Download as PDF, PPTX










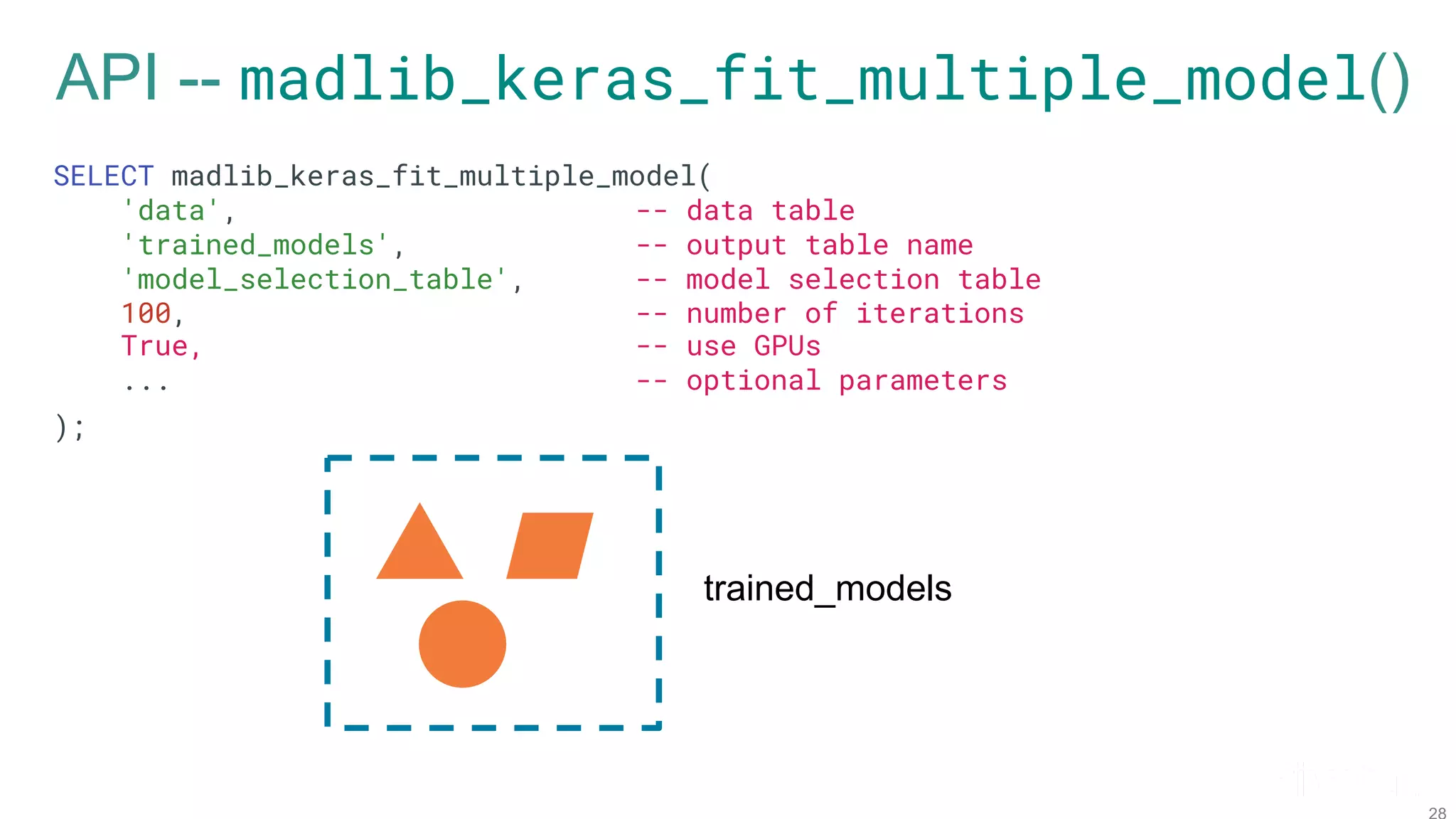
![API -- load_model_selection_table() SELECT load_model_selection_table( 'model_arch_table', -- model architecture table 'model_selection_table’, -- output table ARRAY[...], -- model architecture ids ARRAY[...], -- compile hyperparameters ARRAY[...] -- fit hyperparameters ); model_selection_table](https://image.slidesharecdn.com/fosdem2020talkonmodelhopperfinal-200203205651/75/Efficient-Model-Selection-for-Deep-Neural-Networks-on-Massively-Parallel-Processing-Databases-27-2048.jpg)



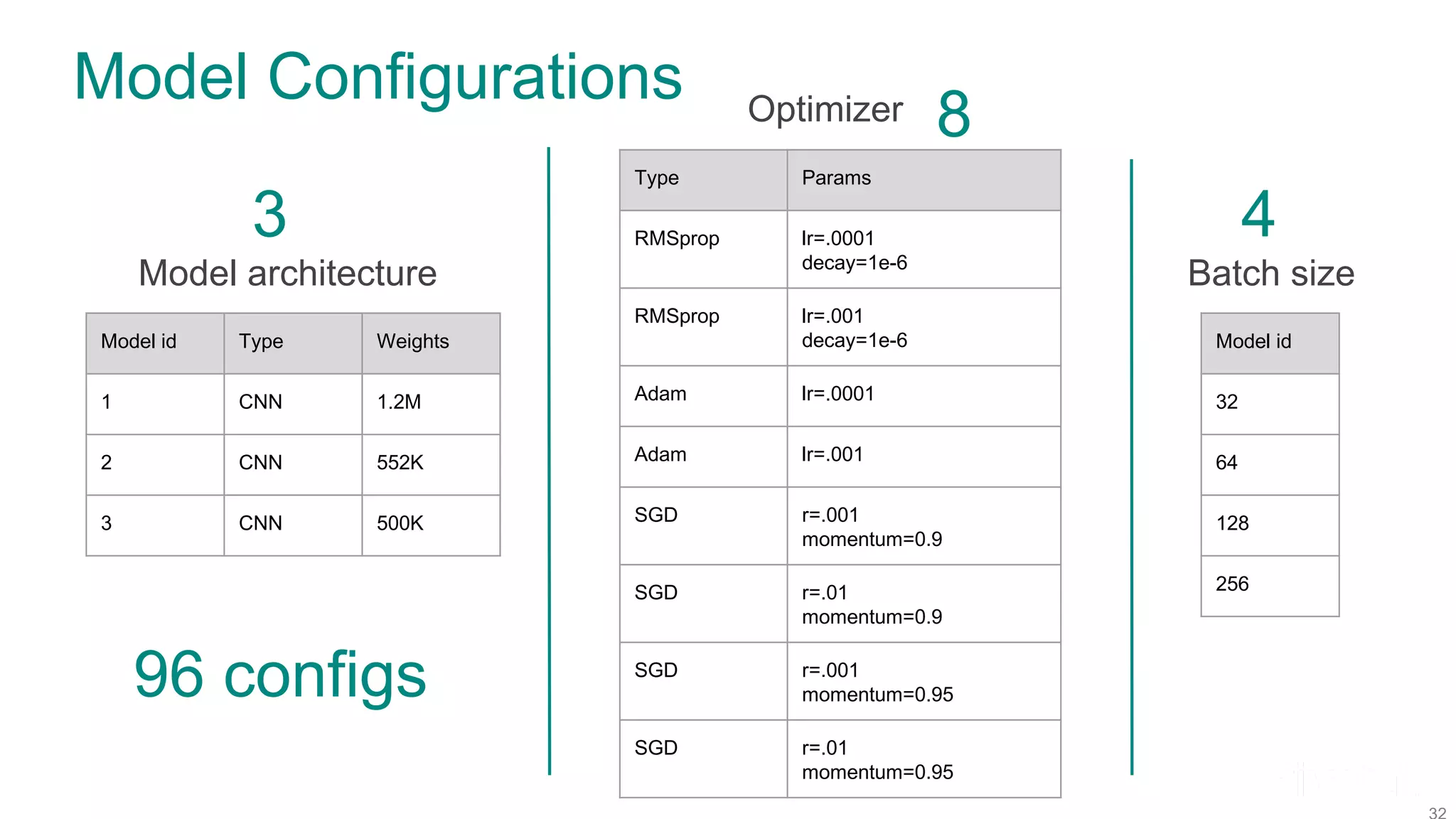
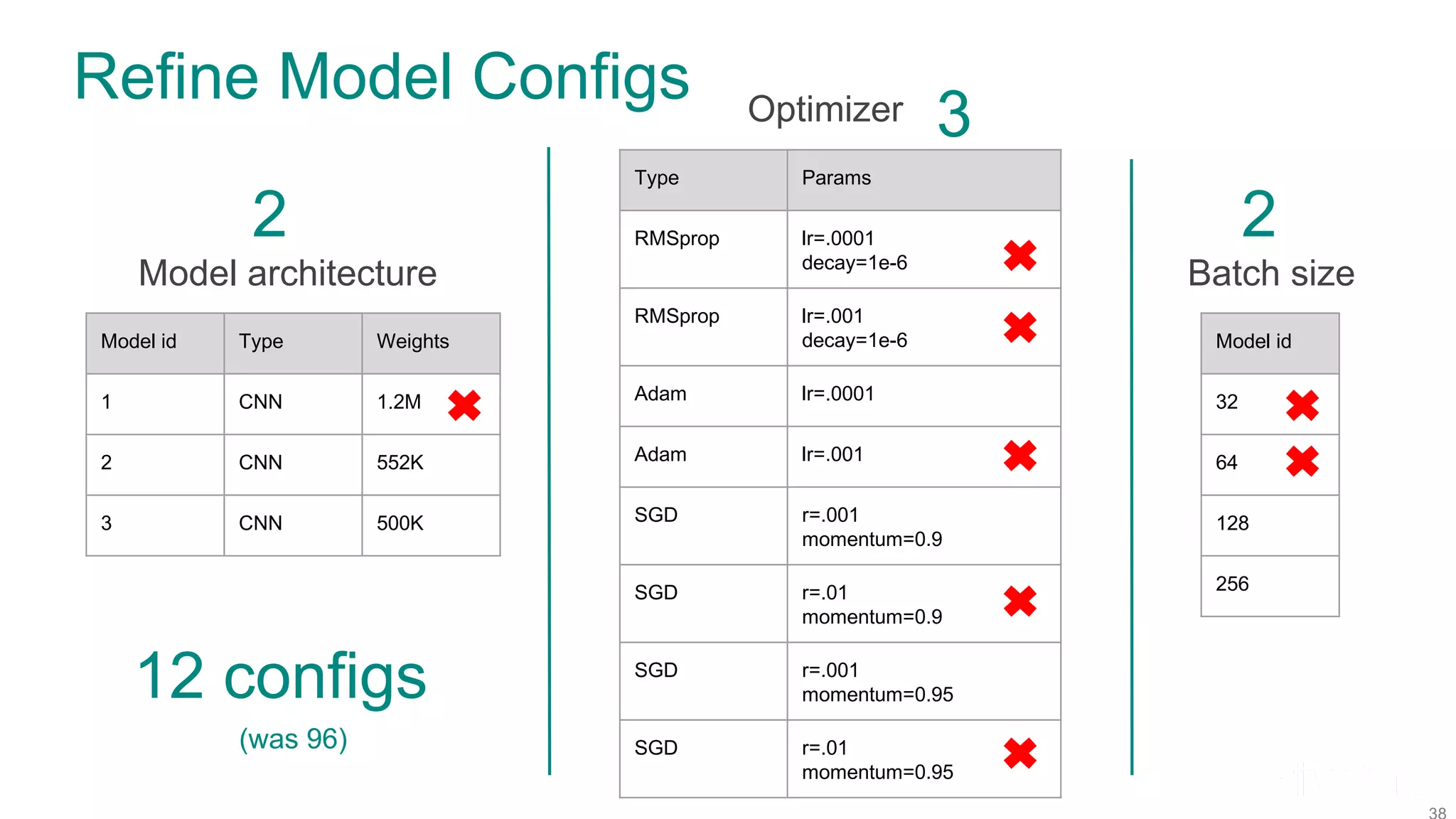


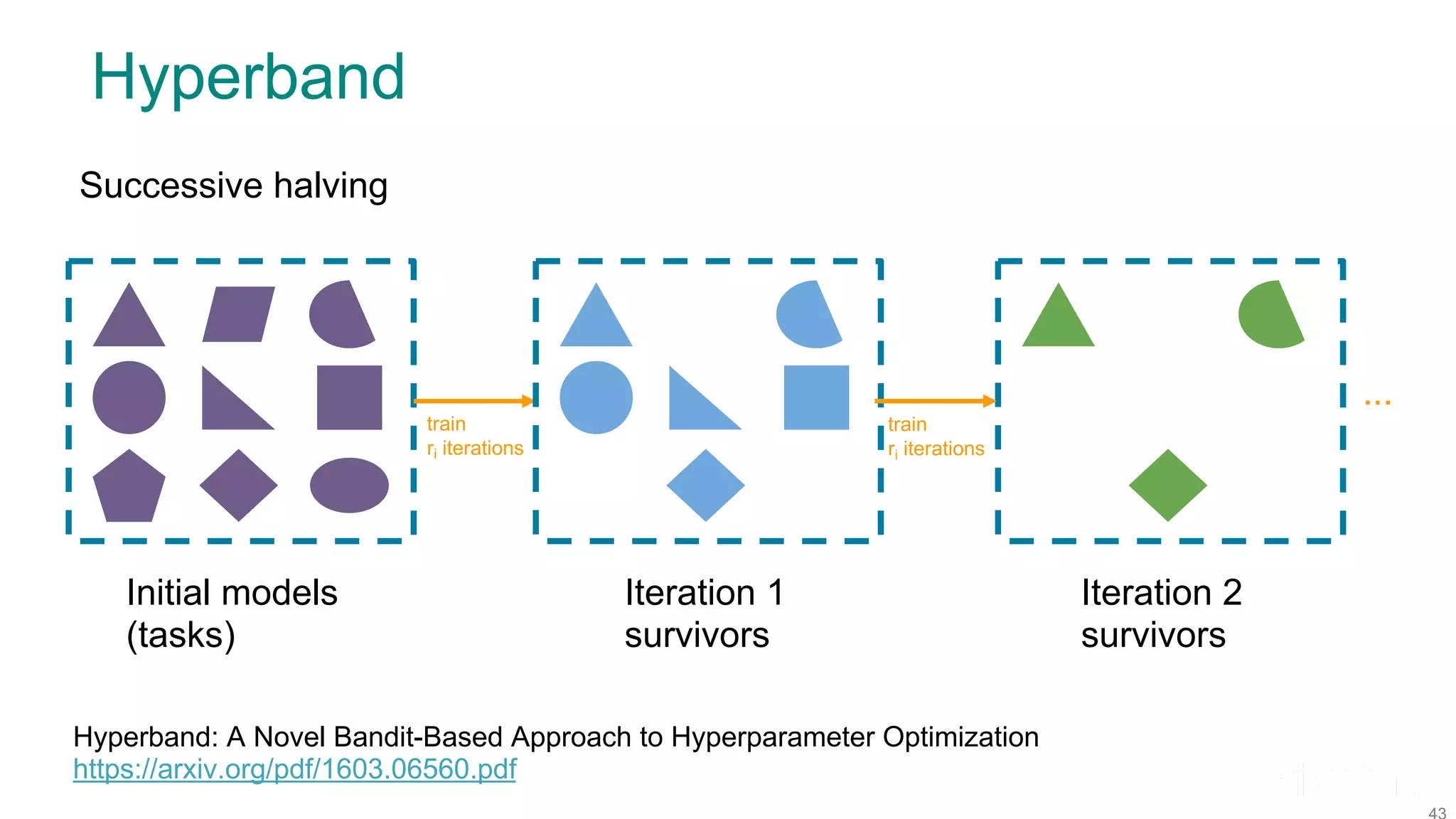
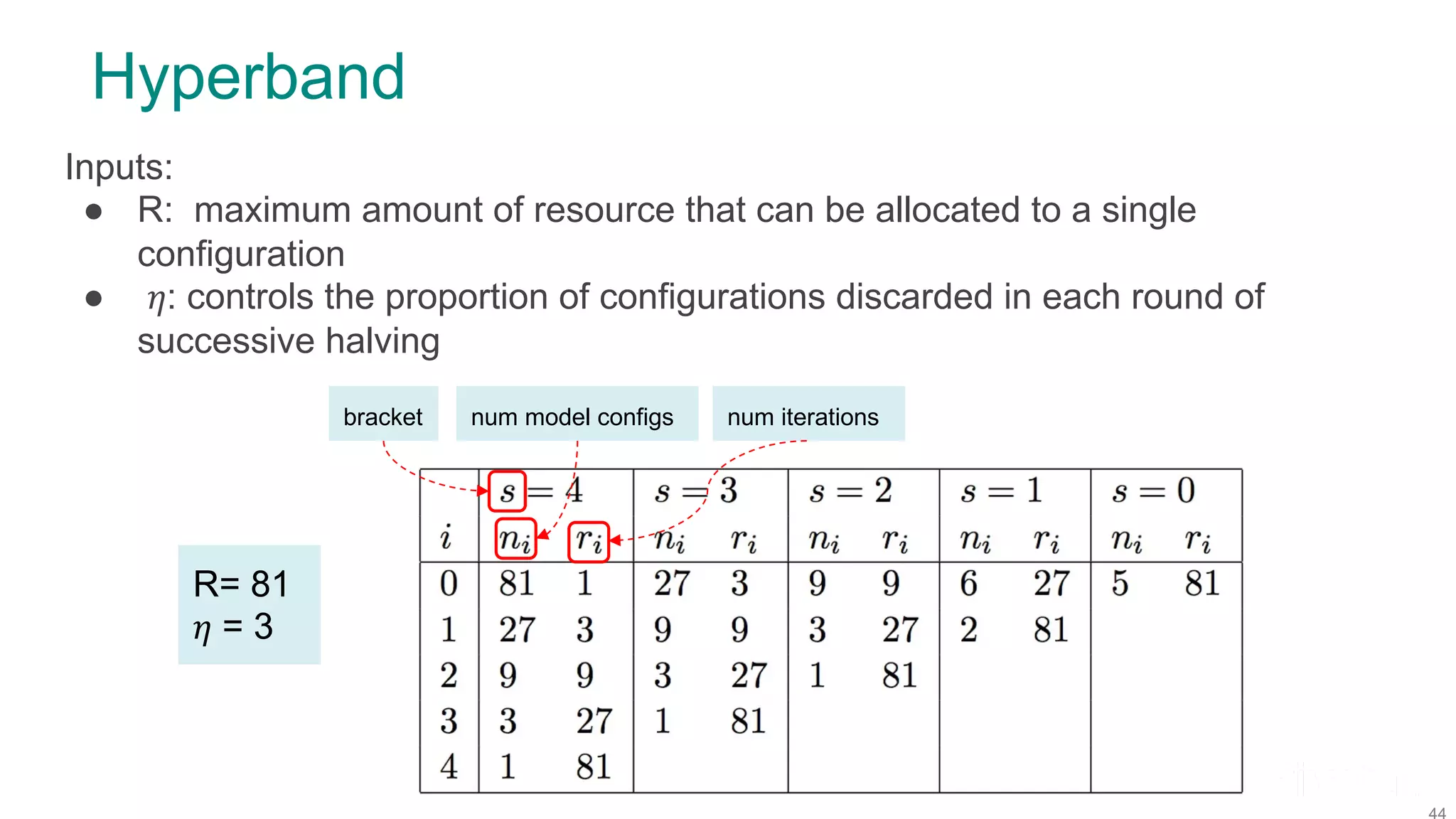
![Model Configurations Model architecture Model id Type Weights 1 CNN 1.2M 2 CNN 552K 3 CNN 500K Optimizer Type Params RMSprop lr=[.0001, 0.001] decay=1e-6 Adam lr=[.0001, 0.001] SGD lr=[.001, 0.01] momentum=[0.9, 0.95] Batch size Model id 32 64 128 256 Hyperband schedule Note ranges specified, not exact values](https://image.slidesharecdn.com/fosdem2020talkonmodelhopperfinal-200203205651/75/Efficient-Model-Selection-for-Deep-Neural-Networks-on-Massively-Parallel-Processing-Databases-45-2048.jpg)
![Refine Model Configurations Model architecture Model id Type Weights 1 CNN 1.2M 2 CNN 552K 3 CNN 500K Optimizer Type Params RMSprop lr=[.0001, 0.001] decay=1e-6 Adam lr=[.0001, 0.0005] SGD lr=[.001, 0.01] lr=[.001, 0.005] momentum=[0.9, 0.95] Batch size Model id 32 64 128 256 Adjust Hyperband schedule Adjust ranges](https://image.slidesharecdn.com/fosdem2020talkonmodelhopperfinal-200203205651/75/Efficient-Model-Selection-for-Deep-Neural-Networks-on-Massively-Parallel-Processing-Databases-47-2048.jpg)
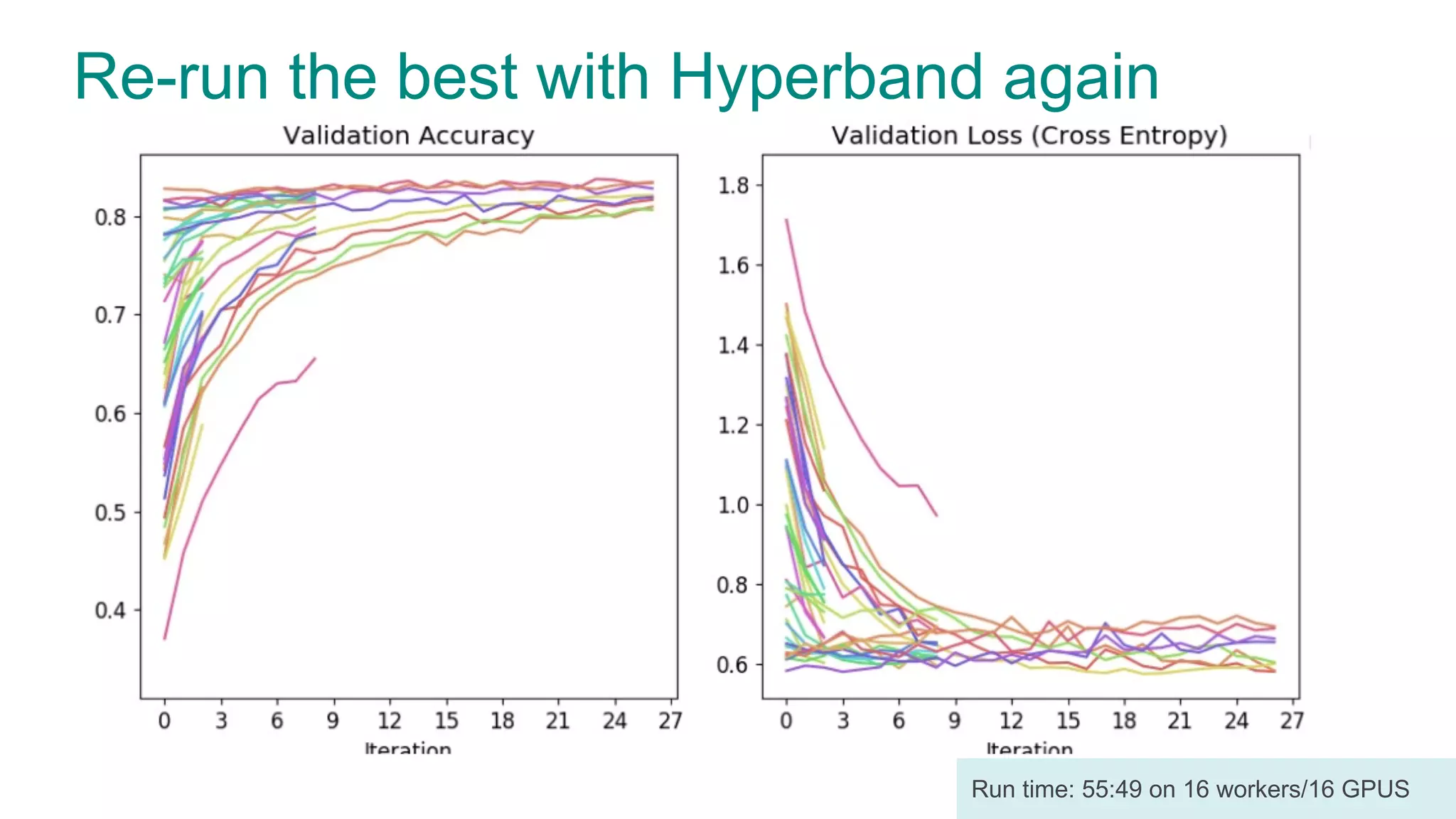
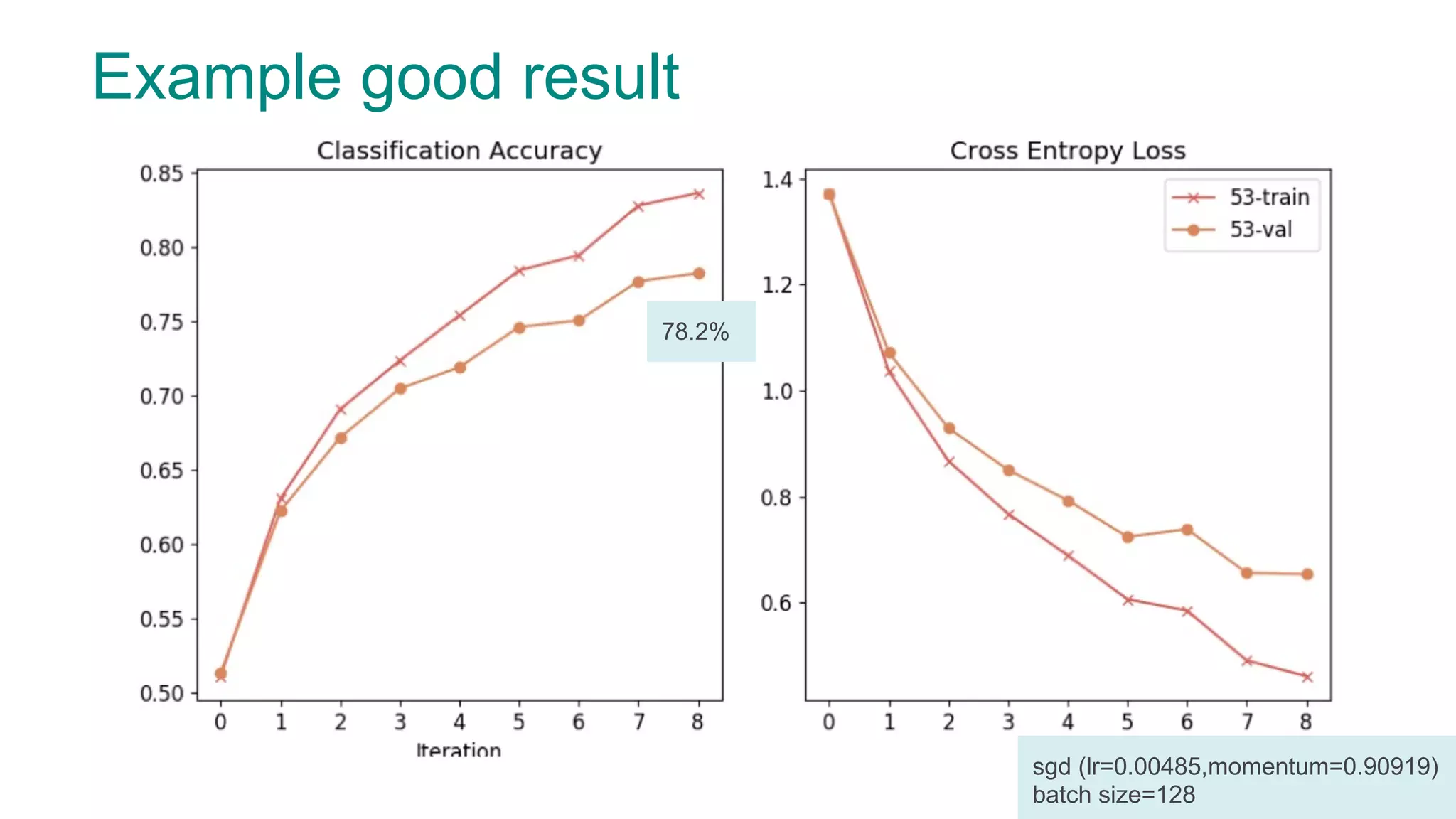





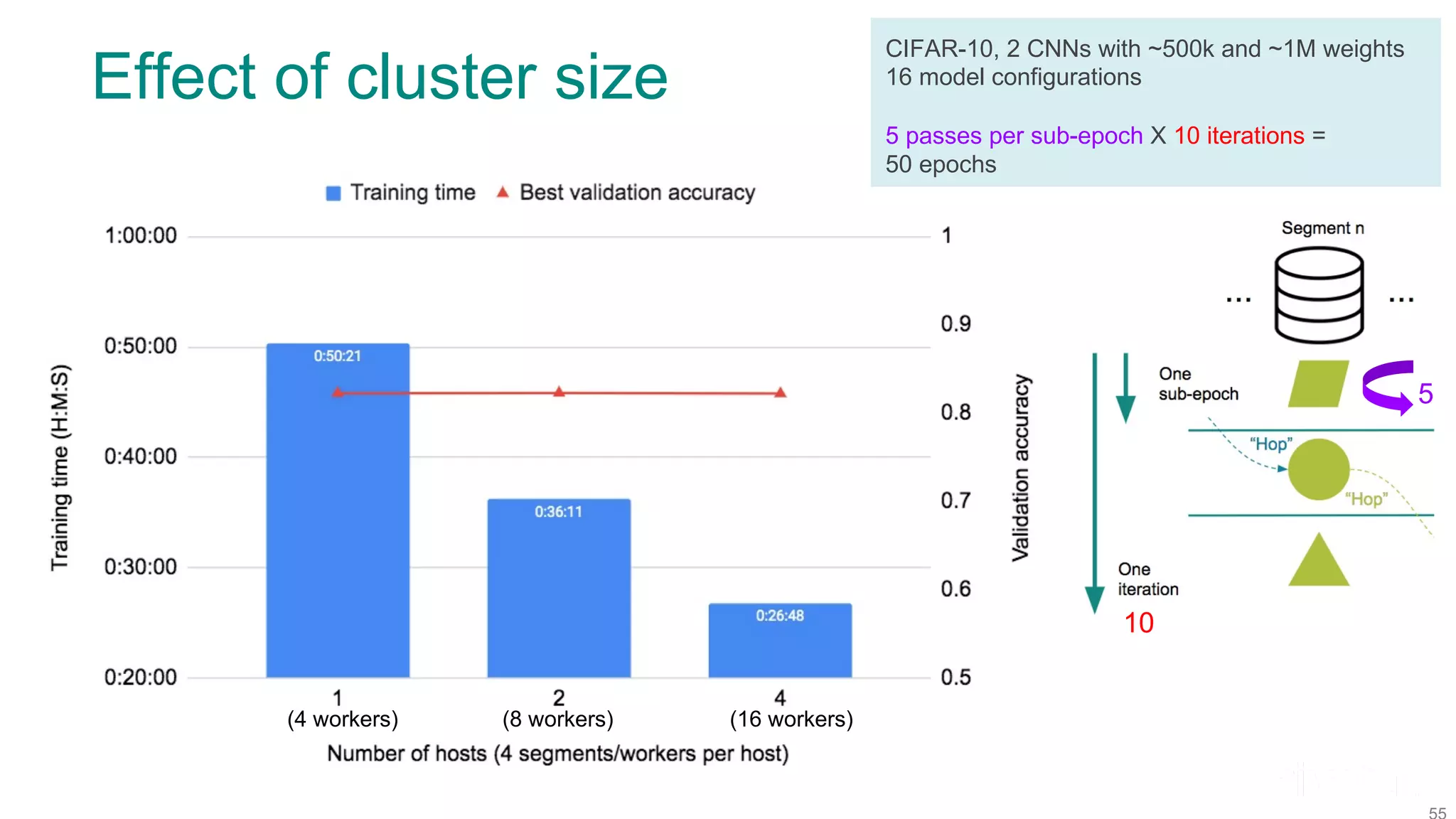
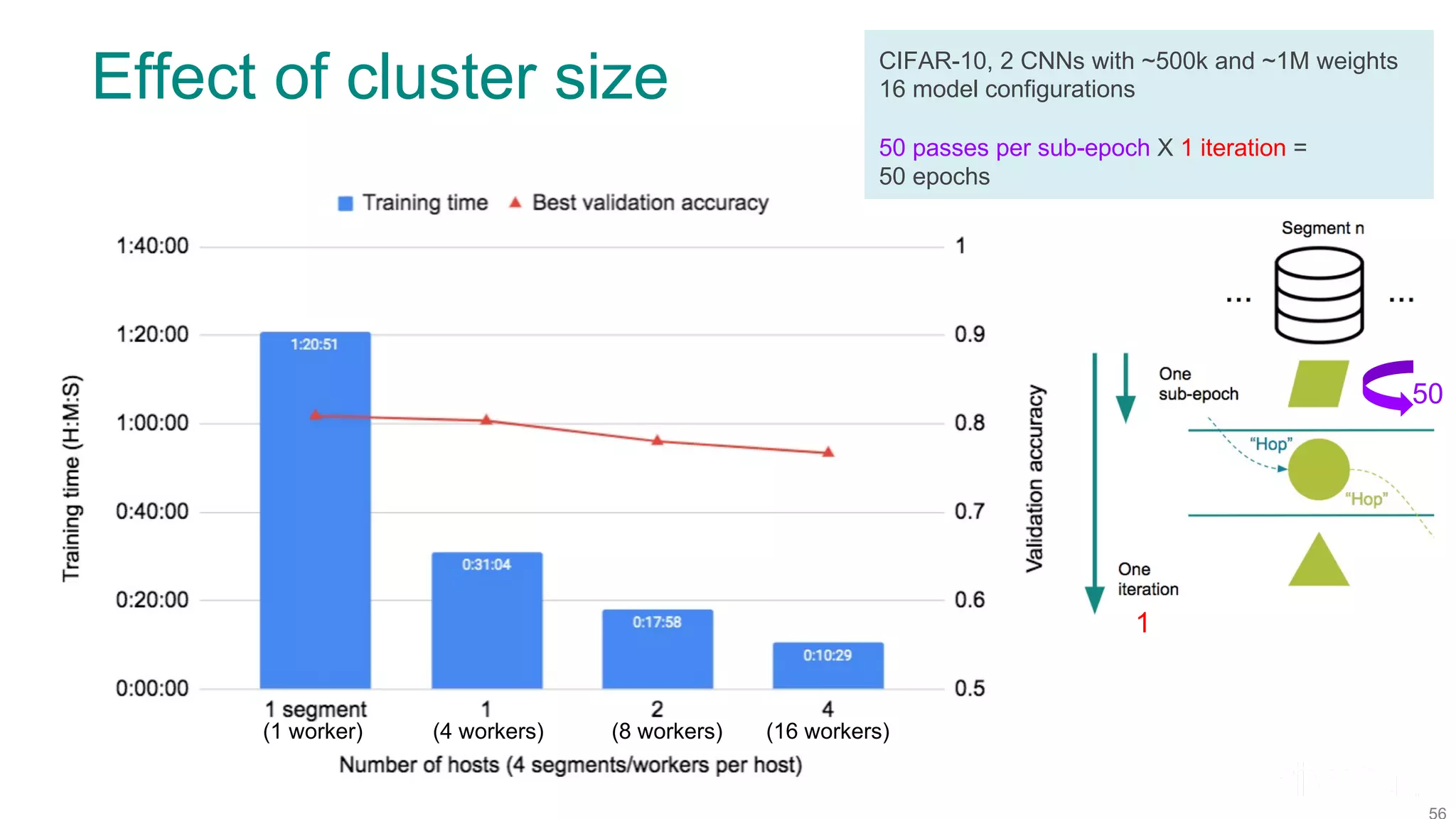
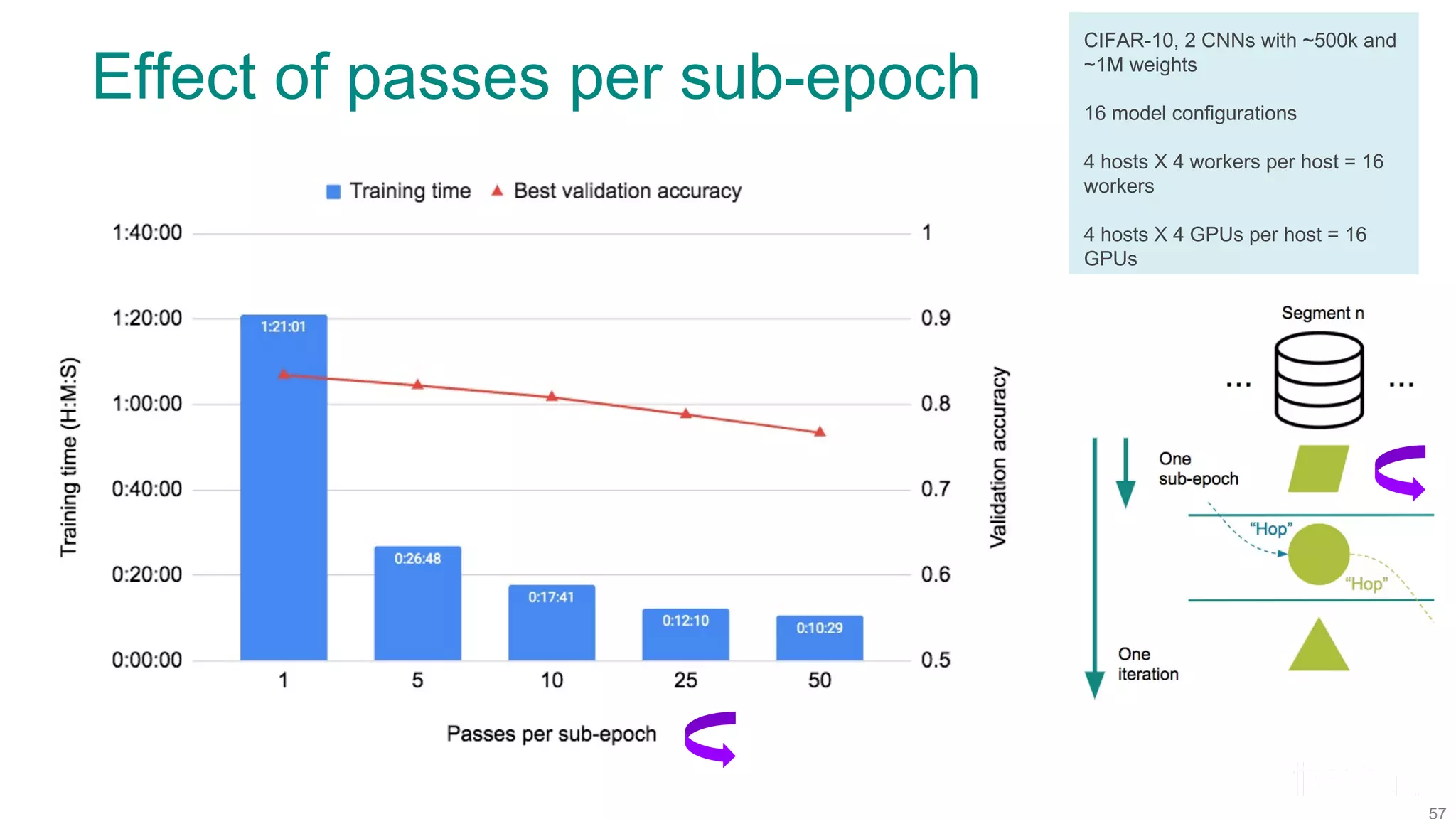

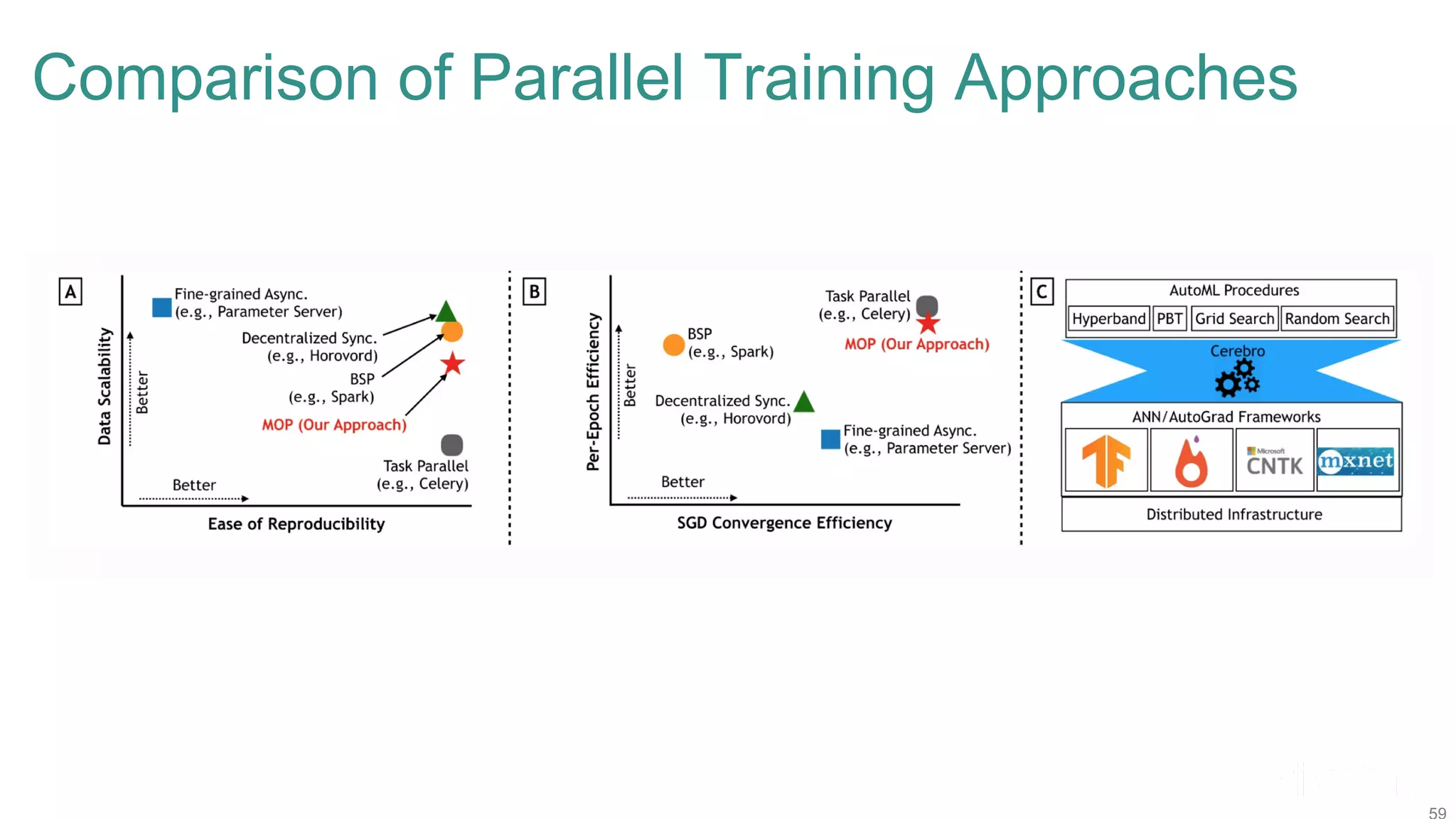

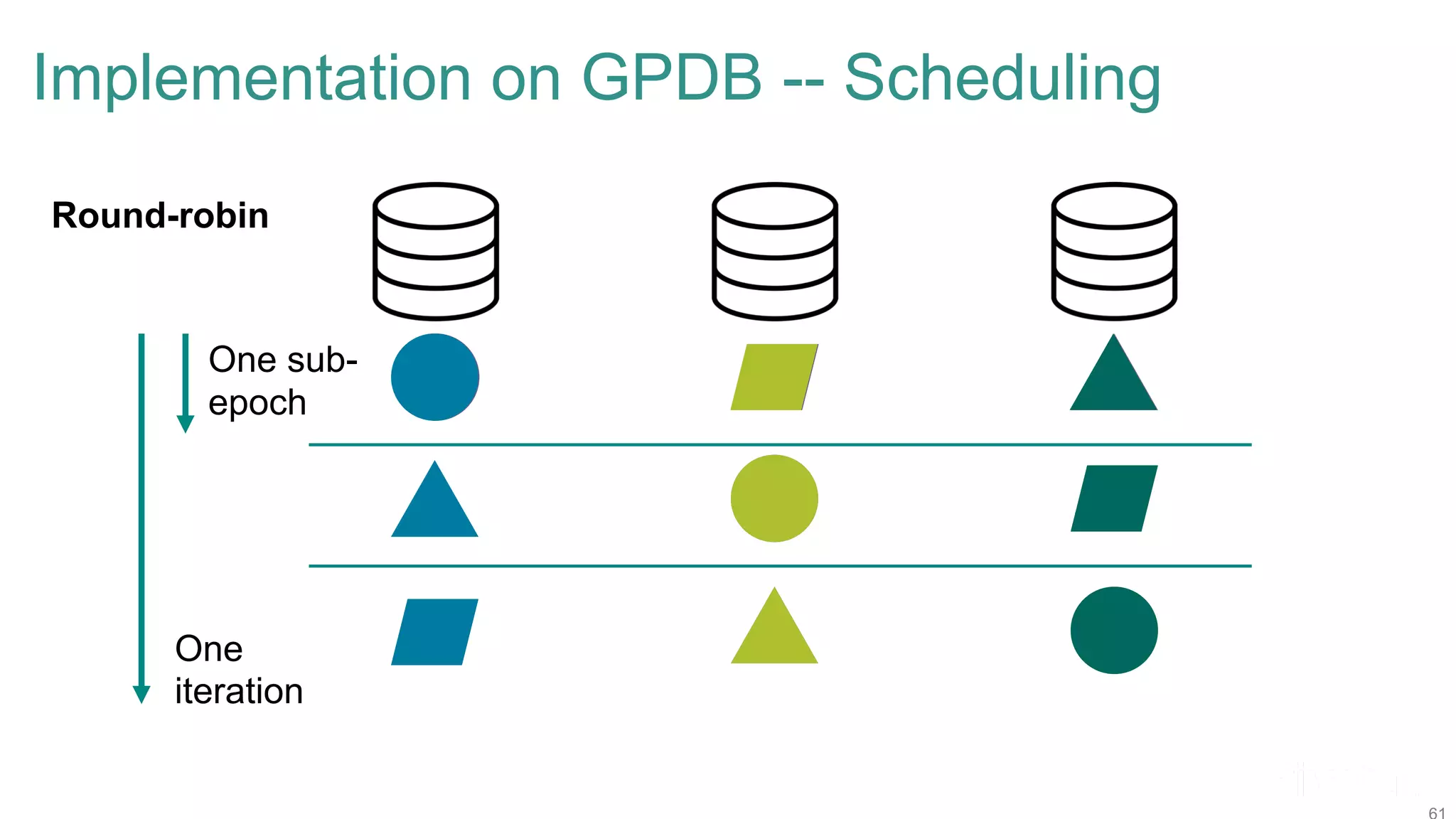
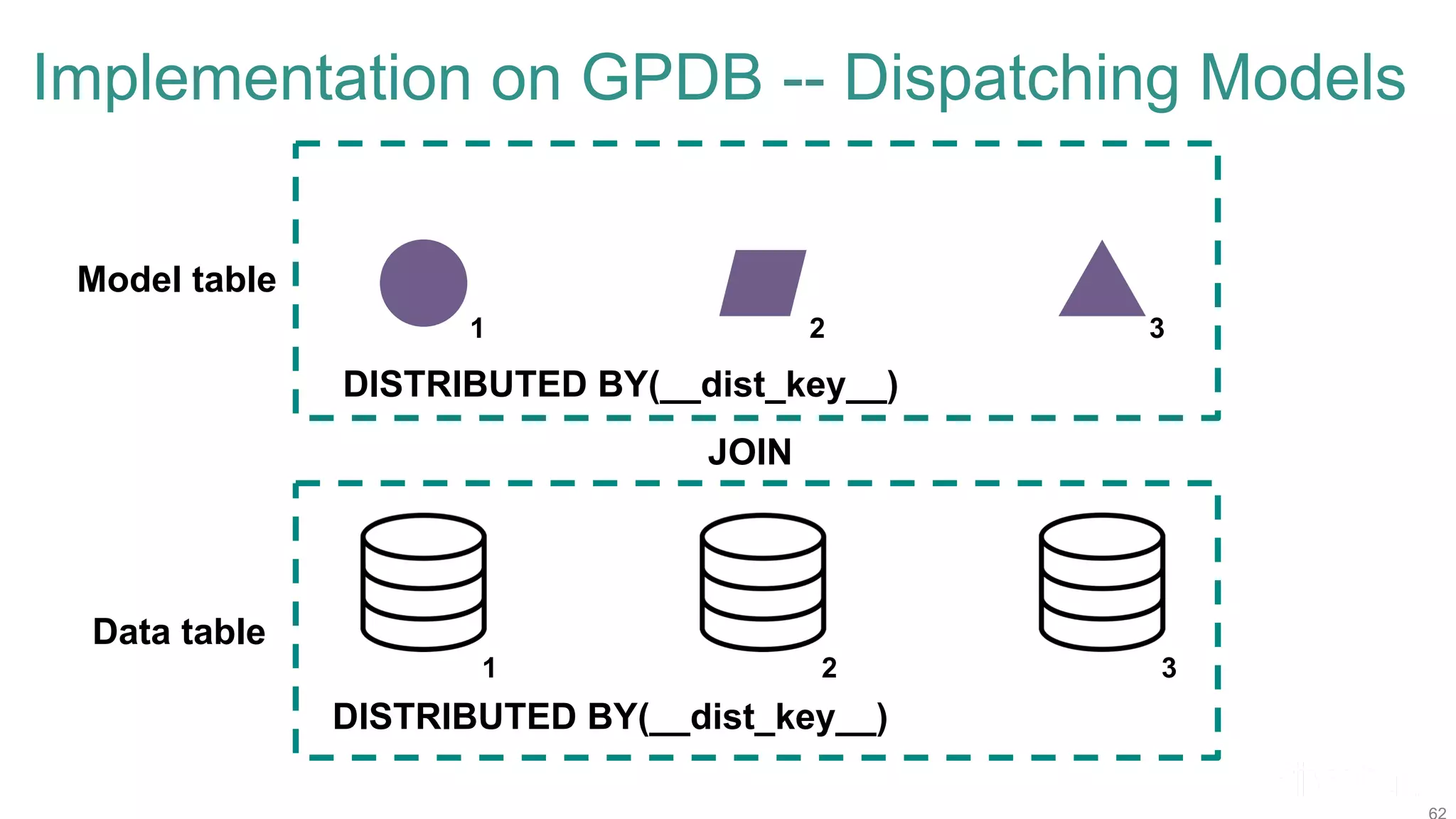
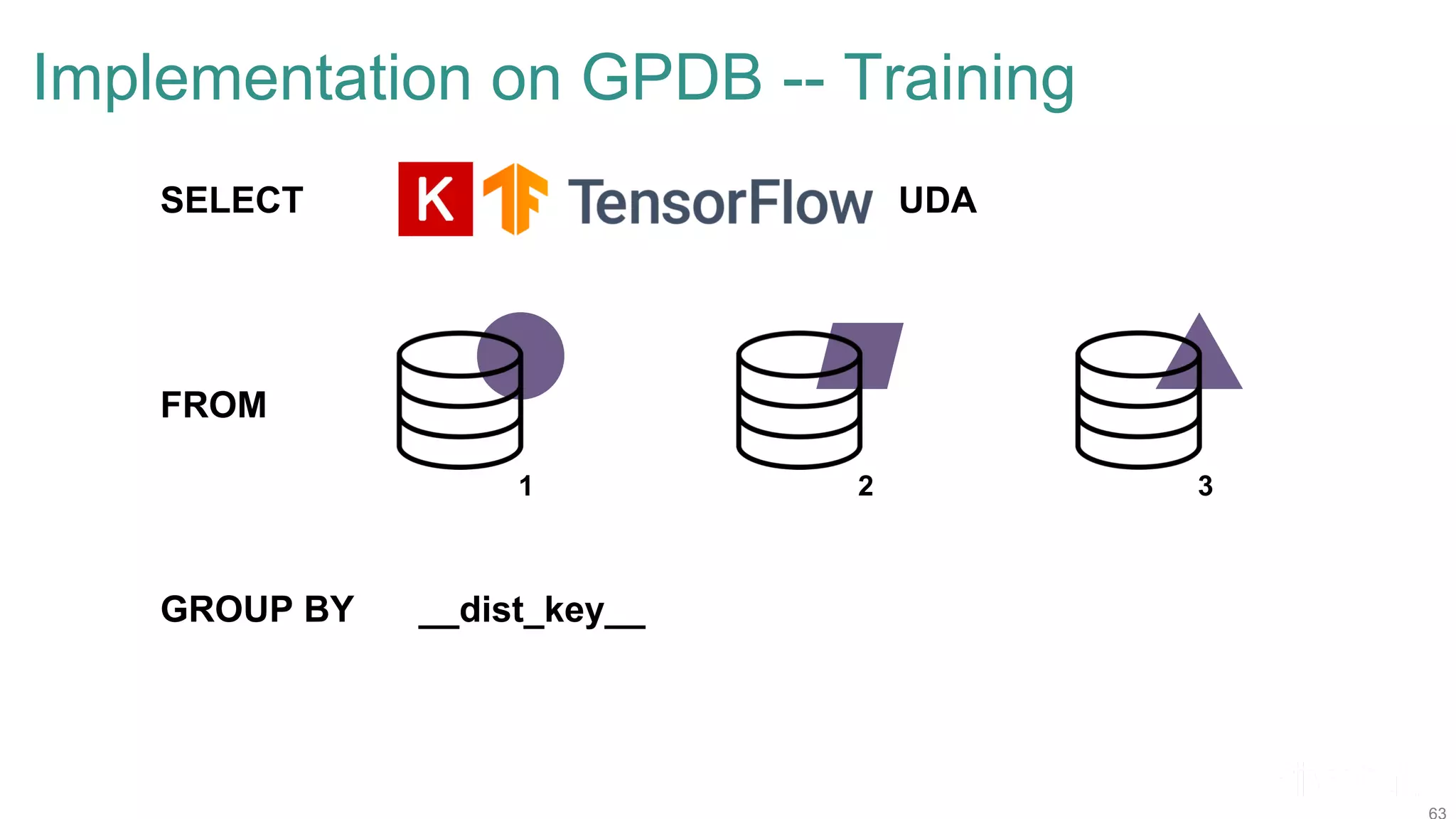


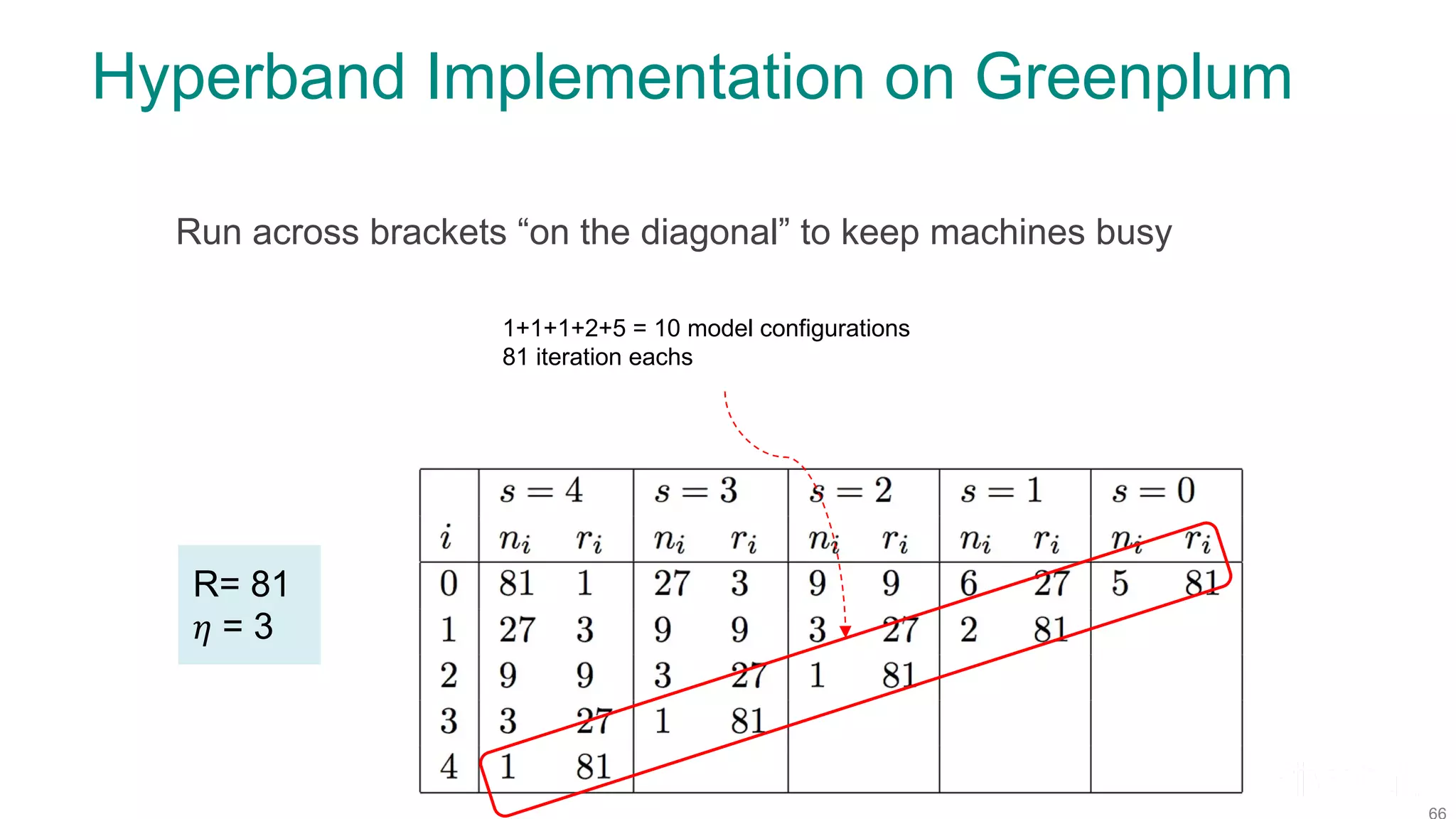

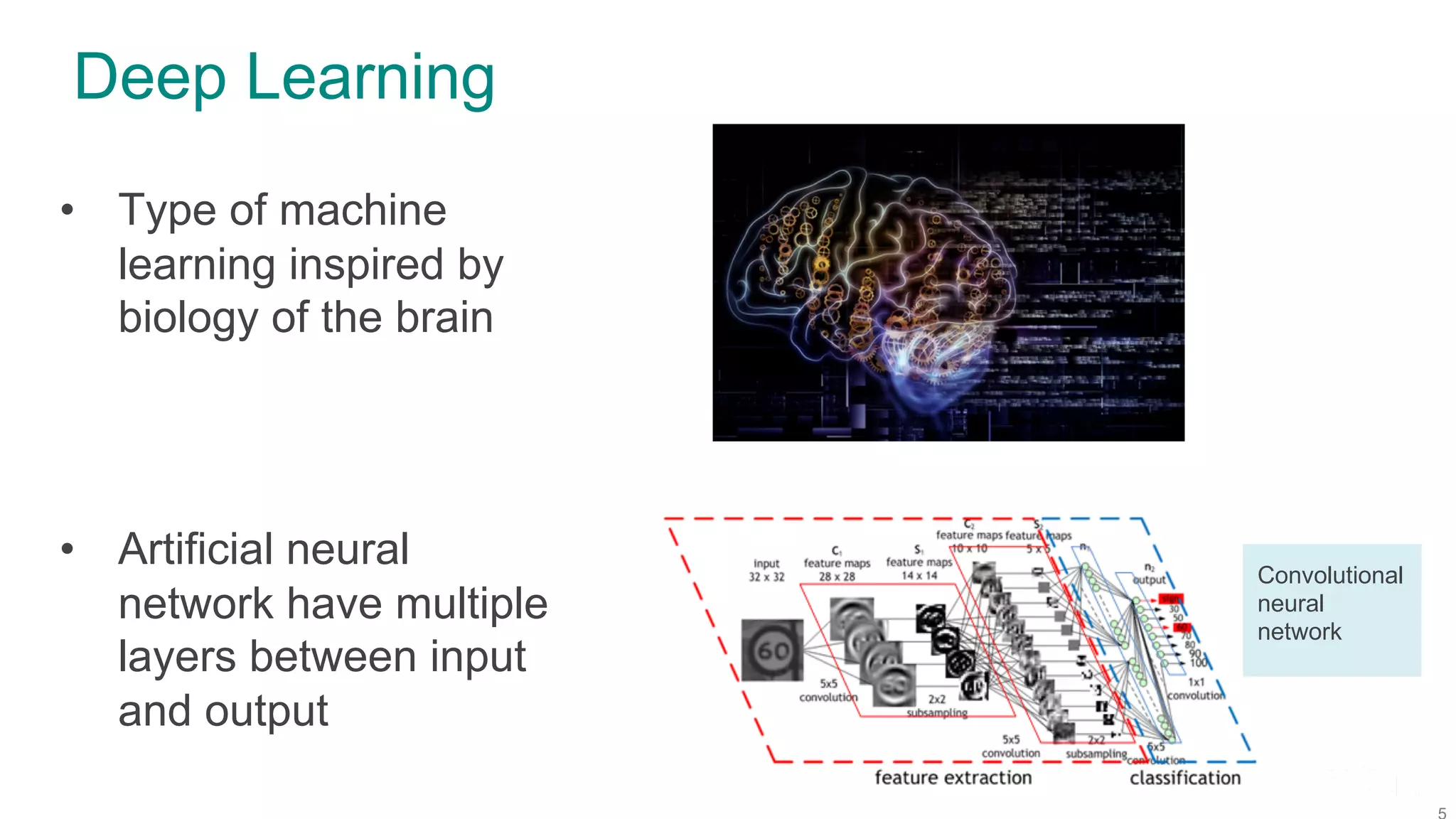
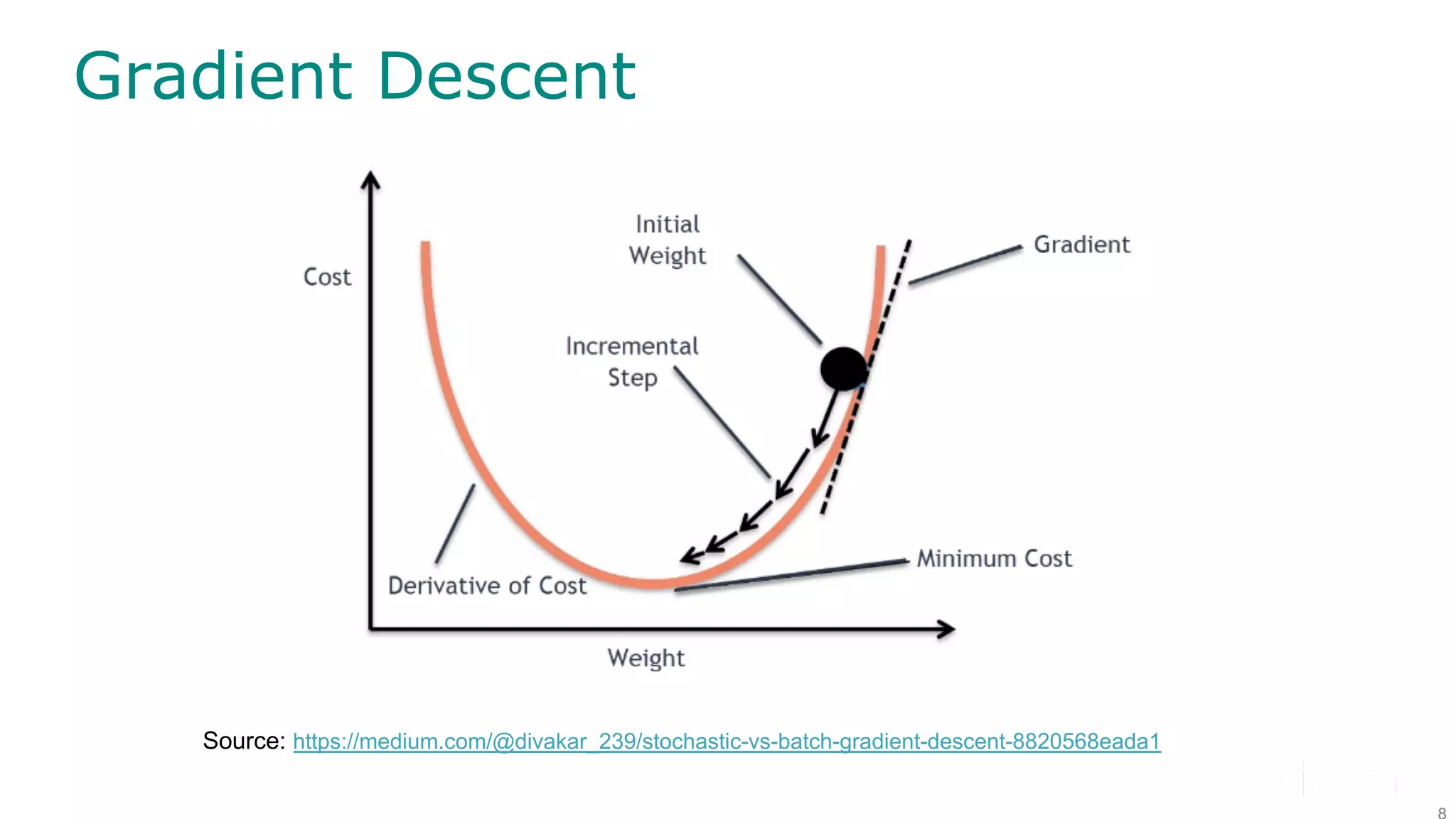
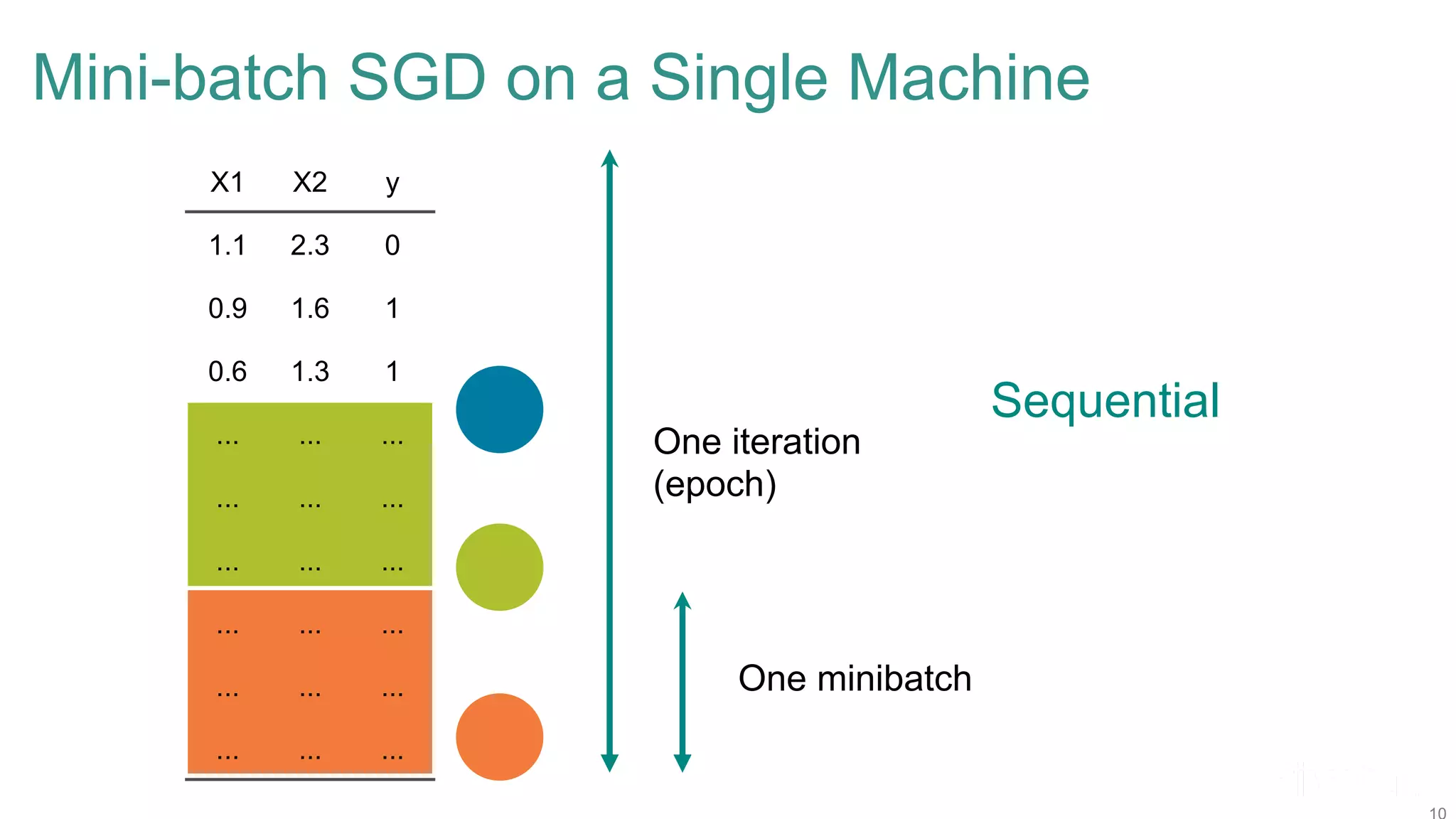
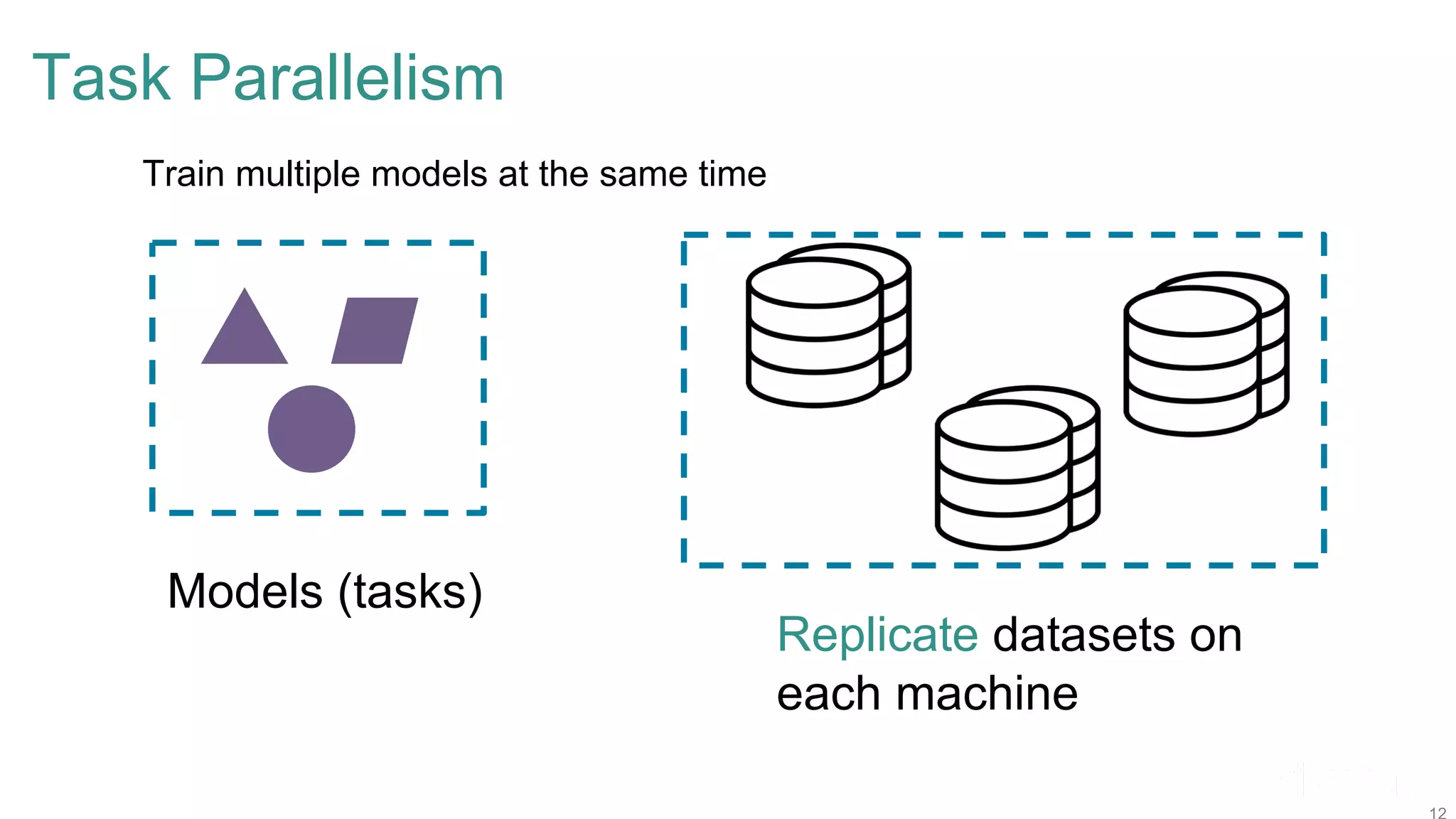
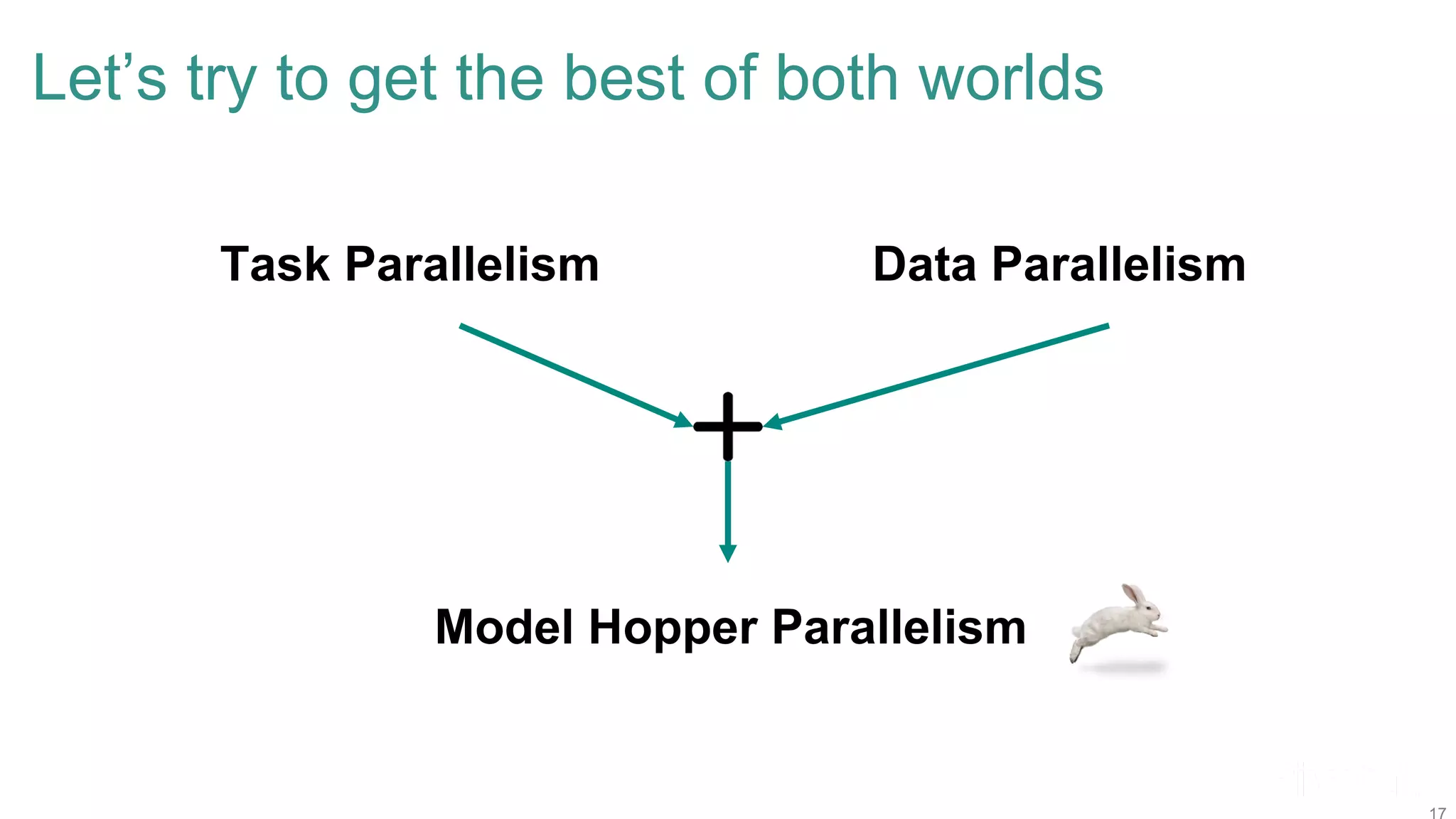
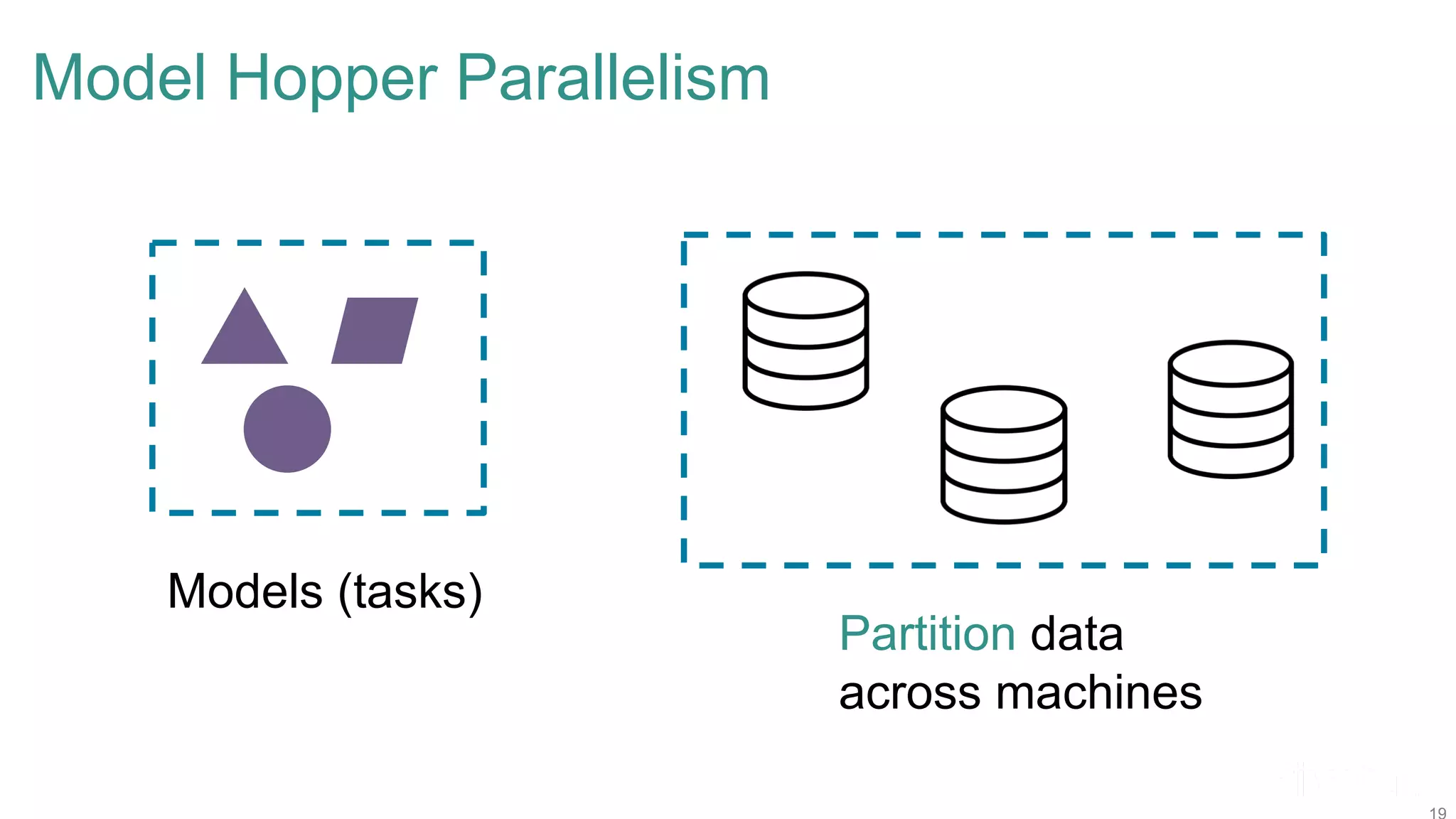
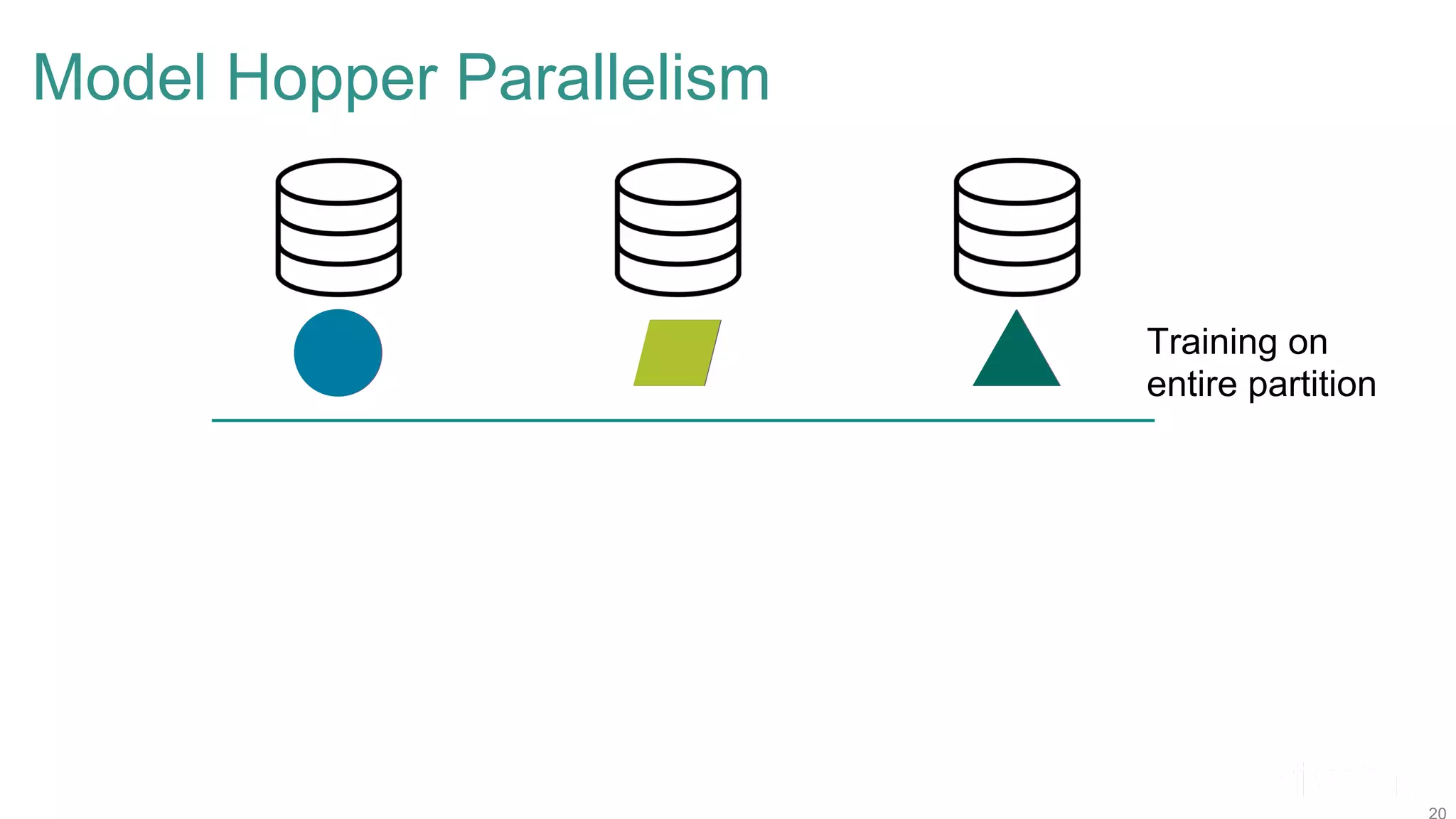
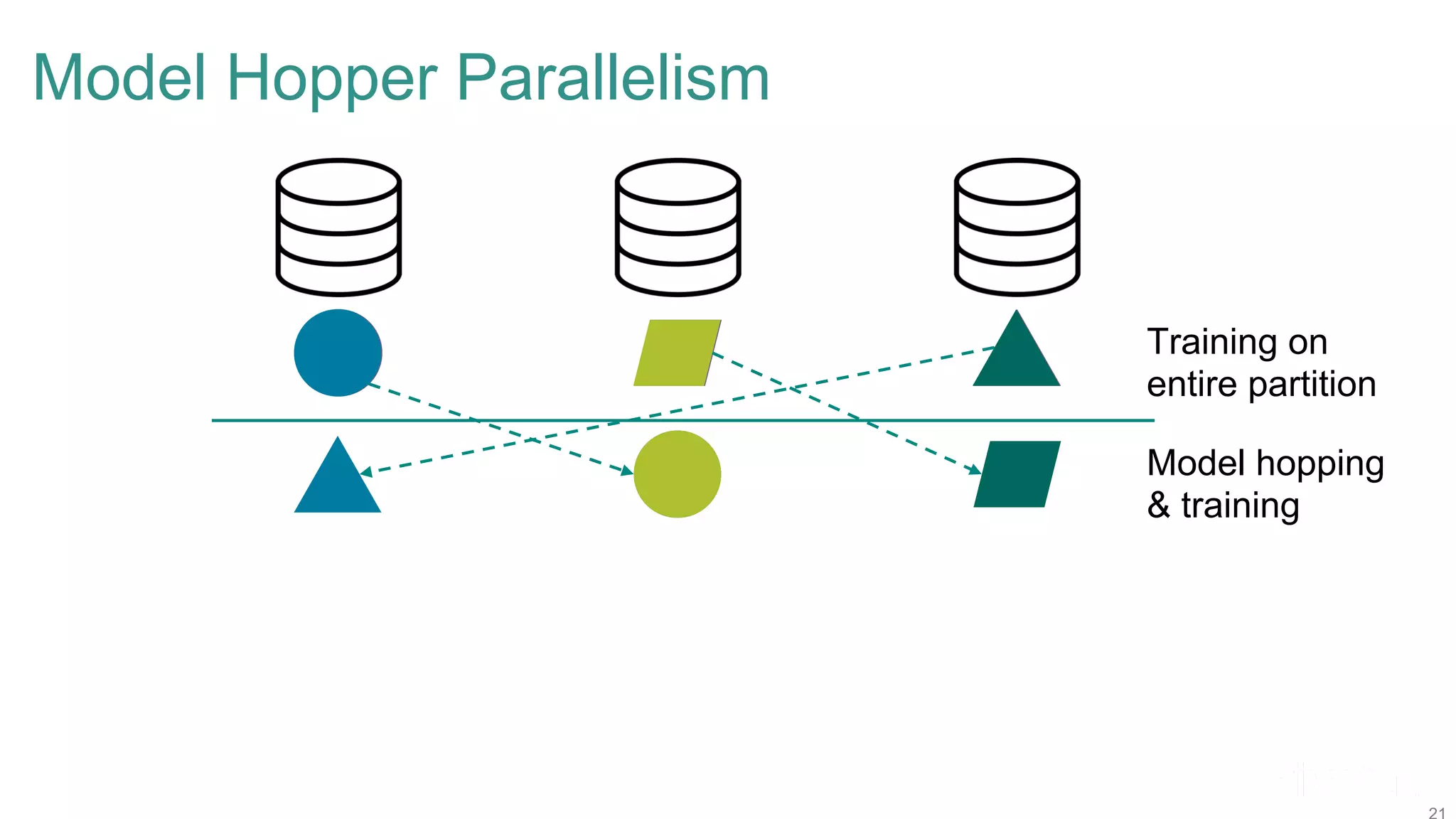
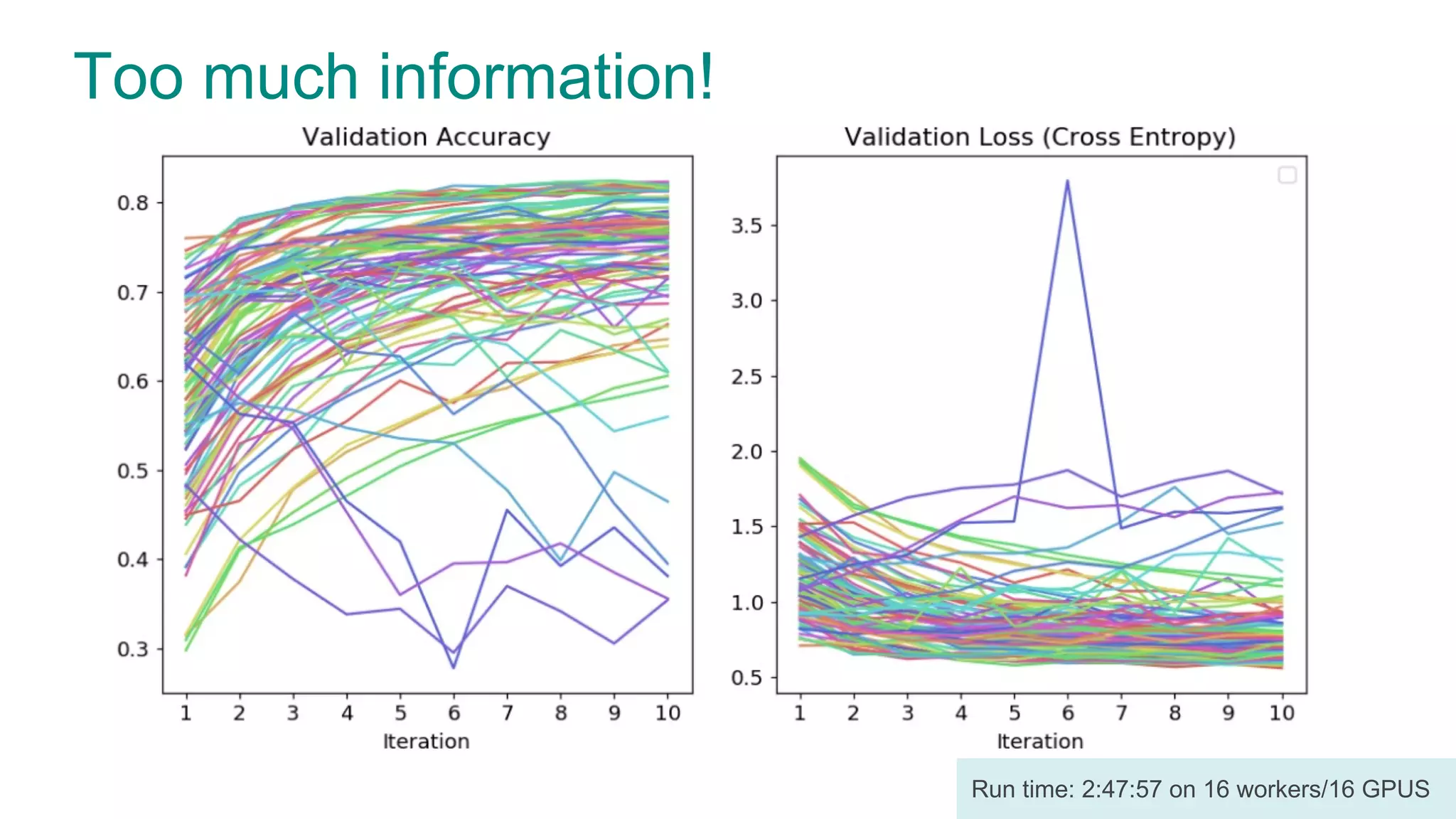
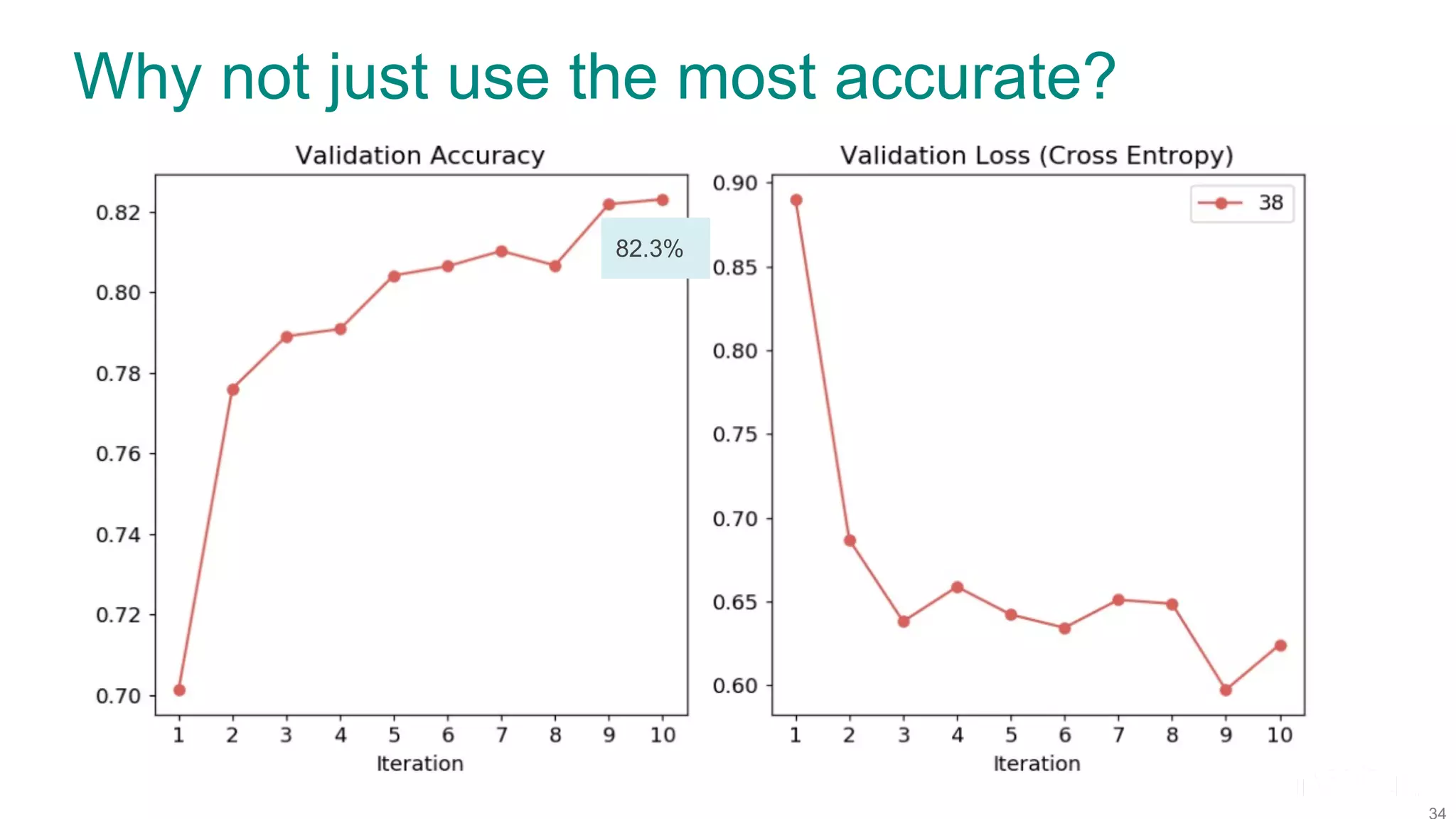
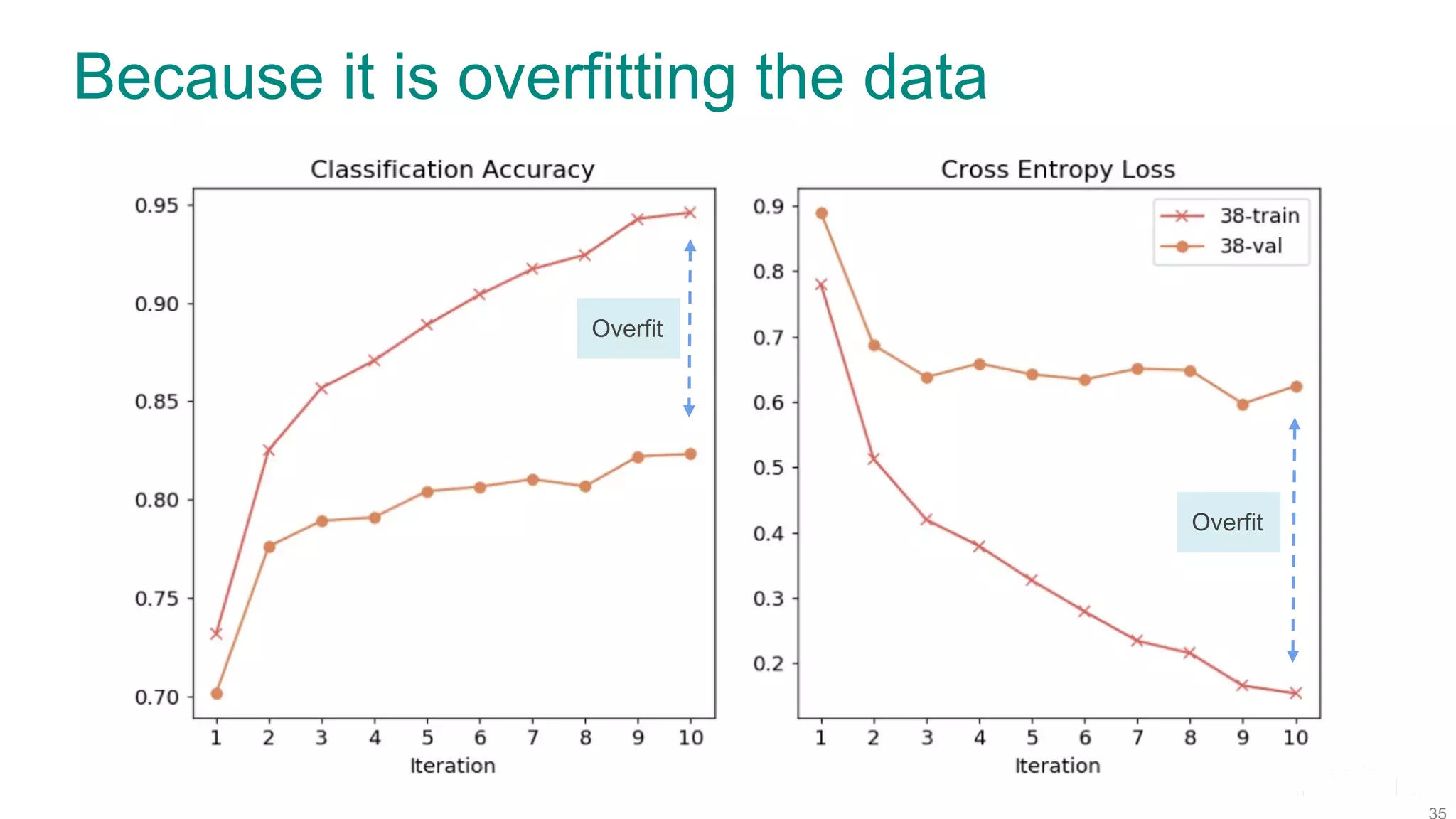
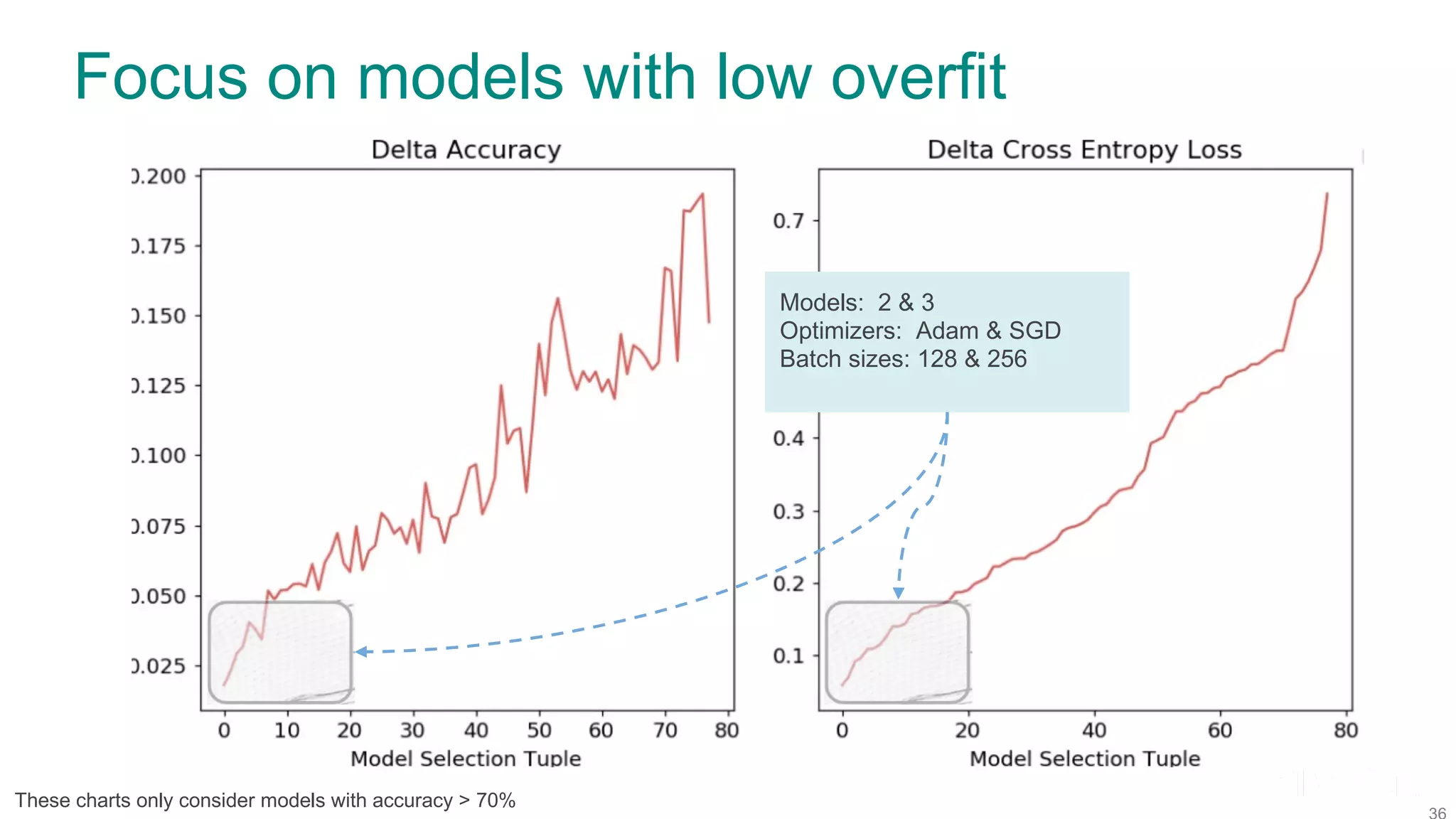
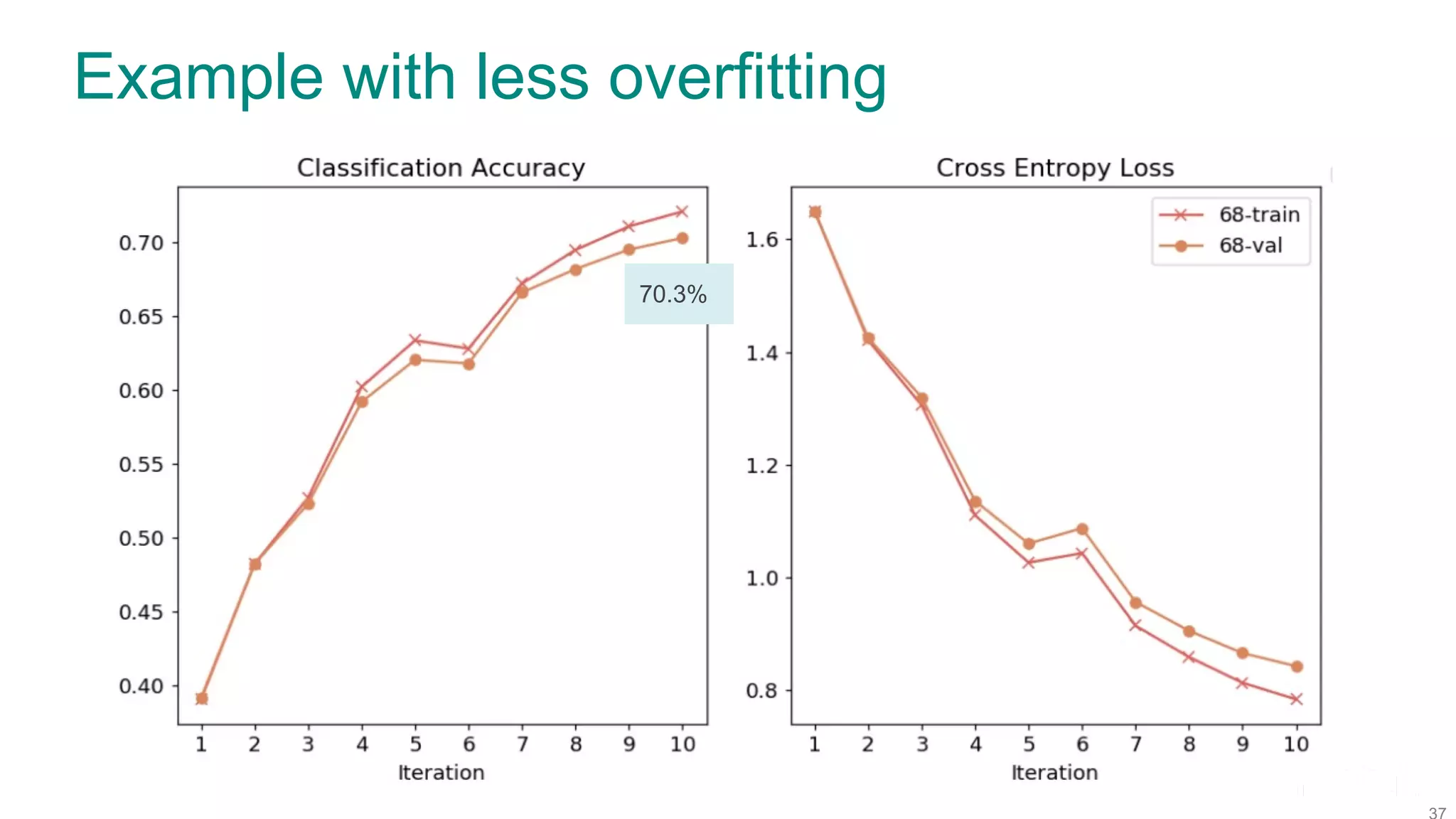
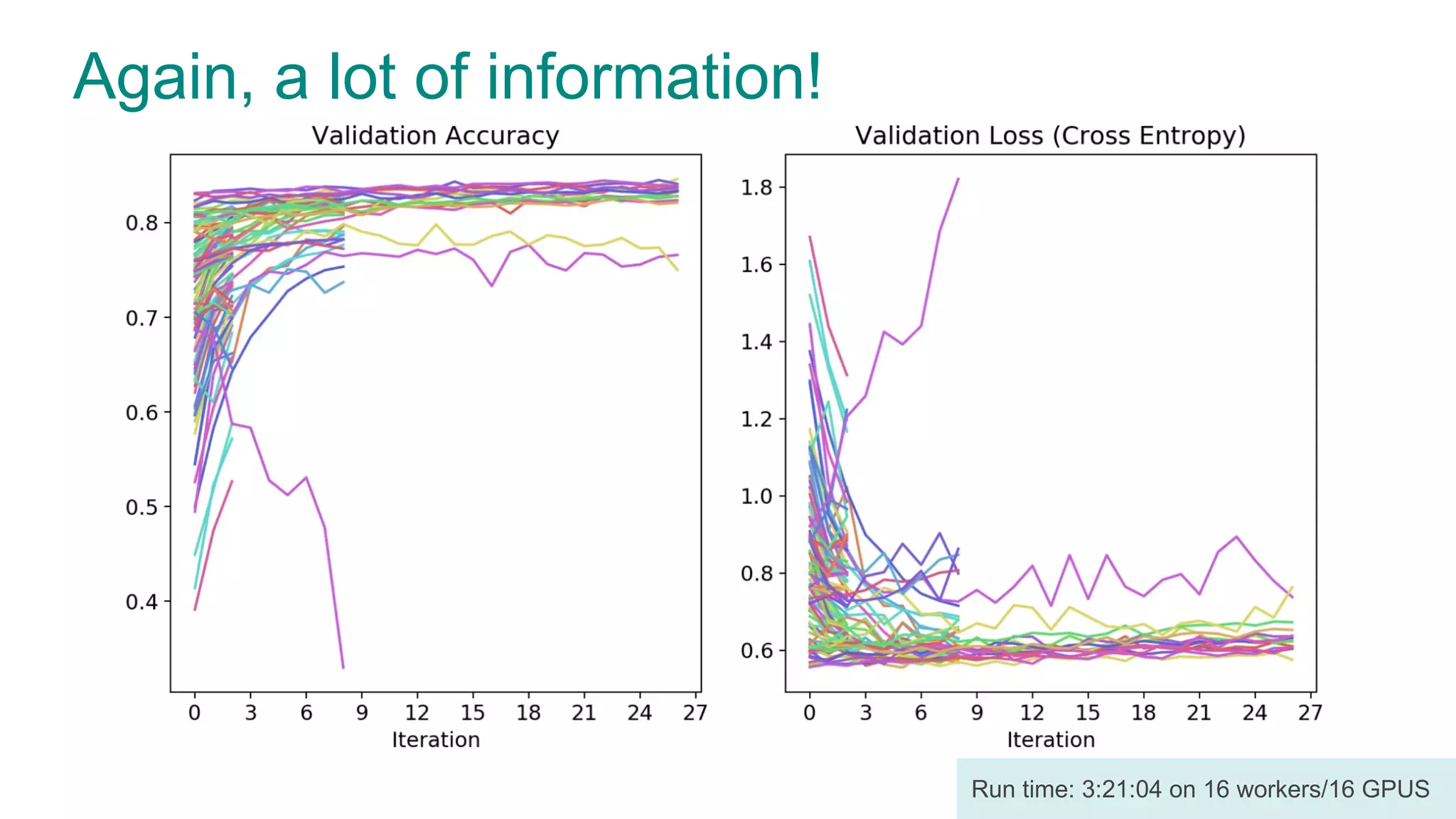
The document discusses efficient model selection for training deep neural networks using parallel processing on massively parallel processing (MPP) databases. It explains two primary approaches: model hopper parallelism and data parallelism, alongside practical examples and techniques such as grid search and AutoML with Hyperband. The findings highlight the benefits of optimizing GPU usage and integrating AutoML methods to enhance model training efficiency.