Download as PDF, PPTX



![Managing Services Often you’ll be developing and have Hive, Titan, HBase, etc. on your local machine. Keep them in one place as follows: [srv] |--- spark-1.2.0 |--- spark → [srv]/spark-1.2.0 |--- titan ... export SPARK_HOME=/srv/spark export PATH=$SPARK_HOME/bin:$PATH](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-4-2048.jpg)



















![The Spark Master URL Master URL Meaning local Run Spark locally with one worker thread (i.e. no parallelism at all). local[K] Run Spark locally with K worker threads (ideally, set this to the number of cores on your machine). local[*] Run Spark locally with as many worker threads as logical cores on your machine. spark://HOST:PORT Connect to the given Spark standalone cluster master. The port must be whichever one your master is configured to use, which is 7077 by default. mesos://HOST:PORT Connect to the given Mesos cluster. The port must be whichever one your is configured to use, which is 5050 by default. Or, for a Mesos cluster using ZooKeeper, use mesos://zk://.... yarn-client Connect to a YARN cluster in client mode. The cluster location will be found based on the HADOOP_CONF_DIR variable. yarn-cluster Connect to a YARN cluster in cluster mode. The cluster location will be found based on HADOOP_CONF_DIR.](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-28-2048.jpg)
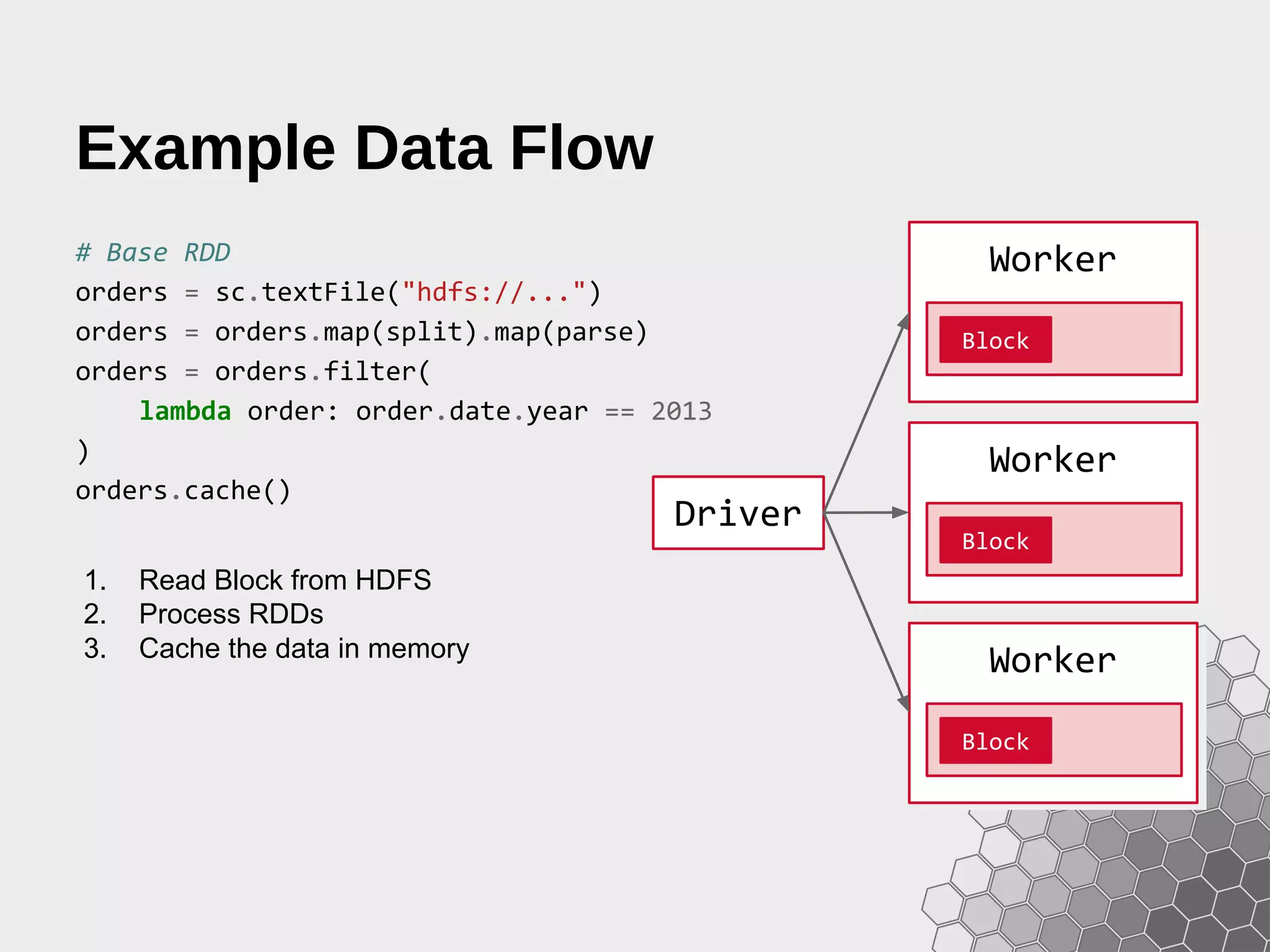
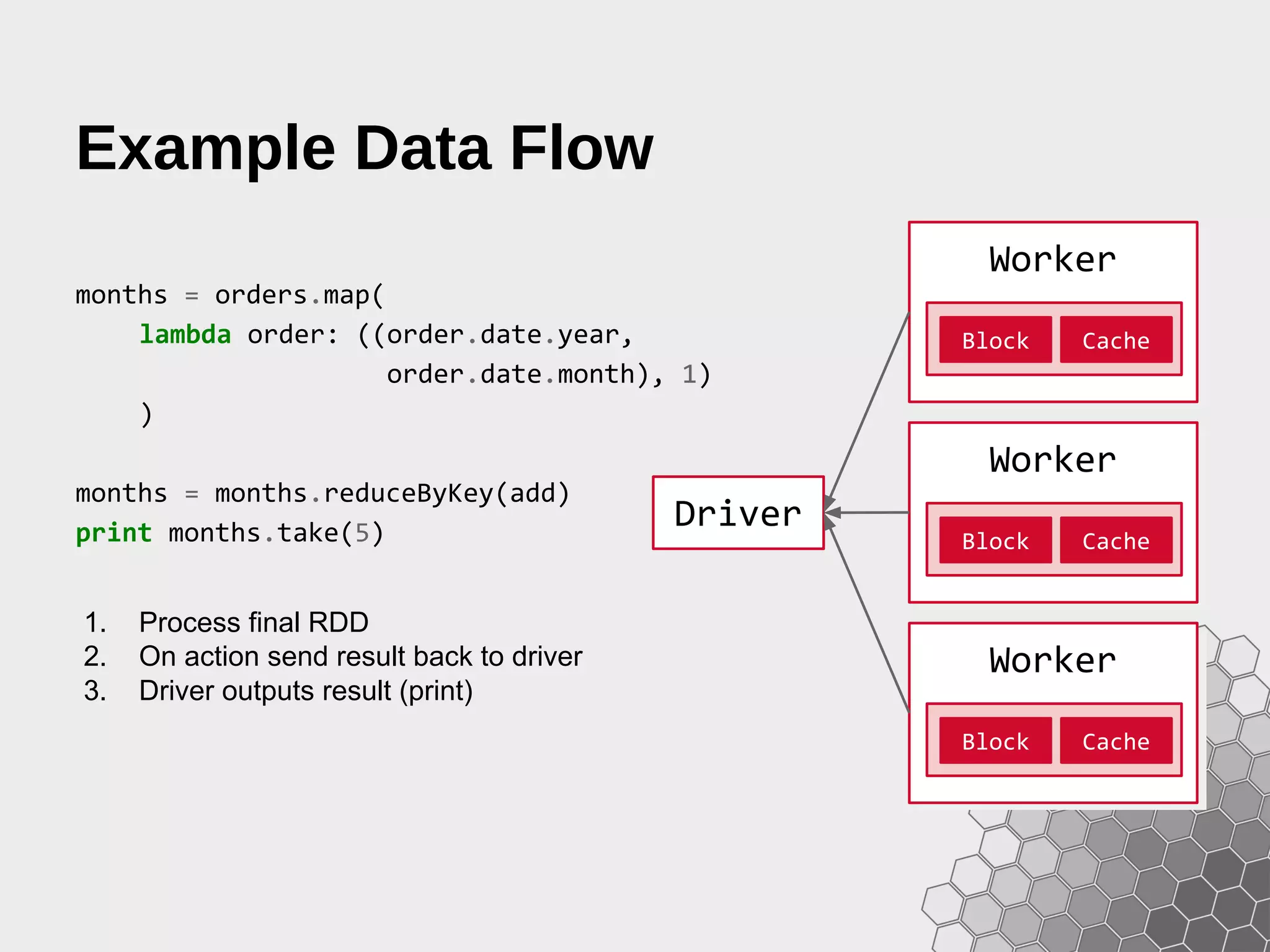
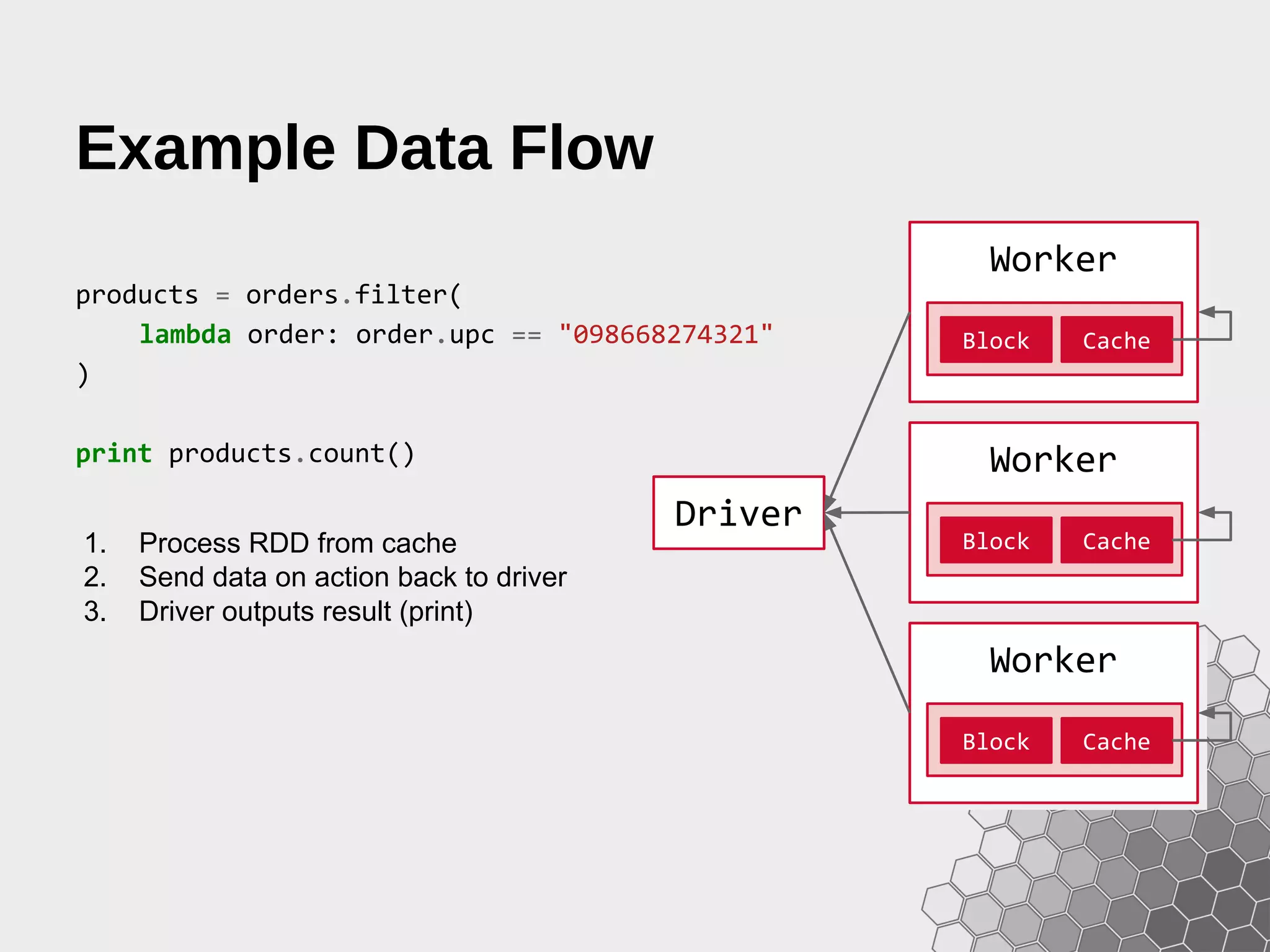
![Debugging Data Flow >>> print months.toDebugString() (9) PythonRDD[9] at RDD at PythonRDD.scala:43 | MappedRDD[8] at values at NativeMethodAccessorImpl.java:-2 | ShuffledRDD[7] at partitionBy at NativeMethodAccessorImpl.java:-2 +-(9) PairwiseRDD[6] at RDD at PythonRDD.scala:261 | PythonRDD[5] at RDD at PythonRDD.scala:43 | PythonRDD[2] at RDD at PythonRDD.scala:43 | orders.csv MappedRDD[1] at textFile | orders.csv HadoopRDD[0] at textFile Operator Graphs and Lineage can be shown with the toDebugString method, allowing a visual inspection of what is happening under the hood.](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-33-2048.jpg)







![Transformations Transformation Description distinct([numTasks])) Return a new dataset that contains the distinct elements of the source dataset. groupByKey([numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, Iterable<V>) pairs. reduceByKey(func, [numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, V) pairs where the values for each key are aggregated using the given reduce function func, which must be of type (V,V) => V. aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) When called on a dataset of (K, V) pairs, returns a dataset of (K, U) pairs where the values for each key are aggregated using the given combine functions and a neutral "zero" value. sortByKey([ascending], [numTasks]) When called on a dataset of (K, V) pairs where K implements Ordered, returns a dataset of (K, V) pairs sorted by keys in ascending or descending order.](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-43-2048.jpg)
![Transformations Transformation Description join(otherDataset, [numTasks]) When called on datasets of type (K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all pairs of elements for each key. Outer joins are supported through leftOuterJoin,rightOuterJoin, and fullOuterJoin. cogroup(otherDataset, [numTasks]) When called on datasets of type (K, V) and (K, W), returns a dataset of (K, Iterable<V>, Iterable<W>) tuples. This operation is also called groupWith. cartesian(otherDataset) When called on datasets of types T and U, returns a dataset of (T, U) pairs (all pairs of elements). pipe(command, [envVars]) Pipe each partition of the RDD through a shell command, e.g. a Perl or bash script. RDD elements are written to the process's stdin and lines output to its stdout are returned as an RDD of strings.](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-44-2048.jpg)



![Actions Action Description first() Return the first element of the dataset (similar to take(1)). take(n) Return an array with the first n elements of the dataset. Note that this is currently not executed in parallel. Instead, the driver program computes all the elements. takeSample(withReplacement,num, [seed]) Return an array with a random sample of num elements of the dataset, with or without replacement. takeOrdered(n, [ordering]) Return the first n elements of the RDD using either their natural order or a custom comparator. countByKey() Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. foreach(func) Run a function func on each element of the dataset.](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-48-2048.jpg)










![Parsing CSV data import csv from StringIO import StringIO # Read from CSV def load_csv(contents): return csv.reader(StringIO(contents[1])) data = sc.wholetextFiles("data/").flatMap(load_csv) # Write to CSV def write_csv(records): output = StringIO() writer = csv.writer() for record in records: writer.writerow(record) return [output.get_value()] data.mapPartitions(write_csv).saveAsTextFile("output/")](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-59-2048.jpg)
![Parsing Structured Objects import csv from datetime import datetime from StringIO import StringIO from collections import namedtuple DATE_FMT = "%Y-%m-%d %H:%M:%S" # 2013-09-16 12:23:33 Customer = namedtuple('Customer', ('id', 'name', 'registered')) def parse(row): row[0] = int(row[0]) # Parse ID to an integer row[4] = datetime.strptime(row[4], DATE_FMT) return Customer(*row) def split(line): reader = csv.reader(StringIO(line)) return reader.next() customers = sc.textFile("customers.csv").map(split).map(parse)](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-60-2048.jpg)
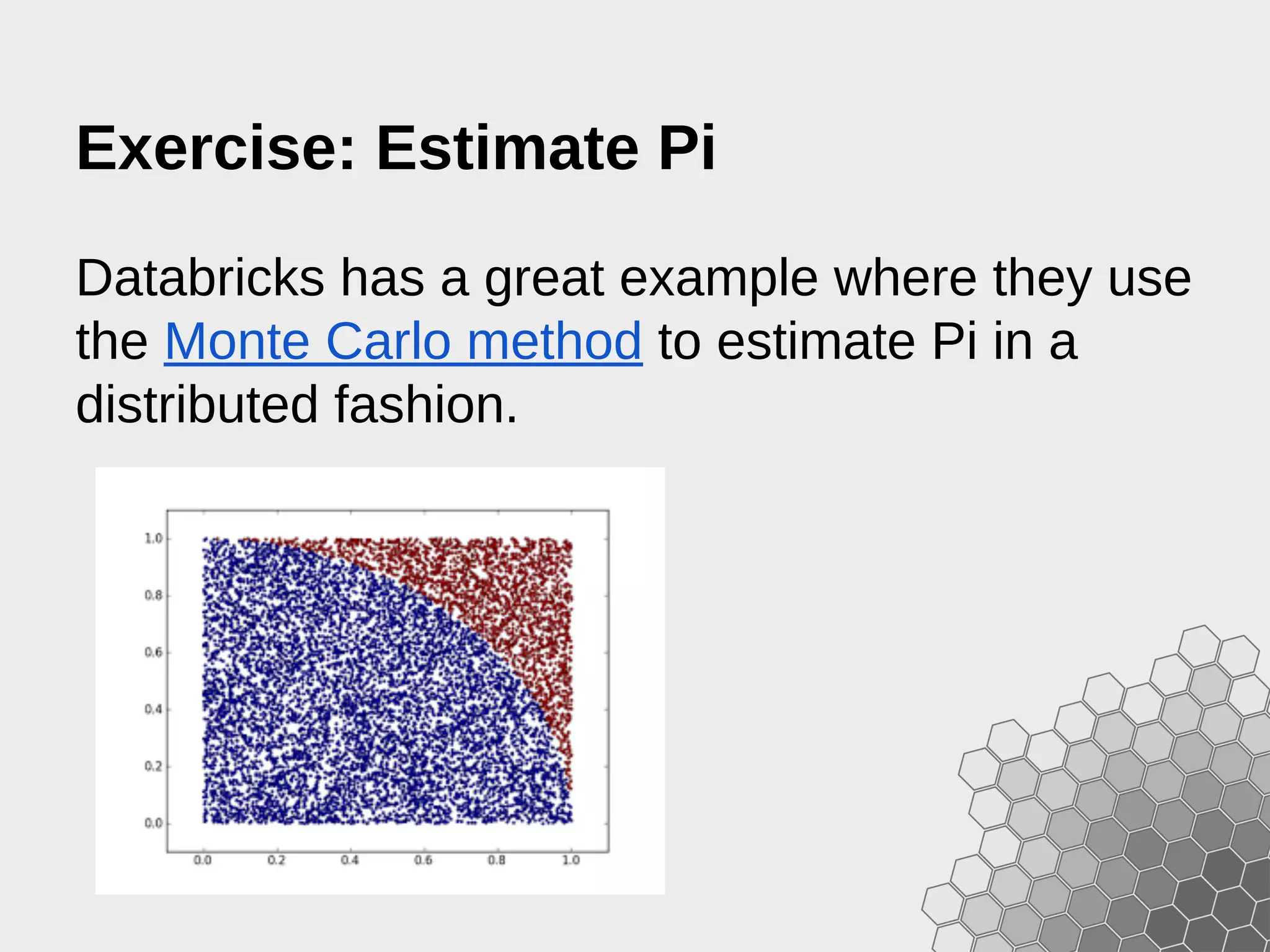
![import sys import random from operator import add from pyspark import SparkConf, SparkContext def estimate(idx): x = random.random() * 2 - 1 y = random.random() * 2 - 1 return 1 if (x*x + y*y < 1) else 0 def main(sc, *args): slices = int(args[0]) if len(args) > 0 else 2 N = 100000 * slices count = sc.parallelize(xrange(N), slices).map(estimate) count = count.reduce(add) print "Pi is roughly %0.5f" % (4.0 * count / N) sc.stop() if __name__ == '__main__': conf = SparkConf().setAppName("Estimate Pi") sc = SparkContext(conf=conf) main(sc, *sys.argv[1:])](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-62-2048.jpg)




![import csv from StringIO import StringIO from pyspark import SparkConf, SparkContext from pyspark.sql import SQLContext, Row def split(line): return csv.reader(StringIO(line)).next() def main(sc, sqlc): rows = sc.textFile("fixtures/shopping/customers.csv").map(split) customers = rows.map(lambda c: Row(id=int(c[0]), name=c[1], state=c[6])) # Infer the schema and register the SchemaRDD schema = sqlc.inferSchema(customers).registerTempTable("customers") maryland = sqlc.sql("SELECT name FROM customers WHERE state = 'Maryland'") print maryland.count() if __name__ == '__main__': conf = SparkConf().setAppName("Query Customers") sc = SparkContext(conf=conf) sqlc = SQLContext(sc) main(sc, sqlc)](https://image.slidesharecdn.com/fastdataanalyticswithsparkandpython-150207060921-conversion-gate02/75/Fast-Data-Analytics-with-Spark-and-Python-67-2048.jpg)








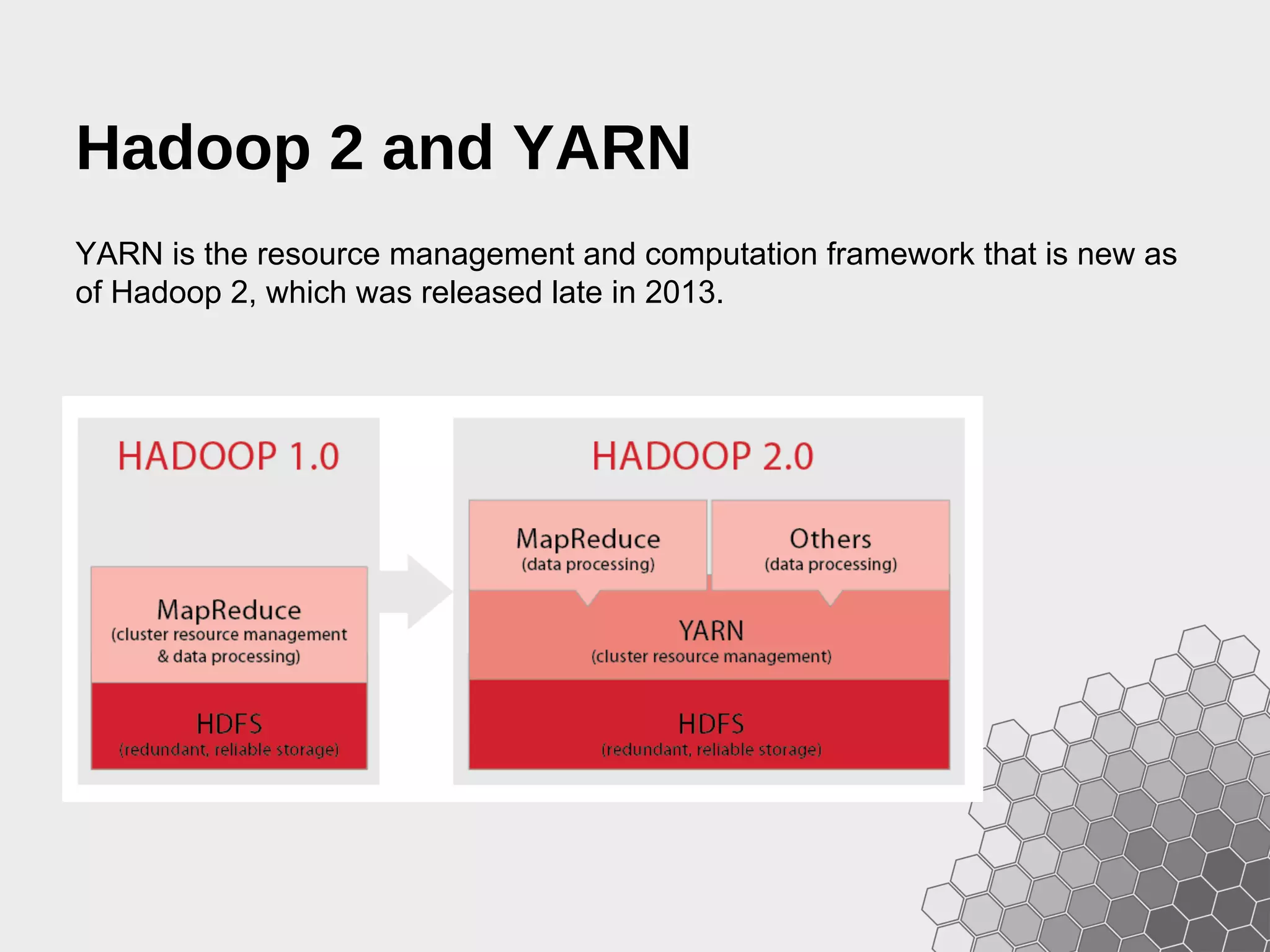
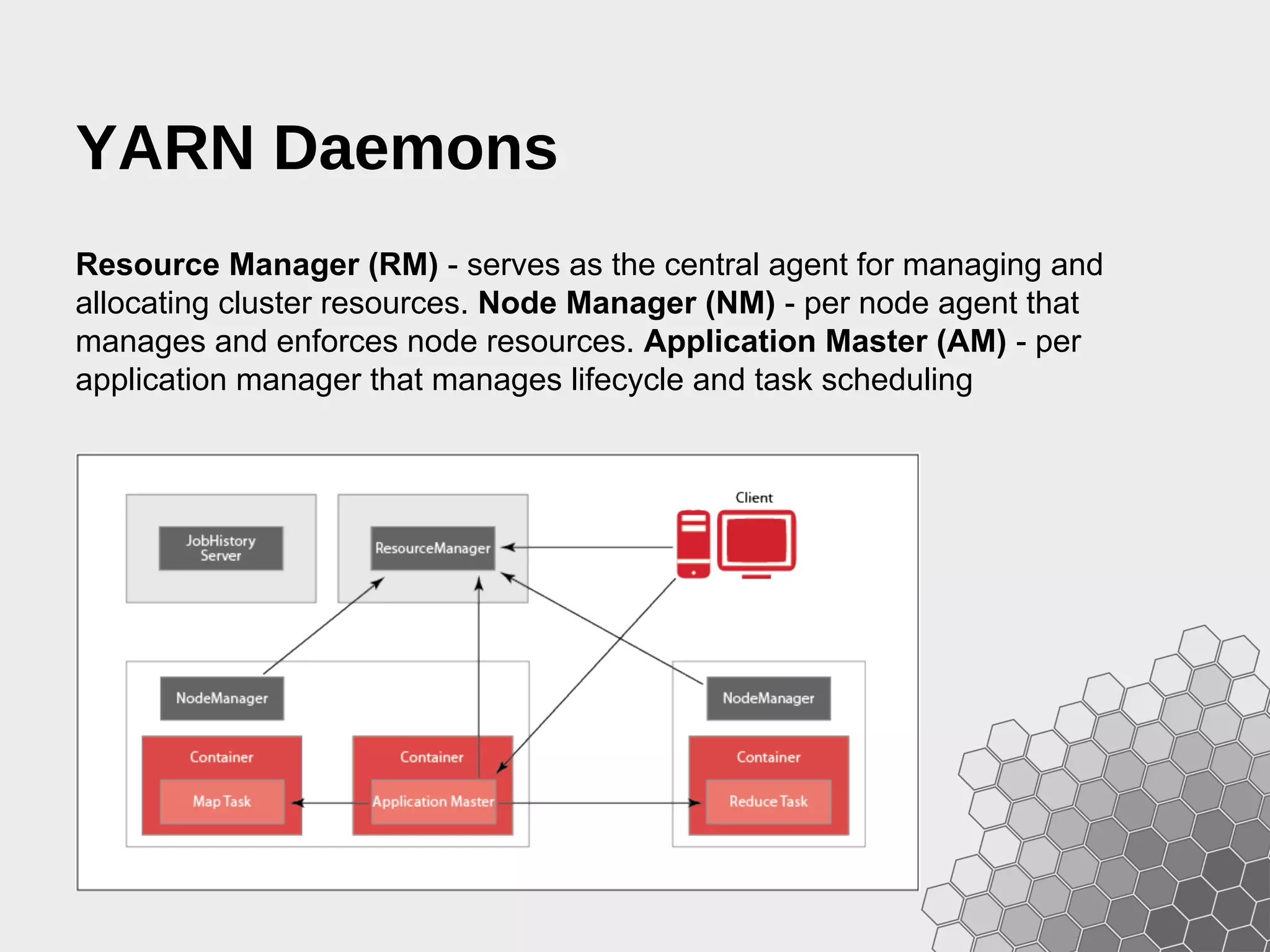
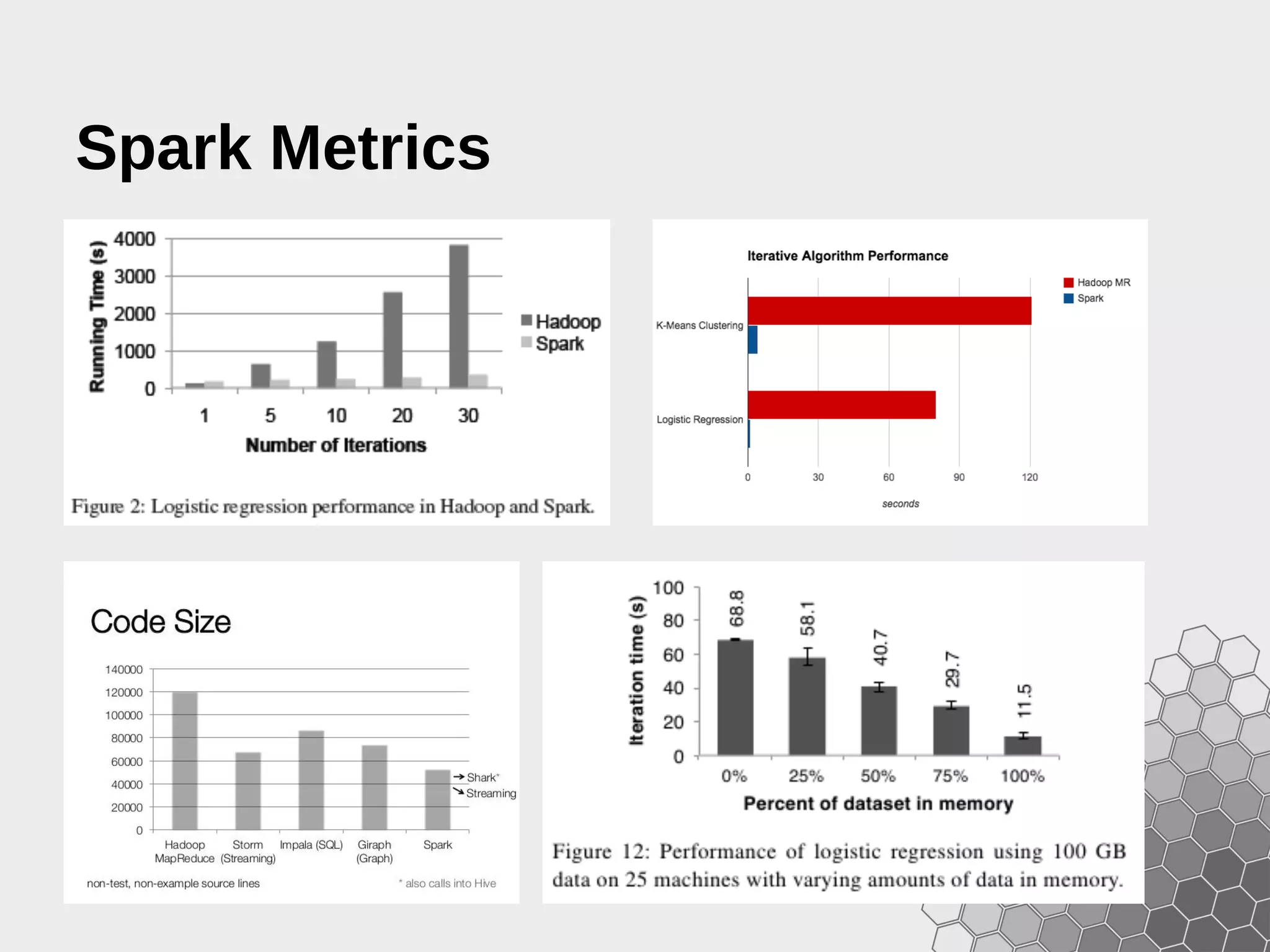
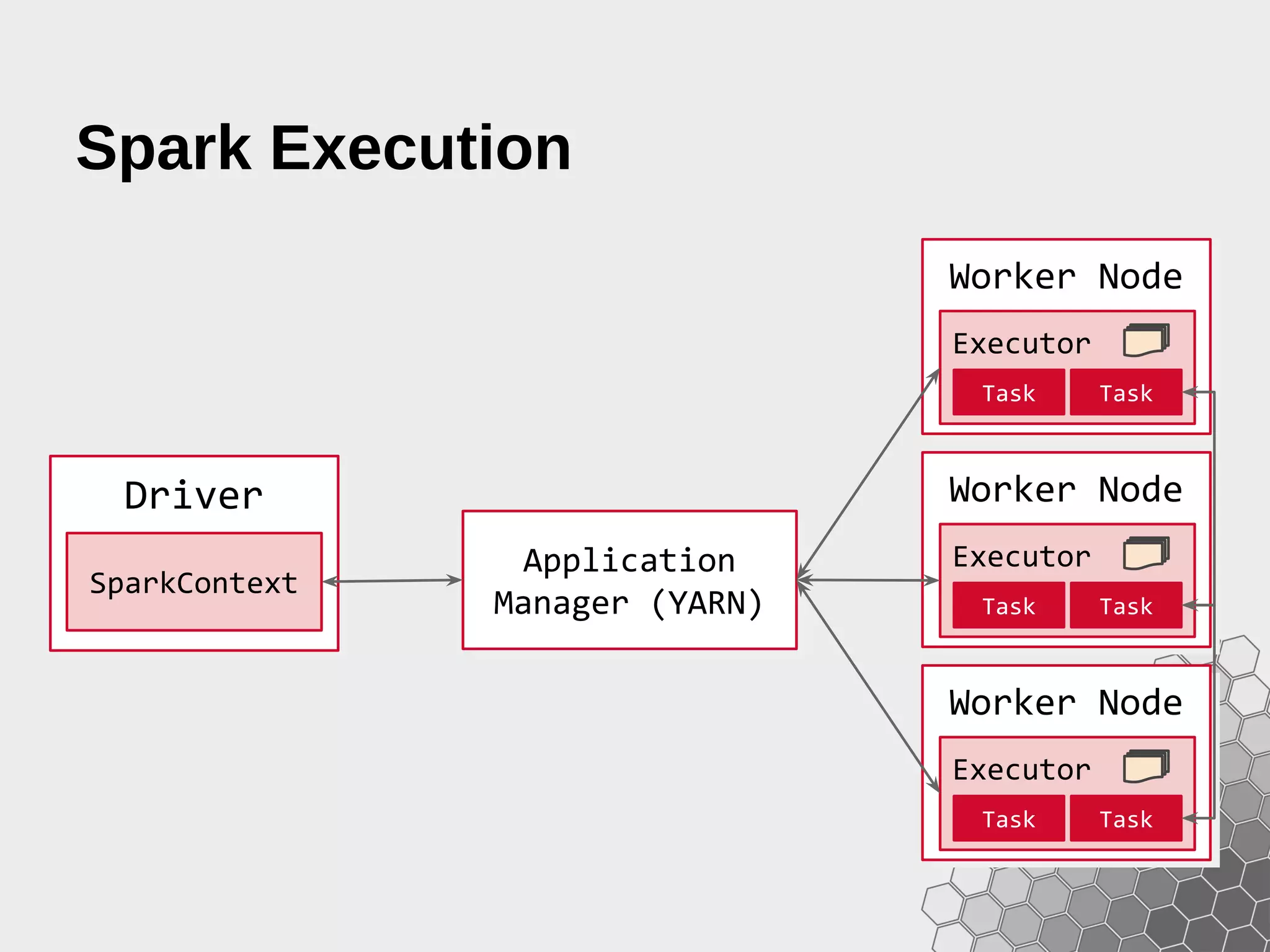
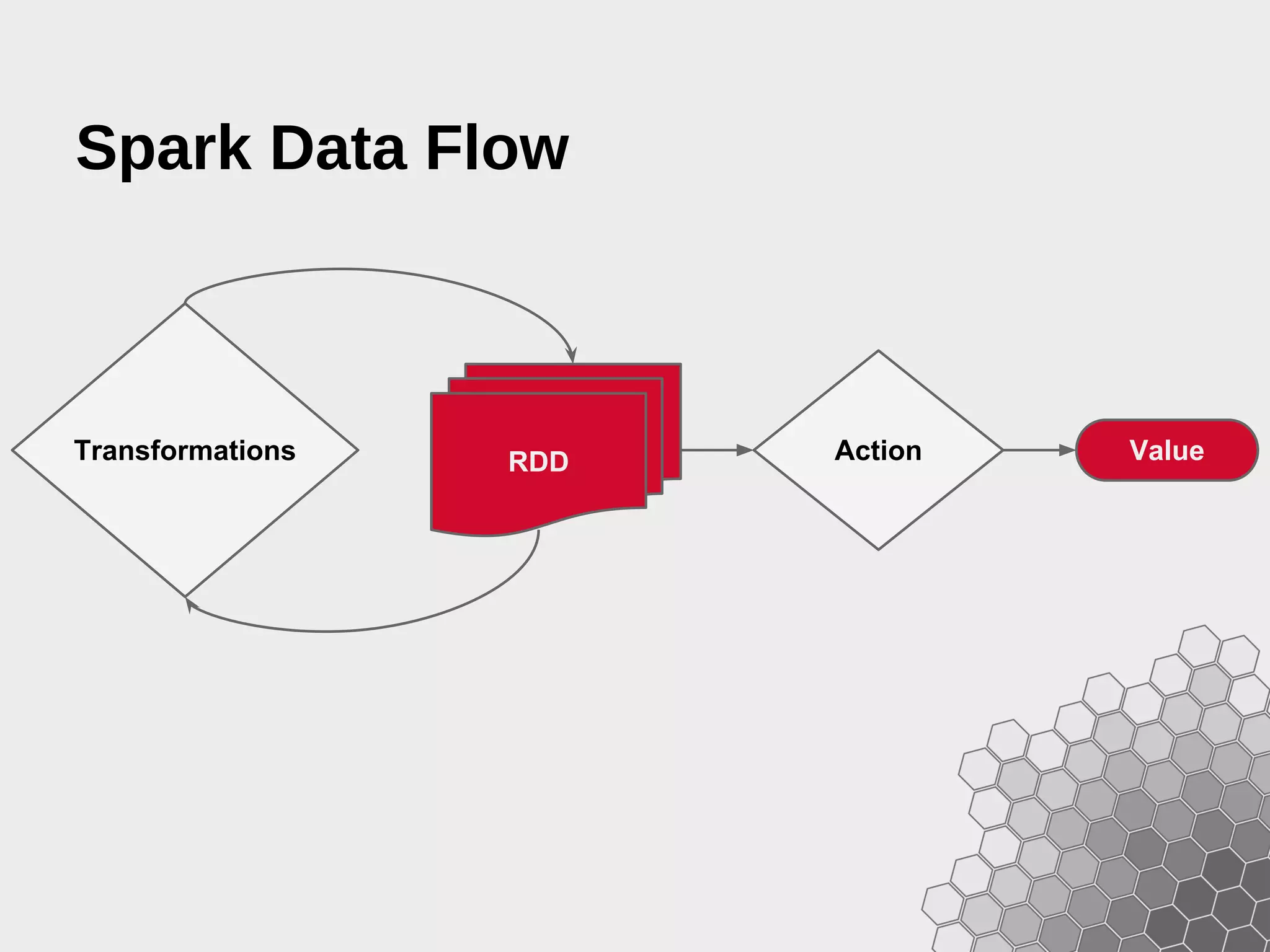
The document provides a comprehensive guide to fast data analytics using Spark and Python (PySpark), detailing installation instructions, the underlying architecture of Spark, its components like Resilient Distributed Datasets (RDDs), and how to write Spark applications. It explains advanced concepts such as execution models, data flow management, and the benefits of Spark over traditional MapReduce frameworks. Additionally, it includes practical examples and programming models for creating and managing RDDs, as well as operations like transformations and actions.