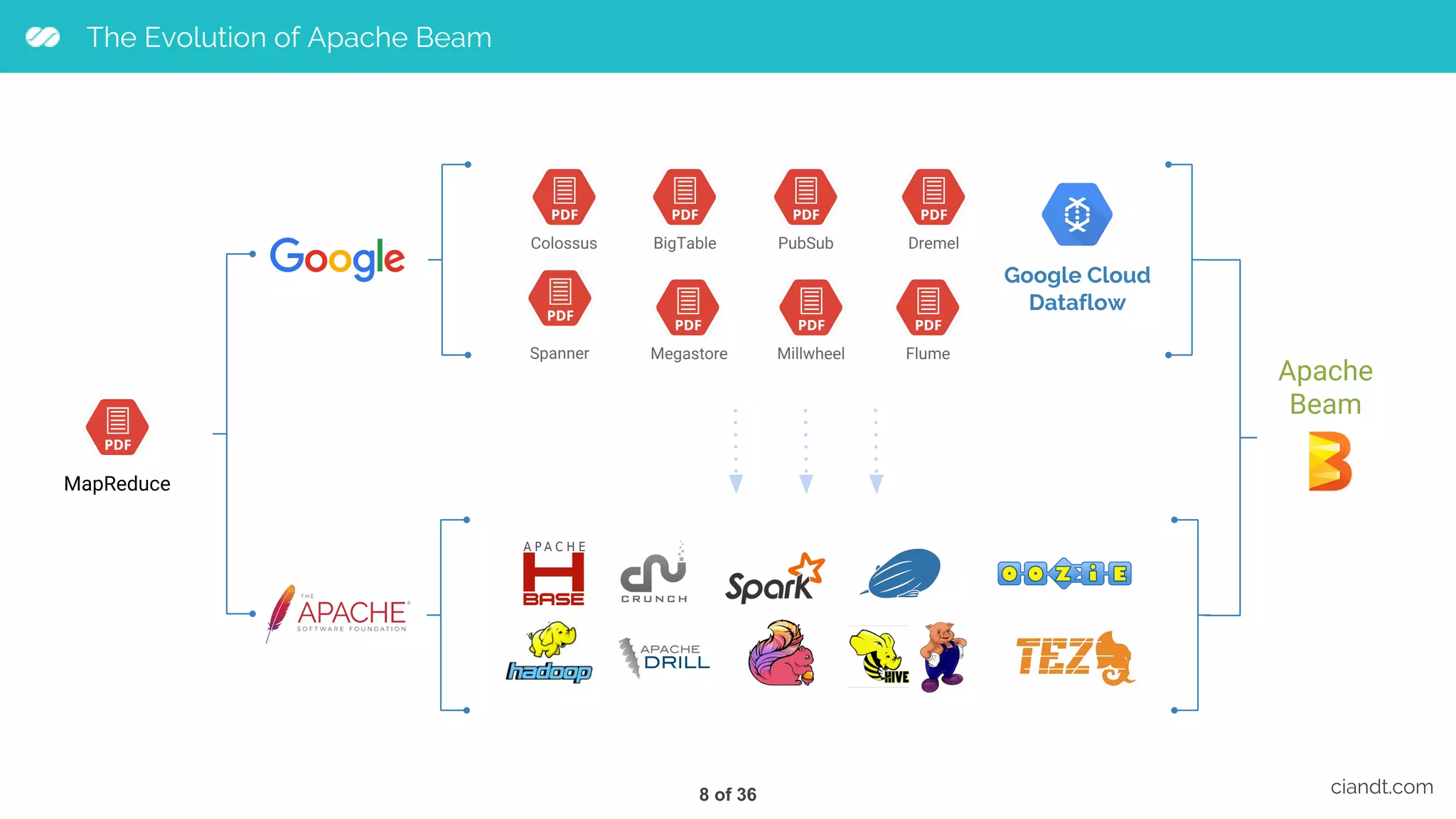
Downloaded 50 times










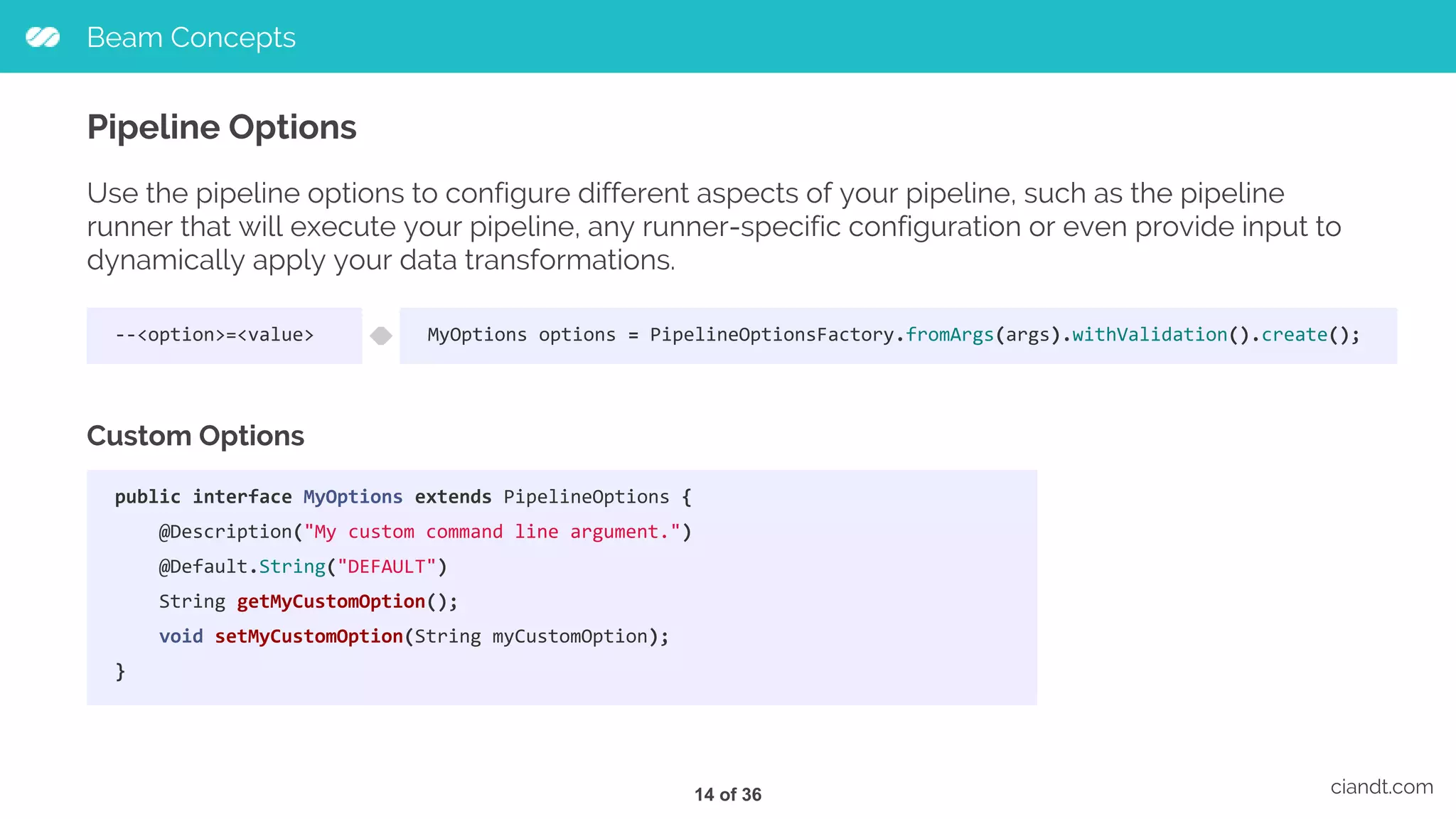
![Beam Concepts ciandt.com PCollections public static void main(String[] args) { // Create the pipeline. PipelineOptions options = PipelineOptionsFactory.fromArgs(args).create(); Pipeline p = Pipeline.create(options); // Create the PCollection 'lines' by applying a 'Read' transform. PCollection<String> lines = p.apply( "ReadMyFile", TextIO.read().from("protocol://path/to/some/inputData.txt")); } The PCollection abstraction represents a potentially distributed, multi-element data set. It is immutable and can be either bounded (size is fixed/known) or unbounded (unlimited size). 11 of 36](https://image.slidesharecdn.com/tdc2017-saopaulo-trilhabigdata-comoconstruirumpipelinedeetlusandoapachebeamnogoogleclouddataflow-170720225243/75/How-to-build-an-ETL-pipeline-with-Apache-Beam-on-Google-Cloud-Dataflow-12-2048.jpg)
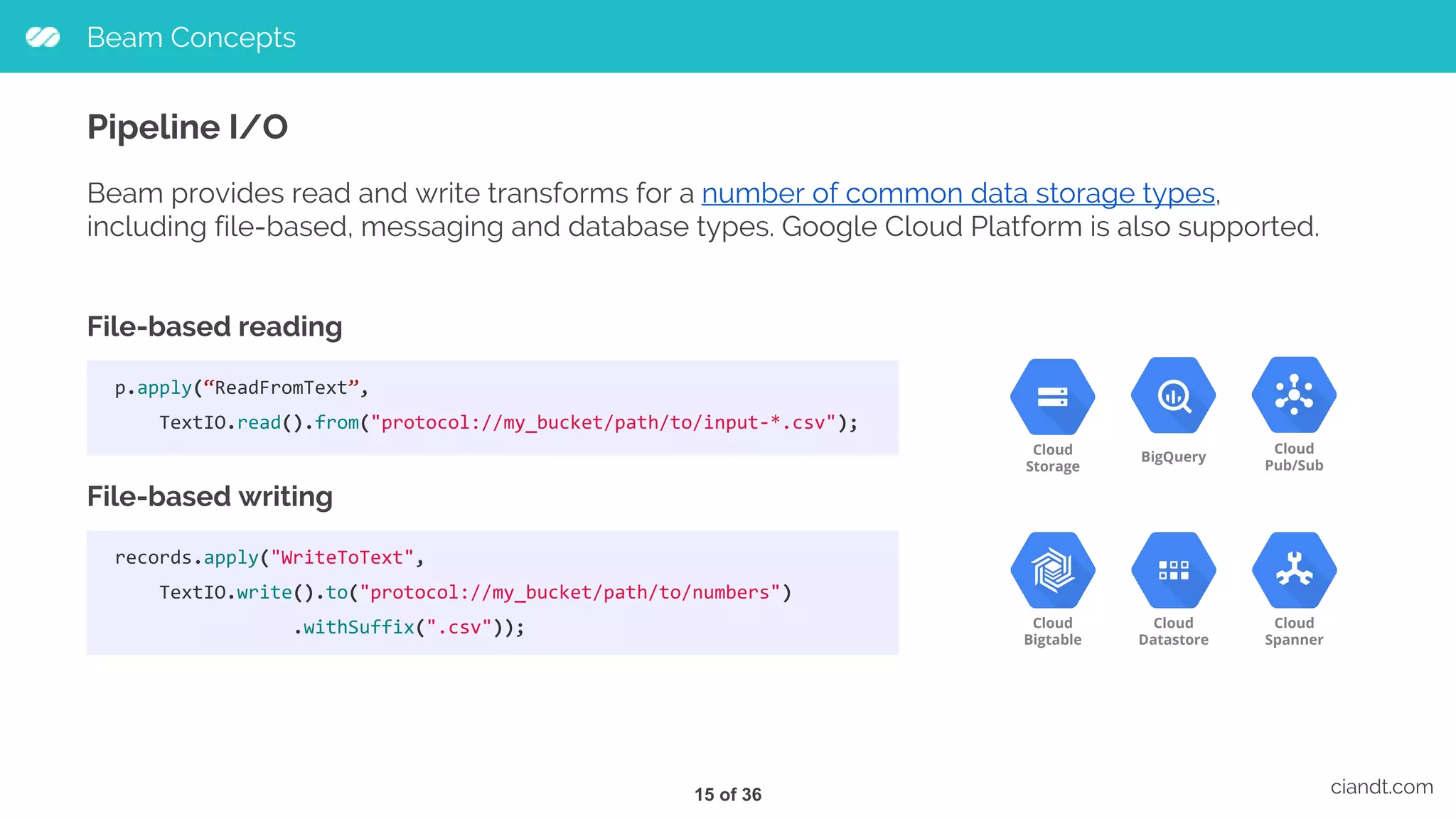
![Beam Concepts ciandt.com PTransforms Transforms are the operations in your pipeline. A transform takes a PCollection (or more than one PCollection) as input, performs an operation that you specify on each element in that collection, and produces a new output PCollection. [Output PCollection] = [Input PCollection].apply([Transform]) The Beam SDK provides the following core transforms: ● ParDo ● GroupByKey ● Combine ● Flatten and Partition [Output PCollection] = [Input PCollection].apply([First Transform]) .apply([Second Transform]) .apply([Third Transform]) 12 of 36](https://image.slidesharecdn.com/tdc2017-saopaulo-trilhabigdata-comoconstruirumpipelinedeetlusandoapachebeamnogoogleclouddataflow-170720225243/75/How-to-build-an-ETL-pipeline-with-Apache-Beam-on-Google-Cloud-Dataflow-13-2048.jpg)
![Beam Concepts - Core PTransforms ParDo // Apply a ParDo to the PCollection PCollection<Integer> wordLengths = words.apply( ParDo .of(new ComputeWordLengthFn())); // Implementation of a DoFn static class ComputeWordLengthFn extends DoFn<String, Integer> { @ProcessElement public void processElement(ProcessContext c) { // Get the input element String word = c.element(); // Emit the output element. c.output(word.length()); } } ciandt.com Combine/Flatten // Sum.SumIntegerFn() combines the elements in the input PCollection. PCollection<Integer> pc = ...; PCollection<Integer> sum = pc.apply( Combine.globally(new Sum.SumIntegerFn())); // Flatten a PCollectionList of PCollection objects of a given type. PCollection<String> pc1 = ...; PCollection<String> pc2 = ...; PCollection<String> pc3 = ...; PCollectionList<String> collections = PCollectionList.of(pc1).and(pc2).and(pc3); PCollection<String> merged = collections.apply(Flatten.<String>pCollections( )); GroupByKey cat, [1,5,9] dog, [5,2] and, [1,2,6] jump, [3] tree, [2] ... cat, 1 dog, 5 and, 1 jump, 3 tree, 2 cat, 5 dog, 2 and, 2 cat, 9 and, 6 ... ciandt.com13 of 36](https://image.slidesharecdn.com/tdc2017-saopaulo-trilhabigdata-comoconstruirumpipelinedeetlusandoapachebeamnogoogleclouddataflow-170720225243/75/How-to-build-an-ETL-pipeline-with-Apache-Beam-on-Google-Cloud-Dataflow-14-2048.jpg)





![<Insert here an image> Logo Dataflow fully automates management of required processing resources. Auto-scaling means optimum throughput and better overall price-to-performance. Monitor your jobs near real-time. Fully managed, no-ops environment ciandt.com Integrates with Cloud Storage, Cloud Pub/Sub, Cloud Datastore, Cloud Bigtable, and BigQuery for seamless data processing. And can be extended to interact with others sources and sinks like Apache Kafka / HDFS. Integrated with GCP products [text] Developers wishing to extend the Dataflow programming model can fork and or submit pull requests on the Apache Beam SDKs. Pipelines can also run on alternate runtimes like Spark and Flink. Based on Apache Beam’s SDK <Insert here an image> Cloud Dataflow provides built-in support for fault-tolerant execution that is consistent and correct regardless of data size, cluster size, processing pattern or pipeline complexity. Reliable & Consistent Processing 30 of 36](https://image.slidesharecdn.com/tdc2017-saopaulo-trilhabigdata-comoconstruirumpipelinedeetlusandoapachebeamnogoogleclouddataflow-170720225243/75/How-to-build-an-ETL-pipeline-with-Apache-Beam-on-Google-Cloud-Dataflow-31-2048.jpg)
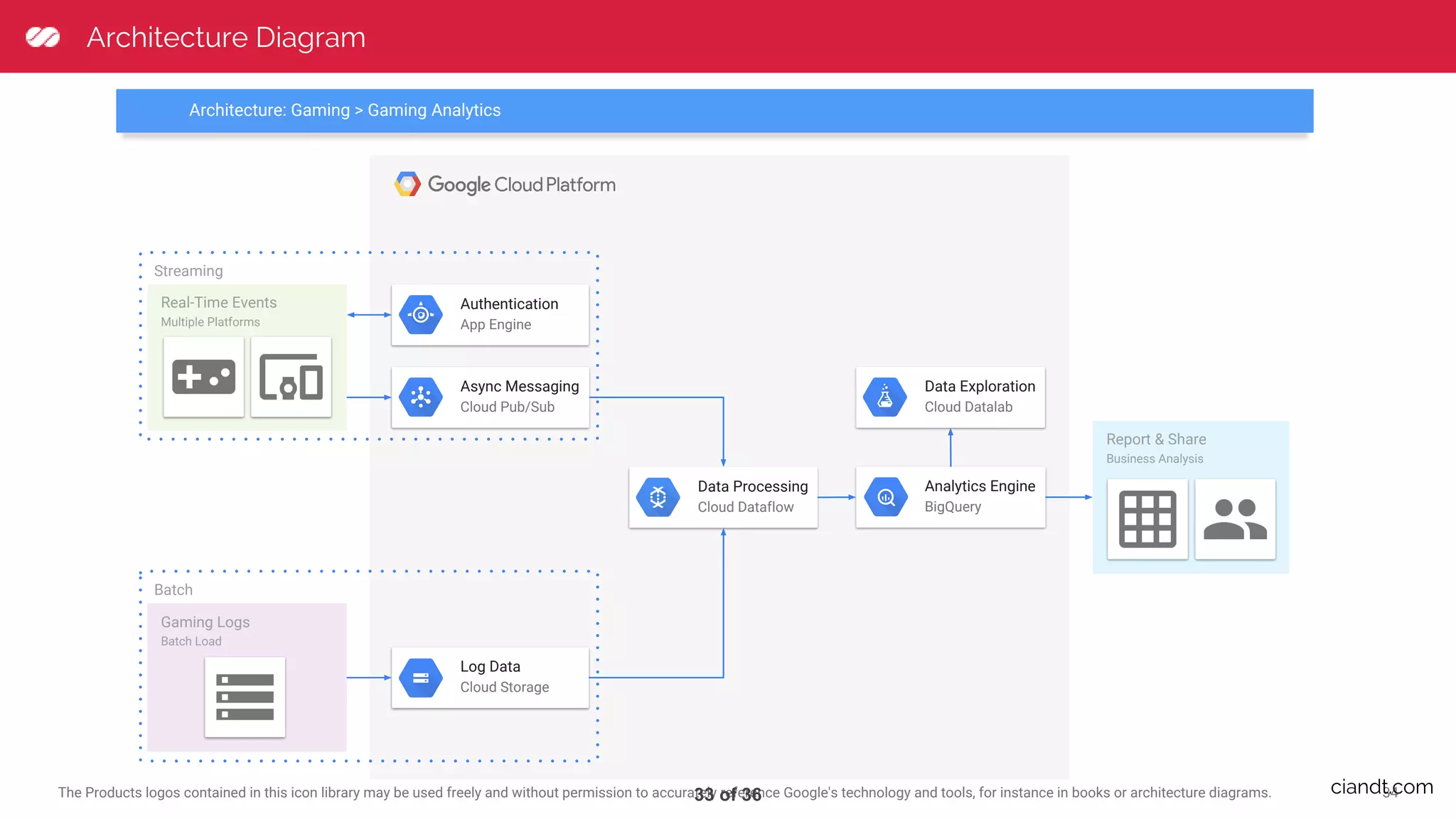
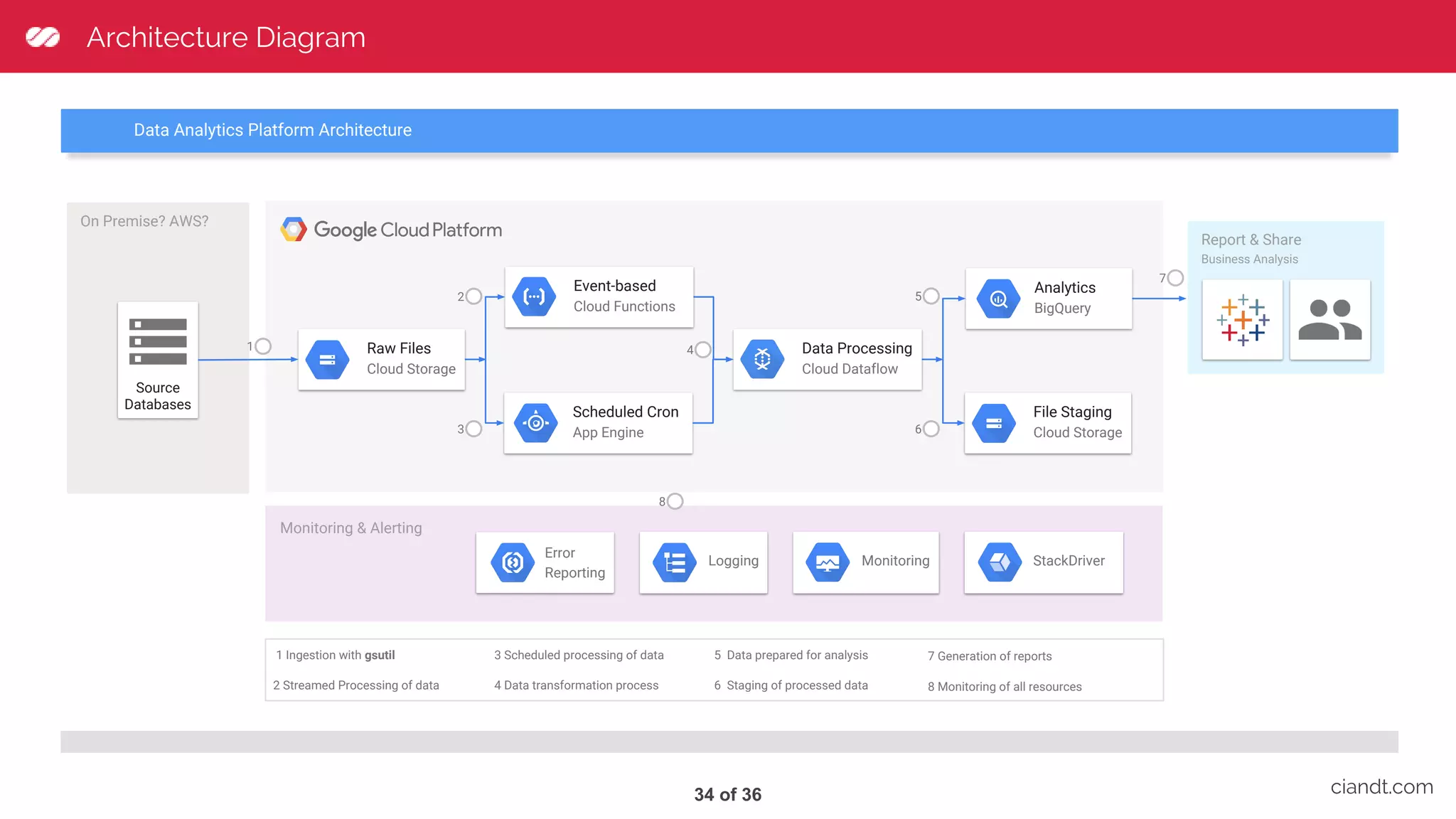



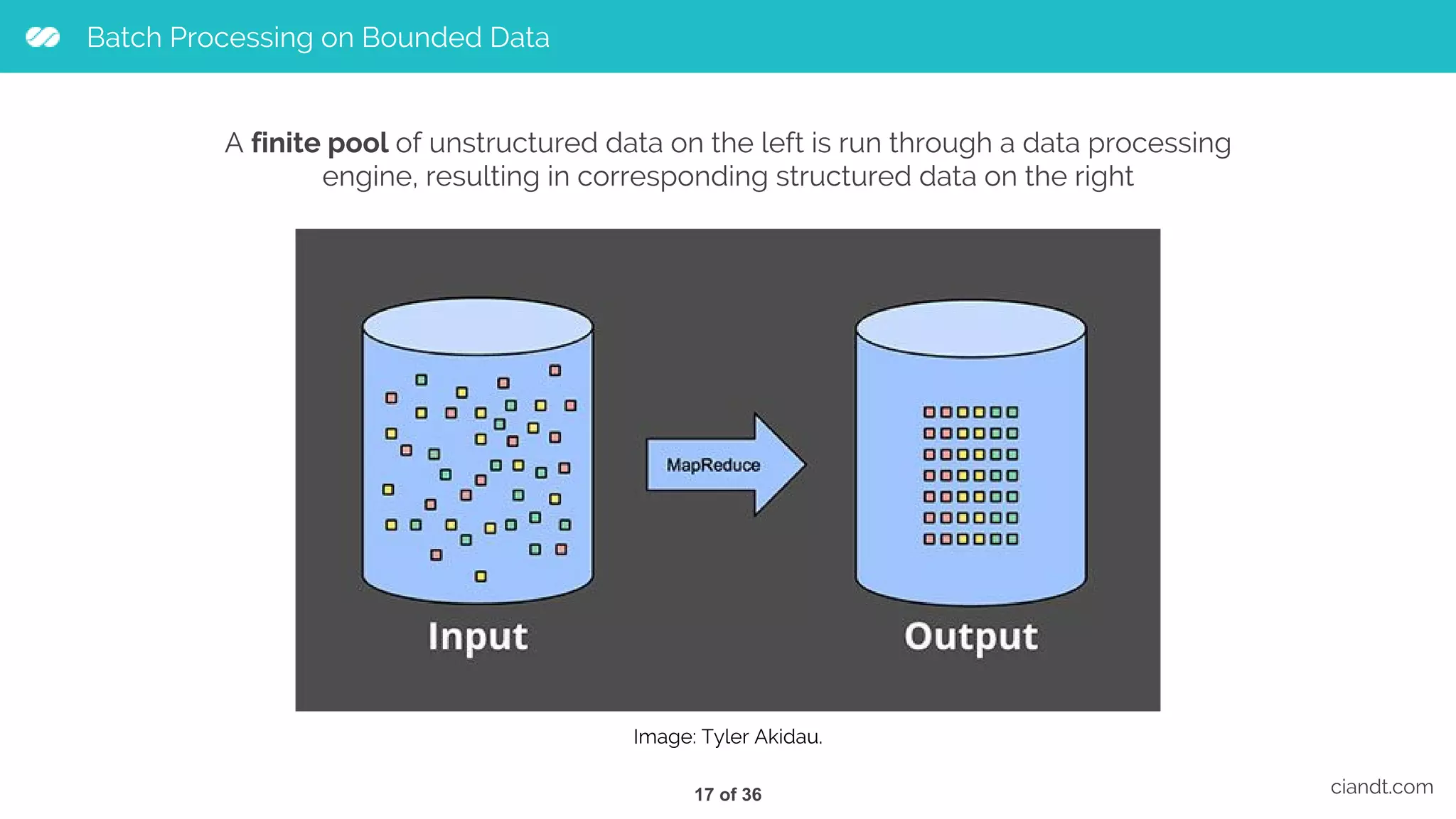
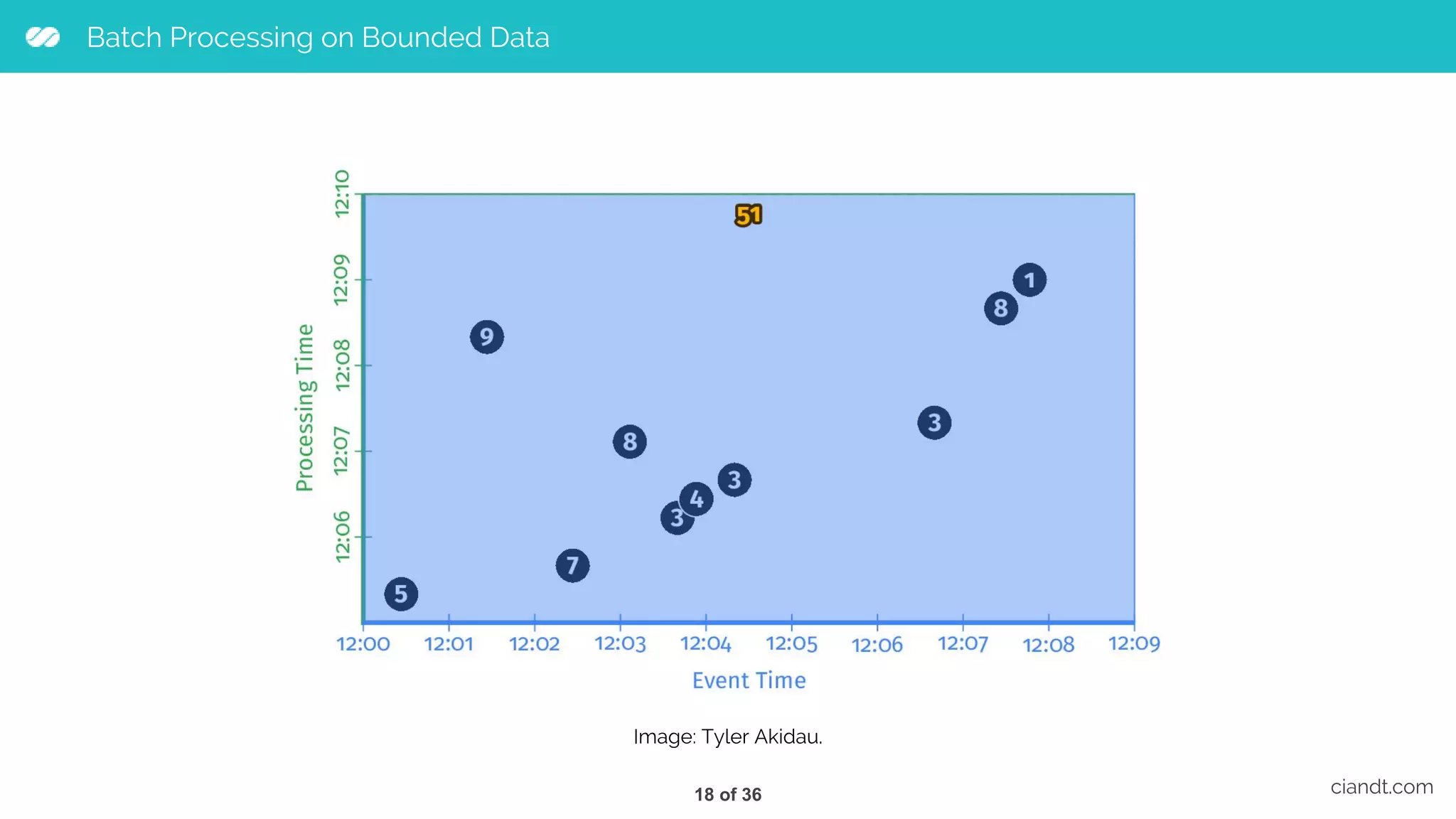
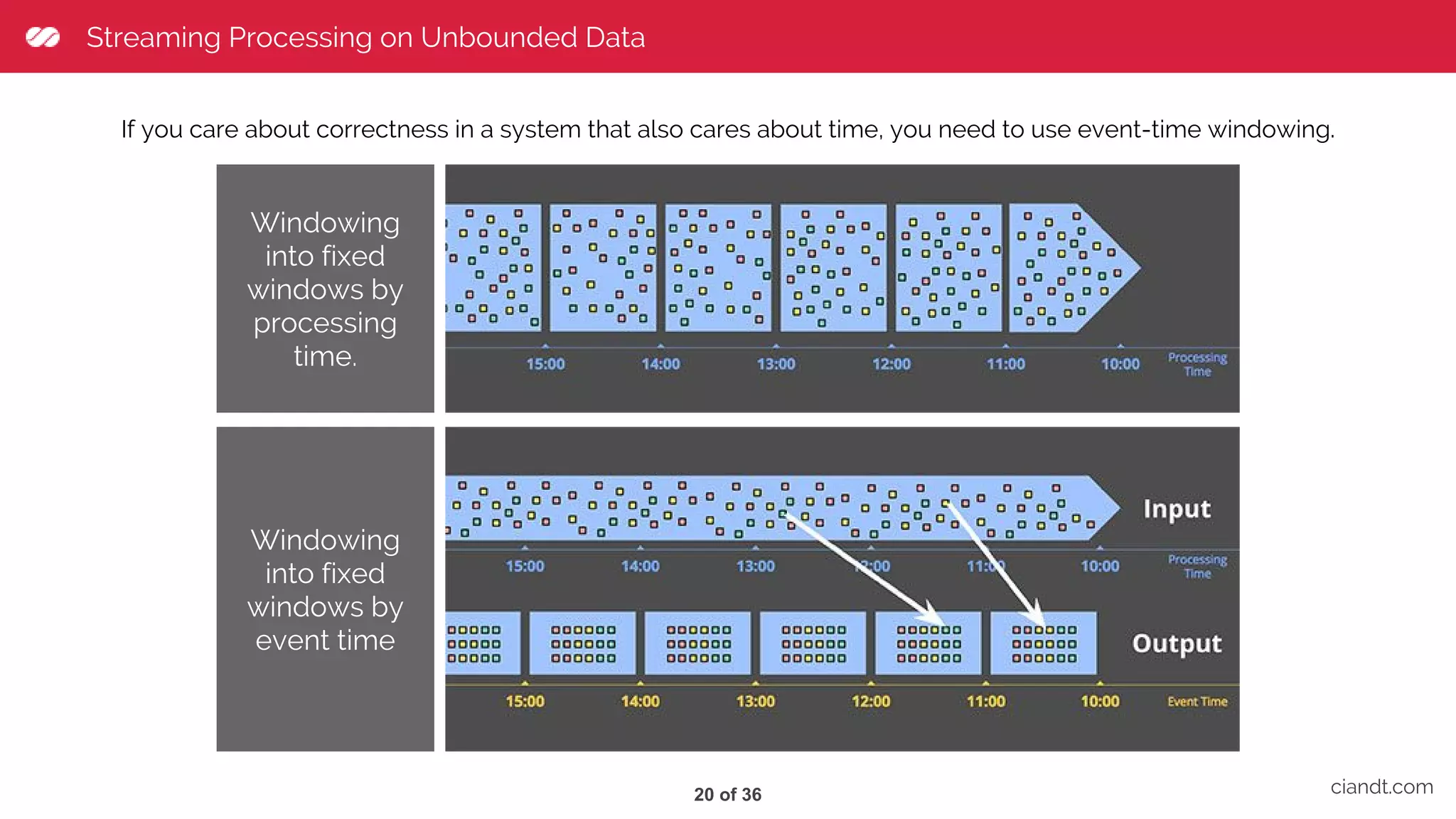
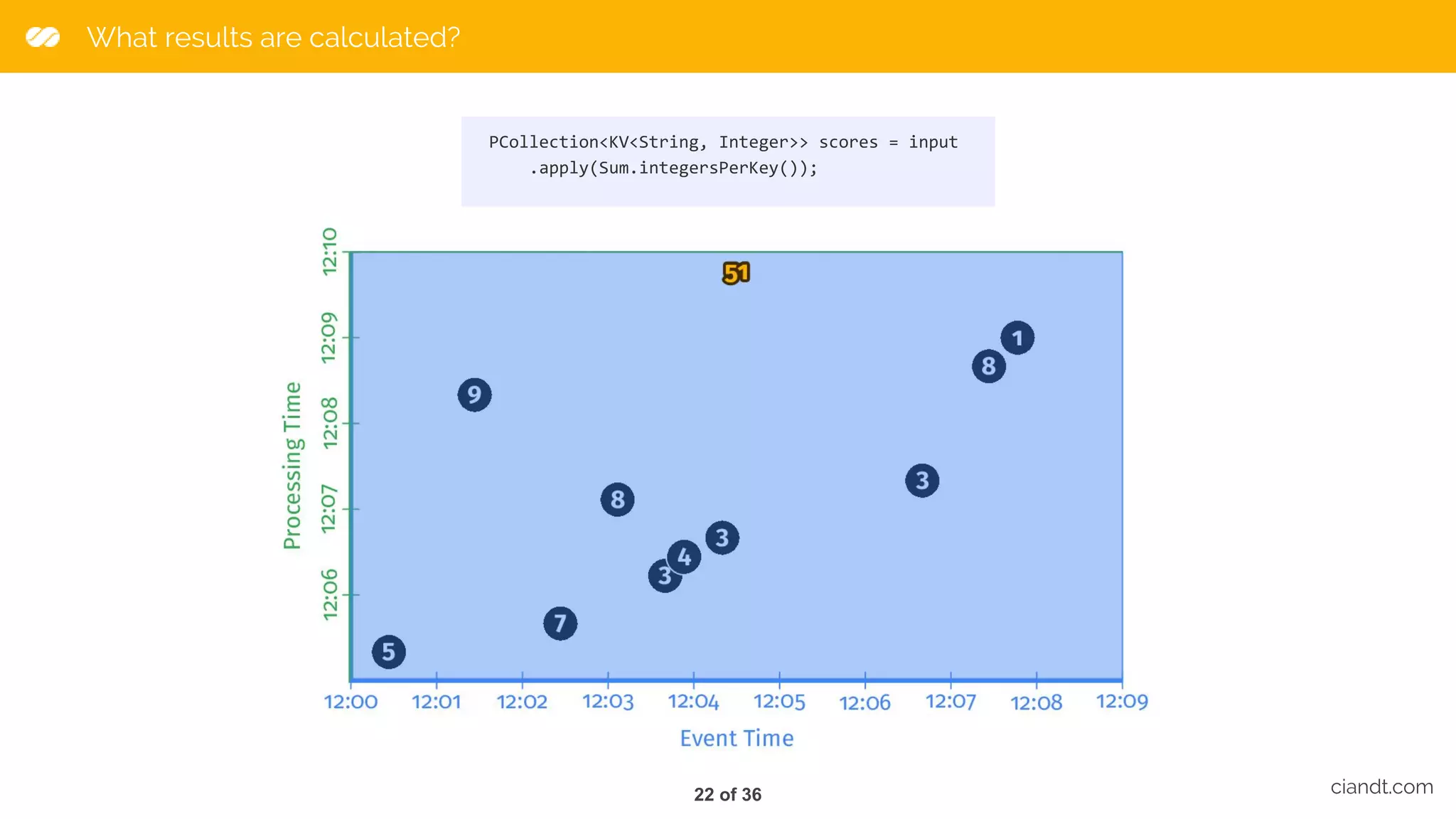
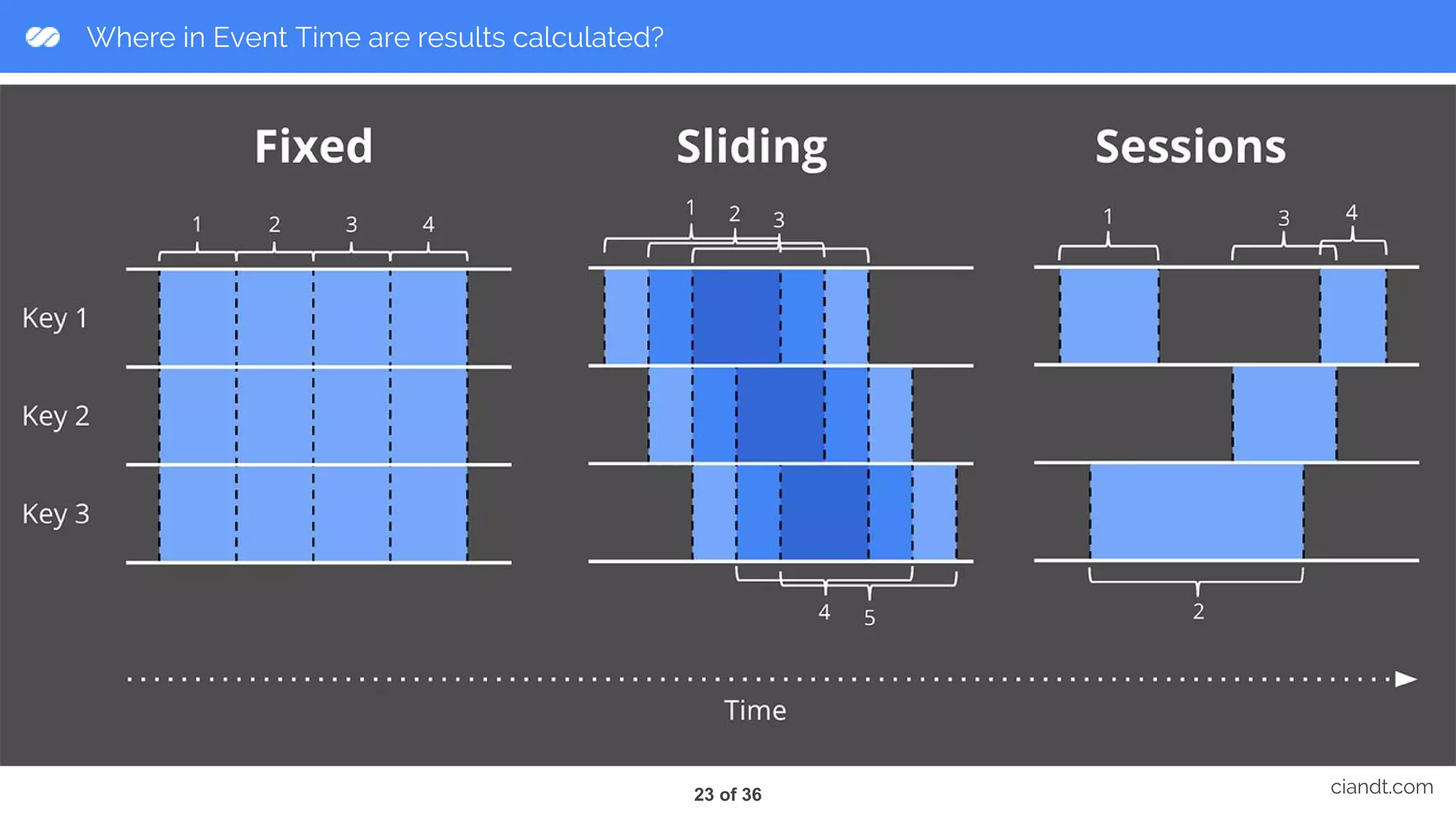
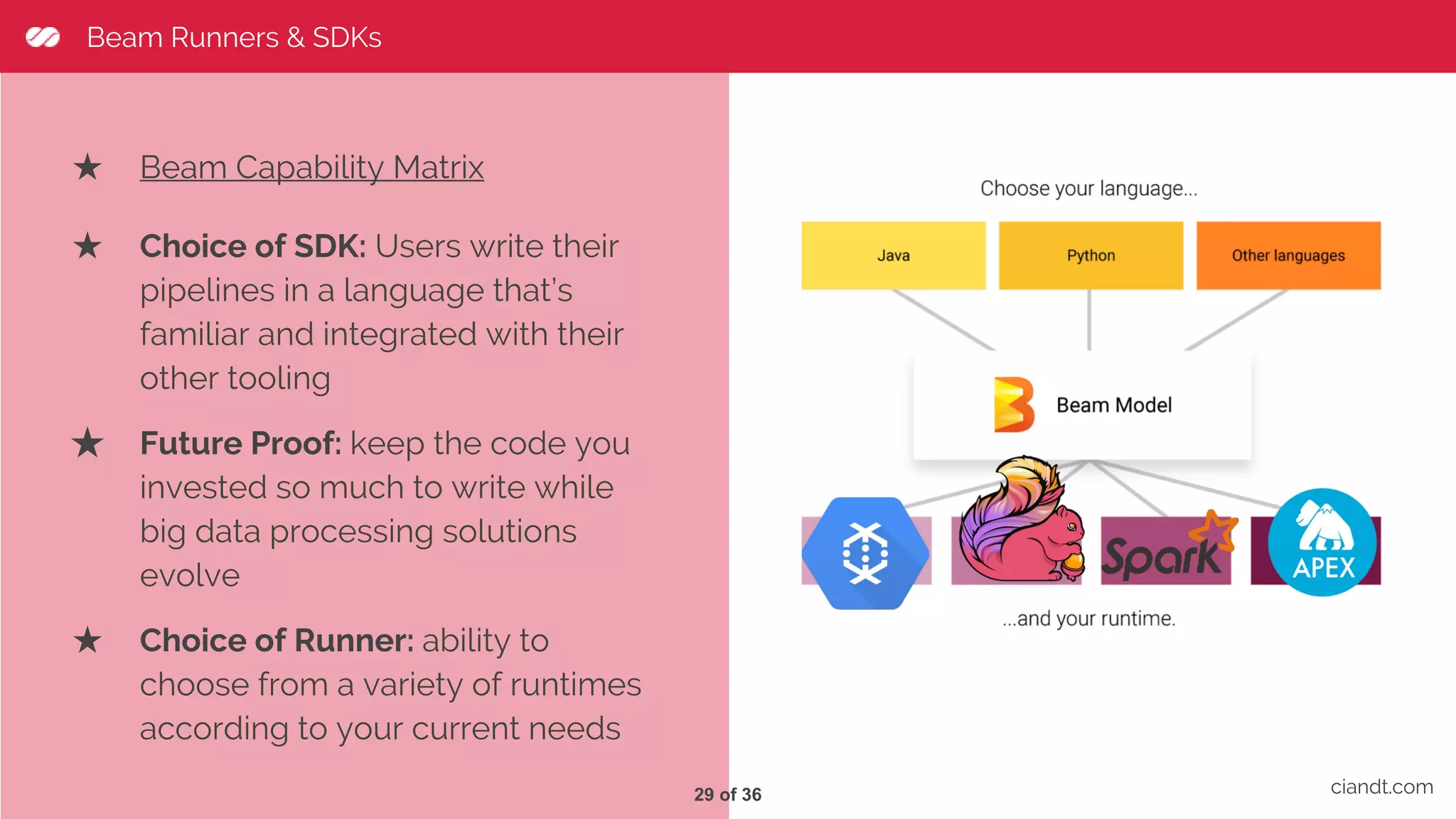
This document provides an overview of building an ETL pipeline with Apache Beam on Google Cloud Dataflow. It introduces key Beam concepts like PCollections, PTransforms, and windowing. It explains how Beam can be used for both batch and streaming ETL workflows on bounded and unbounded data. The document also discusses how Cloud Dataflow is a fully managed Apache Beam runner that integrates with other Google Cloud services and provides reliable, auto-scaled processing. Sample architecture diagrams demonstrate how Cloud Dataflow fits into data analytics platforms.