Download as PDF, PPTX




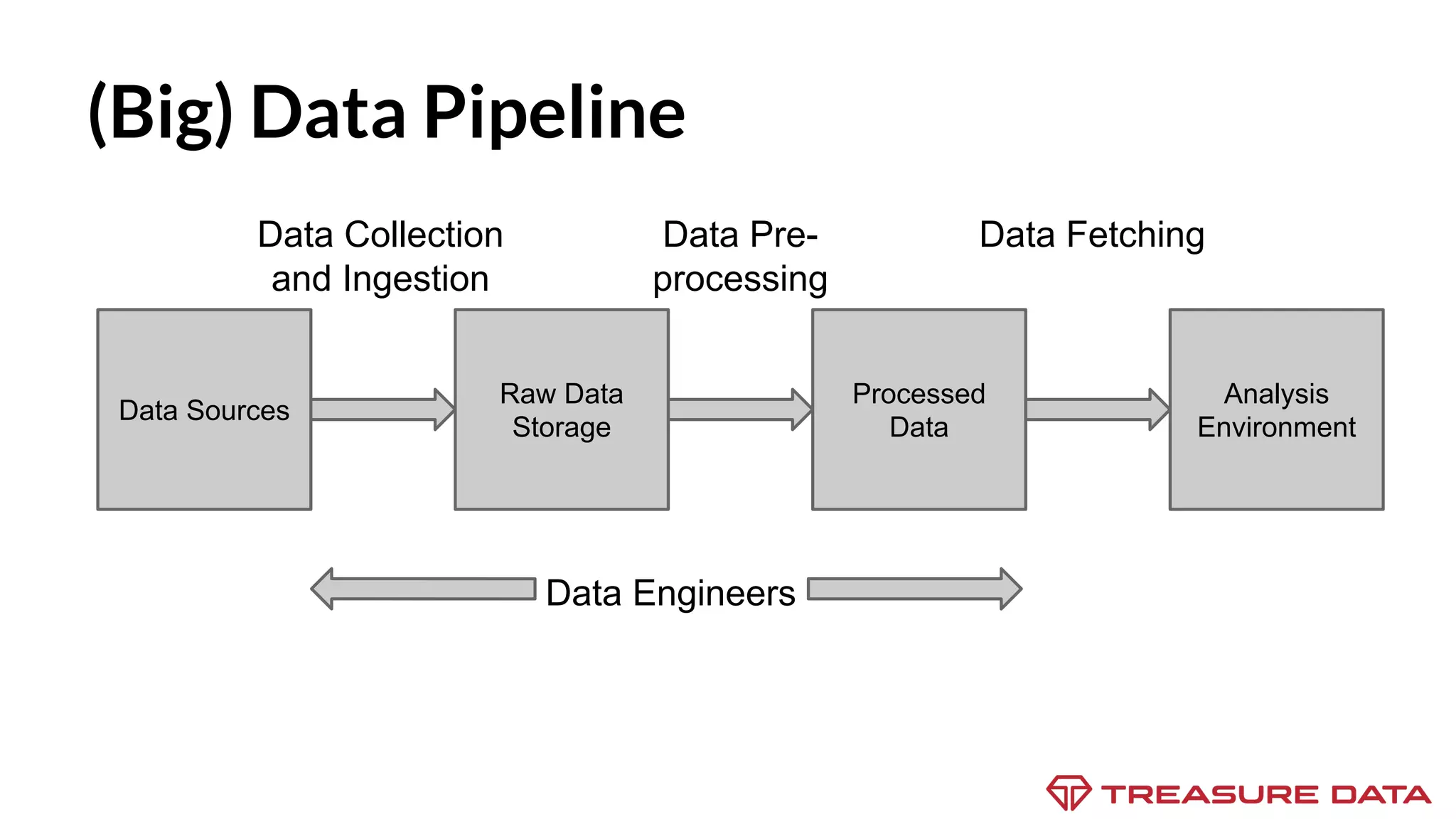
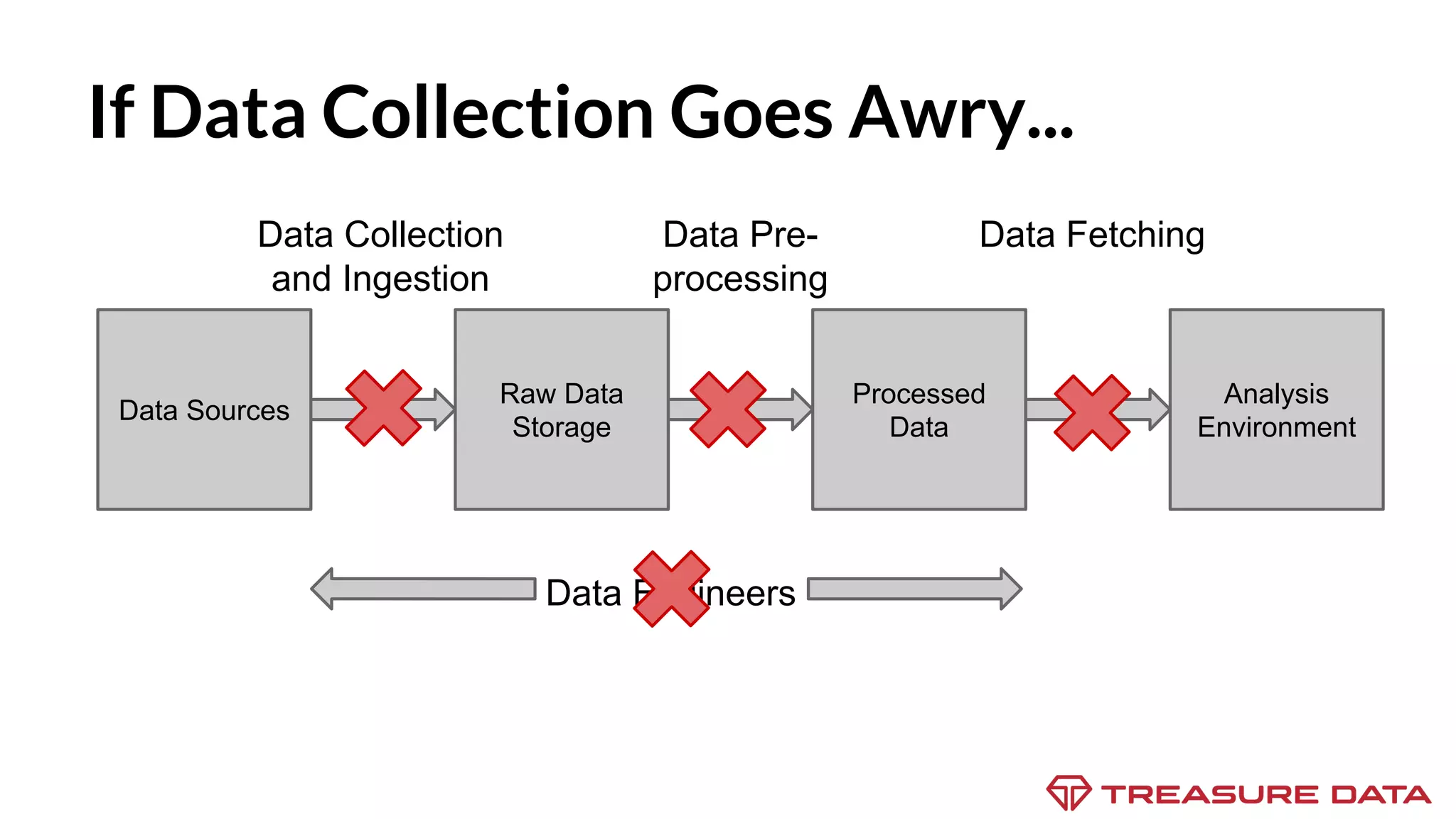


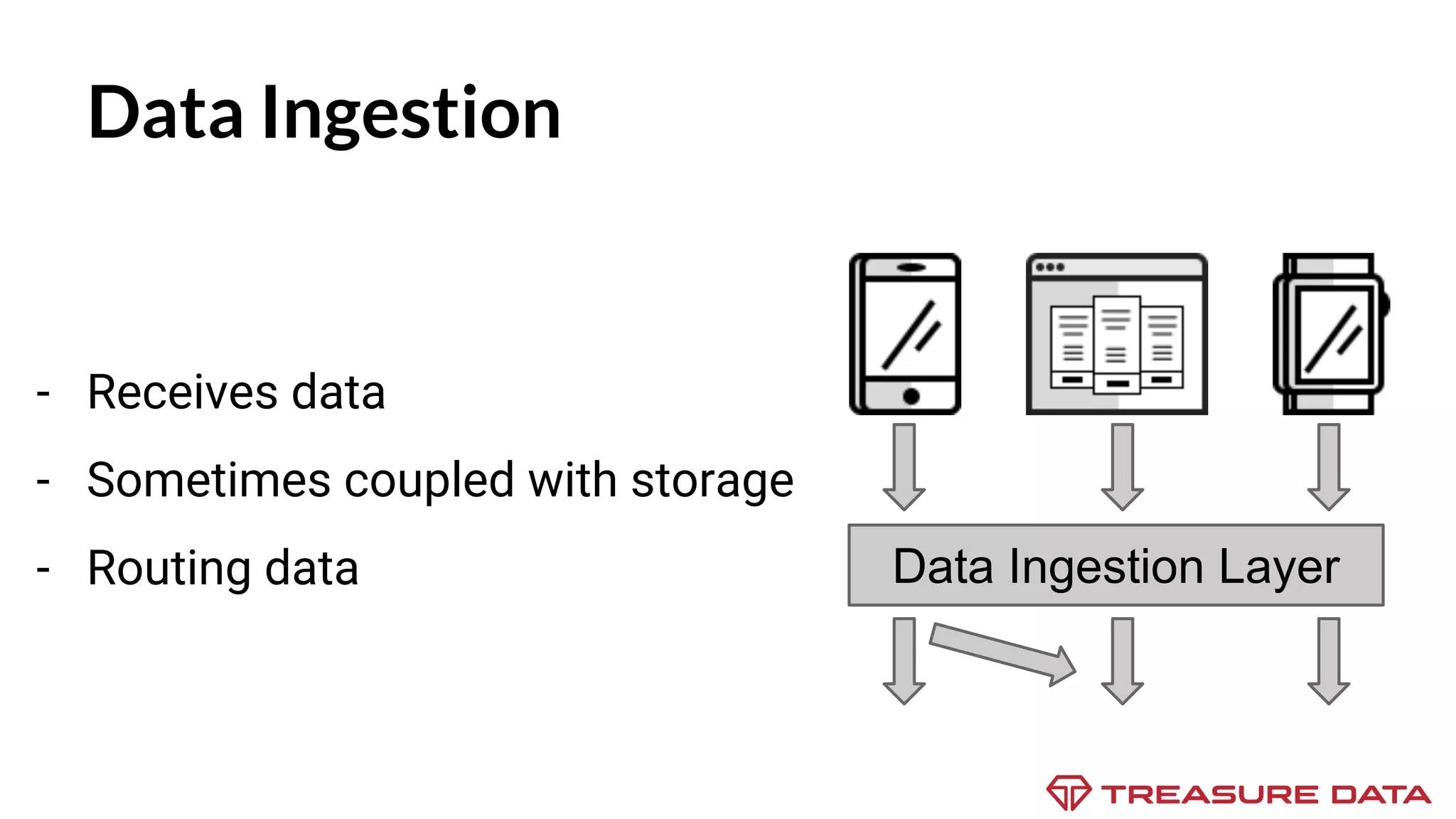




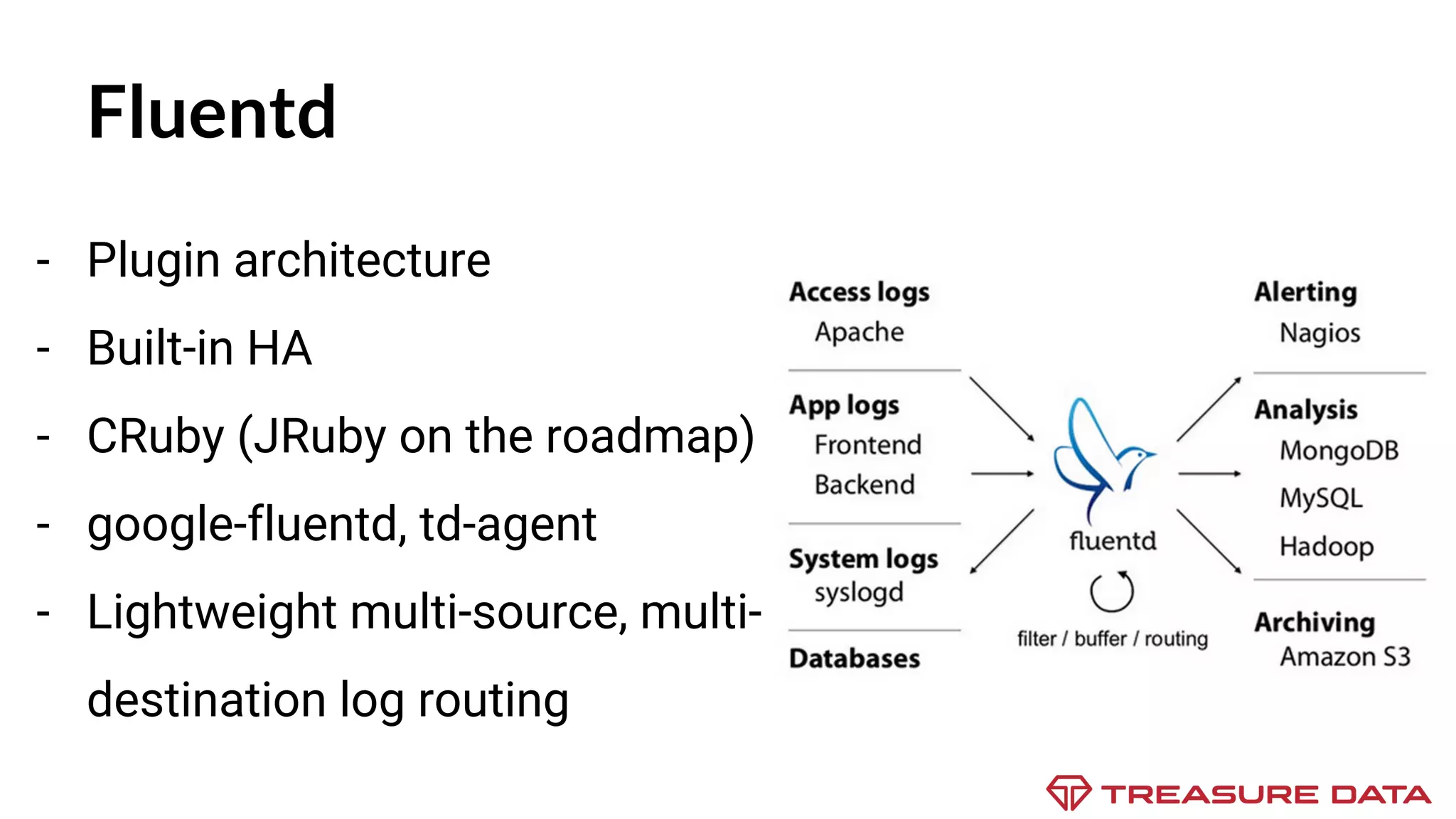
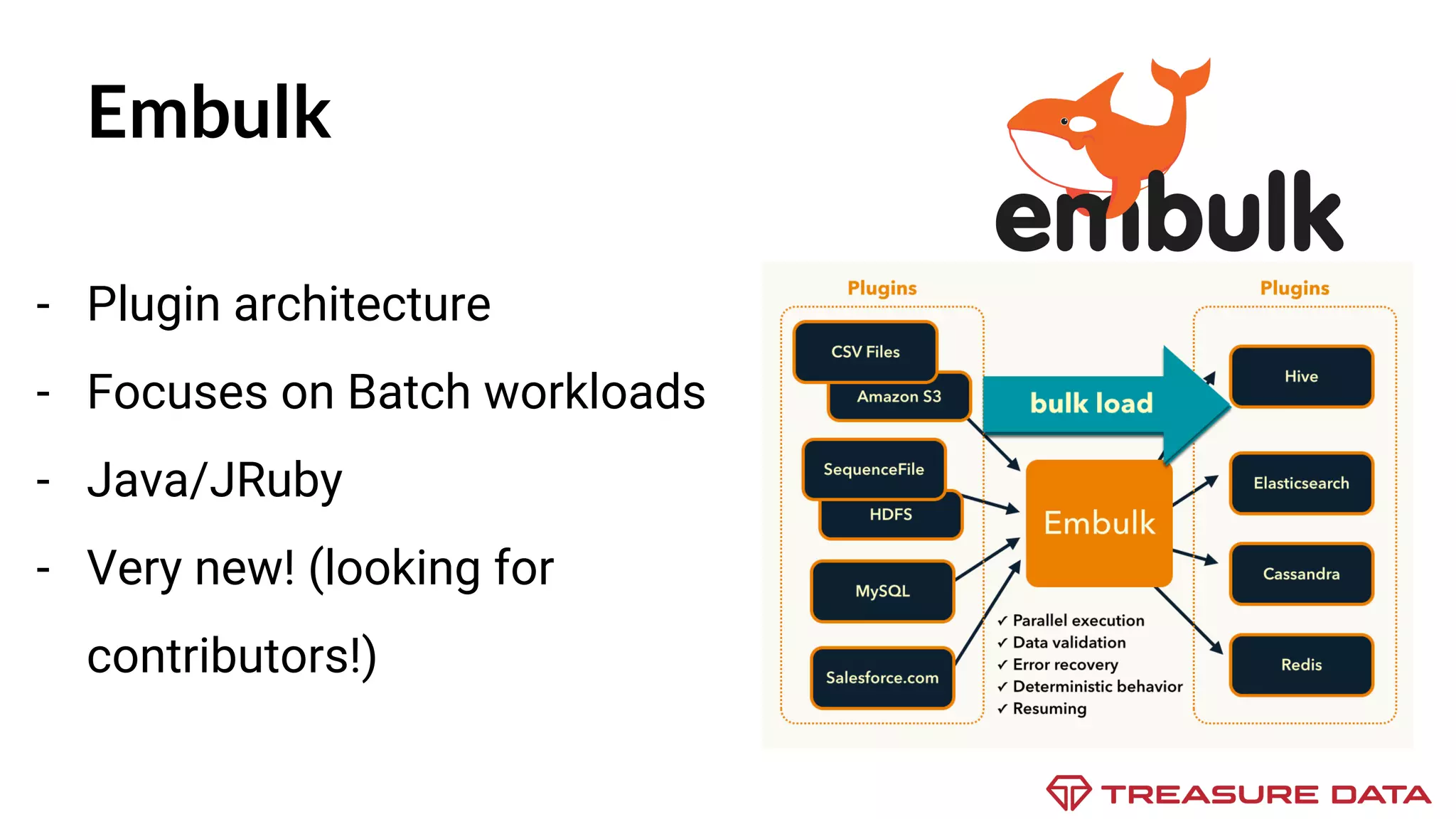



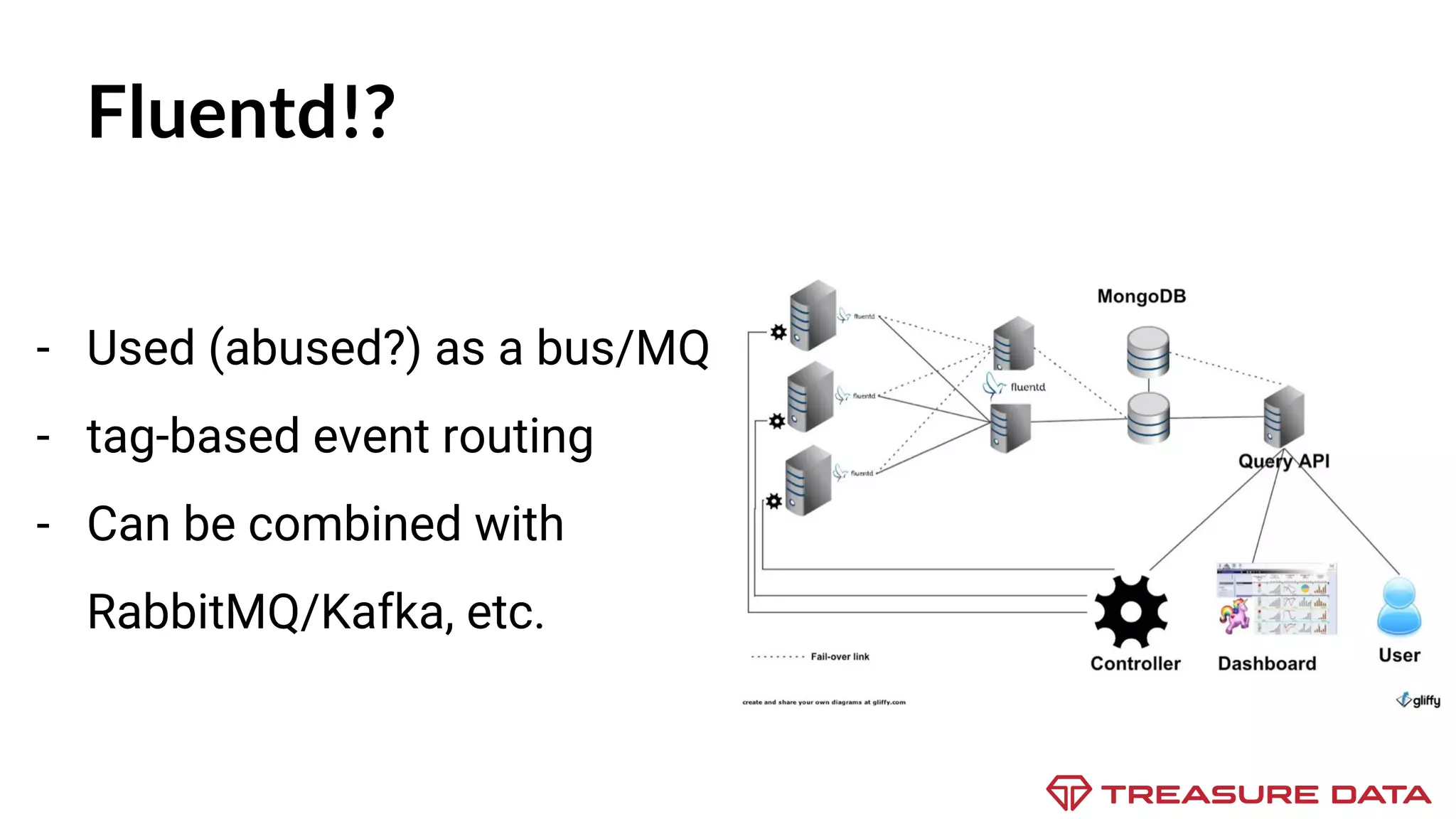

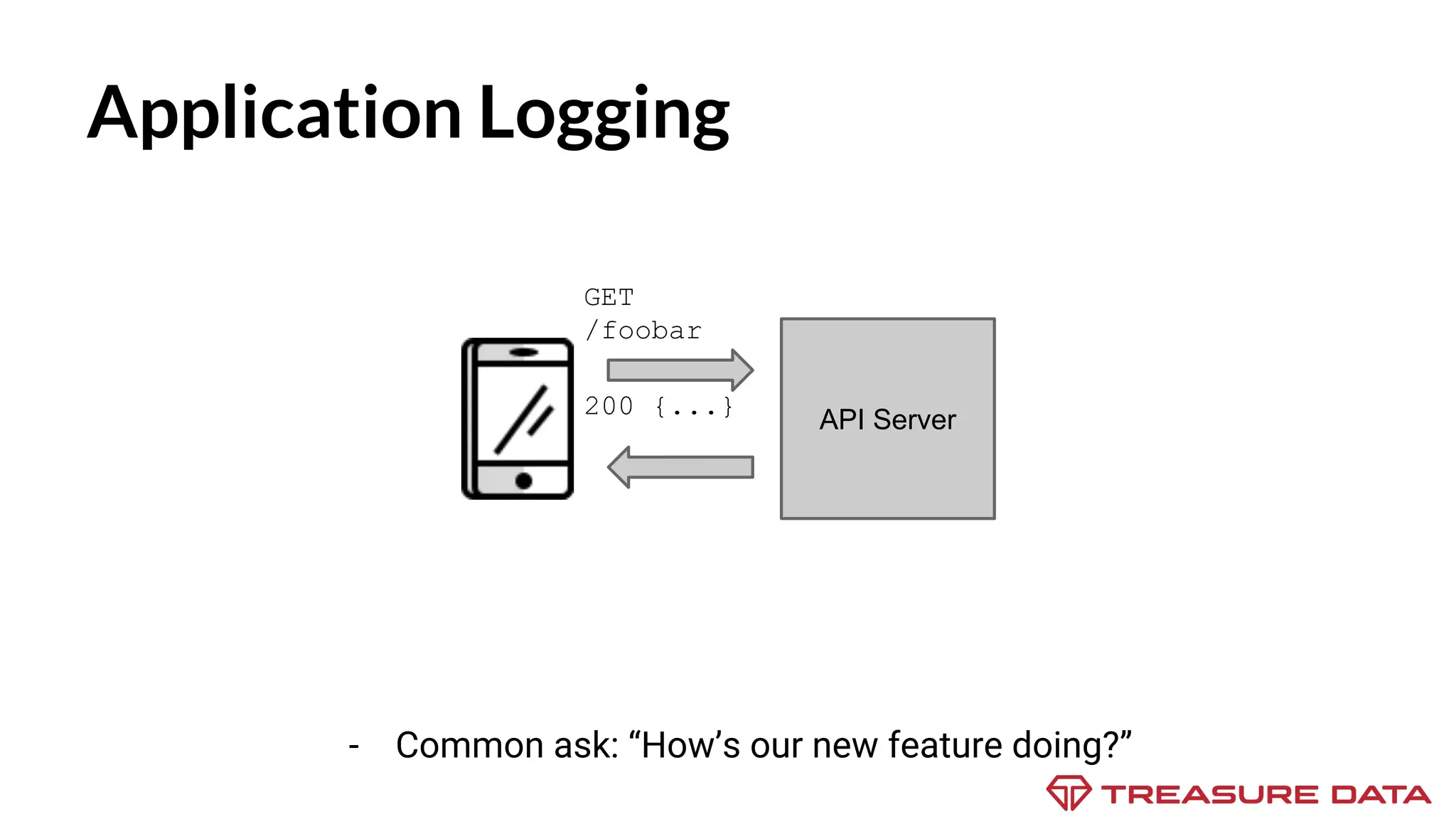
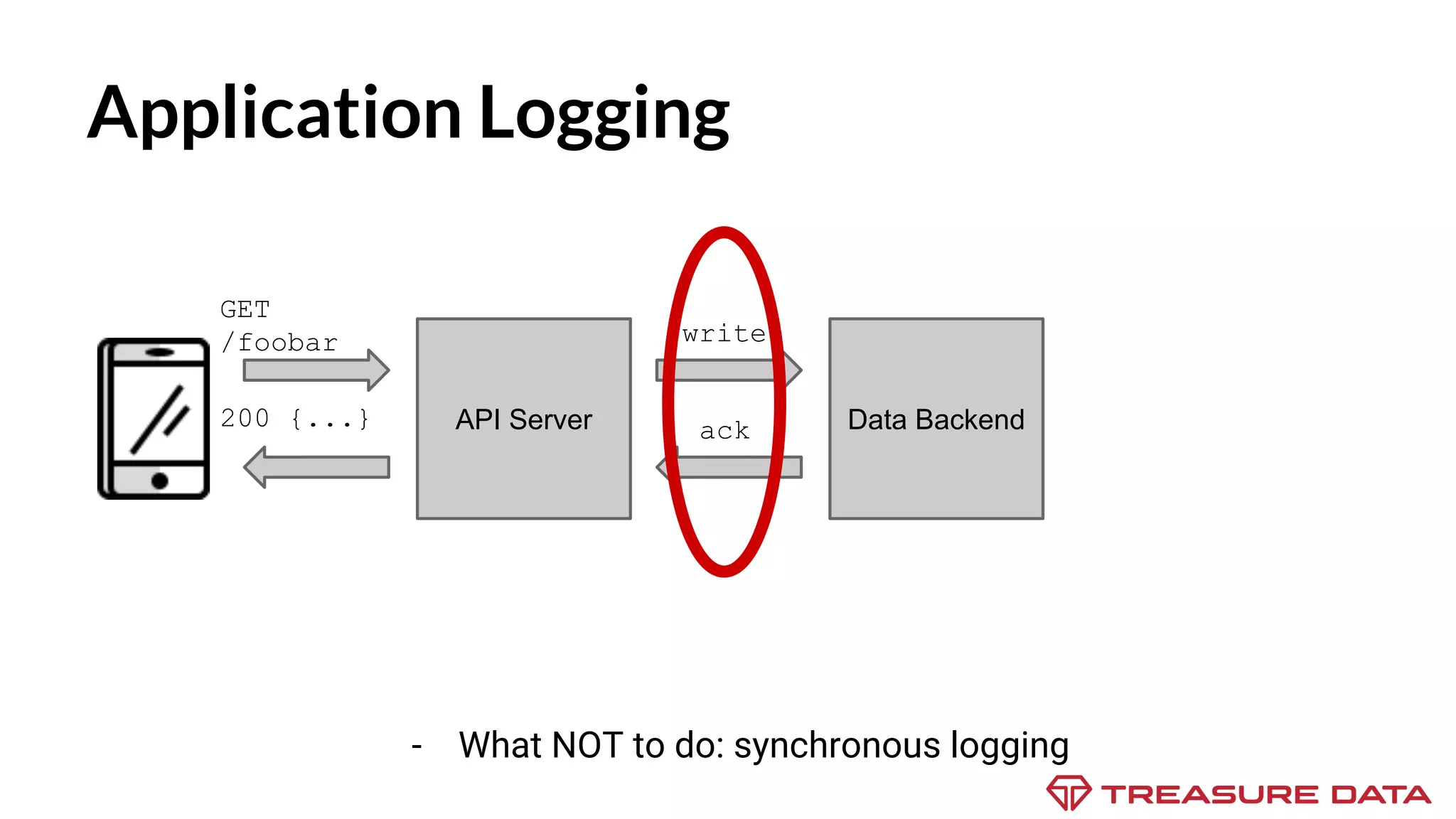
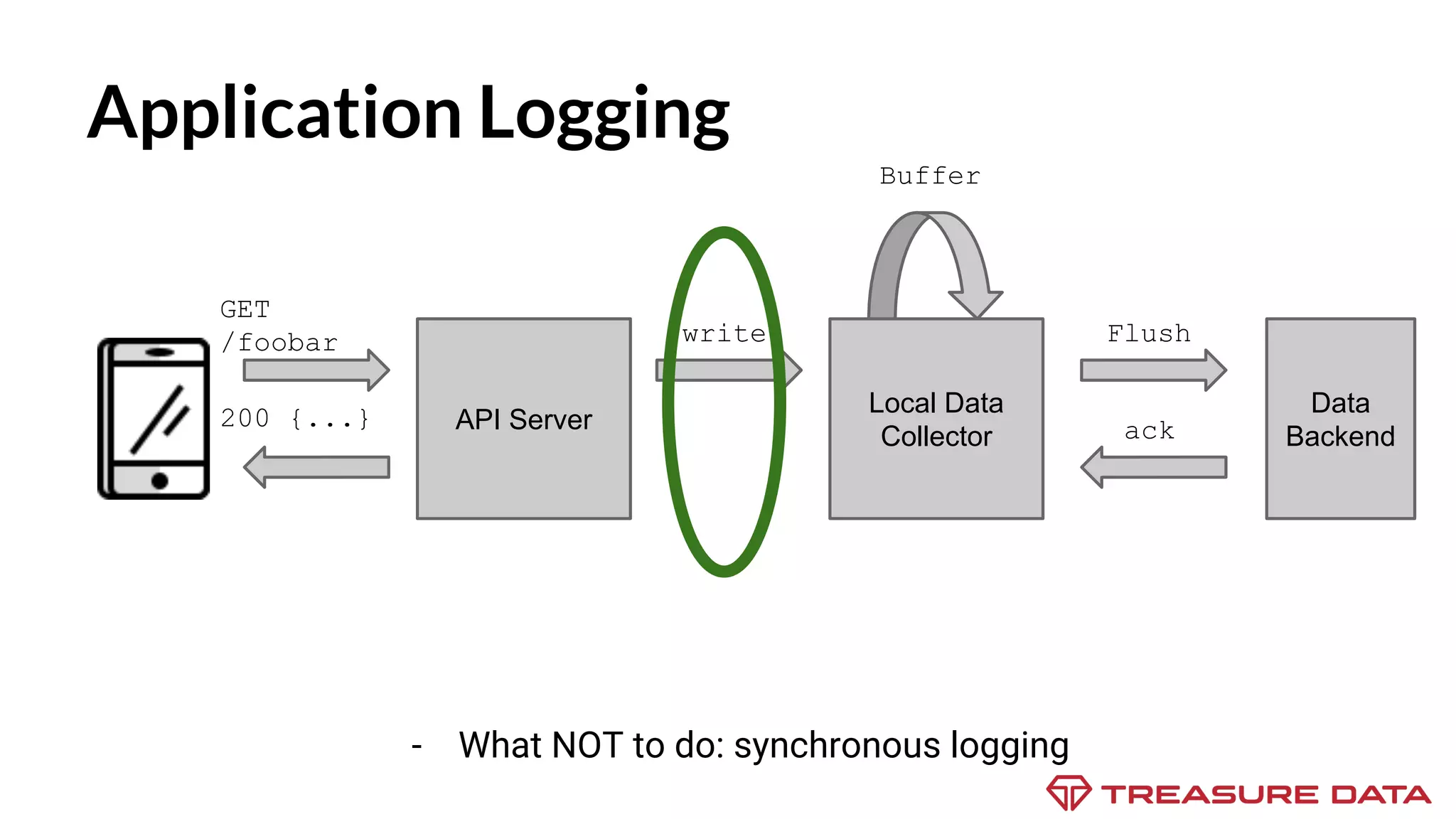





The document discusses the complexities of data collection and ingestion, comparing the two processes and outlining various tools for each. It highlights tools such as rsyslog, Fluentd, and Kafka, detailing their use cases and features. A case study on asynchronous application logging underscores the importance of effective logging practices in data handling.