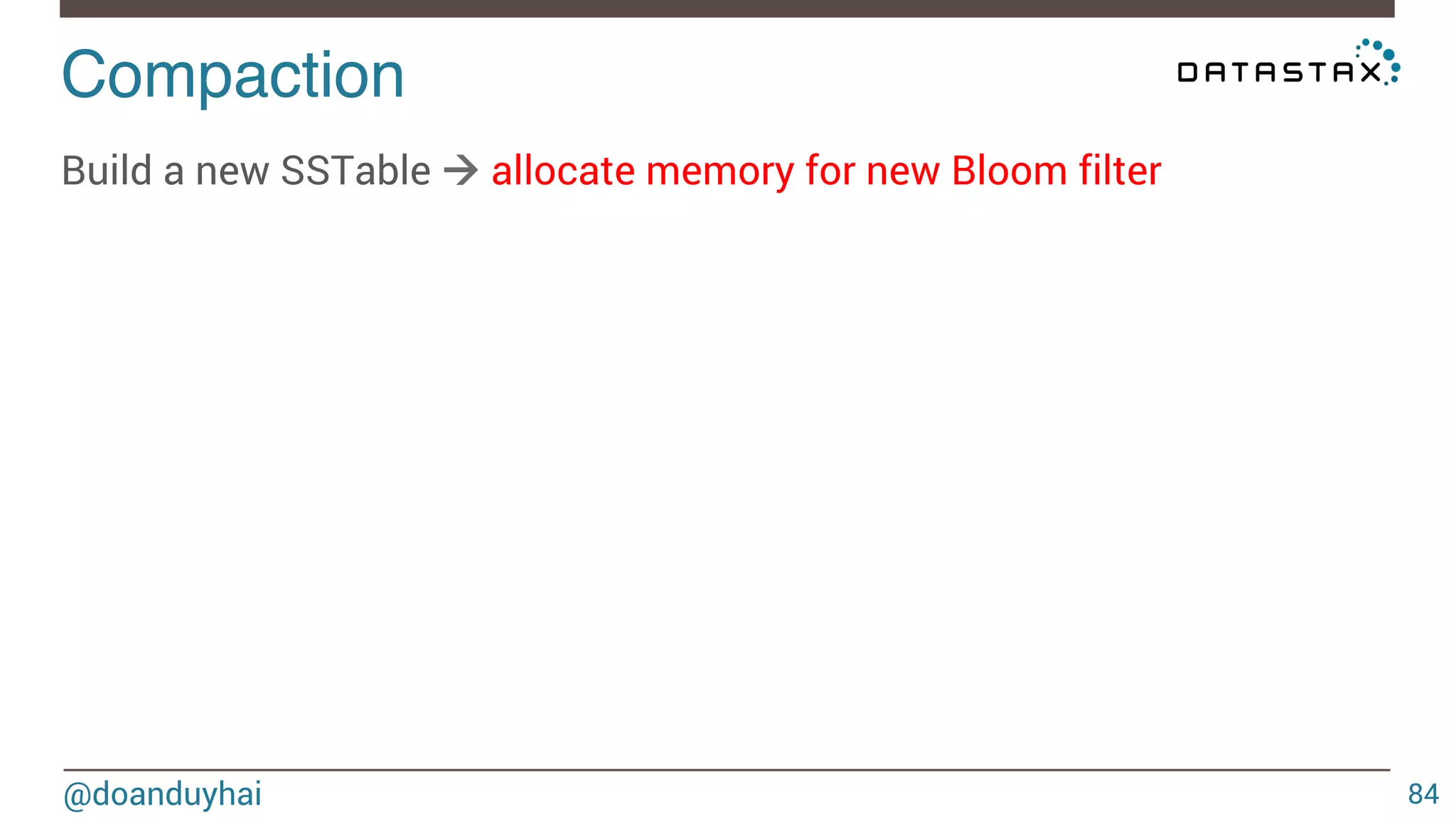
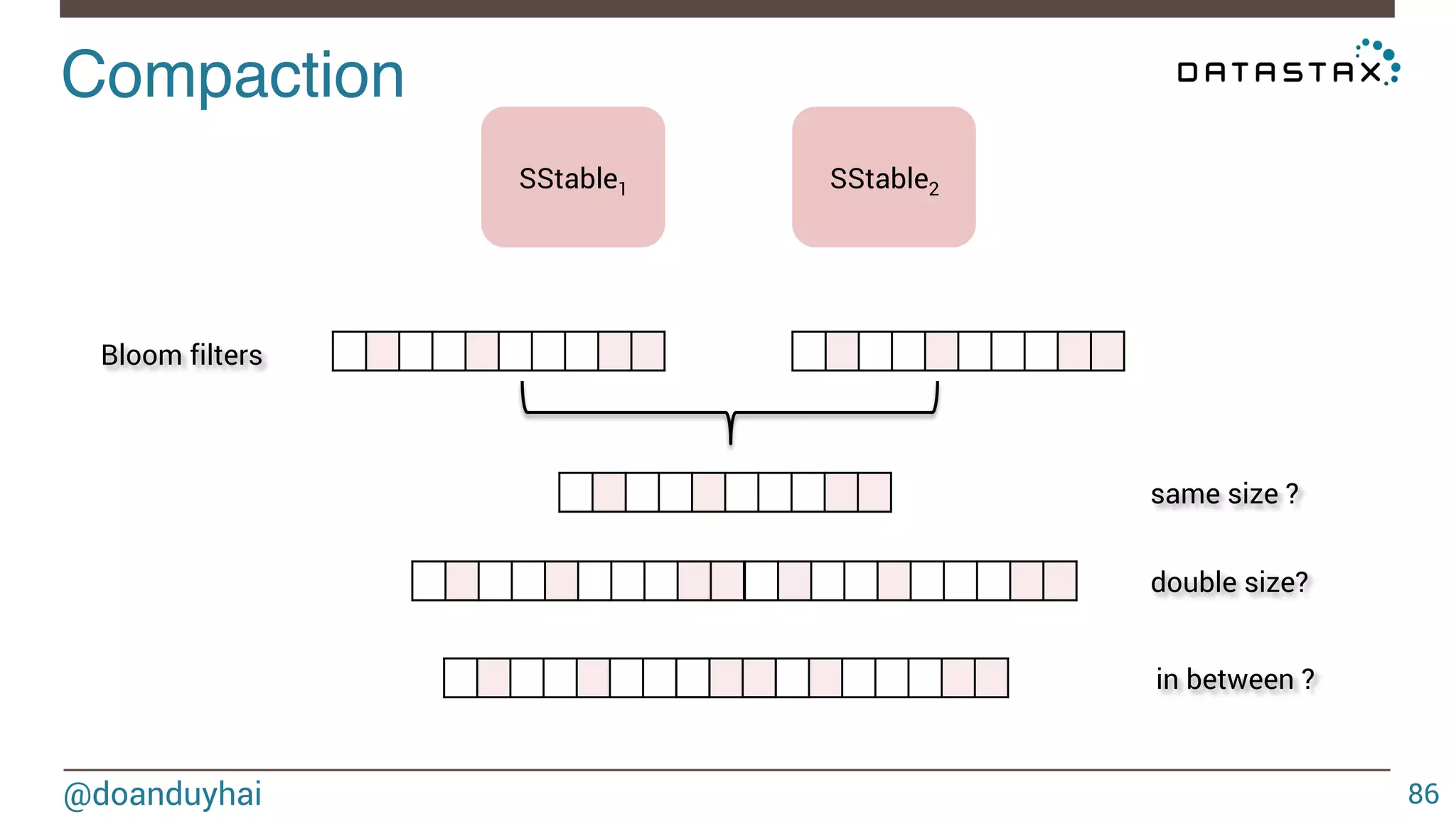
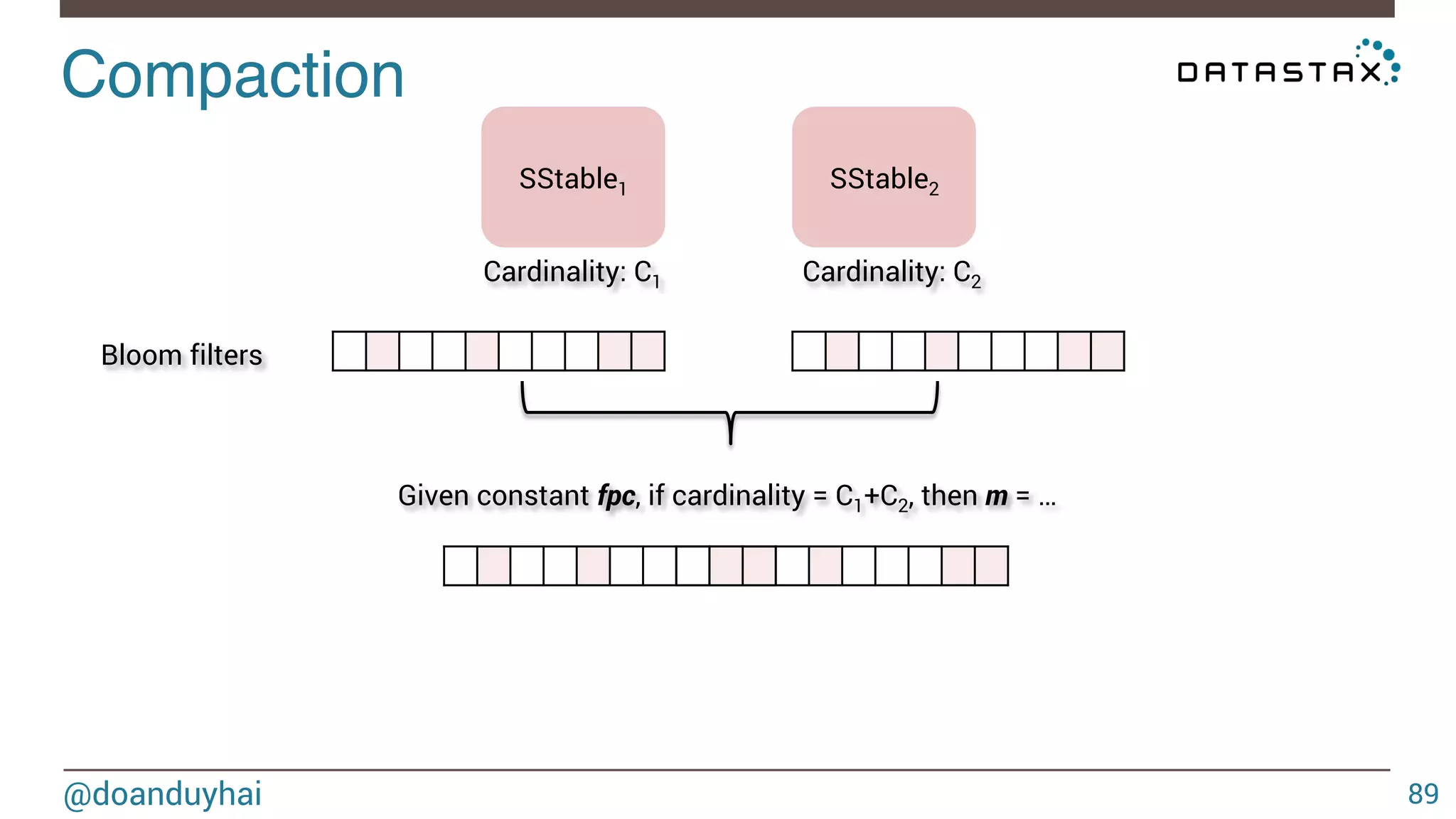
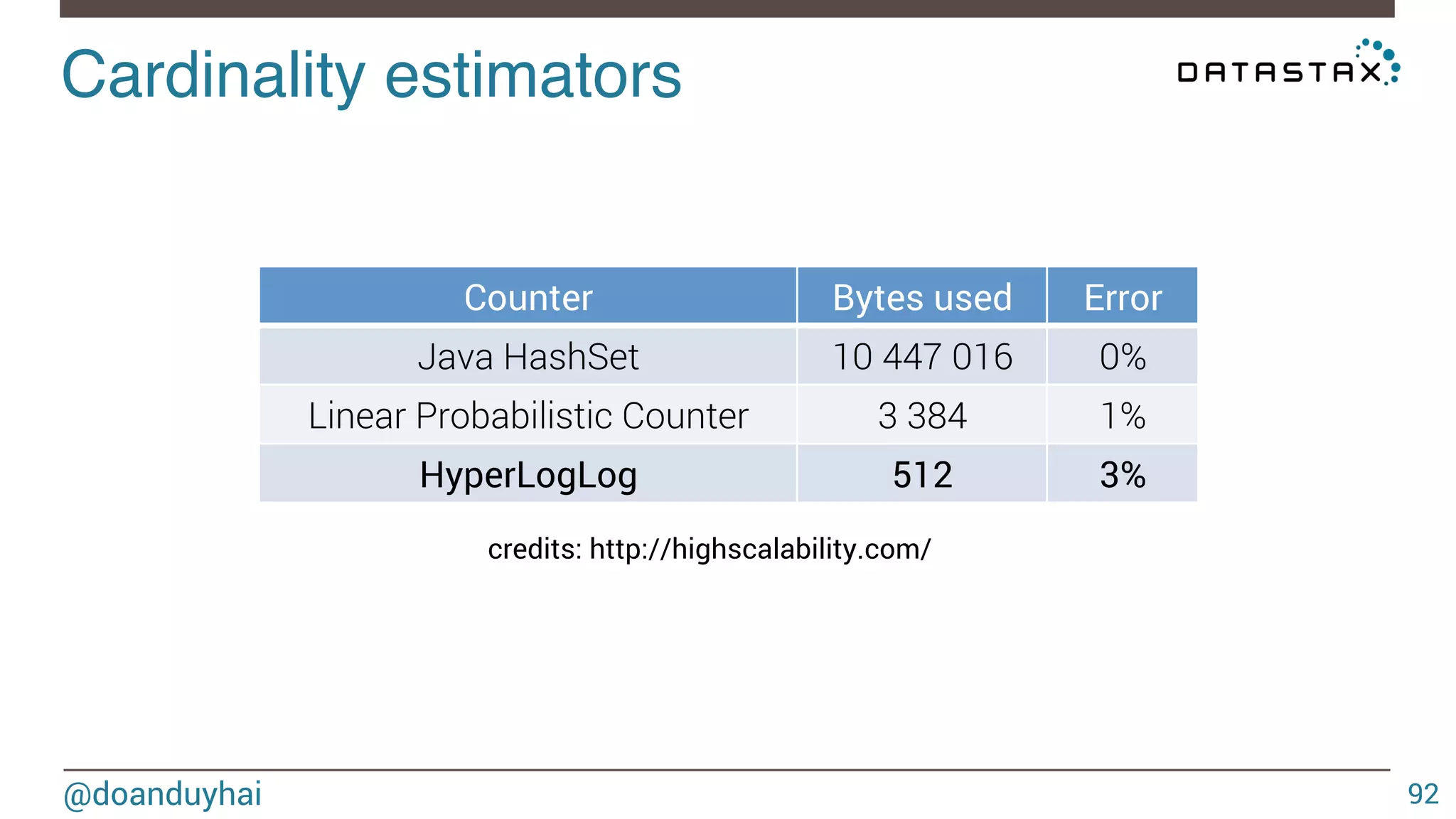
Download as PDF, PPTX









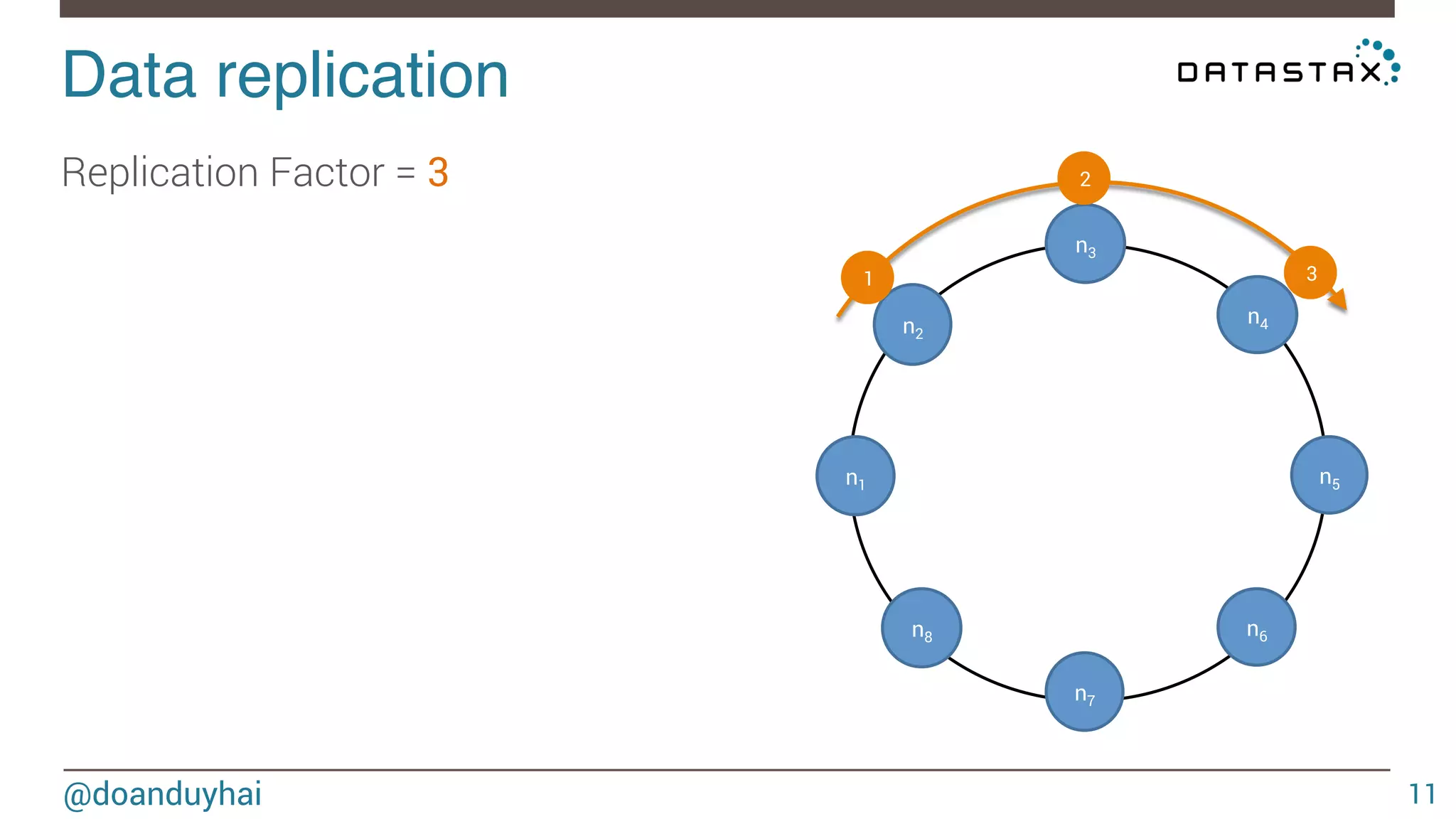
![Data distribution! @doanduyhai 10 Random: hash of #partition → token = hash(#p) Hash: ]0, 2127-1] Each node: 1/8 of ]0, 2127-1] n1 n2 n3 n4 n5 n6 n7 n8](https://image.slidesharecdn.com/cassandradatastructuresandalgorithms-140925165501-phpapp02/75/Cassandra-data-structures-and-algorithms-10-2048.jpg)
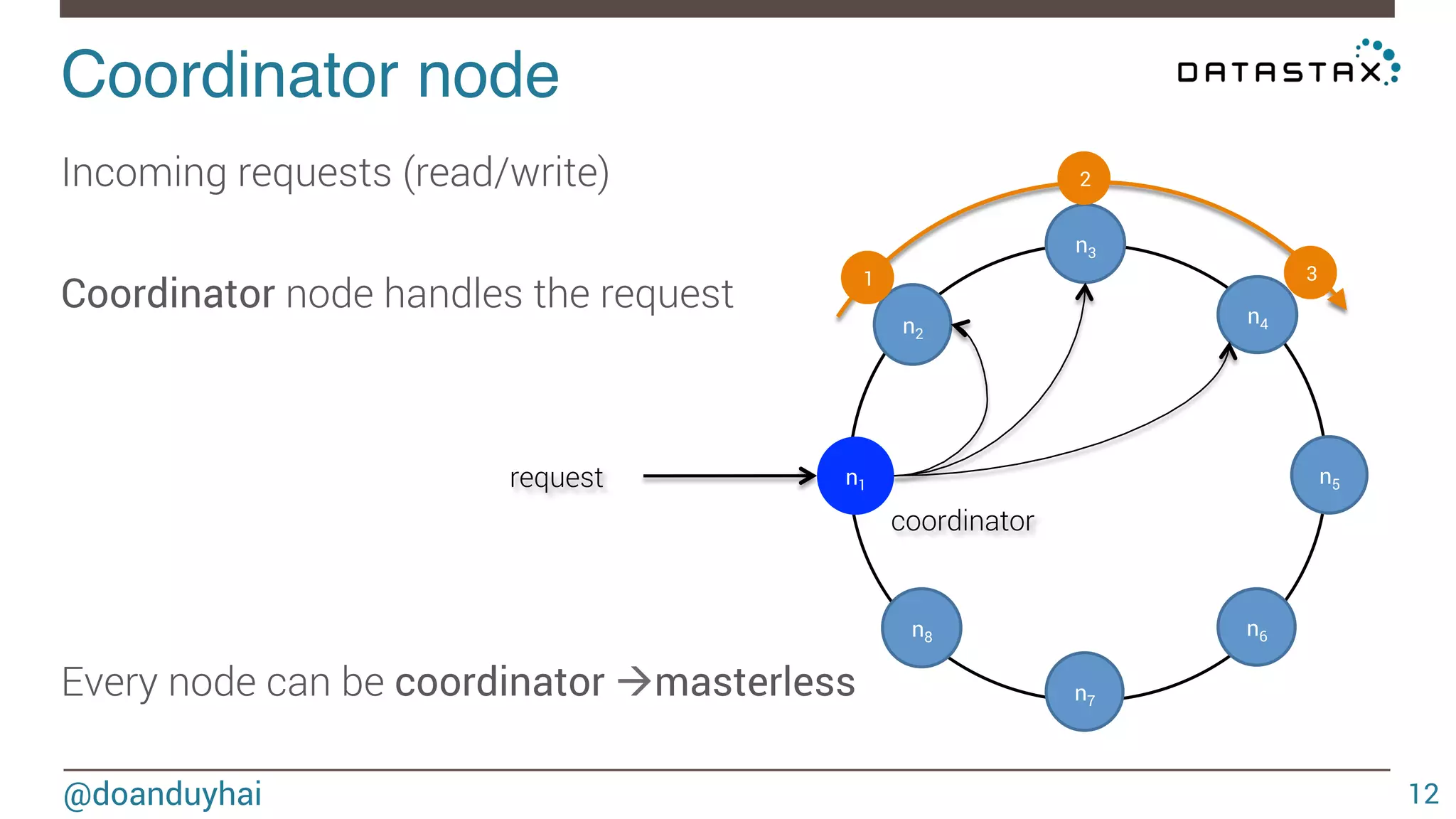

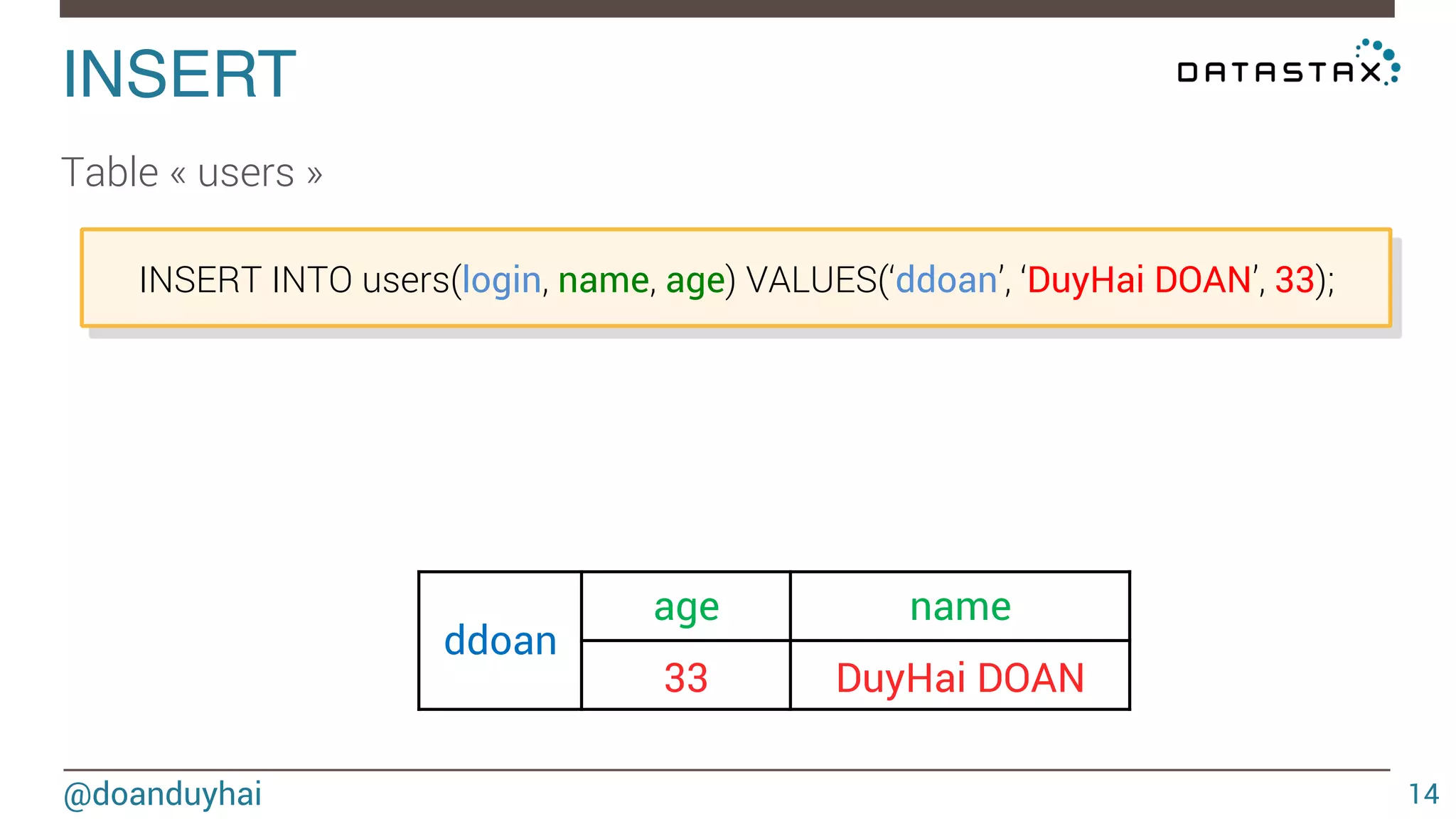
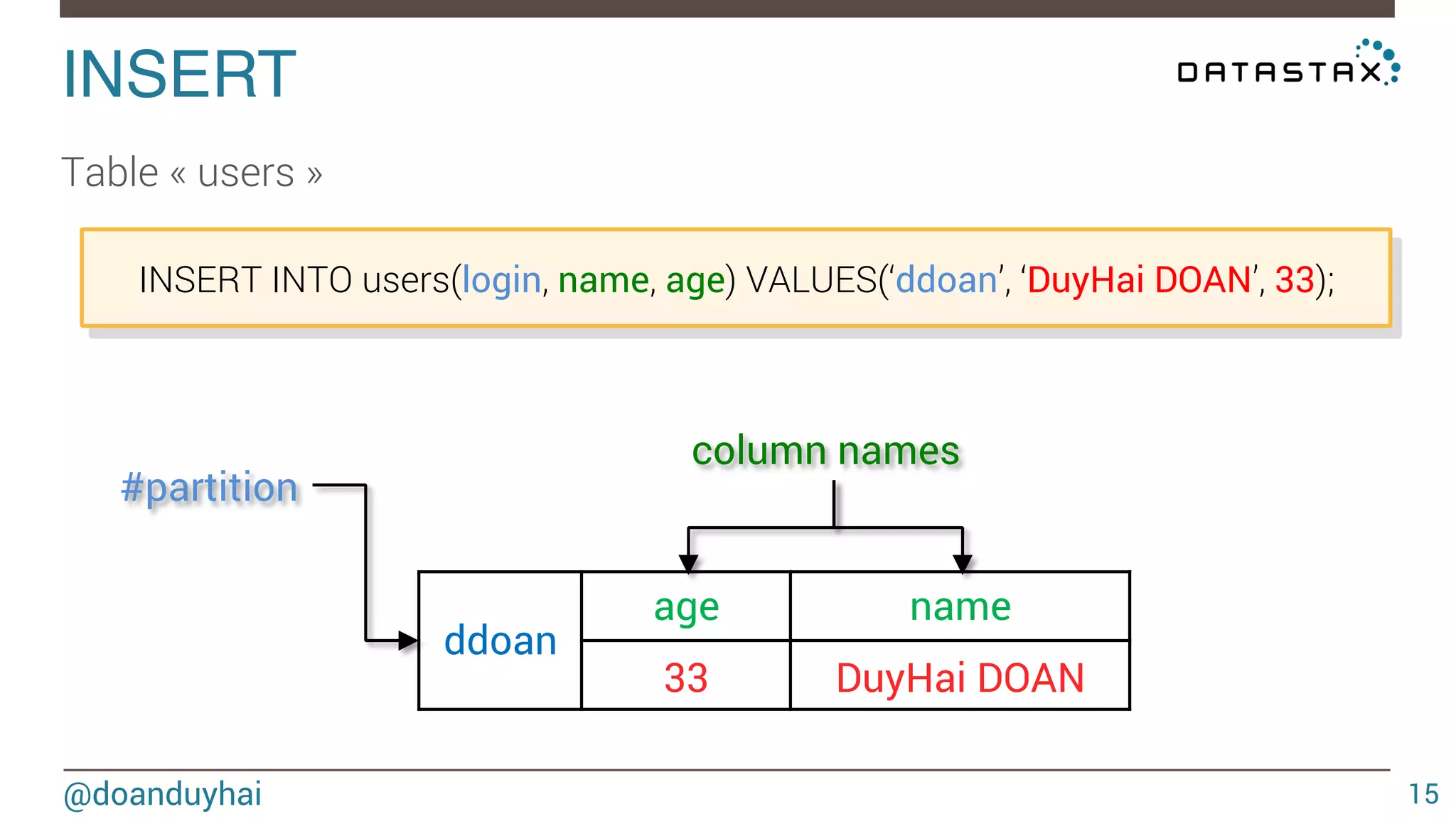

















































![LogLog intuition! @doanduyhai 93 1) given a well distributed hash function h 2) given a sufficiently high number of elements n For a set of n elements, look that the bit pattern ∀ i ∈ [1,n], h(elementi) ≈ n/2 ≈ n/2 0xxxxx… 1xxxxx…](https://image.slidesharecdn.com/cassandradatastructuresandalgorithms-140925165501-phpapp02/75/Cassandra-data-structures-and-algorithms-93-2048.jpg)
![LogLog intuition! ≈ n/4 ≈ n/4 ≈ n/4 ≈ n/8 ≈ n/8 ≈ n/8 ≈ n/8 ≈ n/8 ≈ n/8 ≈ n/8 ≈ n/8 @doanduyhai 94 ∀ i ∈ [1,n], h(elementi) 01xxxx… 10xxxx… ≈ n/4 00xxxx… 11xxxx… 000xxx… 001xxx… 010xxx… 011xxx… 100xxx… 101xxx… 110xxx… 111xxx…](https://image.slidesharecdn.com/cassandradatastructuresandalgorithms-140925165501-phpapp02/75/Cassandra-data-structures-and-algorithms-94-2048.jpg)












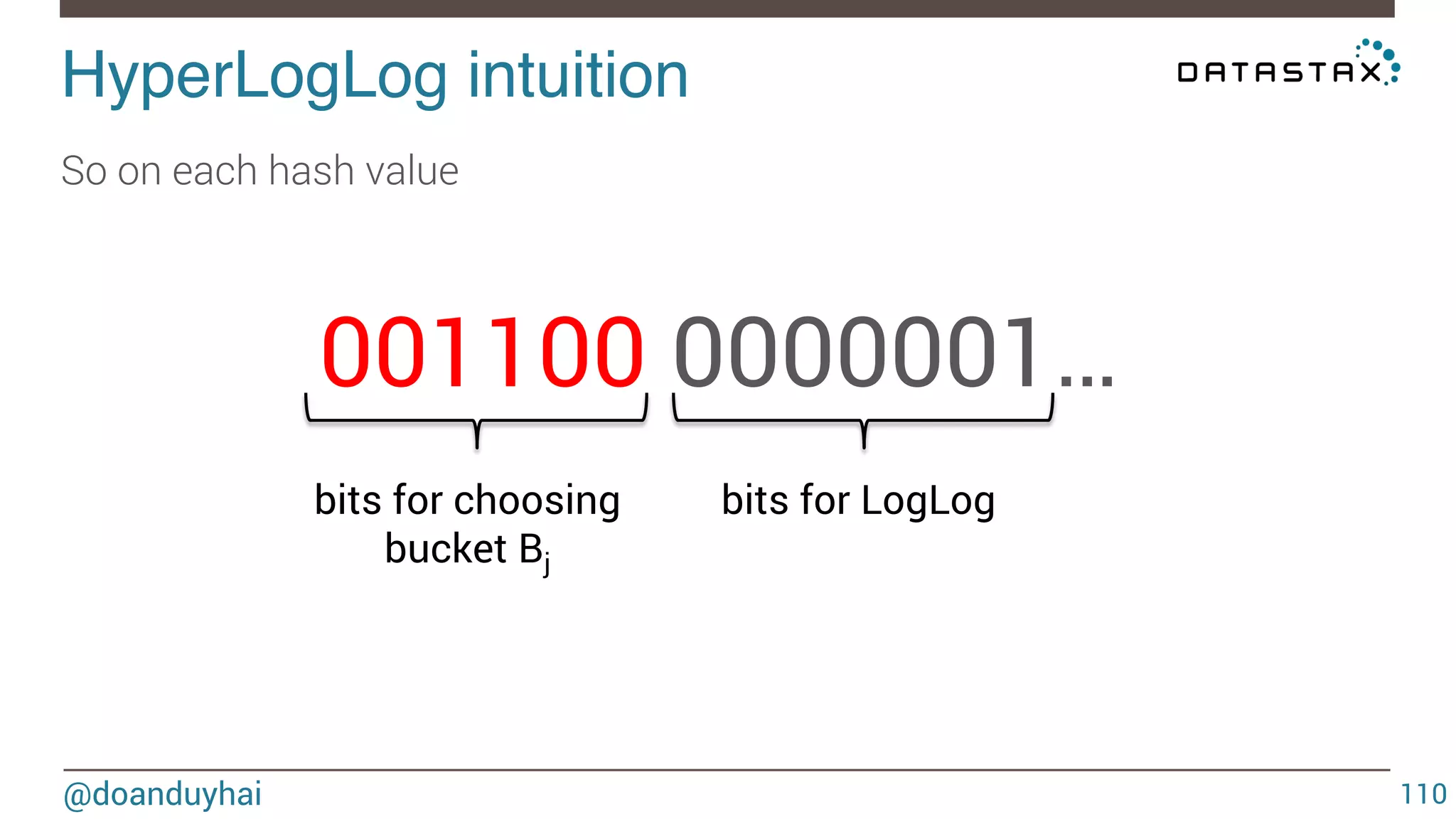
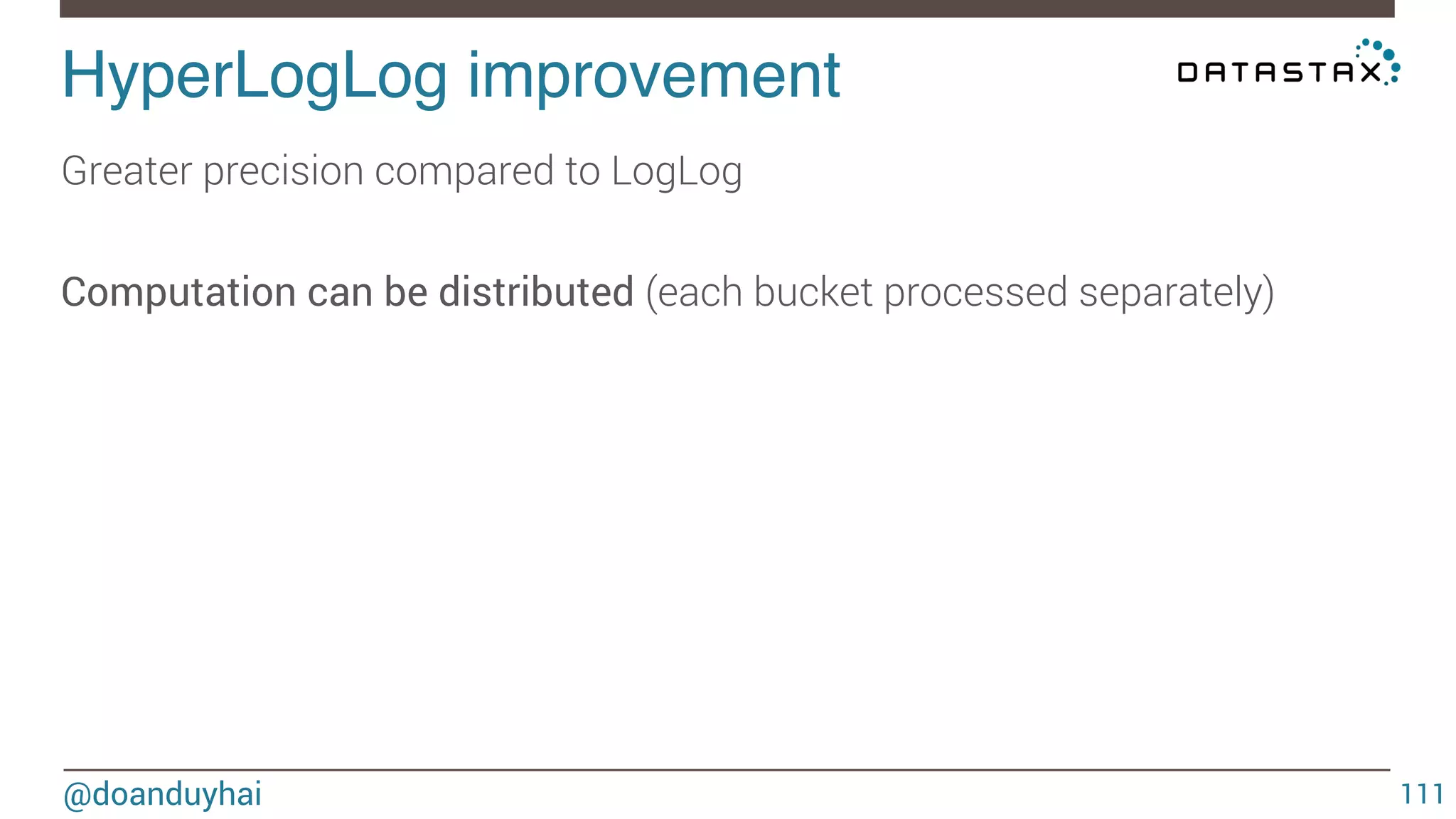

![HyperLogLog formal definition! @doanduyhai 113 Let h : D → [0, 1] ≡ {0, 1}∞ hash data from domain D to the binary domain. Let ρ(s), for s ∈ {0, 1}∞ , be the position of the leftmost 1-bit. (ρ(0001 · · · ) = 4) It is the rank of the 0000..1 observed sequence Let m = 2b with b∈Z>0 m = number of buckets Let M : multiset of items from domain D M is the set of elements to estimate cardinality](https://image.slidesharecdn.com/cassandradatastructuresandalgorithms-140925165501-phpapp02/75/Cassandra-data-structures-and-algorithms-113-2048.jpg)



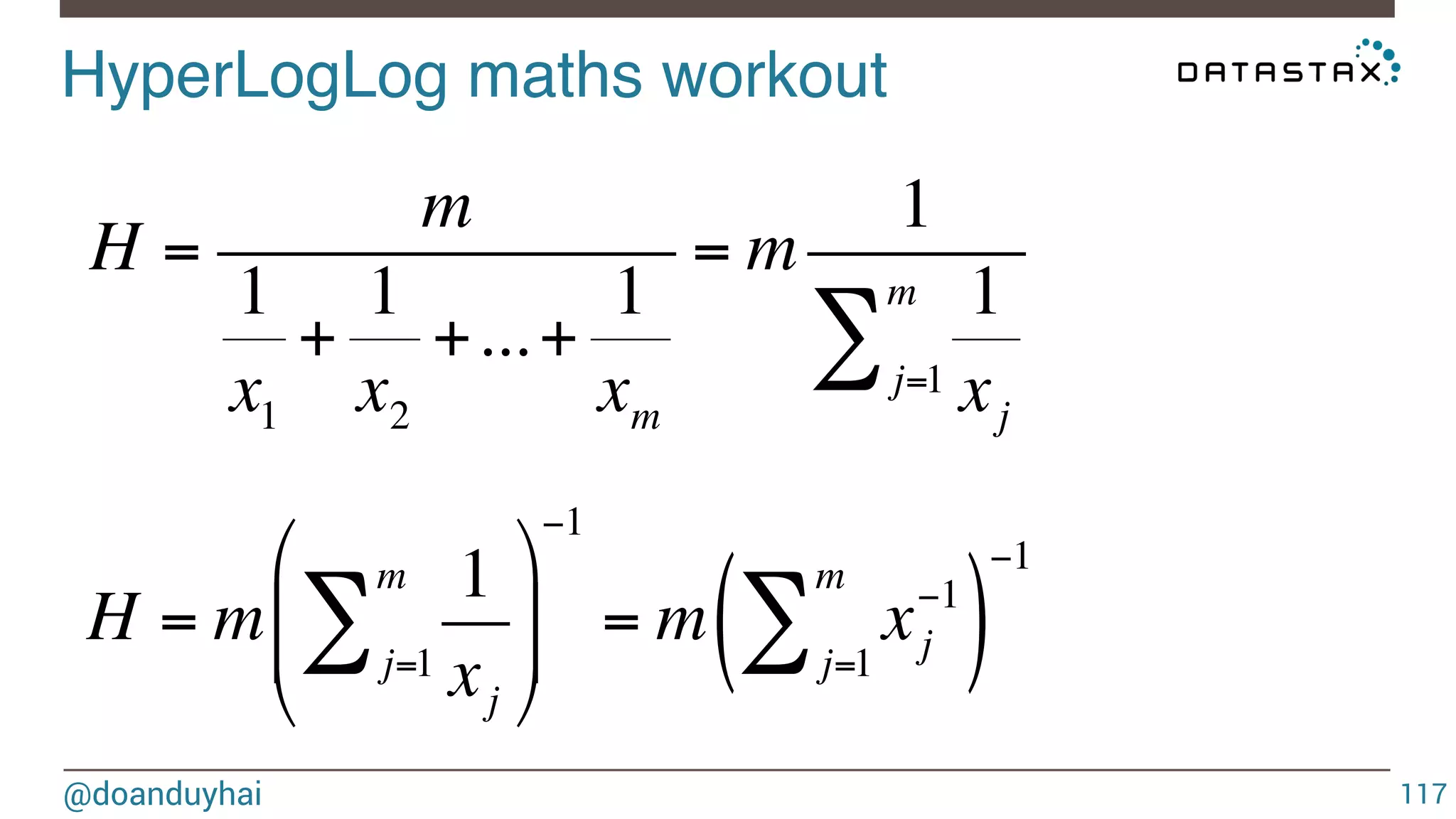





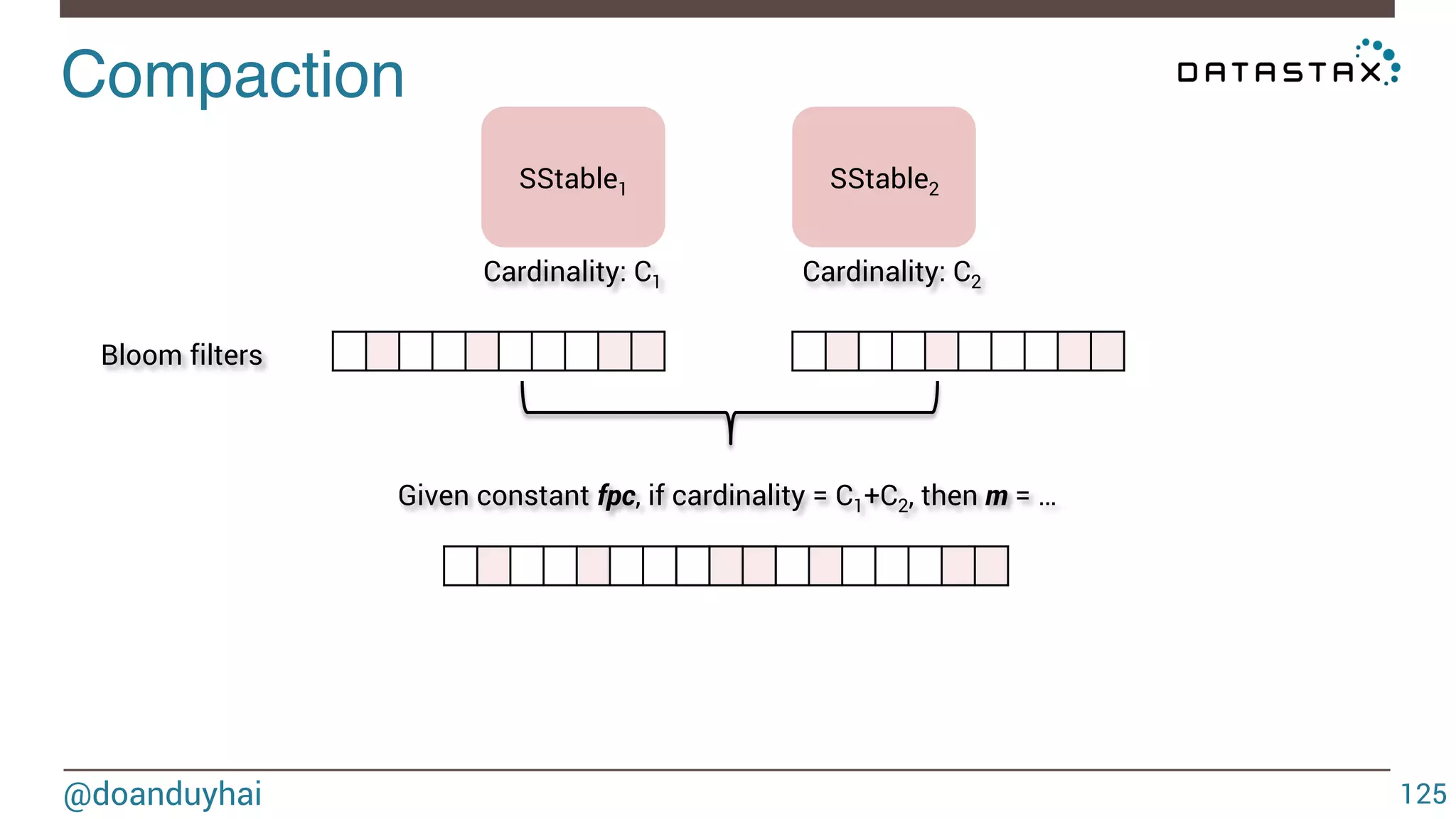



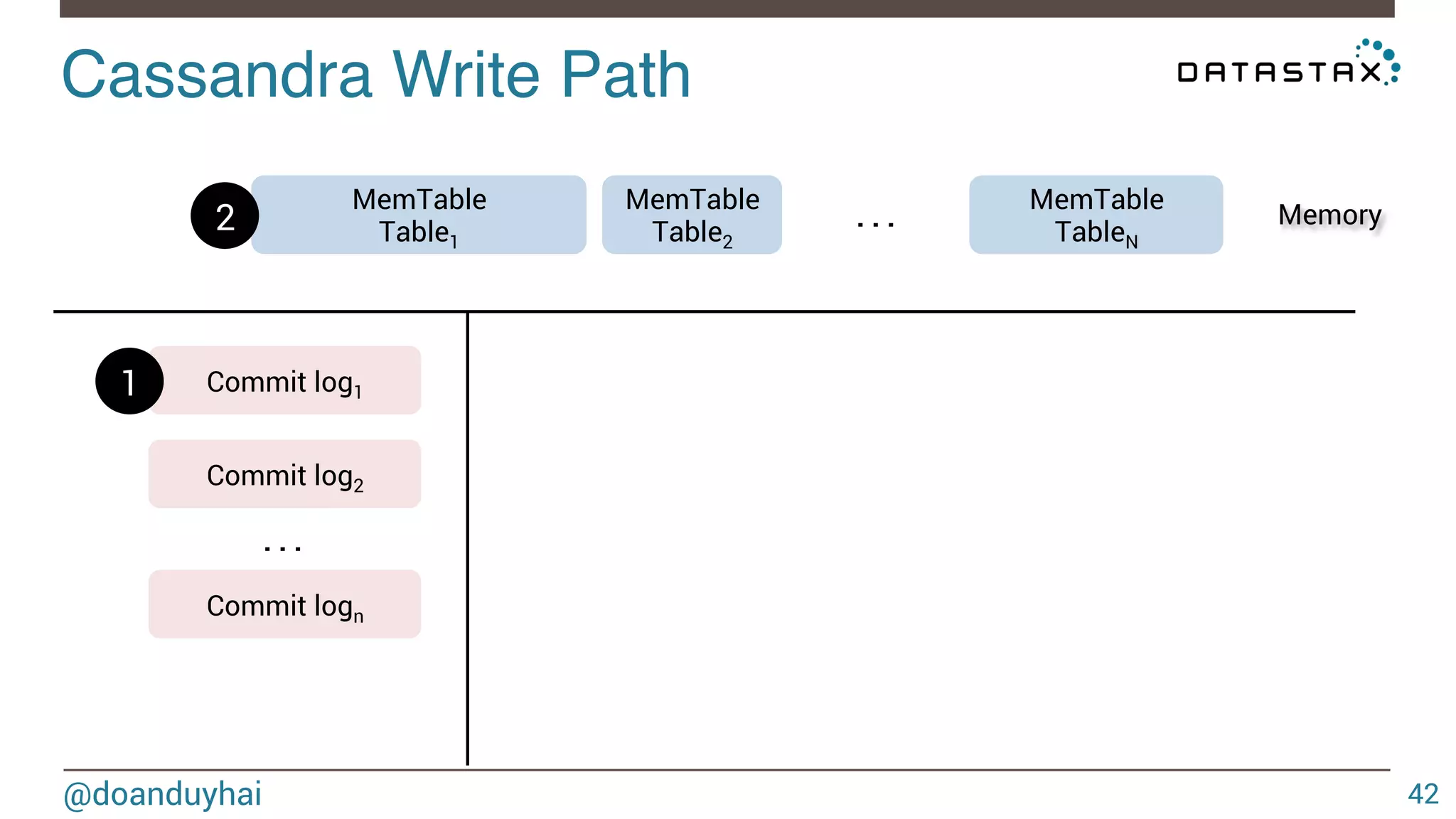
This document discusses Cassandra data structures and algorithms. It begins with an introduction and agenda, then covers Cassandra's use of CRDTs, bloom filters, and Merkle trees for its data model. It explains how Cassandra columns can be modeled as a CRDT join semilattice and proves their eventual convergence. The document also covers Cassandra's write path, read path optimized with bloom filters, and the math behind bloom filter probabilities.