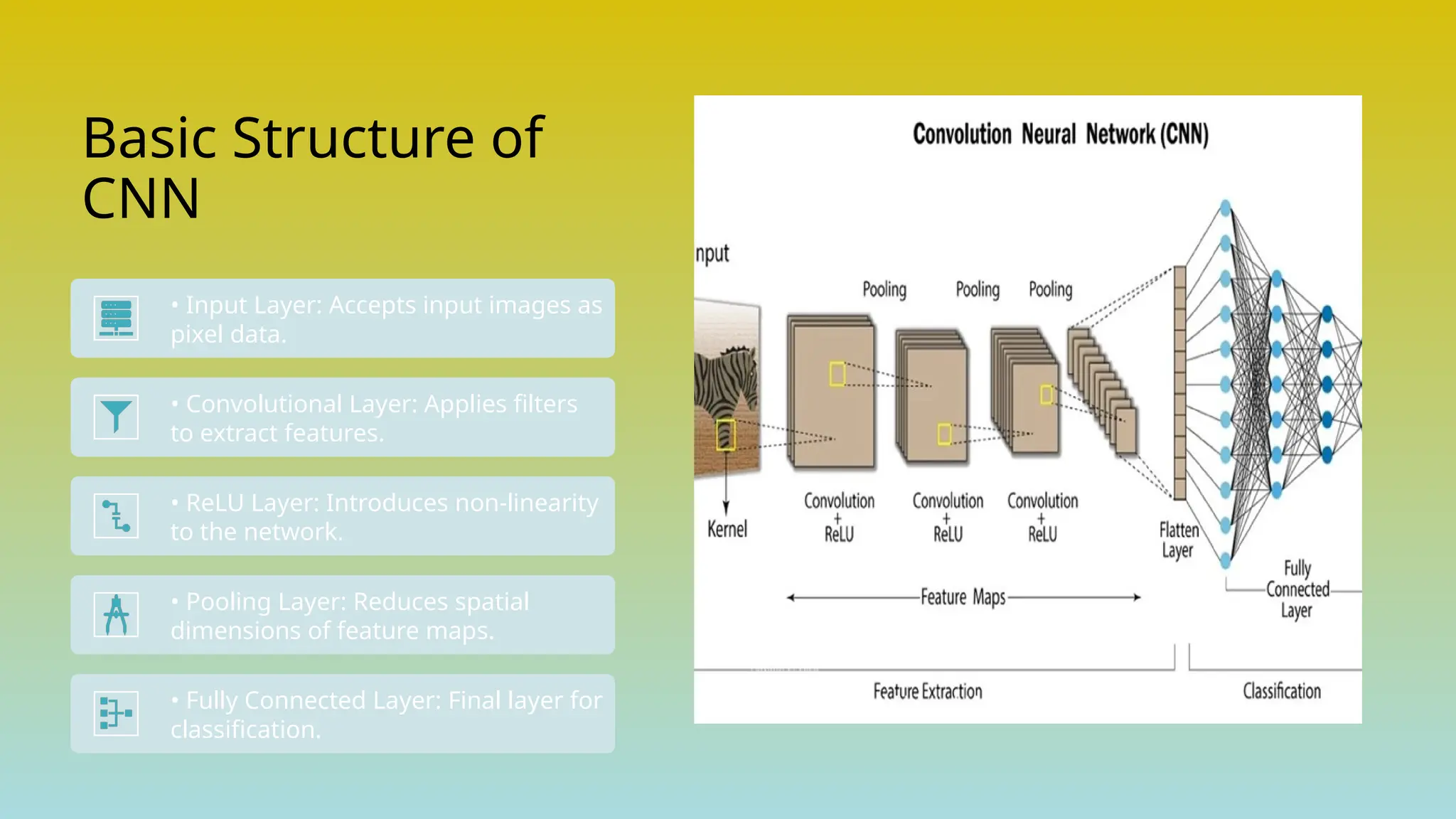
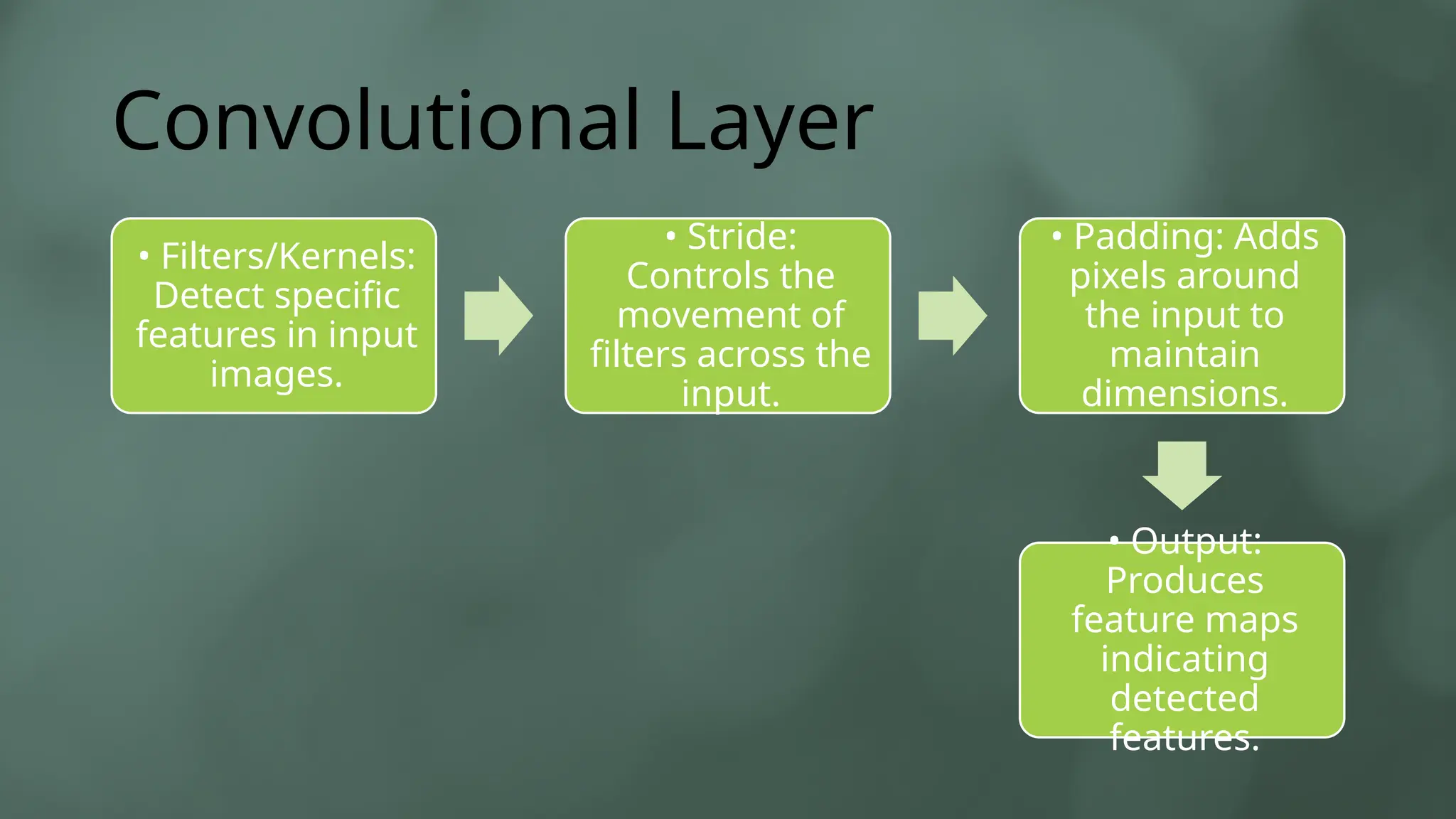
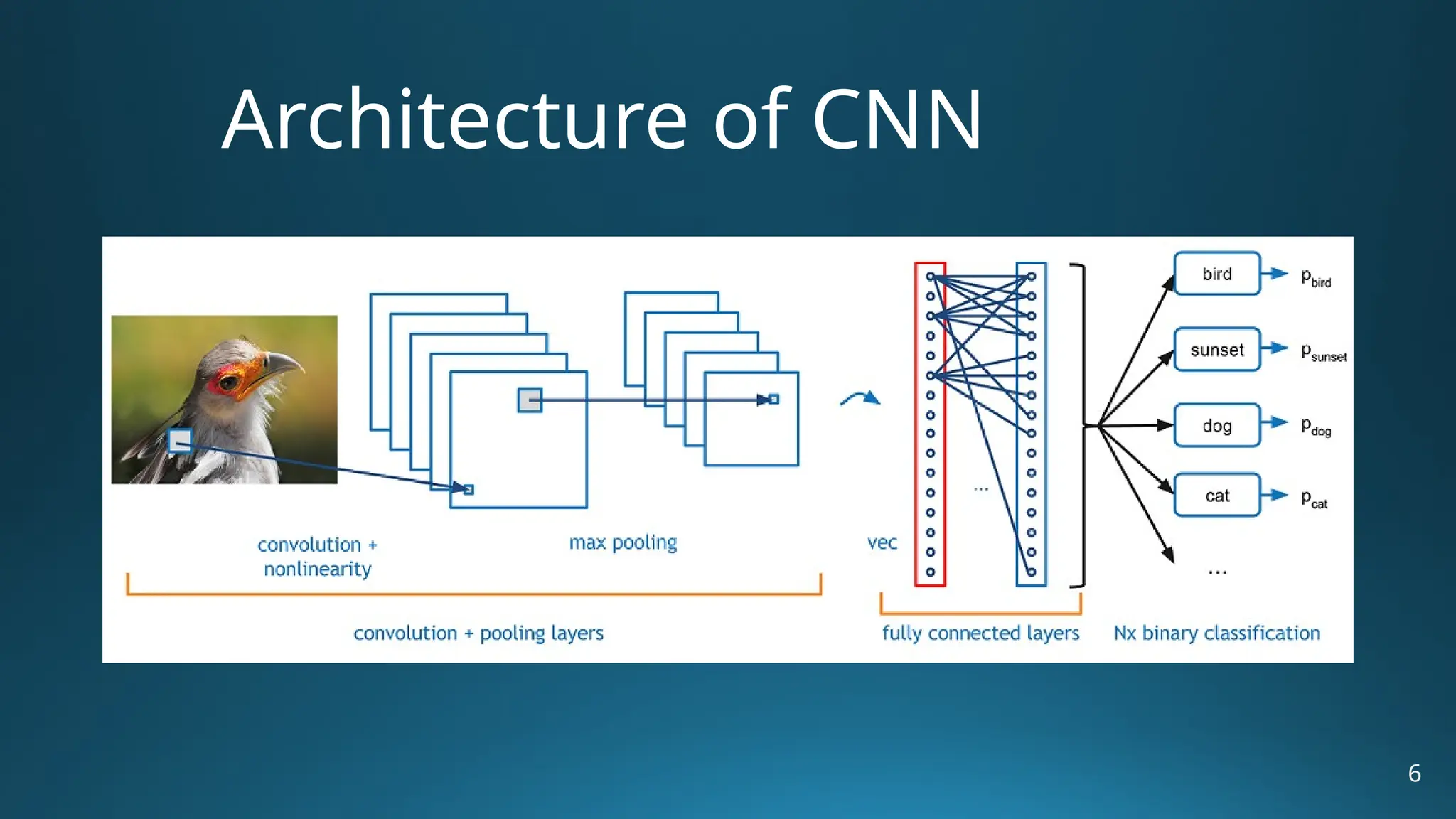
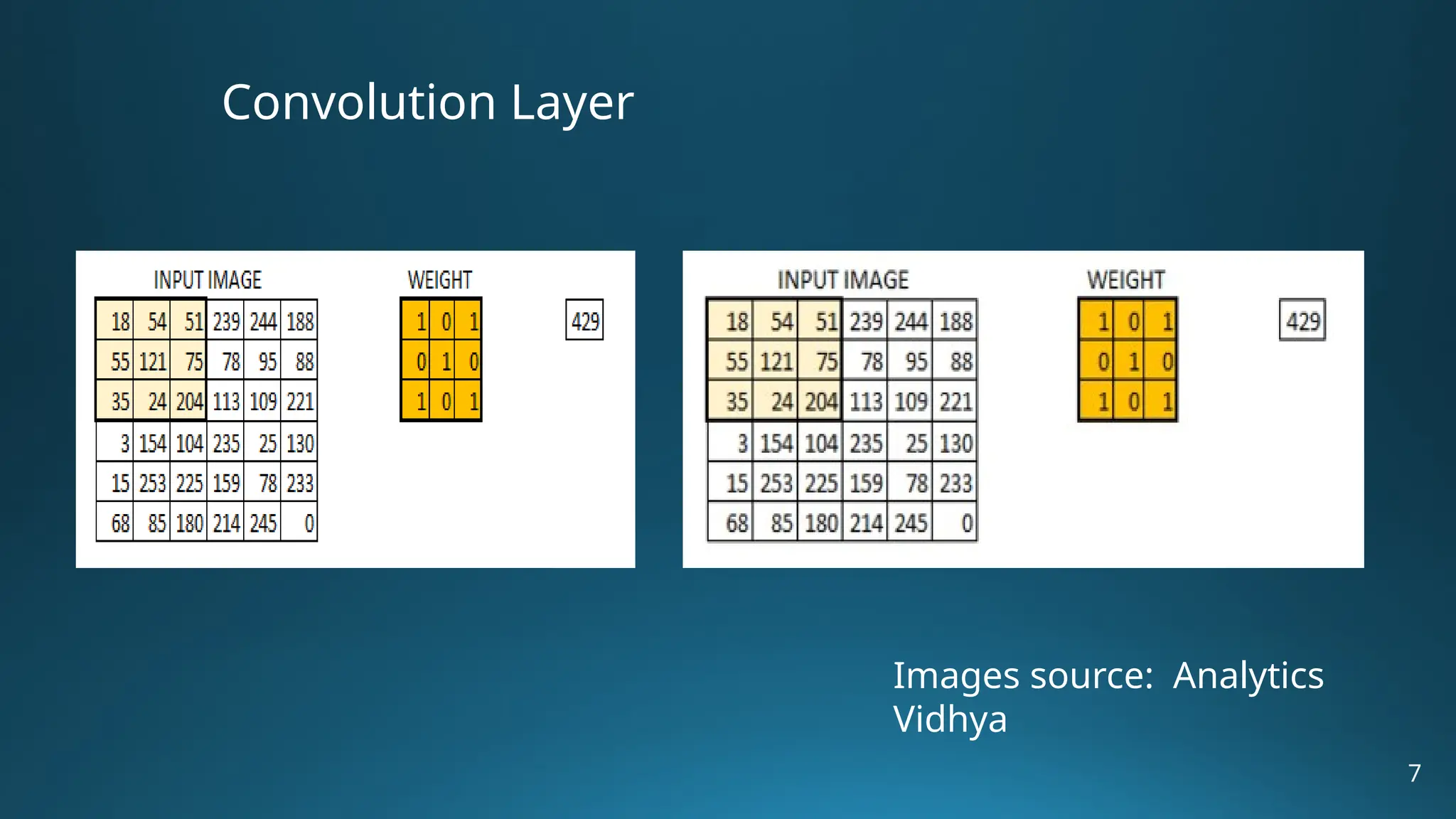
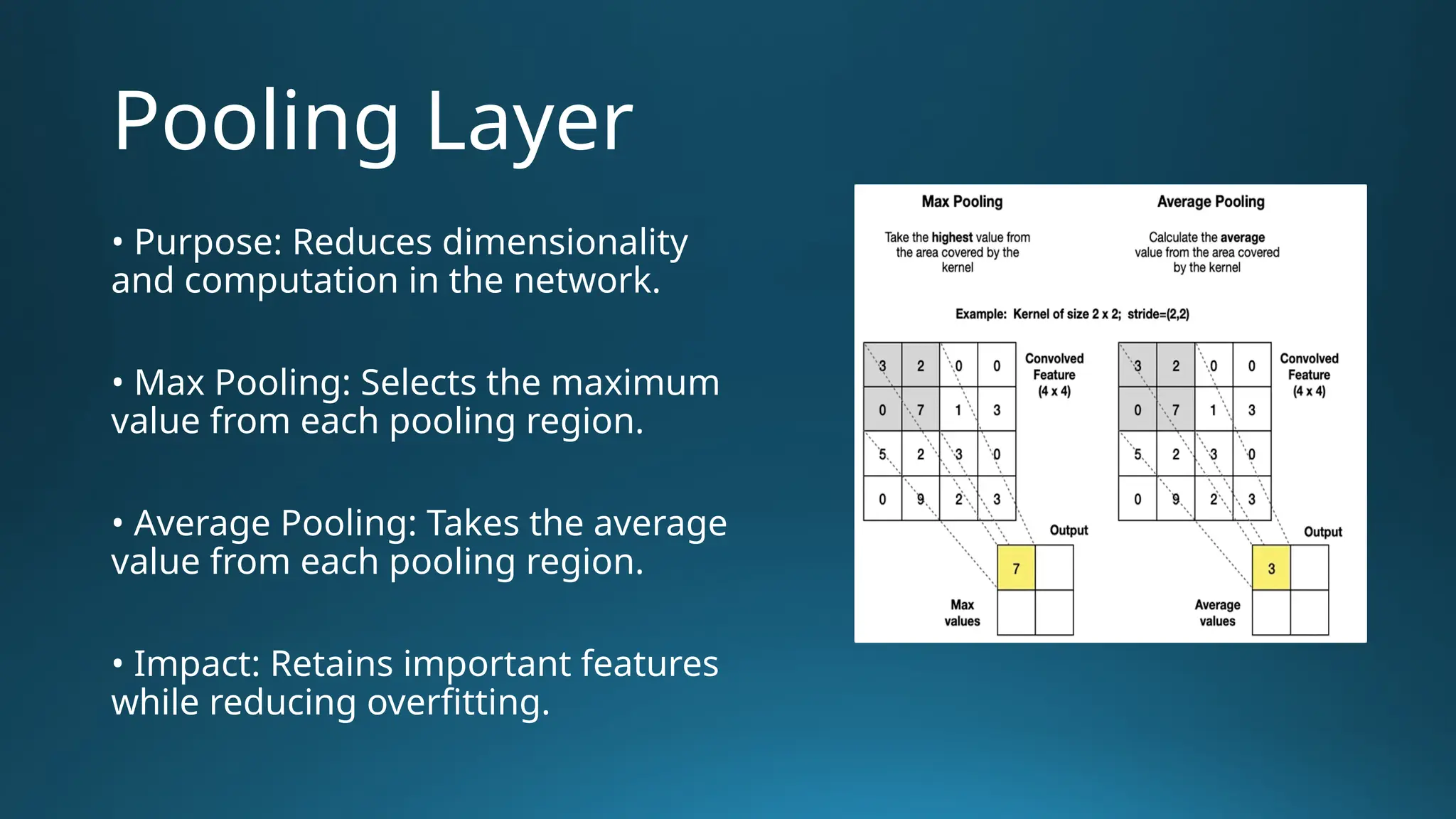
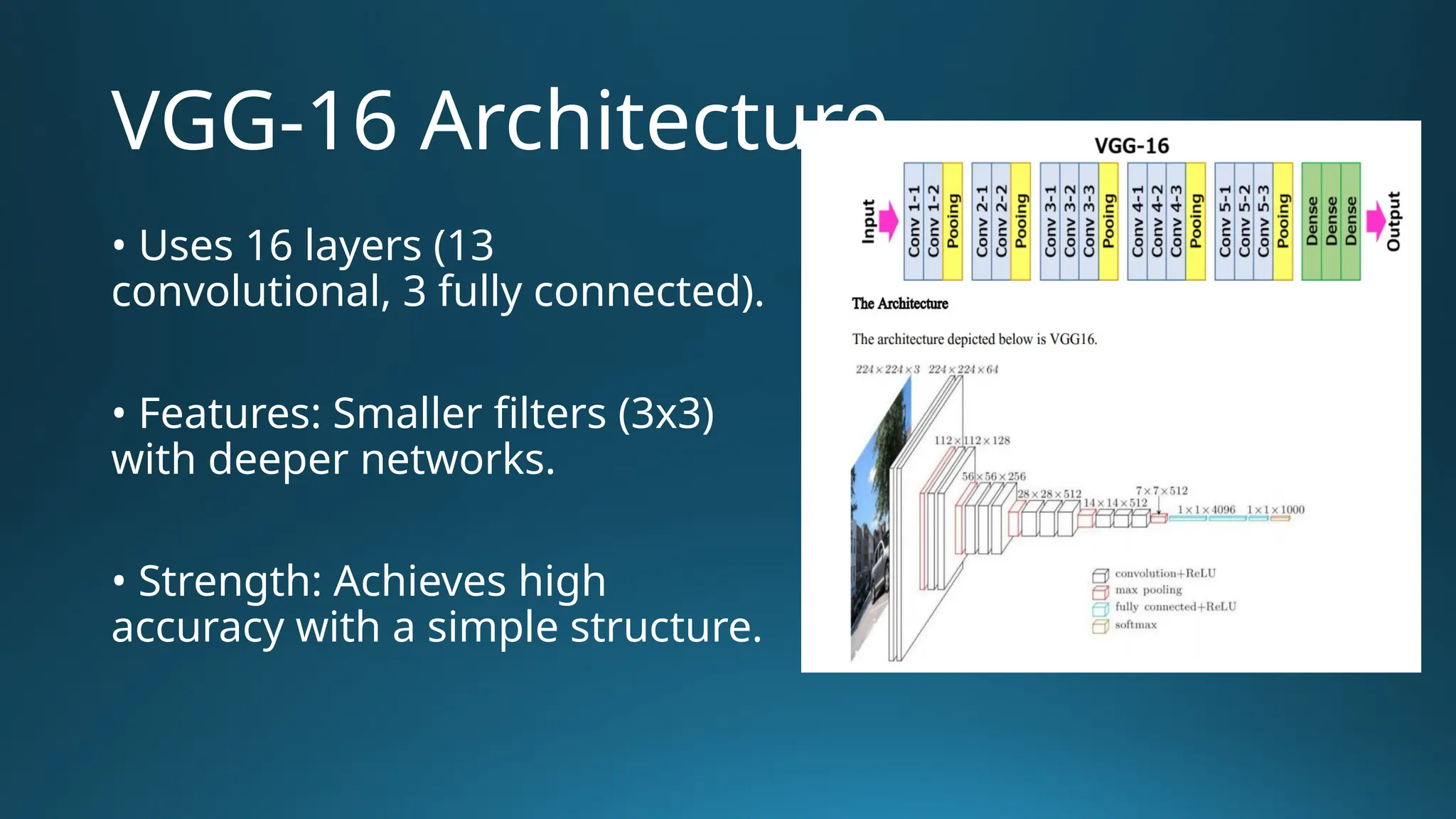
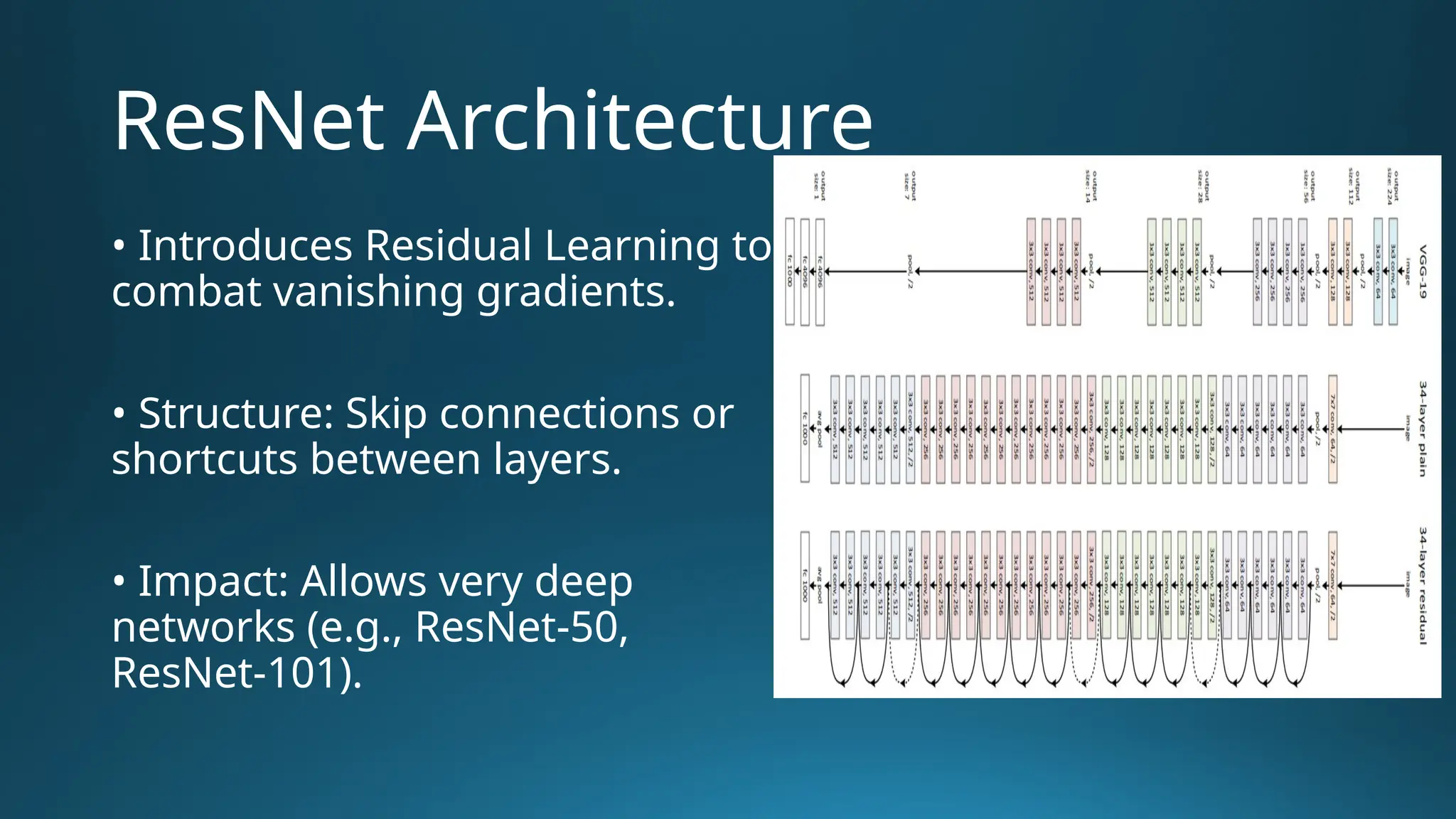
The document provides an overview of Convolutional Neural Networks (CNNs) in the context of computer vision, detailing their structure and functionality, including layers like convolution, pooling, and fully connected. It discusses various CNN architectures such as LeNet, AlexNet, and VGG-16, highlighting their contributions to image classification and recognition tasks. Additionally, it covers applications of CNNs in fields like retail, healthcare, and automotive, emphasizing their revolutionary impact on computer vision.