Downloaded 16 times

![About Laurent Alquier Software engineer, Project lead Johnson & Johnson Pharmaceutical Research & Development, L.L.C [email_address]](https://image.slidesharecdn.com/knowit-wikisym2009-16-110806134647-phpapp02/75/KnowIT-semantic-informatics-knowledge-base-2-2048.jpg)







![Semantic Annotations Tags with meaning Syntax Triple: Page -> Property -> Value [[Has support contact::Help Desk]] Data types Page, URL, Date, String, Text, Number, Geo-location Custom units for Number Browse properties Summary of all properties for a page](https://image.slidesharecdn.com/knowit-wikisym2009-16-110806134647-phpapp02/75/KnowIT-semantic-informatics-knowledge-base-11-2048.jpg)
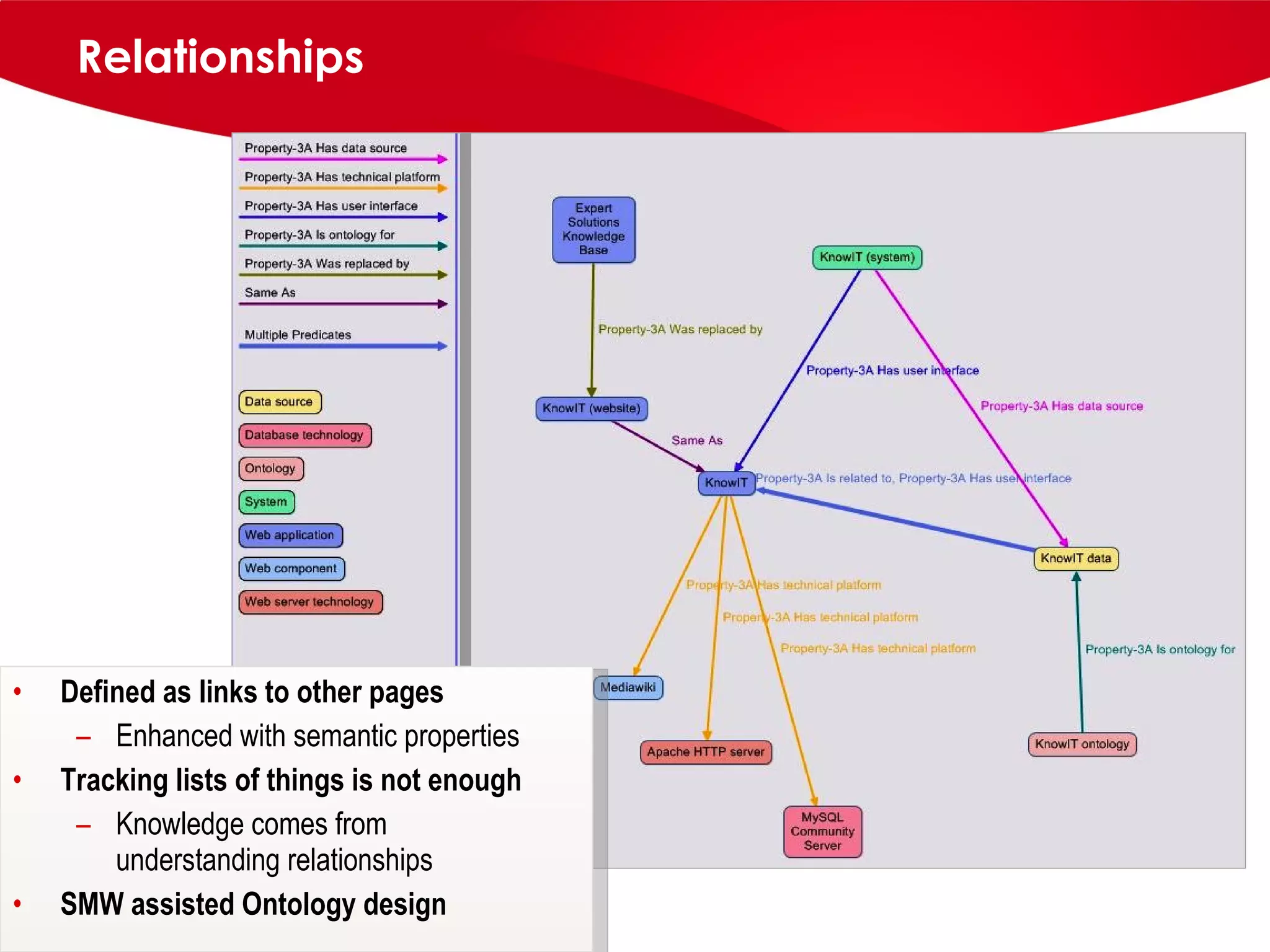

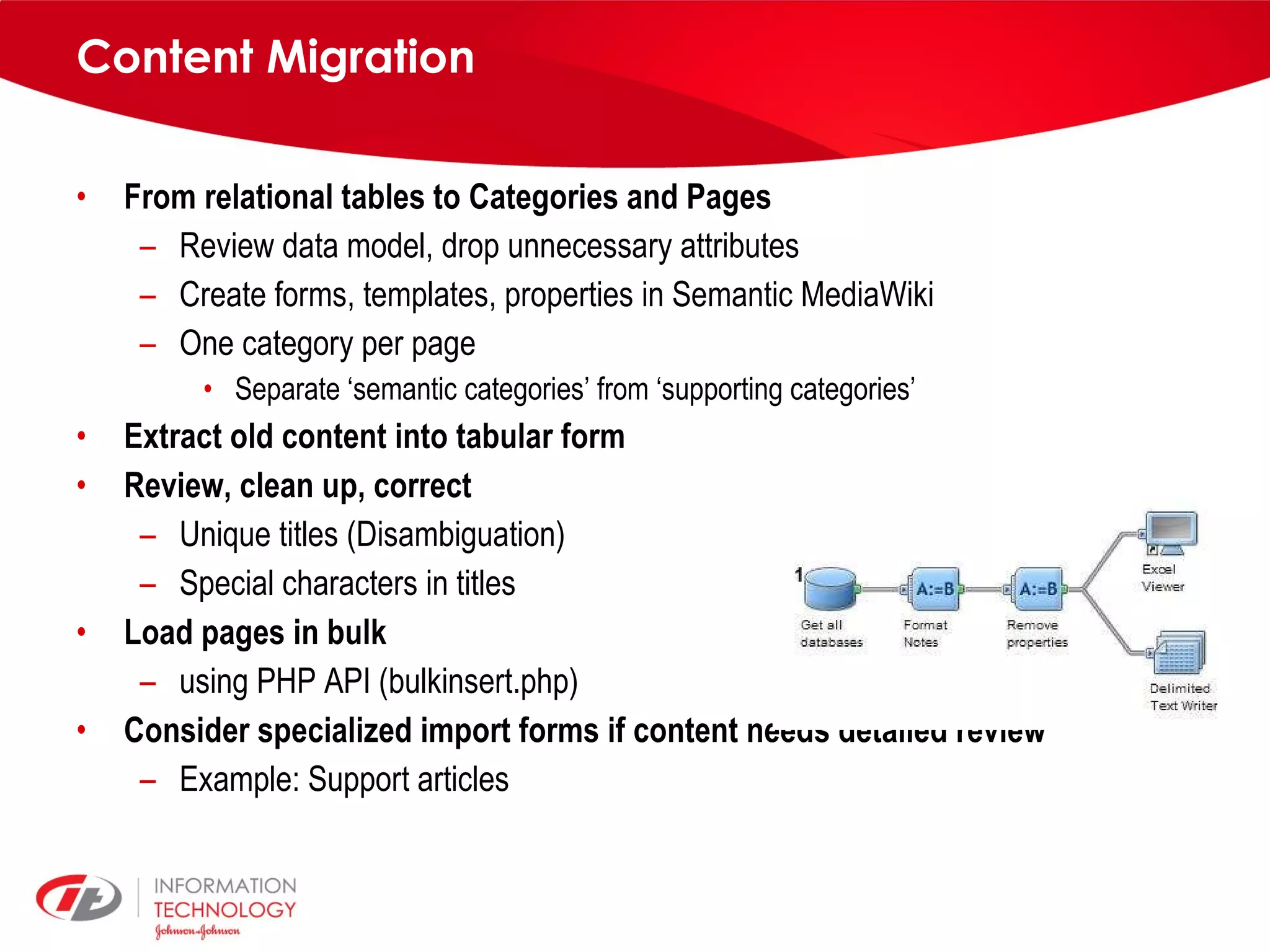

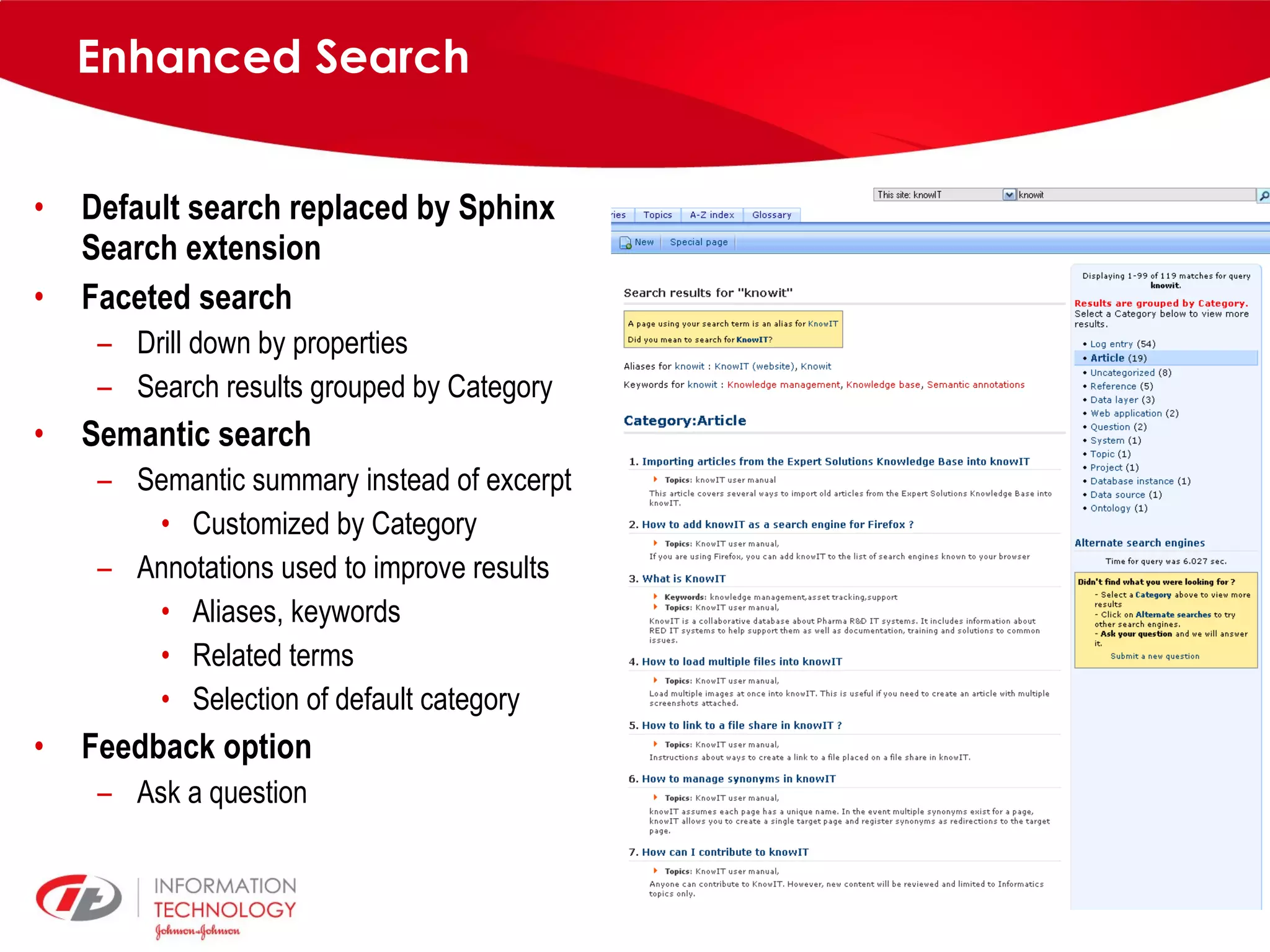


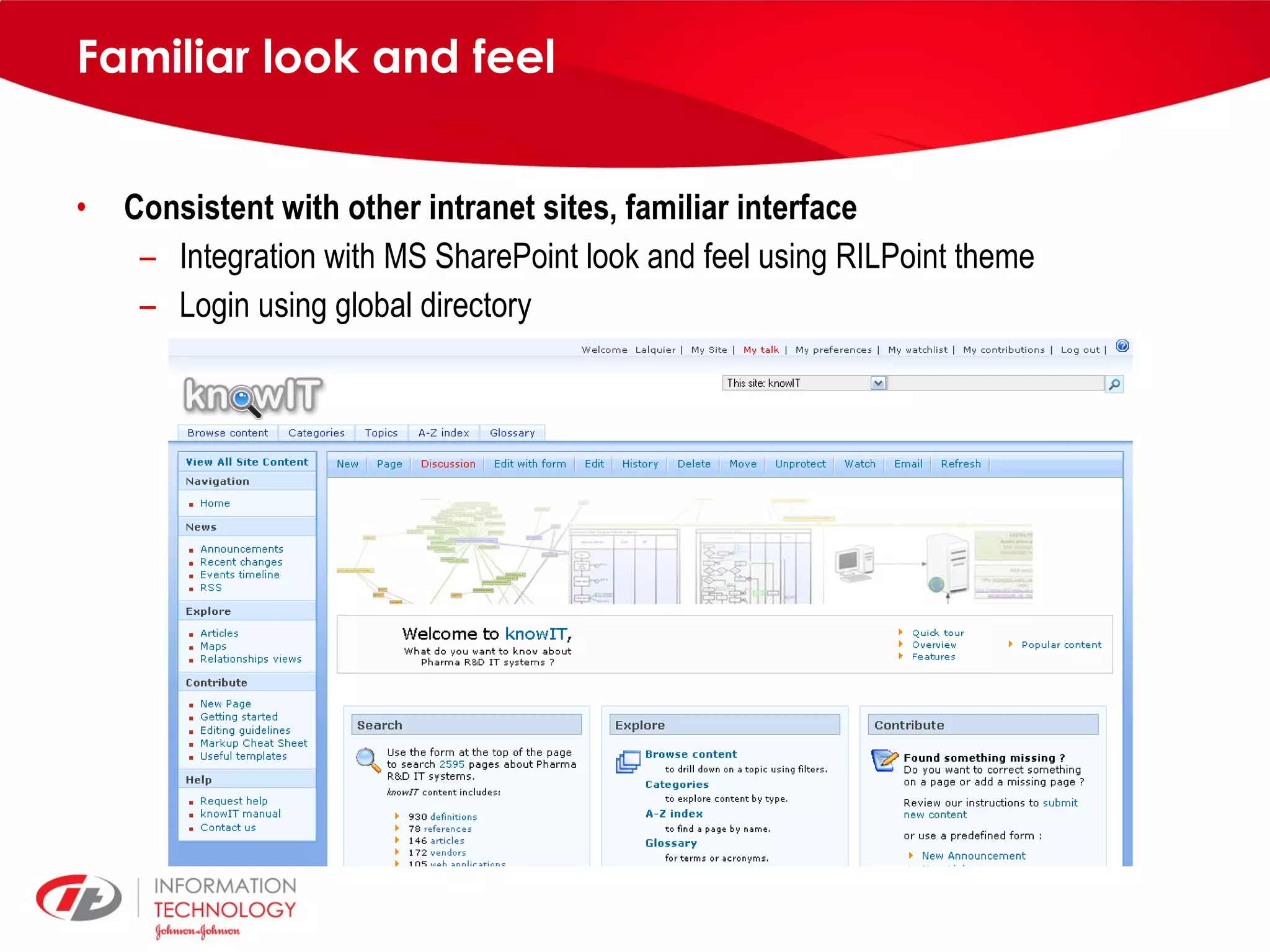
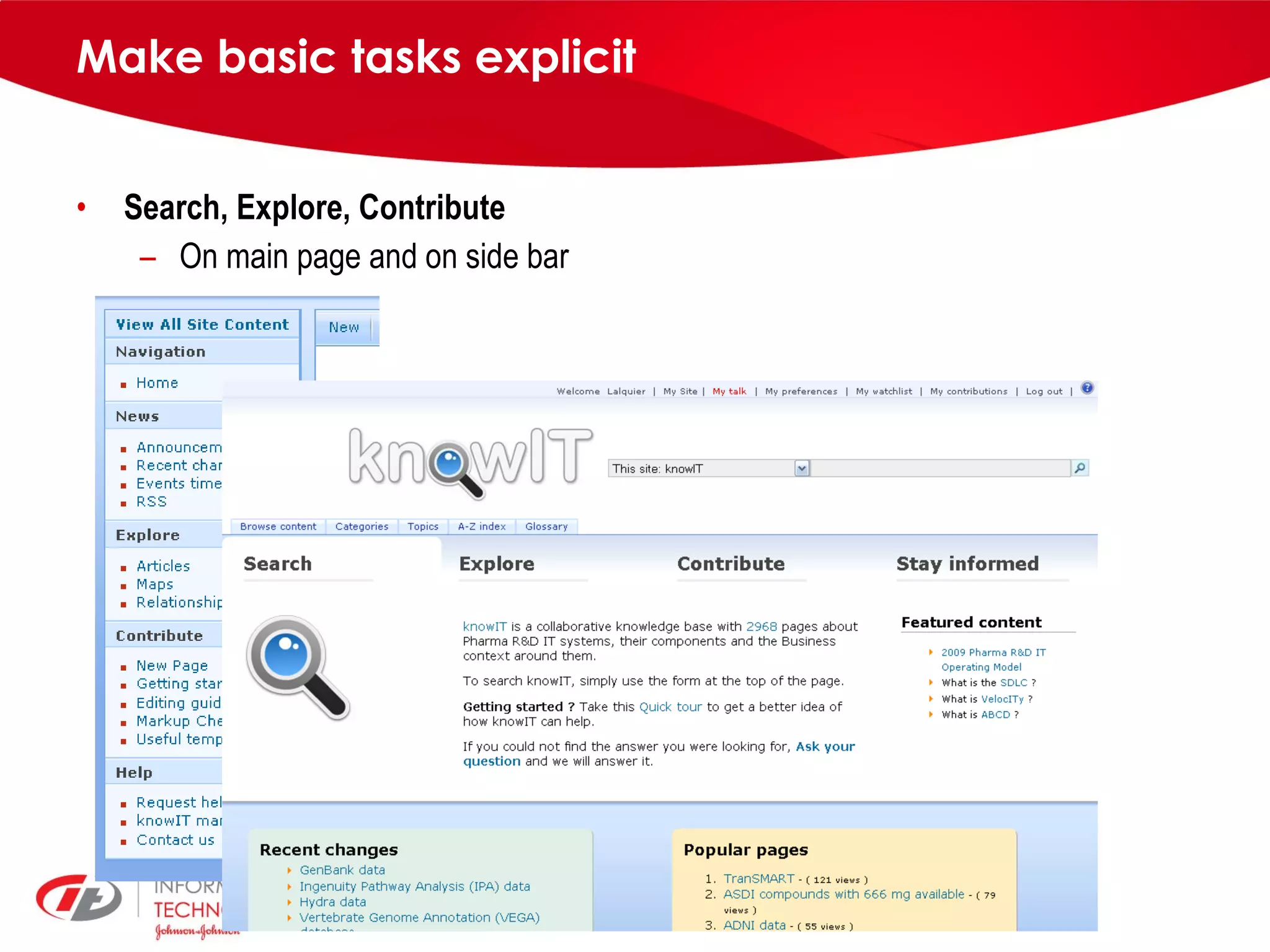


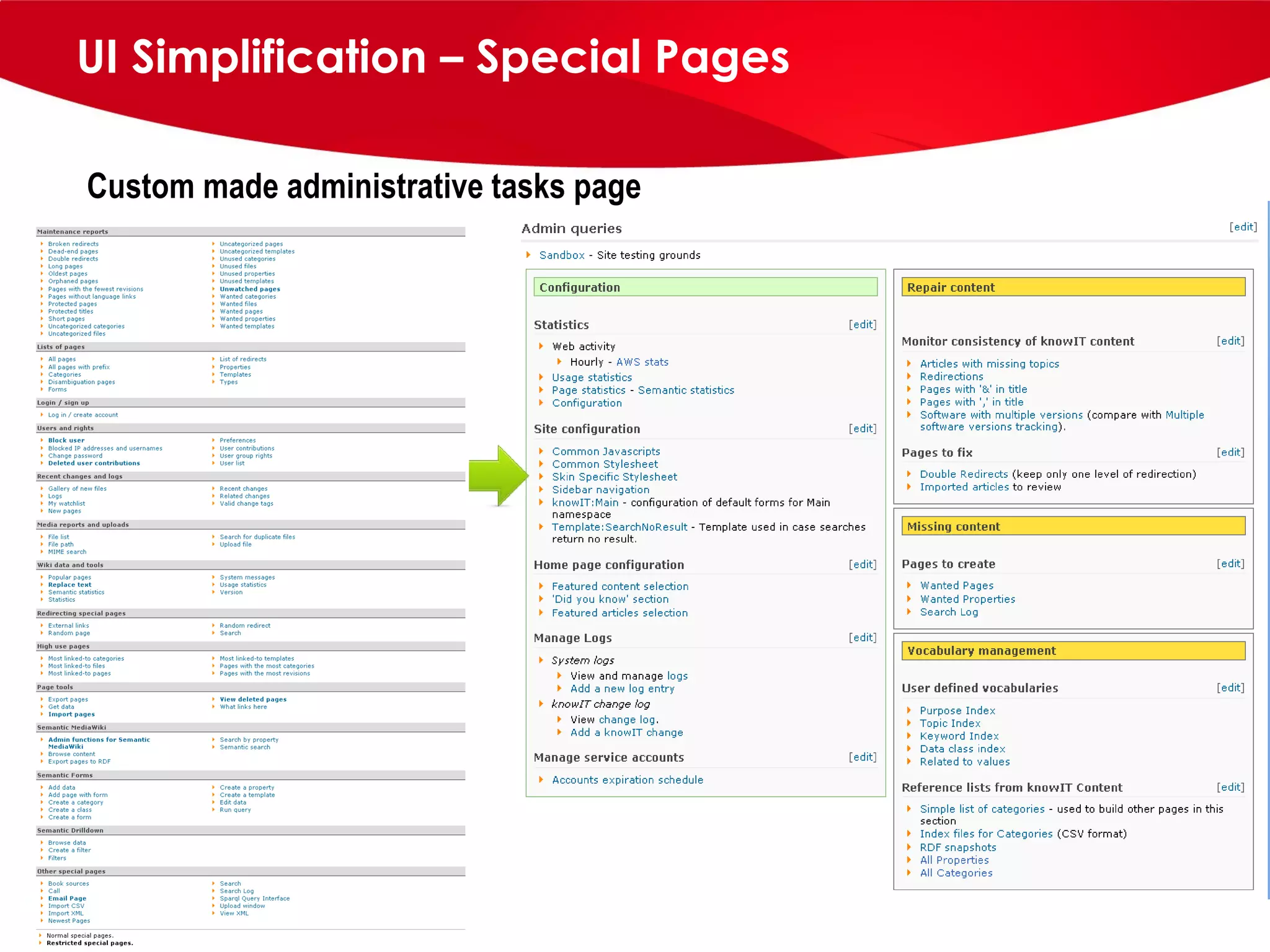

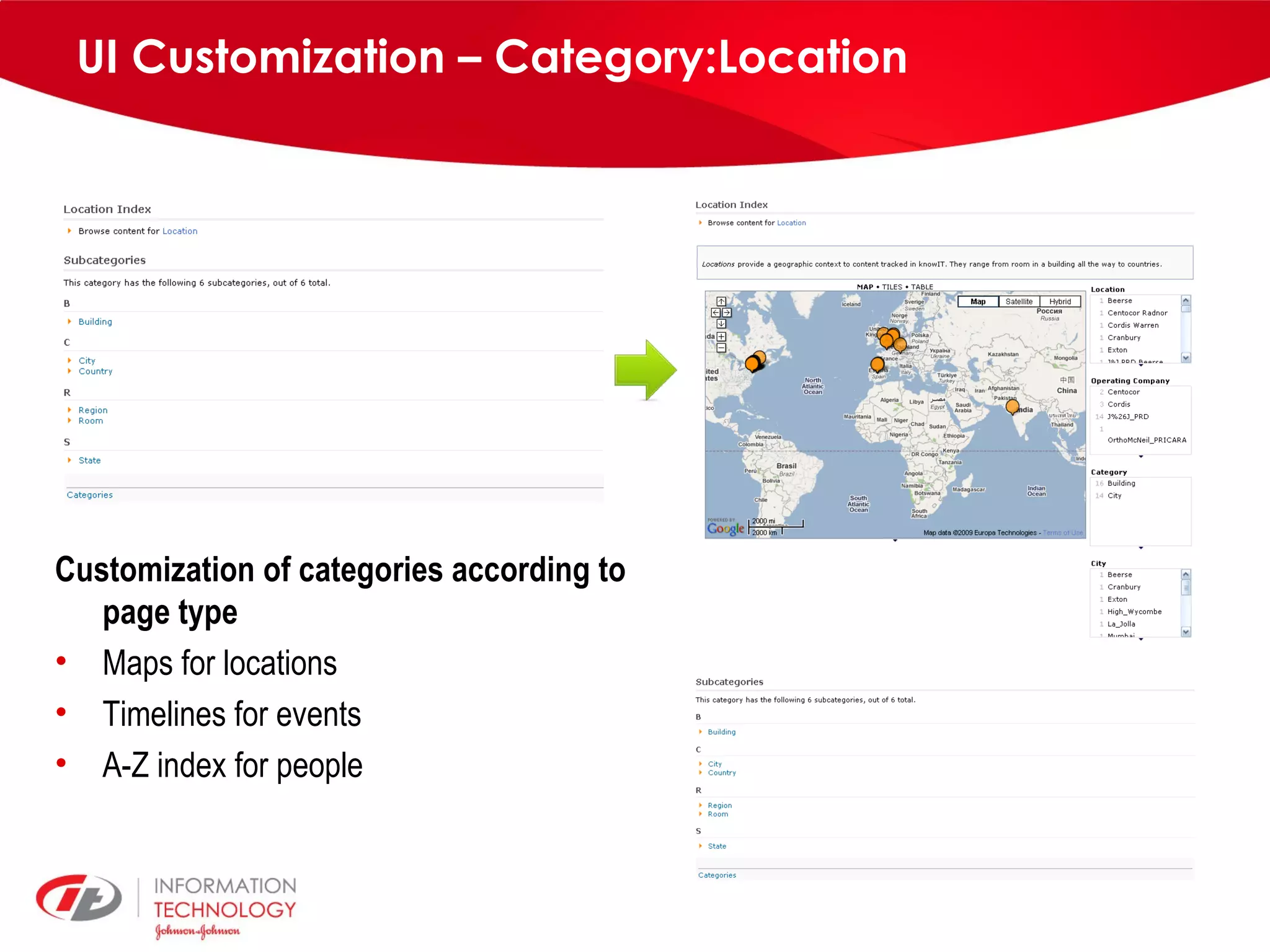
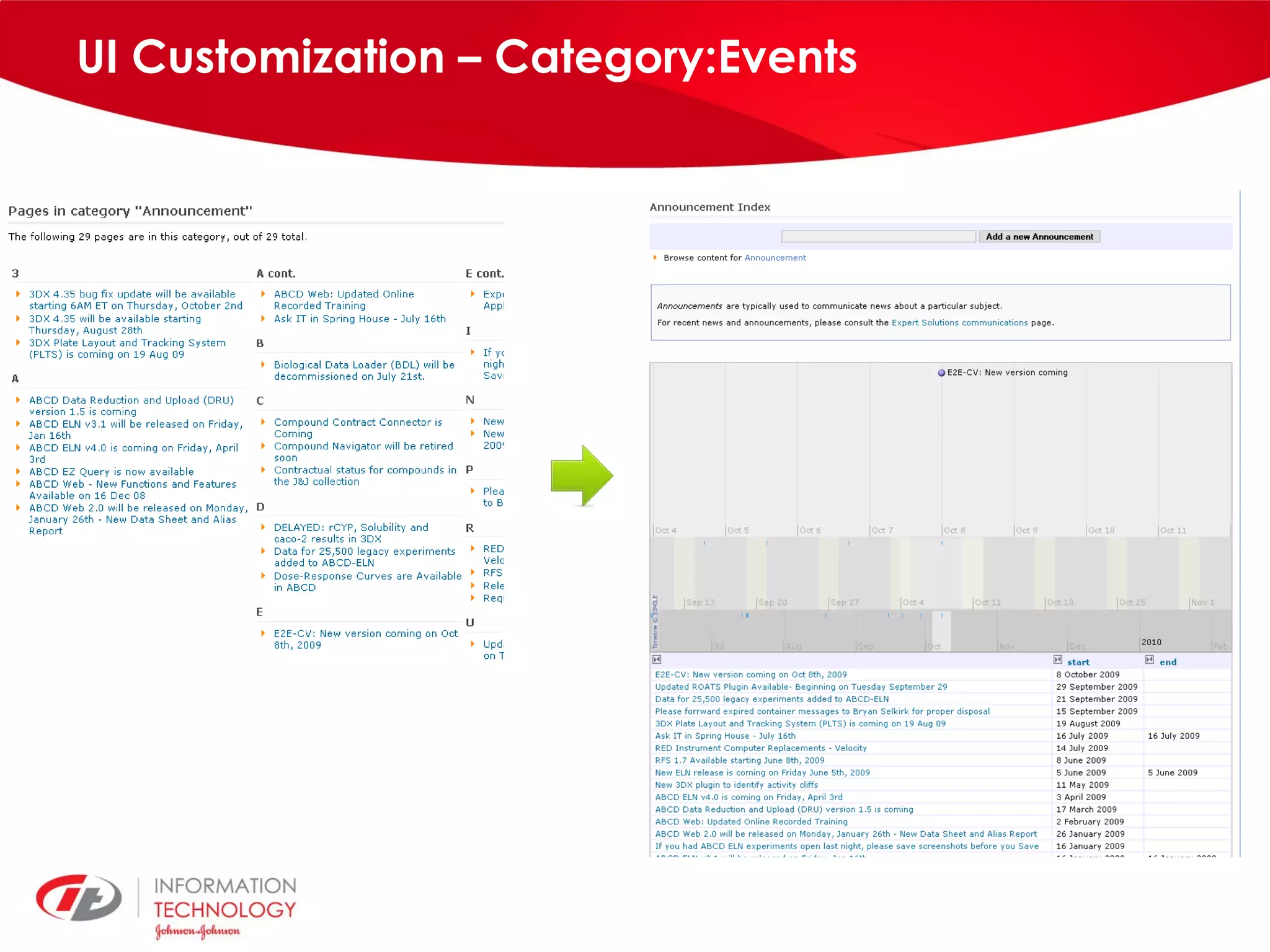
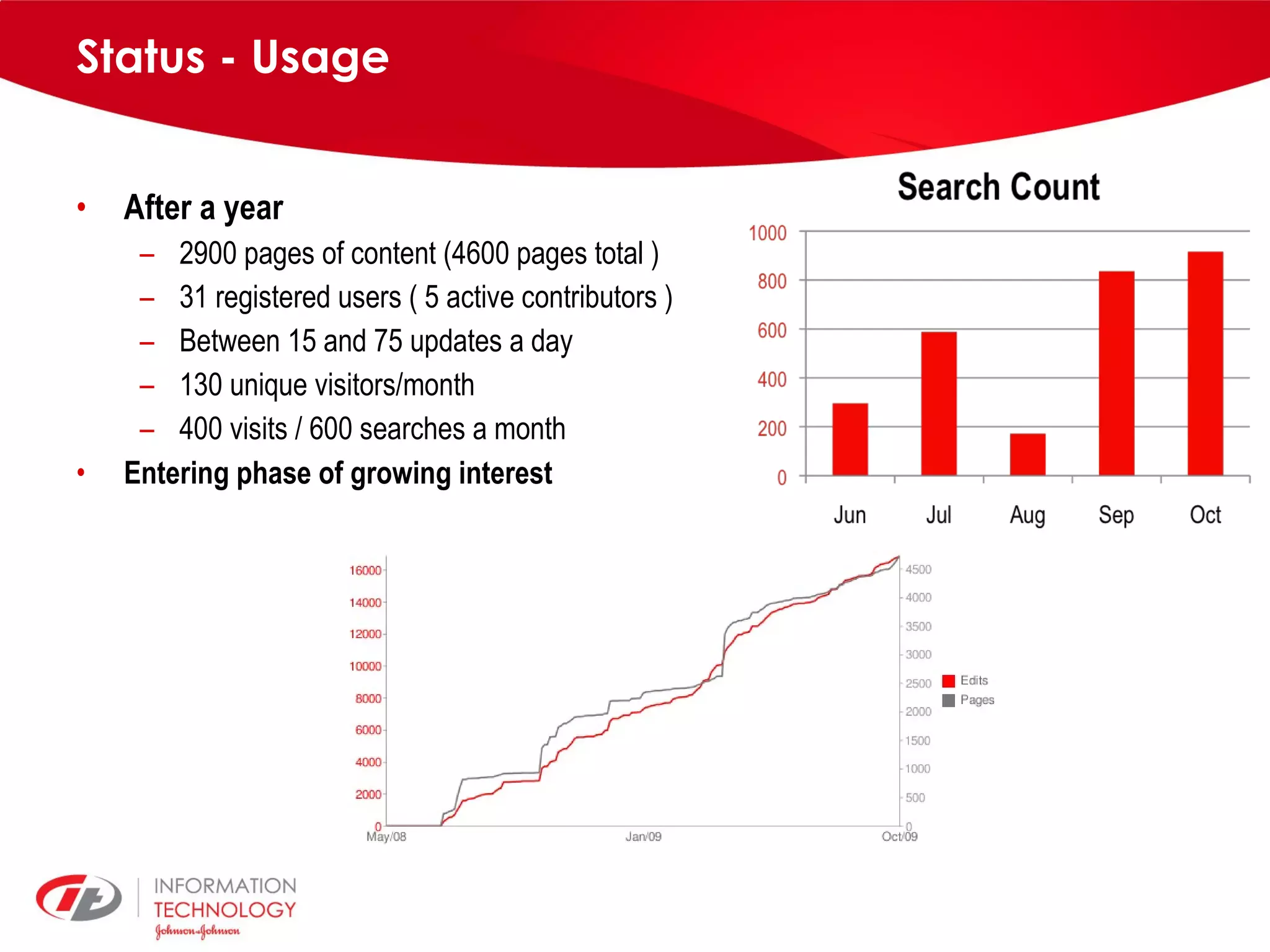






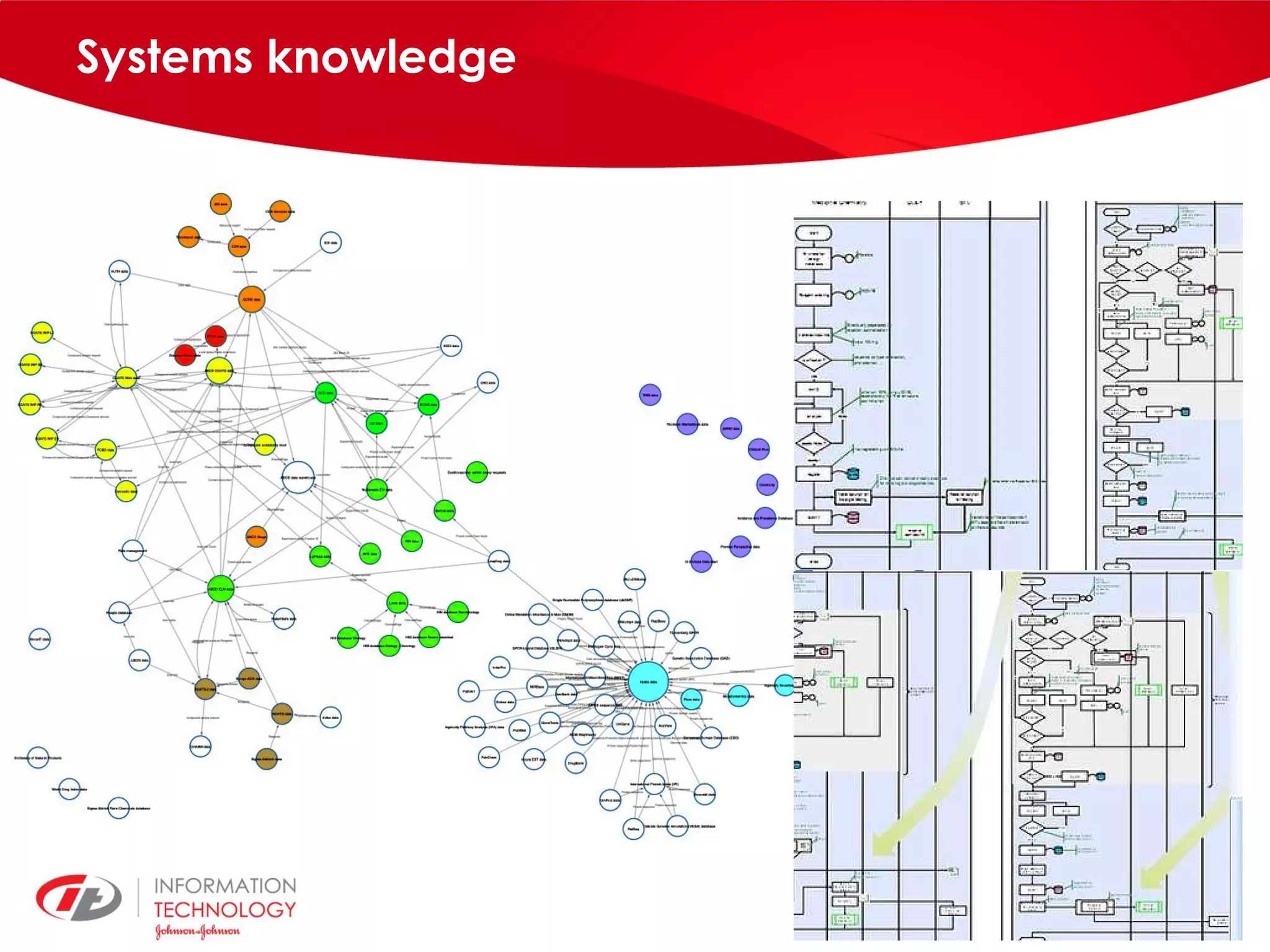
knowIT is a collaborative semantic wiki used by Johnson & Johnson to map their IT systems, applications, servers and stakeholders. It aims to capture knowledge about these informatics systems, their relationships and components to answer questions, facilitate knowledge sharing and enable self-service. The wiki uses Semantic MediaWiki and has grown to include systems portfolio management, configuration management and other features to increase IT systems knowledge across the organization.