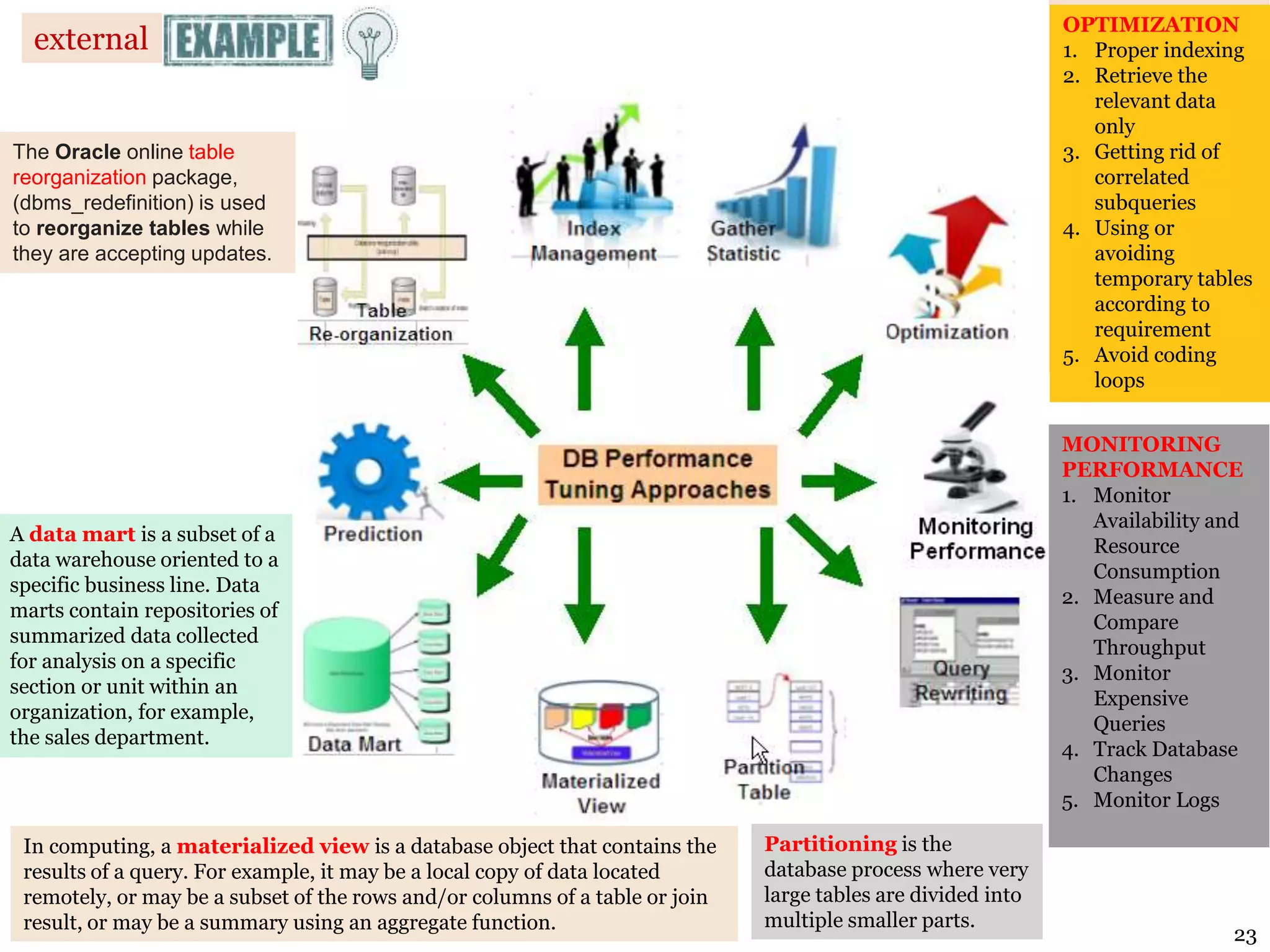
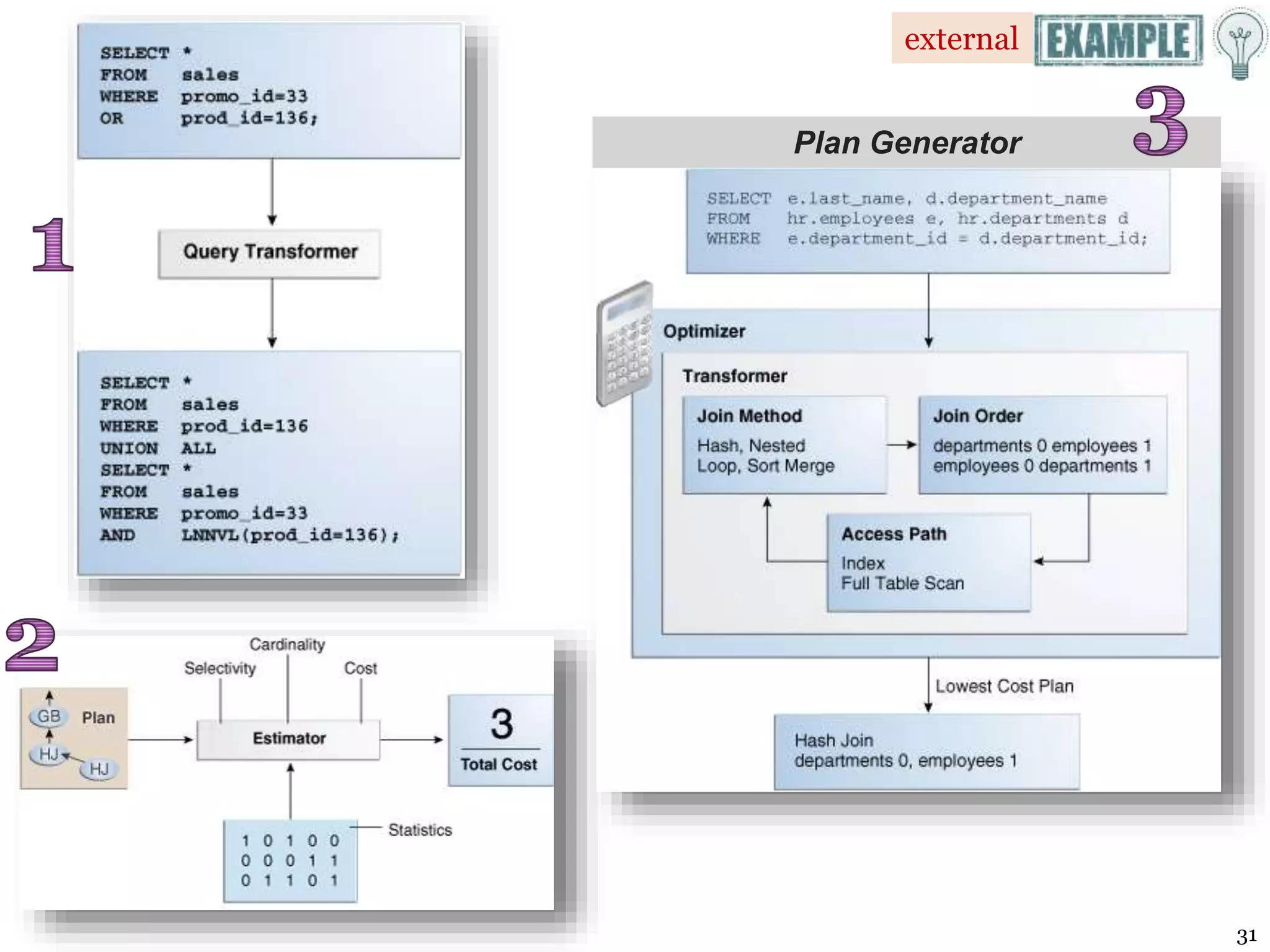
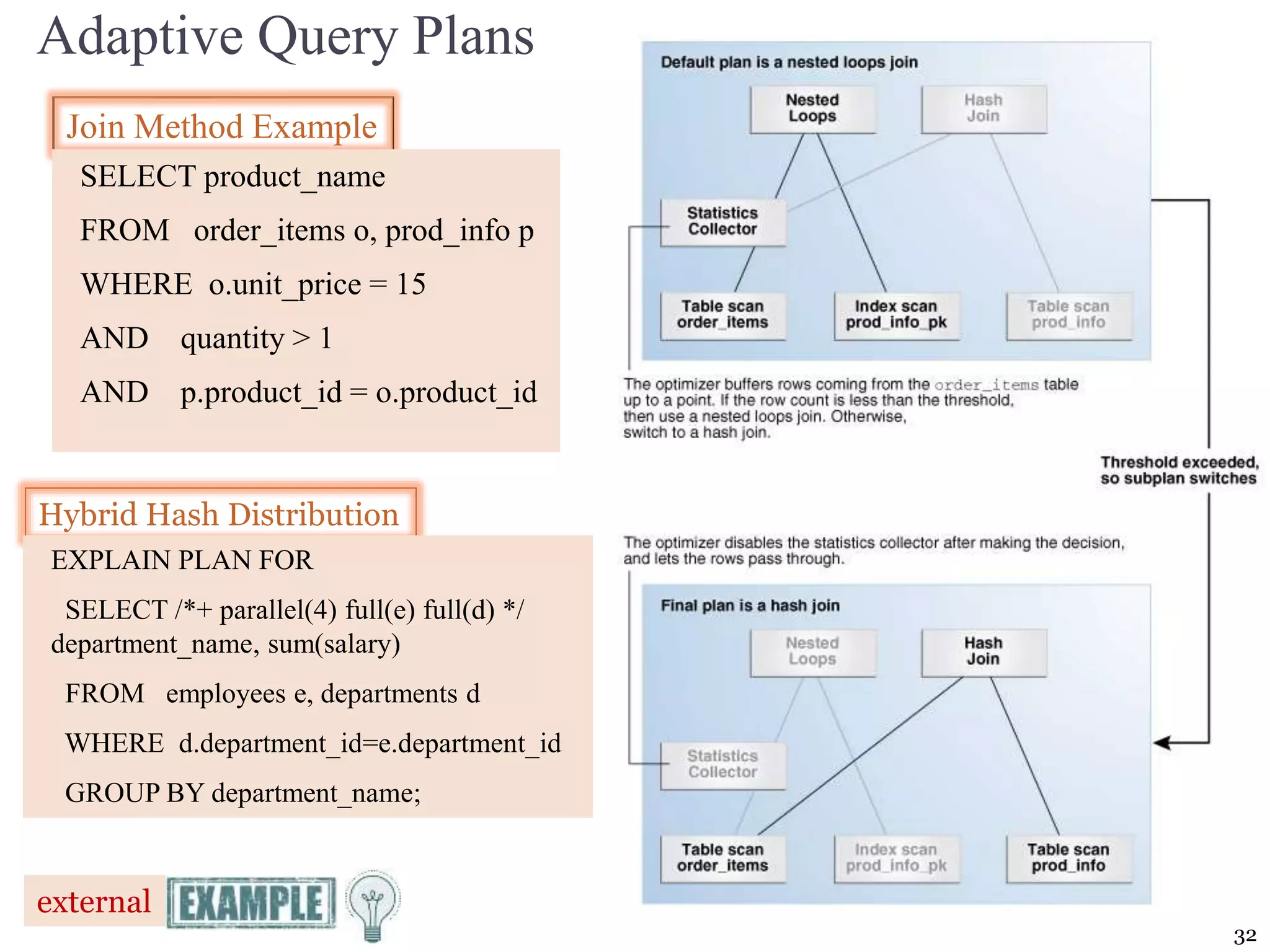
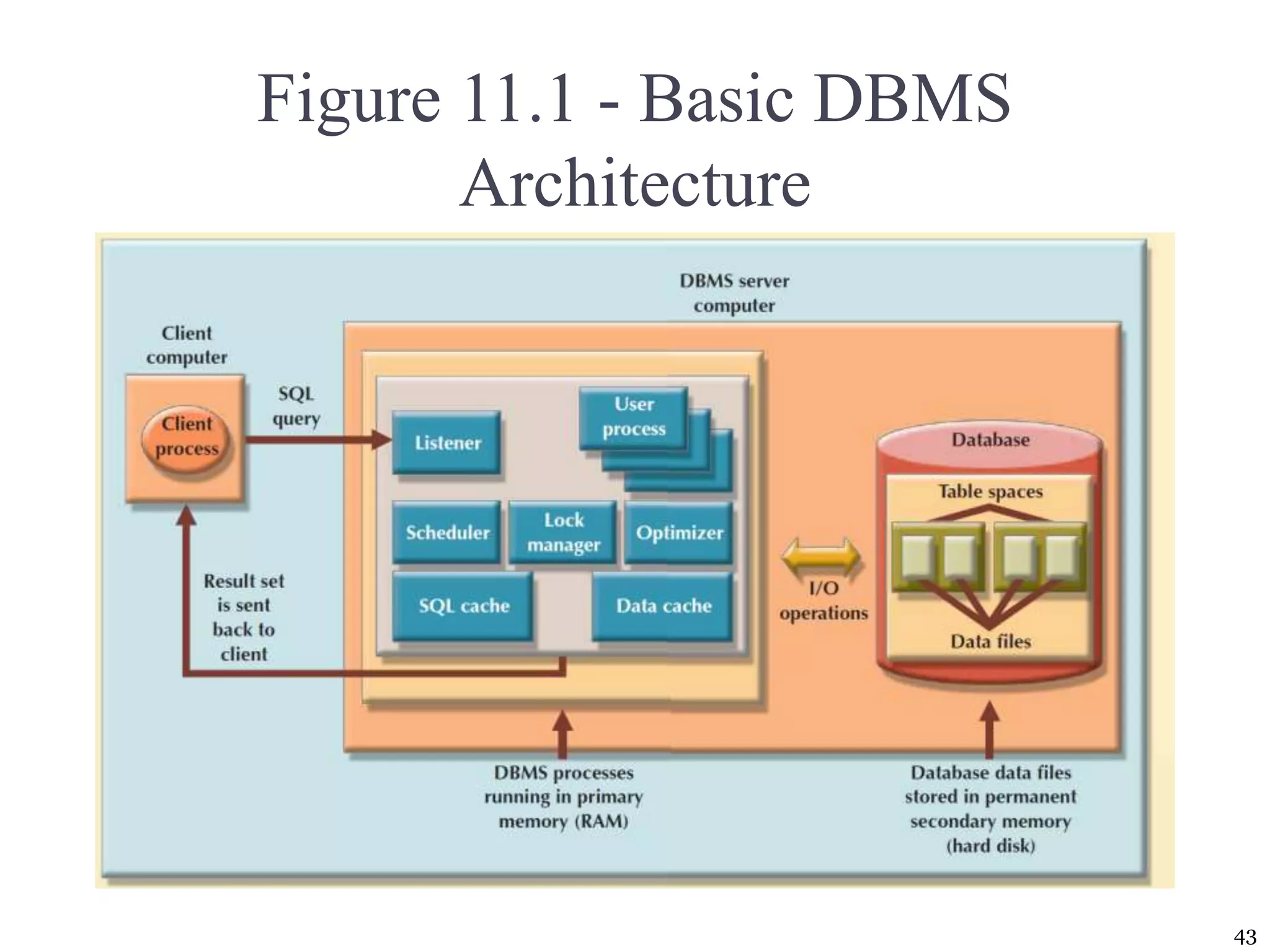
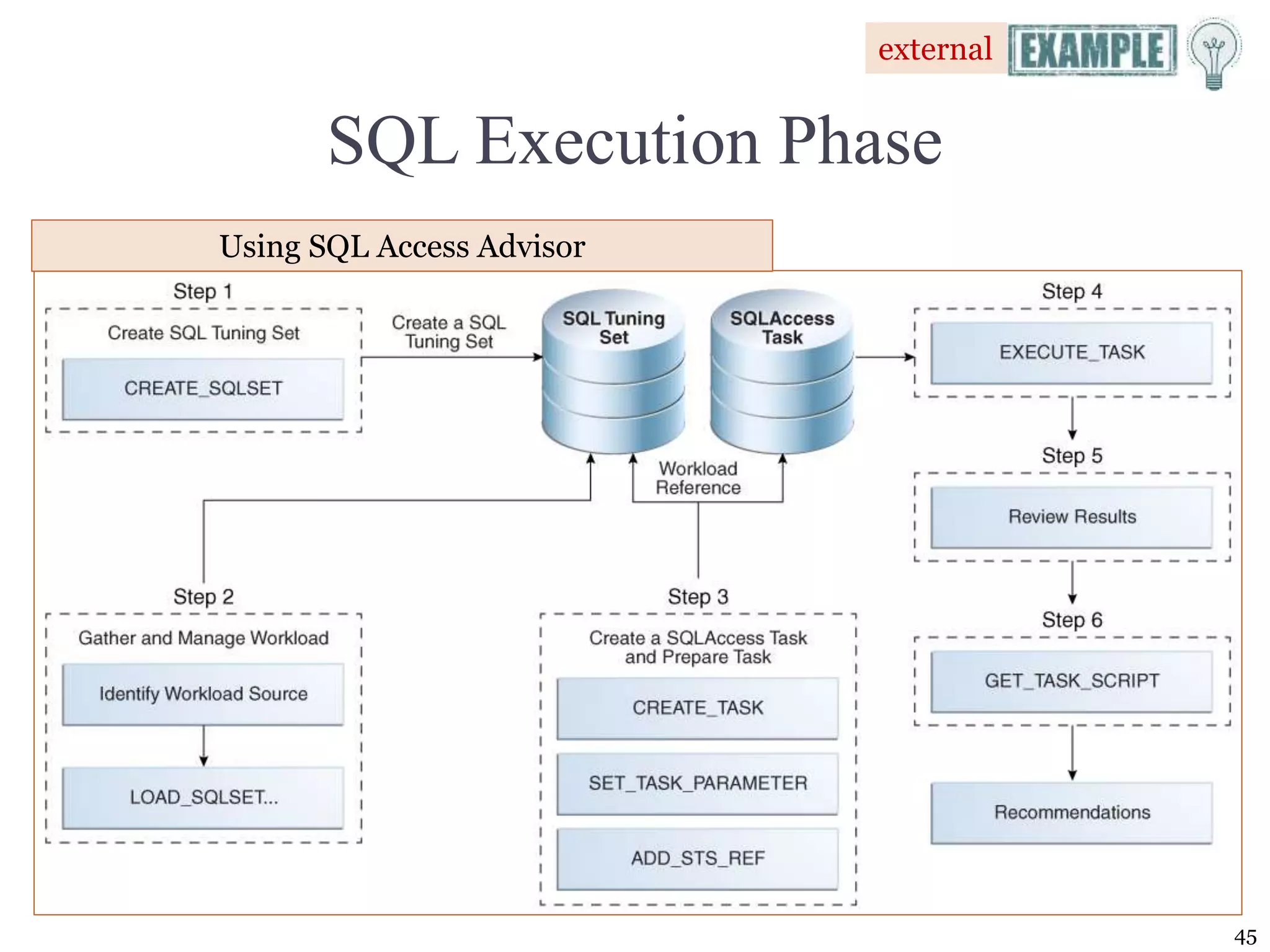
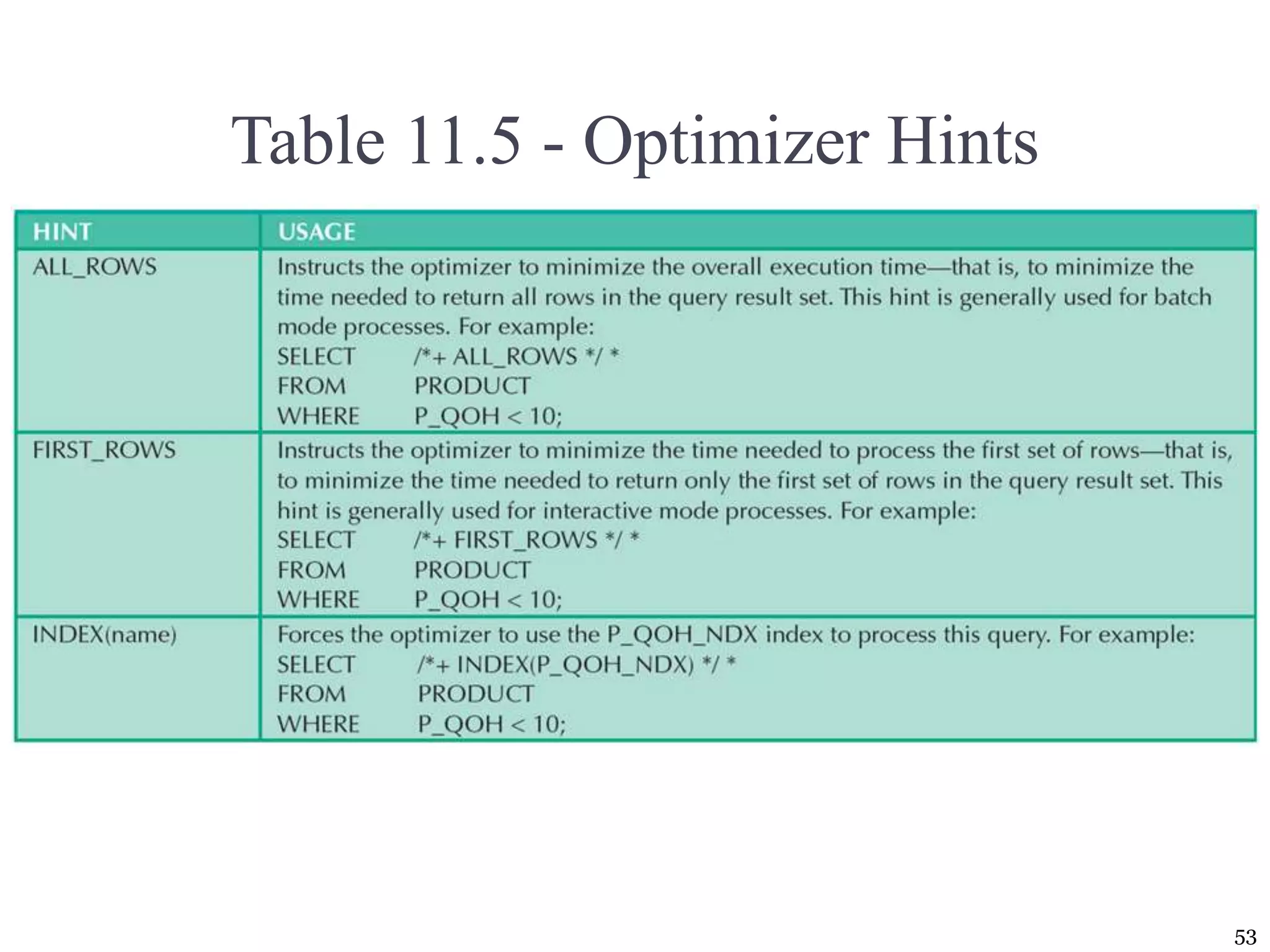
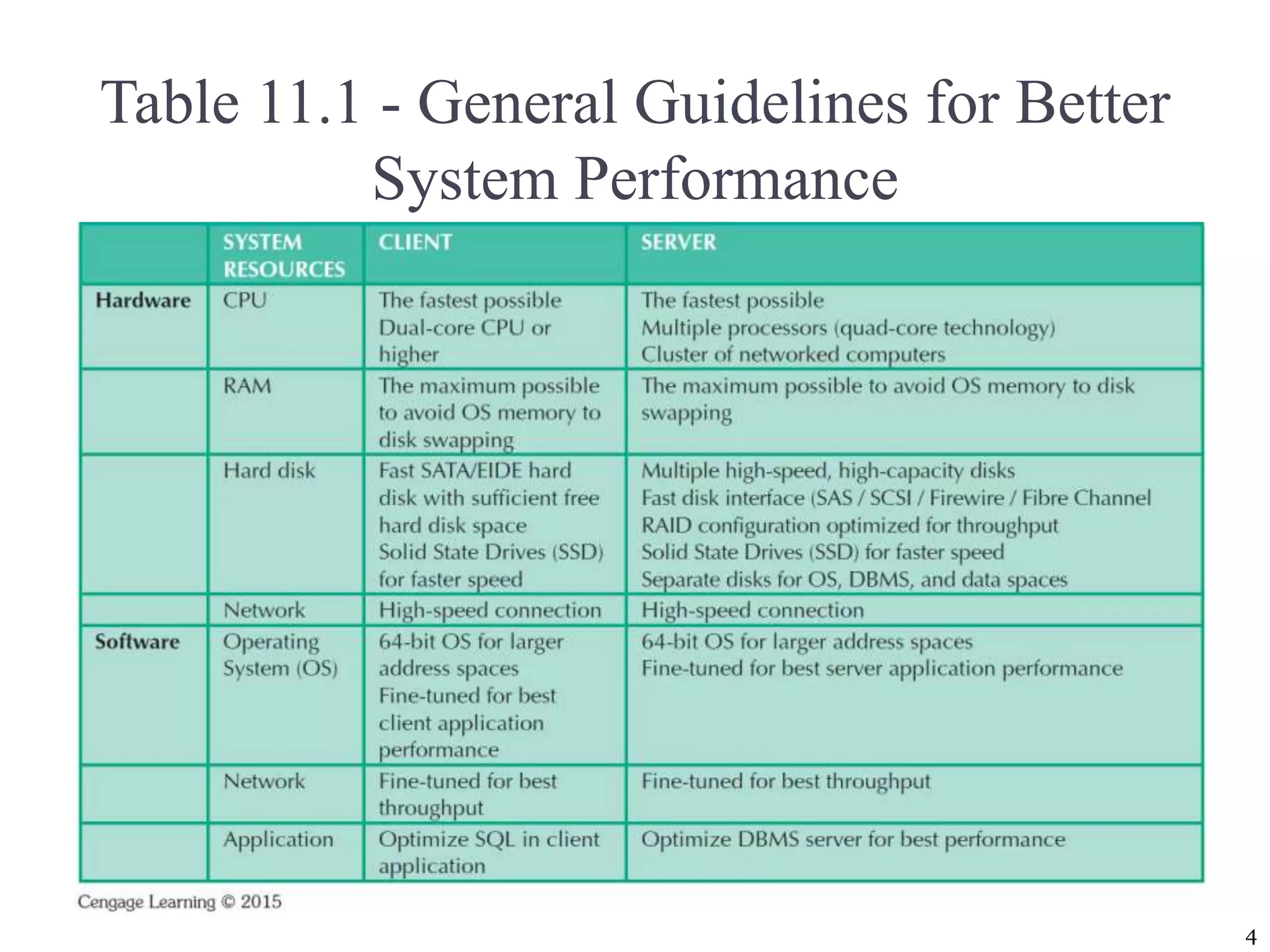
The document covers essential concepts of database performance tuning and query optimization, including SQL query processing, the significance of indexing, and practices for writing efficient SQL code. It highlights aspects like client/server performance tuning, the mechanics behind query parsing, and monitoring database performance. Additionally, it discusses DBMS architecture and various optimization strategies to improve query execution times and resource utilization.








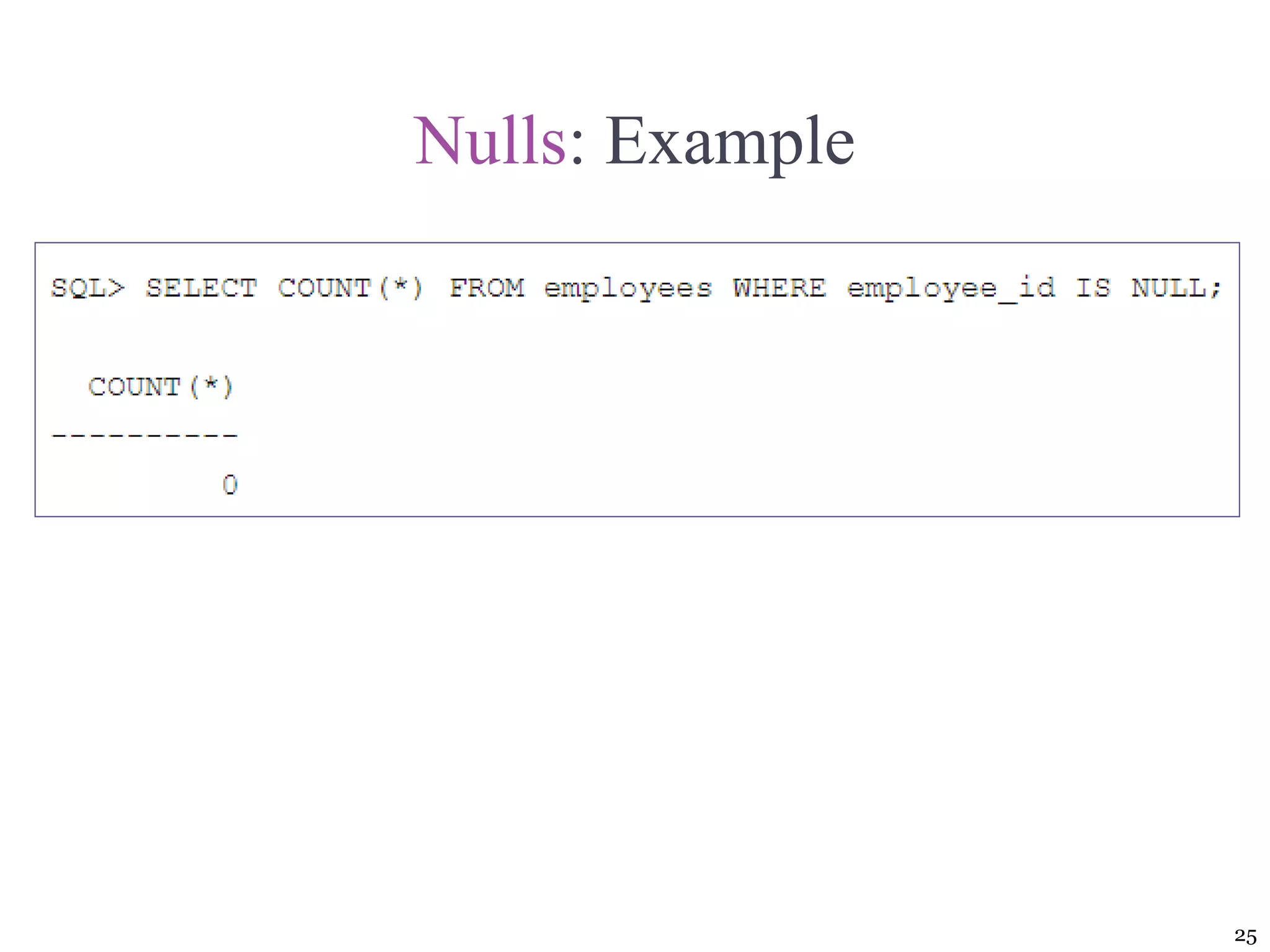
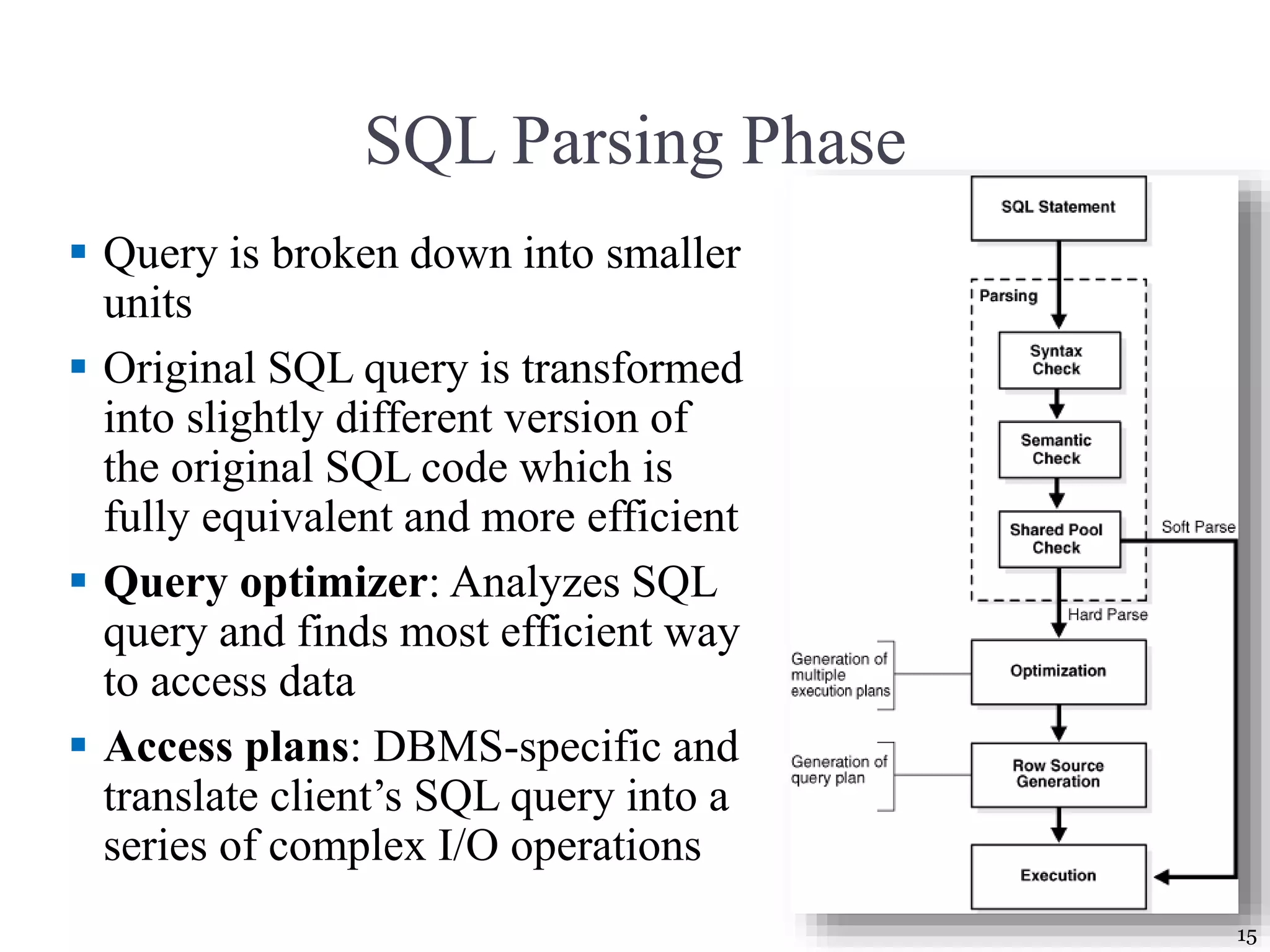
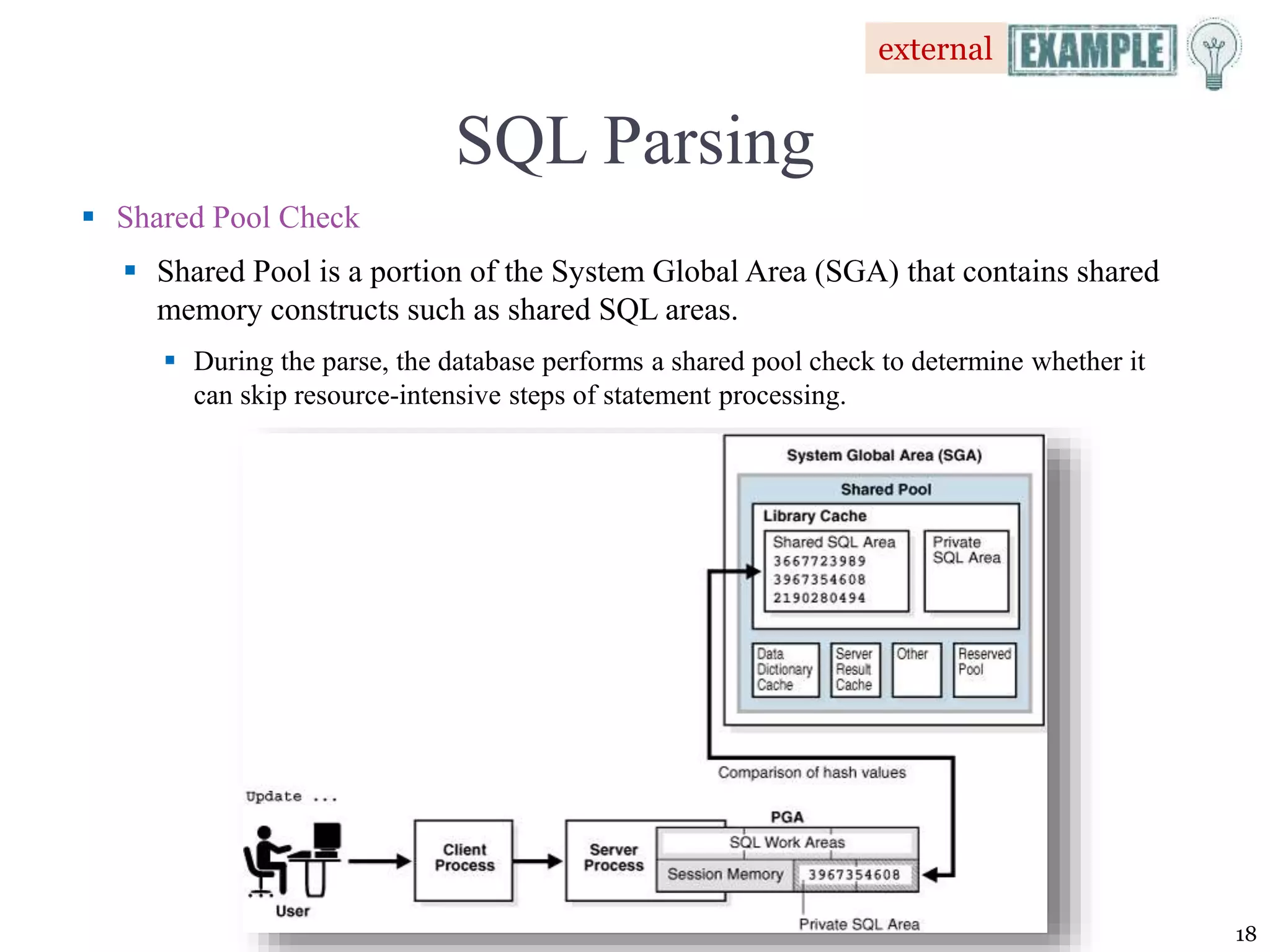
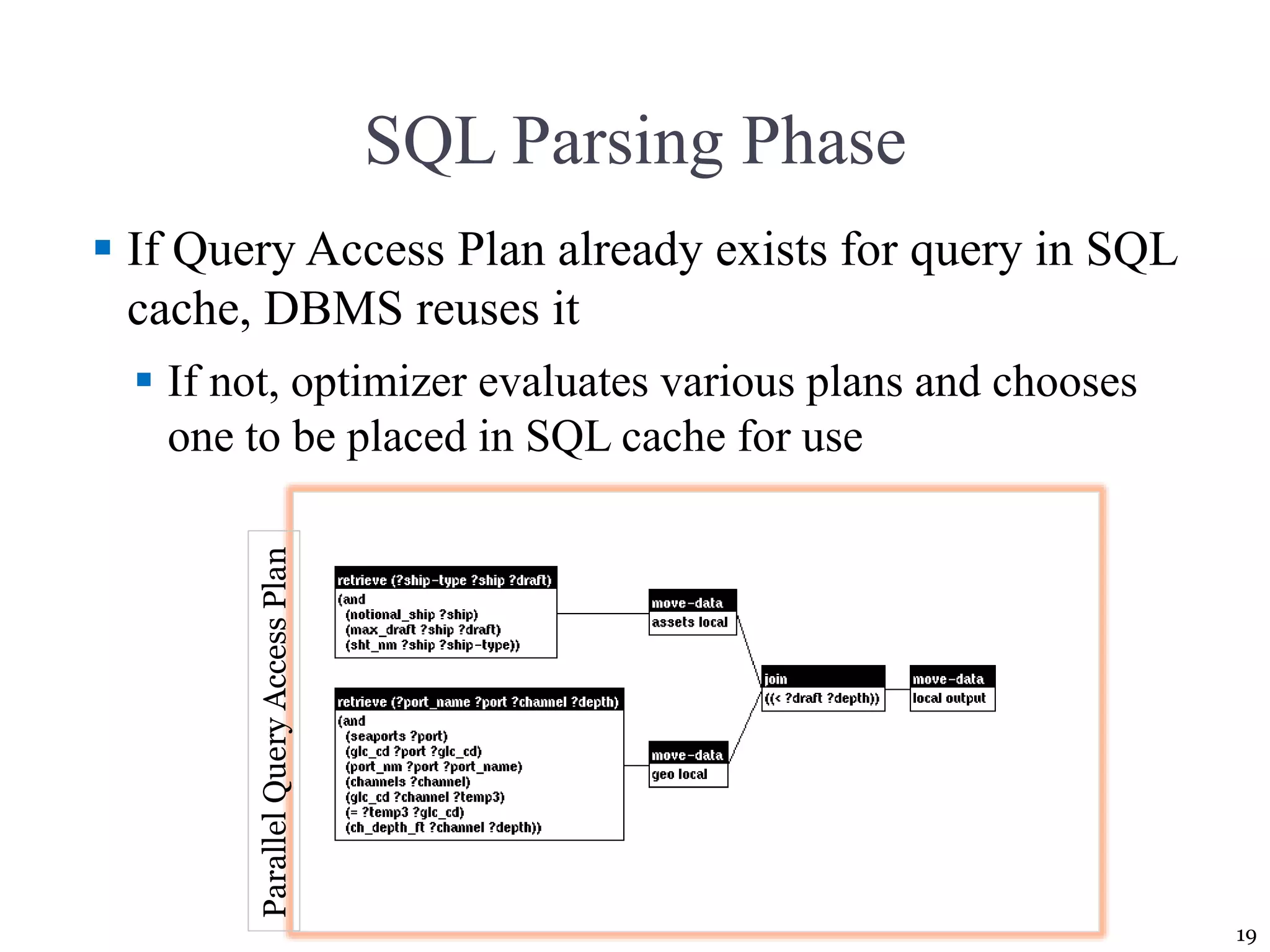
![Query Processing [1/2] Parsing. The DBMS parses the SQL query and chooses the most efficient access/execution plan. Execution. The DBMS executes the SQL query using the chosen execution plan. Fetching. The DBMS fetches the data and sends the result set back to the client. 13 SQL query is: 1. Validated for syntax compliance 2. Validated against the data dictionary to ensure that table names and column names are correct 3. Validated against the data dictionary to ensure that the user has proper access rights 4. Analyzed and decomposed into more atomic components](https://image.slidesharecdn.com/coronelpptch11-databaseperformancetuningandqueryoptimization-191215041455/75/Database-performance-tuning-and-query-optimization-13-2048.jpg)
![Query Processing [2/2] 14](https://image.slidesharecdn.com/coronelpptch11-databaseperformancetuningandqueryoptimization-191215041455/75/Database-performance-tuning-and-query-optimization-14-2048.jpg)



![Use WHERE instead of HAVING to define filters [1/2] SELECT Customers.CustomerID, Customers.Name, Count(Sales.SalesID) FROM Customers INNER JOIN Sales ON Customers.CustomerID = Sales.CustomerID GROUP BY Customers.CustomerID, Customers.Name HAVING Sales.LastSaleDate BETWEEN #1/1/2019# AND #12/31/2019# 21 SELECT Customers.CustomerID, Customers.Name, Count(Sales.SalesID) FROM Customers INNER JOIN Sales ON Customers.CustomerID = Sales.CustomerID WHERE Sales.LastSaleDate BETWEEN #10/10/2019# AND #17/10/2019# GROUP BY Customers.CustomerID, Customers.Name](https://image.slidesharecdn.com/coronelpptch11-databaseperformancetuningandqueryoptimization-191215041455/75/Database-performance-tuning-and-query-optimization-21-2048.jpg)
![Use WHERE instead of HAVING to define filters [2/2] 22 SELECT Customers.CustomerID, Customers.Name, Count(Sales.SalesID) FROM Customers INNER JOIN Sales ON Customers.CustomerID = Sales.CustomerID WHERE Sales.LastSaleDate BETWEEN #10/10/2019# AND #17/10/2019# GROUP BY Customers.CustomerID, Customers.Name HAVING Count(Sales.SalesID) > 5 HAVING should only be used when filtering on an aggregated field. In the query above, we could additionally filter for customers with greater than 5 sales using a HAVING statement.](https://image.slidesharecdn.com/coronelpptch11-databaseperformancetuningandqueryoptimization-191215041455/75/Database-performance-tuning-and-query-optimization-22-2048.jpg)