Apache Flink Internals: Stream & Batch Processing in One System – Apache Flink's Streaming Data Flow Engine
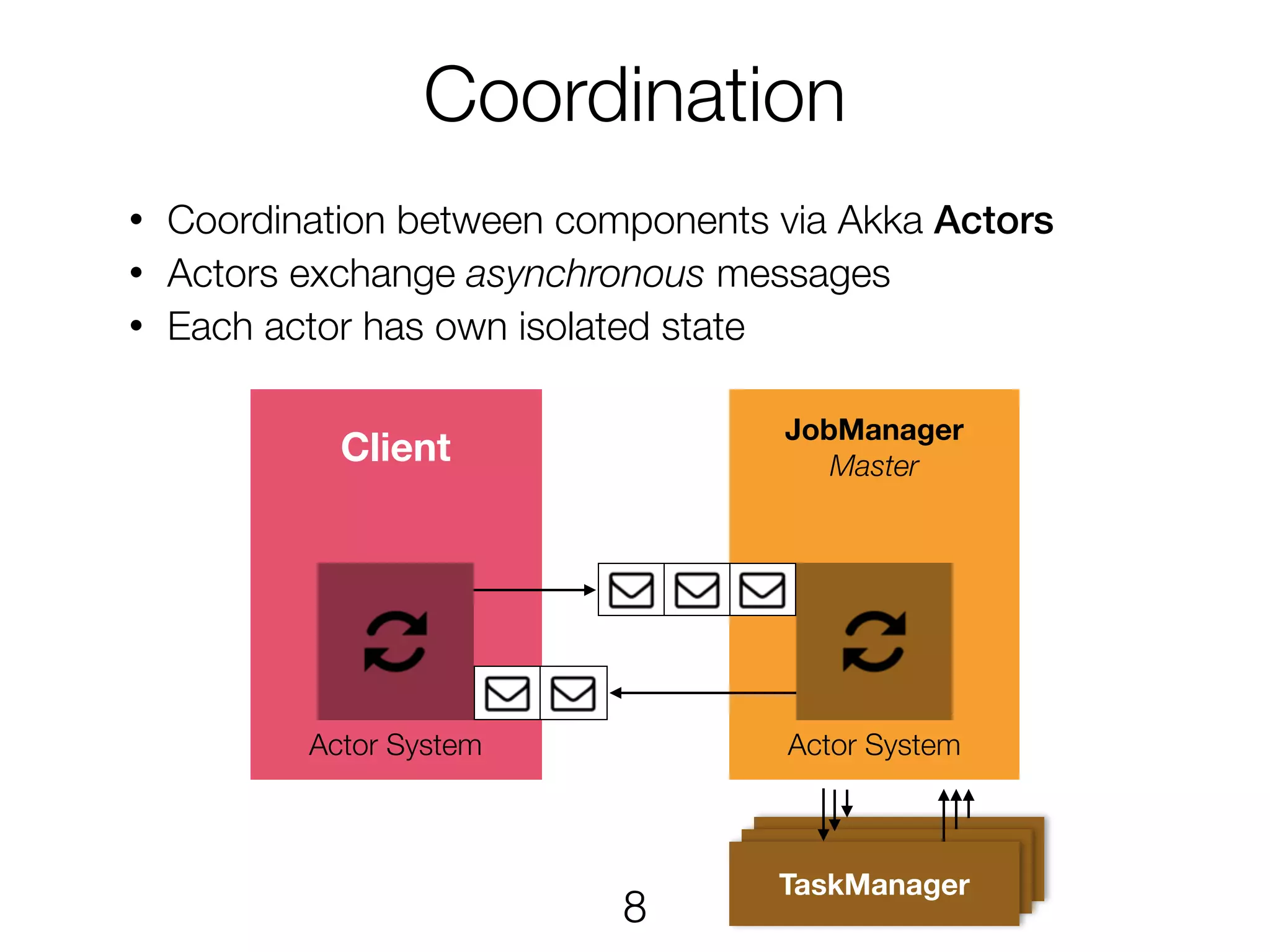
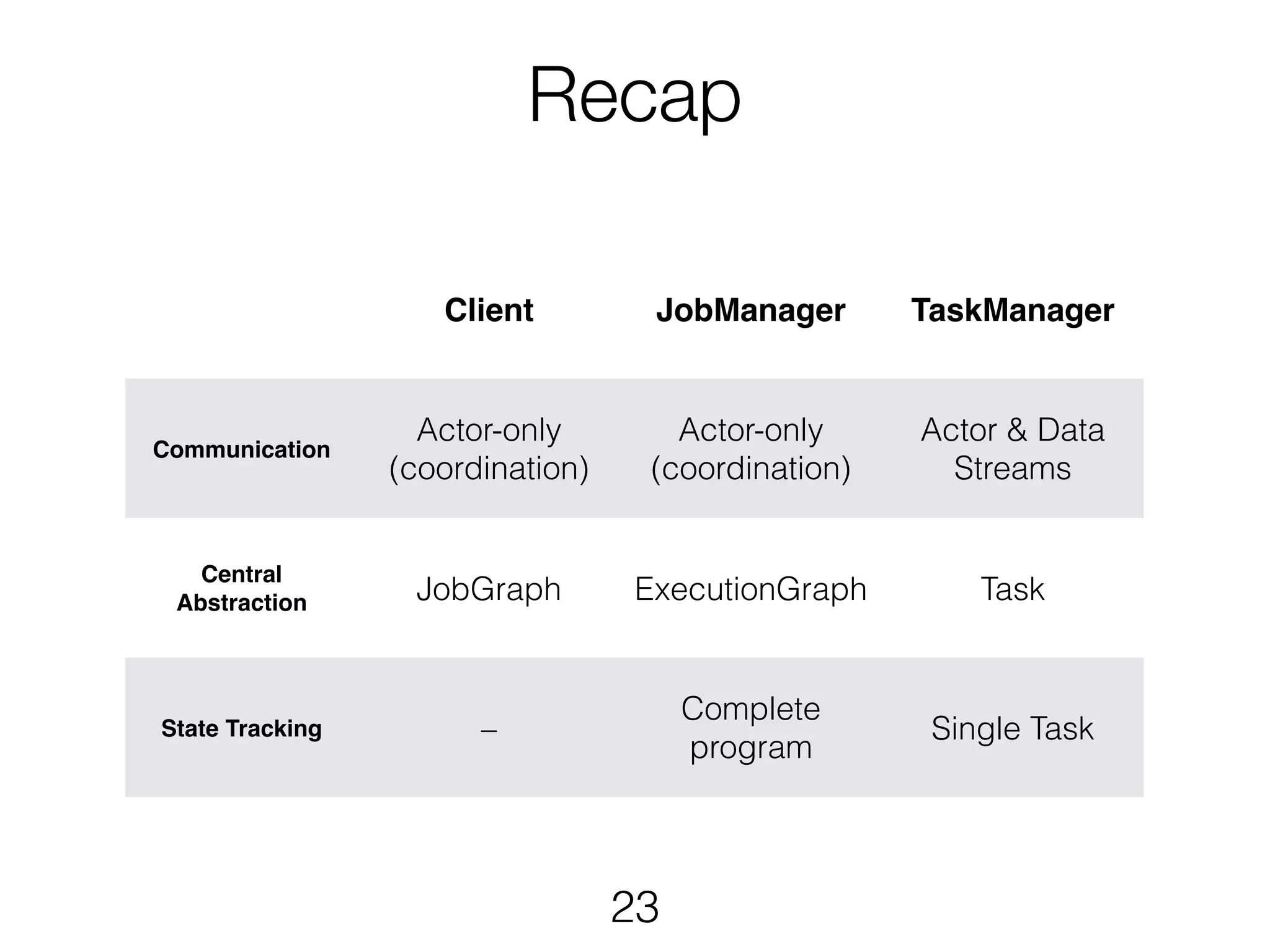
Ufuk Celebi presented on the architecture and execution of Apache Flink's streaming data flow engine. Flink allows for both stream and batch processing using a common runtime. It translates APIs into a directed acyclic graph (DAG) called a JobGraph. The JobGraph is distributed across TaskManagers which execute parallel tasks. Communication between components like the JobManager and TaskManagers uses an actor system to coordinate scheduling, checkpointing, and monitoring of distributed streaming data flows.
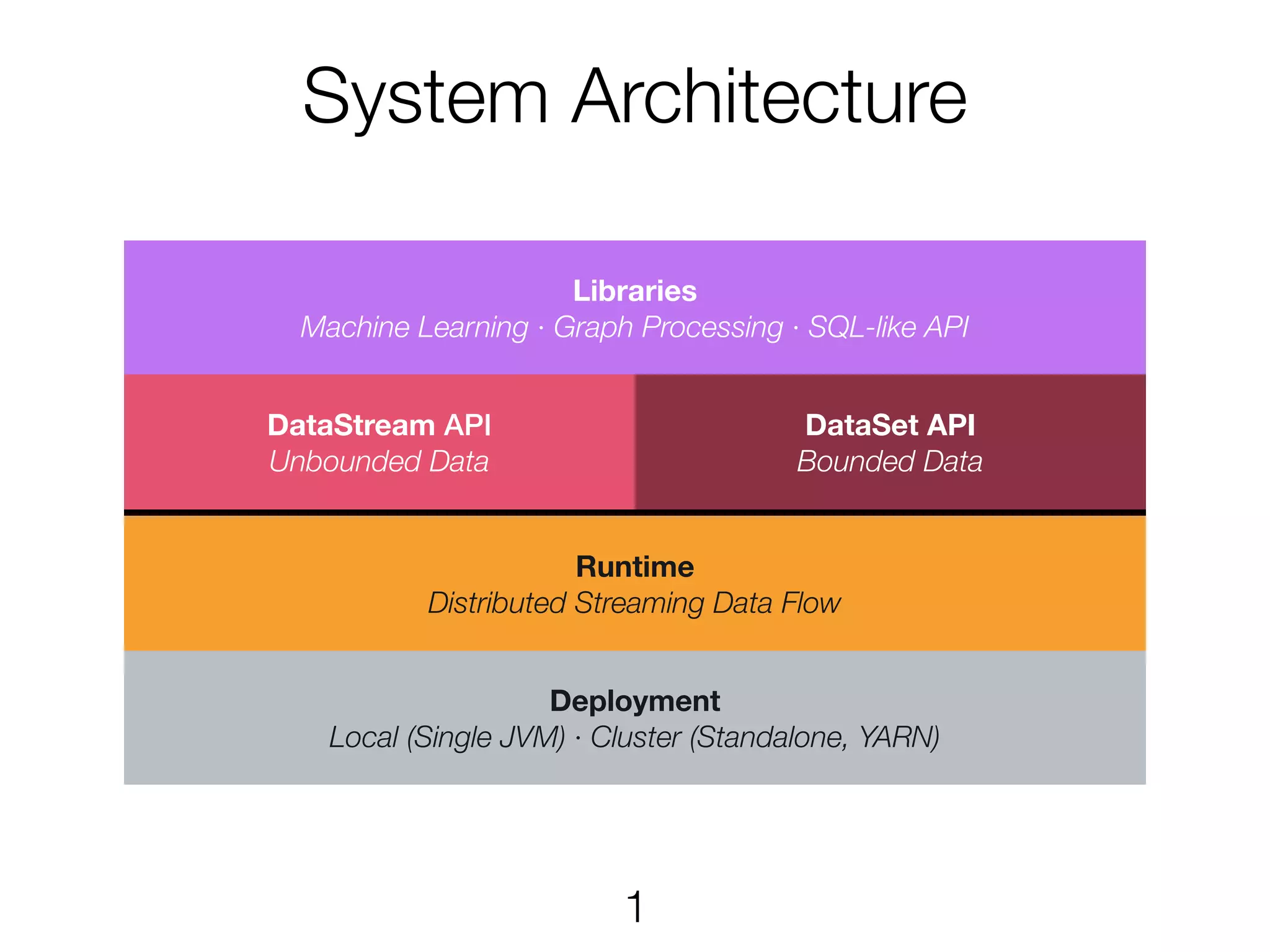
System Architecture Deployment Local (SingleJVM) · Cluster (Standalone, YARN) DataStream API Unbounded Data DataSet API Bounded Data Runtime Distributed Streaming Data Flow Libraries Machine Learning · Graph Processing · SQL-like API 1
3.
Today Journey from APIsto Parallel Execution A look behind the scenes. You don’t have to worry about this.
4.
Components JobManager Master Client TaskManager Worker TaskManager Worker TaskManager Worker TaskManager Worker User System public classWordCount { public static void main(String[] args) throws Exception { // Flink’s entry point StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment(); DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?", "Deny thy father and refuse thy name", "Or, if thou wilt not, be but sworn my love,", "And I'll no longer be a Capulet."); // Split by whitespace to (word, 1) and sum up ones DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) .keyBy(0) .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); counts.print(); // Today: What happens now? env.execute(); } } Submit Program Schedule Execute 2
5.
Client Translates the APIcode to a data flow graph called JobGraph and submits it to the JobManager. Source Transform Sink public class WordCount { public static void main(String[] args) throws Exception { // Flink’s entry point StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment(); DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?", "Deny thy father and refuse thy name", "Or, if thou wilt not, be but sworn my love,", "And I'll no longer be a Capulet."); // Split by whitespace to (word, 1) and sum up ones DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) .keyBy(0) .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); counts.print(); // Today: What happens now? env.execute(); } } Translate 3
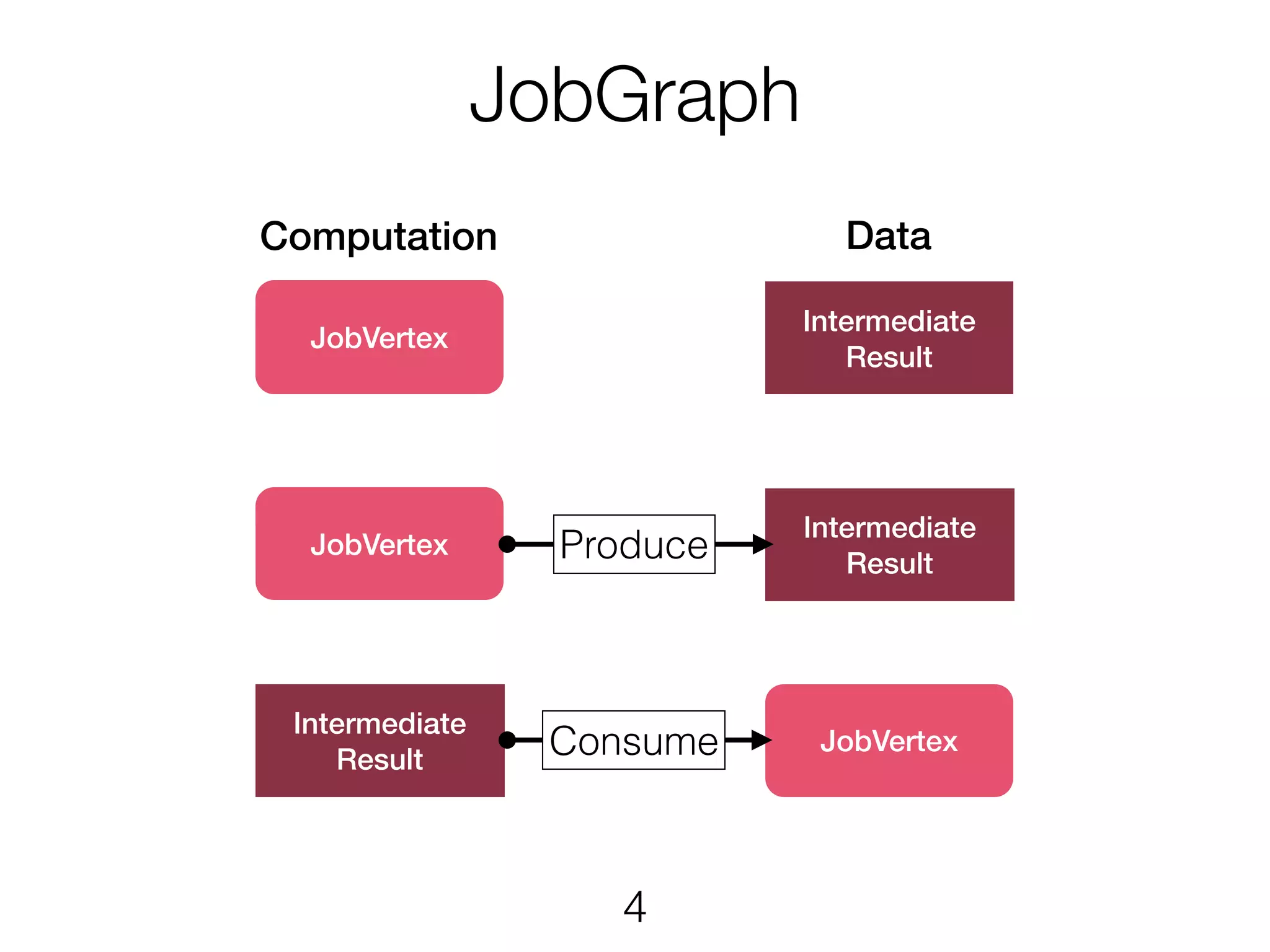
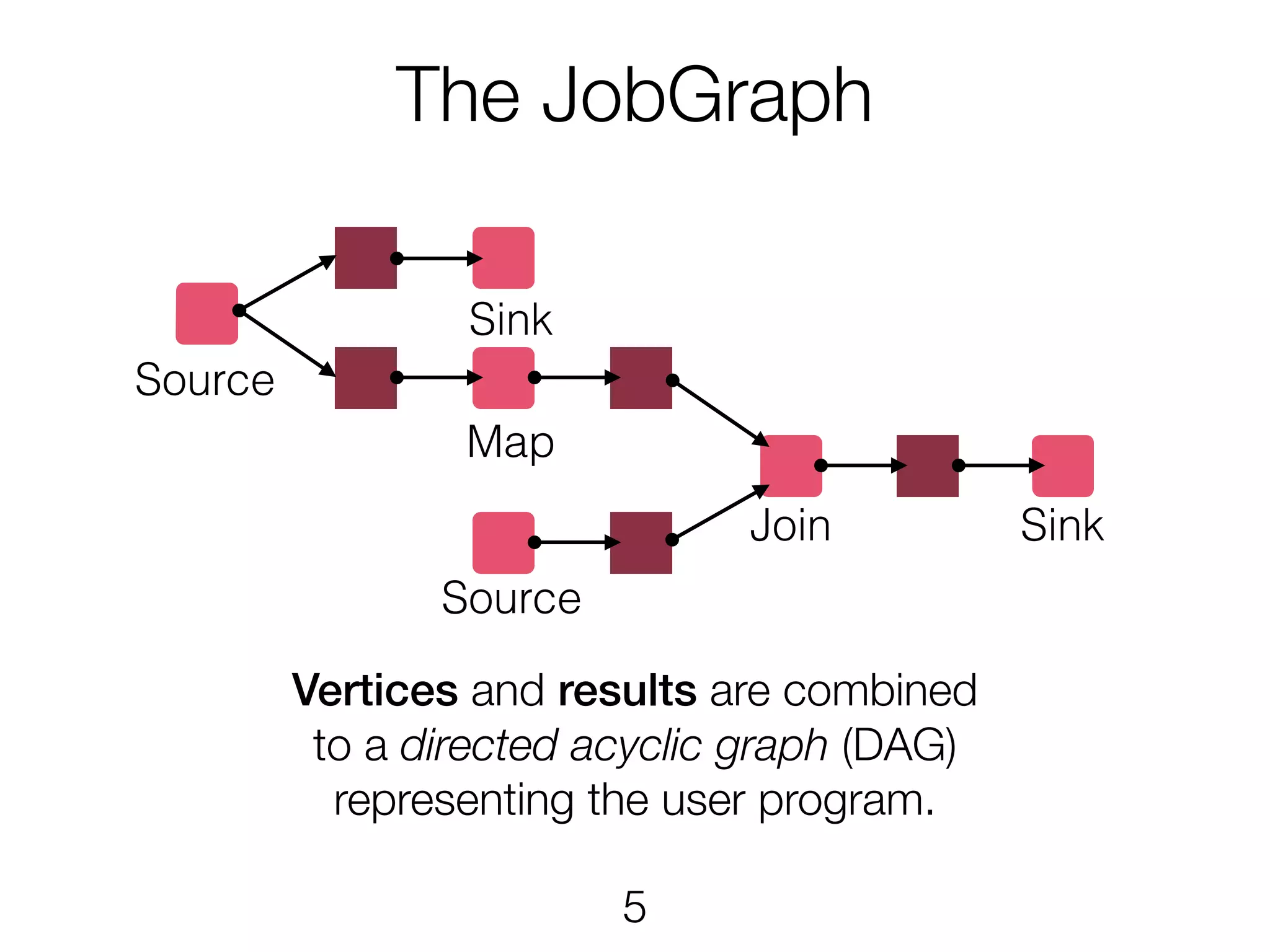
The JobGraph Vertices andresults are combined to a directed acyclic graph (DAG) representing the user program. 5 Source Source Sink SinkJoin Map
8.
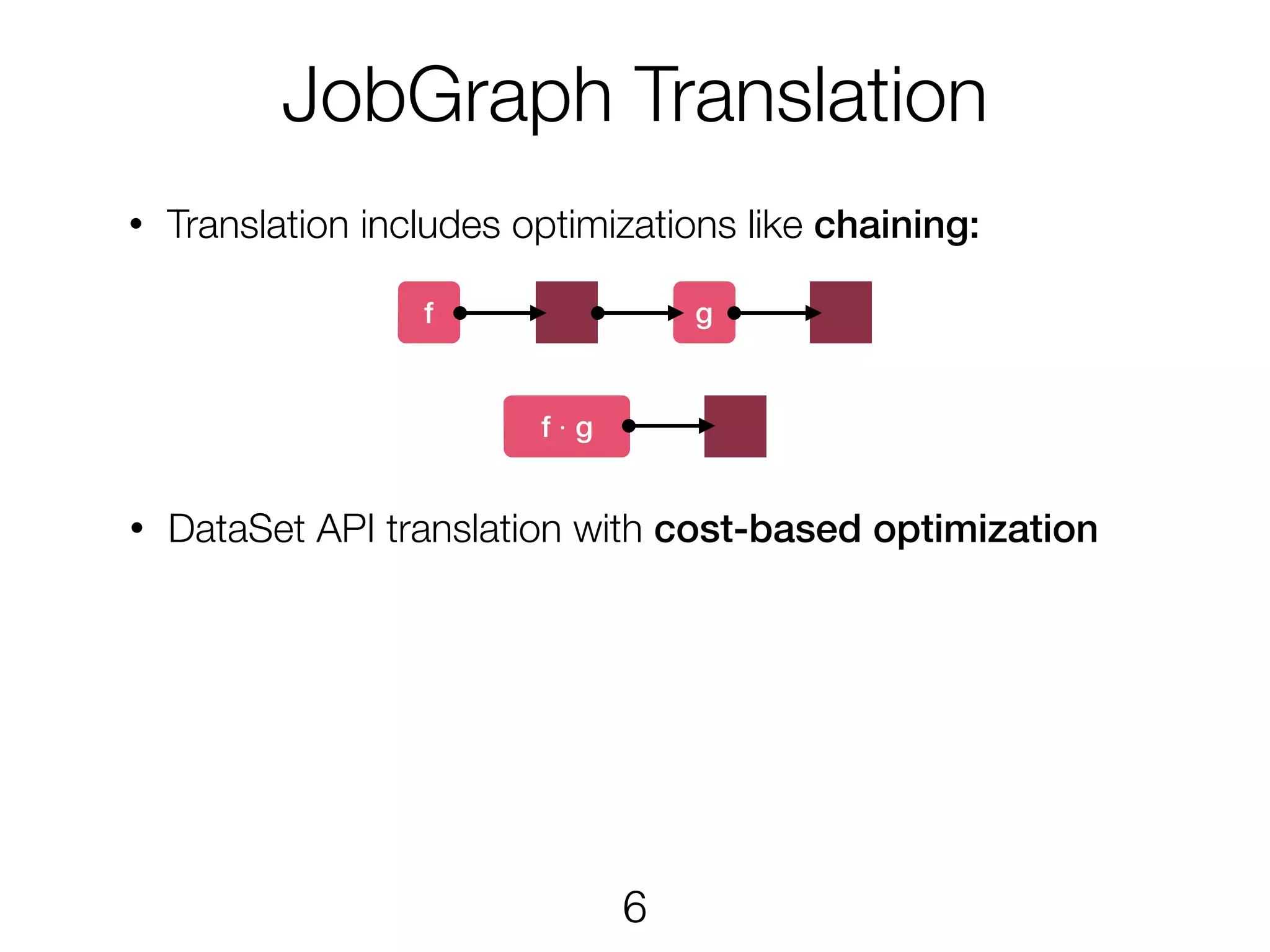
JobGraph Translation • Translationincludes optimizations like chaining: f g f · g • DataSet API translation with cost-based optimization 6
9.
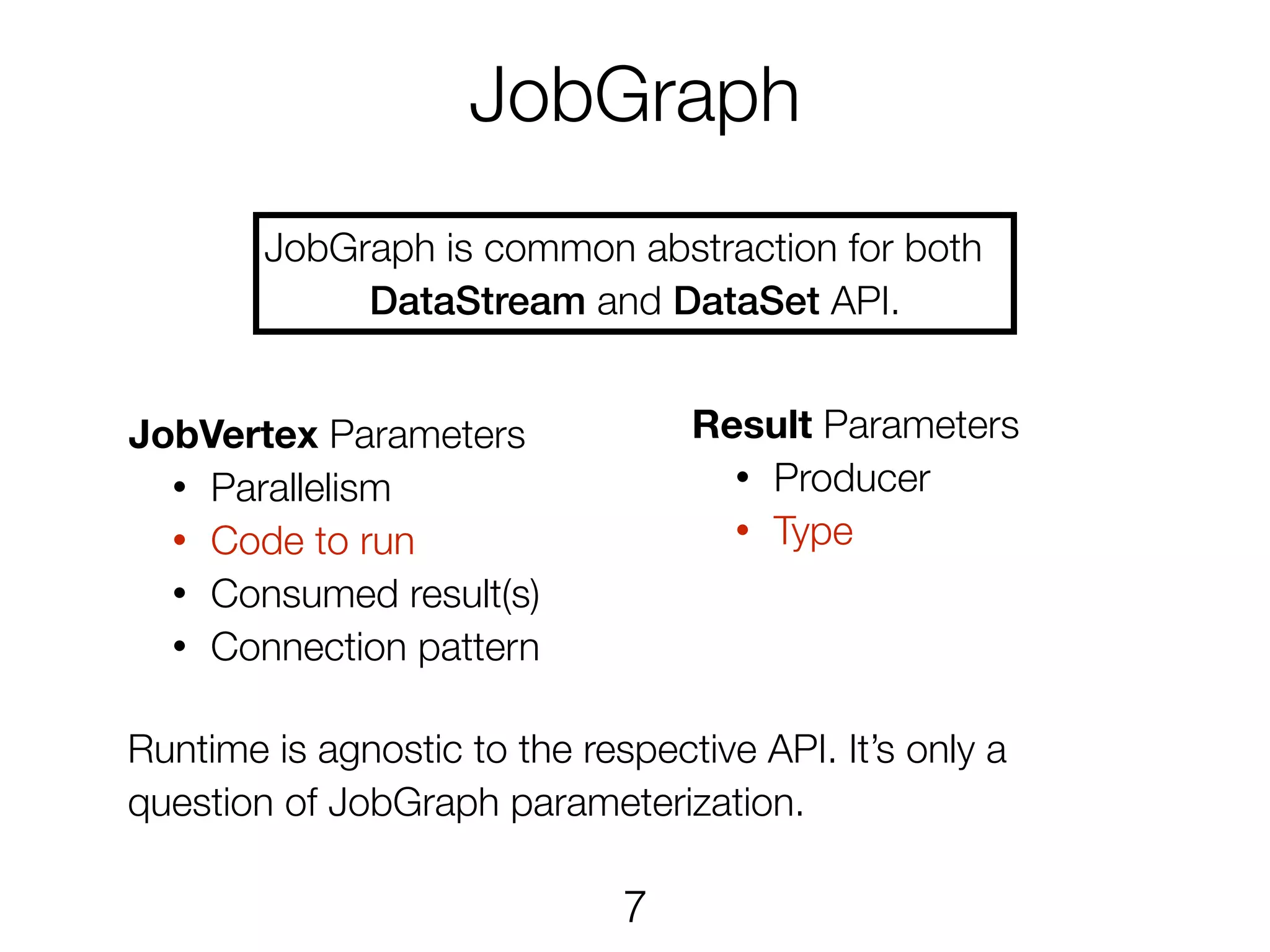
JobGraph JobVertex Parameters • Parallelism •Code to run • Consumed result(s) • Connection pattern JobGraph is common abstraction for both DataStream and DataSet API. Result Parameters • Producer • Type Runtime is agnostic to the respective API. It’s only a question of JobGraph parameterization. 7
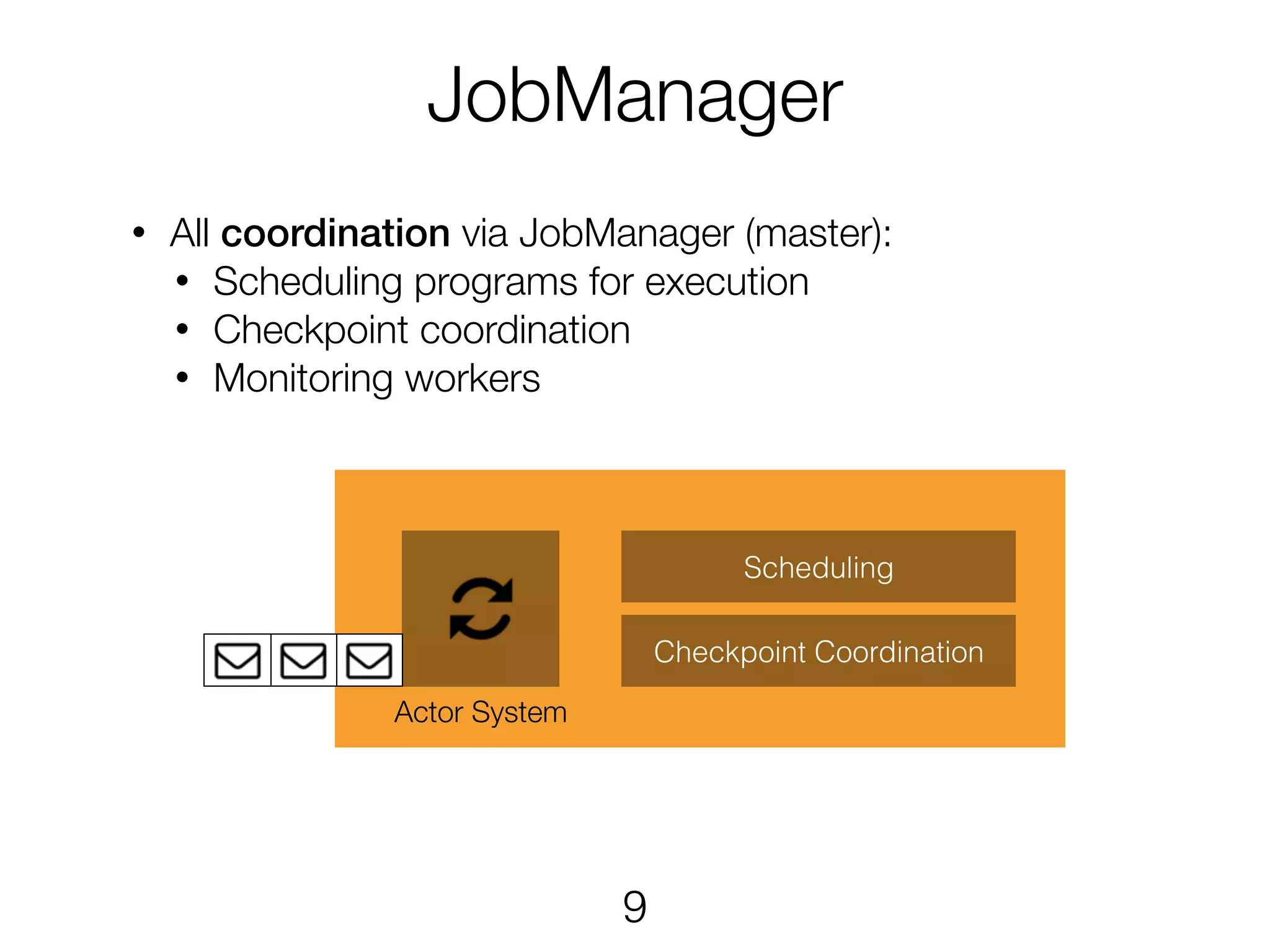
JobManager • All coordinationvia JobManager (master): • Scheduling programs for execution • Checkpoint coordination • Monitoring workers Actor System Scheduling Checkpoint Coordination 9
12.
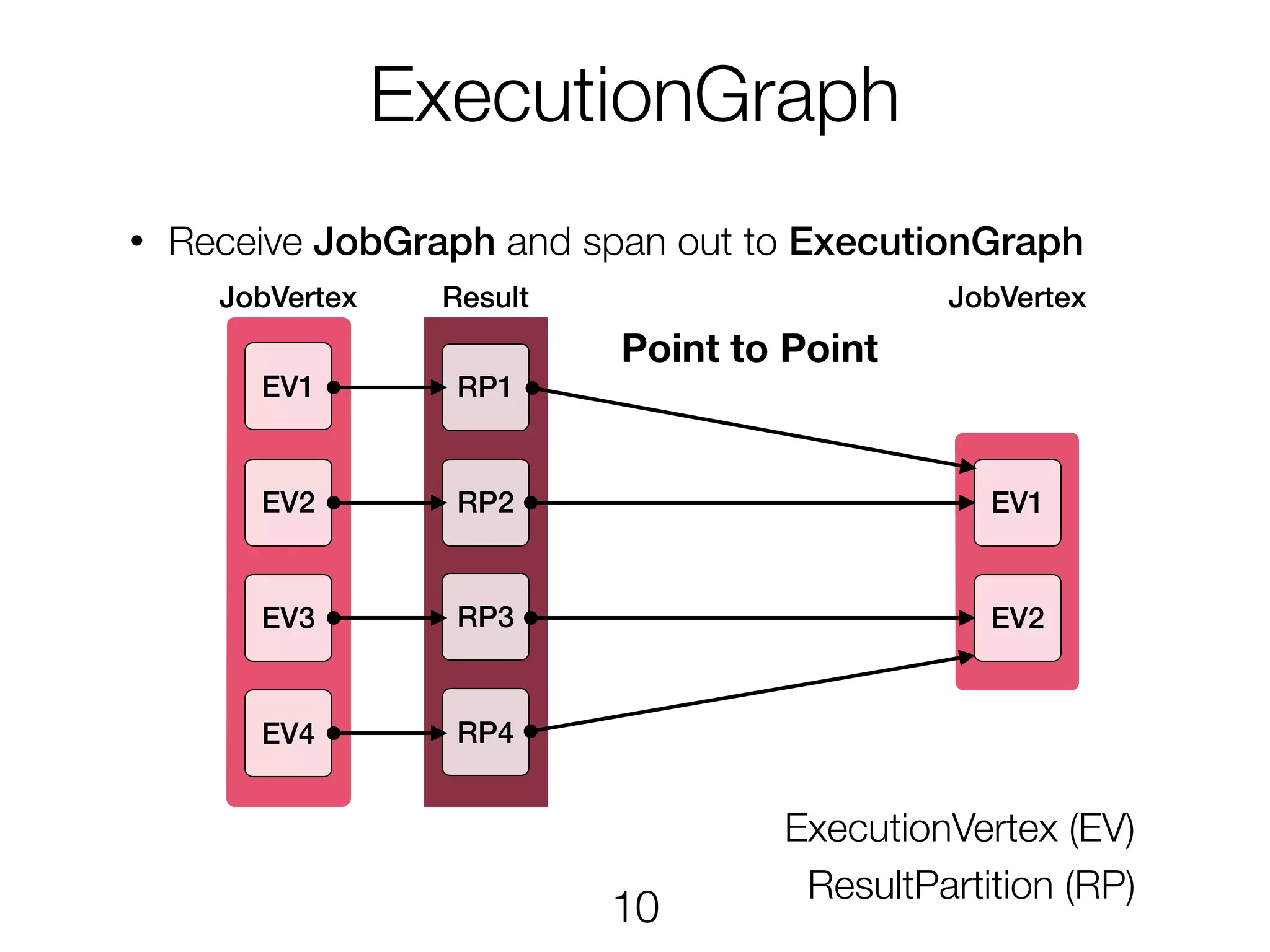
ExecutionGraph • Receive JobGraphand span out to ExecutionGraph EV1 EV3 EV2 EV4 RP1 RP2 RP3 RP4 EV1 EV2 Point to Point JobVertex Result ExecutionVertex (EV) ResultPartition (RP) JobVertex 10
13.
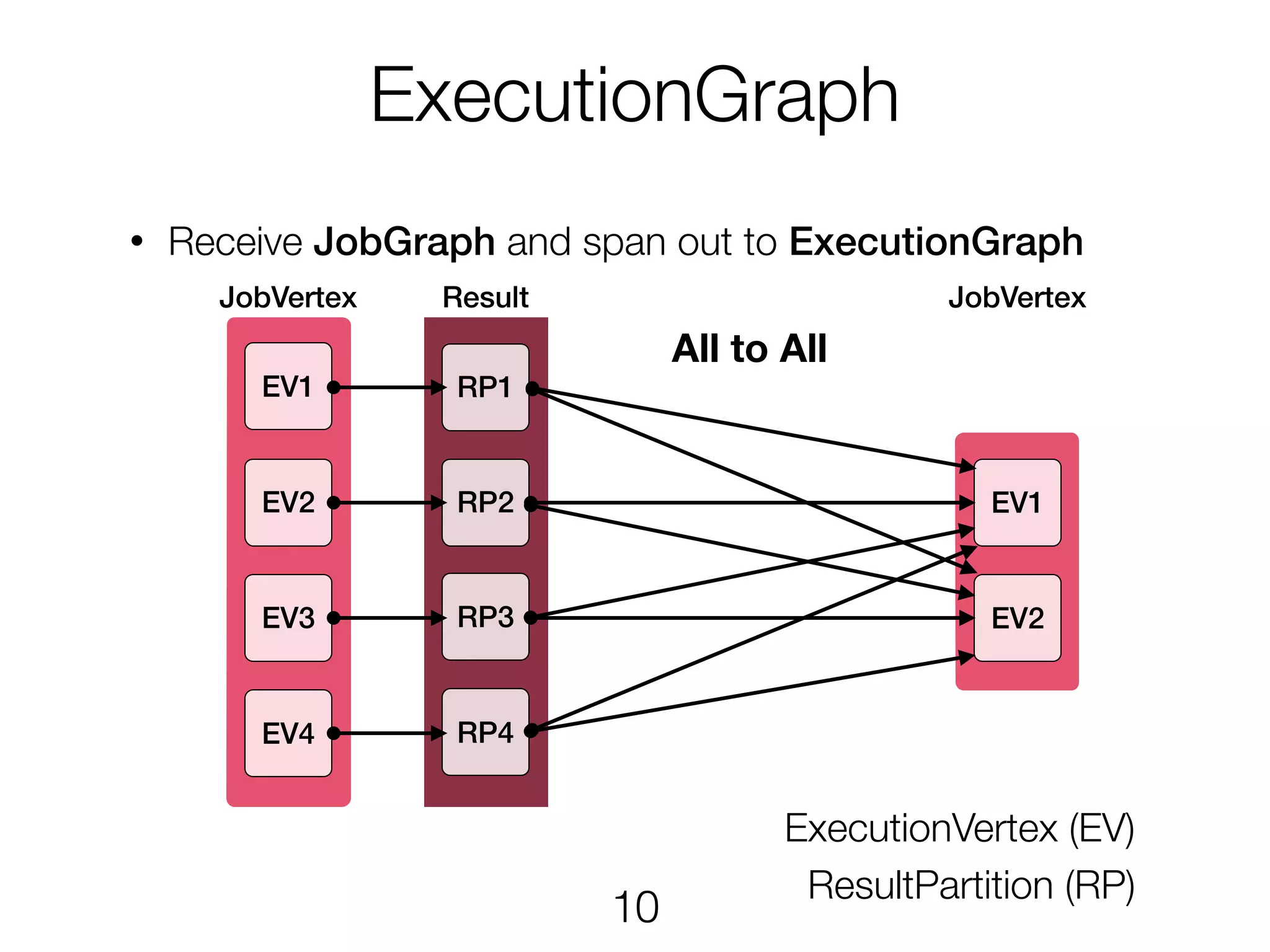
ExecutionGraph • Receive JobGraphand span out to ExecutionGraph EV1 EV3 EV2 EV4 RP1 RP2 RP3 RP4 EV1 EV2 All to All JobVertex Result ExecutionVertex (EV) ResultPartition (RP) JobVertex 10
14.
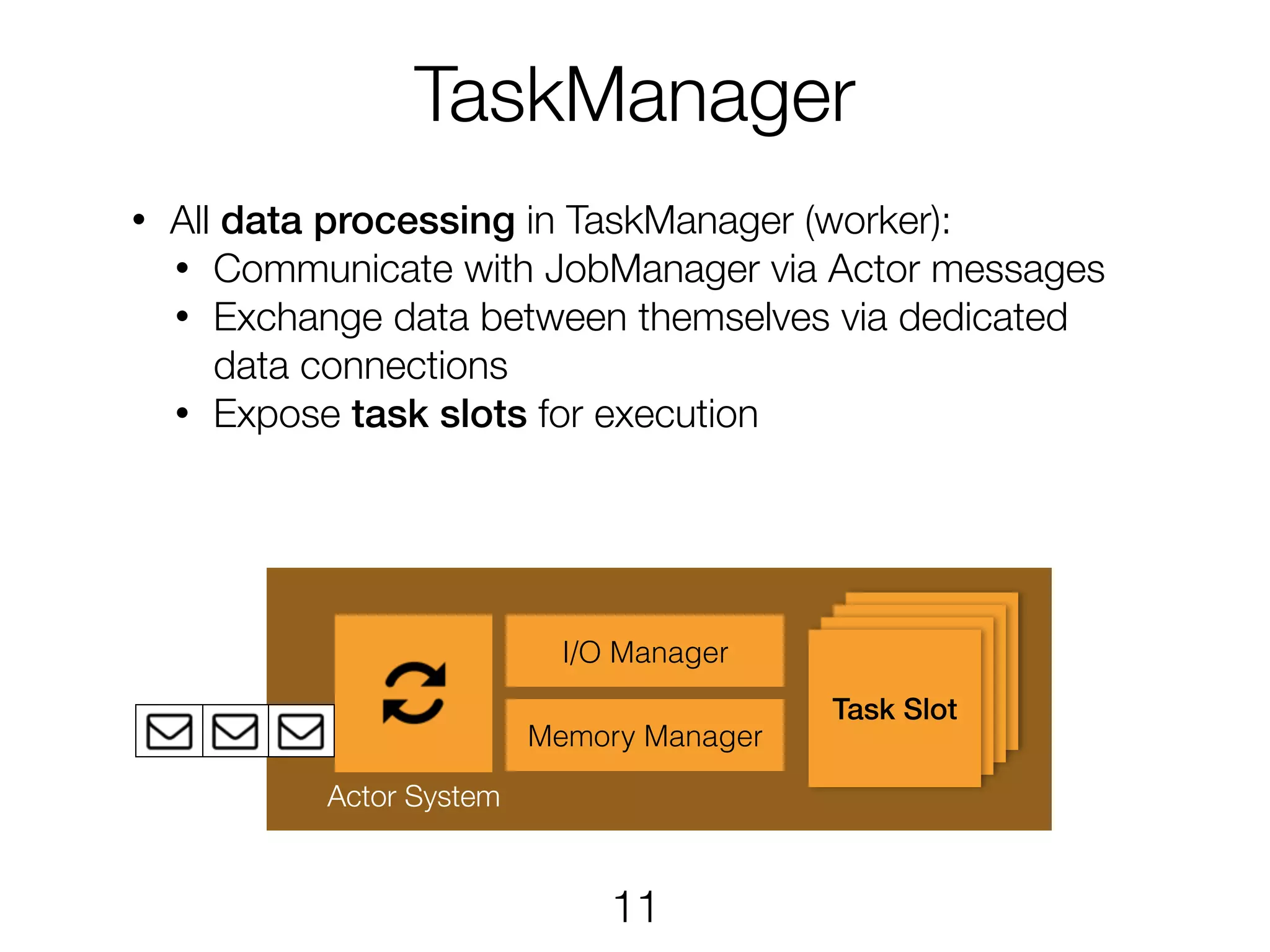
TaskManager Actor System Task SlotTaskSlotTask SlotTask Slot • All data processing in TaskManager (worker): • Communicate with JobManager via Actor messages • Exchange data between themselves via dedicated data connections • Expose task slots for execution I/O Manager Memory Manager 11
15.
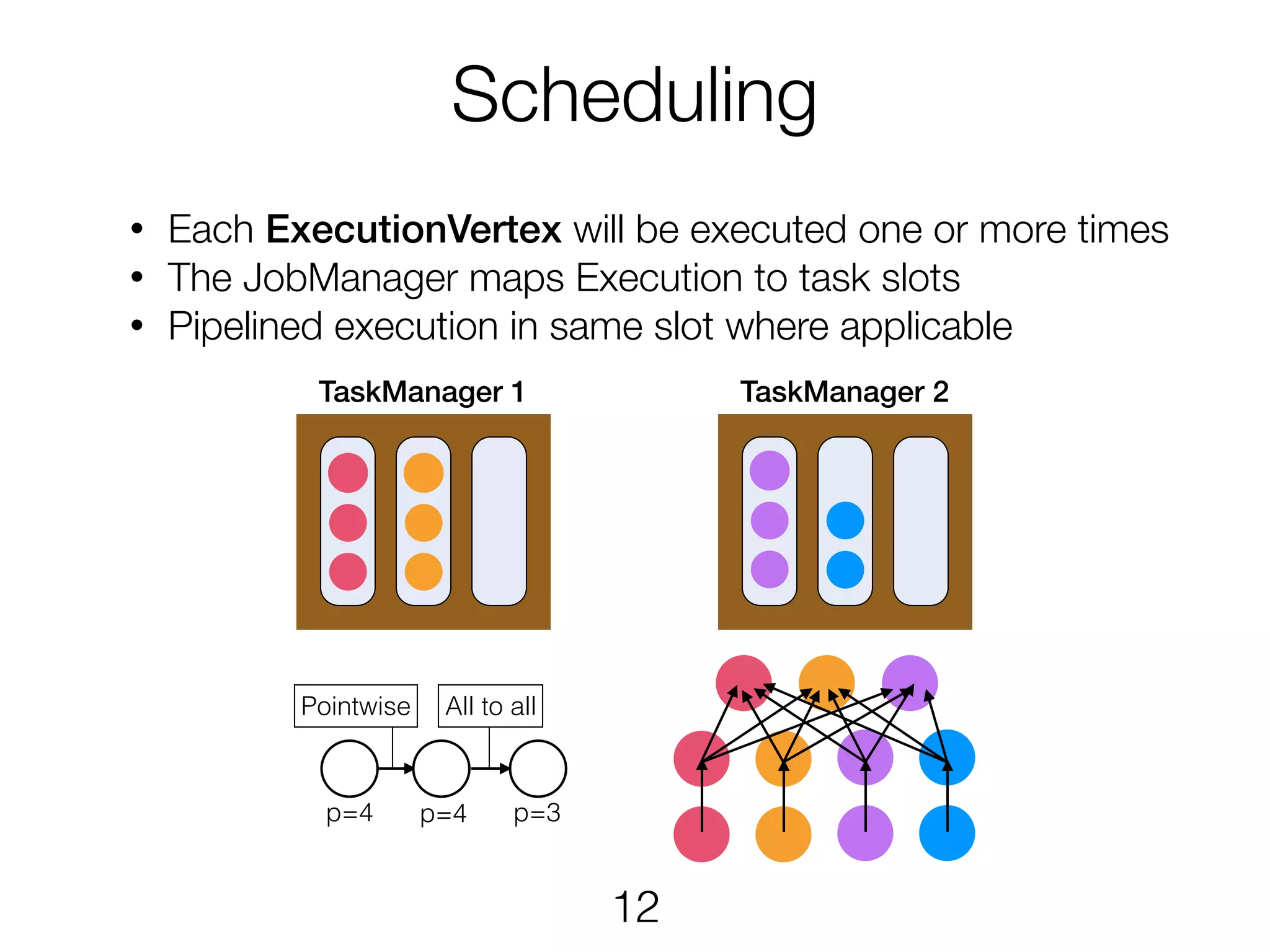
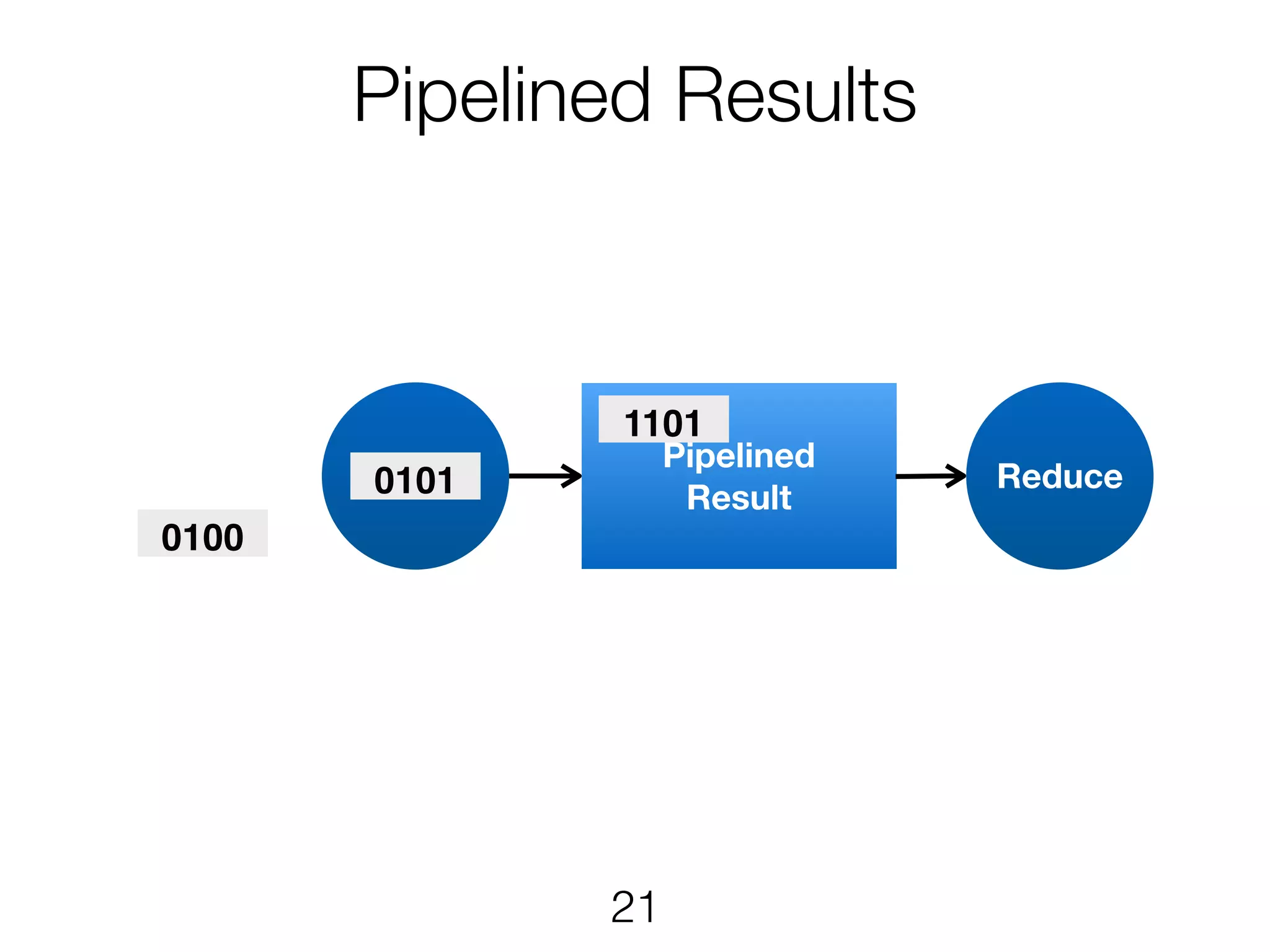
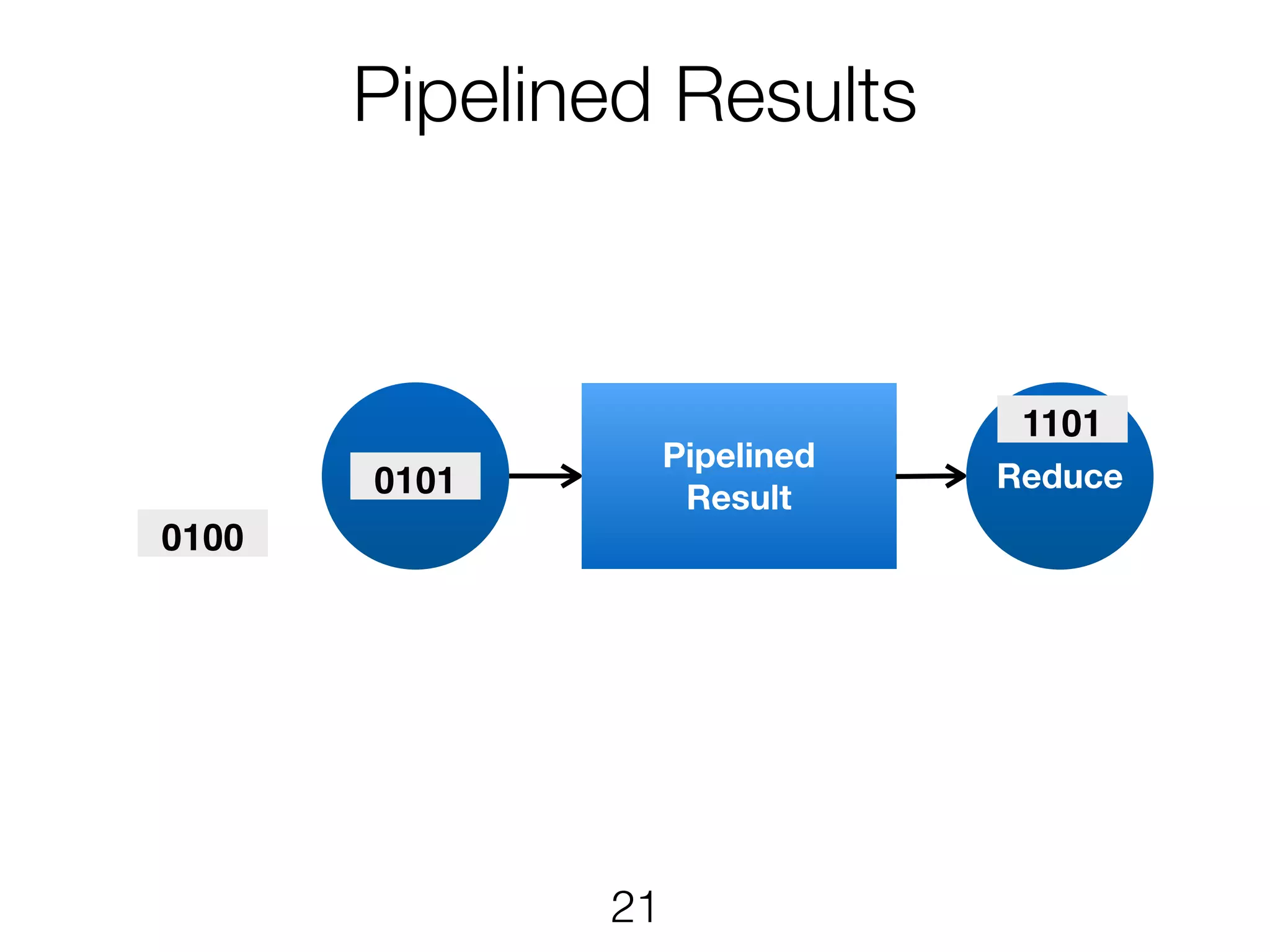
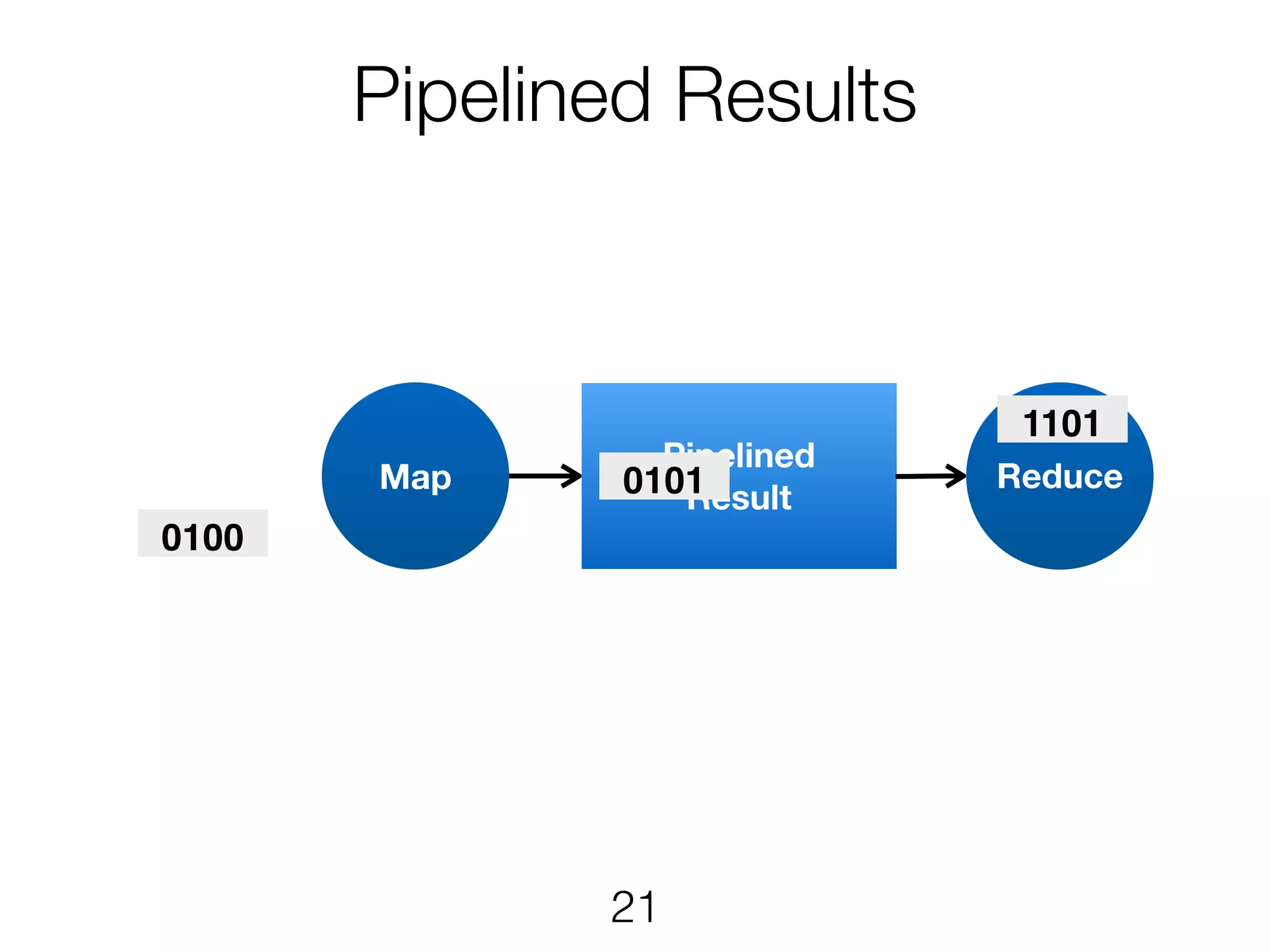
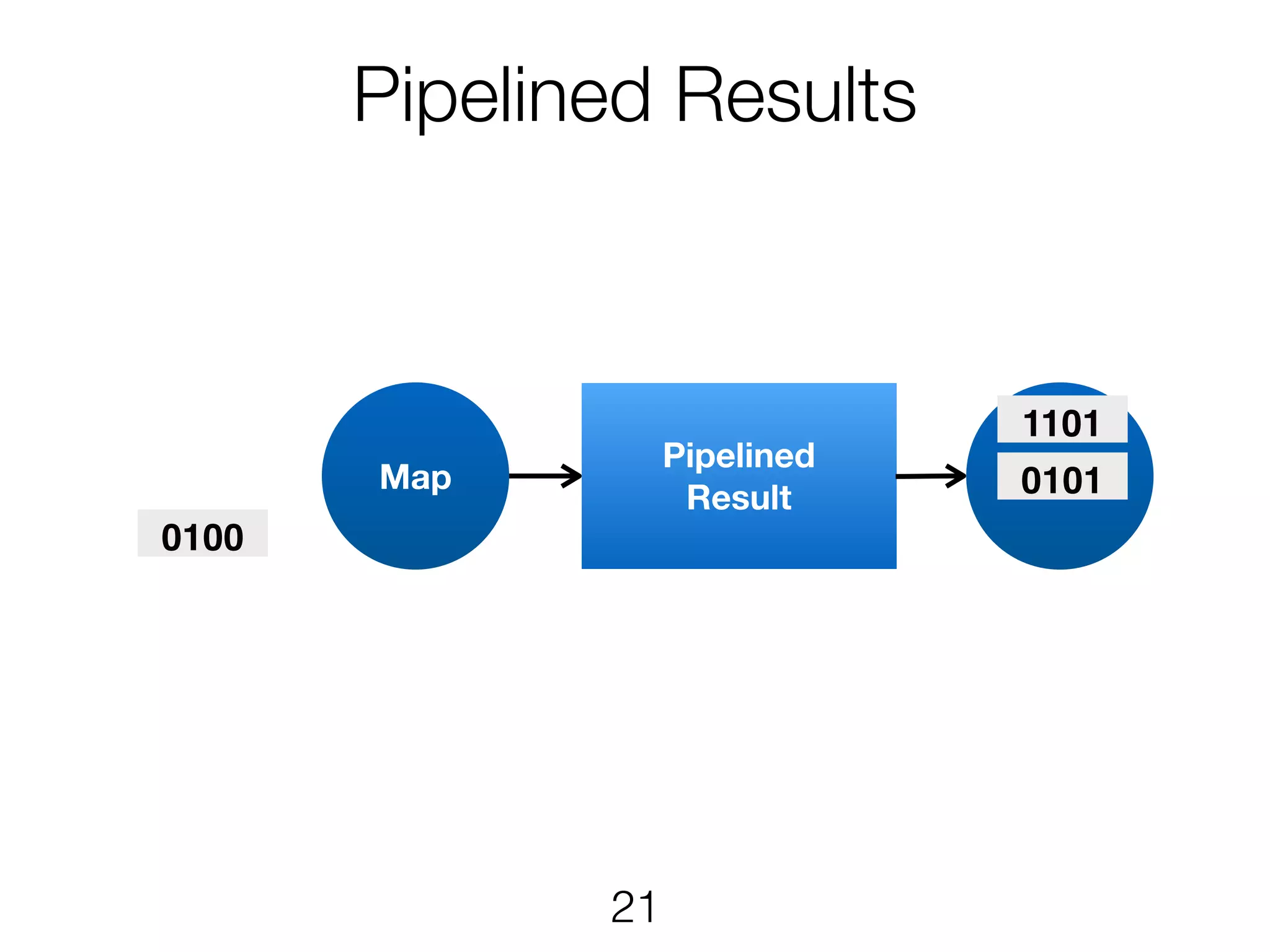
Scheduling TaskManager 1 TaskManager2 • Each ExecutionVertex will be executed one or more times • The JobManager maps Execution to task slots • Pipelined execution in same slot where applicable p=4 p=4 p=3 All to allPointwise 12
16.
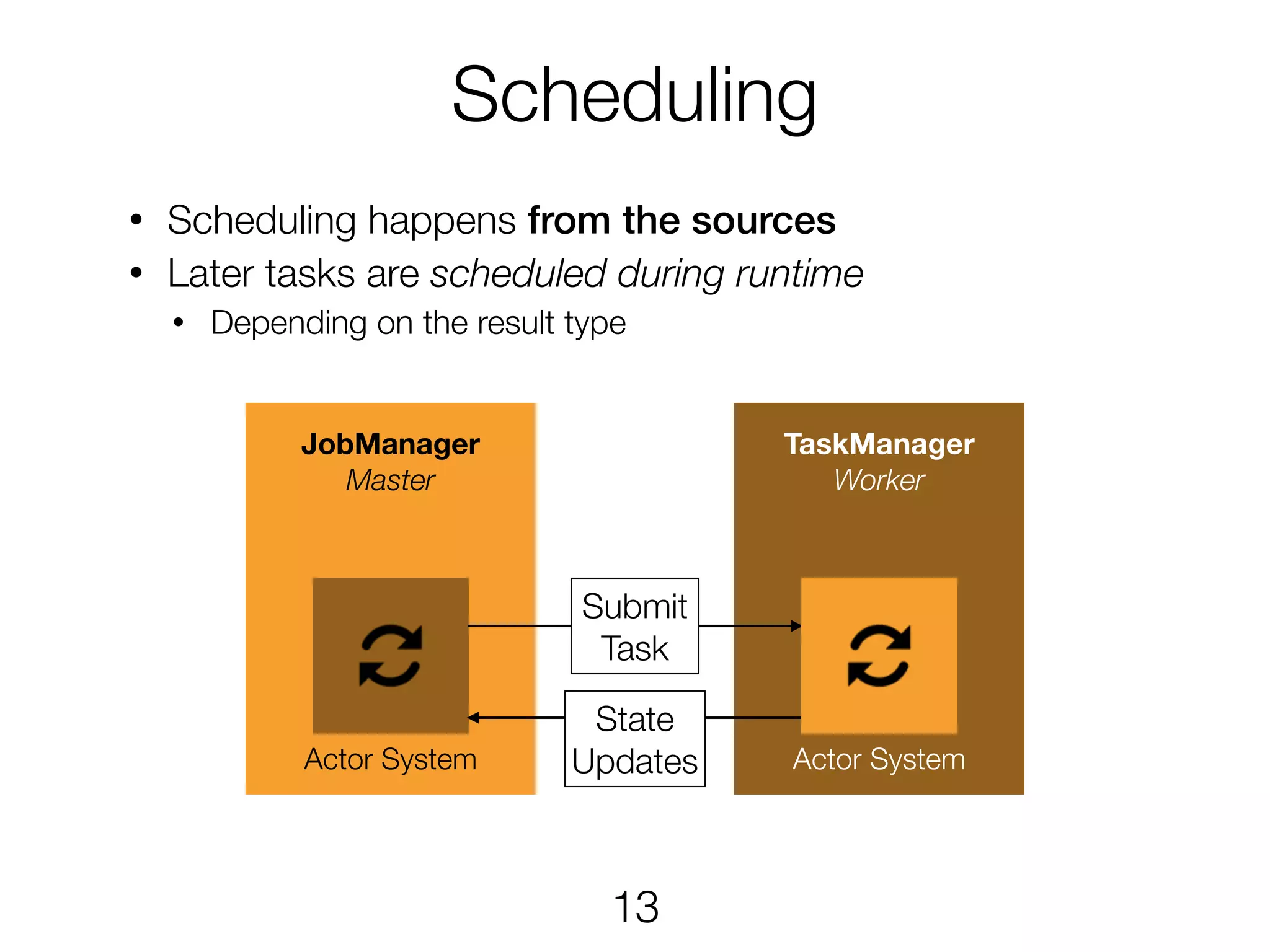
Scheduling • Scheduling happensfrom the sources • Later tasks are scheduled during runtime • Depending on the result type JobManager Master Actor System TaskManager Worker Actor System Submit Task State Updates 13
17.
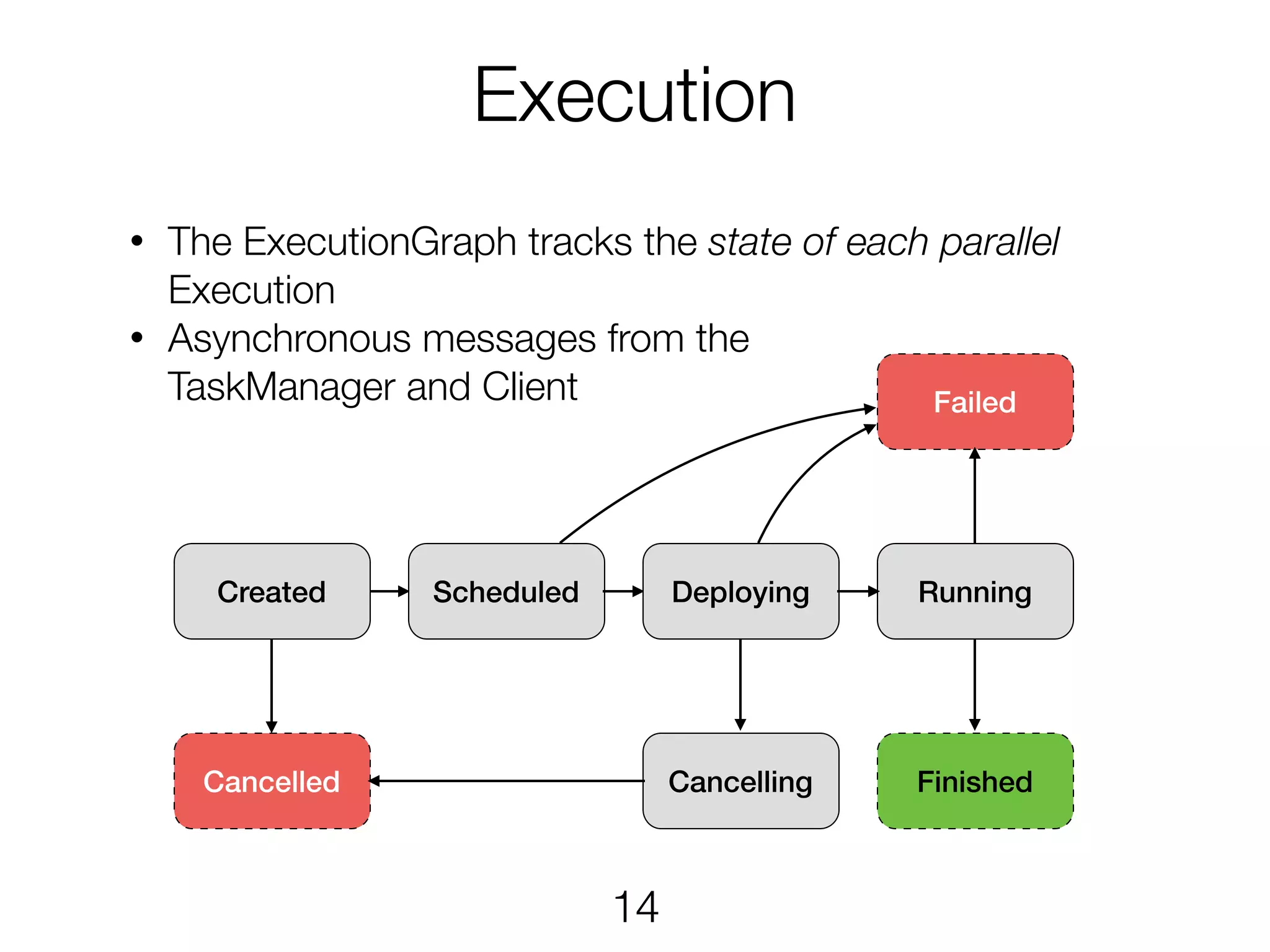
Execution • The ExecutionGraphtracks the state of each parallel Execution • Asynchronous messages from the TaskManager and Client Failed FinishedCancellingCancelled Created Scheduled RunningDeploying 14
18.
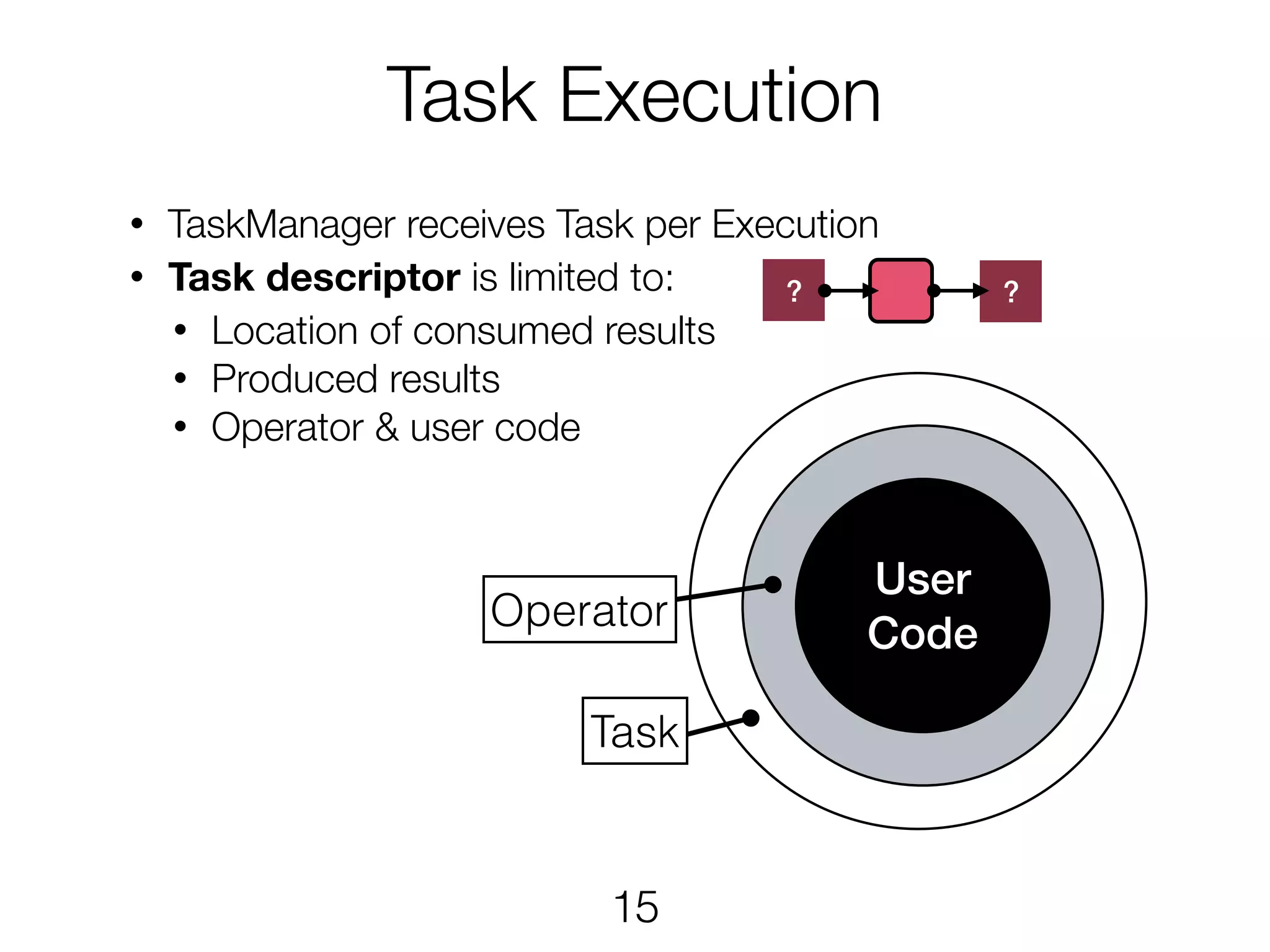
Task Execution • TaskManagerreceives Task per Execution • Task descriptor is limited to: • Location of consumed results • Produced results • Operator & user code User Code Operator Task 15 ? ?
19.
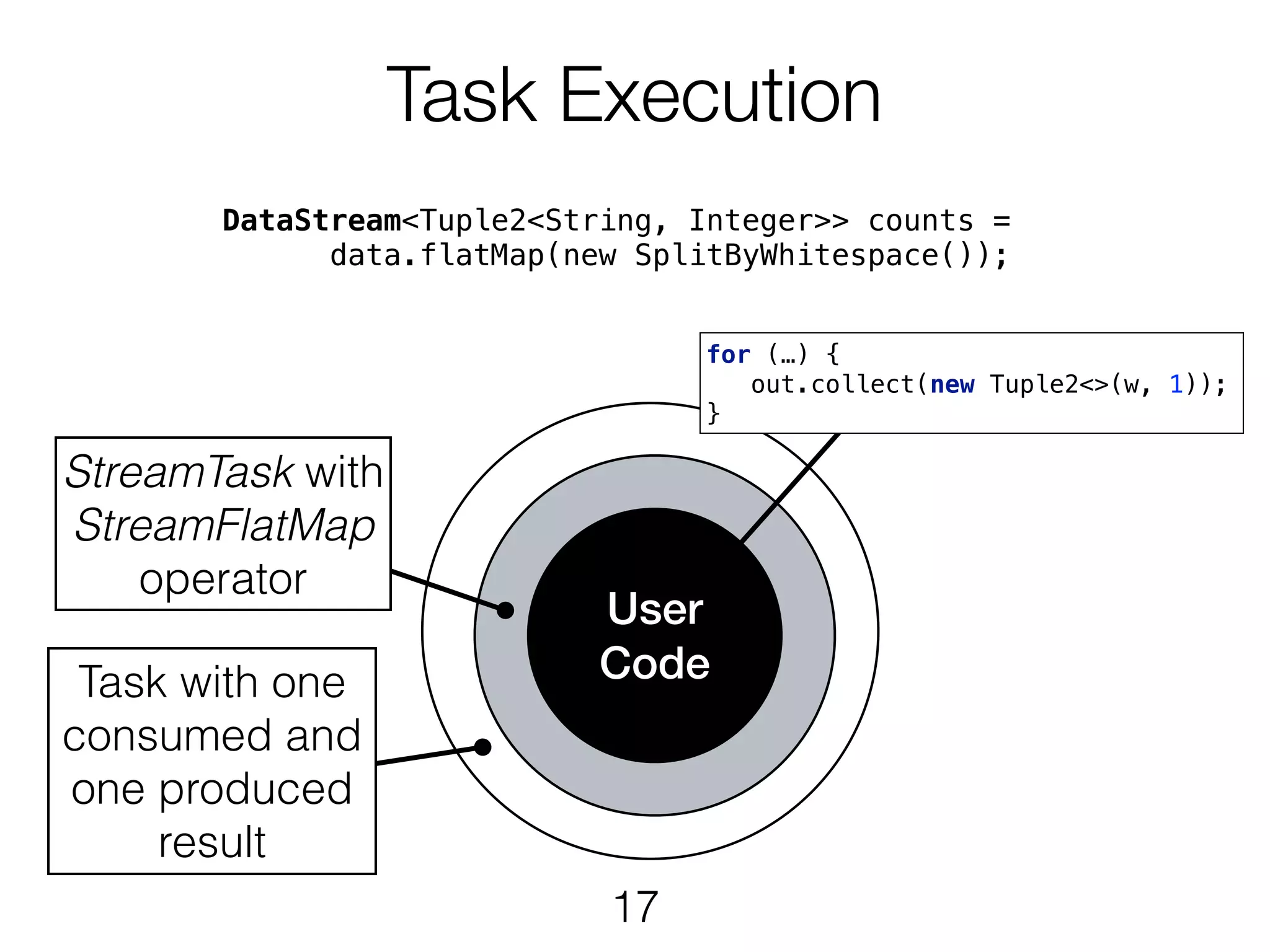
Task Execution DataStream<Tuple2<String, Integer>>counts = data.flatMap(new SplitByWhitespace()); User Code StreamTask with StreamFlatMap operator Task with one consumed and one produced result for (…) { out.collect(new Tuple2<>(w, 1)); } 17
20.
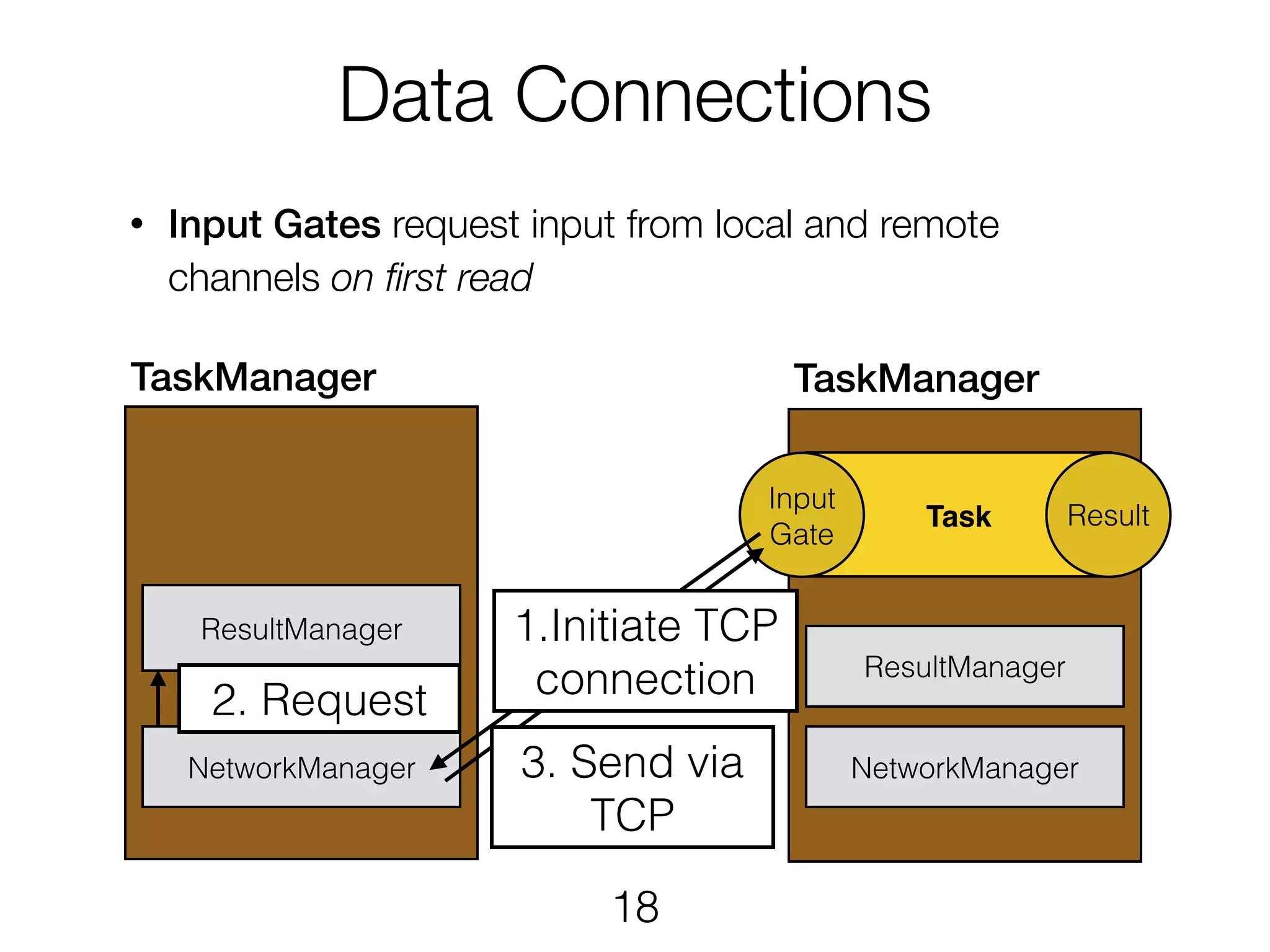
Data Connections • InputGates request input from local and remote channels on first read Task Result ResultManager TaskManager ResultManager TaskManager NetworkManagerNetworkManager Input Gate 2. Request 3. Send via TCP 1.Initiate TCP connection 18
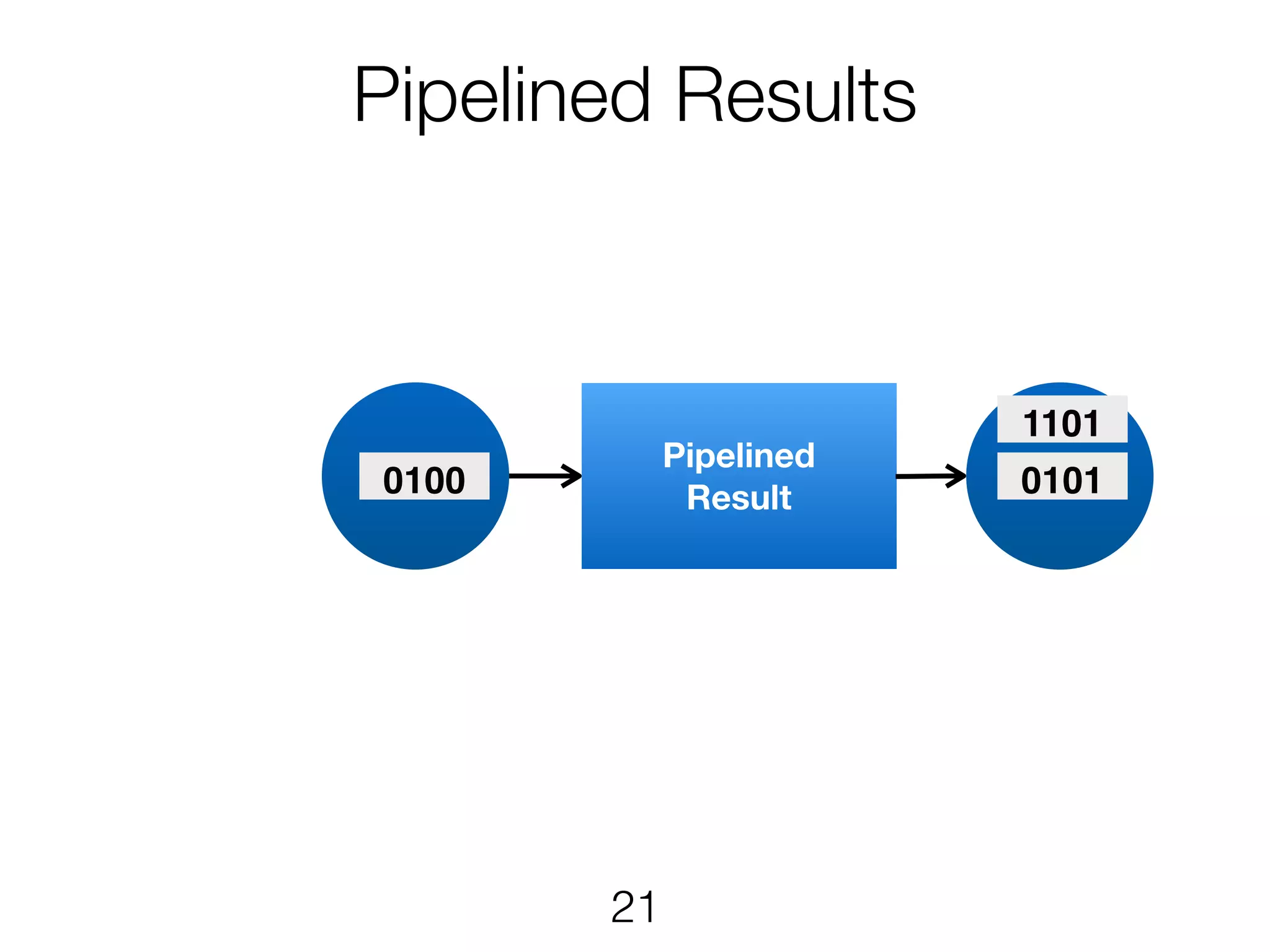
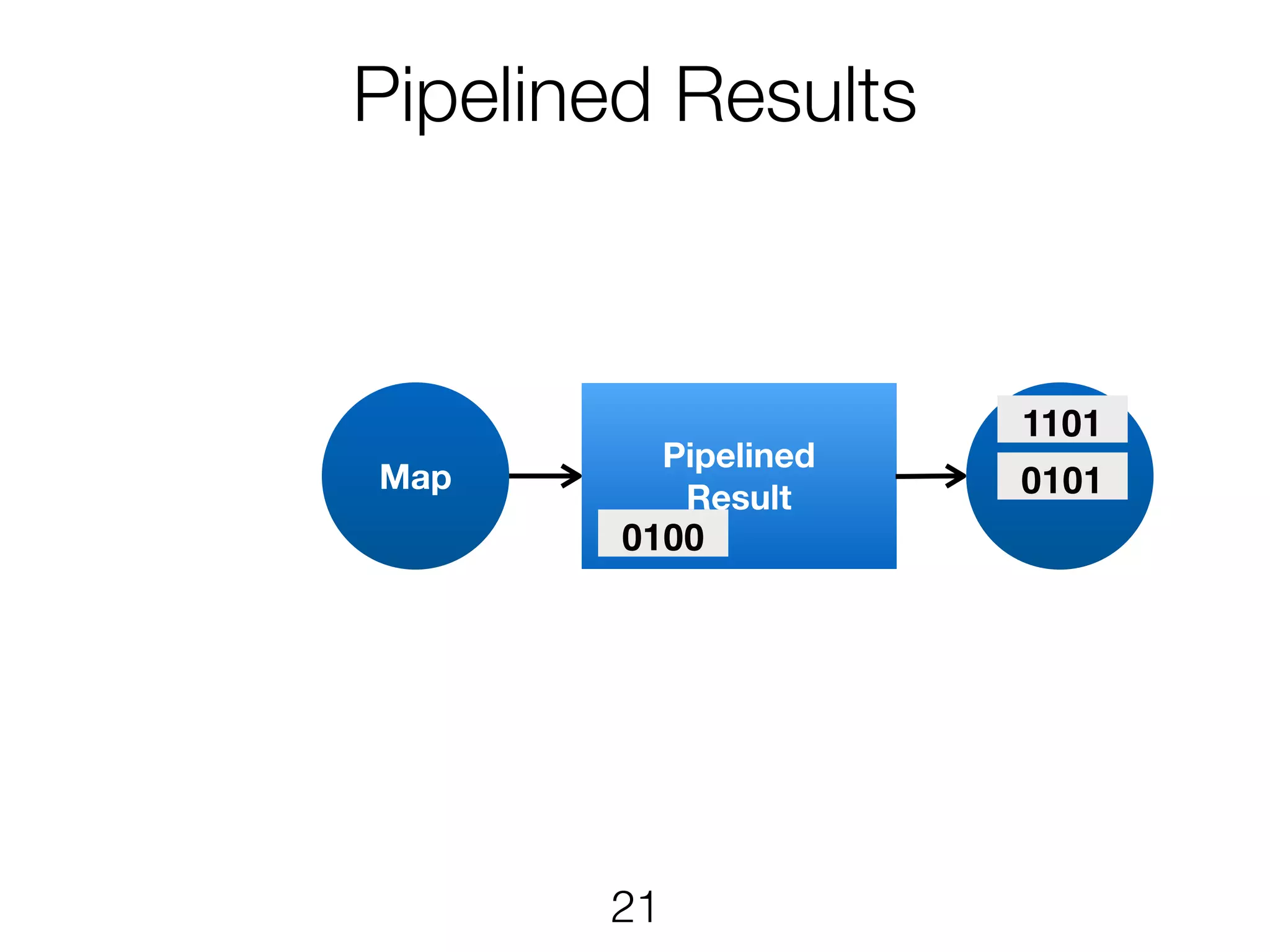
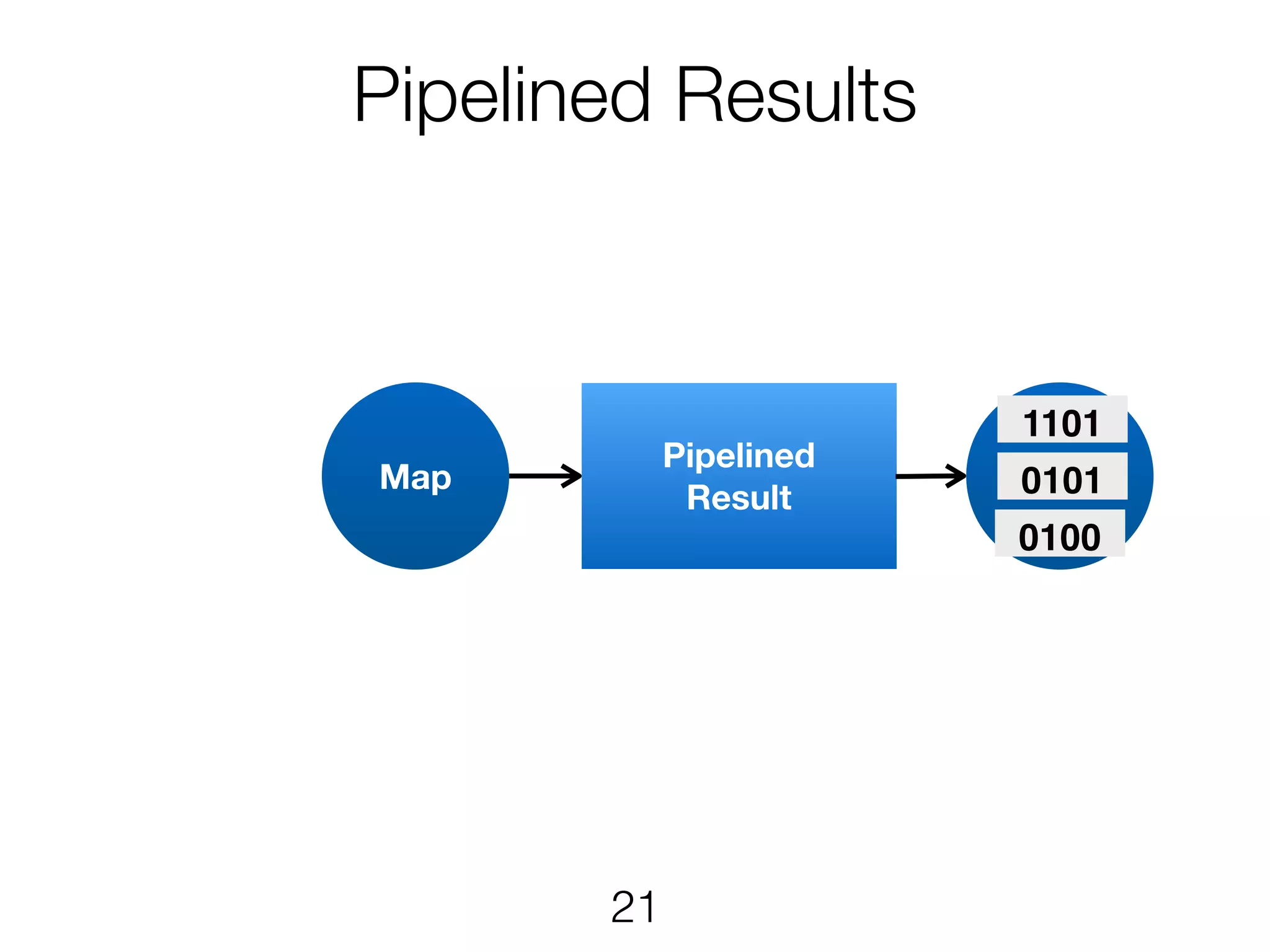
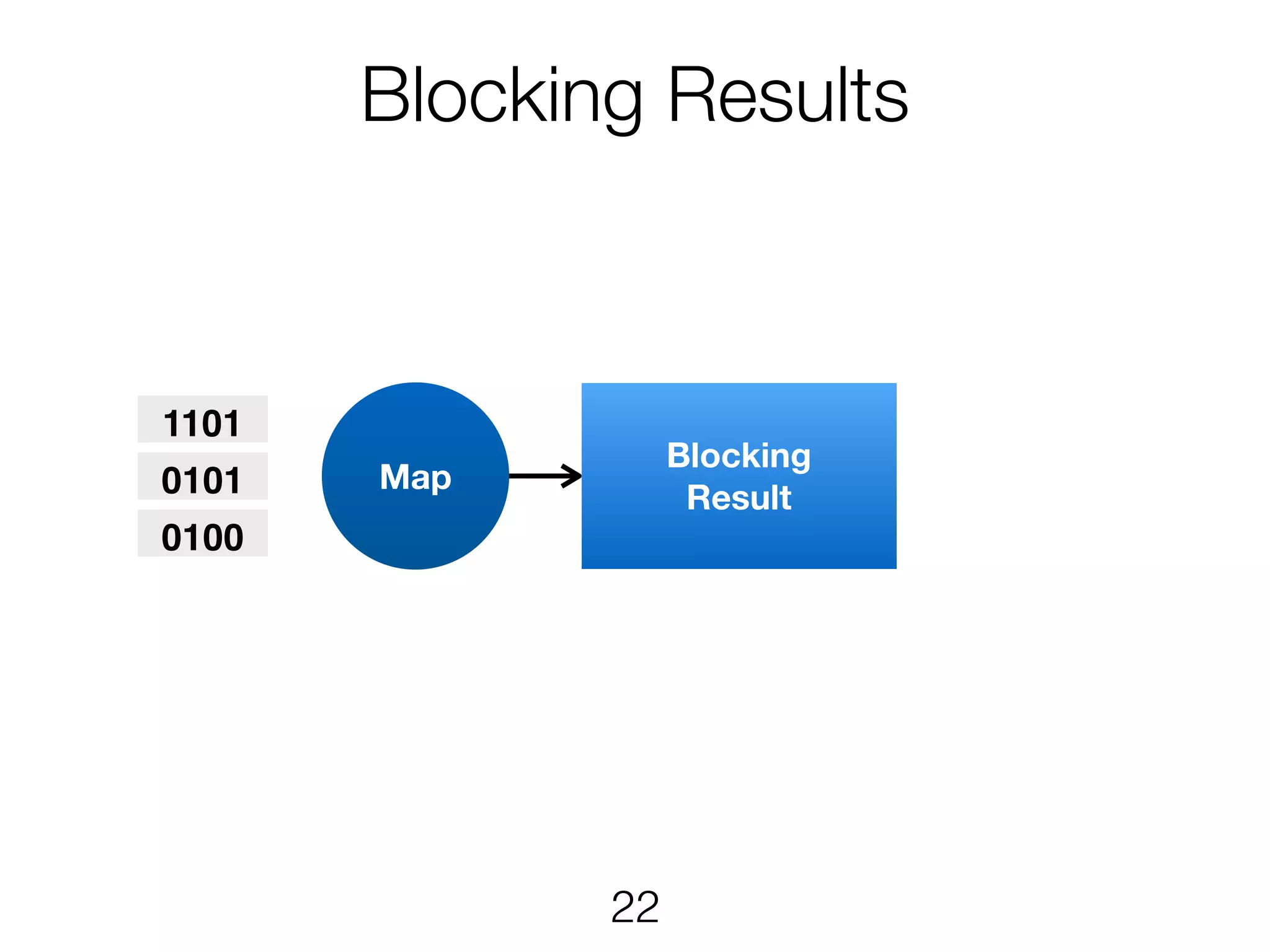
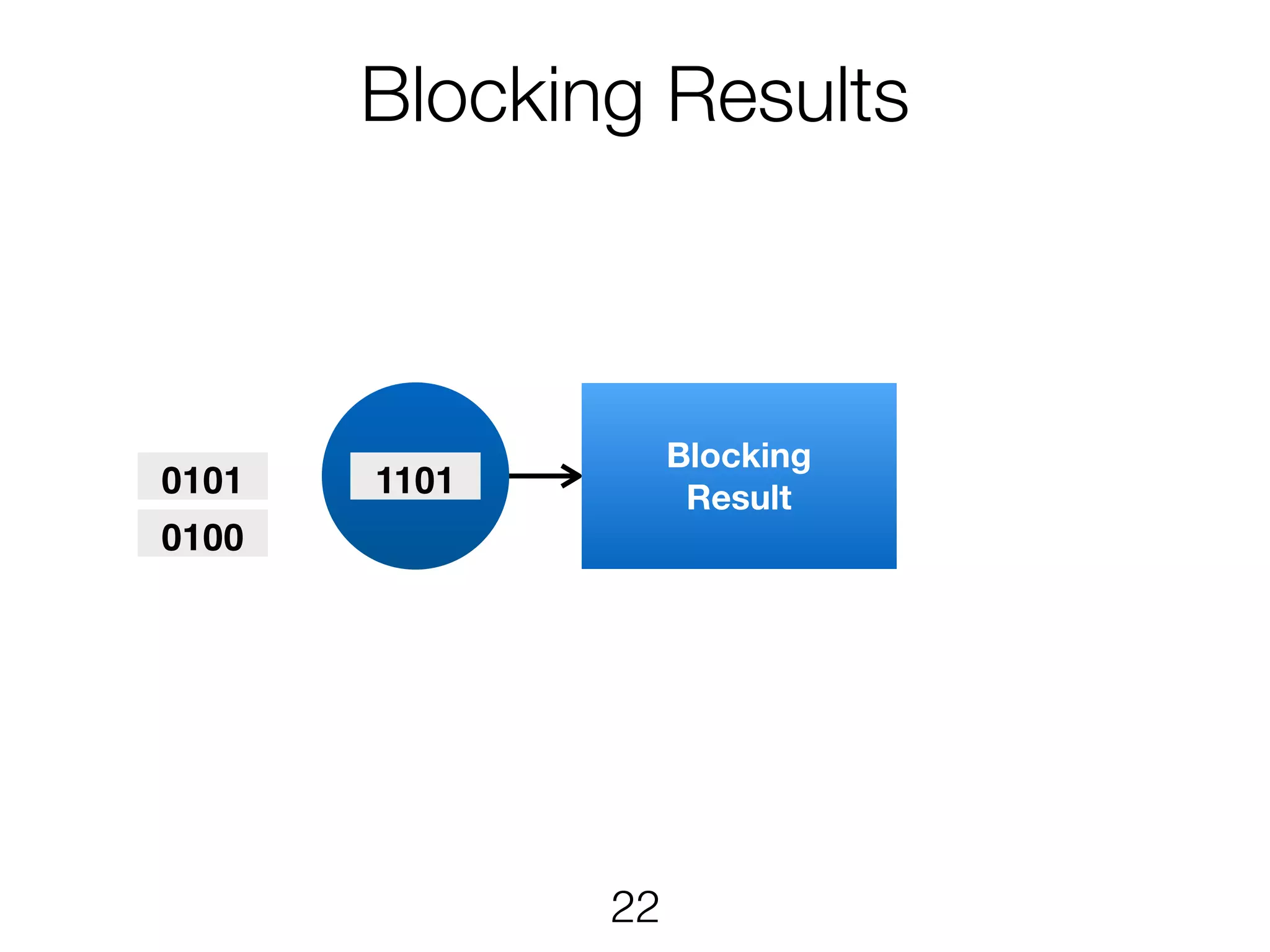
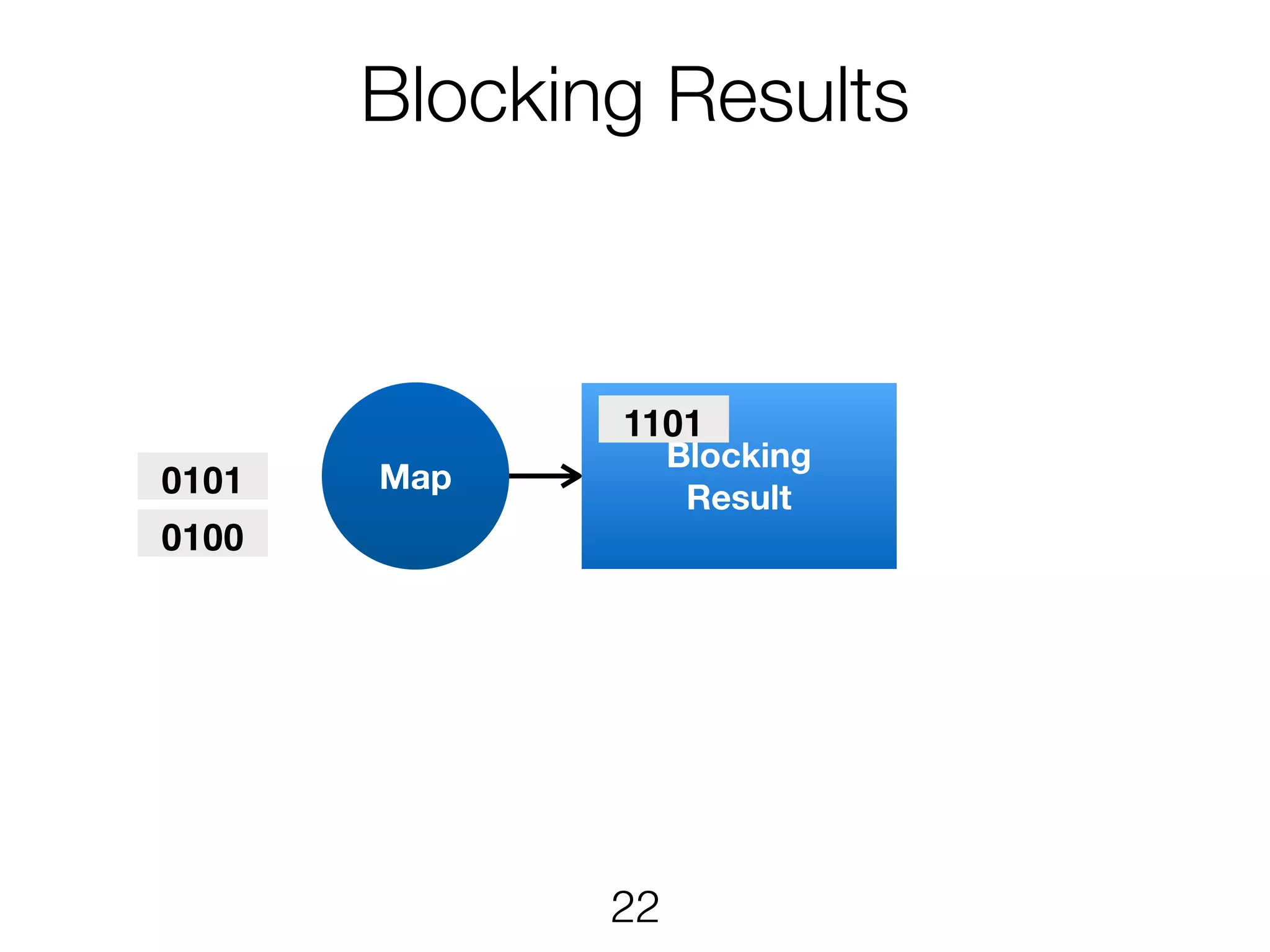
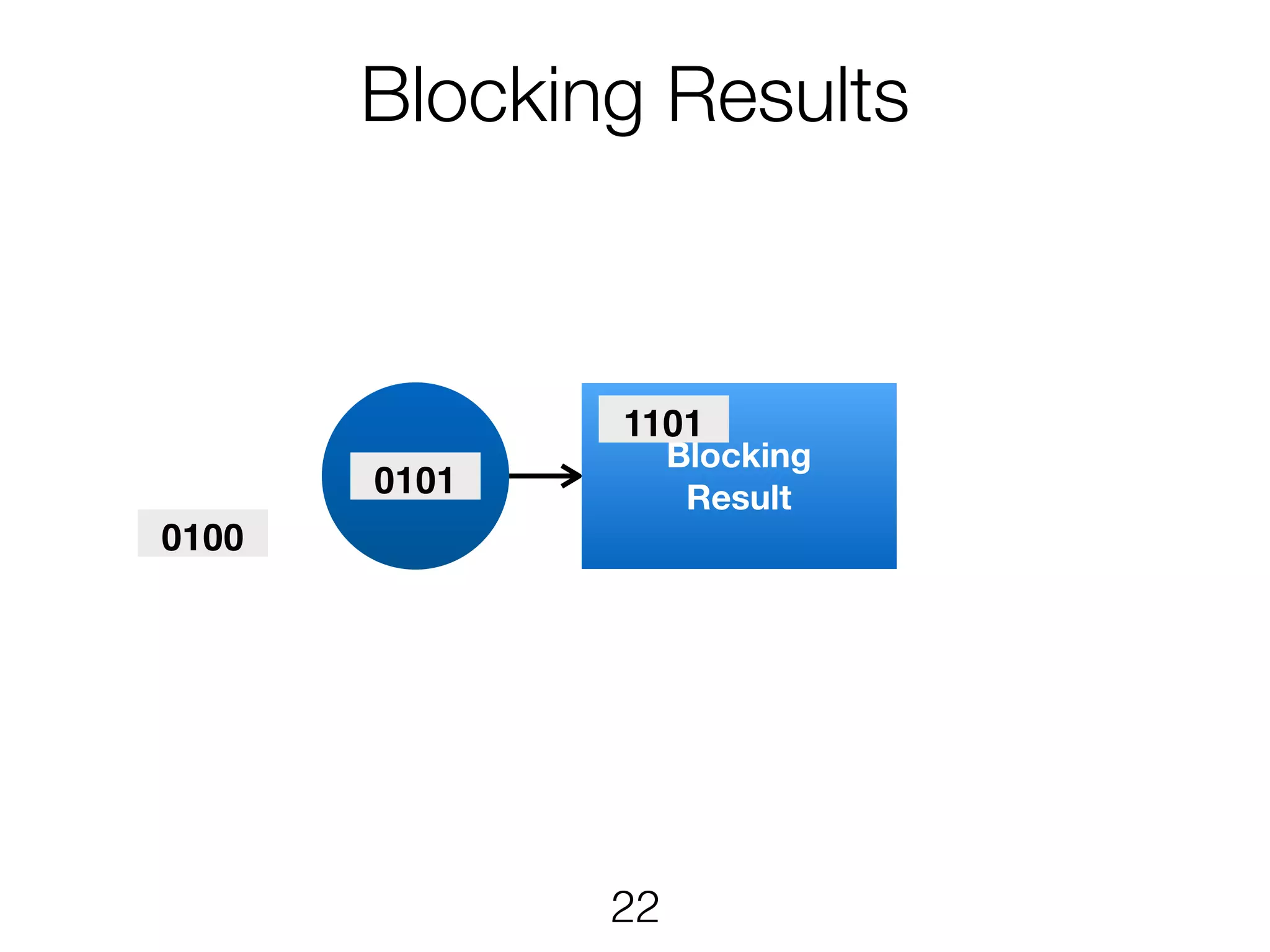
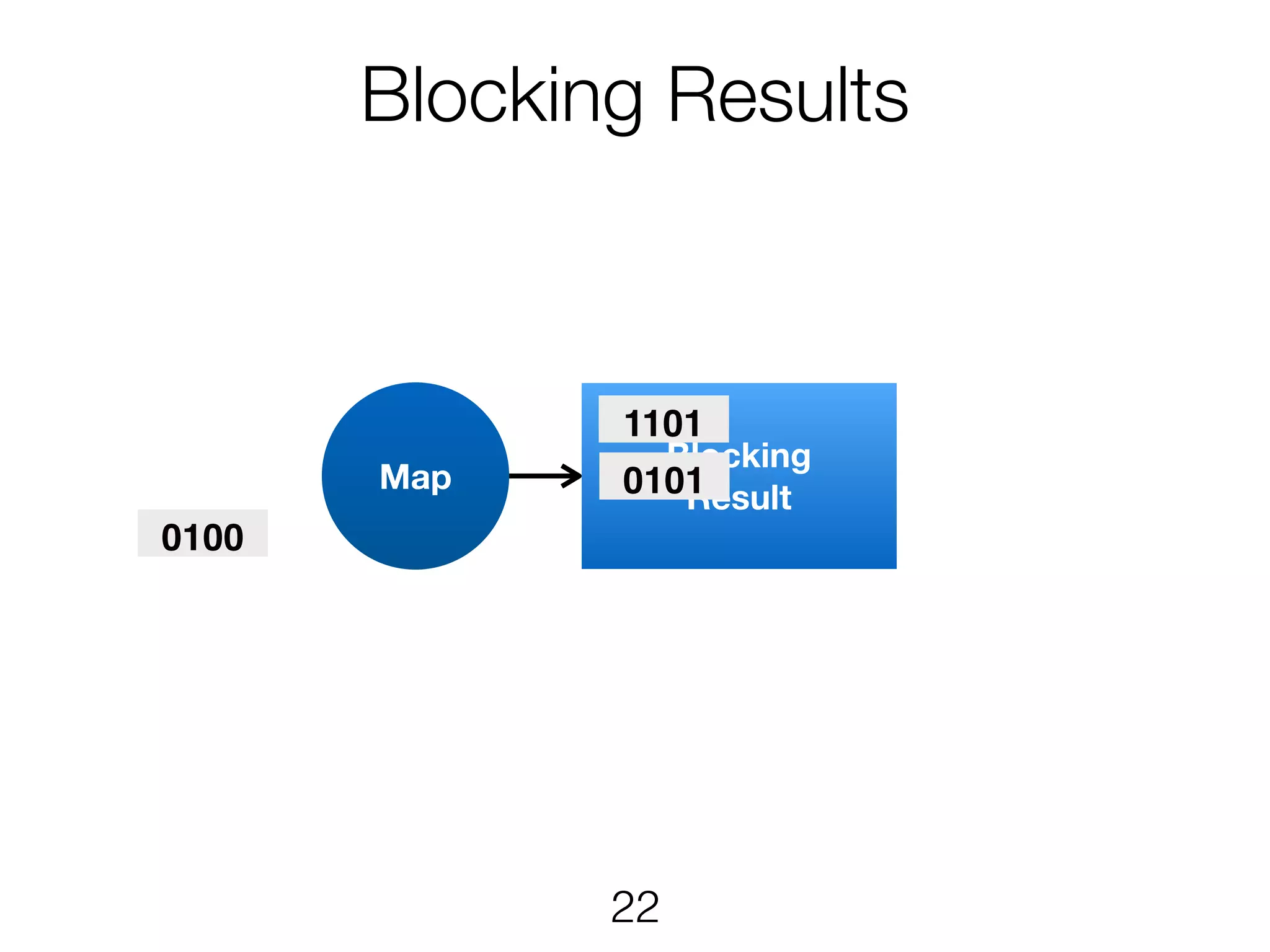
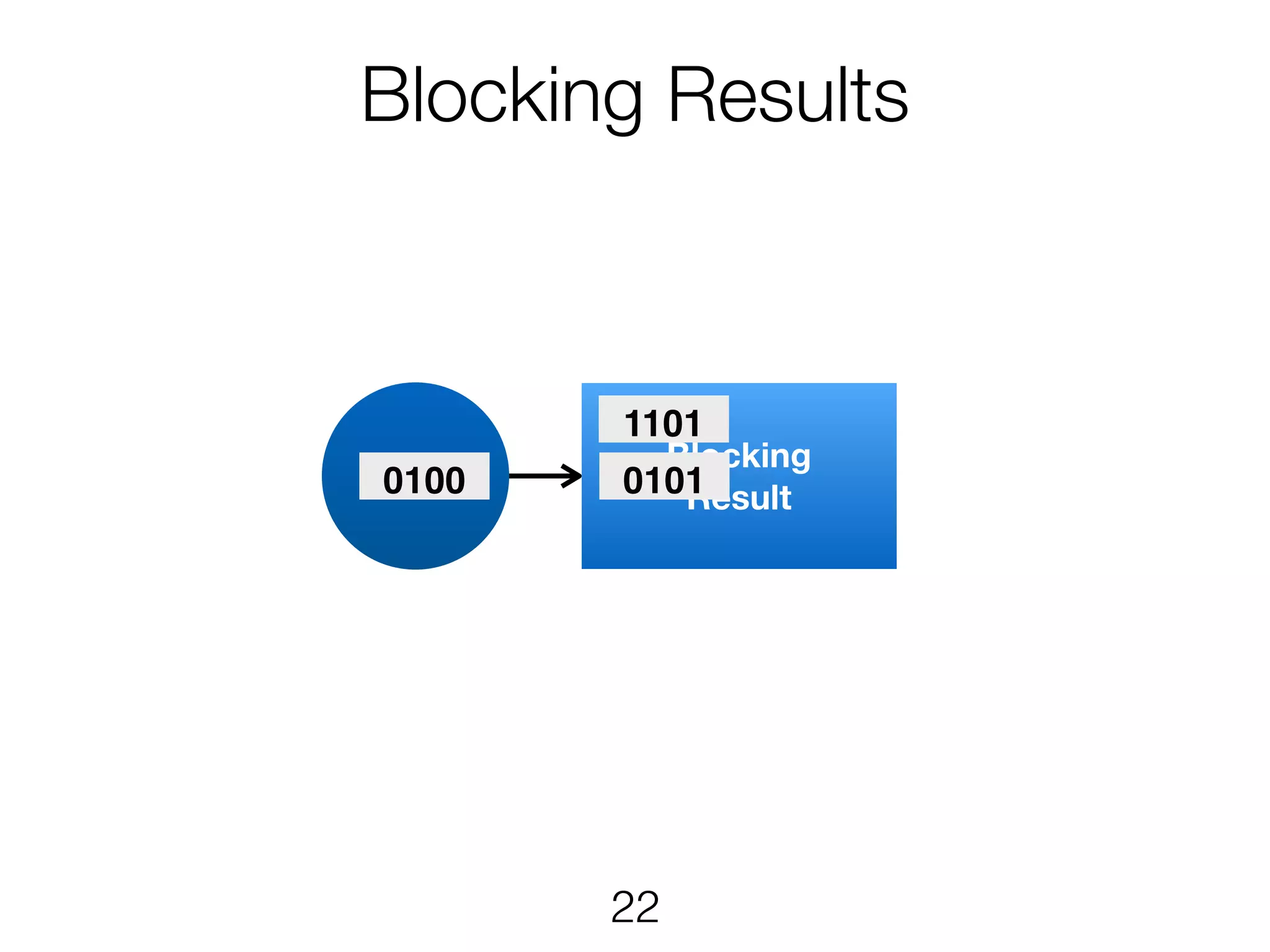
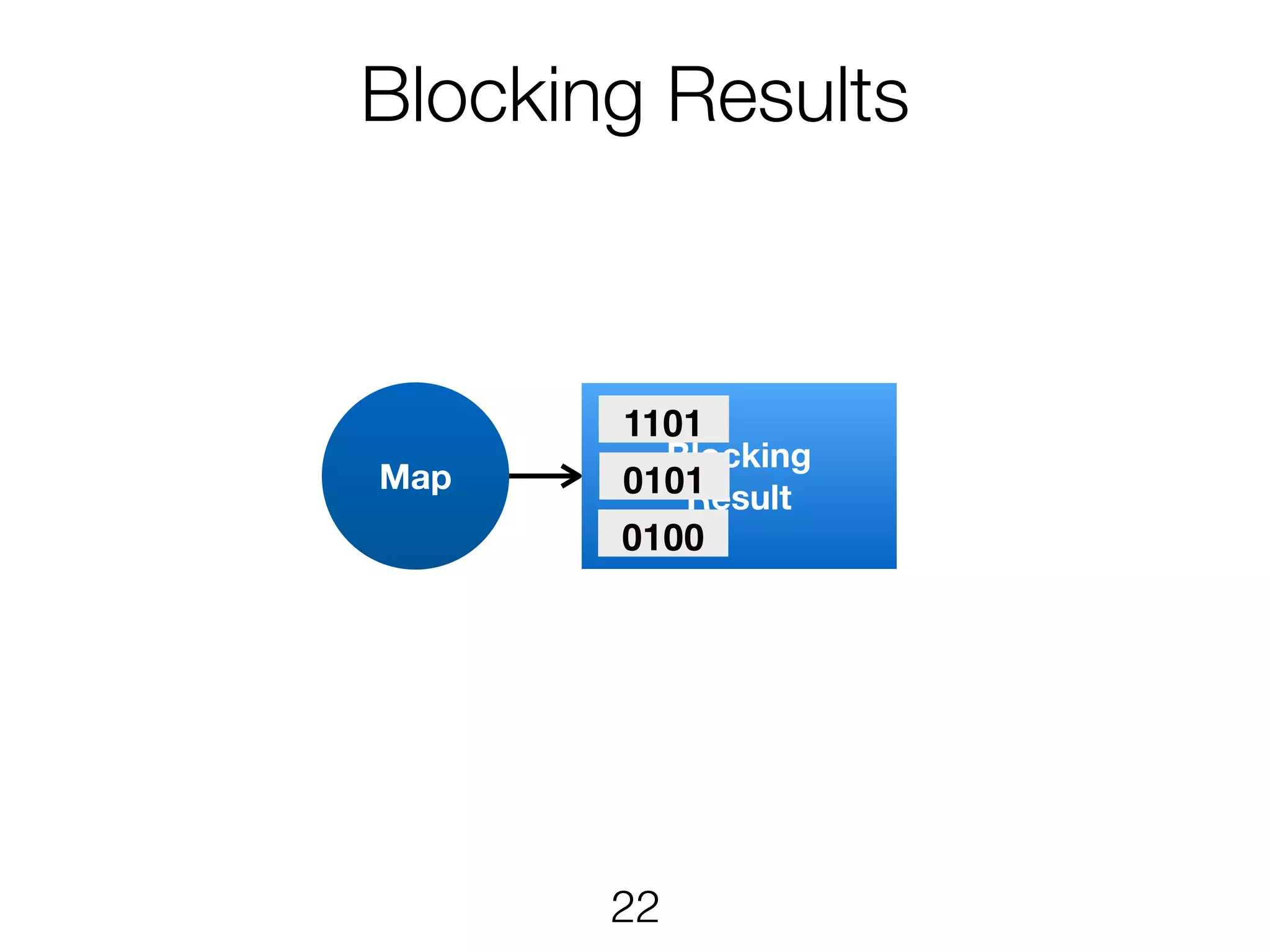
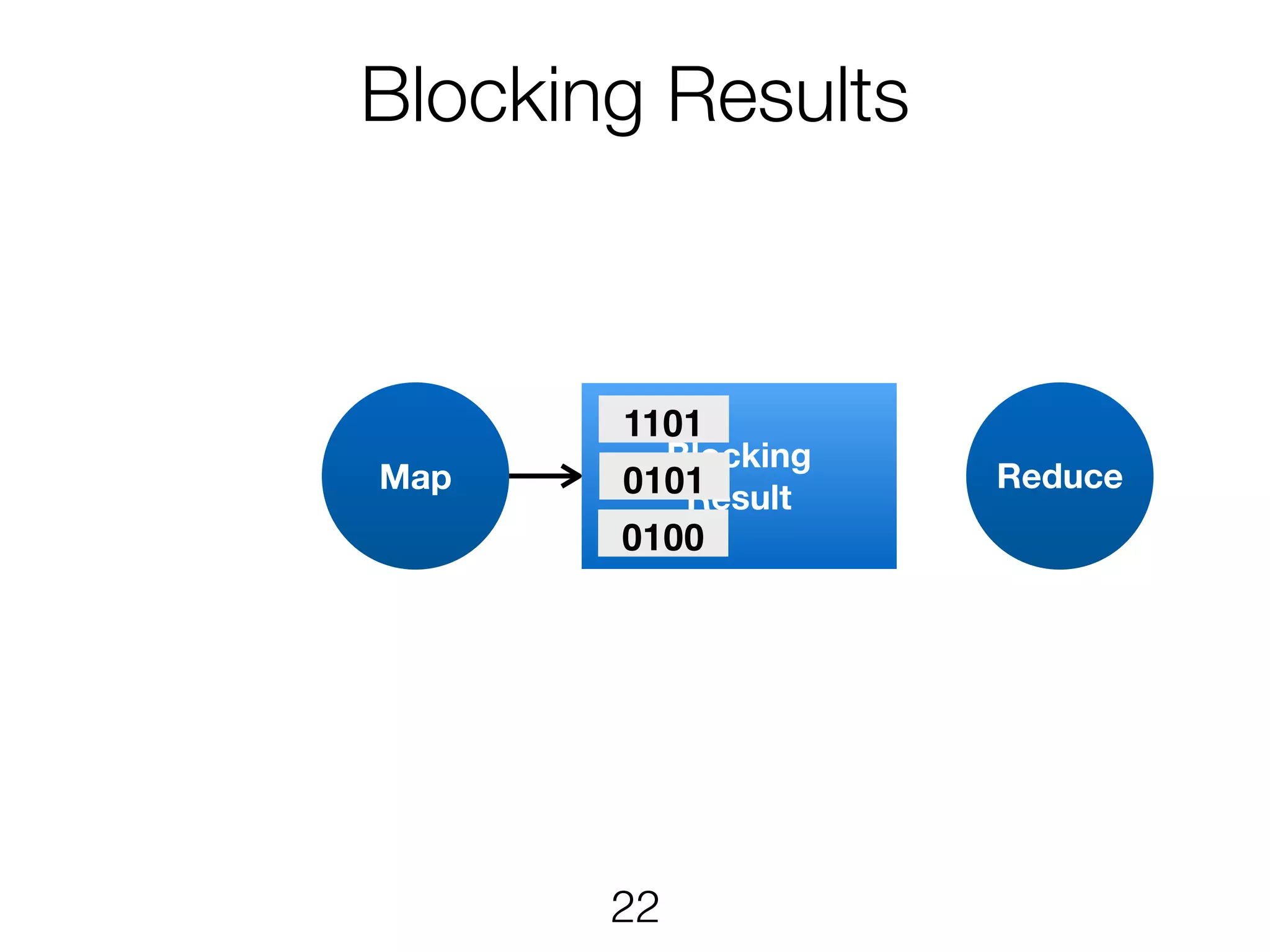
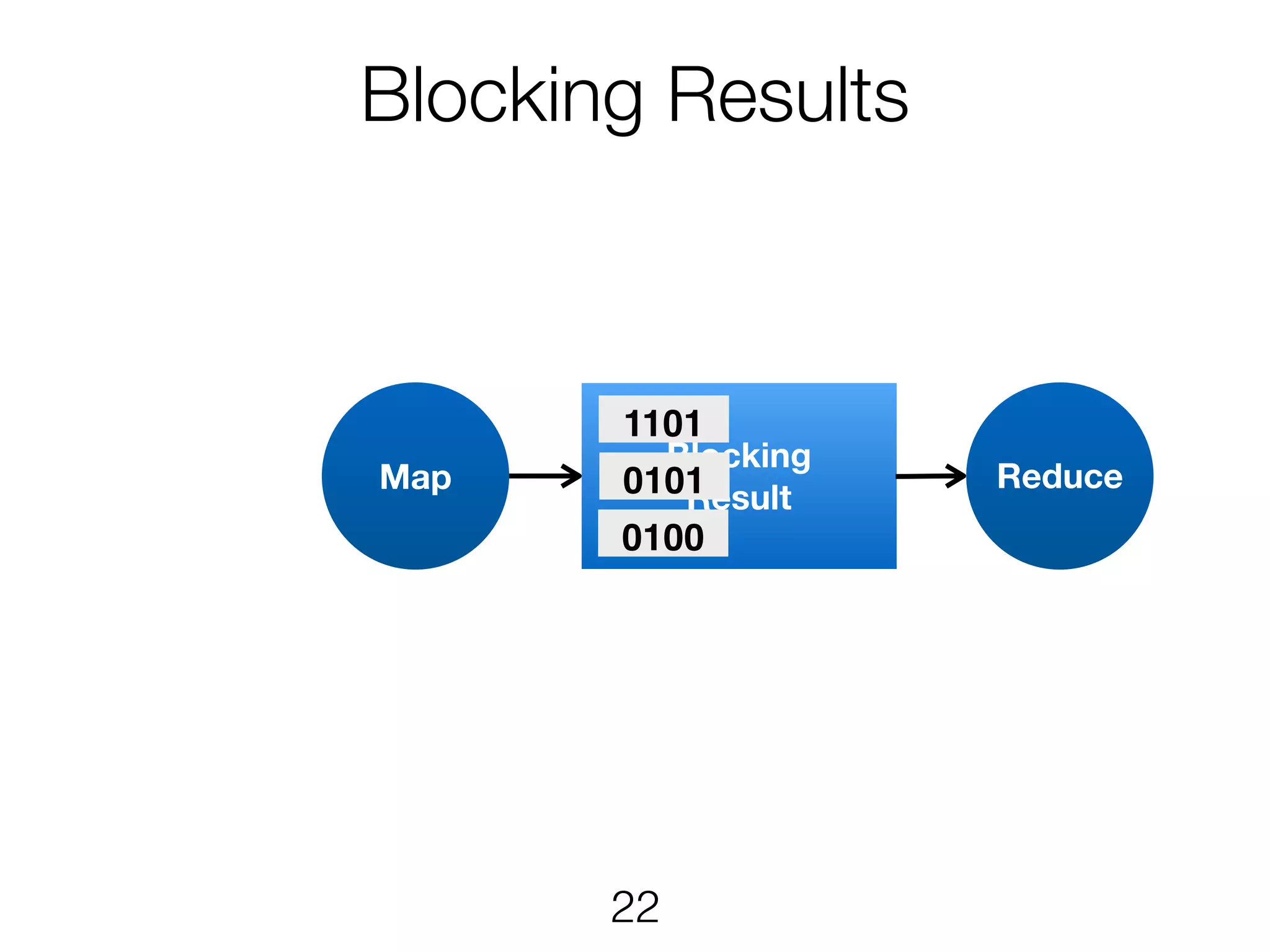
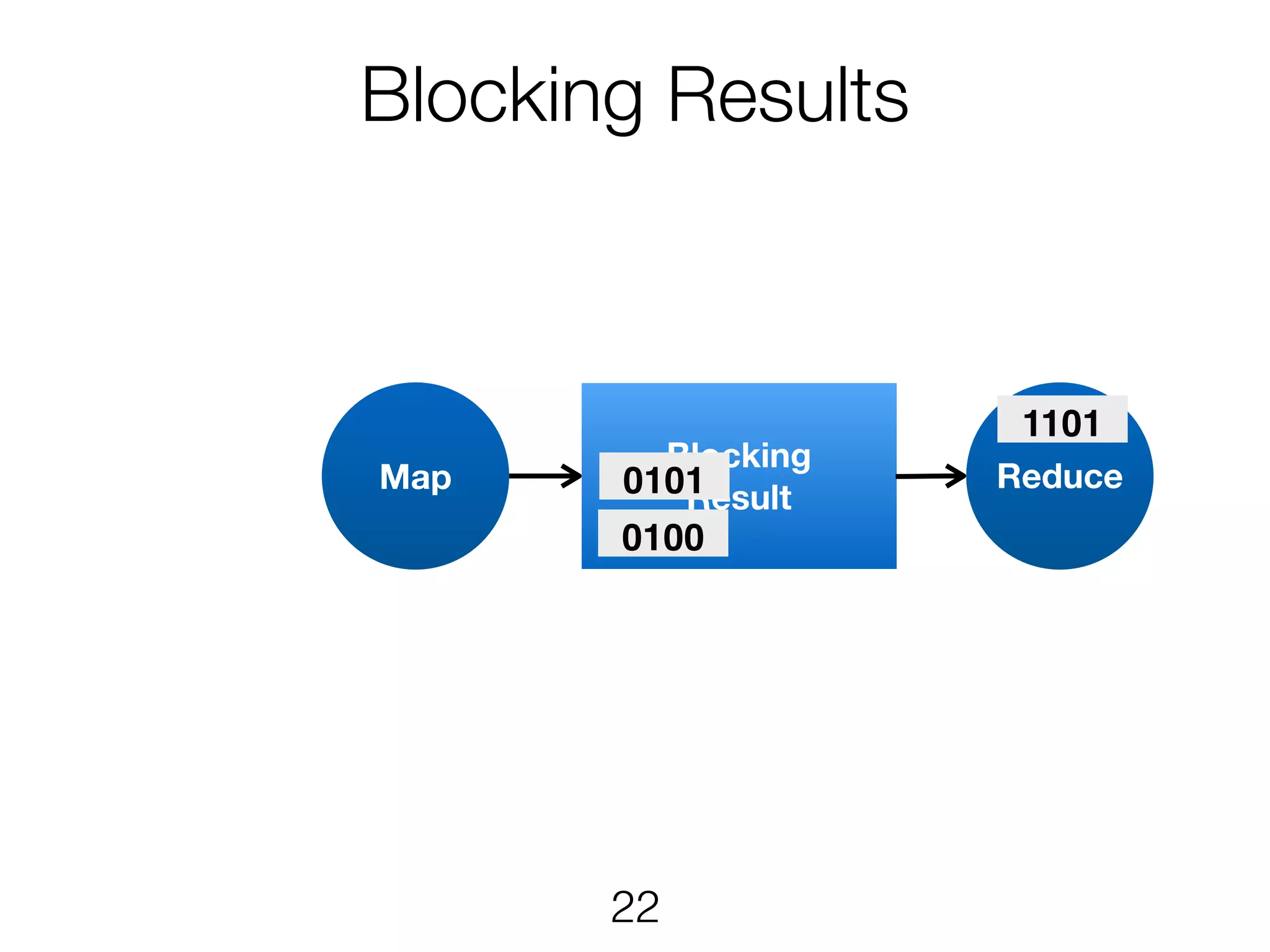
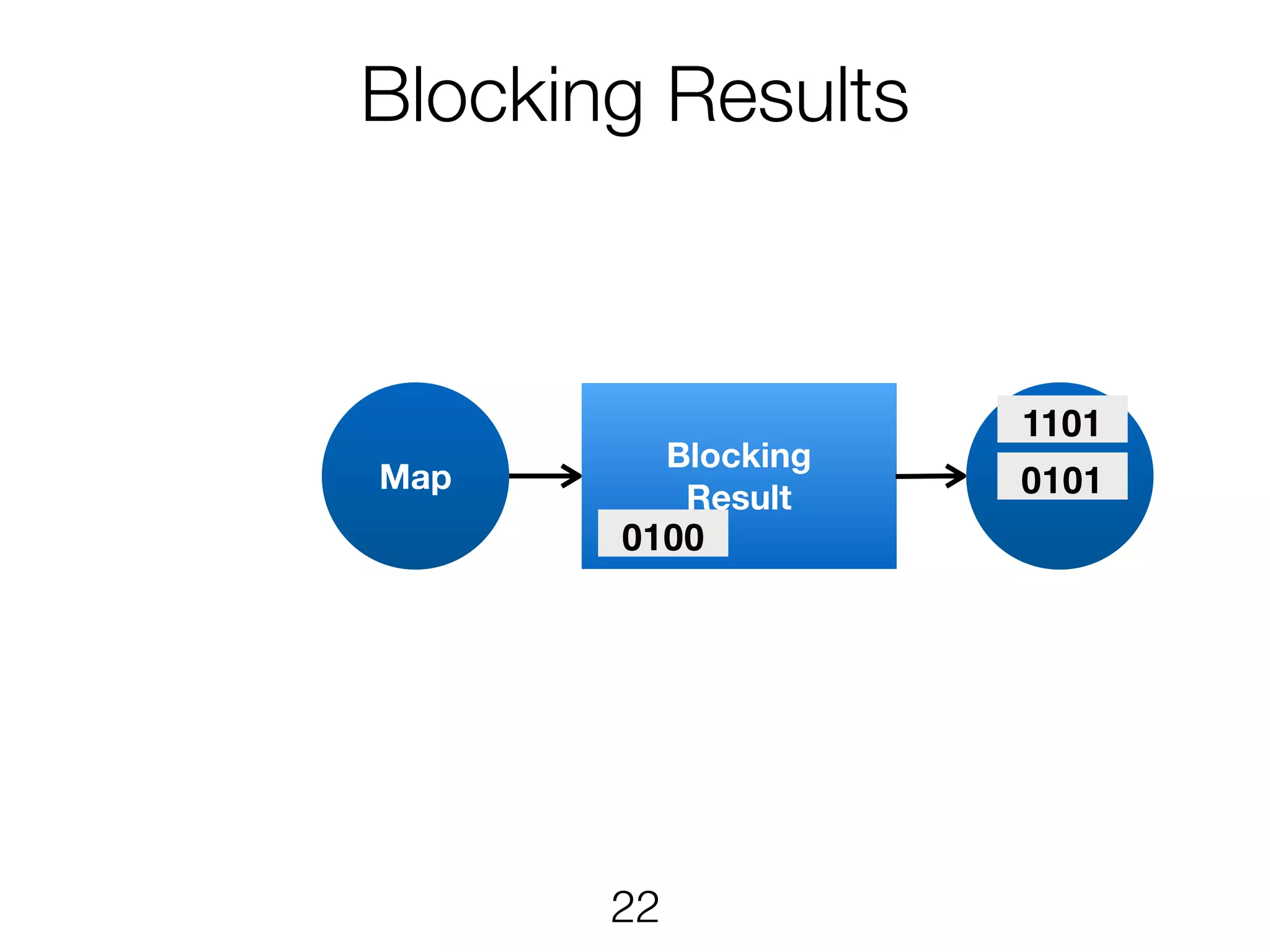
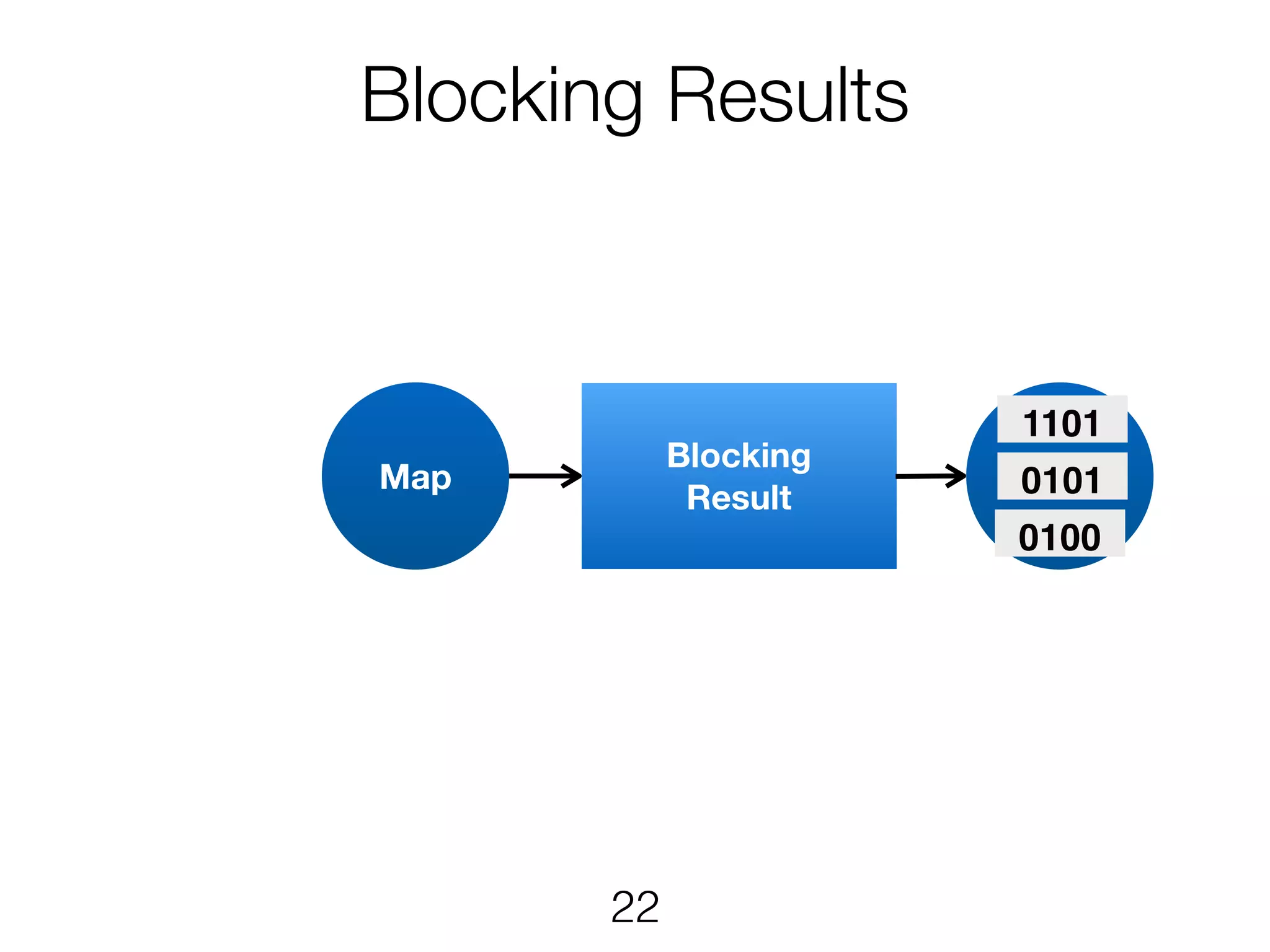
Stream & BatchProcessing • Stream and Batch programs are different parameterizations of the JobGraph • Everything goes down to the same runtime • Streaming first, batch as special case • Cost-based optimizer on translation • Blocking results for less resource fragmentation • But still profit from streaming • DataSet and DataStream API are essentially all user code to the runtime 24
48.
Stream & BatchProcessing DataStream DataSet JobGraph Chaining Chaining and cost- based optimisation Intermediate Results Pipelined Pipelined and Blocking Operators Stream operators Batch operators User function Common interface for map, reduce, … 25


![Components JobManager Master Client TaskManager Worker TaskManager Worker TaskManager Worker TaskManager Worker User System public class WordCount { public static void main(String[] args) throws Exception { // Flink’s entry point StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment(); DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?", "Deny thy father and refuse thy name", "Or, if thou wilt not, be but sworn my love,", "And I'll no longer be a Capulet."); // Split by whitespace to (word, 1) and sum up ones DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) .keyBy(0) .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); counts.print(); // Today: What happens now? env.execute(); } } Submit Program Schedule Execute 2](https://image.slidesharecdn.com/flinkforward-10-13-15-flinkinternals-151014095859-lva1-app6891/75/Apache-Flink-Internals-Stream-Batch-Processing-in-One-System-Apache-Flink-s-Streaming-Data-Flow-Engine-4-2048.jpg)
![Client Translates the API code to
a data flow graph called JobGraph and submits it to the JobManager. Source Transform Sink public class WordCount { public static void main(String[] args) throws Exception { // Flink’s entry point StreamExecutionEnvironment env = StreamExecutionEnvironment .getExecutionEnvironment(); DataStream<String> data = env.fromElements( "O Romeo, Romeo! wherefore art thou Romeo?", "Deny thy father and refuse thy name", "Or, if thou wilt not, be but sworn my love,", "And I'll no longer be a Capulet."); // Split by whitespace to (word, 1) and sum up ones DataStream<Tuple2<String, Integer>> counts = data .flatMap(new SplitByWhitespace()) .keyBy(0) .timeWindow(Time.of(10, TimeUnit.SECONDS)) .sum(1); counts.print(); // Today: What happens now? env.execute(); } } Translate 3](https://image.slidesharecdn.com/flinkforward-10-13-15-flinkinternals-151014095859-lva1-app6891/75/Apache-Flink-Internals-Stream-Batch-Processing-in-One-System-Apache-Flink-s-Streaming-Data-Flow-Engine-5-2048.jpg)