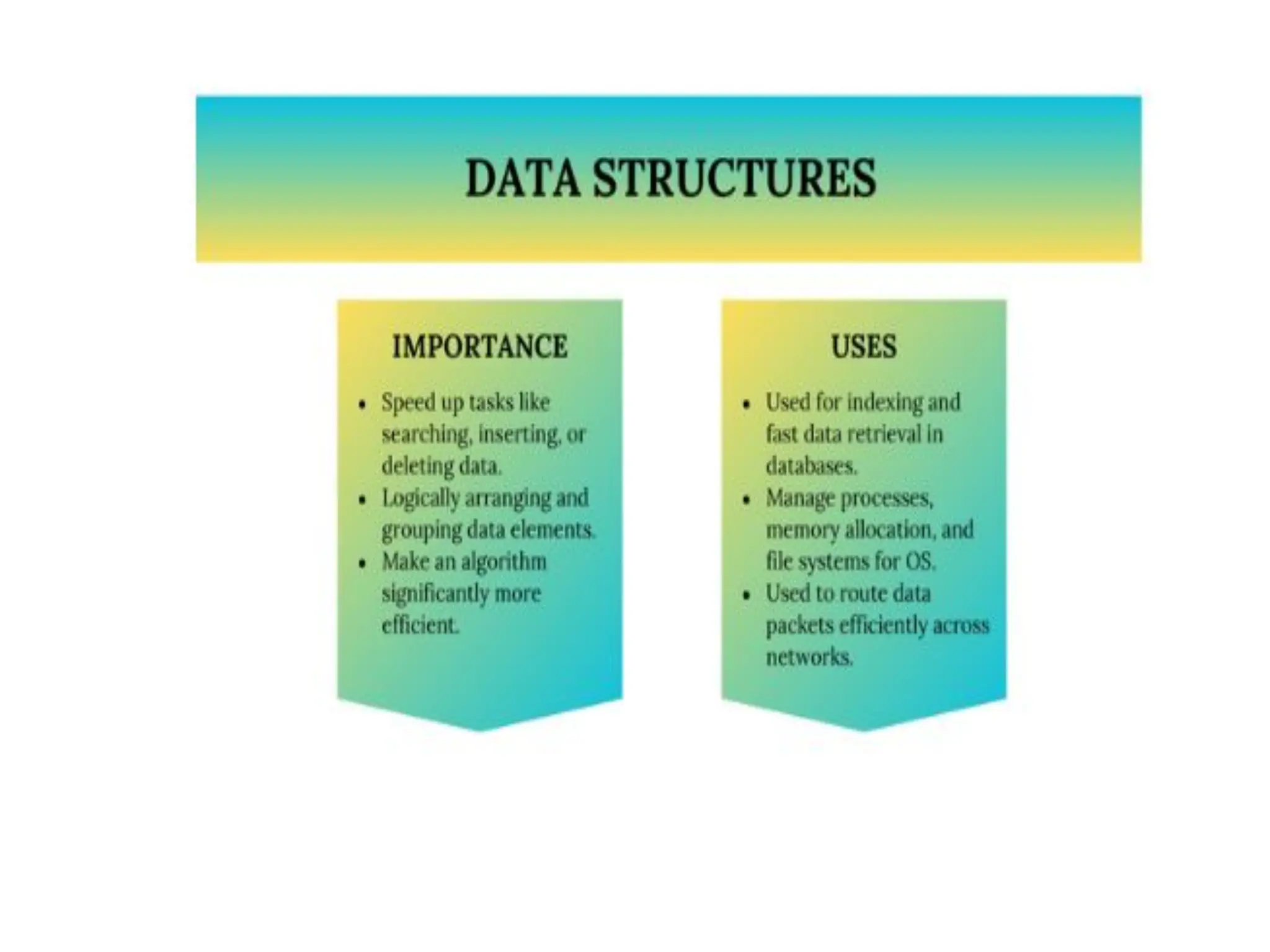
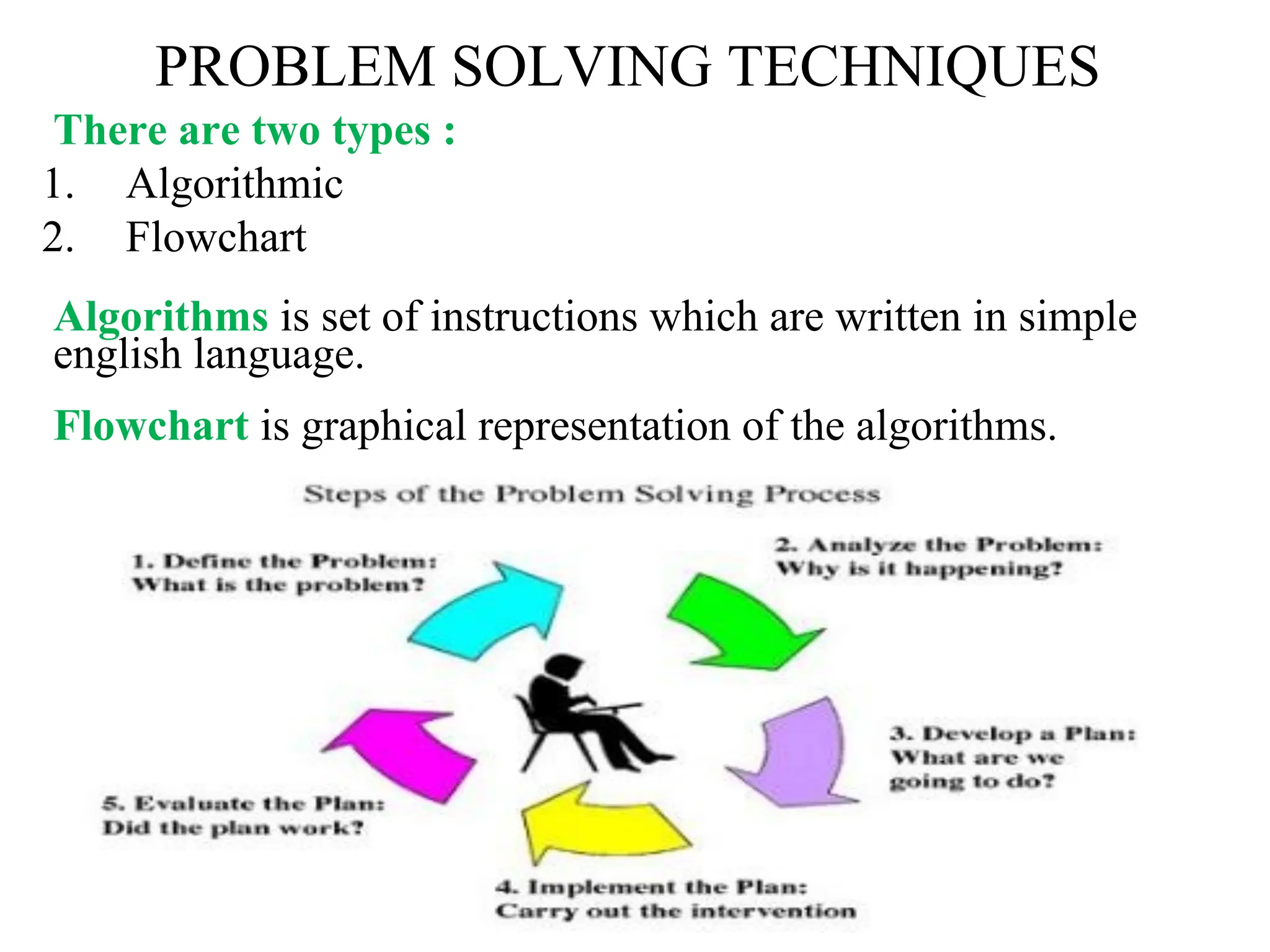
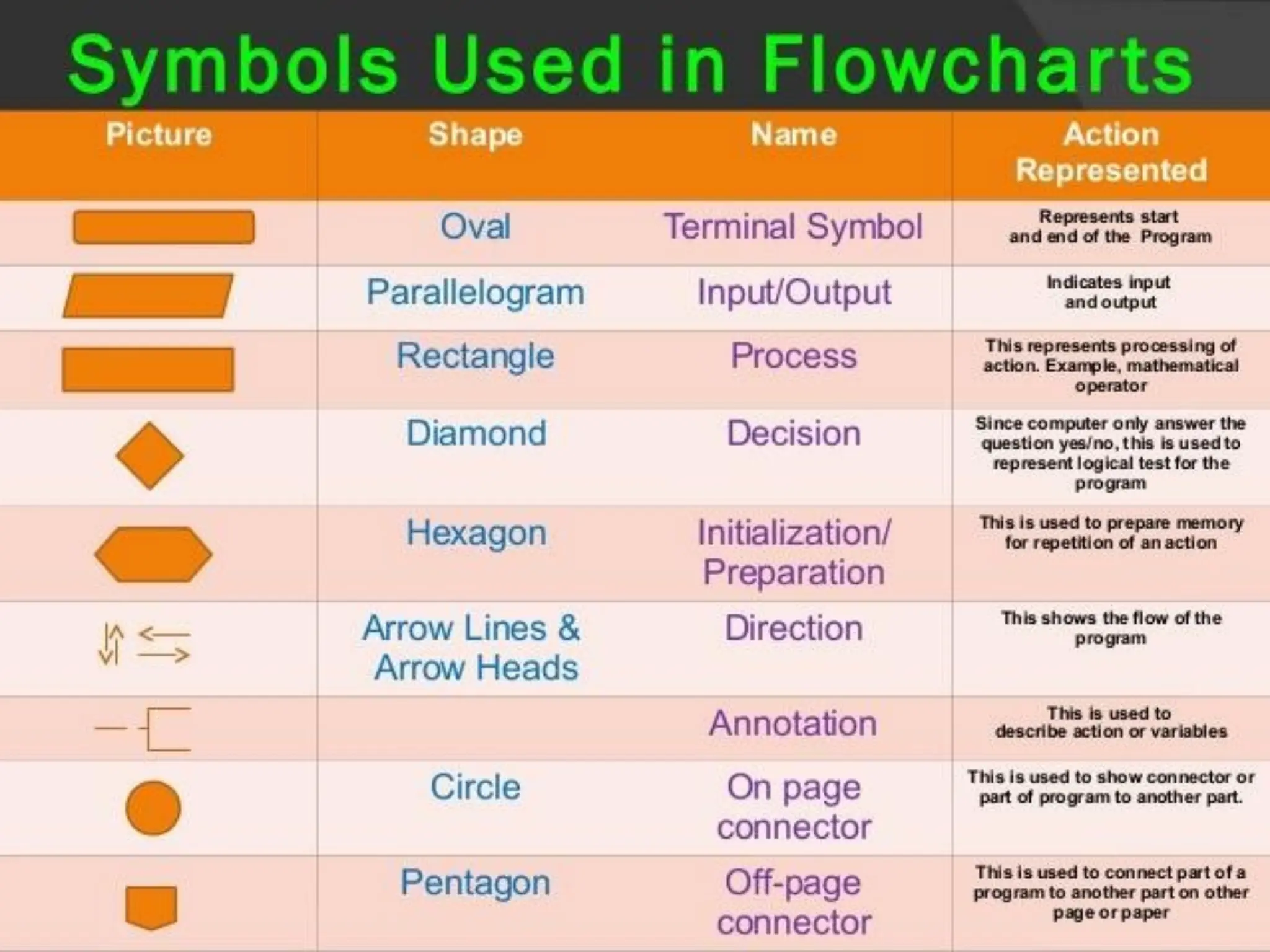
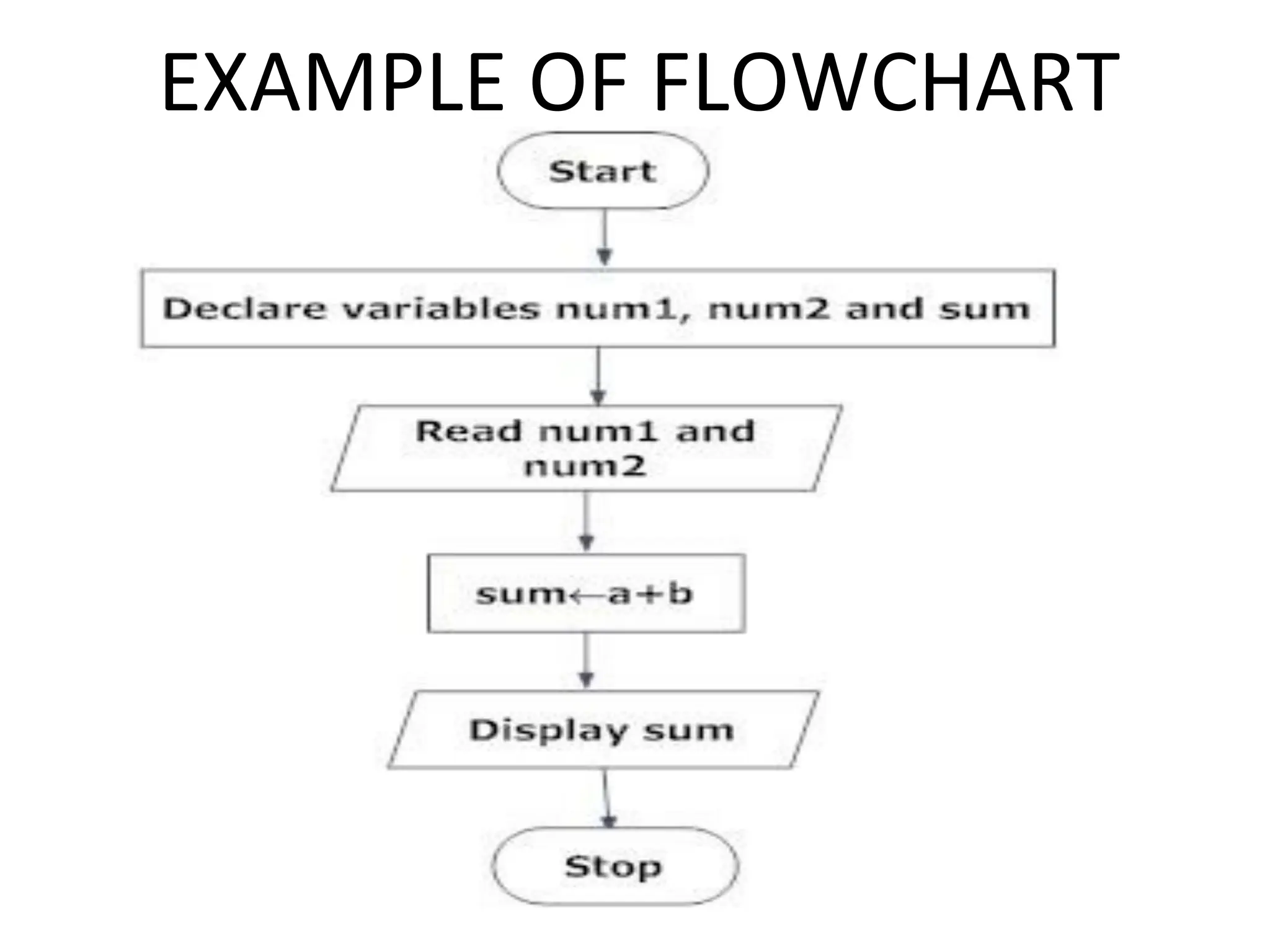
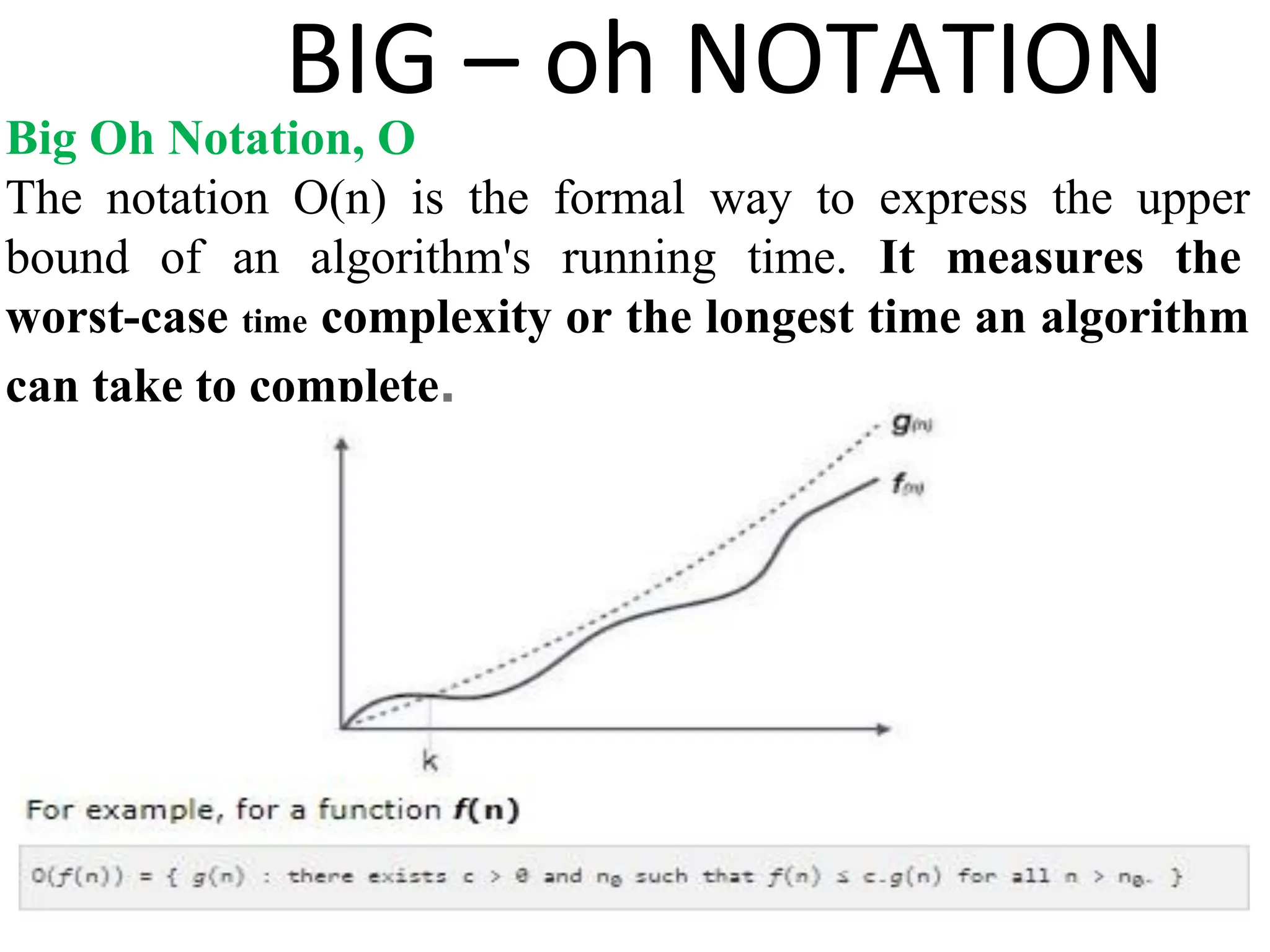
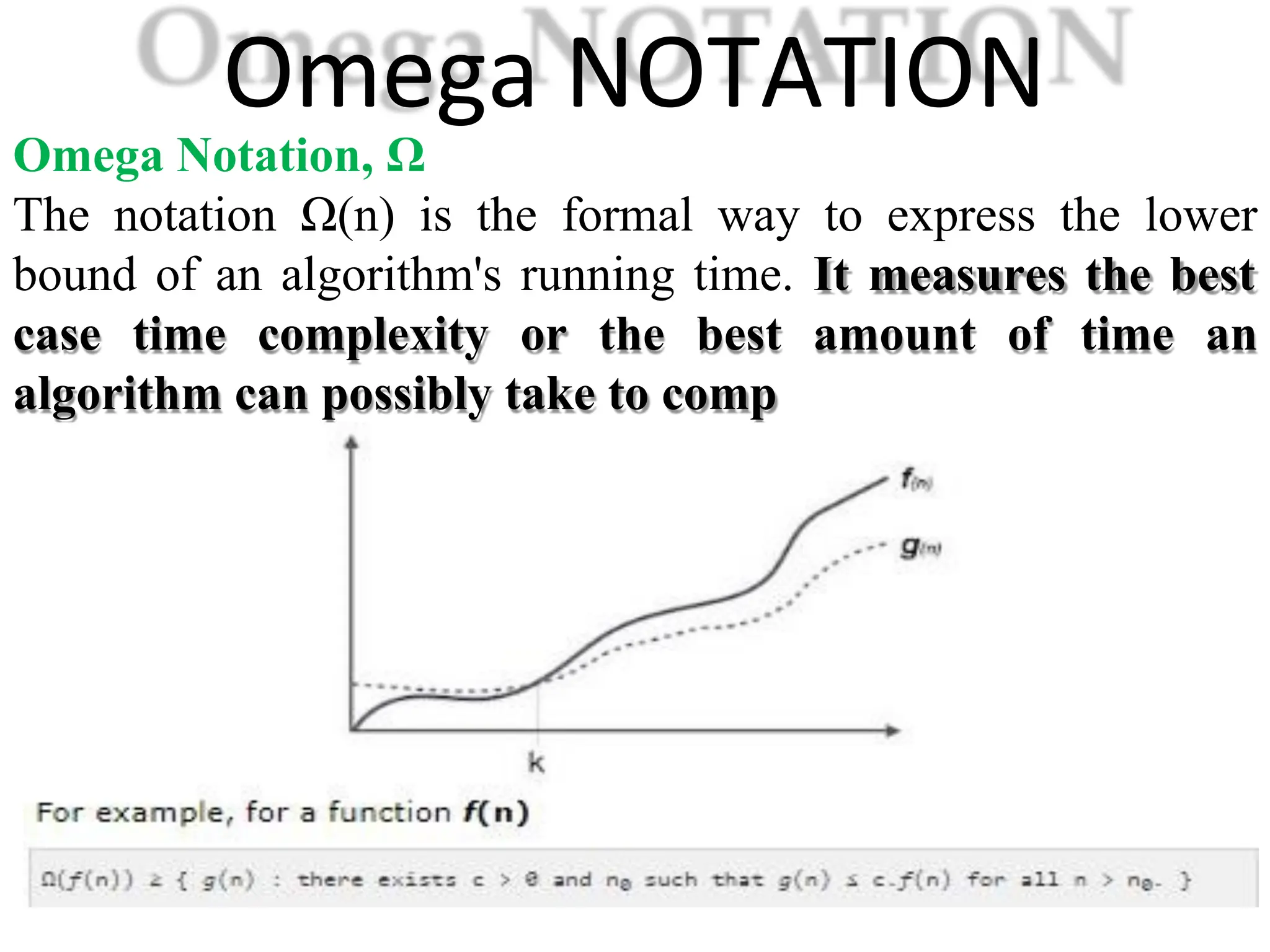
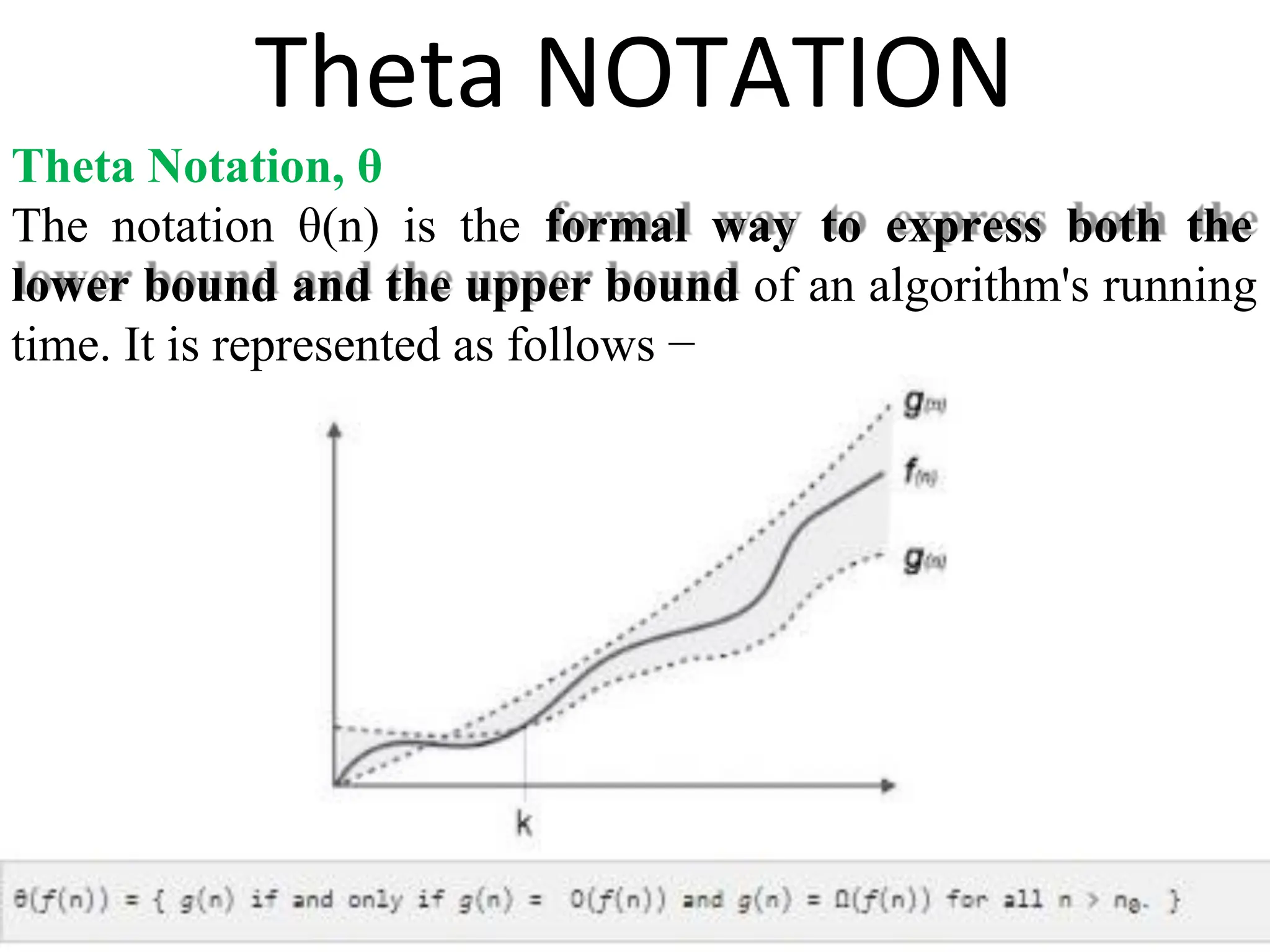
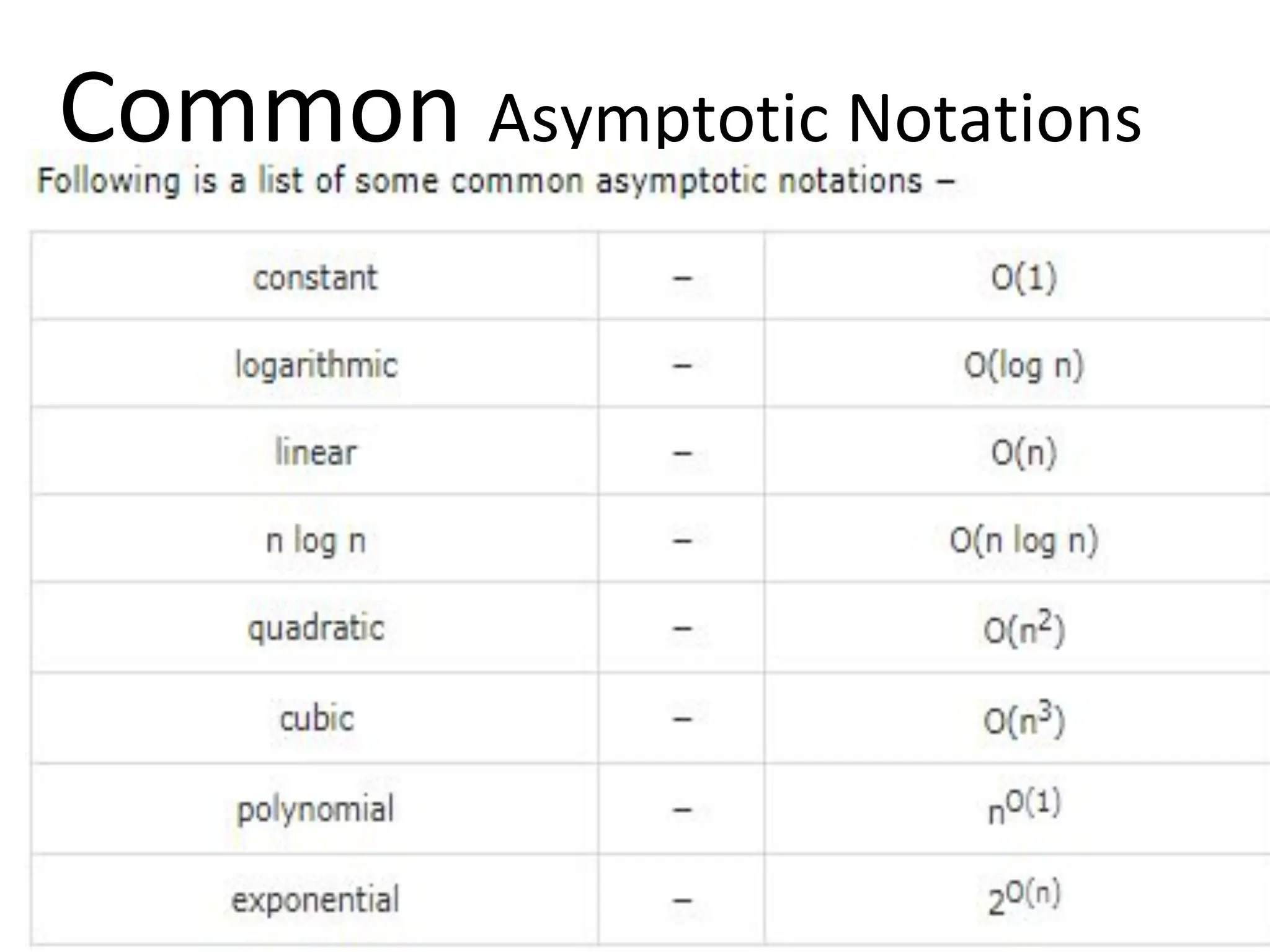
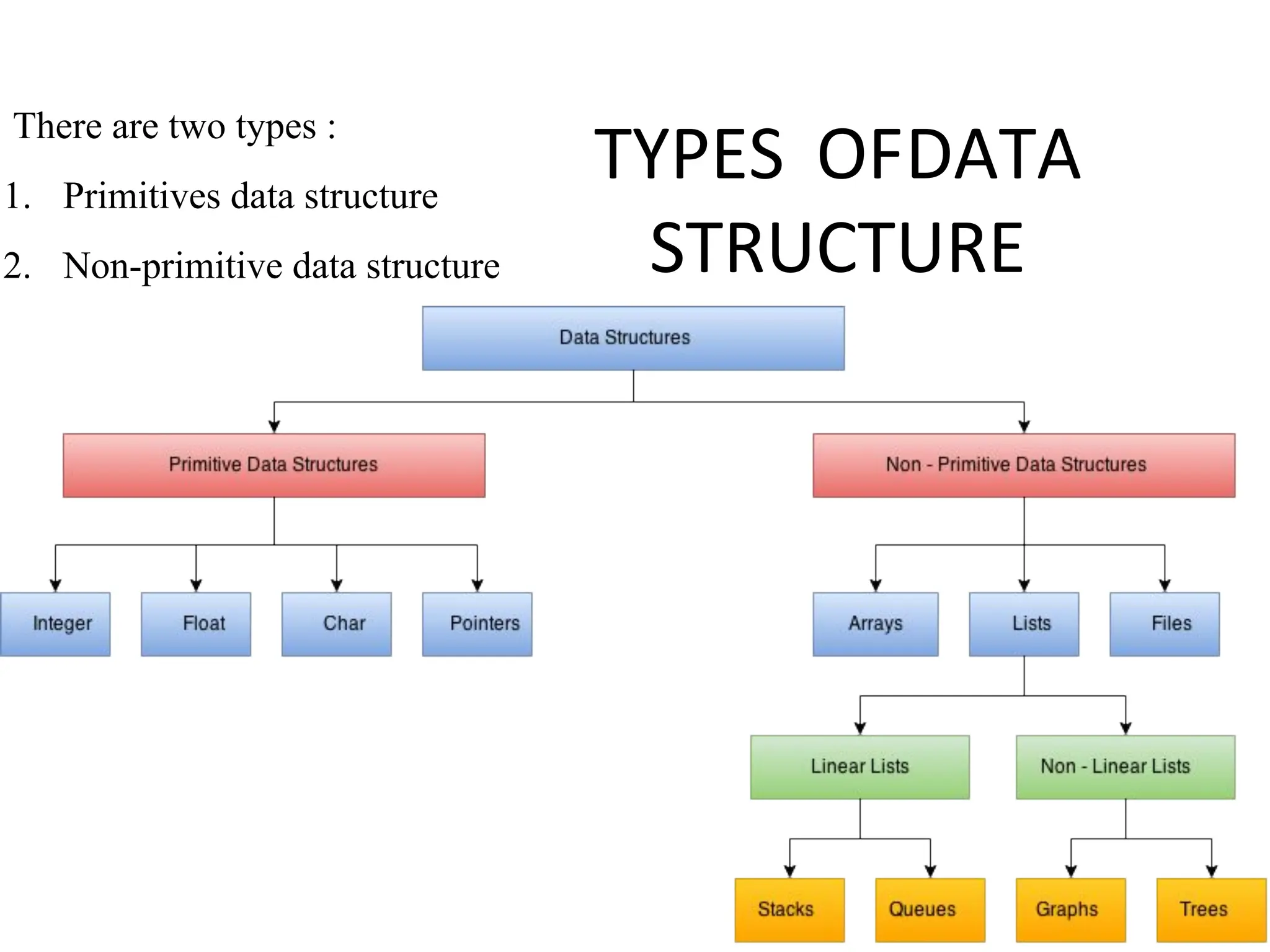
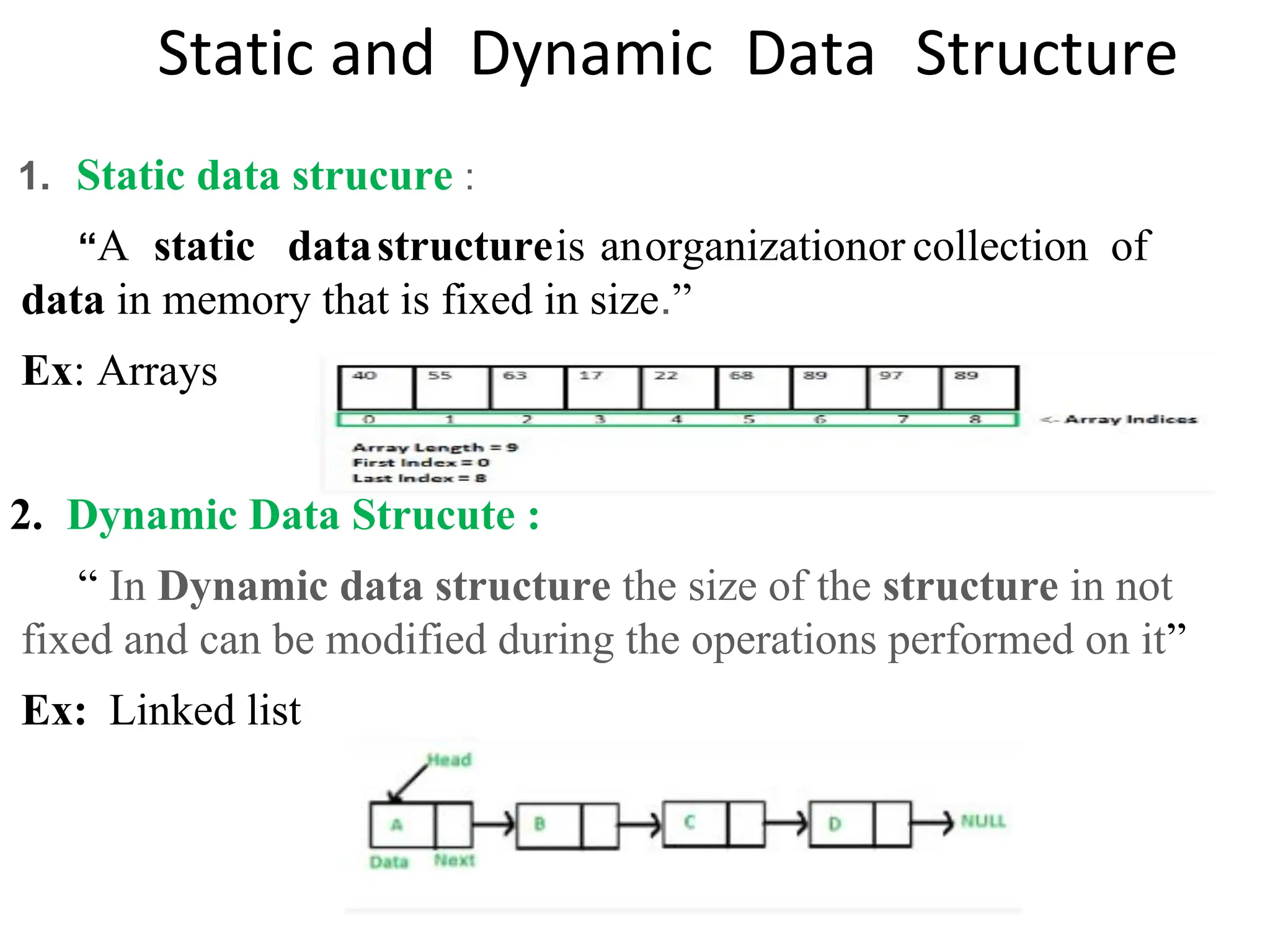
Introduction to algorithm: Definition of algorithm, characteristics of algorithm, pseudo code and flowcharts, role of algorithms in AI and data Science. Performance Analysis: Time and space complexity, asymptotic notations: Big-O, Big-Theta, Big-Omega, best, worst, and average case analysis, solving recurrence relations (substitution and iteration methods). Introduction to Data Structures: Concept of data, data object, data structure, concept of primitive and non-primitive, persistent and ephemeral data structures, Abstract Data Type (ADT). Arrays: Array operations (traversal, insertion, deletion, searching), multidimensional arrays. Linked Organization: Concept of linked organization, singly linked list, doubly linked list, circular linked list
















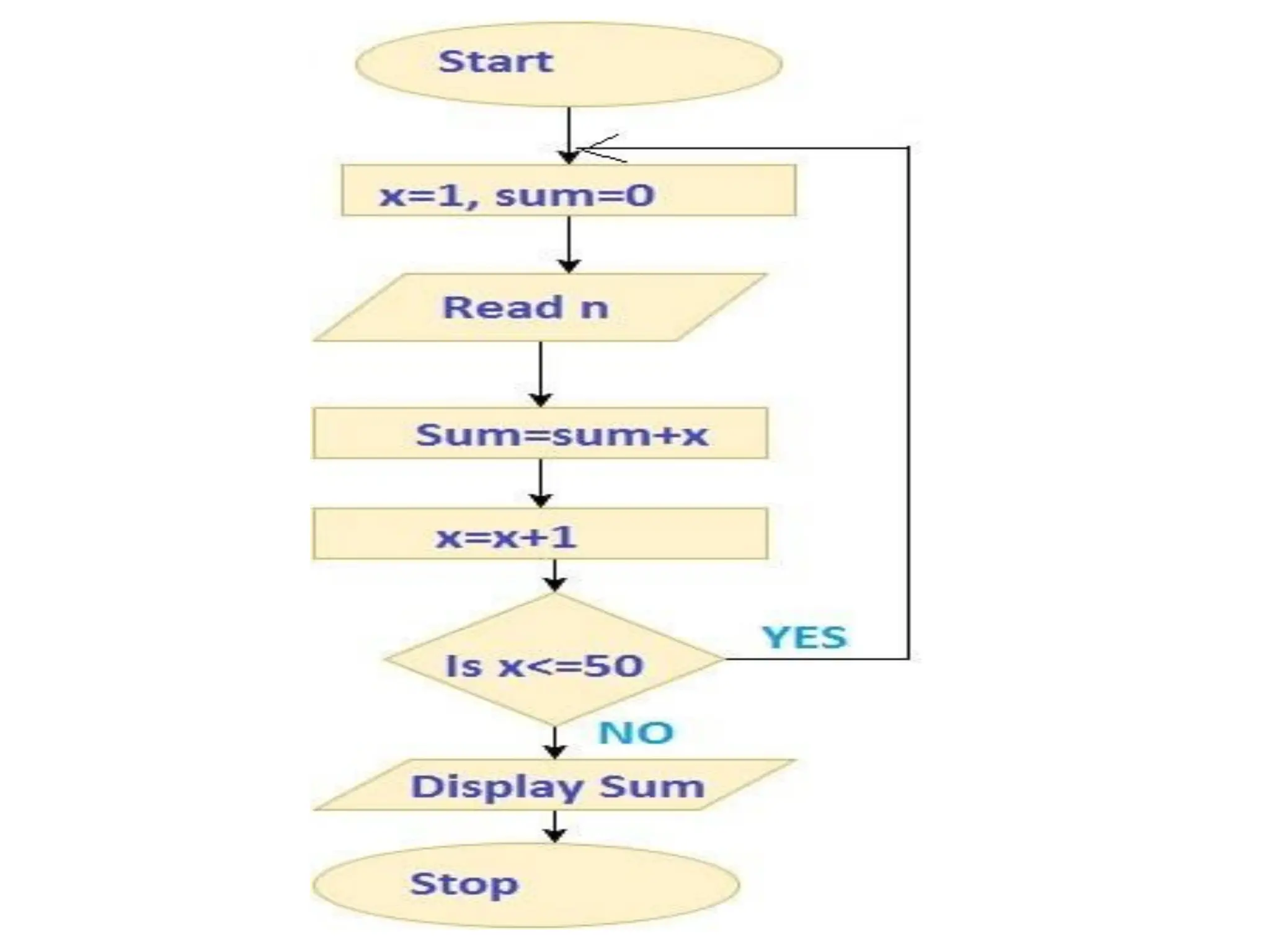
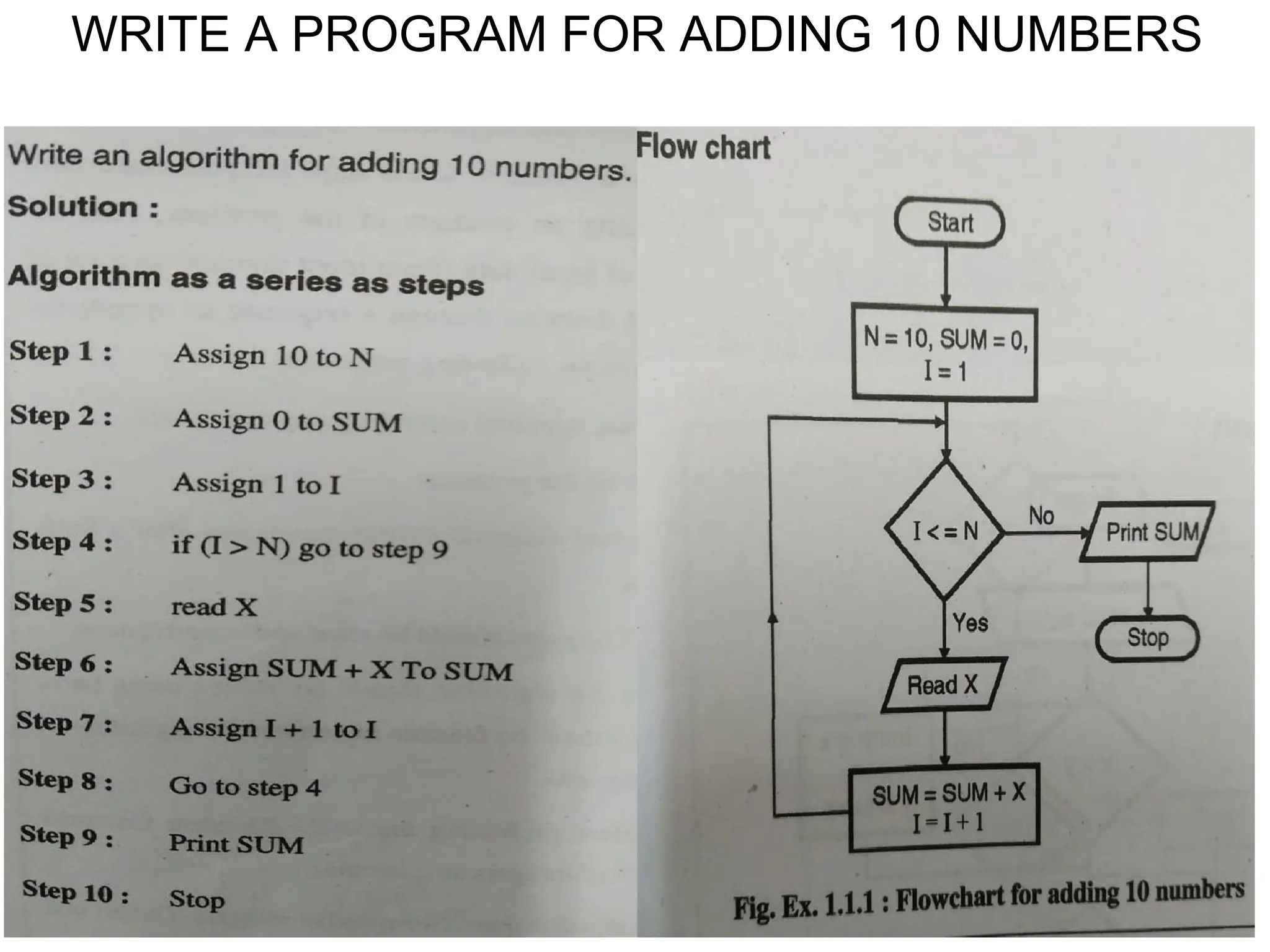
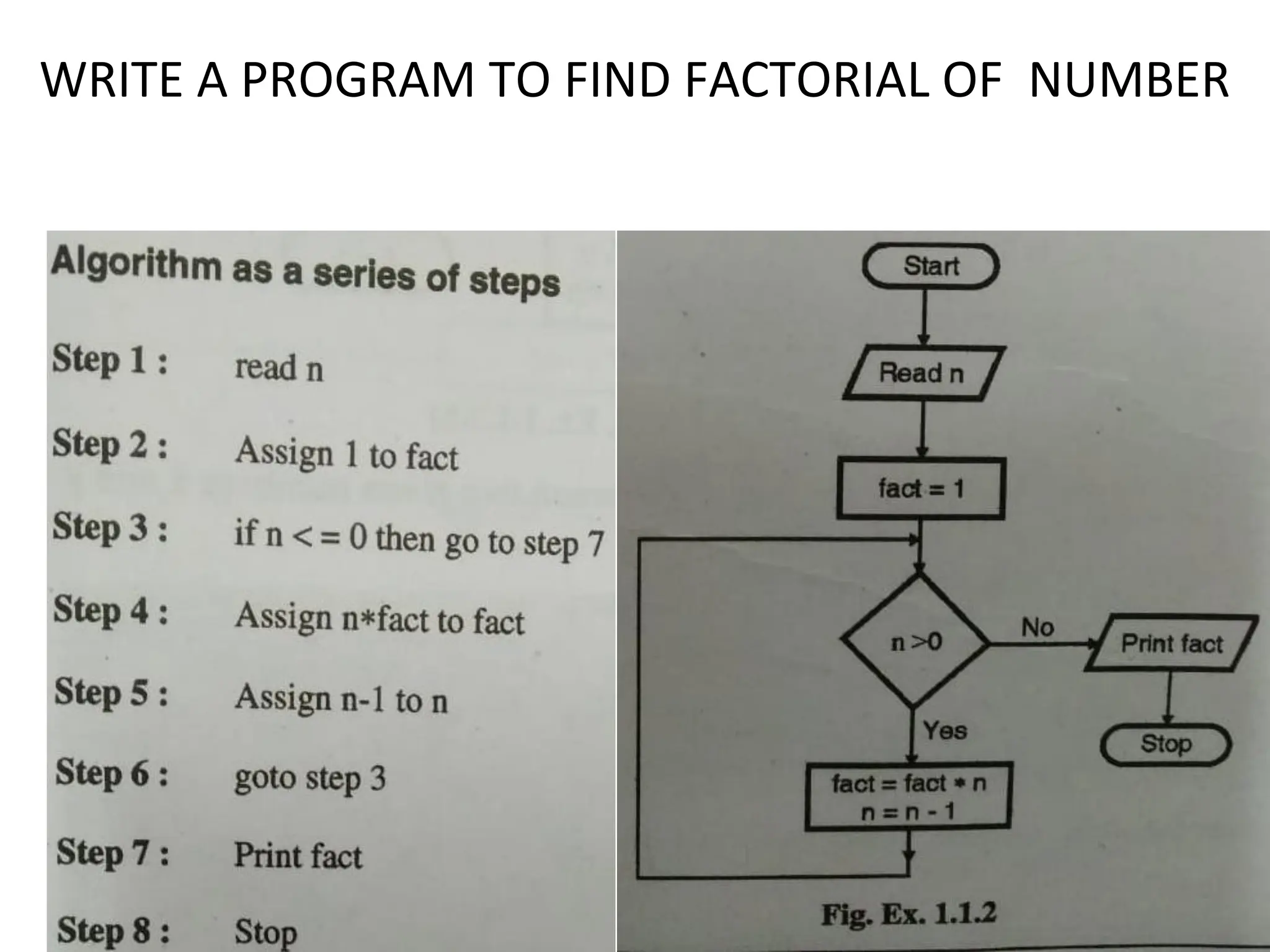




















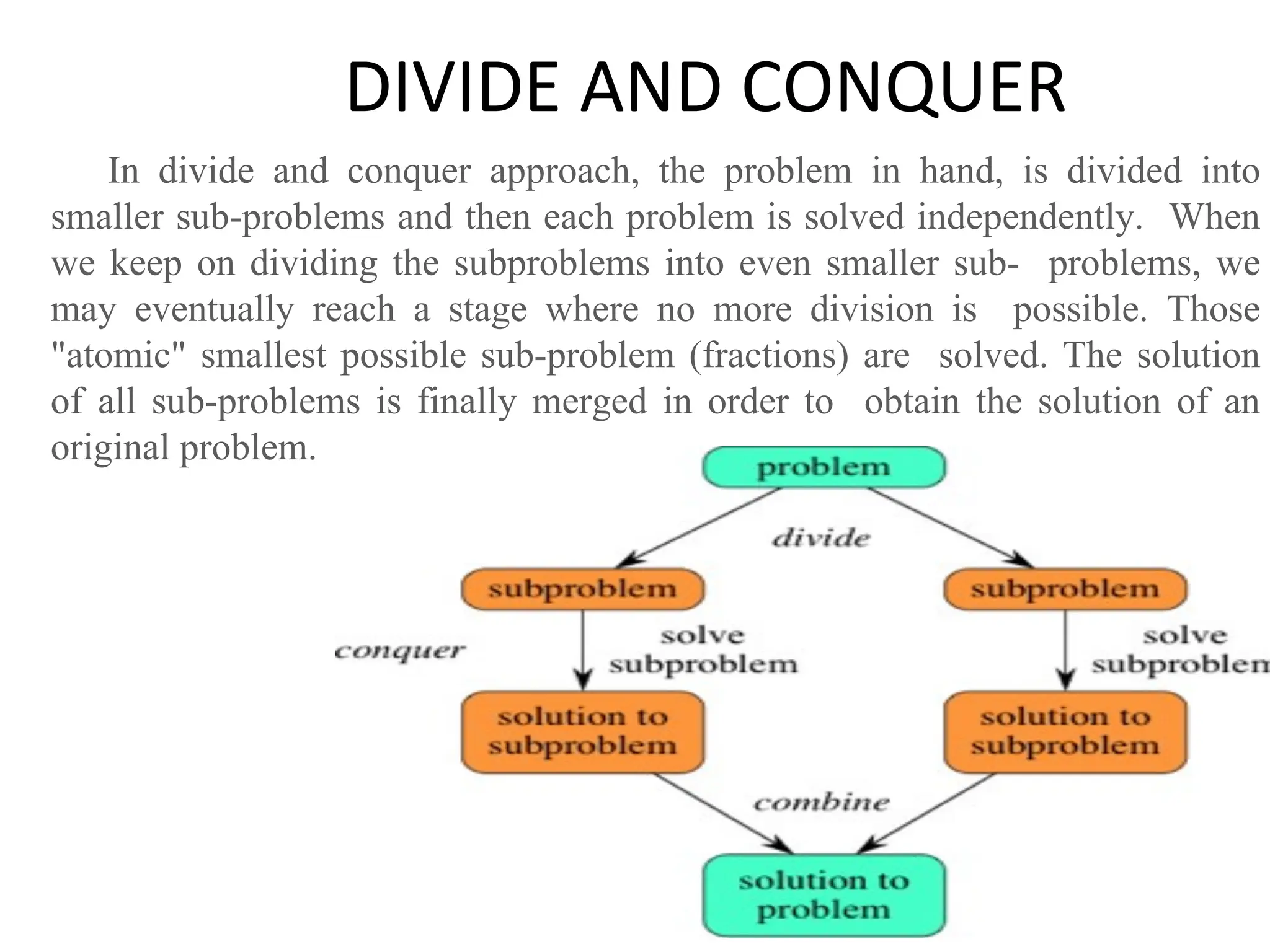

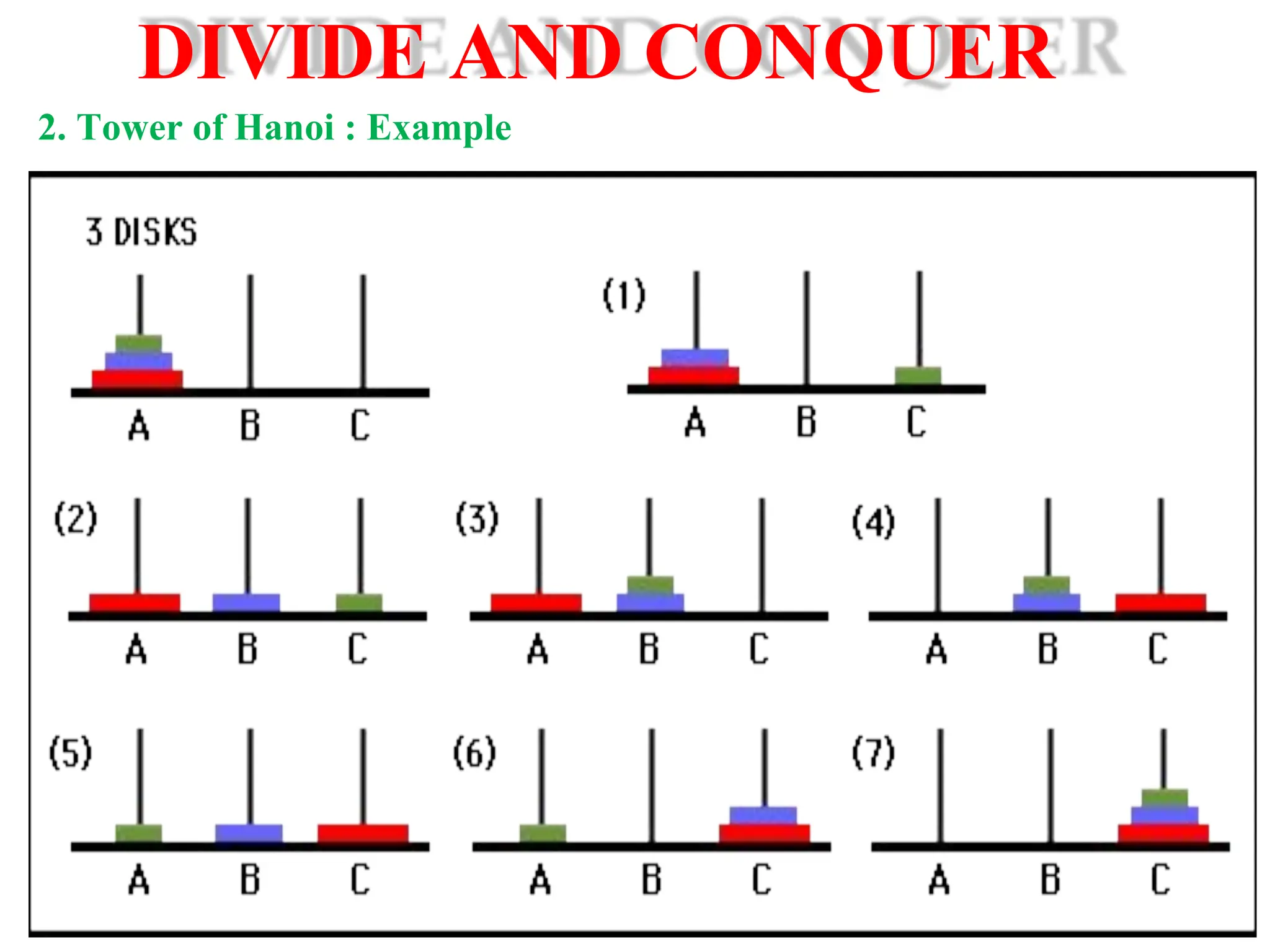
![DIVIDE AND CONQUER 1. Merge sort : Merge Sort is a divide-and-conquer algorithm. It divides the input array in two halves, calls itself for the two halves and then merges the two sorted halves. The merge() function is used for merging two halves. The merge(arr, l, m, r) is key process that assumes that arr[l..m] and arr[m+1..r] are sorted and merges the two sorted sub-arrays into one.](https://image.slidesharecdn.com/1ppt-250728172232-24fd028b/75/Introduction-to-data-structure-and-algorithm-53-2048.jpg)





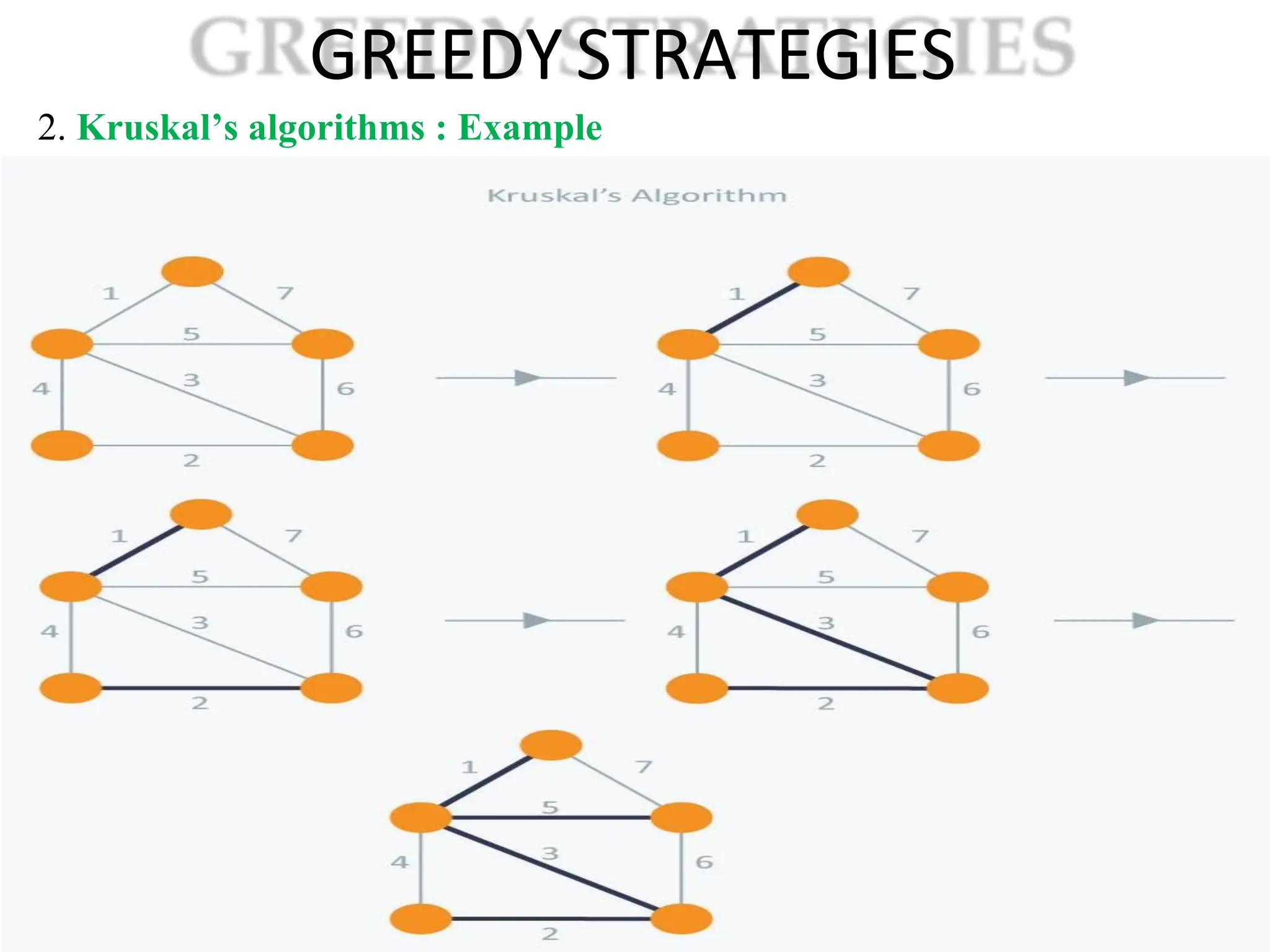

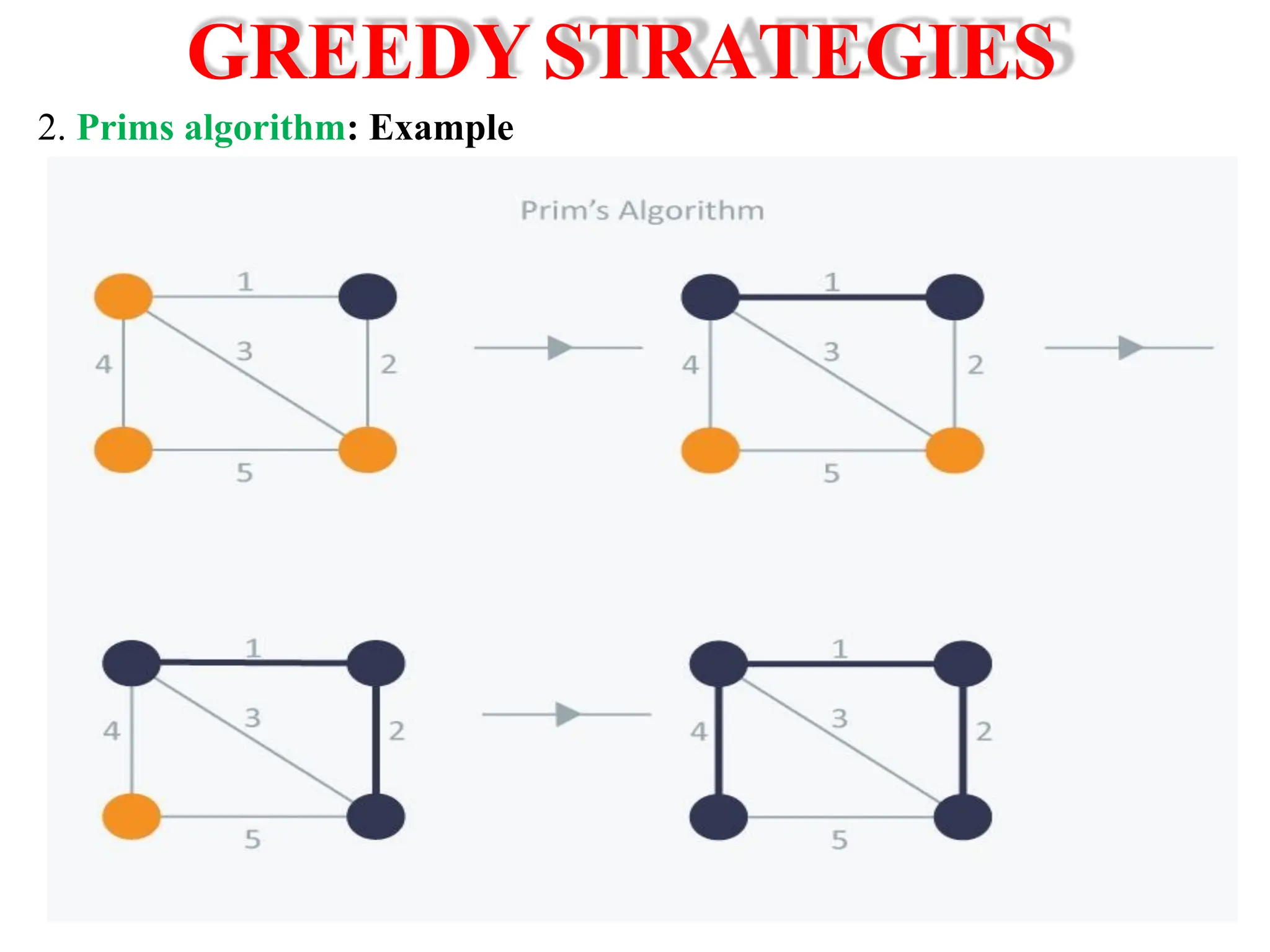




![Analysis of Linear Search algorithm Let us consider a Linear Search Algorithm. Linearsearch(arr, n, key) { i = 0; for(i = 0; i < n; i++) { if(arr[i] == key) { printf(“Found”); } }](https://image.slidesharecdn.com/1ppt-250728172232-24fd028b/75/Introduction-to-data-structure-and-algorithm-67-2048.jpg)
![Where, i = 0, is an initialization statement and takes O(1) times. for(i = 0;i < n ; i++), is a loop and it takes O(n+1) times . if(arr[i] == key), is a conditional statement and takes O(1) times. printf(“Found”), is a function and that takes O(0)/O(1) times. Therefore Total Number of times it is executed is n + 4 times. As we ignore lower exponents in time complexity total time became O(n). Time complexity: O(n).](https://image.slidesharecdn.com/1ppt-250728172232-24fd028b/75/Introduction-to-data-structure-and-algorithm-68-2048.jpg)






