Download as KEY, PPTX


















 = { log.debug("making thriftCall for server %s", this) pool.withClient { client => f(client) } } def replica: Replica = { Replica(ShardMap.serversToShards(this), this) } }](https://image.slidesharecdn.com/phillyetepayne-100411190225-phpapp01/75/Building-Distributed-Systems-in-Scala-24-2048.jpg)
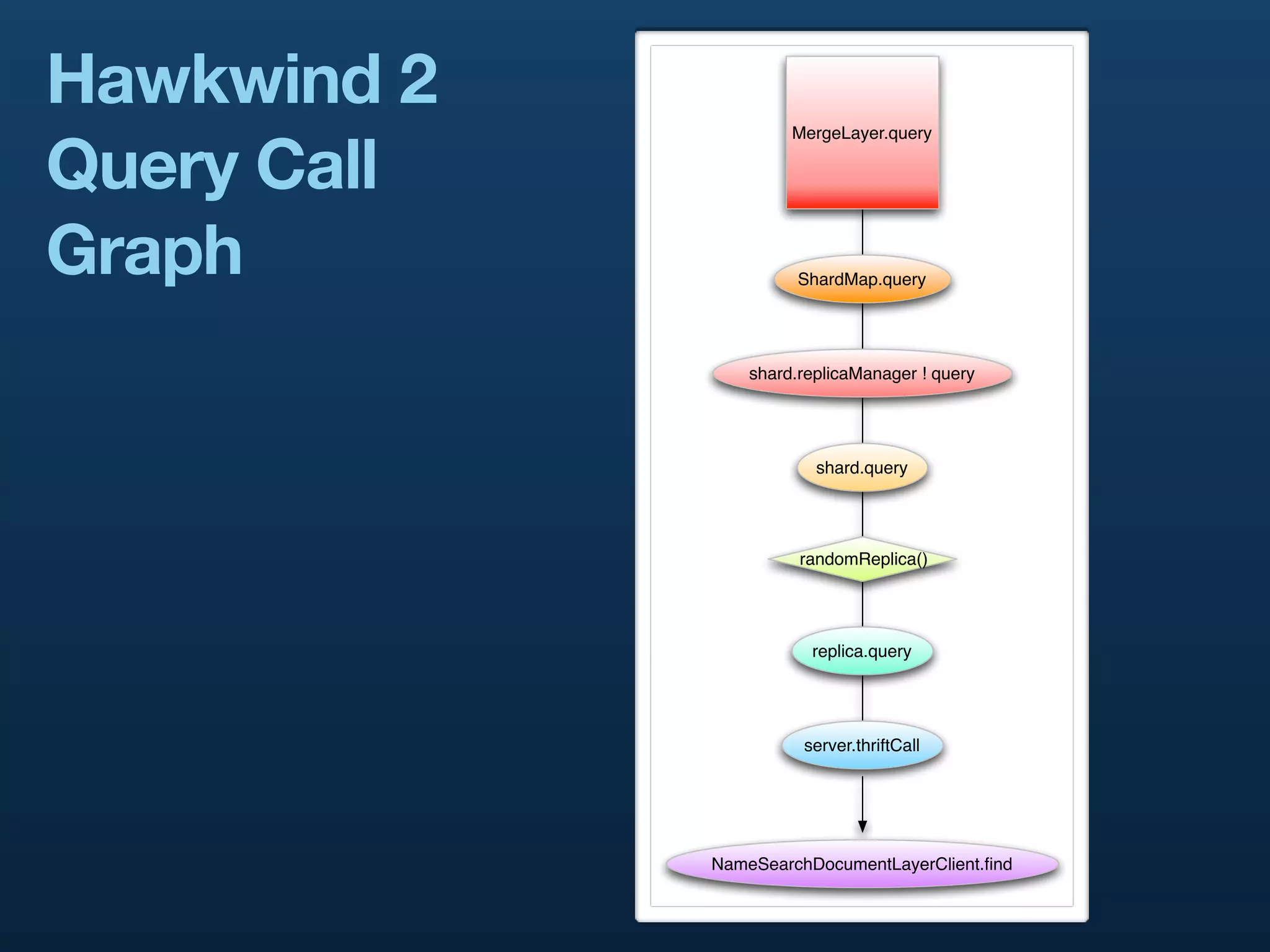











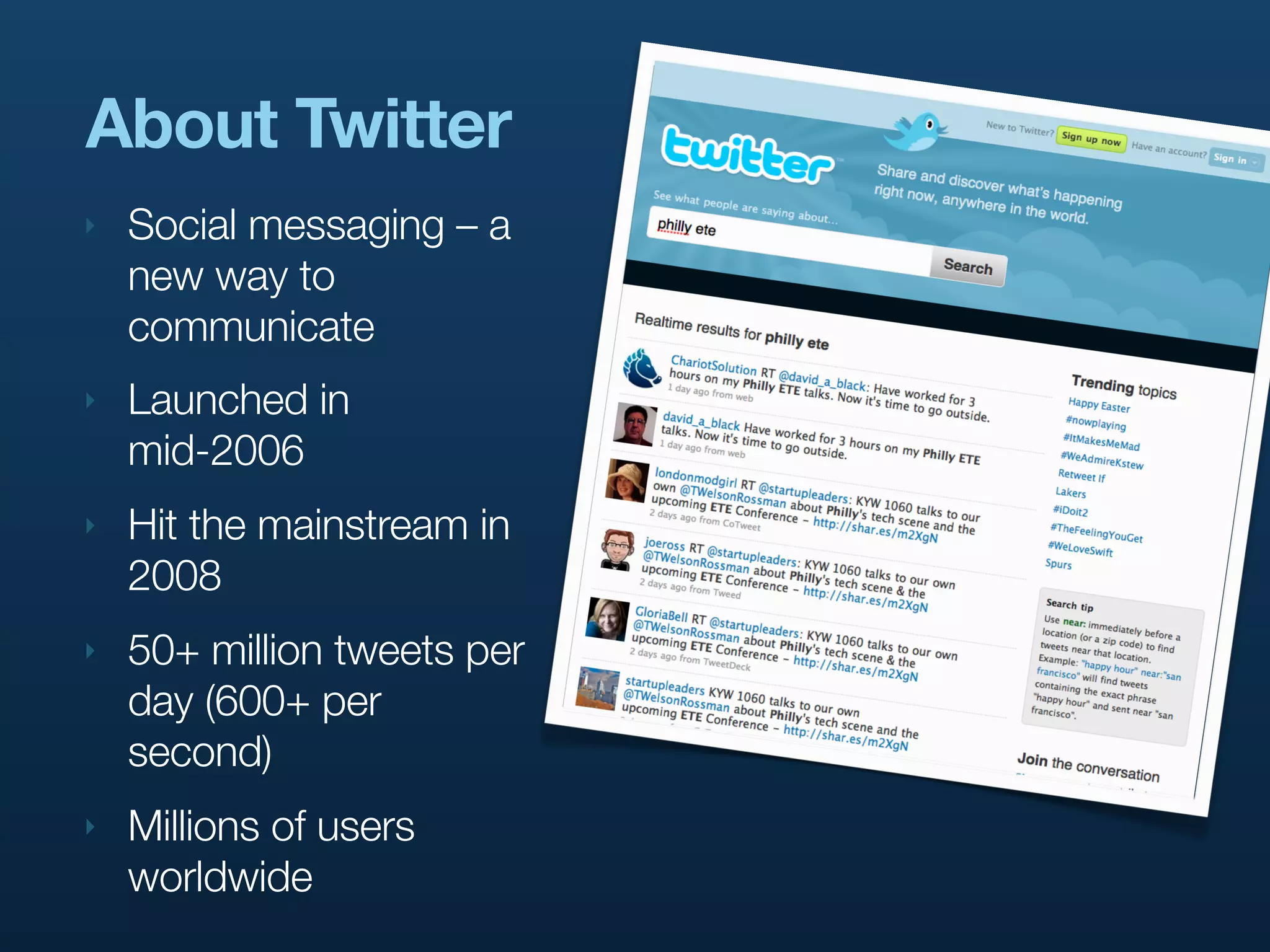
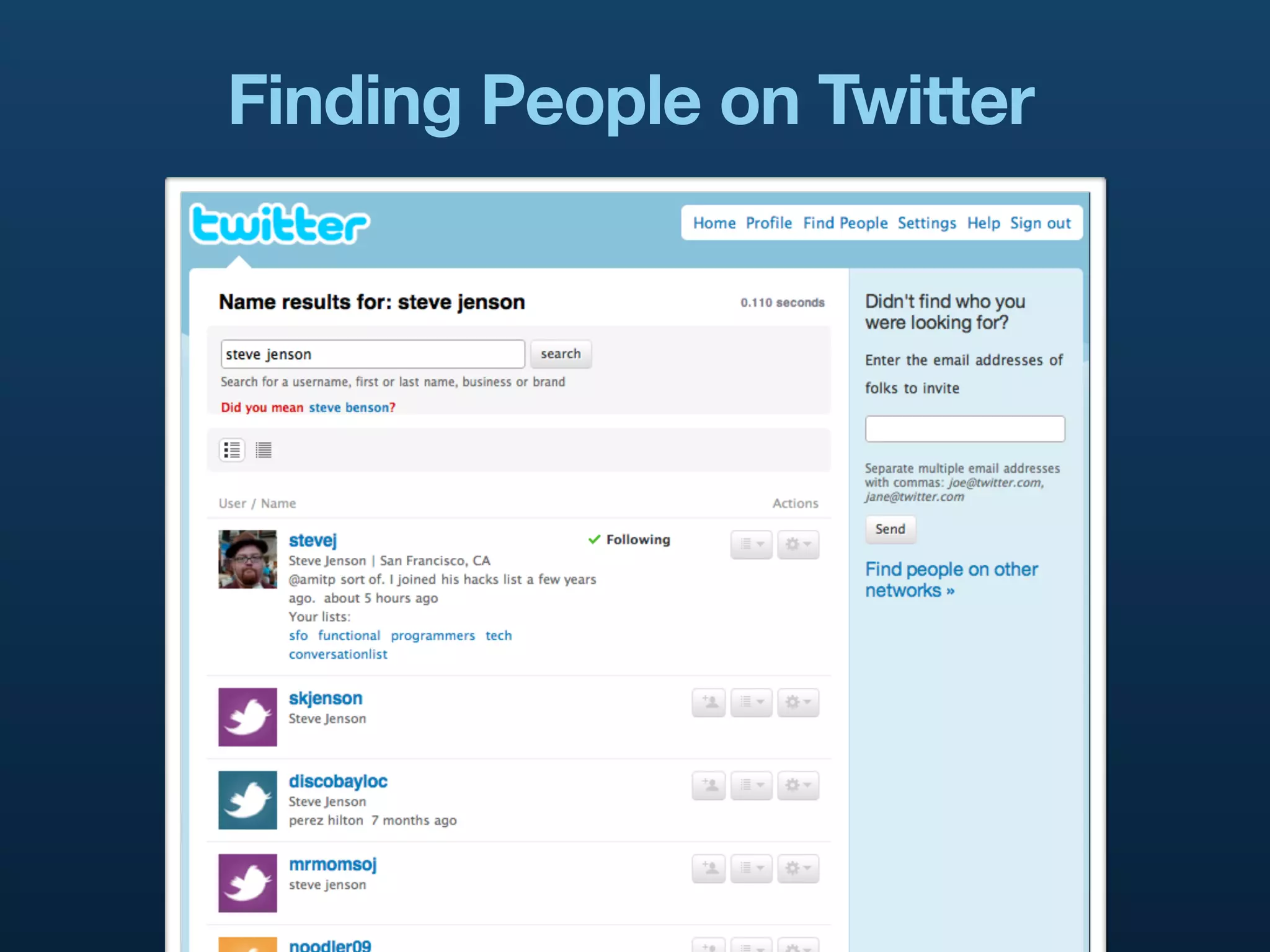
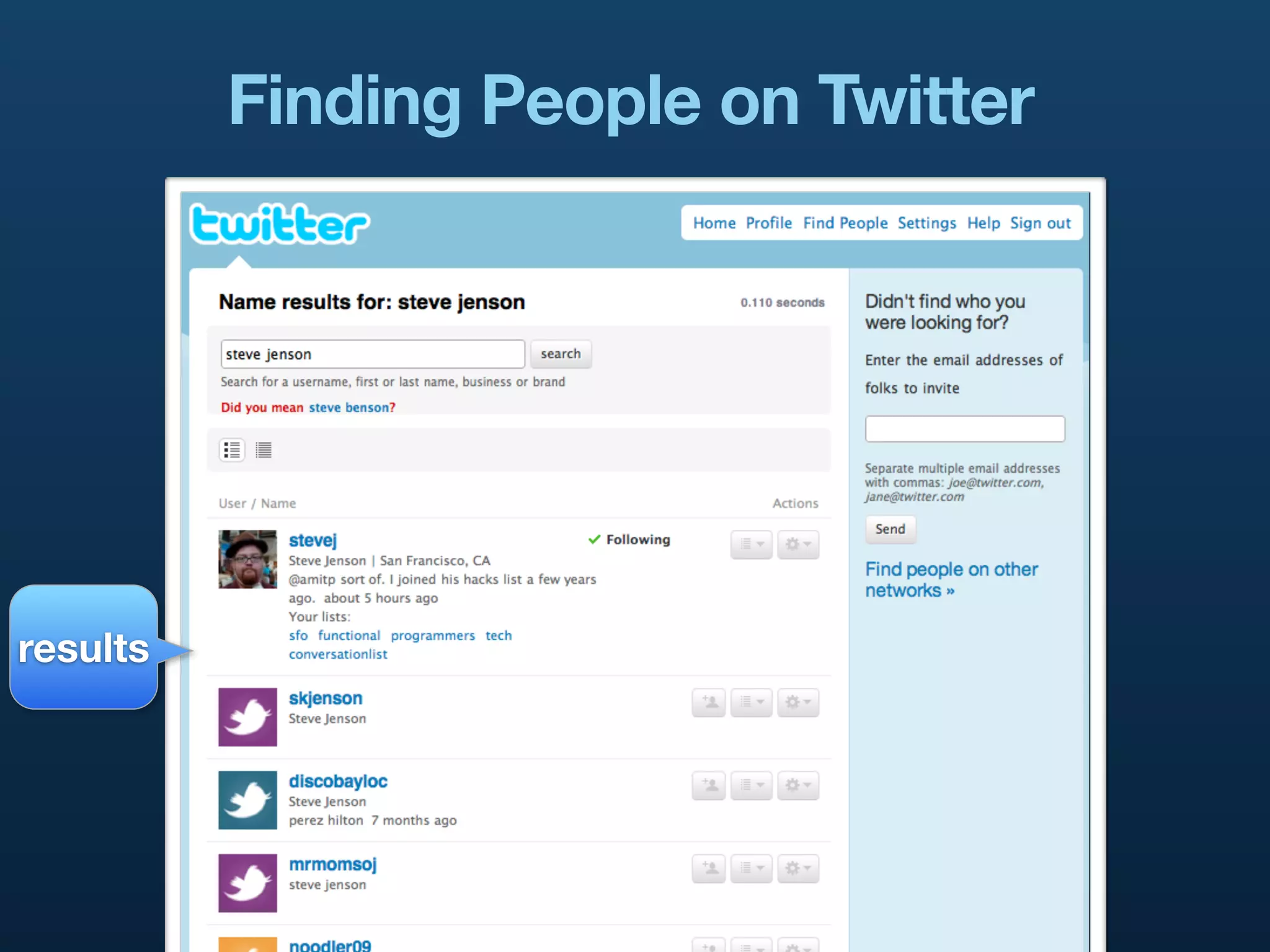
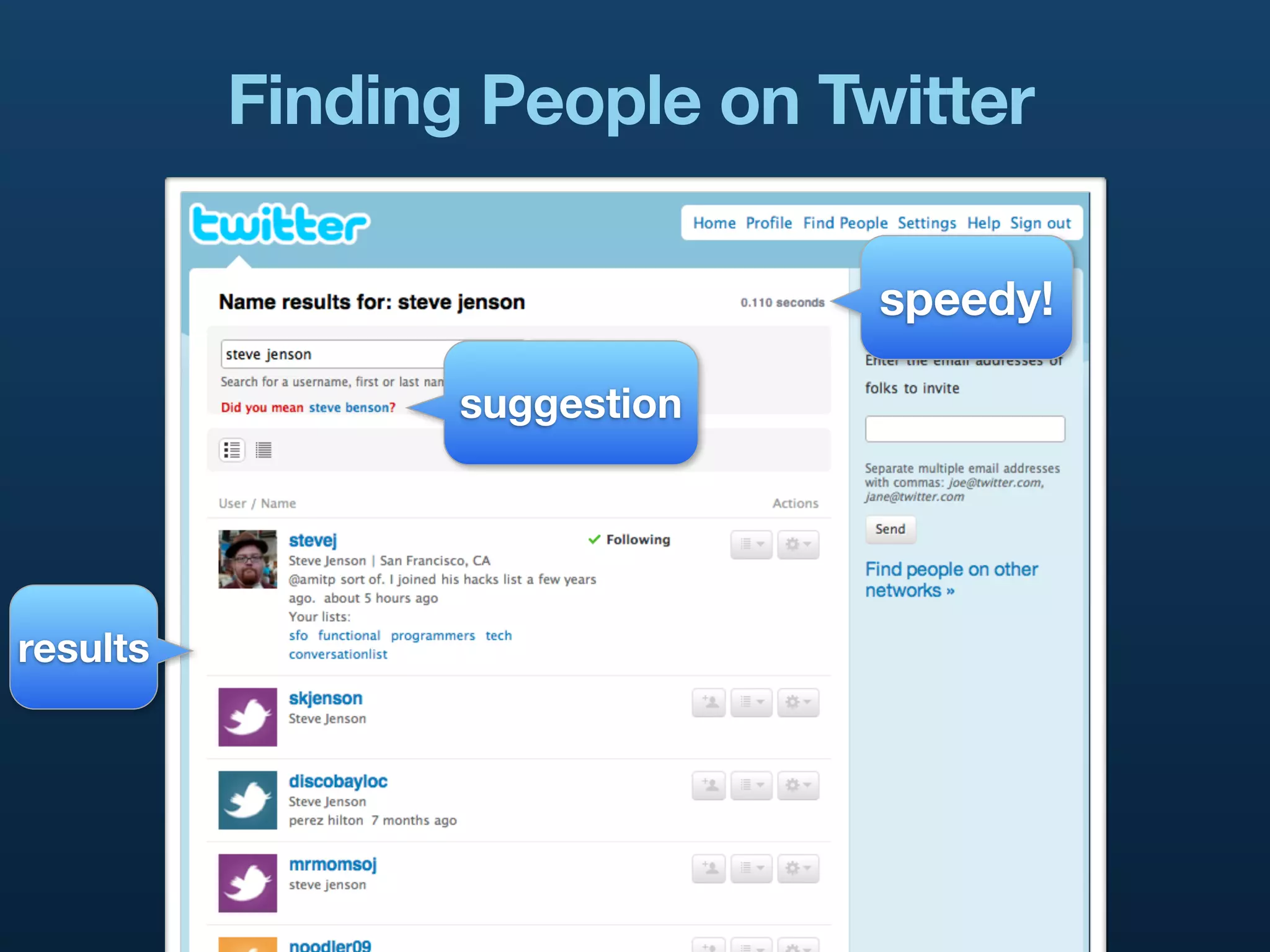
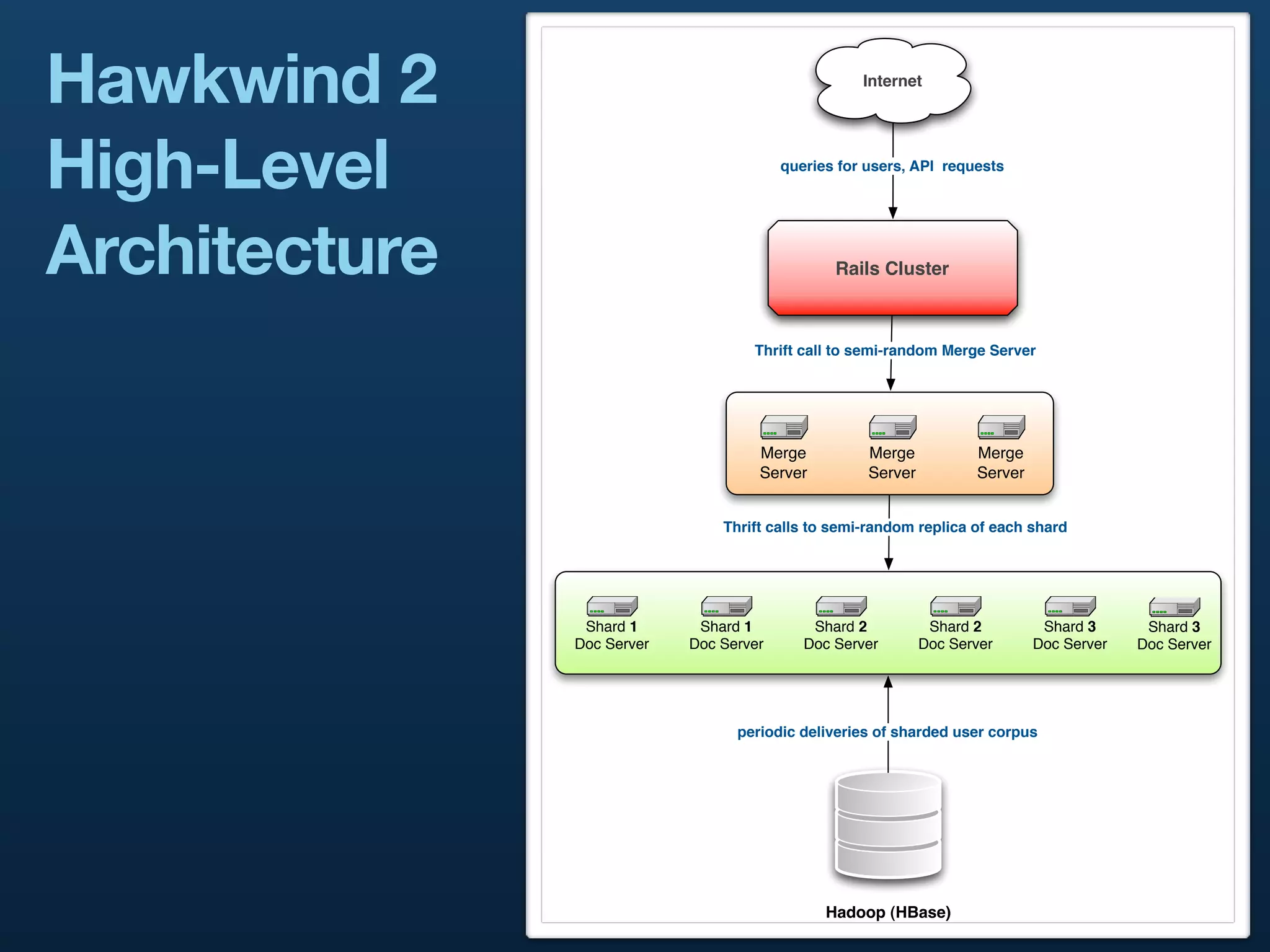
The document presents a case study on building distributed systems in Scala, focusing on Twitter's architecture and the implementation of their user search system through a project called Hawkwind. It outlines the technical challenges and solutions, showcasing how they transitioned from a Rails app to a service-oriented architecture using Scala, Thrift, and various data storage technologies. The discussion includes high-level concepts of scalability, query handling, and the importance of a well-structured codebase for maintaining and growing their services.