Downloaded 66 times























![Questions? [email_address] @derekg http://open.nytimes.com/](https://image.slidesharecdn.com/hw09-countingandclusteringandotherdatatricks-091025150759-phpapp01/75/Hw09-Counting-And-Clustering-And-Other-Data-Tricks-28-2048.jpg)

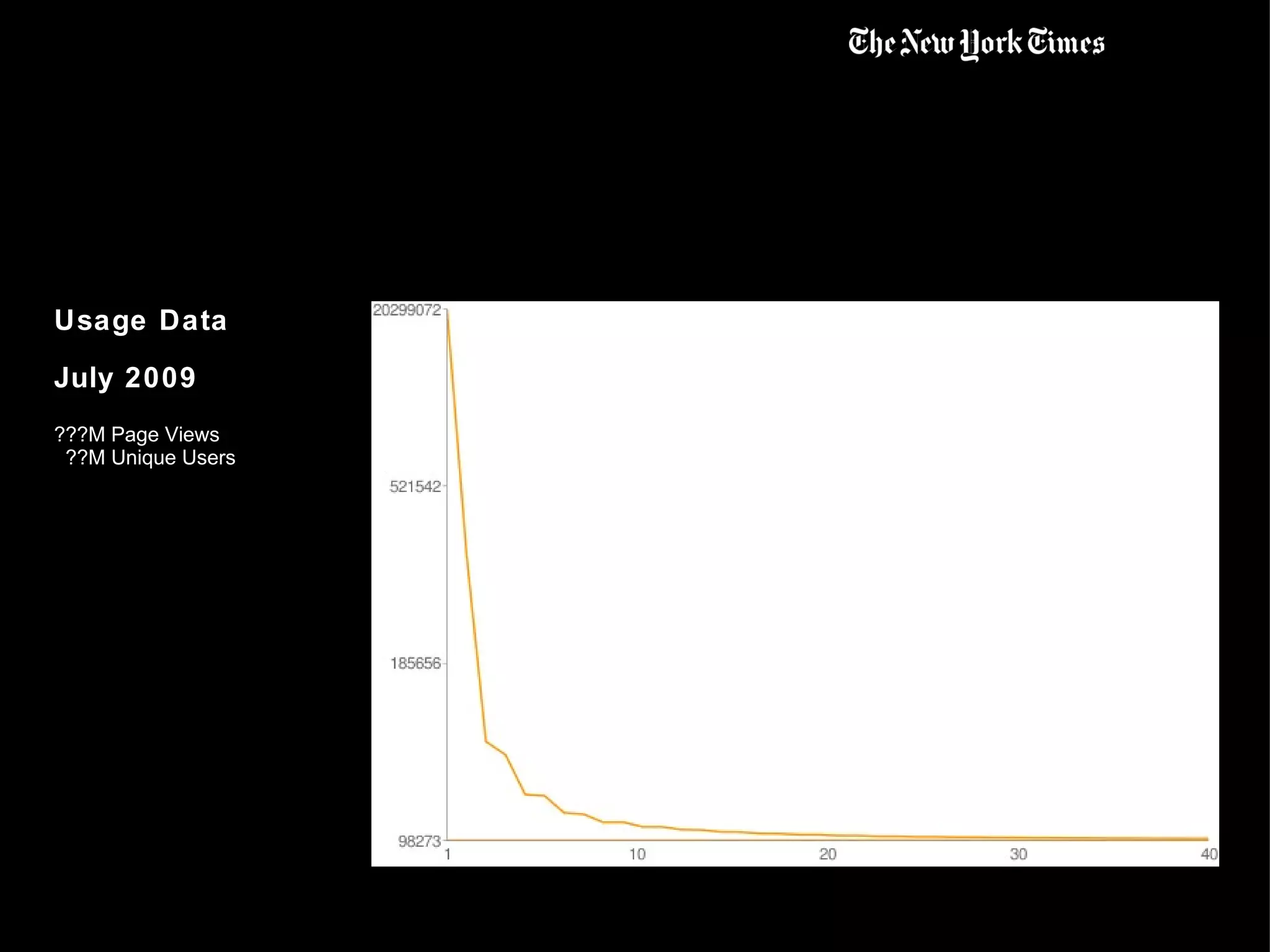
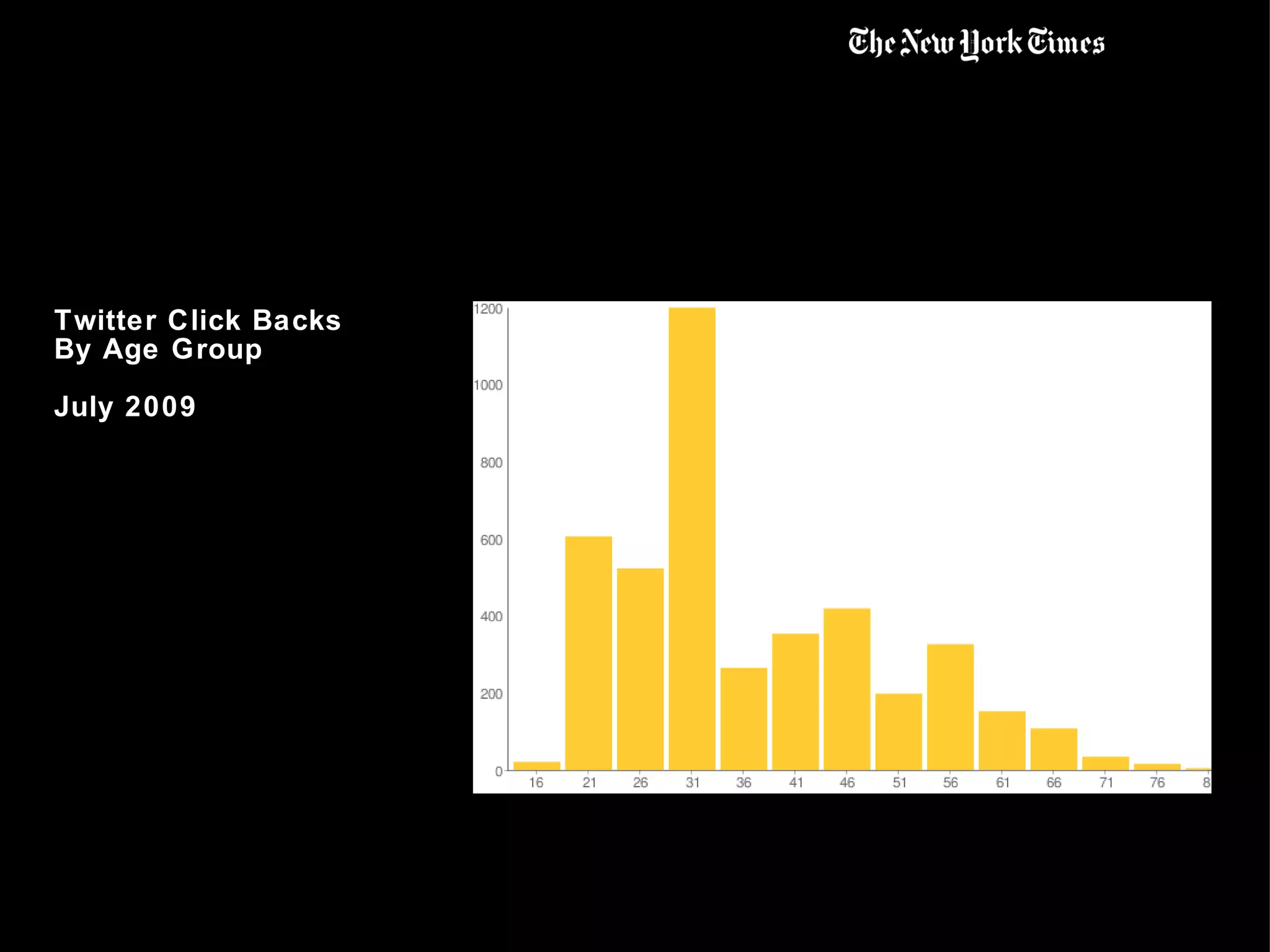
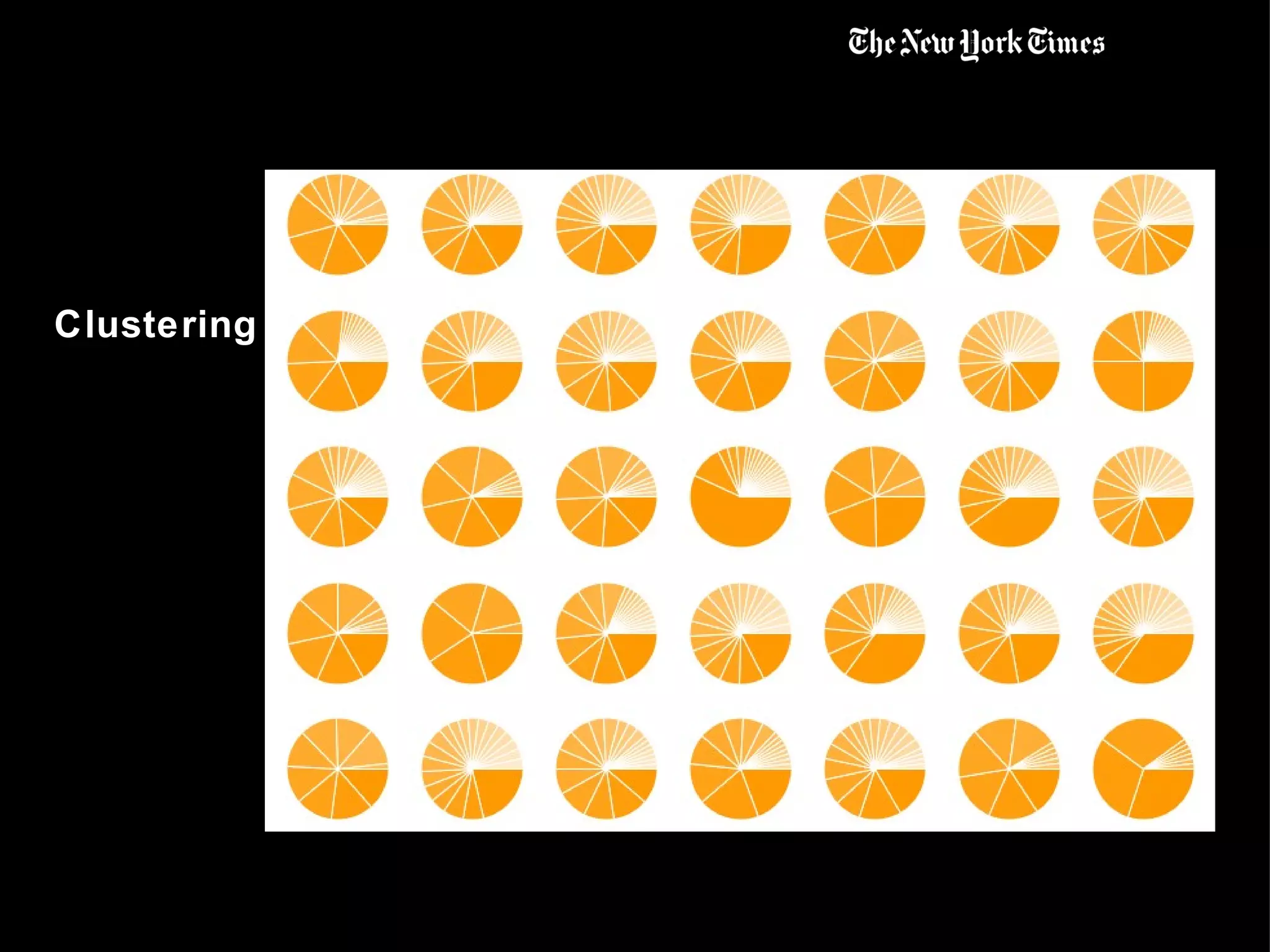
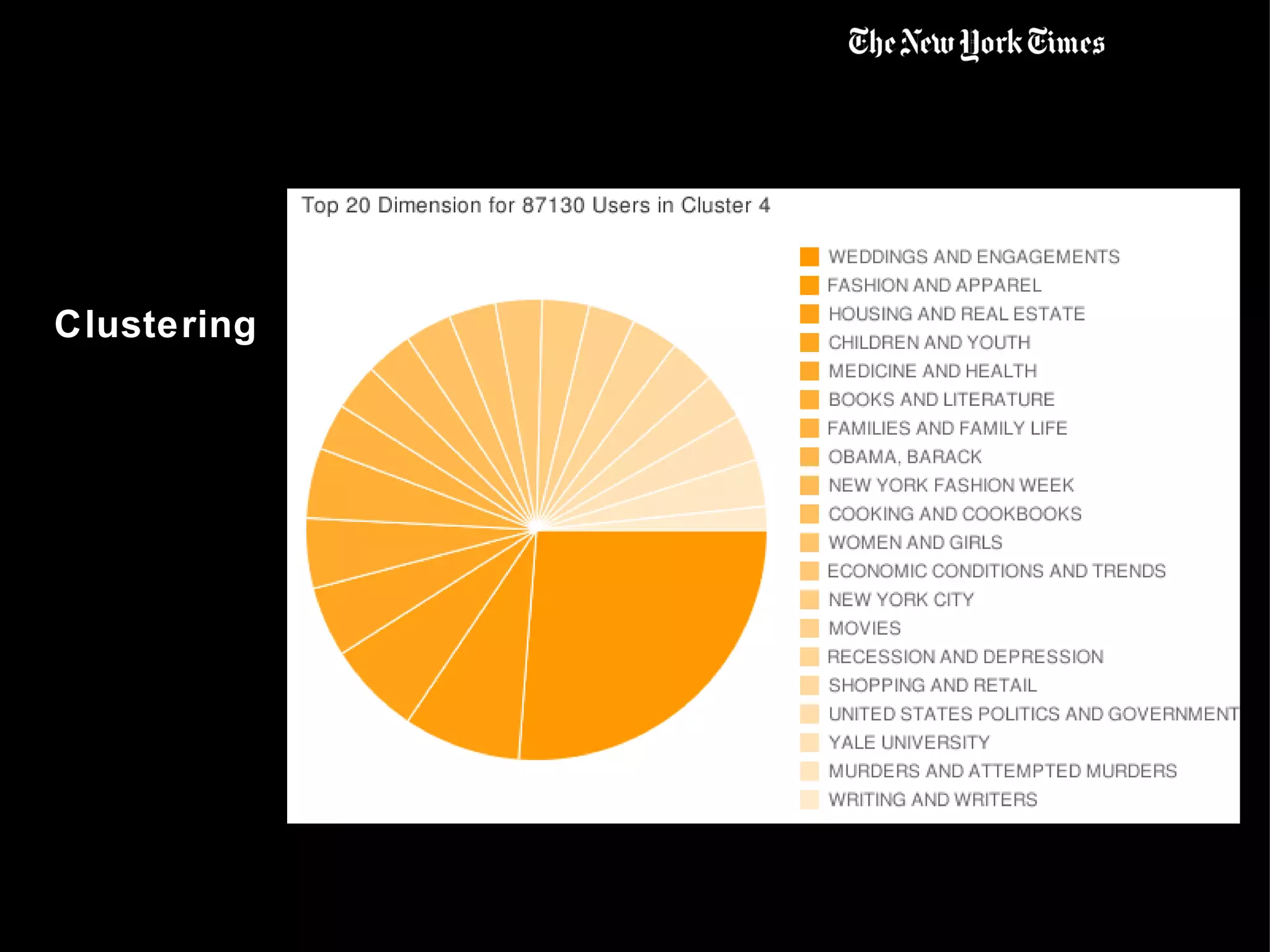
This document summarizes the early use of Hadoop at The New York Times to generate PDFs of archived newspaper articles and analyze web traffic data. It describes how over 100 Amazon EC2 instances were used with Hadoop to pre-generate over 11 million PDFs from 4.3TB of source data in under 24 hours for a total cost of $240. The document then discusses how the Times began using Hadoop to perform web analytics, counting page views and unique users, and merging this data with demographic and article metadata to better understand user traffic and behavior.