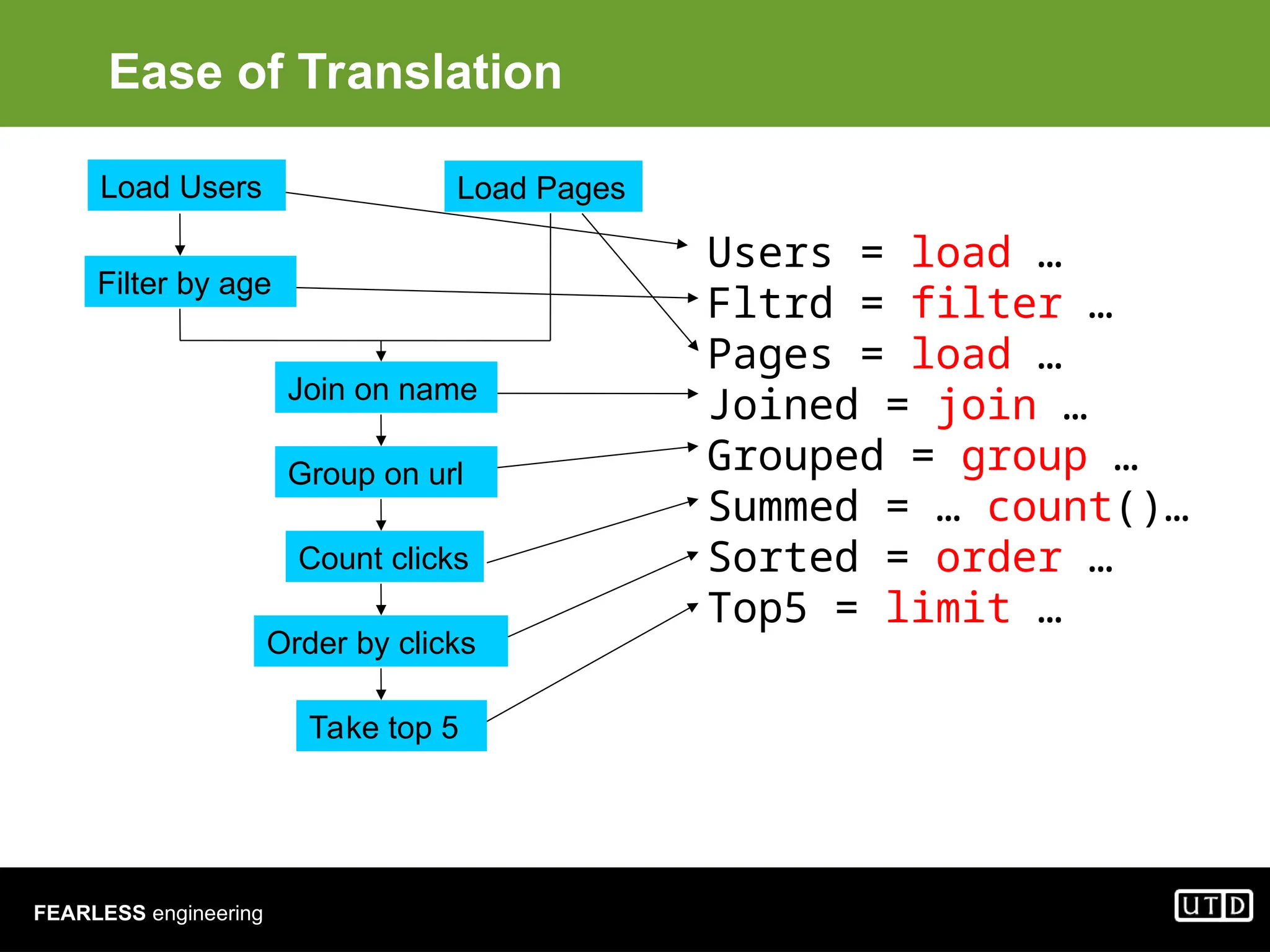
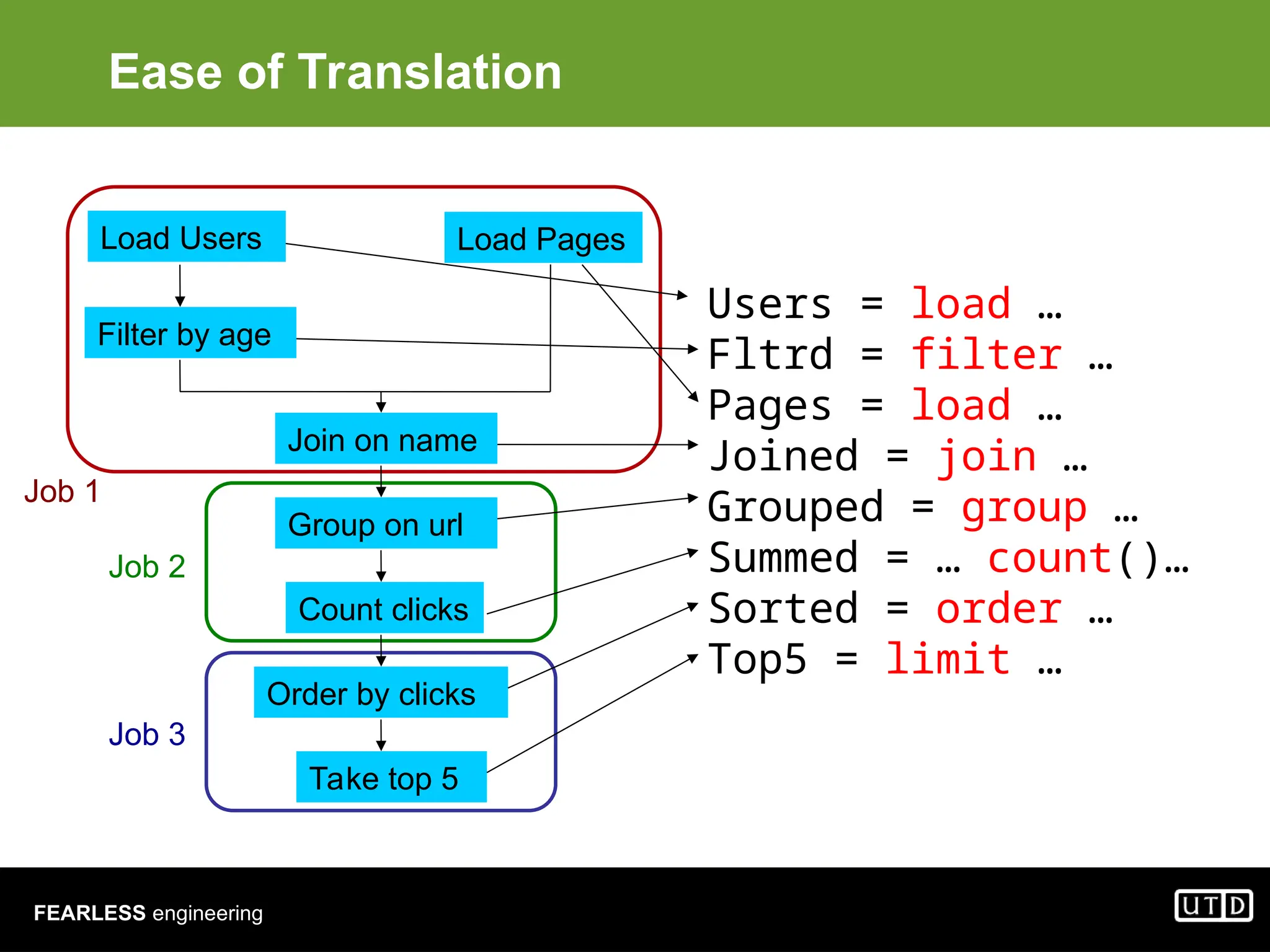
The document provides an overview of Hadoop, including its architecture and components such as HDFS and MapReduce, highlighting its capacity to manage huge datasets across clusters of commodity hardware. It explains the implementation of MapReduce for efficient distributed computing with examples like word counting and finding the shortest path through graph traversal. Various Apache sub-projects related to Hadoop, such as Pig for data analysis and HBase for storage, are also discussed.



























![FEARLESS engineering Putting it all together JobConf conf = new JobConf(WordCount.class); conf.setJobName(“wordcount”); conf.setOutputKeyClass(Text.class); conf.setOutputValueClass(IntWritable.class); conf.setMapperClass(Map.class); conf.setCombinerClass(Reduce.class); conf.setReducer(Reduce.class); conf.setInputFormat(TextInputFormat.class); Conf.setOutputFormat(TextOutputFormat.class); FileInputFormat.setInputPaths(conf, new Path(args[0])); FileOutputFormat.setOutputPath(conf, new Path(args[1])); JobClient.runJob(conf);](https://image.slidesharecdn.com/lectureoinhadooptechnology-240910115014-f42e6c5b/75/Lecture-on-Hadoop-Technology-MCA-Engg-ppt-33-2048.jpg)









![FEARLESS engineering Distributed File Cache • Sometimes need read-only copies of data on the local computer – Downloading 1GB of data for each Mapper is expensive • Define list of files you need to download in JobConf • Files are downloaded once per computer • Add to launching program: DistributedCache.addCacheFile(new URI(“hdfs://nn:8020/foo”), conf); • Add to task: Path[] files = DistributedCache.getLocalCacheFiles(conf);](https://image.slidesharecdn.com/lectureoinhadooptechnology-240910115014-f42e6c5b/75/Lecture-on-Hadoop-Technology-MCA-Engg-ppt-43-2048.jpg)
![FEARLESS engineering Tool • Handle “standard” Hadoop command line options – -conf file - load a configuration file named file – -D prop=value - define a single configuration property prop • Class looks like: public class MyApp extends Configured implements Tool { public static void main(String[] args) throws Exception { System.exit(ToolRunner.run(new Configuration(), new MyApp(), args)); } public int run(String[] args) throws Exception { …. getConf() …. } }](https://image.slidesharecdn.com/lectureoinhadooptechnology-240910115014-f42e6c5b/75/Lecture-on-Hadoop-Technology-MCA-Engg-ppt-44-2048.jpg)










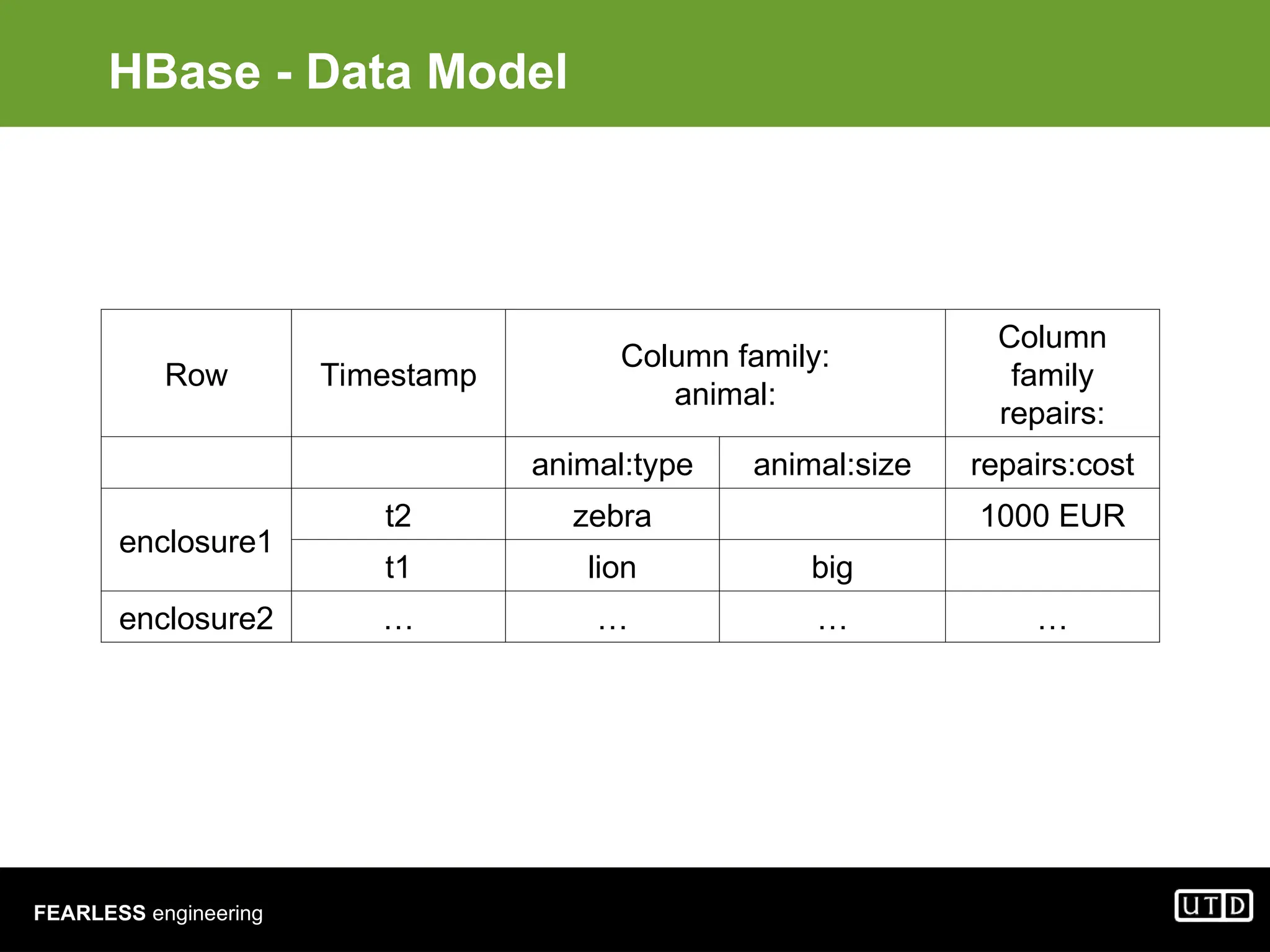
![FEARLESS engineering HBase - What? • Modeled on Google’s Bigtable • Row/column store • Billions of rows/millions on columns • Column-oriented - nulls are free • Untyped - stores byte[]](https://image.slidesharecdn.com/lectureoinhadooptechnology-240910115014-f42e6c5b/75/Lecture-on-Hadoop-Technology-MCA-Engg-ppt-60-2048.jpg)


![FEARLESS engineering HBase - Querying • Retrieve a cell Cell = table.getRow(“enclosure1”).getColumn(“animal:type”).getValue(); • Retrieve a row RowResult = table.getRow( “enclosure1” ); • Scan through a range of rows Scanner s = table.getScanner( new String[] { “animal:type” } );](https://image.slidesharecdn.com/lectureoinhadooptechnology-240910115014-f42e6c5b/75/Lecture-on-Hadoop-Technology-MCA-Engg-ppt-64-2048.jpg)