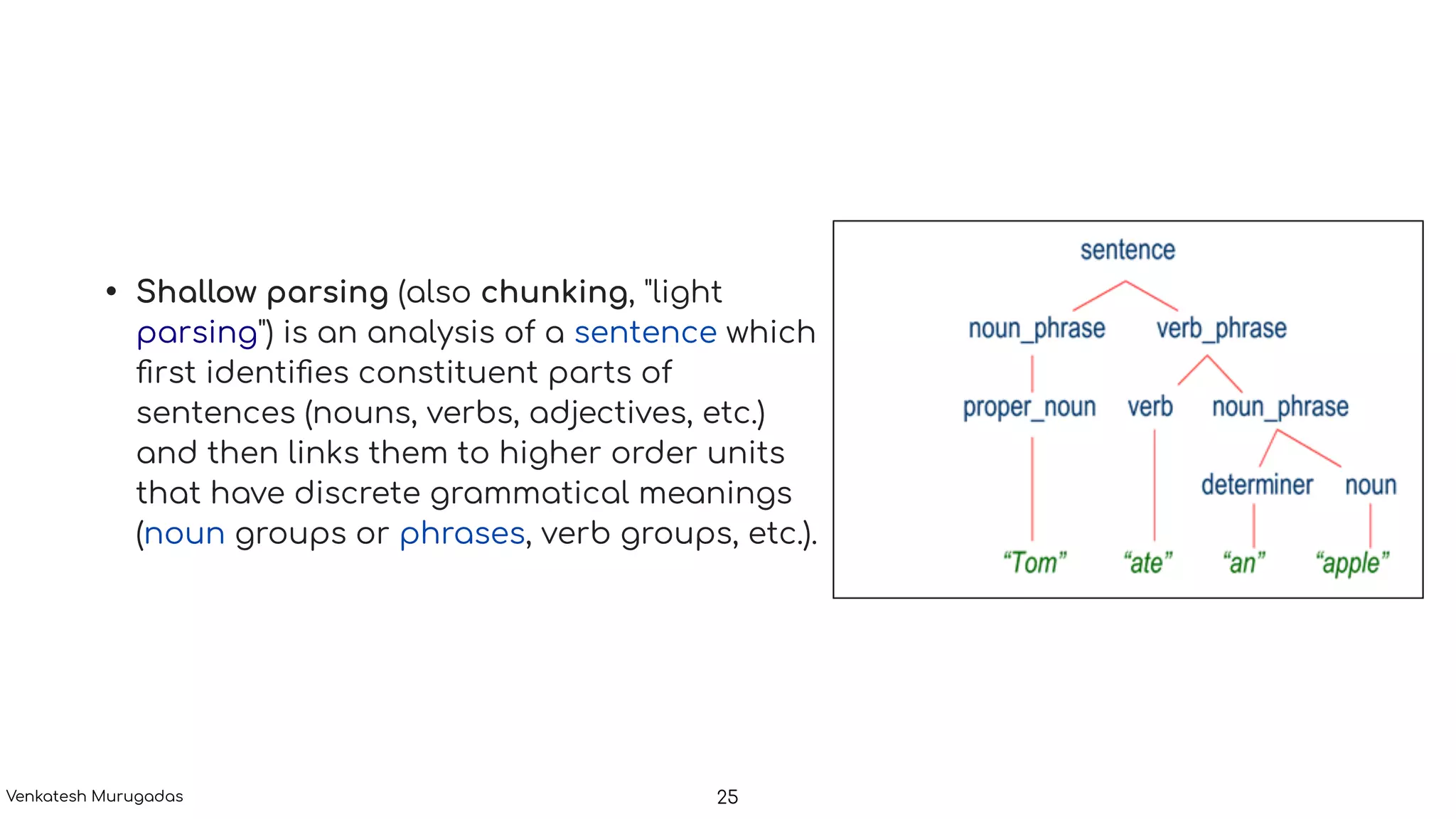
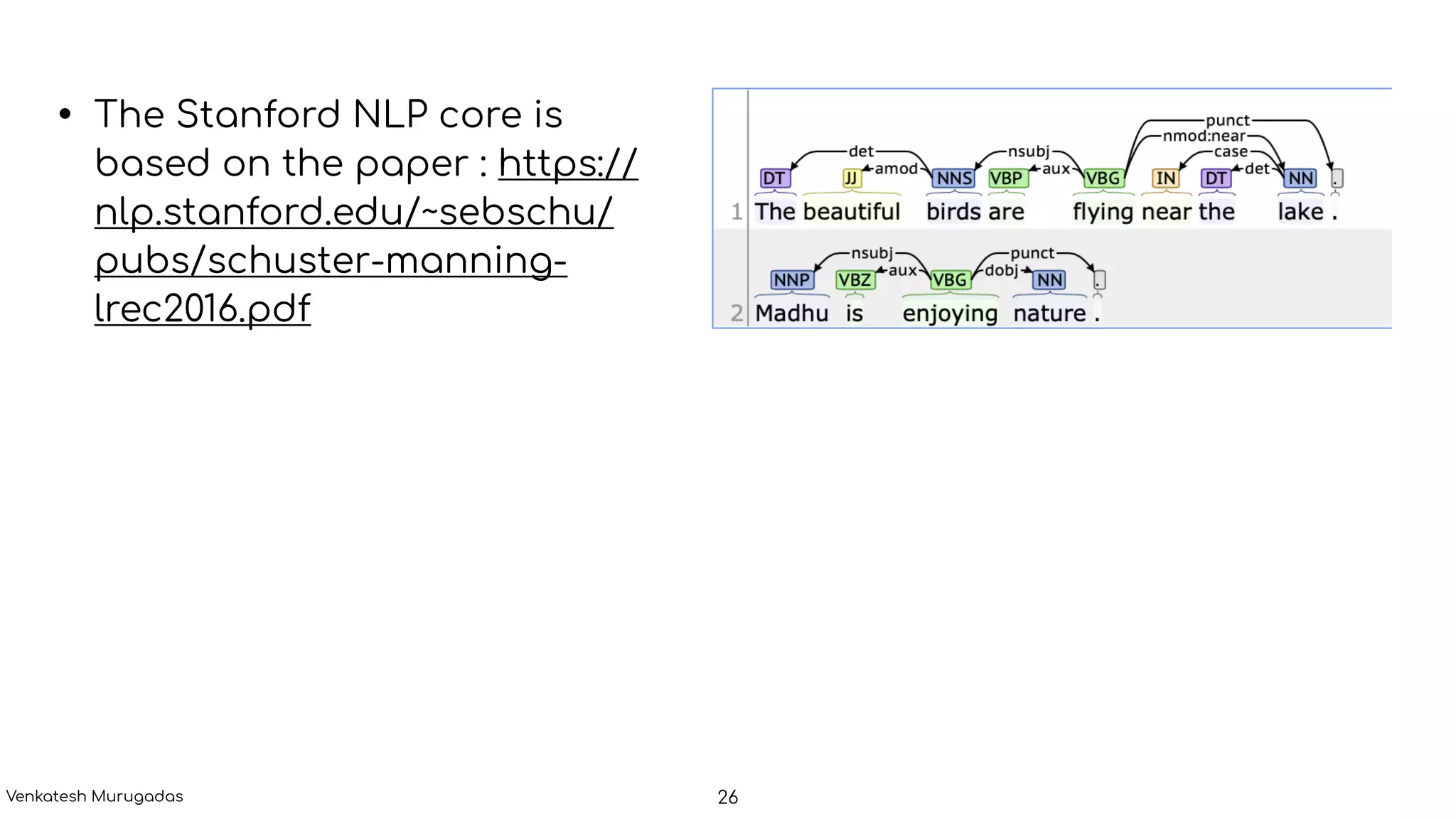
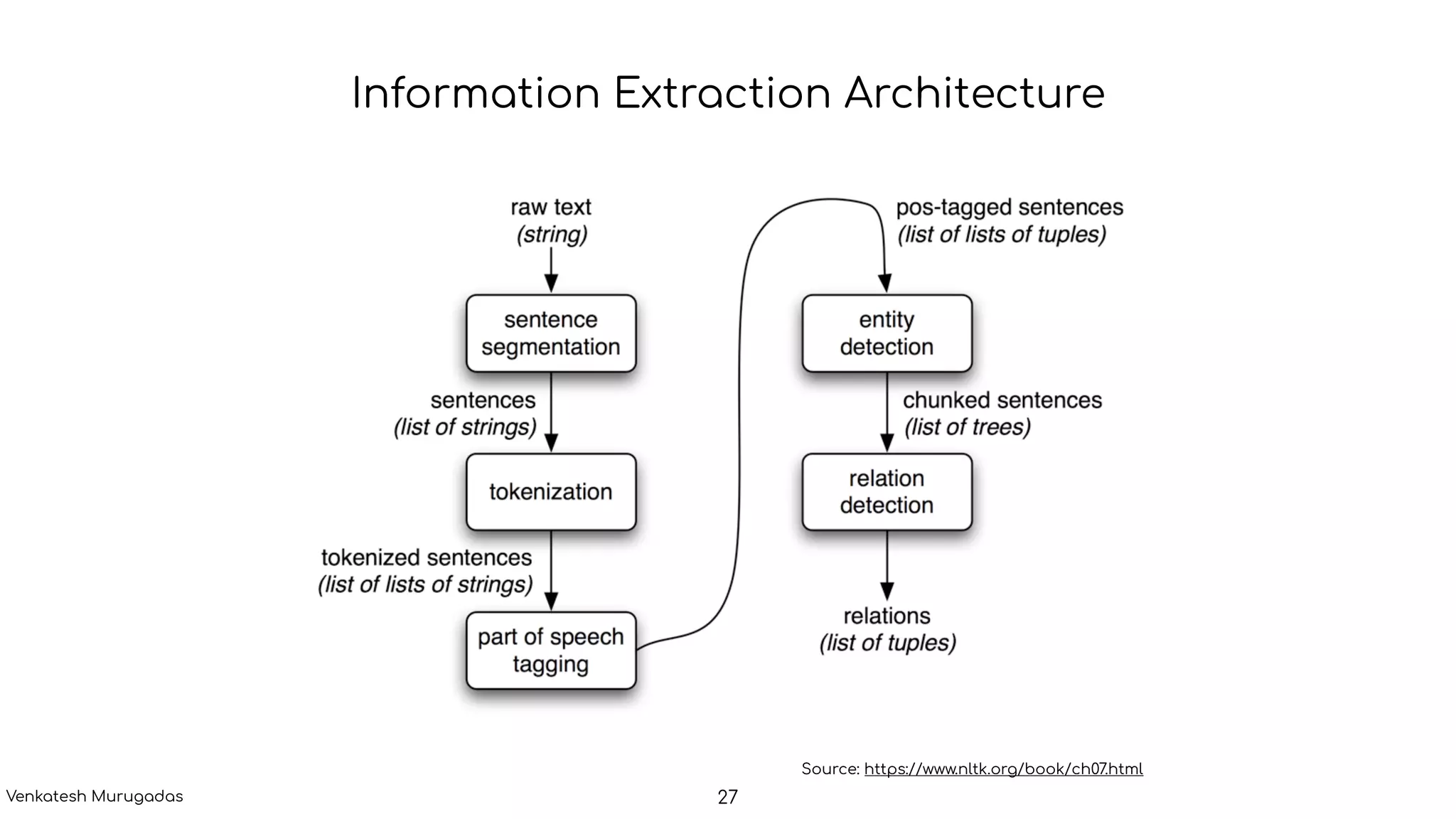
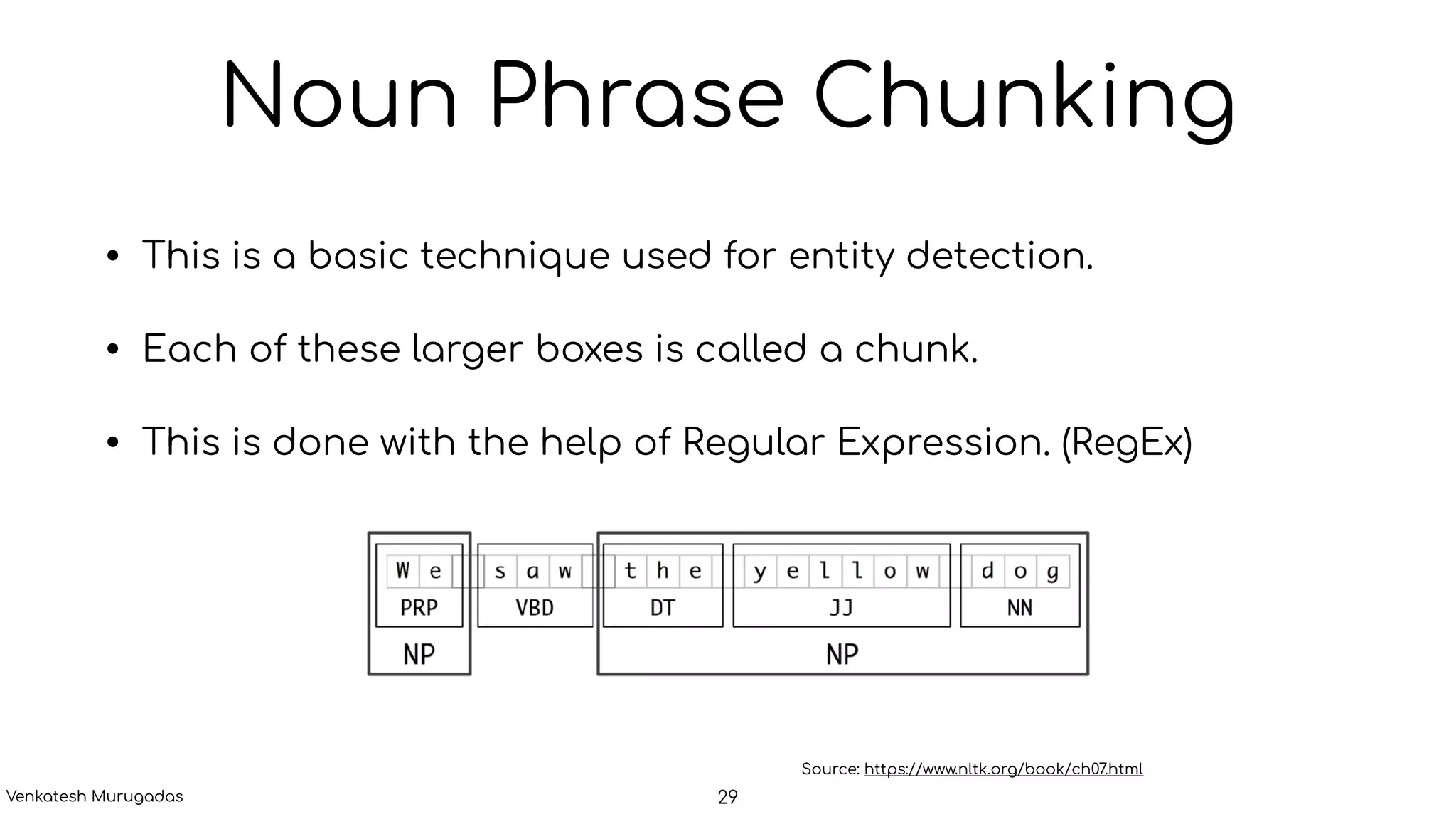
The document provides an introduction to natural language processing (NLP), highlighting its challenges due to the complexity and ambiguity of human language. It outlines various NLP applications, including text classification, named entity recognition, and conversational AI, along with key processes such as tokenization, sentence segmentation, and dependency parsing. The discussion includes the role of computational linguistics and statistical methods in enhancing NLP capabilities.