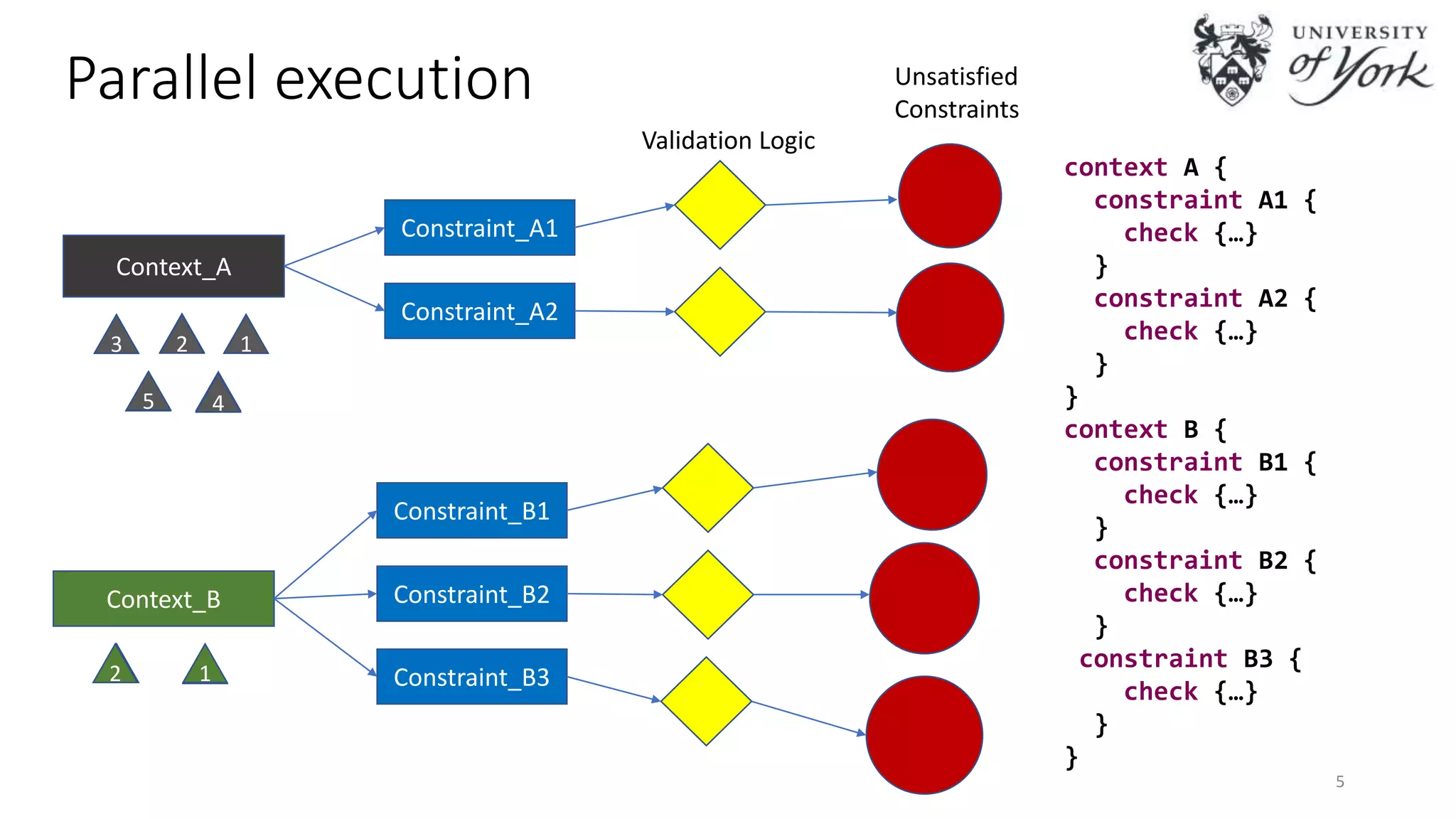
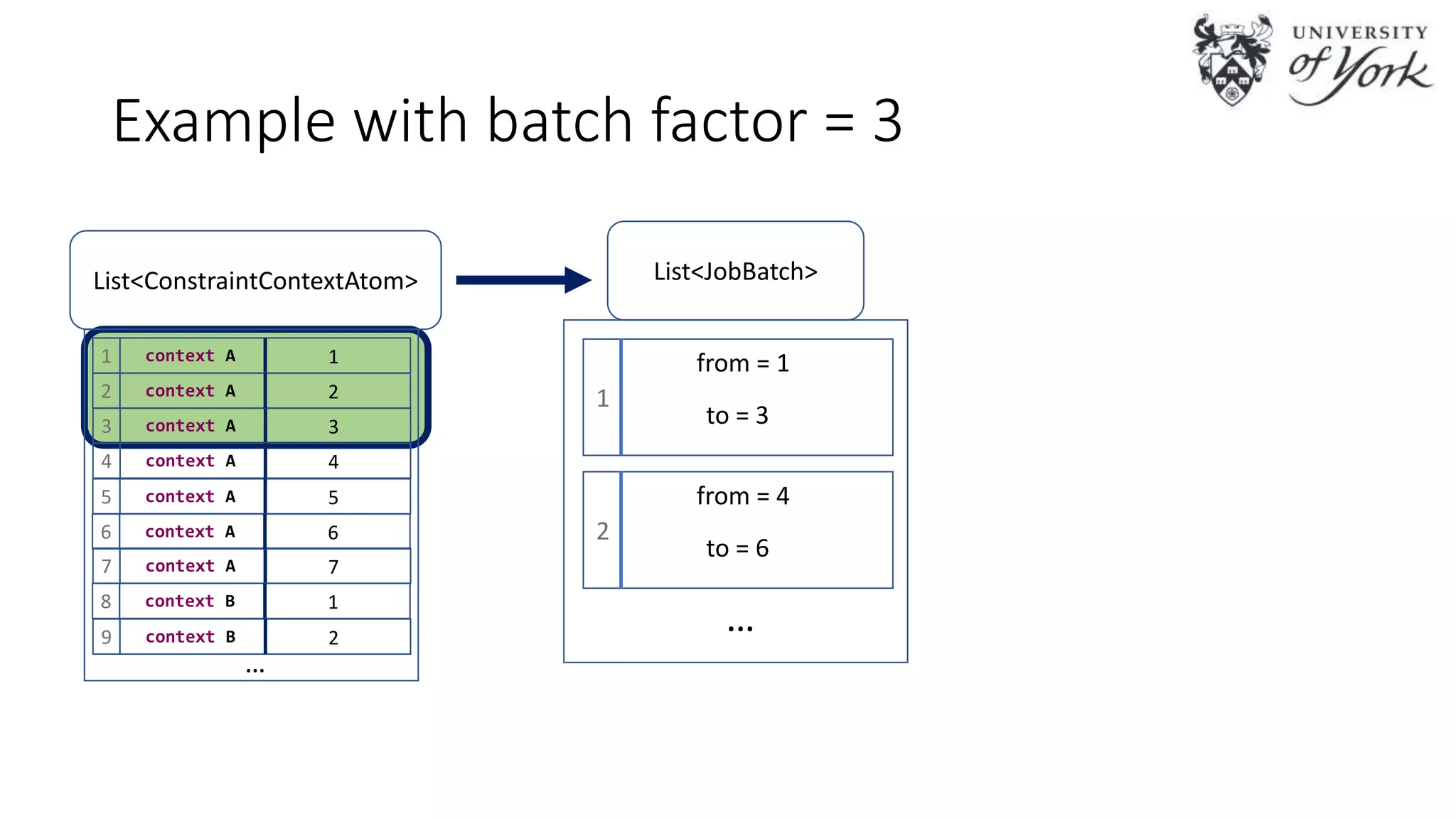
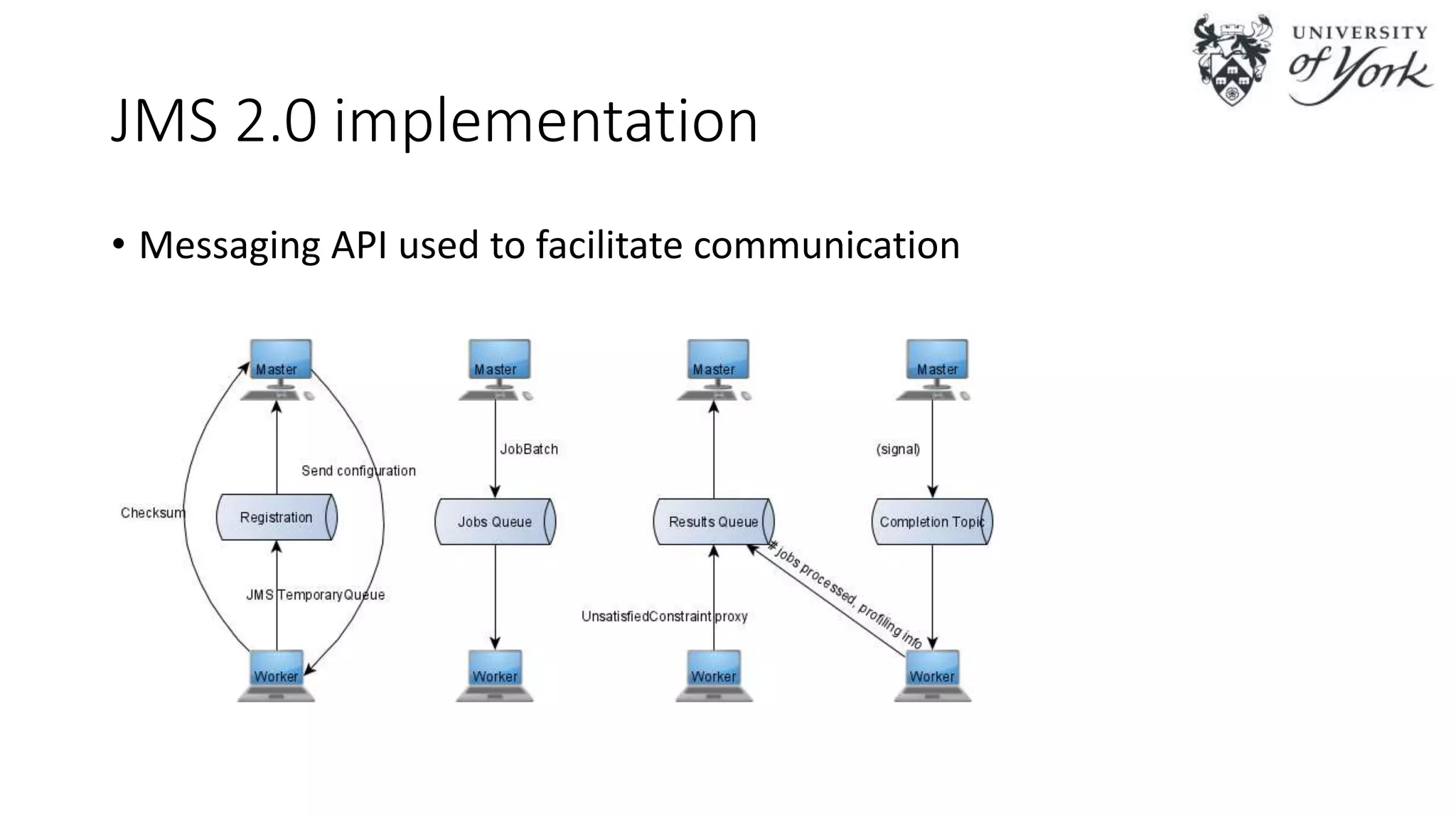
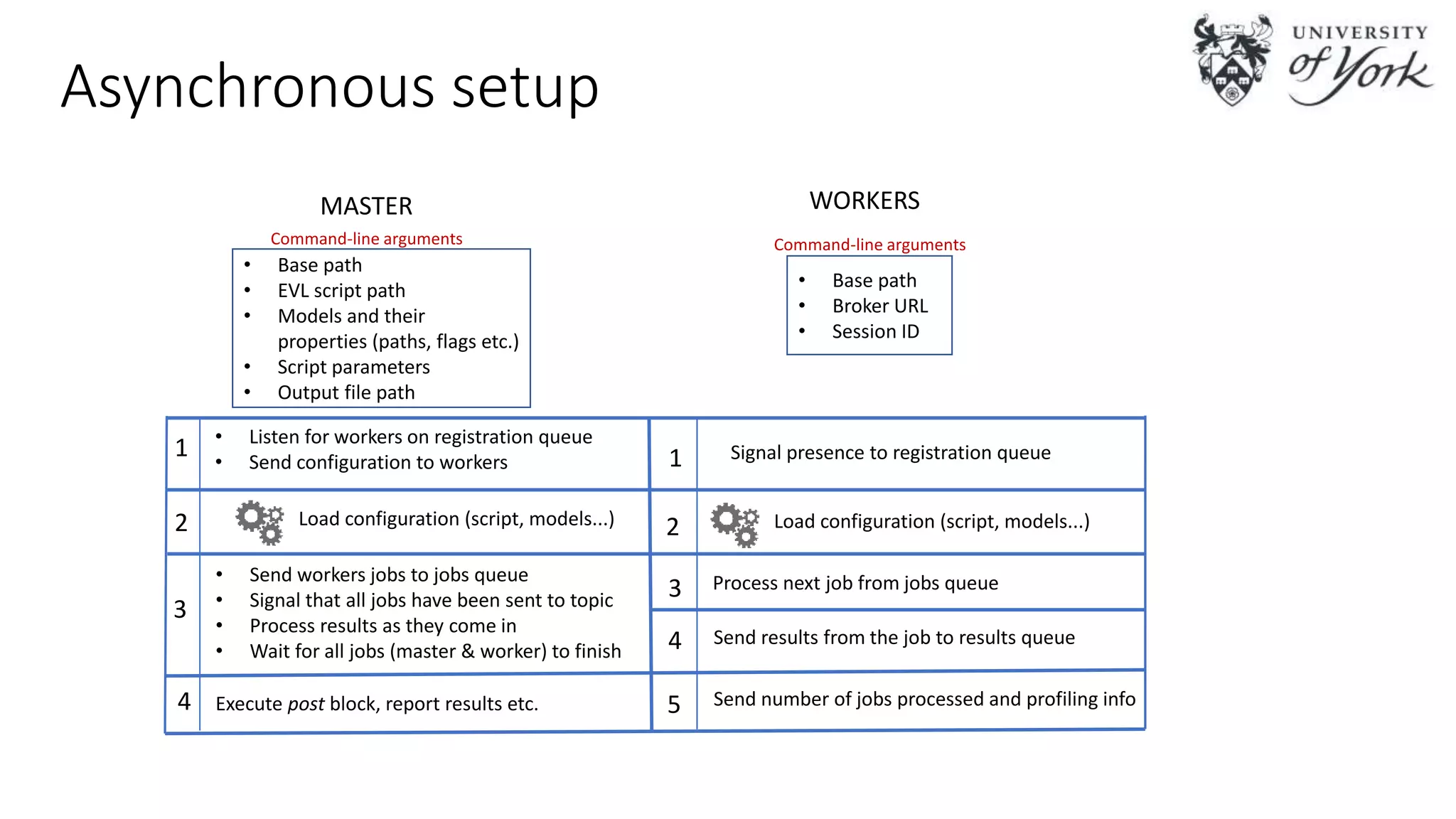
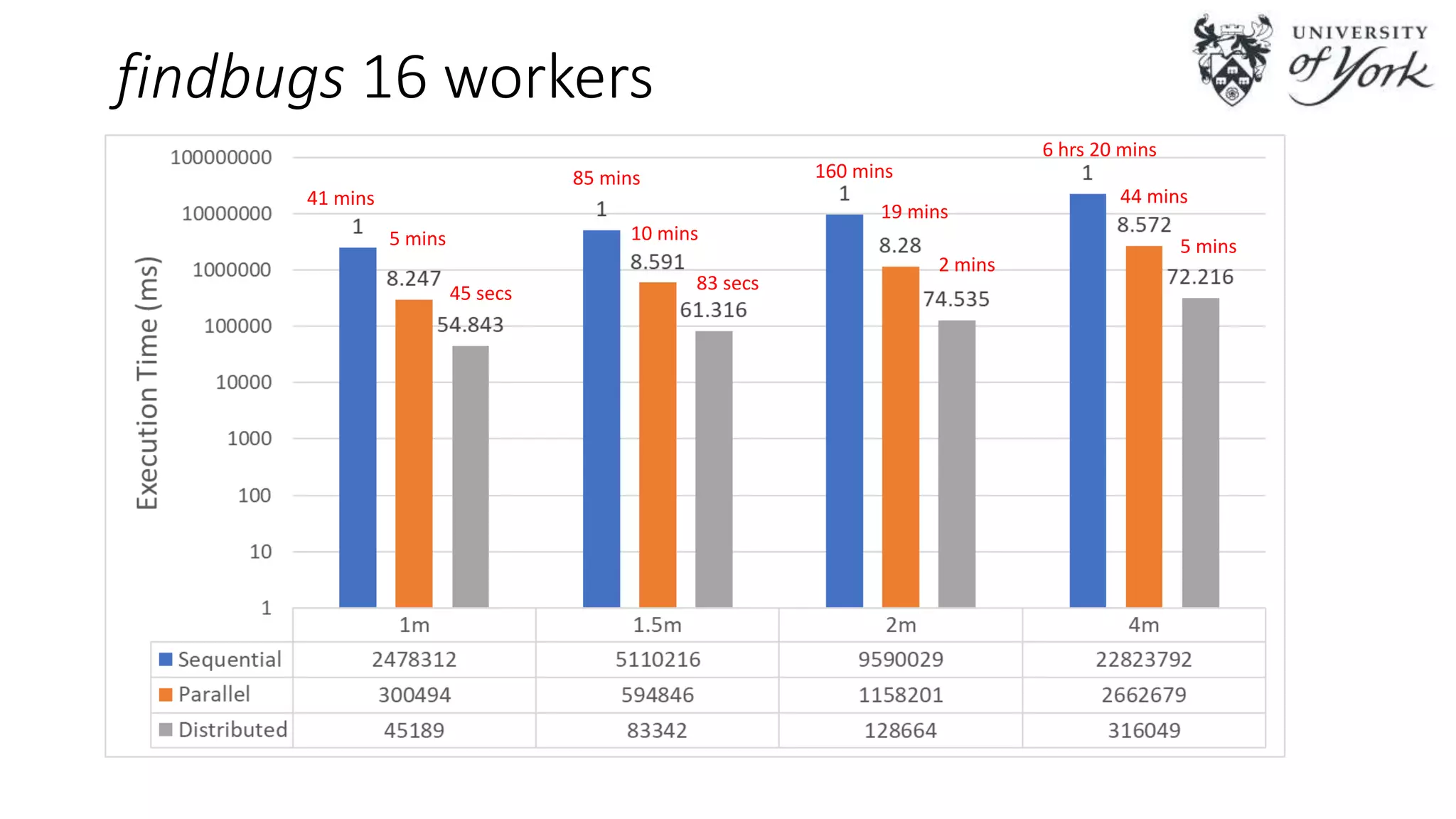
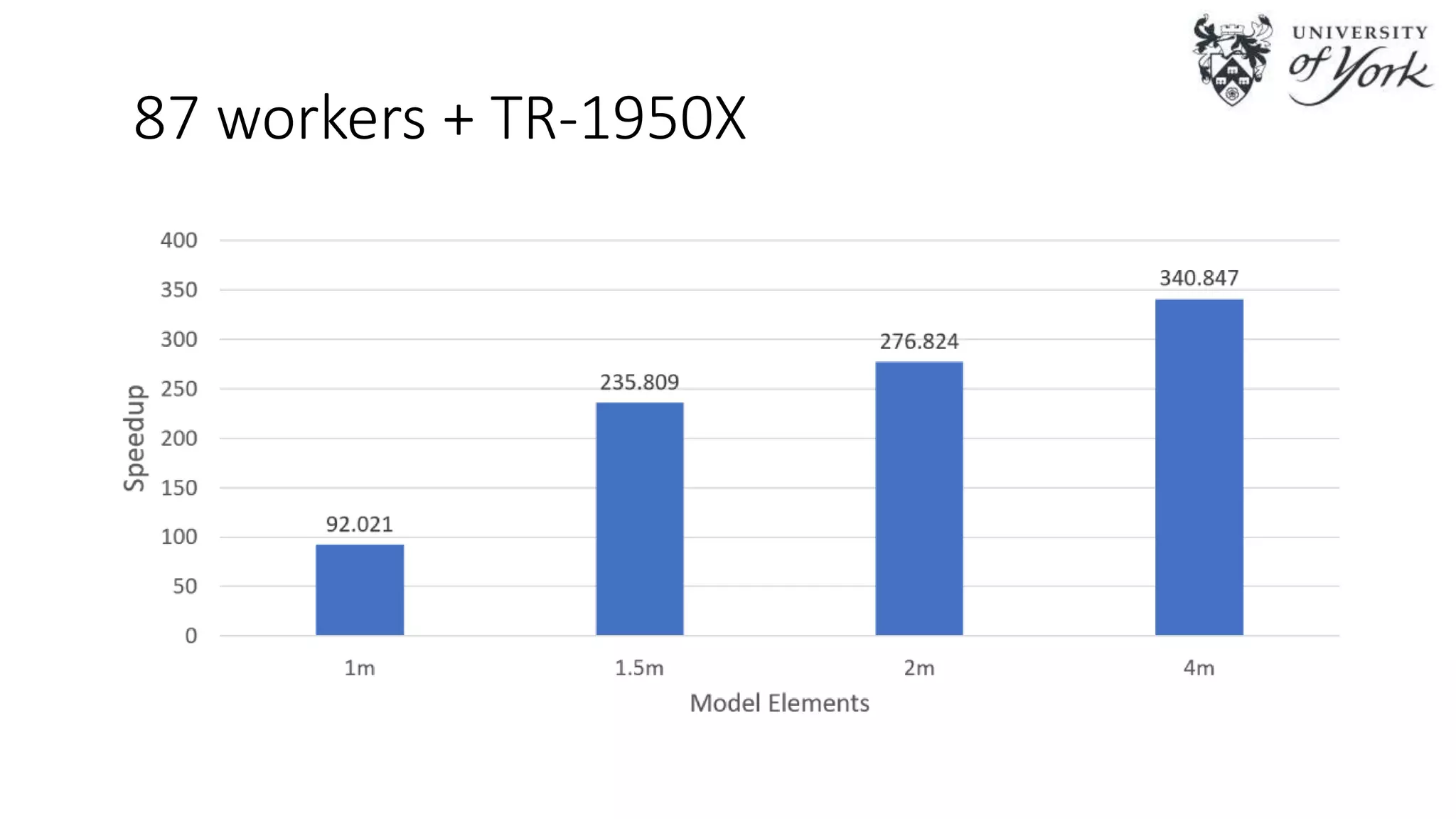
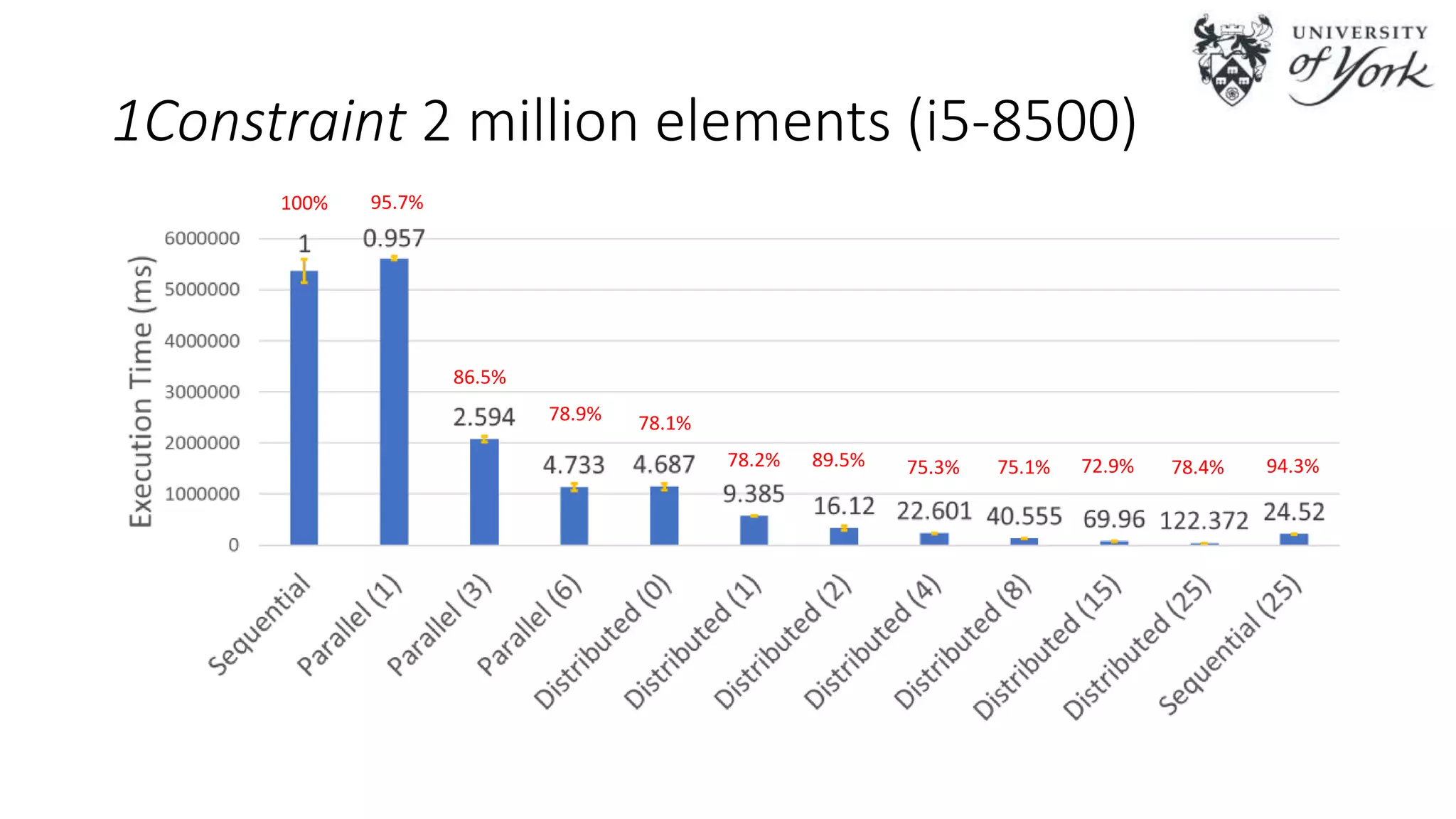
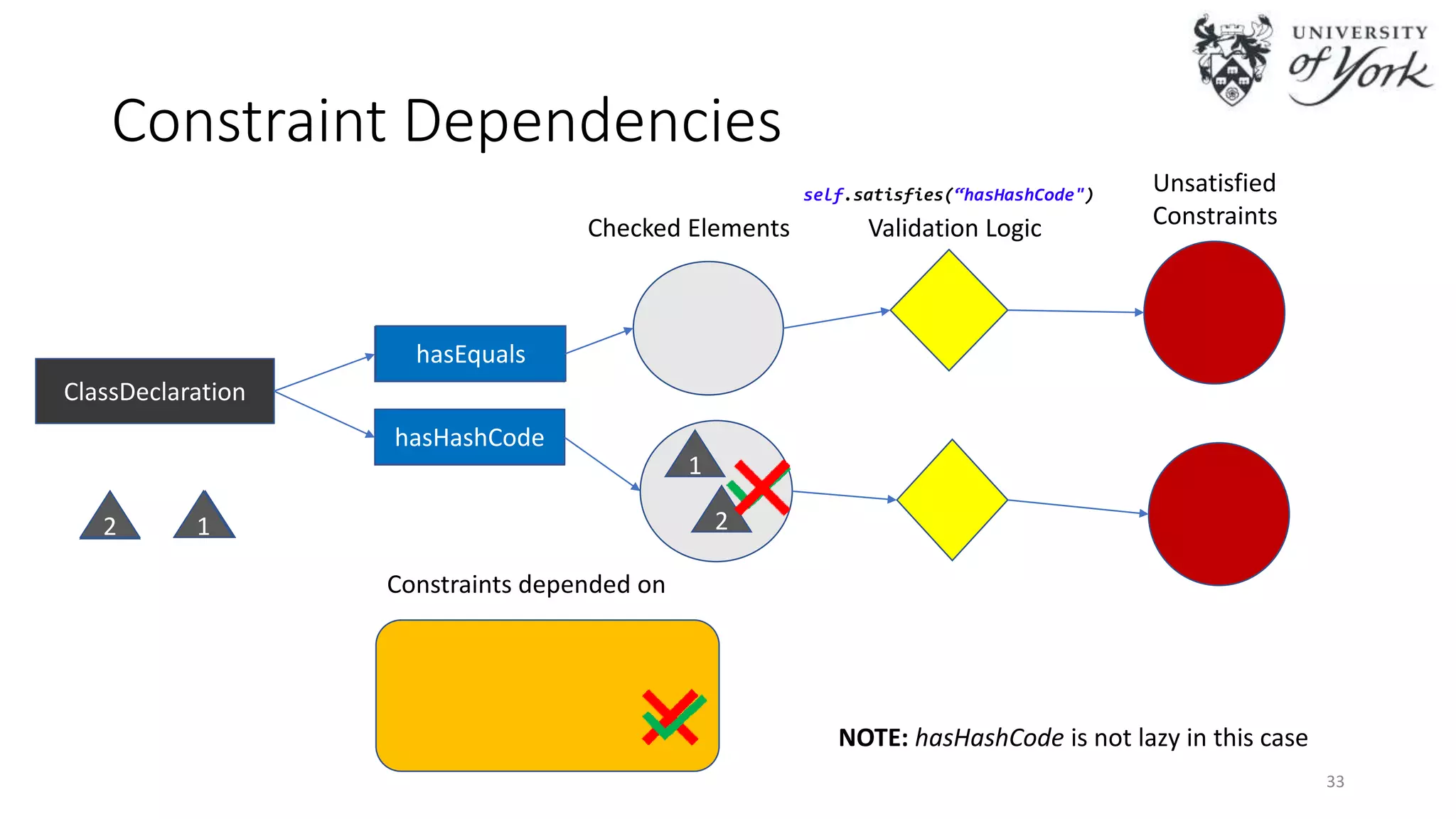
The document discusses the challenges of scalability in model-driven engineering (MDE) and introduces the Epsilon Validation Language (EVL), which is designed to improve the efficiency of MDE tools by enabling better management of large models and complex workflows. It explores various technical aspects of EVL, including its ability to handle concurrency and the use of parallel execution to enhance performance, as well as the implications of data structure management in a distributed environment. Future work is outlined, focusing on enhancing the configuration and job assignment processes and the potential for partial model loading.