Download as PDF, PPTX









![Spark + XGBoost on Ray import ray import raydp ray.init(address='auto') spark = raydp.init_spark('Spark + XGBoost', num_executors=2, executor_cores=4, executor_memory='8G') df = spark.read.csv(...) ... train_df, test_df = random_split(df, [0.9, 0.1]) train_dataset = RayMLDataset.from_spark(train_df, ...) test_dataset = RayMLDataset.from_spark(test_df, ...) from xgboost_ray import RayDMatrix, train, RayParams dtrain = RayDMatrix(train_dataset, label='fare_amount') dtest = RayDMatrix(test_dataset, label='fare_amount’) … bst = train( config, dtrain, evals=[(dtest, "eval")], evals_result=evals_result, ray_params=RayParams(…) num_boost_round=10) Data Preprocessing Model Training End-to-End Integrated Python Program RayD P RayD P](https://image.slidesharecdn.com/176wangliu-210608234541/75/Build-Large-Scale-Data-Analytics-and-AI-Pipeline-Using-RayDP-20-2048.jpg)
![Spark + Horovod on Ray import ray import raydp ray.init(address='auto') spark = raydp.init_spark('Spark + Horovod', num_executors=2, executor_cores=4, executor_memory=‘8G’) df = spark.read.csv(...) ... torch_ds= RayMLDataset.from_spark(df, …) .to_torch(...) #PyTorch Model class My_Model(nn.Module): … #Horovod on Ray def train_fn(dataset, num_features): hvd.init() rank = hvd.rank() train_data = dataset.get_shard(rank) ... from horovod.ray import RayExecutor executor = RayExecutor(settings, num_hosts=1, num_slots=1, cpus_per_slot=1) executor.start() executor.run(train_fn, args=[torch_ds, num_features]) Data Preprocessing Model Training End-to-End Integrated Python Program RayD P RayD P](https://image.slidesharecdn.com/176wangliu-210608234541/75/Build-Large-Scale-Data-Analytics-and-AI-Pipeline-Using-RayDP-21-2048.jpg)
![Spark + Horovod + RayTune on Ray import ray import raydp ray.init(address='auto') spark = raydp.init_spark(‘Spark + Horovod', num_executors=2, executor_cores=4, executor_memory=‘8G’) df = spark.read.csv(...) ... torch_ds= RayMLDataset.from_spark(df, …) .to_torch(...) #PyTorch Model class My_Model(nn.Module): … #Horovod on Ray + Ray Tune def train_fn(config: Dict): ... trainable = DistributedTrainableCreator( train_fn, num_slots=2, use_gpu=use_gpu) analysis = tune.run( trainable, num_samples=2, config={ "epochs": tune.grid_search([1, 2, 3]), "lr": tune.grid_search([0.1, 0.2, 0.3]), } ) print(analysis.best_config) Data Preprocessing Model Training/Tuning End-to-End Integrated Python Program RayD P RayD P](https://image.slidesharecdn.com/176wangliu-210608234541/75/Build-Large-Scale-Data-Analytics-and-AI-Pipeline-Using-RayDP-22-2048.jpg)



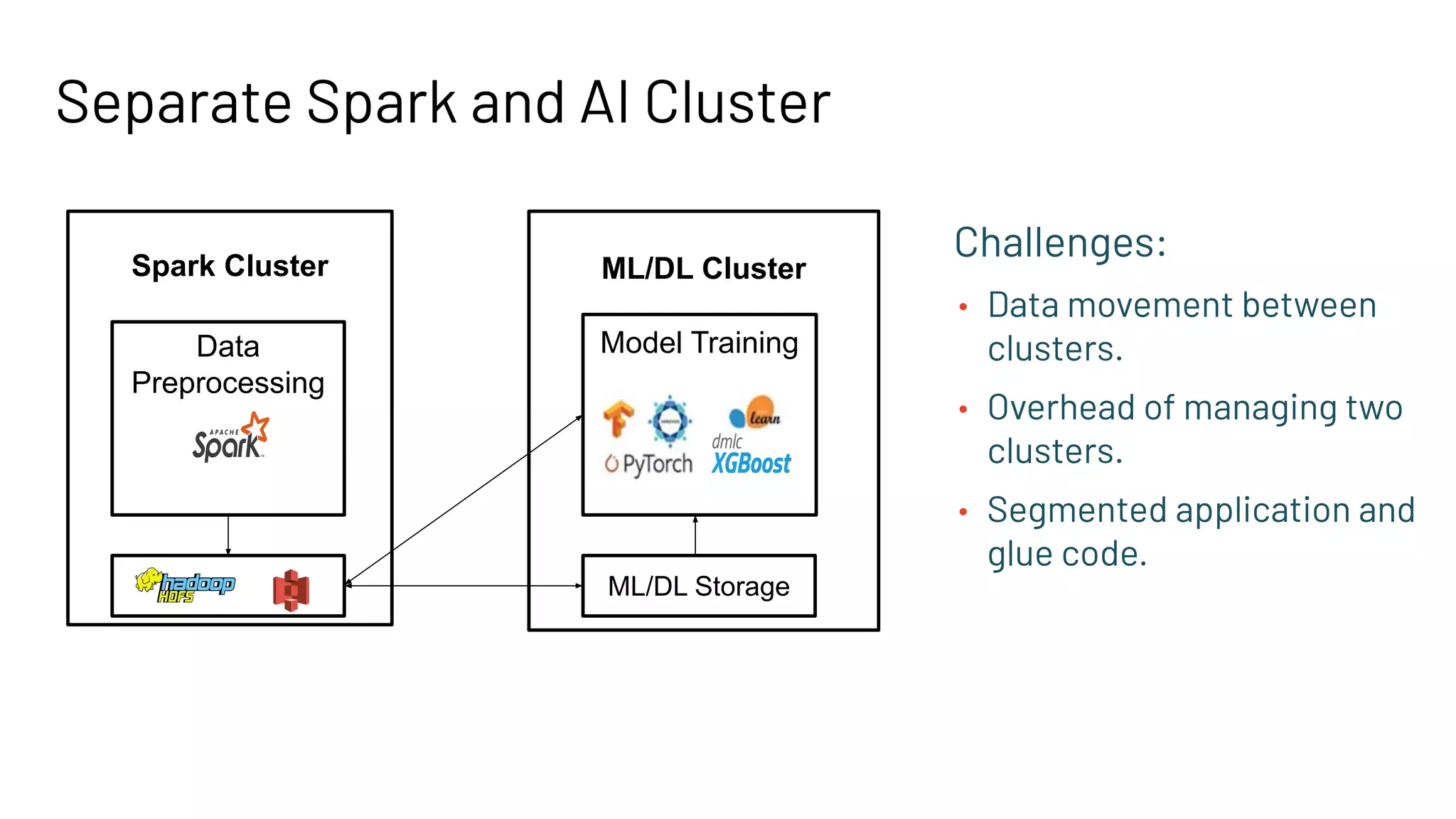
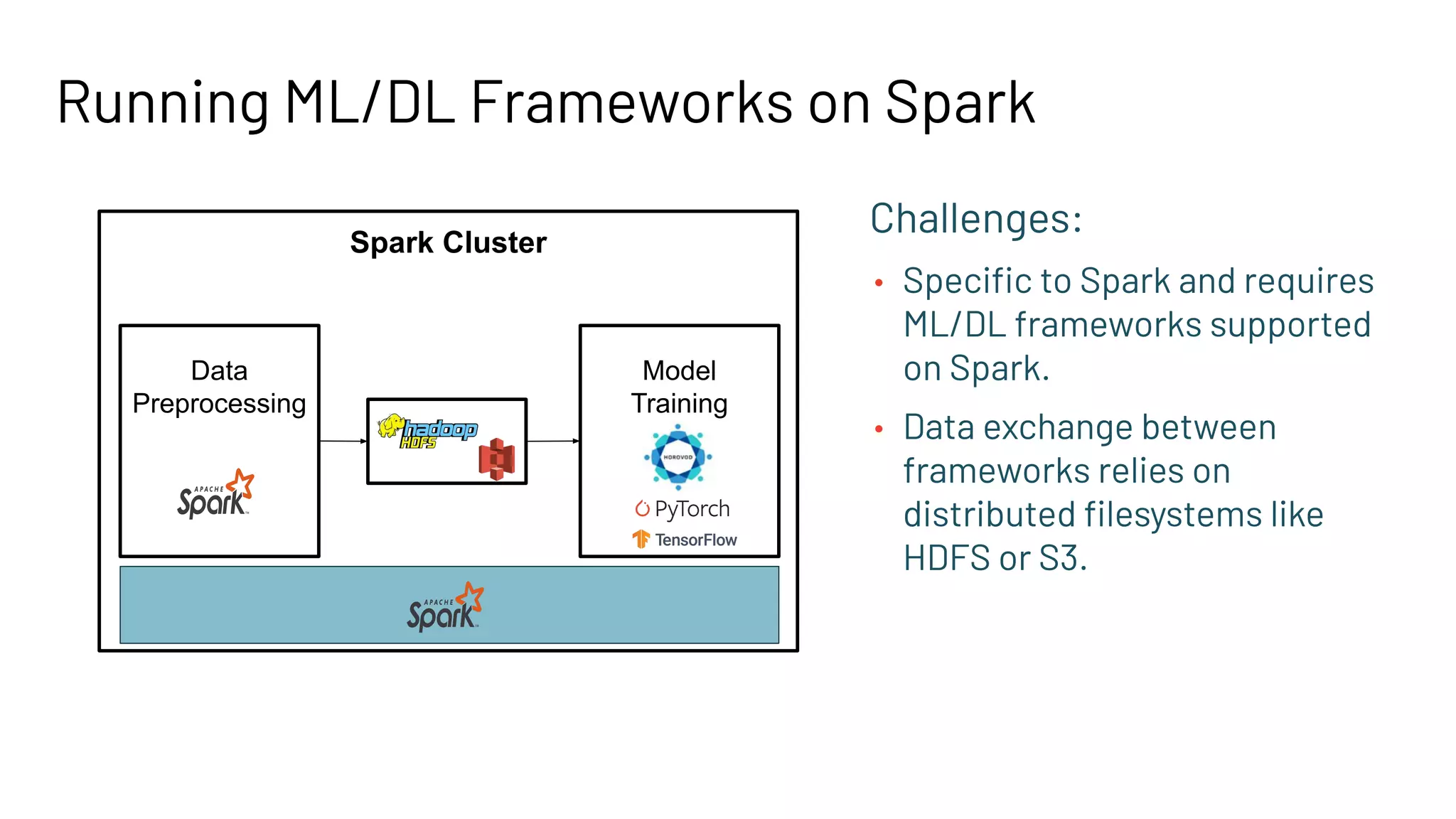
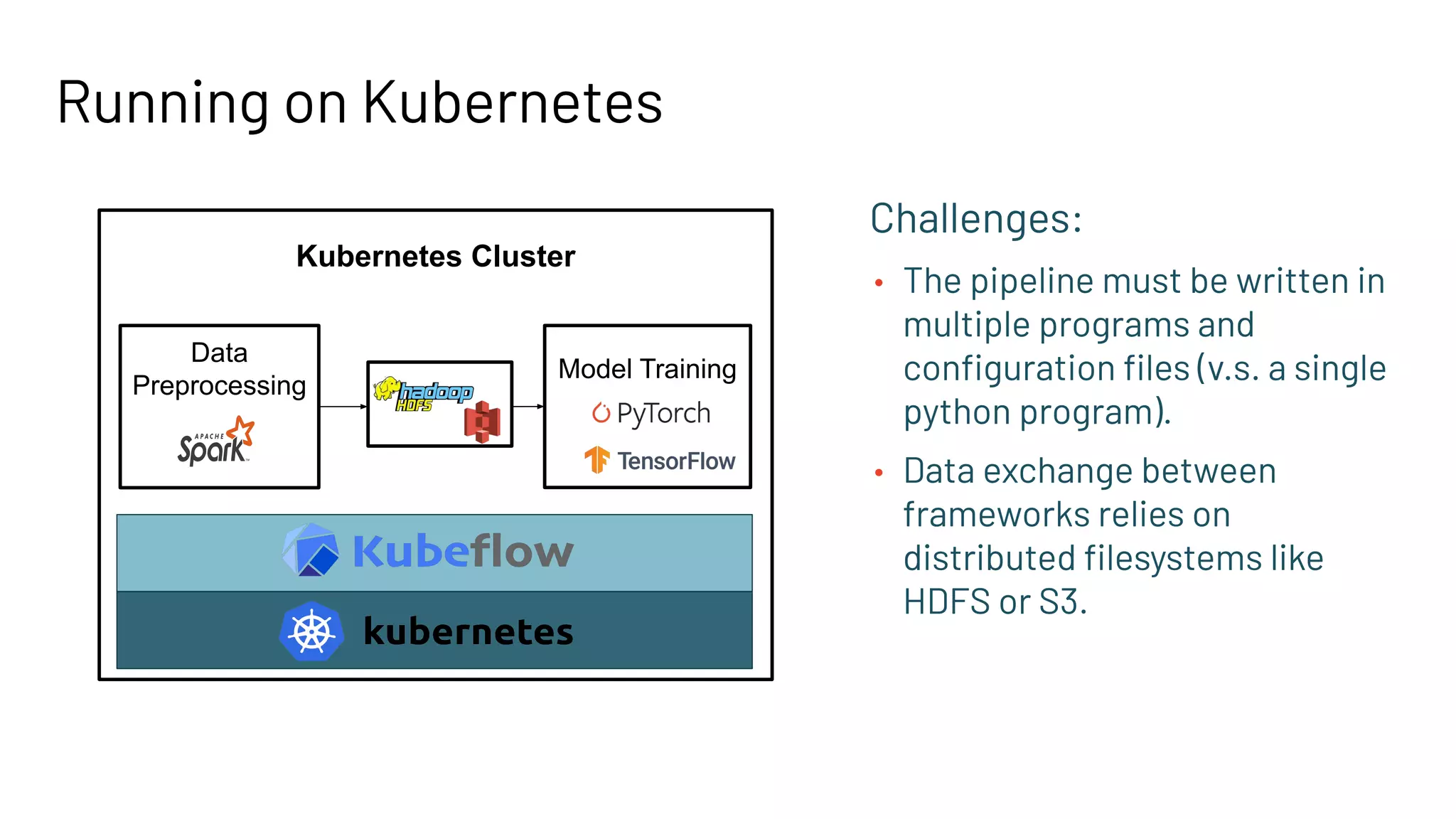
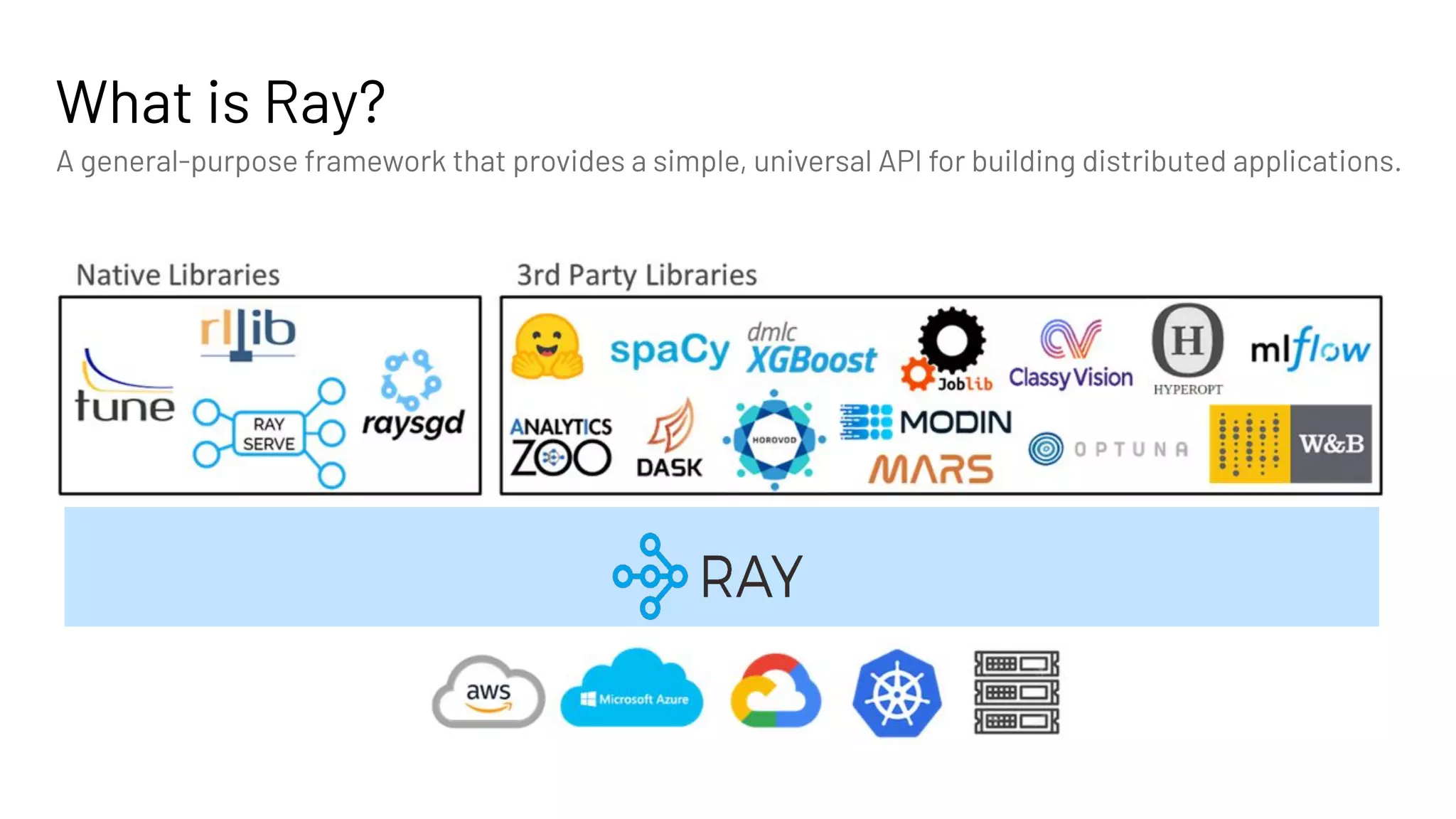
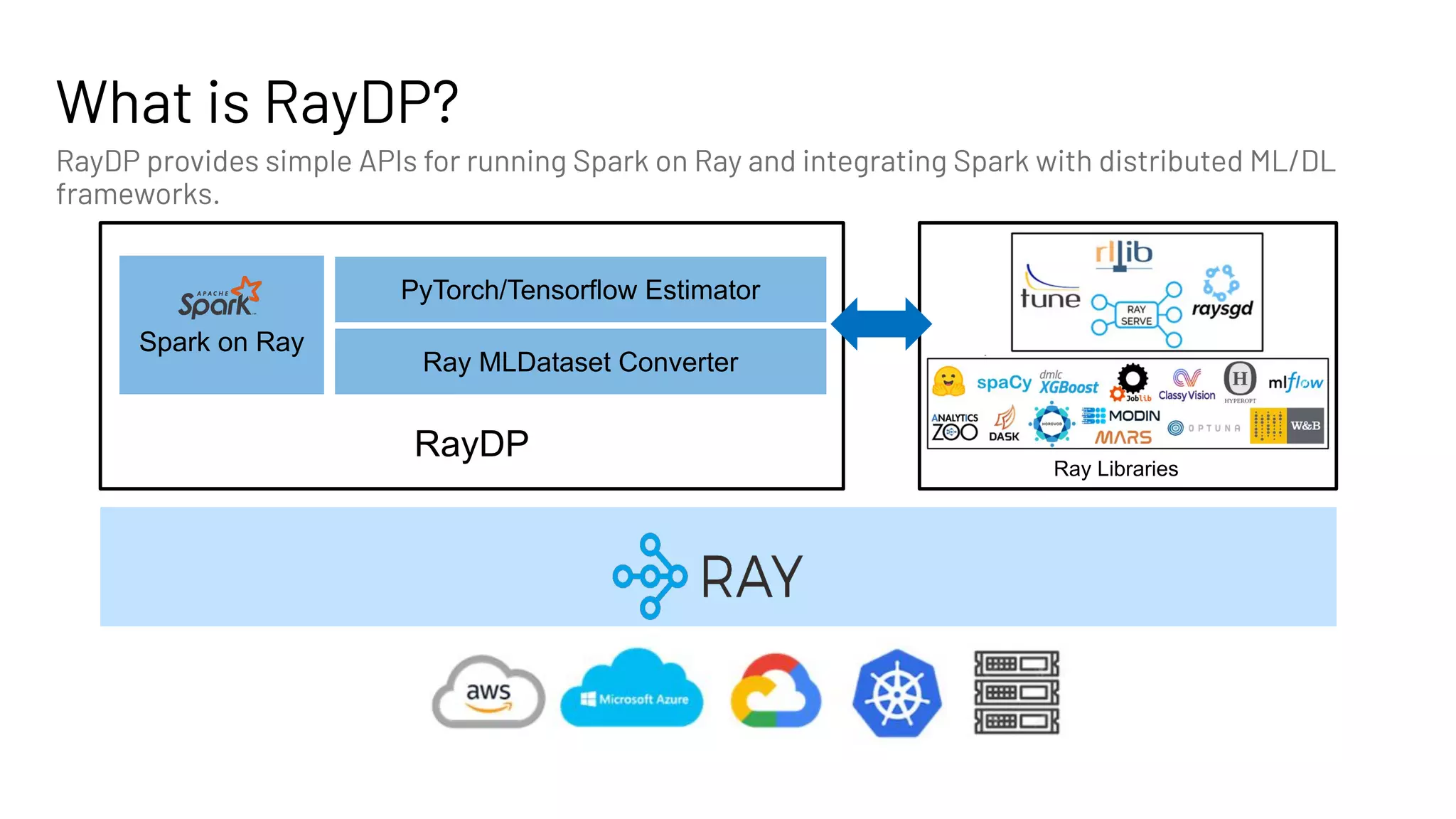
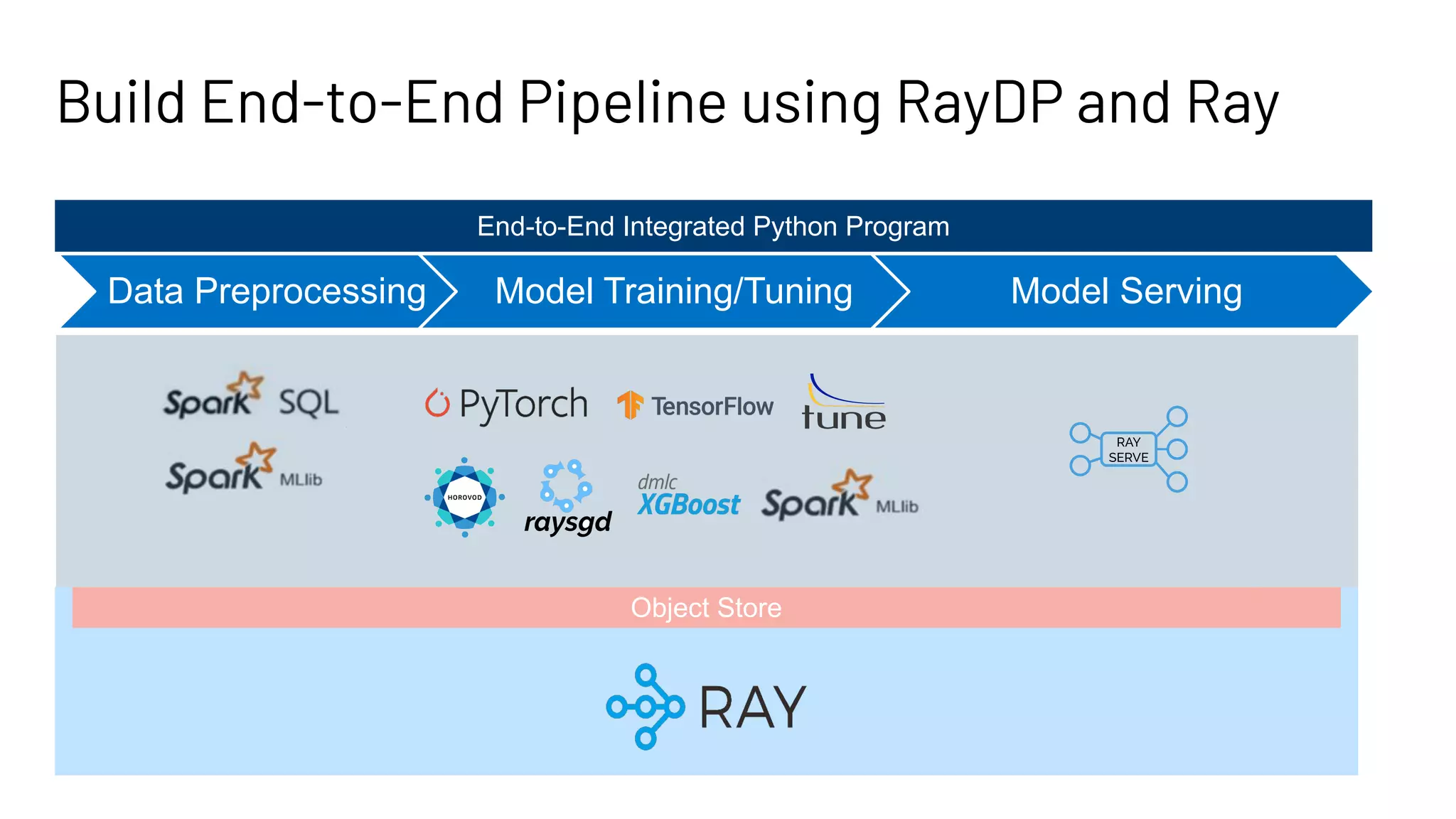
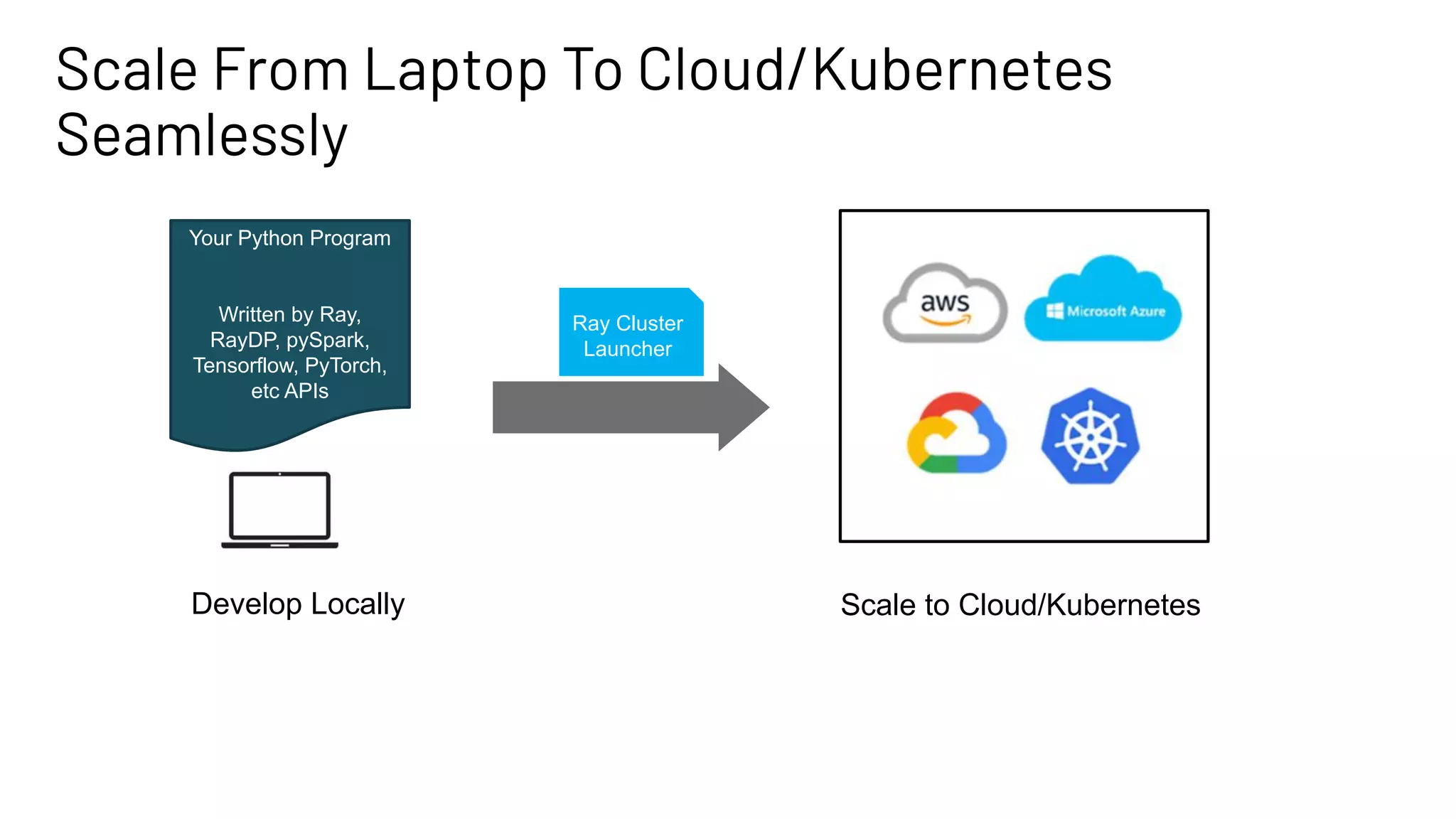
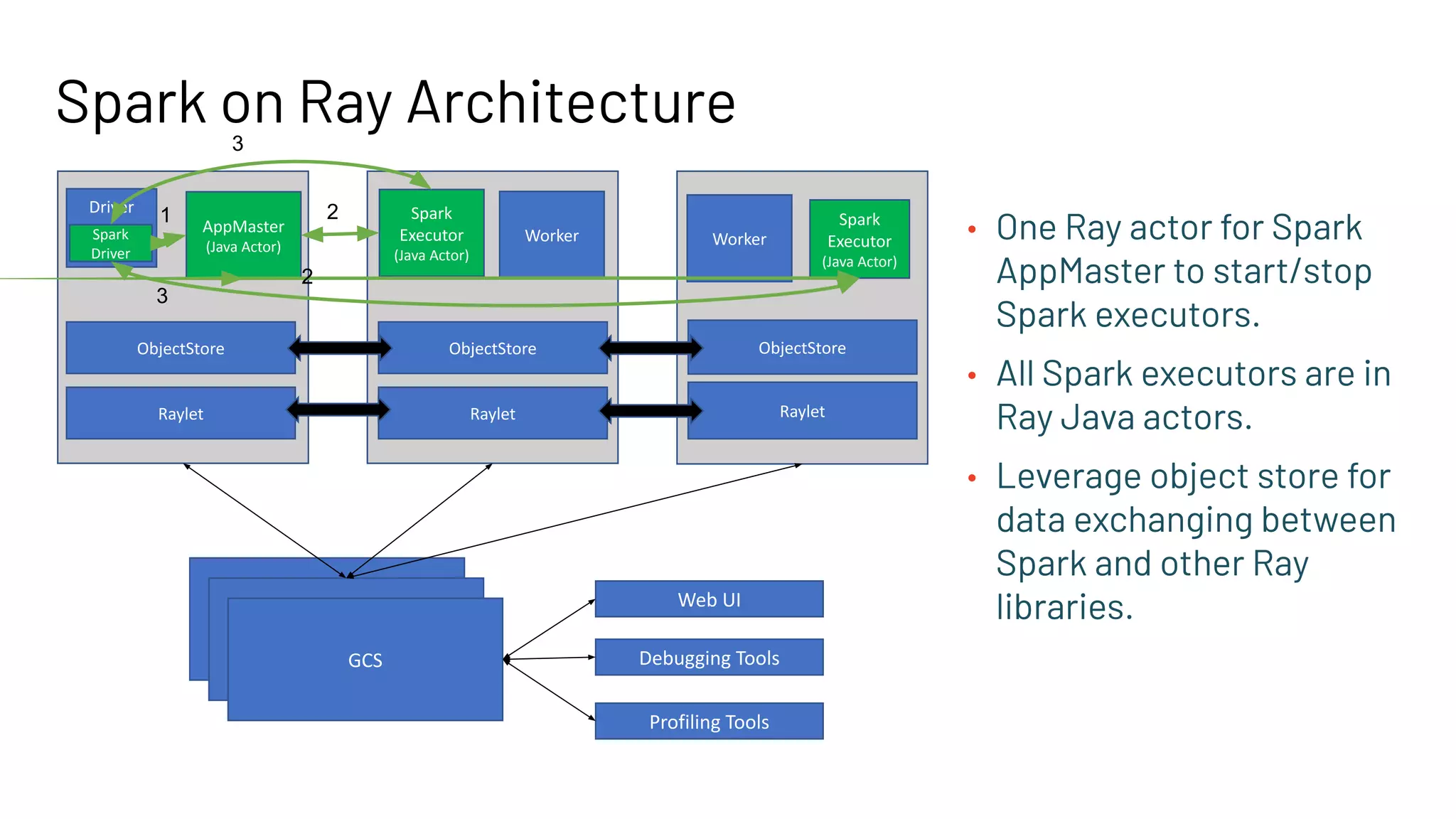
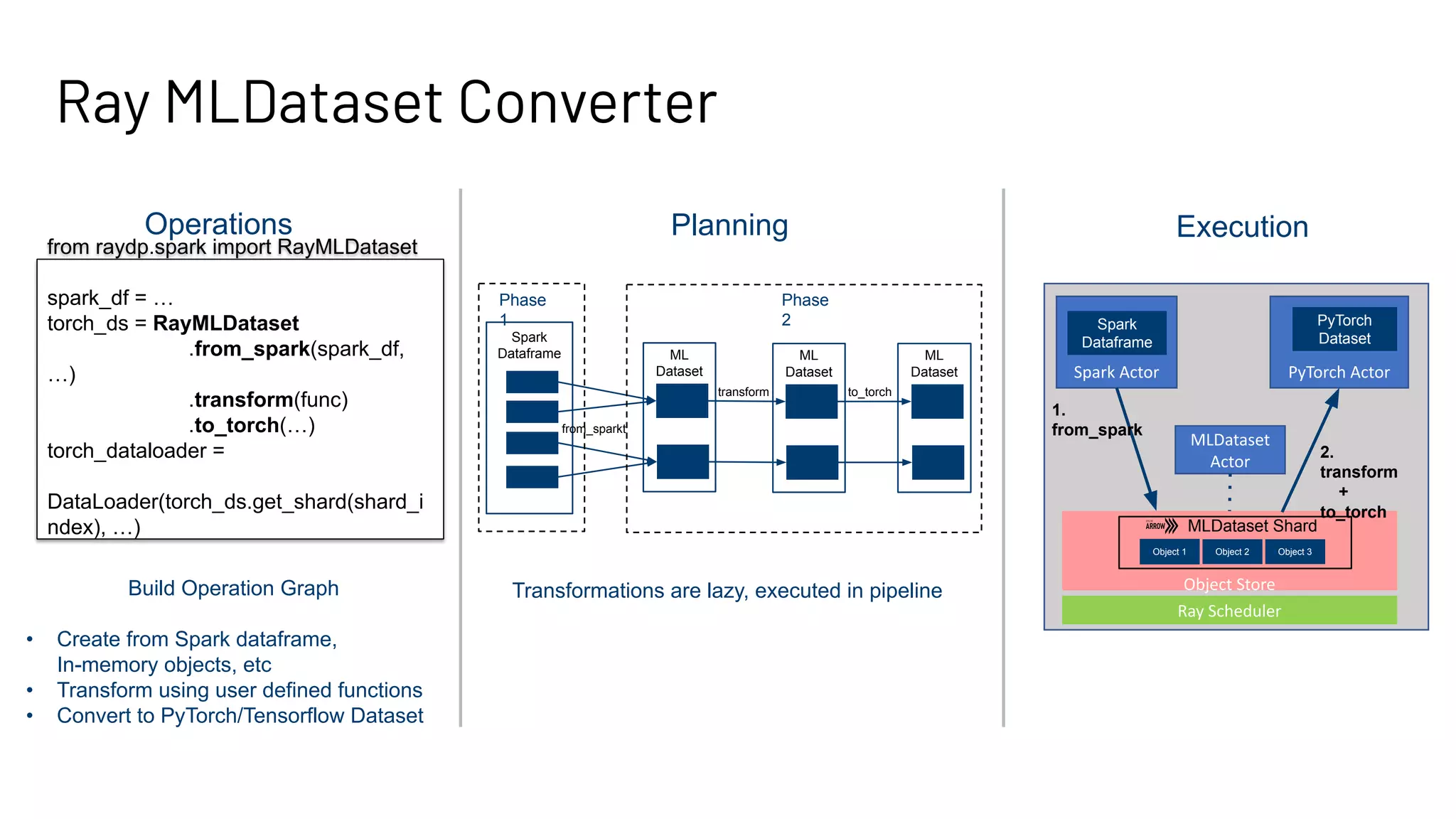
The document discusses building large-scale data analytics and AI pipelines using RayDP, a framework that integrates Spark with distributed machine learning frameworks. It highlights the benefits of RayDP, such as increased productivity, performance, and resource utilization through a seamless API for development across multiple platforms. The document also provides examples of using RayDP with various ML frameworks for end-to-end workflows in data preprocessing and model training.