Download as PDF, PPTX





















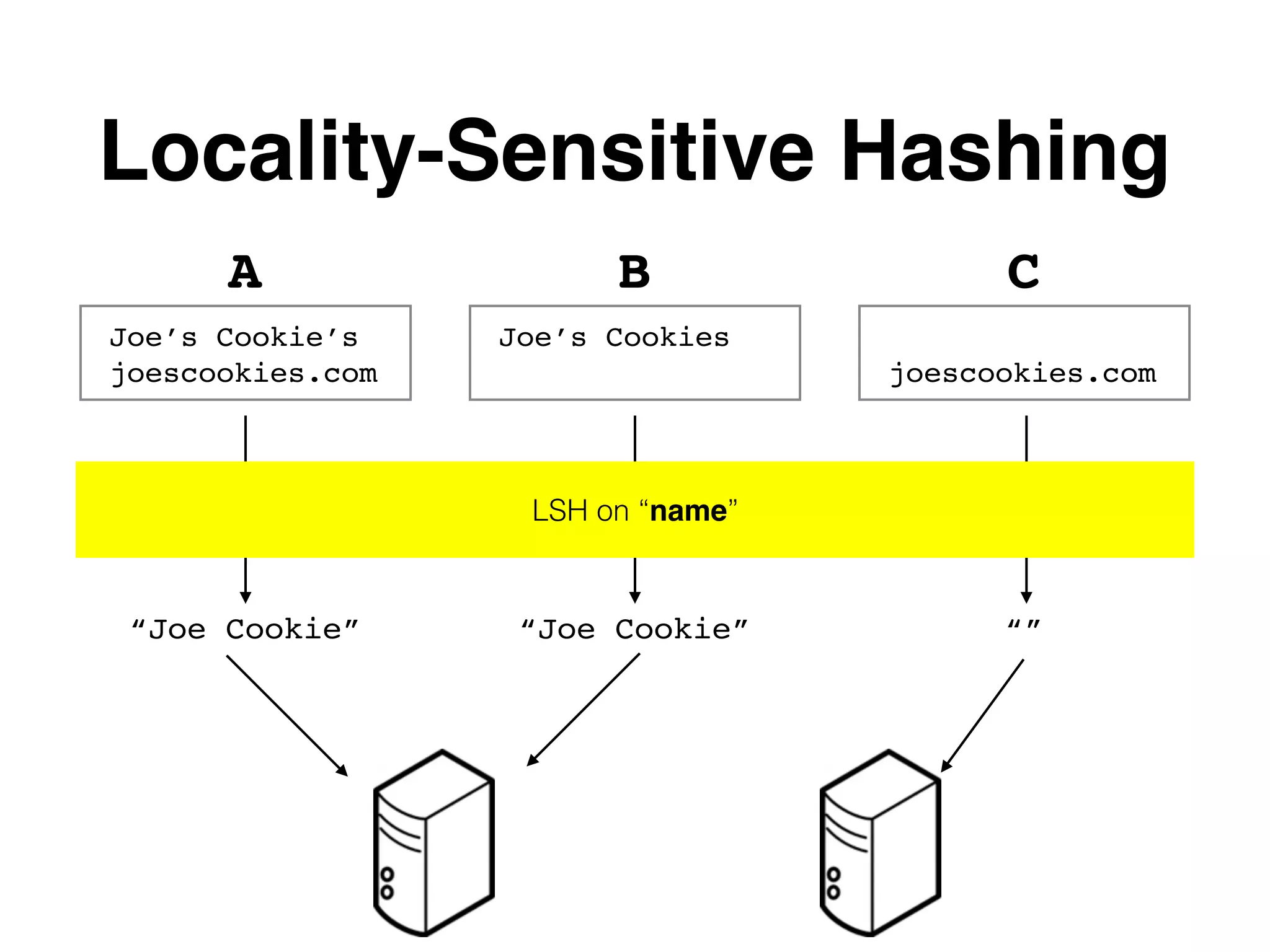
![Locality-Sensitive Hashing (LSH) Basic Idea: Use Map Reduce to get likely matches onto the same machines “Johnathon” “Sequoia Capital, LLC” [37.773972, -122.431297] “John” “Sequoia” [37.73, -122.43] “app.example.com” “example.com”](https://image.slidesharecdn.com/er-160414221920/75/DataEngConf-SF16-Entity-Resolution-in-Data-Pipelines-Using-Spark-28-2048.jpg)




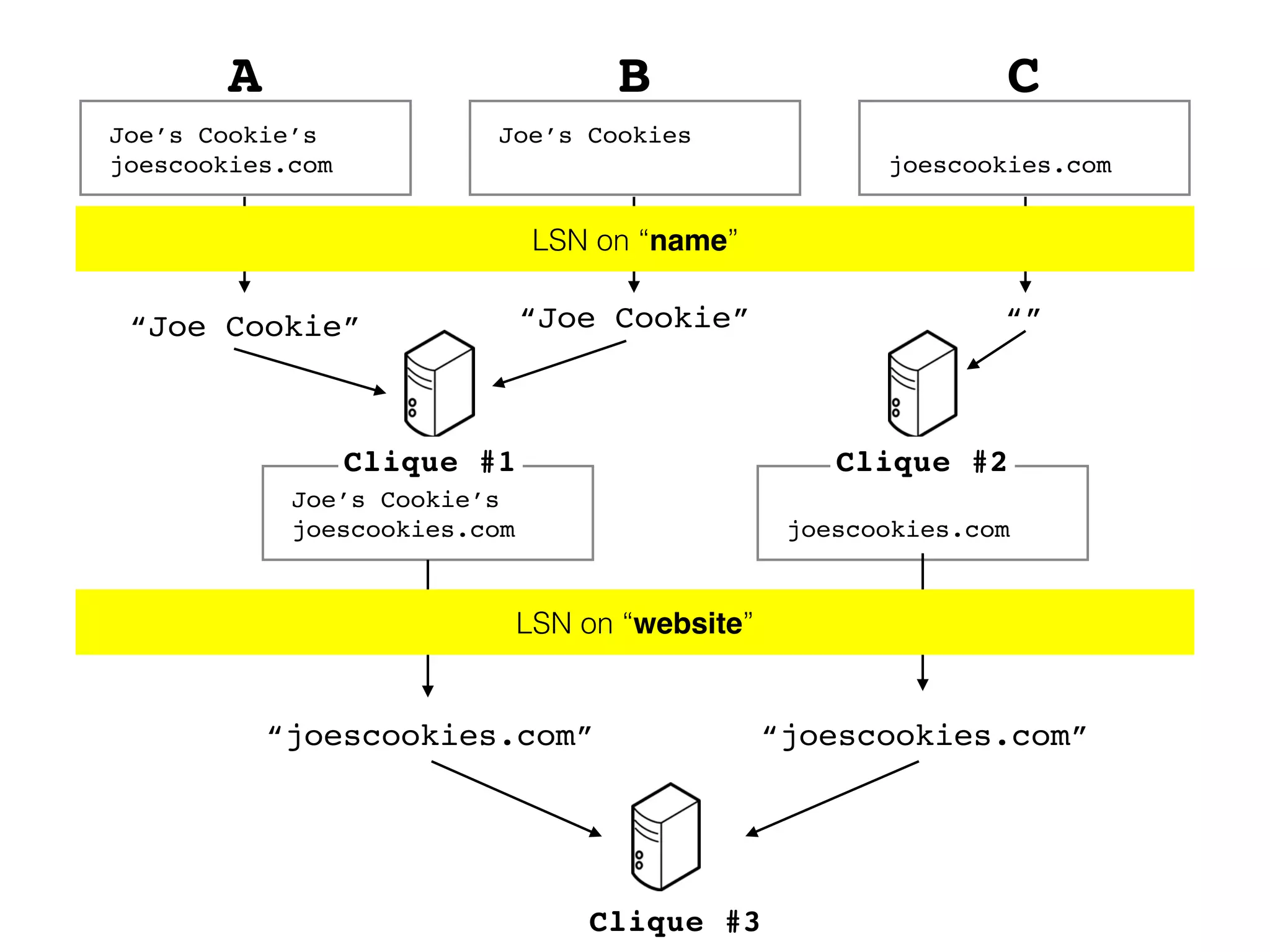

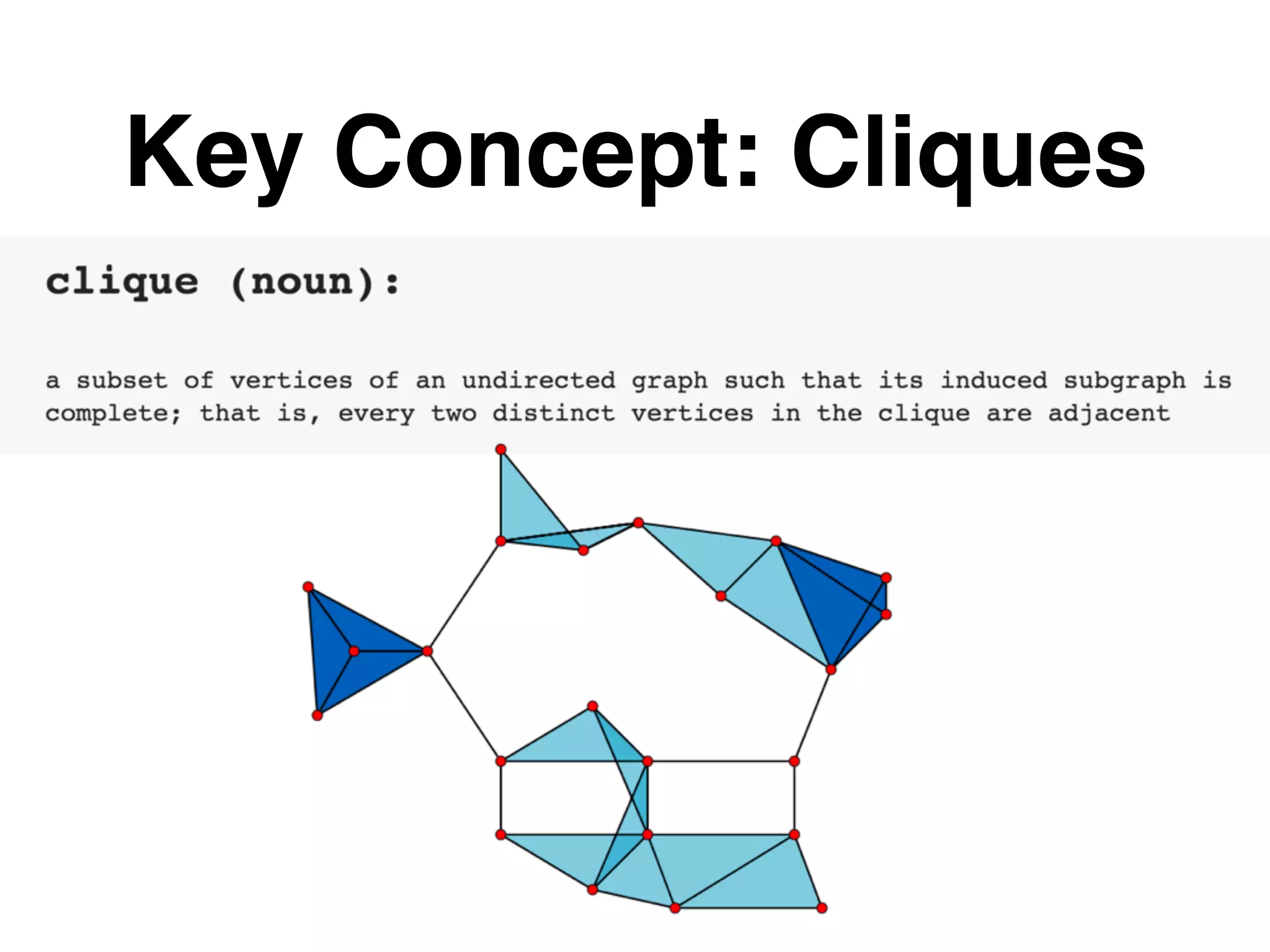
![Clique Choosing RDD[T].toLocalIterator() : Iterator[T] • Produces an iterator on the Driver that seamlessly iterates every partition](https://image.slidesharecdn.com/er-160414221920/75/DataEngConf-SF16-Entity-Resolution-in-Data-Pipelines-Using-Spark-36-2048.jpg)








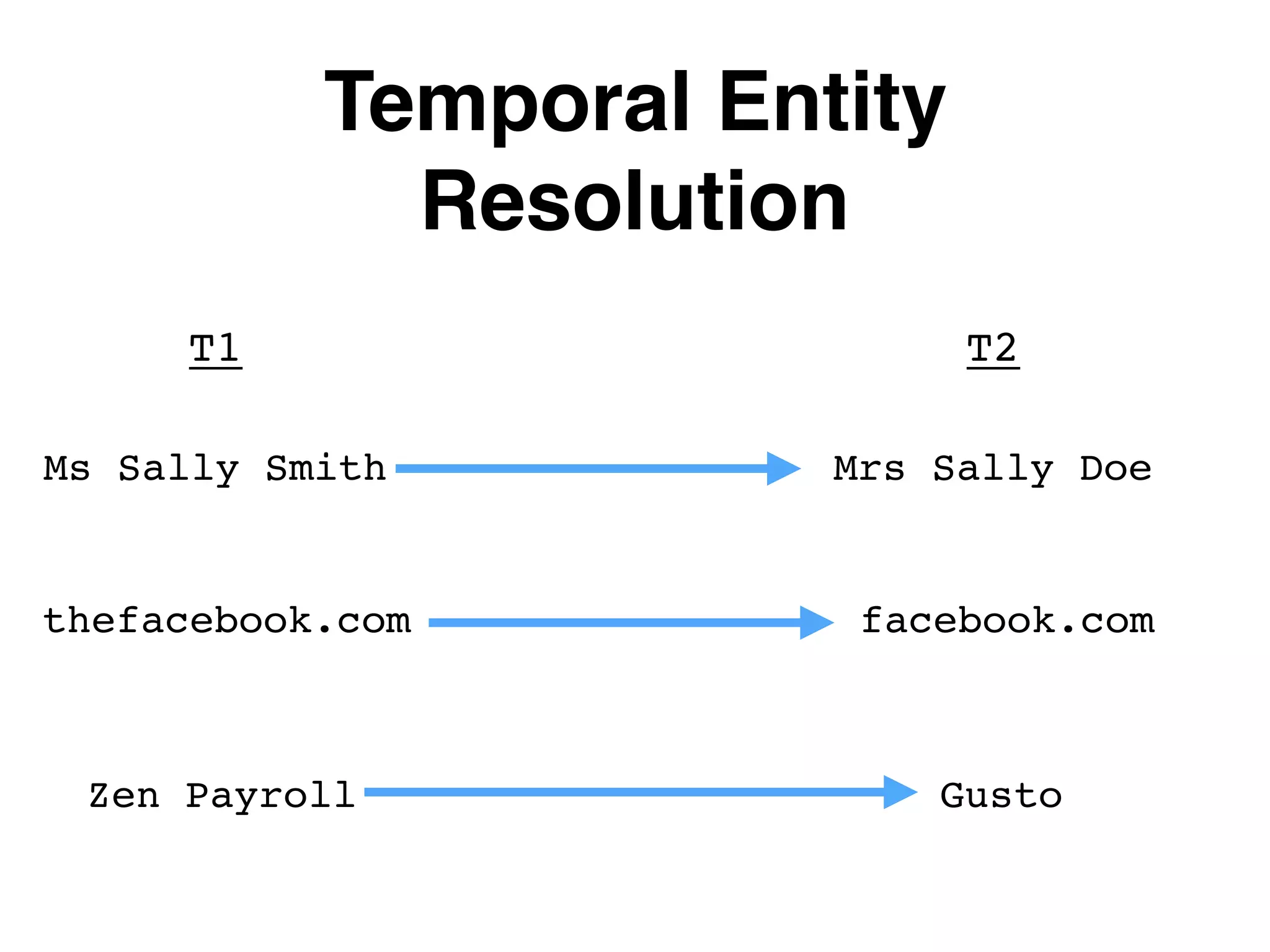

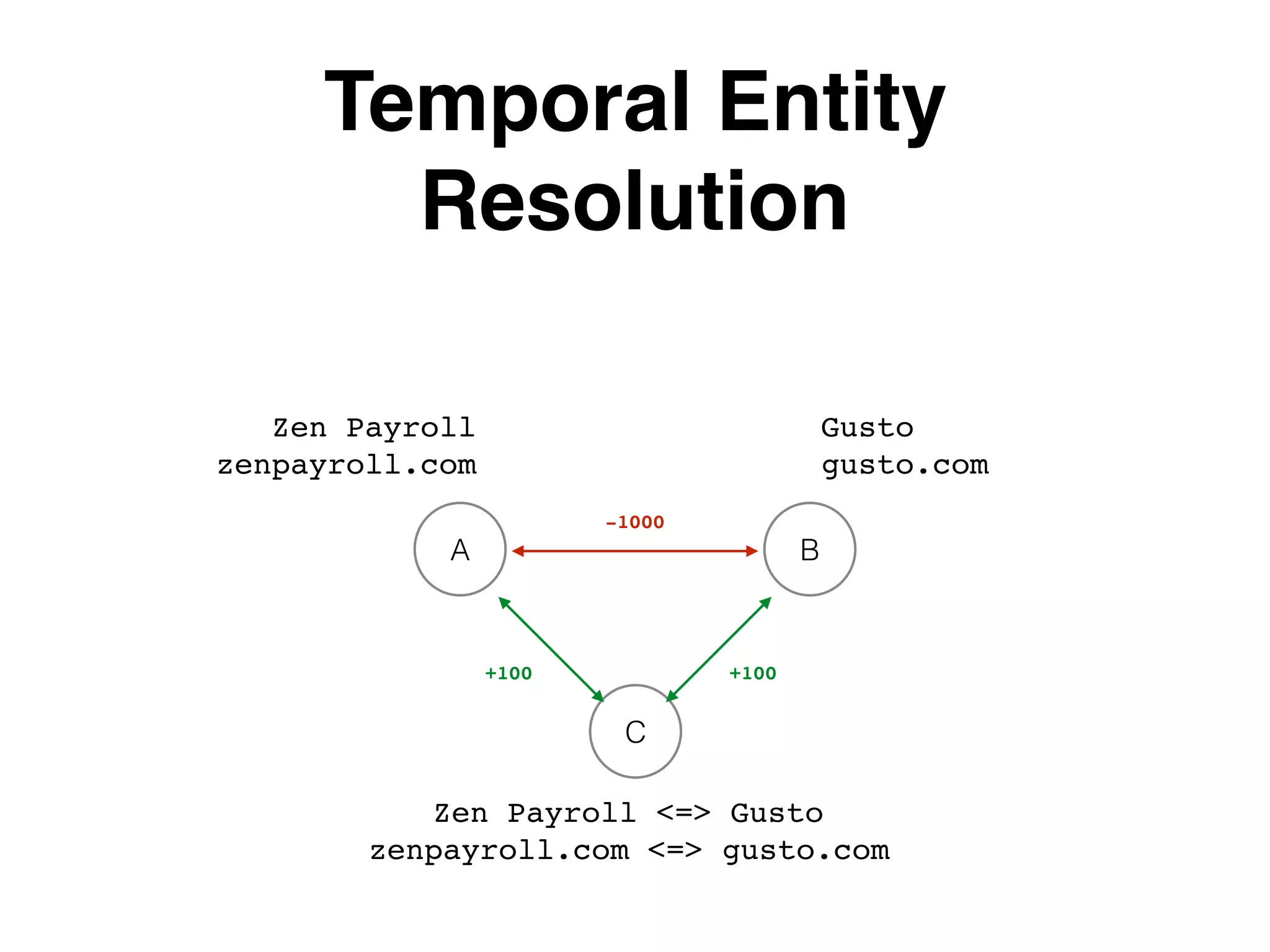

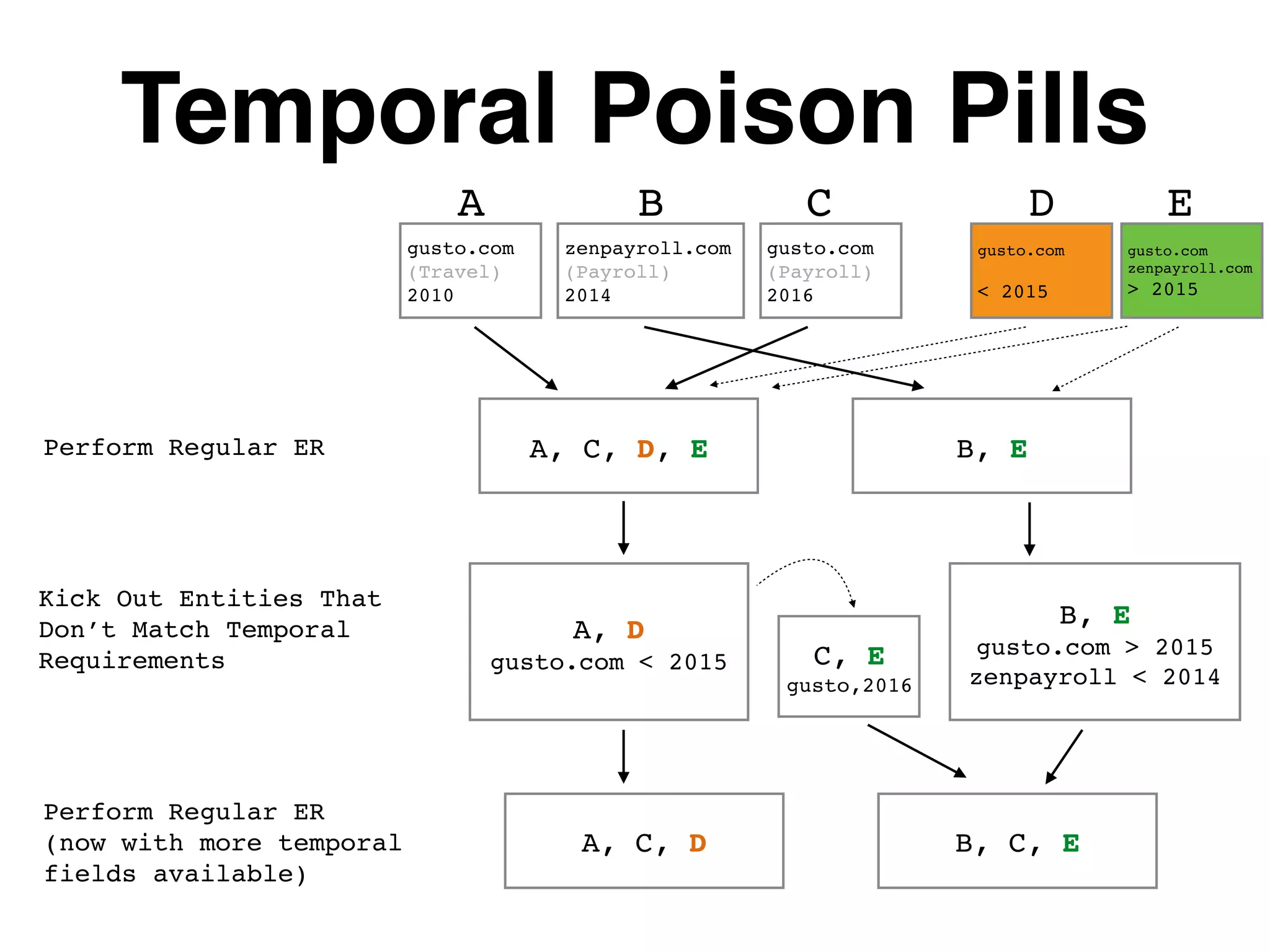









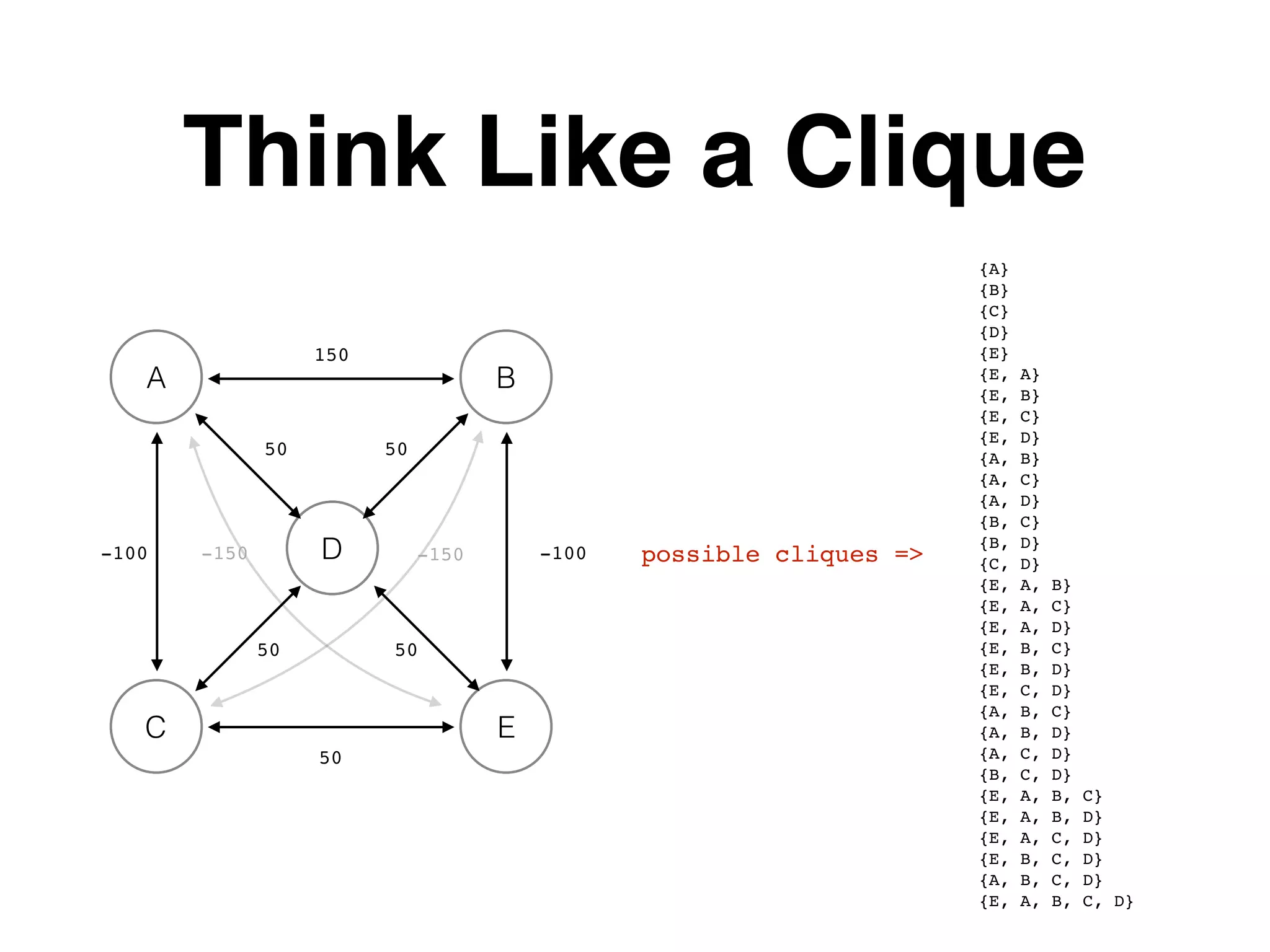
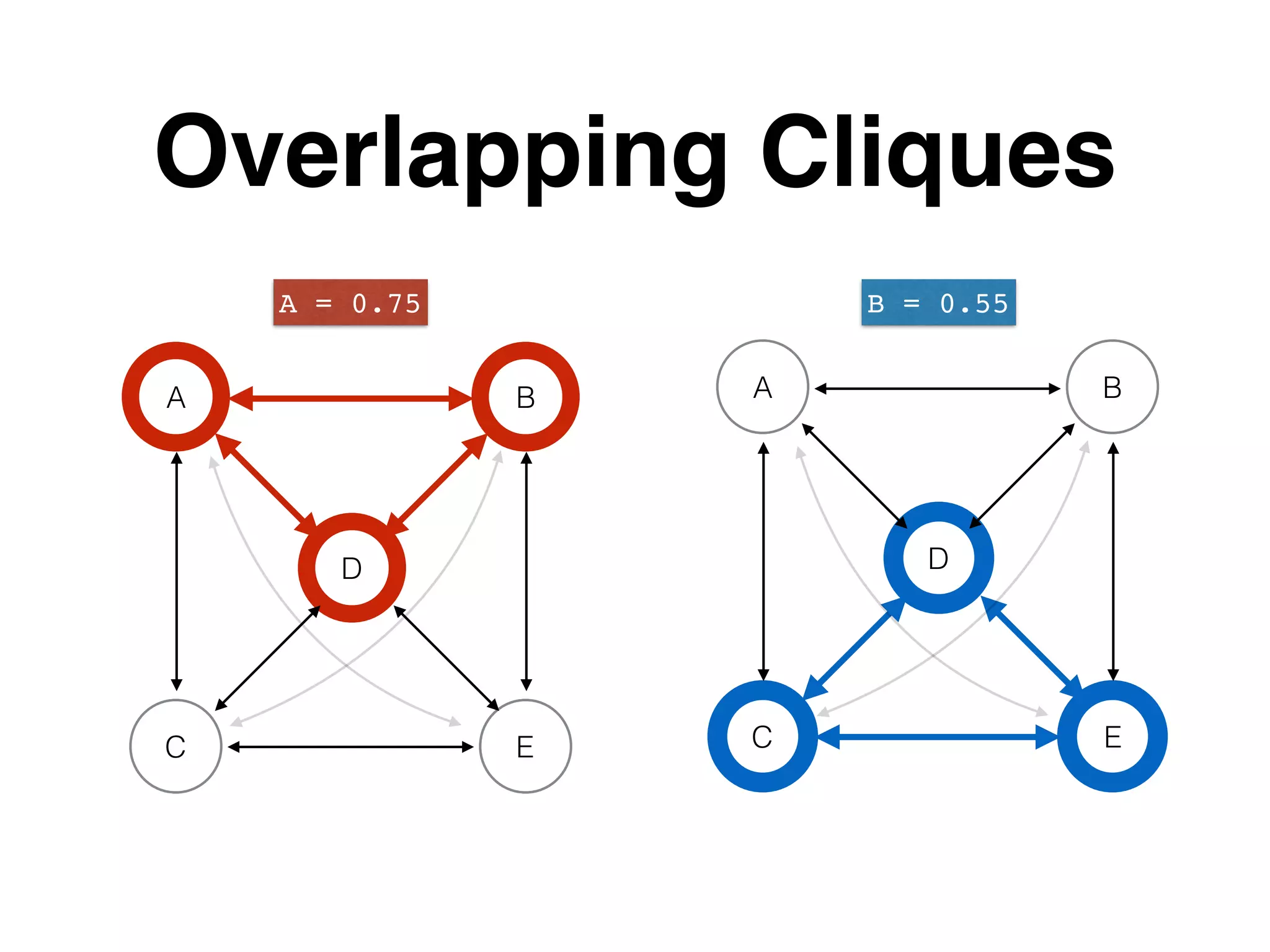
The document outlines various layers of entity resolution (ER) techniques, including naive, graphical, big data, temporal, and learned ER, illustrating their structures and challenges. It emphasizes the importance of matching entity properties and addresses issues like clique selection and locality-sensitive hashing to improve performance. Additionally, it discusses the use of supervised learning for optimizing scoring functions in ER processes.