Download as PDF, PPTX



![siliconANGLE ● “...cross-platform model compilers [...] are harbingers of the new age in which it won’t matter what front-end tool you used to build your AI algorithms and what back-end clouds, platforms or chipsets are used to execute them.” ● “Cross-platform AI compilers will become standard components of every AI development environment, enabling developers to access every deep learning framework and target platform without having to know the technical particular of each environment.” ● “...within the next two to three years, the AI industry will converge around one open-source cross-compilation supported by all front-end and back-end environments” 4 Read the article April 2018 Quotes from article:](https://image.slidesharecdn.com/253sameerfarooqui-210616155050/75/How-to-use-Apache-TVM-to-optimize-your-ML-models-4-2048.jpg)
![Venture Beat “With PyTorch and TensorFlow, you’ve seen the frameworks sort of converge. The reason quantization comes up, and a bunch of other lower-level efficiencies come up, is because the next war is compilers for the frameworks — XLA, TVM, PyTorch has Glow, a lot of innovation is waiting to happen,” he said. “For the next few years, you’re going to see … how to quantize smarter, how to fuse better, how to use GPUs more efficiently, [and] how to automatically compile for new hardware.” 5 Read the article Quote from Soumith Chintala: (co-creator of PyTorch and distinguished engineer at Facebook AI) Jan 2020](https://image.slidesharecdn.com/253sameerfarooqui-210616155050/75/How-to-use-Apache-TVM-to-optimize-your-ML-models-5-2048.jpg)












![TIR Script ● TIR provides more flexibility than high level tensor expressions. ● Not everything is expressible in TE and auto-scheduling is not always perfect. ○ AutoScheduling 3.0 (code- named AutoTIR coming later this year) ○ We can also directly write TIR directly using TIRScript. 33 @tvm.script.tir def fuse_add_exp(a: ty.handle, c: ty.handle) -> None: A = tir.match_buffer(a, (64,)) C = tir.match_buffer(c, (64,)) B = tir.alloc_buffer((64,)) with tir.block([64], "B") as [vi]: B[vi] = A[vi] + 1 with tir.block([64], "C") as [vi]: C[vi] = exp(B[vi])](https://image.slidesharecdn.com/253sameerfarooqui-210616155050/75/How-to-use-Apache-TVM-to-optimize-your-ML-models-33-2048.jpg)

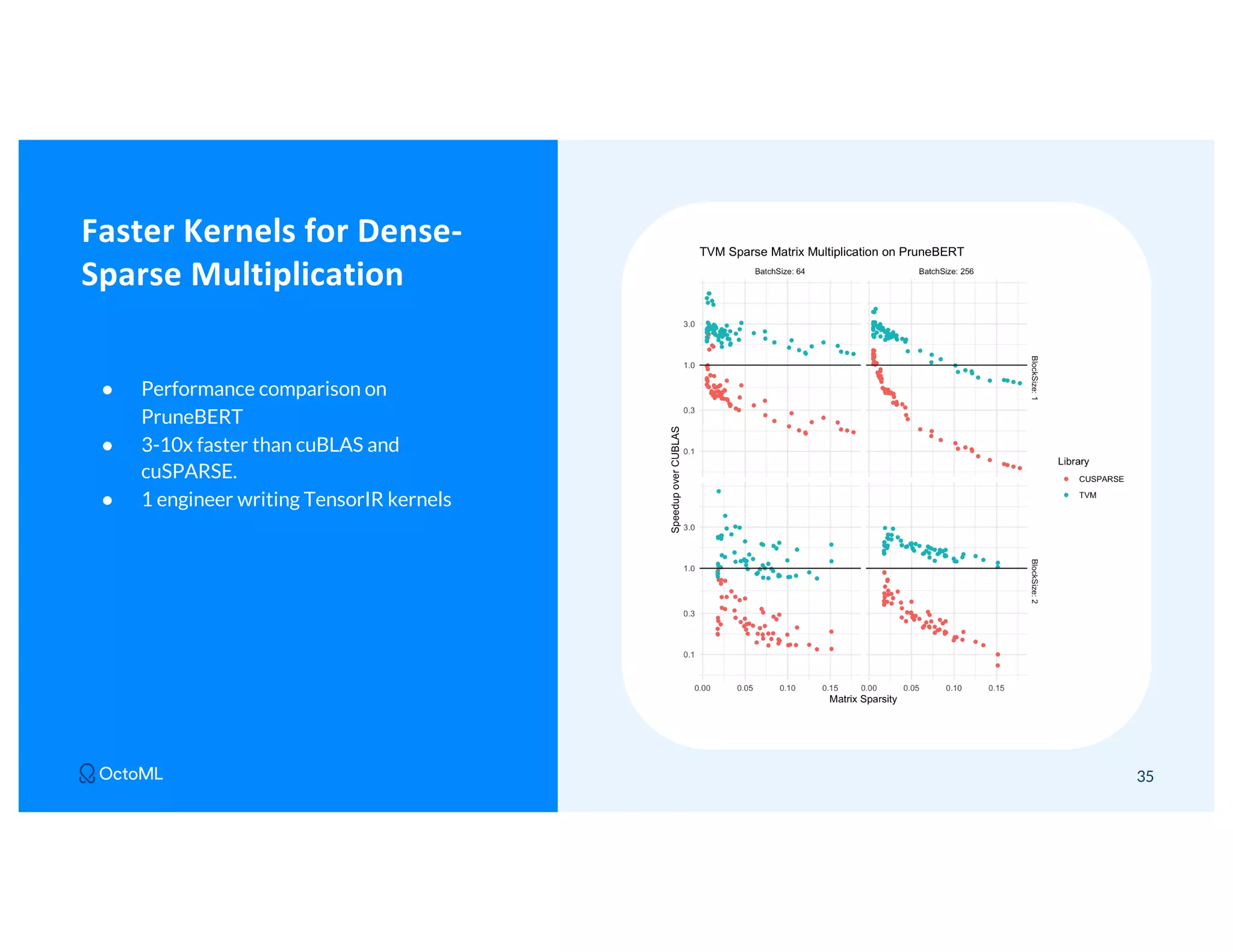

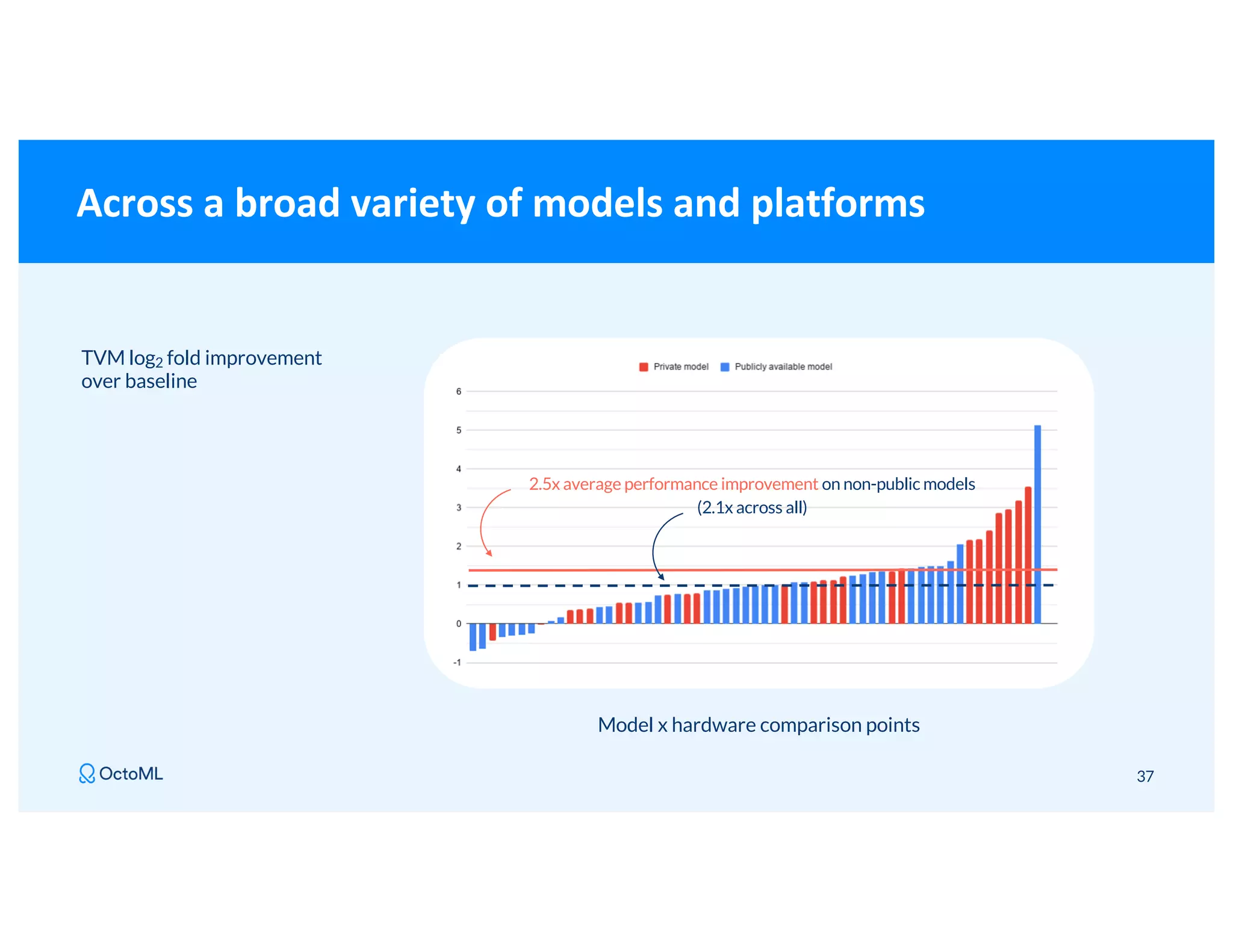
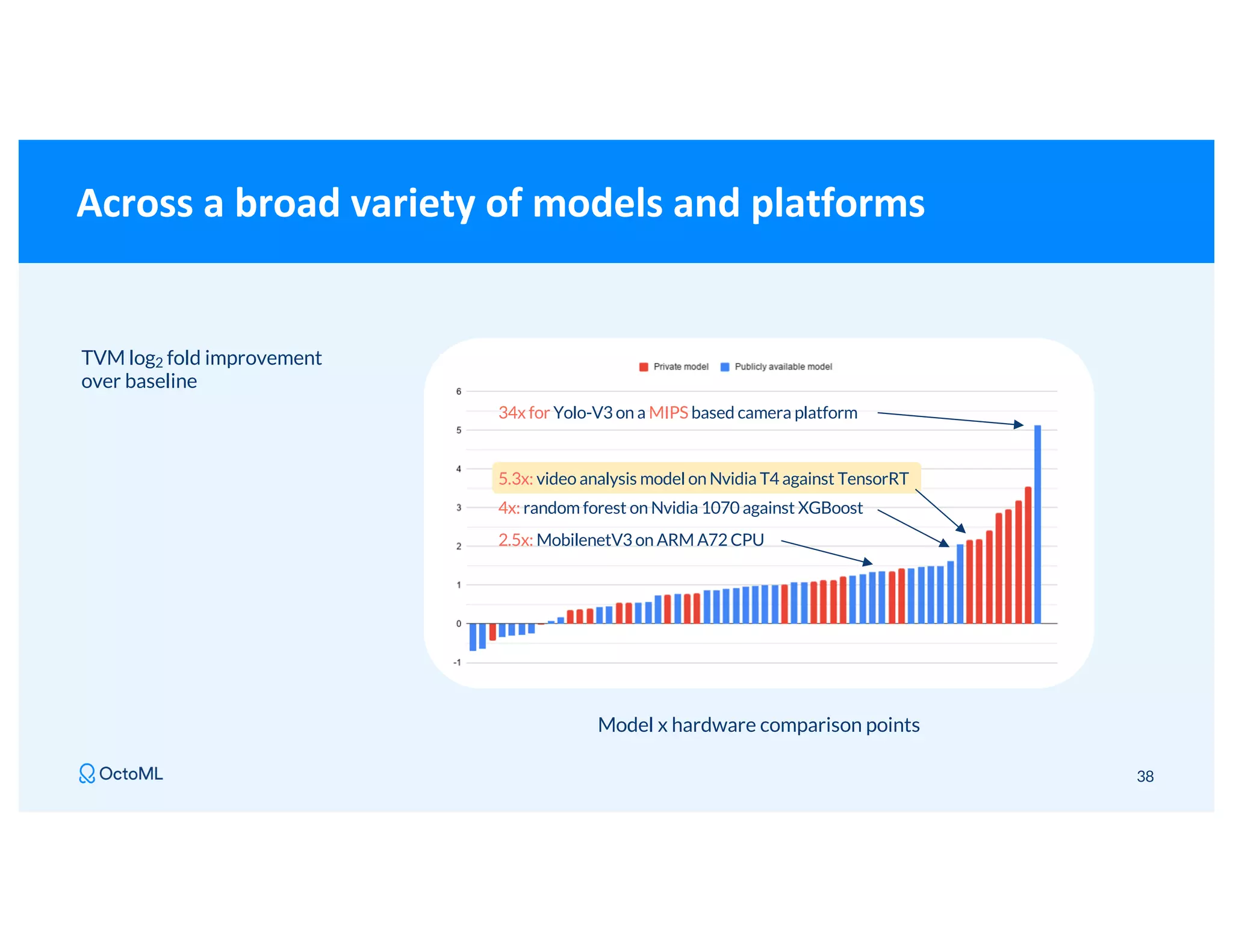
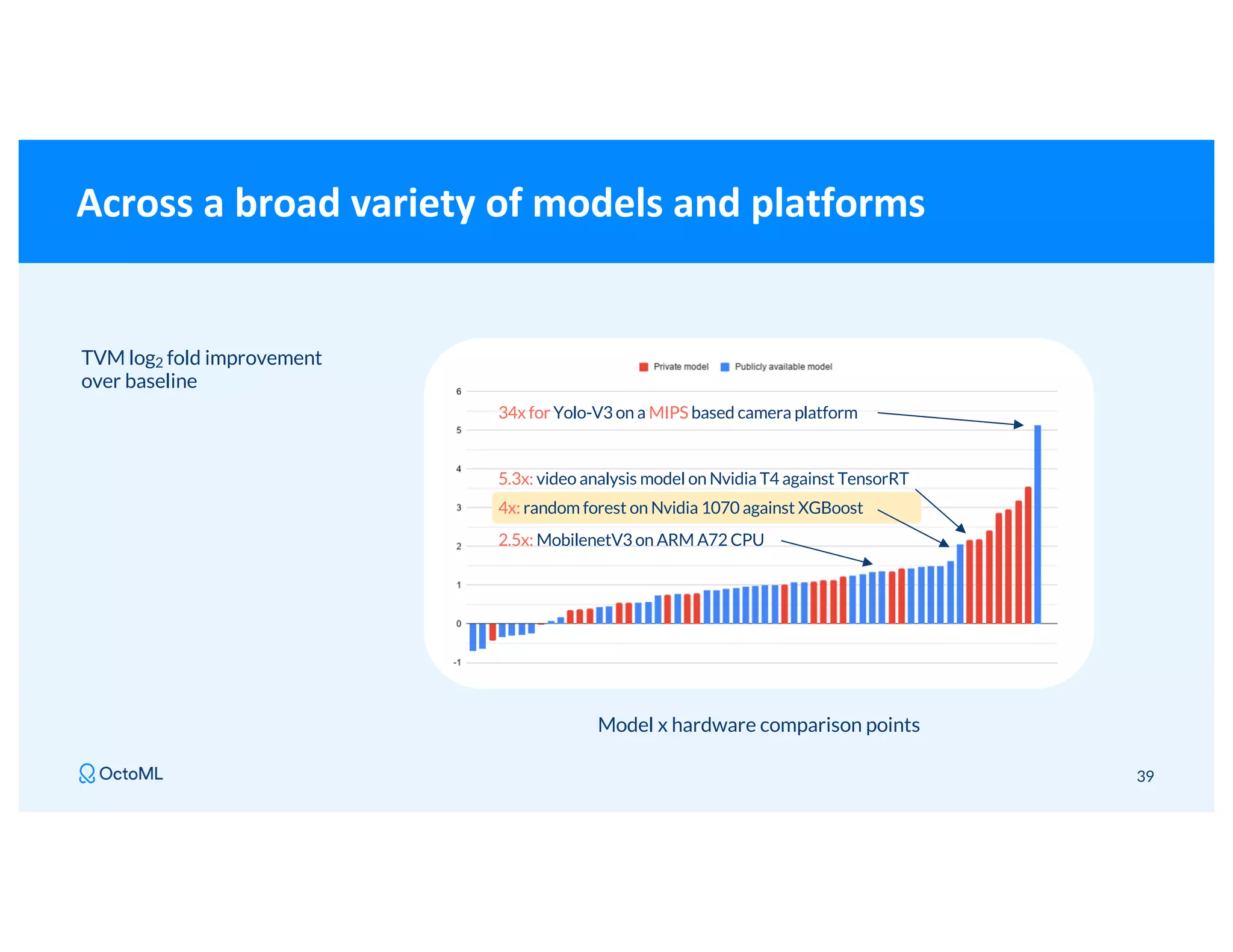
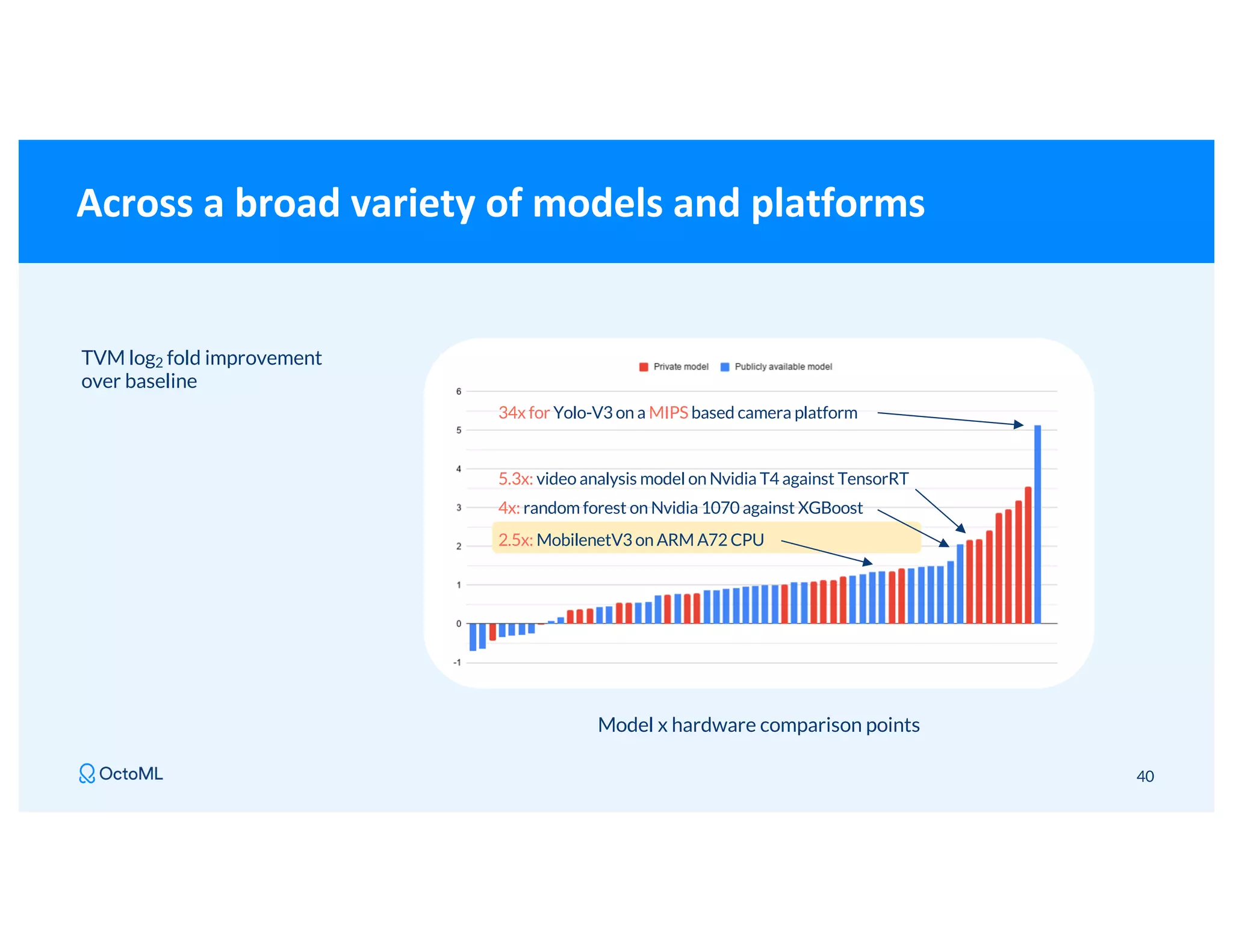
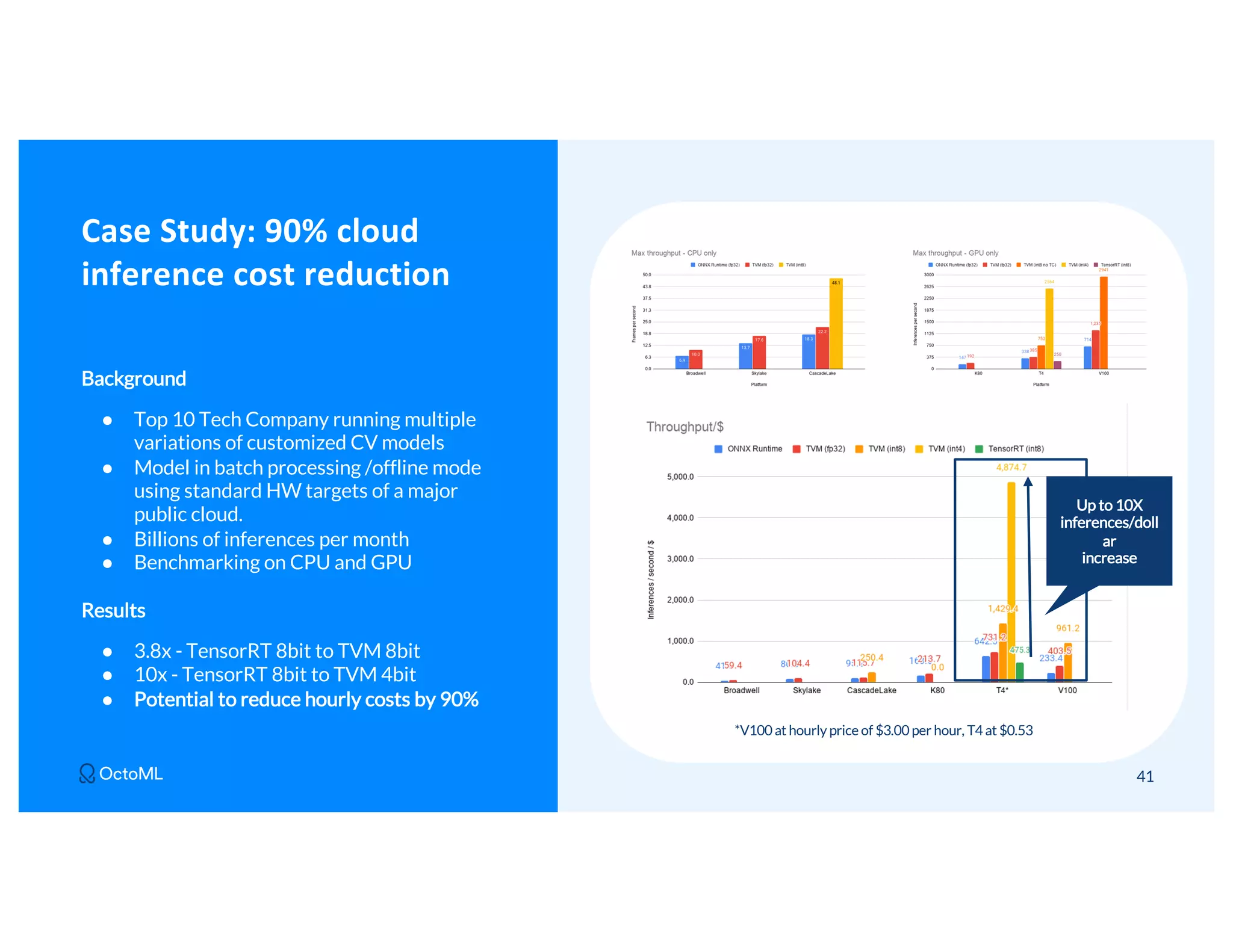
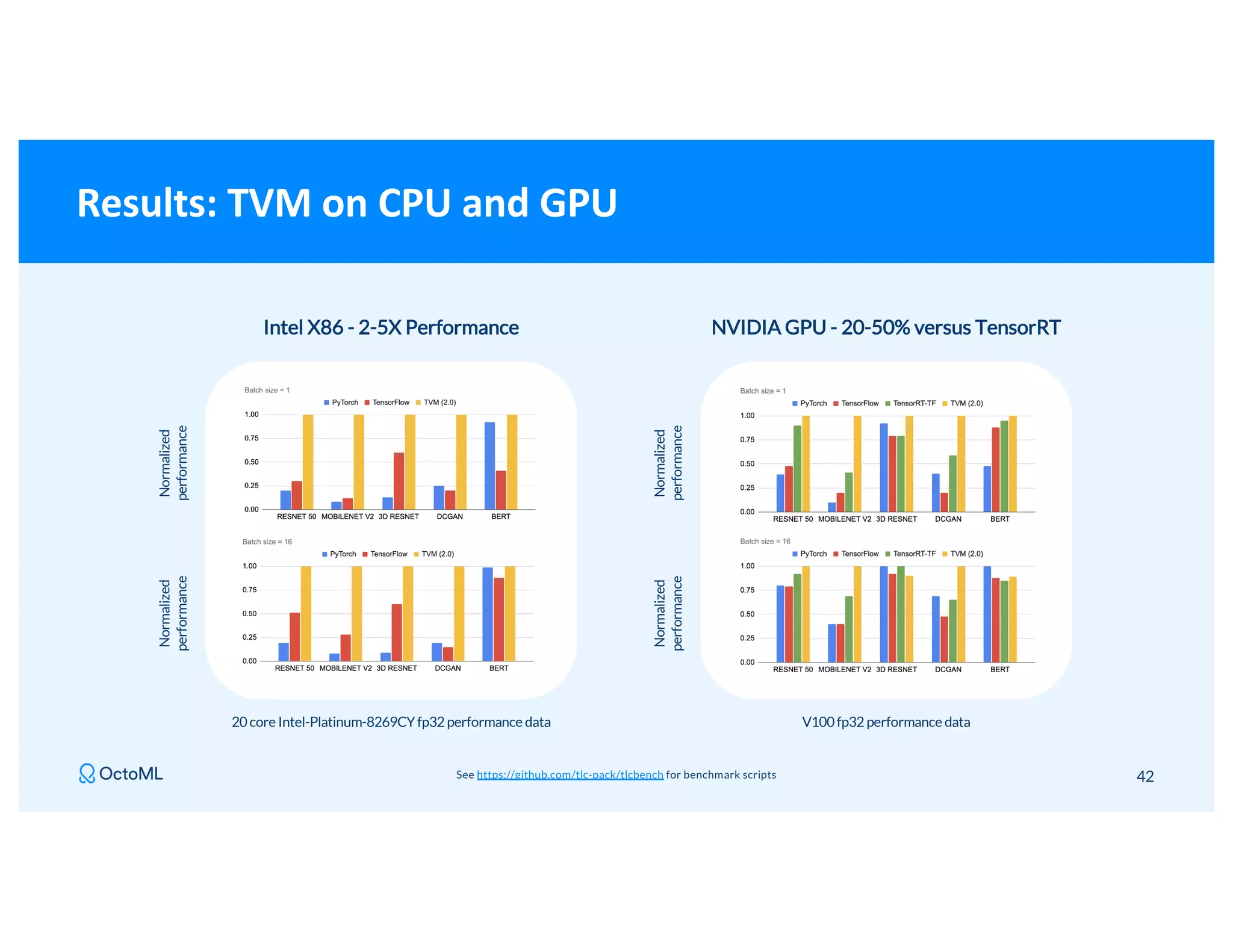
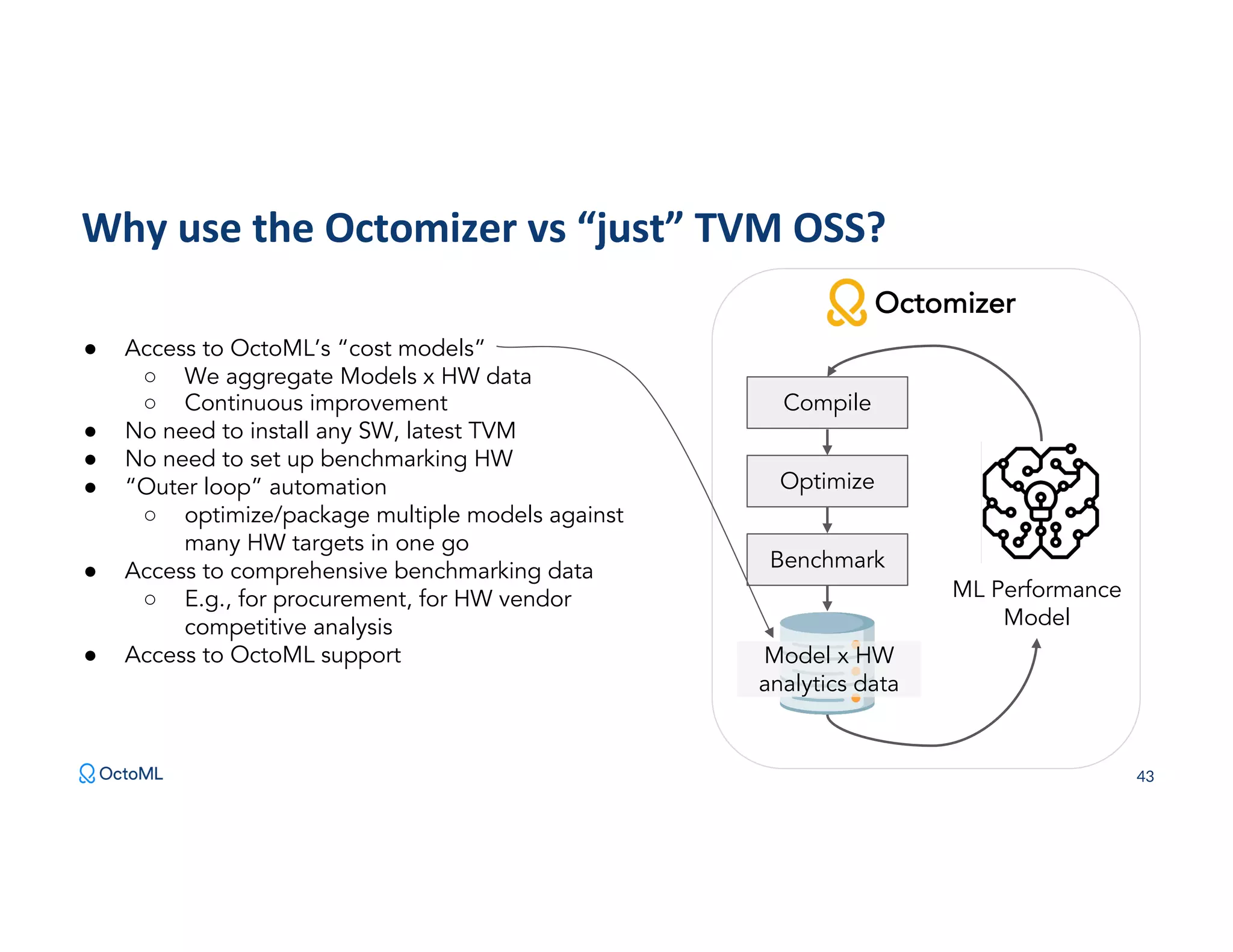








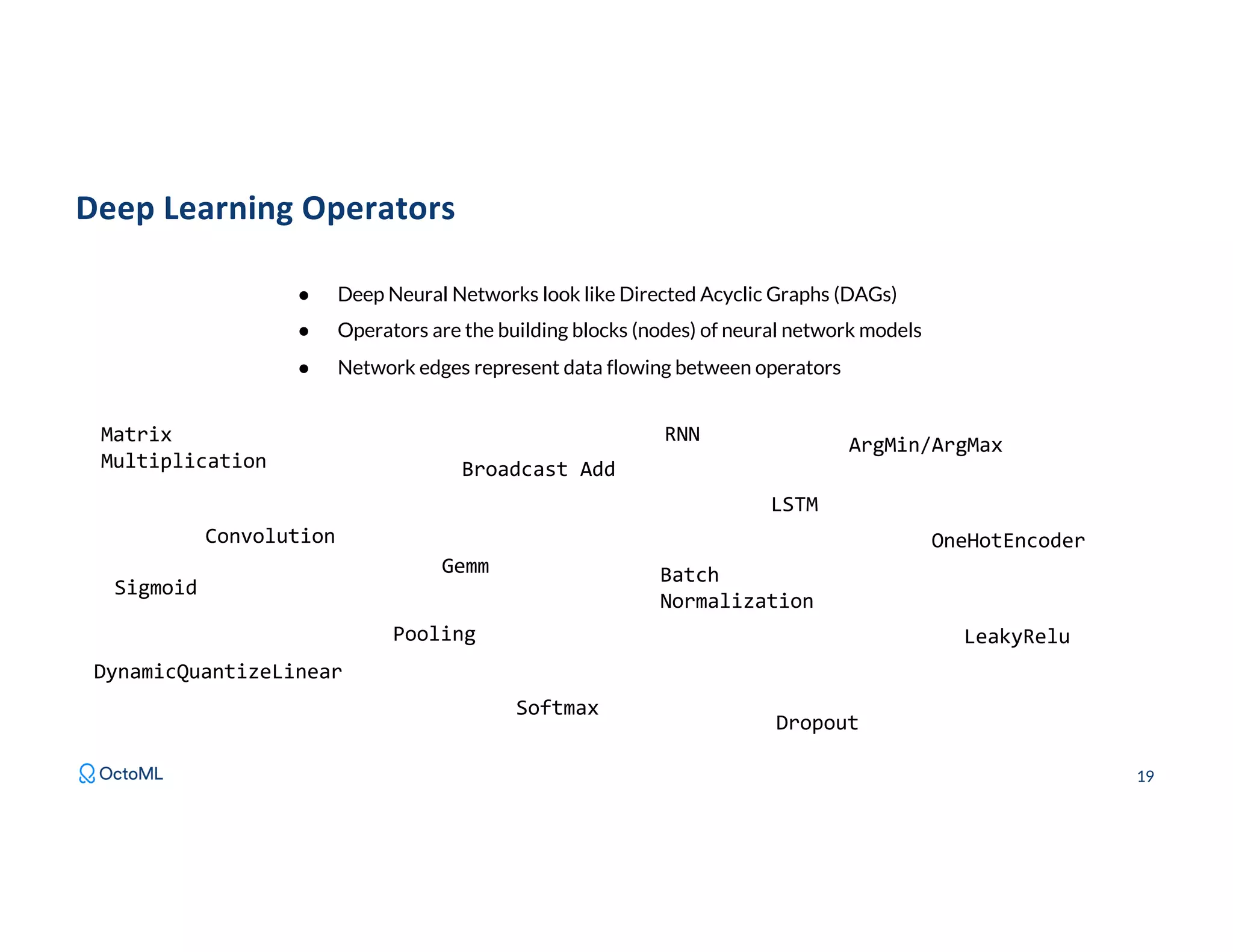
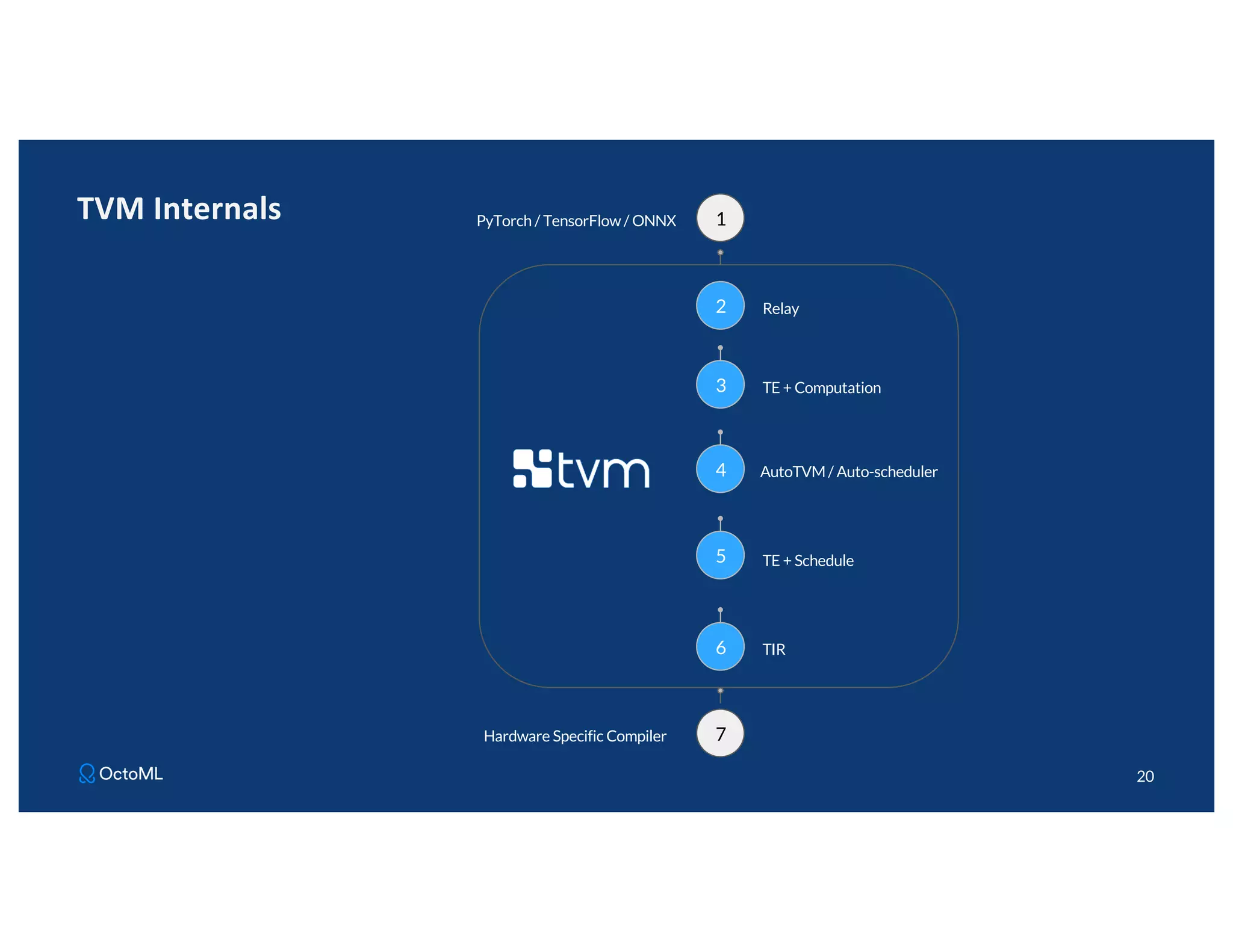
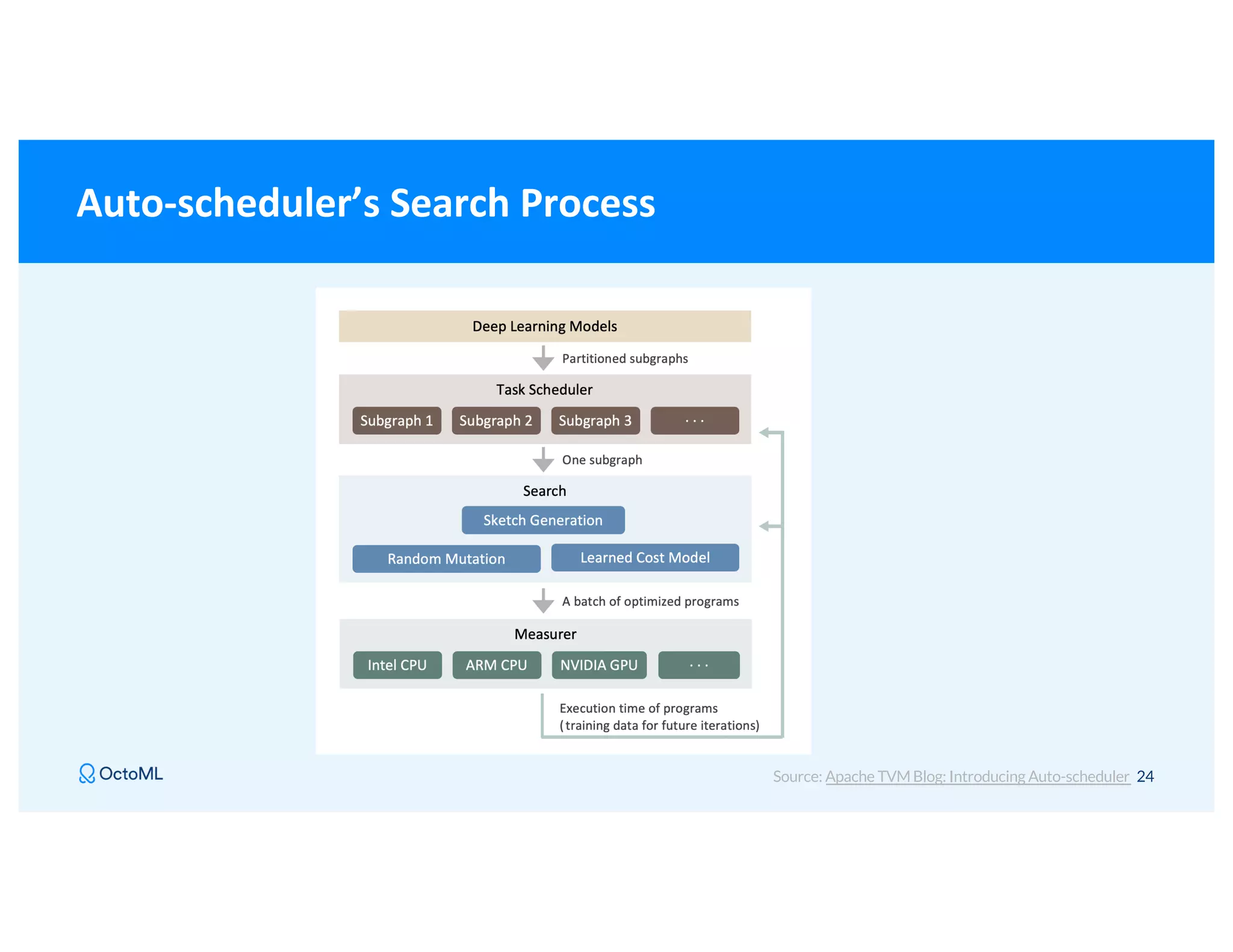
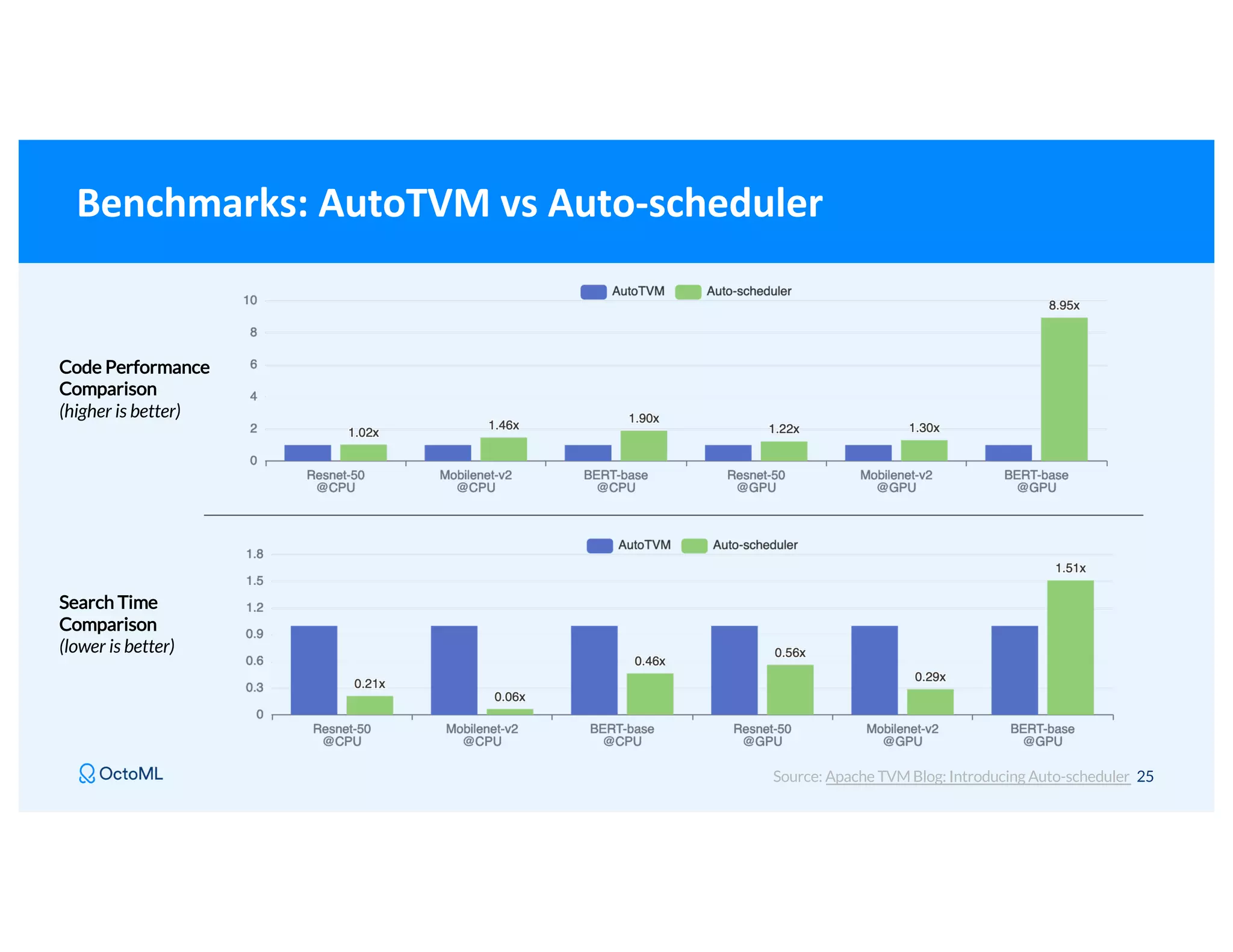
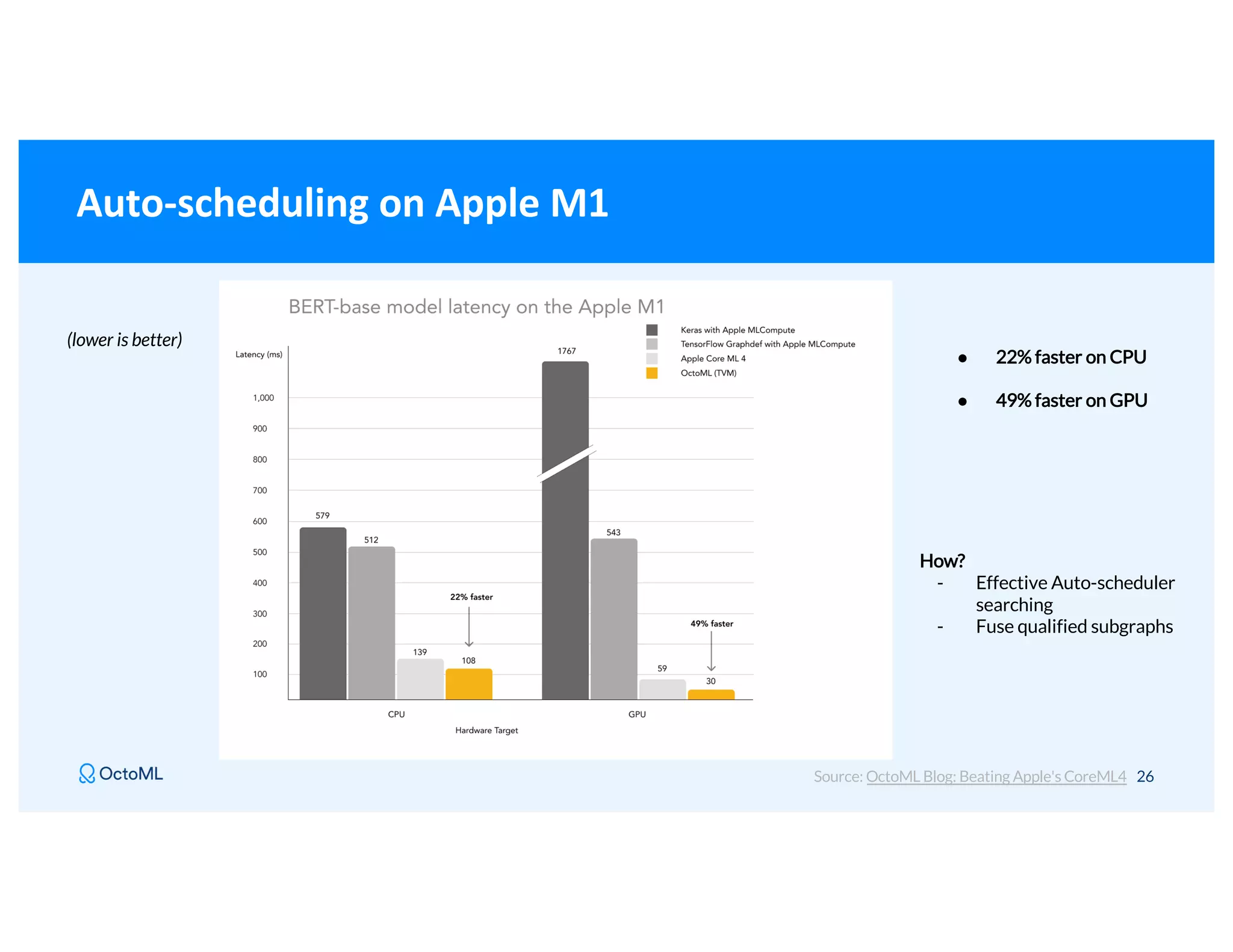
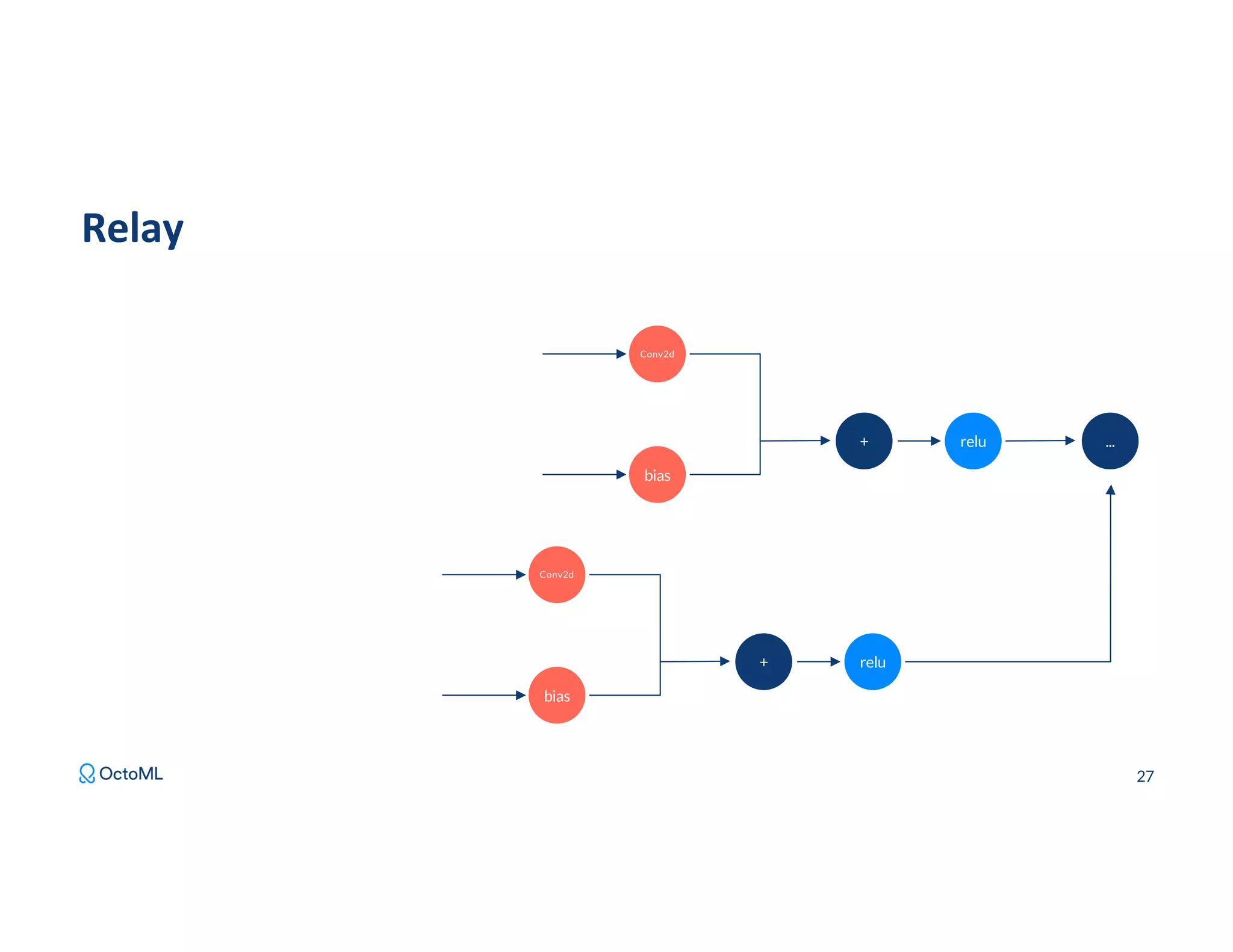
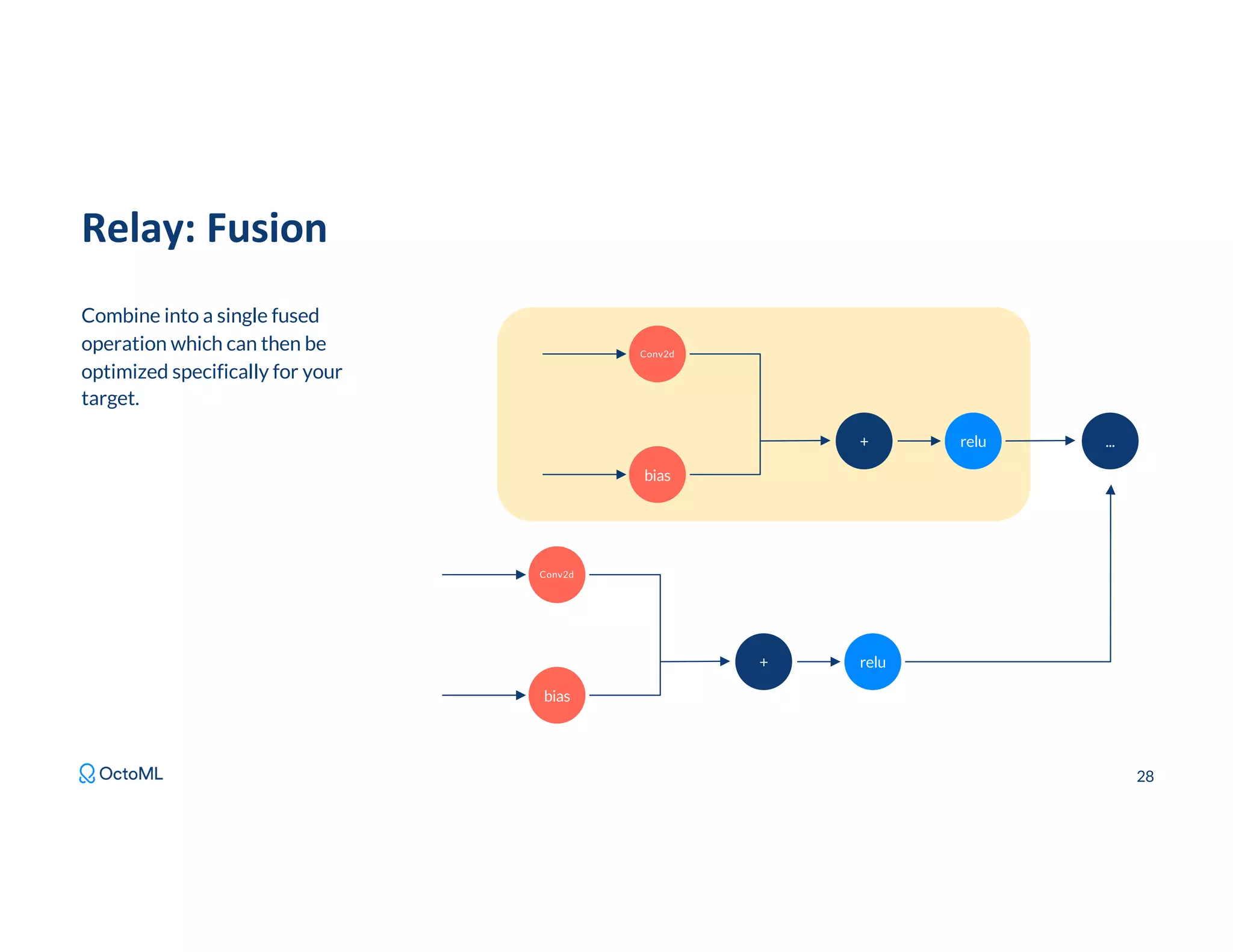
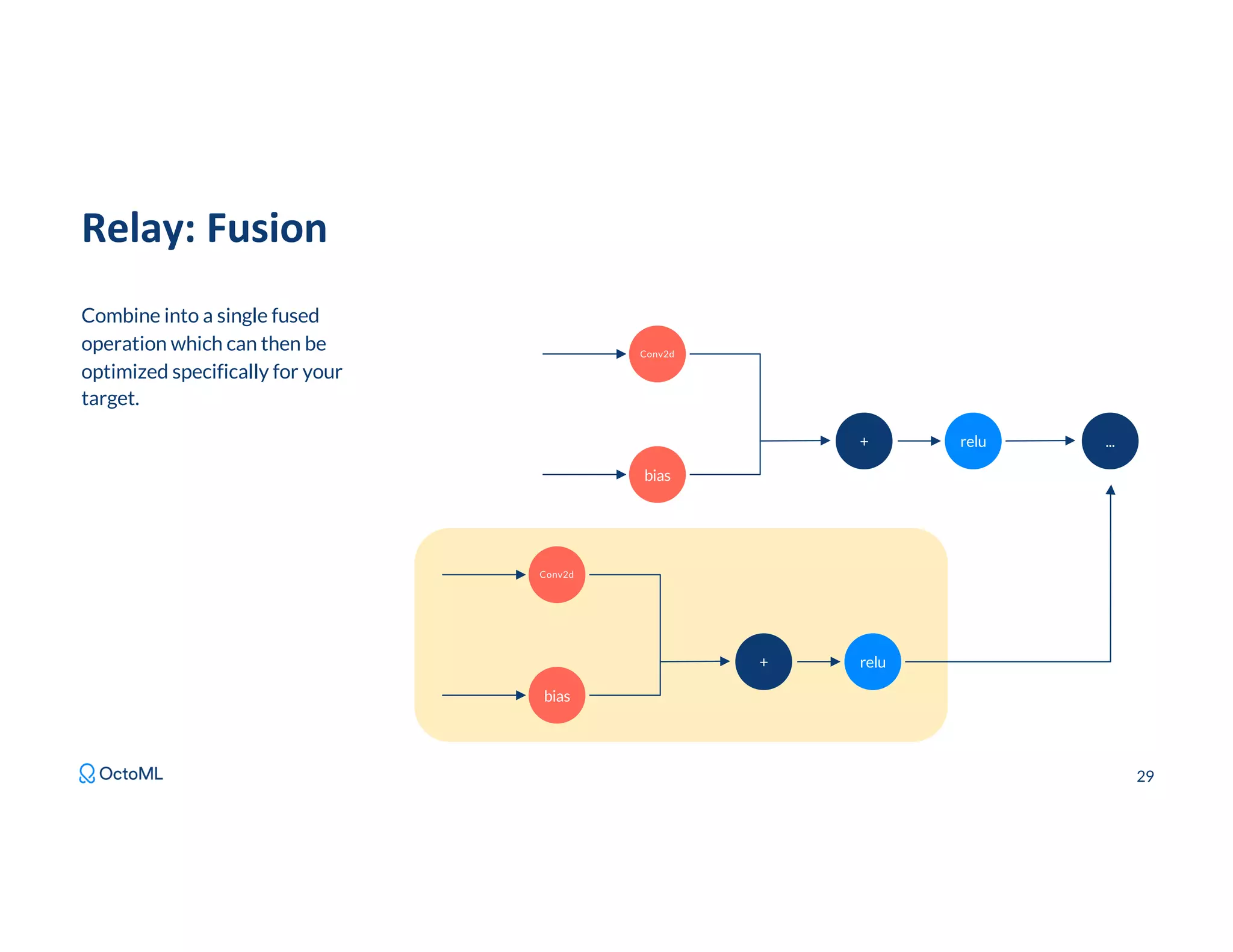
The document discusses Apache TVM, an open-source compiler that optimizes machine learning models for diverse hardware platforms, enhancing performance and efficiency across CPUs, GPUs, and mobile devices. It emphasizes the significance of cross-platform AI compilers and presents TVM's capabilities in executing high-performance tensor programs while suggesting potential cost reductions in cloud inference. Additionally, it covers advancements like the auto-scheduler and features of related frameworks that improve model execution and benchmarking processes.