This document discusses distributed database management systems (DBMS). It covers topics like distributed database design, distributed query processing, and transaction management in a distributed environment. It also discusses parallel DBMS architectures like shared memory, shared disk, and shared nothing and techniques for data partitioning, parallel query processing and optimization in a distributed parallel DBMS.
Introduction to distributed DBMS, focusing on design, integration, processing, transaction management, and current issues.
Identifies the I/O bottleneck in databases, predicts growth in technology, and concludes worsening impact on performance.
Discusses increasing I/O bandwidth via data partitioning and parallel access, transitioning from hardware-focused to multiprocessor solutions.
Highlights goals for multiprocessors including high performance and effective load balancing in communication.
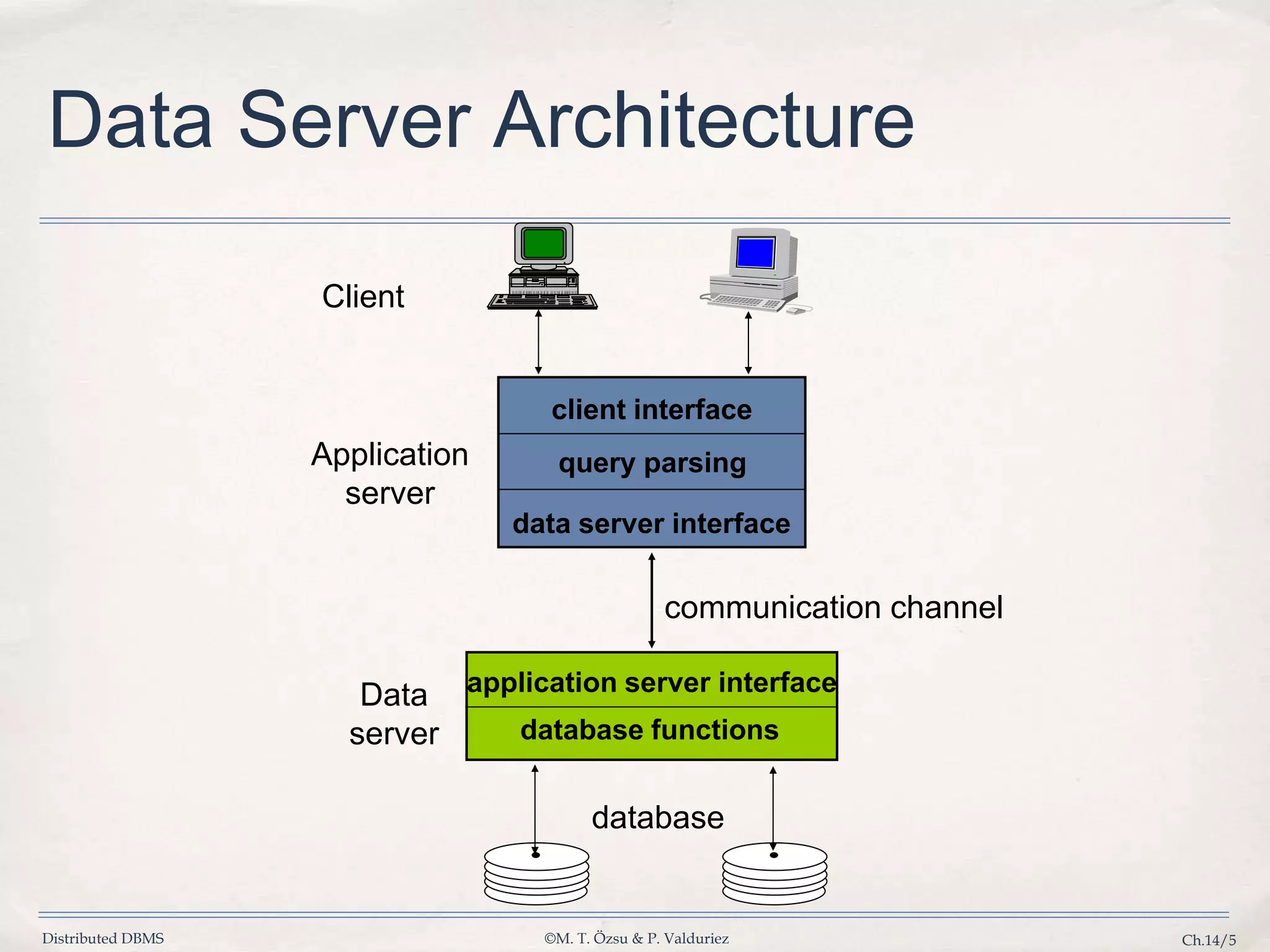
Illustrates the layered architecture of data servers, including client interfaces and communication channels.
Describes benefits of separating application and data management functions to improve efficiency.
Lists advantages like integrated data control and performance, and challenges such as communication overhead.
Explains methods for leveraging multiprocessor systems, discussing automatic detection of parallelism, language enhancements, and new language offerings.
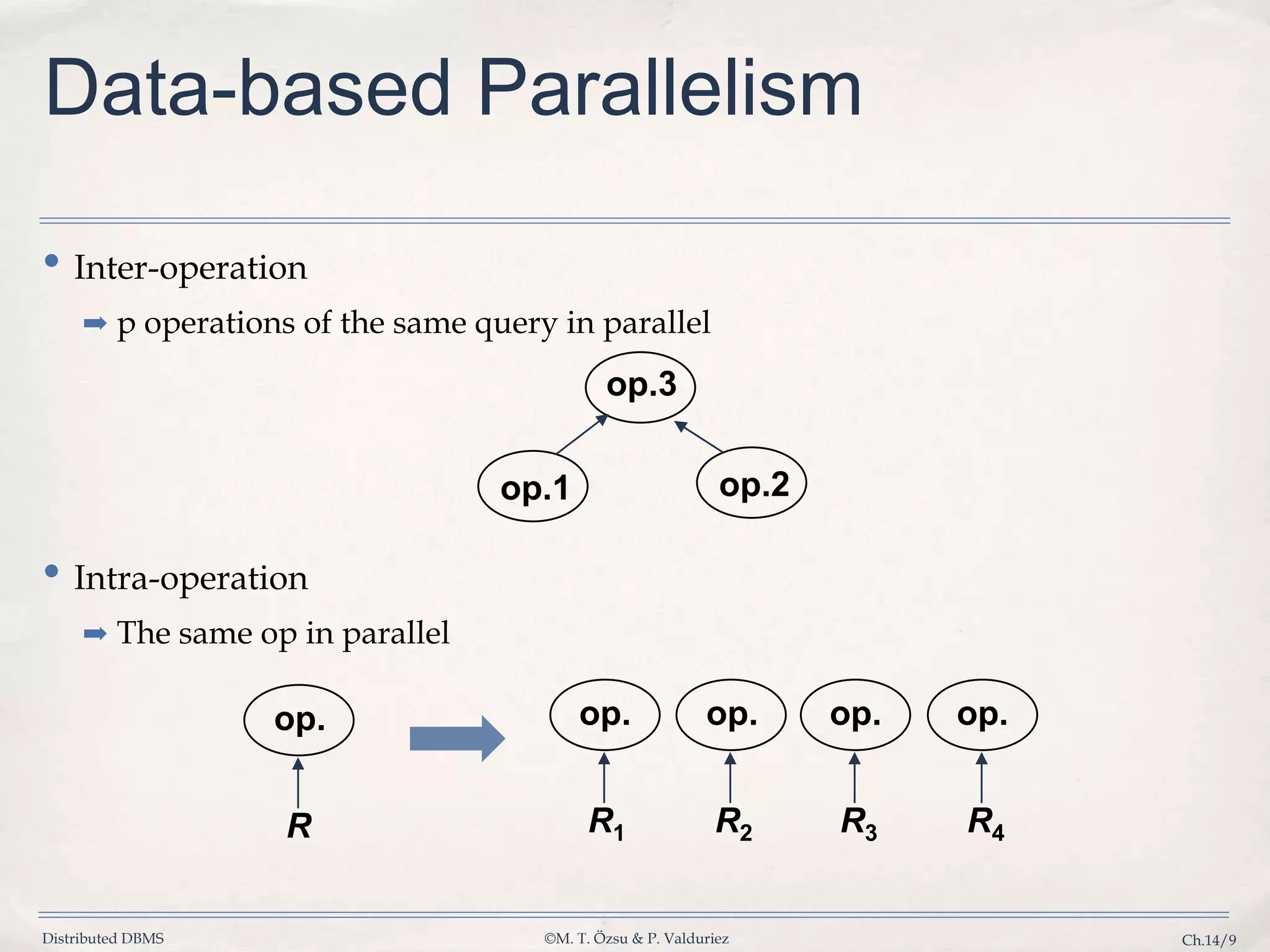
Differentiates between inter-operation and intra-operation parallelism for improved query execution.
Defines parallel DBMS and contrasts between straightforward ports of relational DBMS and new hardware/software combinations.
Outlines goals for cost-performance, high throughput, low response time, and reliability through replication.
Discusses linear speed-up and scale-up strategies by increasing components or database size while maintaining performance.
Identifies barriers such as startup time, interference, and skew in parallel processing and management.
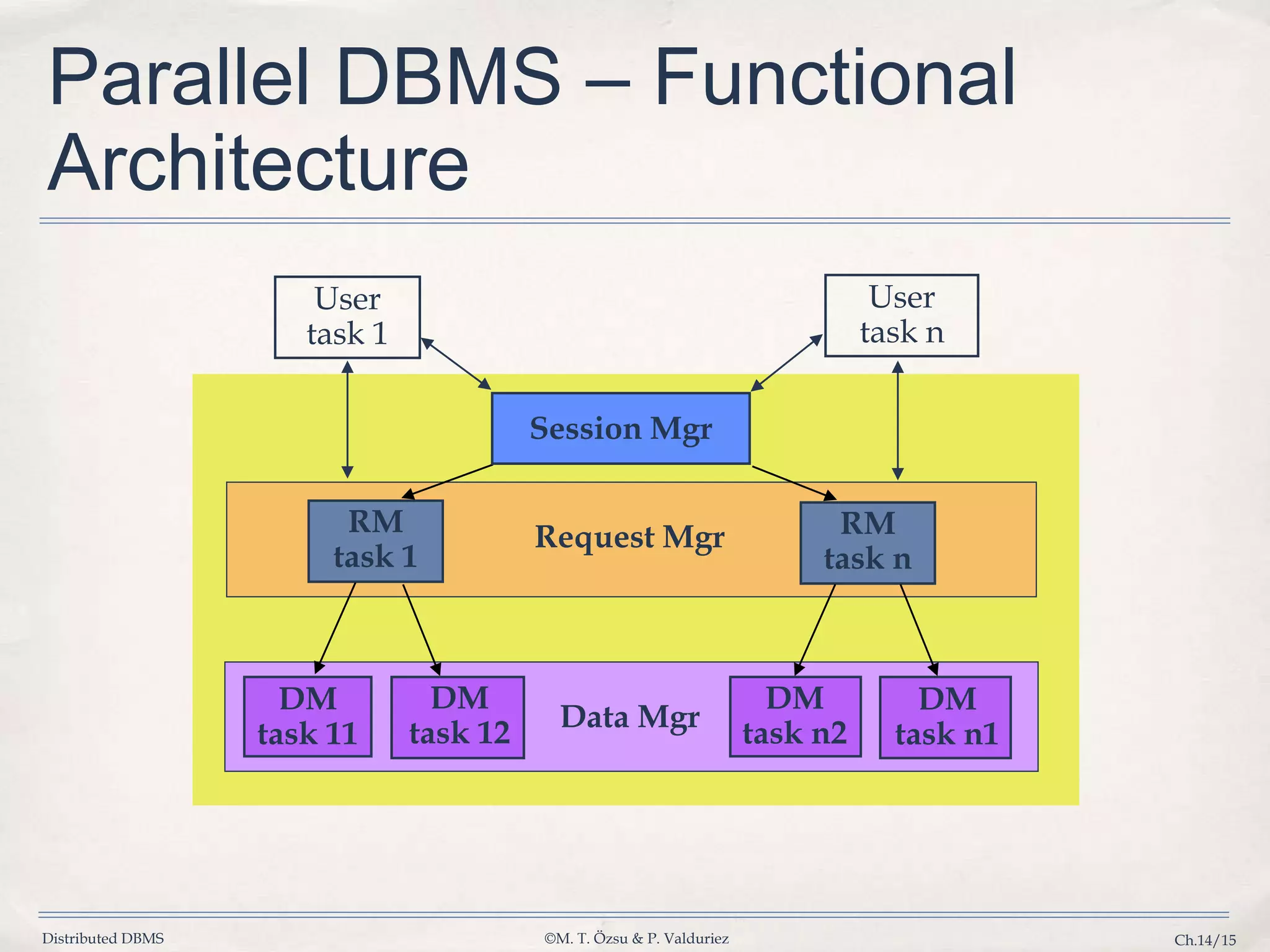
Presentation of the functional architecture with roles of session, request, and data managers.
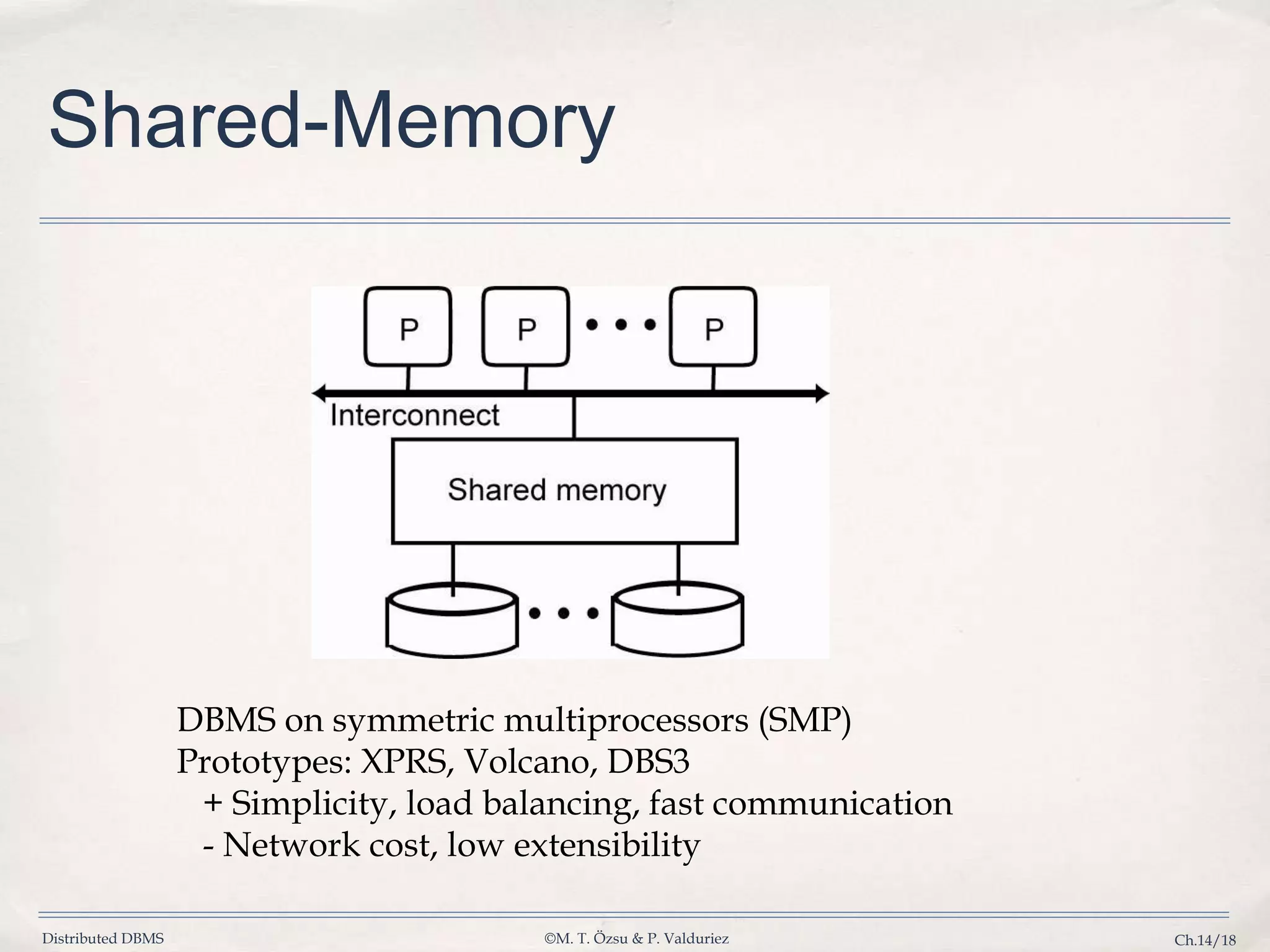
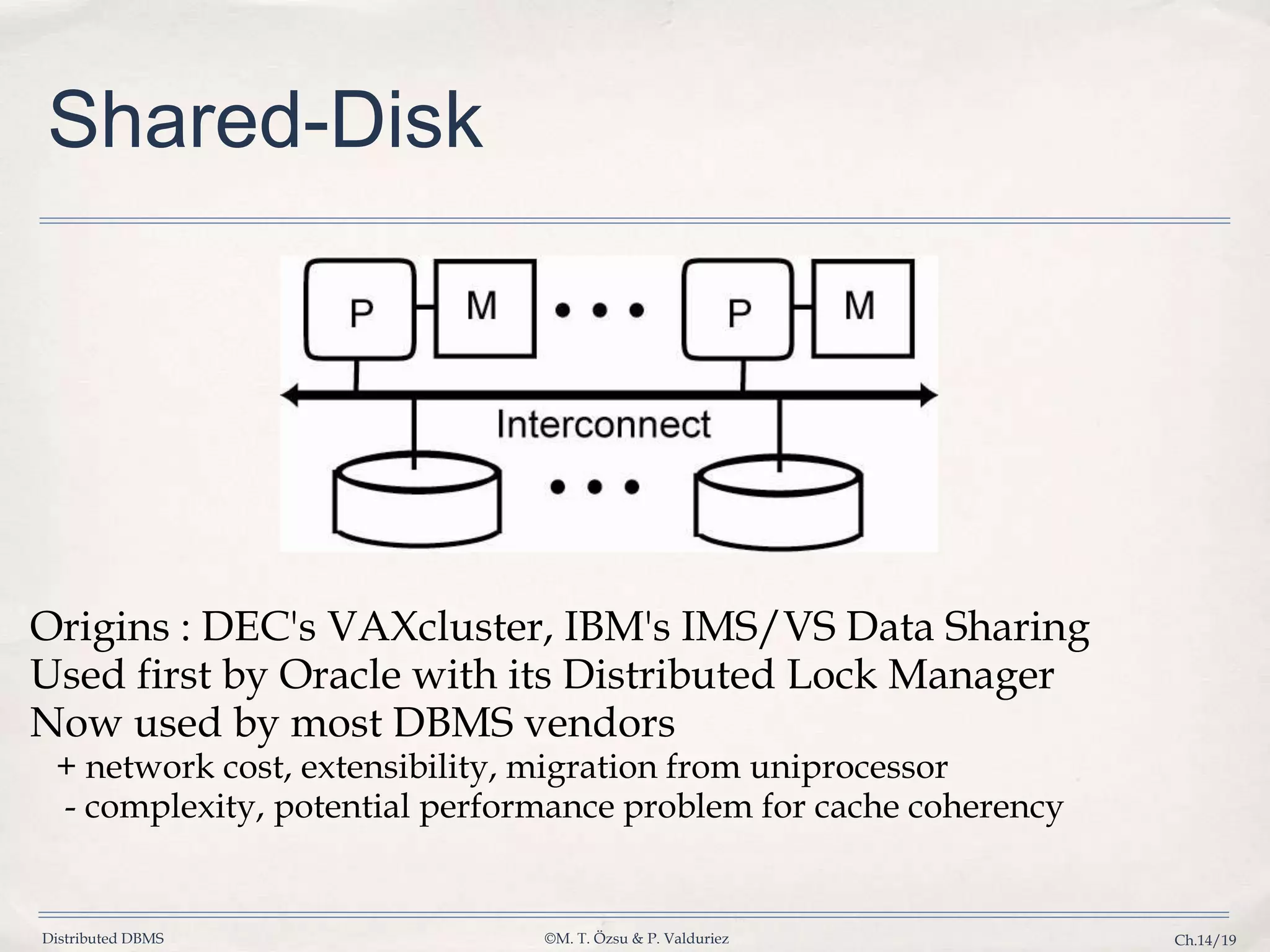
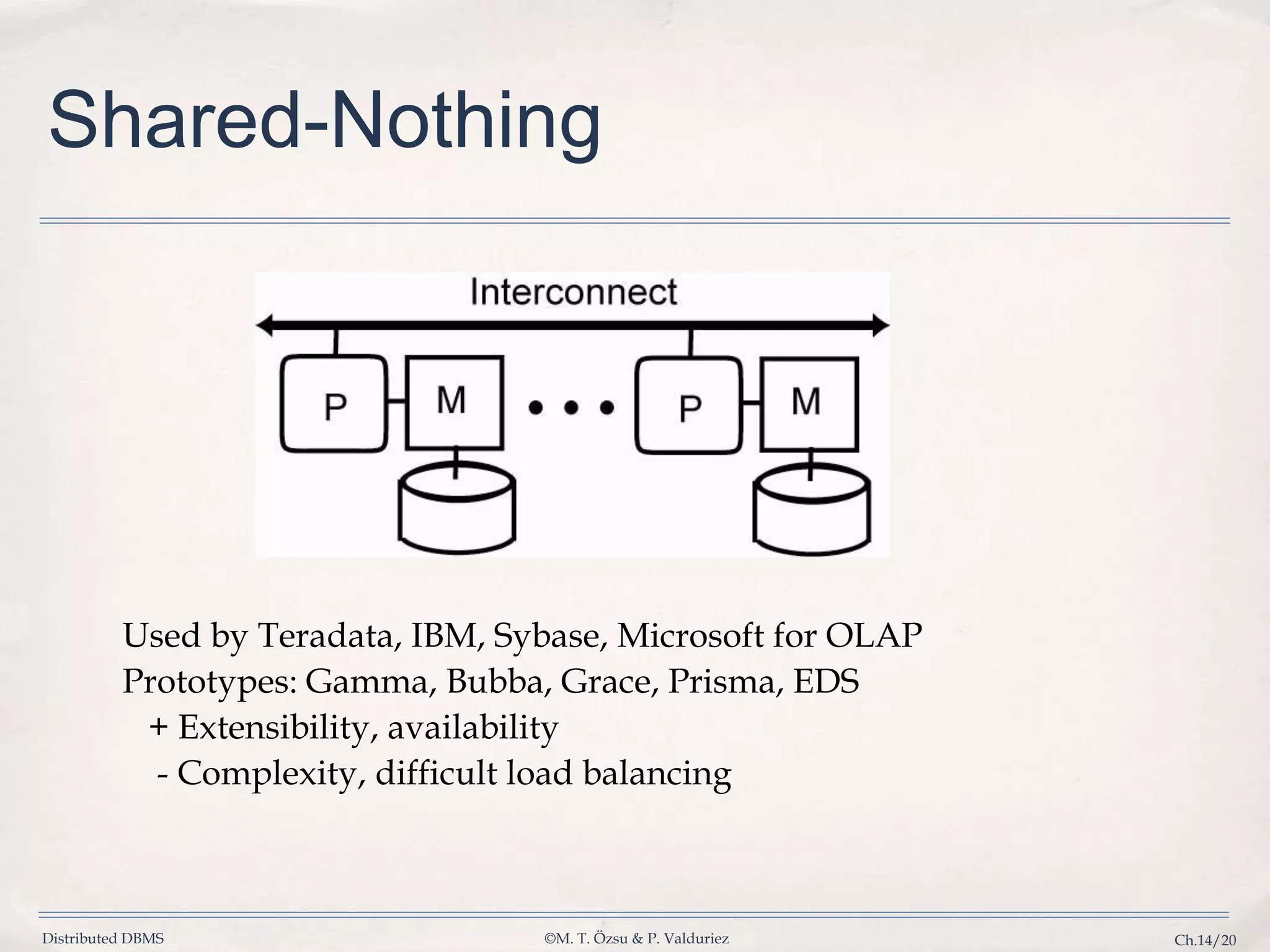
Discusses shared-memory, shared-disk, shared-nothing architectures, and hybrid systems to achieve an optimal DBMS.
Describes the NUMA architecture, its advantages for application portability, and details on the Cache Coherent NUMA implementation.
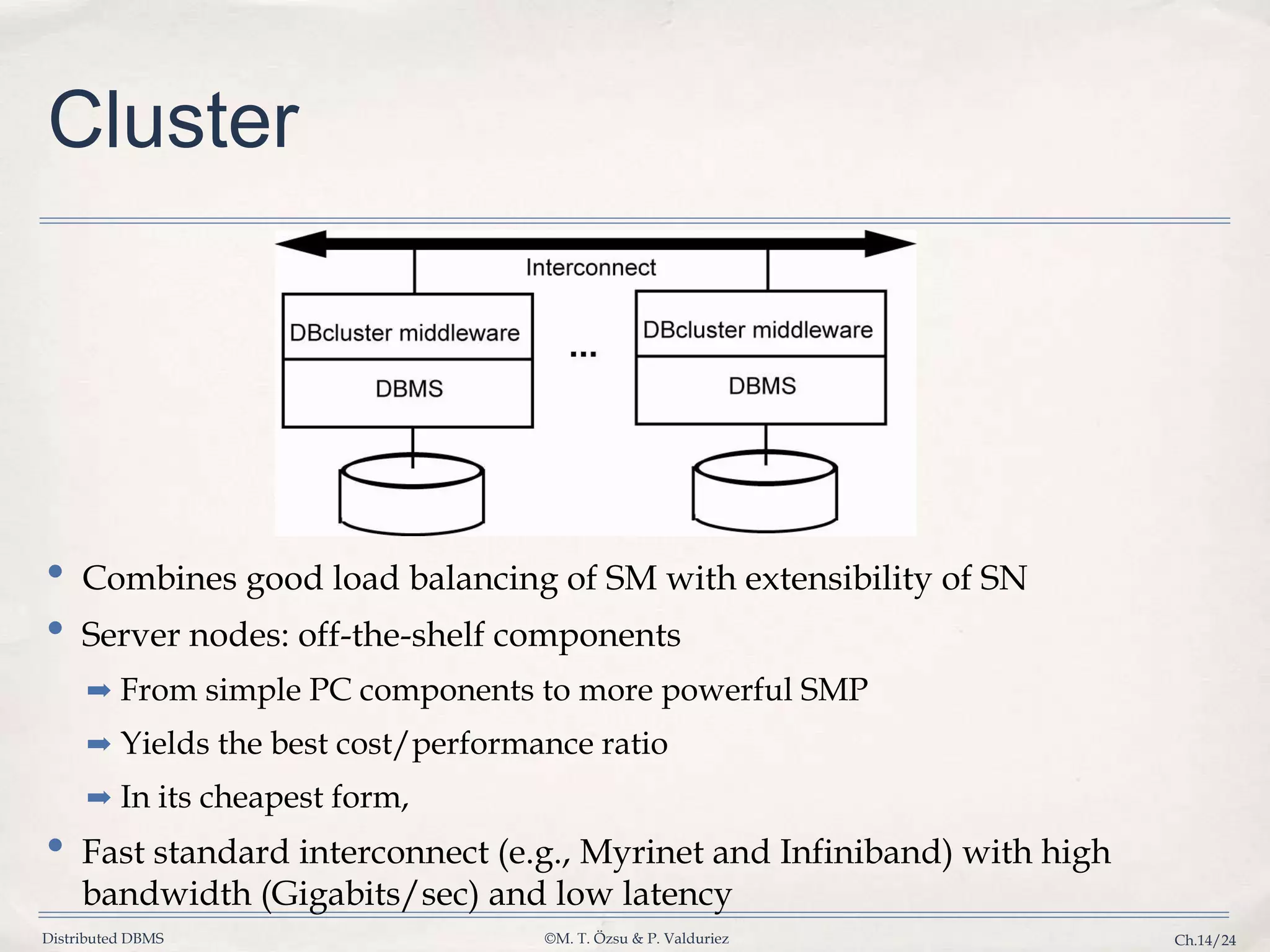
Explains benefits of cluster architecture combining load balancing and extensibility while addressing cost performance.
Discusses trade-offs between SN and SD clusters regarding performance, simplicity, and management for OLTP and OLAP.
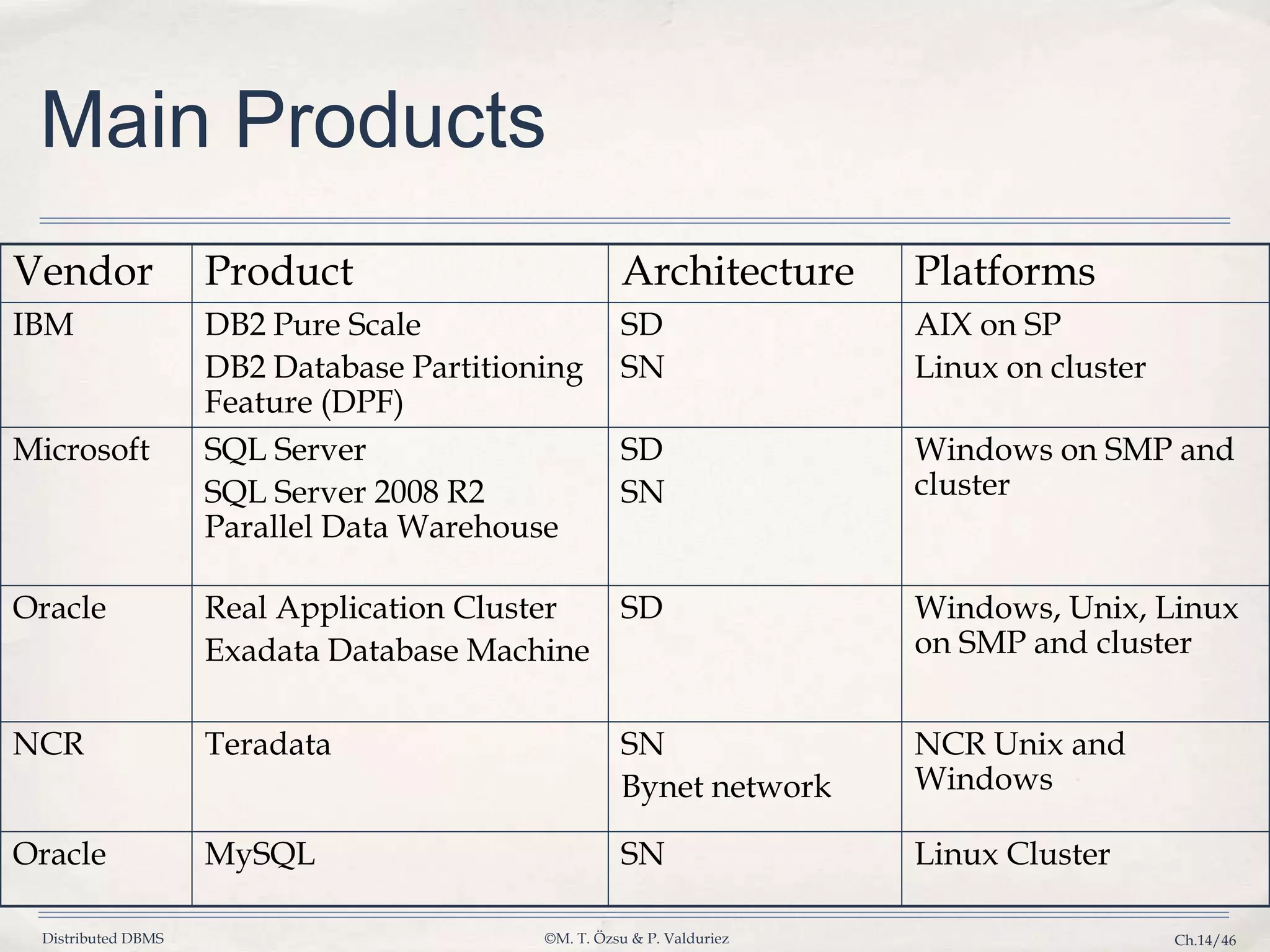
Outlines techniques for data placement, parallel processing, and transaction management in a distributed DBMS.
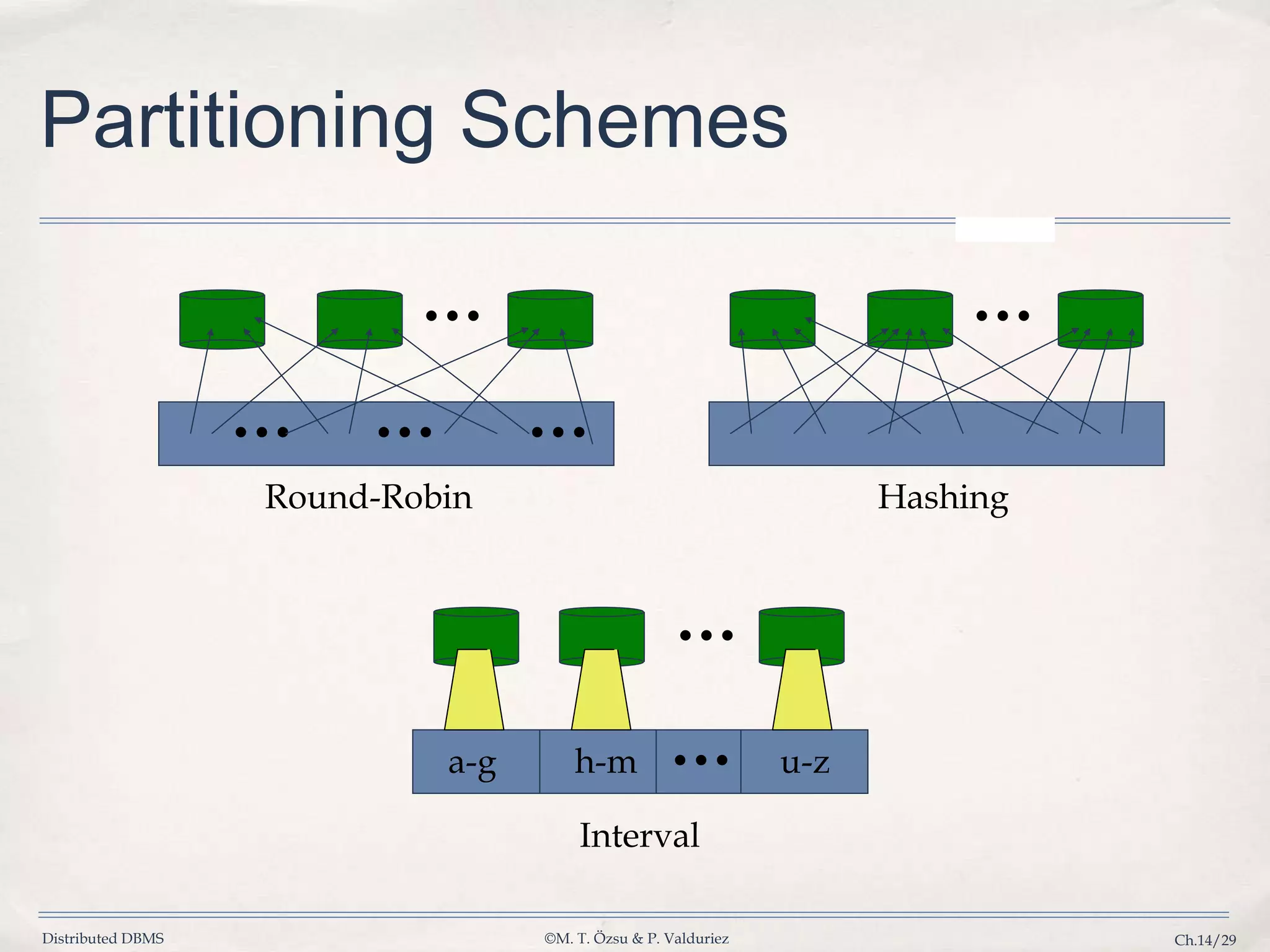
Explains methods for partitioning data, including round-robin, B-tree, and hash functions for efficient data management.
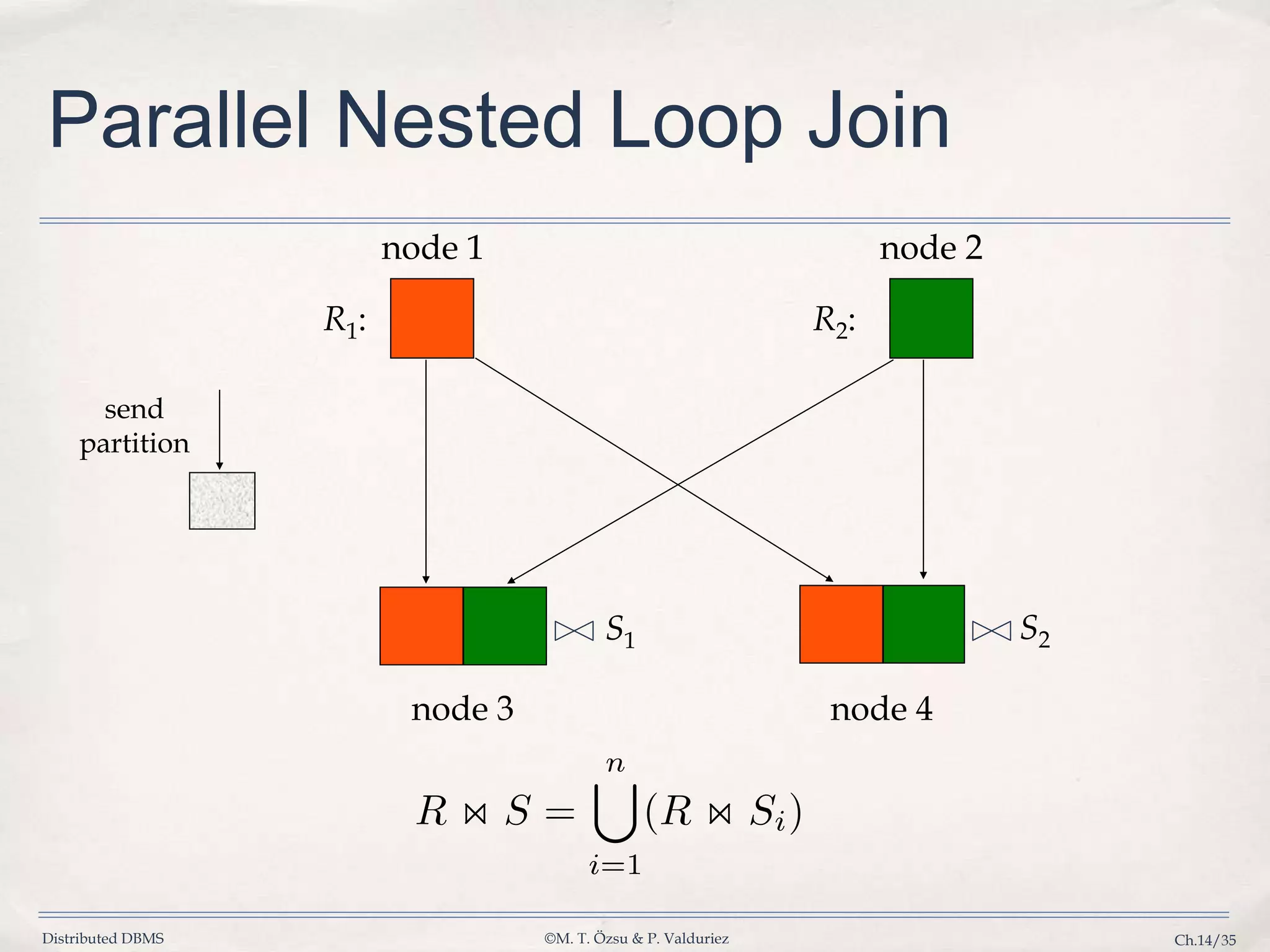
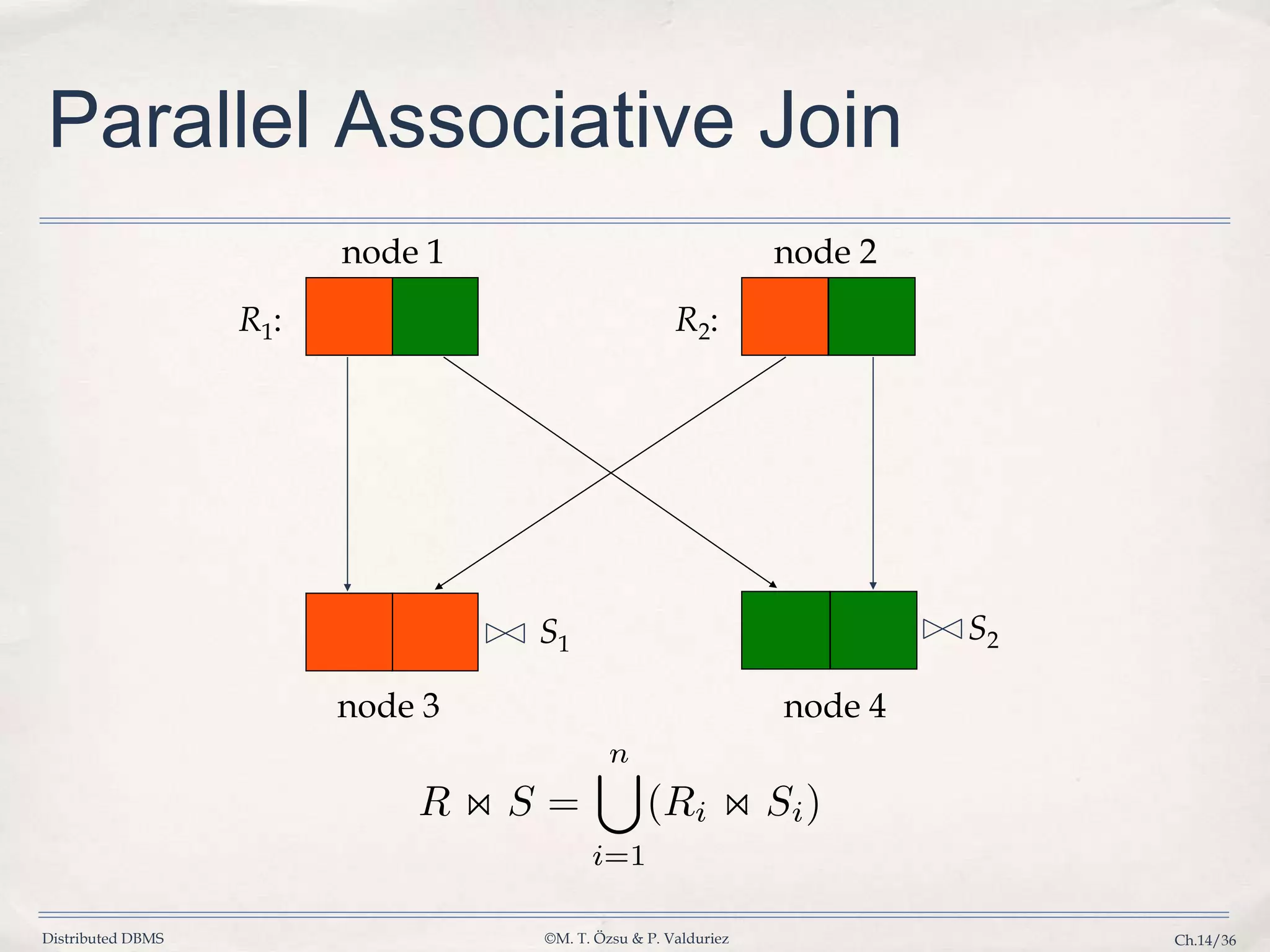
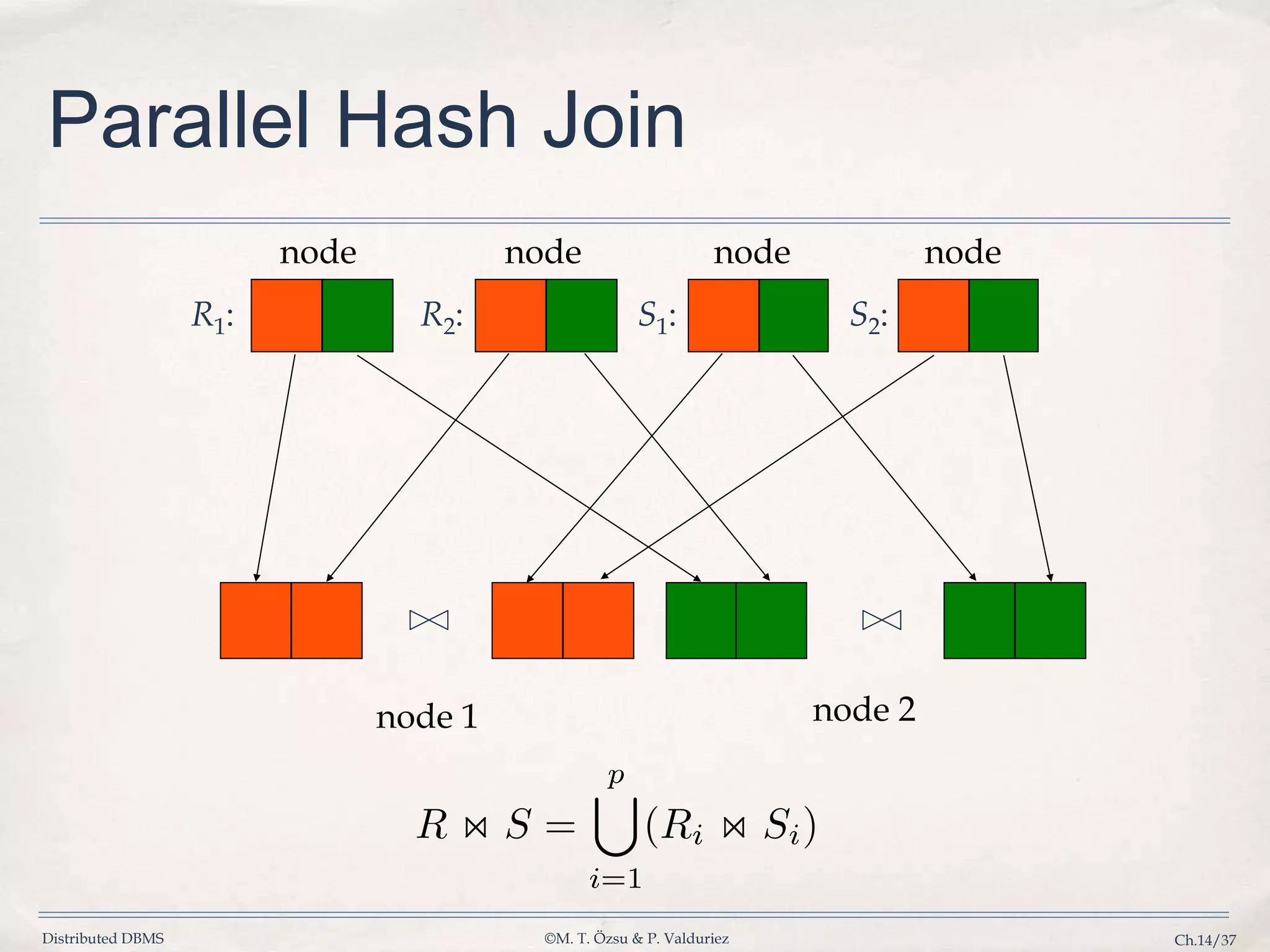
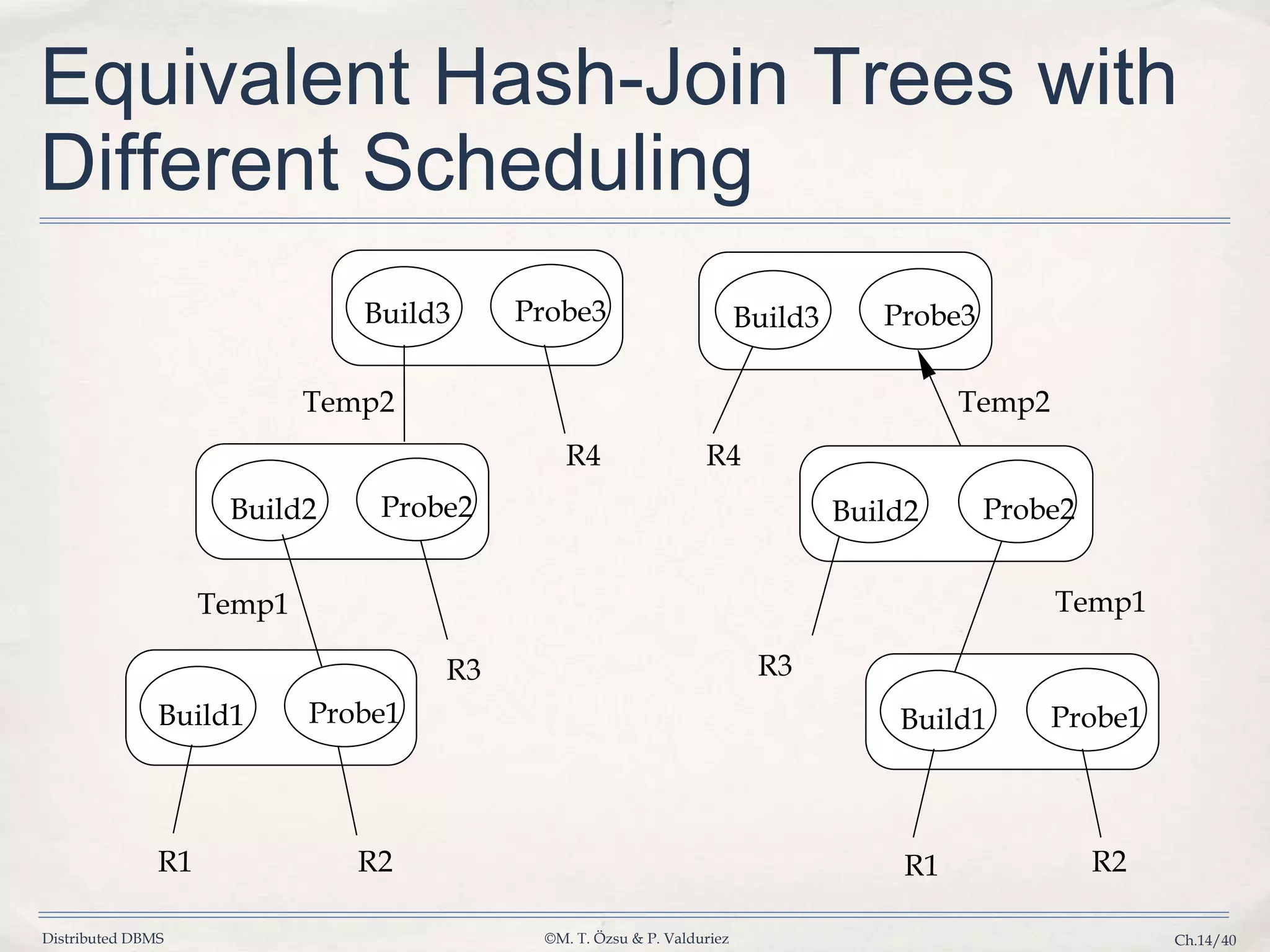
Details algorithms for parallel join operations including nested loop, associative, and hash joins.
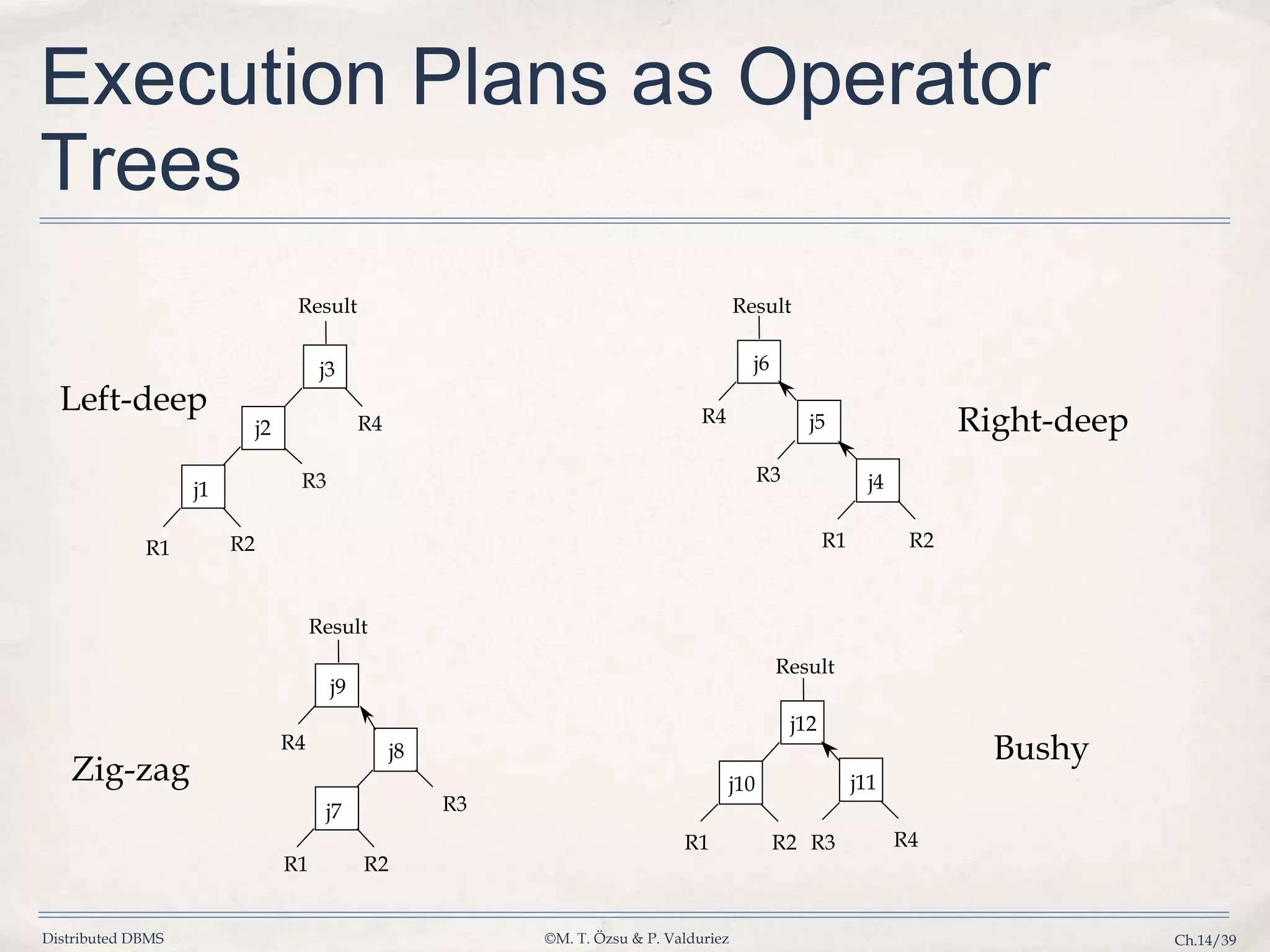
Describes strategies for selecting optimal execution plans for parallel queries using operator trees and cost models.
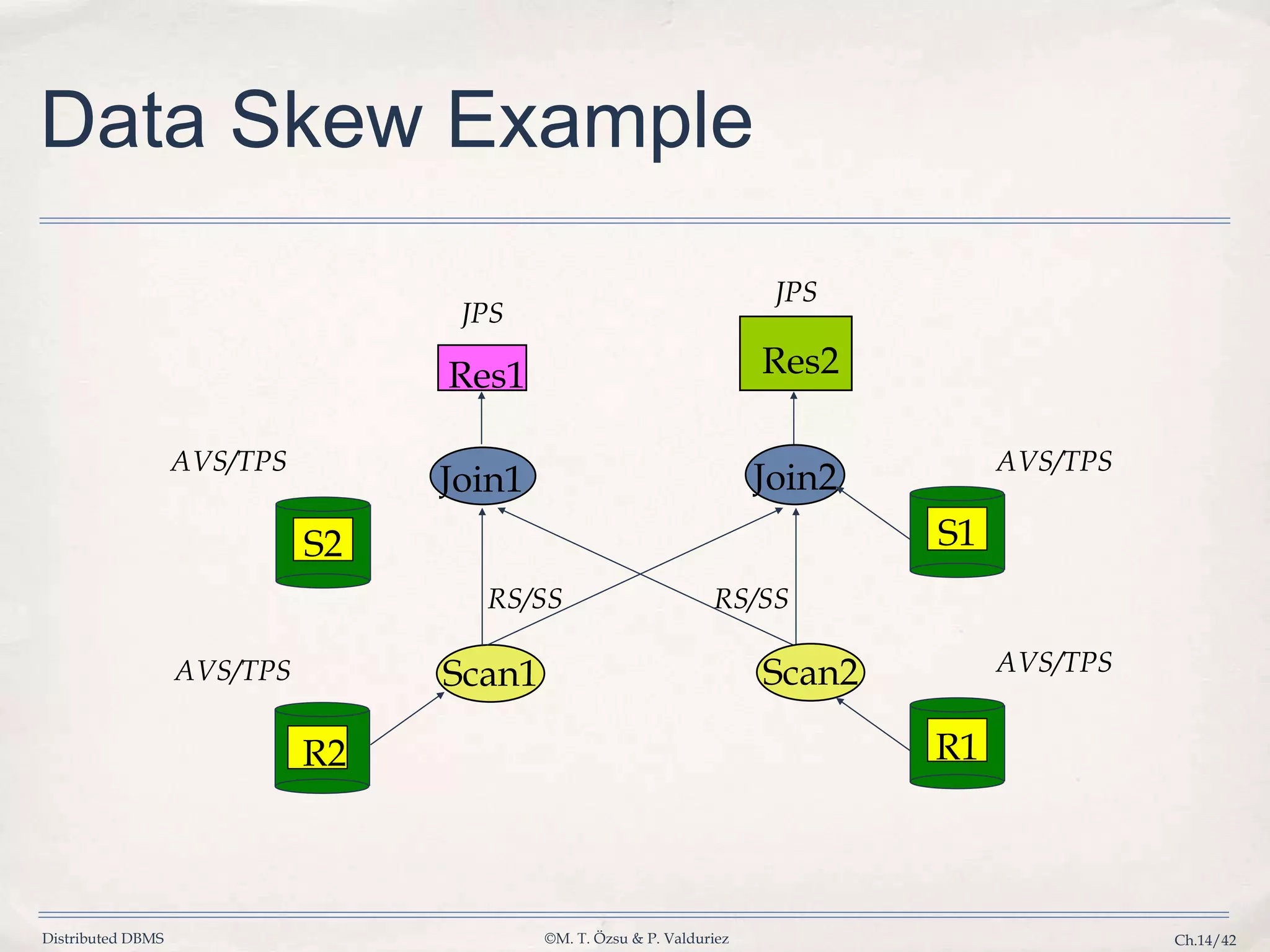
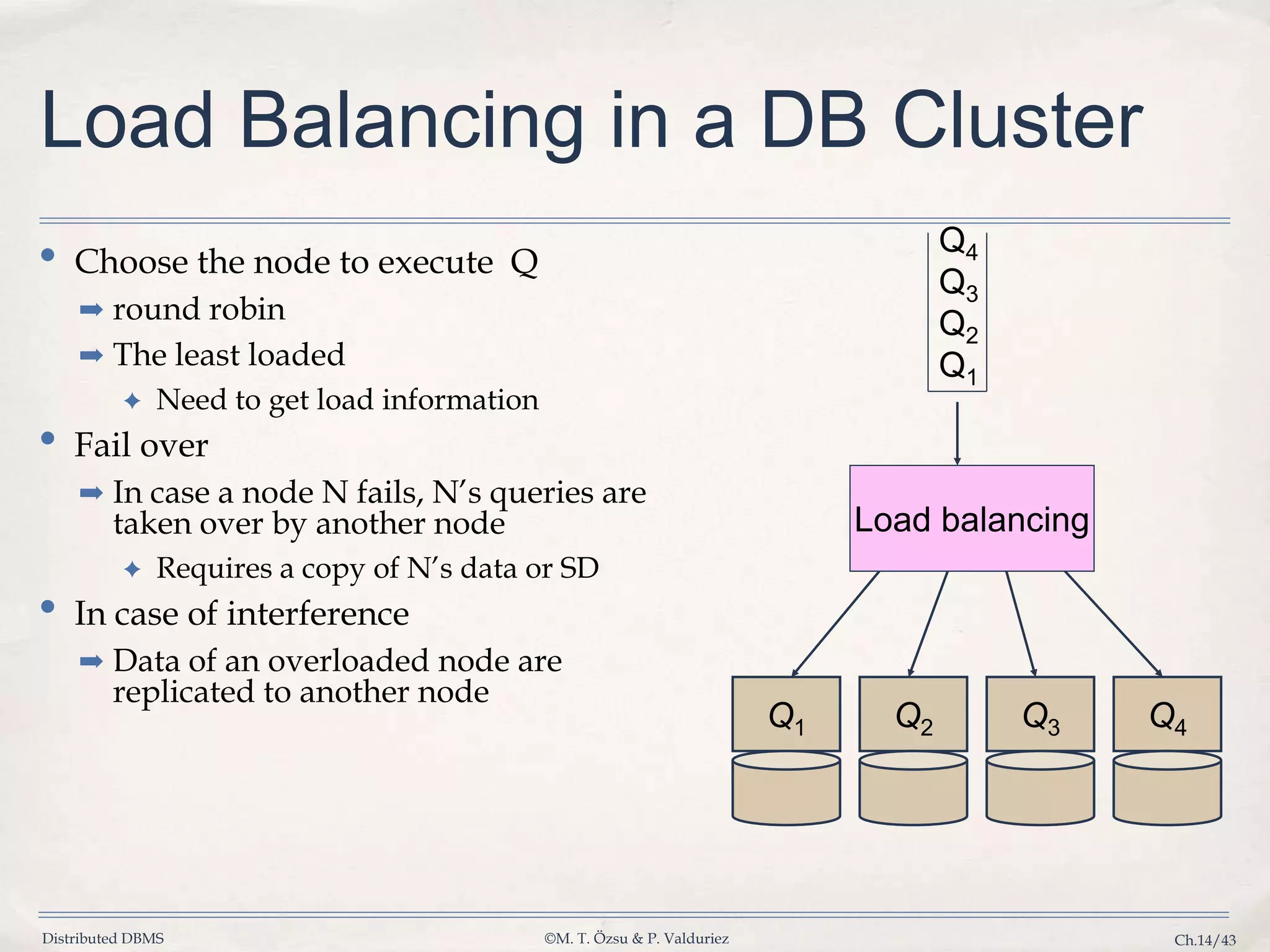
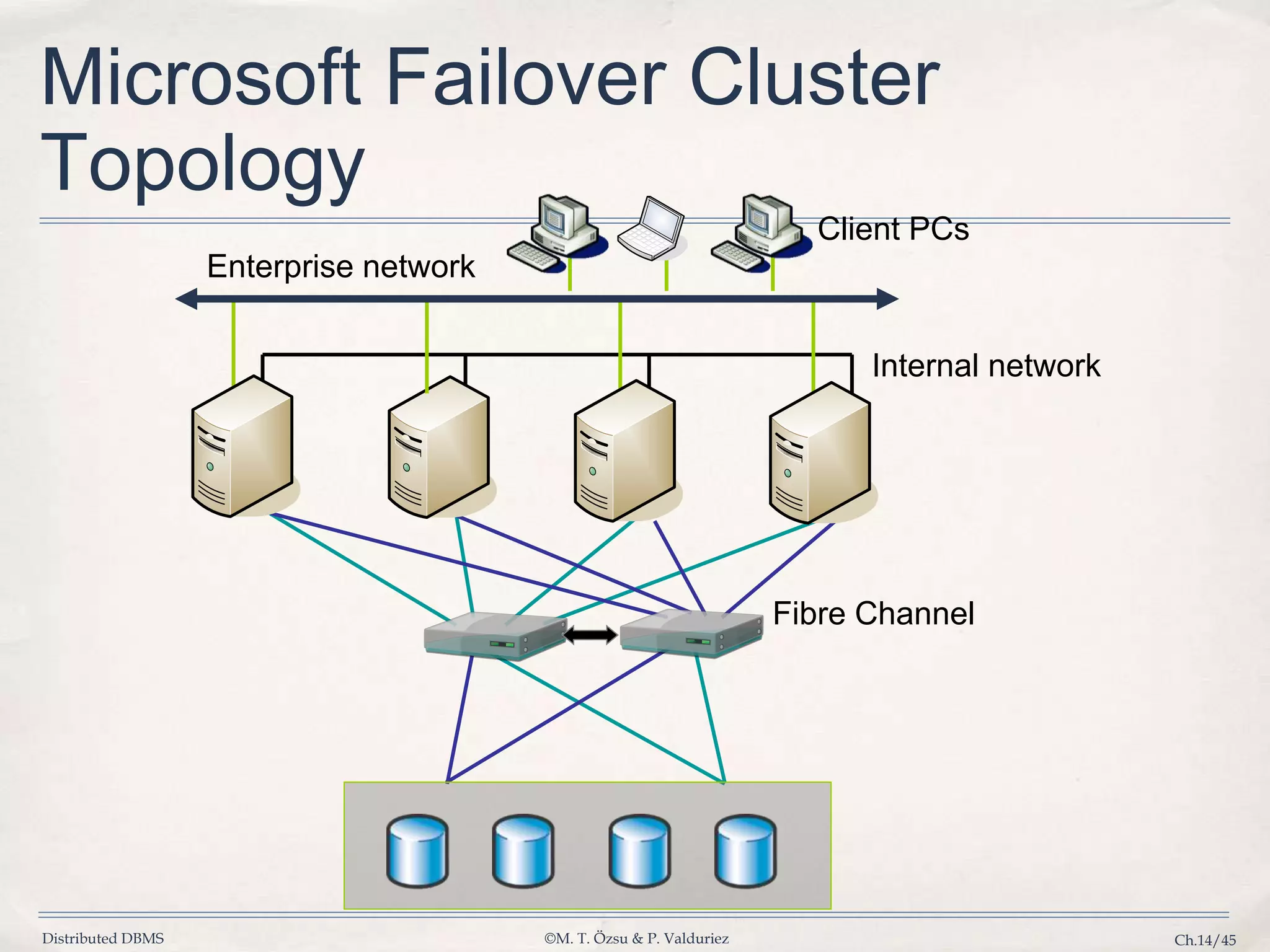
Discusses issues caused by data skew in parallelism and strategies for efficient load distribution and failover.
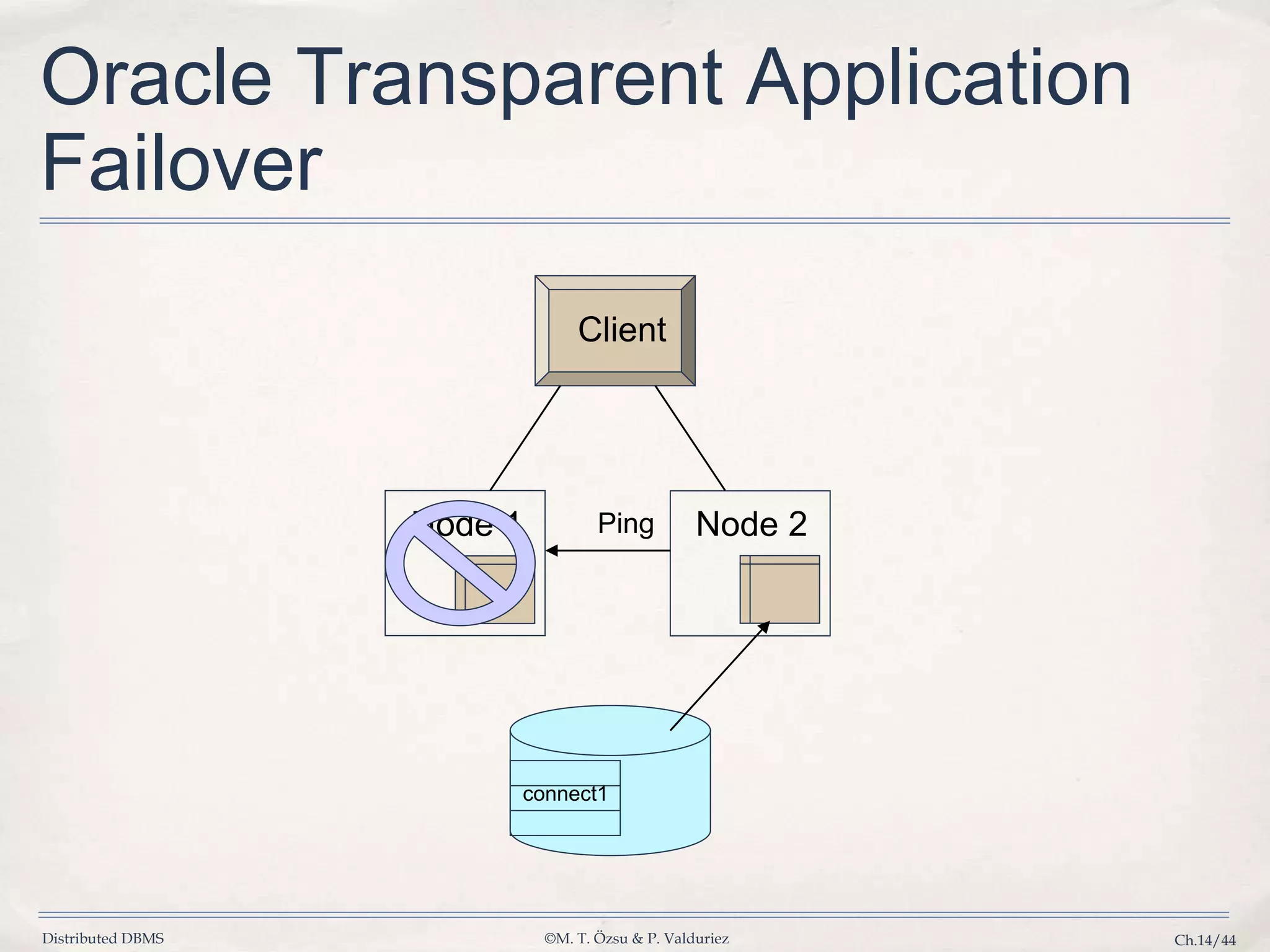
Presents Oracle's transparent application failover solutions and the necessary network architecture.
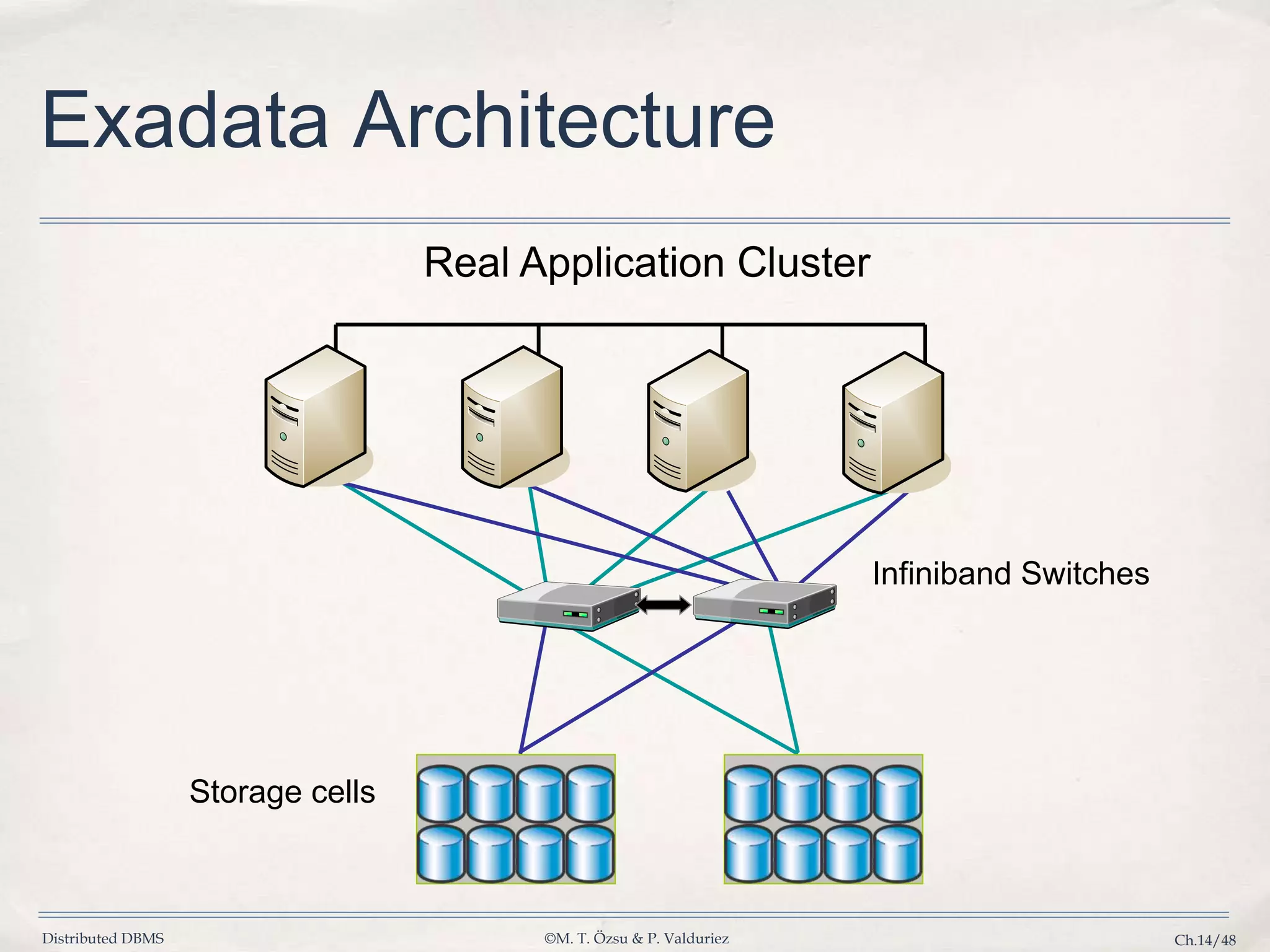
Details the capabilities of Oracle's Exadata machine for handling various workloads and its unique architecture.