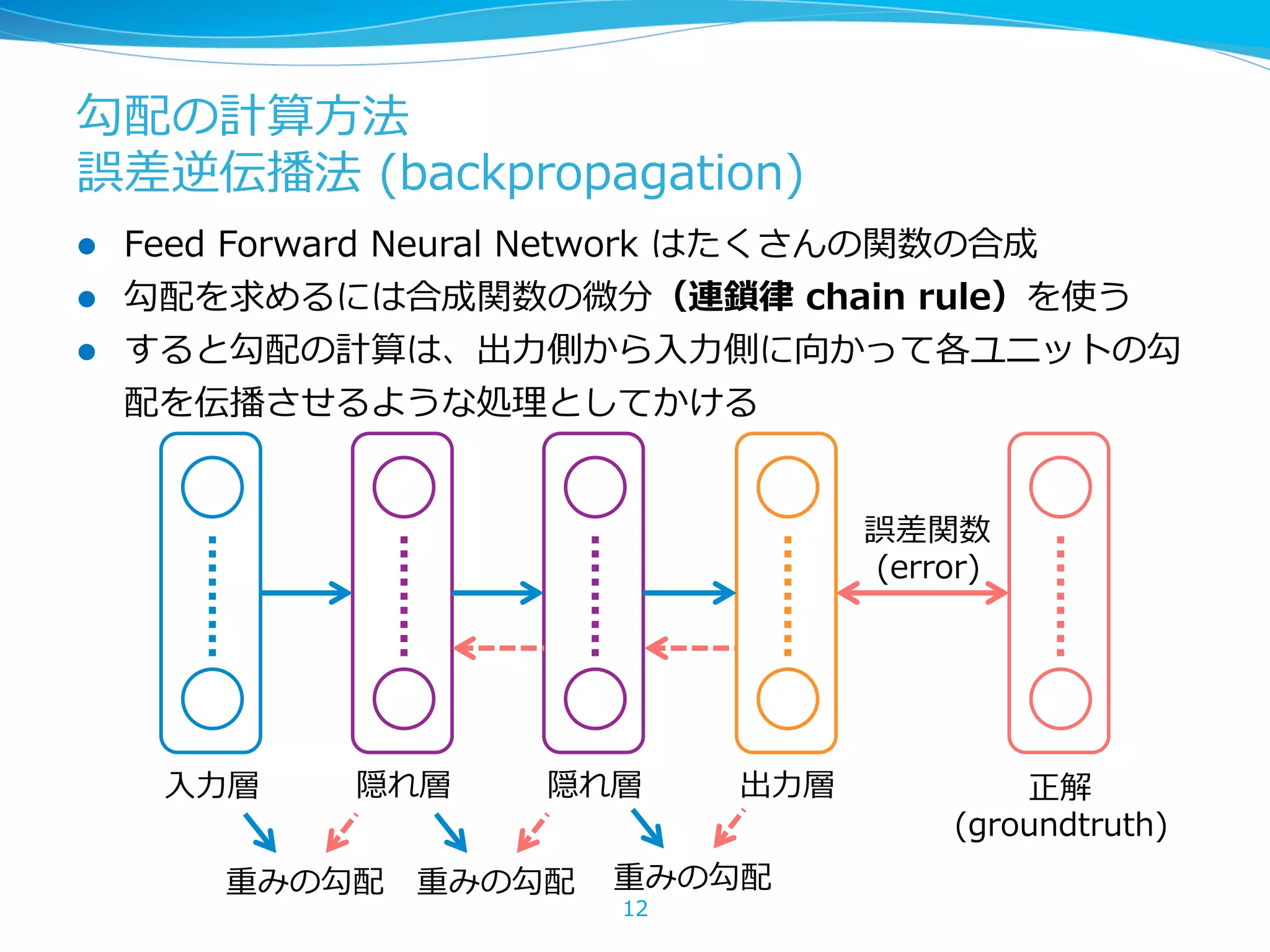
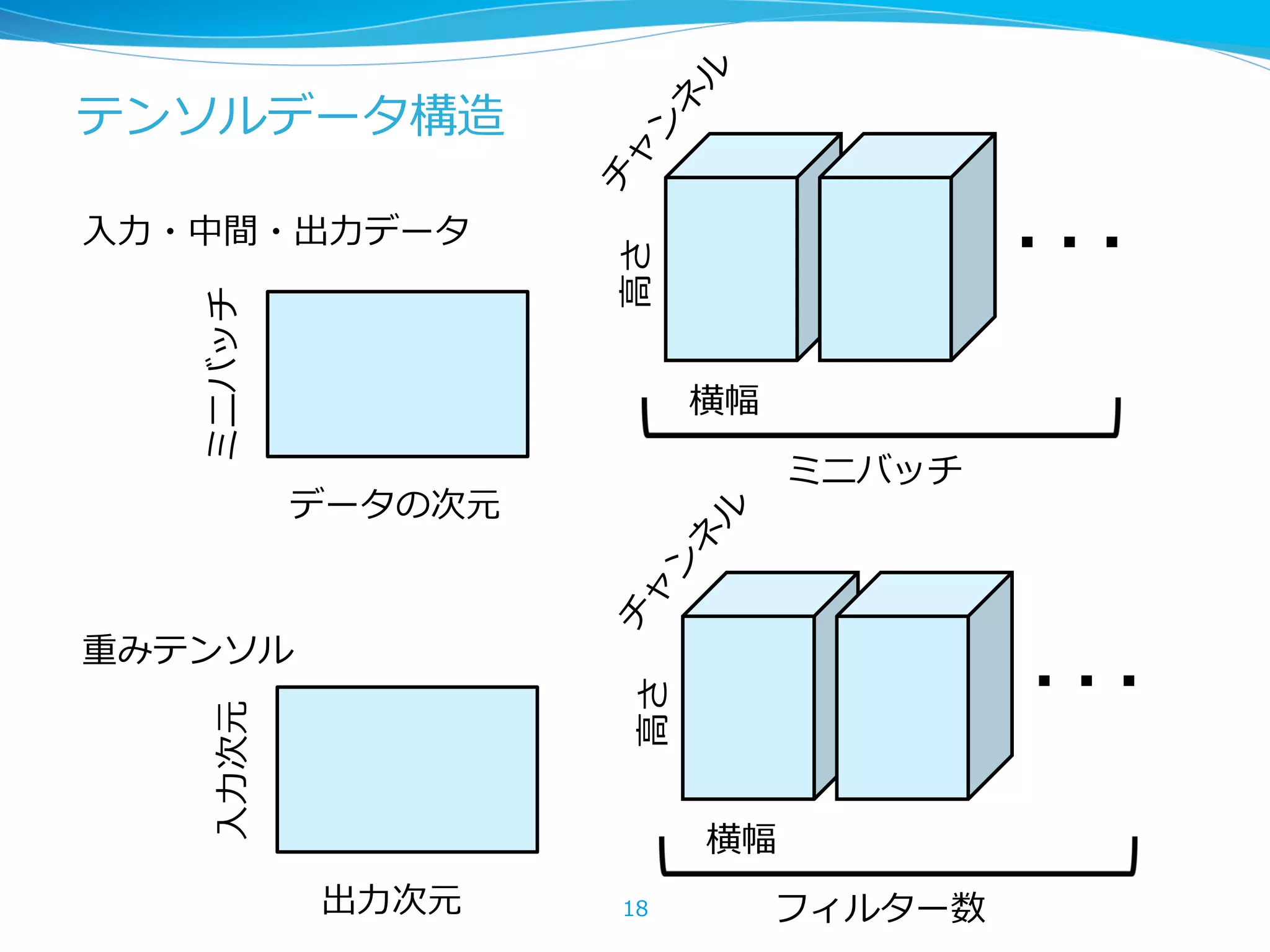
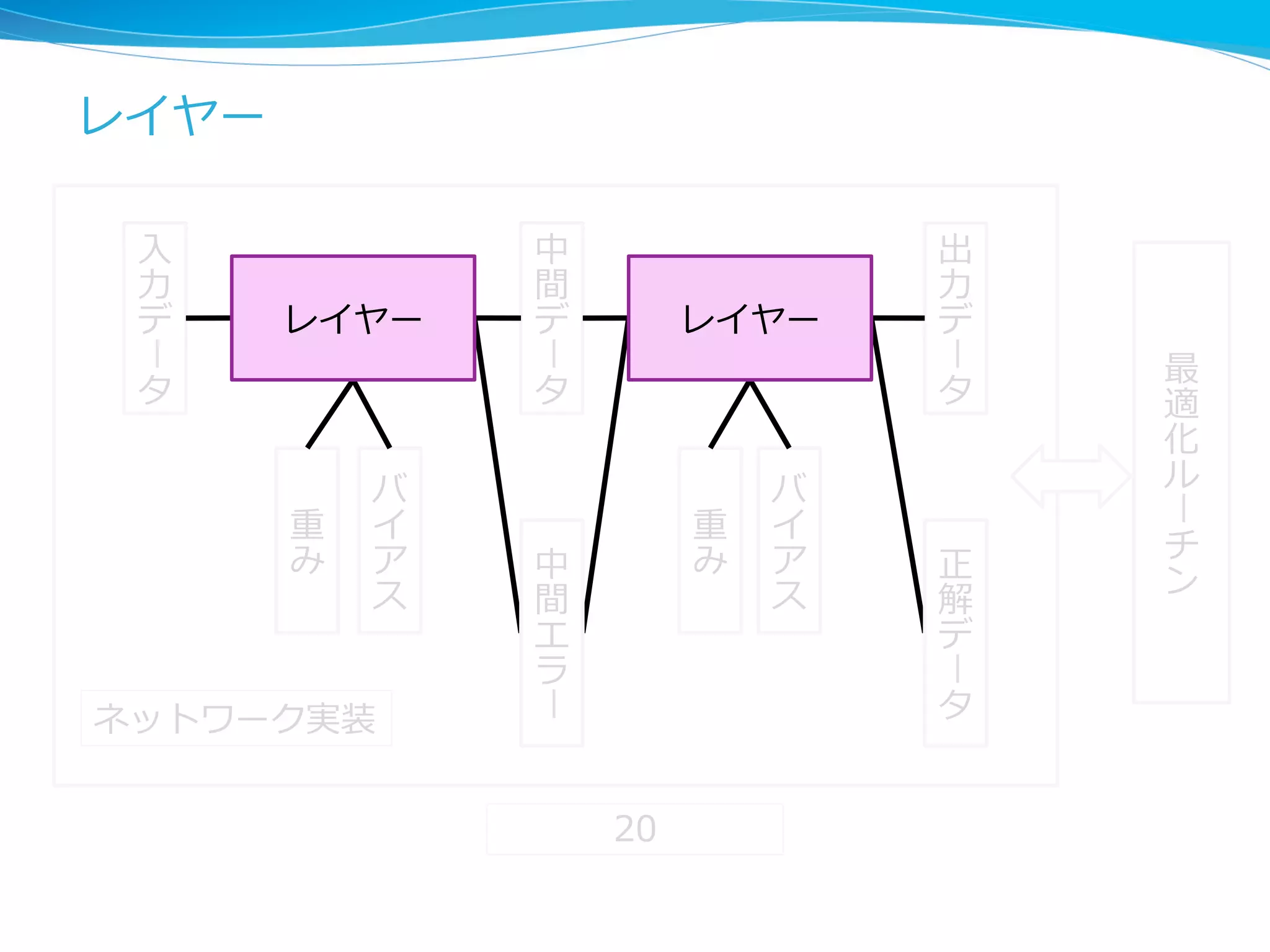
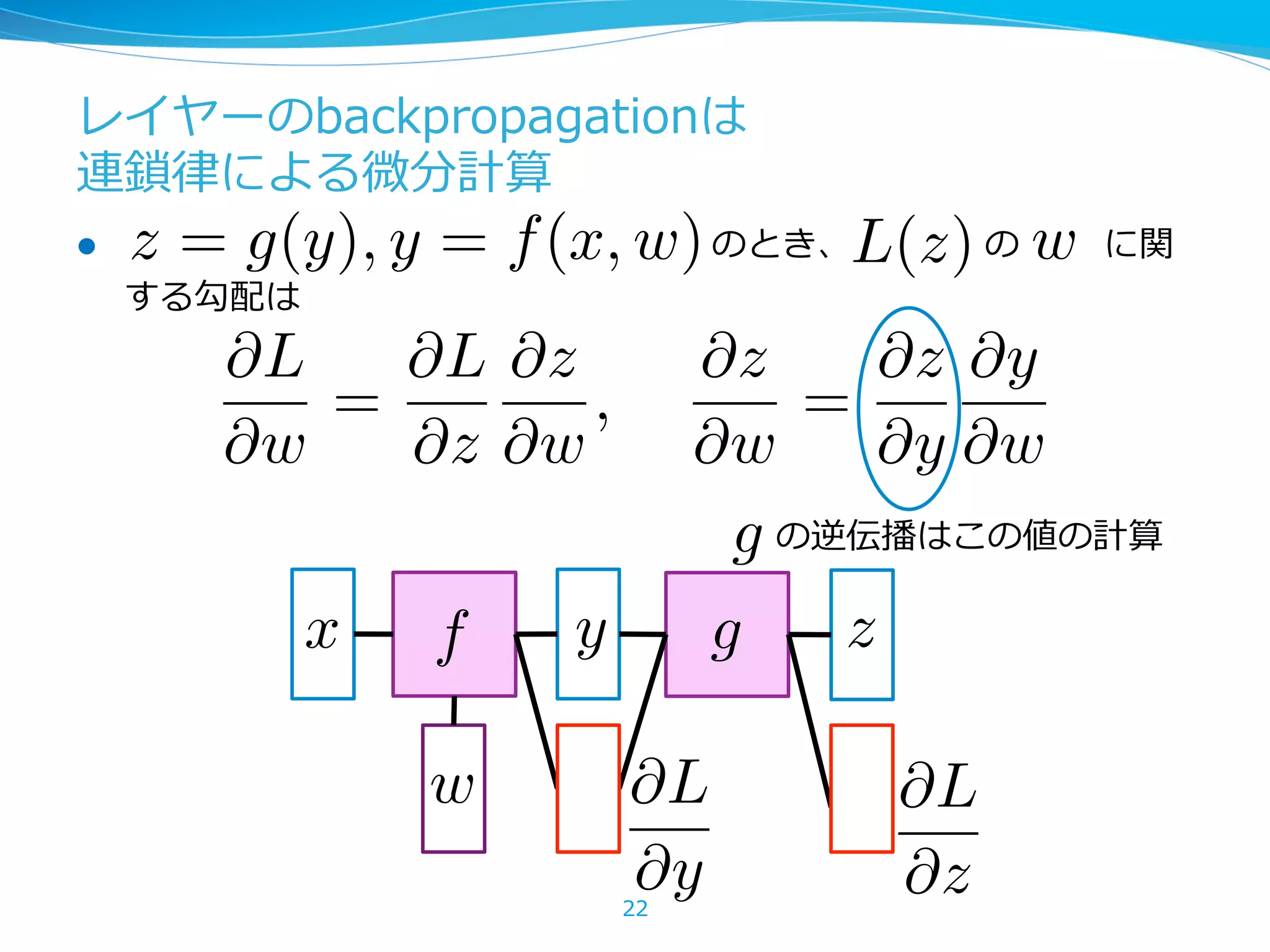
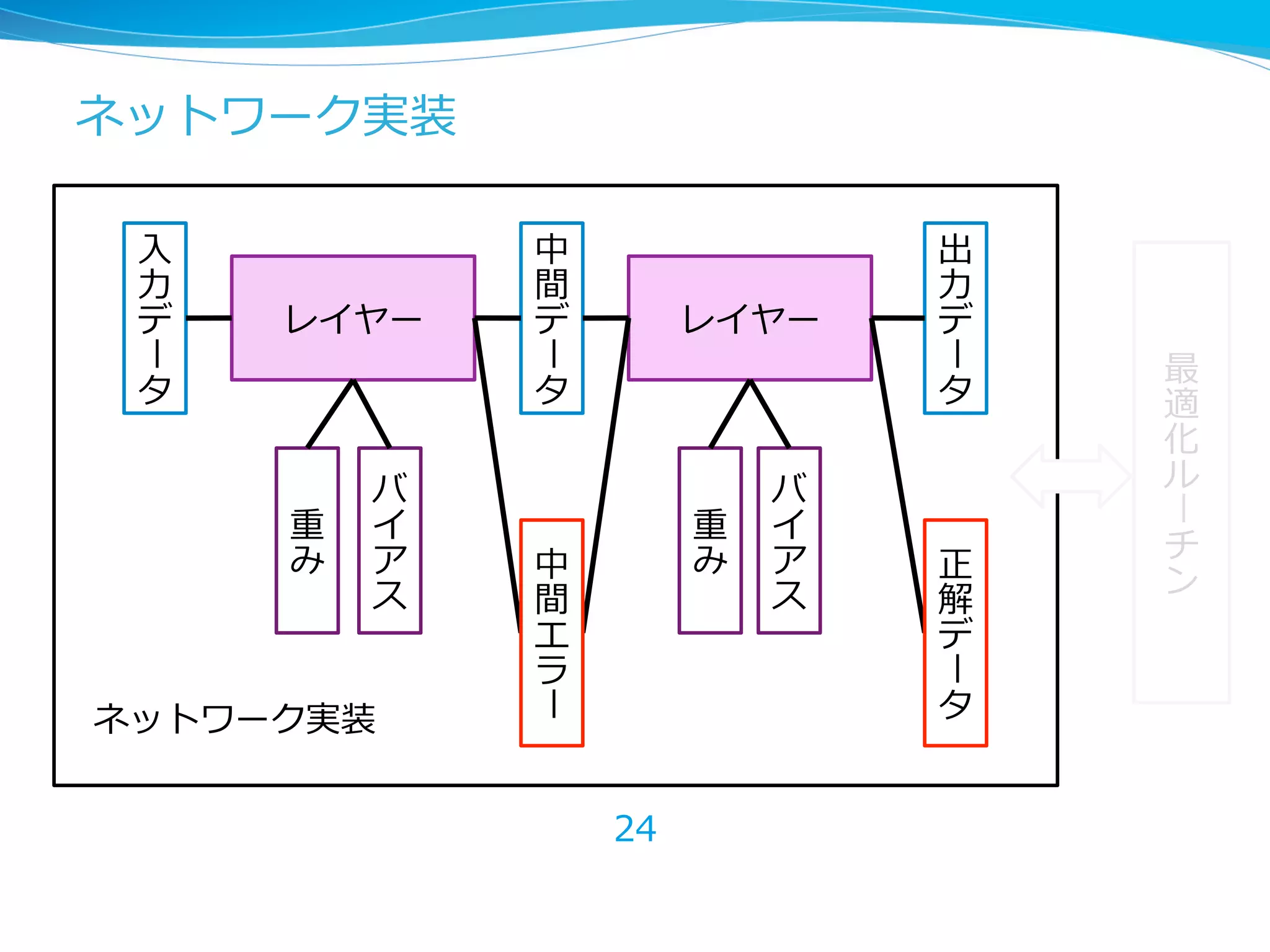
レイヤーのbackpropagationは 連鎖律律による微分計算 lz = g(y), y = f(x,w) のとき、 の に関 する勾配は 22 L(z) w x f y g z @L @z @L @y w @L @w = @L @z @z @w , @z @w = @z @y @y @w g の逆伝播はこの値の計算
23.
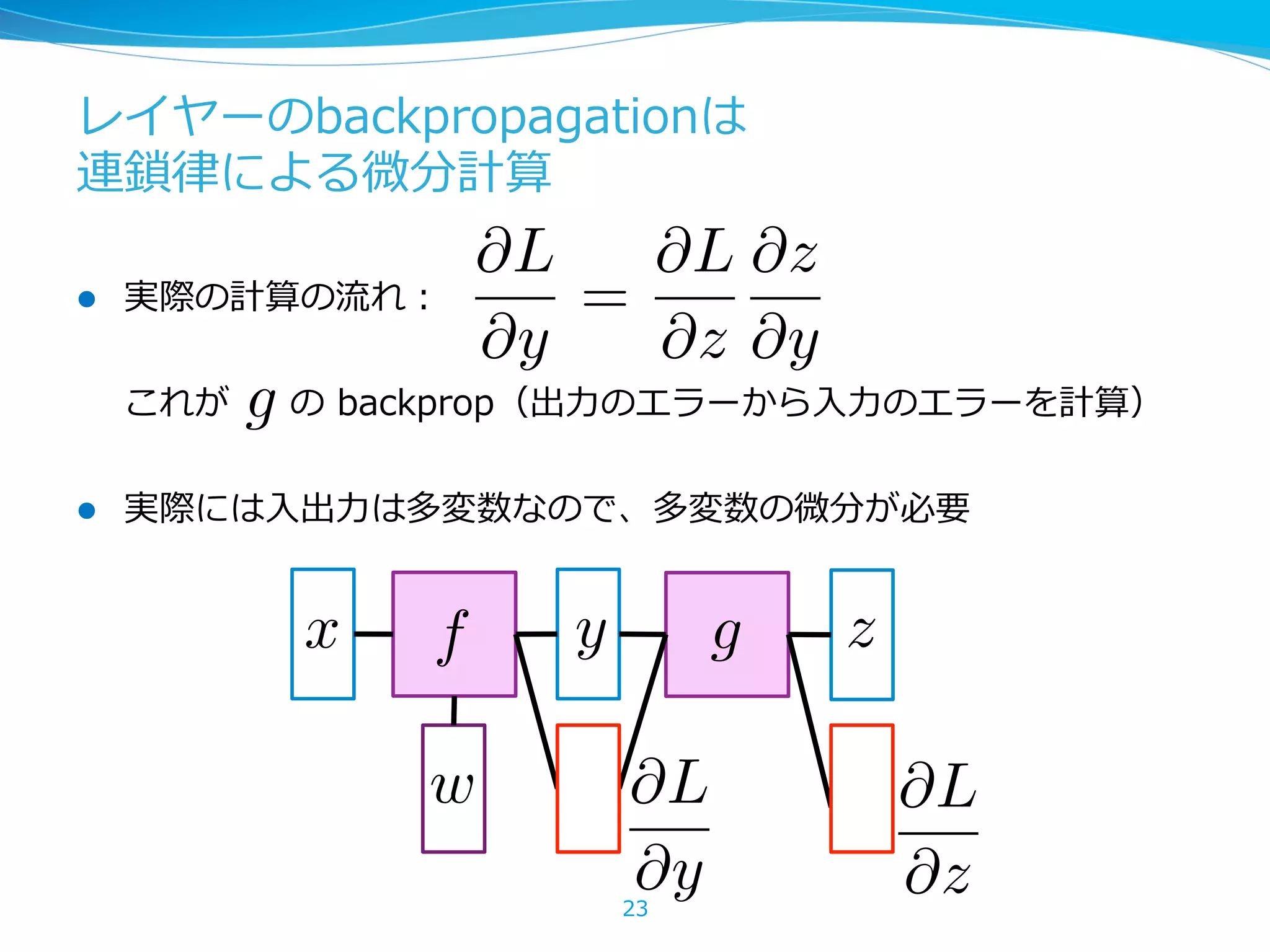
レイヤーのbackpropagationは 連鎖律律による微分計算 l実際の計算の流流れ: これが の backprop(出⼒力力のエラーから⼊入⼒力力のエラーを計算) l 実際には⼊入出⼒力力は多変数なので、多変数の微分が必要 23 @L @y = @L @z @z @y g x f y g z @L @z @L @y w