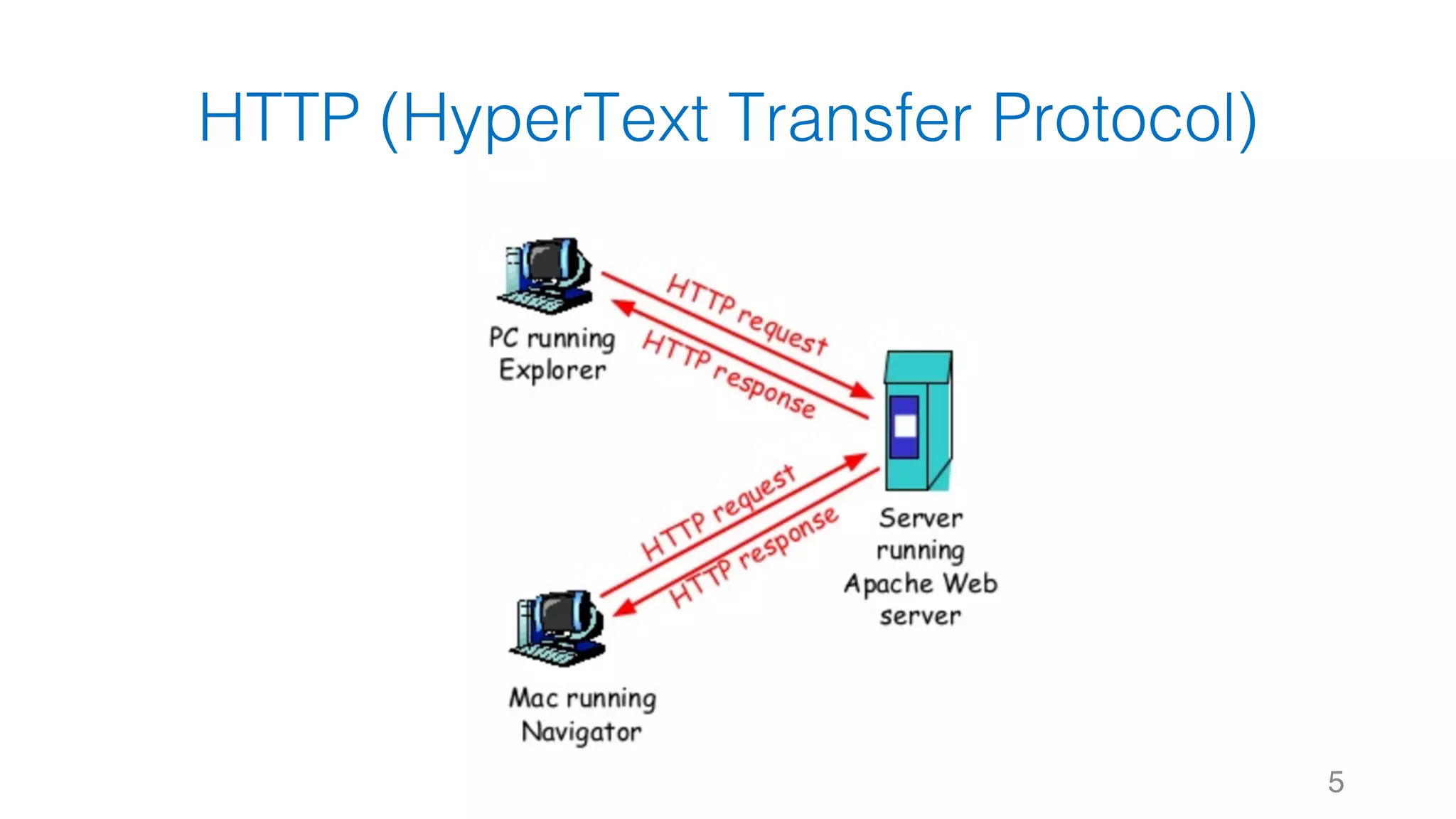
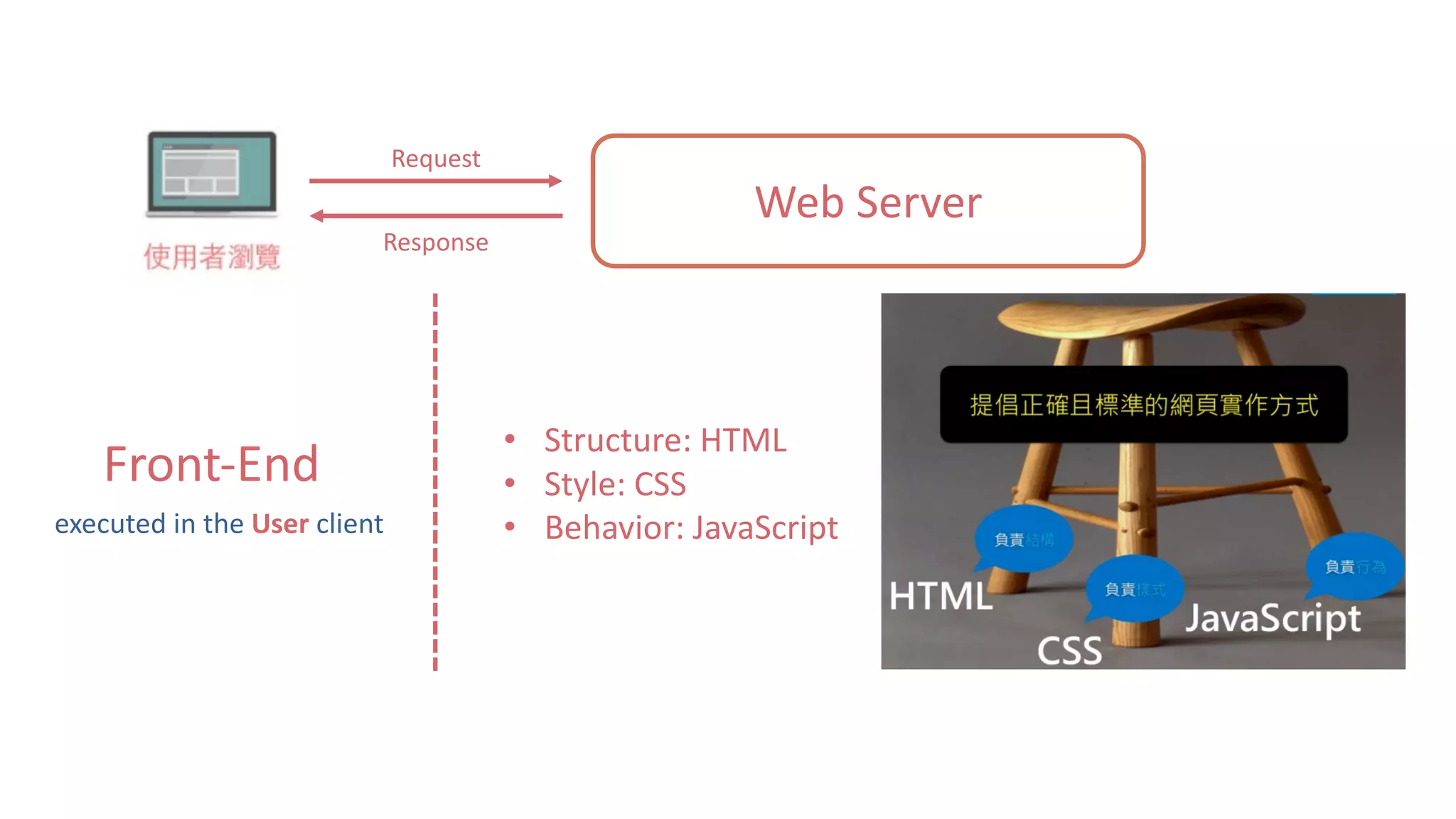
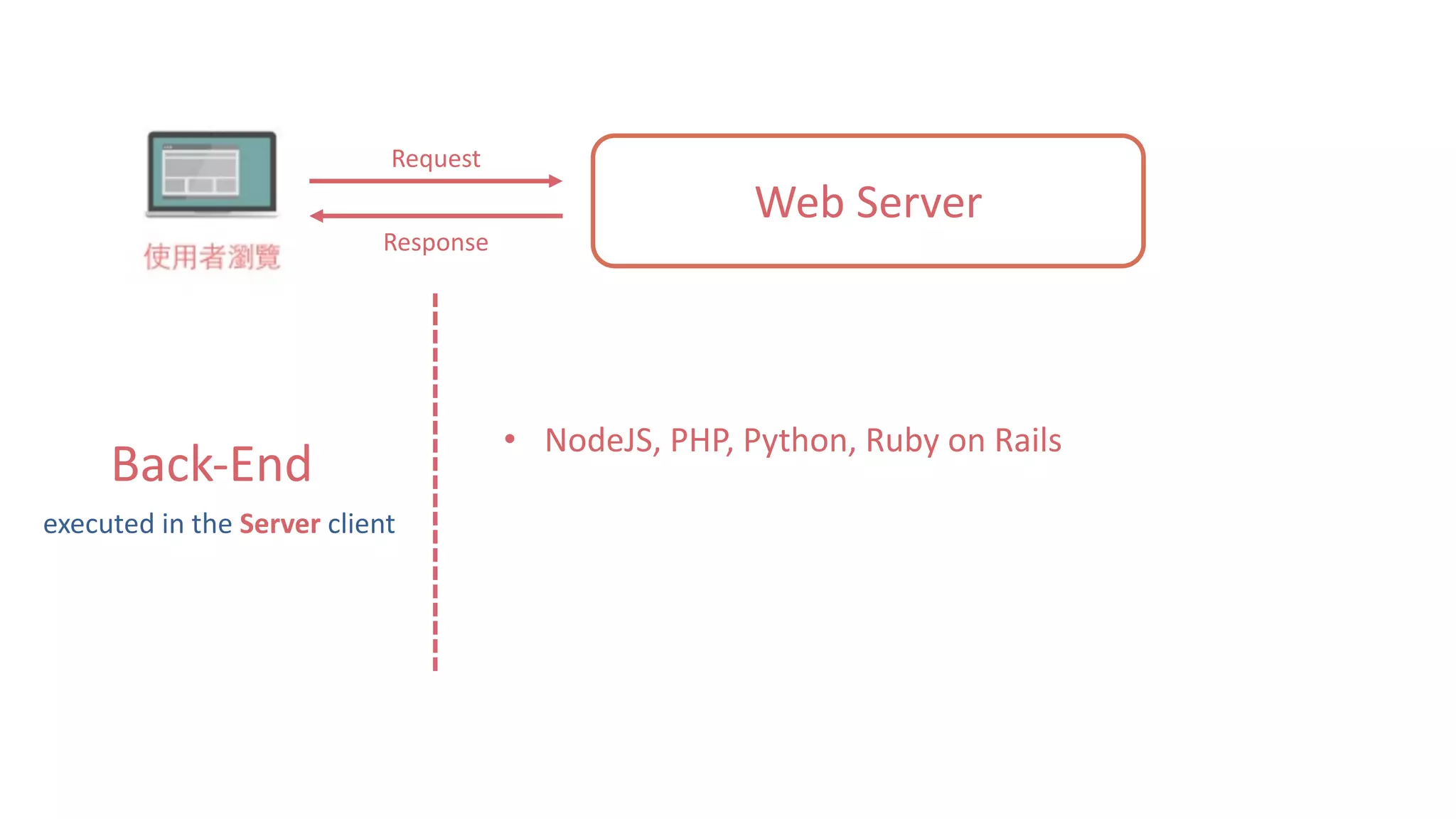
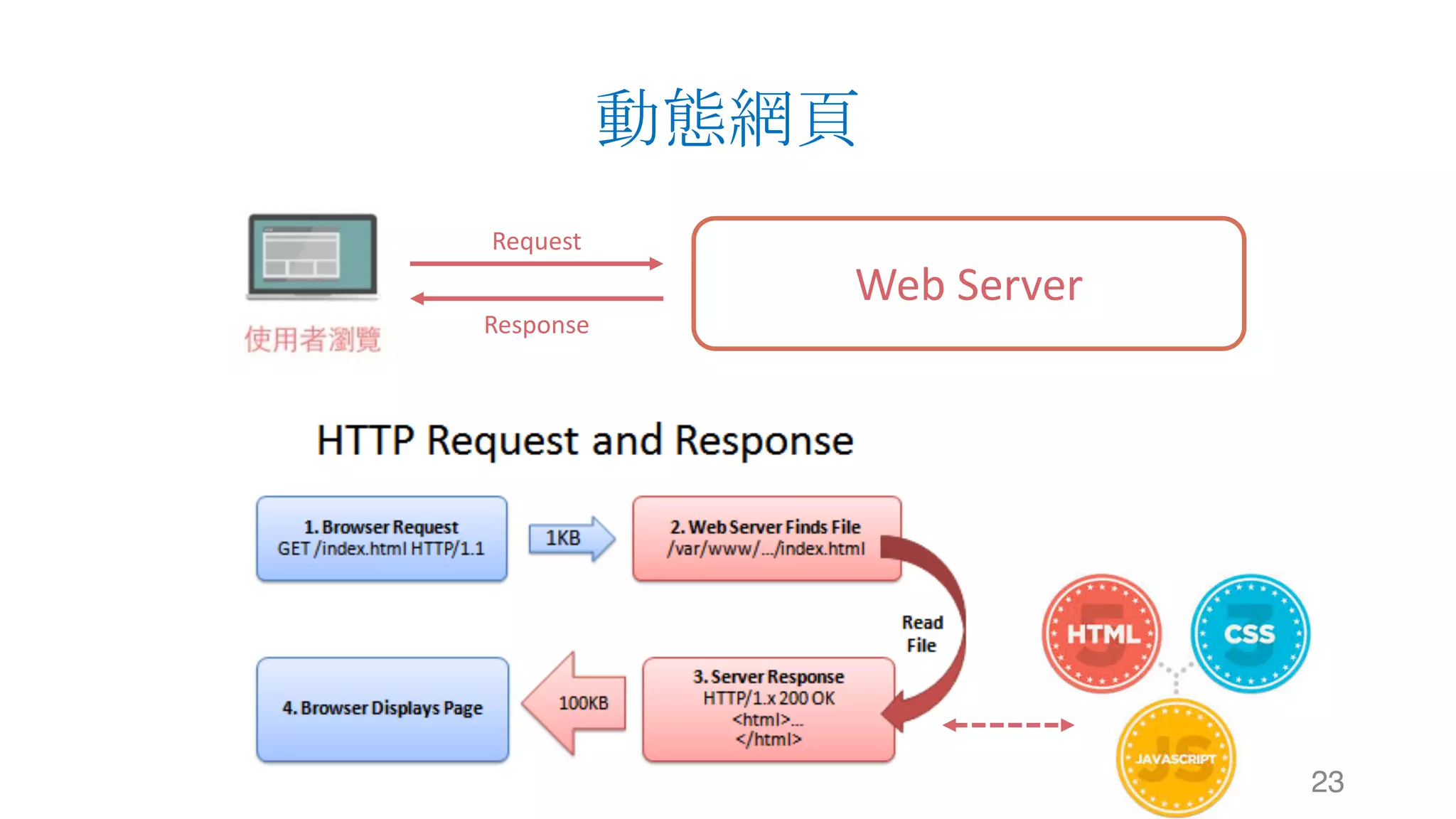
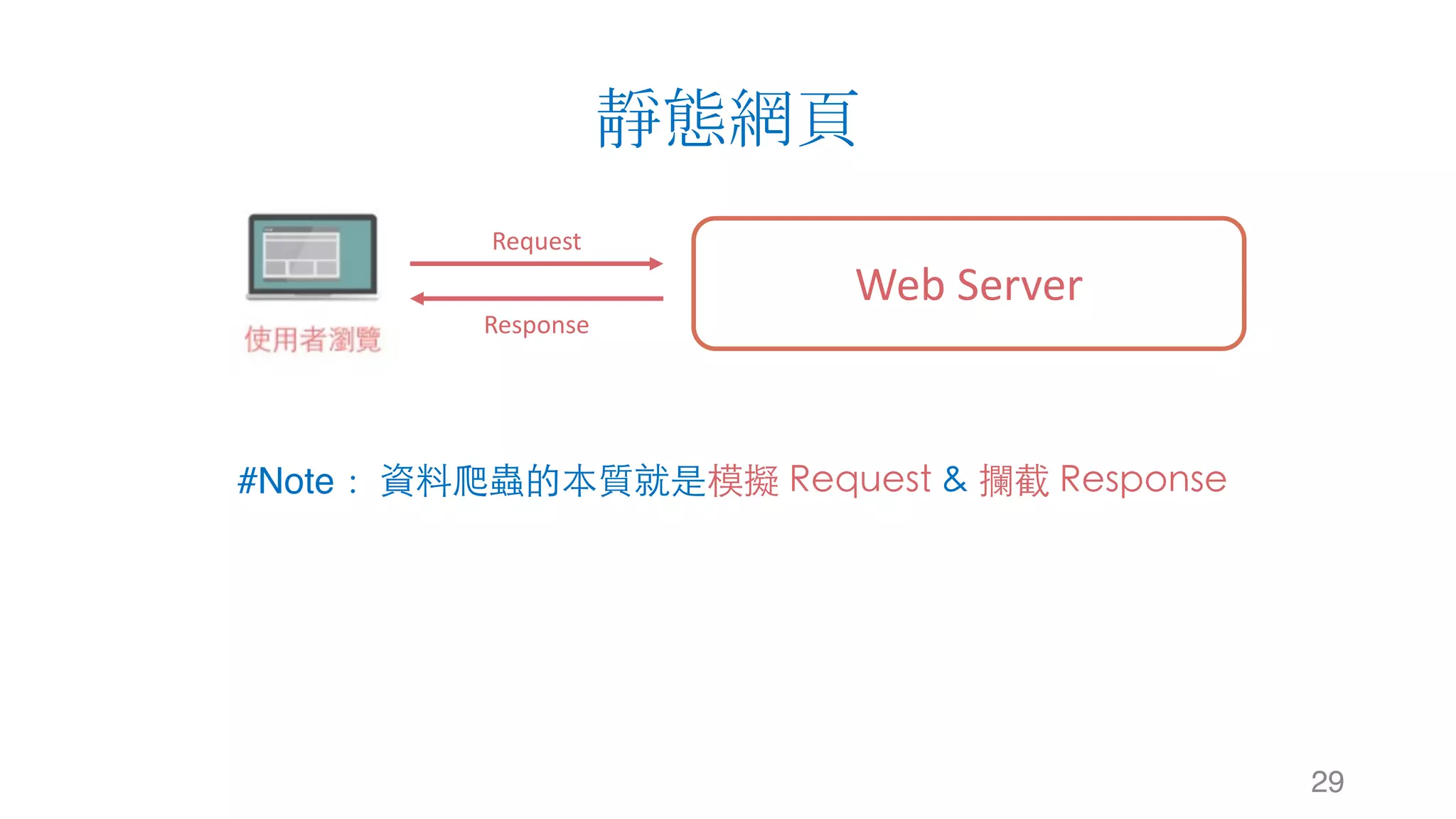
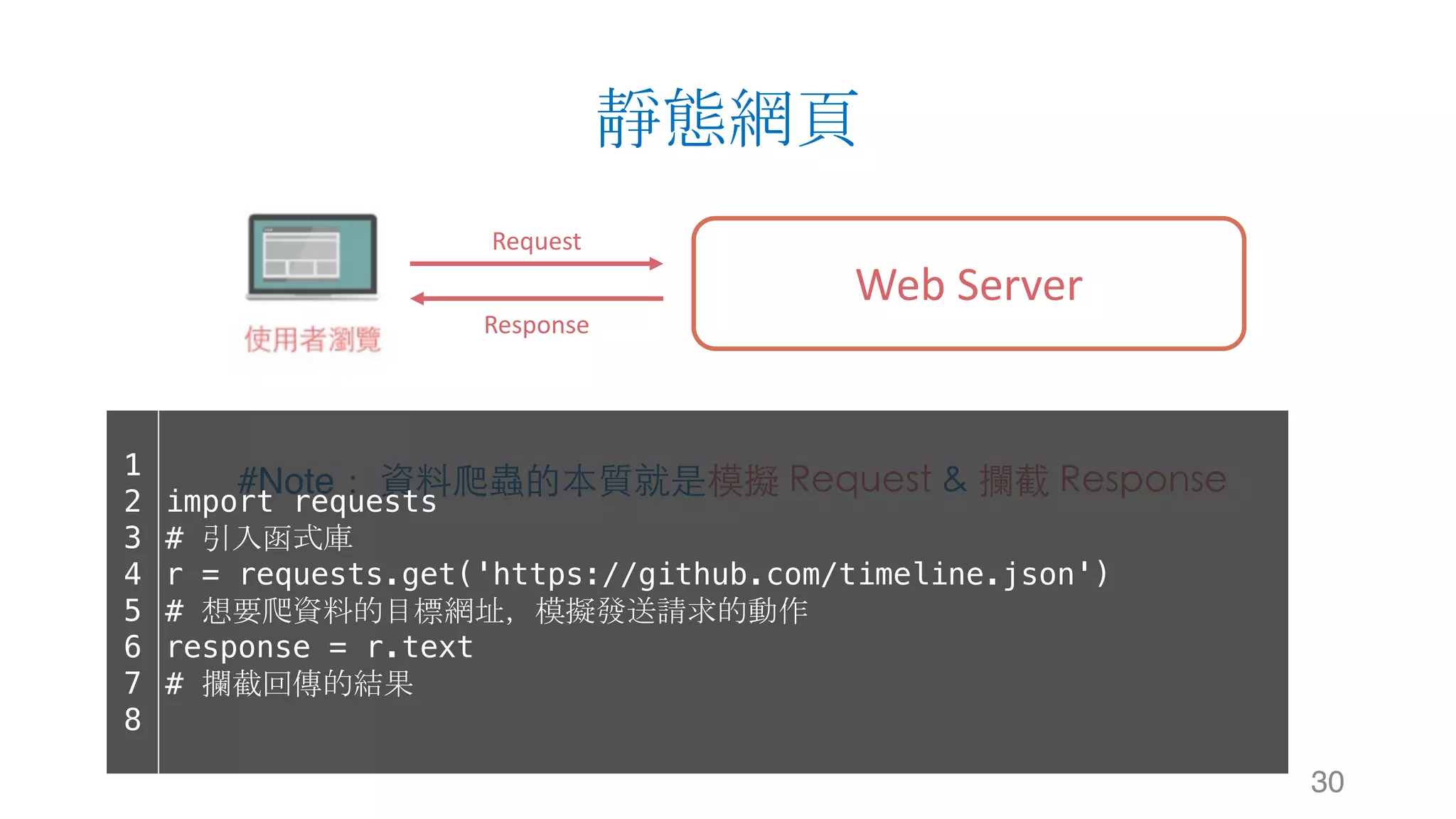
这是关于使用 Python 进行数据爬虫的文档,涵盖了网站运作架构、数据爬虫与搜索引擎的基础知识。文档详细介绍了数据获取的工具和库,如 urllib 和 requests,以及网页解析器 BeautifulSoup 和正则表达式的使用。通过示例代码说明静态网页的数据爬取过程。



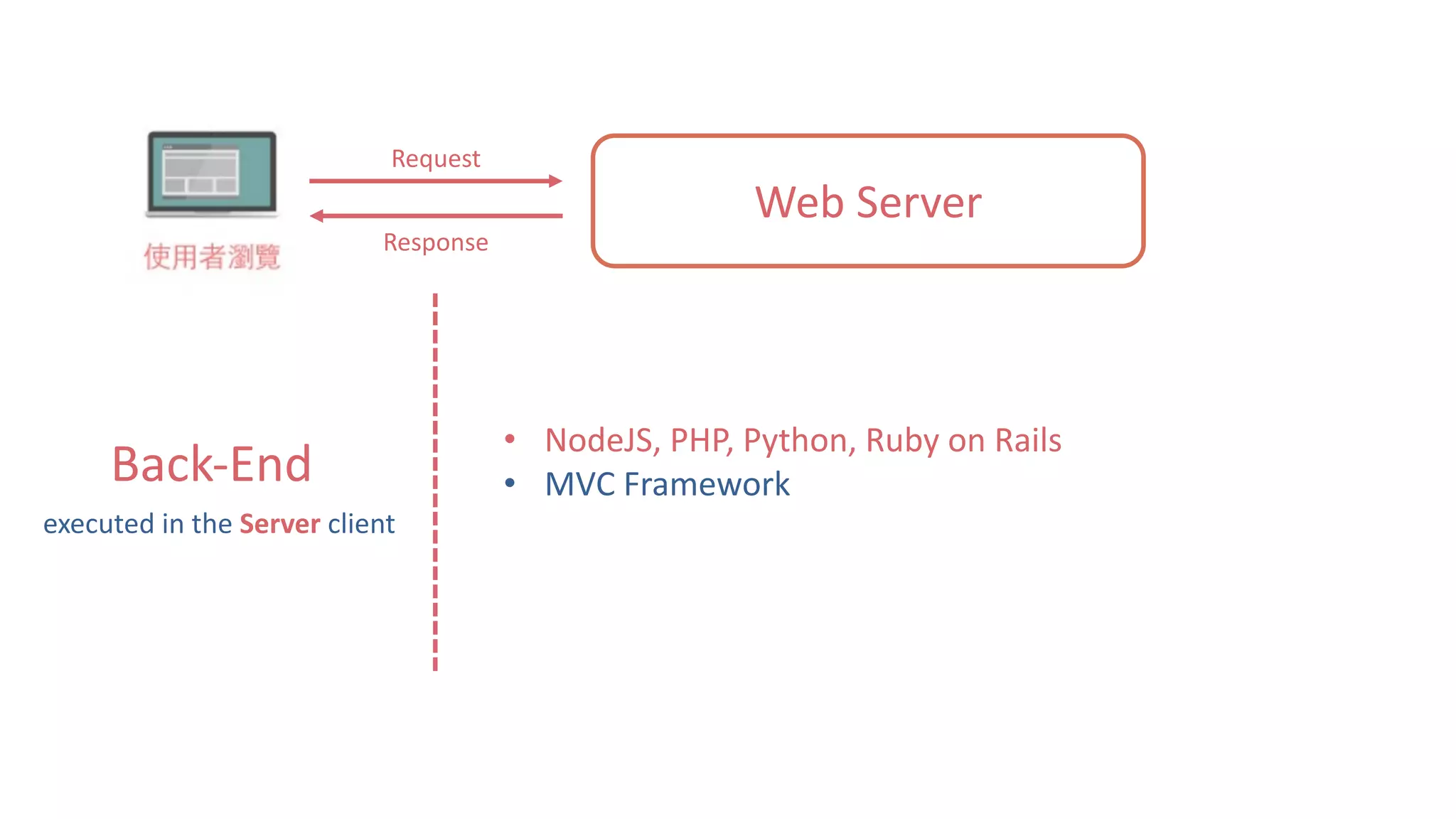
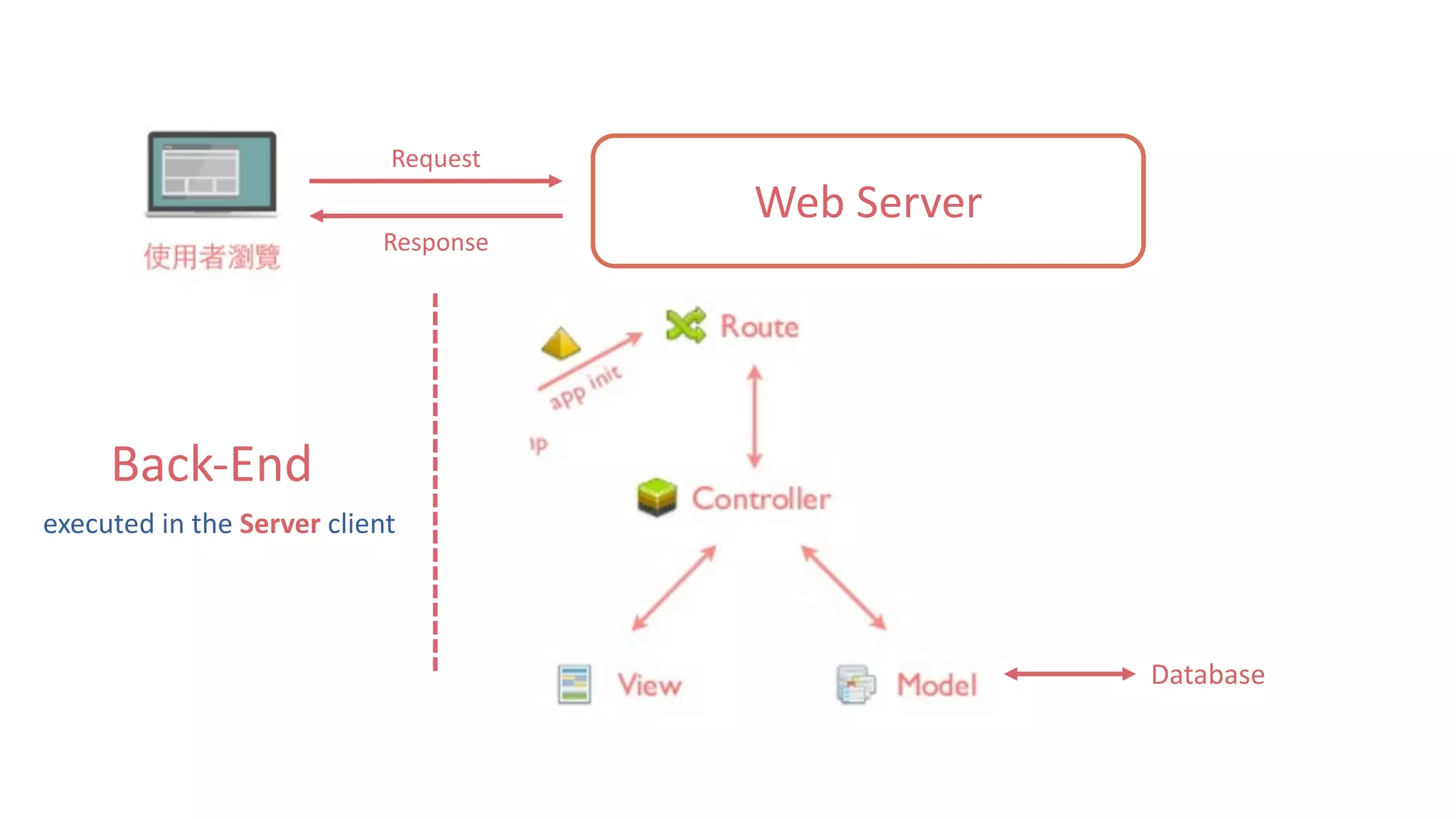
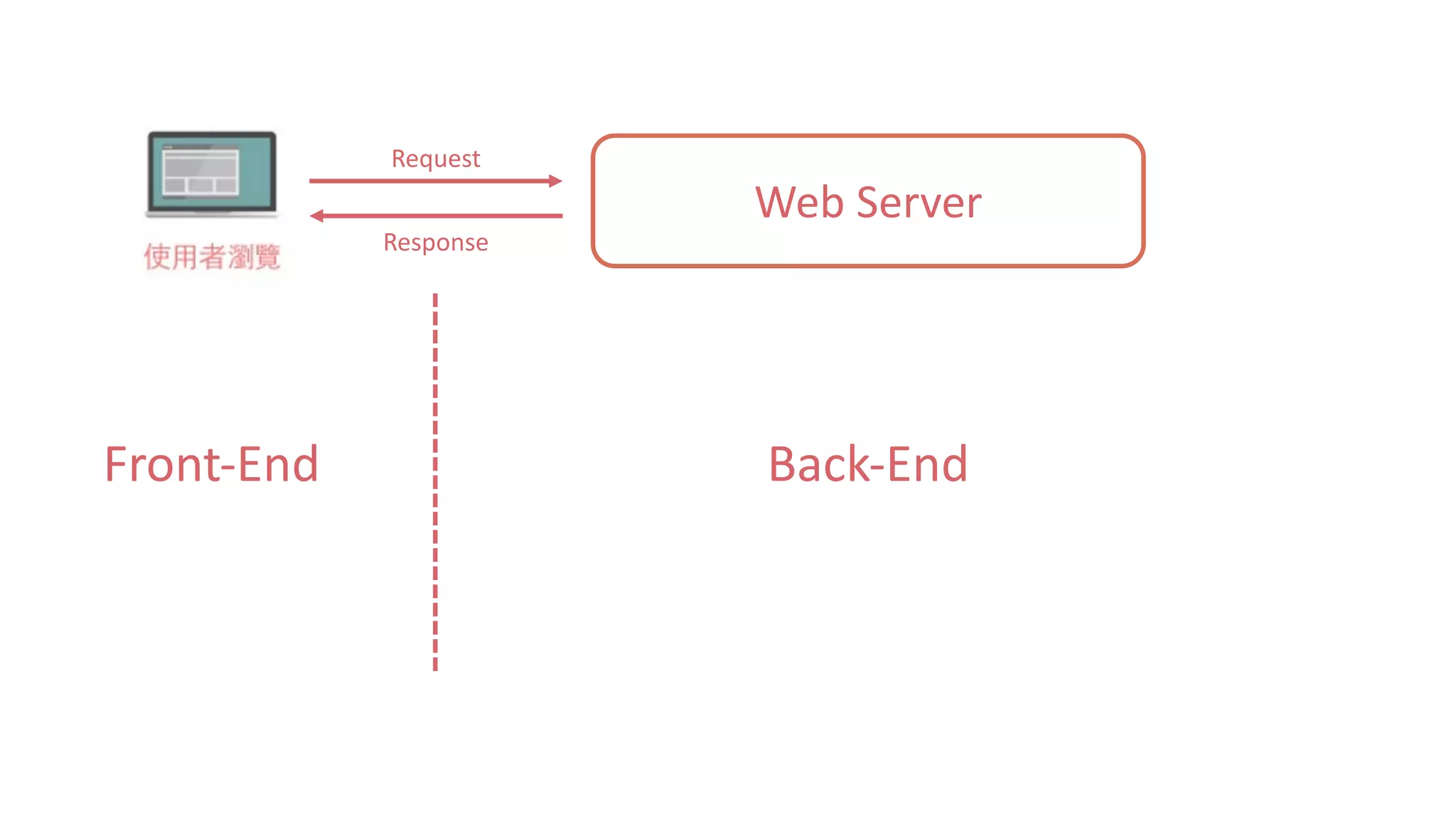
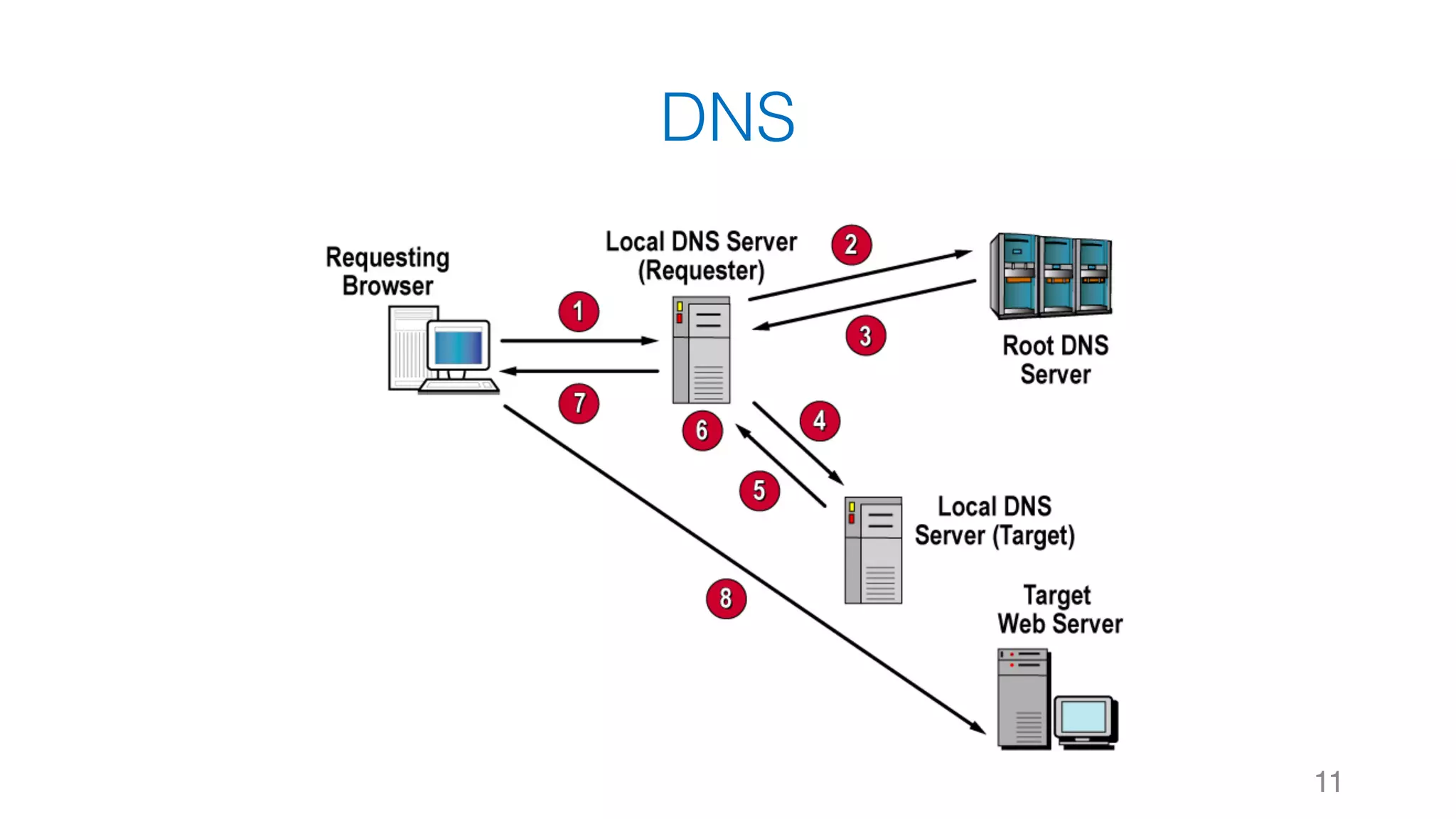
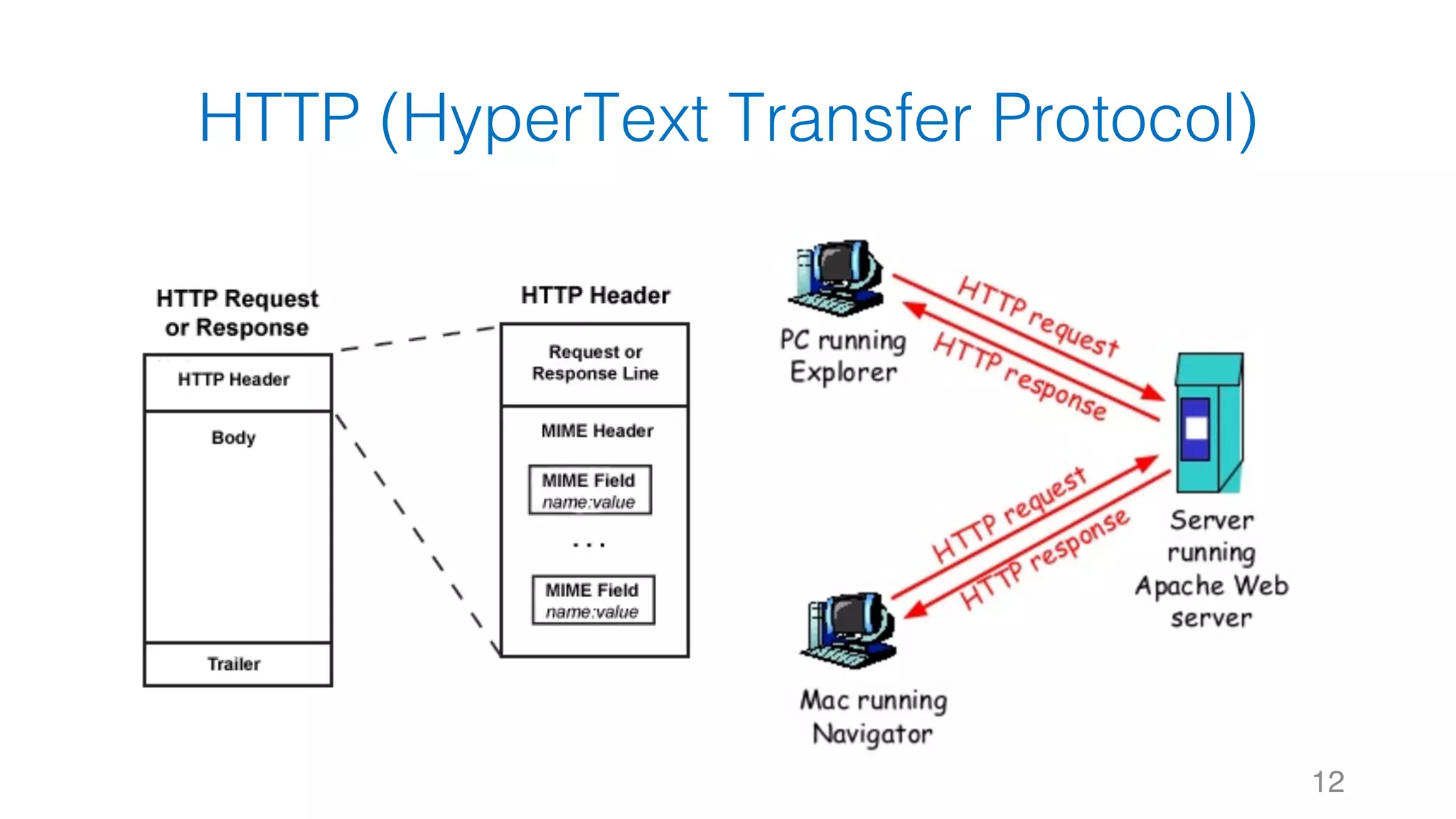
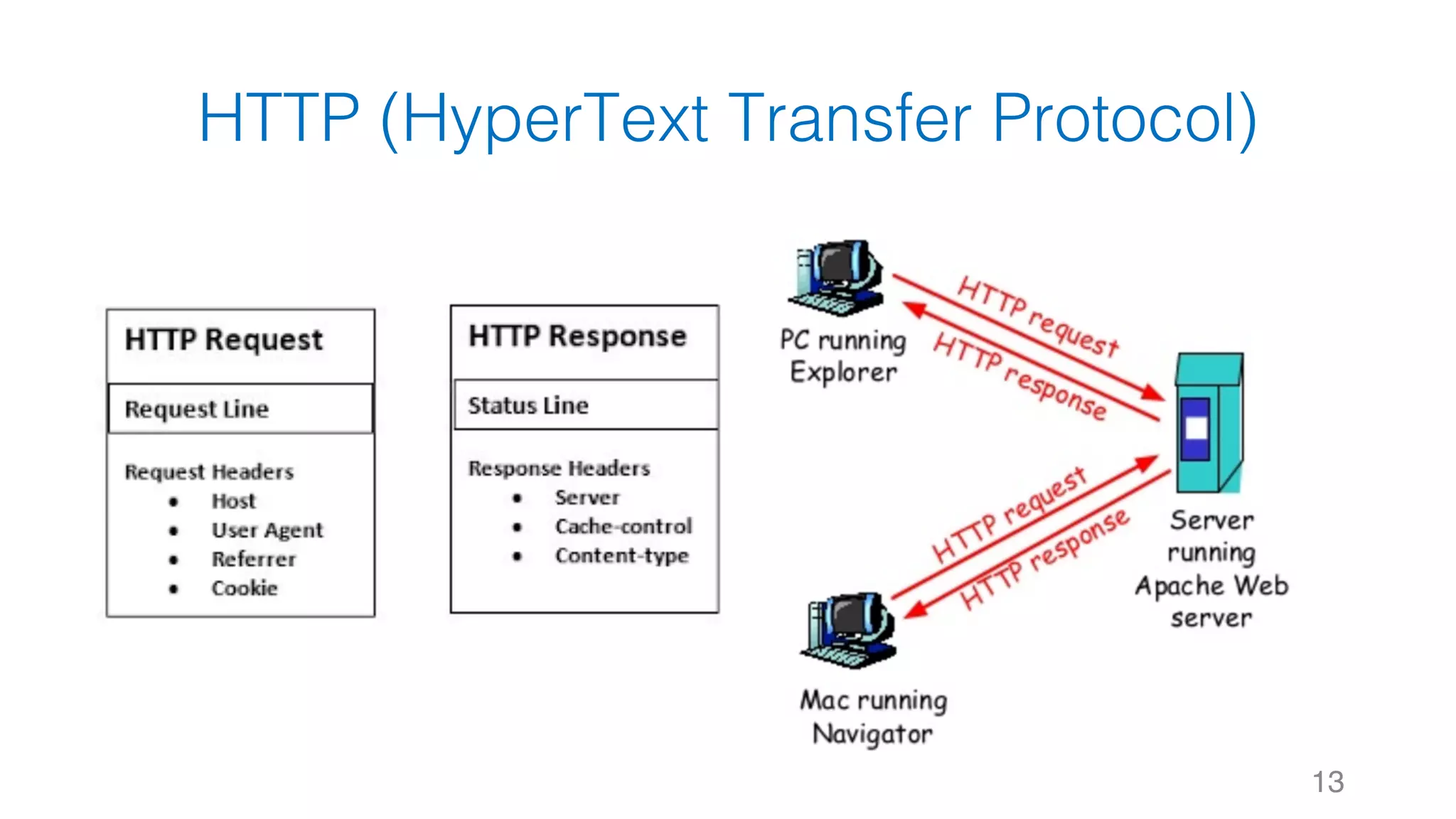
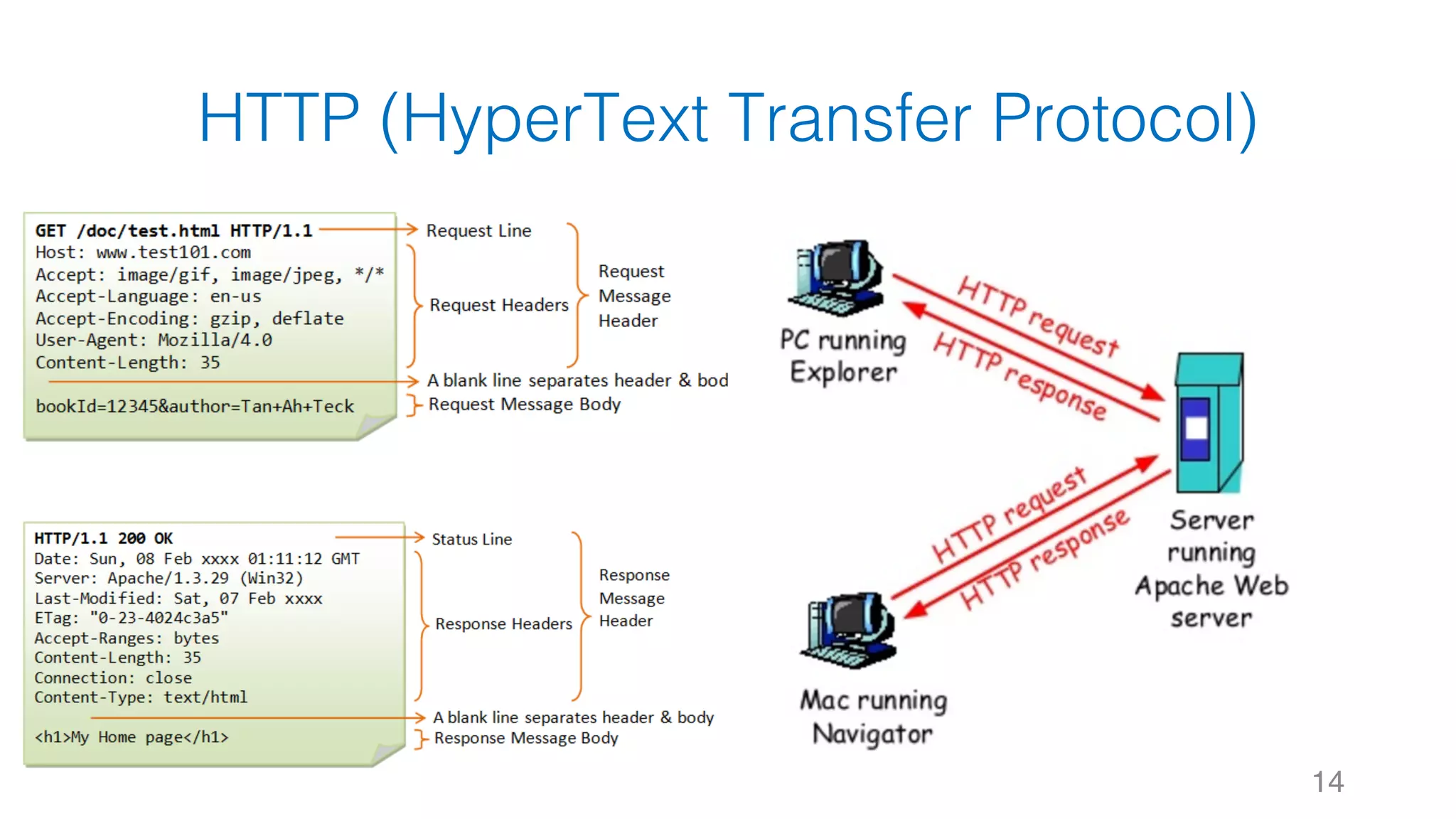
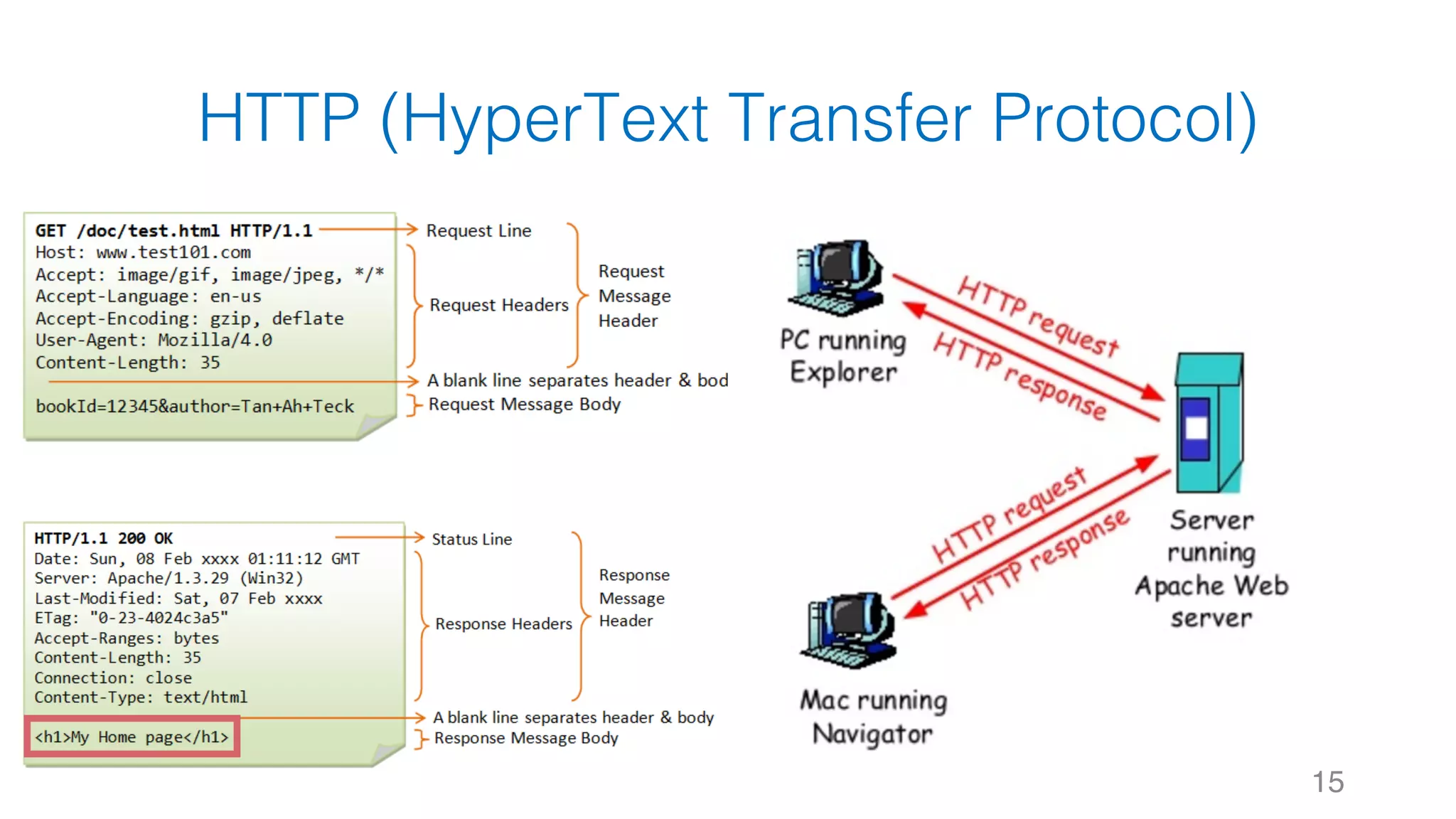
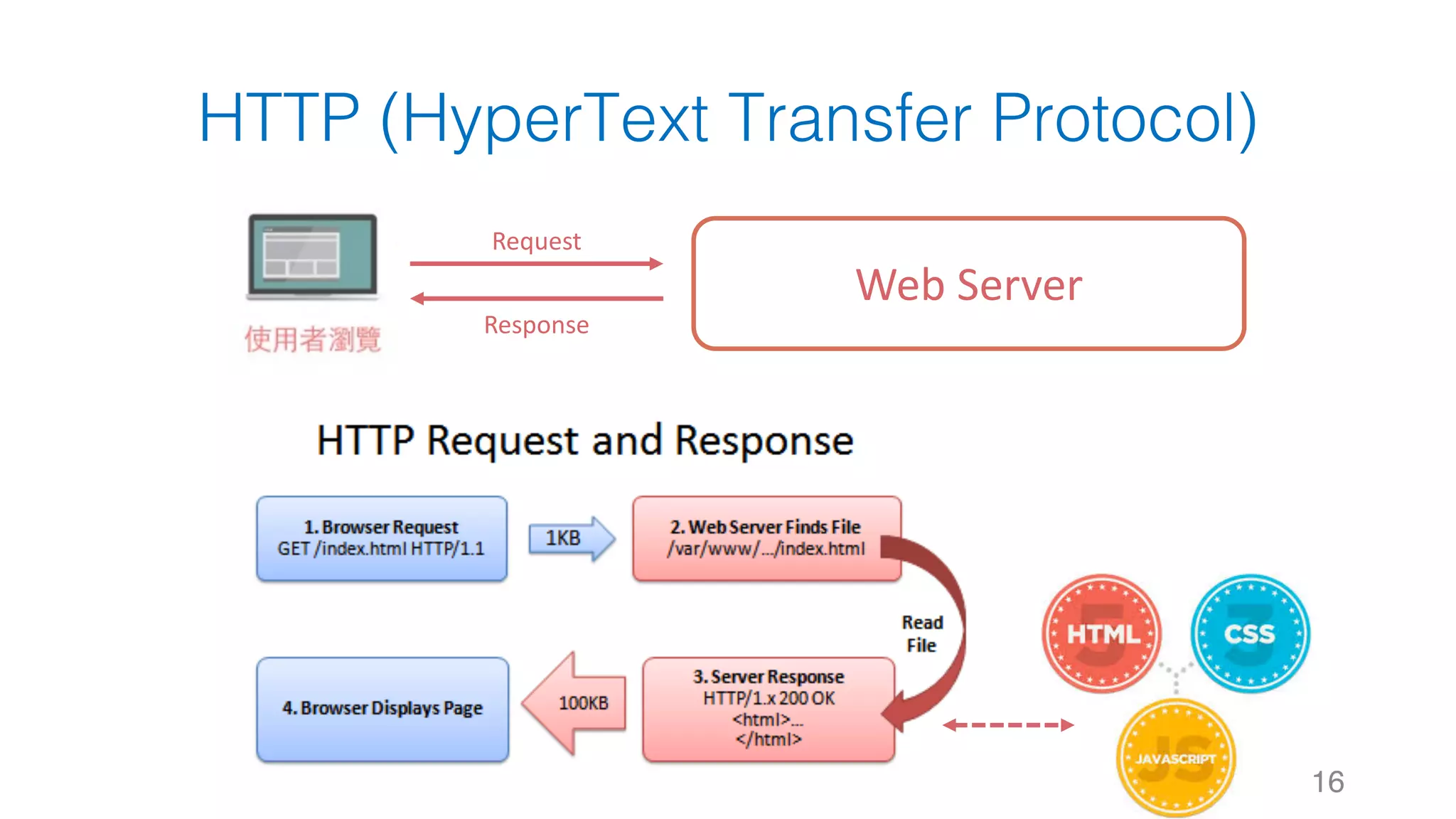

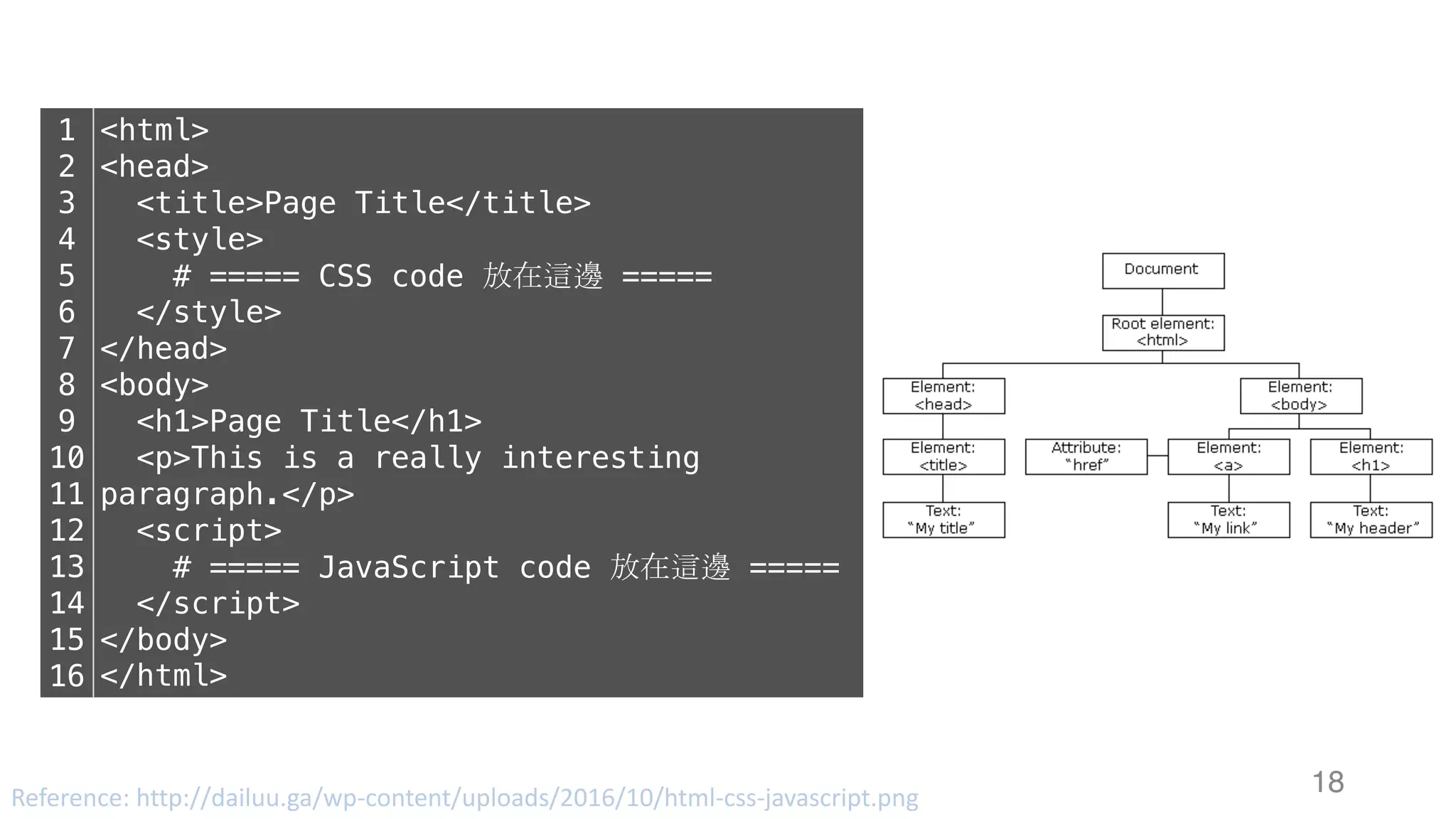

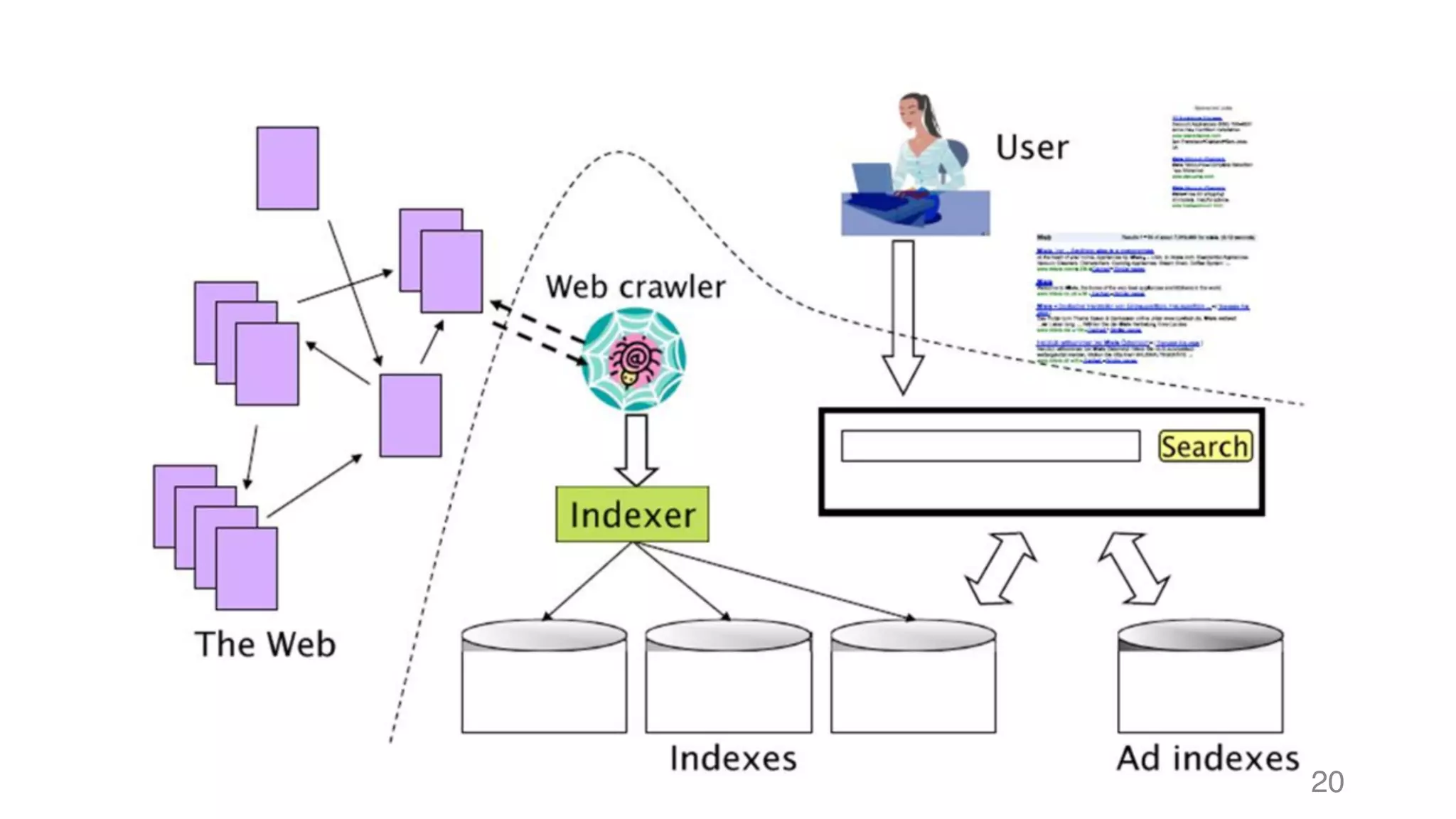

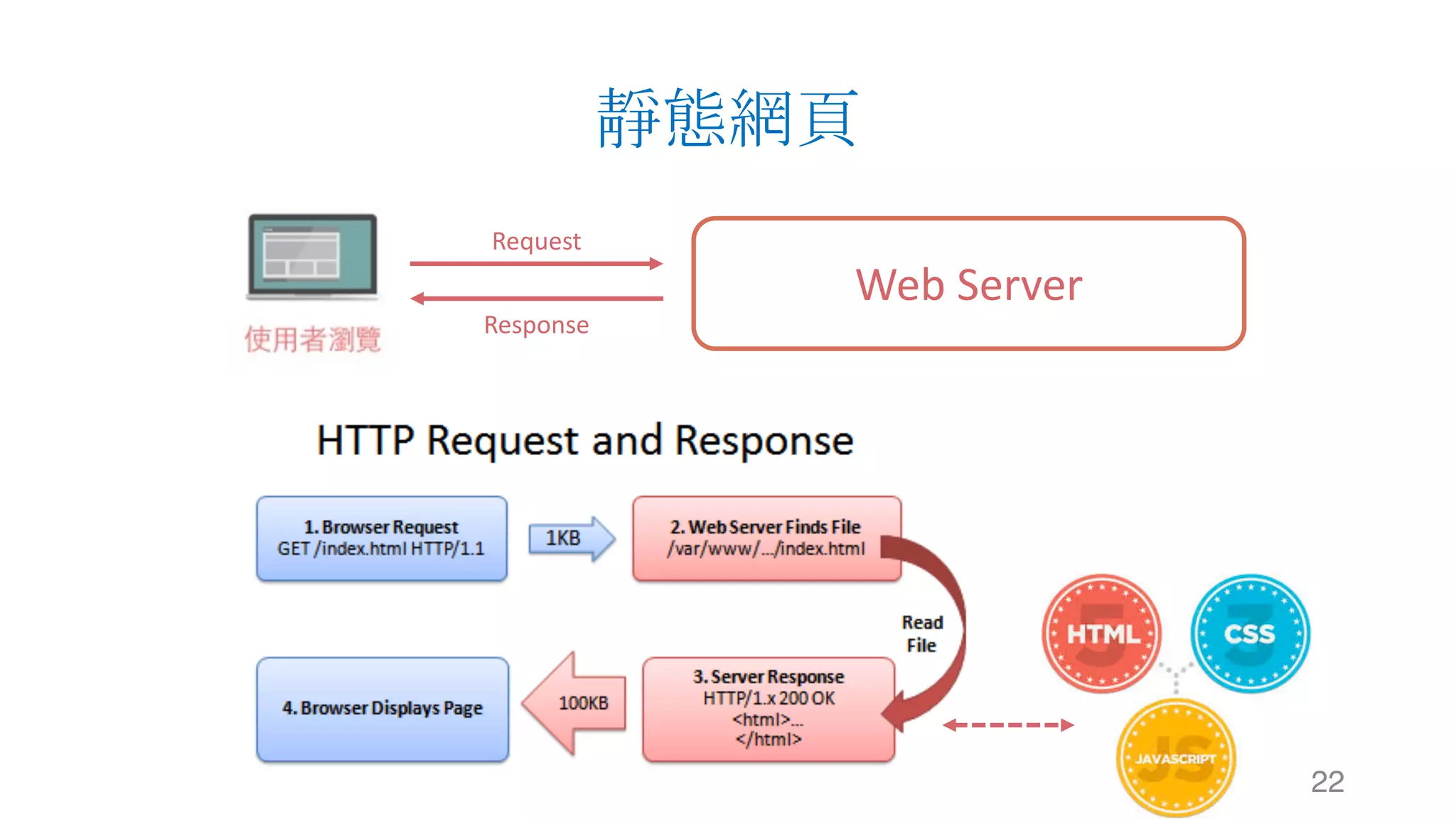







![靜態網頁 34 Web Server Request Response #Note: 攔截到的 Response 其實就是 HTTP 的 Body,網⾴的原始碼1 2 3 4 5 6 7 8 soup.title soup.title.name soup.title.string soup.title.parent.name soup.p soup.p['class']](https://image.slidesharecdn.com/datacrawlerusingpythoni-170904145921/75/Data-Crawler-using-Python-I-WeiYuan-34-2048.jpg)