Downloaded 35 times





![from pystreamliner.api import Extractor class CustomExtractor(Extractor): def initialize(self, streaming_context, sql_context, config, interval, logger): logger.info("Initialized Extractor") def next(self, streaming_context, time, sql_context, config, interval, logger): rdd = streaming_context._sc.parallelize([[x] for x in range(10)]) return sql_context.createDataFrame(rdd, ["number"])](https://image.slidesharecdn.com/streamlinertalkmar16-160311231807/75/Building-a-Real-Time-Data-Pipeline-with-Spark-Kafka-and-Python-12-2048.jpg)
![> memsql-ops pip install [package] distributed cluster-wide any Python package bring your own](https://image.slidesharecdn.com/streamlinertalkmar16-160311231807/75/Building-a-Real-Time-Data-Pipeline-with-Spark-Kafka-and-Python-15-2048.jpg)


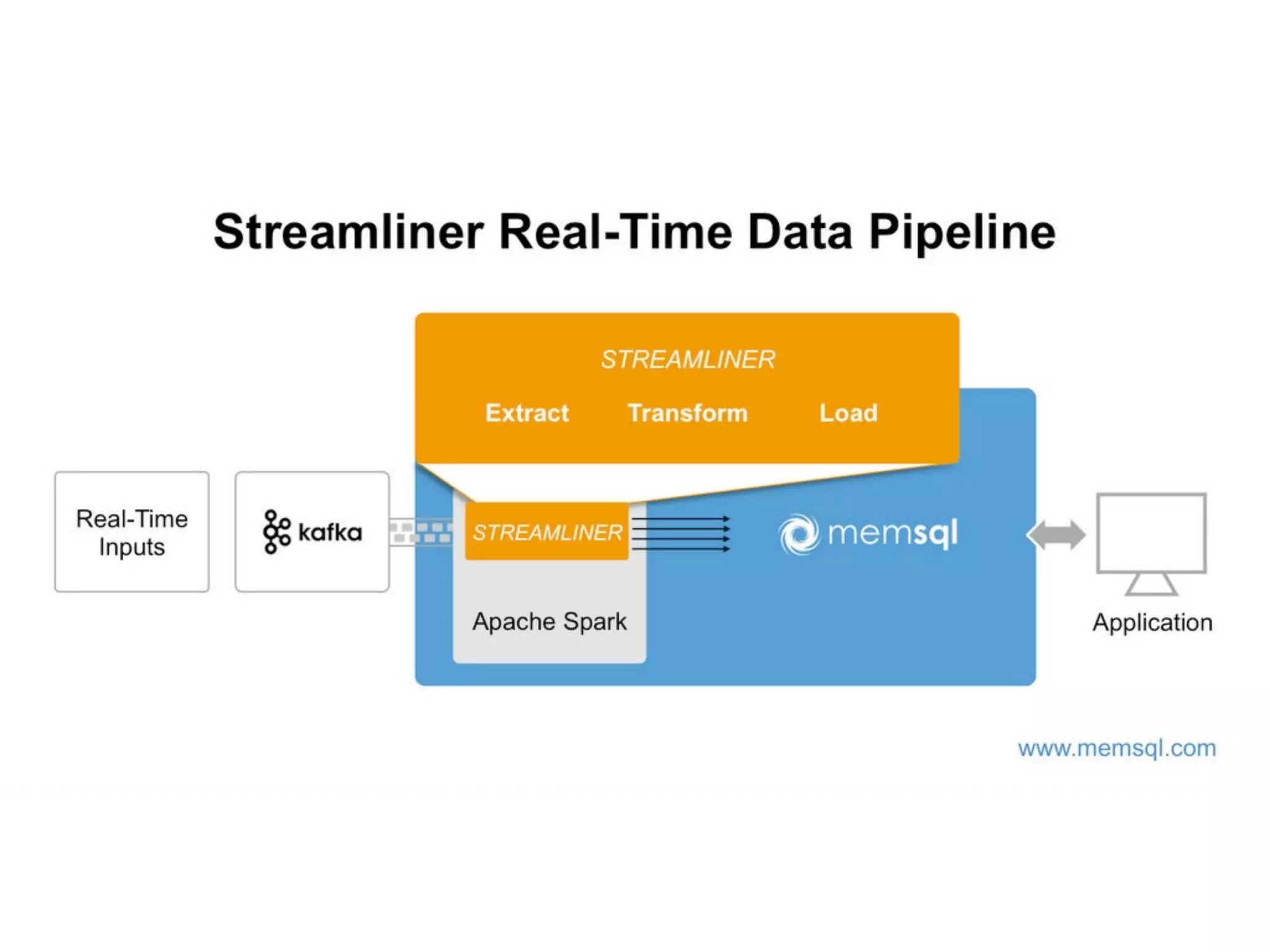
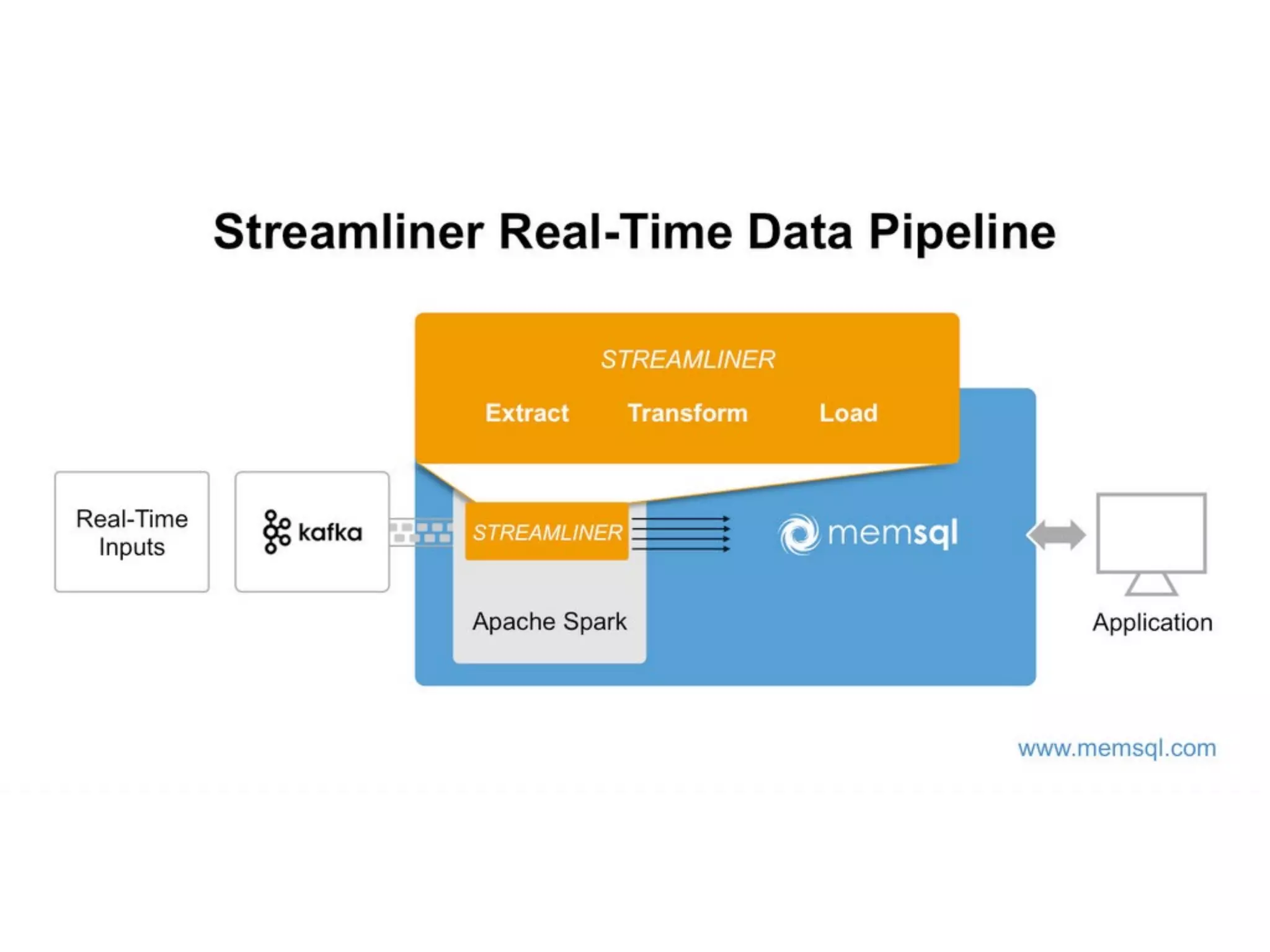
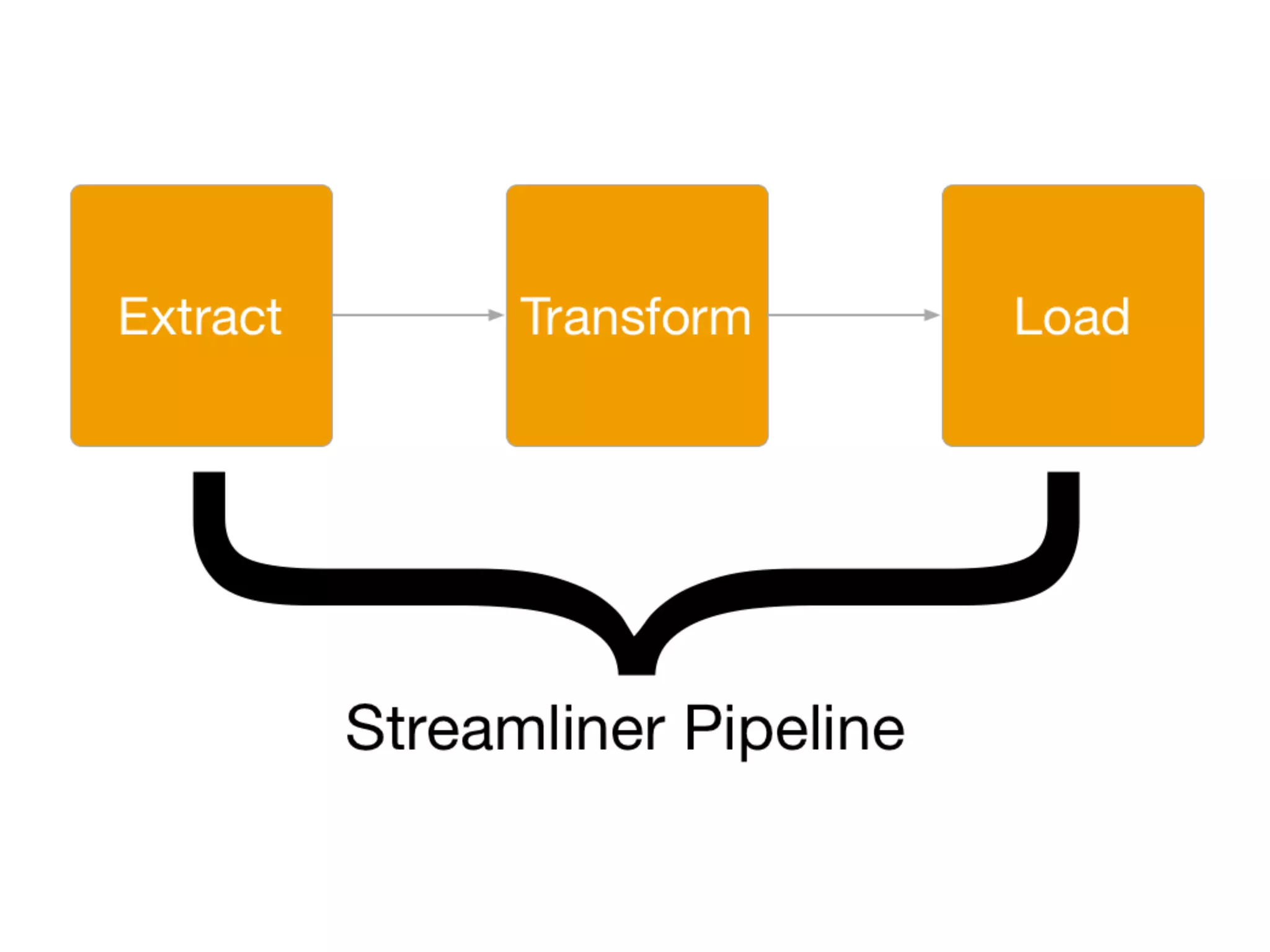
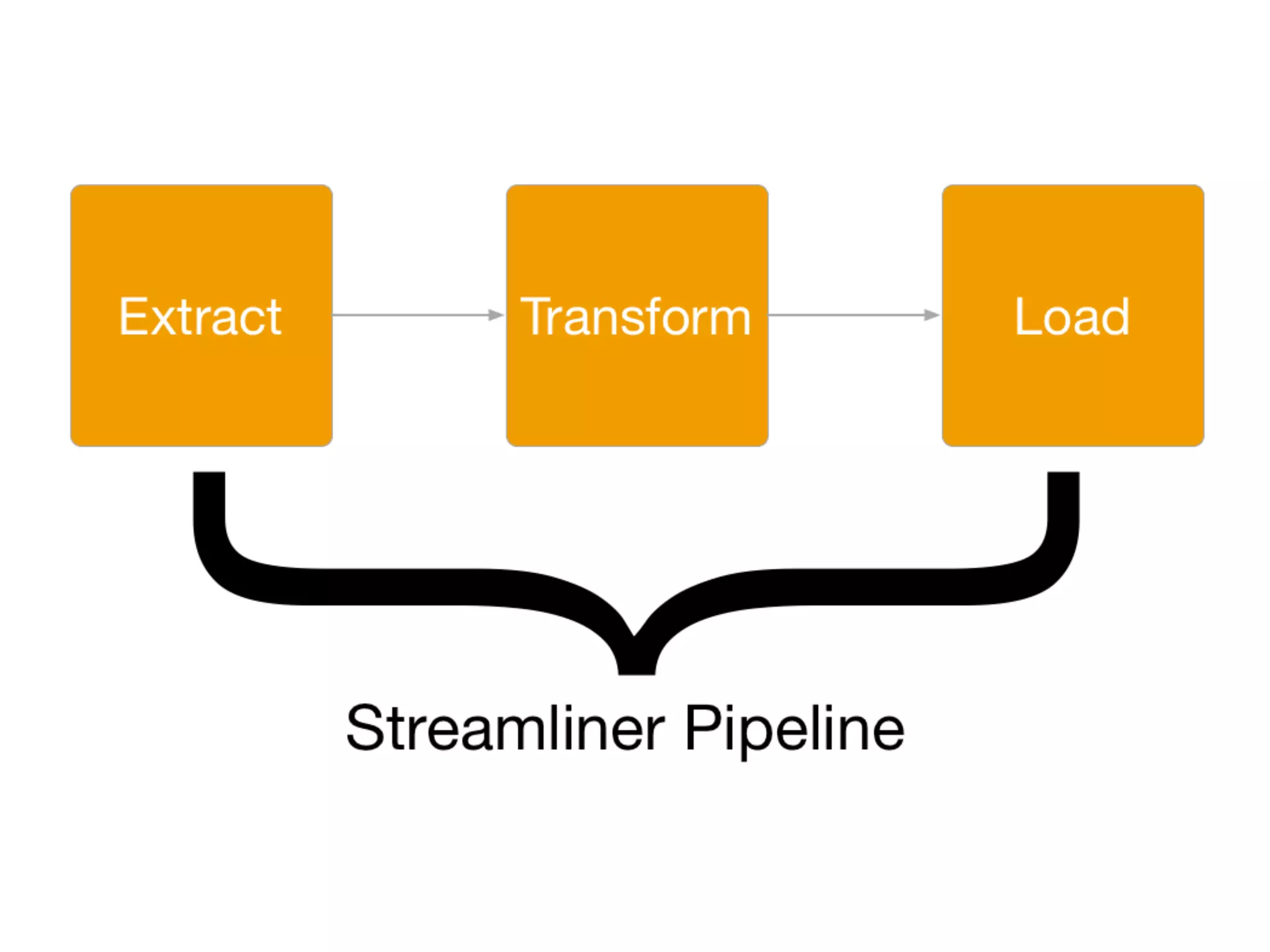
Douglas Butler presented on Massively parallel, lock free, distributed SQL database that is in-memory and on-disk with ACID transactions and support for JSON and geospatial data. The database has a 2 minute install and supports building real-time data pipelines in Python by extracting data from any source using a simple API and custom extractors.