Download as PDF, PPTX






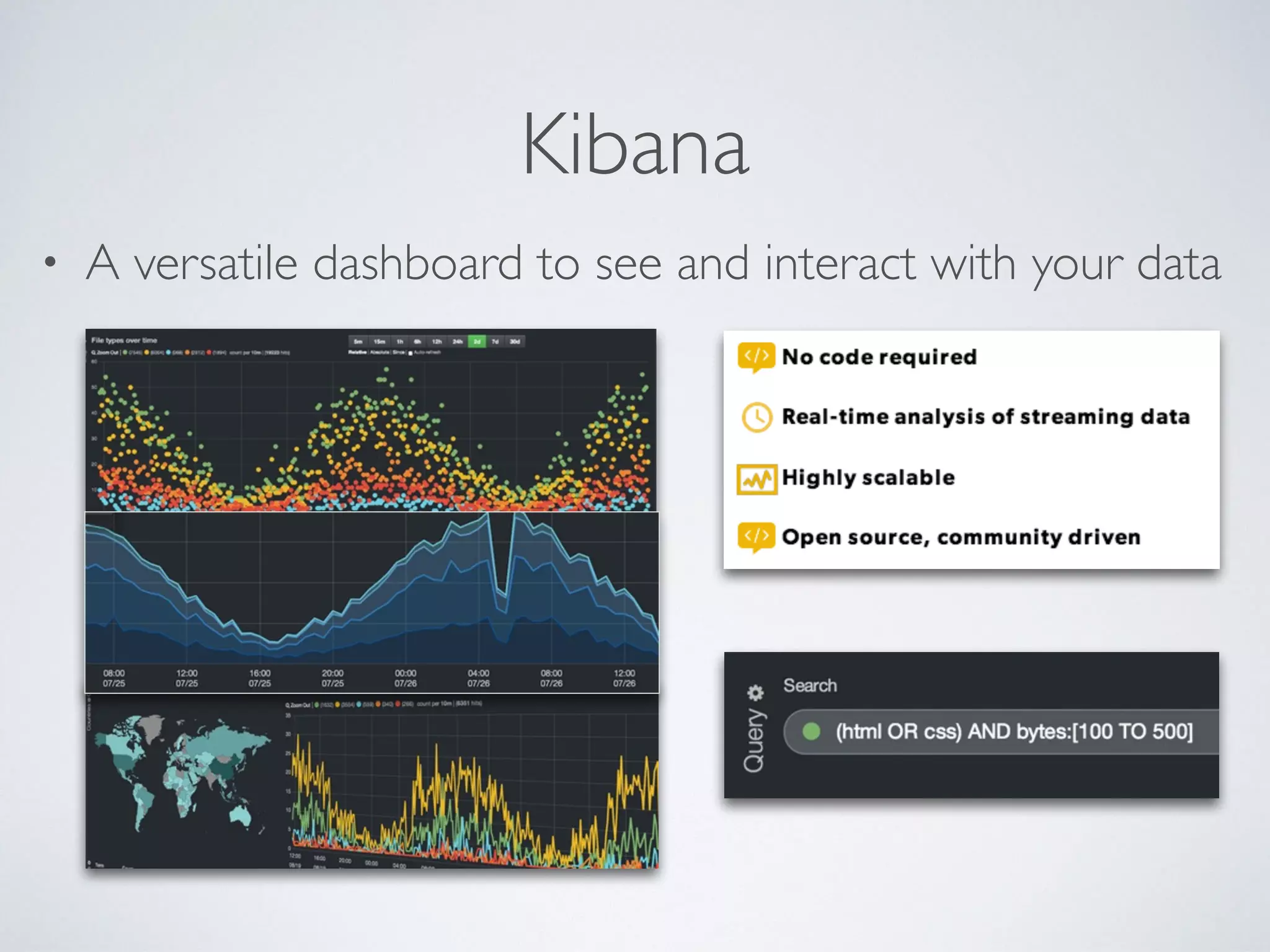


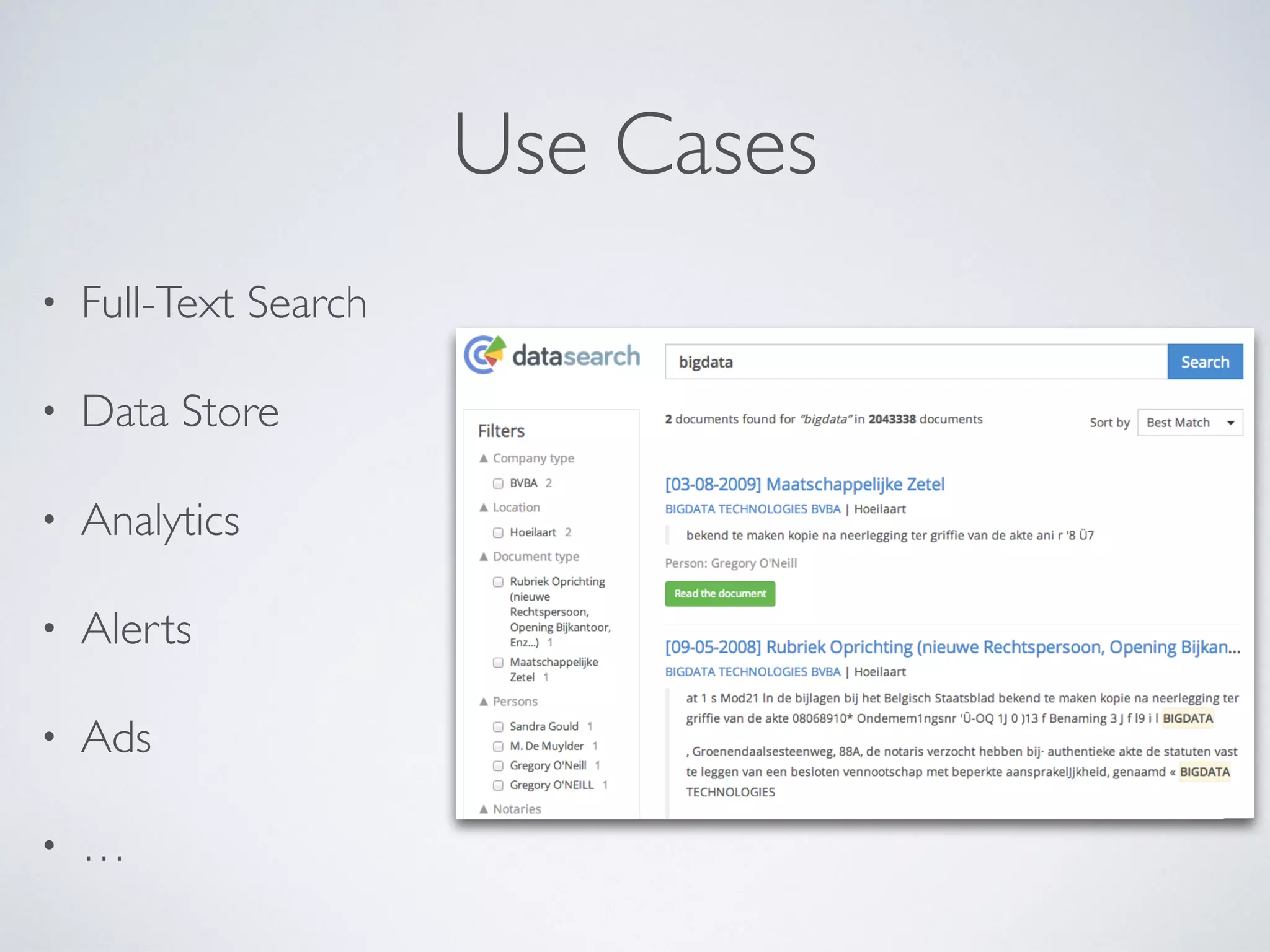

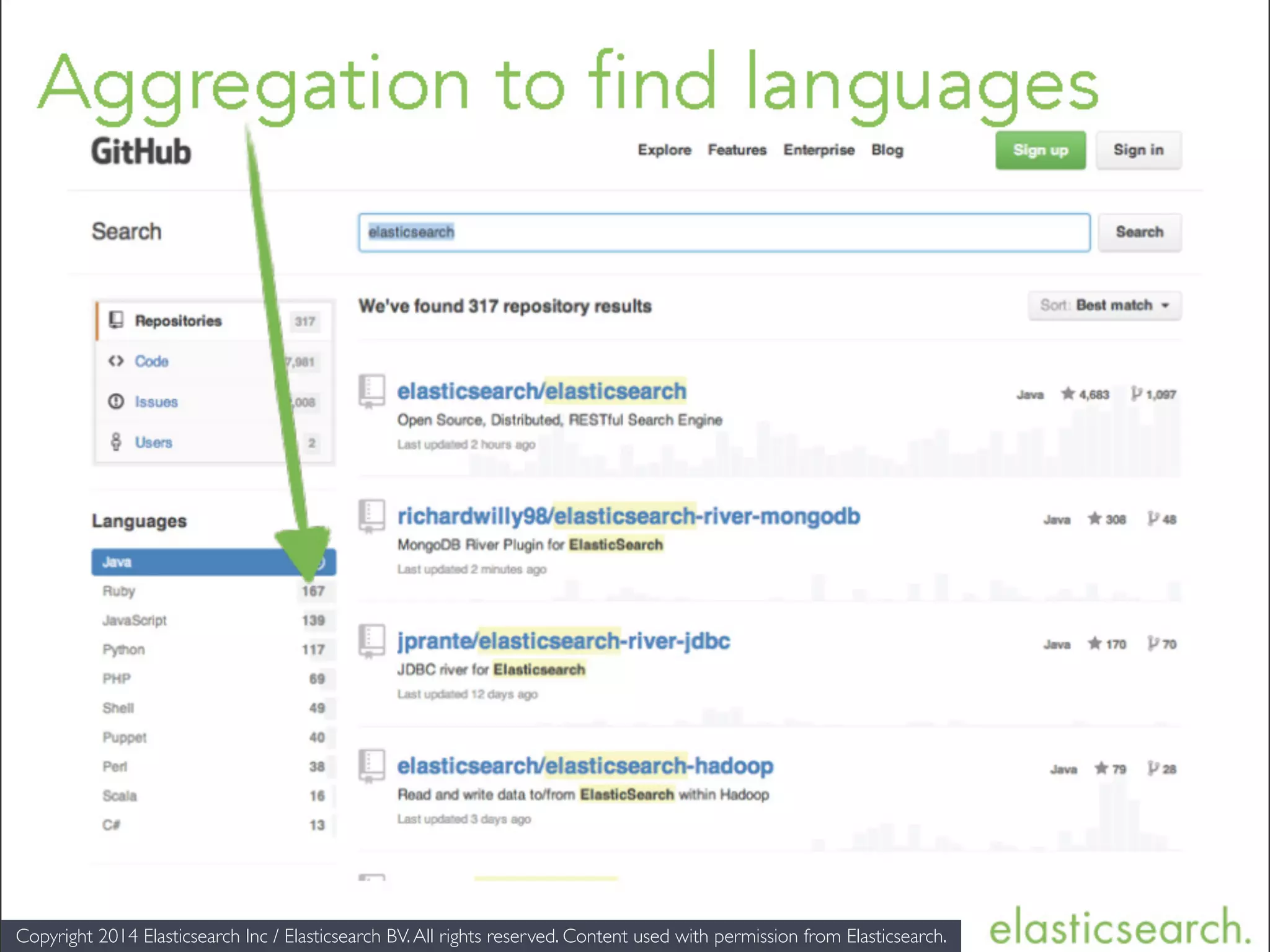
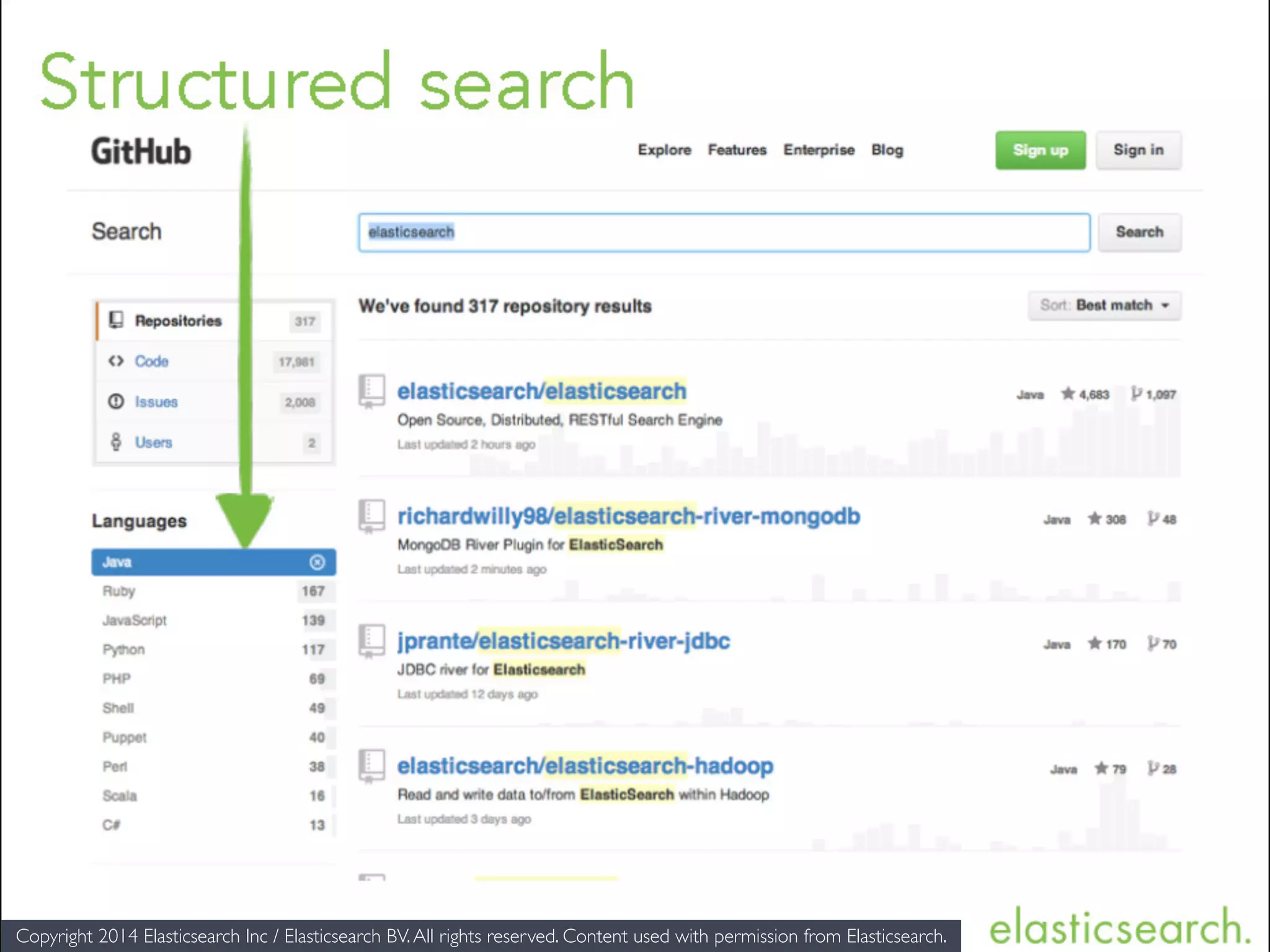

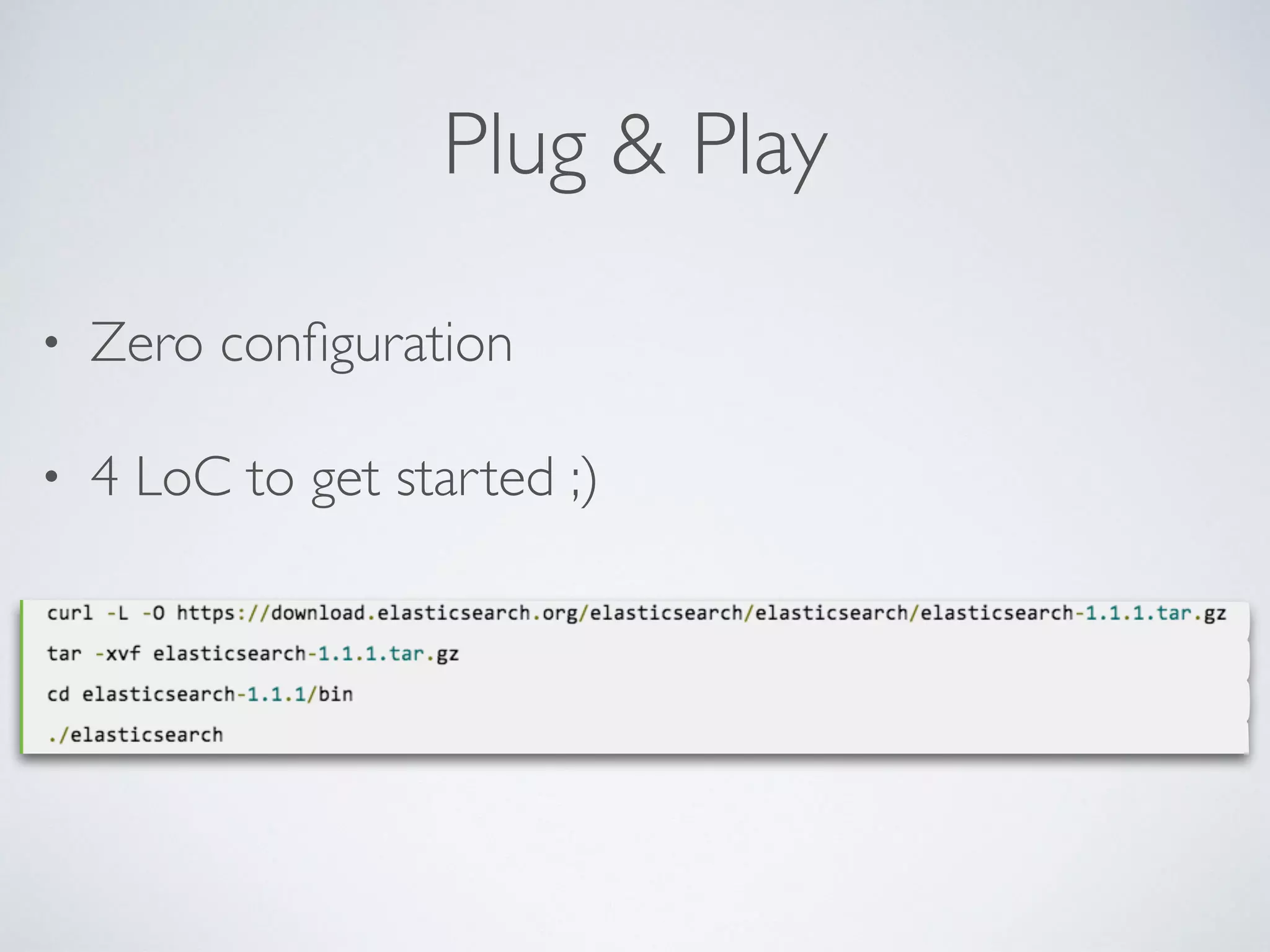
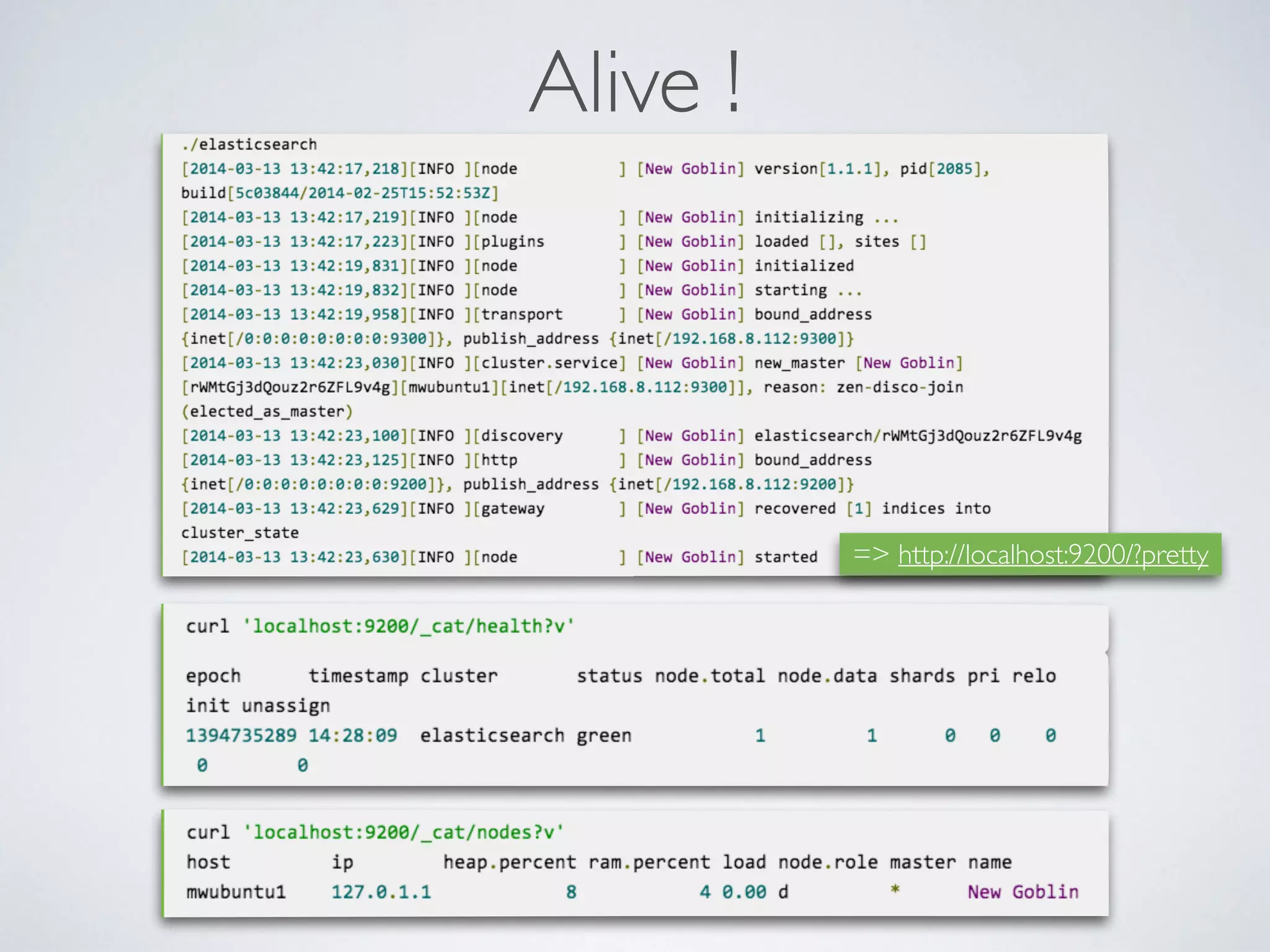

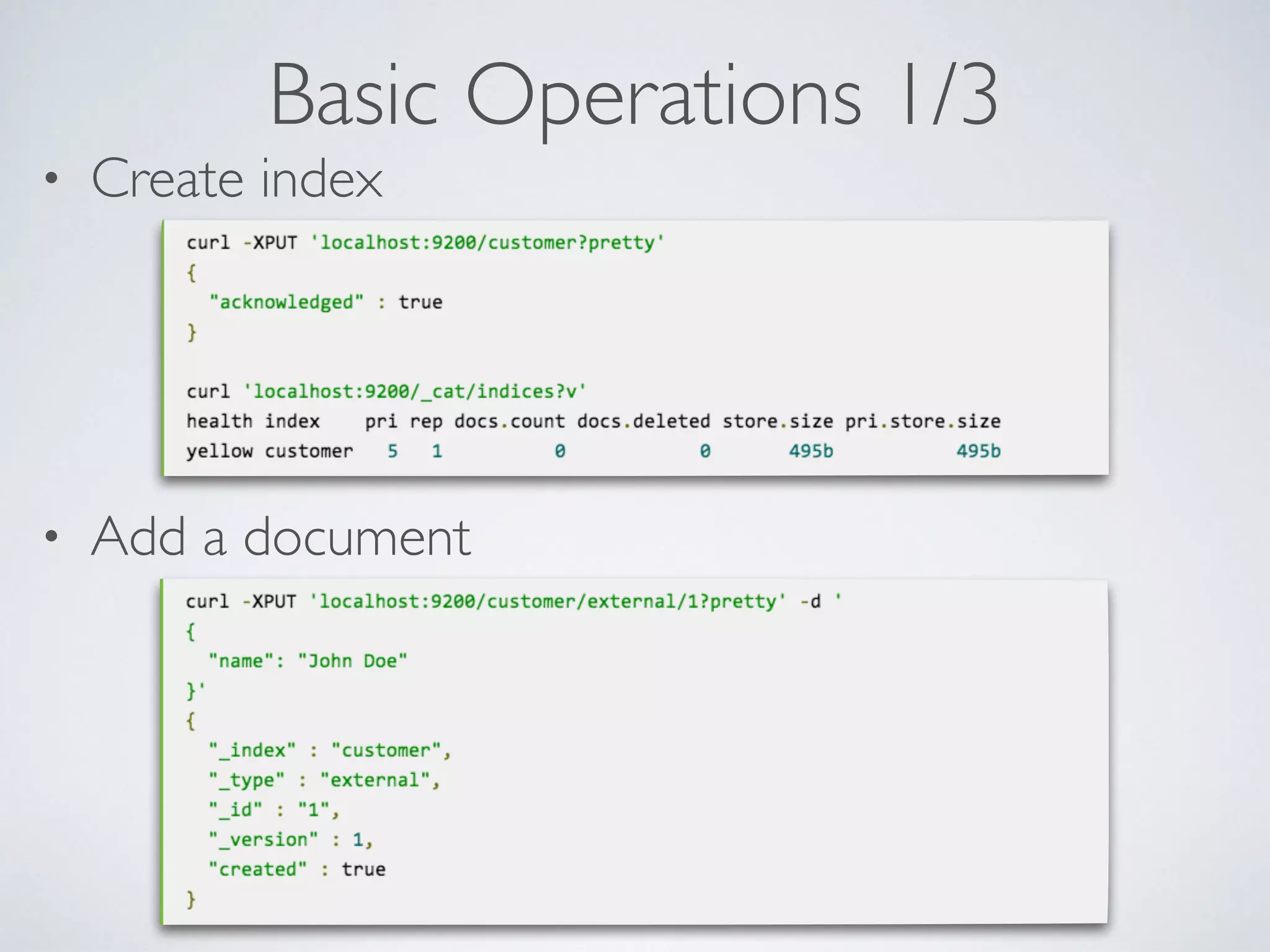



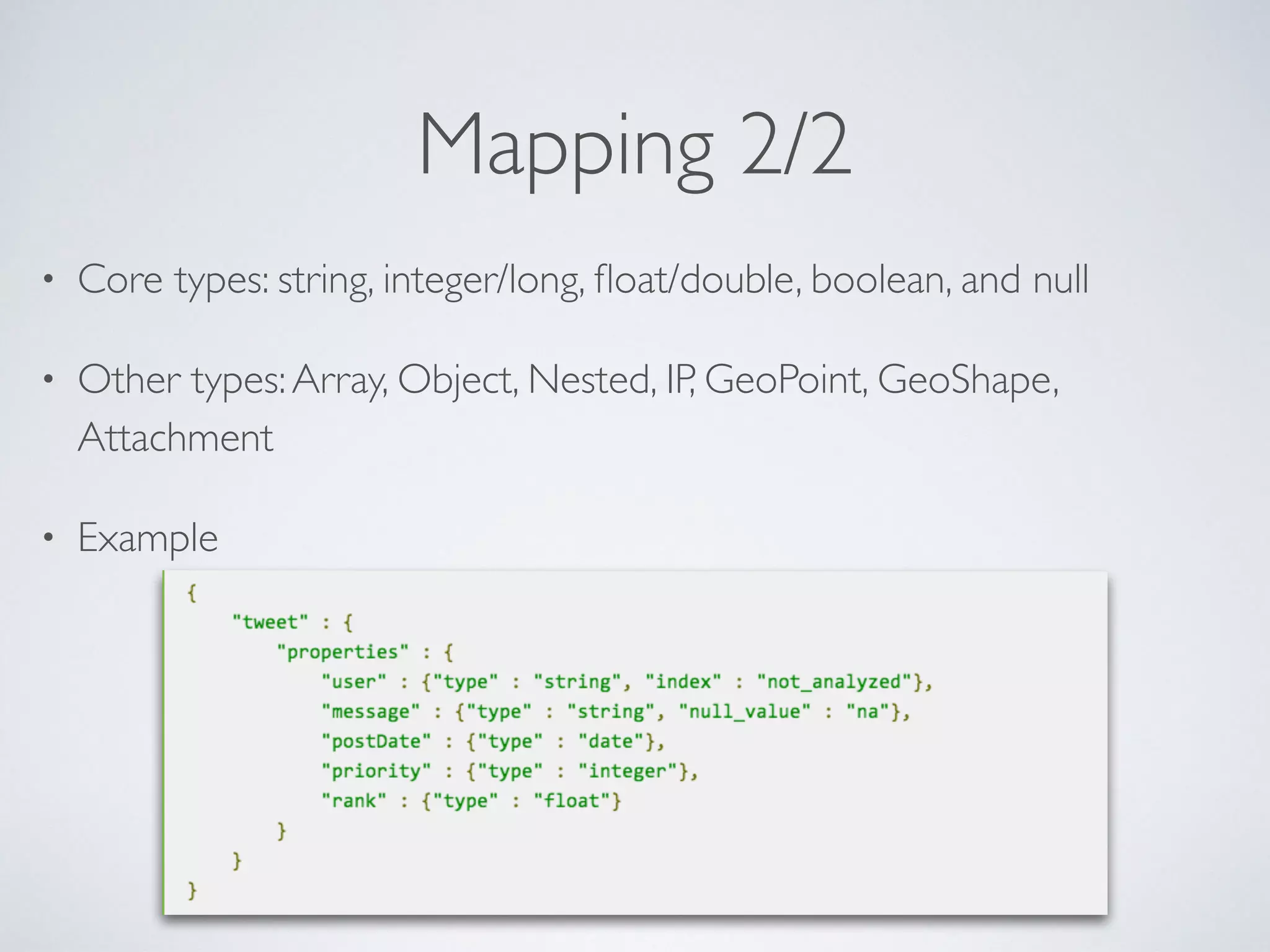
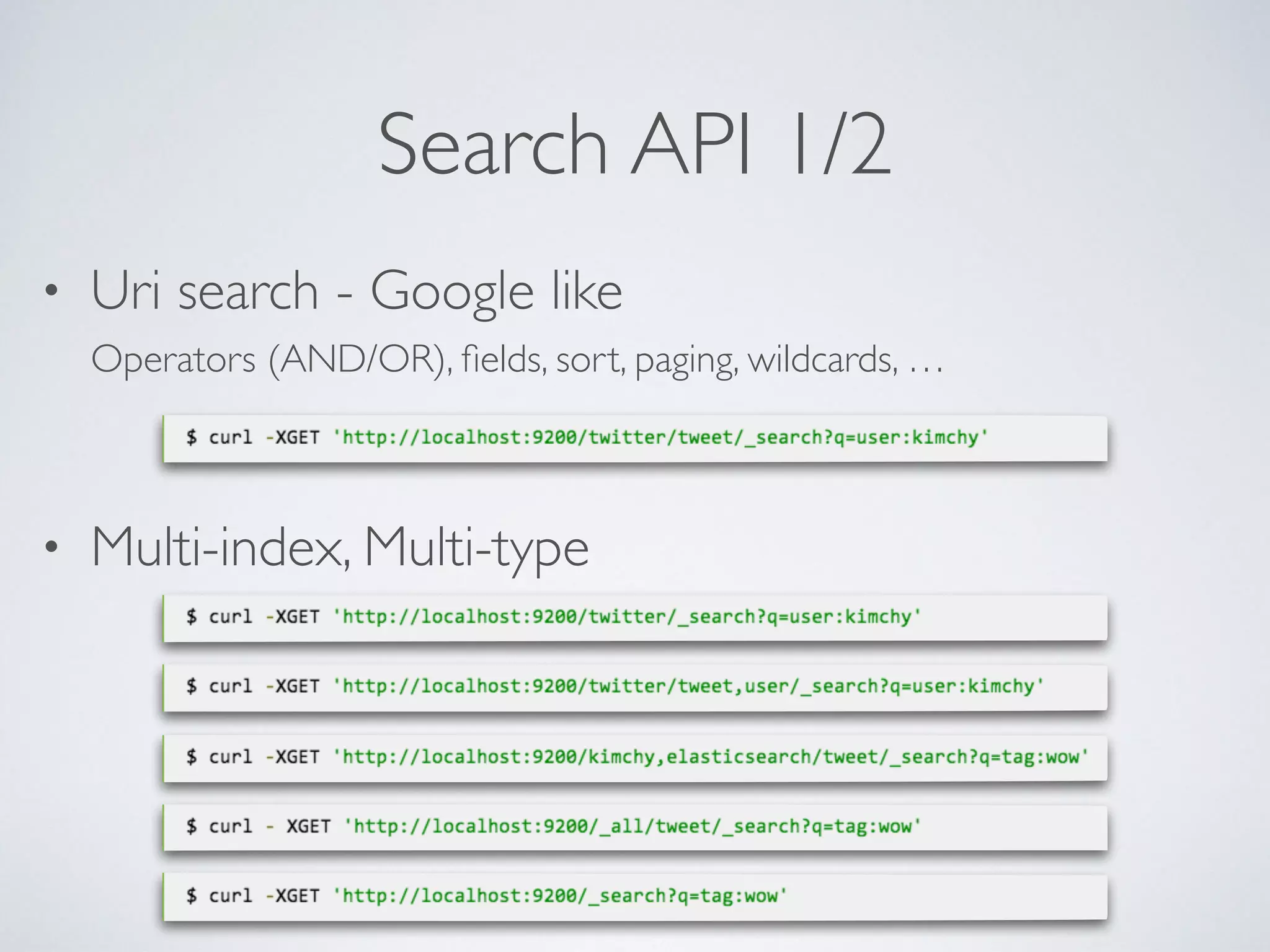






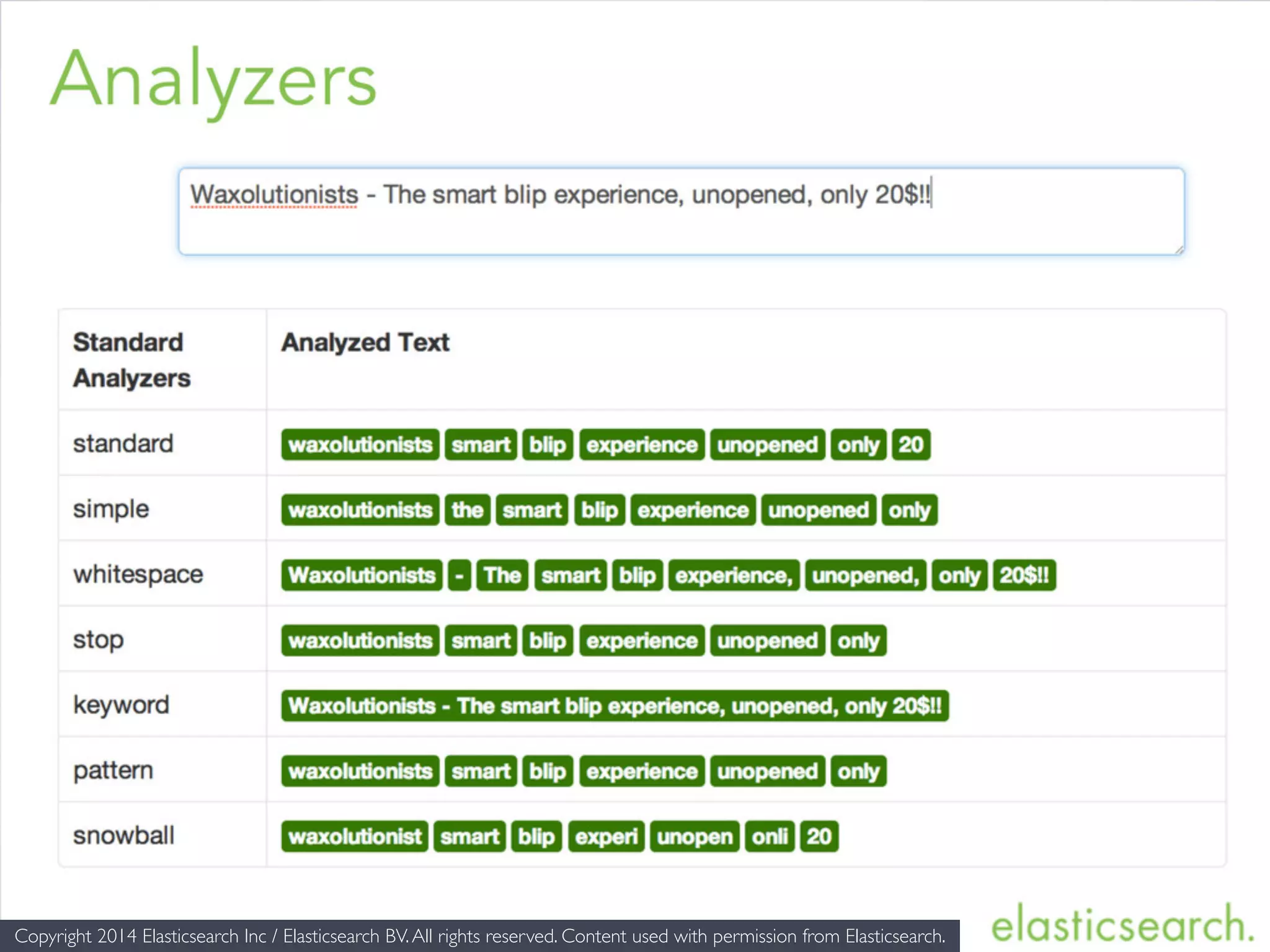






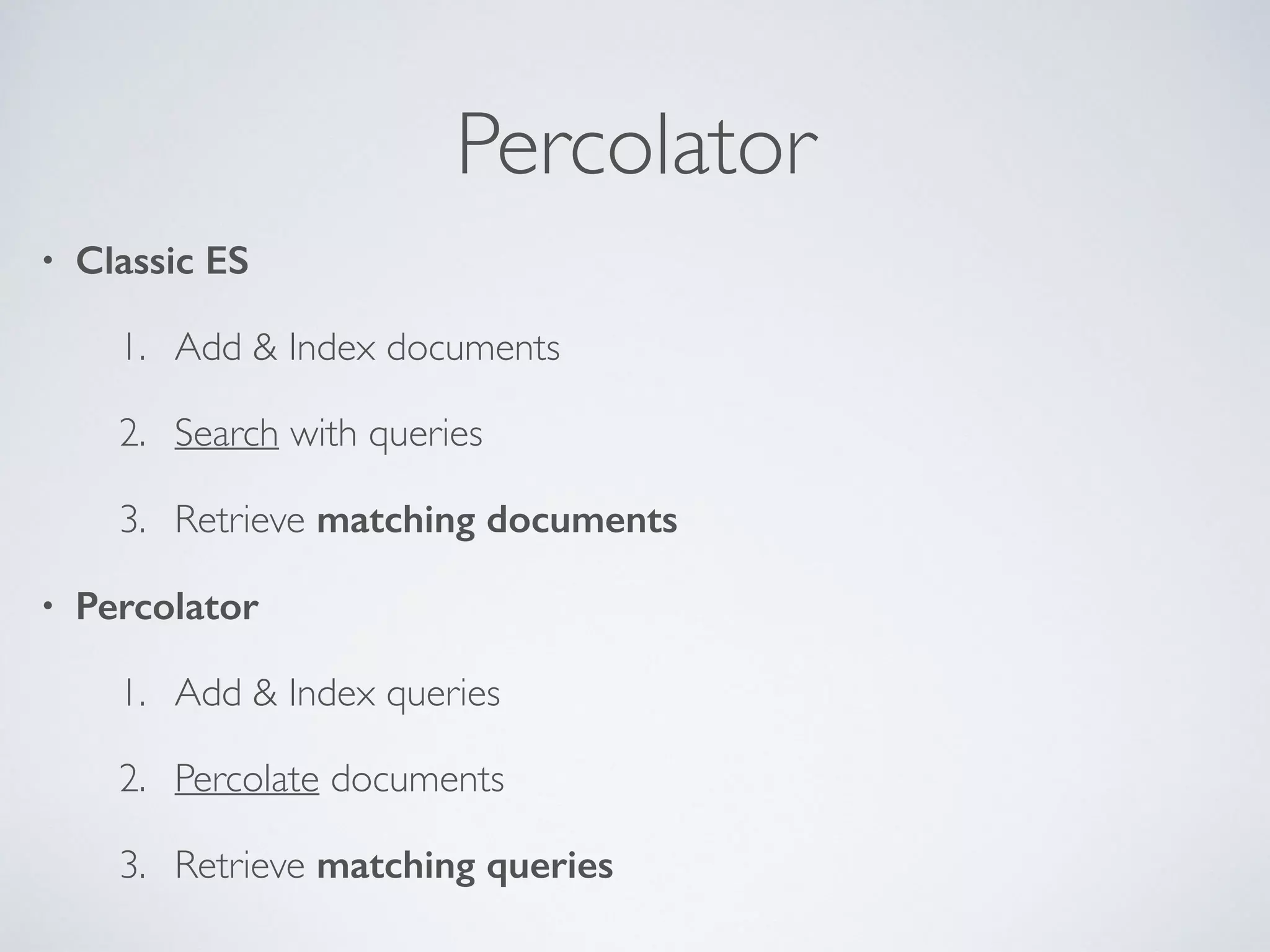












The document provides an introduction to Elasticsearch, a distributed search and analytics engine built on Apache Lucene. It outlines its architecture, core features, key components including Logstash and Kibana, and various use cases such as full-text search and data storage. Additionally, it discusses Elasticsearch's capabilities in handling high availability through sharding and replication, along with its extensive ecosystem of integrations and clients.