In this chapter •This chapter presents the evolutionary changes that have occurred in parallel, distributed, and cloud computing over the past 30 years, driven by applications with variable workloads and large data sets. • We study both high-performance and high-throughput computing systems in parallel computers appearing as computer clusters, service- oriented architecture, computational grids, peer-to-peer networks, Internet clouds, and the Internet of Things. • These systems are distinguished by their hardware architectures, OS platforms, processing algorithms, communication protocols, and service models applied. We also introduce essential issues on the scalability, performance, availability, security, and energy efficiency in distributed systems.
3.
Scalable Computing overthe Internet Scalability is the ability of a system, network, or process to handle a growing amount of work in a capable manner or its ability to be enlarged to accommodate that growth. For example, it can refer to the capability of a system to increase its total output under an increased load when resources (typically hardware) are added.
4.
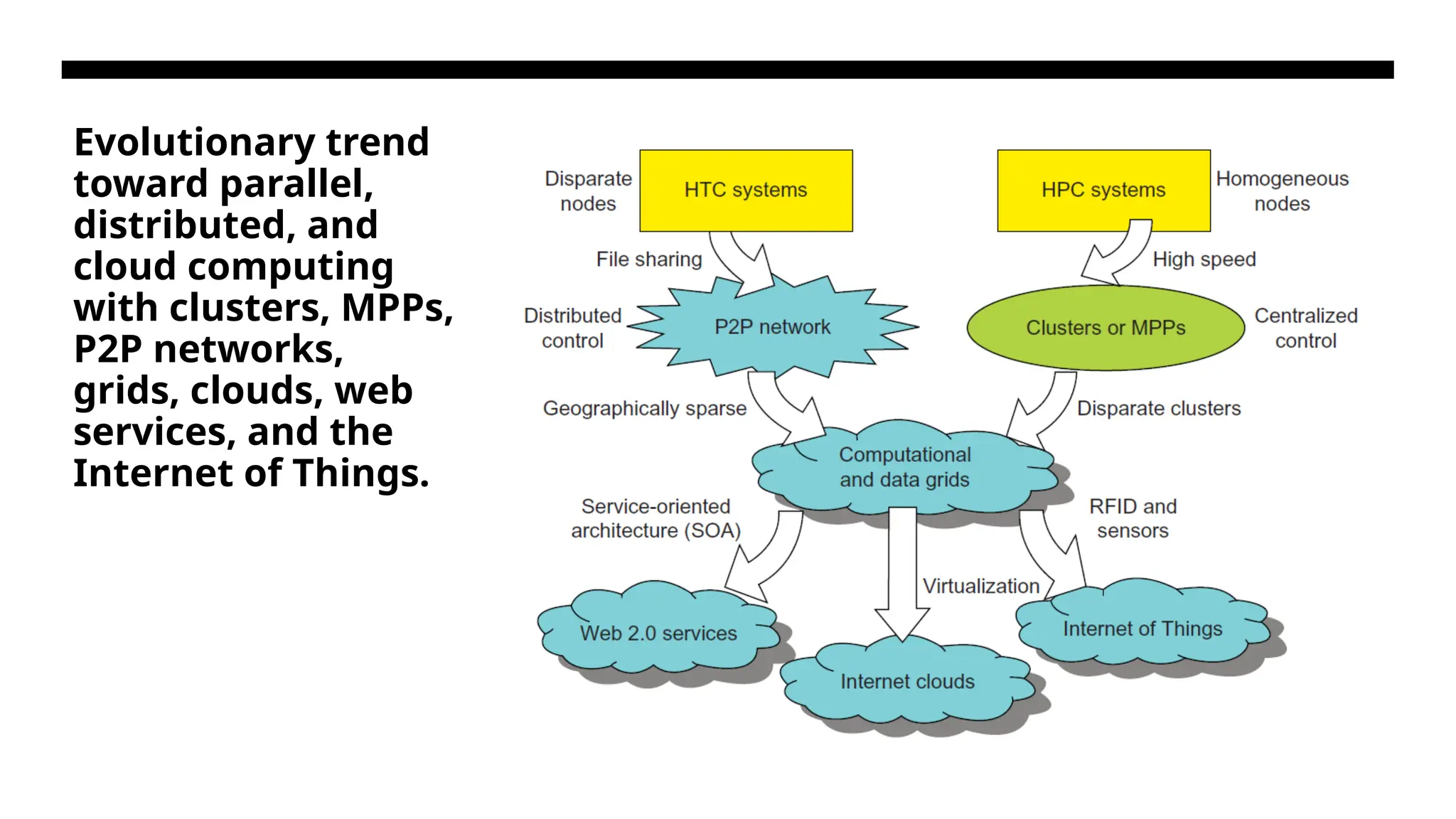
The Age ofInternet Computing • Billions of people use the Internet every day. As a result, supercomputer sites and large data centers must provide high-performance computing services to huge numbers of Internet users concurrently Because of this high demand, high-performance computing (HPC)applications is no longer optimal for measuring system performance. • The emergence of computing clouds instead demands high-throughput computing (HTC) systems built with parallel and distributed computing technologies.
5.
The Platform Evolution Computertechnology has gone through five generations of development, with each generation lasting from 10 to 20 years. Successive generations are overlapped in about 10 years 1950-1970 Mainframe systems Built by IBM and CDC 1960-1980 Low cost mini computers DEC Pdp11 and VAX Series 1970-1990 Personal Computers with VLSI Microprocessors DOS PCs 1980-2000 Huge number of Portable computers Microsoft, Intel
6.
HPC – HighPerformance Computing What is high-performance computing (HPC)? HPC is a technology that uses clusters of powerful processors that work in parallel to process massive, multidimensional data sets and solve complex problems at extremely high speeds. High-Performance Computing(HPC) is a computing technique to process computational problems, and complex data and to perform scientific simulations. HPC systems consist of considerably more number of processors or computer nodes, high-speed interconnects, and specialized libraries and tools Extra Reading - https://www.techtarget.com/searchdatacenter/definition/high-performance-computing-HPC
7.
HTC – HighThroughput Computing High Throughput Computing (HTC) is defined as a type of computing that aims to run a large number of computational tasks using resources in parallel. HTC systems consist of a distributed network of computers known as computing clusters. These systems are used to schedule a large number of jobs effectively. HTC majorly focuses on increasing the overall throughput of the system by running many smaller size tasks parallelly
8.
Advantages of HTC Flexibility:HTC is more flexible and can be used for many computing tasks related to business analytics and scientific research. Cost-Effectiveness: HTC is more cost-effective as compared to the solutions offered by High- Performance Computing(HTC) as it makes use of hardware and software that is available and less expensive and performs more tasks. Reliability: HTC systems are mostly designed to provide high reliability and make sure that all tasks run efficiently even if any one of the individual components fails. Resource Optimization: HTC also does proper resource allocation by ensuring that all the resources that are available are efficiently used and accordingly increases the value of computing resources that are available.
9.
Disparate Systems Disparate systemor a disparate data system is a computer data processing system that was designed to operate as a fundamentally distinct data processing system without exchanging data or interacting with other computer data processing systems.
Advent of 3new computing paradigms 1. RFiD – Radio Frequency Identification - refers to a wireless system comprised of two components: tags and readers. The reader is a device that has one or more antennas that emit radio waves and receive signals back from the RFID tag 2. GPS – Global Positioning Systems - a global navigation satellite system that provides location, velocity and time synchronization. GPS is everywhere. You can find GPS systems in your car, your smartphone and your watch. GPS helps you get where you are going, from point A to point B. 3. IoT – Internet of Things - the collective network of connected devices and the technology that facilitates communication between devices and the cloud, as well as between the devices themselves. Example – Smartwatches, smart appliances.
12.
Computing Paradigm Distinctions •The high-technology community has argued for many years about the precise definitions of centralized computing, parallel computing, distributed computing, and cloud computing. In general, distributed computing is the opposite of centralized computing. • The field of parallel computing overlaps with distributed computing to a great extent, and cloud computing overlaps with distributed, centralized, and parallel computing
13.
Centralized computing This isa computing paradigm by which all computer resources are centralized in one physical system. All resources (processors, memory, and storage) are fully shared and tightly coupled within one integrated OS. Many data centers and supercomputers are centralized systems, but they are used in parallel, distributed, and cloud computing applications. • One example of a centralized computing system is a traditional mainframe system, where a central mainframe computer handles all processing and data storage for the system. In this type of system, users access the mainframe through terminals or other devices that are connected to it.
14.
Parallel Computing • Itis the use of multiple processing elements simultaneously for solving any problem. Problems are broken down into instructions and are solved concurrently as each resource that has been applied to work is working at the same time. • In parallel computing, all processors are either tightly coupled with centralized shared memory or loosely coupled with distributed memory. Interprocessor communication is accomplished through shared memory or via message passing.
15.
Distributed Computing • Distributedcomputing is the method of making multiple computers work together to solve a common problem. It makes a computer network appear as a powerful single computer that provides large-scale resources to deal with complex challenges. • A distributed system consists of multiple autonomous computers, each having its own private memory, communicating through a computer network. Information exchange in a distributed system is accomplished through message passing.
16.
Cloud Computing An Internetcloud of resources can be either a centralized or a distributed computing system. The cloud applies parallel or distributed computing, or both. Clouds can be built with physical or virtualized resources over large data centers that are centralized or distributed. Some authors consider cloud computing to be a form of utility computing or service computing
17.
Scalable Computing andNew Paradigms include • Degrees of Parallelism • Innovative Applications • The Trend toward Utility Computing • The Hype Cycle of New Technologies . • Fifty years ago, when hardware was bulky and expensive, most computers were designed in a bit-serial fashion. • Data-level parallelism (DLP) was made popular through SIMD (single instruction, multiple data) and vector machines using vector or array types of instructions. DLP requires even more hardware support and compiler assistance to work properly.
18.
Innovative Applications • BothHPC and HTC systems desire transparency in many application aspects. For example, data access, resource allocation, process location, concurrency in execution, job replication, and failure recovery should be made transparent to both users and system management.
Trend towards UtilityComputing • Utility computing is defined as a service provisioning model that offers computing resources to clients as and when they require them on an on-demand basis. The charges are exactly as per the consumption of the services provided, rather than a fixed charge or a flat rate. • Utility computing focuses on a business model in which customers receive computing resources from a paid service provider. All grid/cloud platforms are regarded as utility service providers. However, cloud computing offers a broader concept than utility computing
21.
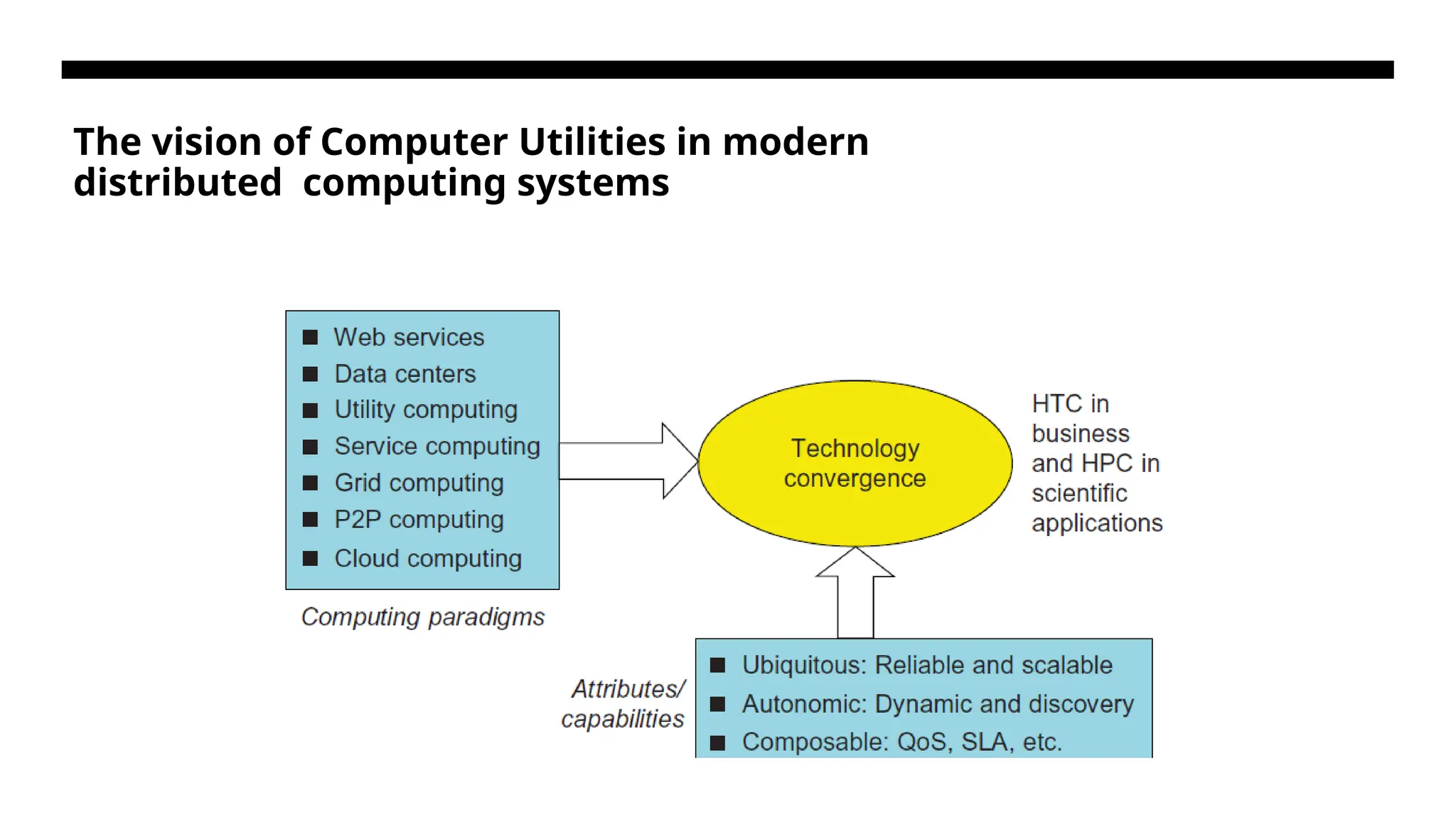
The vision ofComputer Utilities in modern distributed computing systems
22.
From previous diagram Previousdiagram identifies major computing paradigms to facilitate the study of distributed systems and their applications. These paradigms share some common characteristics. First, they are all present in daily life. Reliability and scalability are two major design objectives in these computing models. Second, they are aimed at autonomic operations that can be self- organized to support dynamic discovery.
23.
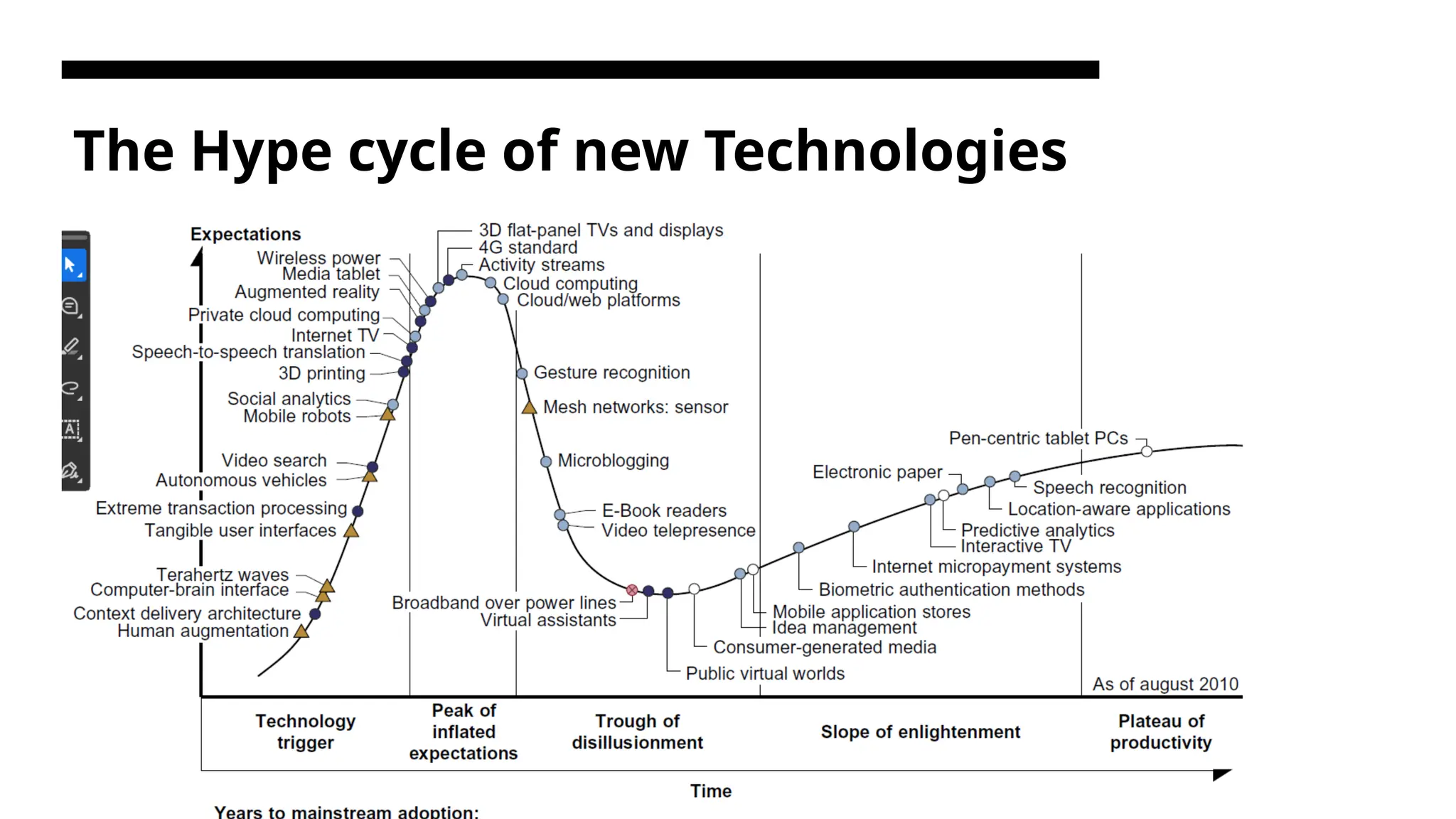
The Hype cycleof new Technologies Any new and emerging computing and information technology may go through a hype cycle, Generally illustrated in Figure 1.3. This cycle shows the expectations for the technology at five different stages.
The Internet ofThings and Cyber-Physical Systems Internet of Things - The traditional Internet connects machines to machines or web pages to web pages. The concept of the IoT was introduced in 1999 at MIT [40]. The IoT refers to the networked interconnection of everyday objects, tools, devices, or computers.
26.
Cyber – PhysicalSystems • A cyber-physical system (CPS) is the result of interaction between computational processes and the physical world. A CPS integrates “cyber” (heterogeneous, asynchronous) with “physical” (concurrent and information-dense) objects. • Few examples of cyber-physical systems are, smart manufacturing facilities with collaborative robots, autonomous vehicles utilizing sensors and AI for navigation, smart grids optimizing energy distribution, implantable medical devices like pacemakers providing automated therapy adjustments, and building automation
27.
Technologies for network-basedSystems With the concept of scalable computing under our belt, it’s time to explore hardware, software, and network technologies for distributed computing system design and applications. We will focus on viable approaches to building distributed operating systems for handling massive parallelism in a distributed environment.
28.
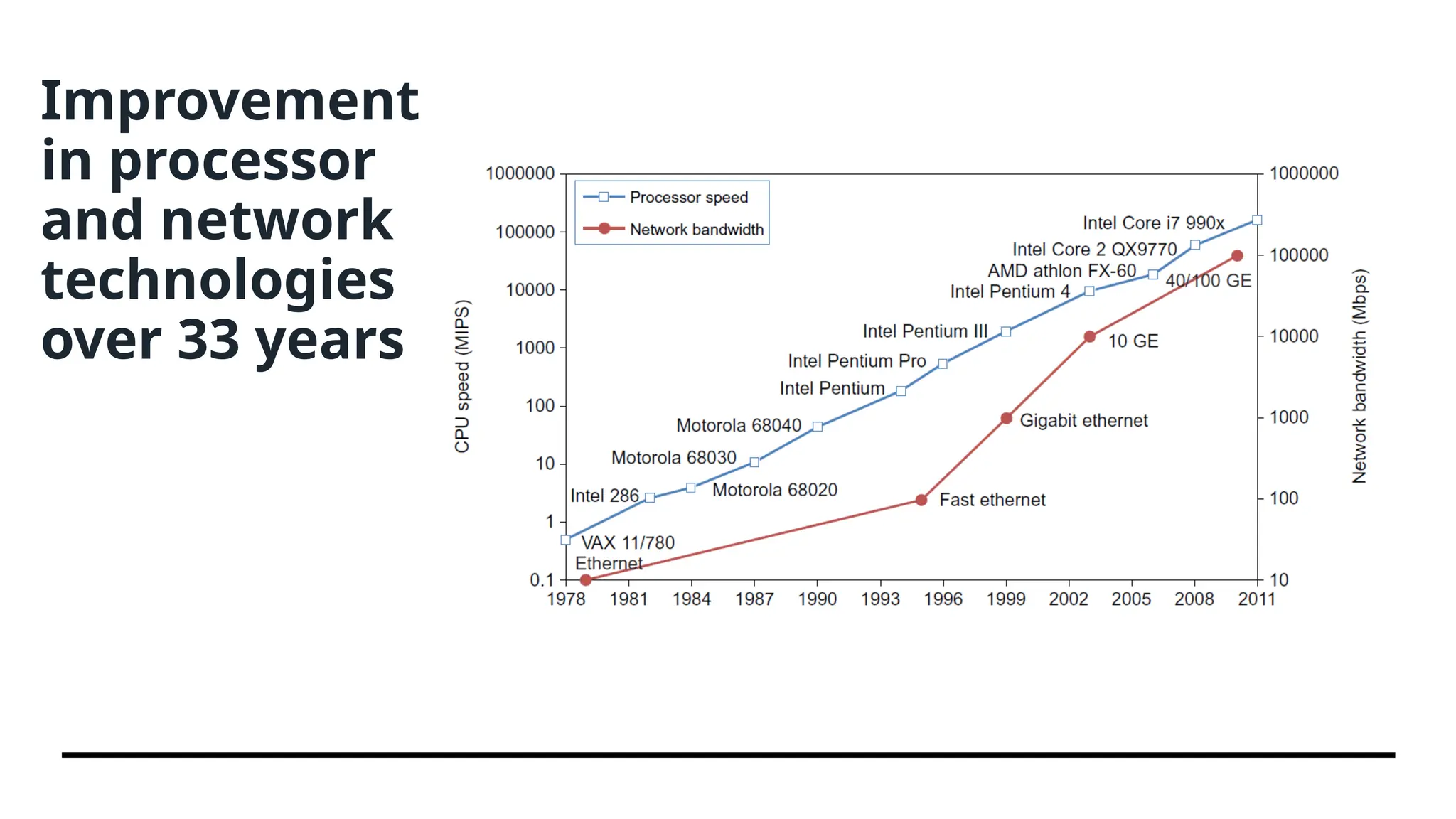
Multicore CPUs andMultithreading Technologies Advances in CPU Processors - Today, advanced CPUs or microprocessor chips assume a multicore architecture with dual, quad, six, or more processing cores. • We see growth from 1 MIPS for the VAX 780 in 1978 to 1,800 MIPS for the Intel Pentium 4 in 2002, up to a 22,000 MIPS peak for the Sun Niagara 2 in 2008. • The clock rate for these processors increased from 10 MHz for the Intel 286 to 4 GHz for the Pentium 4 in 30 years. • However, the clock rate reached its limit on CMOS-based chips due to power limitations. At the time of this writing, very few CPU chips run with a clock rate exceeding 5 GHz
Modern Multicore CPUChip • A multicore processor is an integrated circuit that has two or more processor cores attached for enhanced performance and reduced power consumption. These processors also enable more efficient simultaneous processing of multiple tasks, such as with parallel processing and multithreading.
31.
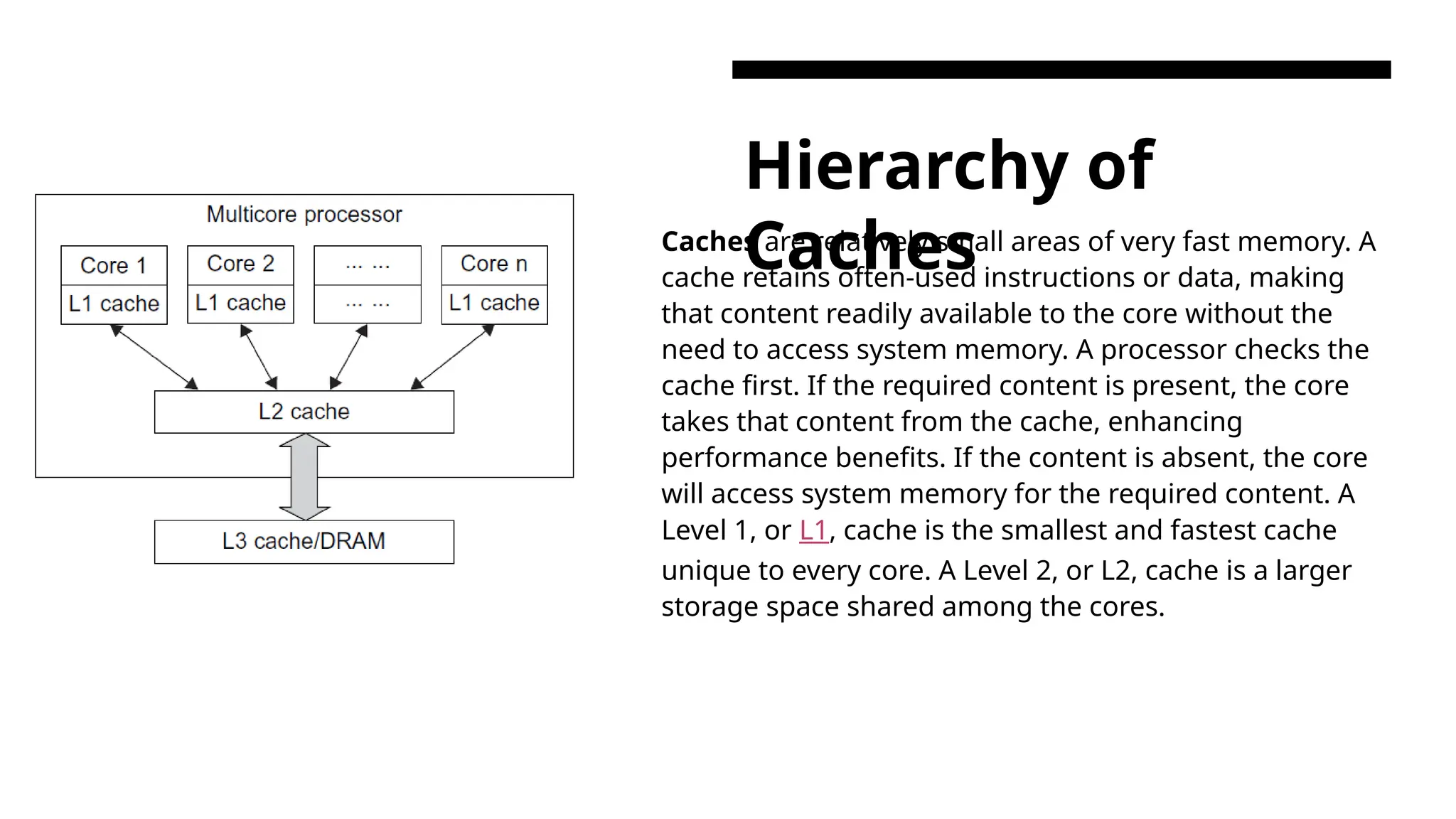
Hierarchy of Caches Caches arerelatively small areas of very fast memory. A cache retains often-used instructions or data, making that content readily available to the core without the need to access system memory. A processor checks the cache first. If the required content is present, the core takes that content from the cache, enhancing performance benefits. If the content is absent, the core will access system memory for the required content. A Level 1, or L1, cache is the smallest and fastest cache unique to every core. A Level 2, or L2, cache is a larger storage space shared among the cores.
32.
Important Terminologies Clock Speed- Clock speed refers to the rate at which a computer's central processing unit (CPU) executes instructions. It's often measured in hertz (Hz) and indicates how many cycles the CPU can complete per second. A higher clock speed generally means faster processing. Hyper-threading - Another approach involved the handling of multiple instruction threads. Intel calls this hyper-threading. With hyper-threading, processor cores are designed to handle two separate instruction threads at the same time
33.
ILP, TLP andDSP • Instruction Level Parallelism(ILP) – Instruction-Level Parallelism (ILP) refers to the technique of executing multiple instructions simultaneously within a CPU core by keeping different functional units busy for different parts of instructions. It enhances performance without requiring changes to the base code, allowing for the overlapping execution of multiple instructions. • Thread Level Parallelism(TLP) - Thread Level Parallelism (TLP) refers to the ability of a computer system to execute multiple threads simultaneously, improving the overall efficiency and performance of applications. TLP is a form of parallel computing where different threads of a program are run concurrently, often on multiple processors or cores. • What is DSP processor architecture? - is described which achieves high processing efficiency by executing concurrently four functions in every processor cycle: instruction prefetching from a dedicated instruction memory and generation of an effective operand, access to a single- port data memory and transfer of a data word over a common data bus, arithmetic/logic-unit (ALU) operation, and multiplication
34.
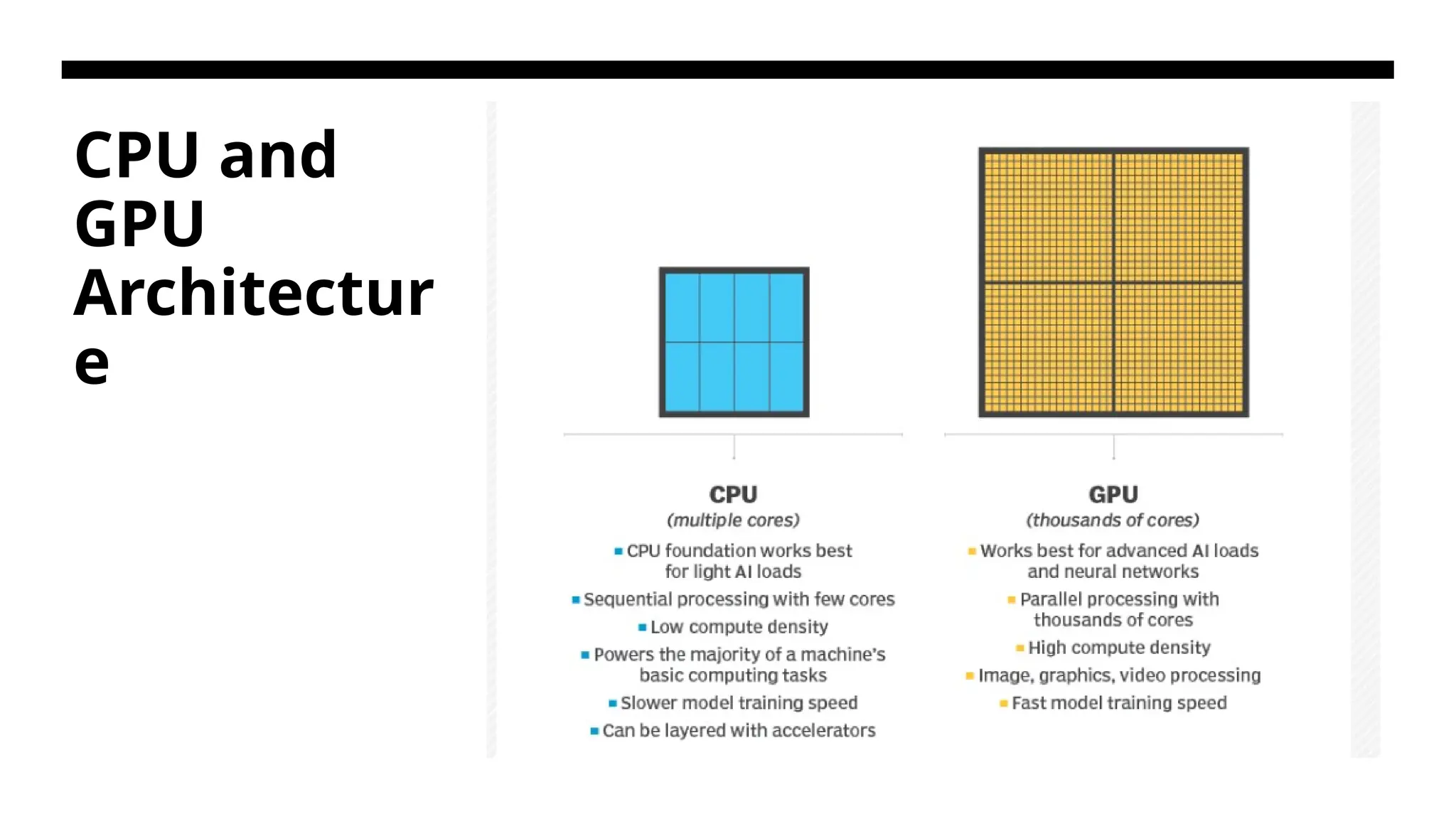
CPU and GPU ACentral processing unit (CPU) is commonly known as the brain of the computer. It is a conventional or general processor used for a wide range of operations encompassing the system instructions to the programs. CPUs are designed for high-performance serial processing which implies they are well-suited for performing large amounts of sequential tasks. The Graphics Processing Unit (GPU) is designed for parallel processing, and it uses dedicated memory known as VRAM (Video RAM). They are designed to tackle thousands of operations at once for tasks like rendering images, 3D rendering, processing video, and running machine learning models. It has it’s own memory separate from the system’s RAM which allows them to handle complex, high-throughput tasks like rendering and AI processing efficiently.
Need for GPUs •Both multi-core CPU and many-core GPU processors can handle multiple instruction threads at different magnitudes today. • Multicore CPUs may increase from the tens of cores to hundreds or more in the future. But the CPU has reached its limit in terms of exploiting massive DLP due to the aforementioned memory wall problem. • This has triggered the development of many-core GPUs with hundreds or more thin cores
37.
Multithreading Technology • Multithreadingis a form of parallelization or dividing up work for simultaneous processing. Instead of giving a large workload to a single core, threaded programs split the work into multiple software threads. These threads are processed in parallel by different CPU cores to save time.
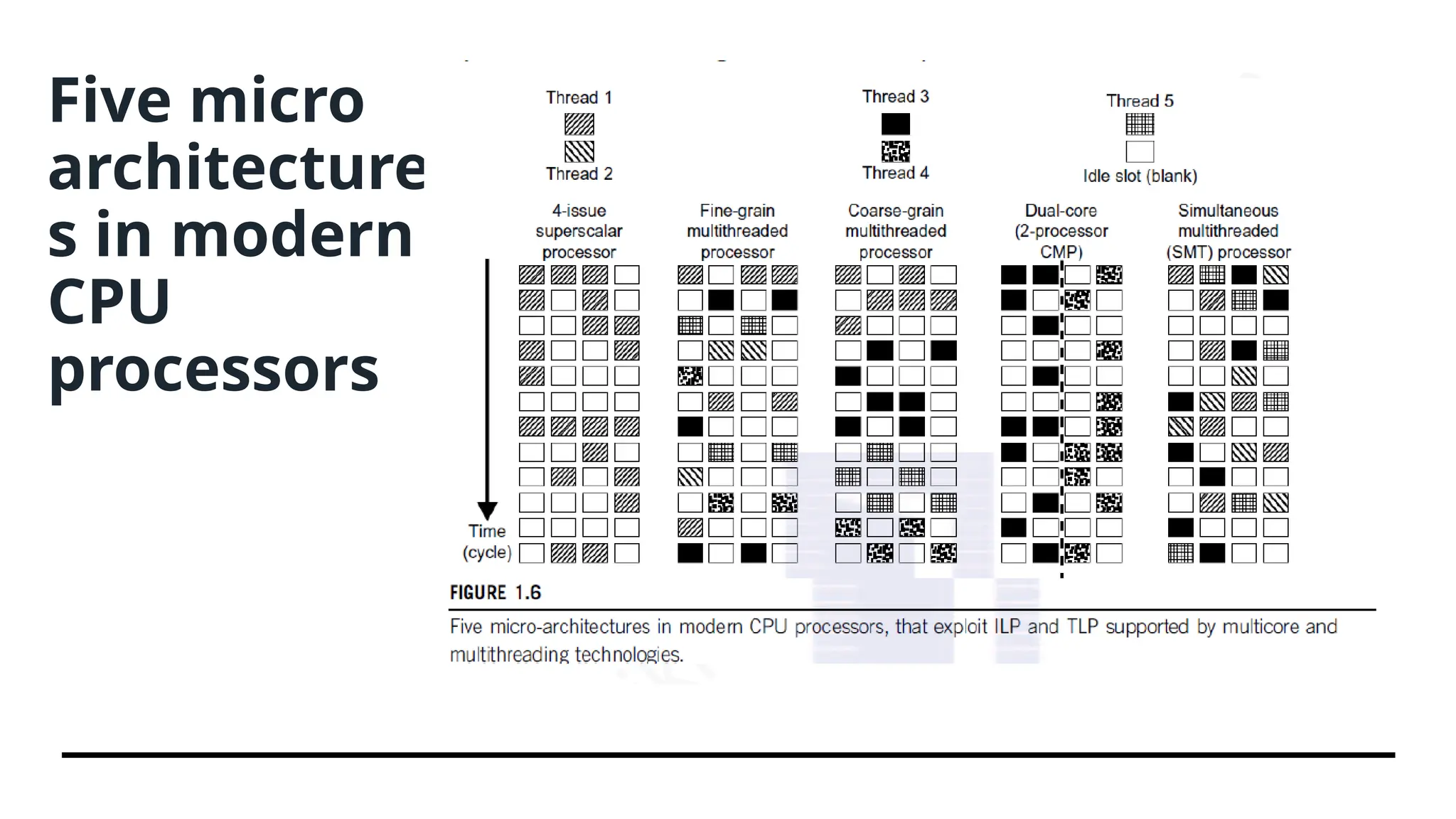
Explanation • The superscalarprocessor is single-threaded with four functional units. Each of the three multithreaded processors is four-way multithreaded over four functional data paths. In the dual- core processor, assume two processing cores, each a single-threaded two-way superscalar processor. • Instructions from different threads are distinguished by specific shading patterns for instructions from five independent threads. • Fine-grain multithreading switches the execution of instructions from different threads per cycle. • Course-grain multithreading executes many instructions from the same thread for quite a few cycles before switching to another thread. • The multicore CMP executes instructions from different threads completely. • The SMT allows simultaneous scheduling of instructions from different threads in the same cycle. • The blank squares correspond to no available instructions for an instruction data path at a particular processor cycle. More blank cells imply lower scheduling efficiency.
40.
GPU Computing • AGPU is a graphics coprocessor or accelerator mounted on a computer’s graphics card or video card. • A GPU offloads the CPU from tedious graphics tasks in video editing applications. • The world’s first GPU, the GeForce 256, was marketed by NVIDIA in 1999. These GPU chips can process a minimum of 10 million polygons per second, and are used in nearly every computer on the market today. • Unlike CPUs, GPUs have a throughput architecture that exploits massive parallelism by executing many concurrent threads slowly, instead of executing a single long thread in a conventional microprocessor very quickly
41.
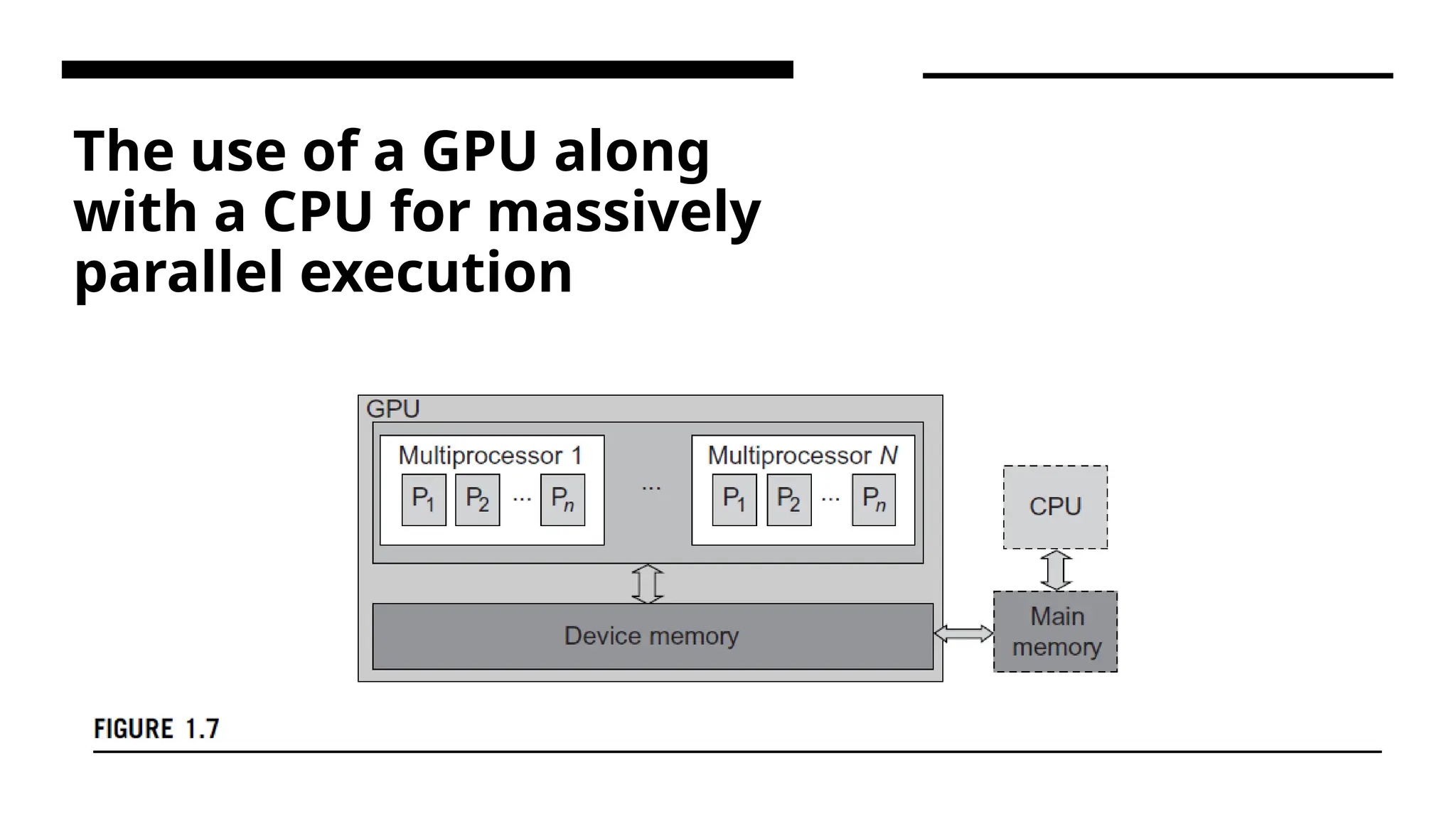
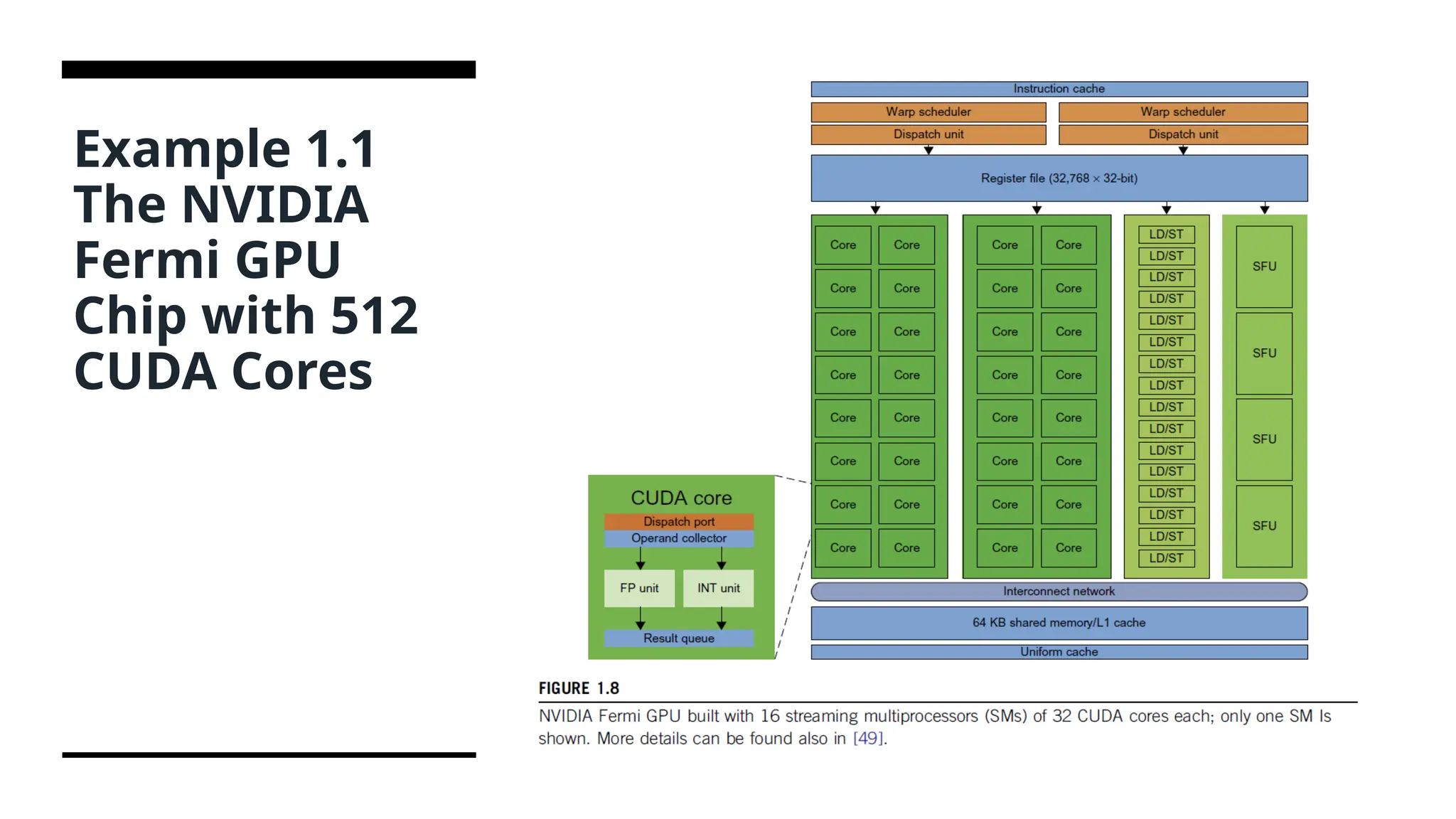
Working of GPU •Modern GPUs are not restricted to accelerated graphics or video coding. They are used in HPC systems to power supercomputers with massive parallelism at multicore and multithreading levels. GPUs are designed to handle large numbers of floating-point operations in parallel. • In a way, the GPU offloads the CPU from all data-intensive calculations, not just those that are related to video processing. Conventional GPUs are widely used in mobile phones, game consoles, embedded systems, PCs, and servers. The NVIDIA CUDA Tesla or Fermi is used in GPU clusters or in HPC systems for parallel processing of massive floating-pointing data.. • The GPU has a many-core architecture that has hundreds of simple processing cores organized as multiprocessors. Each core can have one or more threads. • The CPU instructs the GPU to perform massive data processing. The bandwidth must be matched between the on-board main memory and the on-chip GPU memory. This process is carried out in NVIDIA’s CUDA programming using the GeForce 8800 or Tesla and Fermi GPUs.
42.
The use ofa GPU along with a CPU for massively parallel execution
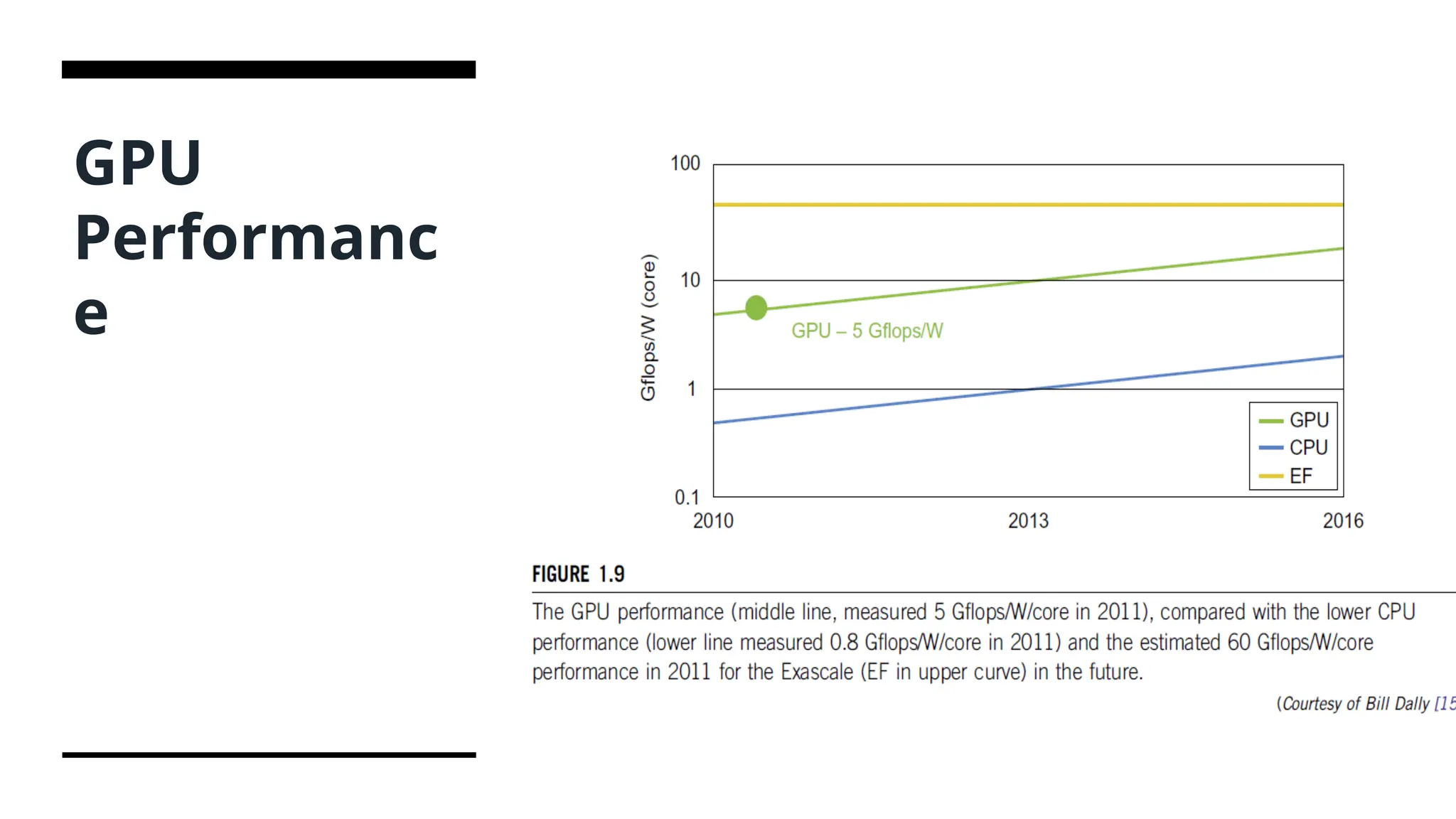
Power Efficiency ofthe GPU • Bill Dally of Stanford University considers power and massive parallelism as the major benefits of GPUs over CPUs for the future. • By extrapolating current technology and computer architecture, it was estimated that 60 Gflops/watt per core is needed to run an exaflops system. • FLOP or floating point operations per second is a measure of performance, meaning how fast the computer can perform calculations. GFLOP is simply a Giga FLOP. So having GPU with 2 times higher GFLOP value is very likely to speed up the training process. • Today's massively parallel supercomputers are measured in teraflops (Tflops: 1012 flops)
Memory, Storage, andWide-Area Networking • Memory Wall Problem - The memory wall refers to the increasing gap between processor speed and memory bandwidth, where the rate of improvement in processor performance outpaces the rate of improvement in memory performance due to limited I/O and decreasing signal integrity.
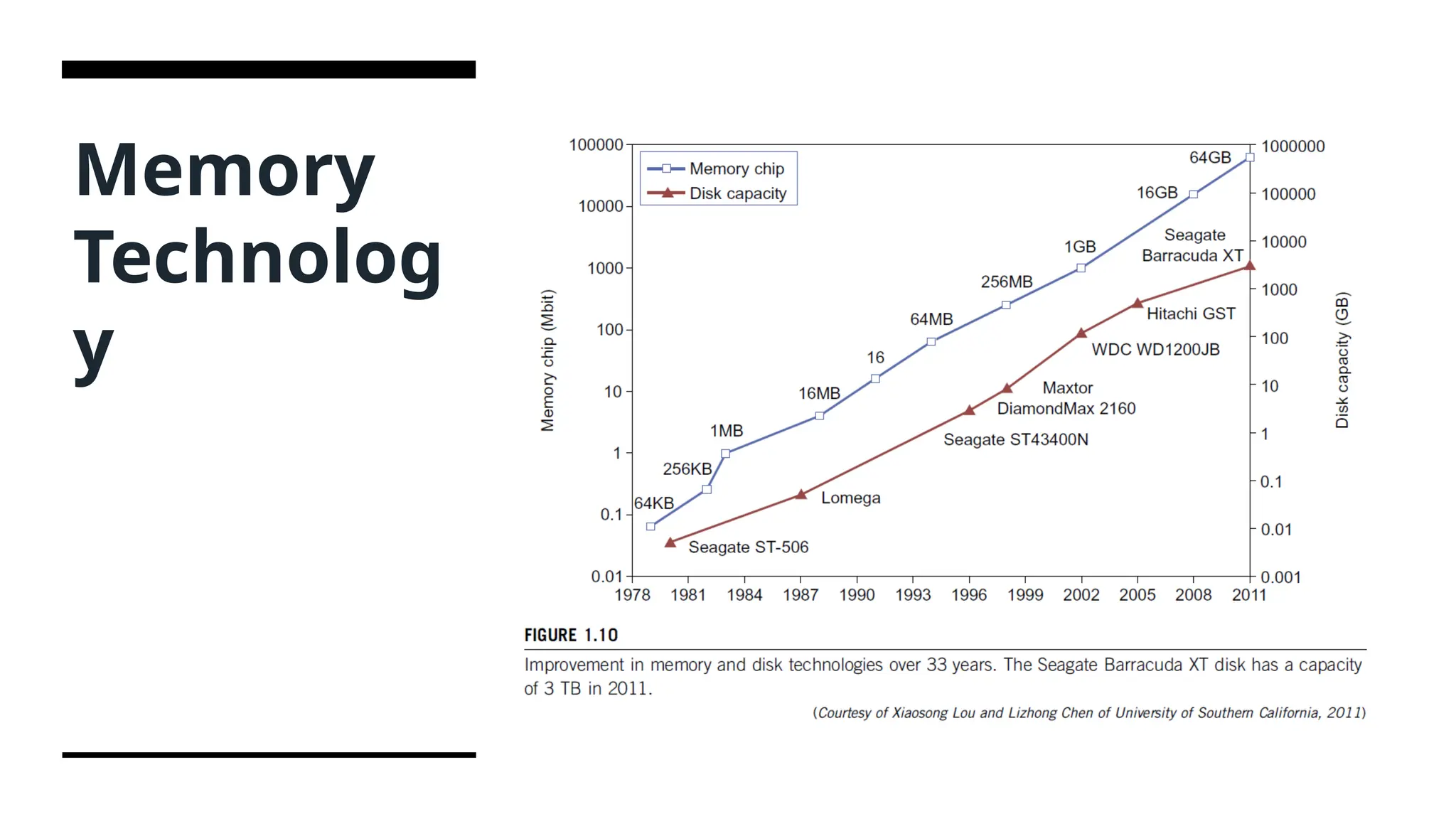
Memory and Storage •The rapid growth of flash memory and solid-state drives (SSDs) also impacts the future of HPC and HTC systems. The mortality rate of SSD is not bad at all. • For hard drives, capacity increased from 260 MB in 1981 to 250 GB in 2004. • A typical SSD can handle 300,000 to 1 million write cycles per block. • Eventually, power consumption, cooling, and packaging will limit large system development. Power increases linearly with respect to clock frequency and quadratic ally with respect to voltage applied on chips.
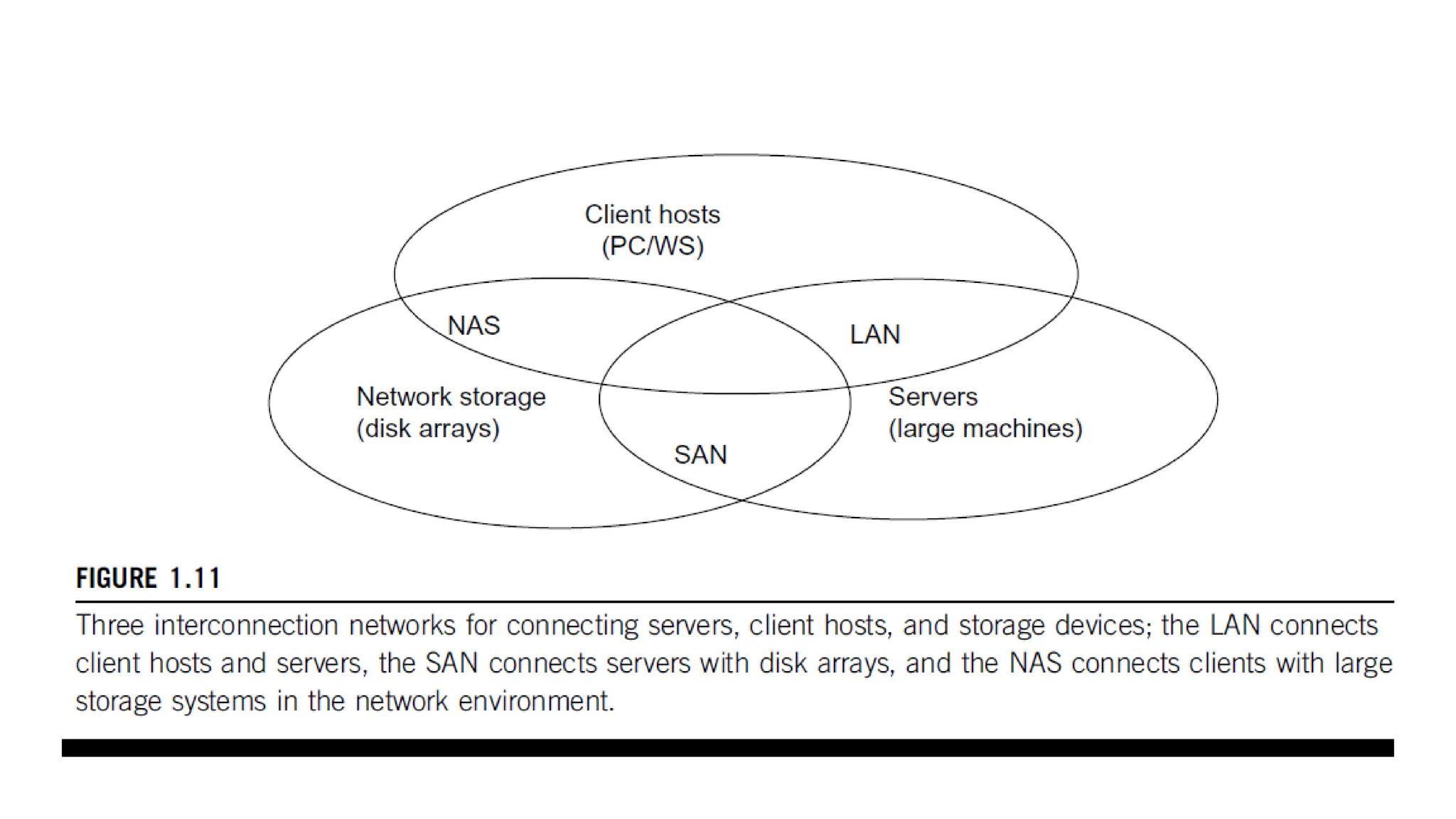
System-Area Interconnects • Thenodes in small clusters are mostly interconnected by an Ethernet switch or a local area network (LAN). • LAN typically is used to connect client hosts to big servers. • A storage area network (SAN) connects servers to network storage such as disk arrays. Network attached storage (NAS) connects client hosts directly to the disk arrays. • All three types of networks often appear in a large cluster built with commercial network components. If no large distributed storage is shared; a small cluster could be built with a multiport Gigabit Ethernet switch plus copper cables to link the end machines.
53.
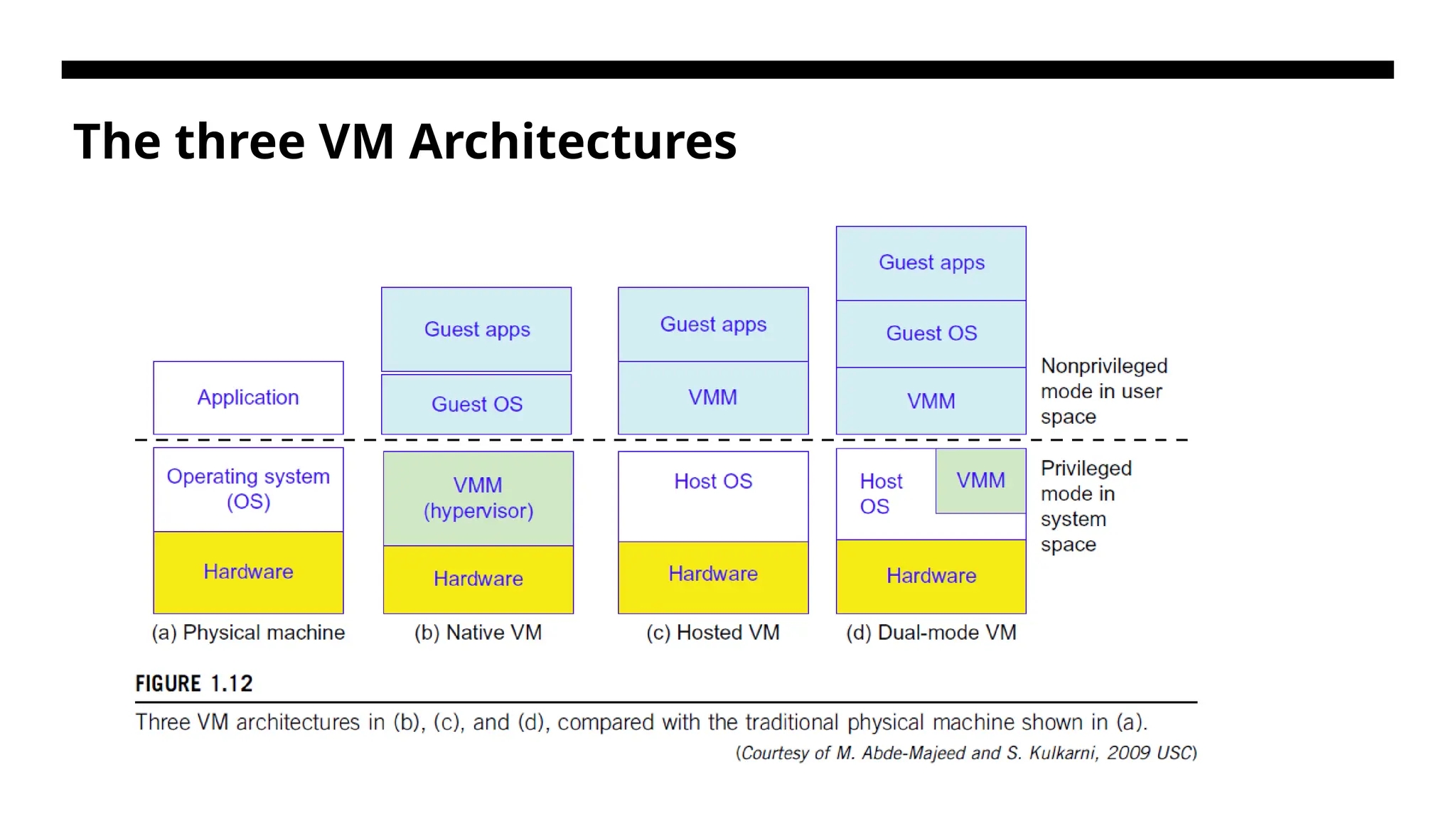
Virtual Machines andVirtualization Middleware In its simplest form, a virtual machine, or VM, is a digitized version of a physical computer. Virtual machines can run programs and operating systems, store data, connect to networks, and do other computing functions. However, a VM uses entirely virtual resources instead of physical components. Virtual machines (VMs) offer novel solutions to underutilized resources, application inflexibility, software manageability, and security concerns in existing physical machines. • Today, to build large clusters, grids, and clouds, we need to access large amounts of computing, storage, and networking resources in a virtualized manner. • We need to aggregate those resources, and hopefully, offer a single system image. In particular, a cloud of provisioned resources must rely on virtualization of processors, memory, and I/O facilities dynamically.
54.
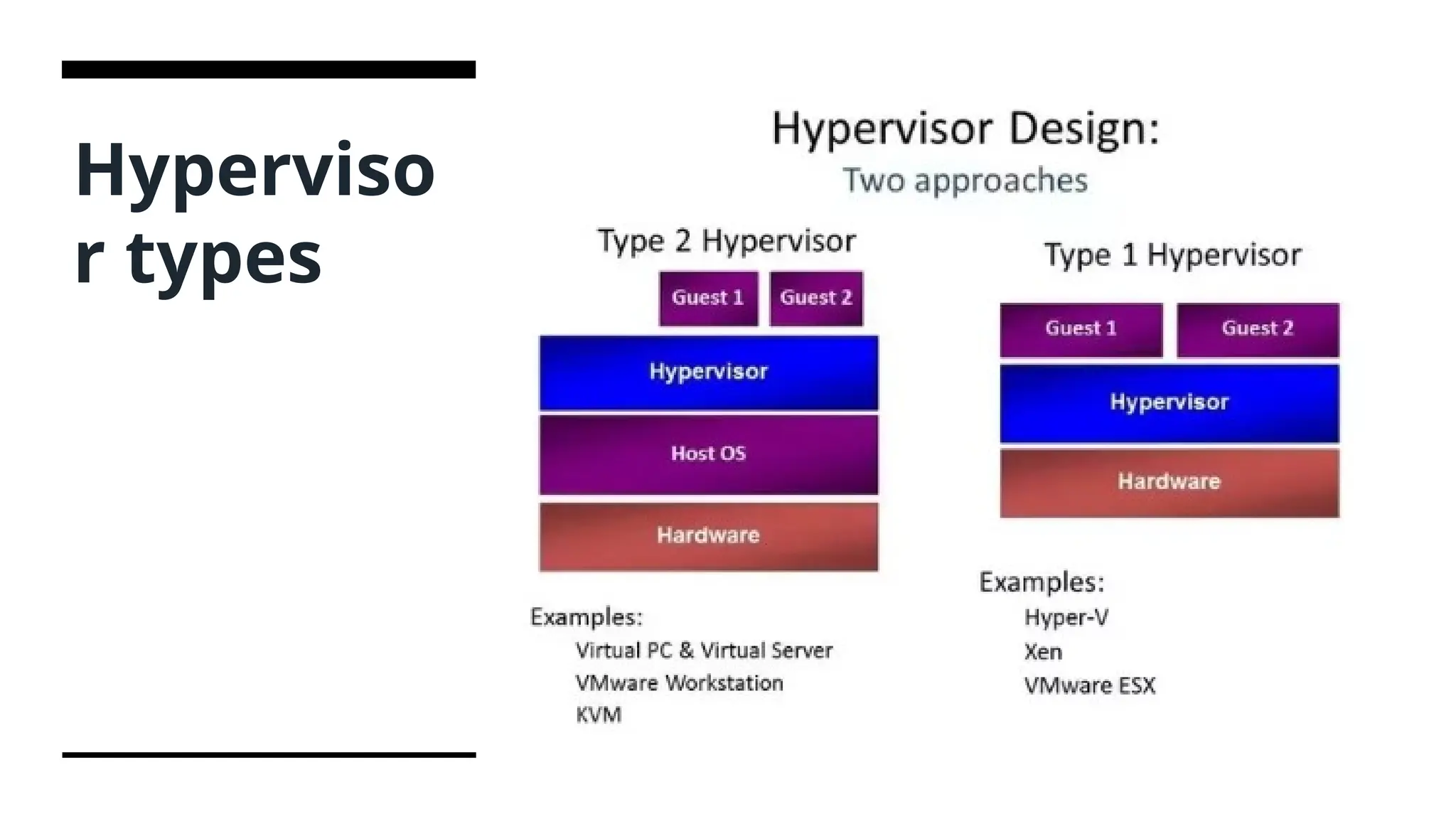
The three VMArchitectures Hypervisor - A hypervisor is a software that you can use to run multiple virtual machines on a single physical machine. The hypervisor allocates the underlying physical computing resources such as CPU and memory to individual virtual machines as required. Hypervisor is a thin software layer running between Operating System(OS) and system hardware that creates and runs virtual machines. Eg - Vmware ESX and ESXi, Quick Emulator, Citrix XenServer, Microsoft Hyper-V, Microsoft Virtual PC Hypervisors are also known as VMM – Virtual Machine Monitor
Types of Hypervisors TYPE-1Hypervisor: The hypervisor runs directly on the underlying host system. It is also known as a “Native Hypervisor” or “Bare metal hypervisor”. It does not require any base server operating system or part of it . It has direct access to hardware resources. Examples of Type 1 hypervisors include VMware ESXi, Citrix XenServer, and Microsoft Hyper- V hypervisor. TYPE-2 Hypervisor: A Host operating system runs on the underlying host system. It is also known as ‘Hosted Hypervisor”. Such kind of hypervisors doesn’t run directly over the underlying hardware rather they run as an application in a Host system(physical machine). Basically, the software is installed on an operating system. Hypervisor asks the operating system to make hardware calls. An example of a Type 2 hypervisor includes VMware Player or Parallels Desktop.
VMM Role • TheVMM provides the VM abstraction to the guest OS. • With full virtualization, the VMM exports a VM abstraction identical to the physical machine so that a standard OS such as Windows 2000 or Linux can run just as it would on the physical hardware.
59.
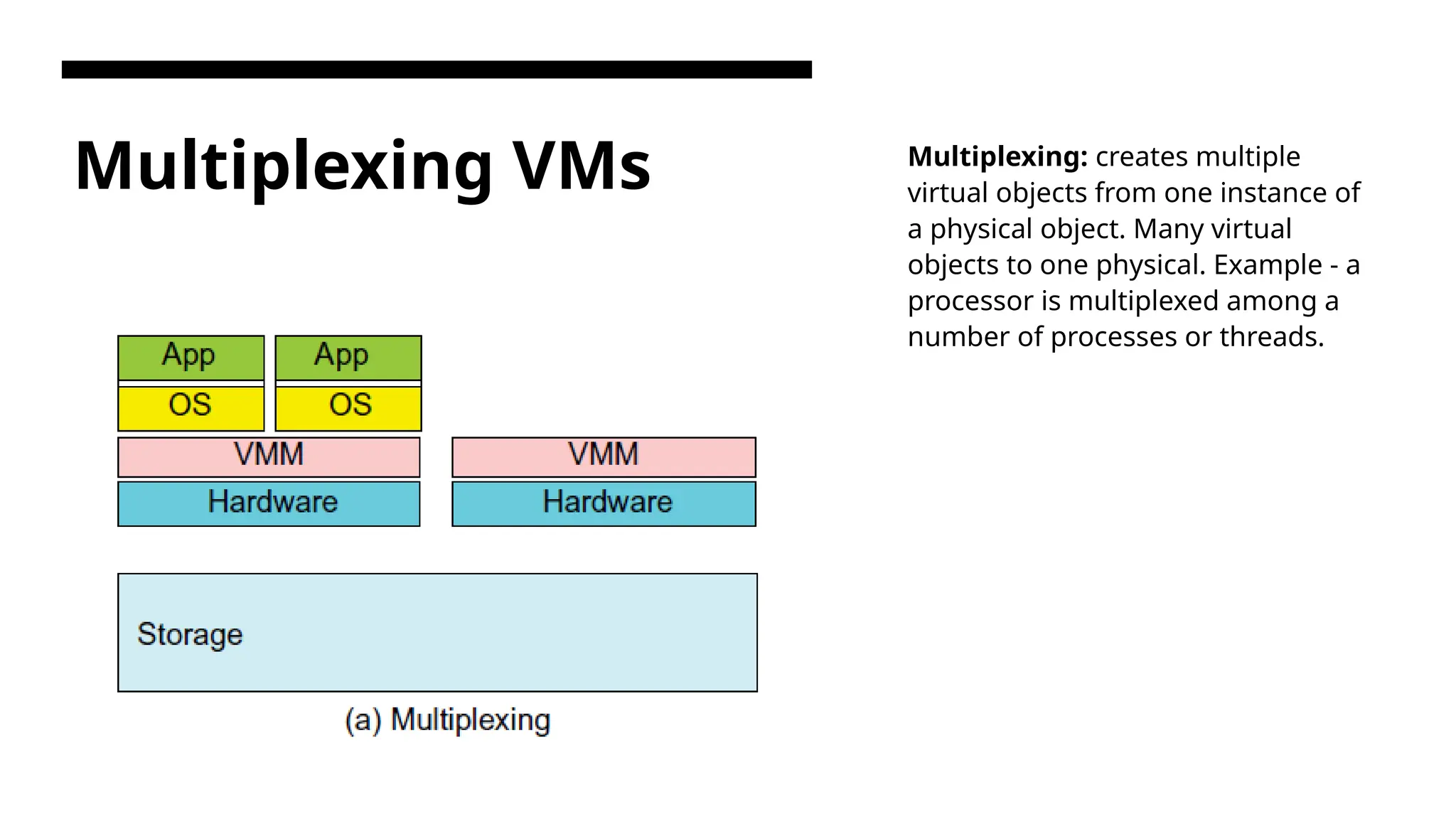
Multiplexing VMs Multiplexing:creates multiple virtual objects from one instance of a physical object. Many virtual objects to one physical. Example - a processor is multiplexed among a number of processes or threads.
60.
VM in Suspendedstate When you suspend a VM, its current state is stored in a file on the default storage repository (SR). This feature allows you to shut down the VM's host server. After rebooting the server, you can resume the VM and return it to its original running state.
61.
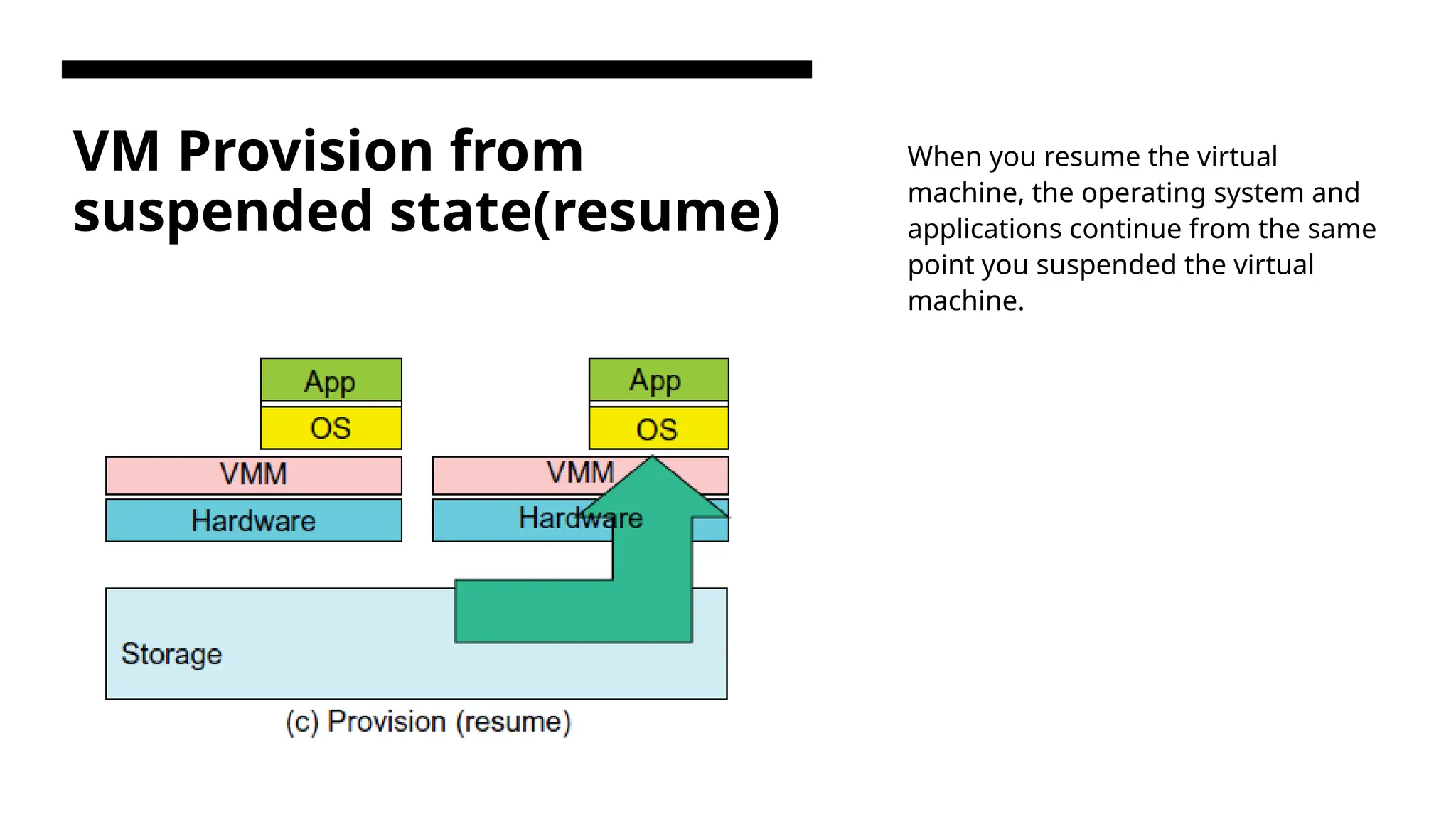
VM Provision from suspendedstate(resume) When you resume the virtual machine, the operating system and applications continue from the same point you suspended the virtual machine.
62.
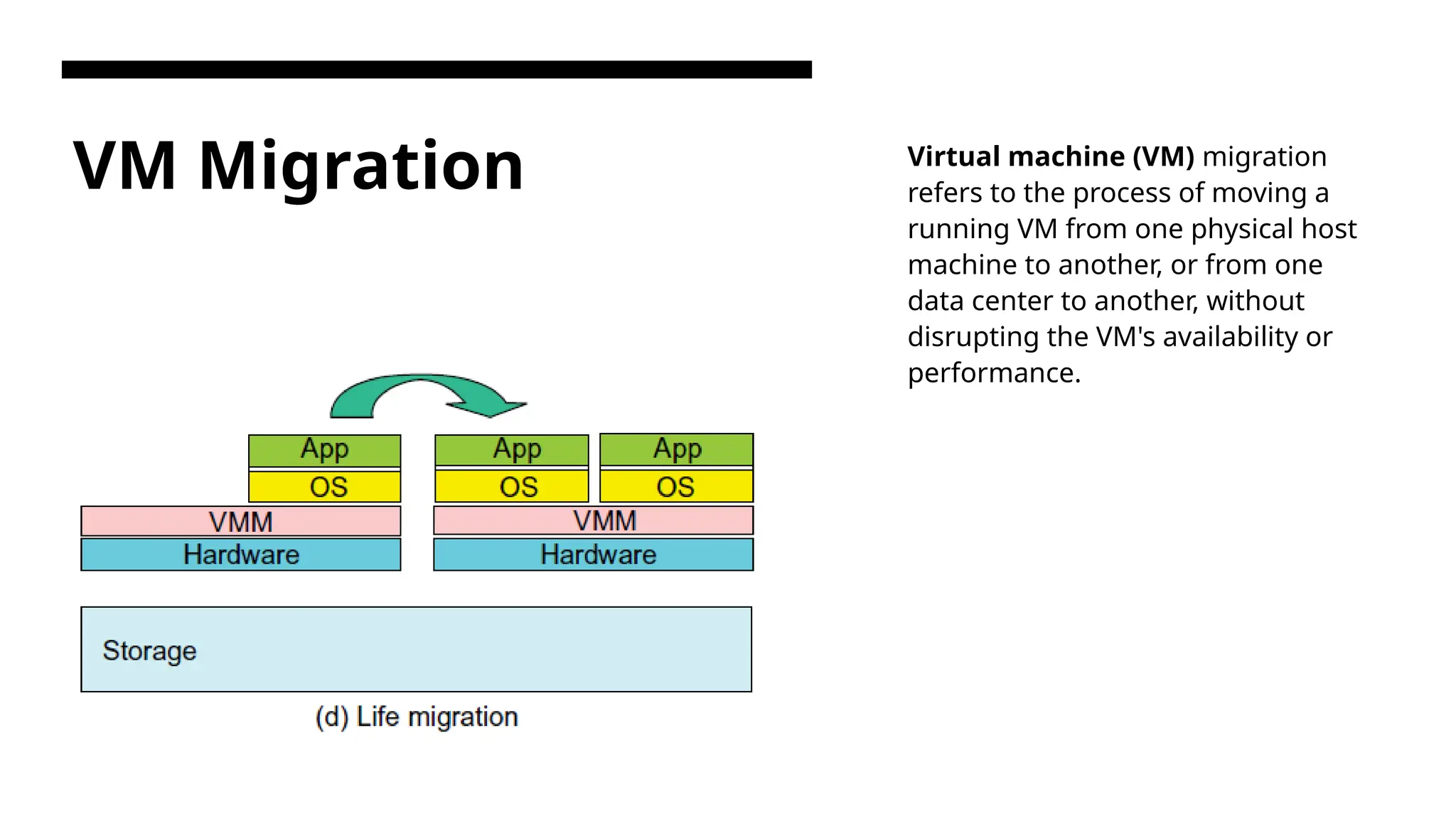
VM Migration Virtualmachine (VM) migration refers to the process of moving a running VM from one physical host machine to another, or from one data center to another, without disrupting the VM's availability or performance.
63.
VM Operations • TheseVM operations enable a VM to be provisioned to any available hardware platform. They also enable flexibility in porting distributed application executions. • Furthermore, the VM approach will significantly enhance the utilization of server resources. • Multiple server functions can be consolidated on the same hardware platform to achieve higher system efficiency. This will eliminate server sprawl via deployment of systems as VMs, which move transparency to the shared hardware. With this approach, VMware claimed that server utilization could be increased from its current 5–15 percent to 60–80 percent.
Data Center Virtualizationfor Cloud Computing Basic architecture and design considerations of data centers - Popular x86 processors. - Low-cost terabyte disks - Gigabit Ethernet Data center design emphasizes the performance/price ratio over speed performance alone. In other words, storage and energy efficiency are more important than shear speed performance.
66.
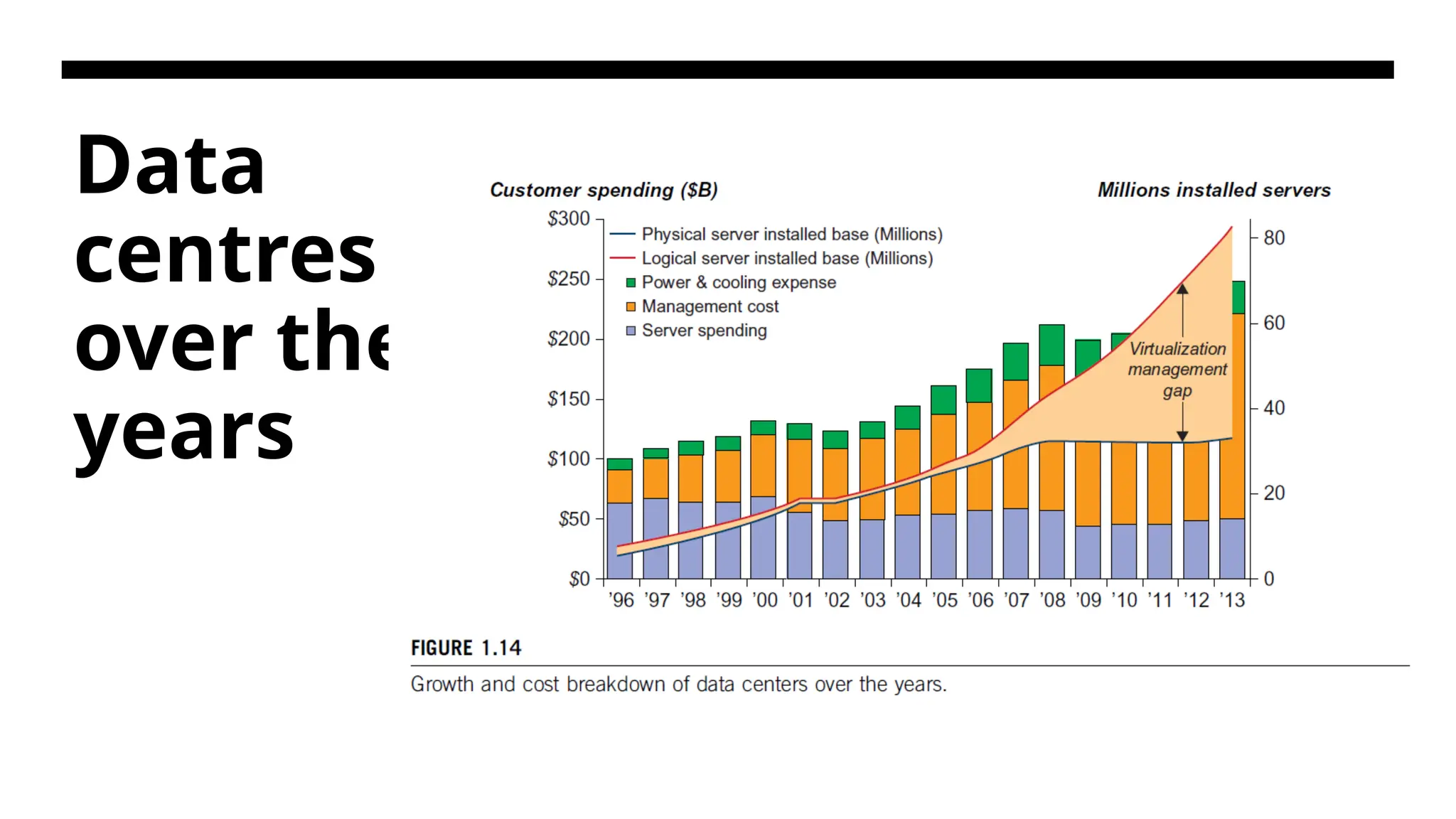
Data Center Growthand Cost Breakdown • A large data center may be built with thousands of servers. Smaller data centers are typically built with hundreds of servers. The cost to build and maintain data center servers has increased over the years. • Typically, only 30 percent of data center costs goes toward purchasing IT equipment (such as servers and disks) • 33 percent is attributed to the chiller, 18 percent to the uninterruptible power supply (UPS), 9 percent to computer room air conditioning (CRAC), and the remaining 7 percent to power distribution, lighting, and transformer costs. • Thus, about 60 percent of the cost to run a data center is allocated to management and maintenance. The server purchase cost did not increase much with time. The cost of electricity and cooling did increase from 5 percent to 14 percent in 15 years. • Further Reading- https://granulate.io/blog/understanding-data-center-costs-and-how-they-compare-to-the-cloud/
67.
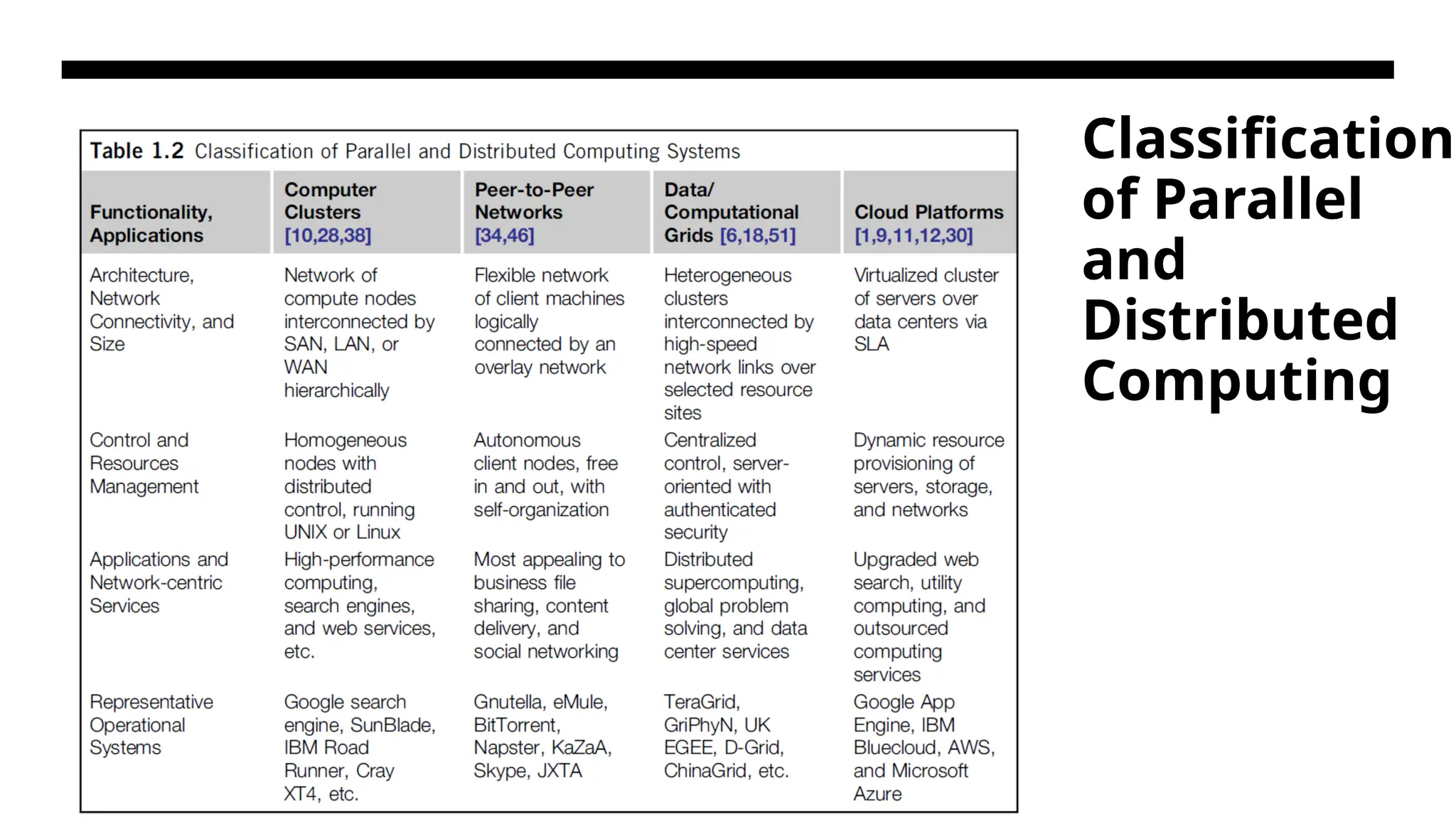
SYSTEM MODELS FORDISTRIBUTED AND CLOUD COMPUTING • Distributed and cloud computing systems are built over a large number of autonomous computer nodes. These node machines are interconnected by SANs, LANs, or WANs in a hierarchical manner. With today’s networking technology, a few LAN switches can easily connect hundreds of machines as a working cluster • A WAN can connect many local clusters to form a very large cluster of clusters. In this sense, one can build a massive system with millions of computers connected to edge networks. • Massive systems are considered highly scalable, and can reach web-scale connectivity, either physically or logically. • massive systems are classified into four groups: clusters, P2P networks, computing grids, and Internet clouds over huge data centers.
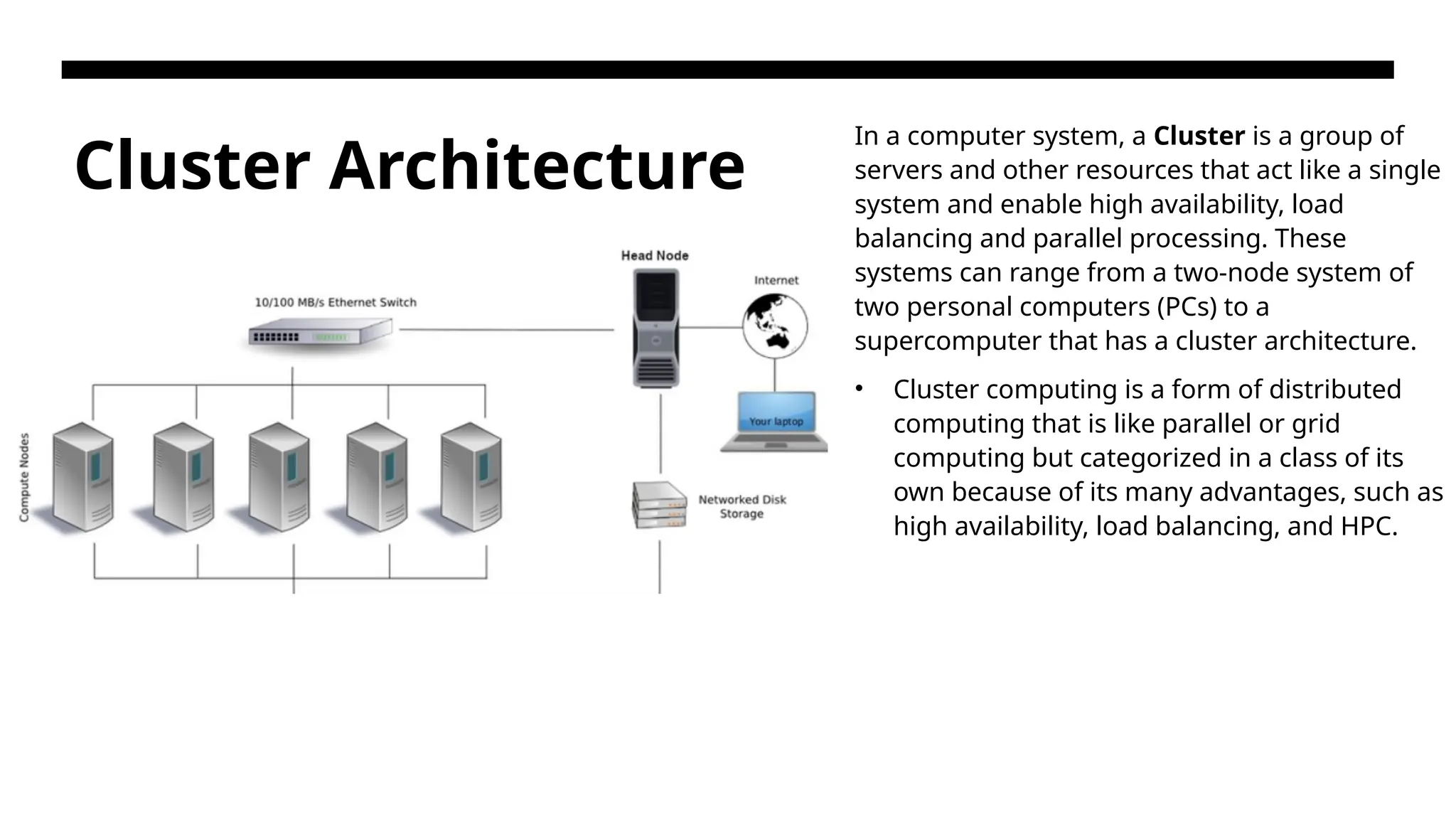
Cluster Architecture In acomputer system, a Cluster is a group of servers and other resources that act like a single system and enable high availability, load balancing and parallel processing. These systems can range from a two-node system of two personal computers (PCs) to a supercomputer that has a cluster architecture. • Cluster computing is a form of distributed computing that is like parallel or grid computing but categorized in a class of its own because of its many advantages, such as high availability, load balancing, and HPC.
70.
SSI – SingleSystem Image in Cluster • SSI - An SSI is an illusion created by software or hardware that presents a collection of resources as one integrated, powerful resource. • SSI makes the cluster appear like a single machine to the user. A cluster with multiple system images is nothing but a collection of independent computers. • Cluster designers desire a cluster operating system or some middleware to support SSI at various levels, including the sharing of CPUs, memory, and I/O across all cluster nodes.
71.
Issues with ClusterDesign 1. High cost It is not so much cost-effective due to its high hardware and its design. 2. Problem in finding fault It is difficult to find which component has a fault. 3. More space is needed Infrastructure may increase as more servers are needed to manage and monitor. 4. Software updates and maintenance. 5. Unfortunately, a cluster-wide OS for complete resource sharing is not available yet. 6. The software environments and applications must rely on the middleware to achieve high performance
72.
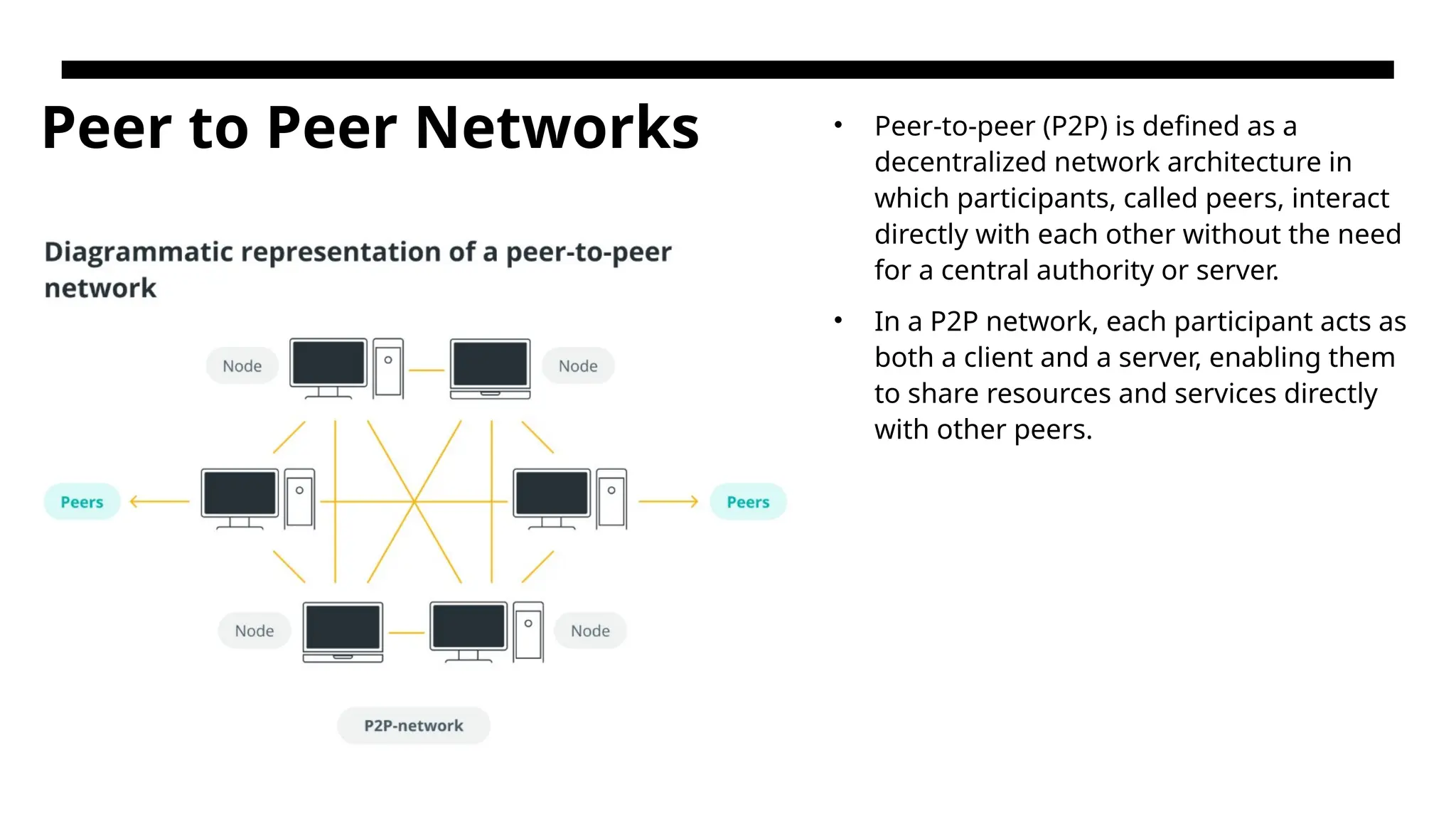
Peer to PeerNetworks • Peer-to-peer (P2P) is defined as a decentralized network architecture in which participants, called peers, interact directly with each other without the need for a central authority or server. • In a P2P network, each participant acts as both a client and a server, enabling them to share resources and services directly with other peers.
73.
Peer to peernetwork • Peer machines are simply client computers connected to the Internet. All client machines act autonomously to join or leave the system freely. This implies that no master-slave relationship exists among the peers. • No central coordination or central database is needed. In other words, no peer machine has a global view of the entire P2P system. The system is self-organizing with distributed control. • Initially, the peers are totally unrelated. Each peer machine joins or leaves the P2P network voluntarily. Only the participating peers form the physical network at any time. Unlike the cluster or grid, a P2P network does not use a dedicated interconnection network.
74.
Overlay and UnderlayNetworks Underlay Network is the physical network infrastructure that provides the foundation for overlay network. Underlay network is responsible for forwarding data packets and are optimized for high performance and low latency. In contrast, an overlay network is a virtual network that is built on top of the underlay network
75.
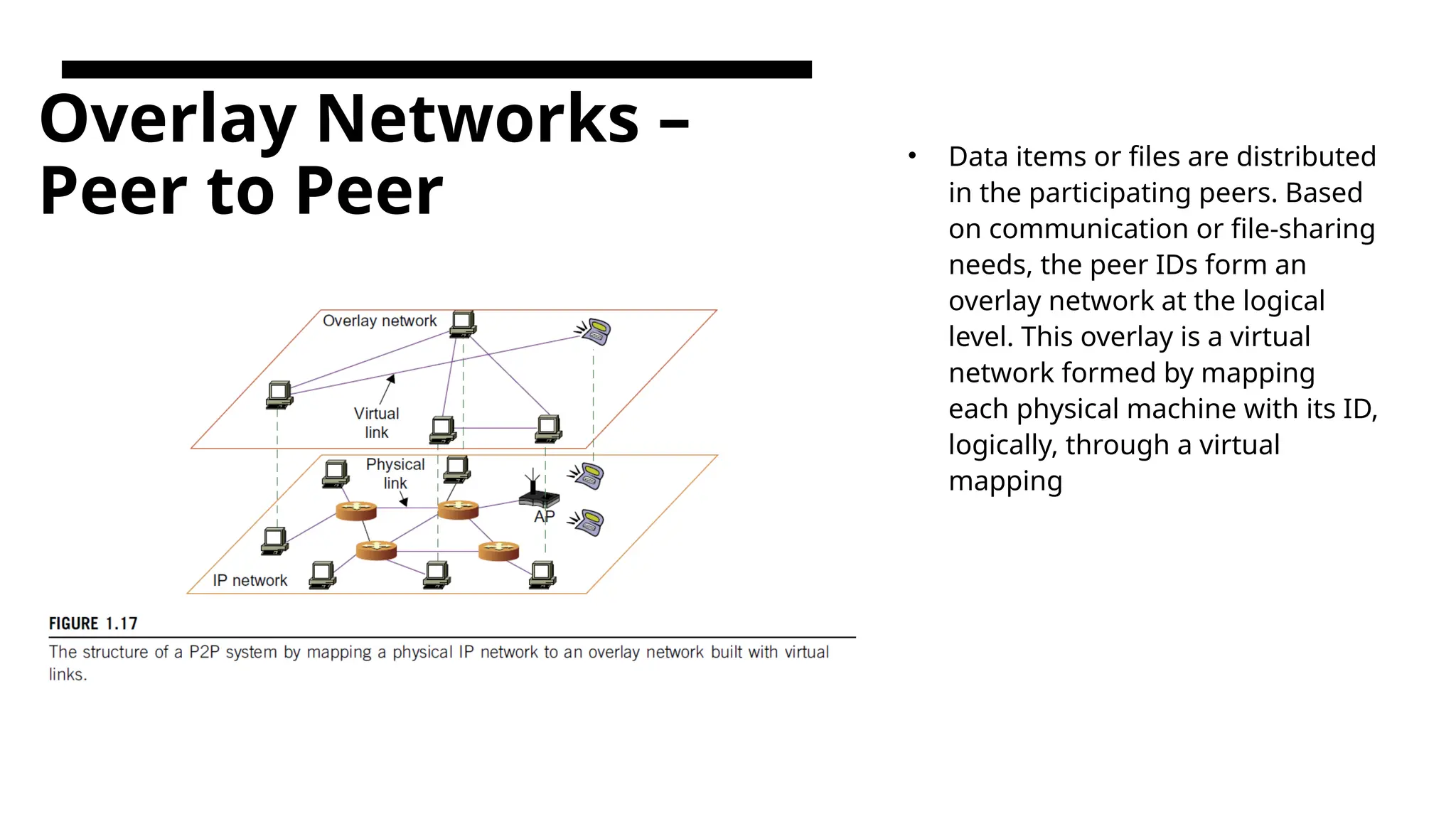
Overlay Networks – Peerto Peer • Data items or files are distributed in the participating peers. Based on communication or file-sharing needs, the peer IDs form an overlay network at the logical level. This overlay is a virtual network formed by mapping each physical machine with its ID, logically, through a virtual mapping
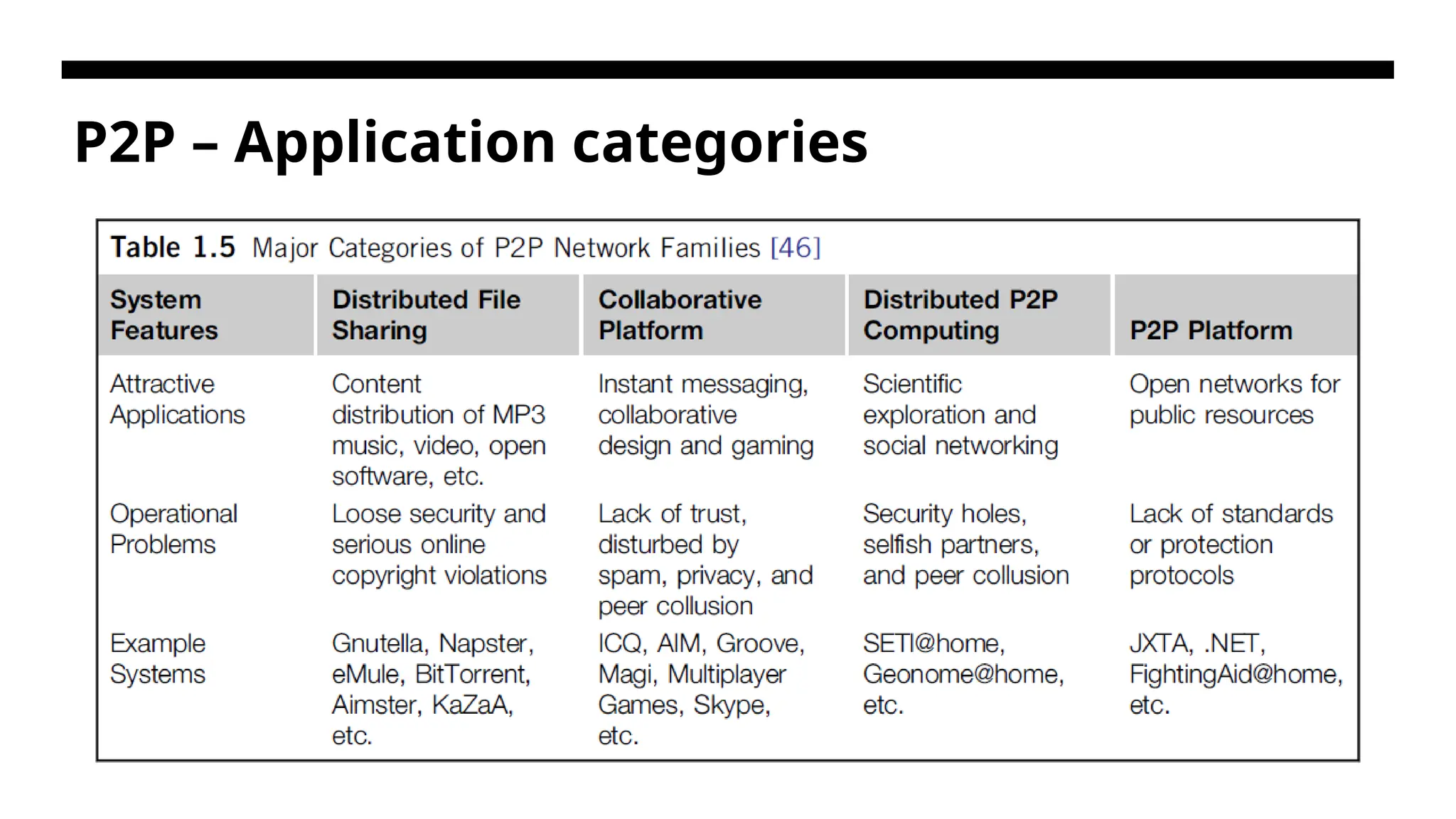
P2P – ComputingChallenges • P2P computing faces three types of heterogeneity problems in hardware, software, and network requirements. • P2P performance is affected by routing efficiency and self-organization by participating peers. Fault tolerance, failure management, and load balancing are other important issues in using overlay networks. • Lack of trust among peers poses another problem. Peers are strangers to one another. Security, privacy, and copyright violations are major worries by those in the industry in terms of applying P2P technology in business applications. • Because the system is not centralized, managing it is difficult. In addition, the system lacks security. Anyone can log on to the system and cause damage or abuse.
78.
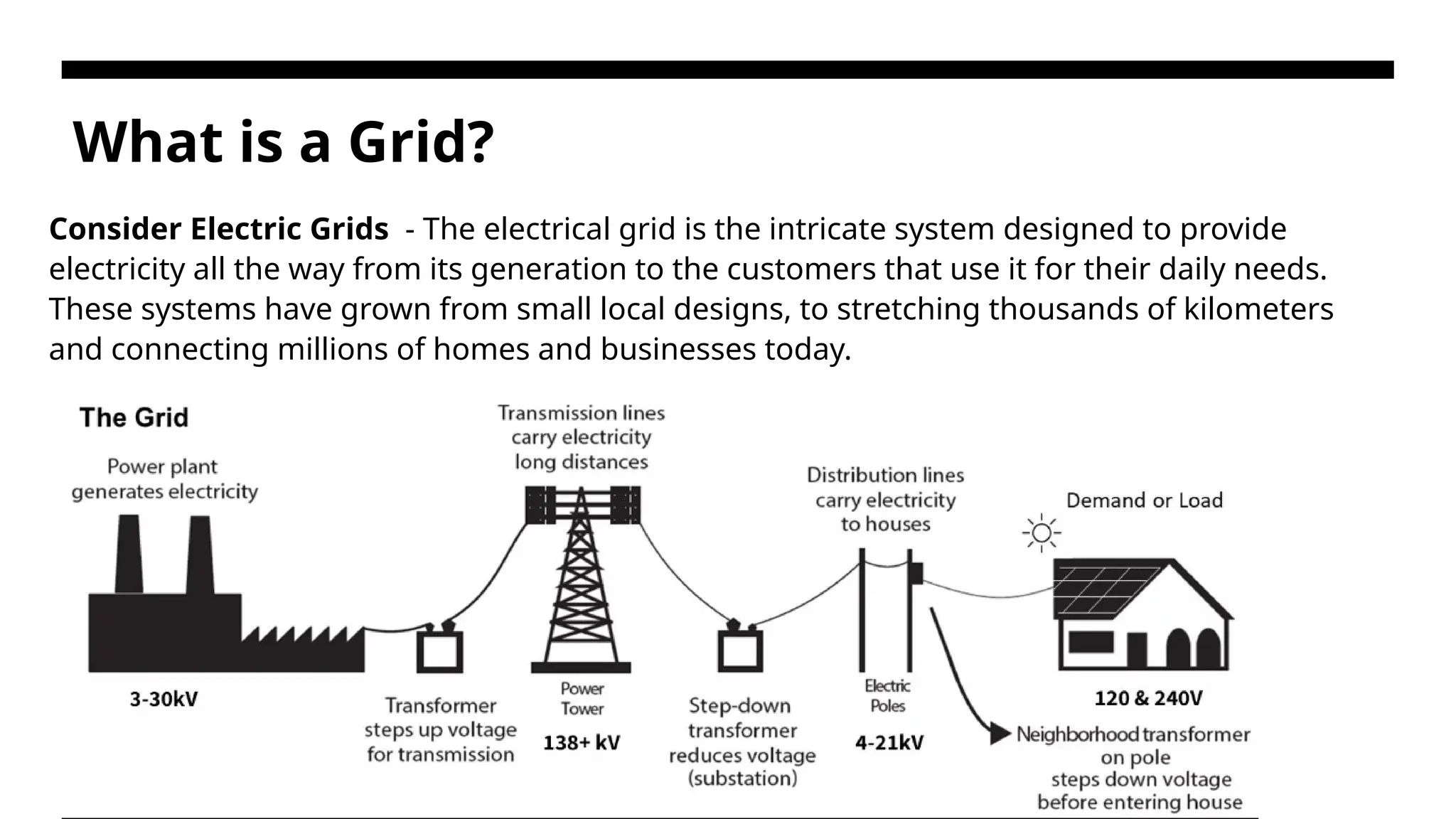
What is aGrid? Consider Electric Grids - The electrical grid is the intricate system designed to provide electricity all the way from its generation to the customers that use it for their daily needs. These systems have grown from small local designs, to stretching thousands of kilometers and connecting millions of homes and businesses today.
79.
Computation Grid Grid computingis a computing infrastructure that combines computer resources spread over different geographical locations to achieve a common goal. All unused resources on multiple computers are pooled together and made available for a single task. • Grid technology demands new distributed computing models, software/middleware support, network protocols, and hardware infrastructures. National grid projects are followed by industrial grid platform development by IBM, Microsoft, Sun, HP, Dell, Cisco, EMC, Platform Computing, and others
80.
Example of Grid• Computational grid built over multiple resource sites owned by different organizations. The resource sites offer complementary computing resources, including workstations, large servers, a mesh of processors, and Linux clusters to satisfy a chain of computational needs. • The grid is built across various IP broadband networks including LANs and WANs already used by enterprises or organizations over the Internet. The grid is presented to users as an integrated resource pool
Advantages of GridComputing • Grid Computing provide high resources utilization. • Grid Computing allow parallel processing of task. • Grid Computing is designed to be scalable.
83.
Disadvantages of GridComputing • The software of the grid is still in the evolution stage. • Grid computing introduce Complexity. • Limited Flexibility • Security Risks
84.
Difference between Grid andCloud Computing Cloud Computing and Grid Computing are two model in distributed computing. They are used for different purposes and have different architectures. Cloud Computing is the use of remote servers to store, manage, and process data rather than using local servers while Grid Computing can be defined as a network of computers working together to perform a task that would rather be difficult for a single machine.
85.
Cloud Computing overthe Internet • Cloud computing has been defined differently by many users and designers. For example, IBM, a major player in cloud computing, has defined it as follows: “A cloud is a pool of virtualized computer resources. A cloud can host a variety of different workloads, including batch-style backend jobs and interactive and user-facing applications.” • Based on this definition, a cloud allows workloads to be deployed and scaled out quickly through rapid provisioning of virtual or physical machines. • The cloud supports redundant, self-recovering, highly scalable programming models that allow workloads to recover from many unavoidable hardware/software failures. Finally, the cloud system should be able to monitor resource use in real time to enable rebalancing of allocations when needed.
86.
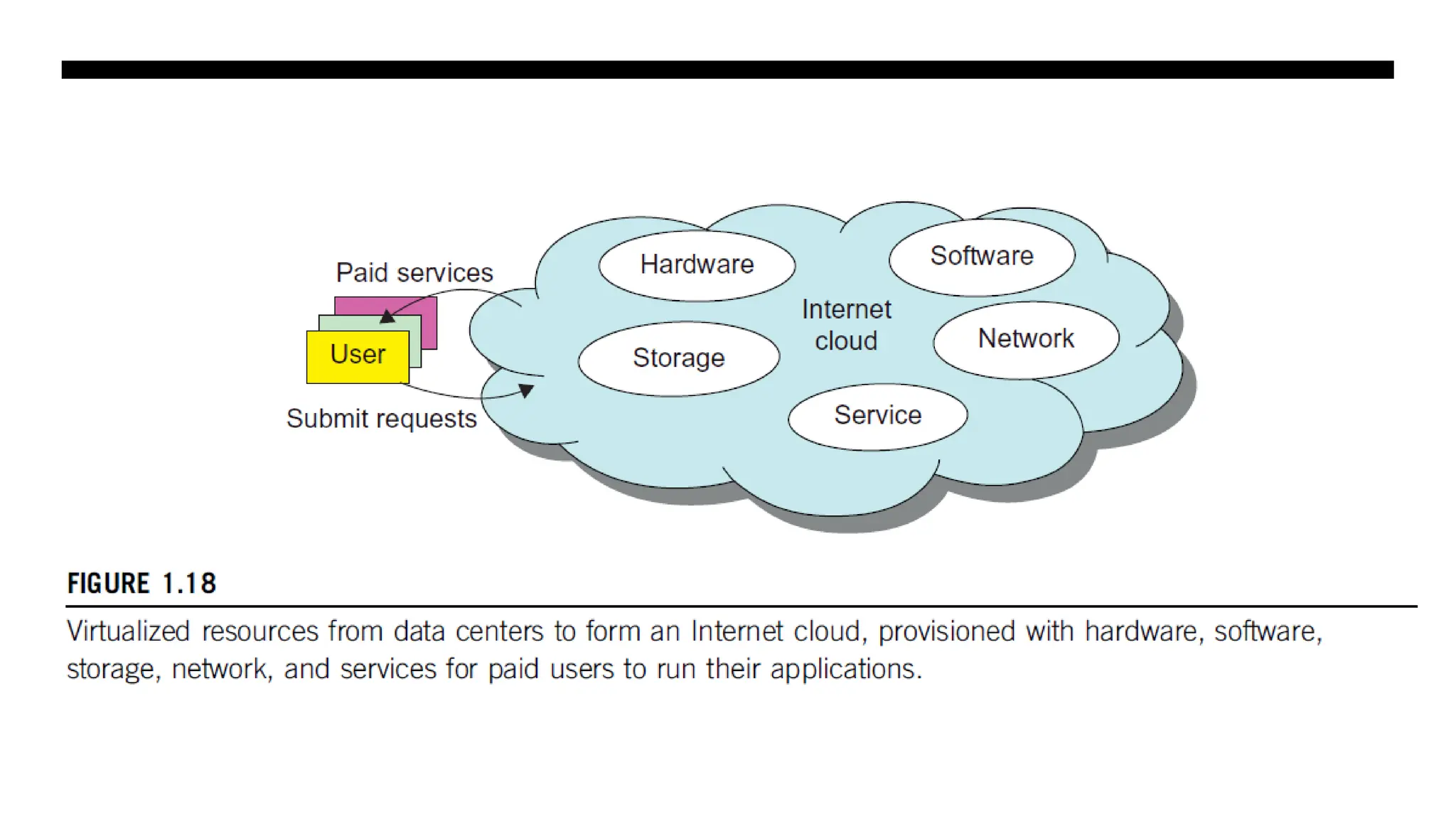
Internet Clouds • Cloudcomputing applies a virtualized platform with elastic resources on demand by provisioning hardware, software, and data sets dynamically. • The idea is to move desktop computing to a service-oriented platform using server clusters and huge databases at data centers. • Cloud computing leverages its low cost and simplicity to benefit both users and providers.. • Cloud computing intends to satisfy many user applications simultaneously. • The cloud ecosystem must be designed to be secure, trustworthy, and dependable.
88.
The Cloud Landscape •Traditionally, a distributed computing system tends to be owned and operated by an autonomous administrative domain (e.g., a research laboratory or company) for on- premises computing needs. • However, these traditional systems have encountered several performance bottlenecks: constant system maintenance, poor utilization, and increasing costs associated with hardware/software upgrades • Cloud computing as an on-demand computing paradigm resolves or relieves us from these problems.
89.
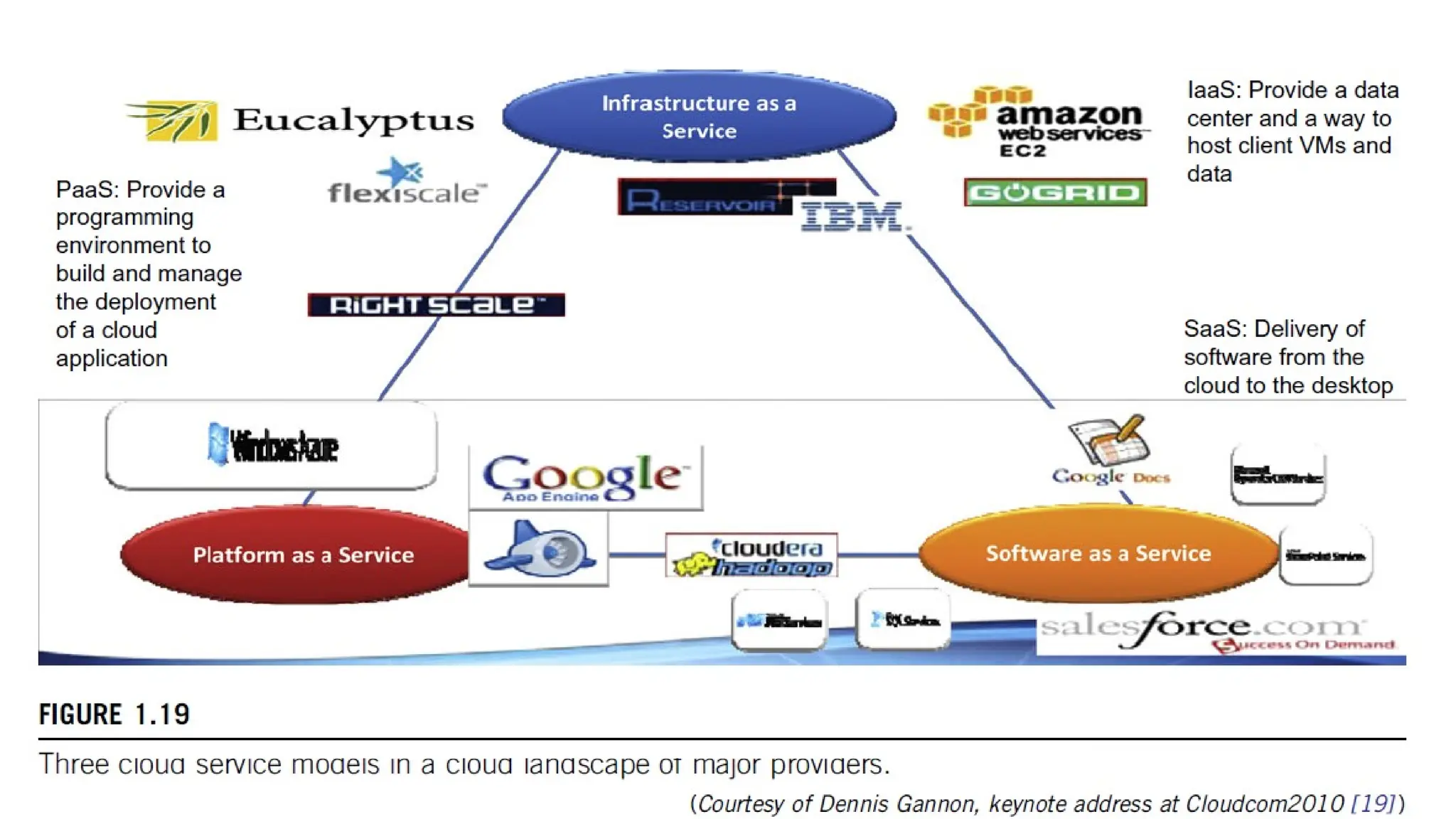
3 Cloud ServiceModels • Infrastructure as a Service (IaaS) - This model puts together infrastructures demanded by users—namely servers, storage, networks, and the data center fabric. The user can deploy and run on multiple VMs running guest OSes on specific applications. The user does not manage or control the underlying cloud infrastructure, but can specify when to request and release the needed resources. Example – AWS, Azure, GCP
90.
PaaS Platform as aService (PaaS) This model enables the user to deploy user-built applications onto a virtualized cloud platform. PaaS includes middleware, databases, development tools, and some runtime support such as Web 2.0 and Java. The platform includes both hardware and software integrated with specific programming interfaces. The provider supplies the API and software tools (e.g., Java, Python, Web 2.0, .NET). The user is freed from managing the cloud infrastructure. Example – Salesforce,
91.
SaaS Software as aService (SaaS) This refers to browser-initiated application software over thousands of paid cloud customers. The SaaS model applies to business processes, industry applications, consumer relationship management (CRM), enterprise resources planning (ERP), human resources (HR), and collaborative applications. On the customer side, there is no upfront investment in servers or software licensing. On the provider side, costs are rather low, compared with conventional hosting of user applications. Example – Slack, Zoom, DocuSign
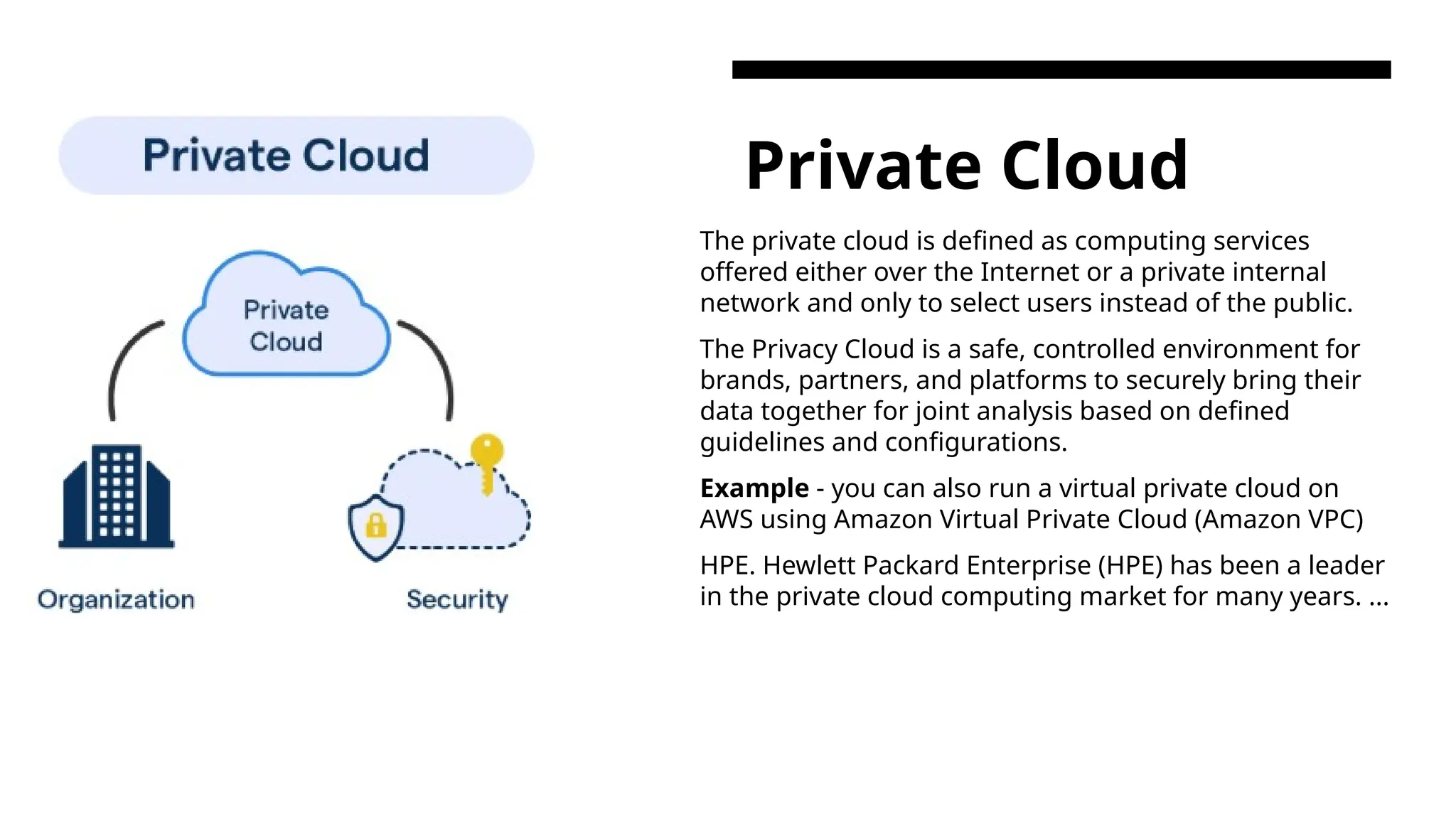
Private Cloud The privatecloud is defined as computing services offered either over the Internet or a private internal network and only to select users instead of the public. The Privacy Cloud is a safe, controlled environment for brands, partners, and platforms to securely bring their data together for joint analysis based on defined guidelines and configurations. Example - you can also run a virtual private cloud on AWS using Amazon Virtual Private Cloud (Amazon VPC) HPE. Hewlett Packard Enterprise (HPE) has been a leader in the private cloud computing market for many years. ...
95.
Public Cloud Thepublic cloud is defined as computing services offered by third-party providers over the public Internet, making them available to anyone who wants to use or purchase them. They may be free or sold on-demand, allowing customers to pay only per usage for the CPU cycles, storage, or bandwidth they consume. Example - Public cloud platforms, such as Google Cloud, pool resources in distributed data centers around the world that multiple companies and users can access from the internet. Rather than an in-house team, the public cloud providers are responsible for managing and maintaining the underlying infrastructure.
96.
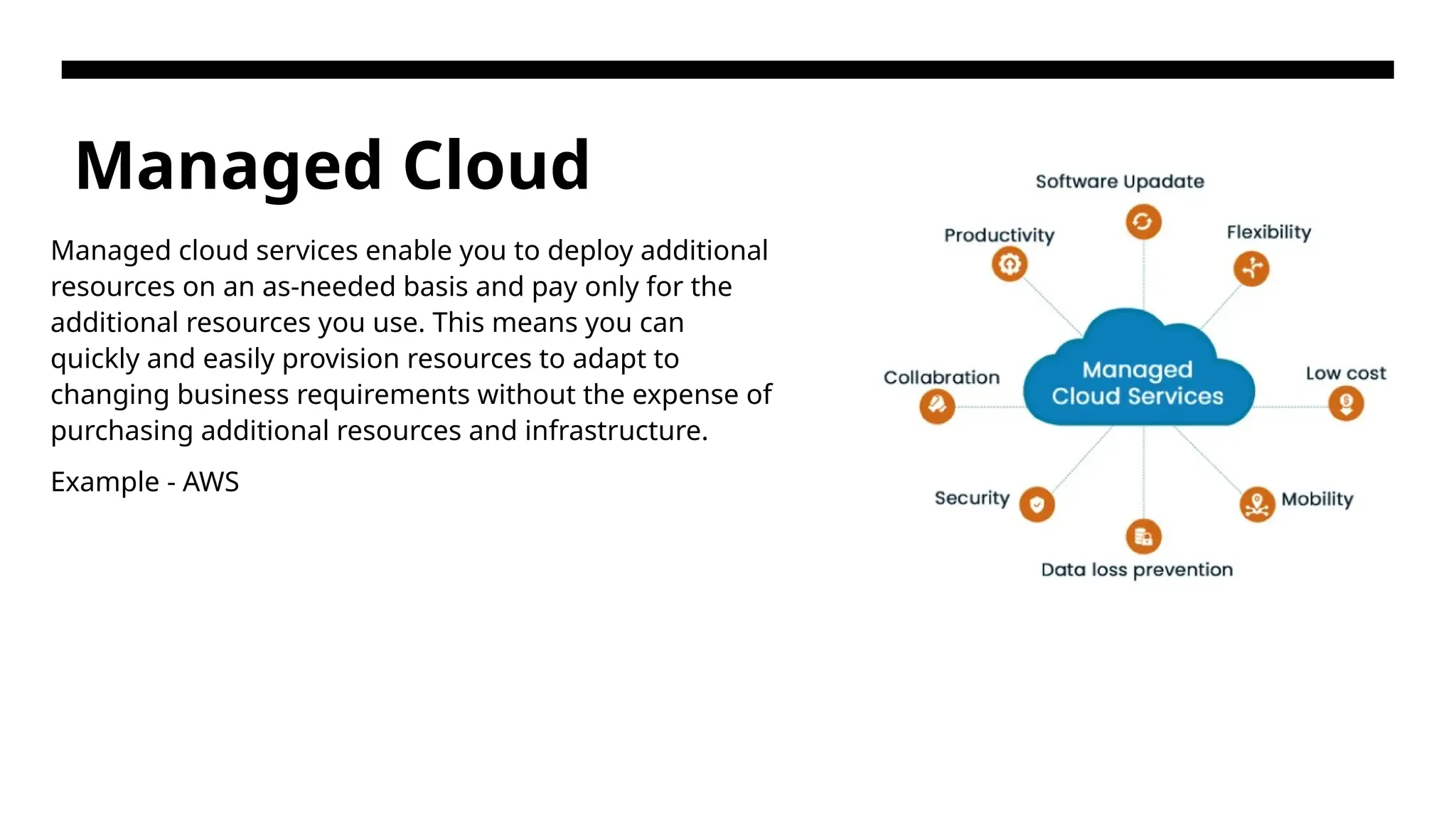
Managed Cloud Managed cloudservices enable you to deploy additional resources on an as-needed basis and pay only for the additional resources you use. This means you can quickly and easily provision resources to adapt to changing business requirements without the expense of purchasing additional resources and infrastructure. Example - AWS
97.
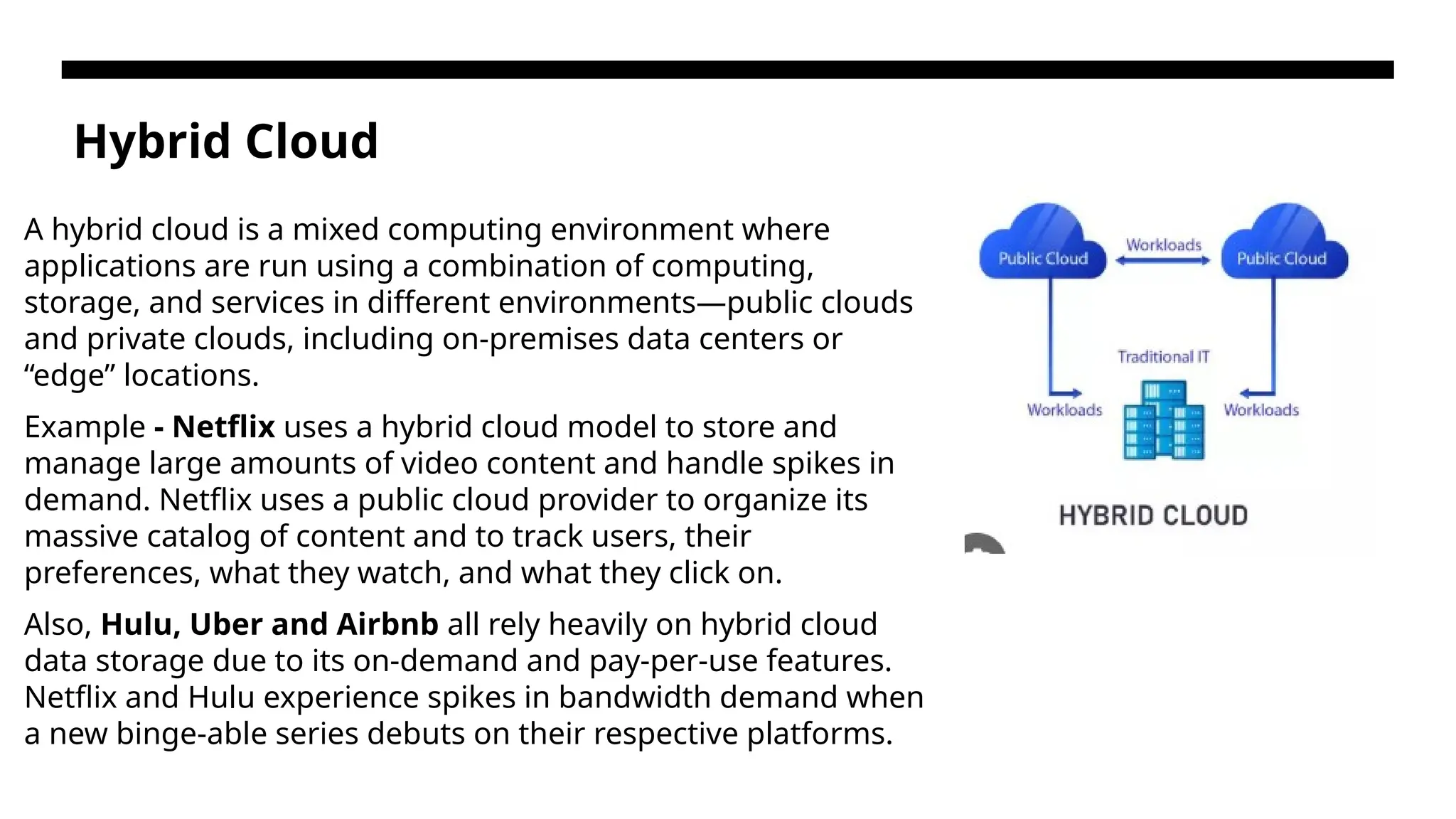
Hybrid Cloud A hybridcloud is a mixed computing environment where applications are run using a combination of computing, storage, and services in different environments—public clouds and private clouds, including on-premises data centers or “edge” locations. Example - Netflix uses a hybrid cloud model to store and manage large amounts of video content and handle spikes in demand. Netflix uses a public cloud provider to organize its massive catalog of content and to track users, their preferences, what they watch, and what they click on. Also, Hulu, Uber and Airbnb all rely heavily on hybrid cloud data storage due to its on-demand and pay-per-use features. Netflix and Hulu experience spikes in bandwidth demand when a new binge-able series debuts on their respective platforms.
98.
Advantages of Cloud 1.Desired location in areas with protected space and higher energy efficiency 2. Sharing of peak-load capacity among a large pool of users, improving overall utilization 3. Separation of infrastructure maintenance duties from domain-specific application development 4. Significant reduction in cloud computing cost, compared with traditional computing paradigms 5. Cloud computing programming and application development 6. Service and data discovery and content/service distribution 7. Privacy, security, copyright, and reliability issues 8. Service agreements, business models, and pricing policies
99.
Software Environments forDistributed systems and Clouds What is Service Oriented Architecture(SOA)? • SOA is an architectural approach in which applications make use of services available in the network. • In this architecture, services are provided to form applications, through a network call over the internet. It uses common communication standards to speed up and streamline the service integrations in applications. • Each service in SOA is a complete business function. The services are published in such a way that it makes it easy for the developers to assemble their apps using those services. • SOA is built on the traditional seven Open Systems Interconnection (OSI) layers that provide the base networking abstractions
100.
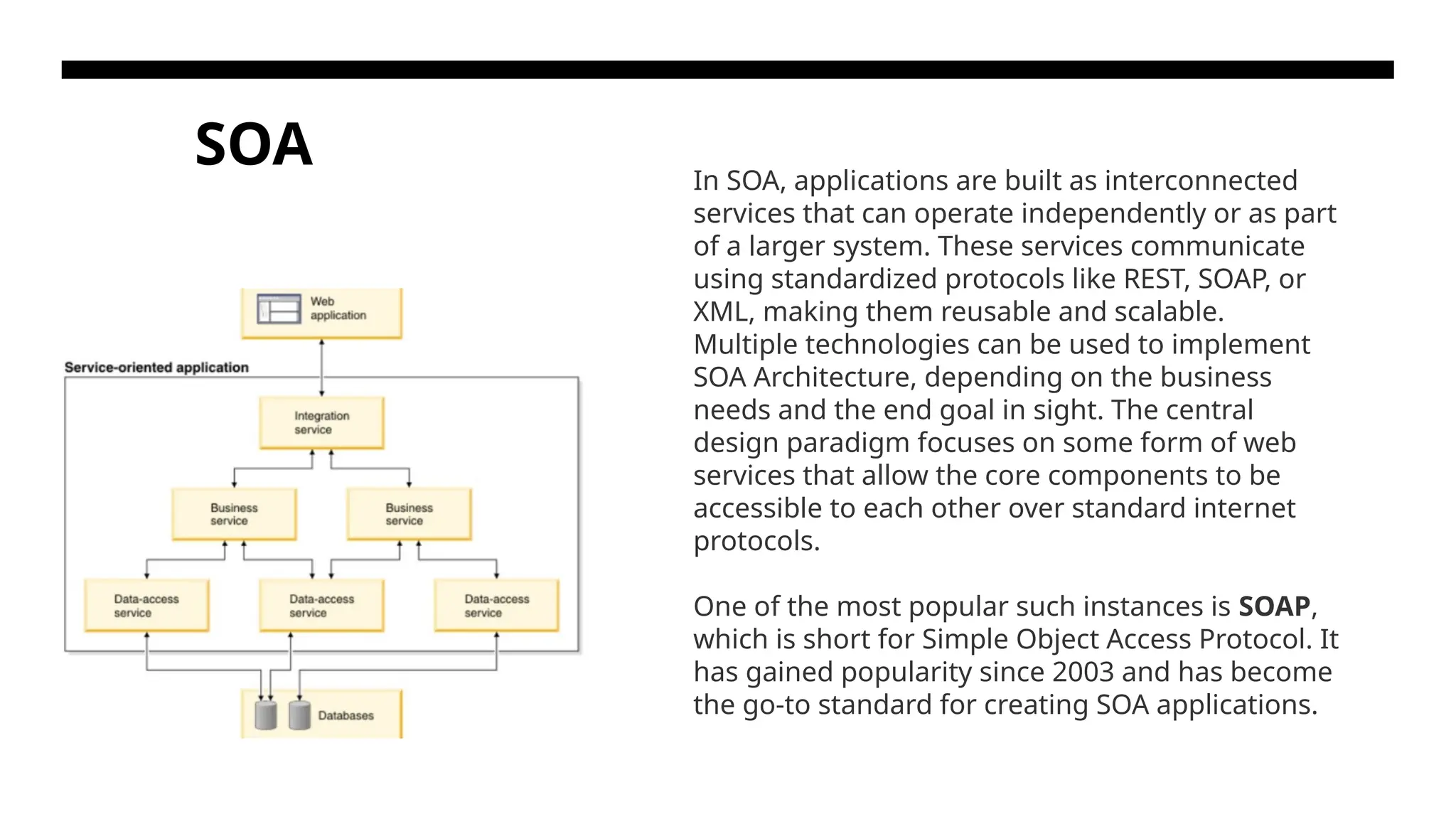
SOA In SOA,applications are built as interconnected services that can operate independently or as part of a larger system. These services communicate using standardized protocols like REST, SOAP, or XML, making them reusable and scalable. Multiple technologies can be used to implement SOA Architecture, depending on the business needs and the end goal in sight. The central design paradigm focuses on some form of web services that allow the core components to be accessible to each other over standard internet protocols. One of the most popular such instances is SOAP, which is short for Simple Object Access Protocol. It has gained popularity since 2003 and has become the go-to standard for creating SOA applications.
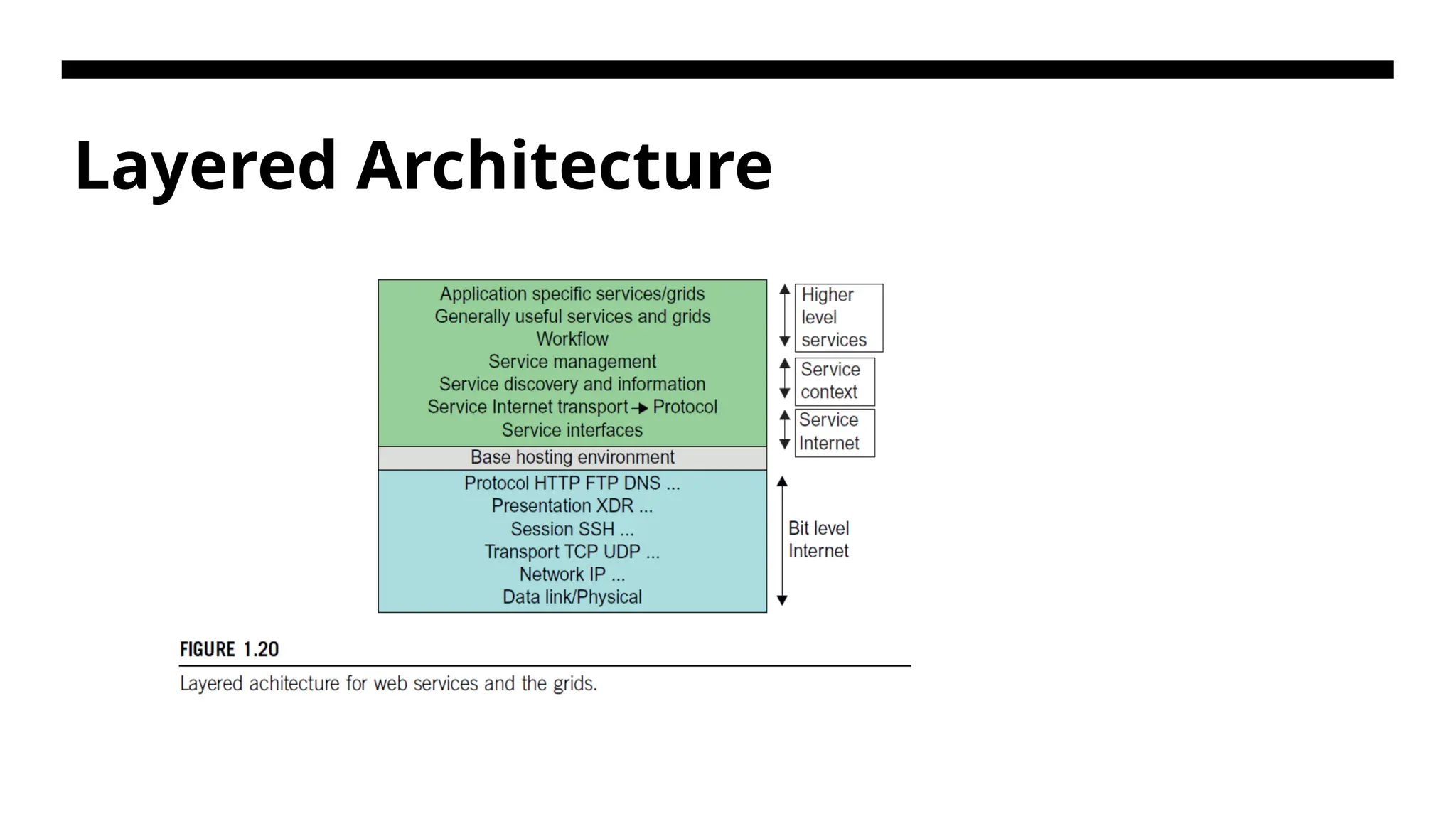
Layered Architecture –Communication Systems Simple Object Access Protocol (SOAP) specification is a set of rules that describe how to format and exchange information between web services and also access web services. Remote Method Invocation( RMI). It is a mechanism that allows an object residing in one system (JVM) to access/invoke an object running on another JVM. RMI is used to build distributed applications; it provides remote communication between Java programs. It is provided in the package java. rmi. IIOP (Internet Inter-ORB Protocol) is a protocol that makes it feasible for distributed applications written in various programming languages to interact over the Internet. IIOP is a vital aspect of a major industry standard, the Common Object Request Broker Architecture (CORBA) (CORBA)
103.
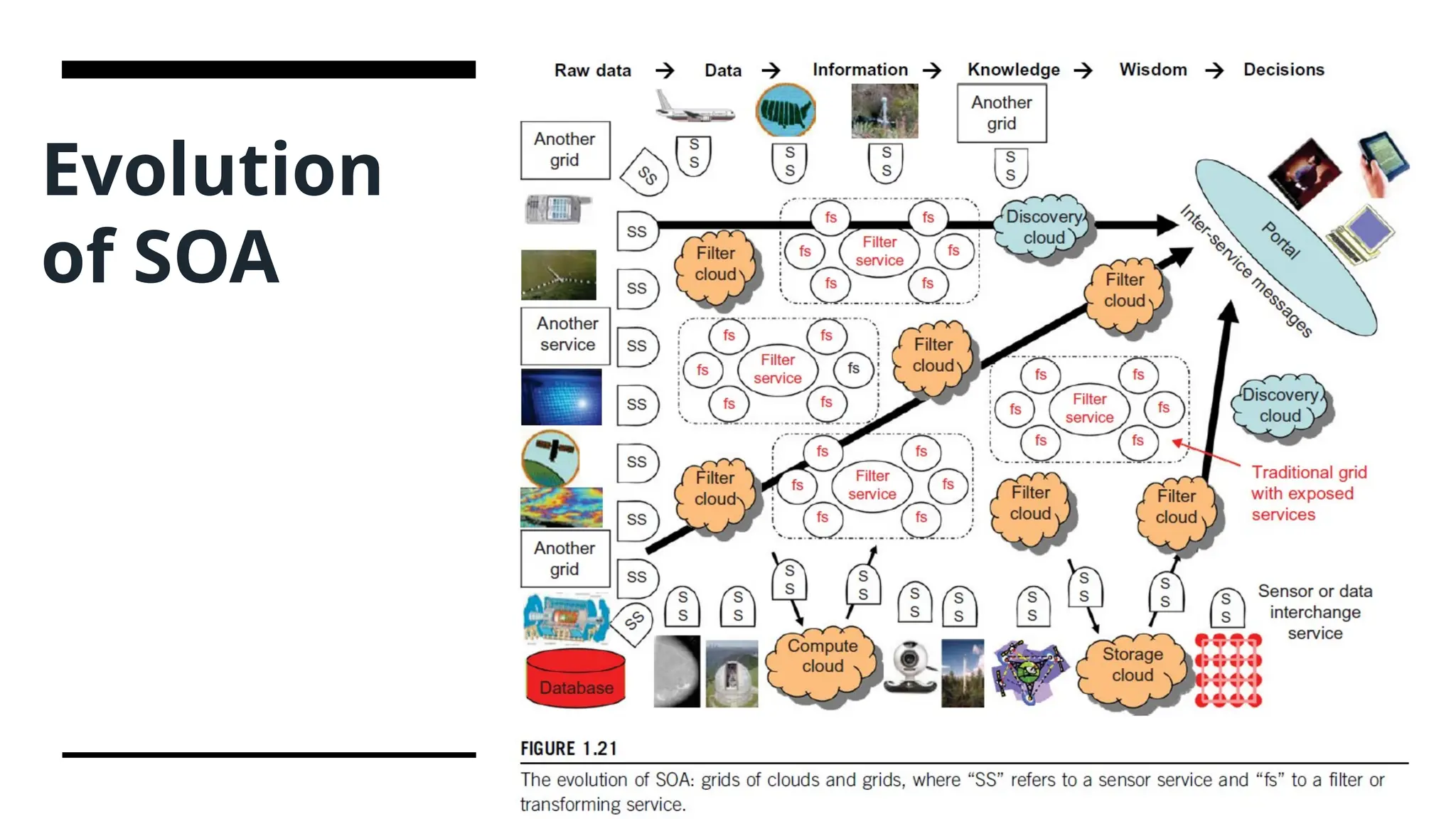
Evolution of SOA-Service oriented architecture • SOA is an architectural approach in which applications make use of services available in the network. • SOA applies to building grids, clouds, grids of clouds, clouds of grids, clouds of clouds (also known as interclouds), and systems of systems in general. • many sensors provide data-collection services, denoted in the figure as SS (sensor service). • SOA allows users to combine many facilities from existing services to form applications. • SOA encompasses a set of design principles that structure system development and provide means for integrating components into a coherent and decentralized system. • SOA-based computing packages functionalities into a set of interoperable services, which can be integrated into different software systems belonging to separate business domains.
104.
Characteristics of SOA oProvides interoperability between the services. o Provides methods for service encapsulation, service discovery, service composition, service reusability and service integration. o Facilitates QoS (Quality of Services) through service contract based on Service Level Agreement (SLA). o Provides loosely couples services. o Provides location transparency with better scalability and availability. o Ease of maintenance with reduced cost of application development and deployment.
High Level workingof SOA • Many sensors provide data-collection services, denoted in the figure as SS (sensor service). • A sensor can be a ZigBee device, a Bluetooth device, a WiFi access point, a personal computer, a GPA, or a wireless phone, among other things. Raw data is collected by sensor services. • All the SS devices interact with large or small computers, many forms of grids, databases, the compute cloud, the storage cloud, the filter cloud, the discovery cloud, and so on. • All the SS devices interact with large or small computers, many forms of grids, databases, the compute cloud, the storage cloud, the filter cloud, the discovery cloud, and so on. • Filter services are used to eliminate unwanted raw data, in order to respond to specific requests from the web, the grid, or web services. • SOA aims to search for, or sort out, the useful data from the massive amounts of raw data items. • Processing this data will generate useful information, and subsequently, the knowledge for our daily use. • Most distributed systems require a web interface or portal. For raw data collected by a large number of sensors to be transformed into useful information or knowledge, the data stream may go through a sequence of compute, storage, filter, and discovery clouds.
107.
Grid Vs Cloud •The boundary between grids and clouds are getting blurred in recent years. For web services, workflow technologies are used to coordinate or orchestrate services with certain specifications used to define critical business process models such as two-phase transactions. • In general, a grid system applies static resources, while a cloud emphasizes elastic resources. For some researchers, the differences between grids and clouds are limited only in dynamic resource allocation based on virtualization and autonomic computing. One can build a grid out of multiple clouds. This type of grid can do a better job than a pure cloud, because it can explicitly support negotiated resource allocation.
108.
Trends towards distributedOperating Systems. • The computers in most distributed systems are loosely coupled. • Thus, a distributed system inherently has multiple system images. This is mainly due to the fact that all node machines run with an independent operating system.. • To promote resource sharing and fast communication among node machines, it is best to have a distributed OS that manages all resources coherently and efficiently. • Such a system is most likely to be a closed system, and it will likely rely on message passing and RPCs for internode communications
109.
Distributed Operating System ADistributed Operating System refers to a model in which applications run on multiple interconnected computers, offering enhanced communication and integration capabilities compared to a network operating system. In a Distributed Operating System, multiple CPUs are utilized, but for end-users, it appears as a typical centralized operating system. It enables the sharing of various resources such as CPUs, disks, network interfaces, nodes, and computers across different sites, thereby expanding the available data within the entire system.
Message Passing Interface(MPI) •The Message Passing Interface (MPI) is an Application Program Interface that defines a model of parallel computing where each parallel process has its own local memory, and data must be explicitly shared by passing messages between processes. • MPI is the most popular programming model for message-passing systems. Google’s MapReduce and BigTable are for effective use of resources from Internet clouds and data centers. Service clouds demand extending Hadoop, EC2, and S3 to facilitate distributed computing over distributed storage systems.
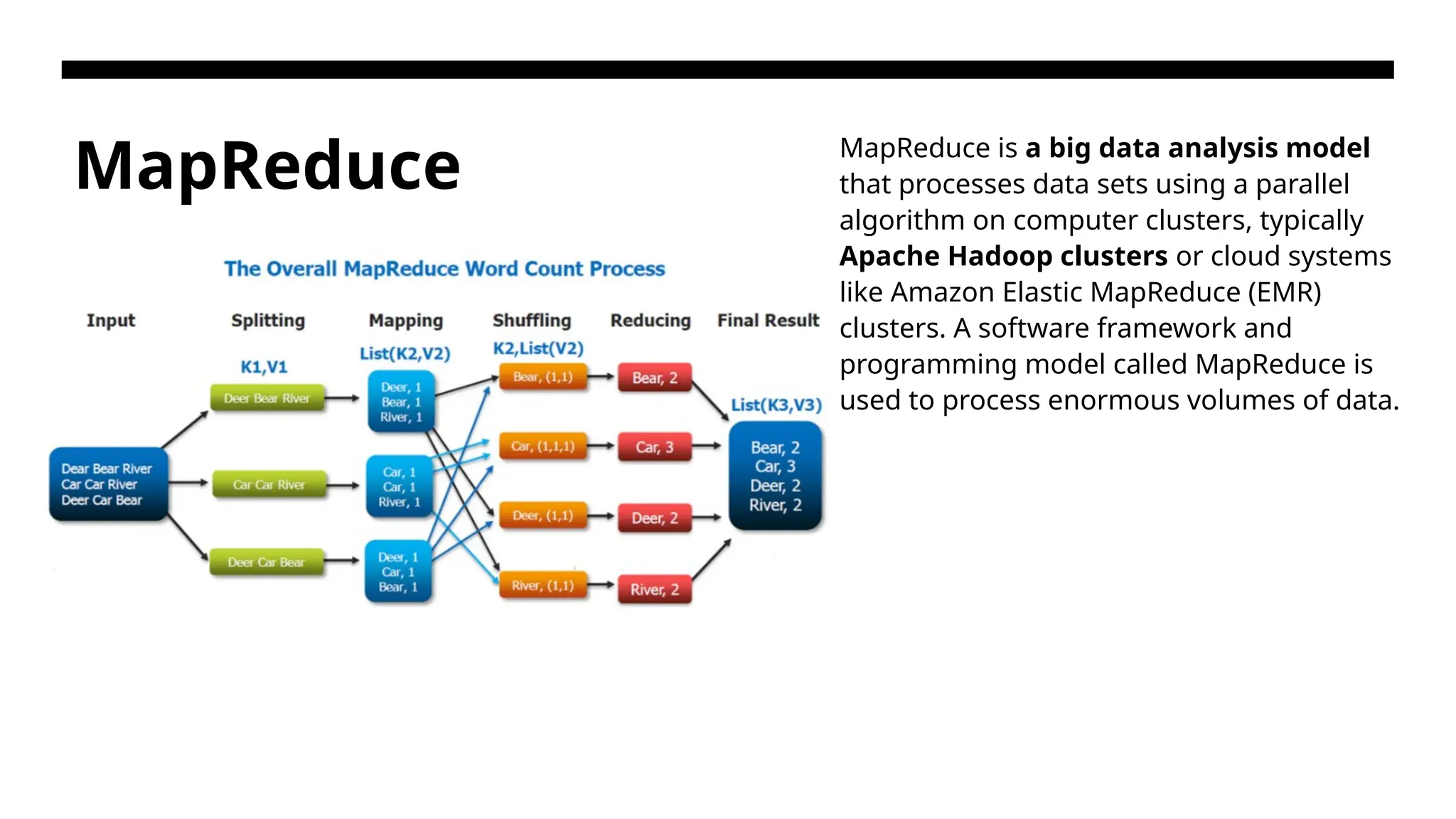
MapReduce • MapReduce isa Java-based, distributed execution framework within the Apache Hadoop Ecosystem. • This is a web programming model for scalable data processing on large clusters over large data sets. • The model is applied mainly in web-scale search and cloud computing applications. The user specifies a Map function to generate a set of intermediate key/value pairs. Then the user applies a Reduce function to merge all intermediate values with the same intermediate key. • More on Apache Hadoop - https://www.spiceworks.com/tech/big-data/articles/what-is-map-reduce/#:~:text=What%20Is%20M apReduce%3F-,MapReduce%20is%20a%20big%20data%20analysis%20model%20that%20processes %20data,process%20enormous%20volumes%20of%20data
115.
MapReduce MapReduce isa big data analysis model that processes data sets using a parallel algorithm on computer clusters, typically Apache Hadoop clusters or cloud systems like Amazon Elastic MapReduce (EMR) clusters. A software framework and programming model called MapReduce is used to process enormous volumes of data.
116.
Hadoop Library • Hadoopoffers a software platform that was originally developed by a Yahoo! group. The package enables users to write and run applications over vast amounts of distributed data. • Users can easily scale Hadoop to store and process petabytes of data in the web space. Also, Hadoop is economical in that it comes with an many version of MapReduce that minimizes overhead in task spawning and massive data communication. • It is efficient, as it processes data with a high degree of parallelism across a large number of commodity nodes, and it is reliable in that it automatically keeps multiple data copies to facilitate redeployment of computing tasks upon unexpected system failures.
Performance, Security andEnergy efficiency Performance metrics are needed to measure various distributed systems. In this section, we will discuss various dimensions of scalability and performance laws. Then we will examine system scalability against OS images and the limiting factors encountered.
119.
Performance Metrices • Systemthroughput is often measured in MIPS, Tflops (tera floating-point operations per second), or TPS (transactions per second). Other measures include job response time and network latency. • An interconnection network that has low latency and high bandwidth is preferred. System overhead is often attributed to OS boot time, compile time, I/O data rate, and the runtime support system used. • Other performance-related metrics include the QoS for Internet and web services; system availability and dependability; and security resilience for system defense against network attacks.
120.
Dimensions of Scalibility •Scaling is the ability to adjust the number of resources a system has to meet changing demands. This can be done by increasing or decreasing the size or power of an IT resource. • Users want to have a distributed system that can achieve scalable performance. Any resource upgrade in a system should be backward compatible with existing hardware and software resources. • Overdesign may not be cost-effective. System scaling can increase or decrease resources depending on many practical factors
121.
Size Scalability • Thisrefers to achieving higher performance or more functionality by increasing the machine size. The word “size” refers to adding processors, cache, memory, storage, or I/O channels.
122.
Software Scalability • Thisrefers to upgrades in the OS or compilers, adding mathematical and engineering libraries, porting new application software, and installing more user-friendly programming environments. Some software upgrades may not work with large system configurations. Testing and fine-tuning of new software on larger systems is a nontrivial job.
123.
Application scalability This refersto matching problem size scalability with machine size scalability. Problem size affects the size of the data set or the workload increase. Instead of increasing machine size, users can enlarge the problem size to enhance system efficiency or cost-effectiveness.
124.
Technology scalability • Thisrefers to a system that can adapt to changes in building technologies, such as the component and networking technologies. • When scaling a system design with new technology one must consider three aspects: time, space, and heterogeneity. (1) Time refers to generation scalability. When changing to new-generation processors, one must consider the impact to the motherboard, power supply, packaging and cooling, and so forth. Based on past experience, most systems upgrade their commodity processors every three to five years. (2) Space is related to packaging and energy concerns. Technology scalability demands harmony and portability among suppliers. (3) Heterogeneity refers to the use of hardware components or software packages from different vendors. Heterogeneity may limit the scalability.
125.
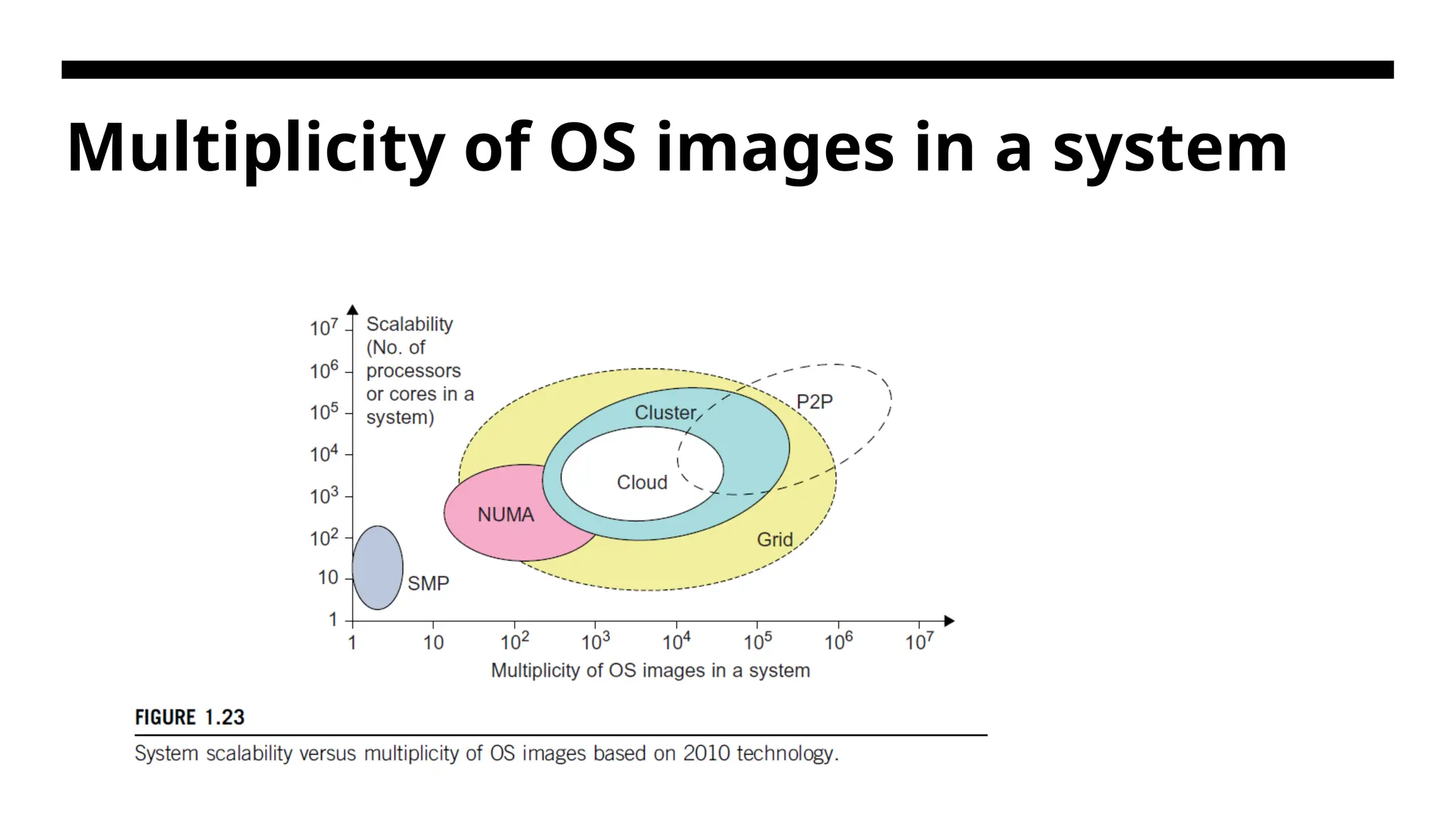
System Scalability VsOS Image count • Scalable performance implies that the system can achieve higher speed by adding more processors or servers, enlarging the physical node’s memory size, extending the disk capacity or adding more I/O channels. • The OS image is counted by the number of independent OS images observed in a cluster, grid, P2P network, or the cloud. • An SMP (symmetric multiprocessor) server has a single system image, which could be a single node in a large cluster. • As of 2010, the largest cloud was able to scale up to a few thousand VMs.
126.
NUMA • NUMA (nonuniformmemory access) machines are often made out of SMP nodes with distributed, shared memory. • A NUMA machine can run with multiple operating systems, and can scale to a few thousand processors communicating with the MPI library. • For example, a NUMA machine may have 2,048 processors running 32 SMP operating systems, resulting in 32 OS images in the 2,048-processor NUMA system. The cluster nodes can be either SMP servers or high-end machines that are loosely coupled together. • The grid node could be a server cluster, or a mainframe, or a supercomputer, or an MPP. Therefore, the number of OS images in a large grid structure could be hundreds or thousands fewer than the total number of processors in the grid.
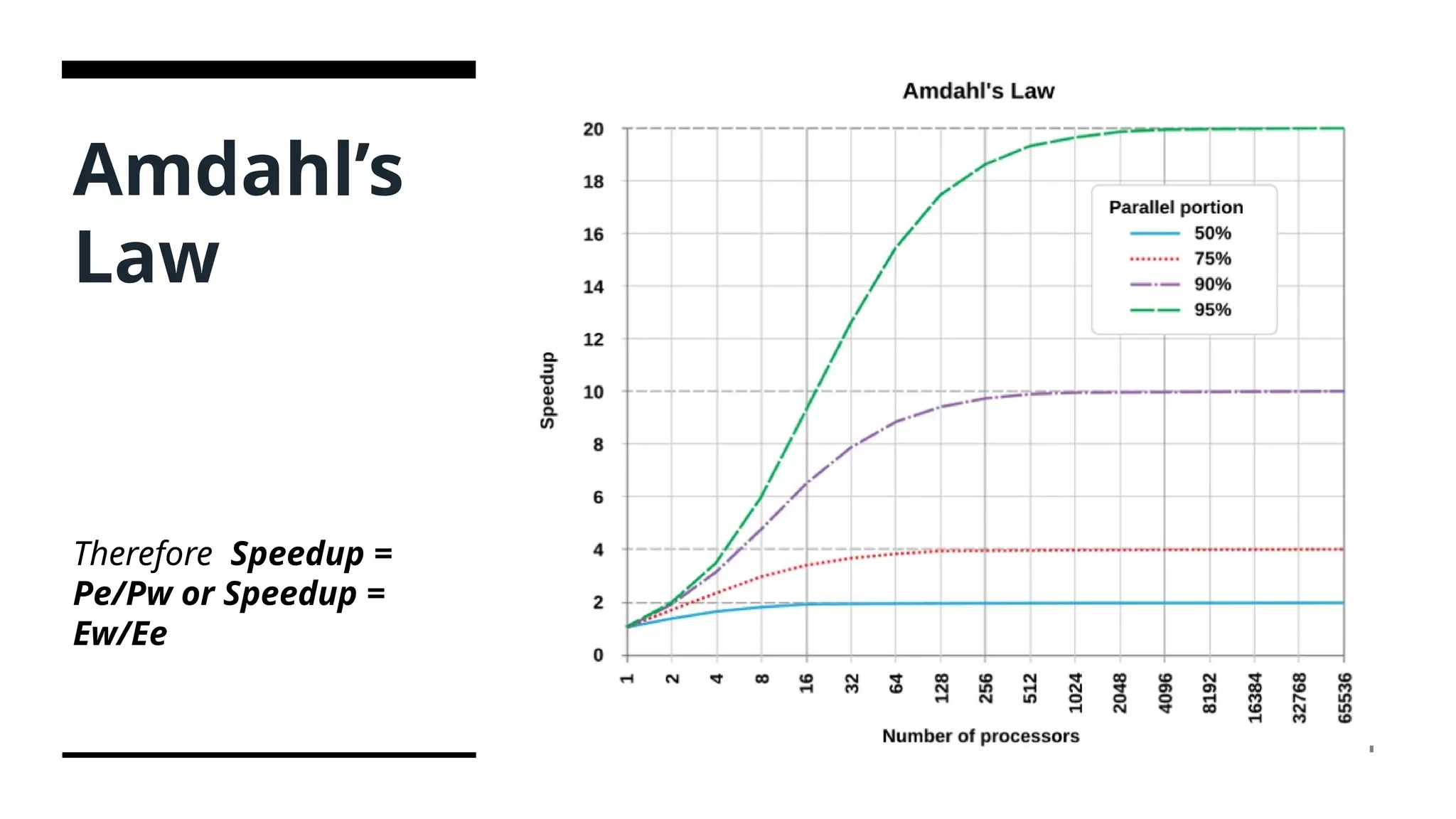
Amdahl’s Law • Amdahl'slaw is a formula that estimates how much faster a task can be completed when a system's resources are improved. • It is often used in parallel computing to predict the theoretical speedup when using multiple processors. • Speedup- Speedup is defined as the ratio of performance for the entire task using the enhancement and performance for the entire task without using the enhancement • Pe is the performance for the entire task using the enhancement when possible. • Pw is the performance for the entire task without using the enhancement • Ew is the execution time for the entire task without using the enhancement • Ee is the execution time for the entire task using the enhancement when possible
Amdahl’s Law The formulafor Amdahl’s law is: S = 1 / (1 – P + (P / N)) Where: S is the speedup of the system P is the proportion of the system that can be improved N is the number of processors in the system For example, if a system has a single bottleneck that occupies 20% of the total execution time, and we add 4 more processors to the system, the speedup would be: S = 1 / (1 – 0.2 + (0.2 / 5)) S = 1 / (0.8 + 0.04) S = 1 / 0.84 S = 1.19 This means that the overall performance of the system would improve by about 19% with the addition of the 4 processors. It’s important to note that Amdahl’s law assumes that the rest of the system is able to fully utilize the additional processors, which may not always be the case in practice.
131.
Disadvantages of Amdahl’sLaw • Assumes that the portion of the program that cannot be parallelized is fixed, which may not be the case in practice. For example, it is possible to optimize code to reduce the portion of the program that cannot be parallelized, making Amdahl’s law less accurate. • Assumes that all processors have the same performance characteristics, which may not be the case in practice. For example, in a heterogeneous computing environment, some processors may be faster than others, which can affect the potential speedup that can be achieved. • Does not take into account other factors that can affect the performance of parallel programs, such as communication overhead and load balancing. These factors can impact the actual speedup that is achieved in practice, which may be lower than the theoretical maximum predicted by Amdahl’s law. • Application of Amdahl’s law - Amdahl’s law can be used when the workload is fixed, as it calculates the potential speedup with the assumption of a fixed workload. Moreover, it can be utilized when the non-parallelizable portion of the task is relatively large, highlighting the diminishing returns of parallelization.
132.
Gustafson’s Law Gustafson's lawis a principle in computer architecture that describes how parallel computing can speed up the execution of a task. • Gustafson’s law/(Gustafson-Barsis’s law) addresses shortcomings of the Amdahl’s law, which is based on the assumption of a fixed problem size and increase in resources does not improve the workload • Gustafson’s Law states that by increasing the problem size, we can increase the scalability and make use of all the resources you have. • By increasing resources and problem size, speed will theoretically be a linear. The amount of speed we get is still be determined by the ratio of how much of our problem is parallelized and how much is sequential
Gustafson’s Law Gustafson’s LawApplications - Gustafson’s law is applicable when the workload or problem size can be scaled proportionally with the available resources. It also addresses problems requiring larger problem sizes or workloads, promoting the development of systems capable of handling such realistic computations.
135.
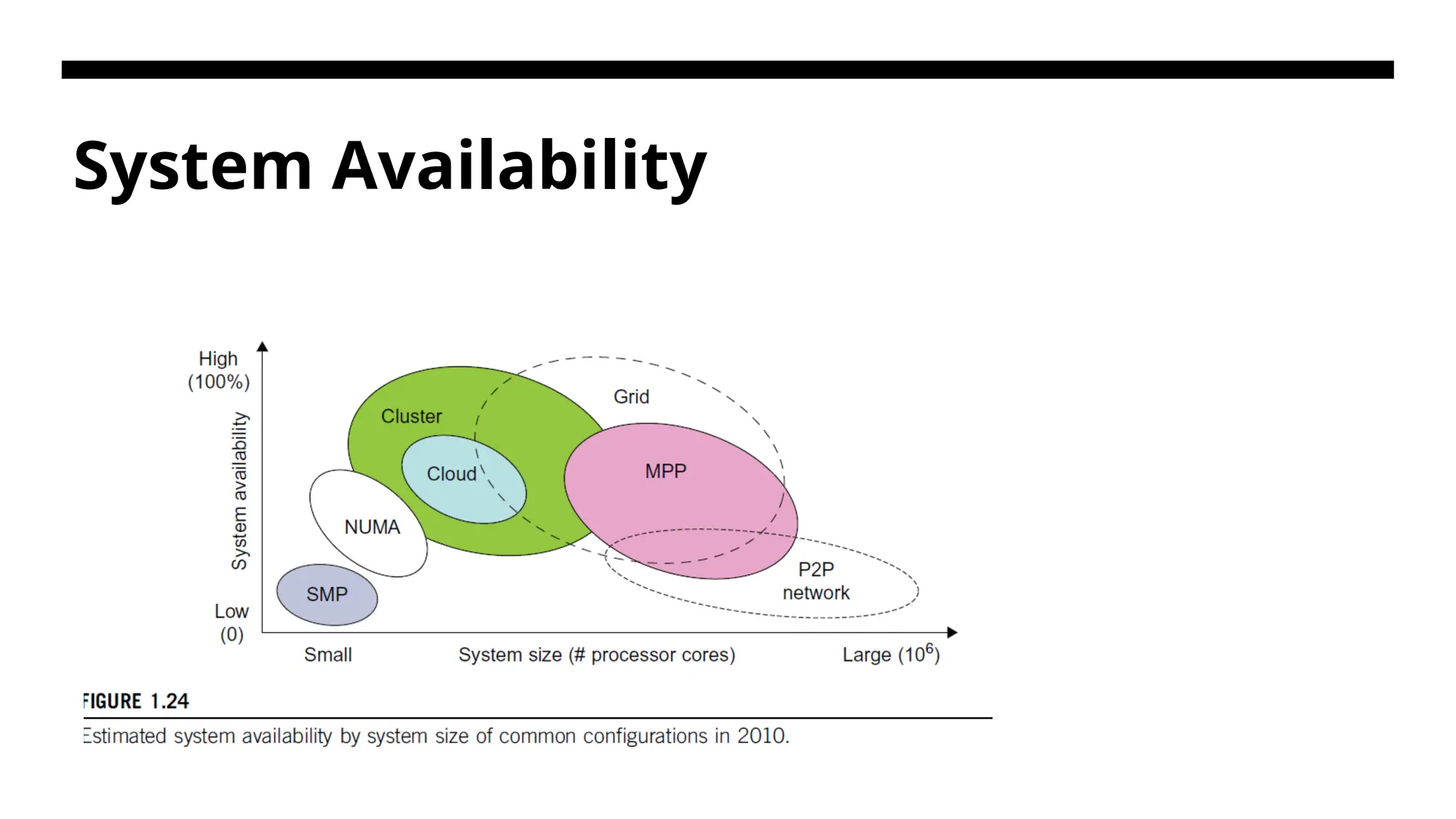
System Availability HA (highavailability) is desired in all clusters, grids, P2P networks, and cloud systems. A system is highly available if it has a long mean time to failure (MTTF) and a short mean time to repair (MTTR). System availability is formally defined as follows: System Availability =MTTF/(MTTF +MTTR)
136.
System Availability • Symmetricmultiprocessing (SMP) - The SMP databases/applications can run on multiple servers and share resources in cluster configurations. • massively parallel processing (MPP) - An MPP system has its dedicated resources and shares nothing, while the SMP counterpart shares the same resources. • NUMA may refer to Non-Uniform Memory Access - Non-uniform memory access, or NUMA, is a method of configuring a cluster of microprocessors in a multiprocessing system so they can share memory locally. The idea is to improve the system's performance and allow it to expand as processing needs evolve.
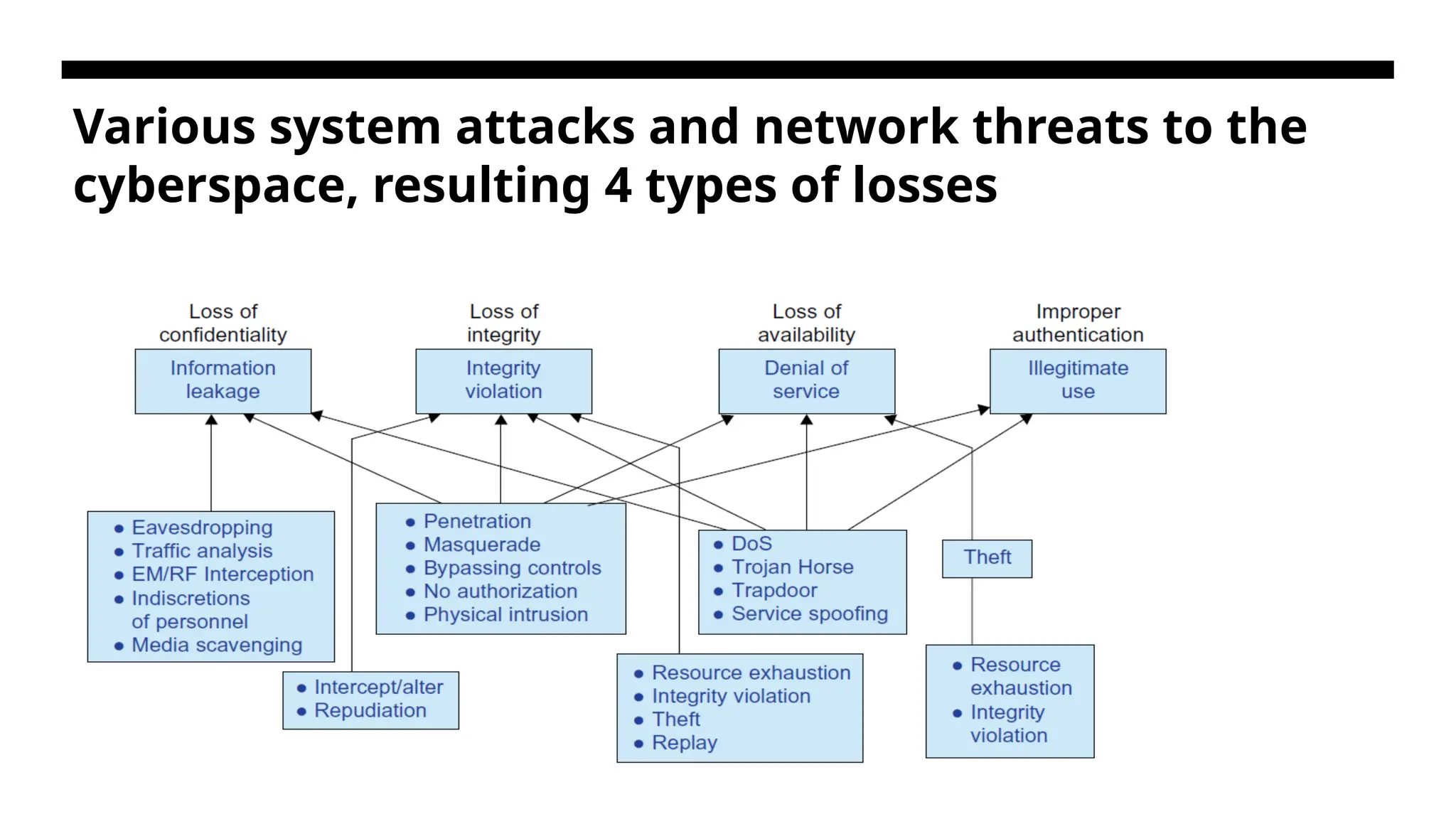
Network Threats andData Security • Network viruses have threatened many users in widespread attacks. These incidents have created a worm epidemic by pulling down many routers and servers, and are responsible for the loss of billions of dollars in business, government, and services. • Information leaks lead to a loss of confidentiality. • Loss of data integrity may be caused by user alteration, Trojan horses, and service spoofing attacks. A denial of service (DoS) results in a loss of system operation and Internet connections • Lack of authentication or authorization leads to attackers’ illegitimate use of computing resources. Open resources such as data centers, P2P networks, and grid and cloud infrastructures could become the next targets. Users need to protect clusters, grids, clouds, and P2P systems. Otherwise, users should not use or trust them for outsourced work
139.
Security Responsibility • Threesecurity requirements are often considered: confidentiality, integrity, and availability for most Internet service providers and cloud users. • Collusive piracy is the main source of intellectual property violations within the boundary of a P2P network. Paid clients (colluders) may illegally share copyrighted content files with unpaid clients (pirates).
140.
Various system attacksand network threats to the cyberspace, resulting 4 types of losses
141.
System defence technologies Threegenerations of network defense technologies have appeared in the past. • In the first generation tools were designed to prevent or avoid intrusions. These tools usually manifested themselves a access control policies or tokens, cryptographic systems, and so forth. However, an intruder could always penetrate a secure system because there is always a weak link in the security provisioning process • The second generation detected intrusions in a timely manner to exercise remedial actions. These techniques included firewalls, intrusion detection systems (IDSes), PKI services, reputation systems, and so on • The third generation provides more intelligent responses to intrusions
142.
Energy consumption ofUnused servers • To run a server farm (data center) a company has to spend a huge amount of money for hardware, software, operational support, and energy every year. Therefore, companies should thoroughly identify whether their installed server farm (more specifically, the volume of provisioned resources) is at an appropriate level, particularly in terms of utilization. • It was estimated in the past that, on average, one-sixth (15 percent) of the full-time servers in a company are left powered on without being actively used (i.e., they are idling) on a daily basis. This indicates that with 44 million servers in the world, around 4.7 million servers are not doing any useful work. • This amount of wasted energy is equal to 11.8 million tons of carbon dioxide per year, which is equivalent to the CO pollution of 2.1 million cars. In the United States, this equals 3.17 million tons of carbon dioxide, or 580,678 cars. Therefore, the first step in IT departments is to analyze their servers to find unused and/or underutilized servers.
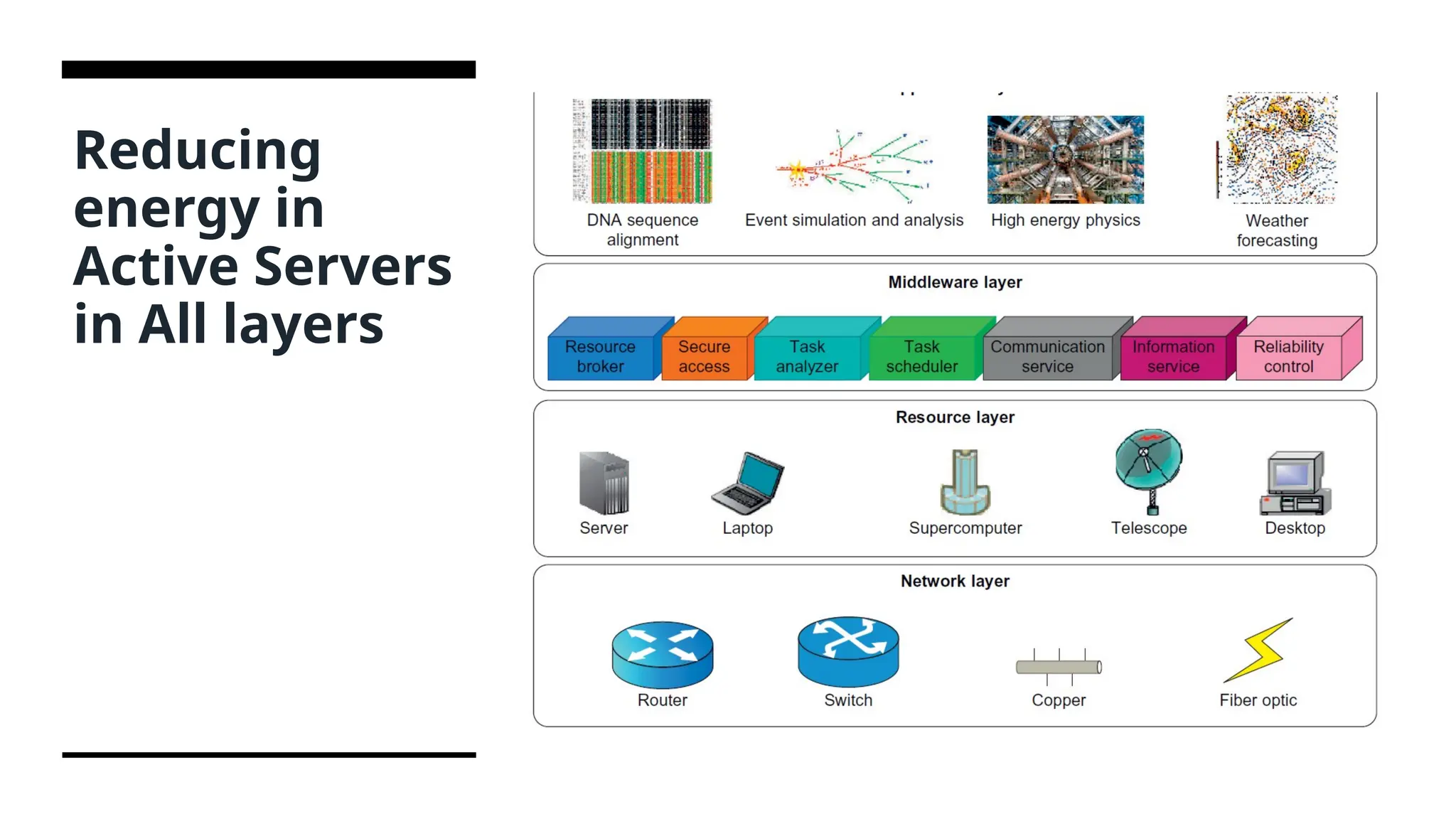
Application Layer • Byintroducing energy-aware applications, the challenge is to design sophisticated multilevel and multi-domain energy management applications without hurting performance. • The first step toward this end is to explore a relationship between performance and energy consumption. Indeed, an application’s energy consumption depends strongly on the number of instructions needed to execute the application and the number of transactions with the storage unit (or memory). These two factors (compute and storage) are correlated and they affect completion time.
145.
Middleware Layer • Themiddleware layer acts as a bridge between the application layer and the resource layer. This layer provides resource broker, communication service, task analyzer, task scheduler, security access, reliability control, and information service capabilities. • Until recently, scheduling was aimed at minimizing makespan, that is, the execution time of a set of tasks. Distributed computing systems necessitate a new cost function covering both makespan and energy consumption.
146.
Resource Layer • Theresource layer consists of a wide range of resources including computing nodes and storage units. • This layer generally interacts with hardware devices and the operating system; therefore, it is responsible for controlling all distributed resources in distributed computing systems. • Dynamic power management (DPM) and dynamic voltage-frequency scaling (DVFS) are two popular methods incorporated into recent computer hardware systems. • In DPM, hardware devices, such as the CPU, have the capability to switch from idle mode to one or more lower power modes. • In DVFS, energy savings are achieved because the power consumption in CMOS(Complementary Metal-Oxide-Semiconductor) circuits has a direct relationship with frequency and the square of the voltage supply. Execution time and power consumption are controllable by switching among different frequencies and voltages
147.
Network Layer • Routingand transferring packets and enabling network services to the resource layer are the main responsibility of the network layer in distributed computing systems. • The major challenge to build energy-efficient networks is, again, determining how to measure, predict, and create a balance between energy consumption and performance. Two major challenges to designing energy-efficient networks are: 1. The models should represent the networks comprehensively as they should give a full understanding of interactions among time, space, and energy. 2. New, energy-efficient routing algorithms need to be developed. New, energy-efficient protocols should be developed against network attacks





















![The Internet of Things and Cyber-Physical Systems Internet of Things - The traditional Internet connects machines to machines or web pages to web pages. The concept of the IoT was introduced in 1999 at MIT [40]. The IoT refers to the networked interconnection of everyday objects, tools, devices, or computers.](https://image.slidesharecdn.com/module1distributedsystemmodels-250323032837-49a959f4/75/DistributedSystemModels-cloud-computing-and-distributed-system-models-25-2048.jpg)