Download as PDF, PPTX













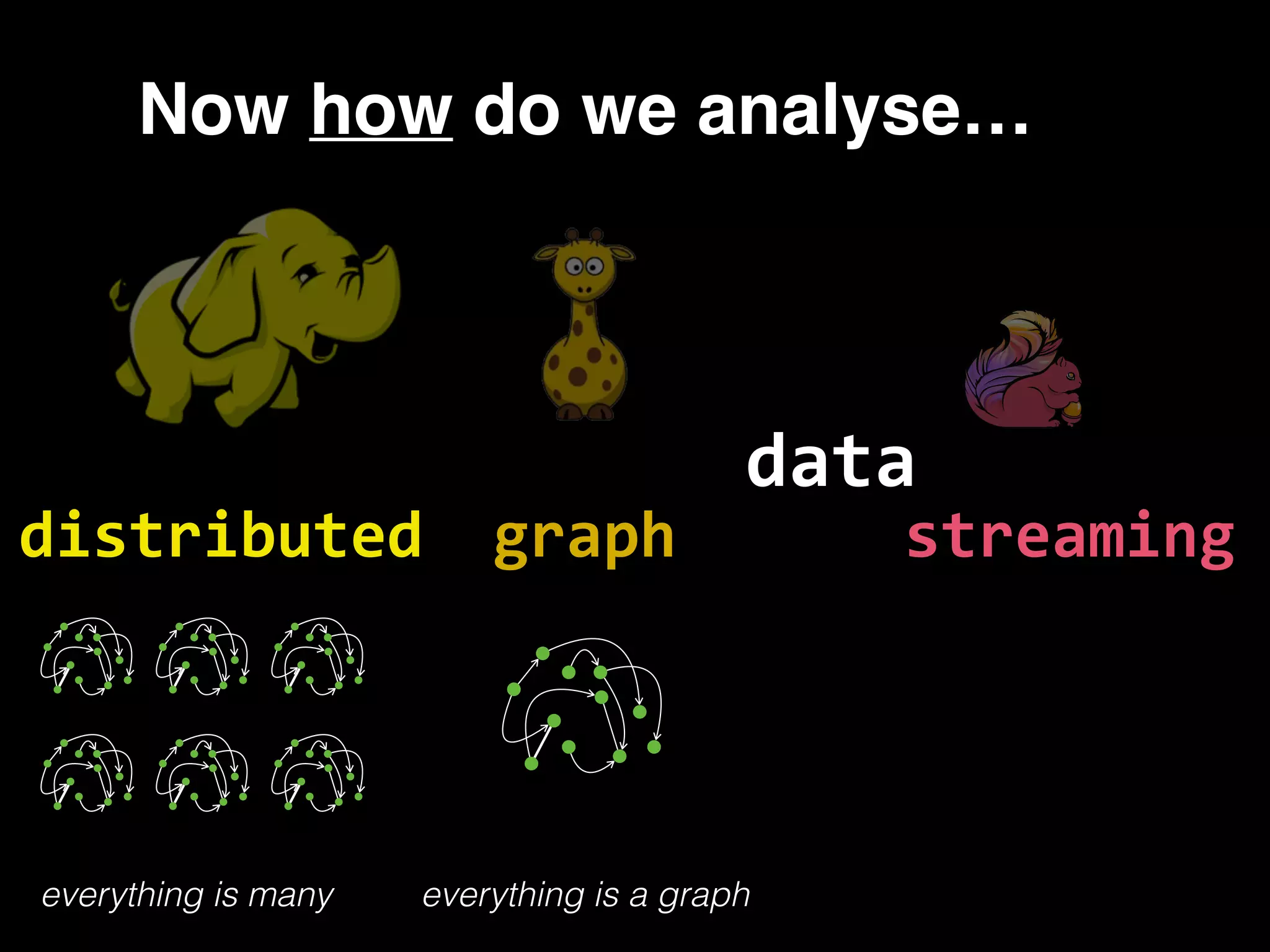
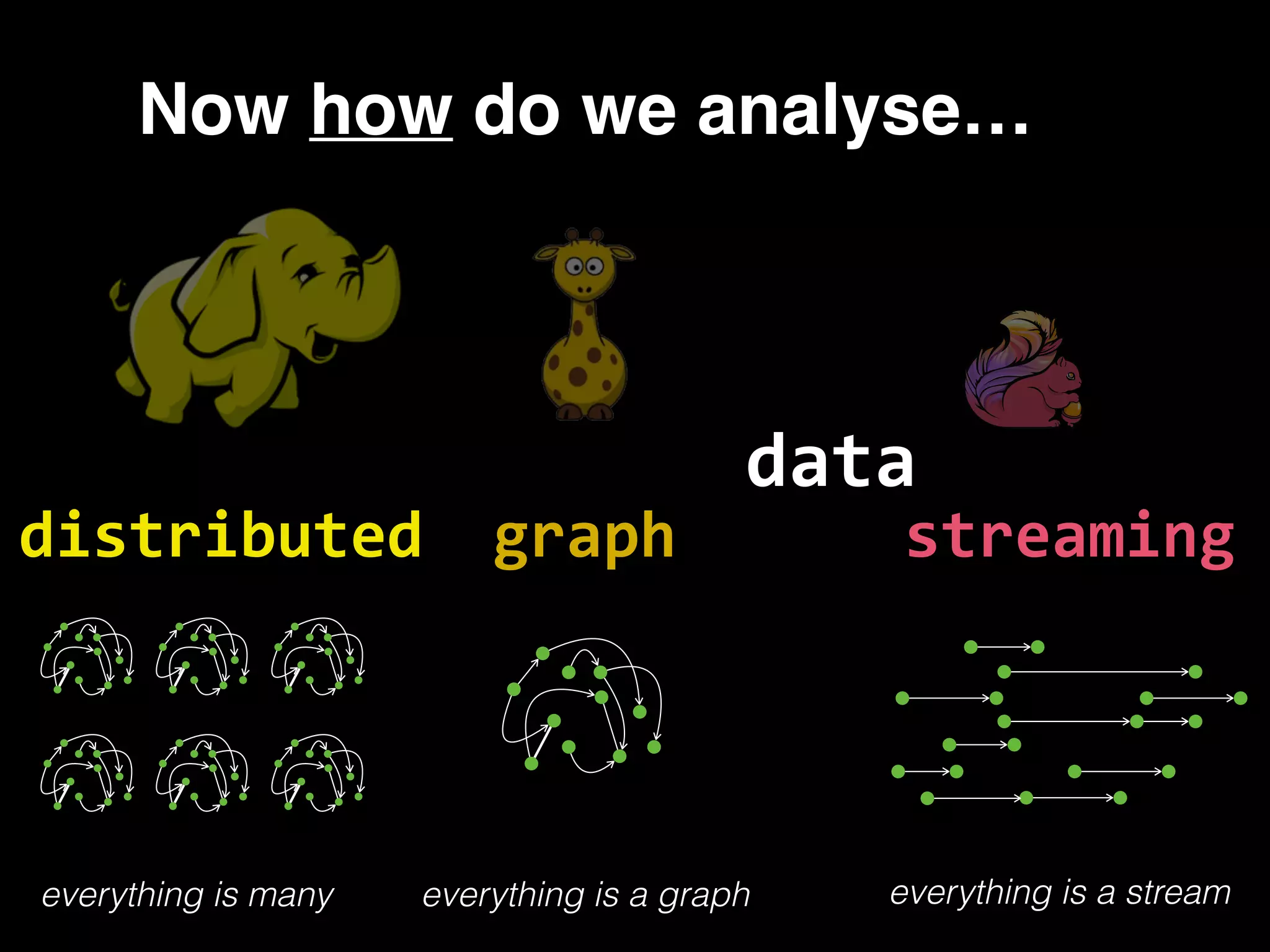



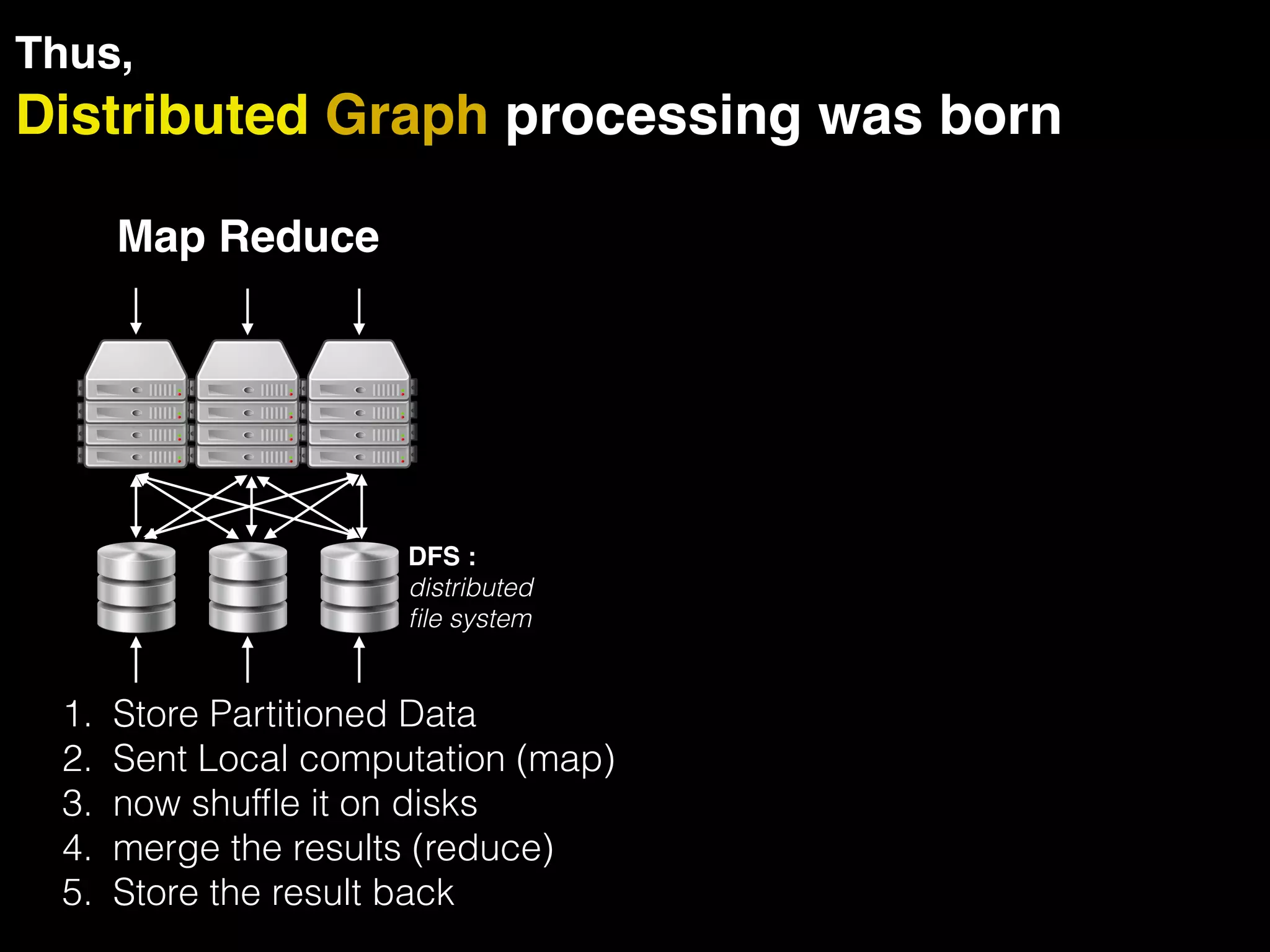
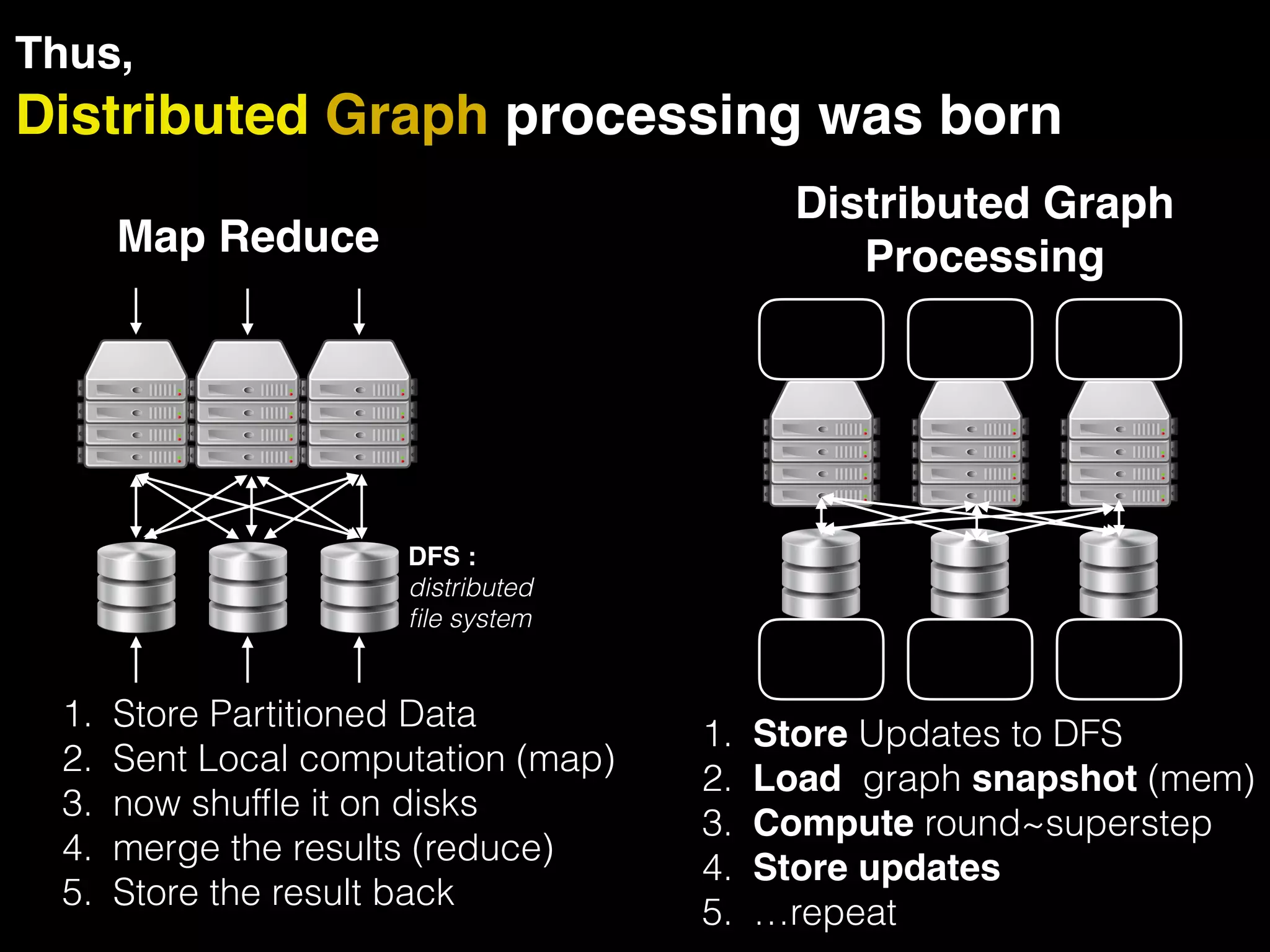
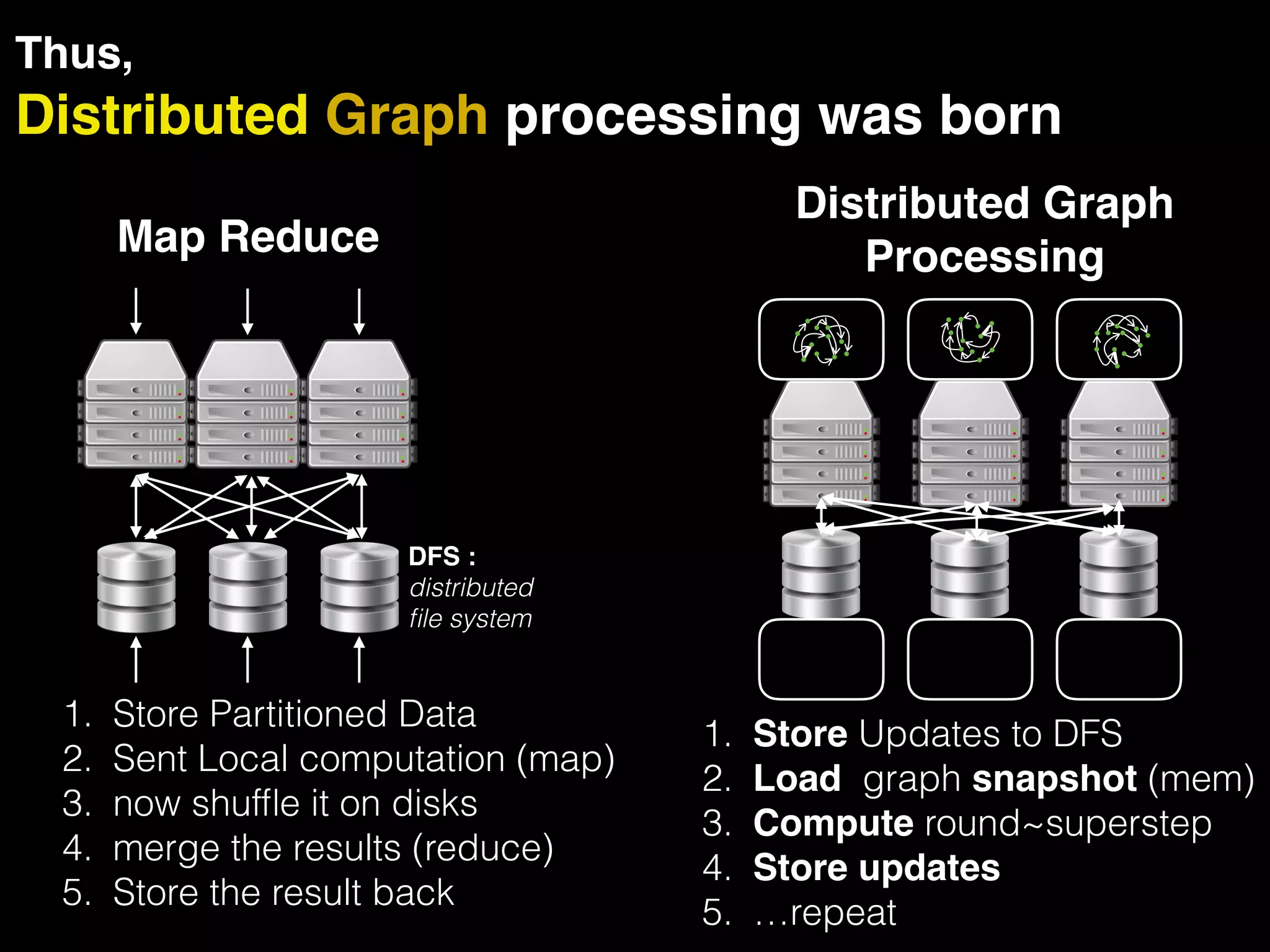
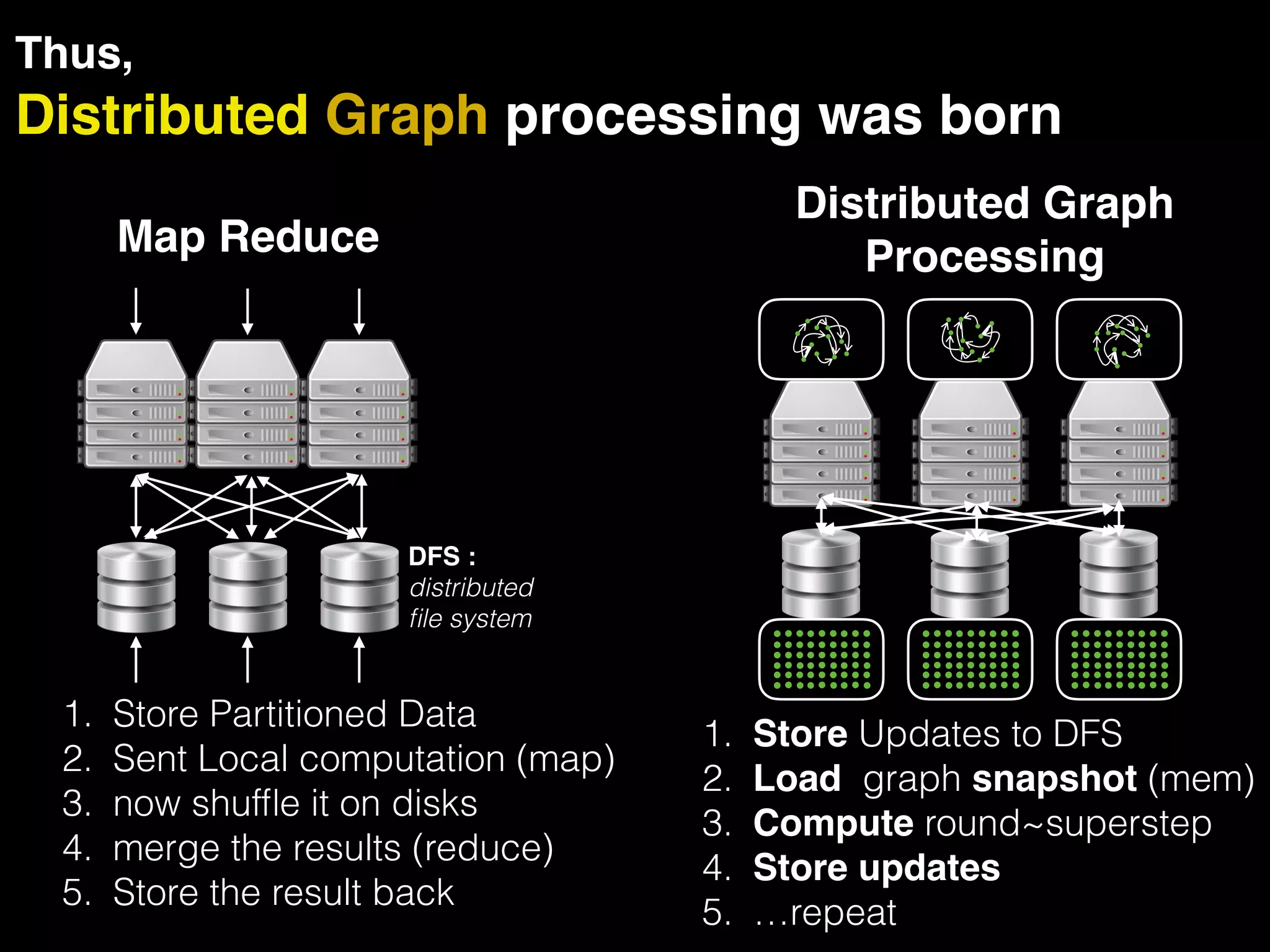
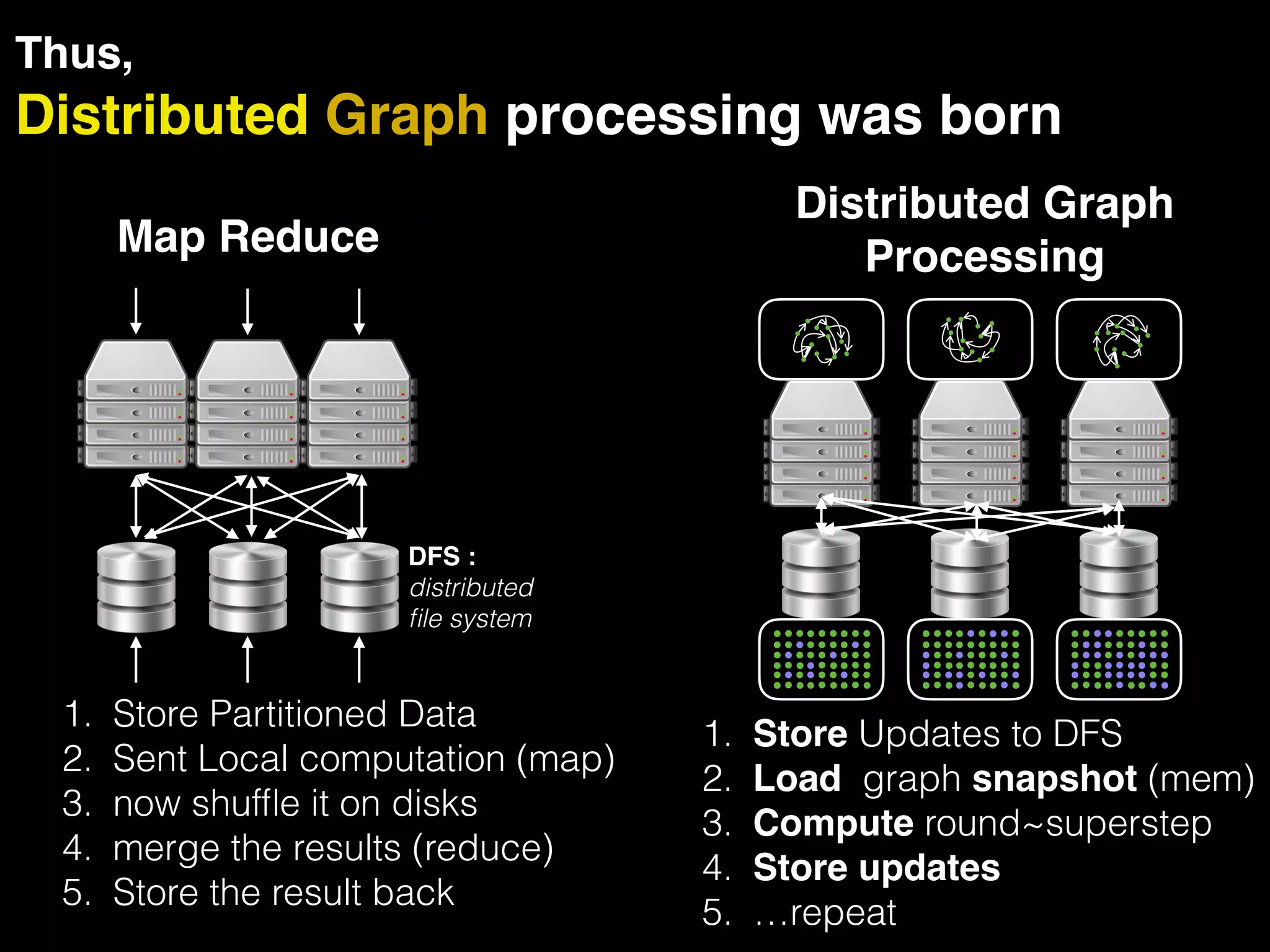
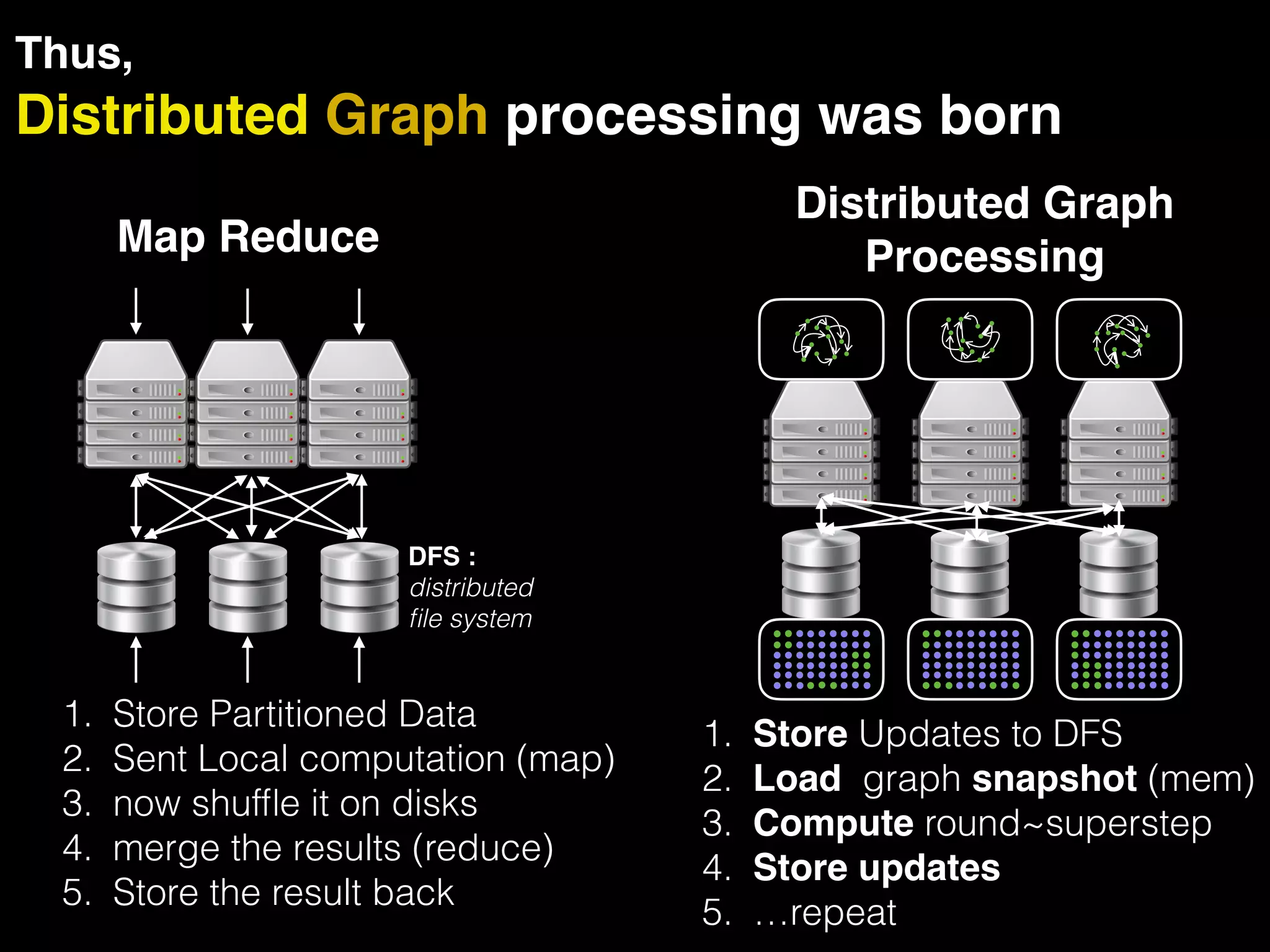
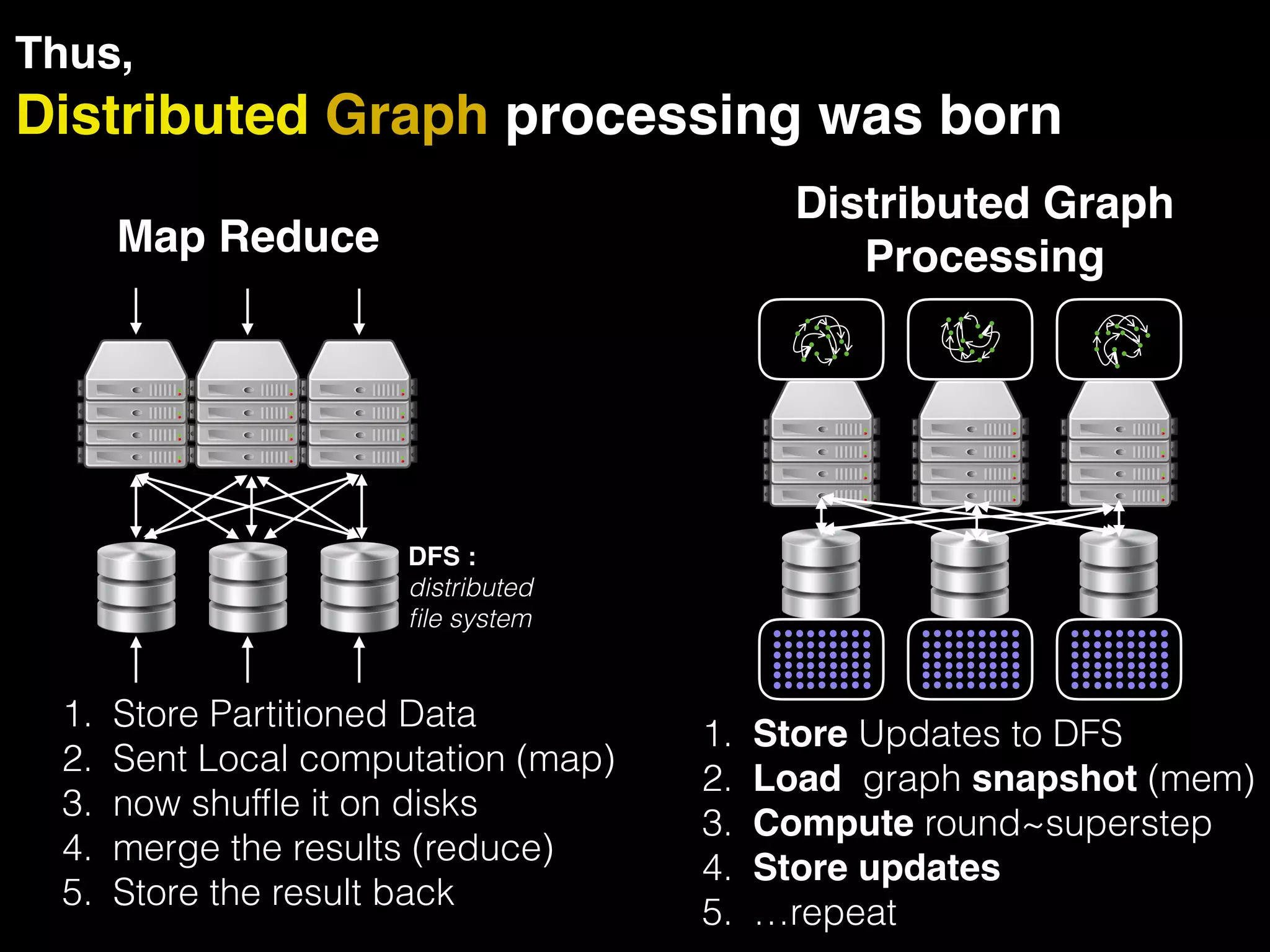

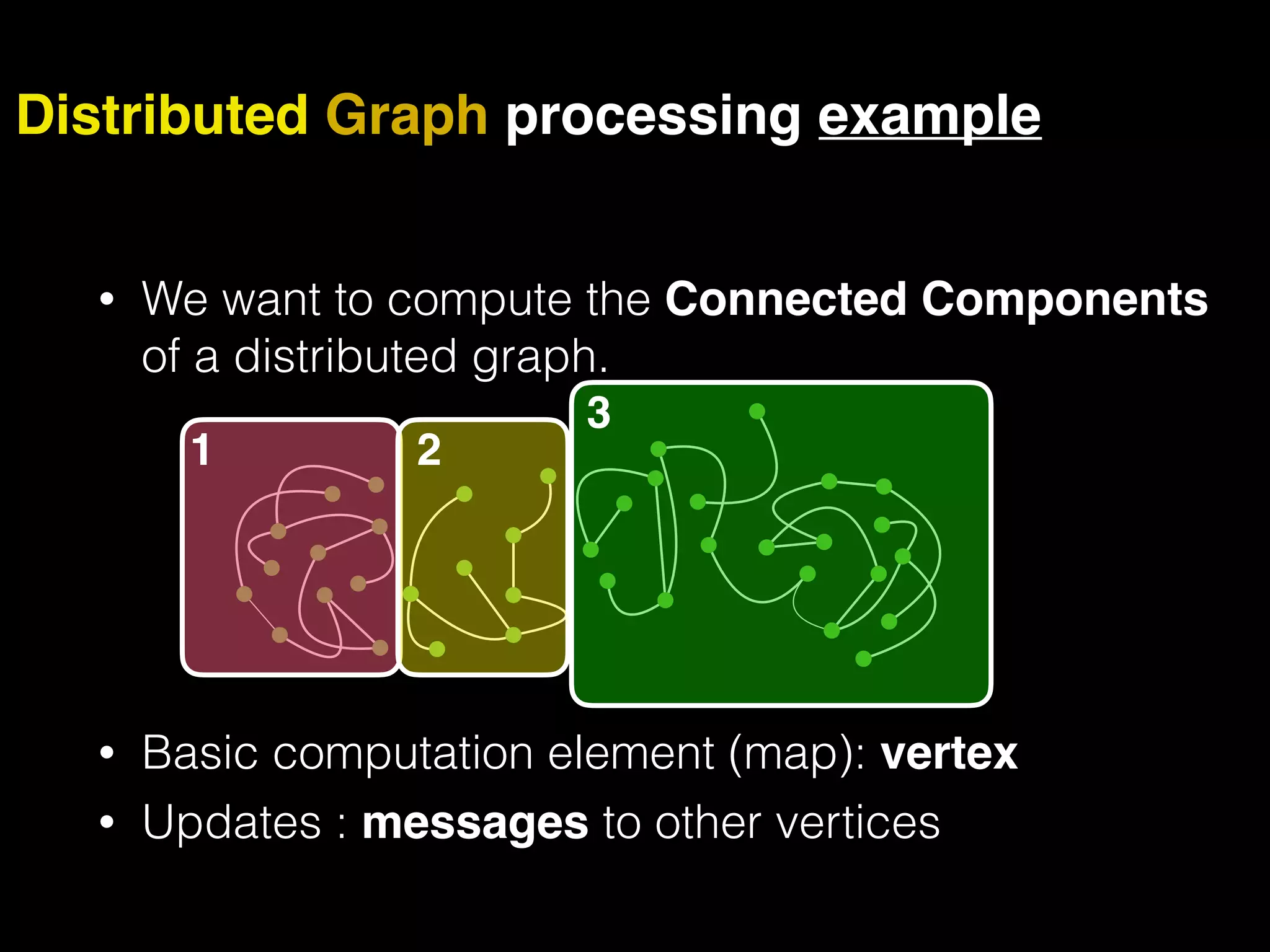
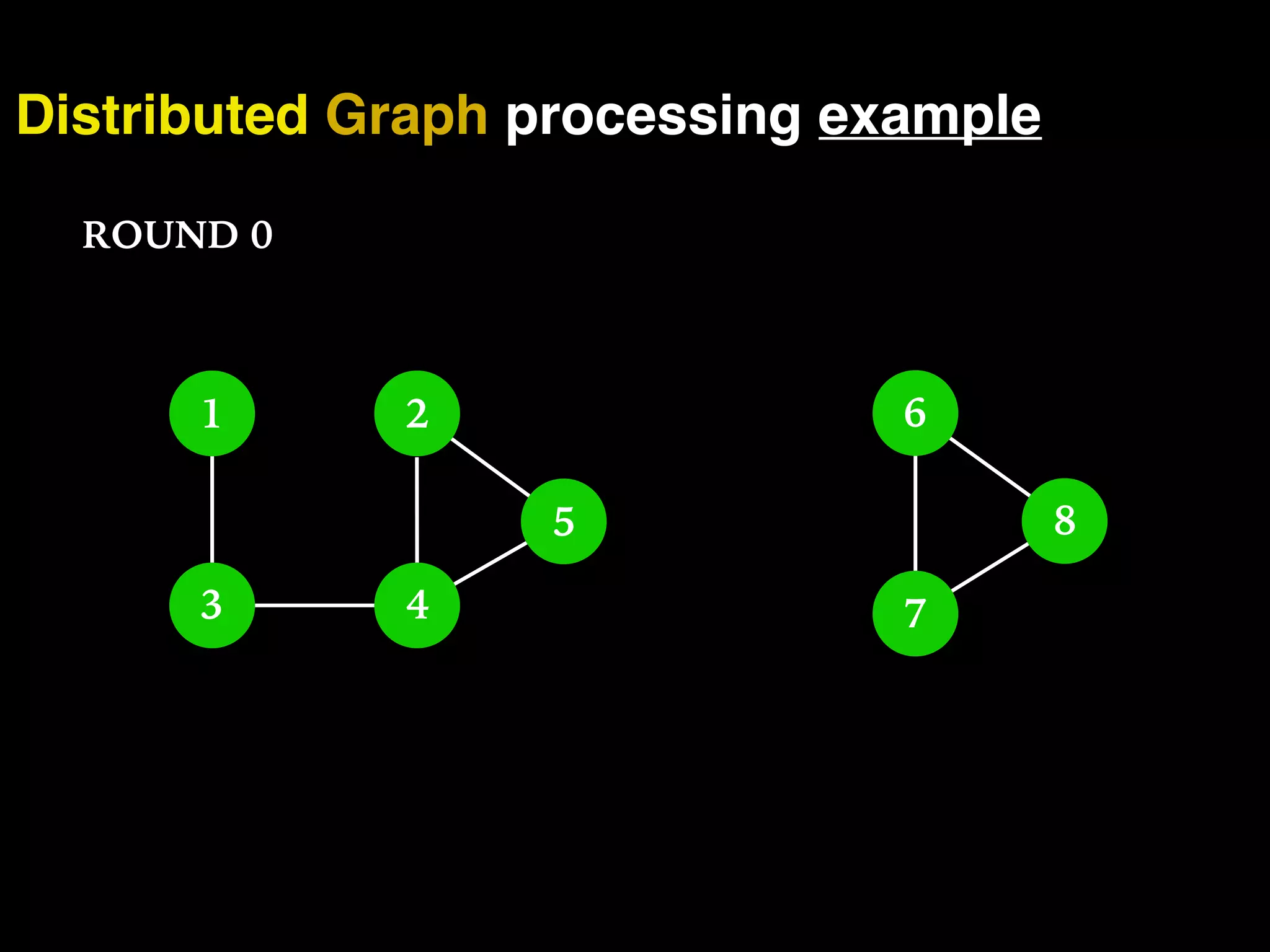
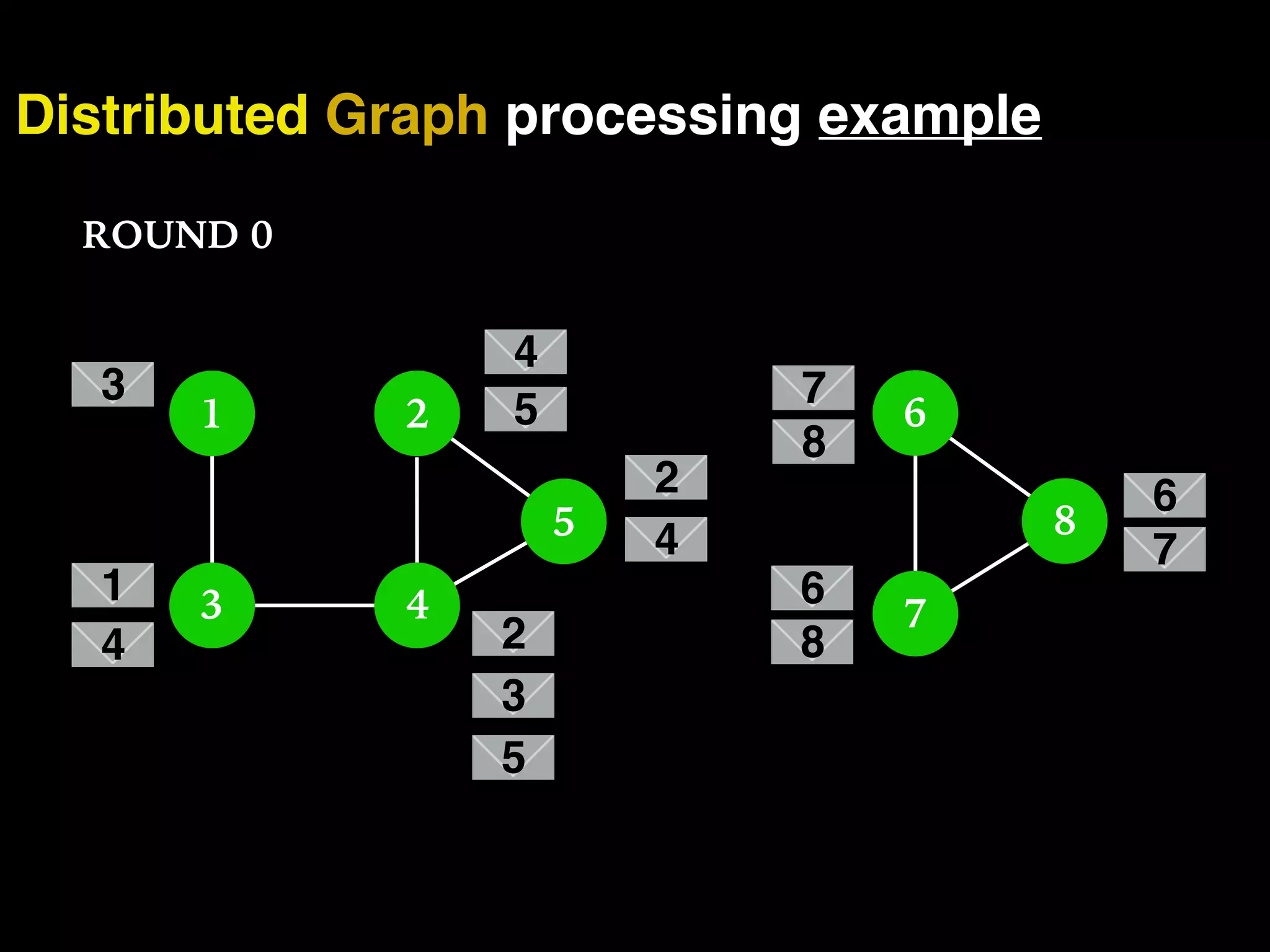
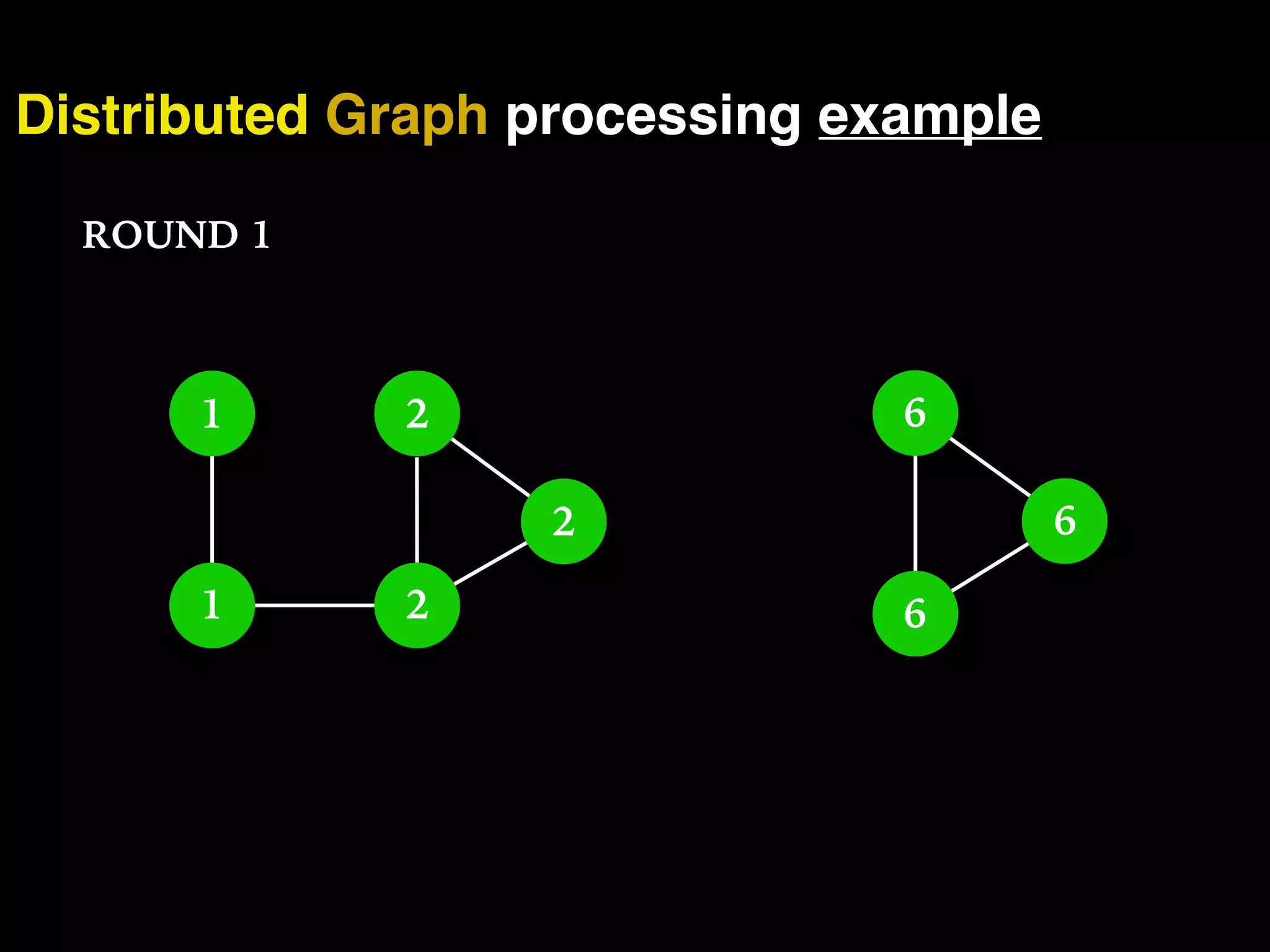
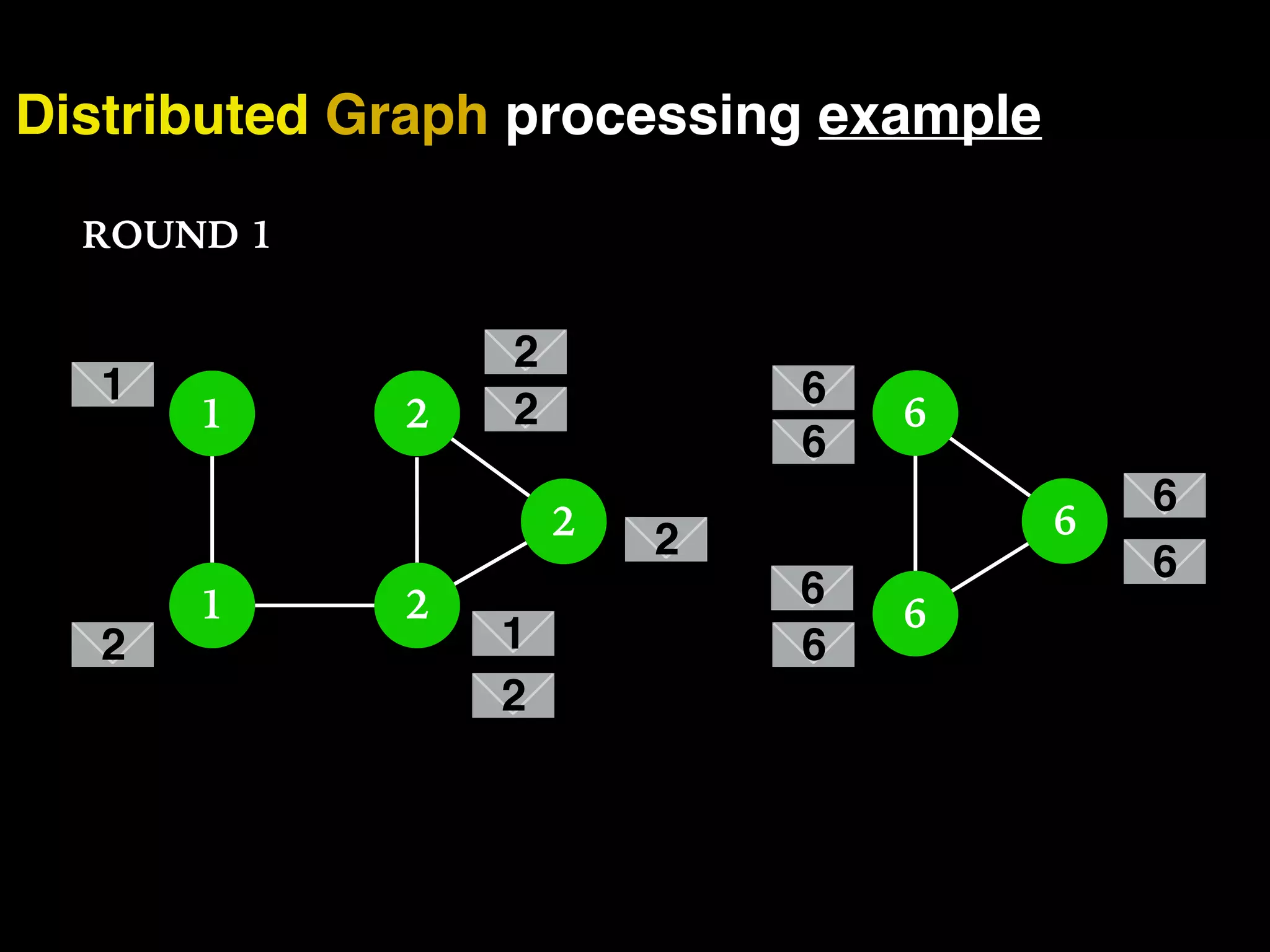
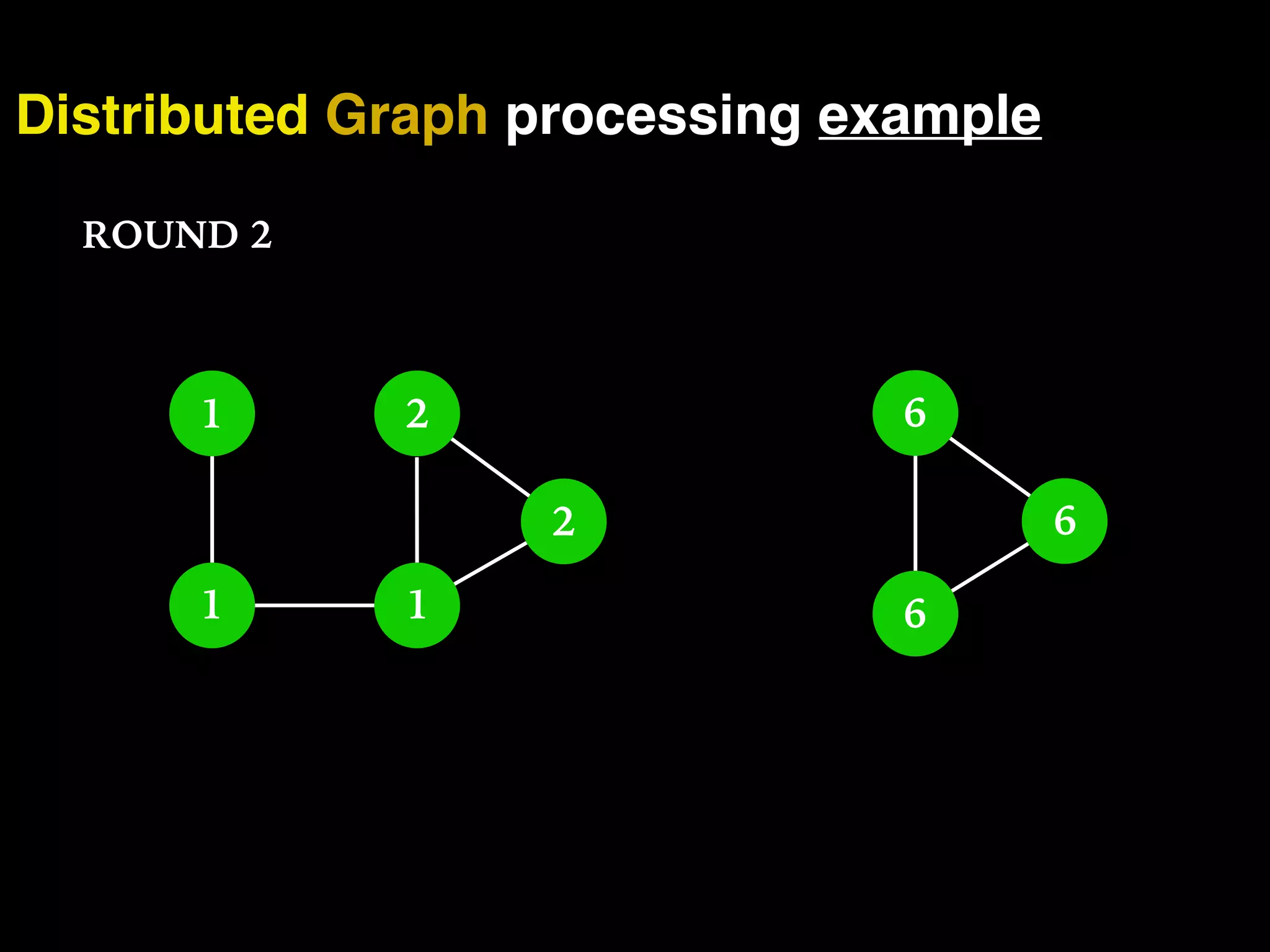
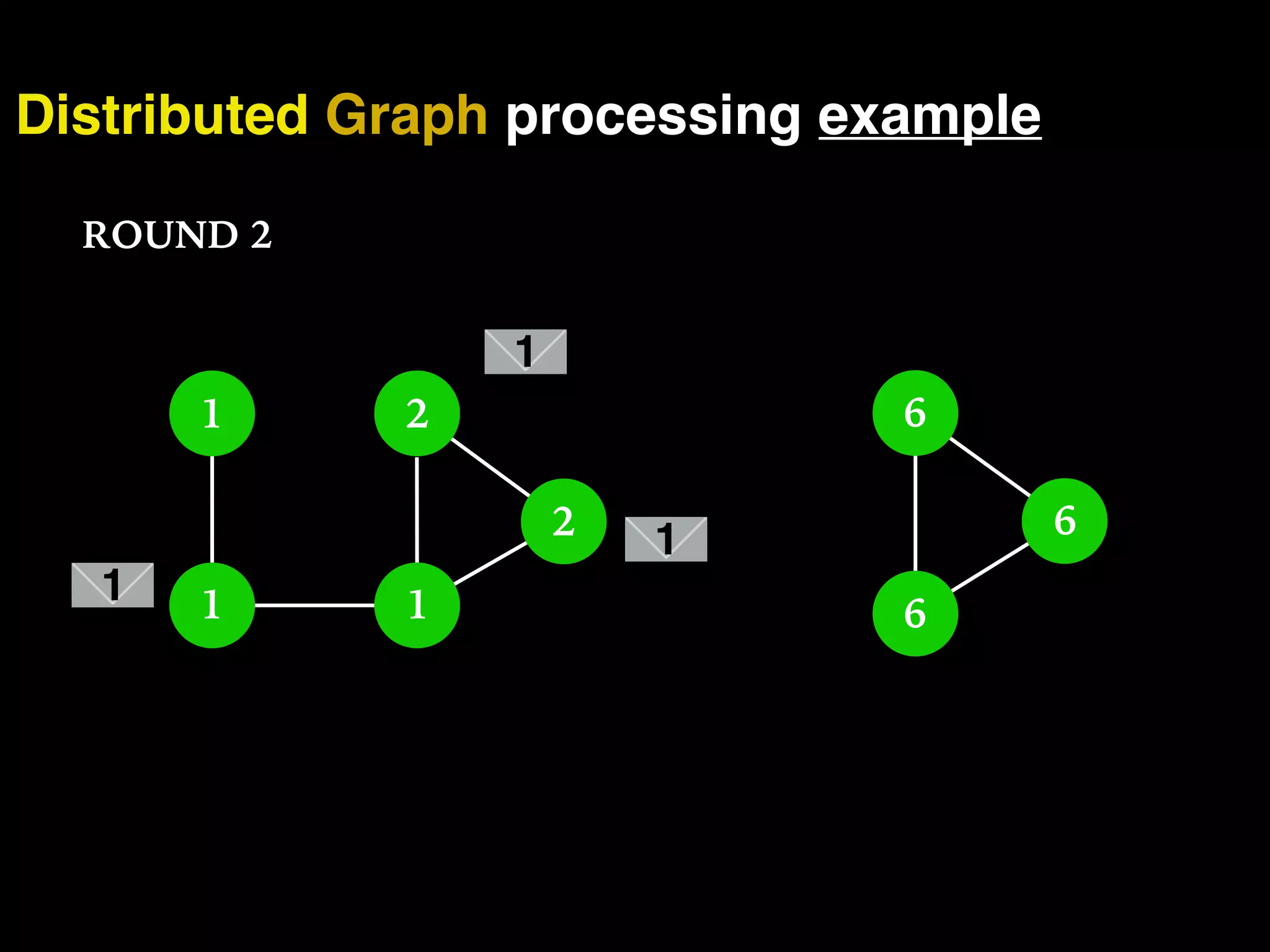
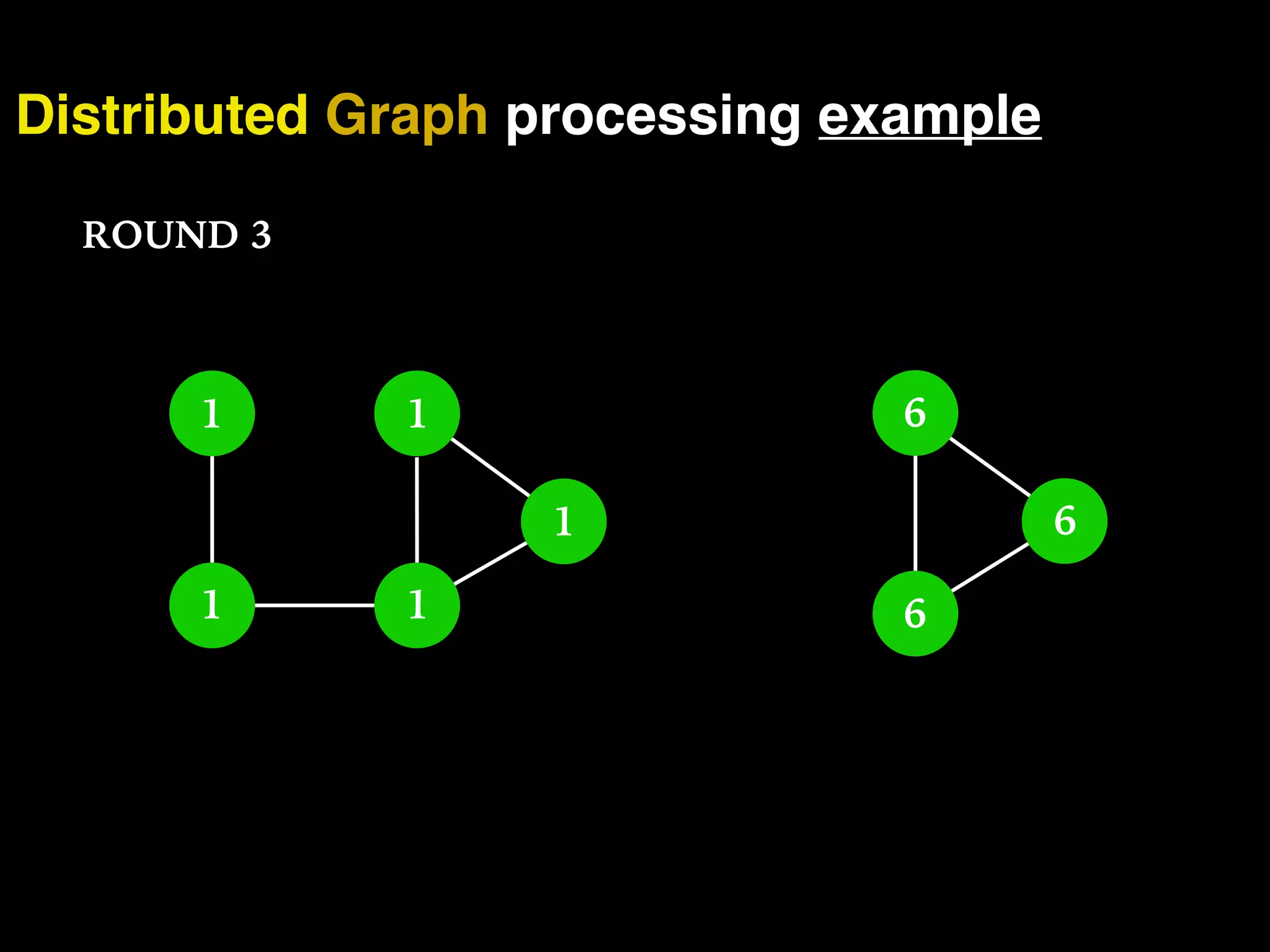
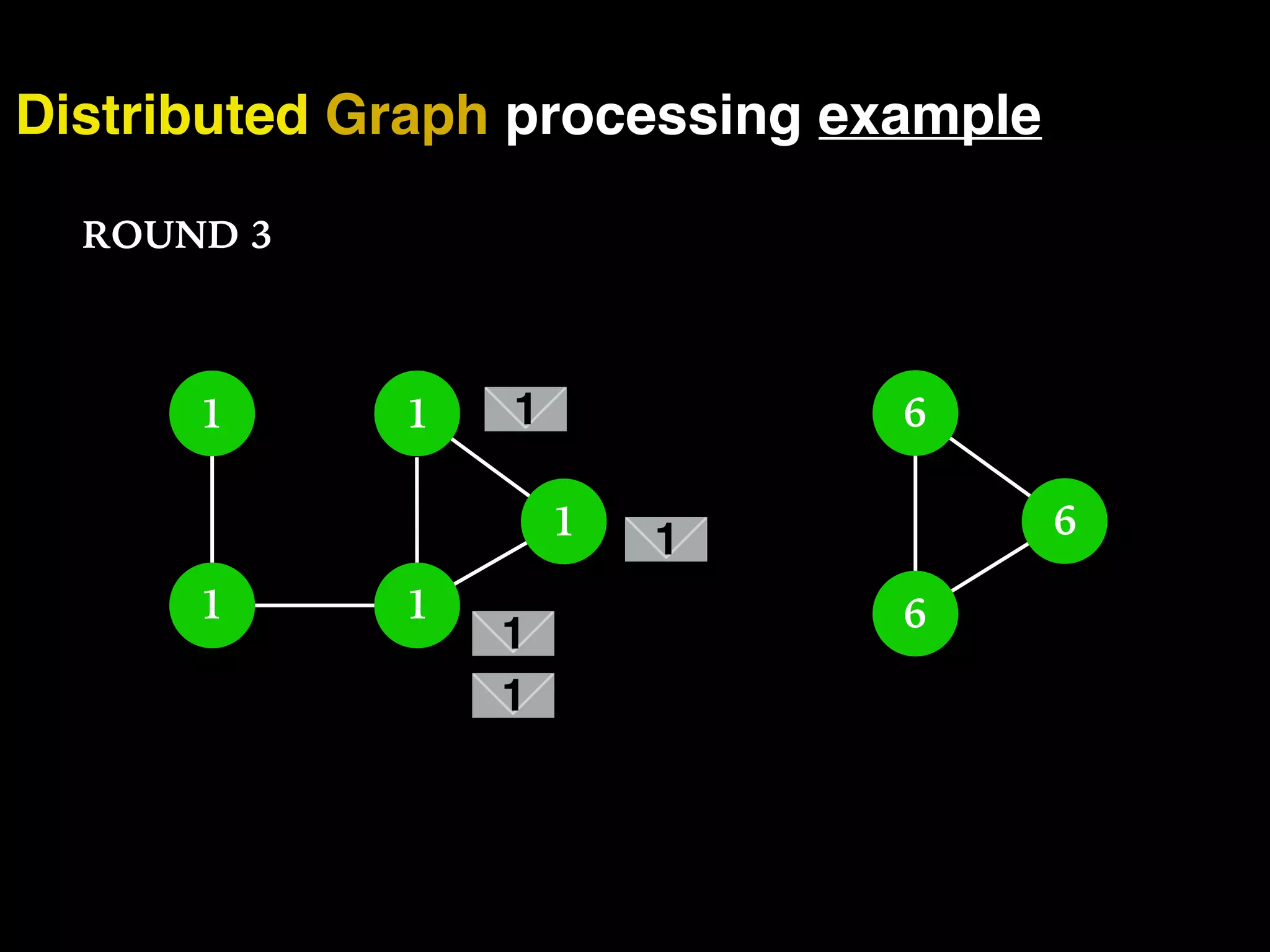
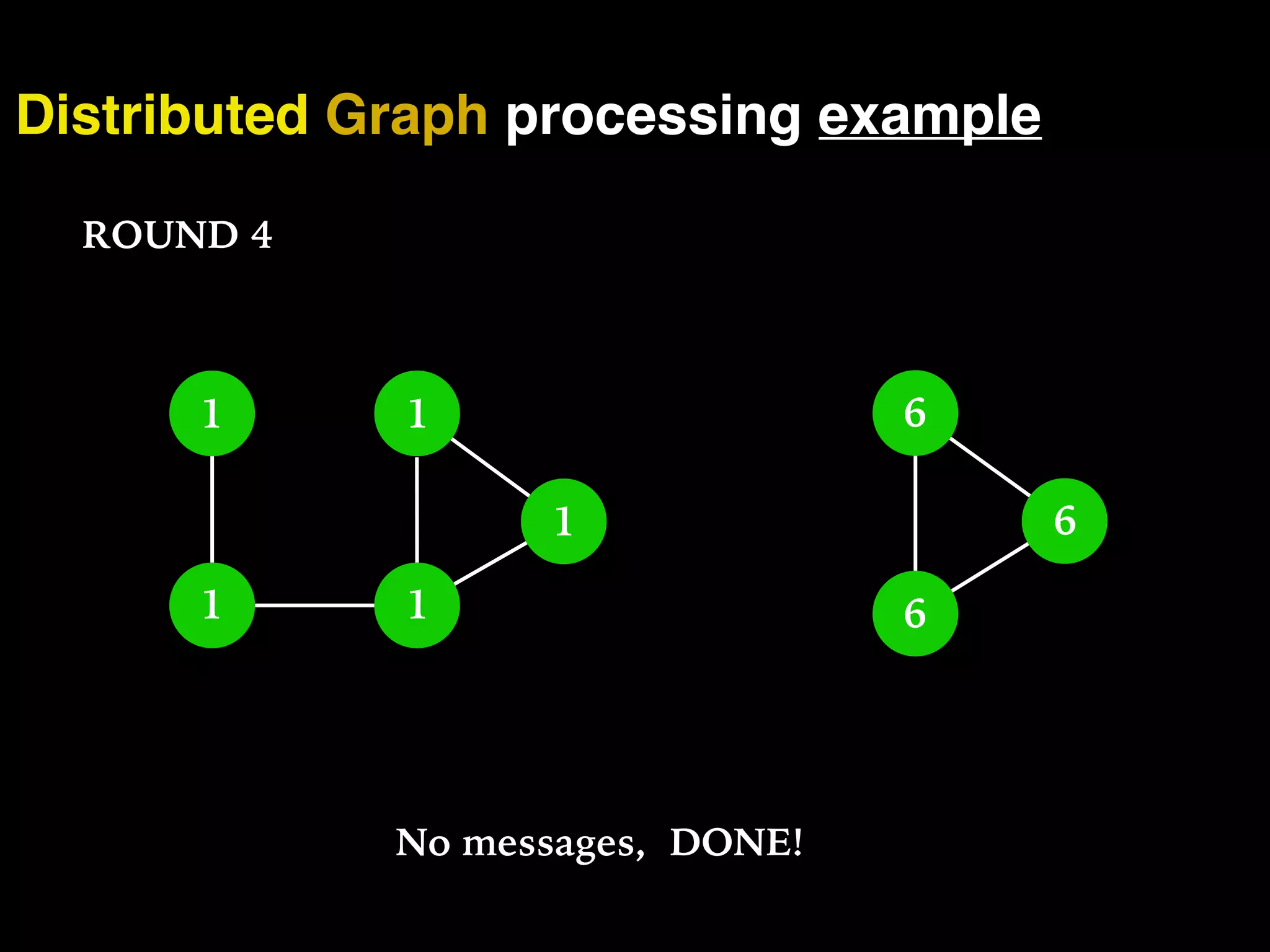




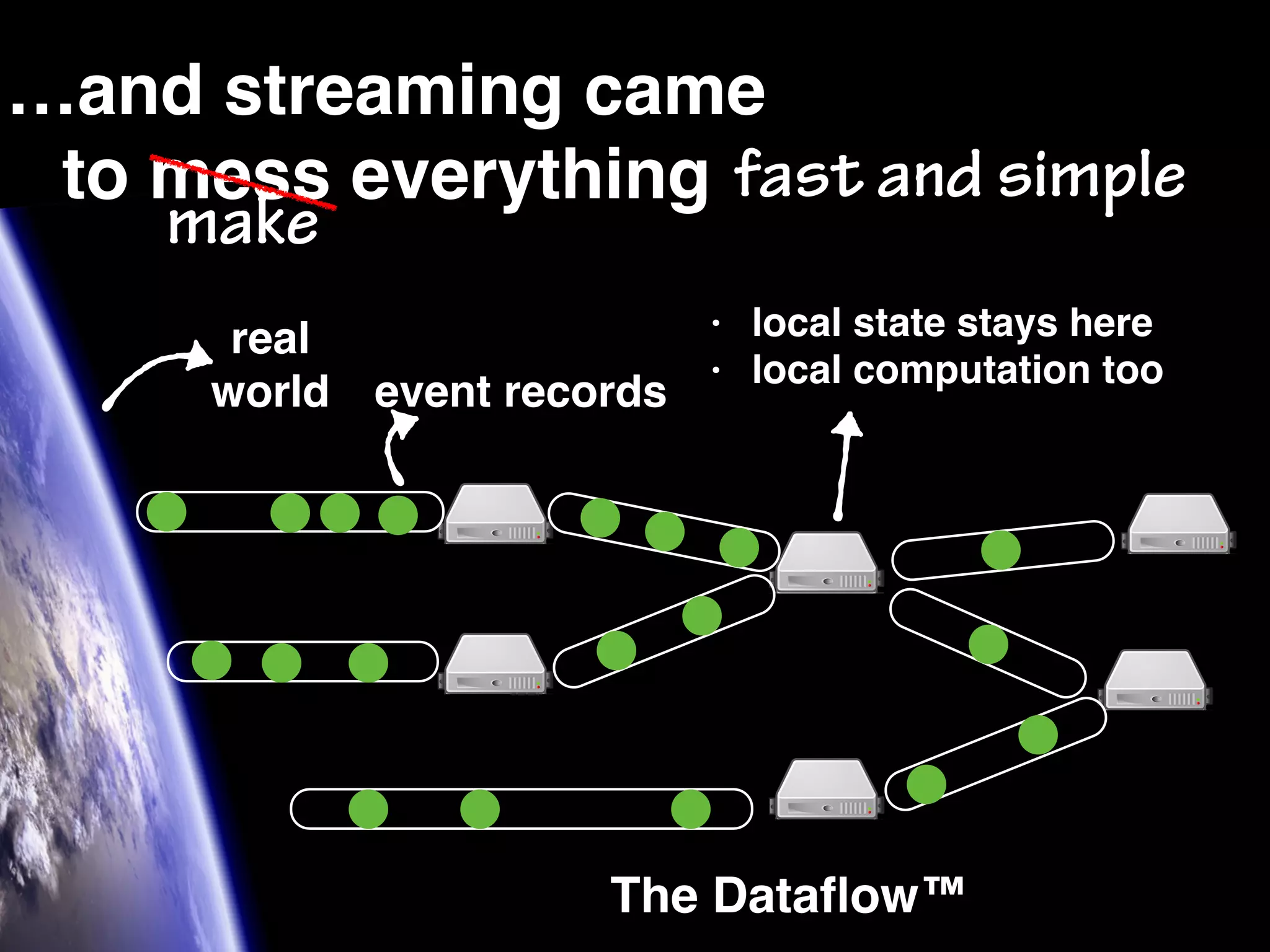








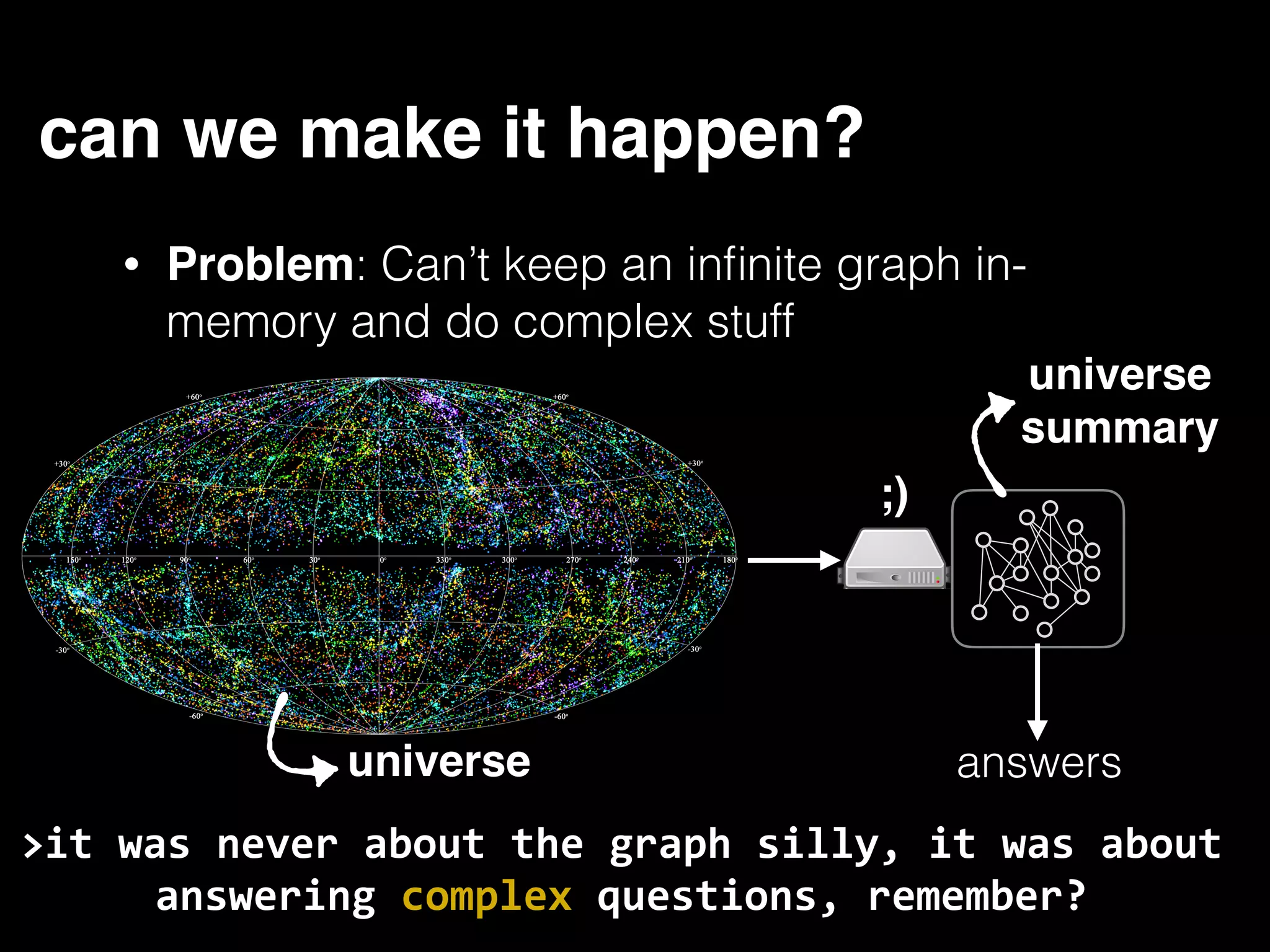
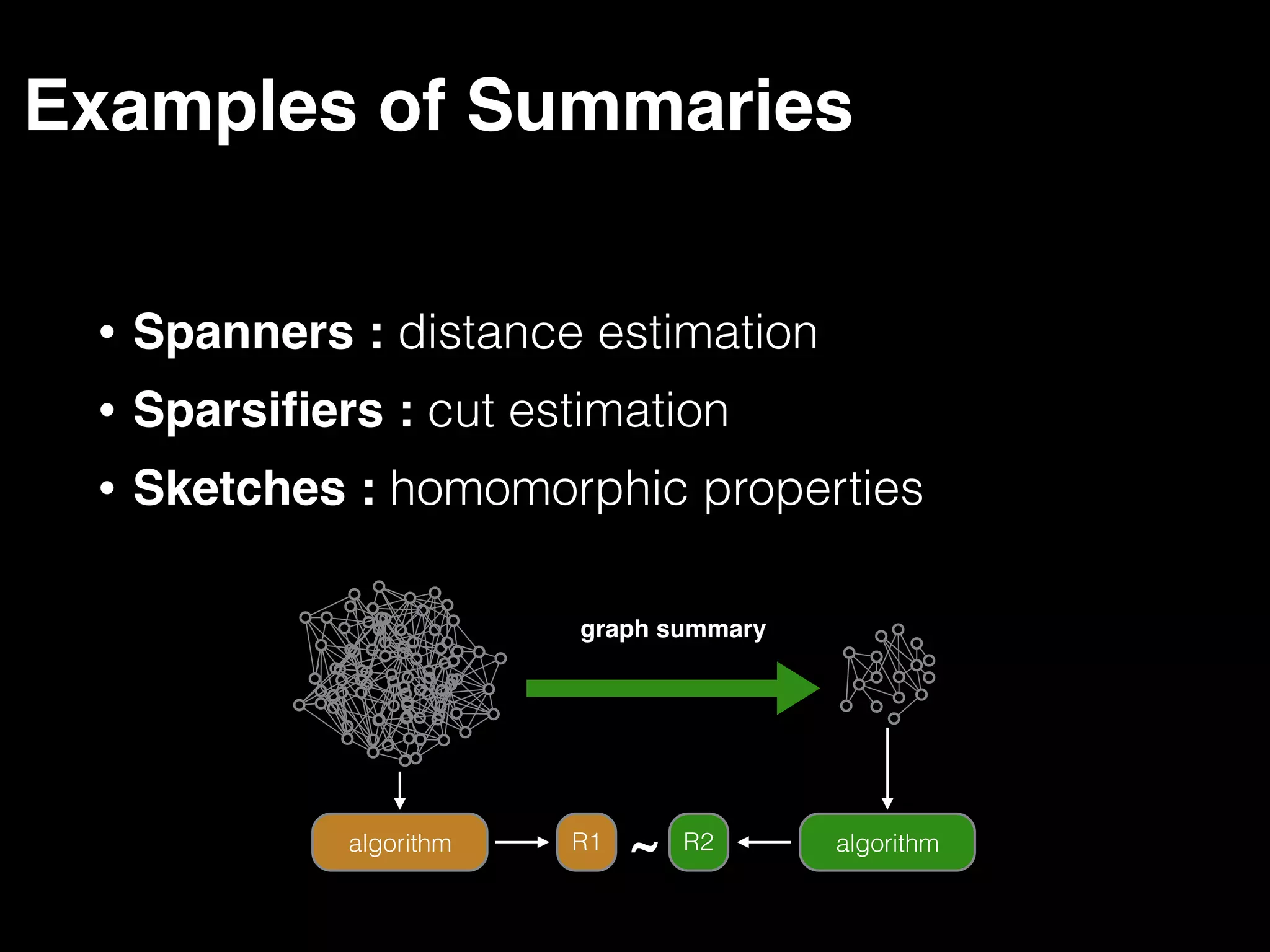


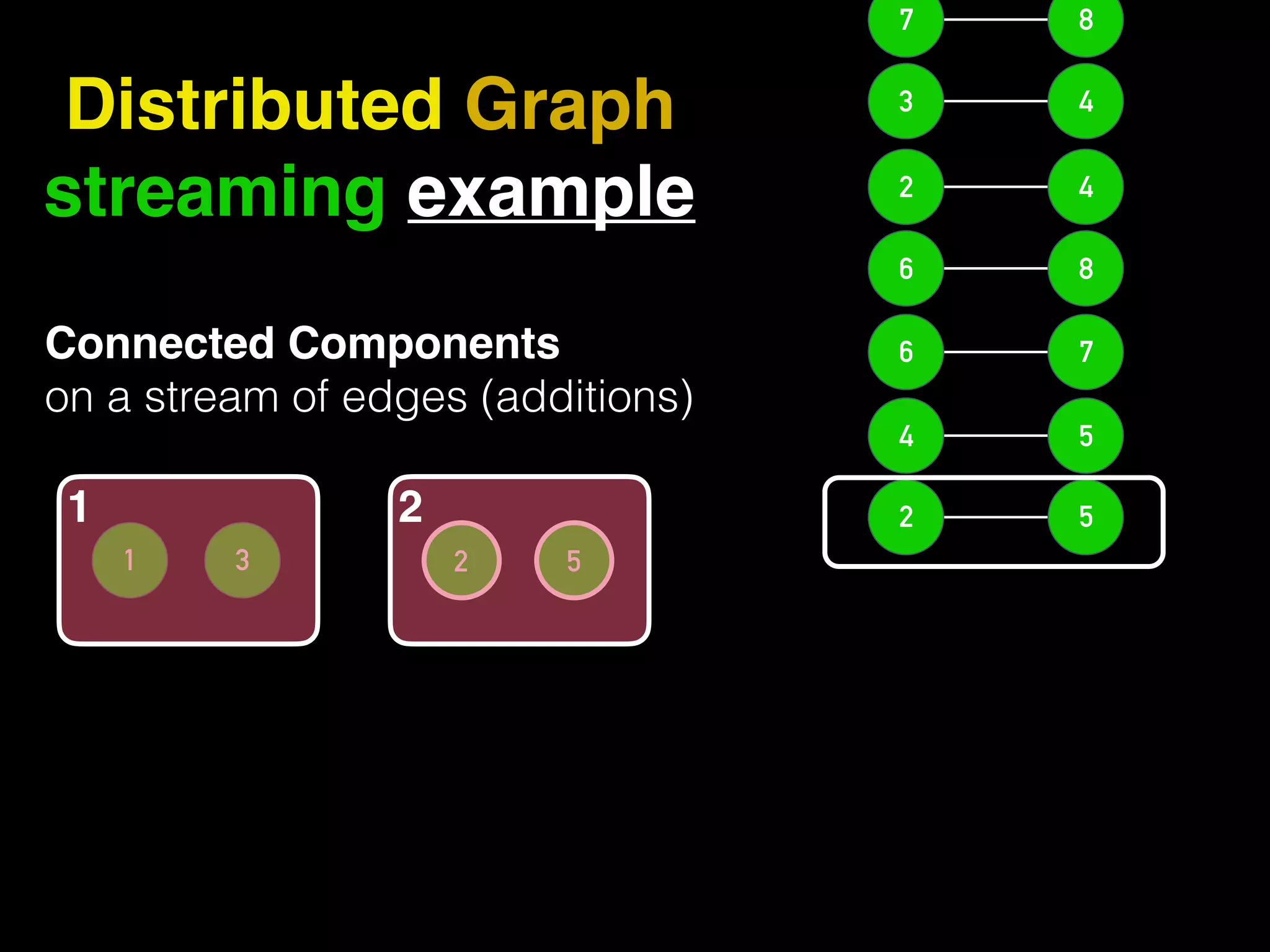
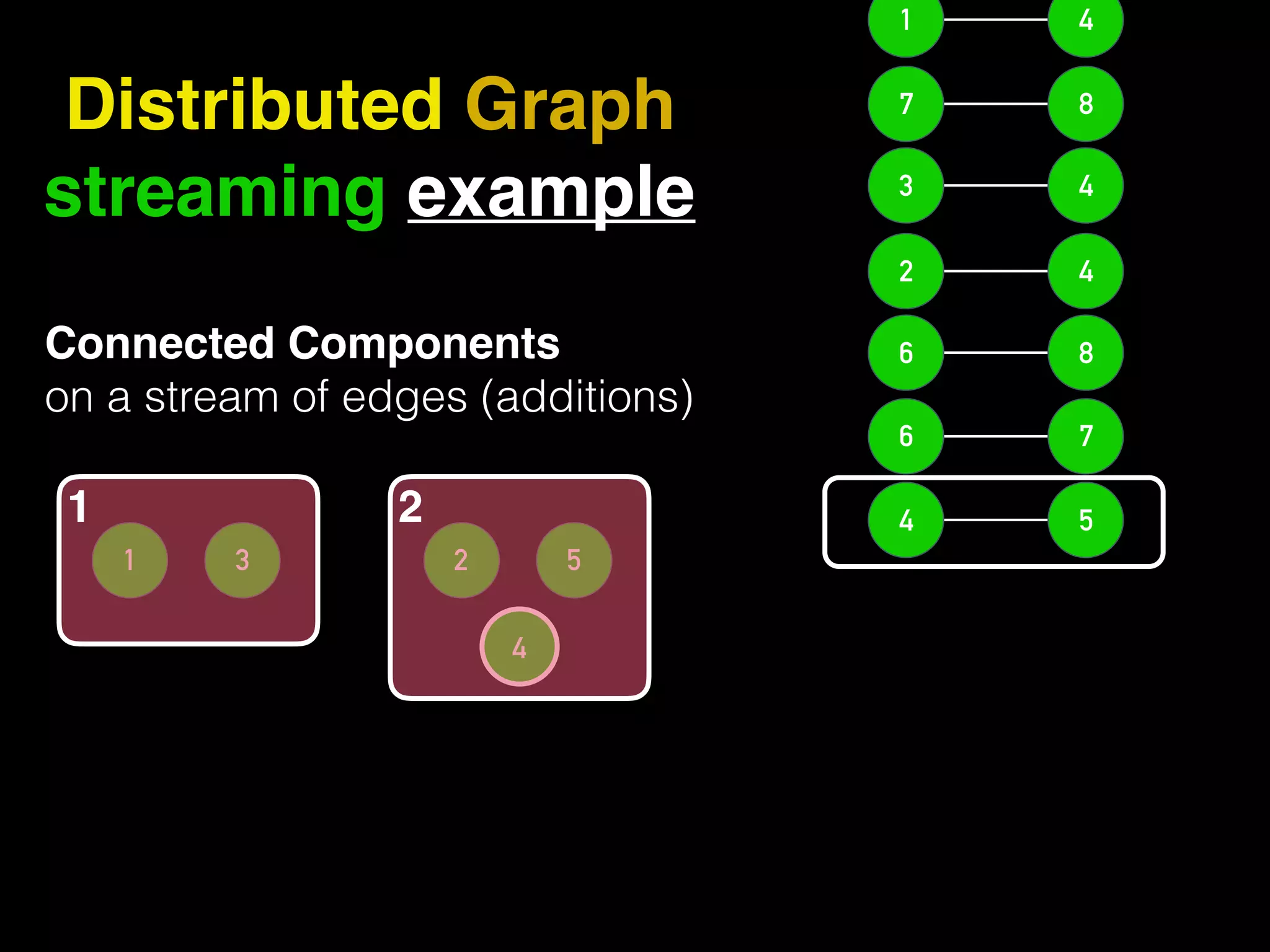
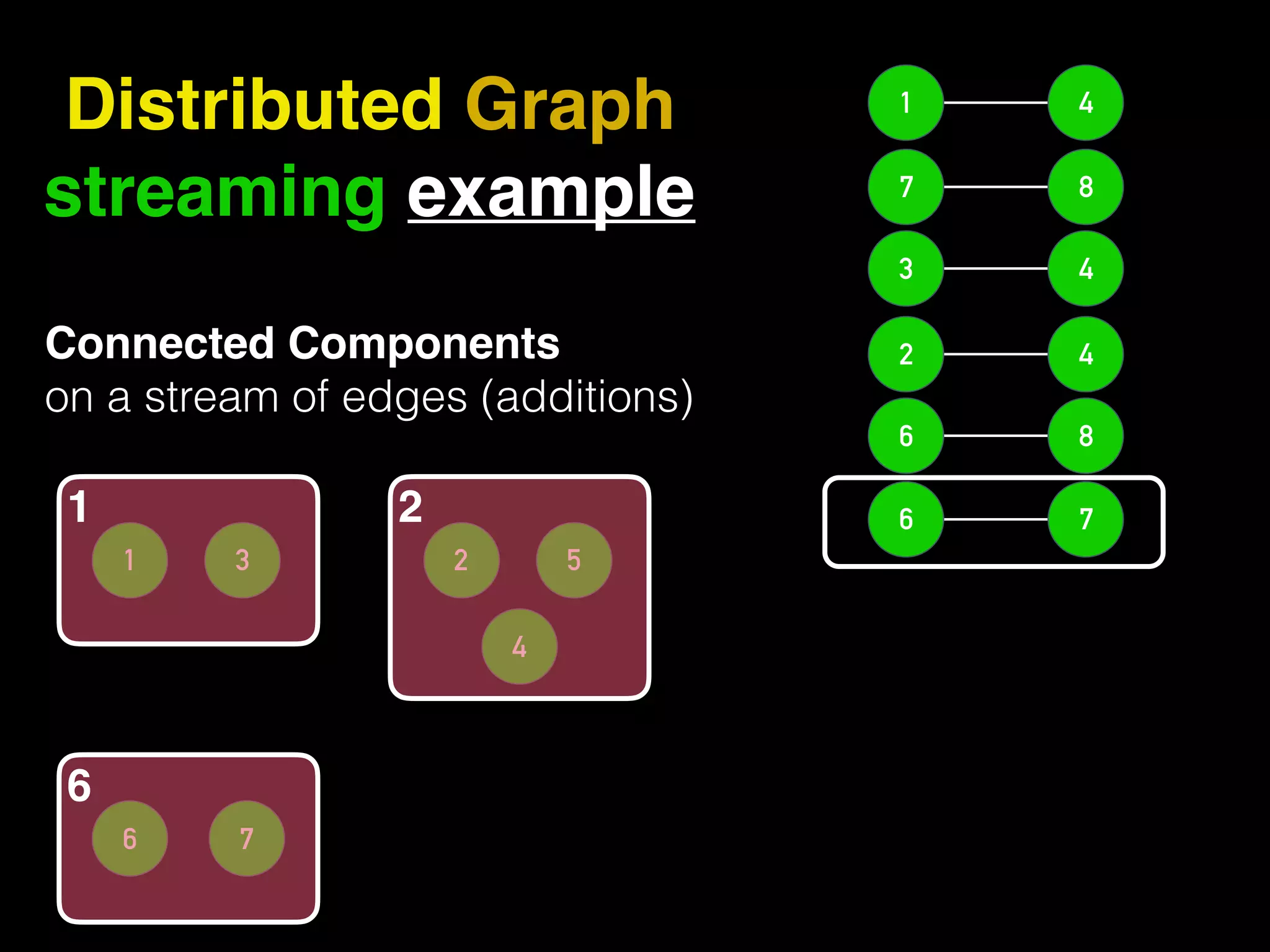
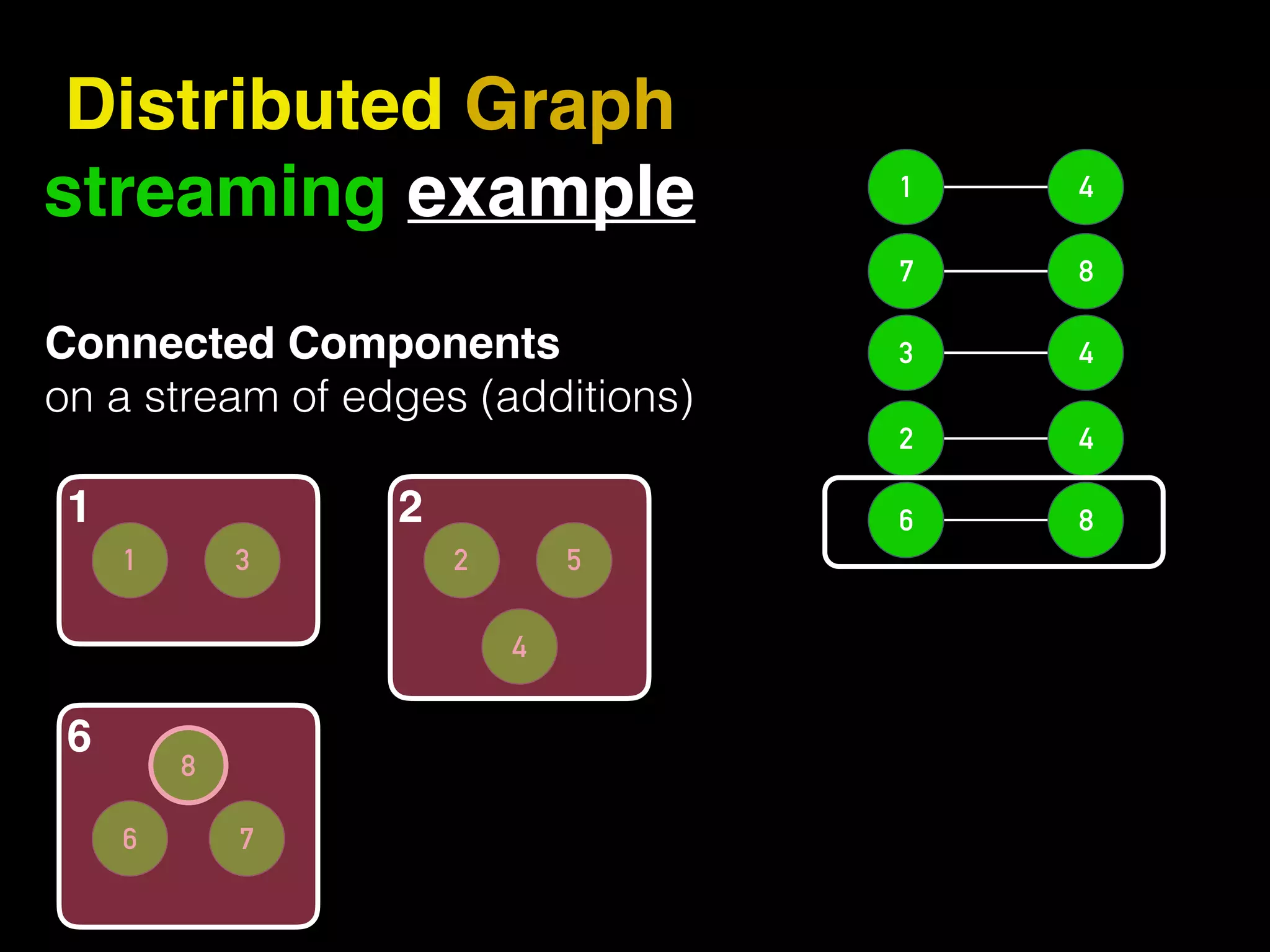
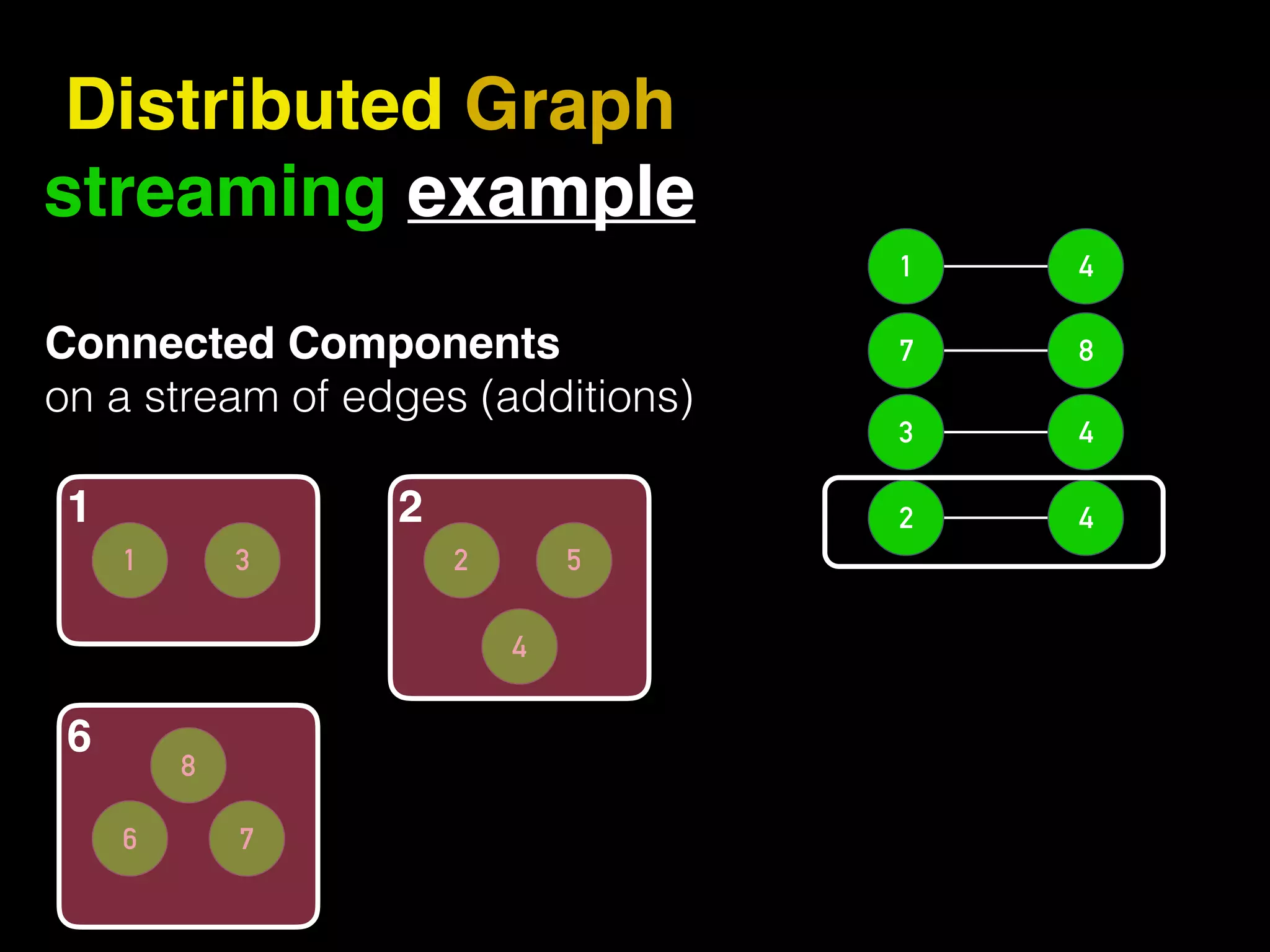
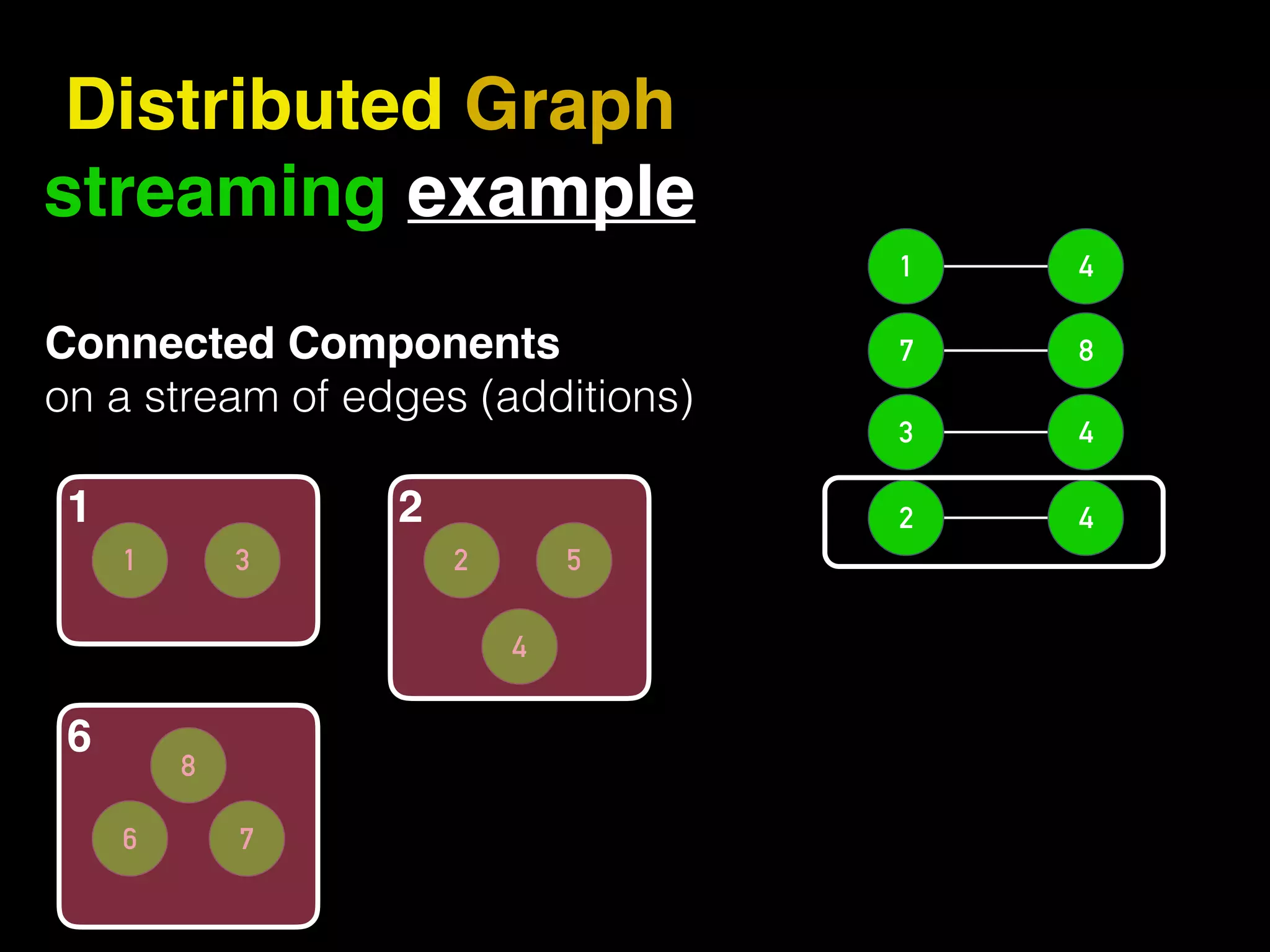
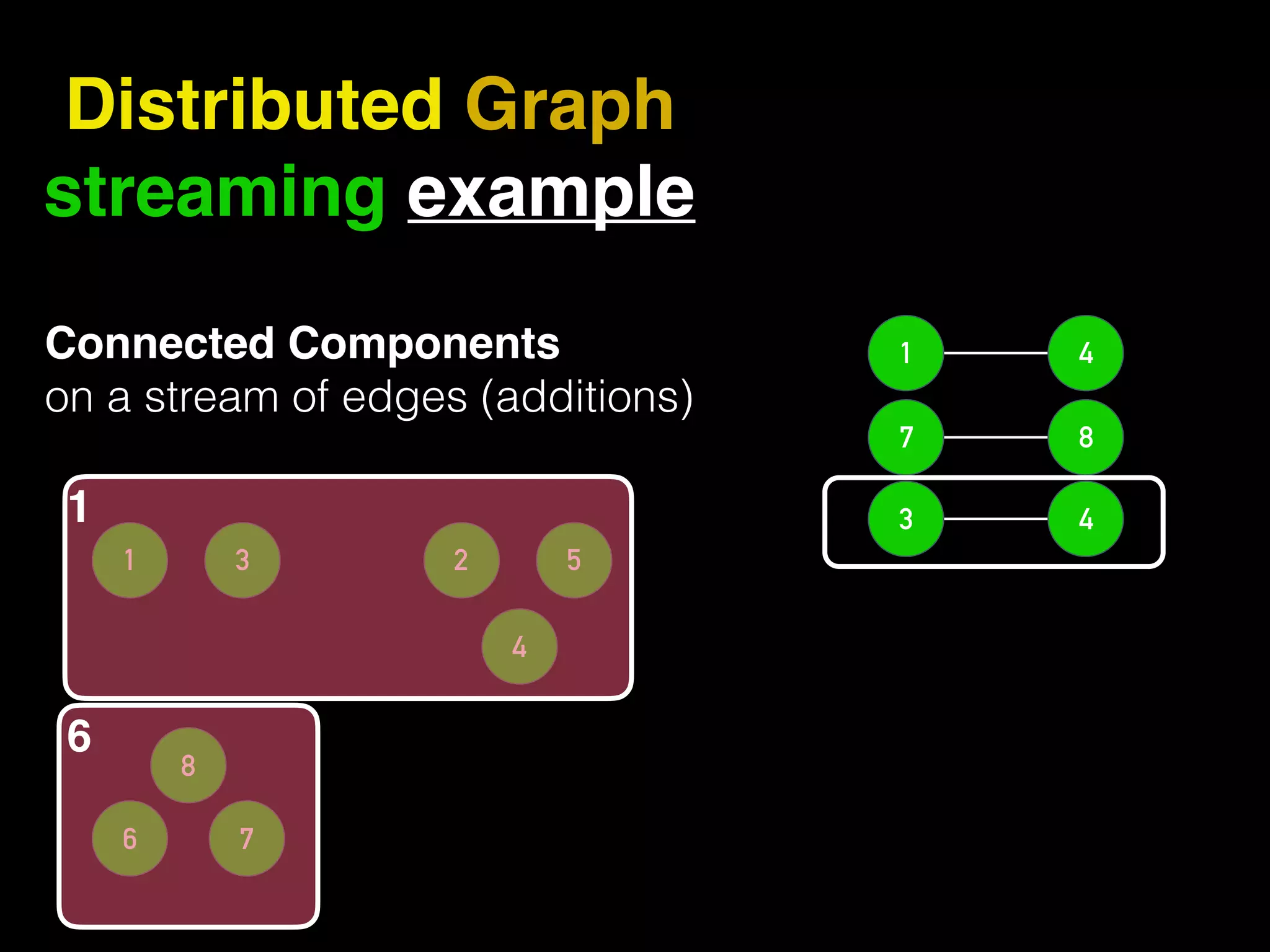
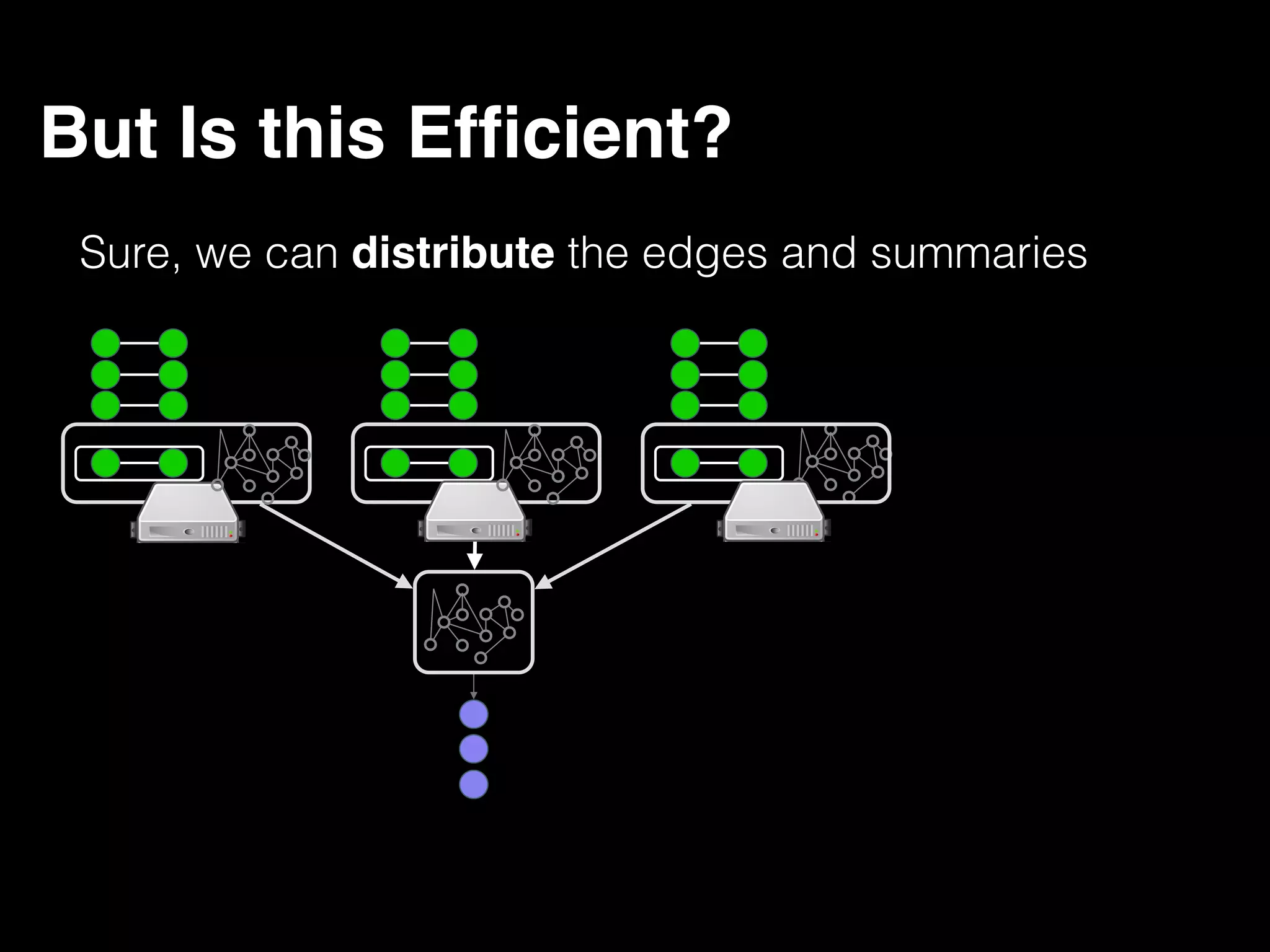
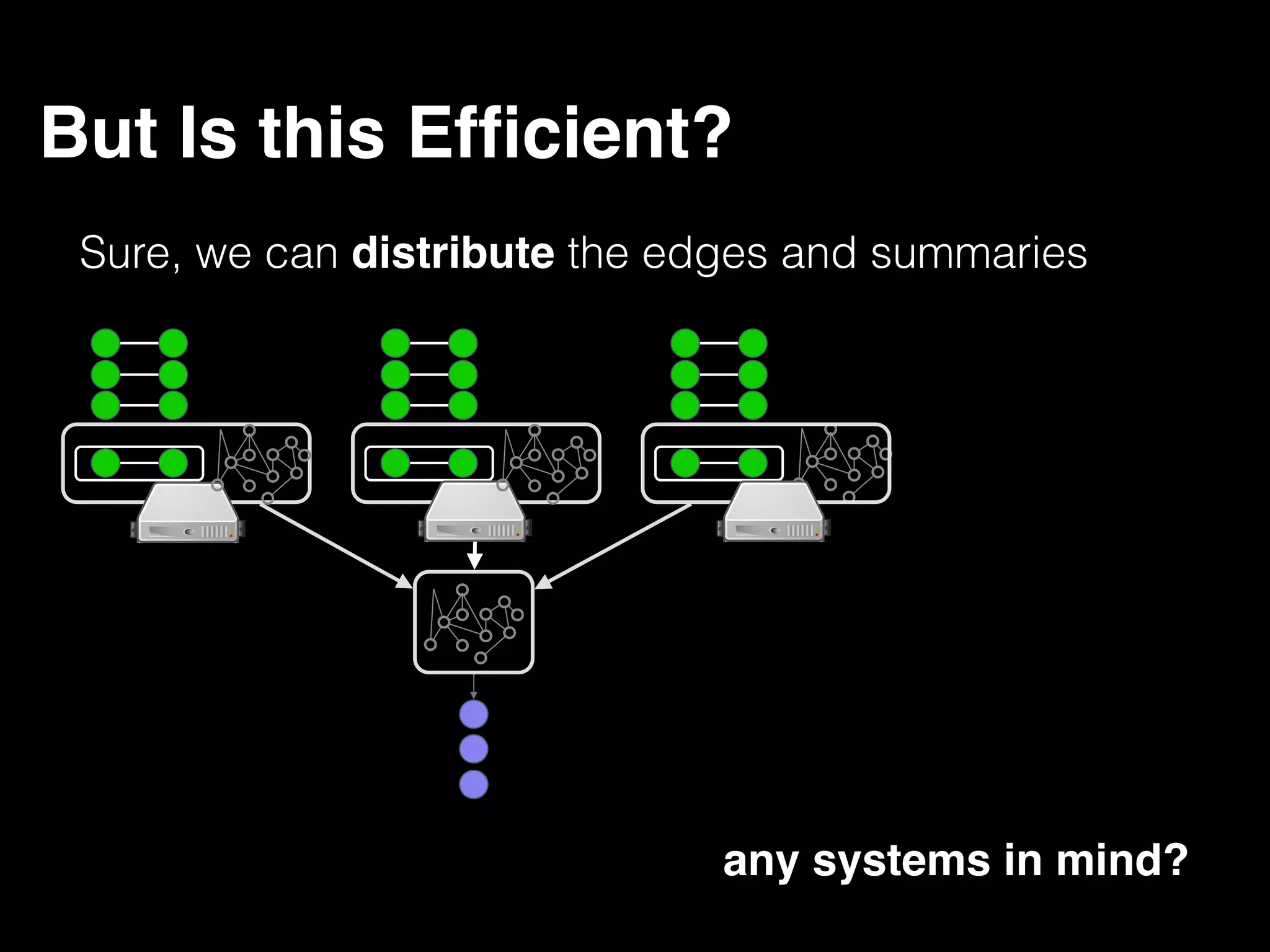

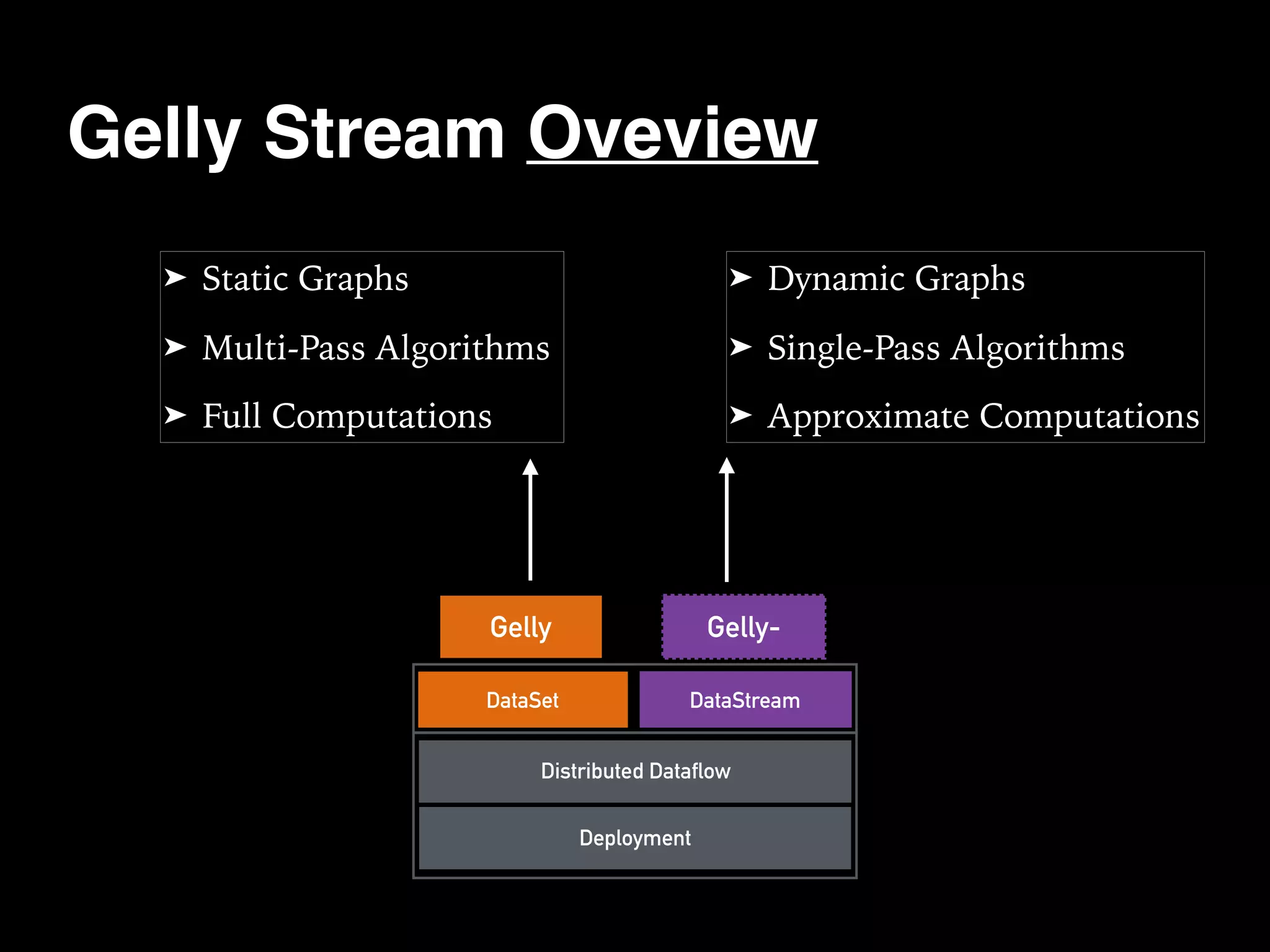




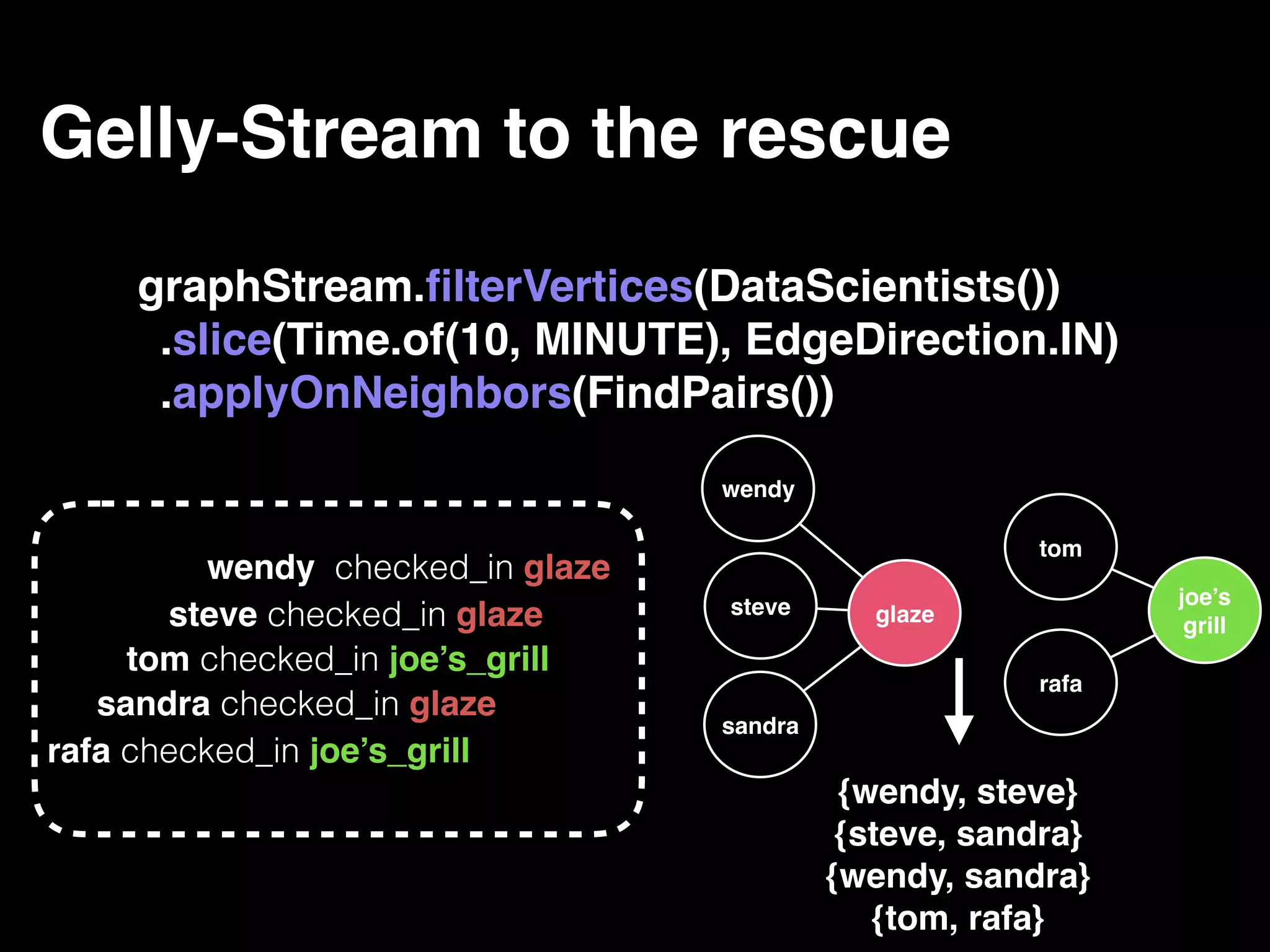



The document discusses the need for large-scale, complex, and fast data analysis to answer significant questions quickly, particularly in the context of graph stream processing. It details the evolution of distributed graph processing, the challenges of real-time analytics, and offers insights into solutions like Apache Flink and Gelly Stream. The emphasis is on addressing complex problems through efficient data analysis techniques and frameworks to support real-time decision-making.