Downloaded 14 times


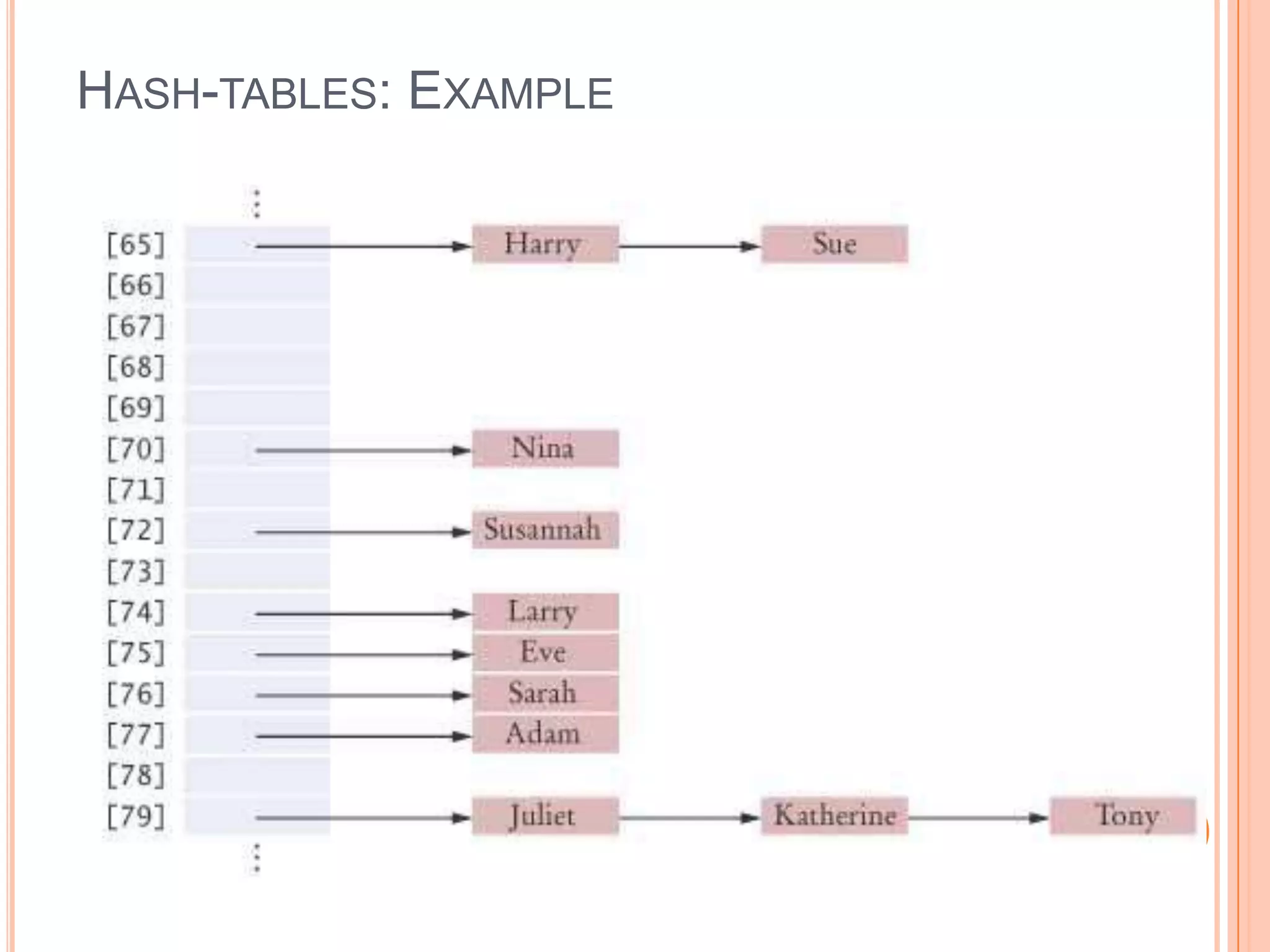
![DICTIONARIES: DUPLICATE KEYS If we have a high number of duplicates (a lot of elements with the same key), the search time will severely increase Solution: make a function to optimize the search criterion, h => solve collisions of keys We will search for T[h(k)] rather than T[k] , where: T is our associative array, k is an index and h(k) is a mapping function](https://image.slidesharecdn.com/datastructuresandalgorithms-lab11-140511125036-phpapp01/75/Data-structures-and-algorithms-lab11-5-2048.jpg)








![HASH TABLE: ASSIGNMENT Hint: Maintain an array H[HMAX] of linked lists The info field of each element of a list consists of a struct containing a key and a value Each key is mapped to a value hkey=hash(key), such that 0≤hkey≤HMAX-1 hash(key) is called the hash function and hkey is the index in a linked list put(k, v) Searches for the key k in the list H[hkey=hash(k)] If the key is found, then we replace the value by v If the key is not found, then we insert the pair (k,v) in H[hkey] get(k) Search for the key k in H[hkey=hash(k)] If it finds the key, then it returns its associated value; otherwise, an error occurs hasKey(k) Search for the key k in H[hkey=hash(k)] If it finds the key, then it returns 1; otherwise, it returns 0](https://image.slidesharecdn.com/datastructuresandalgorithms-lab11-140511125036-phpapp01/75/Data-structures-and-algorithms-lab11-15-2048.jpg)

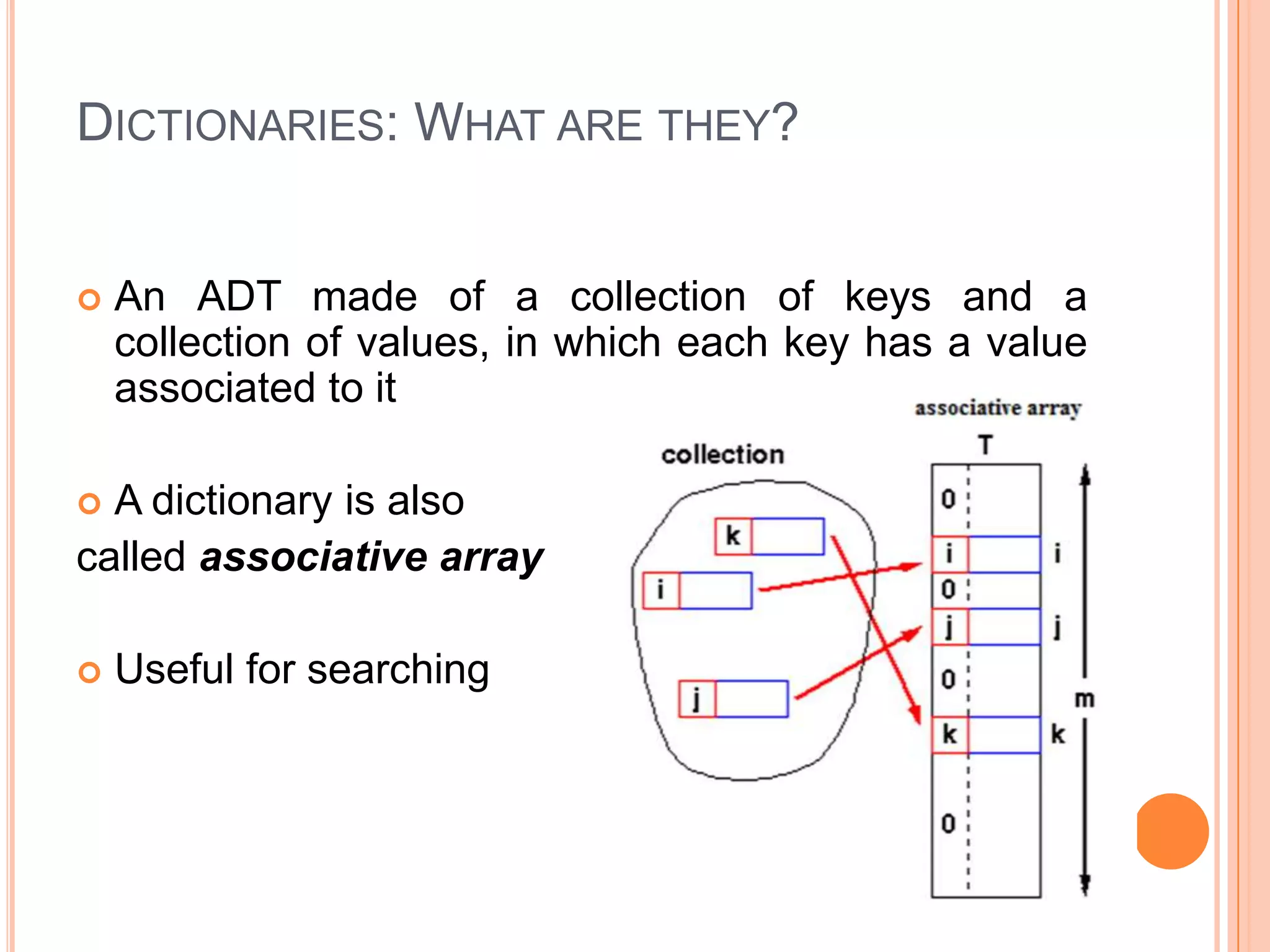
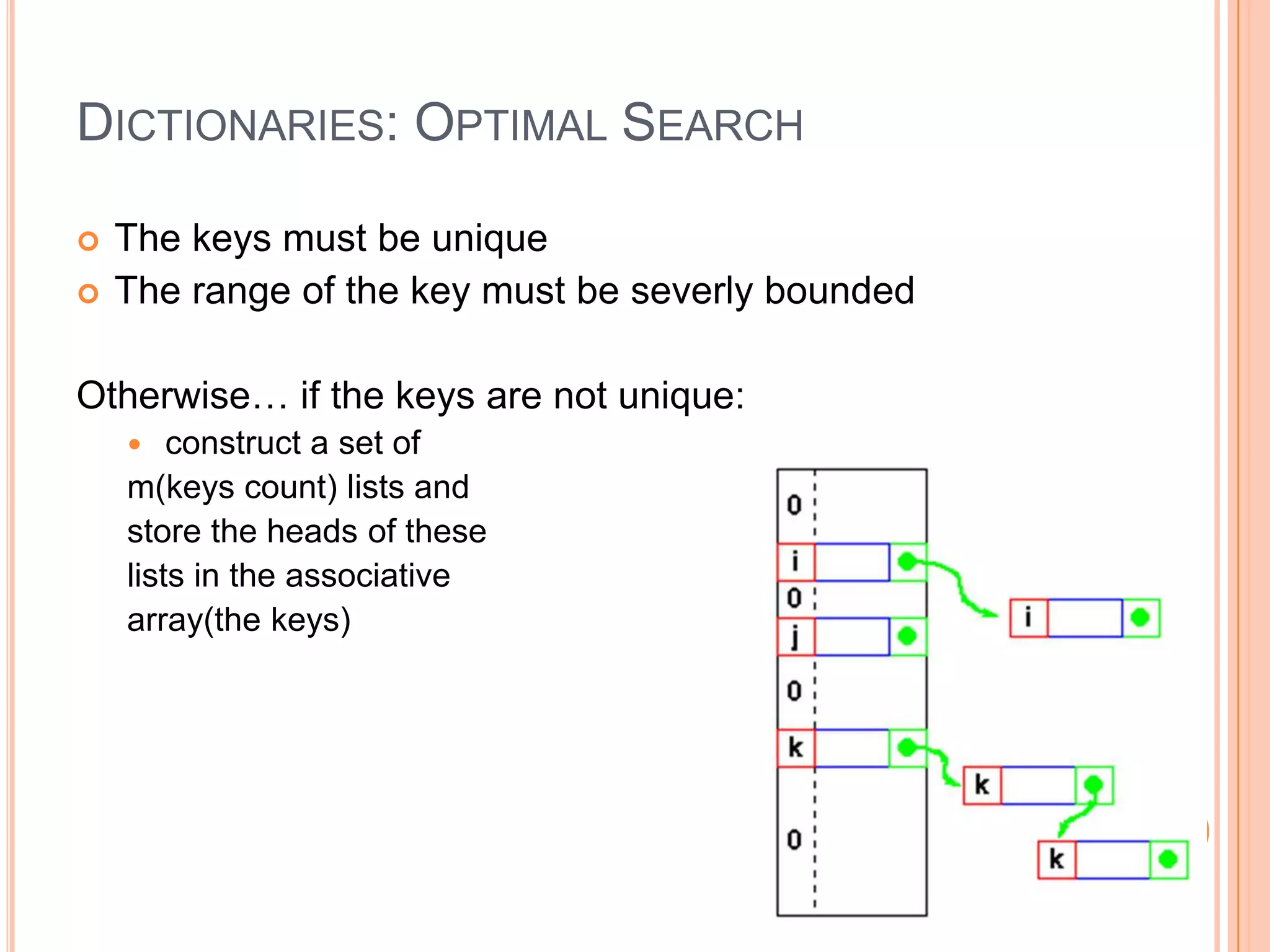
This document discusses data structures and algorithms, specifically dictionaries and hash tables. It defines dictionaries as collections of keys and values where each key maps to a value. Hash tables are described as an optimized data structure for lookup with average constant time search using a hash function to map keys to indexes. The document covers implementing hash tables using linked lists to handle collisions, as well as common operations like put, get, and hasKey. It also provides hints for an assignment to implement a hash table data structure.