Downloaded 23 times



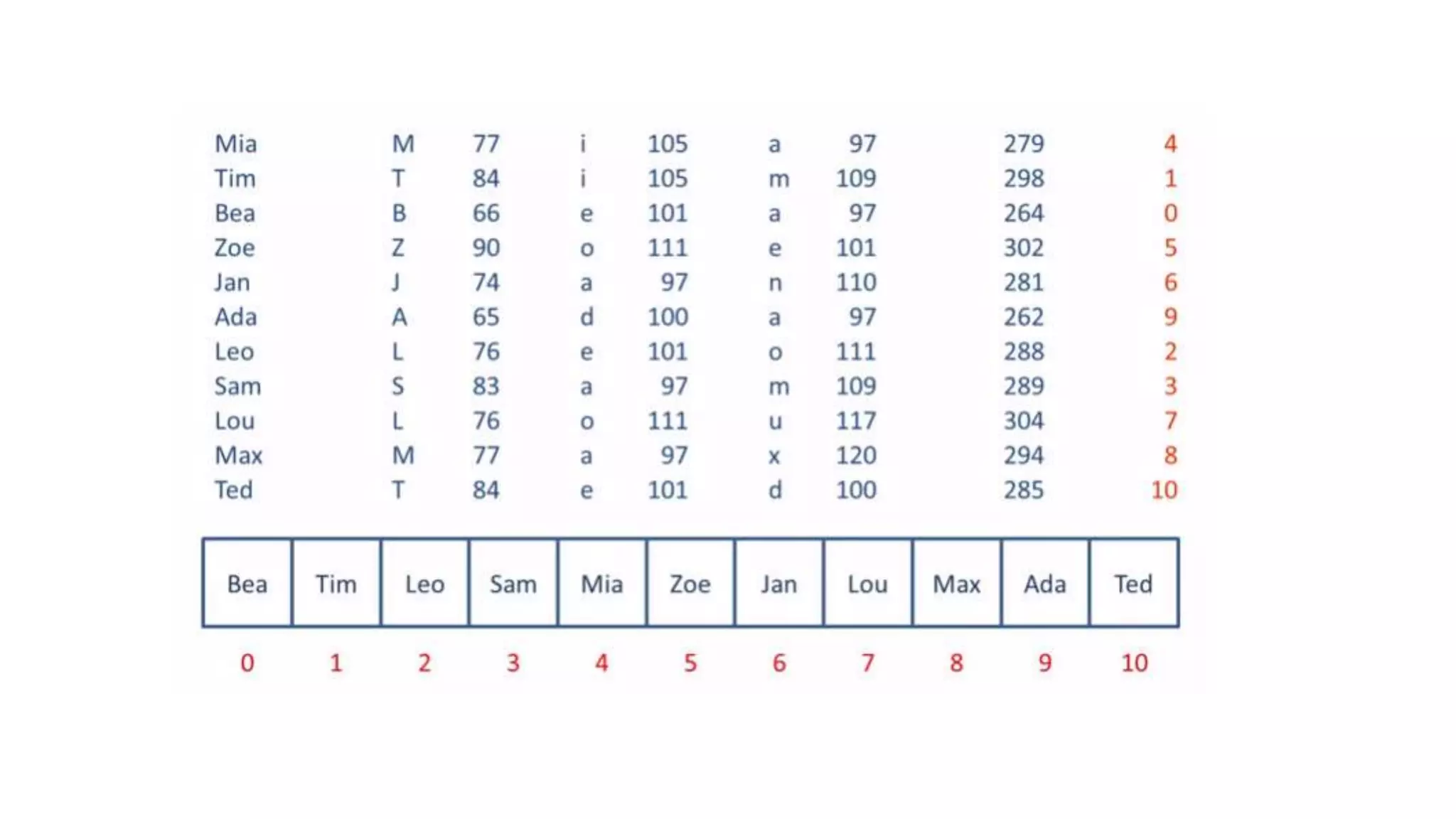
![Hashing Function • Calculates the key for address assignment • Key = position Hasher (Type entry) • position StoringPosition = HashTable[Key] • Here the Hasher is “to add the ASCII values of Each letter and then take modulo 11” • Folding: • A method that divides data into chunks for processing in a Hasher](https://image.slidesharecdn.com/hashingalgorithmsanditsuses-190115162654/75/Hashing-algorithms-and-its-uses-4-2048.jpg)



![Data Searching and Retrieval • The data that we want to search uses the same Hash Function • After the Hasher calculates the Key, it is given directly to the table Variable and that position has the data • Search is usually O(n) for linear search and O(log(n)) for binary search but this method makes the search operation reduced to O(1) • O(1) means that we calculated the key in a fixed time process and the we go to the Array[key] to retrieve data using fixed time again • In case of chaining, we traverse on the node to reach our data so that makes it an O(n), still faster than complete search strategy.](https://image.slidesharecdn.com/hashingalgorithmsanditsuses-190115162654/75/Hashing-algorithms-and-its-uses-9-2048.jpg)
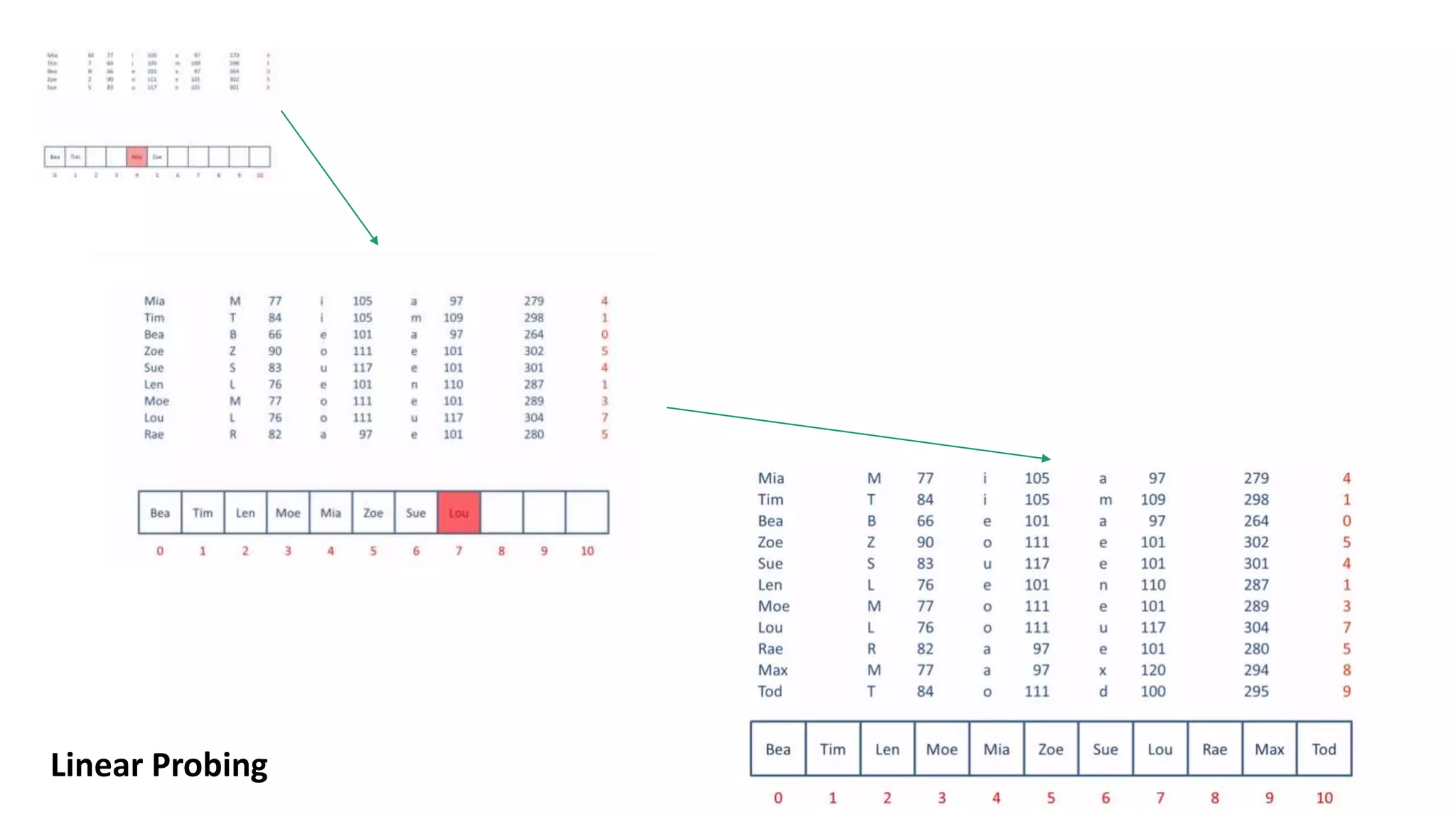
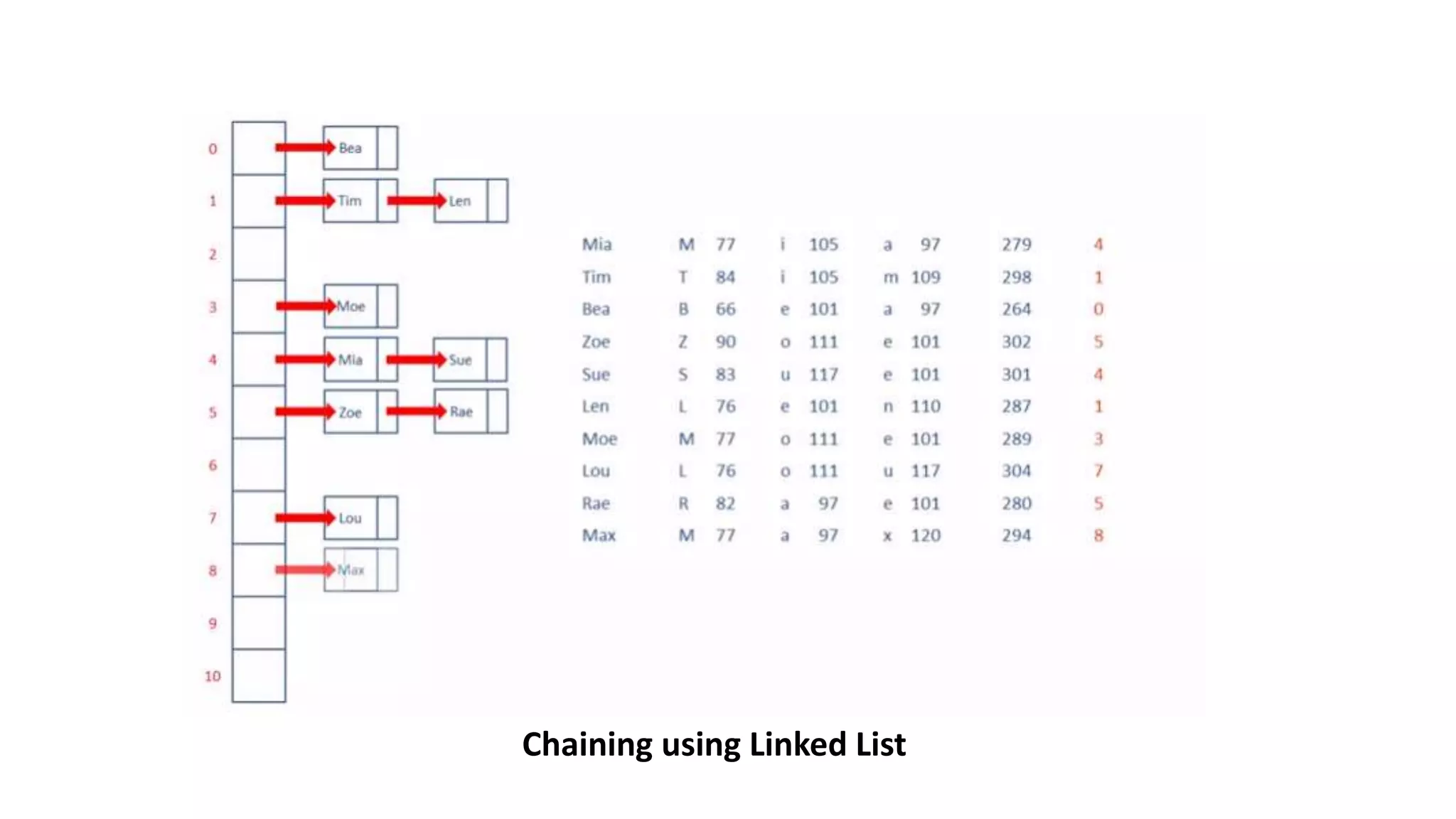



Hashing algorithms are used to access data in hash tables through a hash function that converts data into a hash value or key. This key is used to determine the position of data in the hash table, allowing for fast lookup. Collisions can occur if different data hashes to the same key, and are resolved through techniques like open addressing, chaining, or rehashing. Hashing provides efficient indexing and retrieval of data in many applications like databases, compilers, and blockchain.