Download to read offline

![Machine Learning and Applications: An International Journal (MLAIJ) Vol.3, No.3, September 2016 16 In contrast to finite dataset the infinite dataset, come from known but endless sources, which comprise of continuous data. The algorithm to process infinite dataset must be able to read the data quickly. If the algorithm is slow in processing the data that would result in loss of vital data. 1.1. Data Stream Classification problem The classification of data stream is one of the important areas in the in the data mining. Therefore, the effective algorithms are required to take the data from temporary location into permanent record. There are two typical approaches in the supervised machine learning: 1. Classification: The classification is mainly relevant with class attribute as dependent variables; this can be divided into two levels: building and testing. The building model level could be used to estimate an output from learning algorithm and the testing model level estimate the quality of building model level.2. Regression: Regression is relevant with numerical attributes as its output. The different methods such as neural networks, decision tree, rule based etc are used for the classification. These methods are contrived to build classification model where distinct passes on the stored data is possible. 2. LITERATURE SURVEY ON CLASSIFICATION METHODS 2.1. Ensemble based classification This method is based on classic classification algorithms such as Naïve Bayesian classifier. It is also called decision tree model, which increase the quality of data in the output.[2] 2.2. VFDT (Very Fast Decision Tree): VFDT splits the tree using the current best attribute that satisfies the Hoeffding bound. It has some drawbacks like it ties the attributes and tree grows out of memory.[1] 2.3. On-Demand classification The mechanism of on-demand classification method consists of two principle components. The first component stores the summarized data the input data streams frequently. The second one continuously uses the summary statistics to execute the classification. The main motivation factor of this method is that it can be defined over a time possibility which depends on the nature of the concept drift and data progress.[3],[4]. 2.4. ANNCAD Algorithm The Adaptive Nearest Neighbor Classification Algorithm for Data stream (ANNCAD) is yet another classification algorithm is used currently. This algorithm is used for multiple decision data representation. The classification starts with seeking the records from nearest neighbor at better levels.[5]](https://image.slidesharecdn.com/3316mlaij02-161011054835/75/EVALUATION-OF-A-NEW-INCREMENTAL-CLASSIFICATION-TREE-ALGORITHM-FOR-MINING-HIGH-SPEED-DATA-STREAMS-2-2048.jpg)





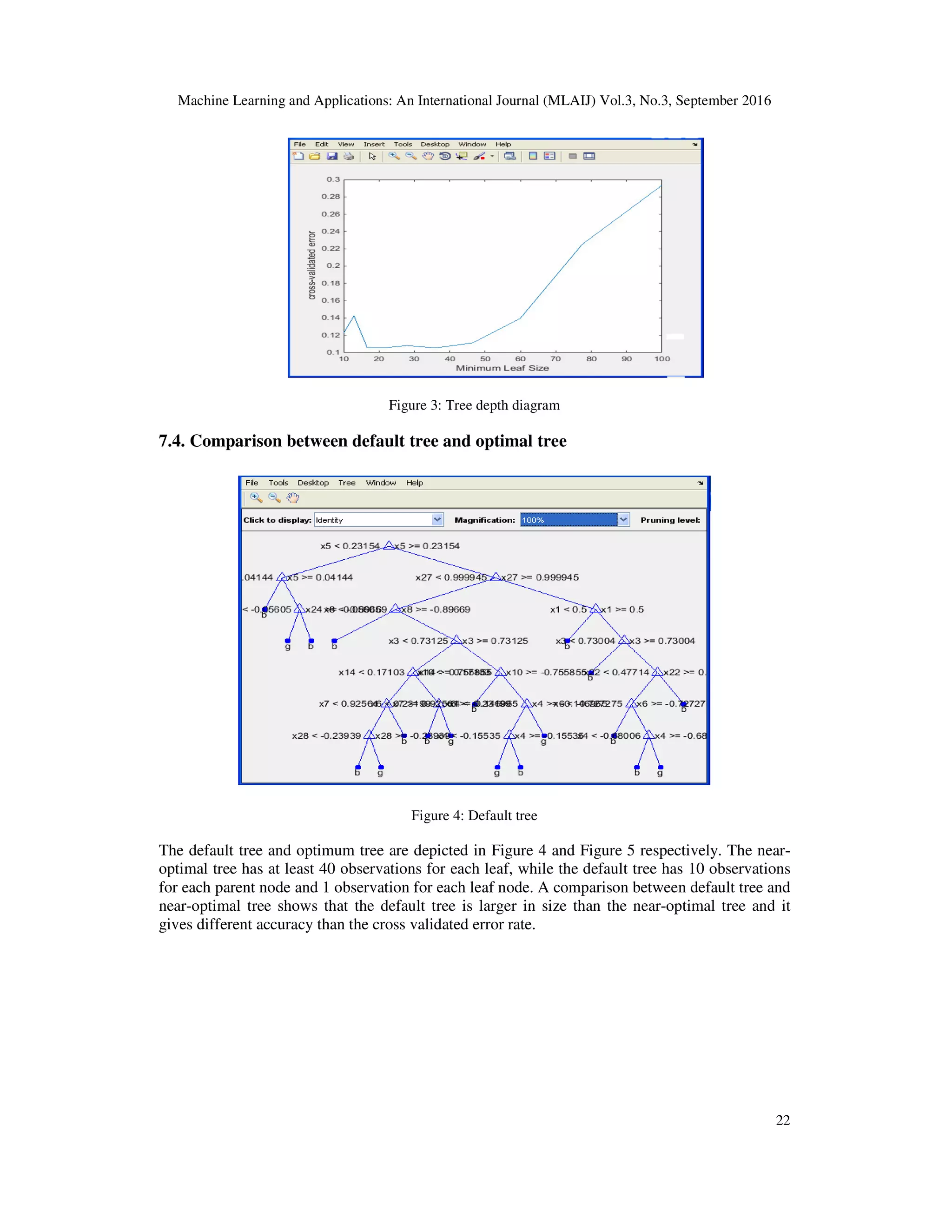
![Machine Learning and Applications: An International Journal (MLAIJ) Vol.3, No.3, September 2016 23 Figure 5: Near-Optimal tree It may also be noted that the near-optimal tree (Figure 5) is much smaller and gives a much higher generalization error. Yet it gives similar accuracy for cross-validated data (Figure 3). 8. CONCLUSION In this paper the incremental classification tree algorithm has been demonstrated to be an important and novel method to mine the high speed streamed data and validate the new data thus predicted. Also, performance of our new algorithm was compared with an existing popular algorithm. The results are explained in detail in section 7. The results obtained revealed that our algorithm performs much faster than the existing algorithm. REFERENCES [1]. Domingo’s P., and Hulten G. ‘Mining high-speed data streams’, in Proc. of 6th ACM SIGKDD International conference on Knowledge Discovery and Data Mining (KDD’00), ACM, New York, NY, USA, pp. 71-80, 2000. [2]. Lazaridis I., and Mehrotra S, ‘Capturing sensor-generated time series with quality guarantees’. In Proceedings of the 19th International Conference on Data Engineering. 2003. [3]. AslamJ., Butler Z., Constantin F., CrespiV., CybenkoG. and RusD., ‘Tracking a Moving Object with a Binary Sensor Network’. In Proceedings of ACM SenSy, 2003. [4]. Babcock B., and Olston C. ‘Distributed top-k monitoring’. In Proceedings of the ACM SIGMOD International Conference on Management of Data, 2003. [5]. Heinzelman,W.R, Chandrakasan.A & Balakrishnan.H ‘Energy-Efficient Communication Protocol for Wireless Micro sensor Networks’. In Proceedings of the 33rd Hawaii Intl. Conf. on System Sciences, Volume 8, 2000. [6]. Hang Yang, ‘Solving Problems of Imperfect Data Streams by Incremental Decision Trees’, journal of emerging technologies in web intelligence, vol. 5, no. 3, August 2013.](https://image.slidesharecdn.com/3316mlaij02-161011054835/75/EVALUATION-OF-A-NEW-INCREMENTAL-CLASSIFICATION-TREE-ALGORITHM-FOR-MINING-HIGH-SPEED-DATA-STREAMS-9-2048.jpg)
![Machine Learning and Applications: An International Journal (MLAIJ) Vol.3, No.3, September 2016 24 [7]. Prerana Gupta, Amit Thakkar, Amit Ganatra, ‘Comprehensive study on techniques of Incremental learning with decision trees for streamed data’, Journal of emerging technologies in web intelligence, vol. 5, NO. 3, August 2013. [8]. Pallavi Kulkarni and Roshani Ade, ‘Incremental learning from Unbalanced data with concept class, Concept drift and missing features: A REVIEW’, International Journal of Data Mining & Knowledge Management Process, Vol.4, No.6, November 2014. [9]. Junhui Wang and Xiaotong Shen, ‘Estimation of Generalization error: Random and Fixed inputs’, Statistica Sinica 16, 569-588, 2006. [10]. Ponkiya Parita, Purnima Singh, ‘A Review on Tree Based Incremental Classification’, Ponkiya Parita et al, International Journal of Computer Science and Information Technologies, Vol. 5 (1) , 306-309, 2014.](https://image.slidesharecdn.com/3316mlaij02-161011054835/75/EVALUATION-OF-A-NEW-INCREMENTAL-CLASSIFICATION-TREE-ALGORITHM-FOR-MINING-HIGH-SPEED-DATA-STREAMS-10-2048.jpg)

This document presents a new incremental classification tree algorithm designed for efficient mining of high-speed data streams, addressing limitations of existing algorithms. The proposed method allows for incremental updates to the classification model while minimizing memory usage and processing time, proving to be effective through experimental results with various datasets. The study indicates that this algorithm outperforms existing models in terms of classification accuracy and speed in handling large data volumes.