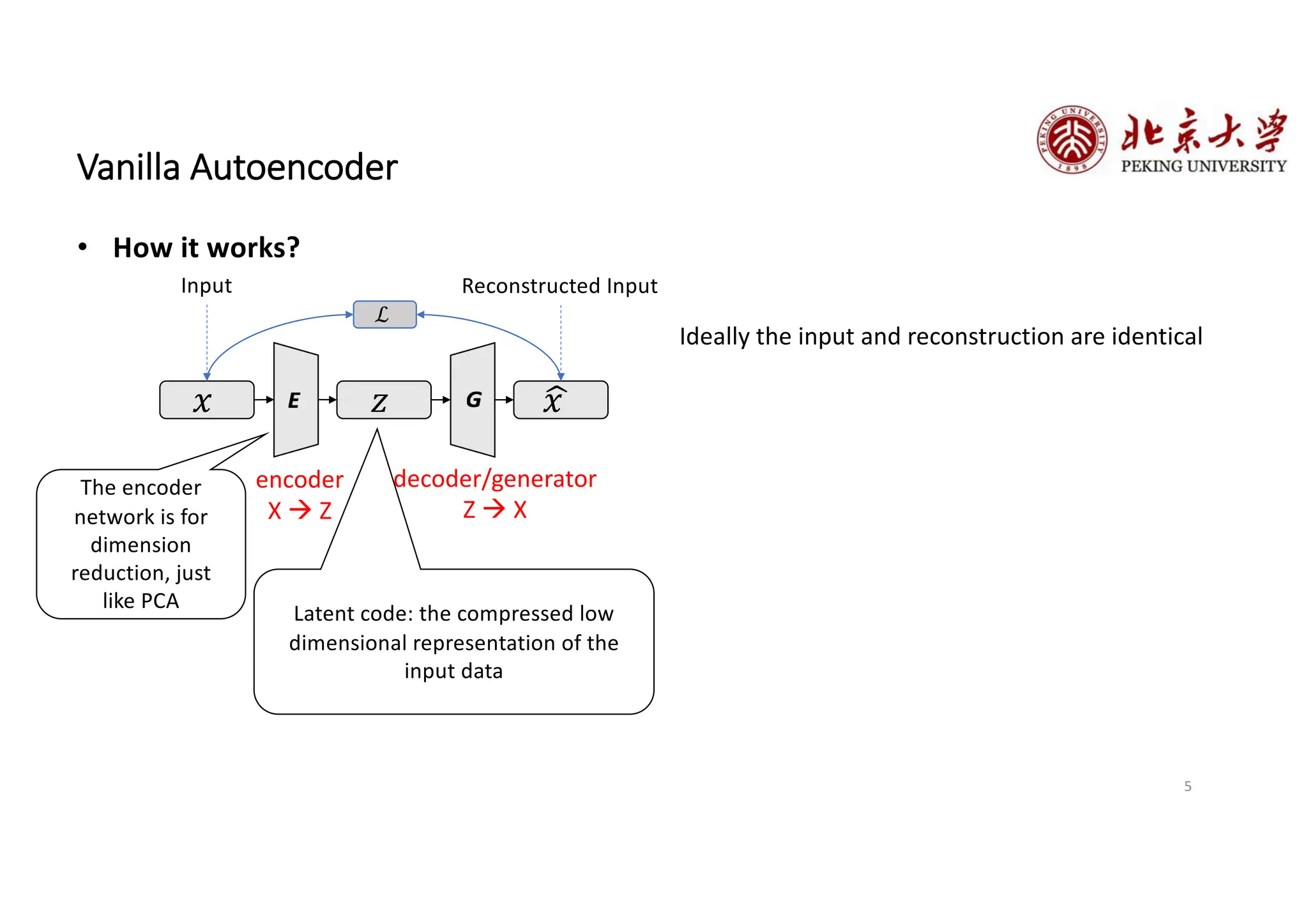
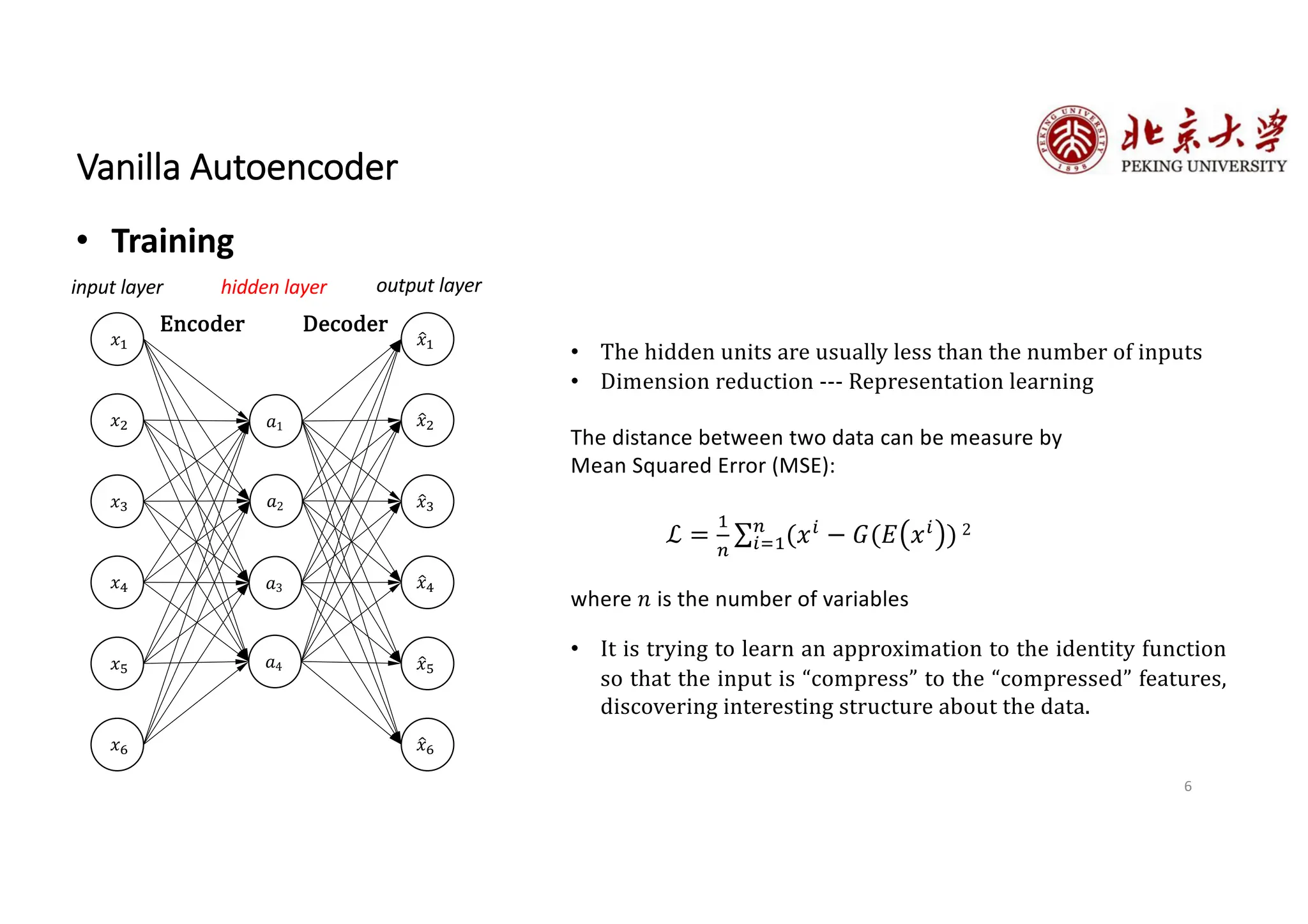
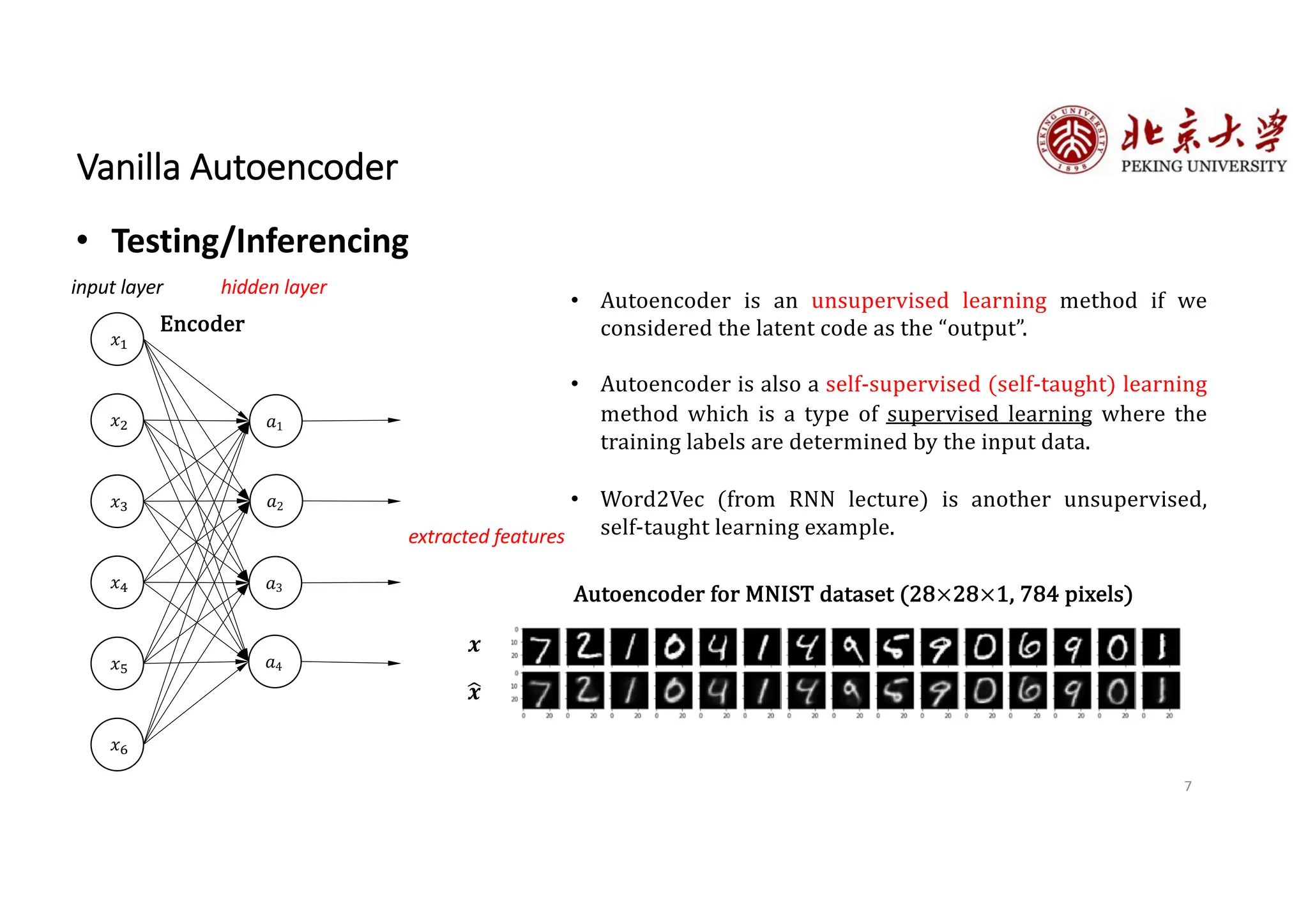
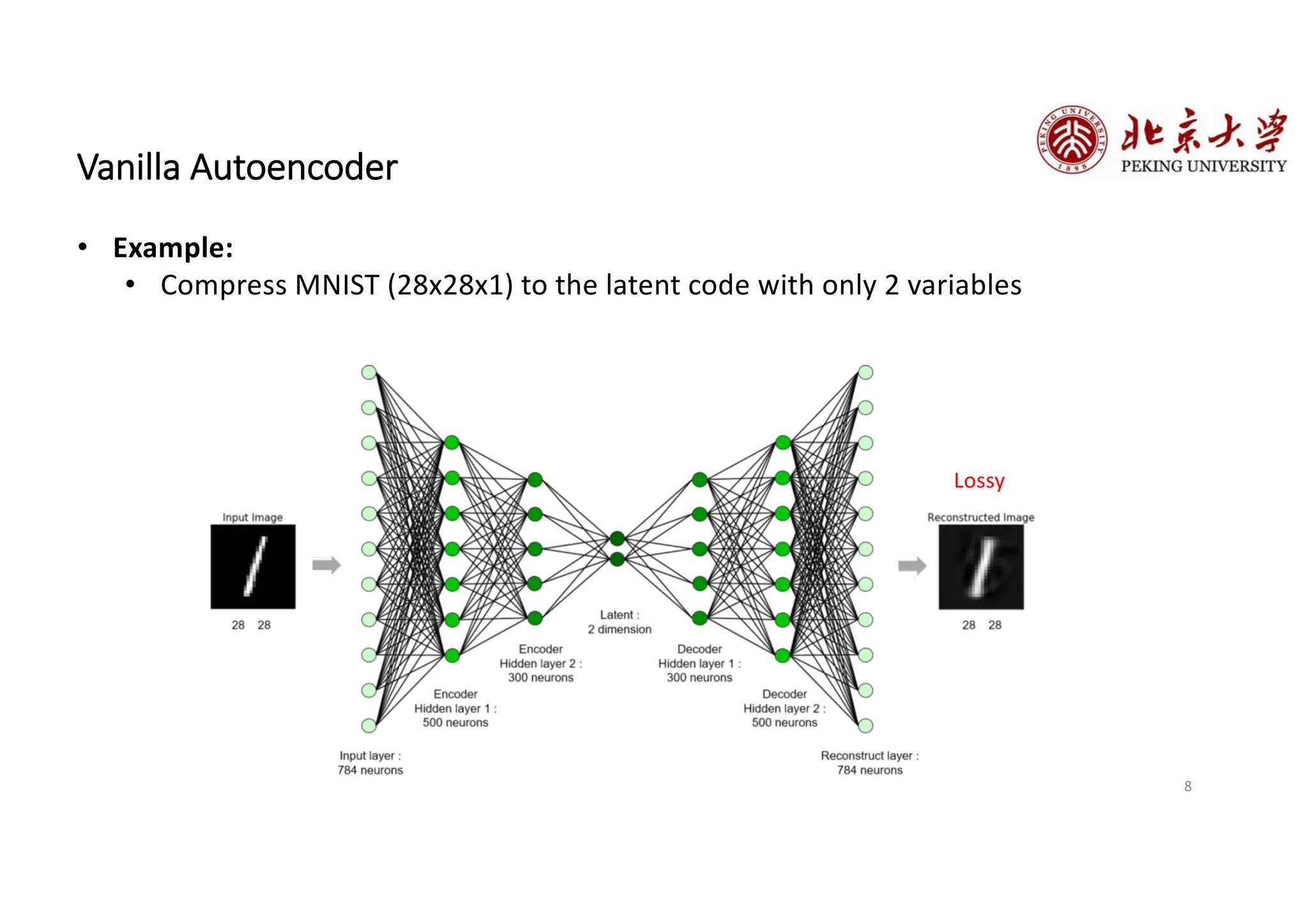
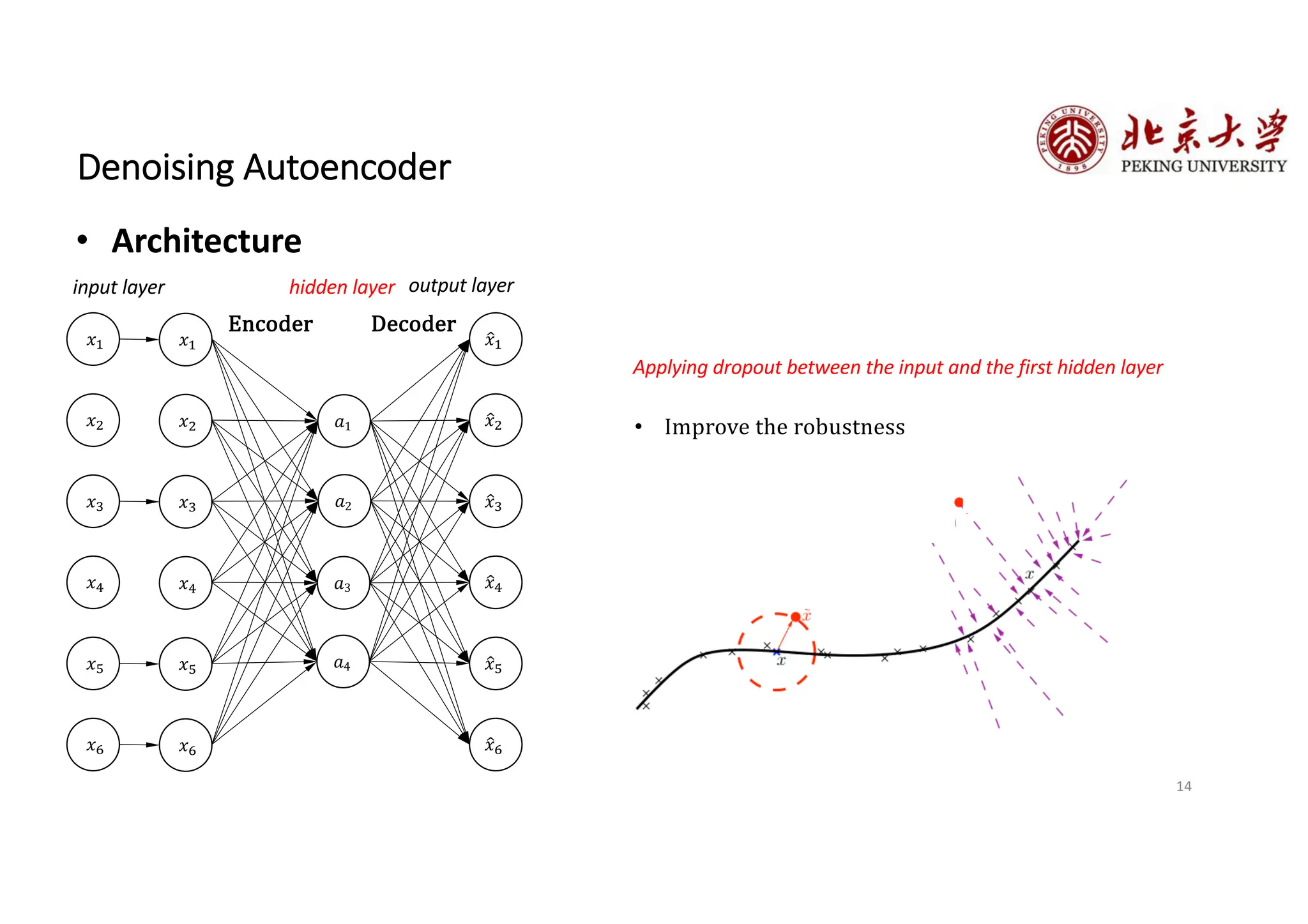
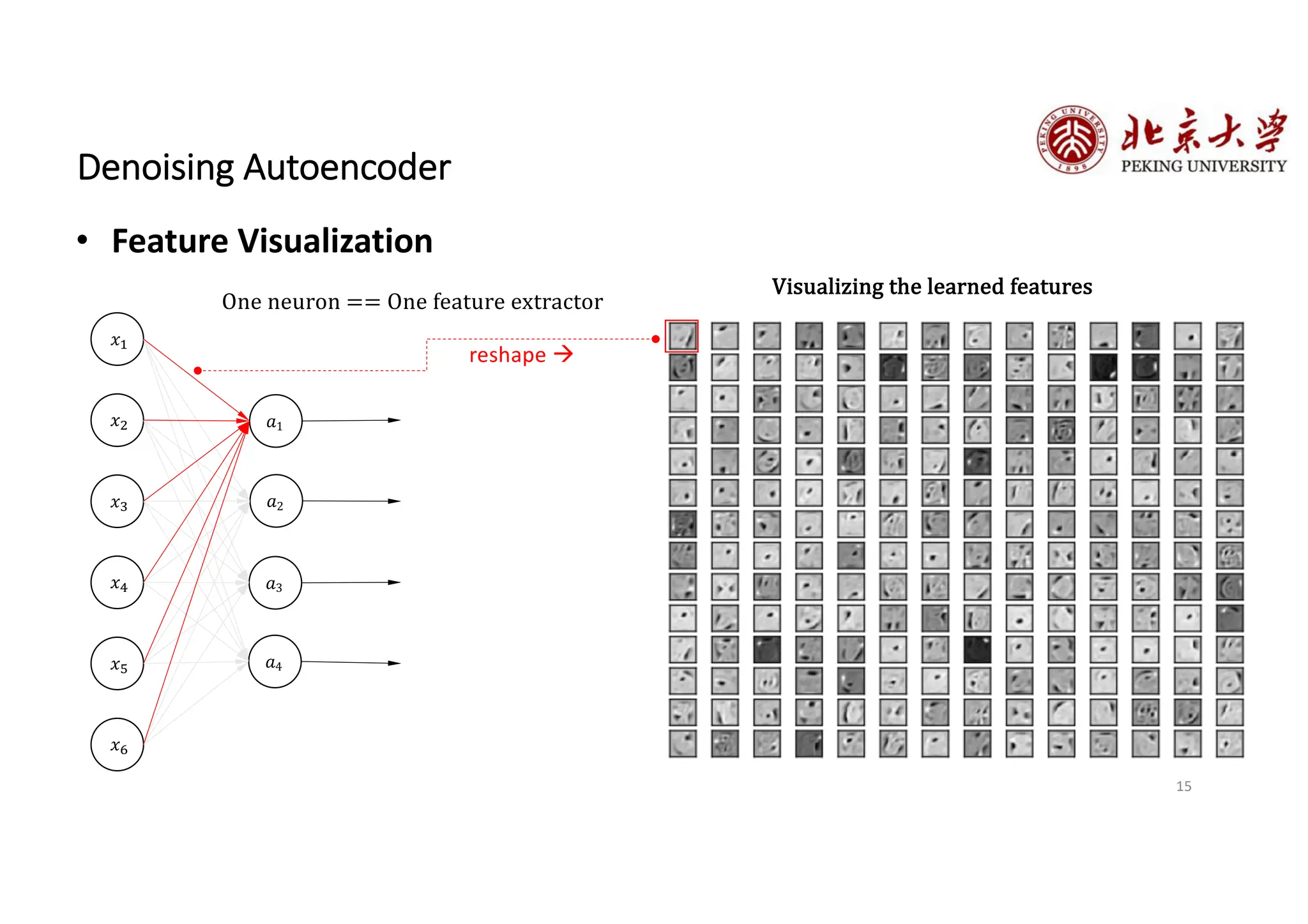
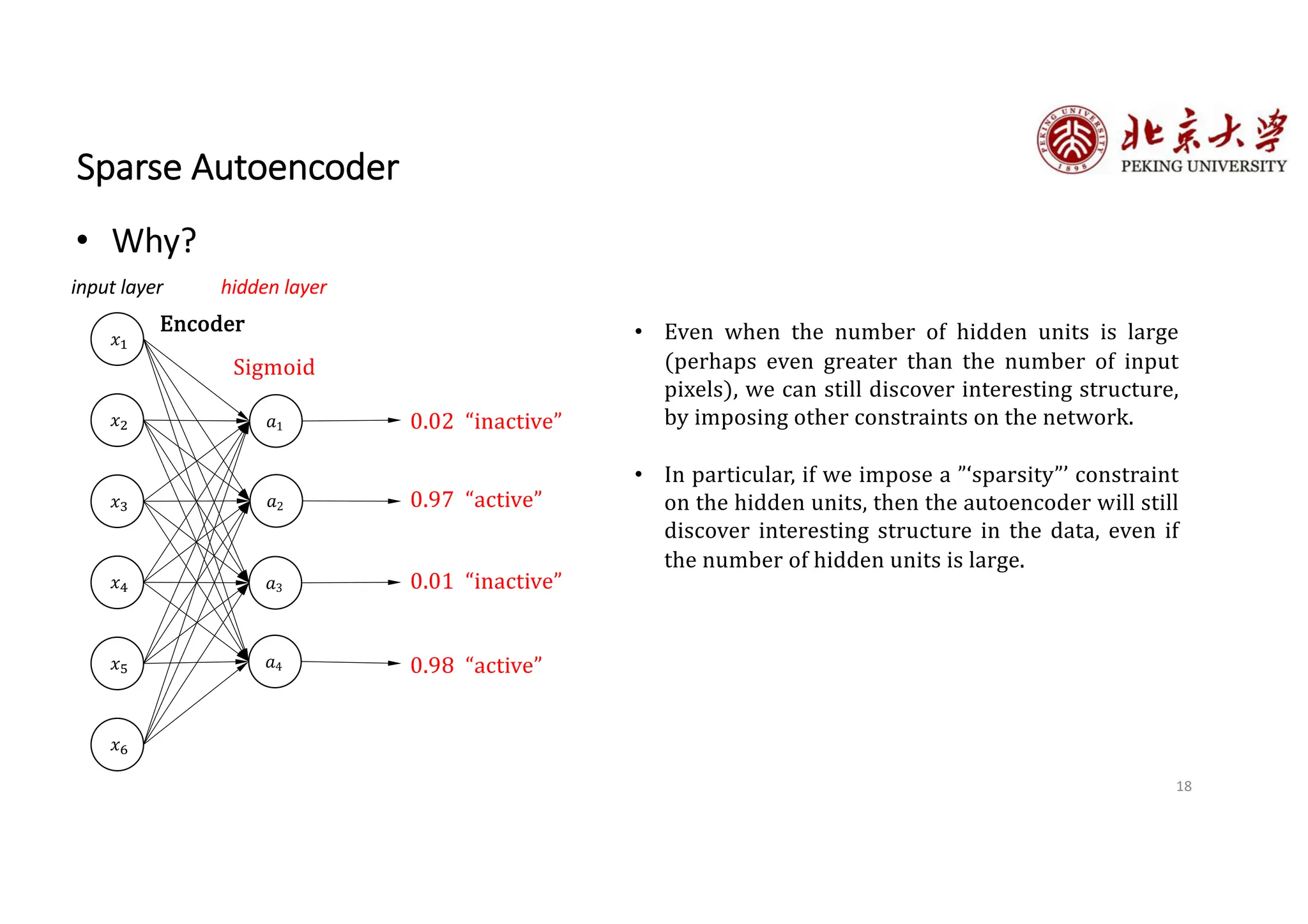
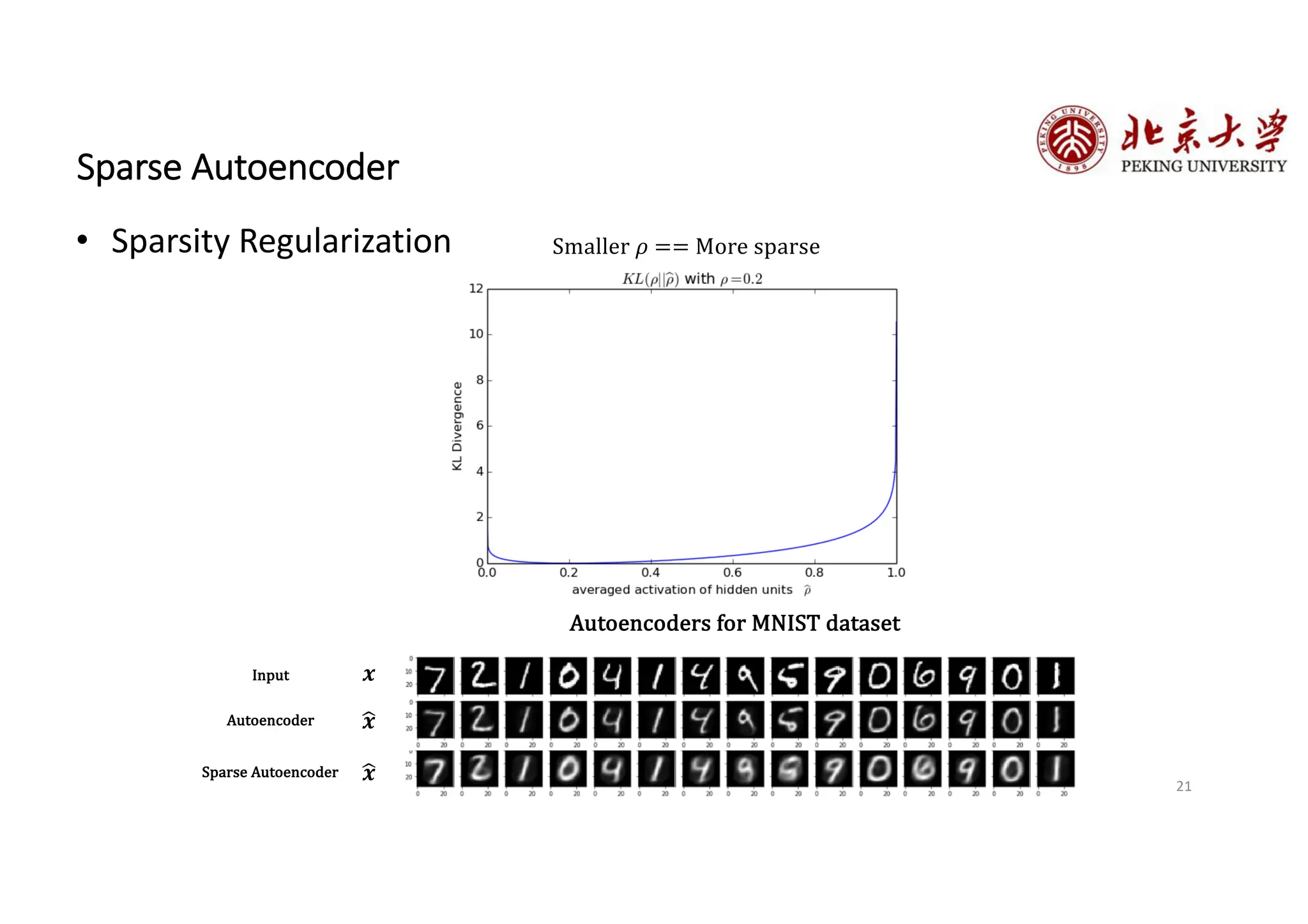
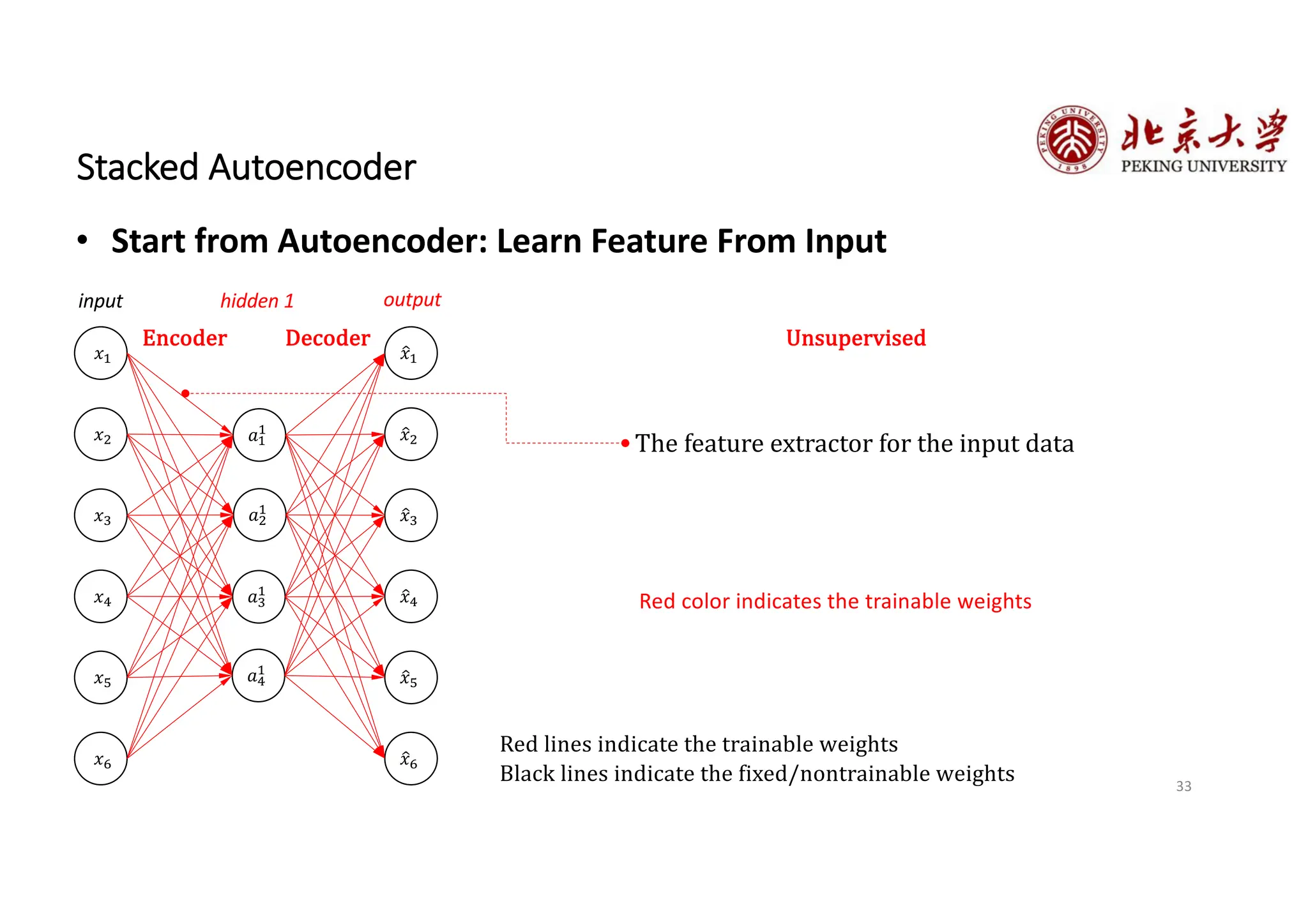
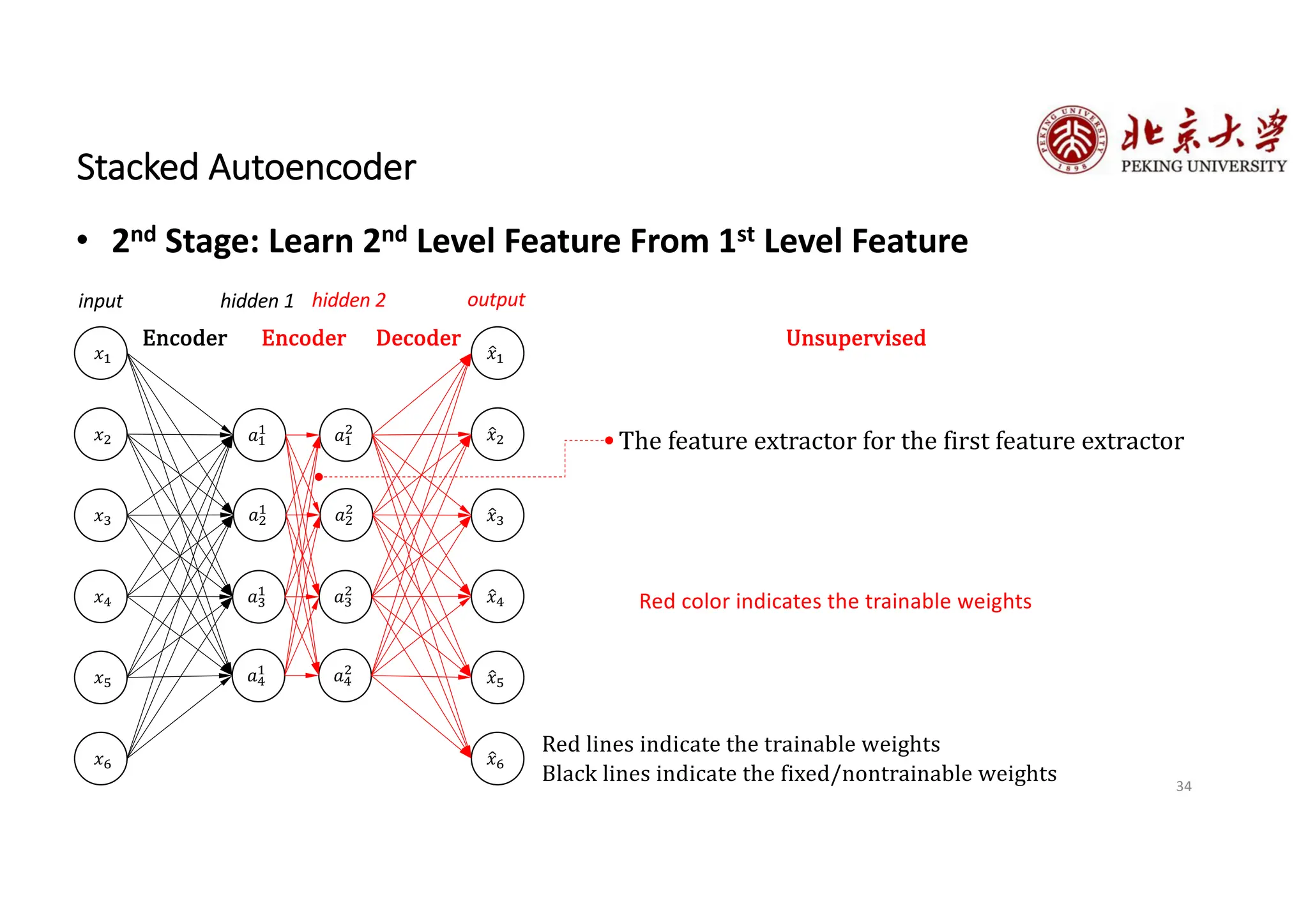
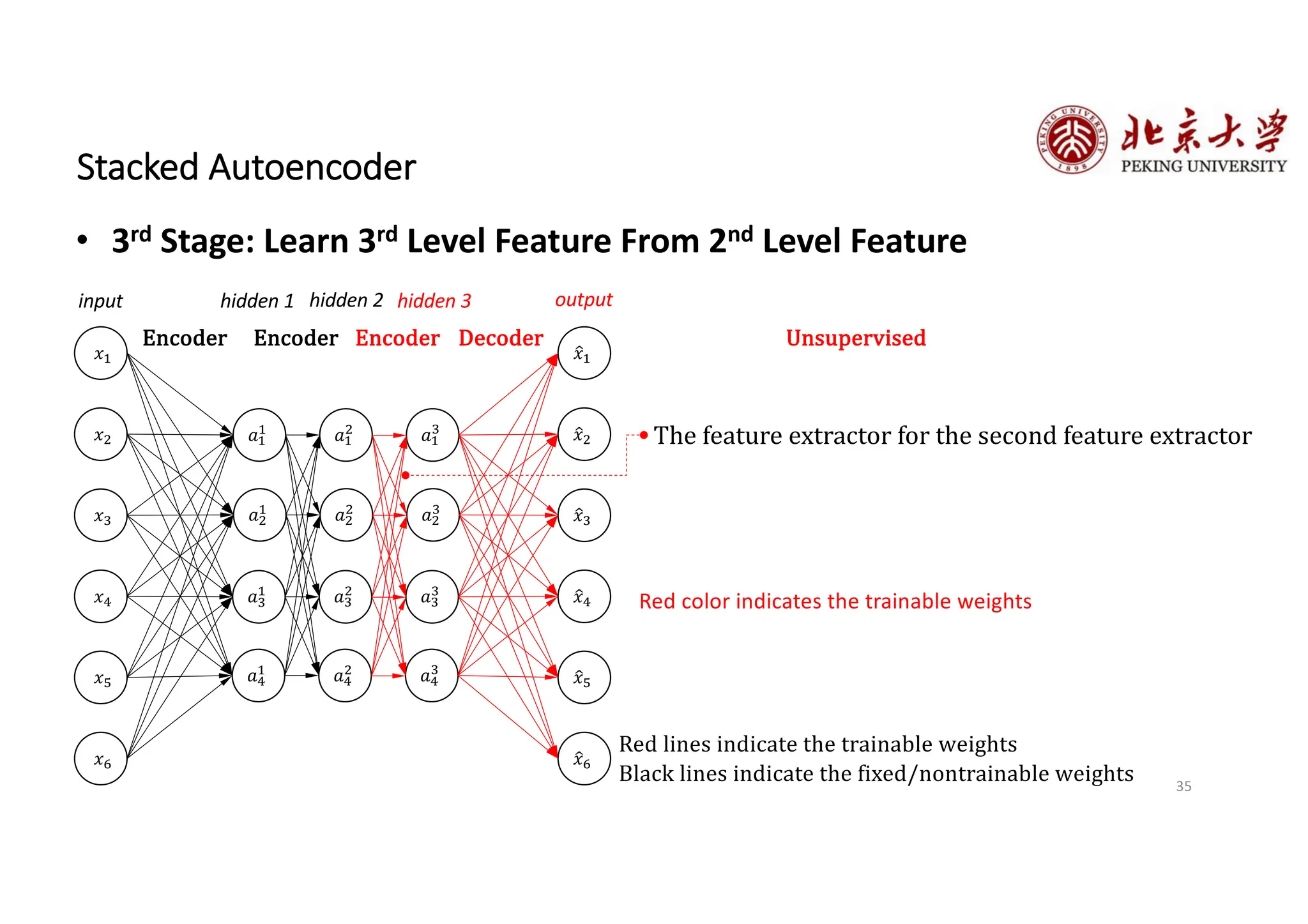
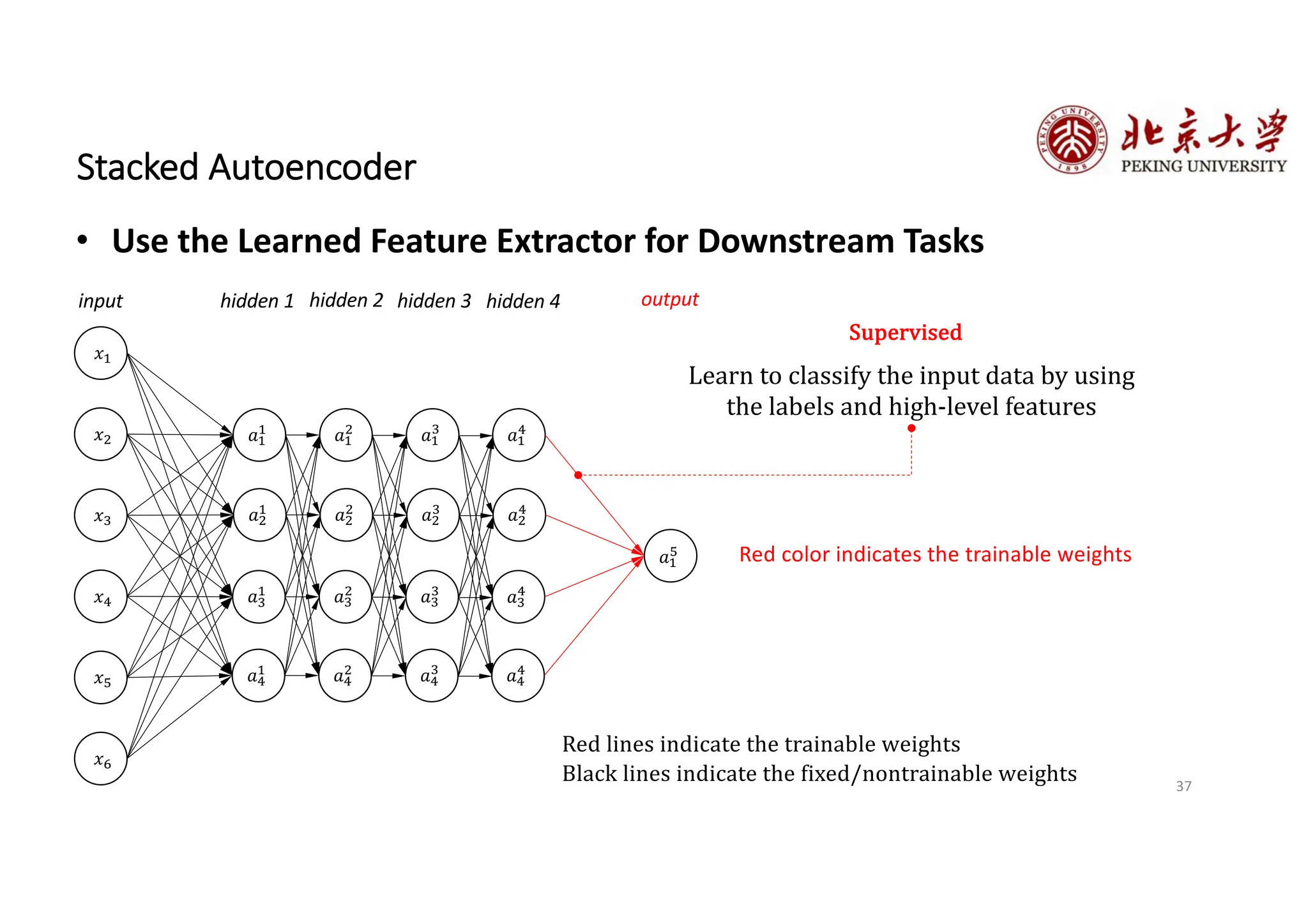
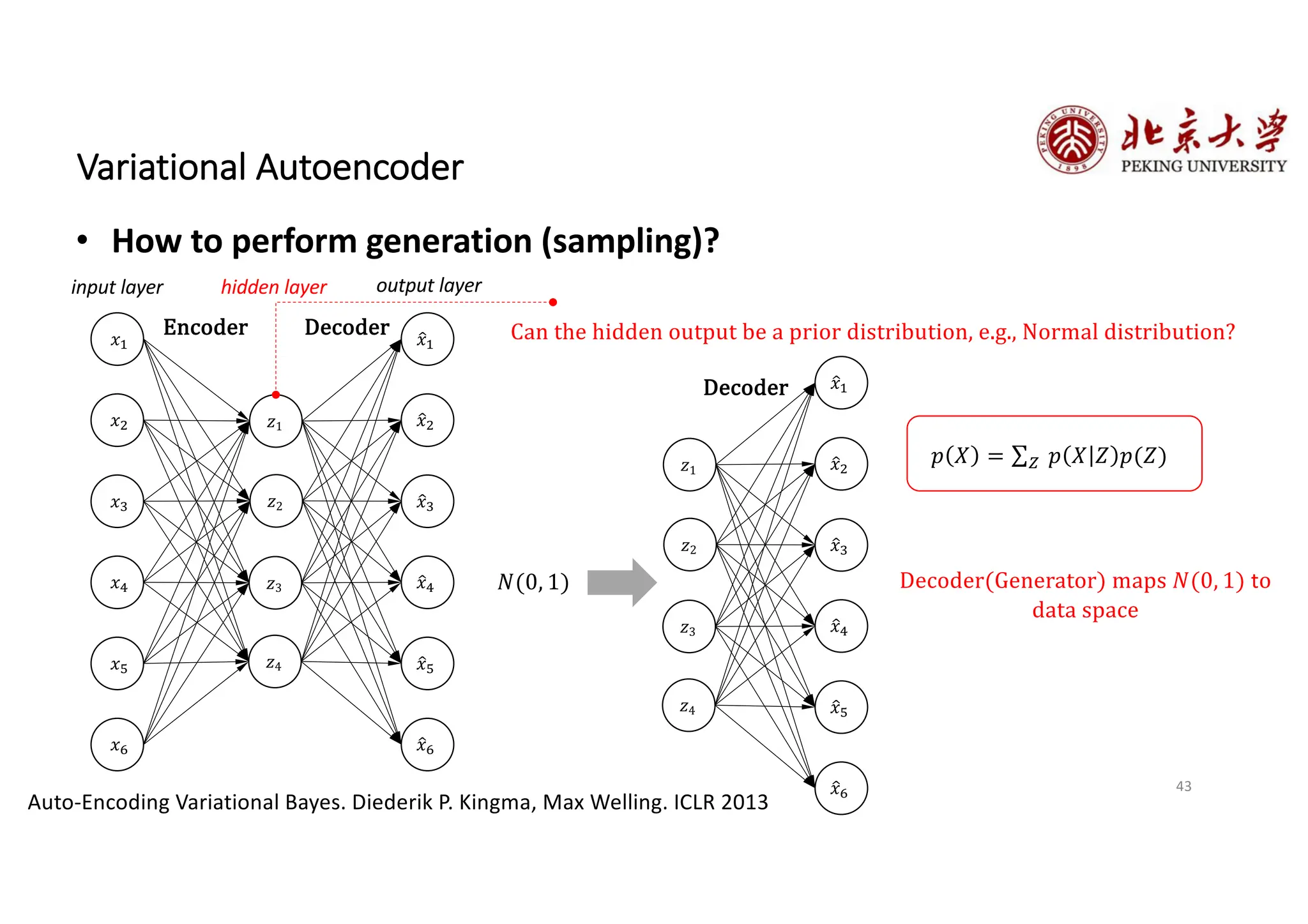
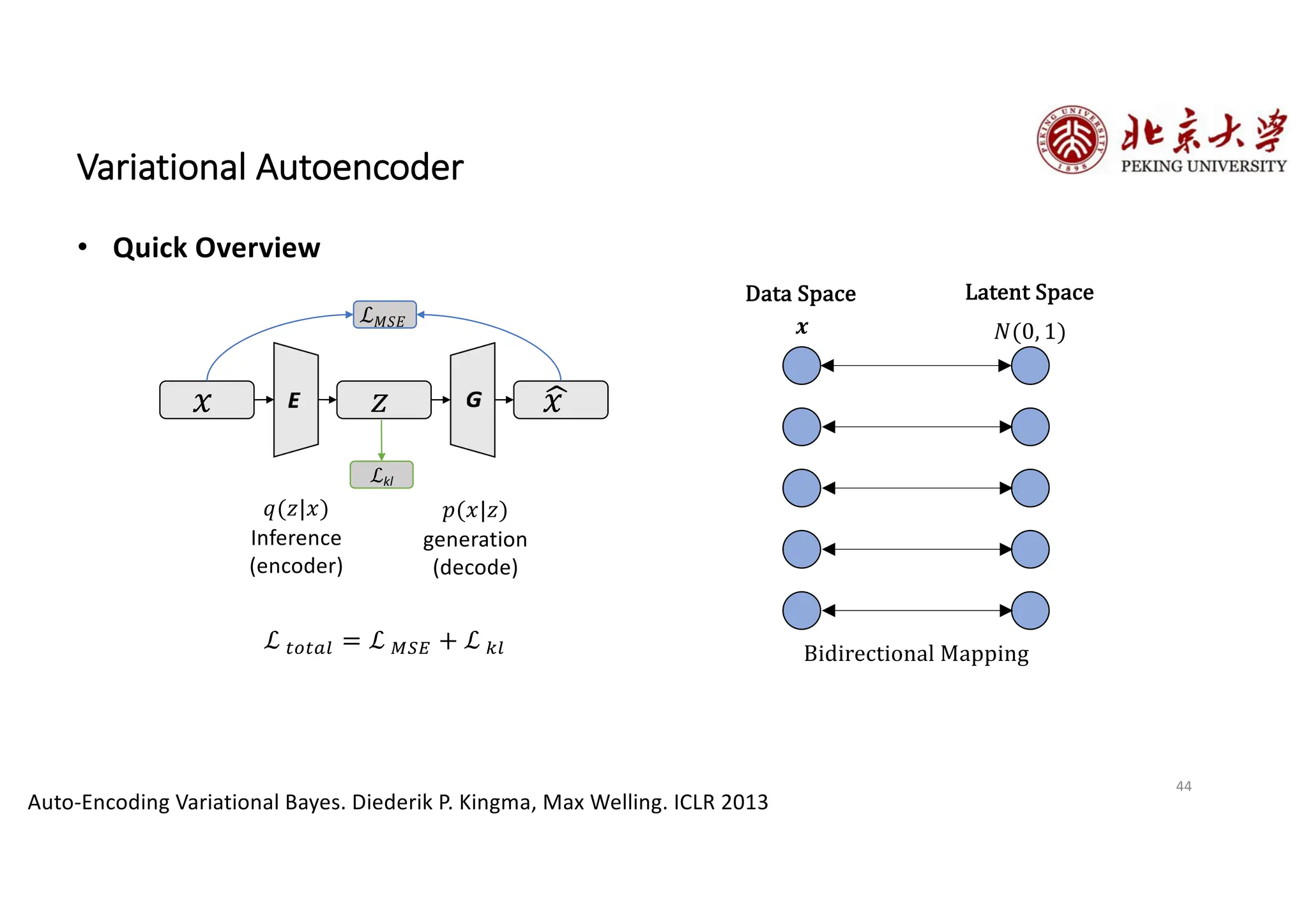
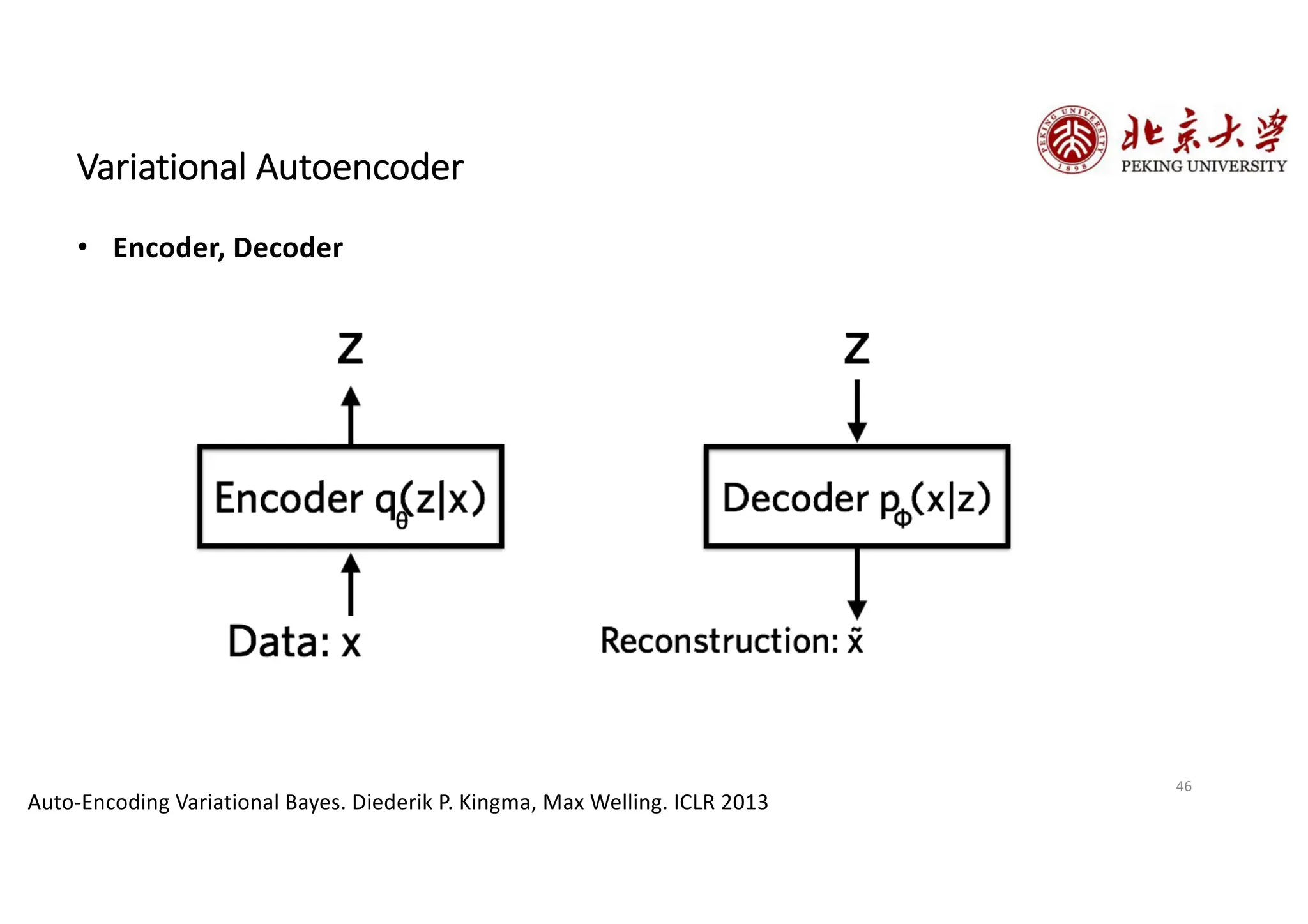
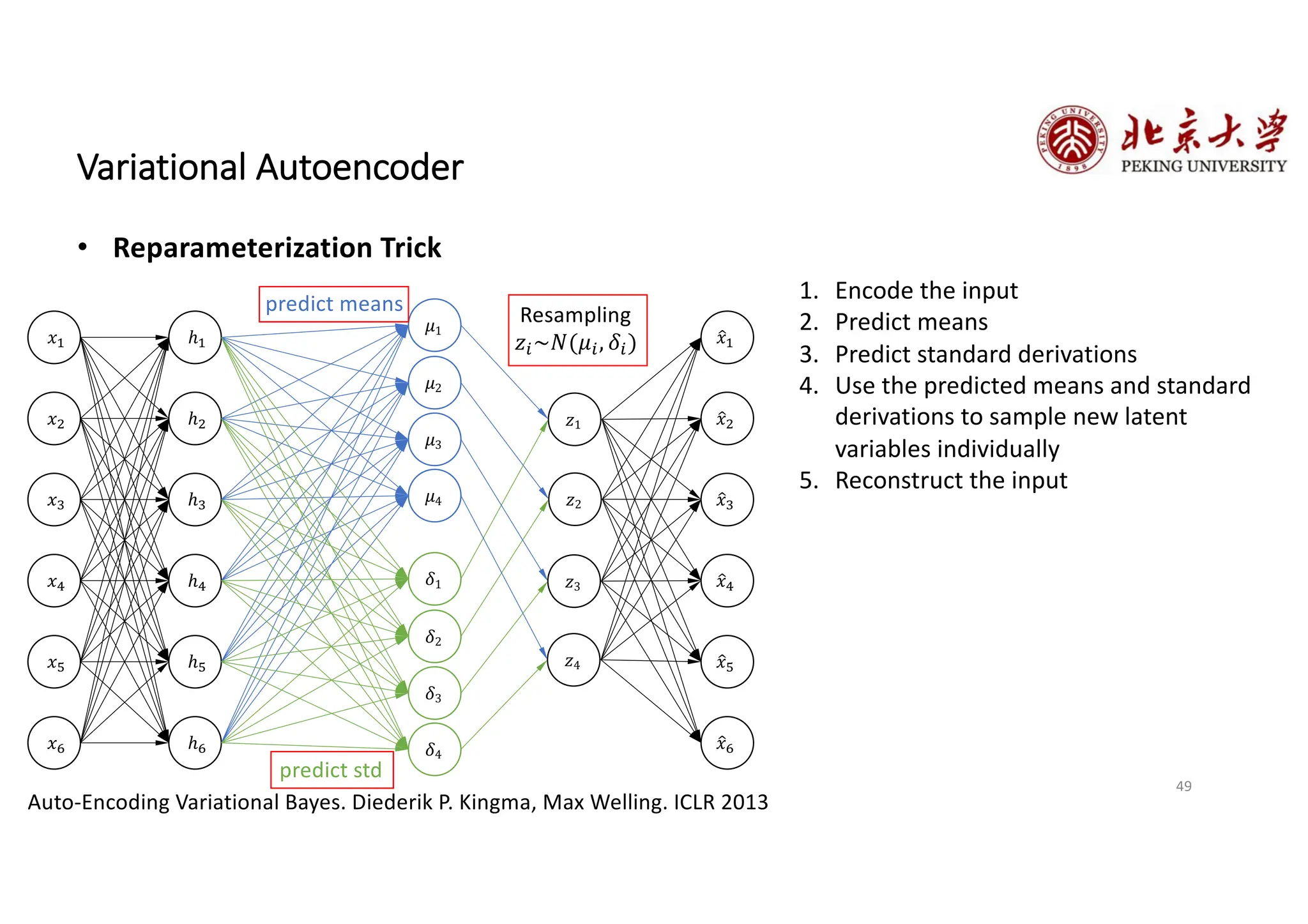
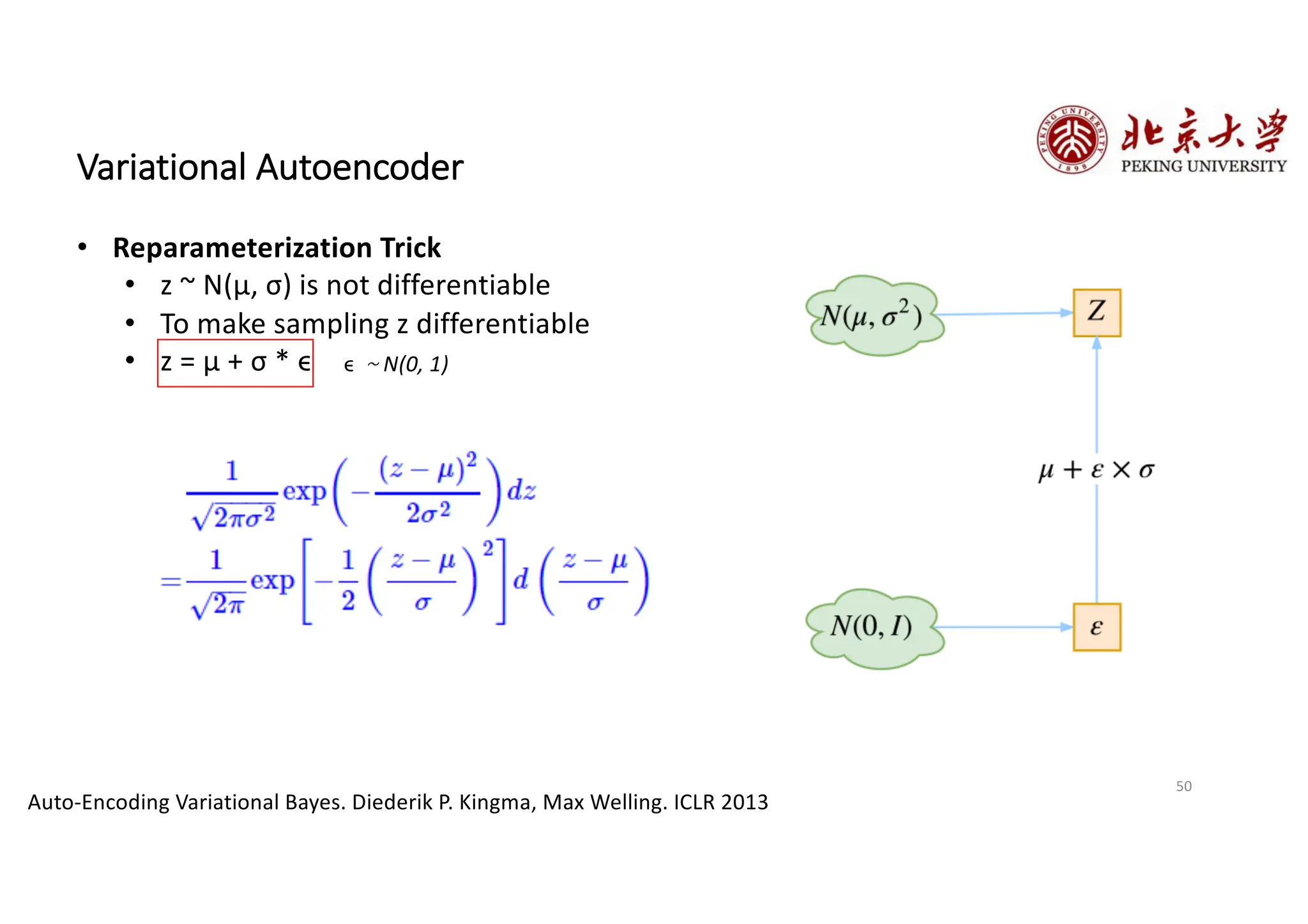
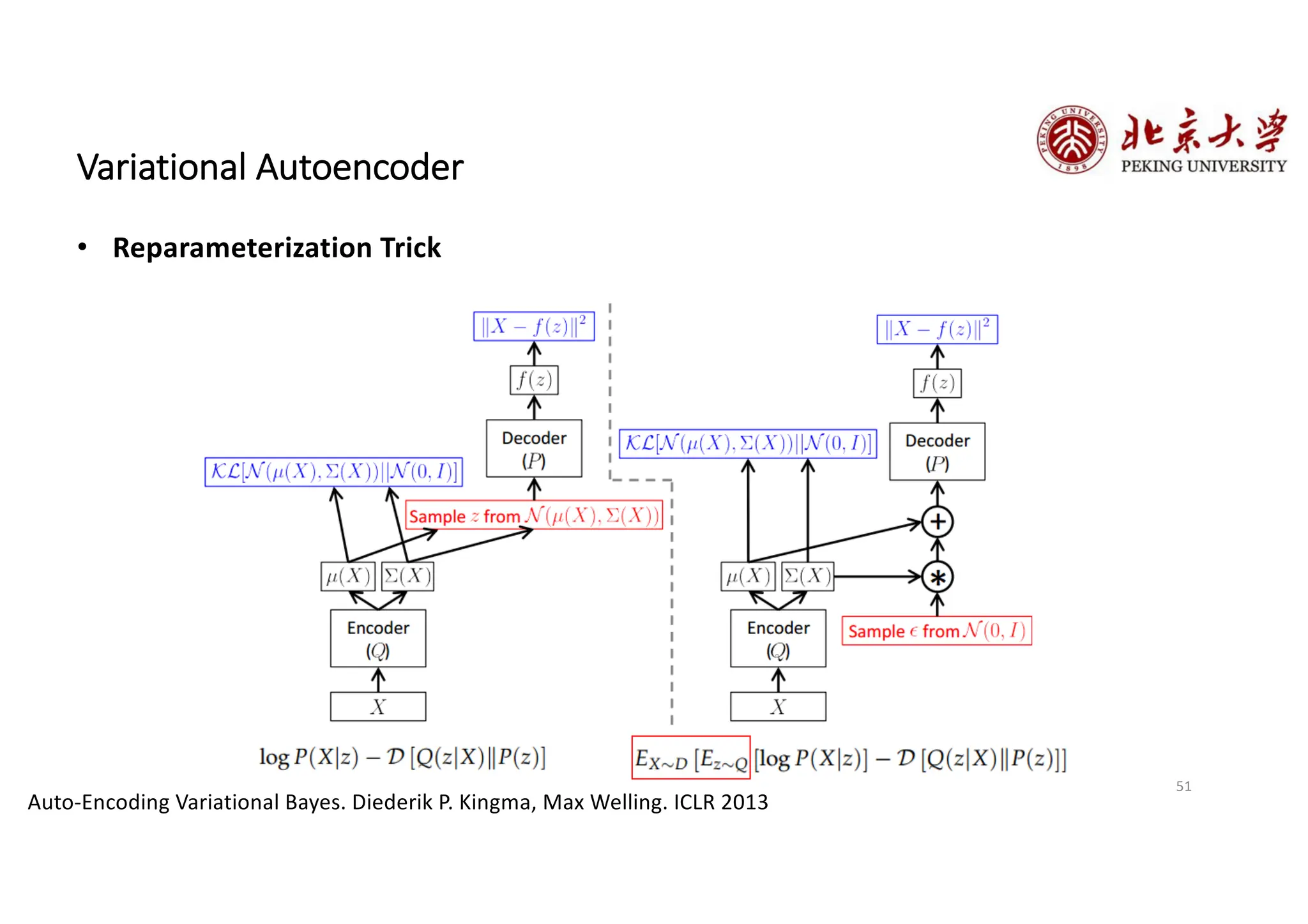
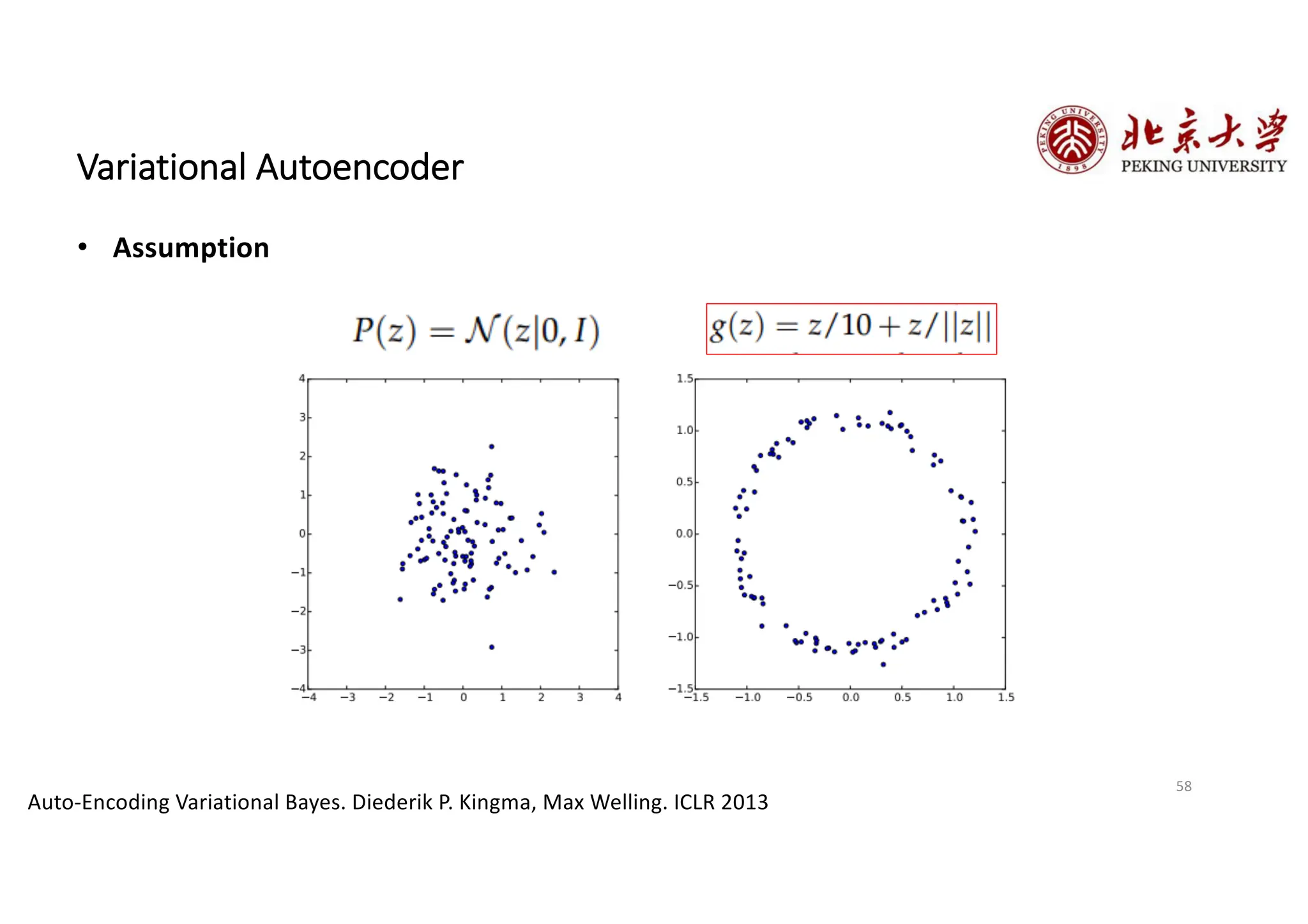
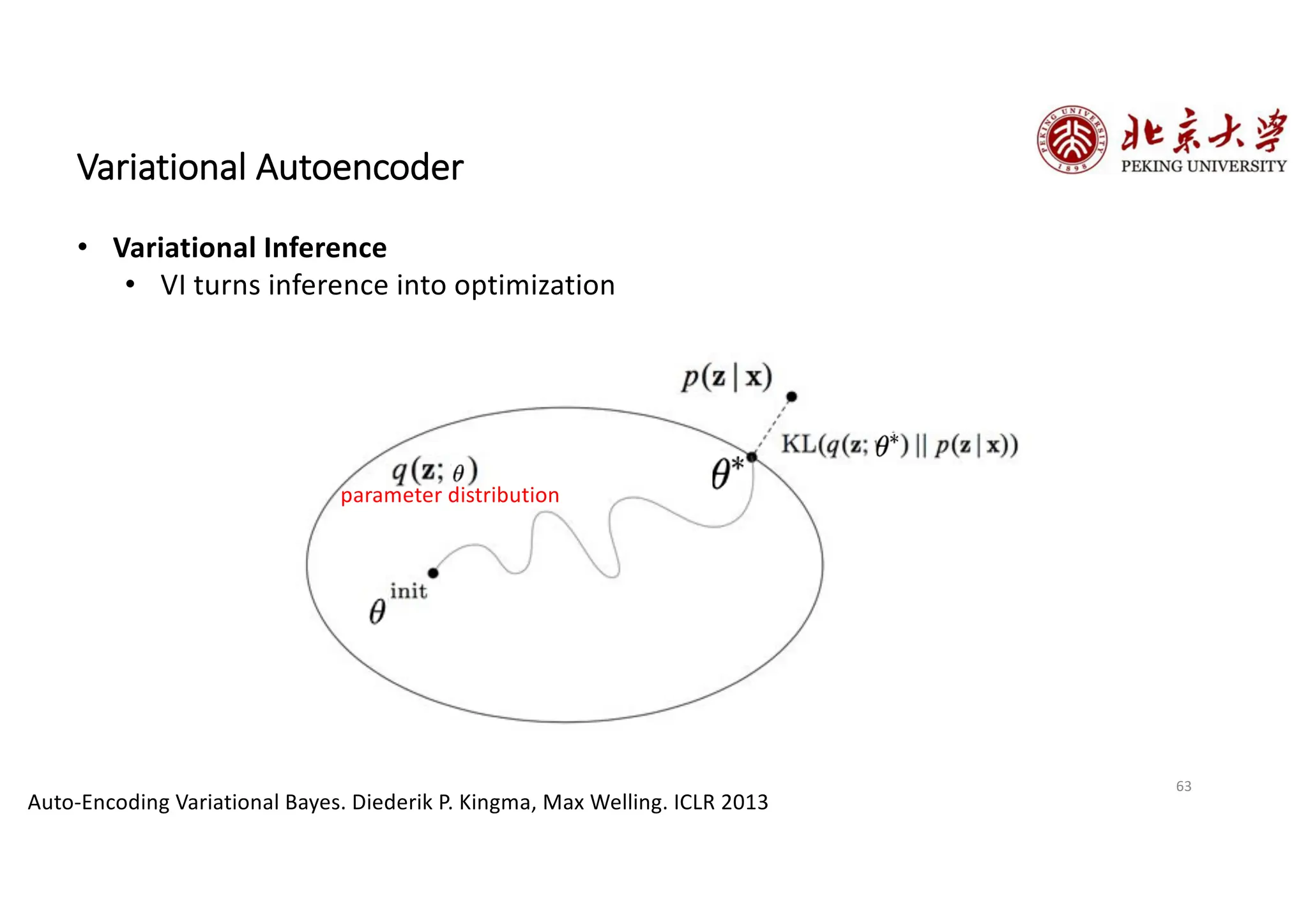
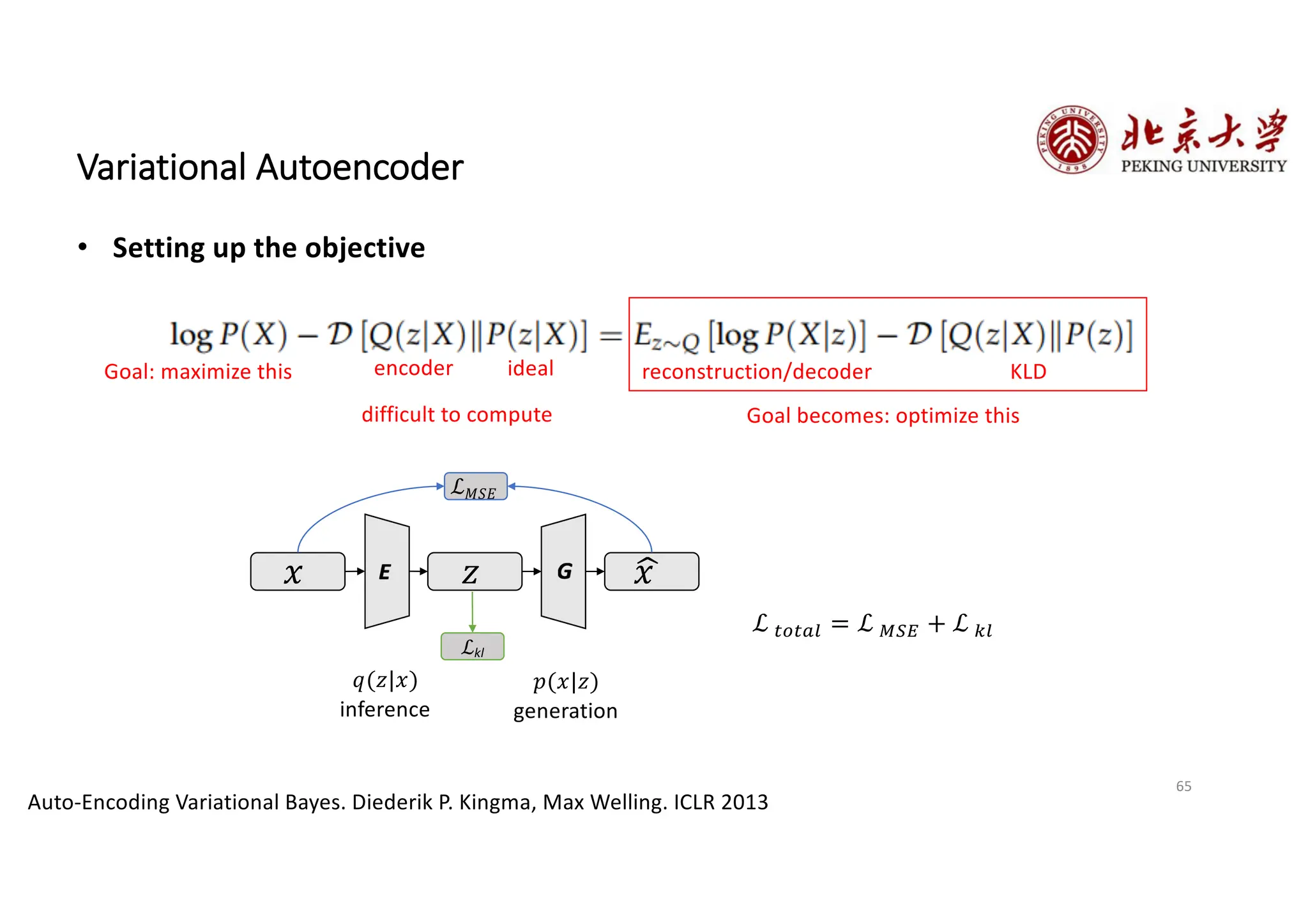
The document provides an overview of various types of autoencoders, including vanilla, denoising, sparse, contractive, stacked, and variational autoencoders (VAEs). It discusses the structure, function, and applications of these models in reducing dimensionality and learning feature representations in data, with a particular focus on the variational autoencoder's generative capabilities. Additionally, the document covers the training methods and advantages of each autoencoder type, with reference to techniques like dropout and KL divergence for improving performance.