Download as PDF, PPTX















![Compare YuniKorn with other K8s schedulers Scheduler Capabilities Resource Sharing Resource Fairness Preemption Gang Scheduling Bin Packing Throughput Hierarchy queues Queue elastic capacity Cross queue fairness User level fairness App level fairness Basic preemption With fairness K8s default scheduler x x x x x v x x v 260 allocs/s (2k nodes) Kube-batch x x v x v v x v v ? Likely slower than kube-default from [1] YuniKorn v v v v v v v v* YUNIKORN-2 v 610 allocs/s (2k nodes) [1] https://github.com/kubernetes-sigs/kube-batch/issues/930](https://image.slidesharecdn.com/377weiweiyangligao-200629025854/75/Cloud-Native-Apache-Spark-Scheduling-with-YuniKorn-Scheduler-27-2048.jpg)




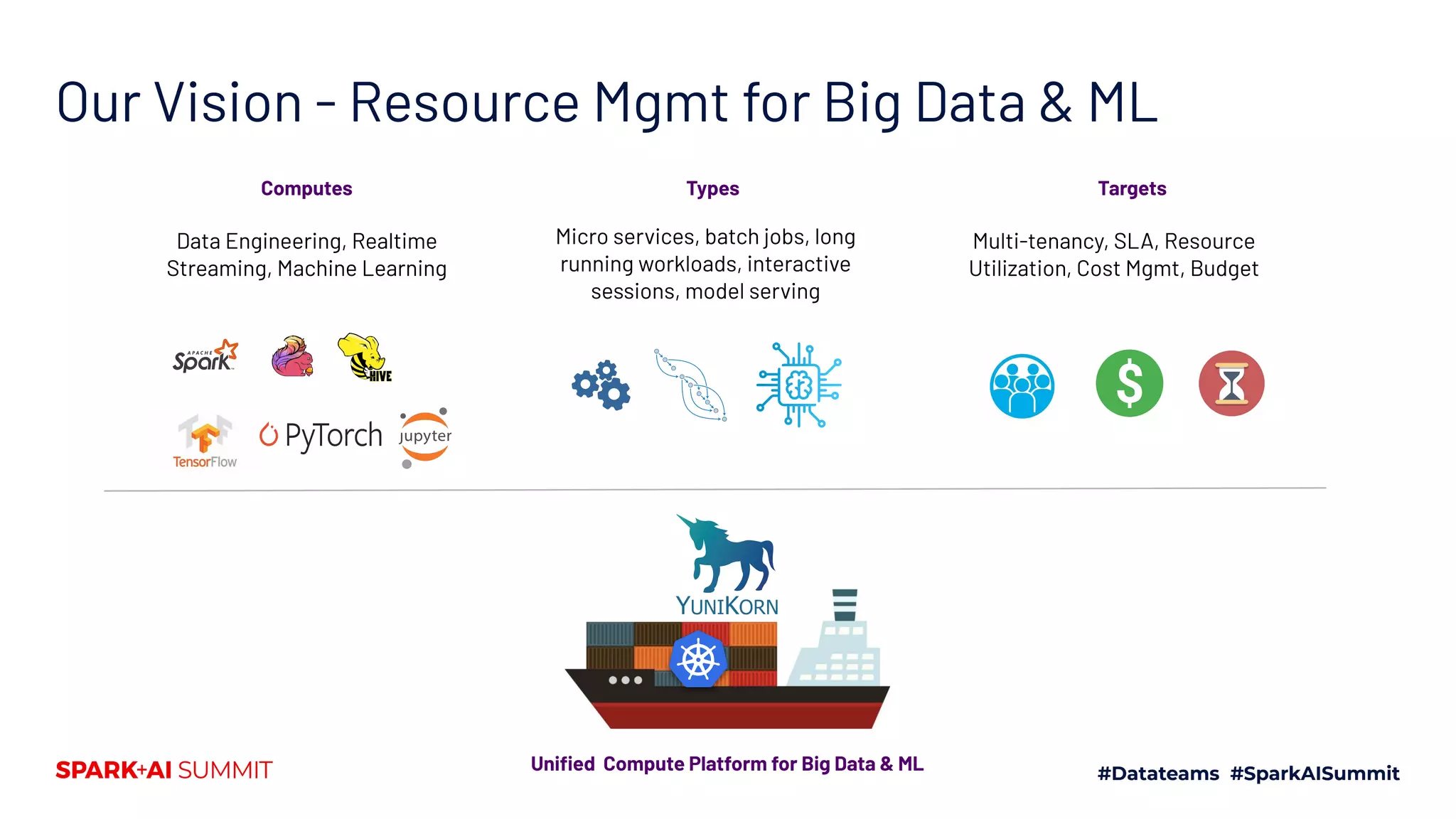



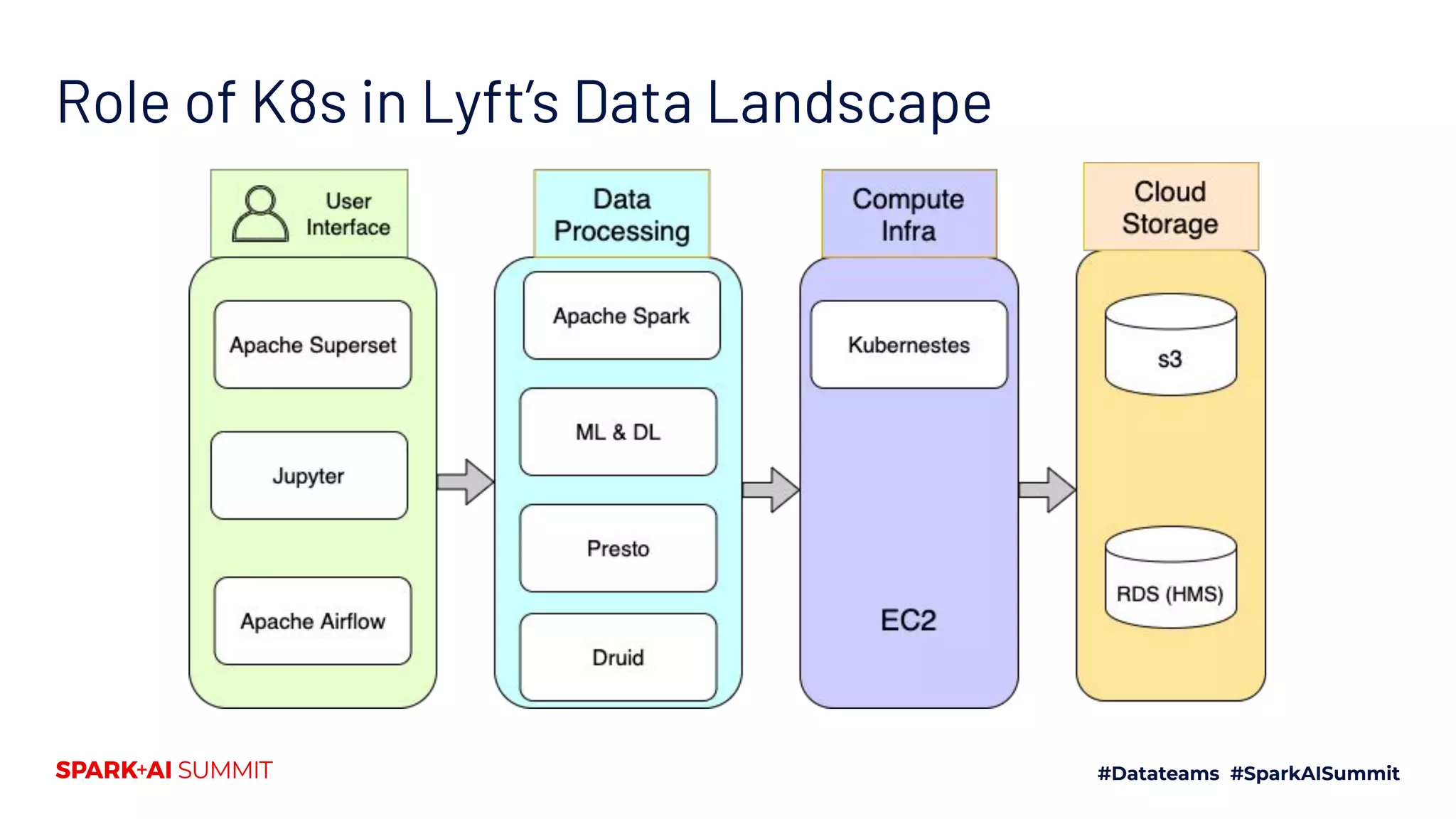
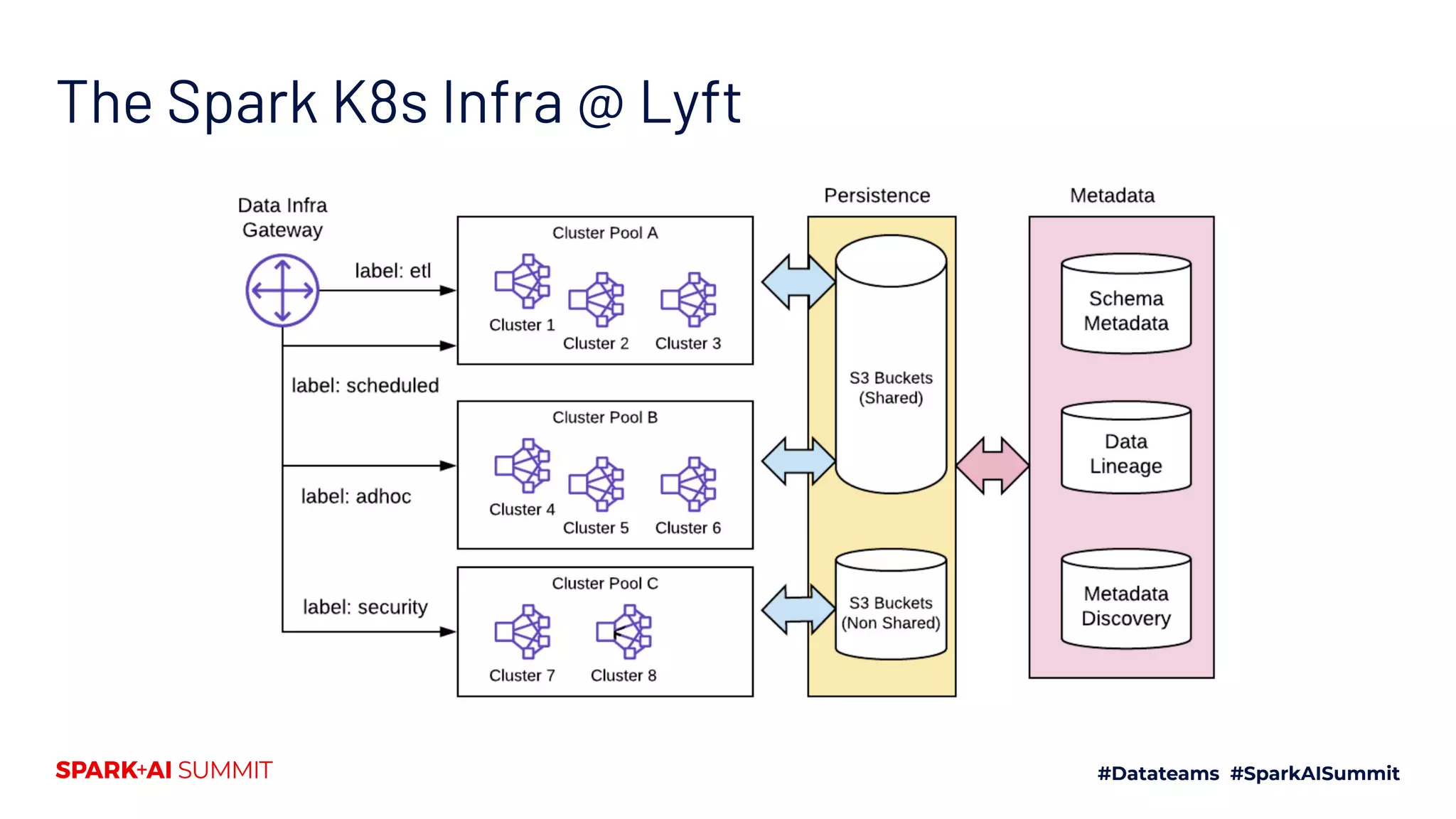
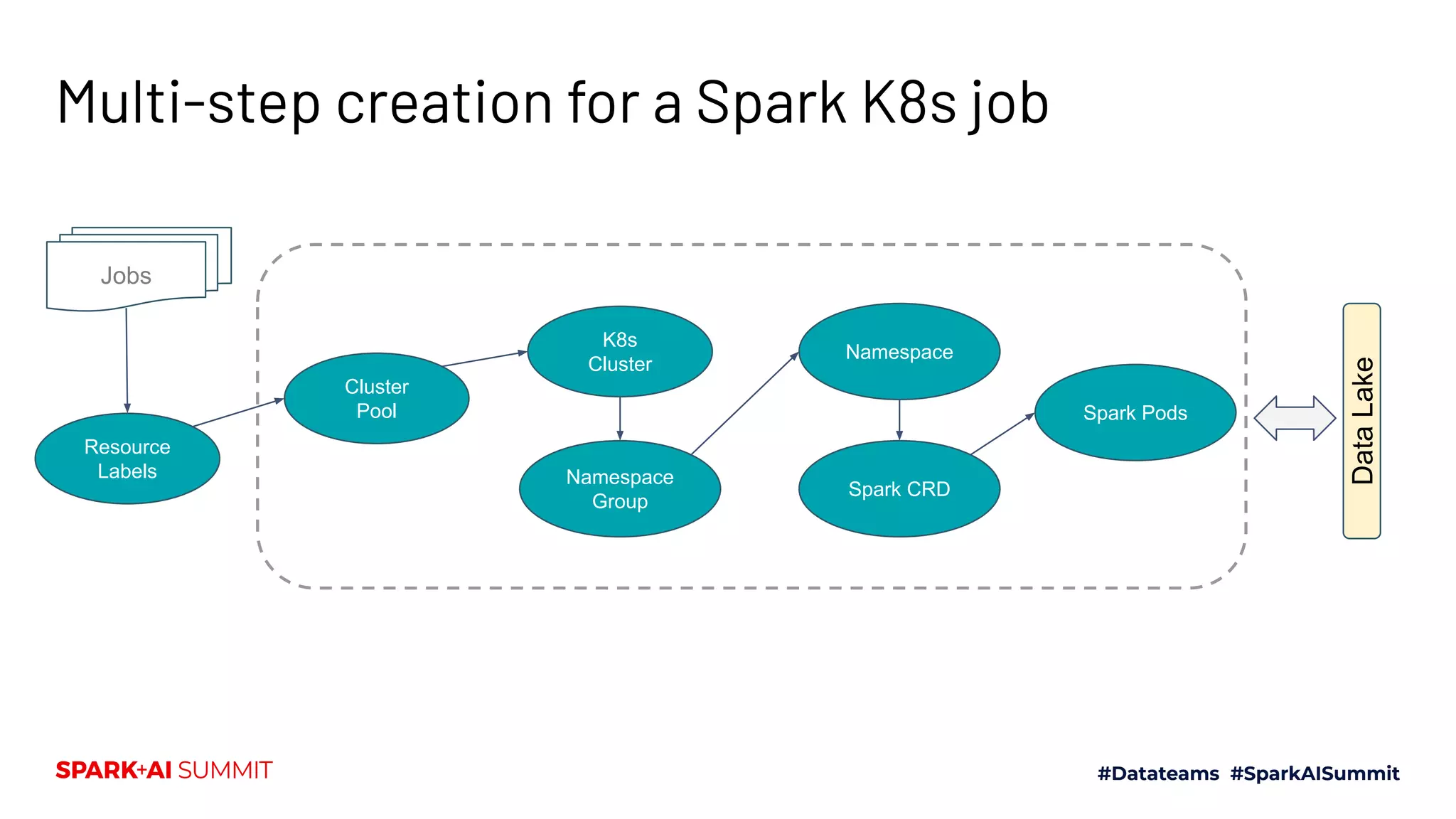
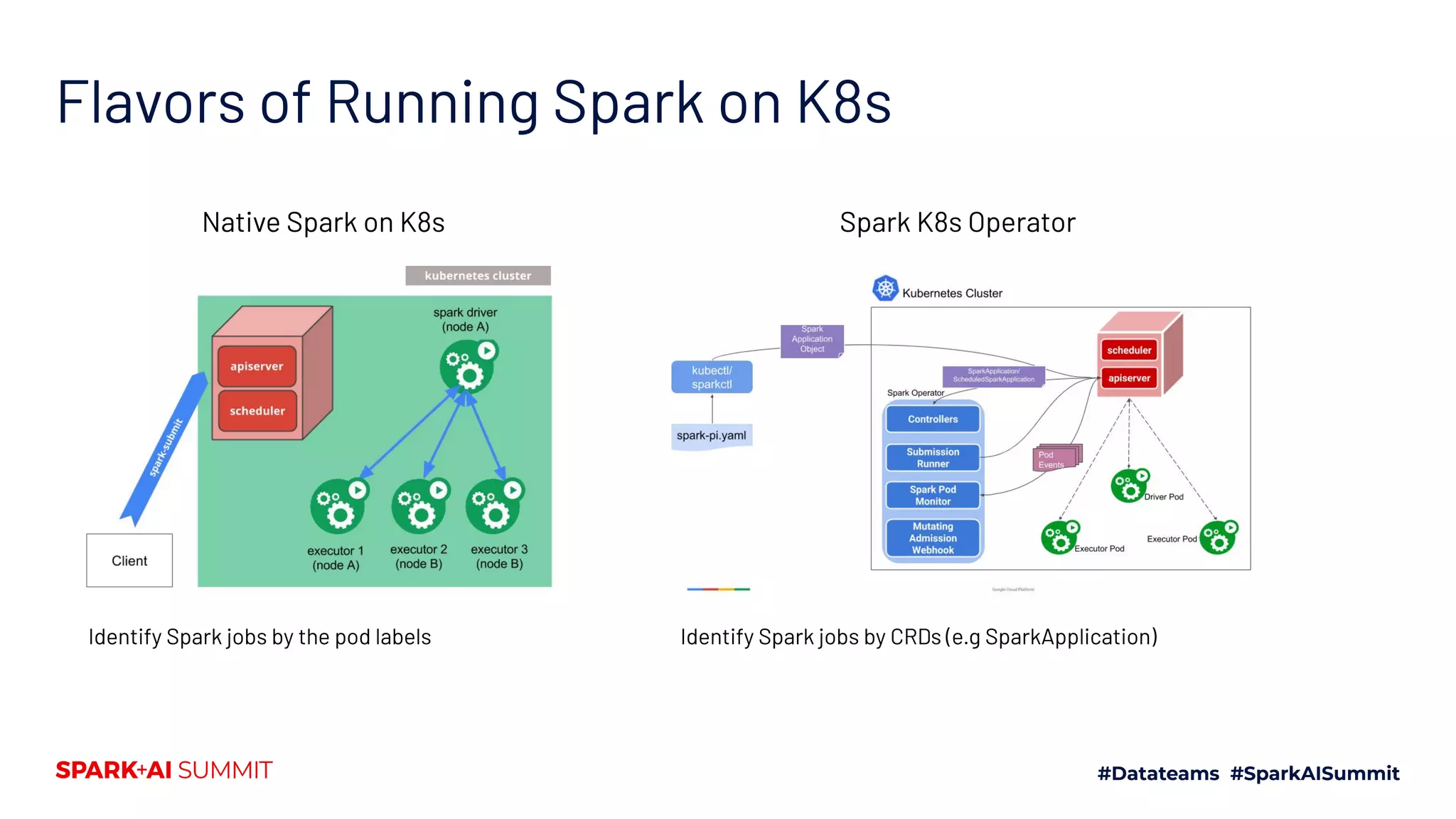
The document discusses the implementation of Yunikorn, a custom Kubernetes scheduler, for Spark at Lyft, addressing the limitations of existing scheduling systems and outlining the need for features like hierarchical priority management and resource fairness. Yunikorn enhances Spark job scheduling, providing better performance and flexibility in handling large data workloads, with a focus on job ordering and resource allocation efficiency. The document also highlights the roadmap for Yunikorn's features and its growing community support.