Downloaded 20 times



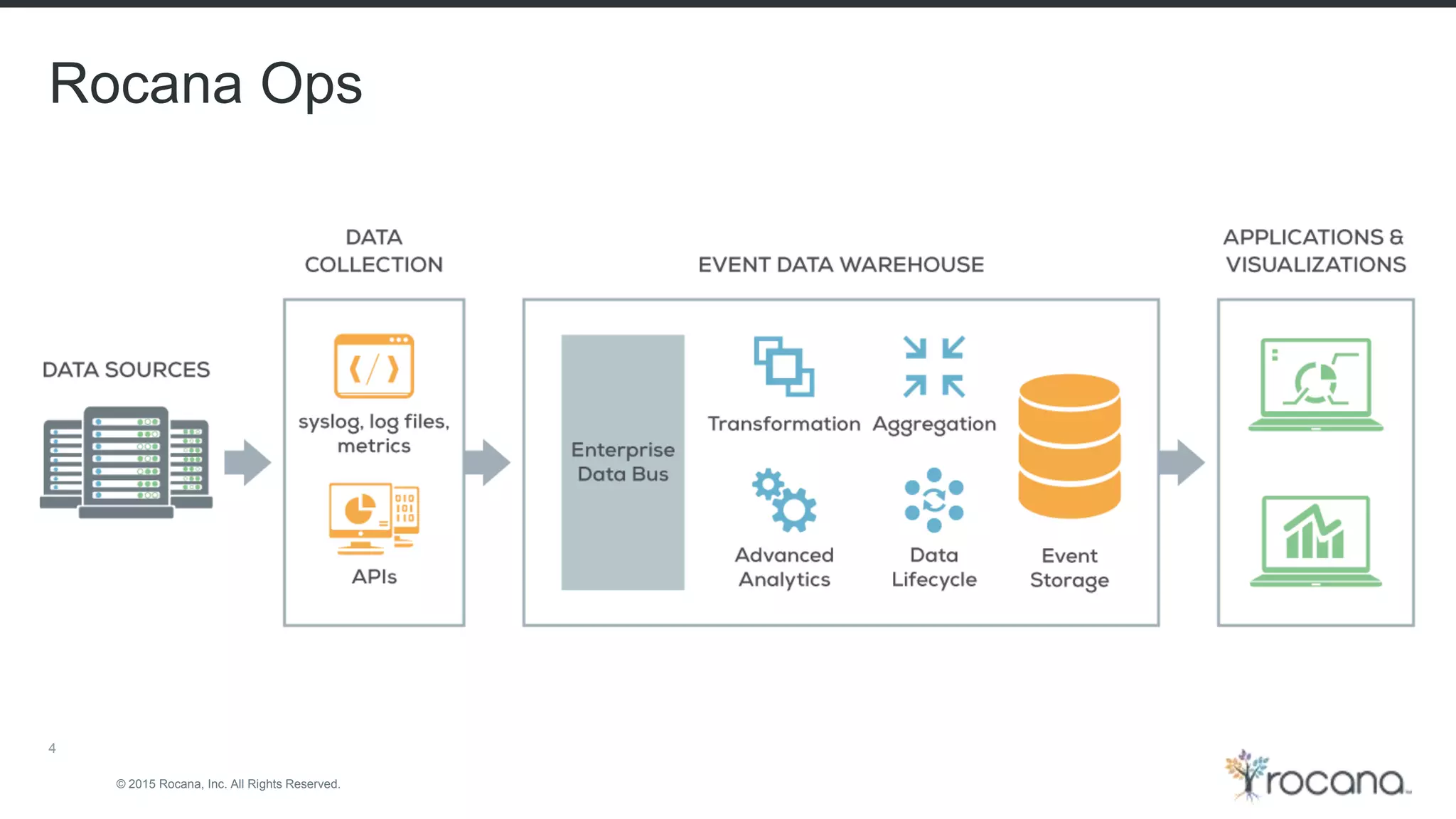


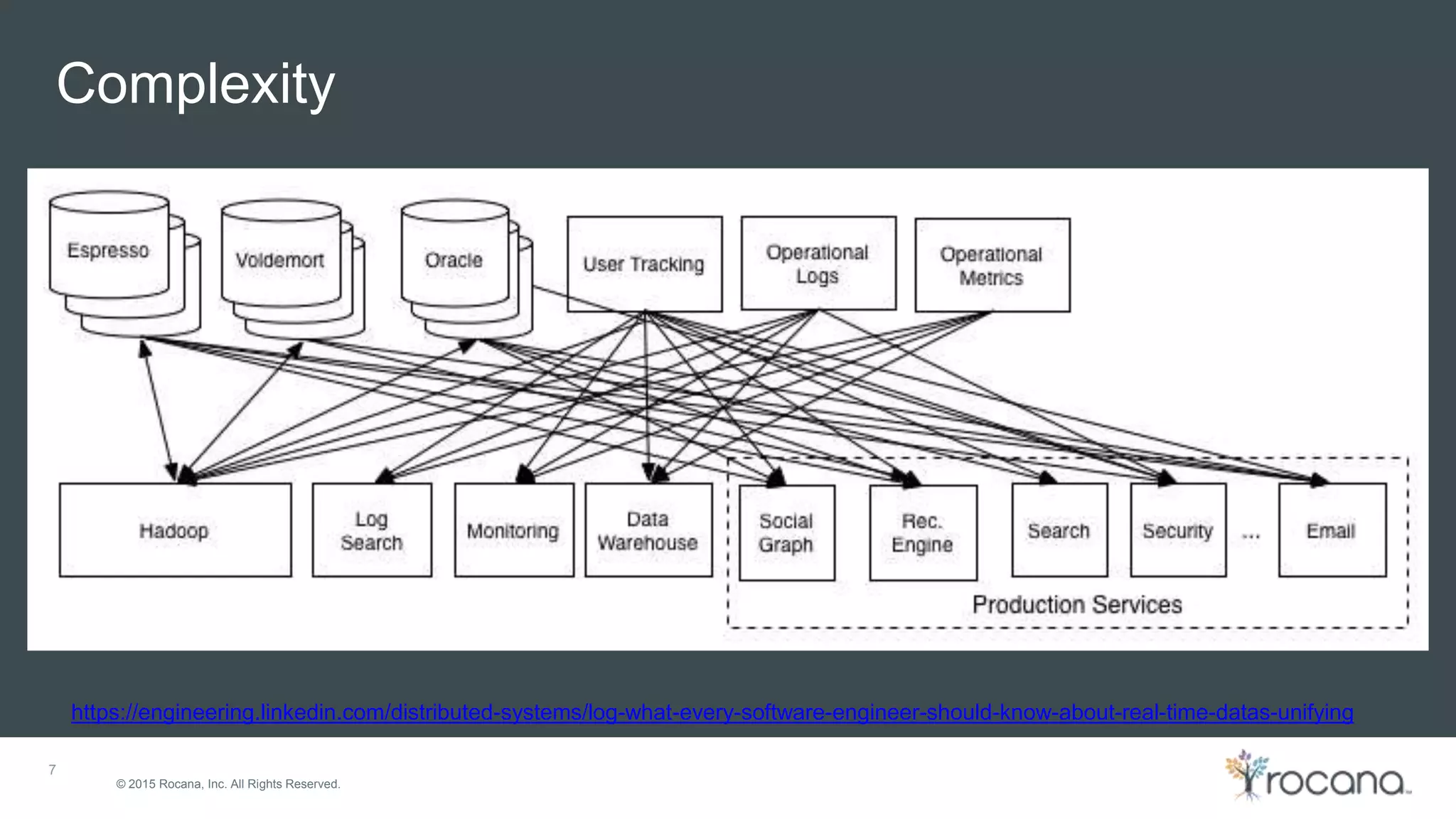

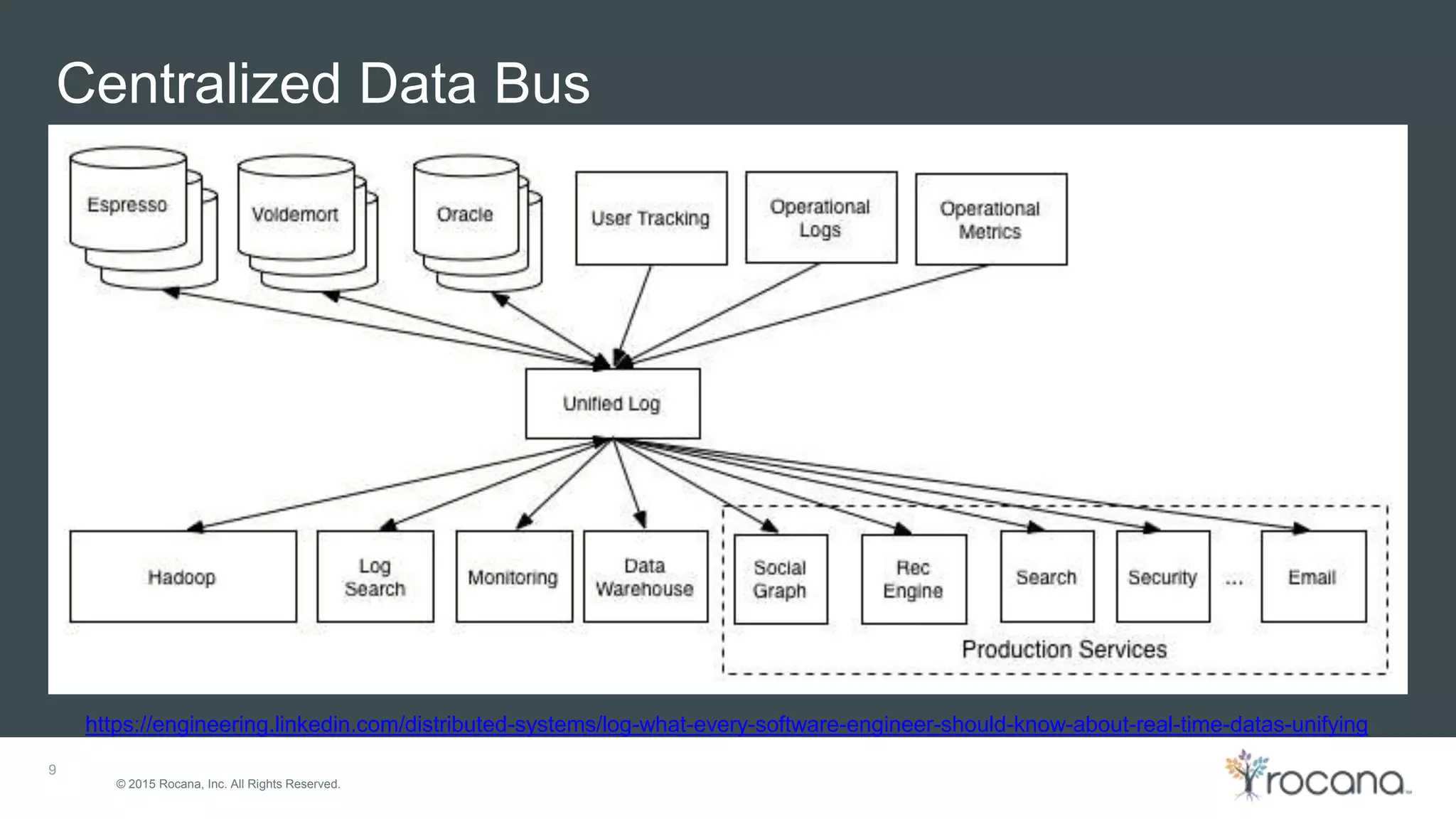


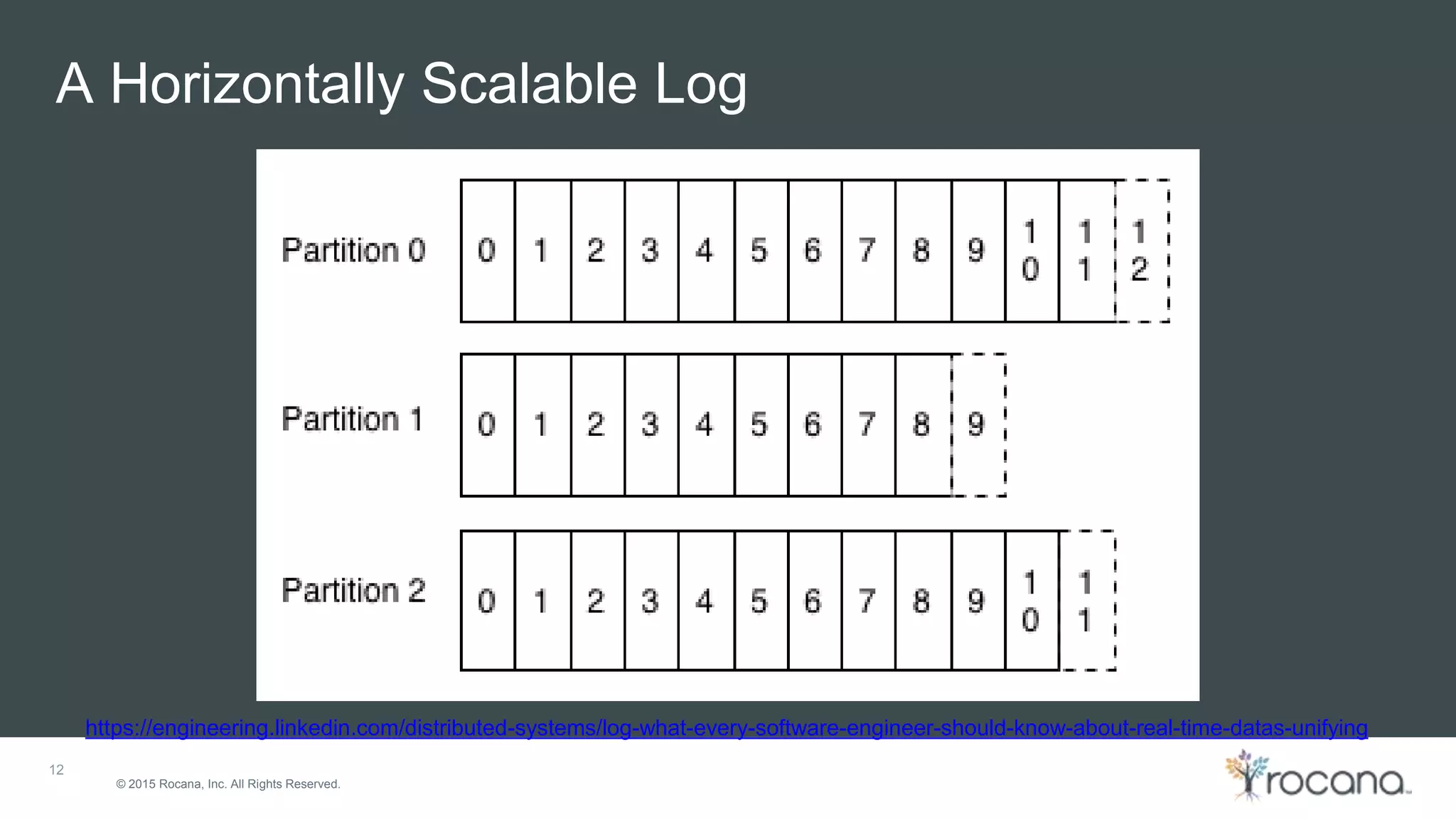
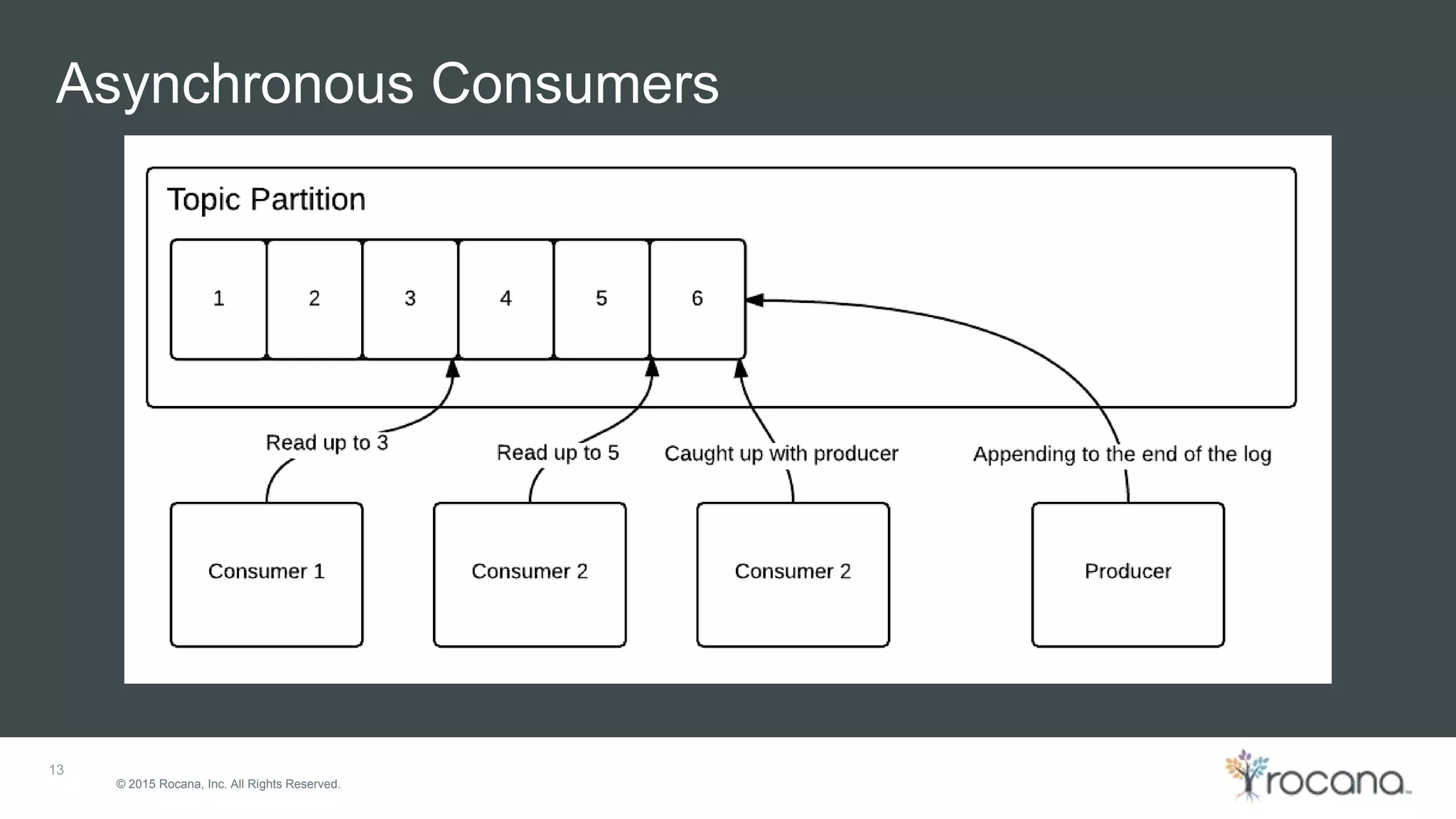

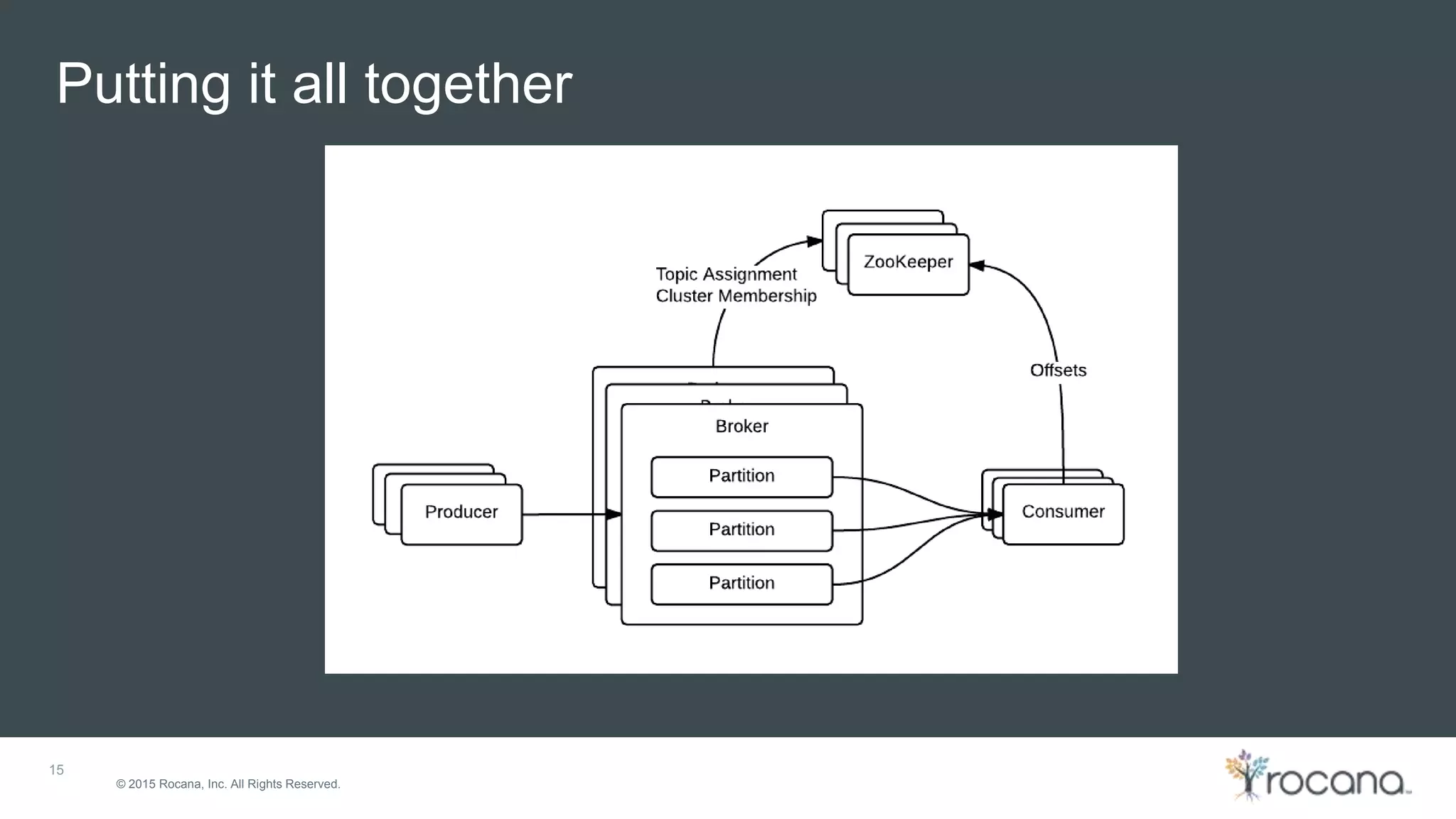

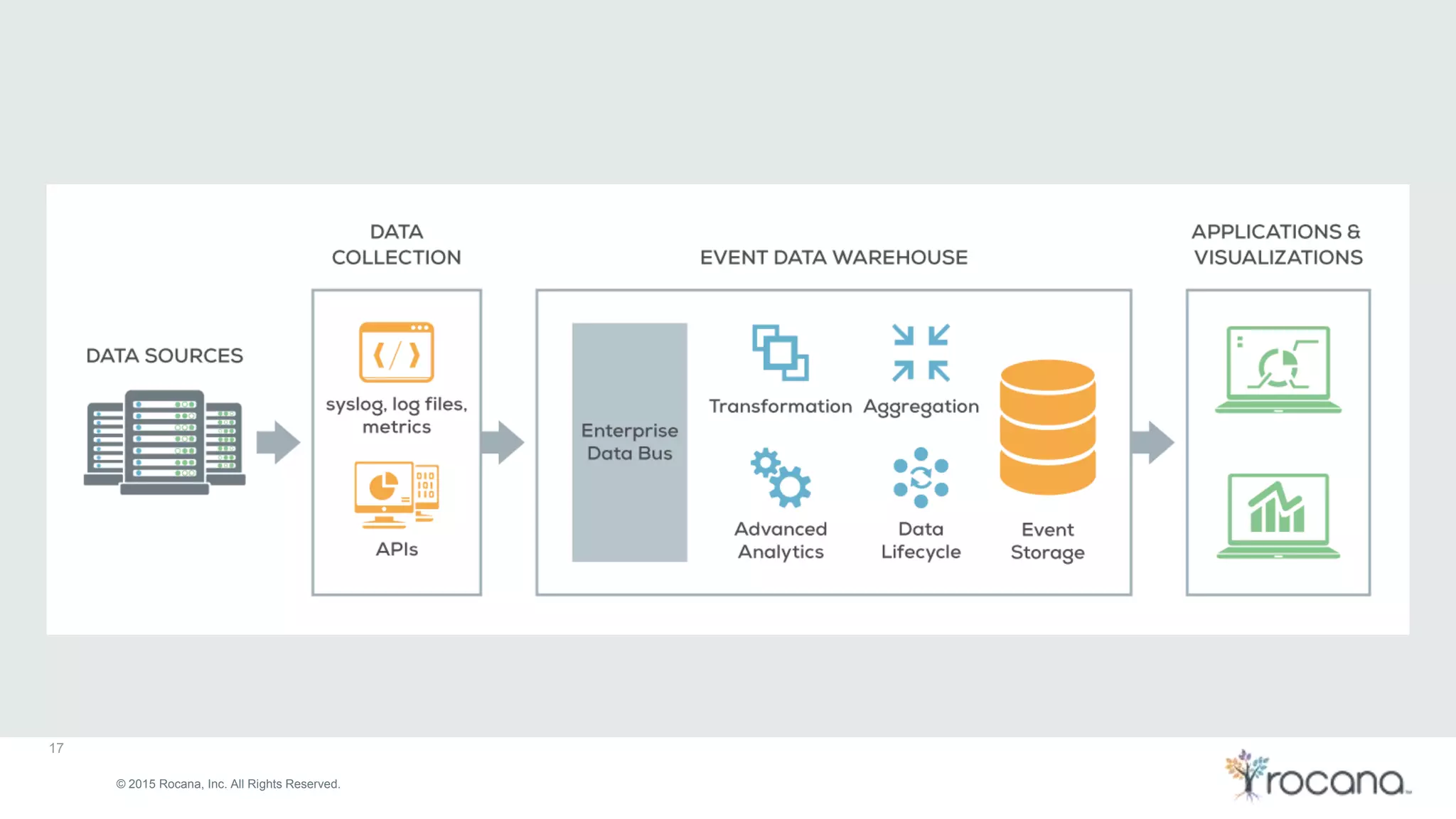












This document discusses Apache Kafka, a distributed streaming platform developed at LinkedIn and open sourced. It provides the following key points: - Kafka was designed at LinkedIn to act as a centralized data bus that scales horizontally, delivers events in order, decouples producers and consumers, and has low latency. - It uses a partitioned log structure to store streams of records immutably, replicating across nodes for fault tolerance. Producers publish records to topics which are divided into partitions. - Consumers can independently consume data from Kafka topics in a pull-based manner without relying on a shared storage layer. This allows for scaling of consumers without additional coordination.