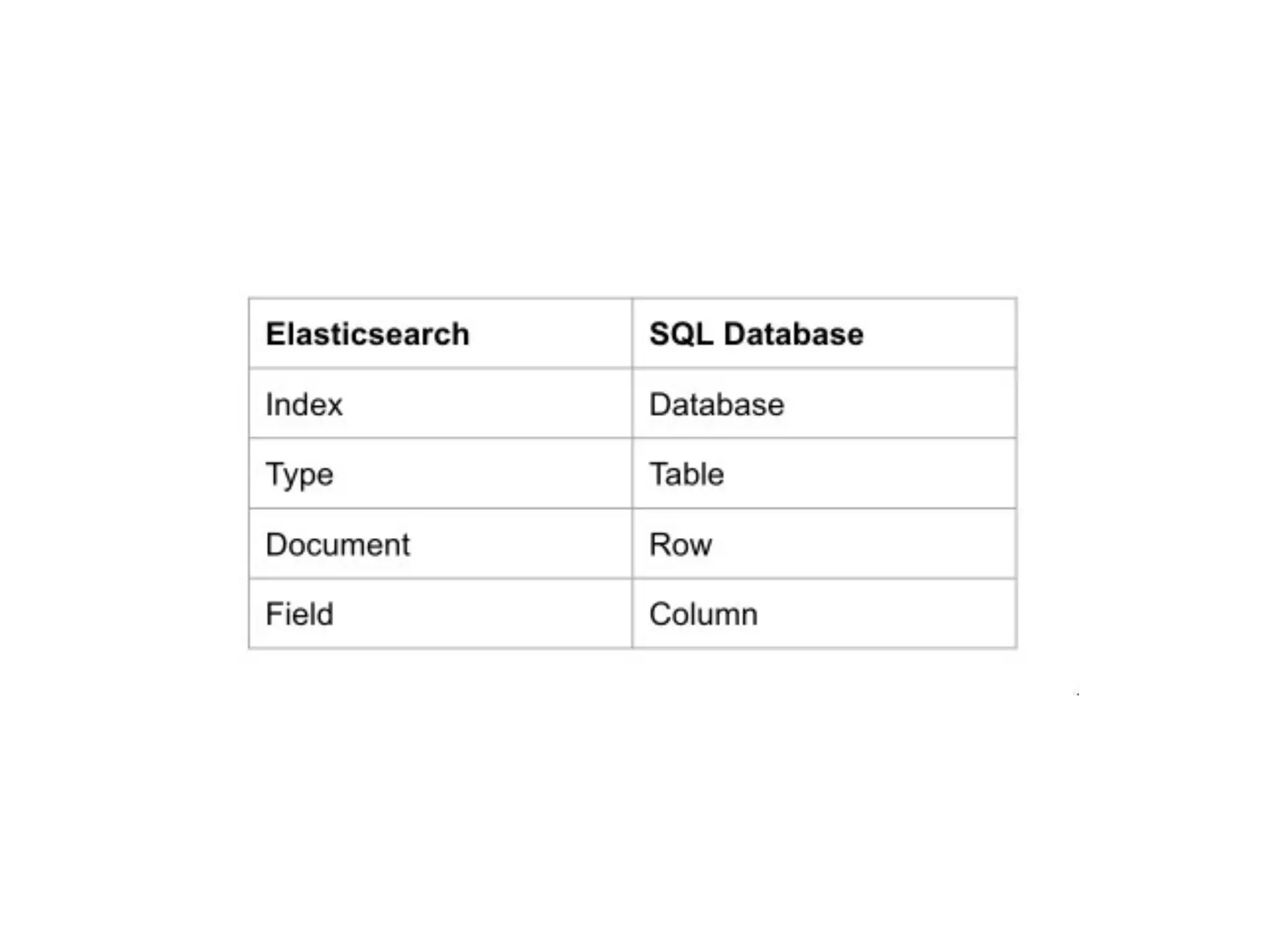
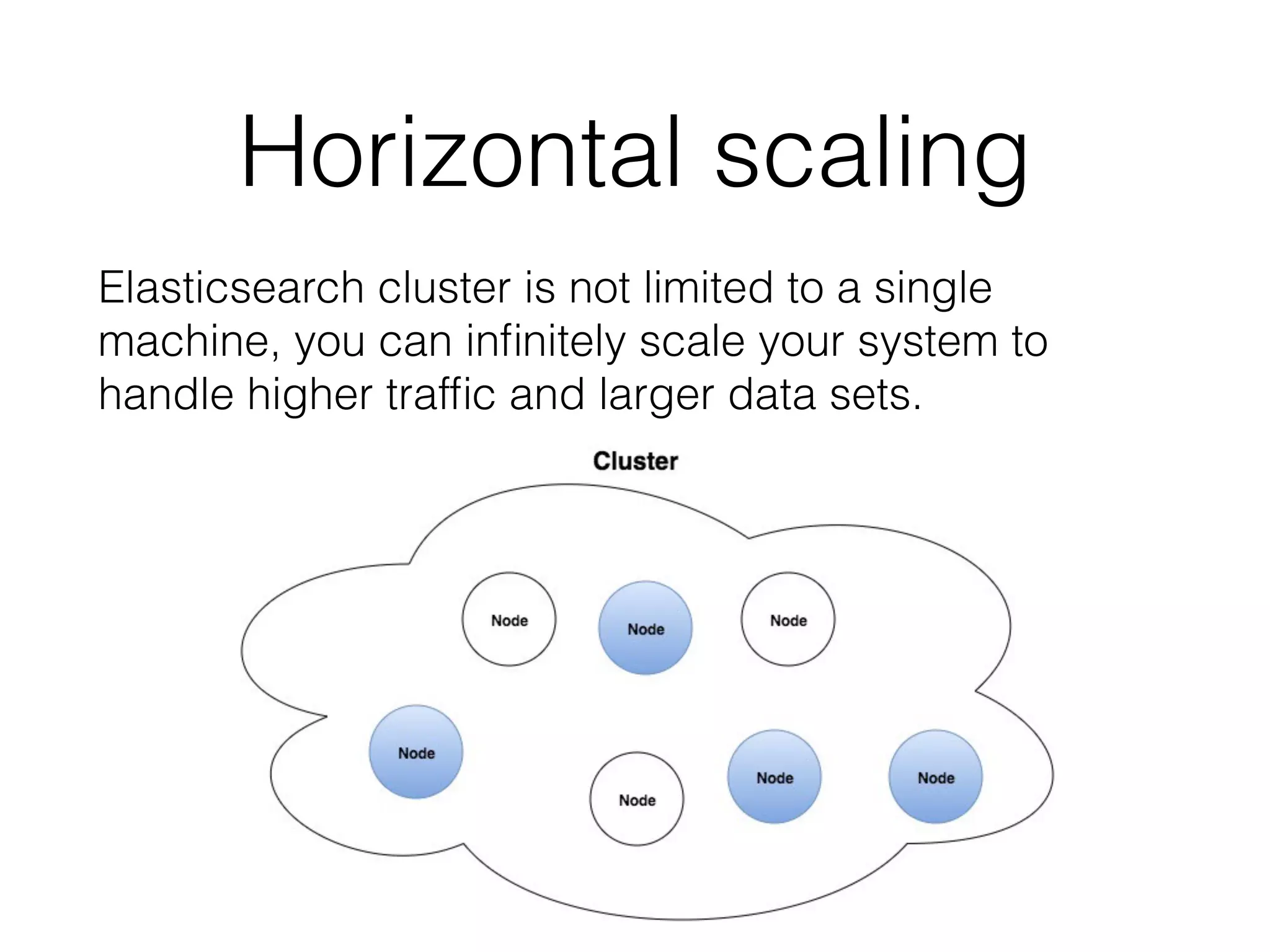
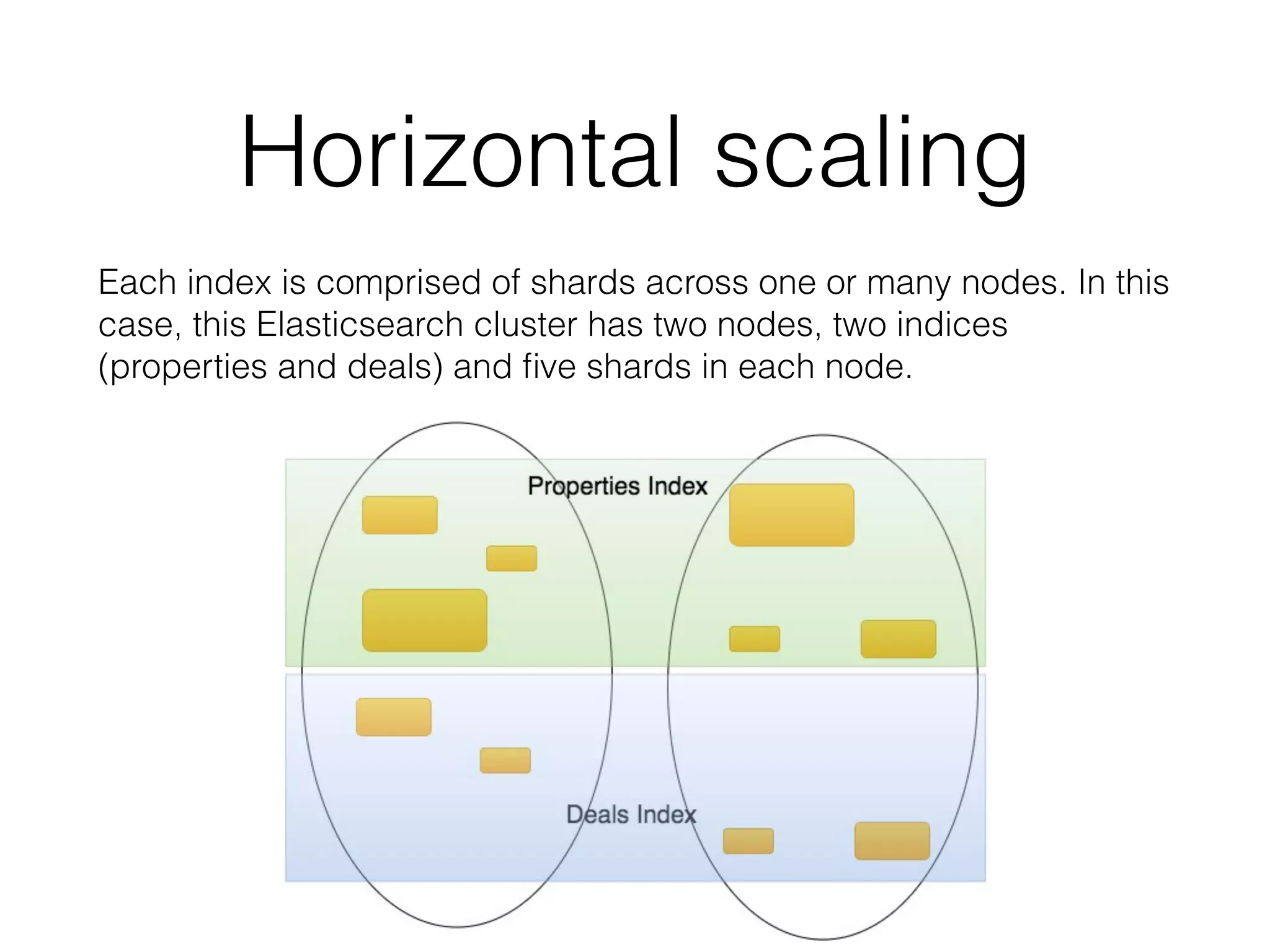
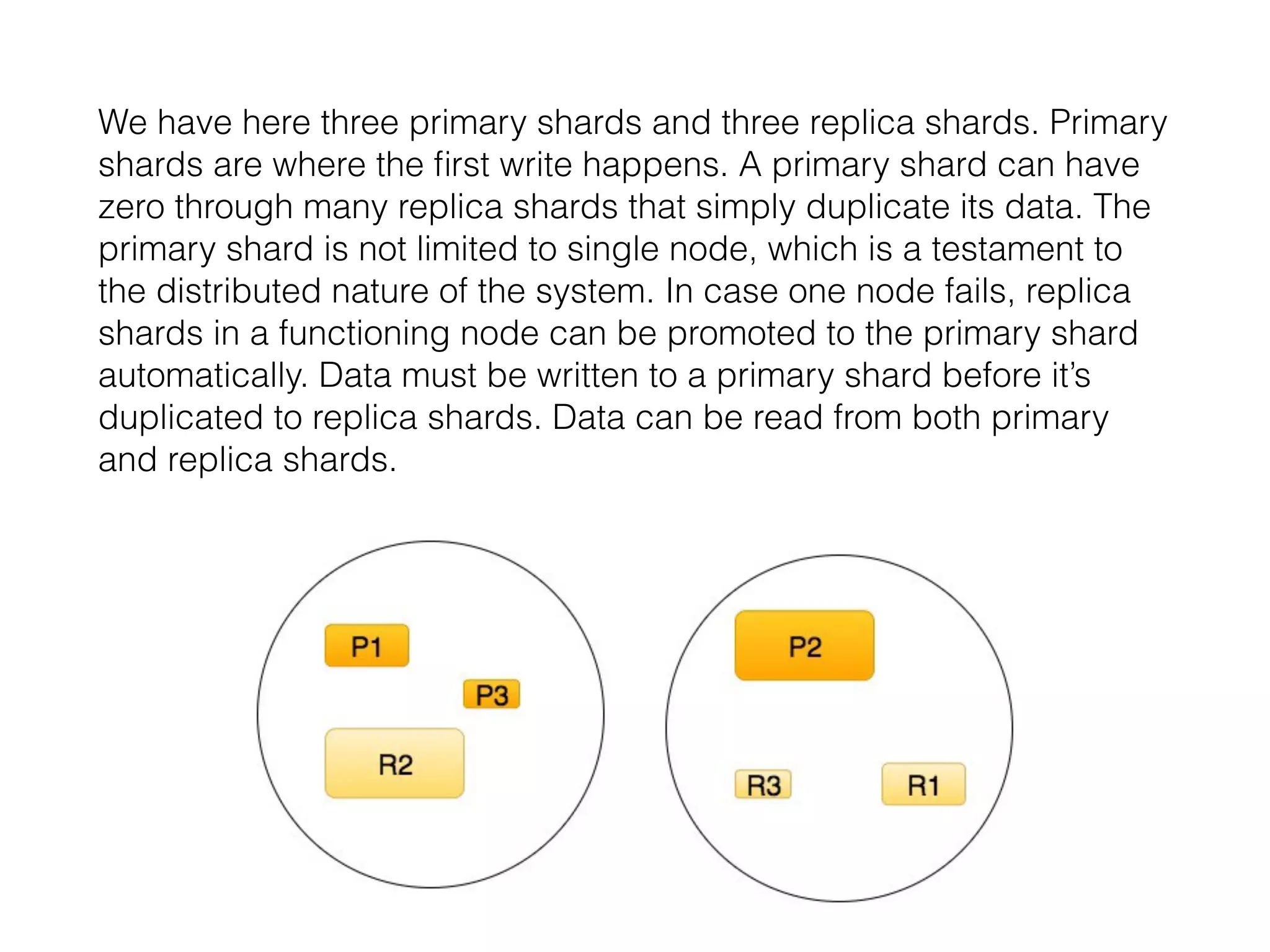
The document provides an overview of a distributed multitenant NoSQL datastore and search engine, emphasizing concepts such as SQL vs NoSQL, the architecture of Elasticsearch, and core components like indices, shards, and nodes. It highlights the capabilities of Elasticsearch, including cloud compatibility, RESTful API support, and its scalability options. Additionally, it discusses practical usage examples, typical queries, and integrations with AWS services.