Downloaded 524 times




















![44 DISINTEGRATOR def get_training_data_by_disintegration(sentence): disintegrated_sentence = konlpy.tag.Twitter().pos(sentence, norm=True, stem=True) original_sentence = konlpy.tag.Twitter().pos(sentence) inputData = [] outputData = [] is_asking = False for w, t in disintegrated_sentence: if t not in ['Eomi', 'Josa', 'Number', 'KoreanParticle', 'Punctuation']: inputData.append(w+’/’+t) for w, t in original_sentence: if t not in ['Number', 'Punctuation']: outputData.append(w) if original_sentence[-1][1] == 'Punctuation' and original_sentence[-1][0] == "?": if len(inputData) != 0 and len(outputData) != 0: is_asking = True # To extract ask-response raw data return ' '.join(inputData), ' '.join(outputData), is_asking get_graining_data_by_disintegration](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-44-2048.jpg)
![45 SAMPLE DISINTEGRATOR Super simple disintegrator using twitter Korean analyzer (with KoNLPy interface) 나는 오늘 아침에 된장국을 먹었습니다. [('나', 'Noun'), ('는', 'Josa'), ('오늘', 'Noun'), ('아침', 'Noun'), ('에', 'Josa'), ('된장국 ', 'Noun'), ('을', 'Josa'), ('먹다', 'Verb'), ('.', 'Punctuation')] 나 오늘 아침 된장국 먹다 (venv) disintegrator » python test.py Original : 나는 오늘 아침에 된장국을 먹었습니다. Disintegrated for bot / grammar input : 나 오늘 아침 된장국 먹다 Training data for grammar model output: 나 는 오늘 아침 에 된장국 을 먹었 습니다 I ate miso soup in this morning. I / this morning / miso soup / eat](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-45-2048.jpg)


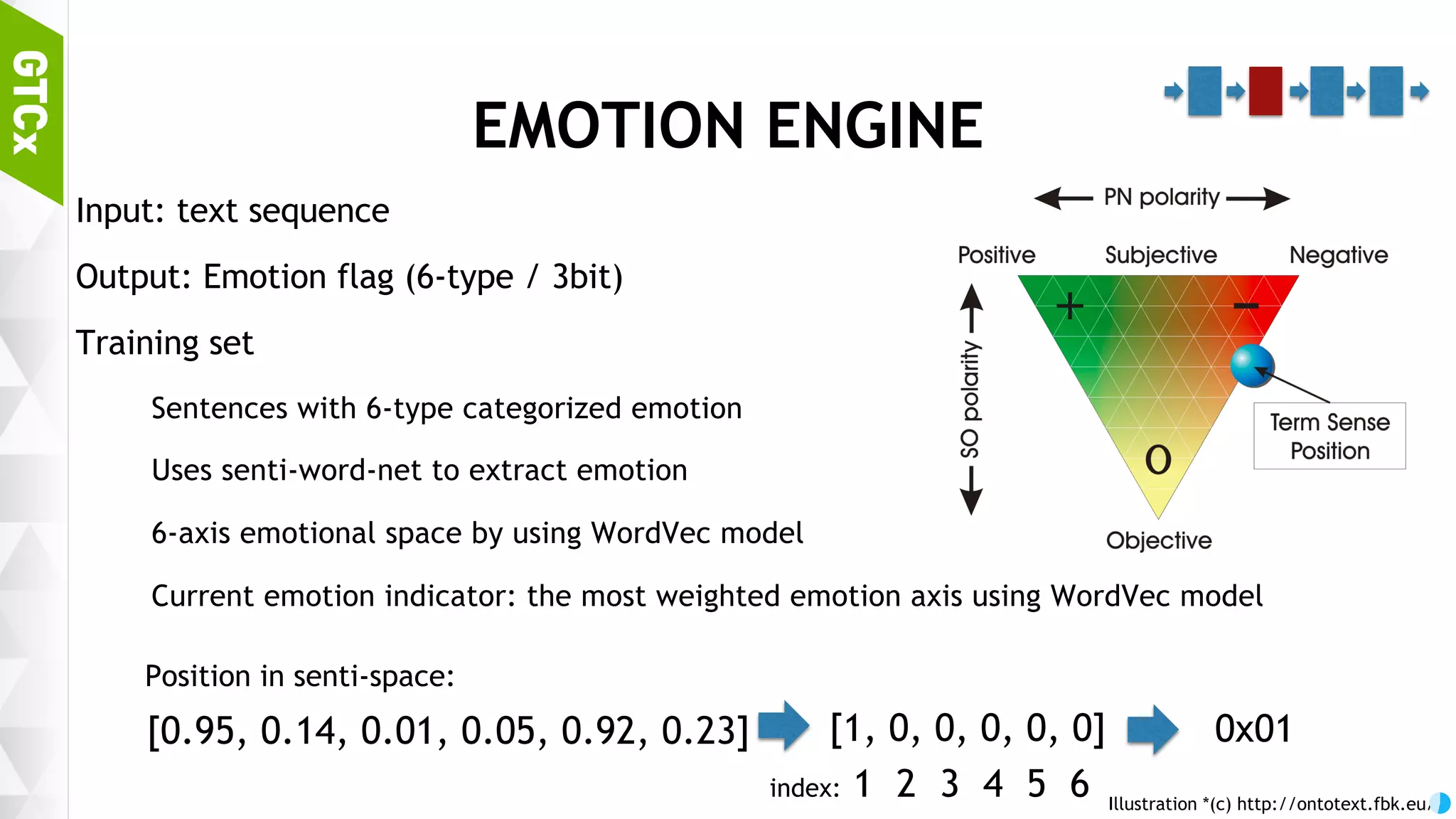


![52 EMOTION ENGINE Input: text sequence Output: Emotion flag (6-type / 3bit) Training set Sentences with 6-type categorized emotion Uses senti-word-net to extract emotion 6-axis emotional space by using WordVec model Current emotion indicator: the most weighted emotion axis using WordVec model Illustration *(c) http://ontotext.fbk.eu/ [0.95, 0.14, 0.01, 0.05, 0.92, 0.23] [1, 0, 0, 0, 0, 0] 0x01 index: 1 2 3 4 5 6 Position in senti-space:](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-52-2048.jpg)











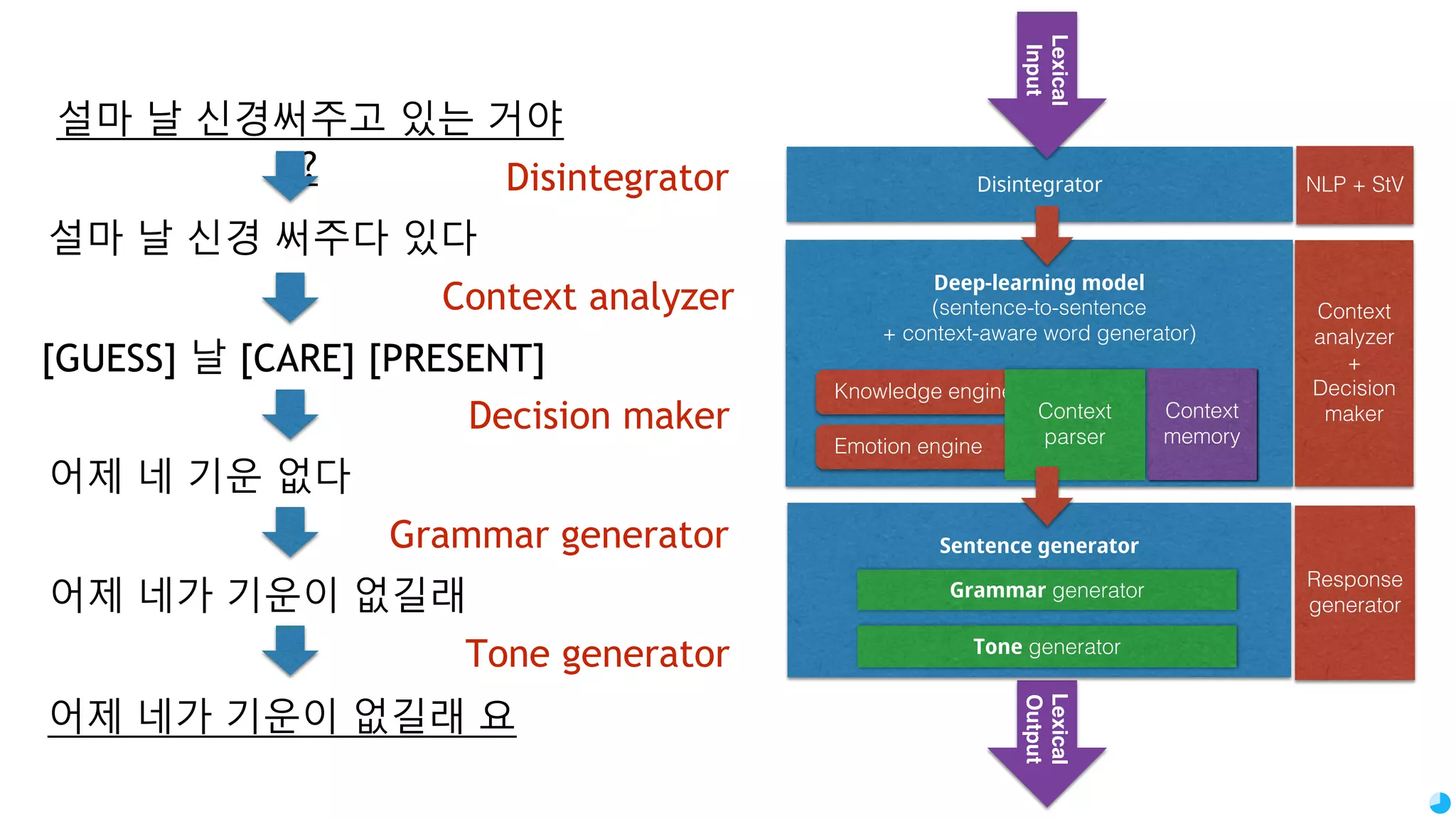


![Lexical Output Sentence generator Deep-learning model (sentence-to-sentence + context-aware word generator) Grammar generator Context memory Knowledge engine Emotion engine Context parser Tone generator Disintegrator Response generator NLP + StV Context analyzer + Decision maker Lexical Input 설마 날 신경써주고 있는 거야 ? 설마 날 신경 써주다 있다 어제 네 기운 없다 어제 네가 기운이 없길래 어제 네가 기운이 없길래 요 [GUESS] 날 [CARE] [PRESENT] Disintegrator Context analyzer Decision maker Grammar generator Tone generator](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-68-2048.jpg)
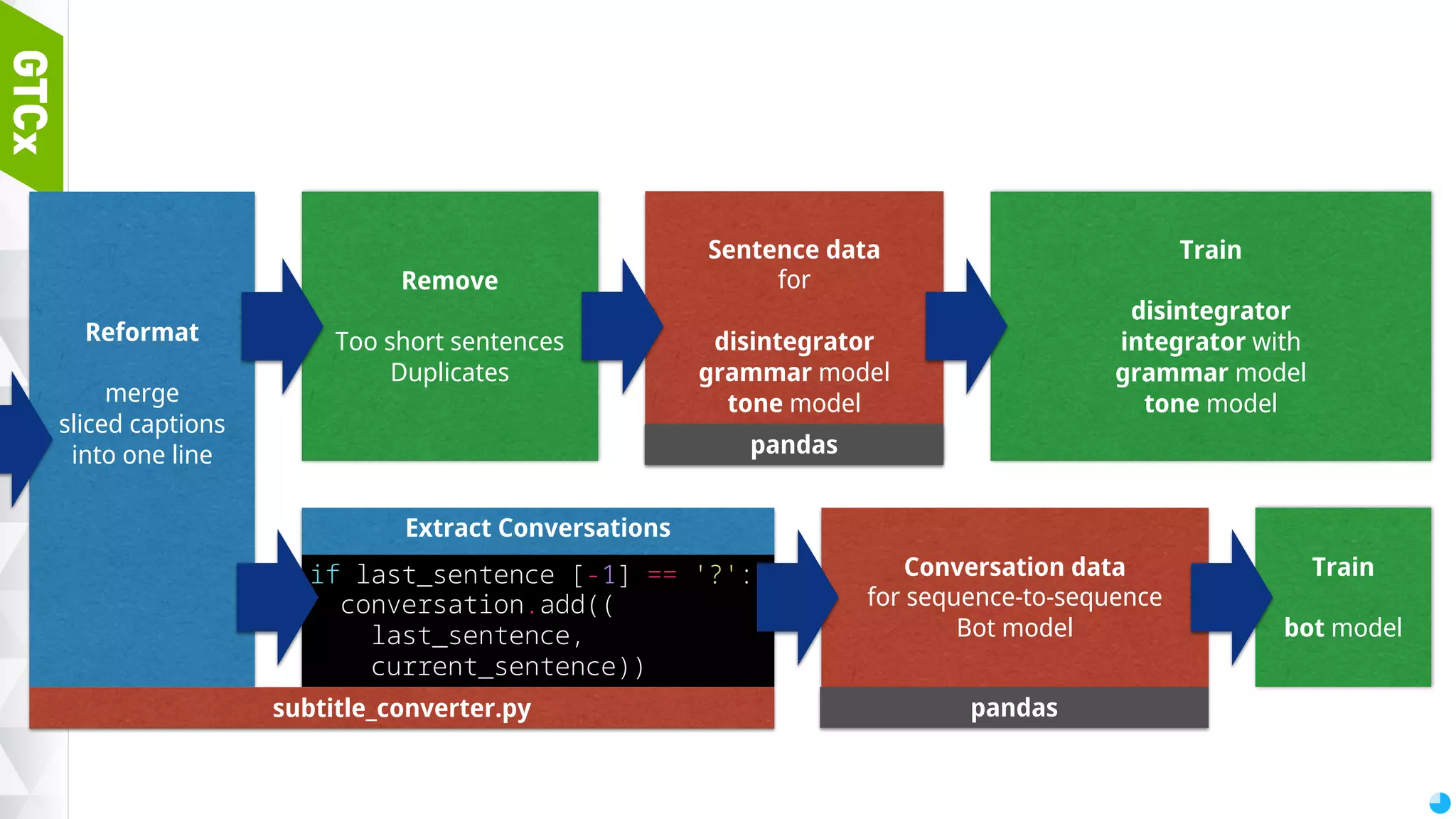


![73 Extract Conversations Conversation data for sequence-to-sequence Bot model Reformat merge sliced captions into one line if last_sentence [-1] == '?': conversation.add(( last_sentence, current_sentence)) Remove Too short sentences Duplicates Sentence data for disintegrator grammar model tone model Train disintegrator integrator with grammar model tone model Train bot model subtitle_converter.py pandas pandas](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-73-2048.jpg)

![I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcudnn.so locally I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcuda.so locally I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally total conversations: 4217 Transforming... Total words, asked: 1062, response: 1128 Steps: 0 I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:924] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero I tensorflow/core/common_runtime/gpu/gpu_init.cc:102] Found device 0 with properties: name: GeForce GTX 970 major: 5 minor: 2 memoryClockRate (GHz) 1.304 pciBusID 0000:01:00.0 Total memory: 4.00GiB Free memory: 3.92GiB I tensorflow/core/common_runtime/gpu/gpu_init.cc:126] DMA: 0 I tensorflow/core/common_runtime/gpu/gpu_init.cc:136] 0: Y I tensorflow/core/common_runtime/gpu/gpu_device.cc:806] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 970, pci bus id: 0000:01:00.0) I tensorflow/core/common_runtime/gpu/pool_allocator.cc:244] PoolAllocator: After 1501 get requests, put_count=1372 evicted_count=1000 eviction_rate=0.728863 and unsatisfied allocation rate=0.818787 I tensorflow/core/common_runtime/gpu/pool_allocator.cc:256] Raising pool_size_limit_ from 100 to 110 I tensorflow/core/common_runtime/gpu/pool_allocator.cc:244] PoolAllocator: After 2405 get requests, put_count=2388 evicted_count=1000 eviction_rate=0.41876 and unsatisfied allocation rate=0.432432 I tensorflow/core/common_runtime/gpu/pool_allocator.cc:256] Raising pool_size_limit_ from 256 to 281 Bot training procedure (initialization)](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-75-2048.jpg)

![I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcublas.so locally I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcudnn.so locally I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcufft.so locally I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcuda.so locally I tensorflow/stream_executor/dso_loader.cc:108] successfully opened CUDA library libcurand.so locally total line: 7496 Fitting dictionary for disintegrated sentence... Fitting dictionary for recovered sentence... Transforming... Total words pool size: disintegrated: 3800, recovered: 5476 I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:924] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero I tensorflow/core/common_runtime/gpu/gpu_init.cc:102] Found device 0 with properties: name: GeForce GTX 970 major: 5 minor: 2 memory ClockRate (GHz) 1.304 pciBusID 0000:01:00.0 Total memory: 4.00GiB Free memory: 3.92GiB I tensorflow/core/common_runtime/gpu/gpu_init.cc:126] DMA: 0 I tensorflow/core/common_runtime/gpu/gpu_init.cc:136] 0: YI tensorflow/core/common_runtime/gpu/gpu_device.cc:806] Creating TensorFlow device (/gpu:0) -> (device: 0, name: GeForce GTX 970, pci bus id: 0000:01:00.0) I tensorflow/core/common_runtime/gpu/pool_allocator.cc:244] PoolAllocator: After 1501 get requests, put_count=1372 evicted_count=1000 eviction_rate=0.728863 and unsatisfied allocation rate=0.818787 I tensorflow/core/common_runtime/gpu/pool_allocator.cc:256] Raising pool_size_limit_ from 100 to 110 I tensorflow/core/common_runtime/gpu/pool_allocator.cc:244] PoolAllocator: After 2405 get requests, put_count=2388 evicted_count=1000 eviction_rate=0.41876 and unsatisfied allocation rate=0.432432 I tensorflow/core/common_runtime/gpu/pool_allocator.cc:256] Raising pool_size_limit_ from 256 to 281 Grammar+Tone model training procedure (initialization)](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-77-2048.jpg)









![88 SERVING TELEGRAM BOT Python 3 Supervisor (for continuous serving) [program:pycon-bot] command = /usr/bin/python3 /home/ubuntu/pycon_bot/serve.py /etc/supervisor/conf.d/pycon_bot.conf ~$ pip3 install python-telegram-bot Install python-telegram-bot package ubuntu@ip-###-###-###-###:~$ sudo supervisorctl pycon-bot RUNNING pid 12417, uptime 3:29:52 supervisorctl](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-88-2048.jpg)
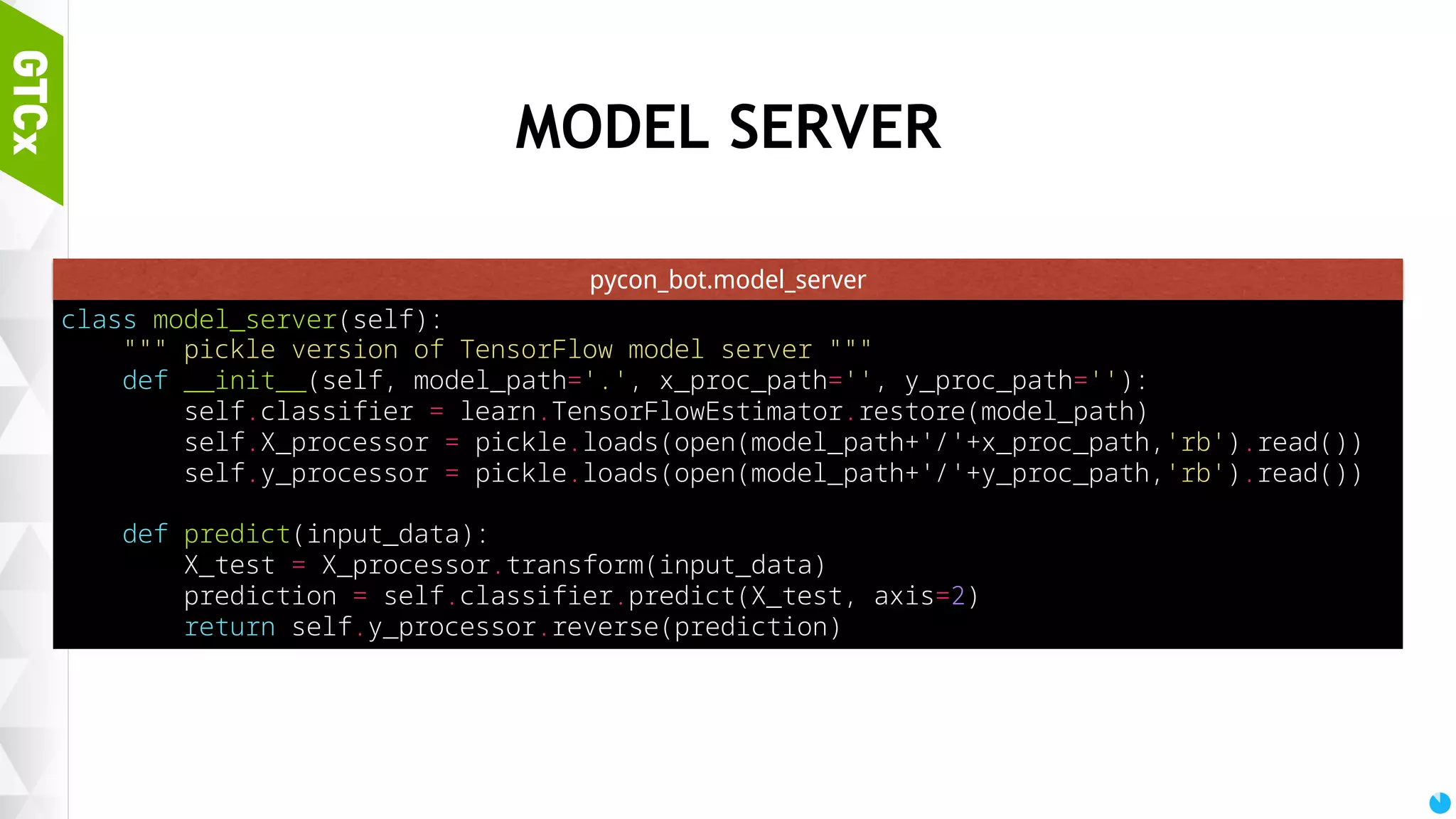
![89 BOT SERVING CODE from telegram import Updater from pycon_bot import pycon_bot, error, model_server bot_server = None grammar_server = None def main(): global bot_server, grammar_server updater = Updater(token=’[TOKENS generated via bot_father]') job_queue = updater.job_queue dispatcher = updater.dispatcher dispatcher.addTelegramCommandHandler('start', start) dispatcher.addTelegramCommandHandler("help", start) dispatcher.addTelegramMessageHandler(pycon_bot) dispatcher.addErrorHandler(error) bot_server = model_server(‘./bot’, ‘ask.vocab’, ‘response.vocab’) grammar_server = model_server(‘./grammar’, ‘fragment.vocab’, ‘result.vocab’) updater.start_polling() updater.idle() if __name__ == '__main__': main() /home/ubuntu/pycon_bot/serve.py](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-89-2048.jpg)

![91 BOT ENGINE CODE def pycon_bot(bot, update): msg = disintegrate(update.message.text) raw_response = bot_server.predict(msg) response = grammar_server.predict(raw_answer) bot.sendMessage(chat_id=update.message.chat_id, text=’ '.join(response)) def disintegrate(sentence): disintegrated_sentence = konlpy.tag.Twitter().pos(sentence, norm=True, stem=True) result = [] for w, t in disintegrated_sentence: if t not in ['Eomi', 'Josa', 'Number', 'KoreanParticle', 'Punctuation']: result.append(w) return ' '.join(result) pycon_bot.pycon_bot pycon_bot.disintegrate](https://image.slidesharecdn.com/gtcxseoulpresentation20161007-withoutmiki-161017020815/75/Chat-bot-making-process-using-Python-3-TensorFlow-91-2048.jpg)









The document outlines the development process of a chatbot using Python 3 and TensorFlow, focusing on machine learning models and techniques for natural language processing. It covers various components of chatbot architecture, including data preprocessing, context analysis, response generation, and disintegration of input for improved understanding. Key challenges in creating effective Korean-specific chatbots and the integration of emotion and context-aware processing in conversations are also discussed.
Introduction by Jeongkyu Shin, discussing his background and the session focus on chat bot creation using Python and TensorFlow.
Overview of components needed for chat bot creation, including data sources, tools like TensorFlow and Python, emphasizing multi-modal learning.
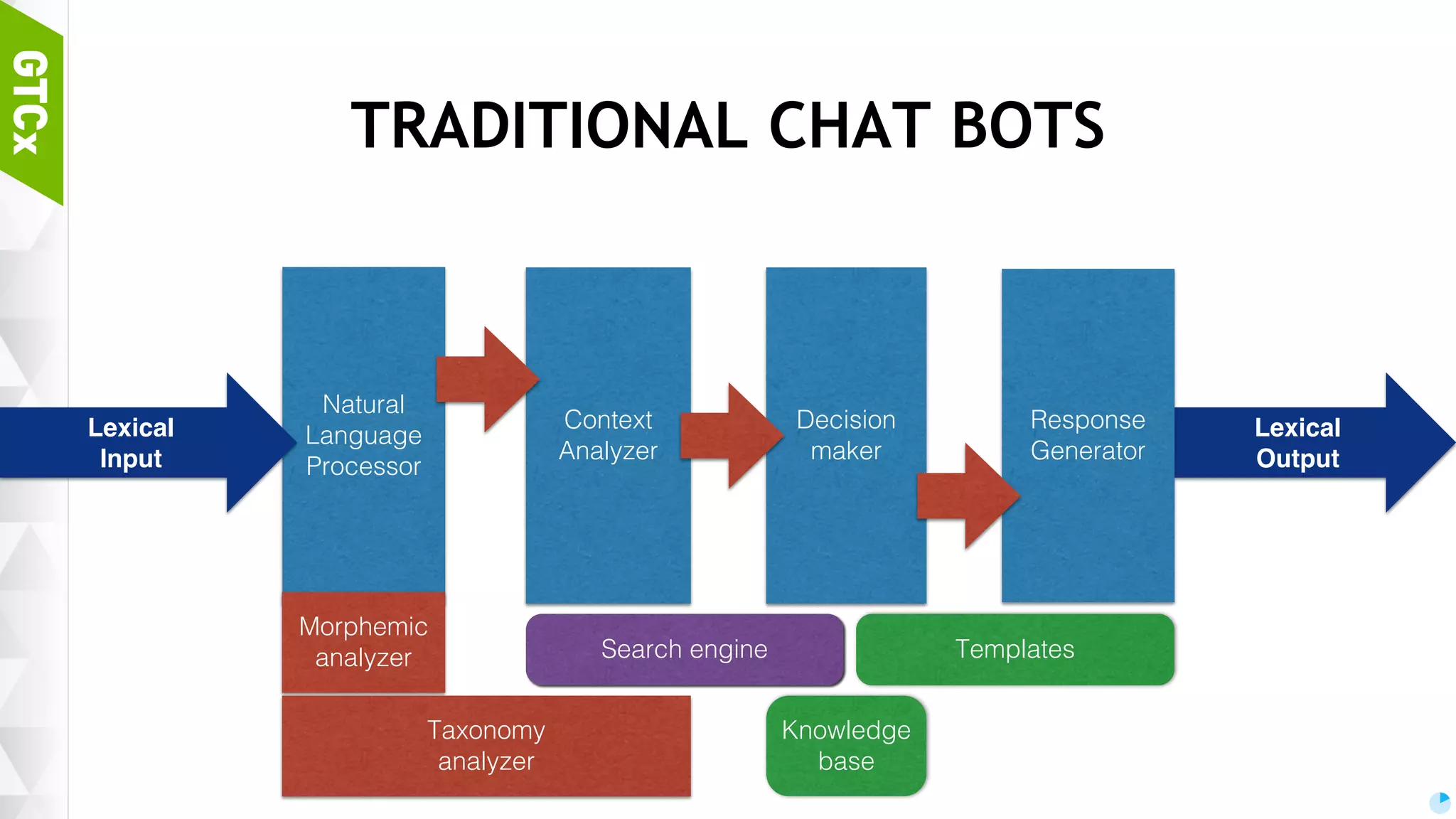
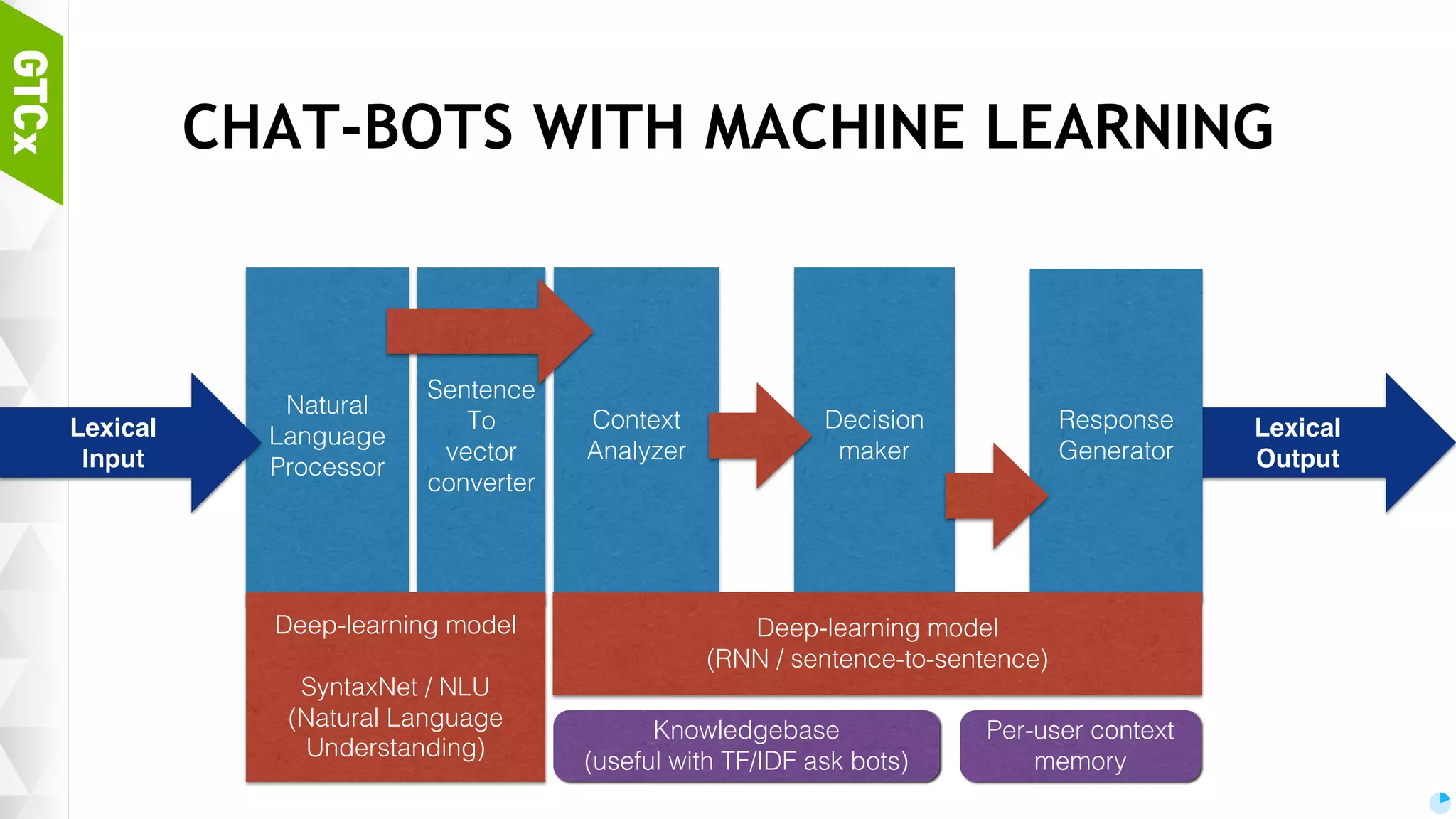
Definition and components of chat bots, distinguishing traditional and machine learning-based models, along with common problems faced in Korean language processing.
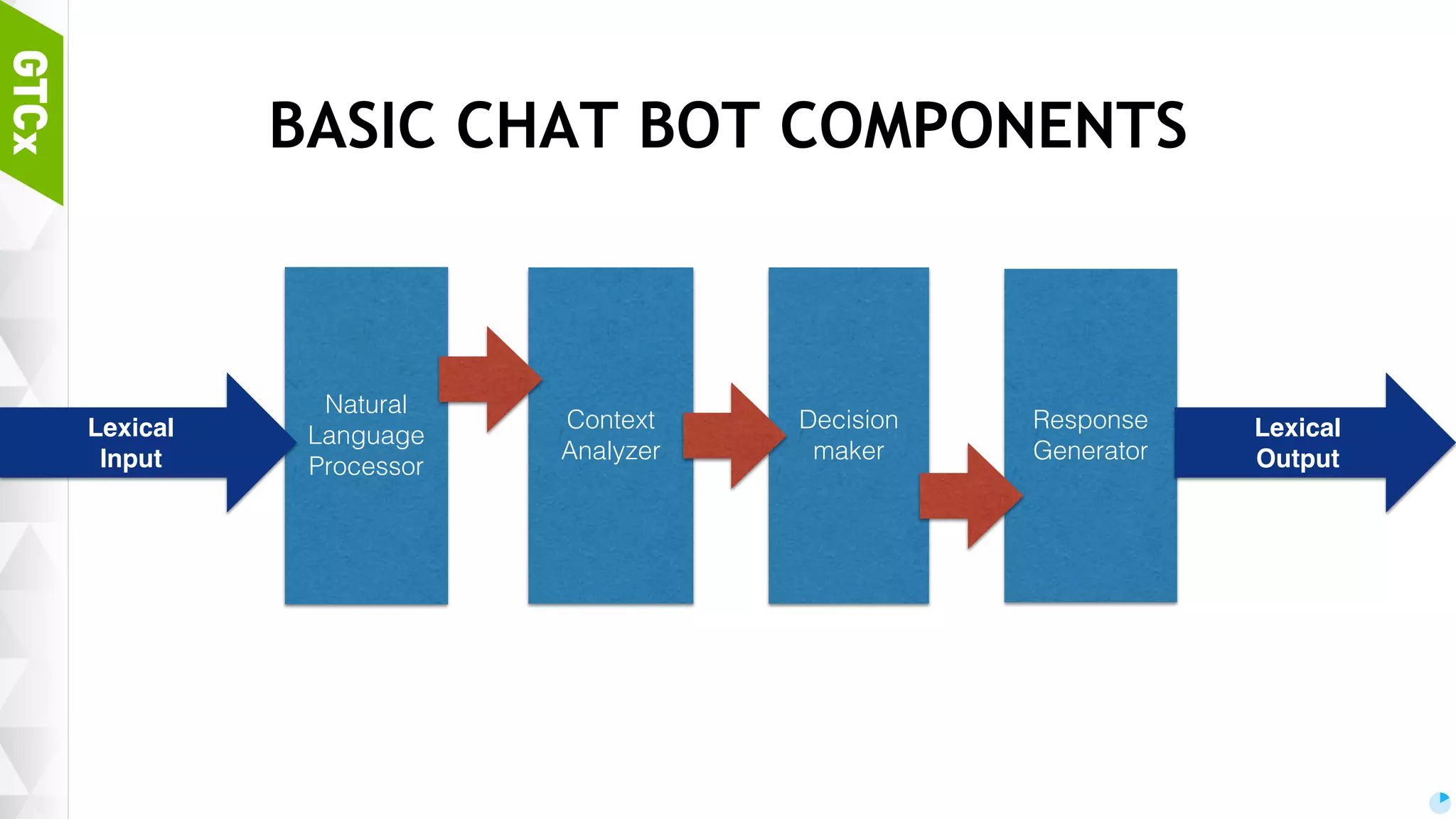
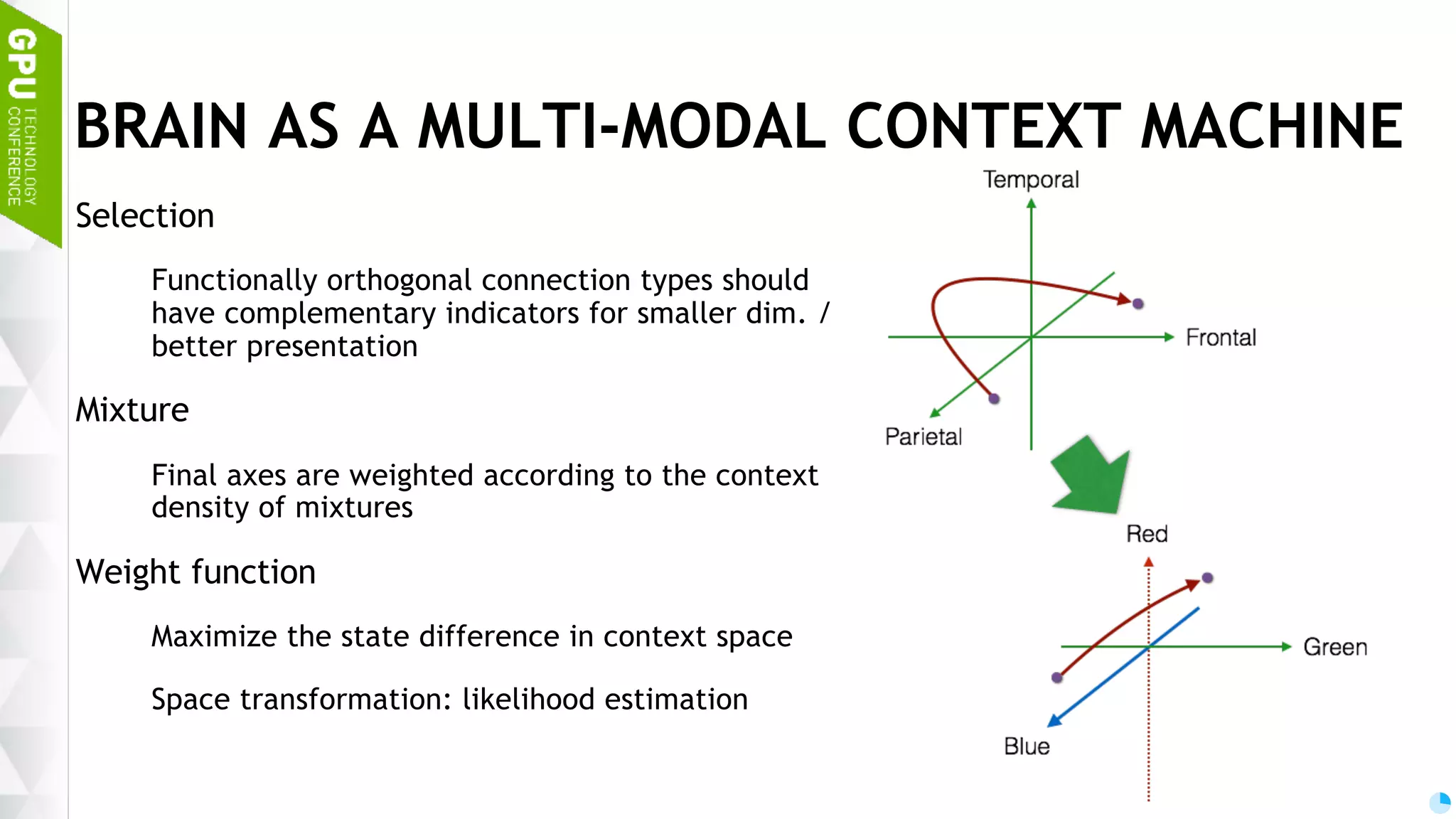
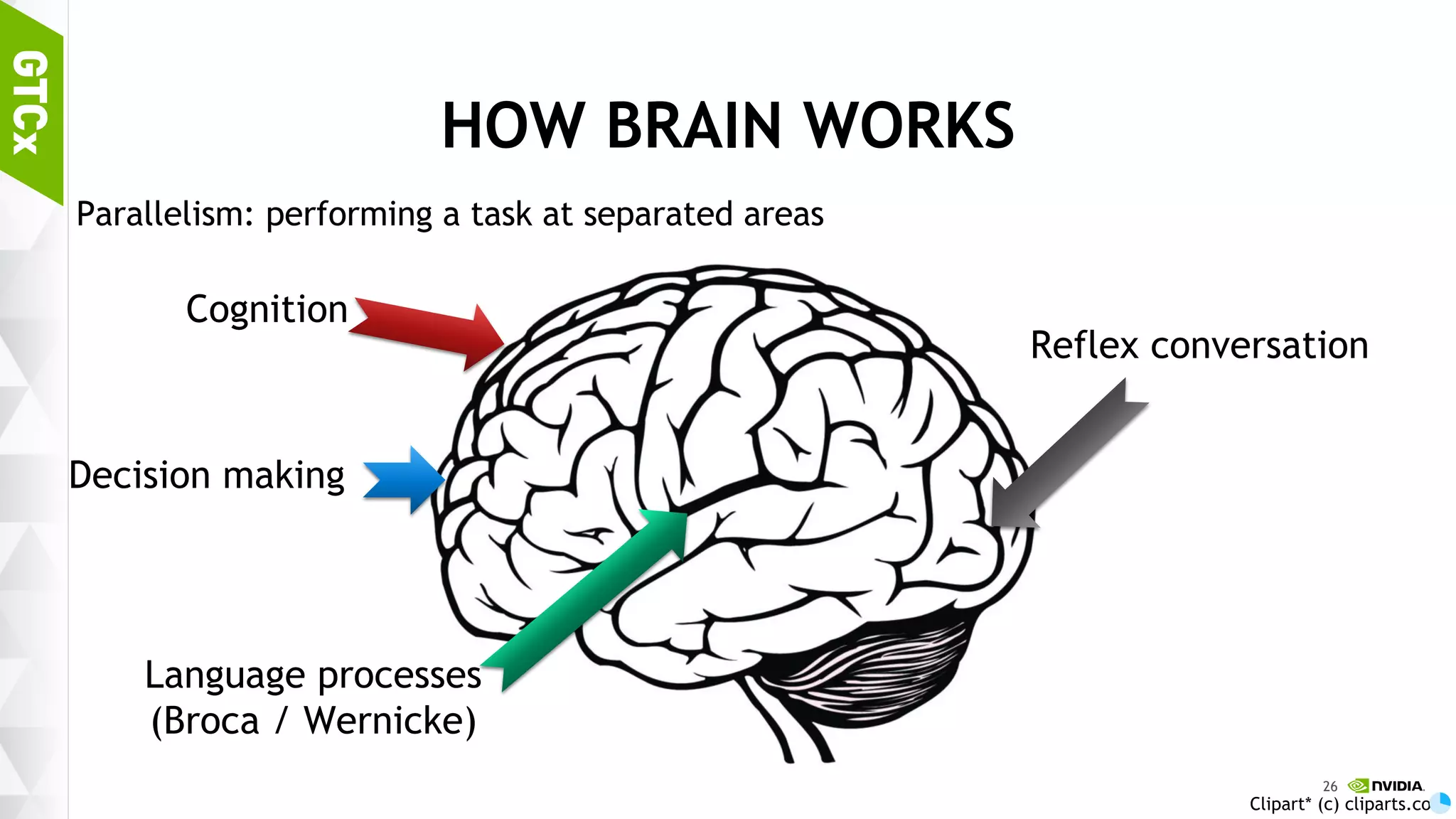
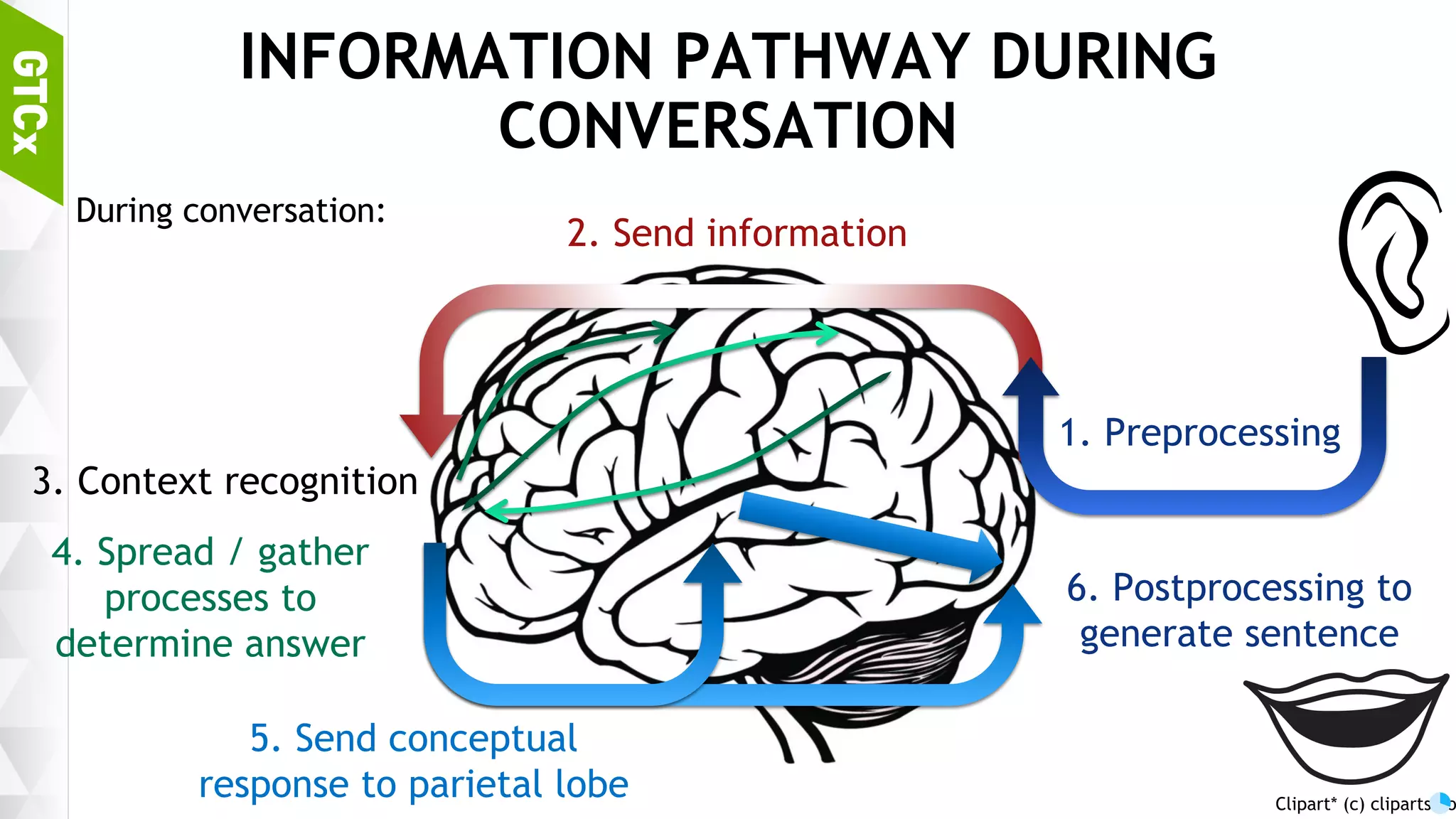
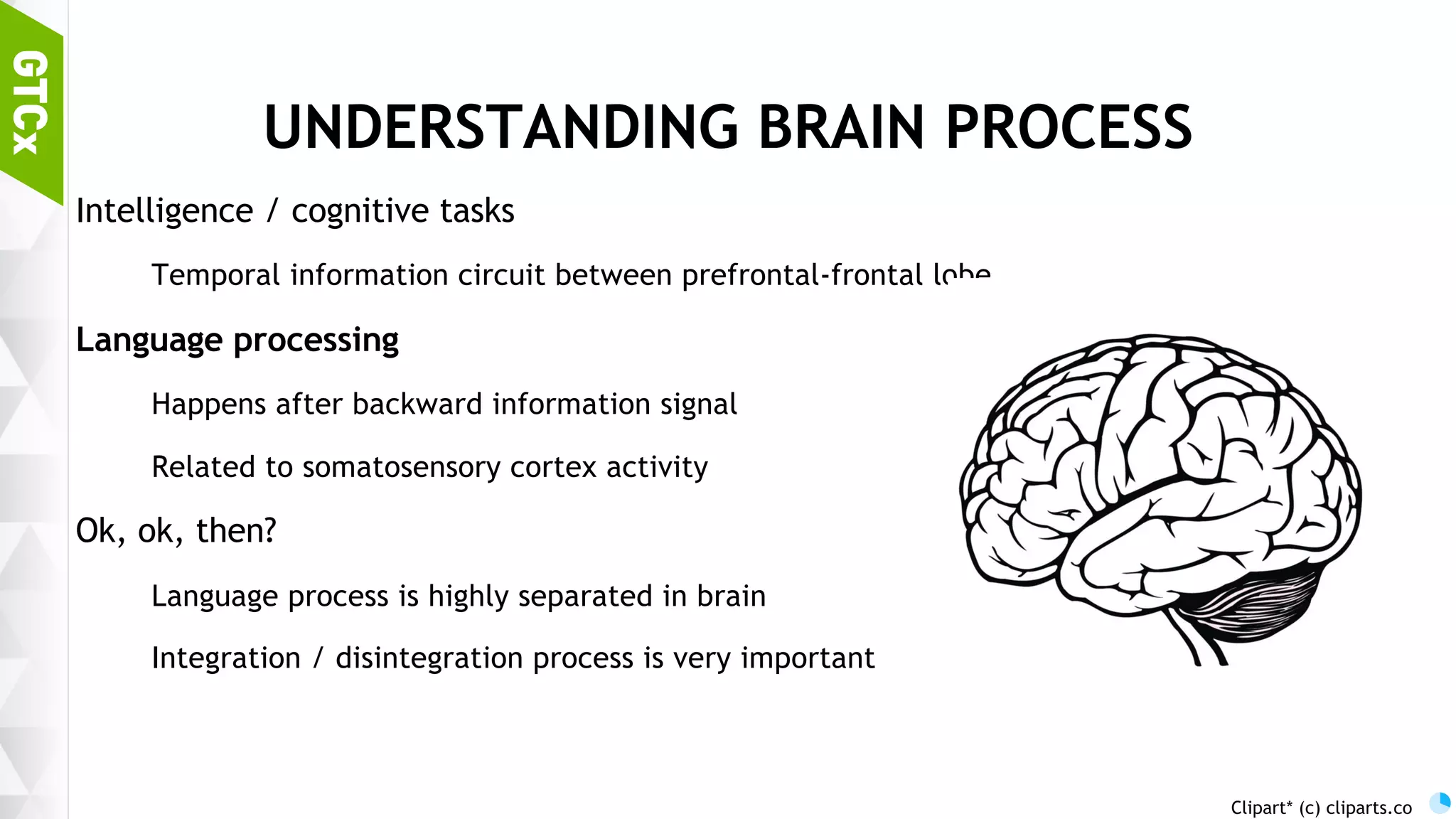
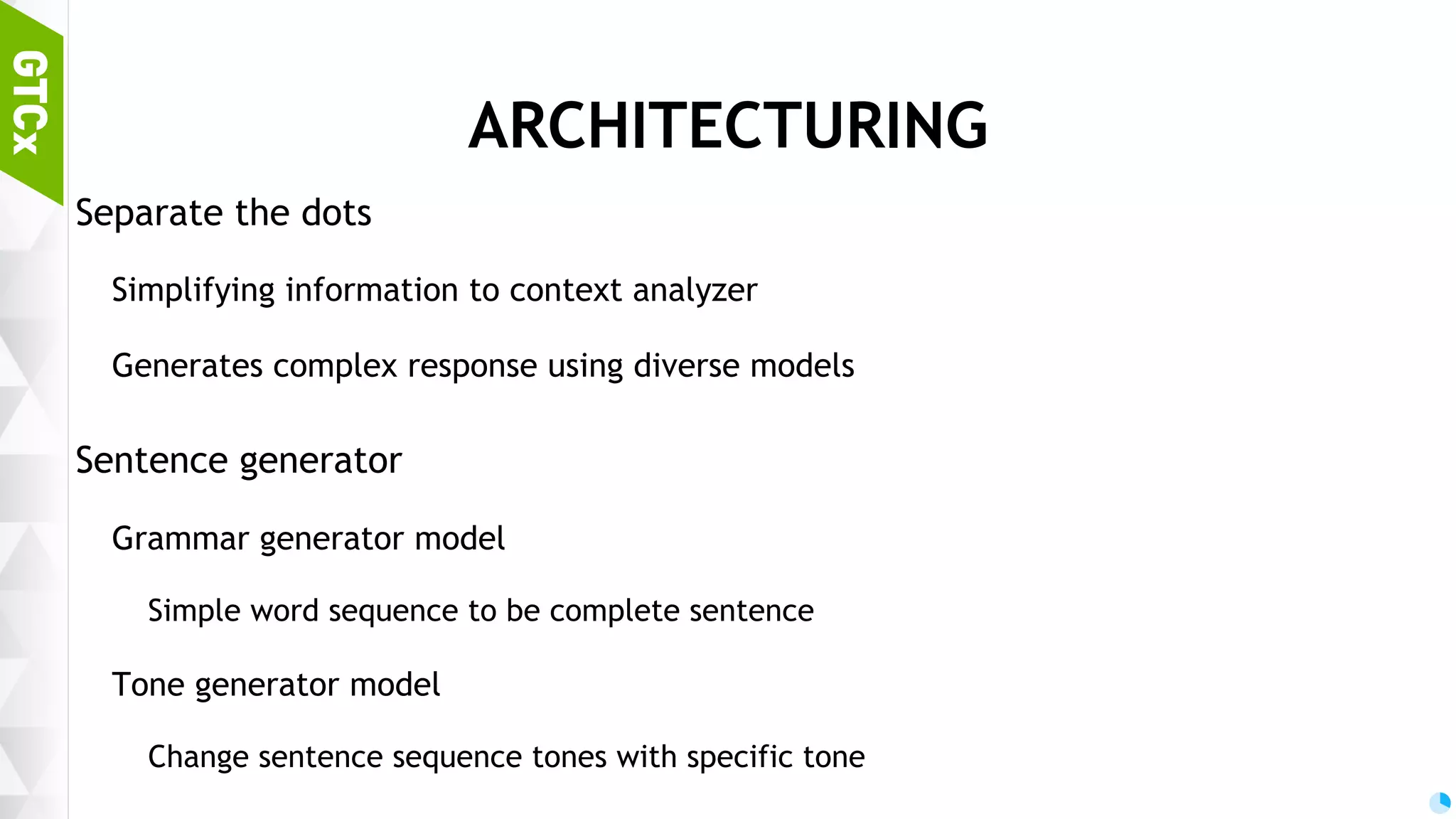
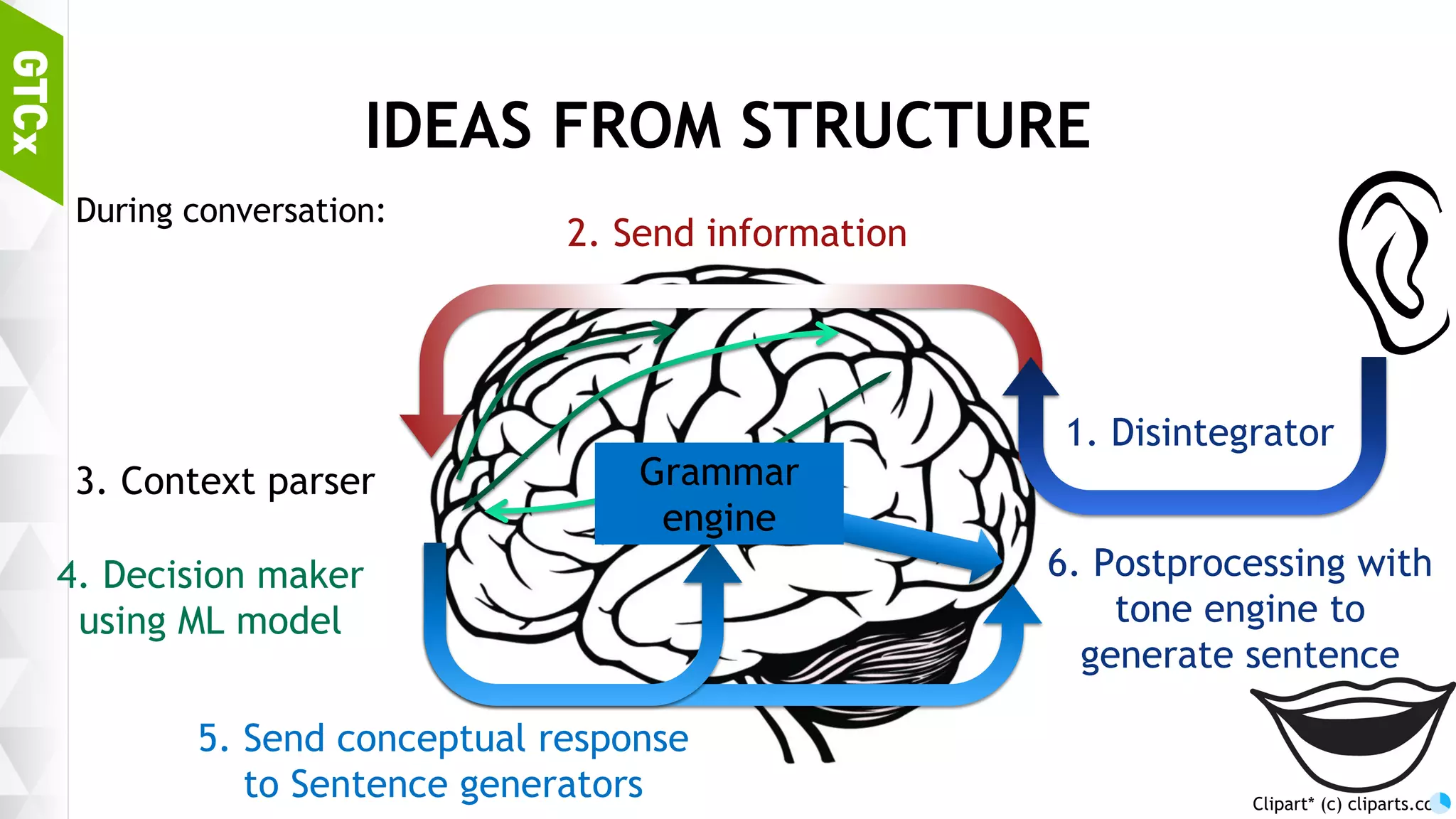
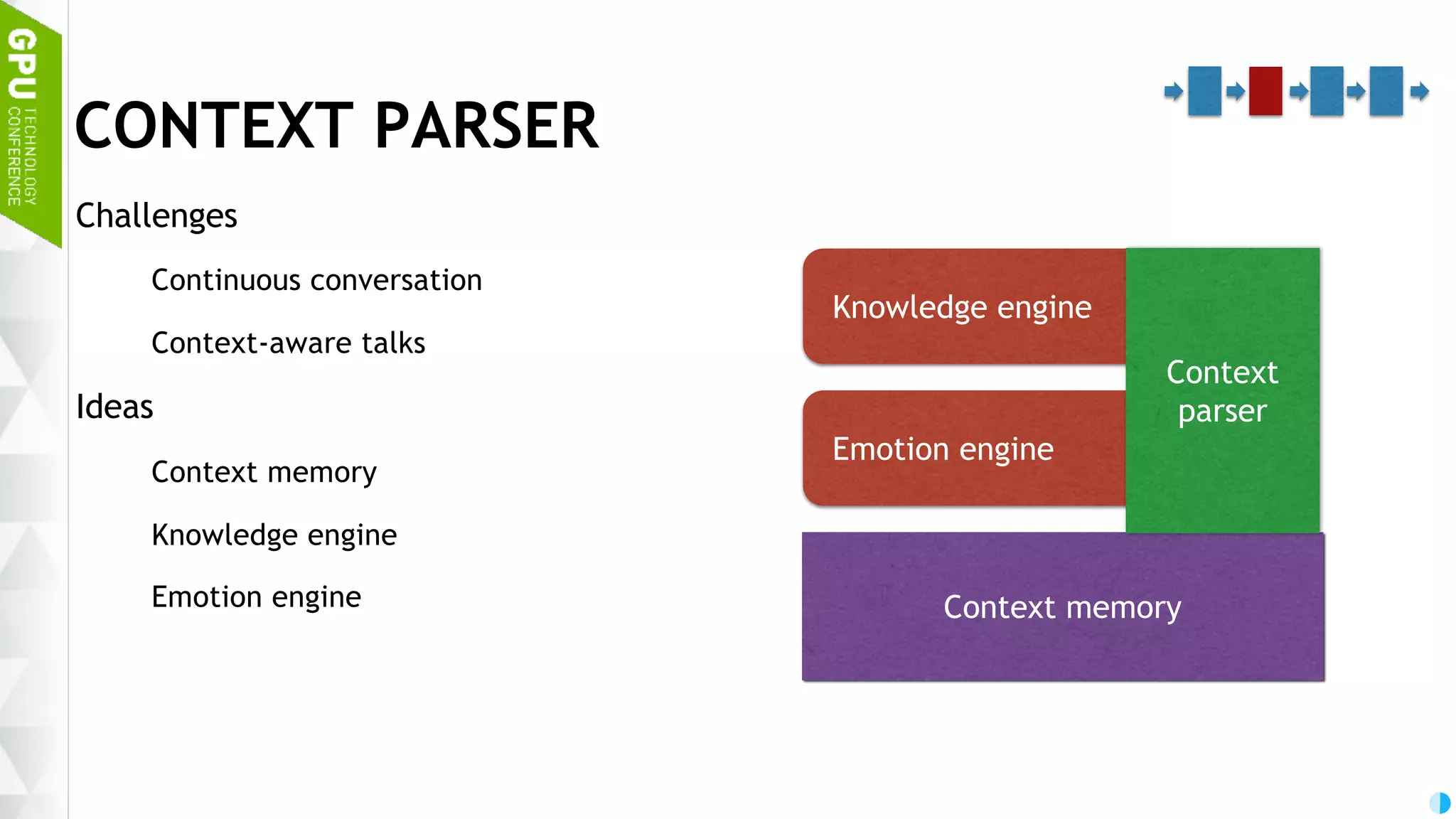
Discussion on brain functions as a multi-modal context machine and architectural ideas for chat bot processing and generating responses.
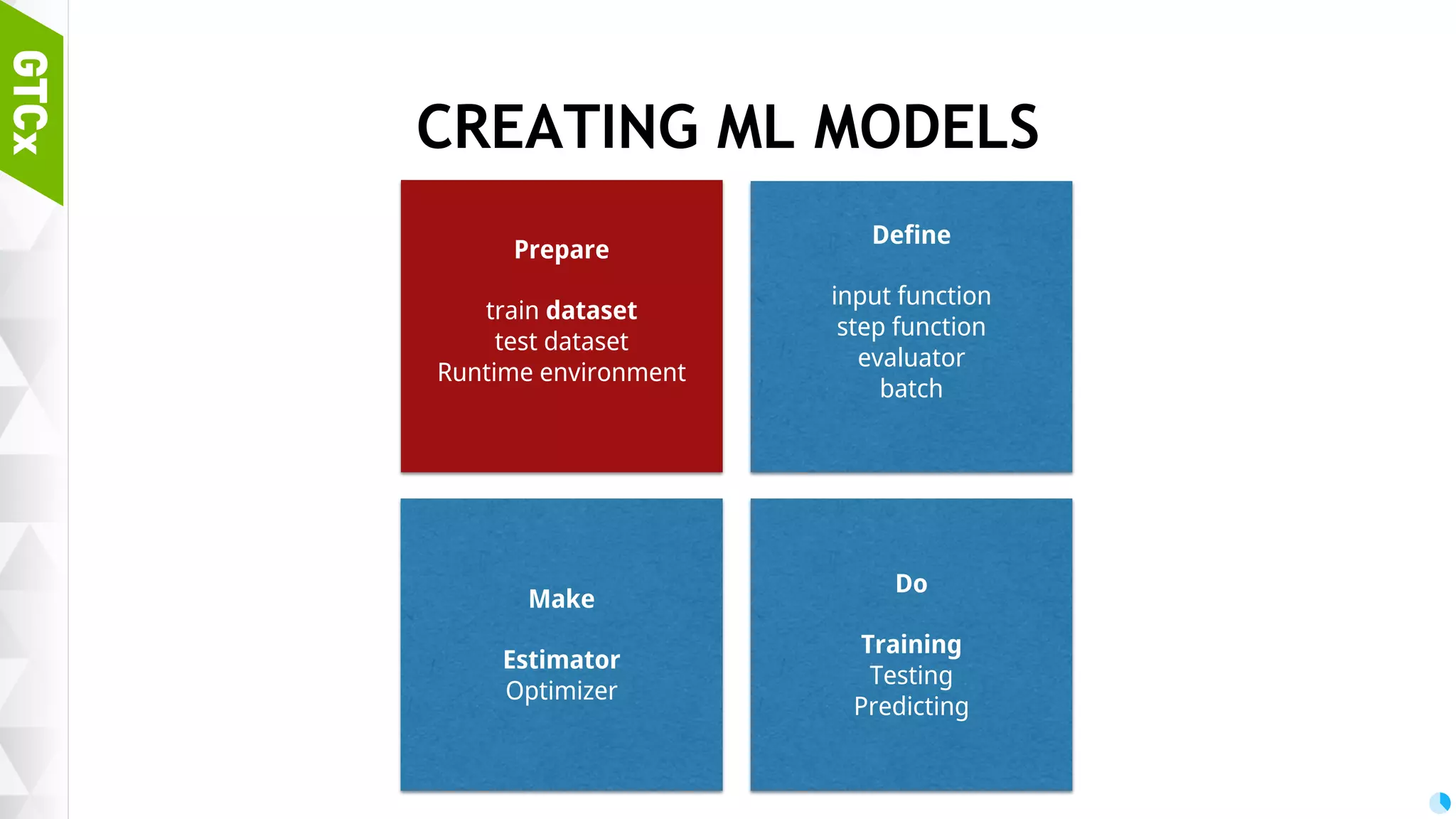
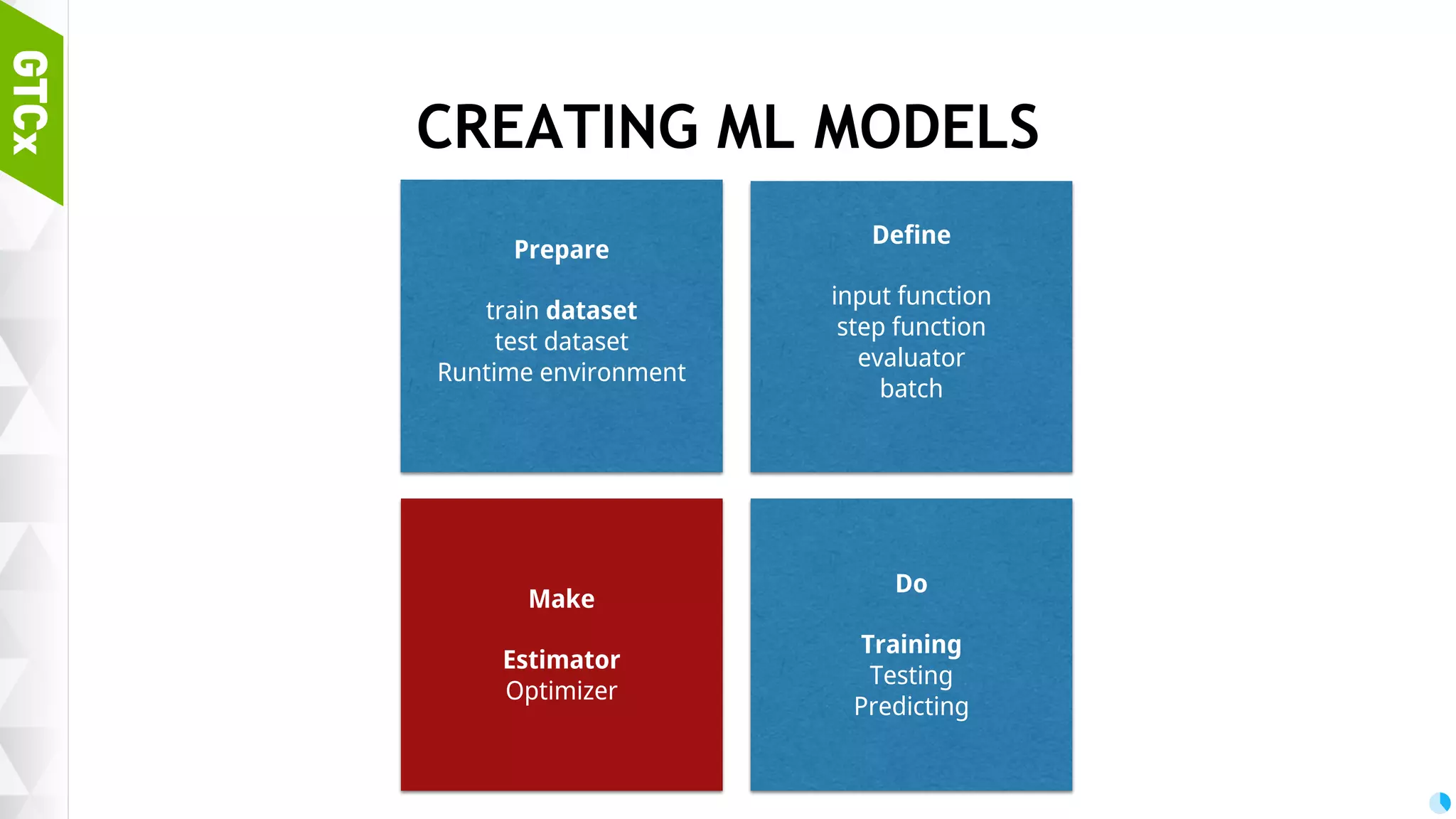
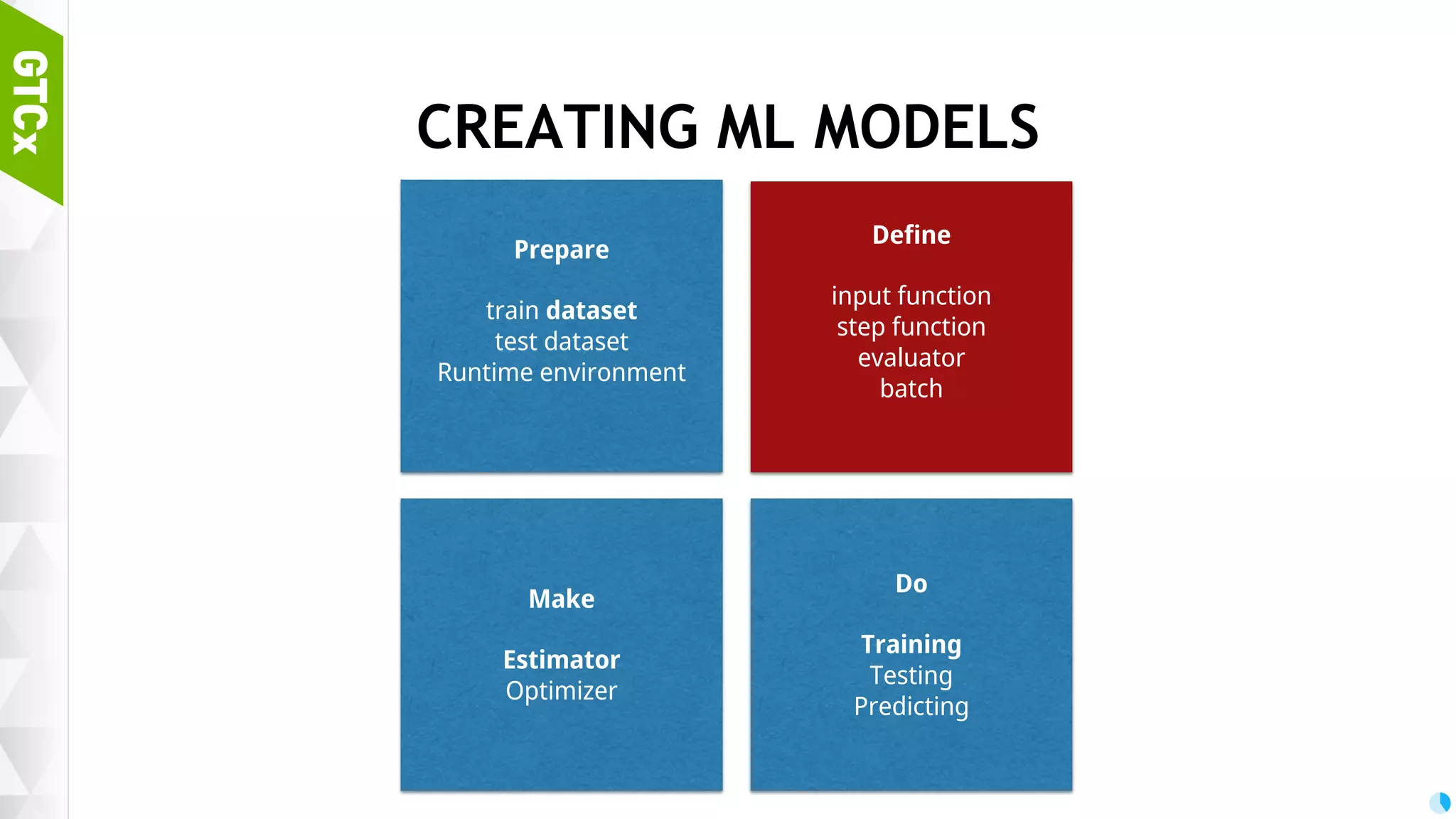
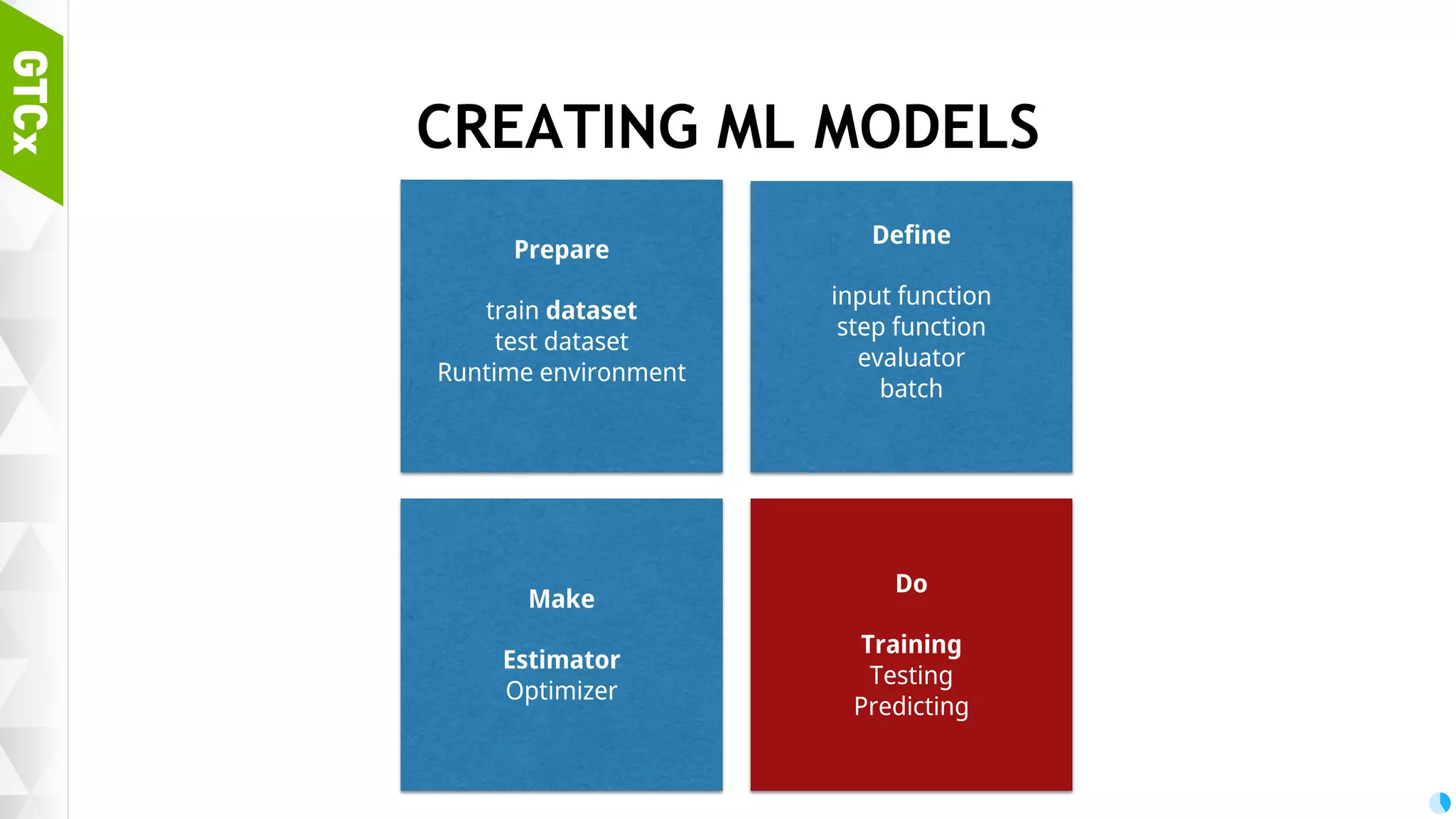
Steps necessary for creating machine learning models including data preparation, training, and testing procedures.
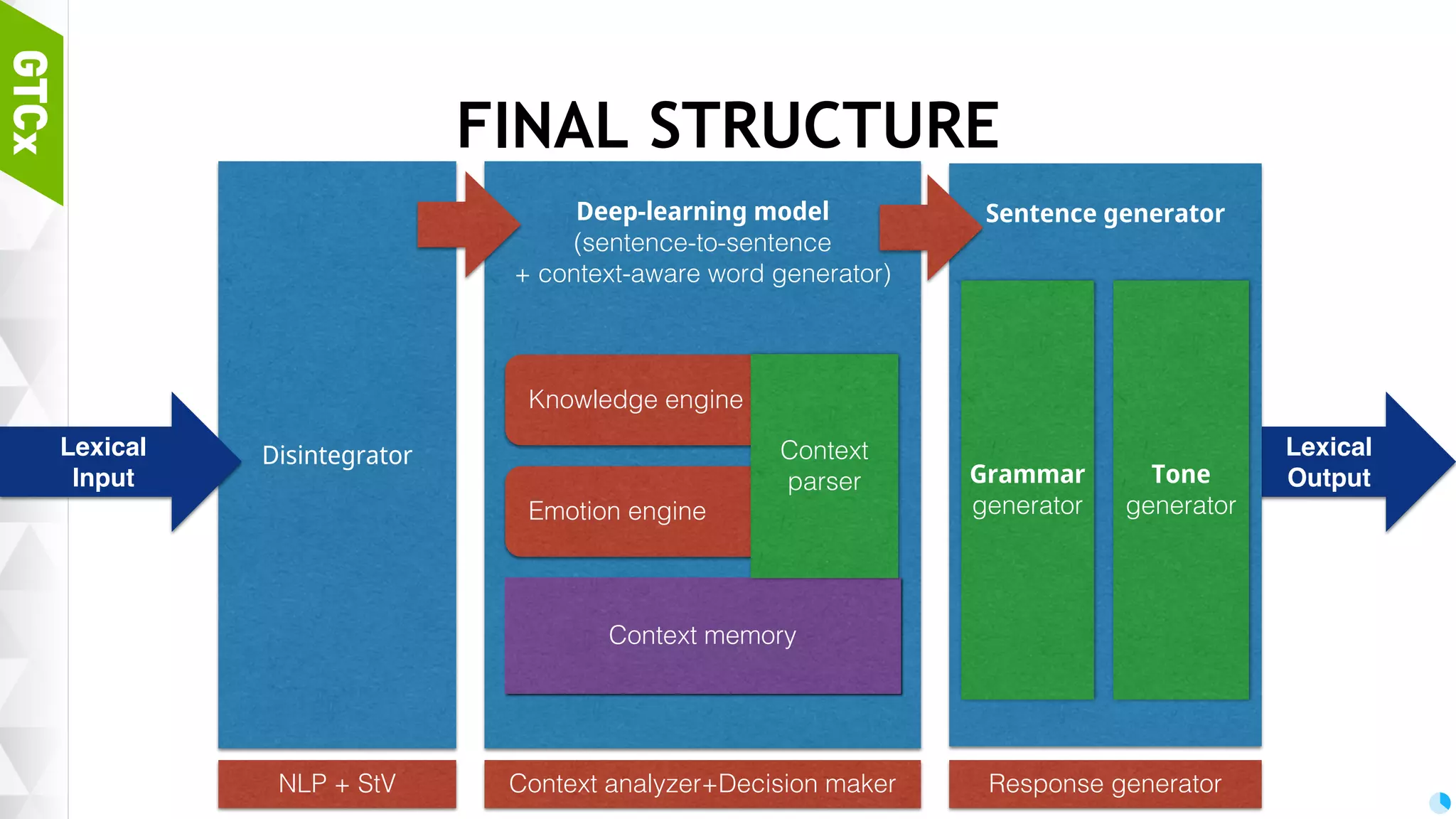
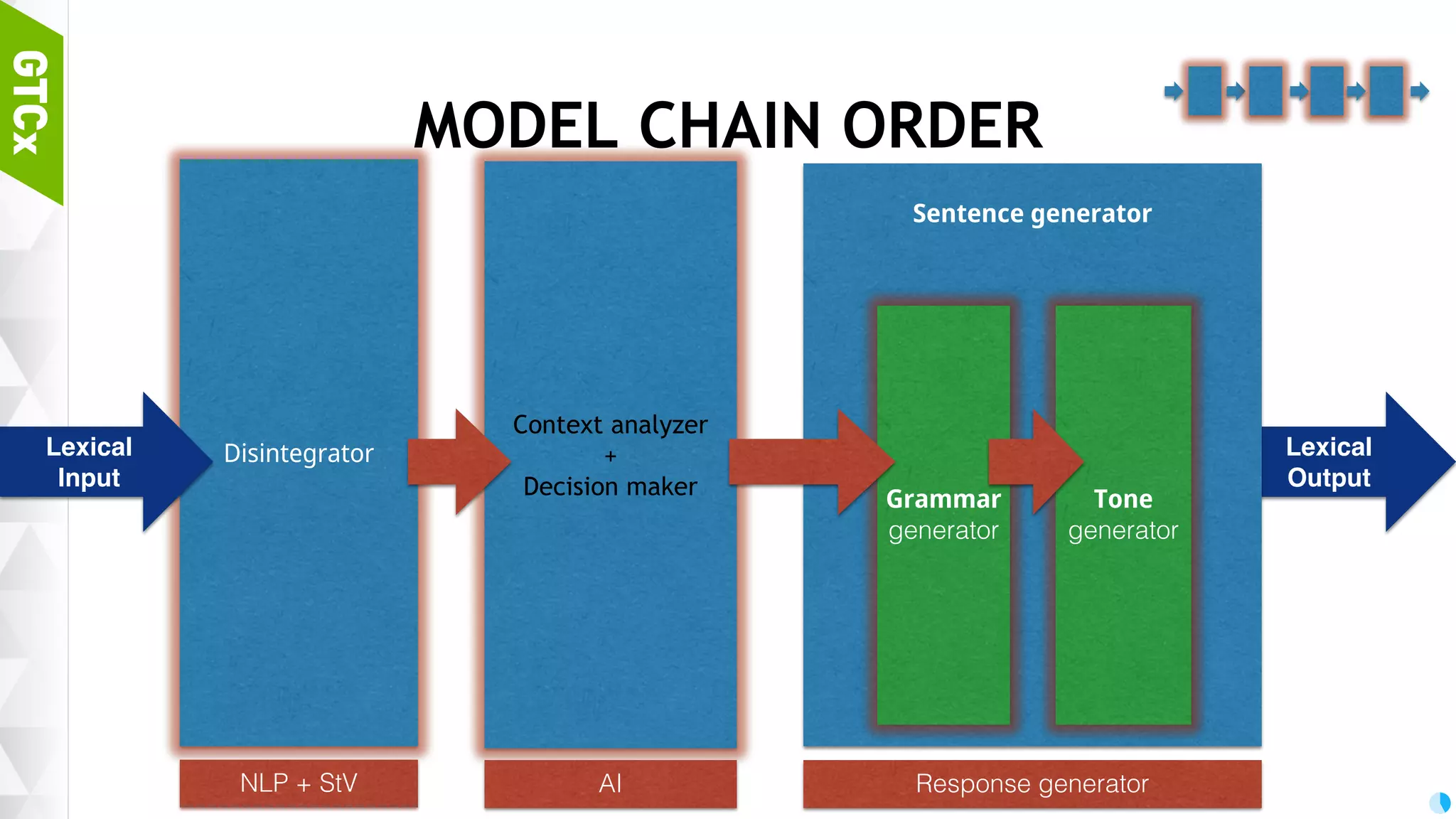
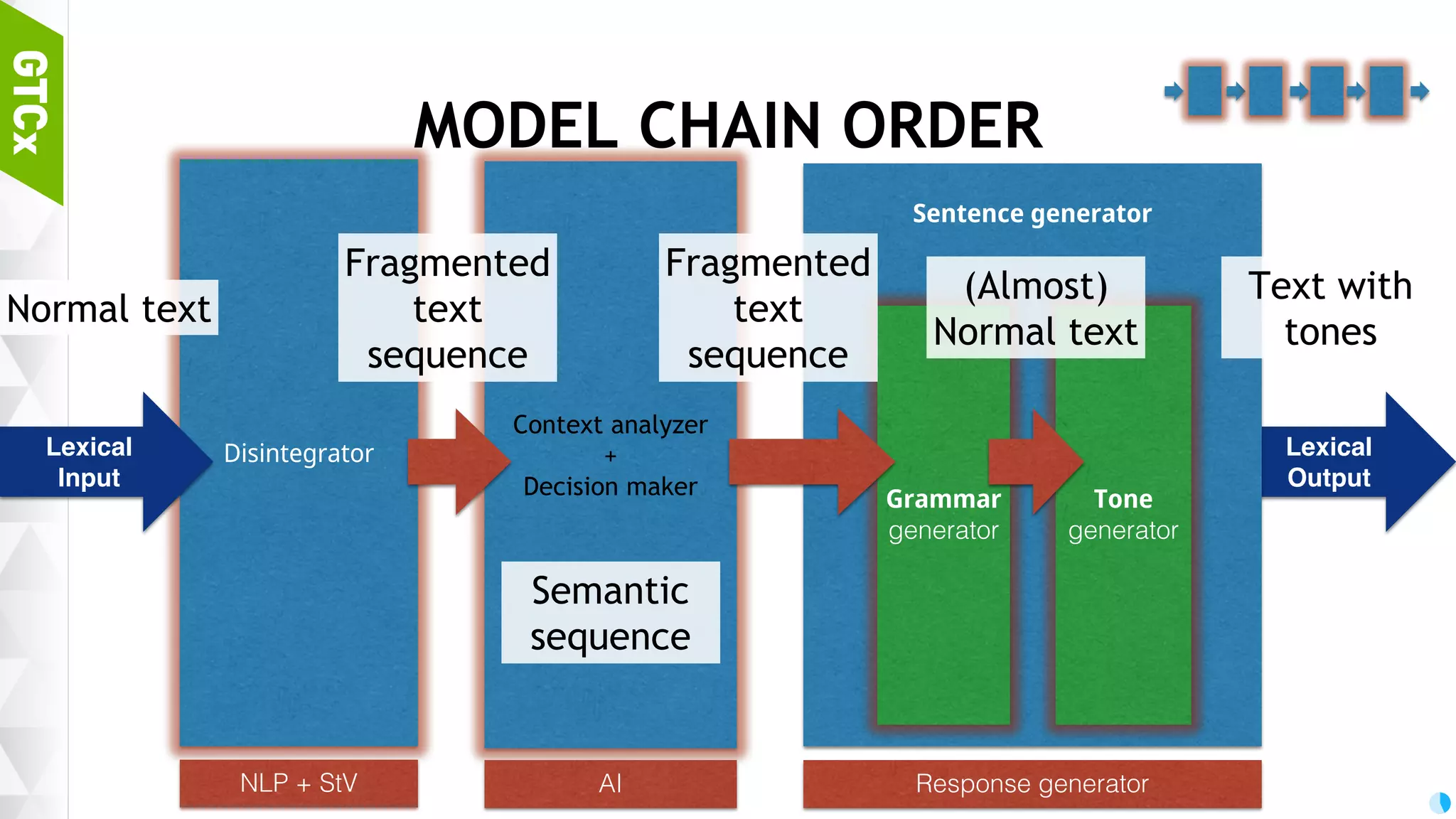
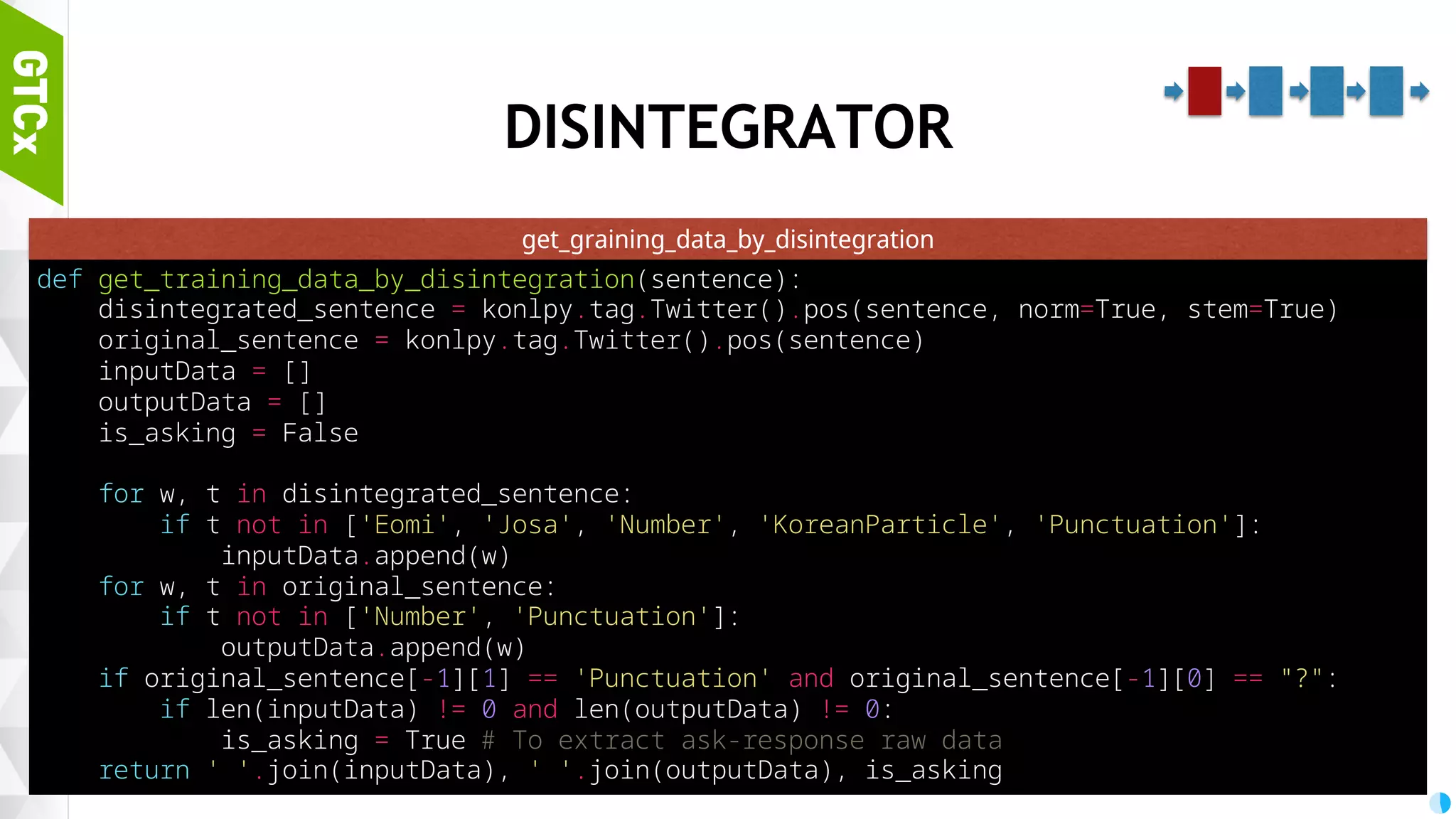
Structure of bot models, importance of disintegration for morpheme analysis and the workflow for transforming sentences for bot training.
Training bot models using sentence sequences, incorporating emotion and context flags, and dealing with training challenges.
Technical specifications, serving of the bot through Telegram API, and implementation instructions.
Recap of the chat bot development process, future plans for improvements and expansions in the dataset used for training.
Thank you note and references for further reading and studies related to the topics discussed in the presentation.