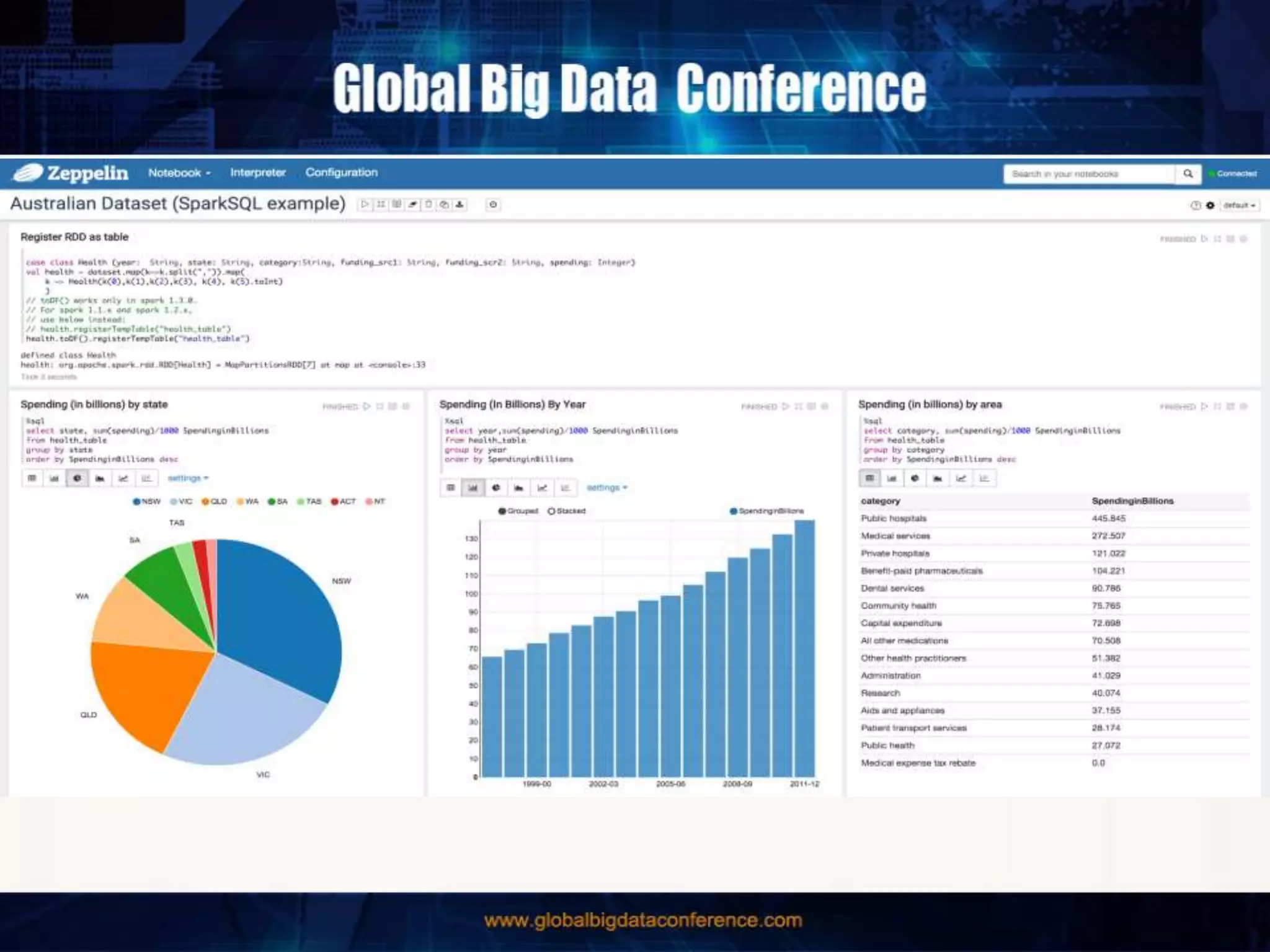
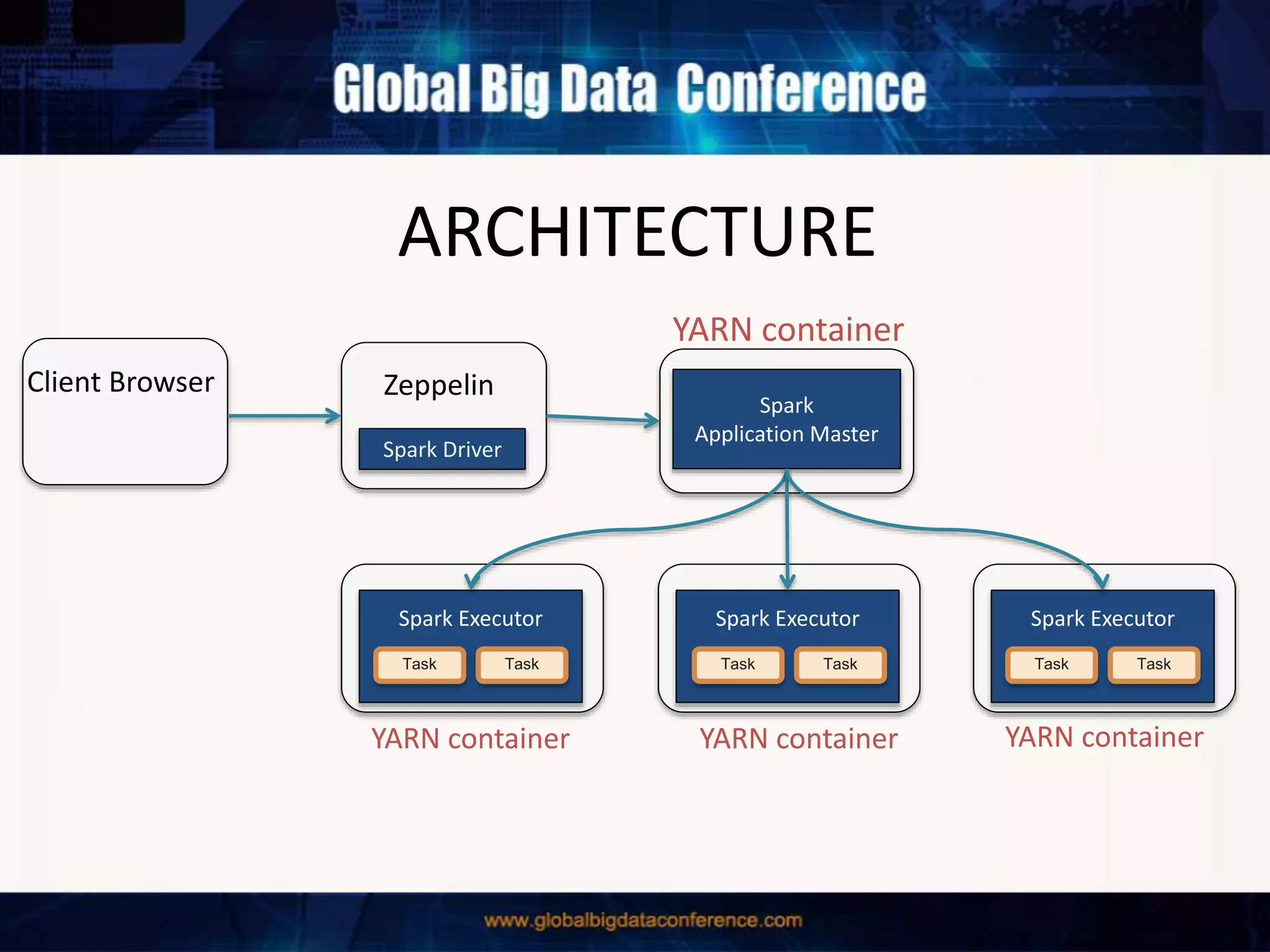
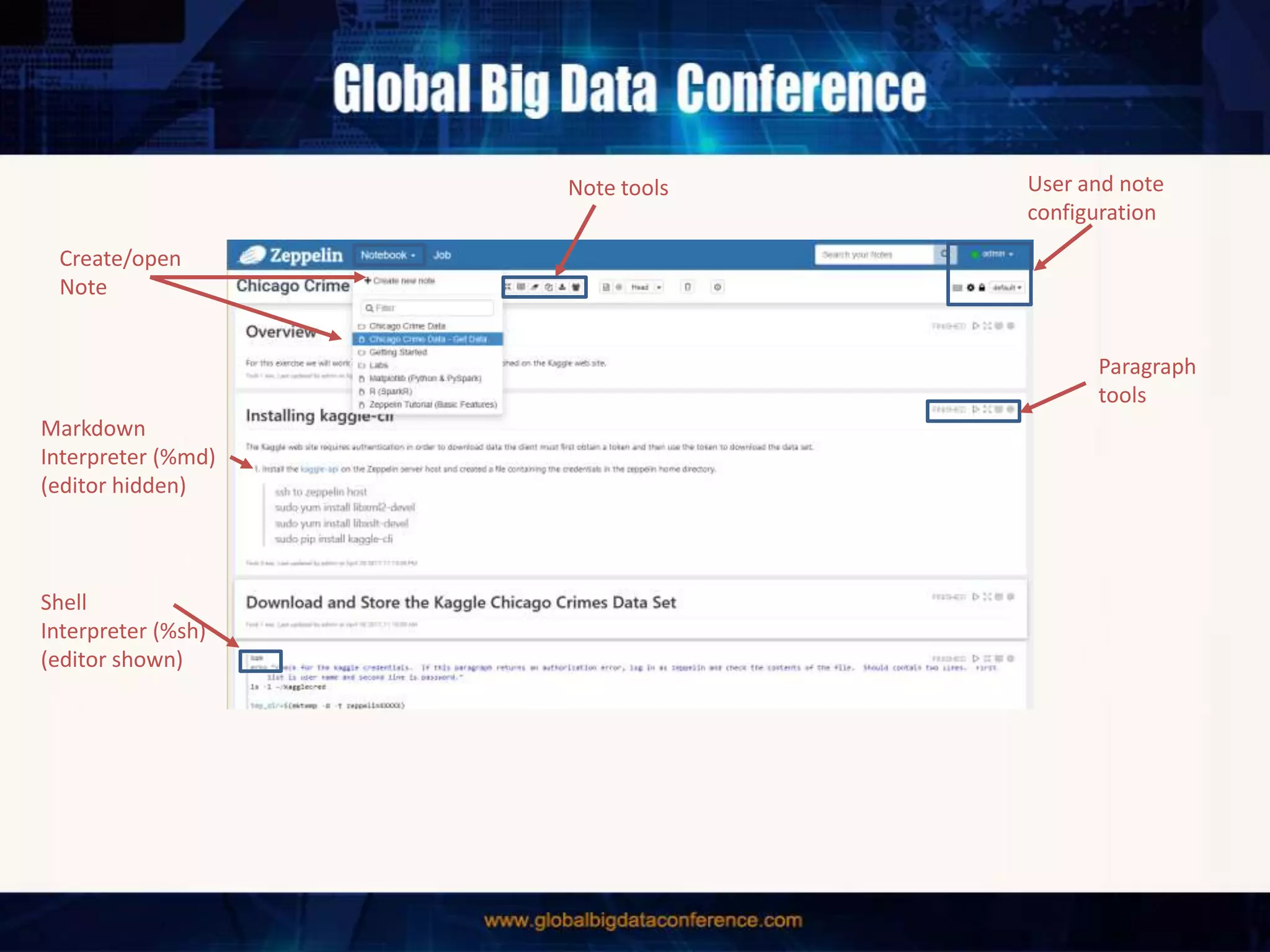
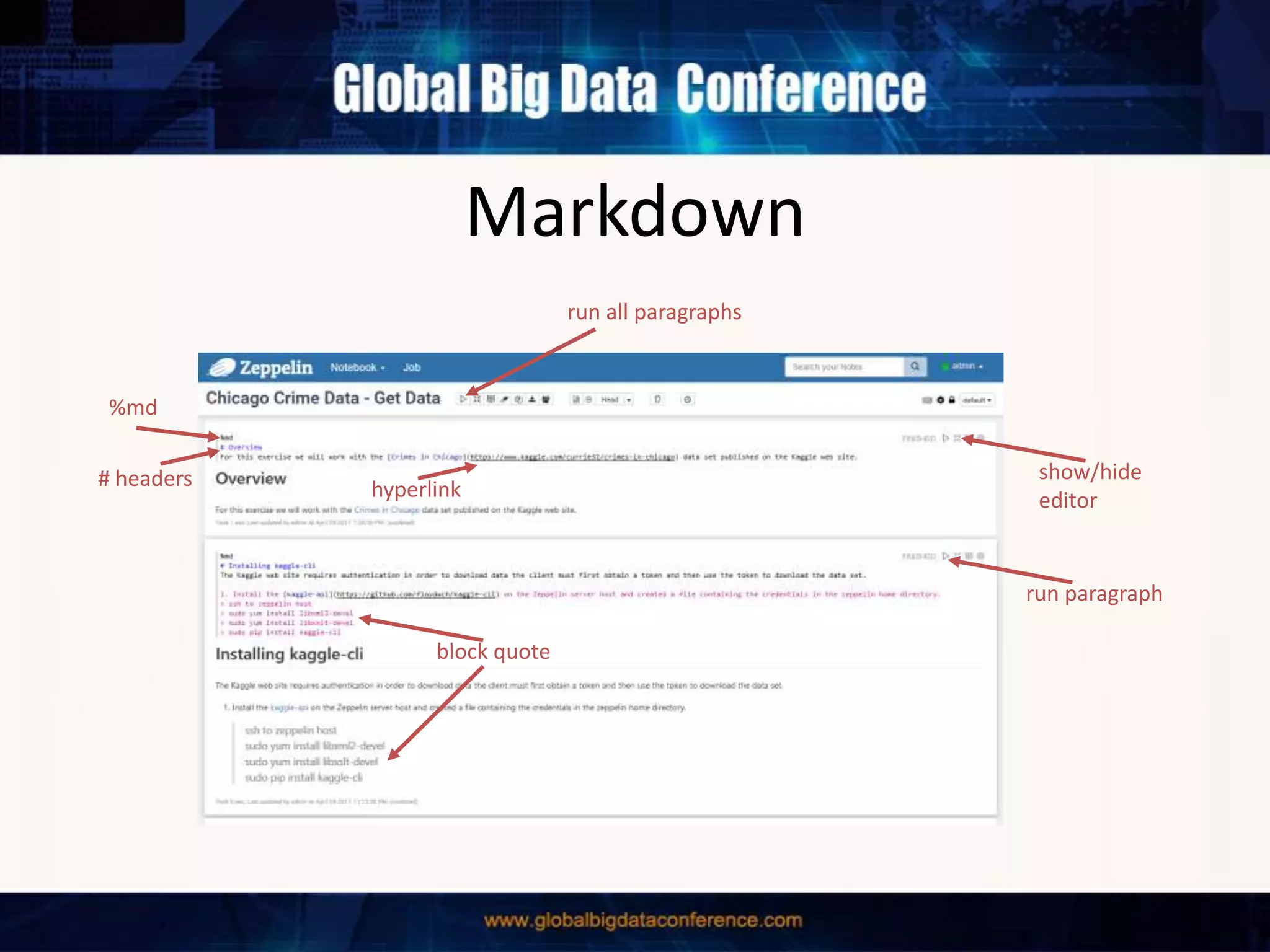
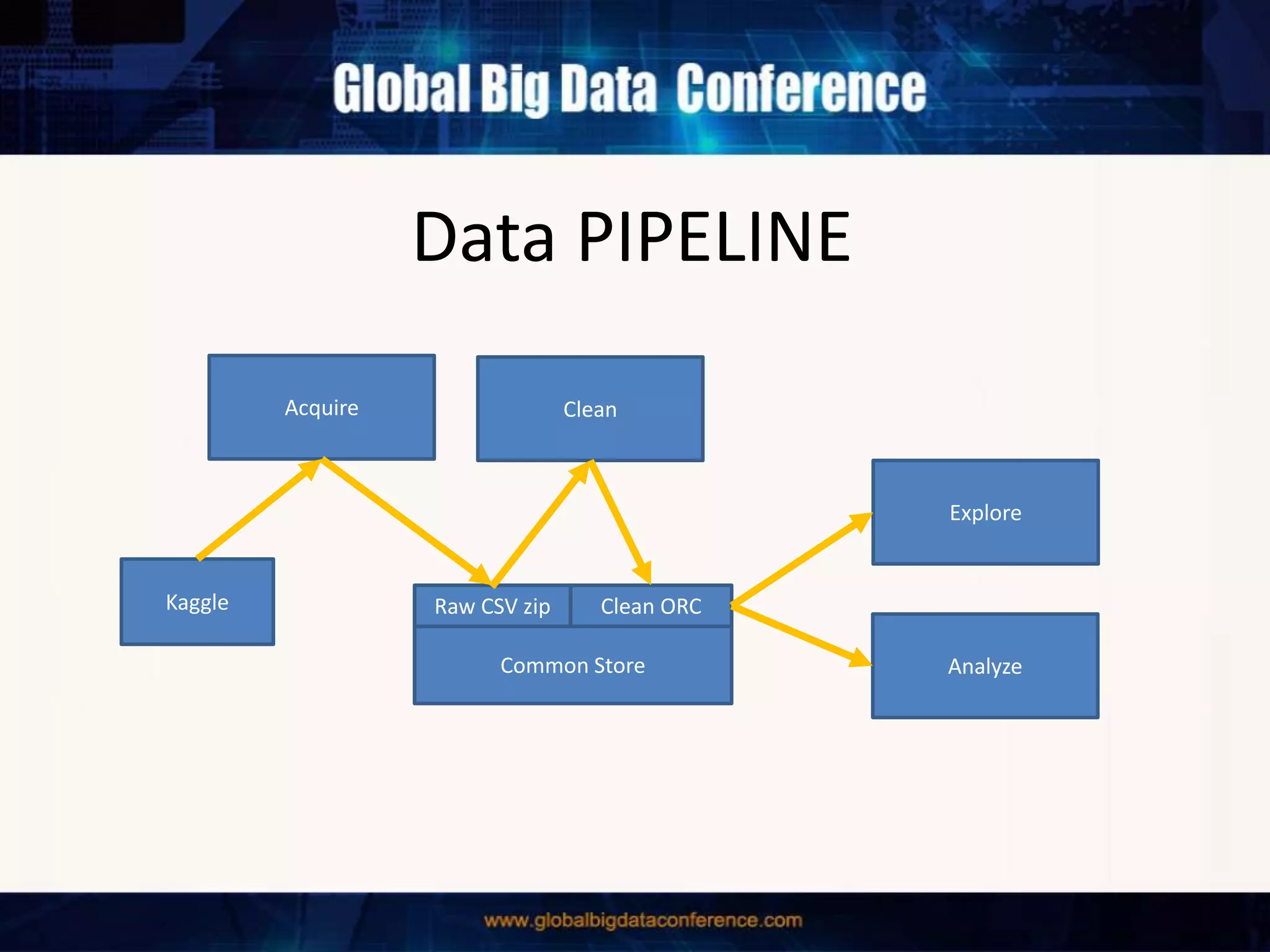
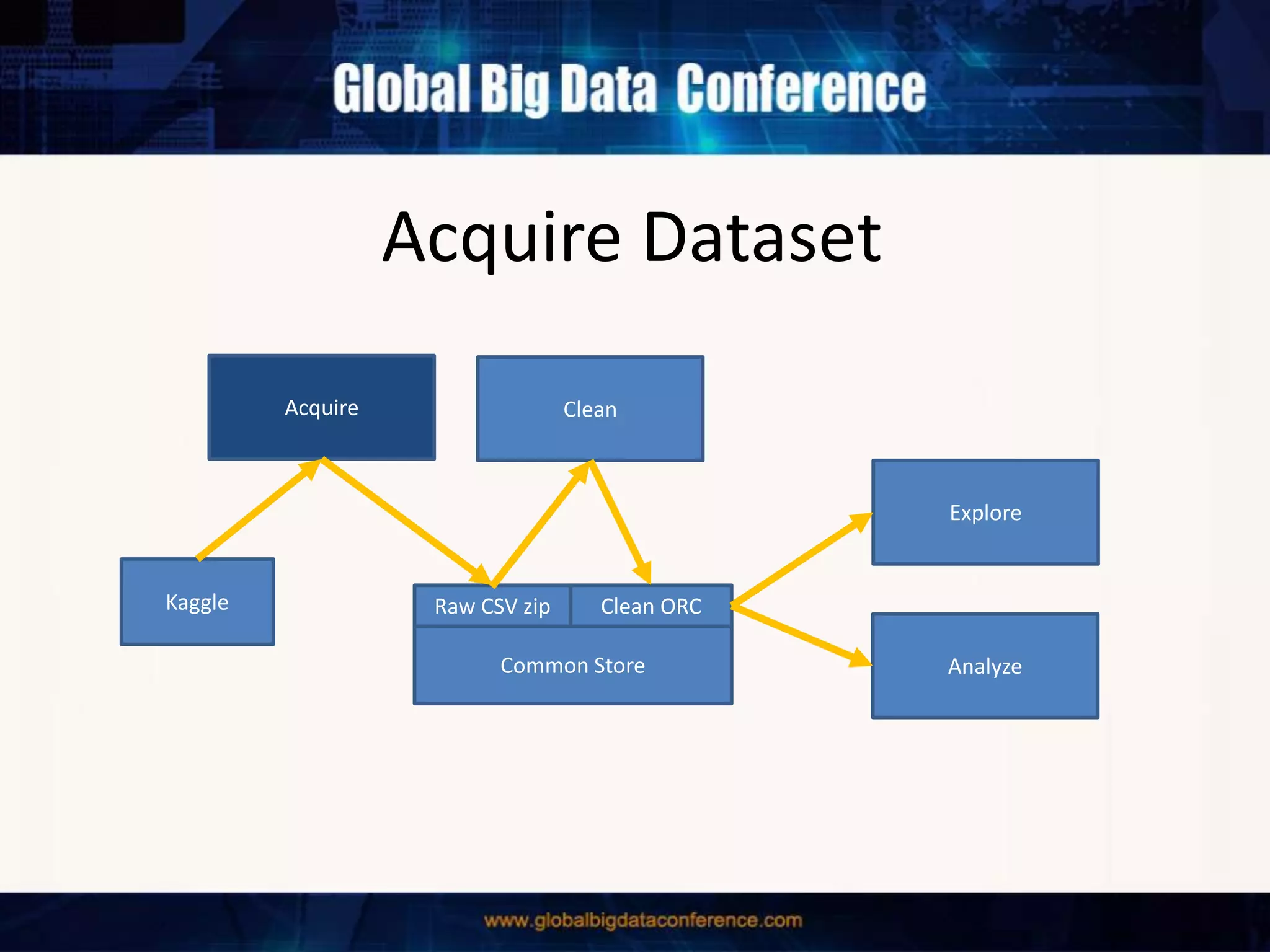
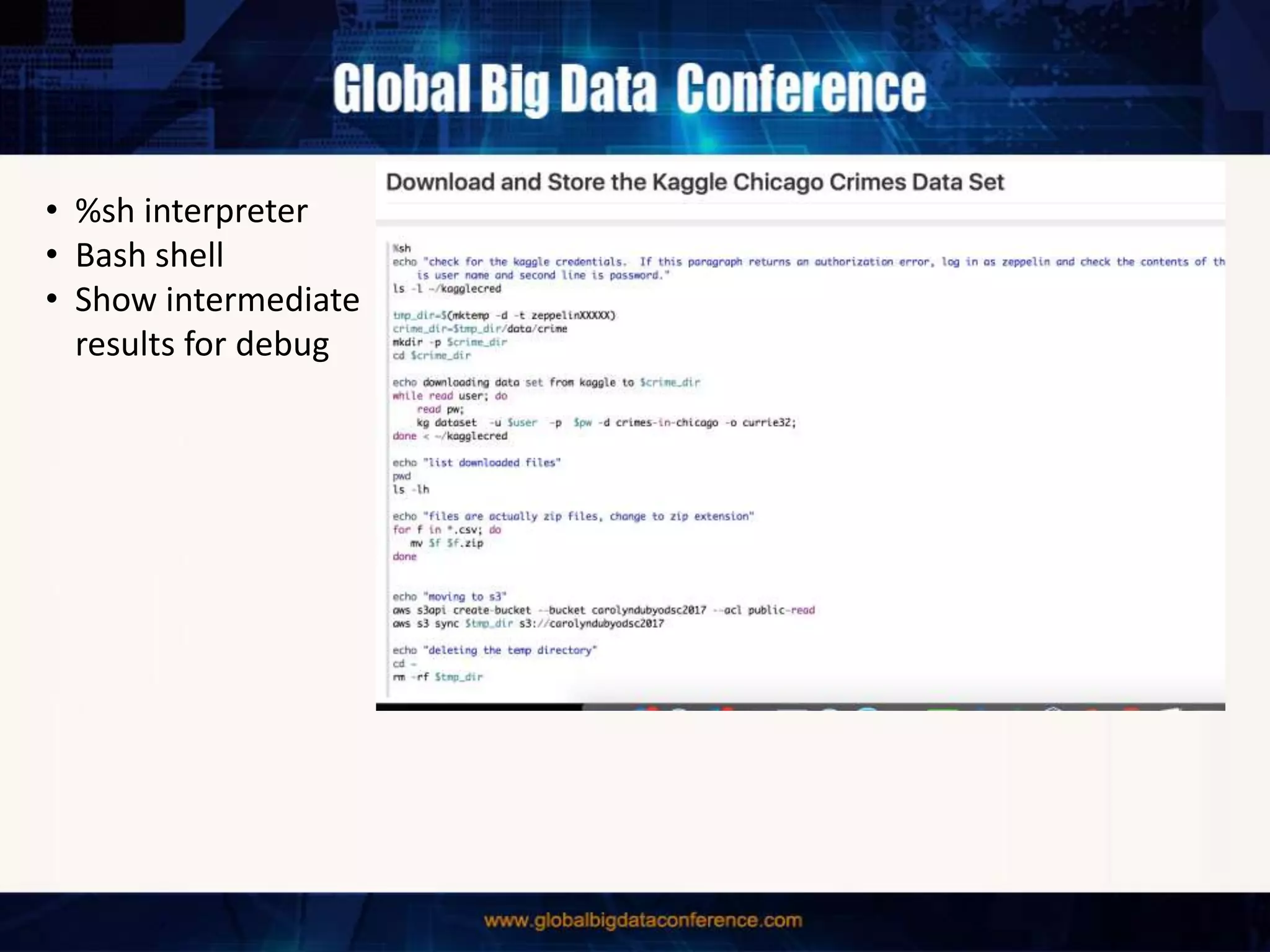
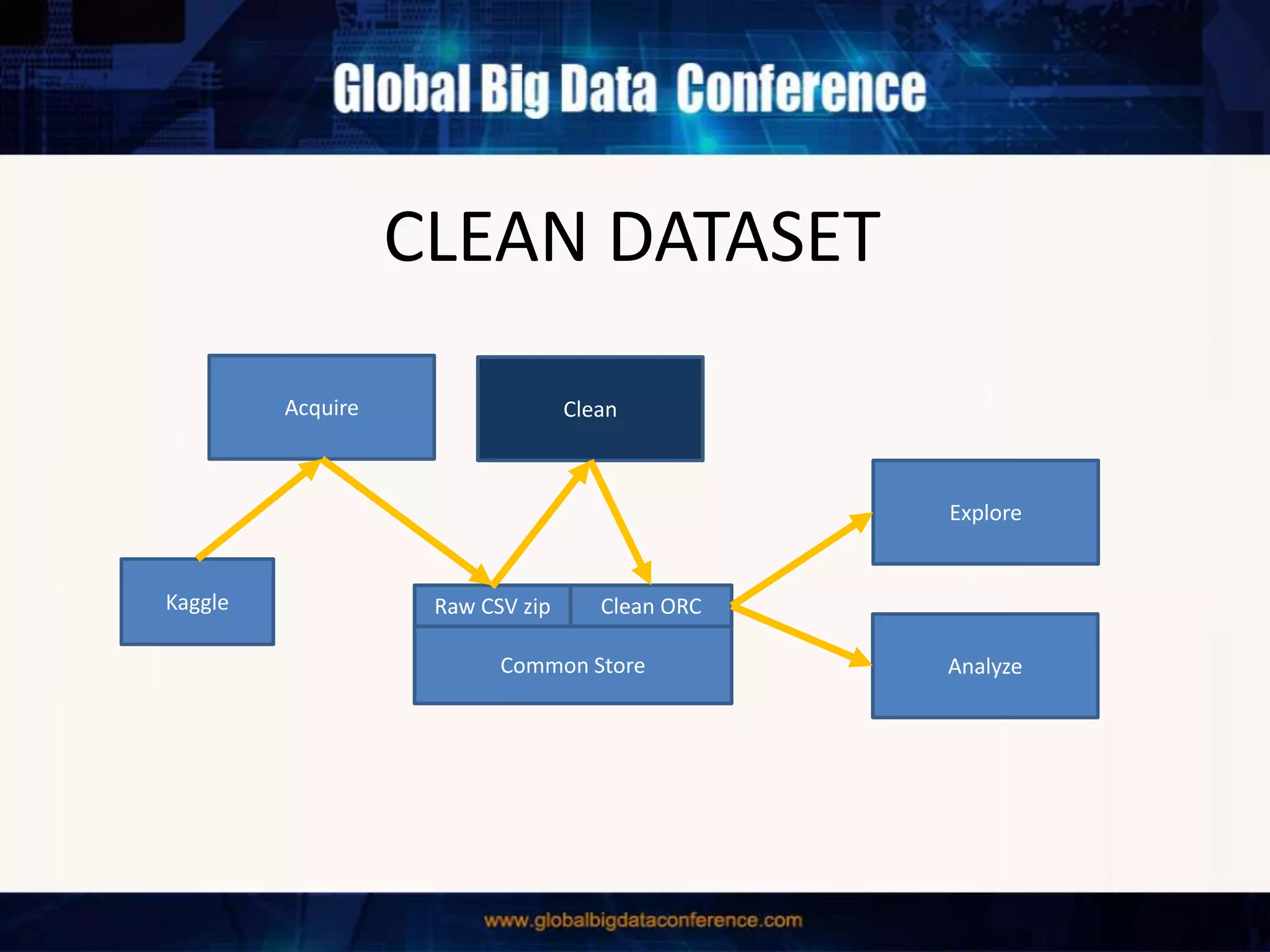
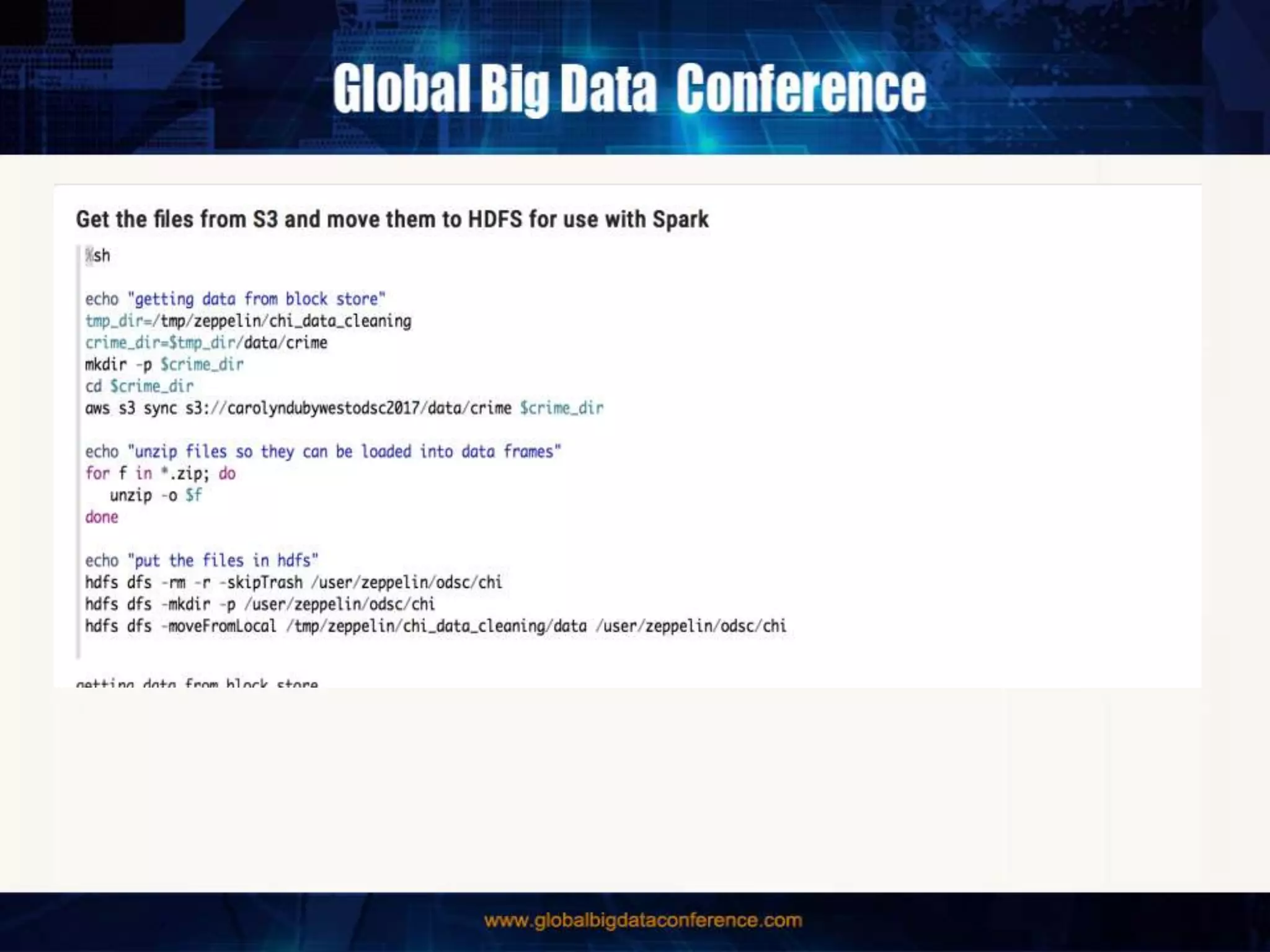
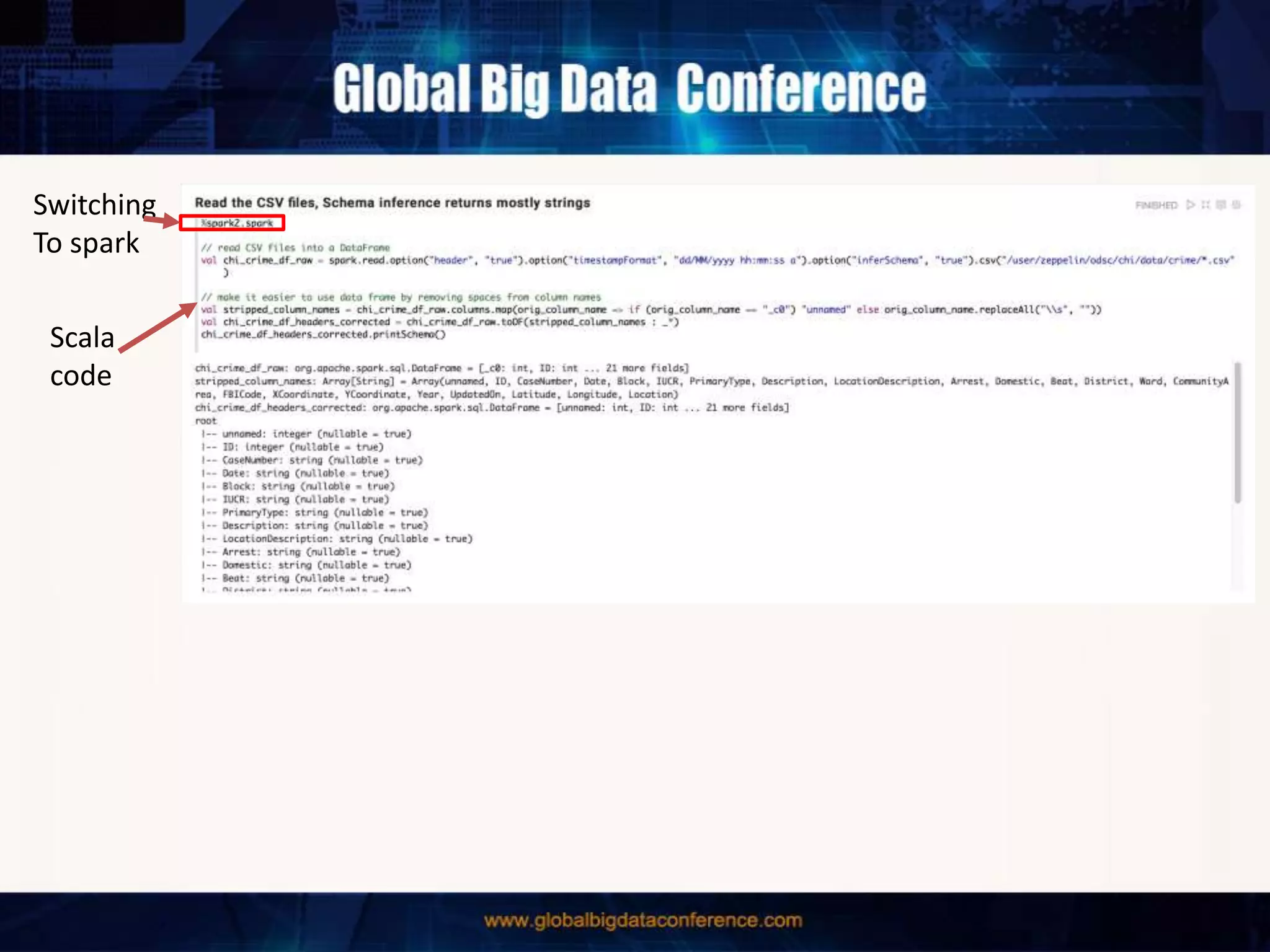
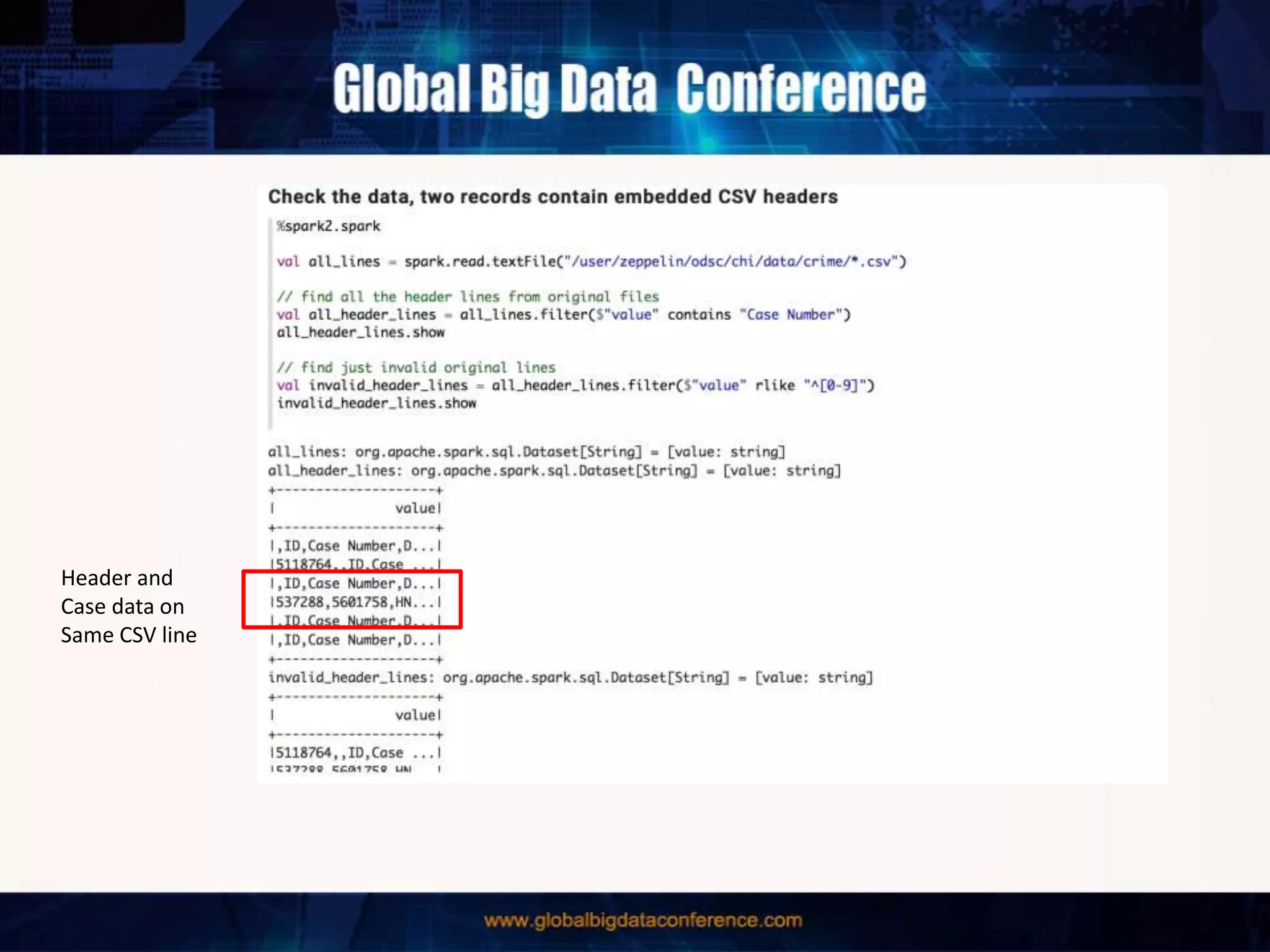
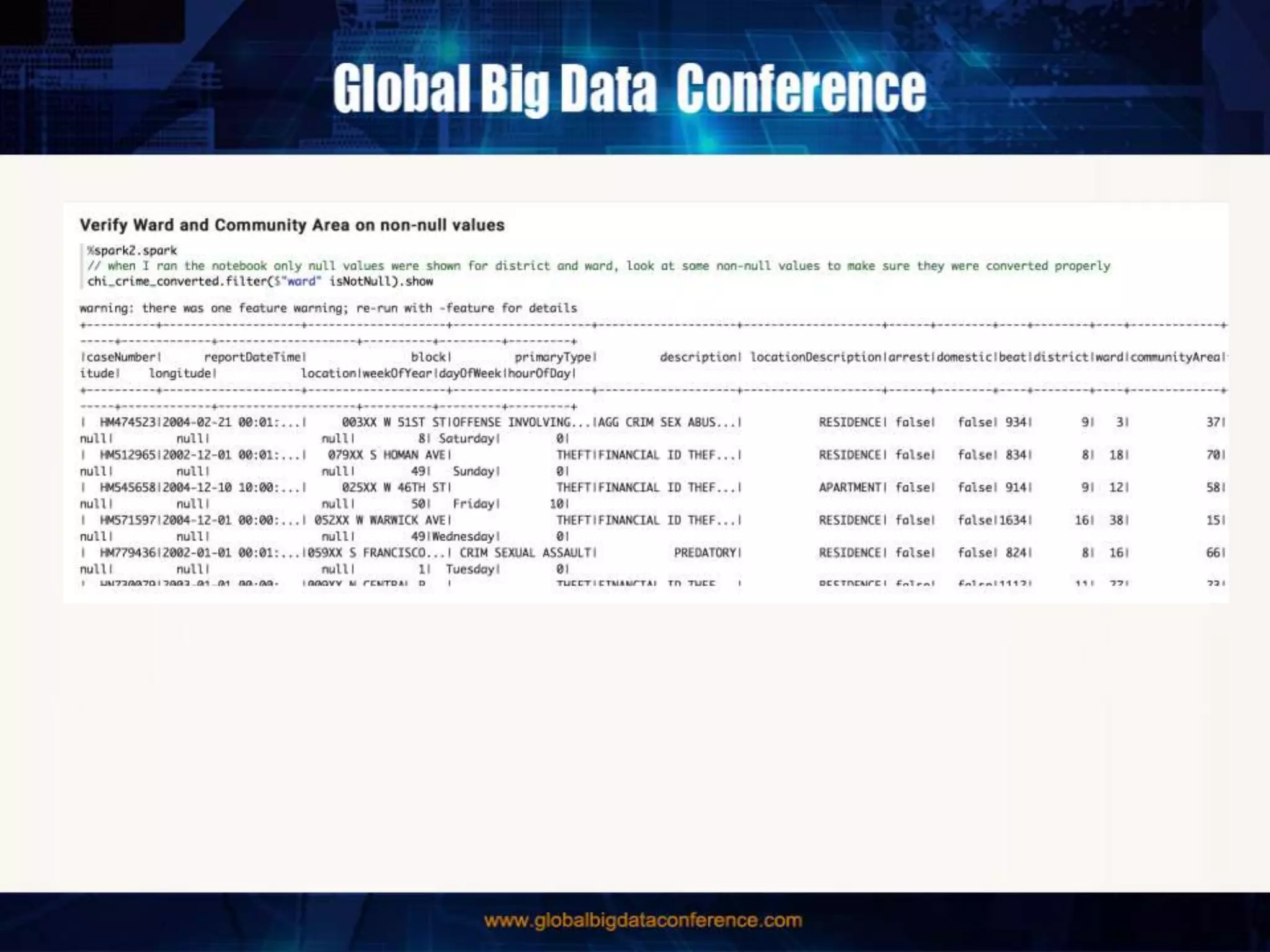
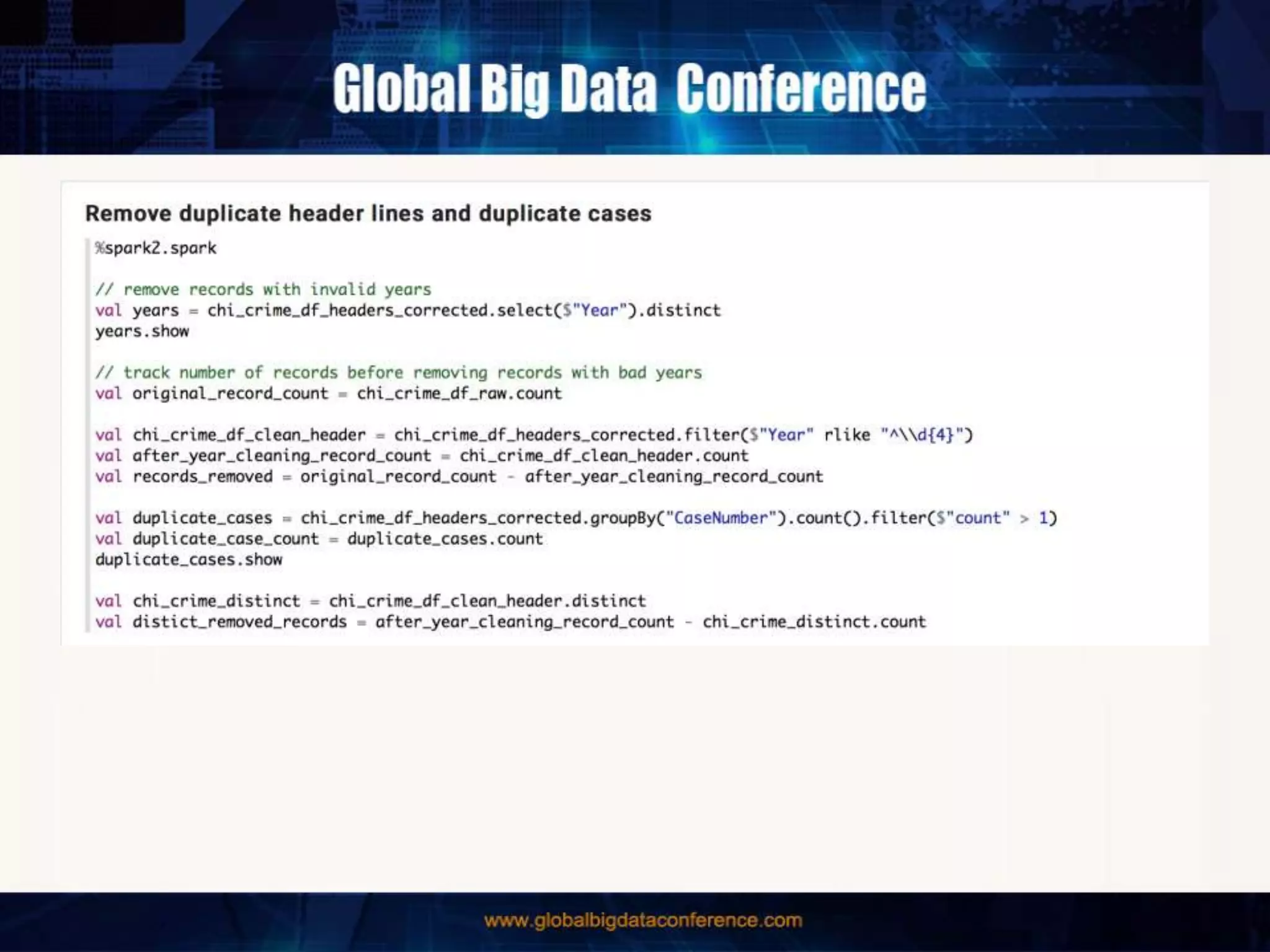
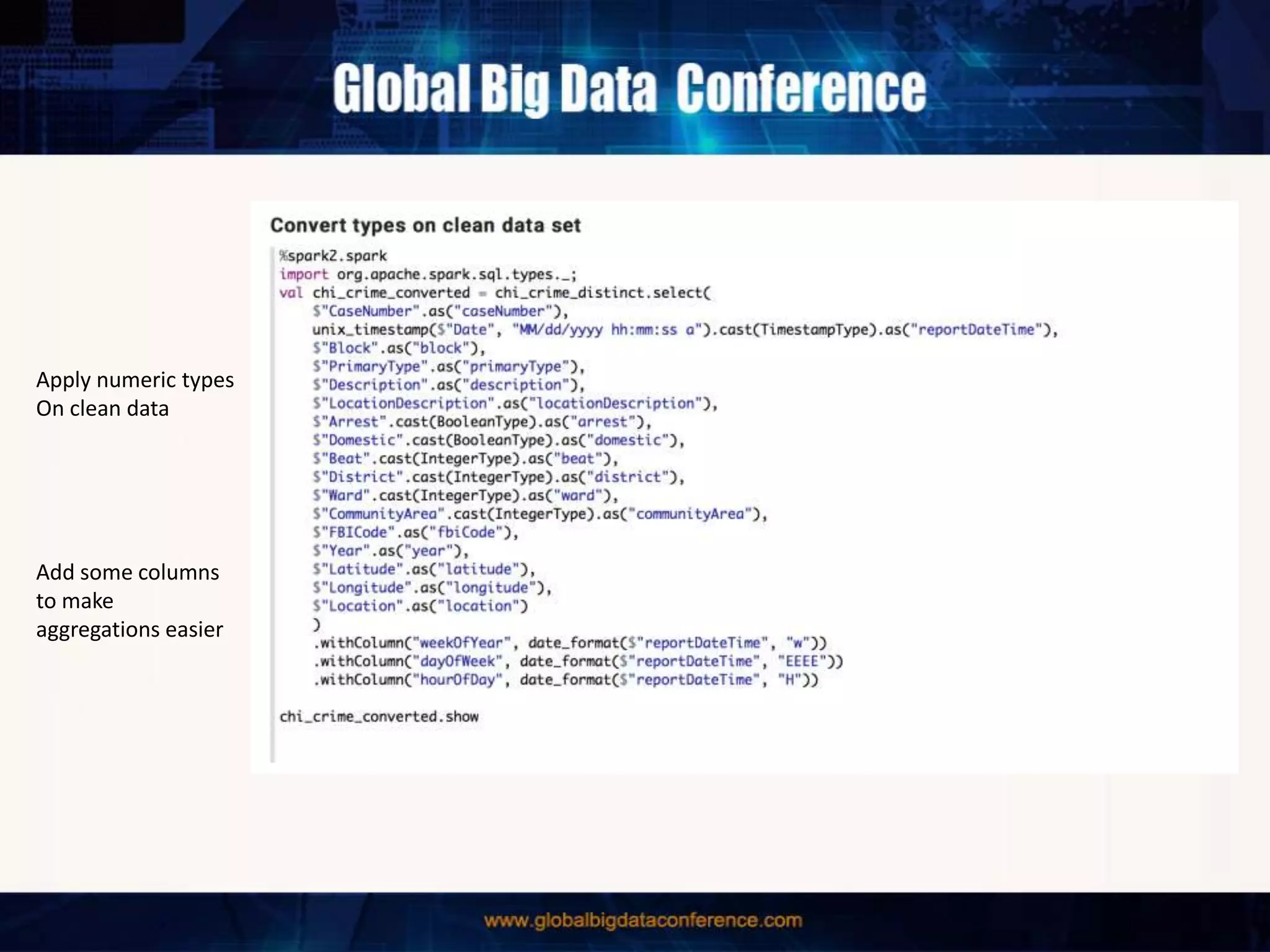
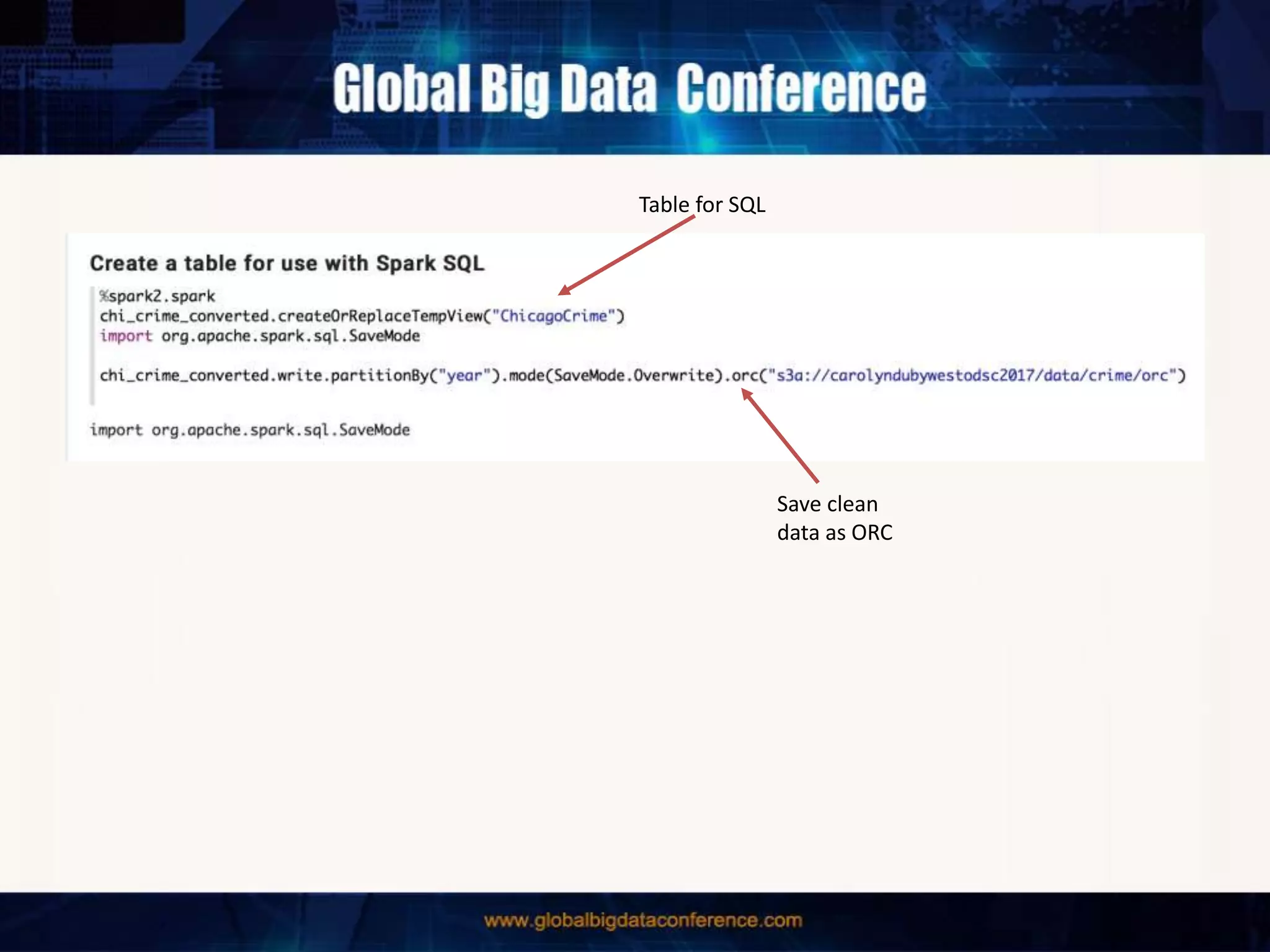
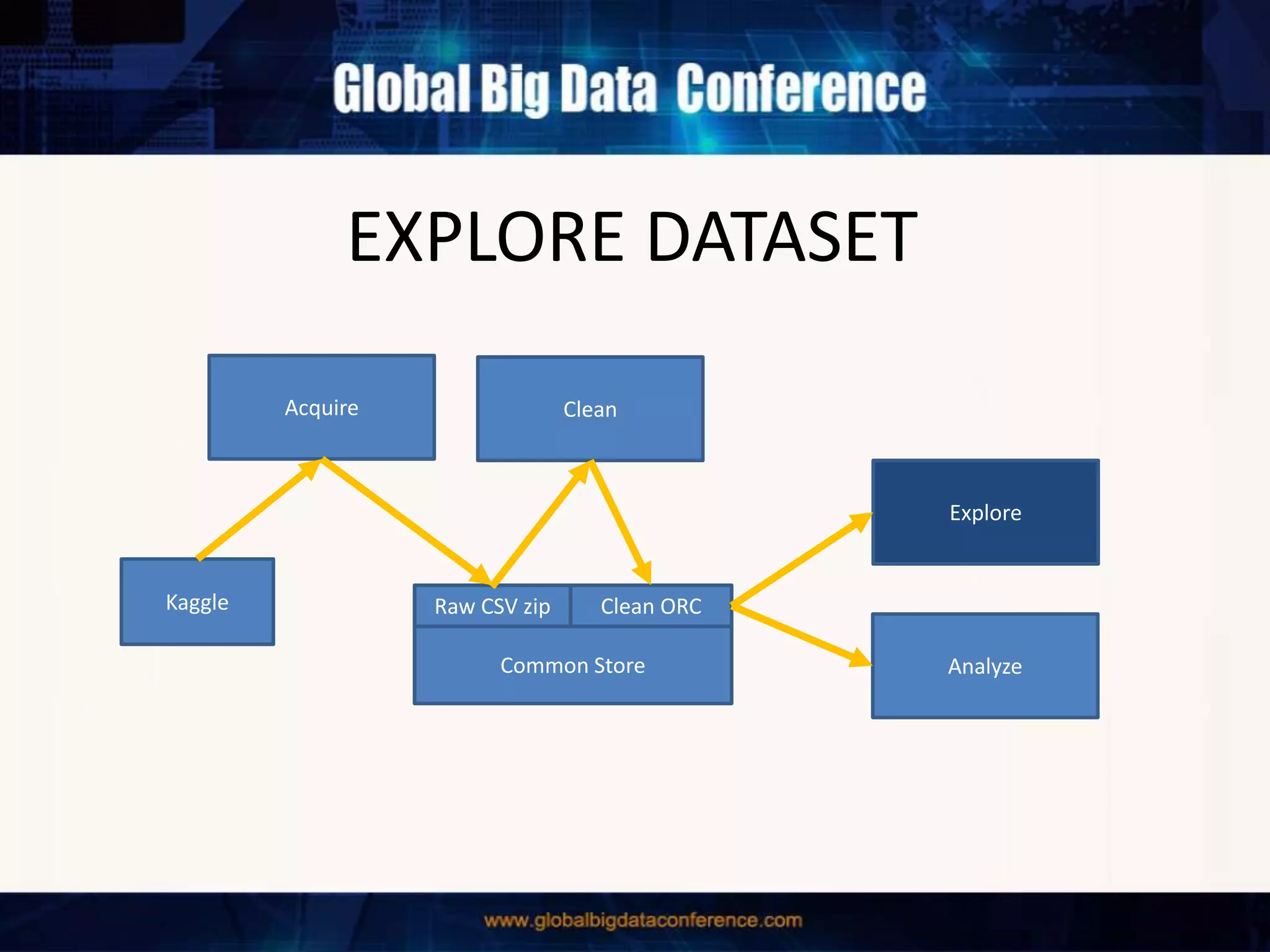
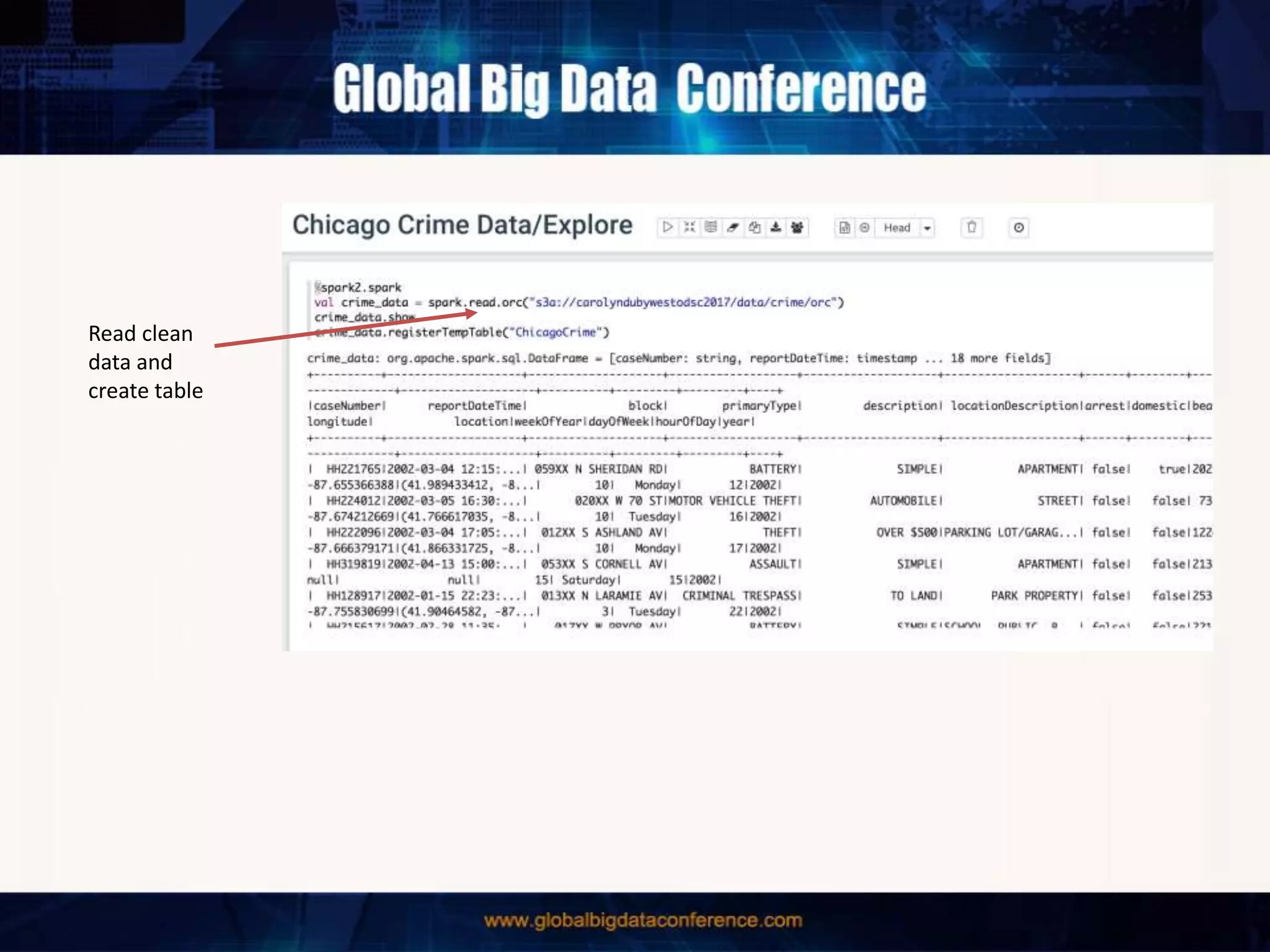
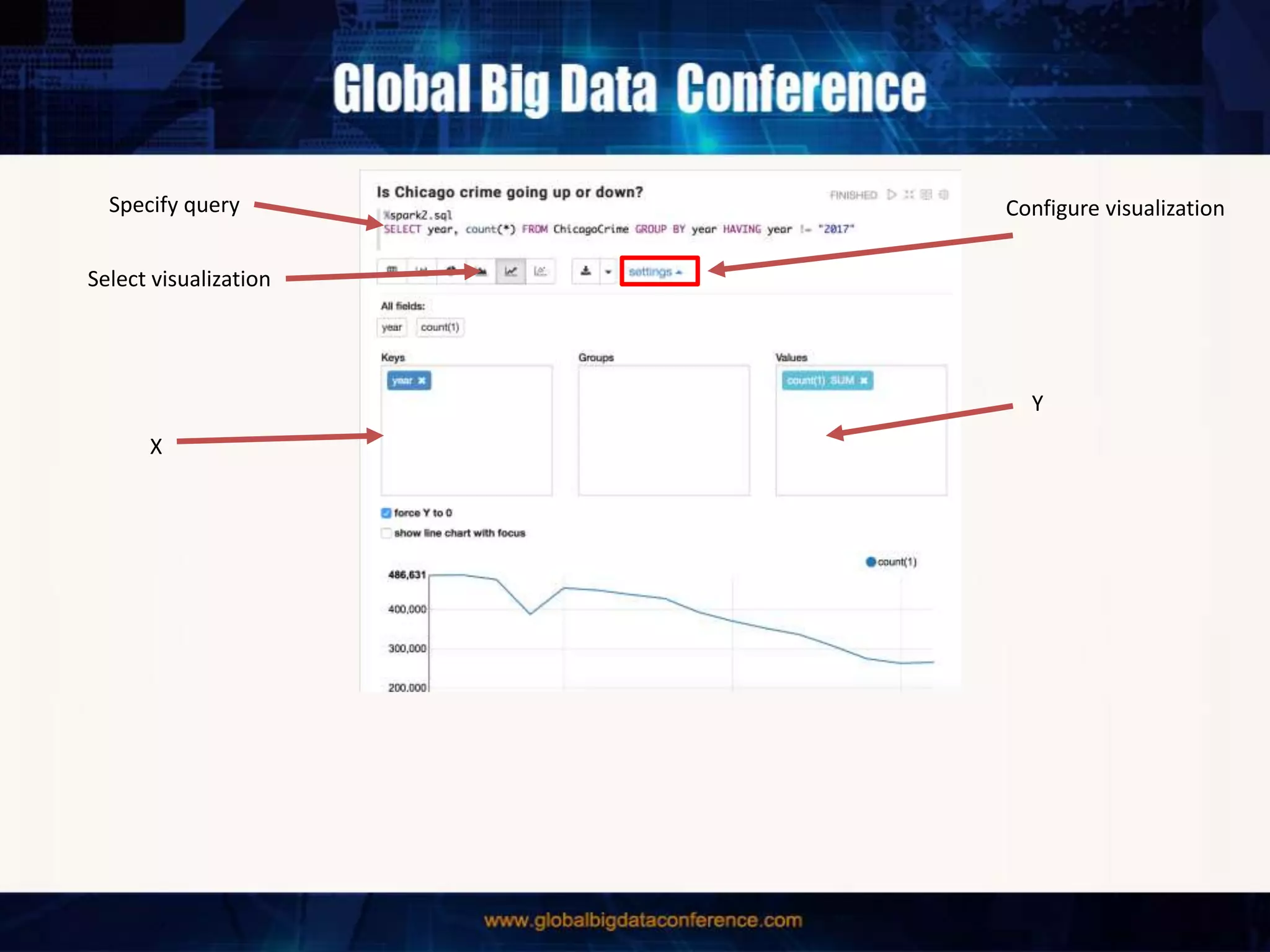
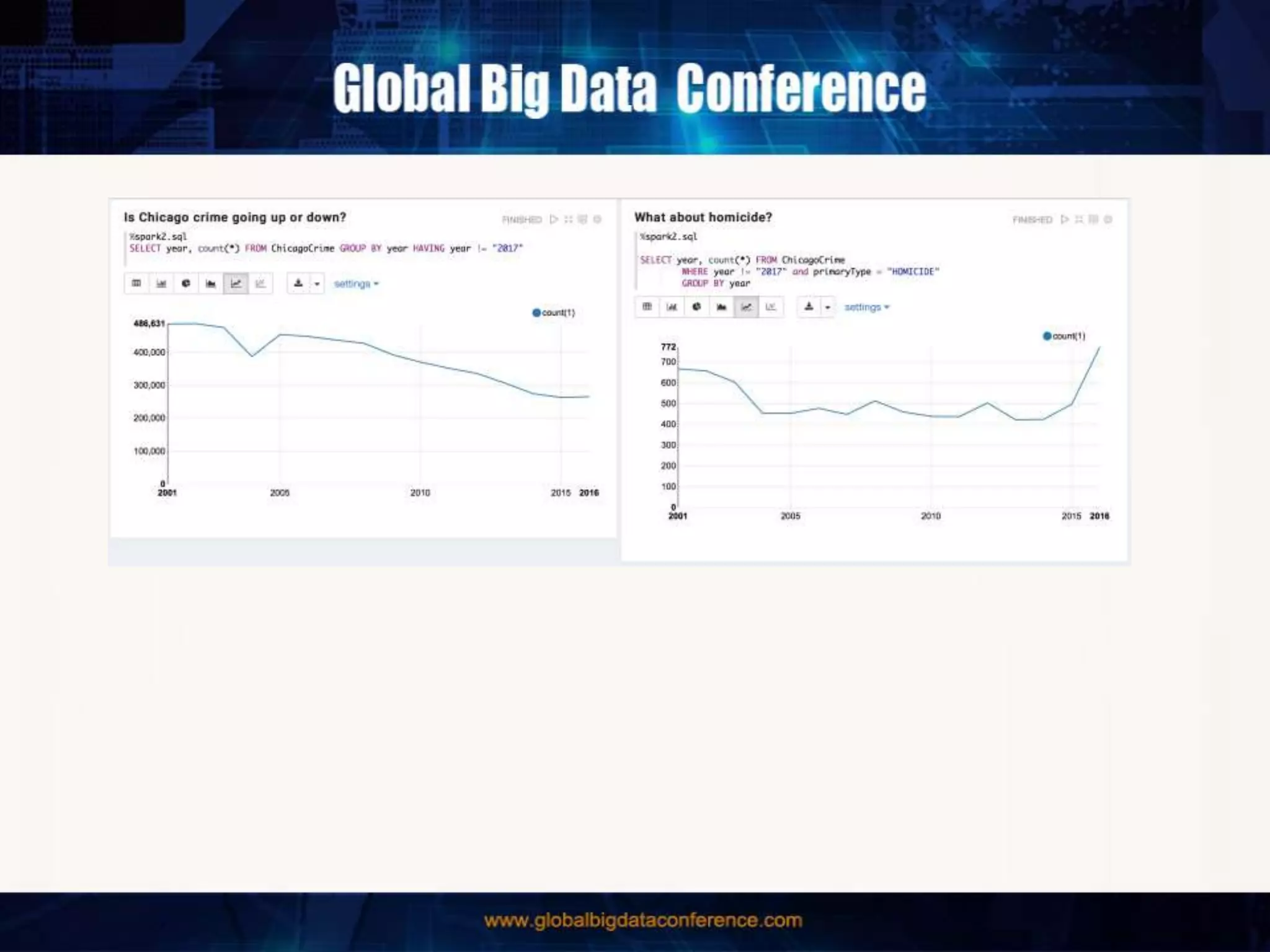
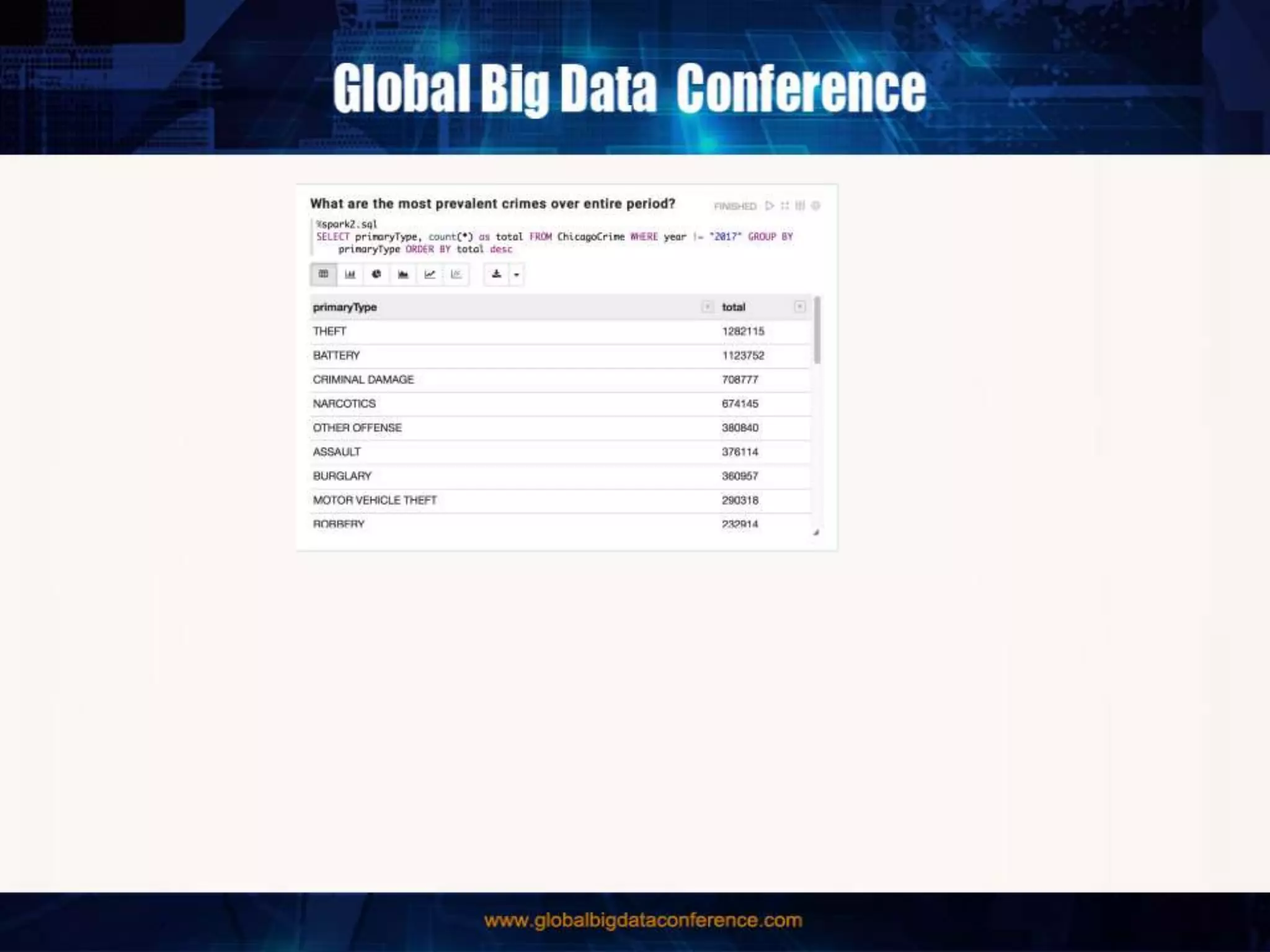
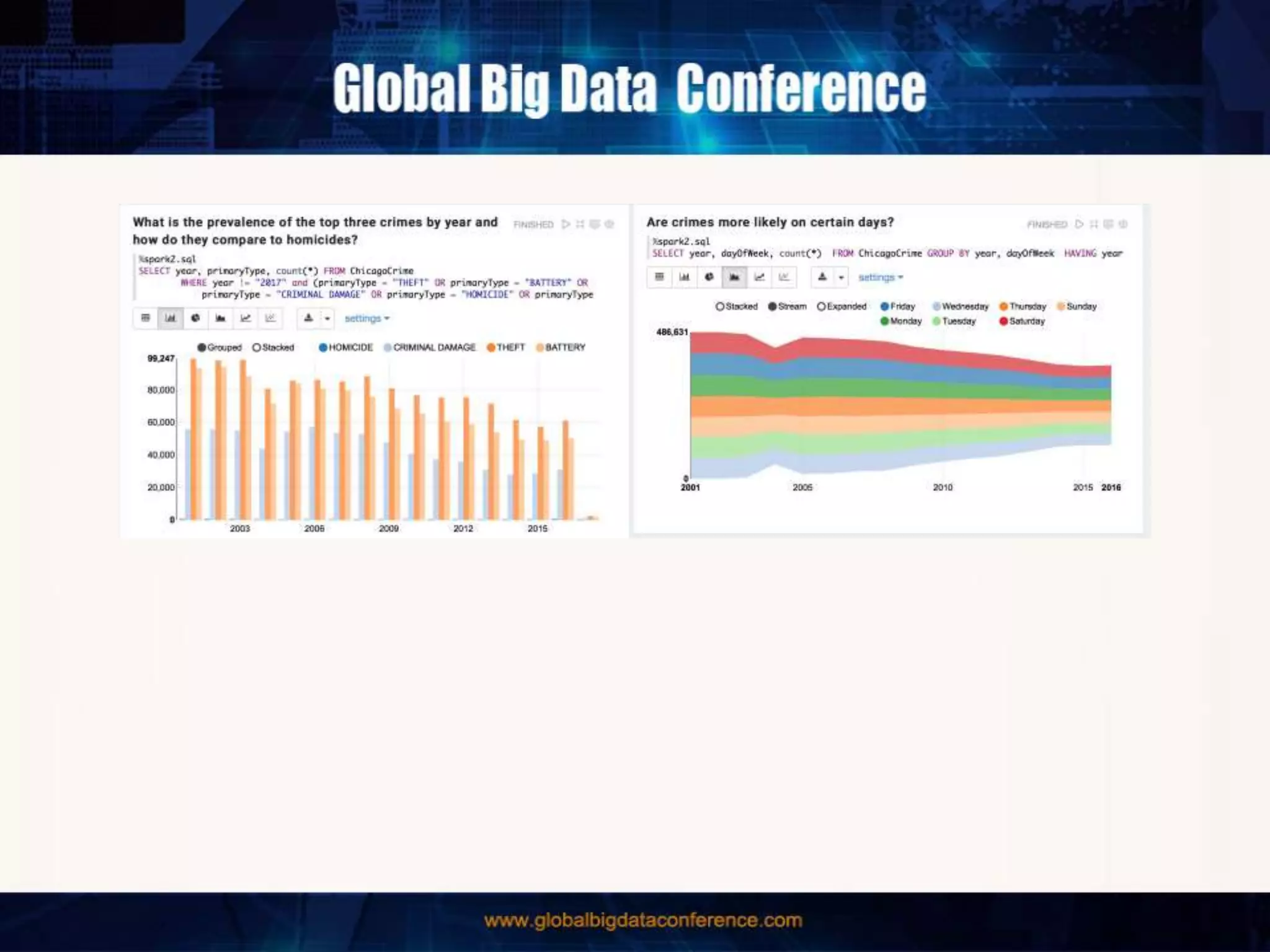
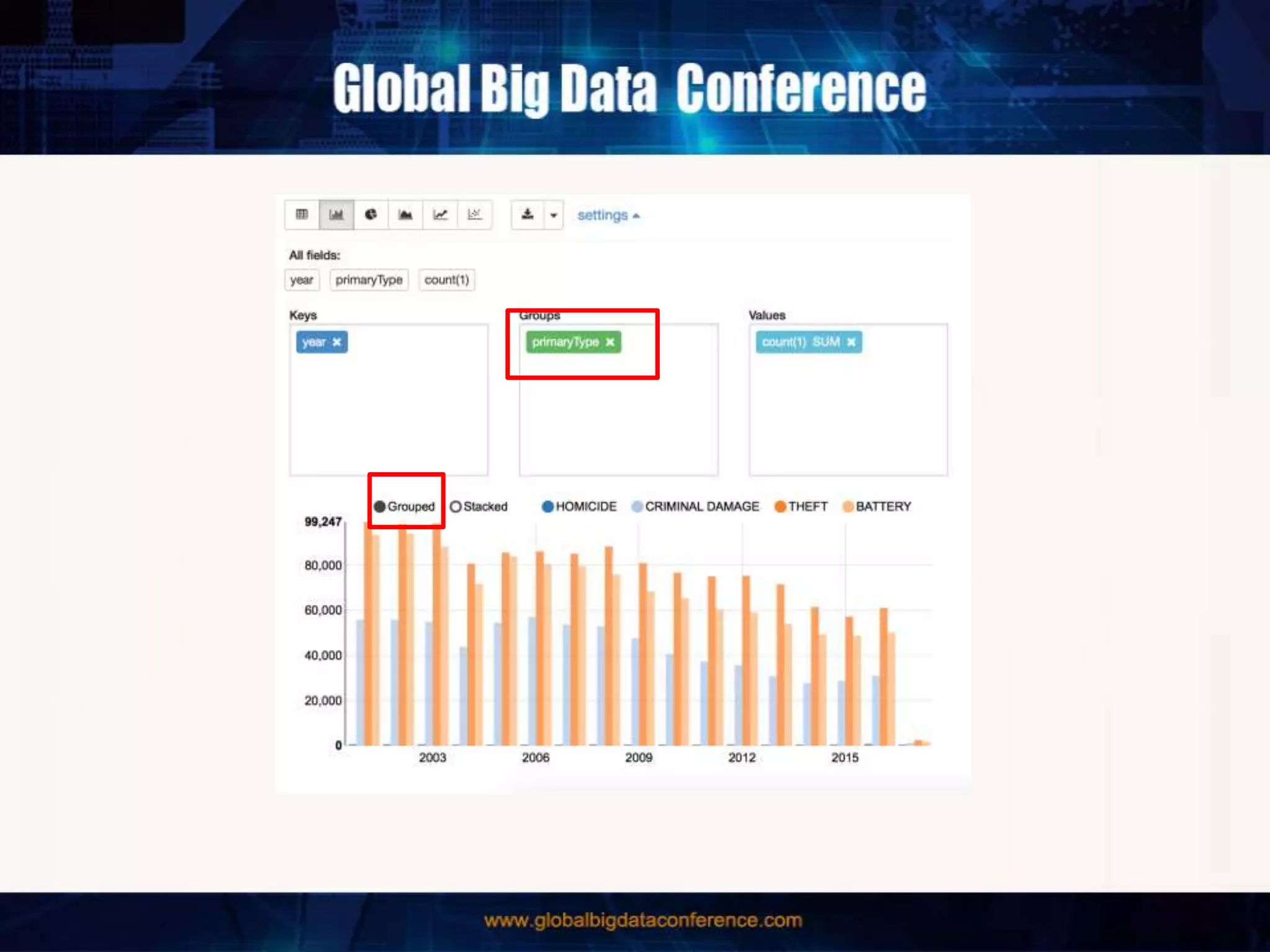
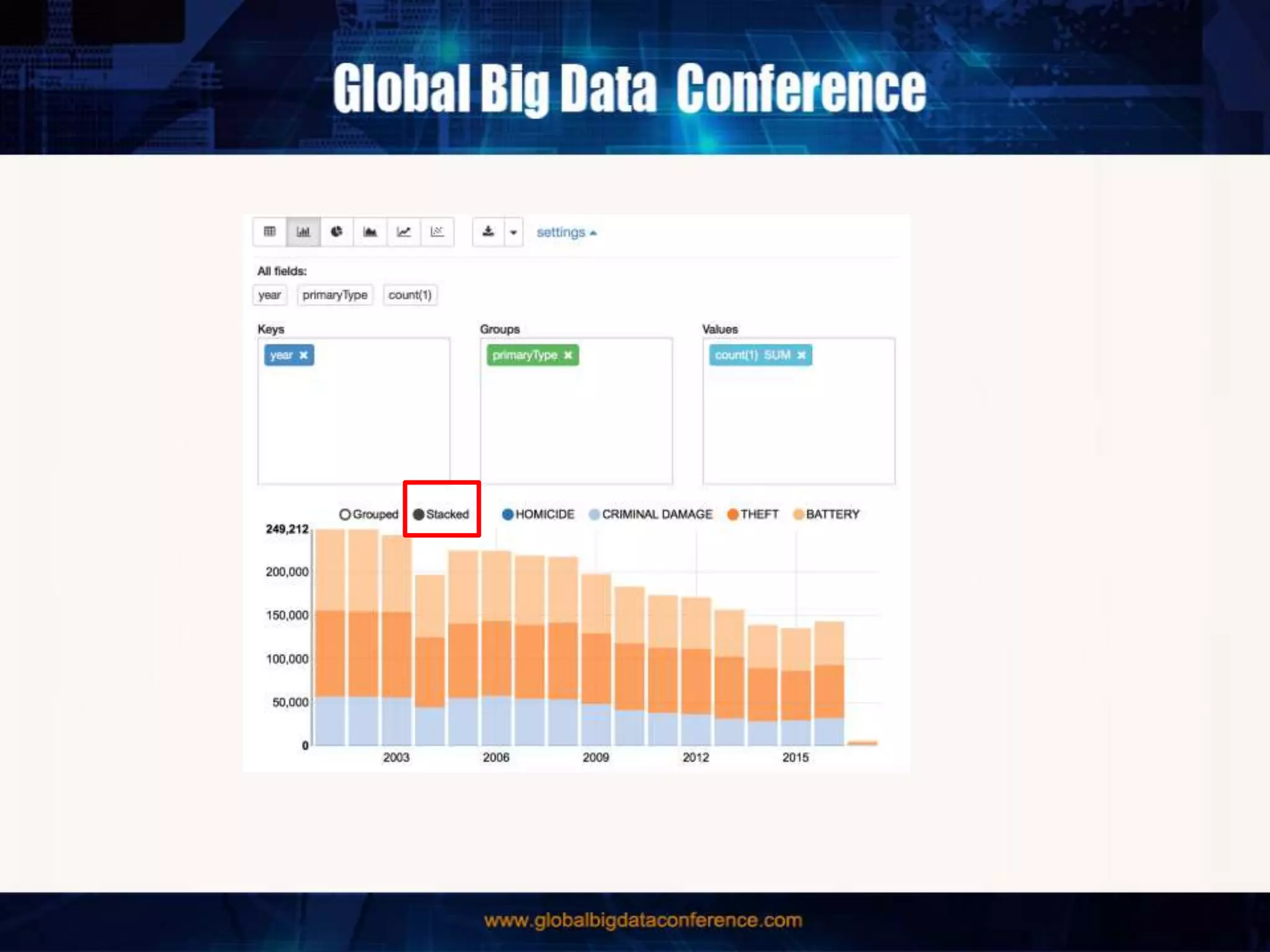
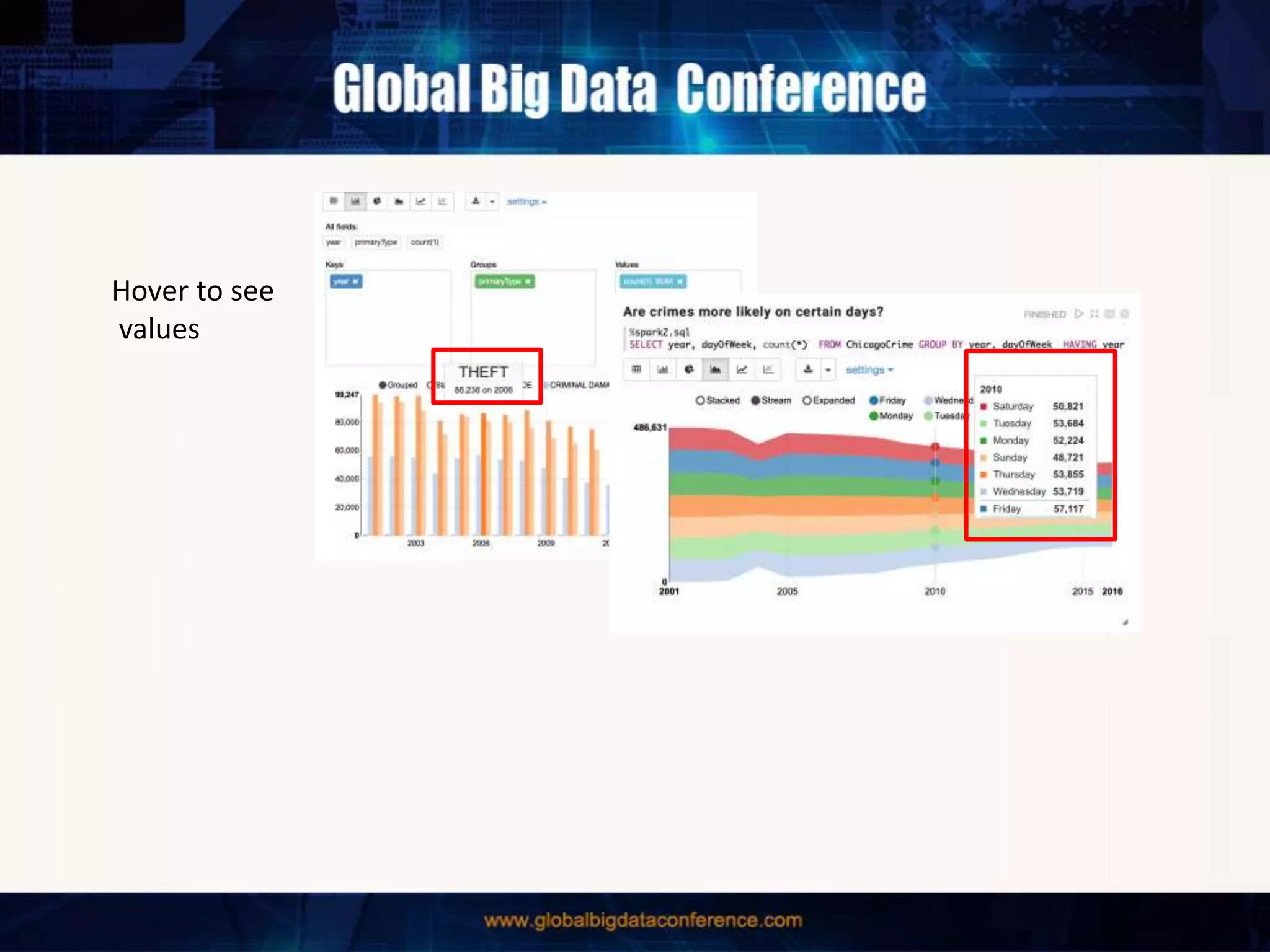
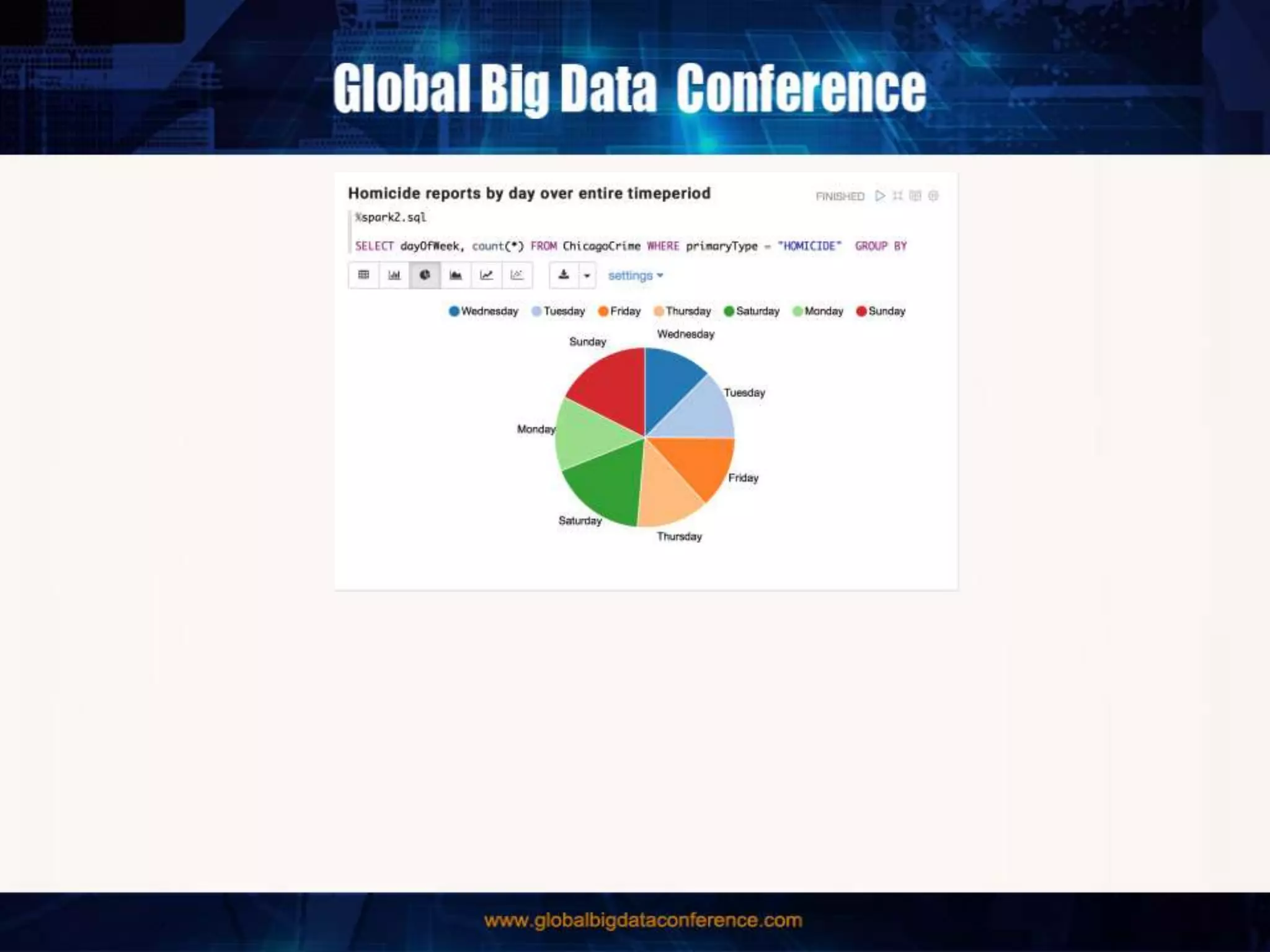
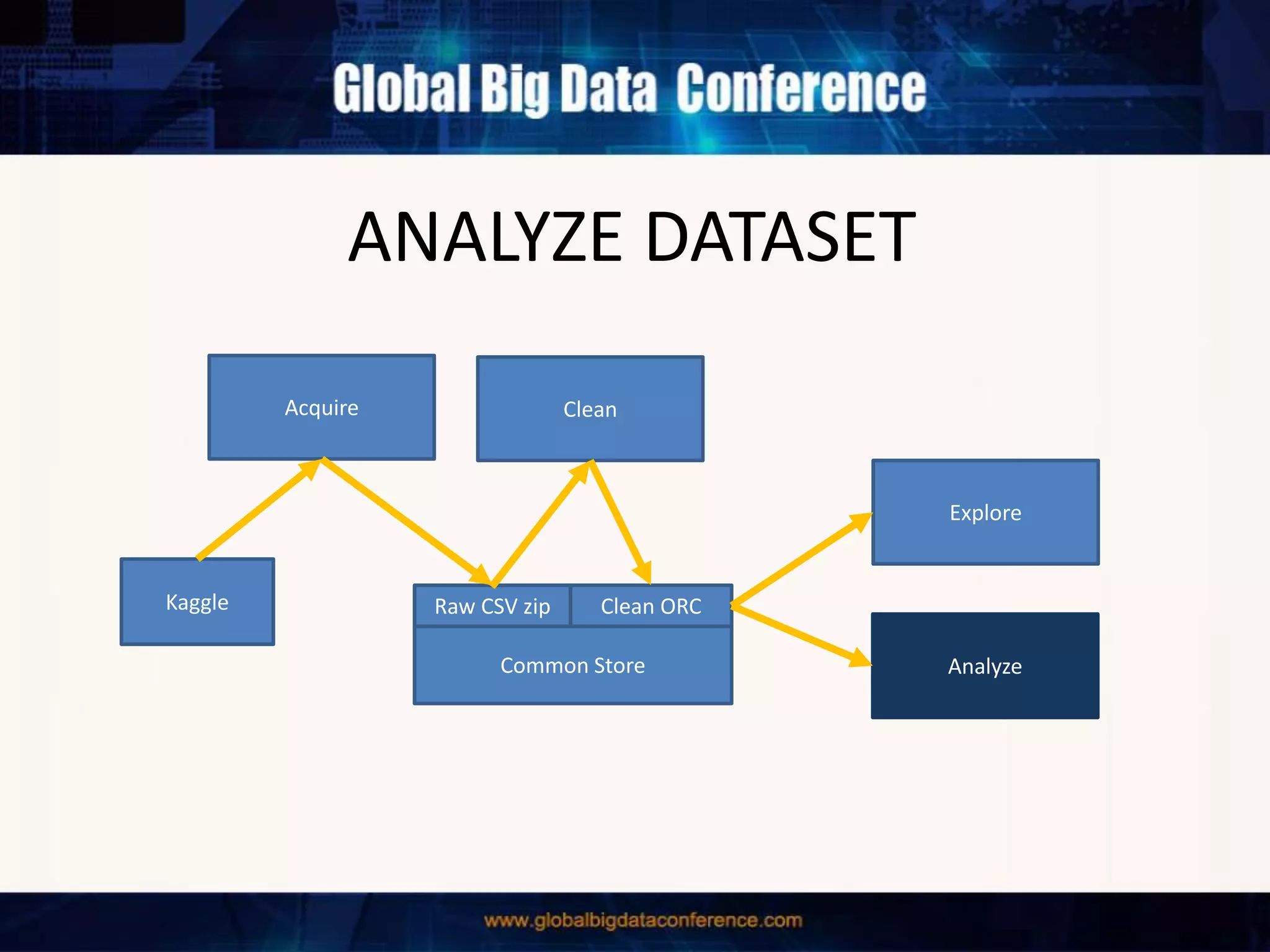
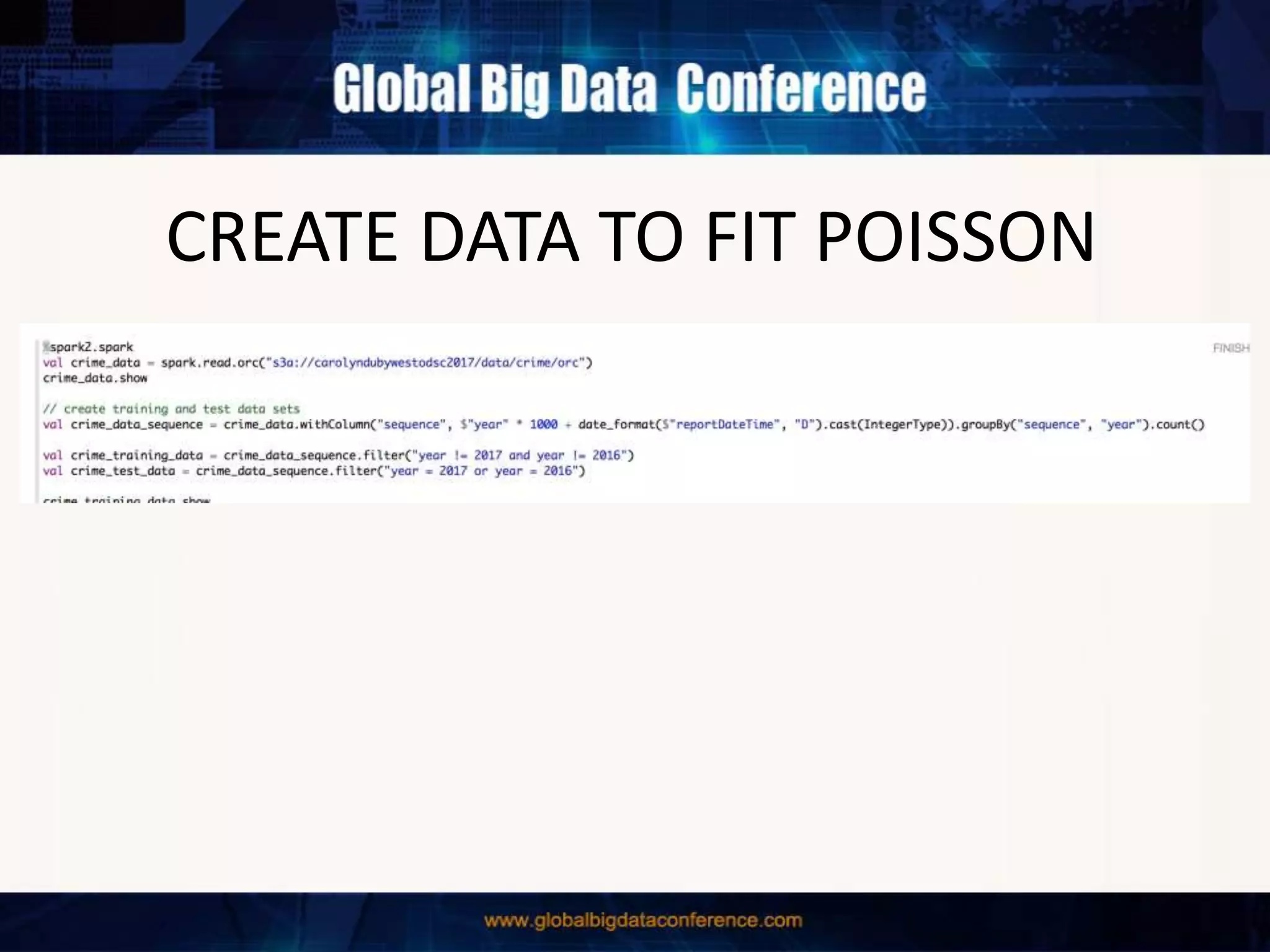
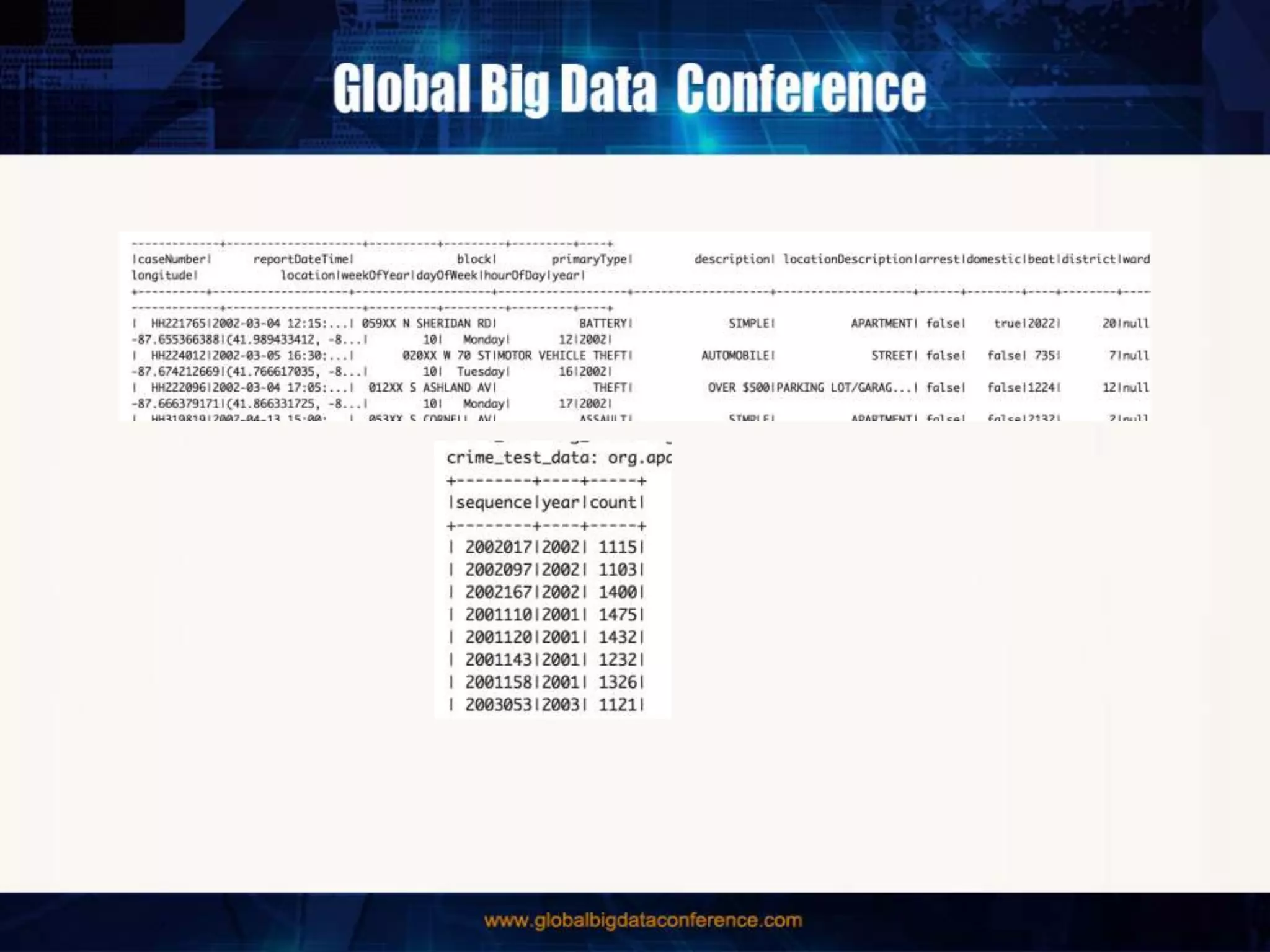
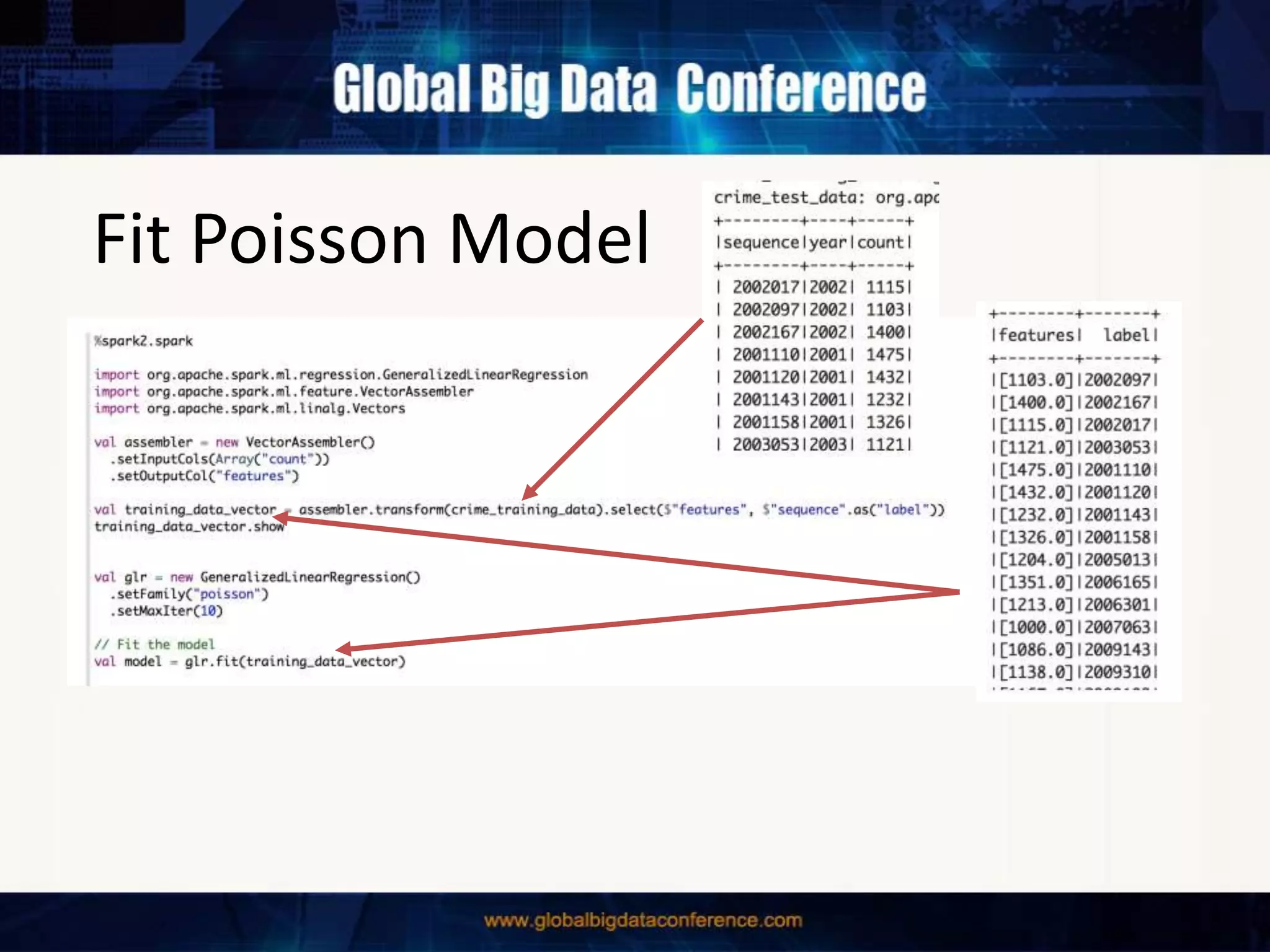
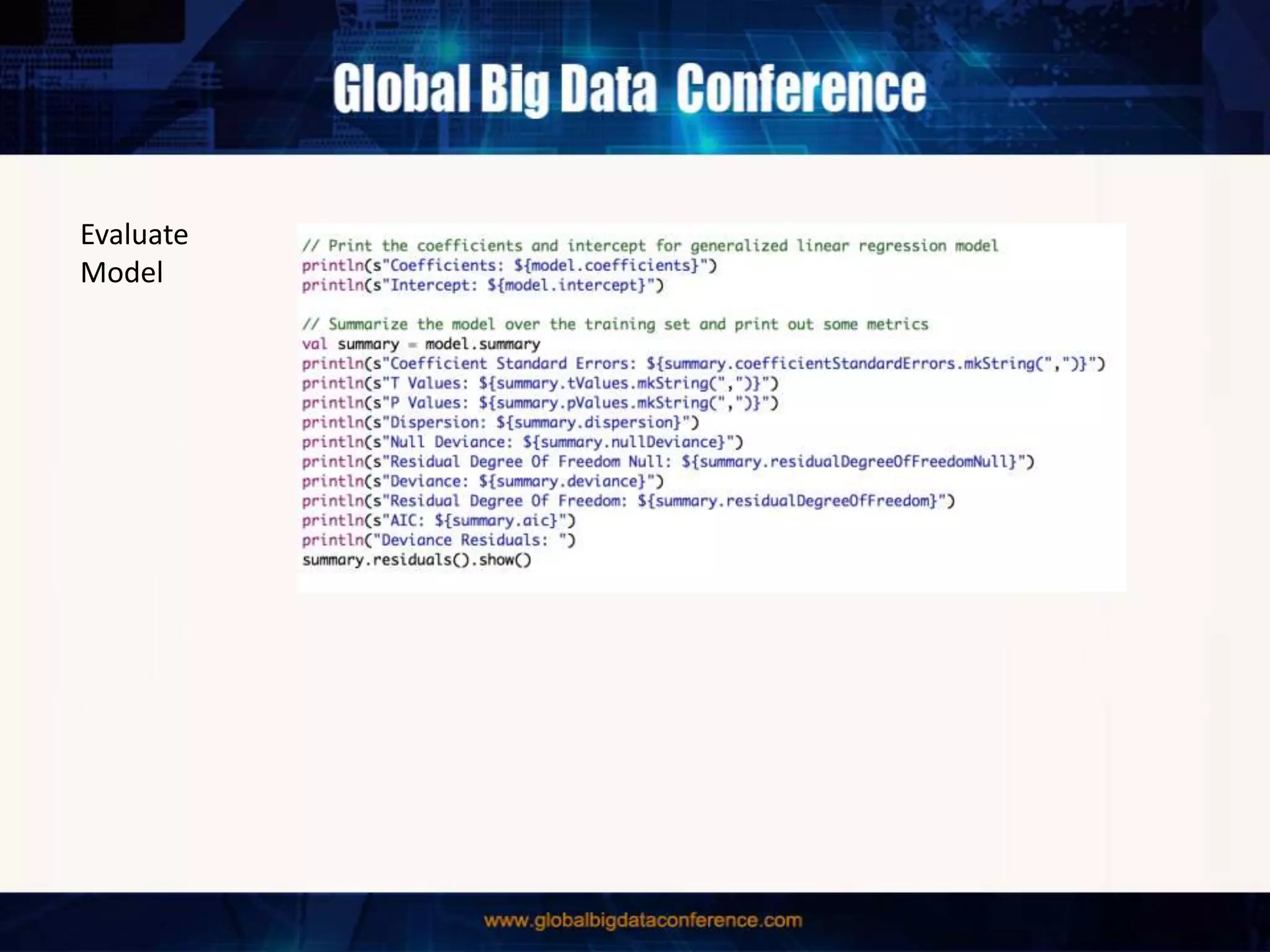
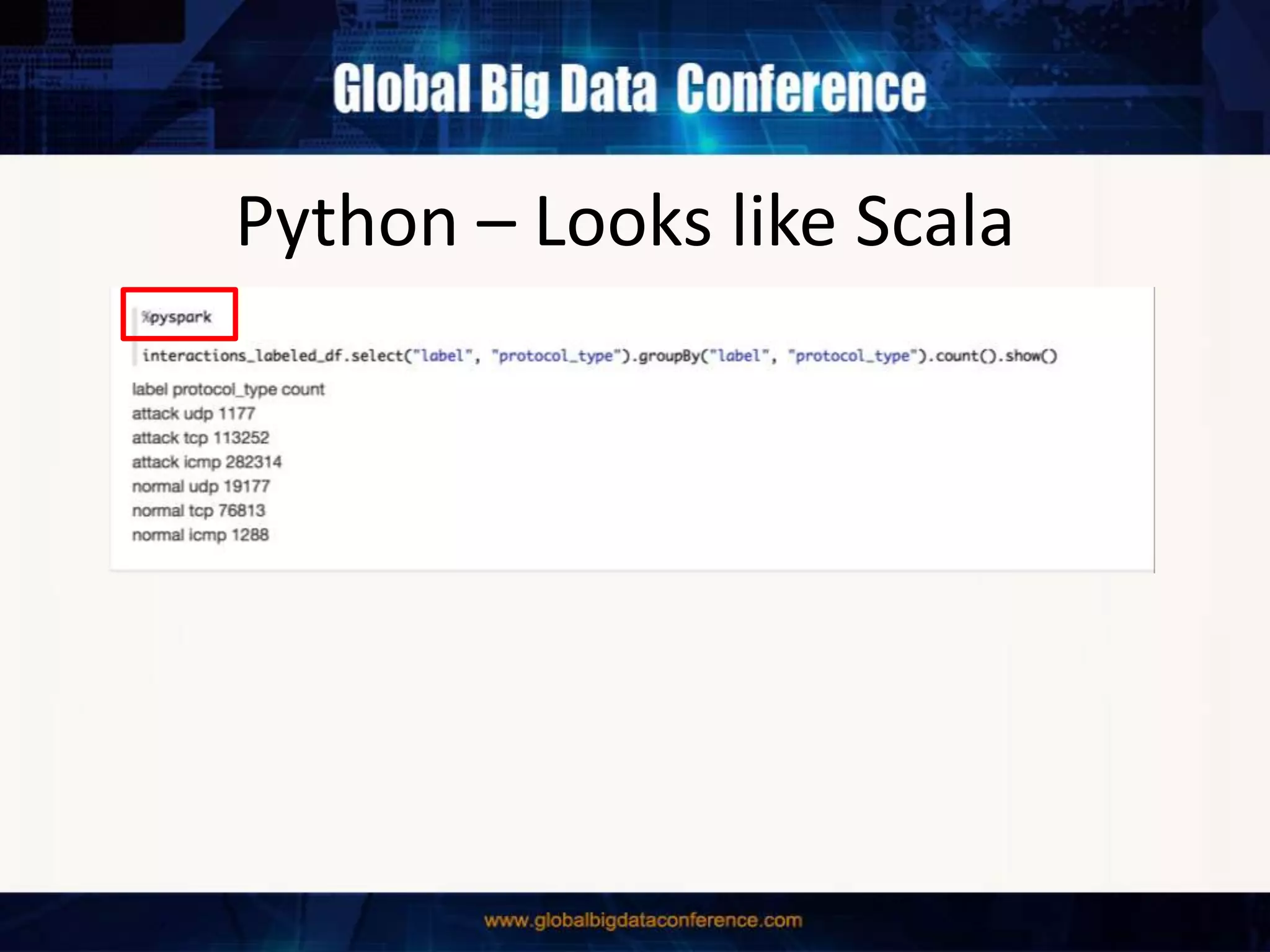
The document discusses the capabilities of Apache Spark and Zeppelin for scalable data science, focusing on distributed computing to overcome desktop limitations. It highlights features such as data cleaning, analysis, and collaborative result sharing, along with various libraries and tools for machine learning, streaming, and visualization. Additionally, it provides guidance on getting started with these technologies, including environment setup and best practices for data pipelines and notebook sharing.