Downloaded 46 times






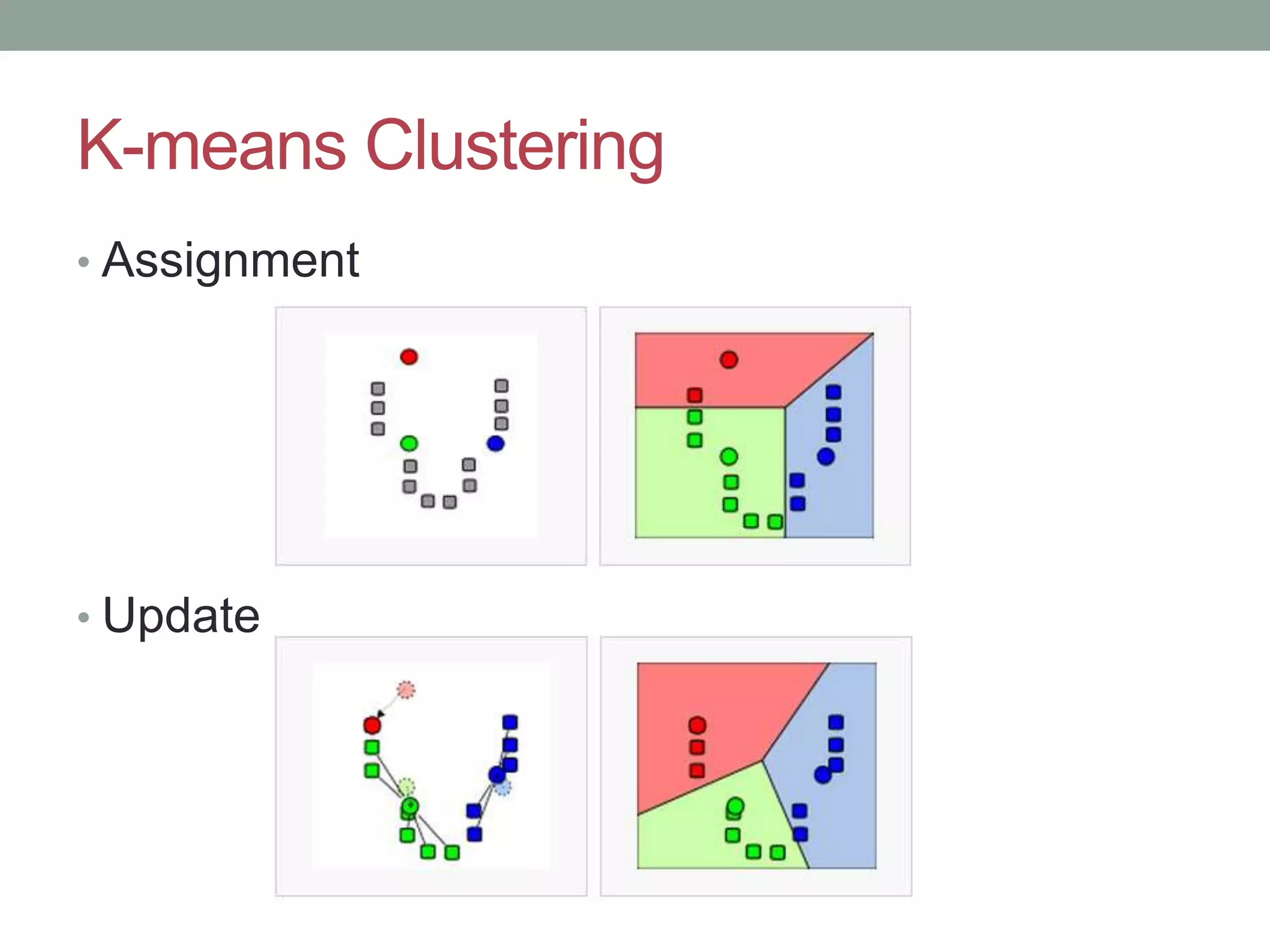





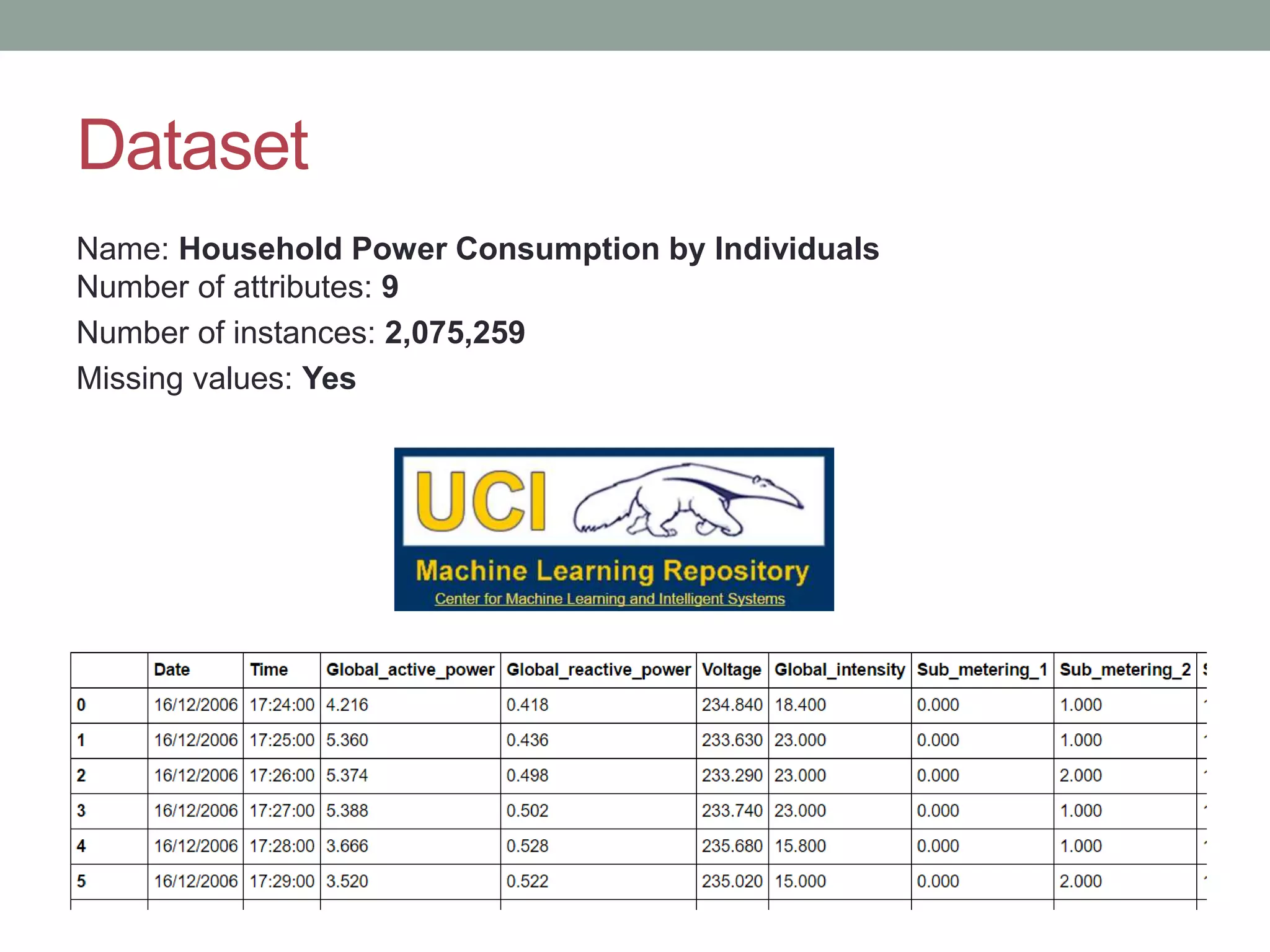





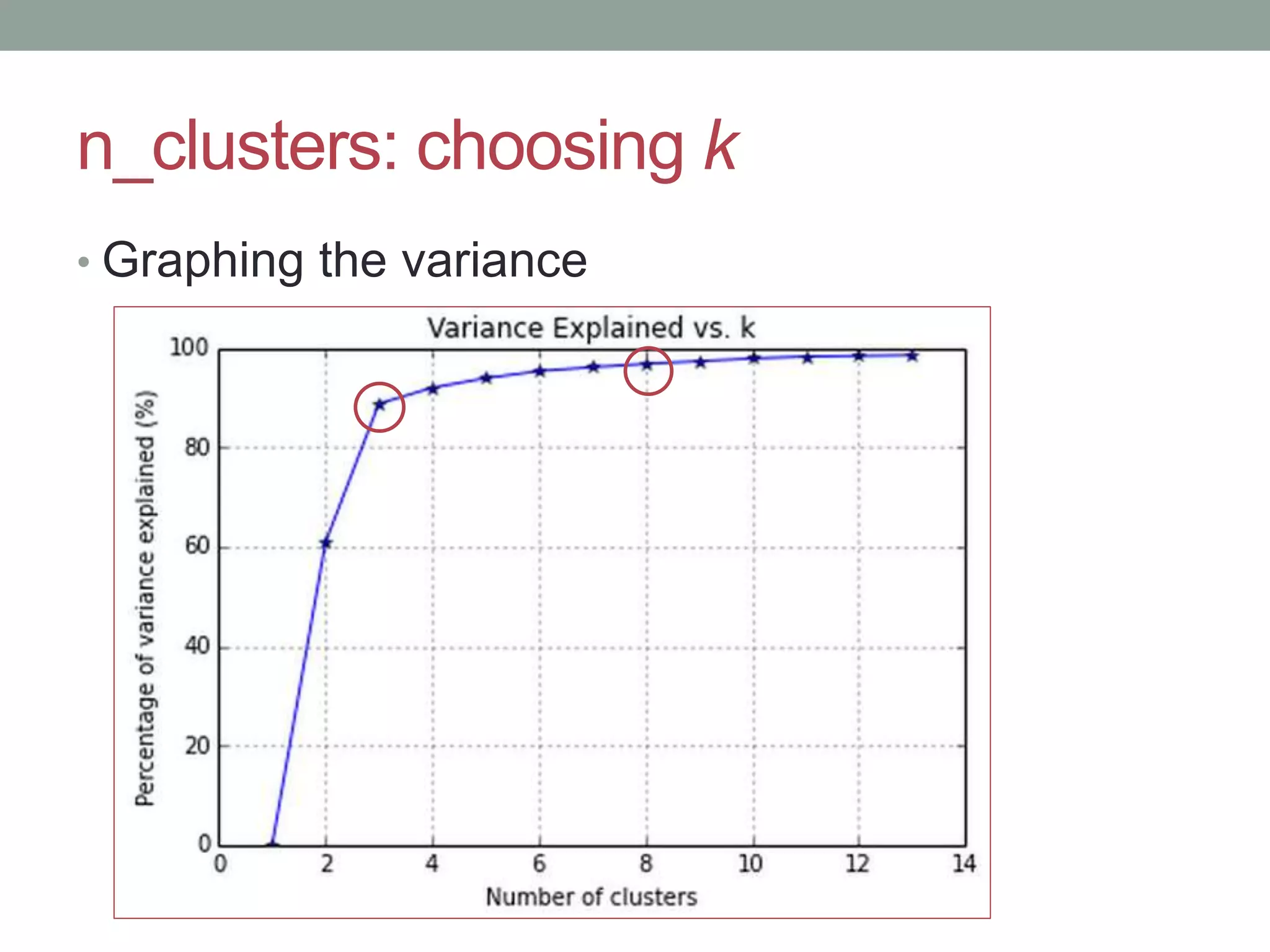
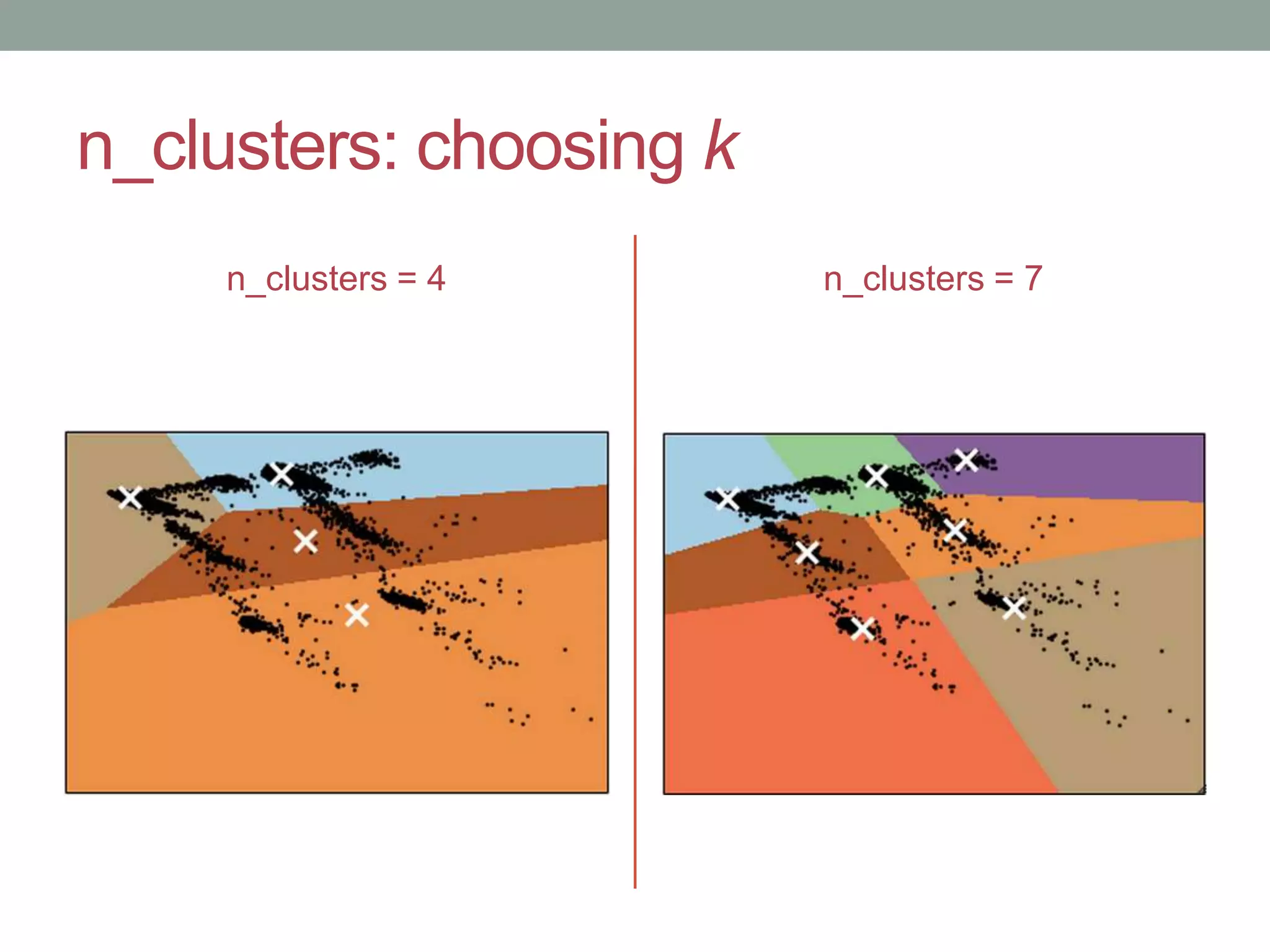
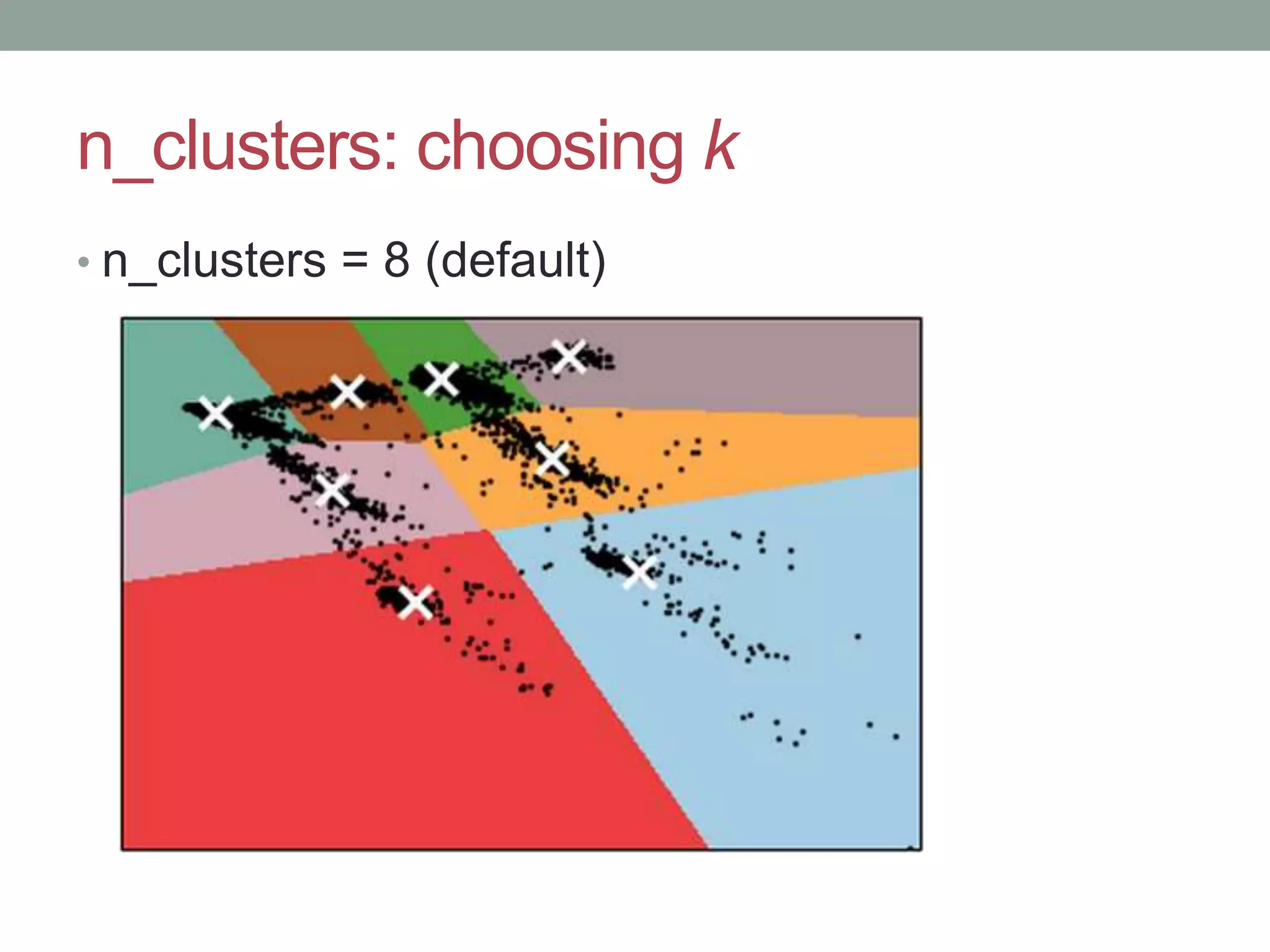

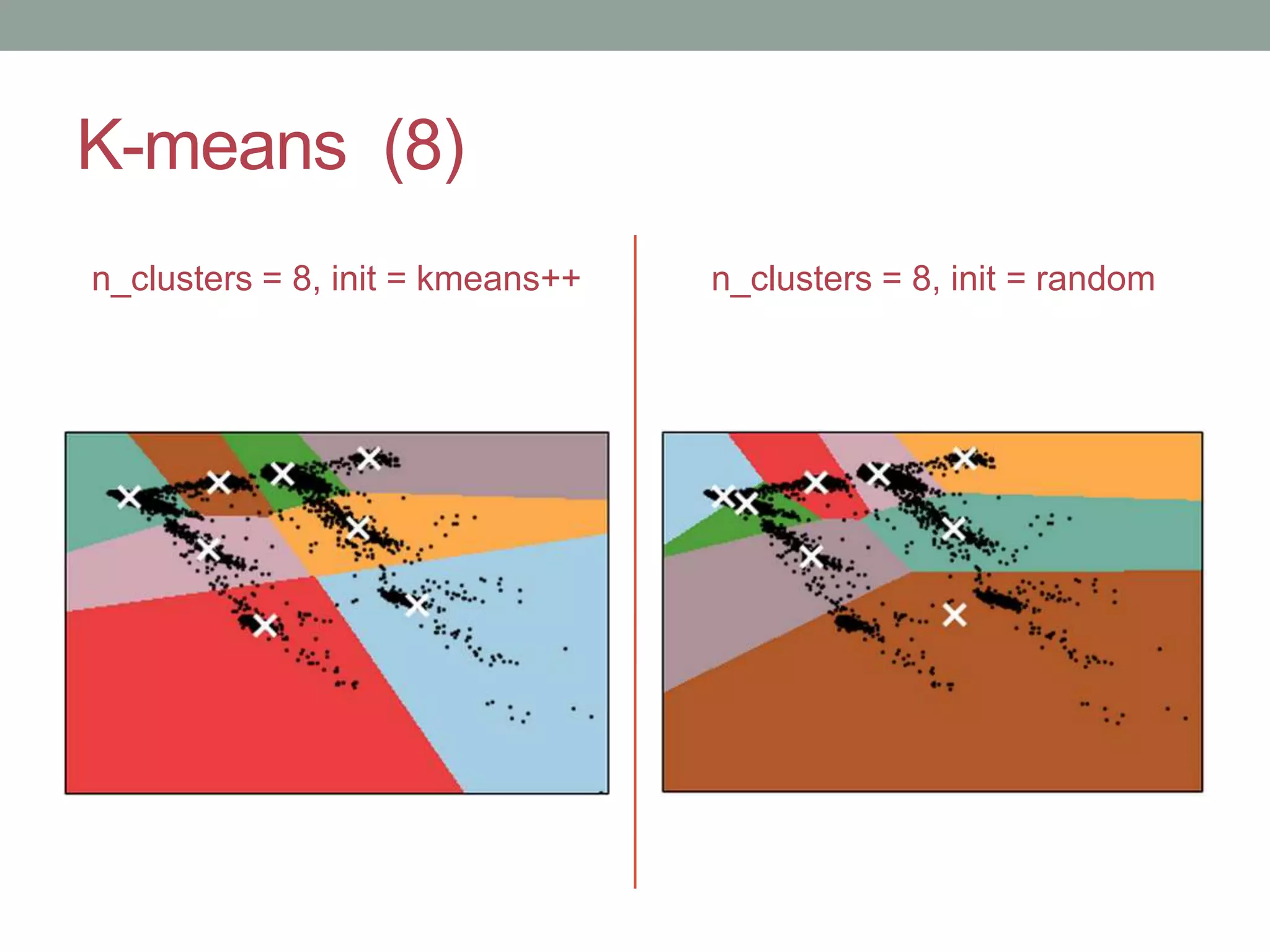
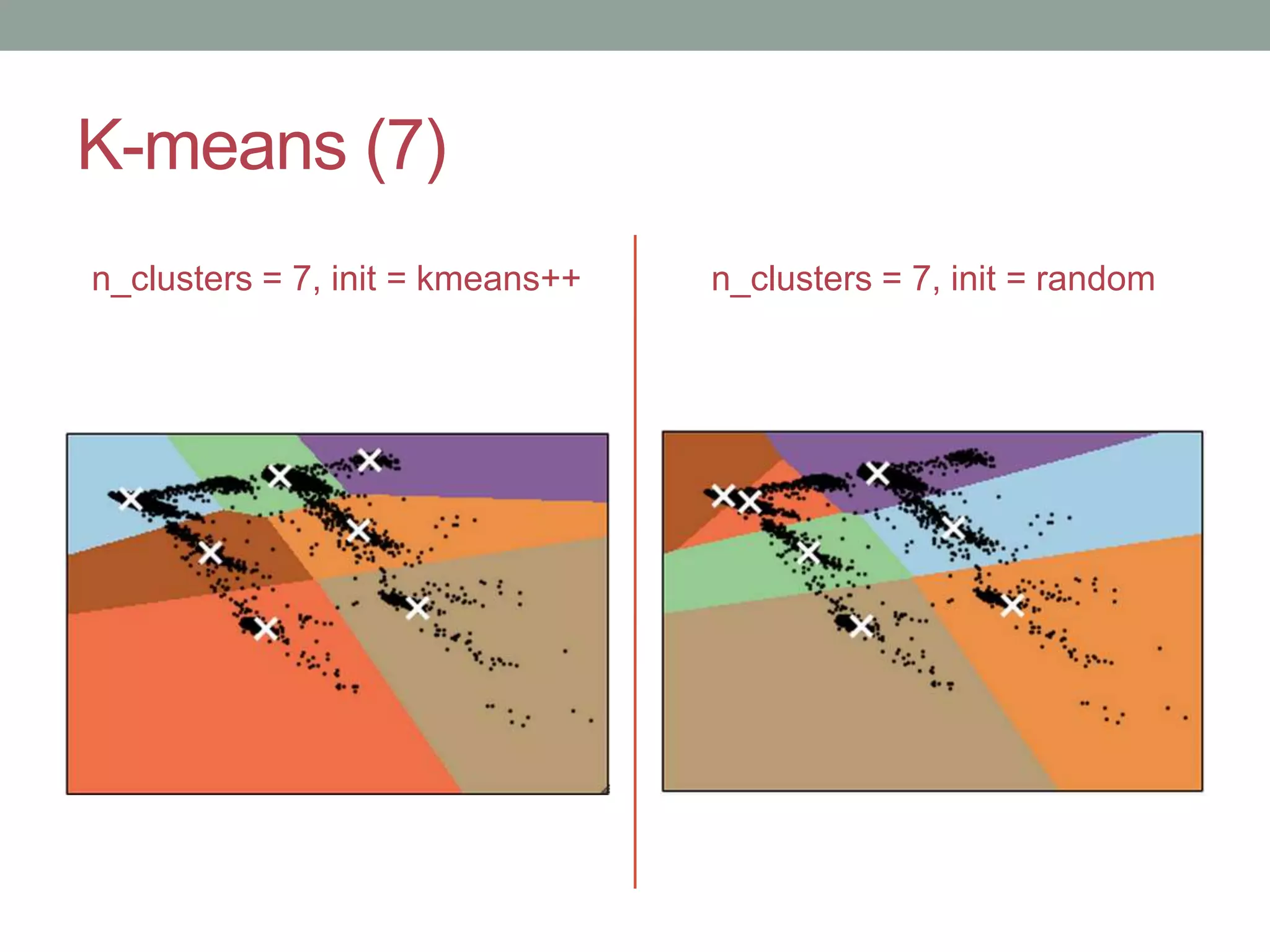

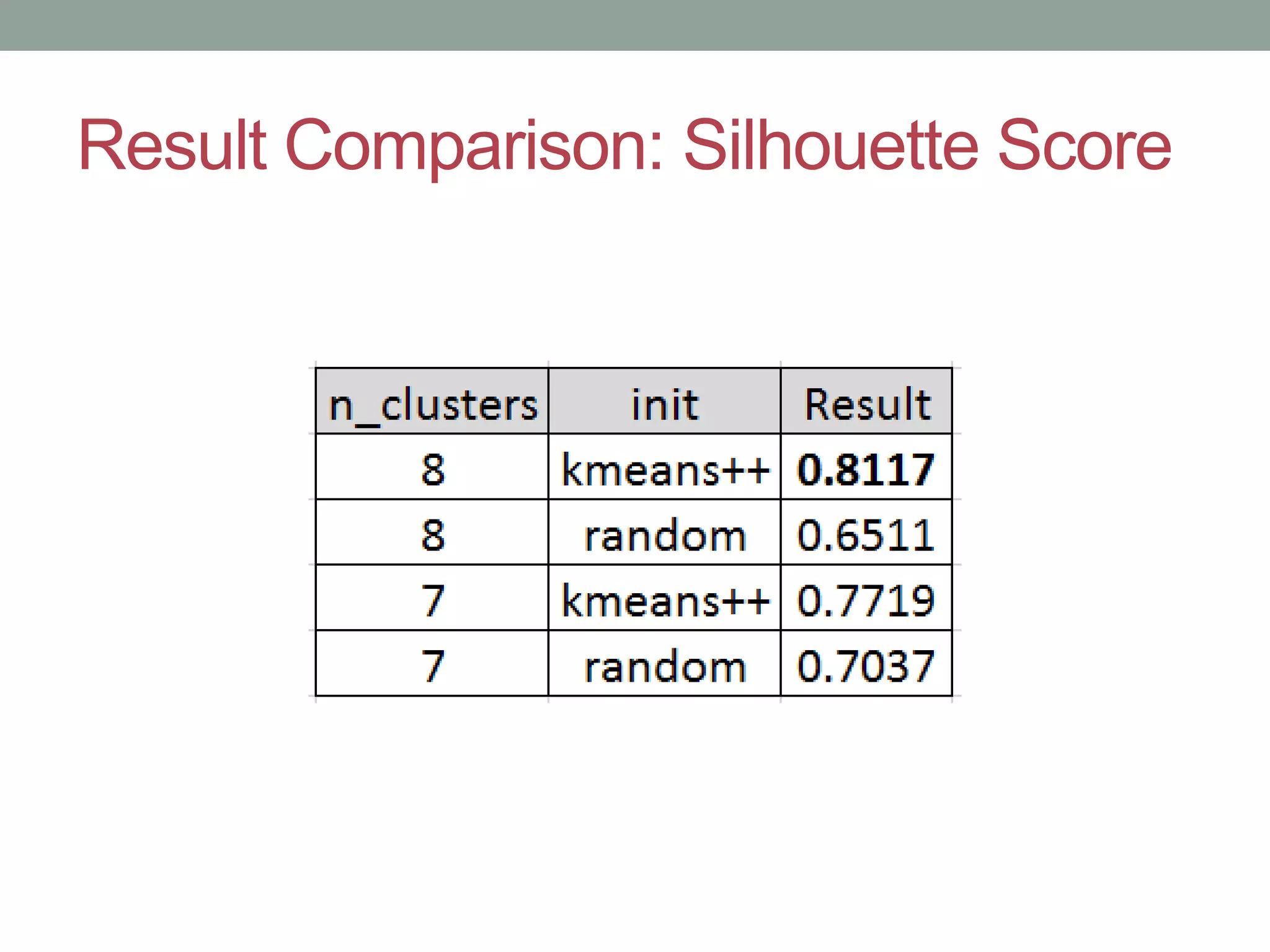



This document provides an overview of k-means clustering, a method of unsupervised learning used to group data by measuring distances between data points. The tutorial covers how to implement k-means in the Python library scikit-learn, including parameters for setting clusters and optimizing results. It discusses the advantages and disadvantages of k-means, conditions for its use, and techniques for determining the optimal number of clusters.