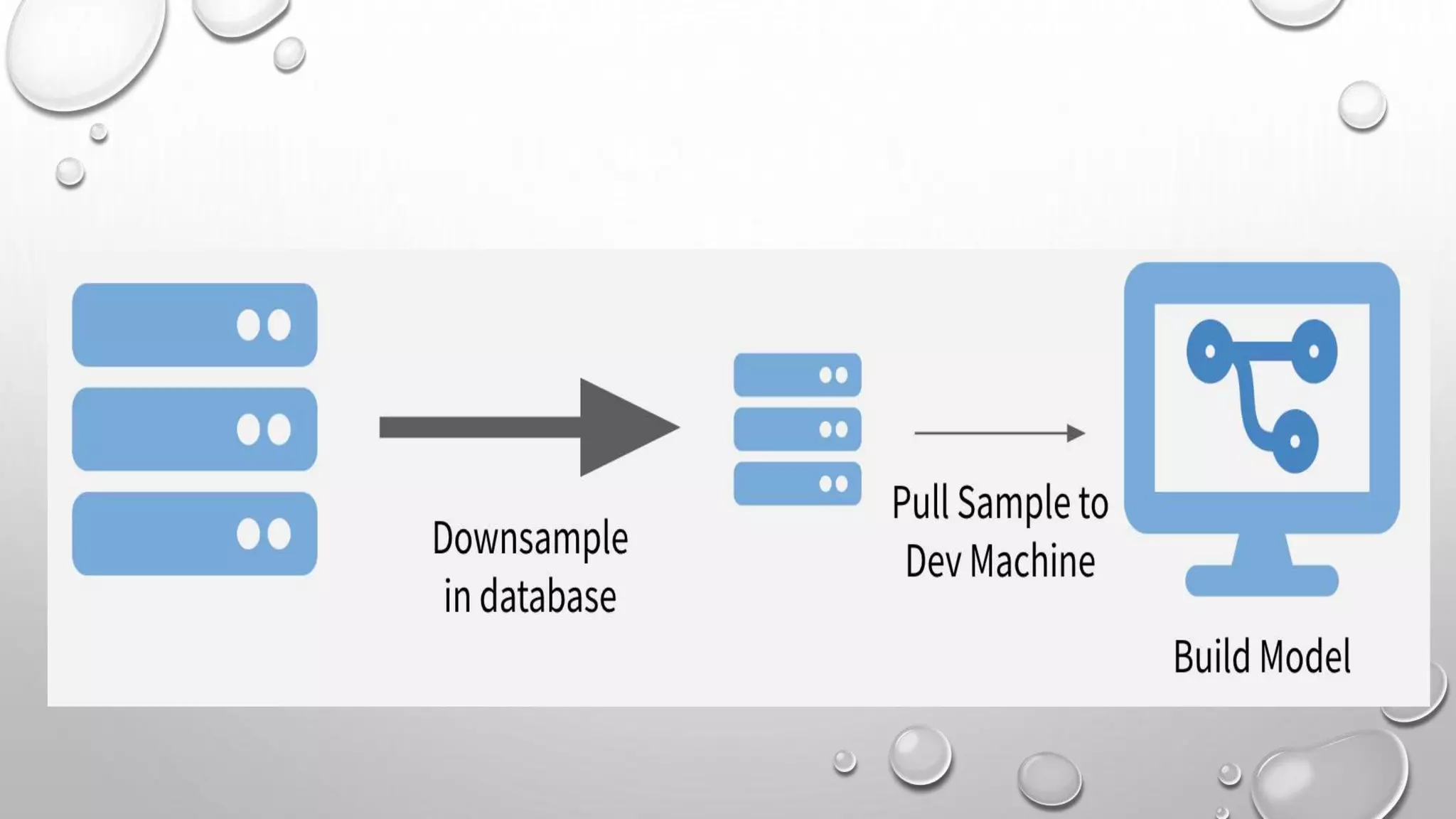
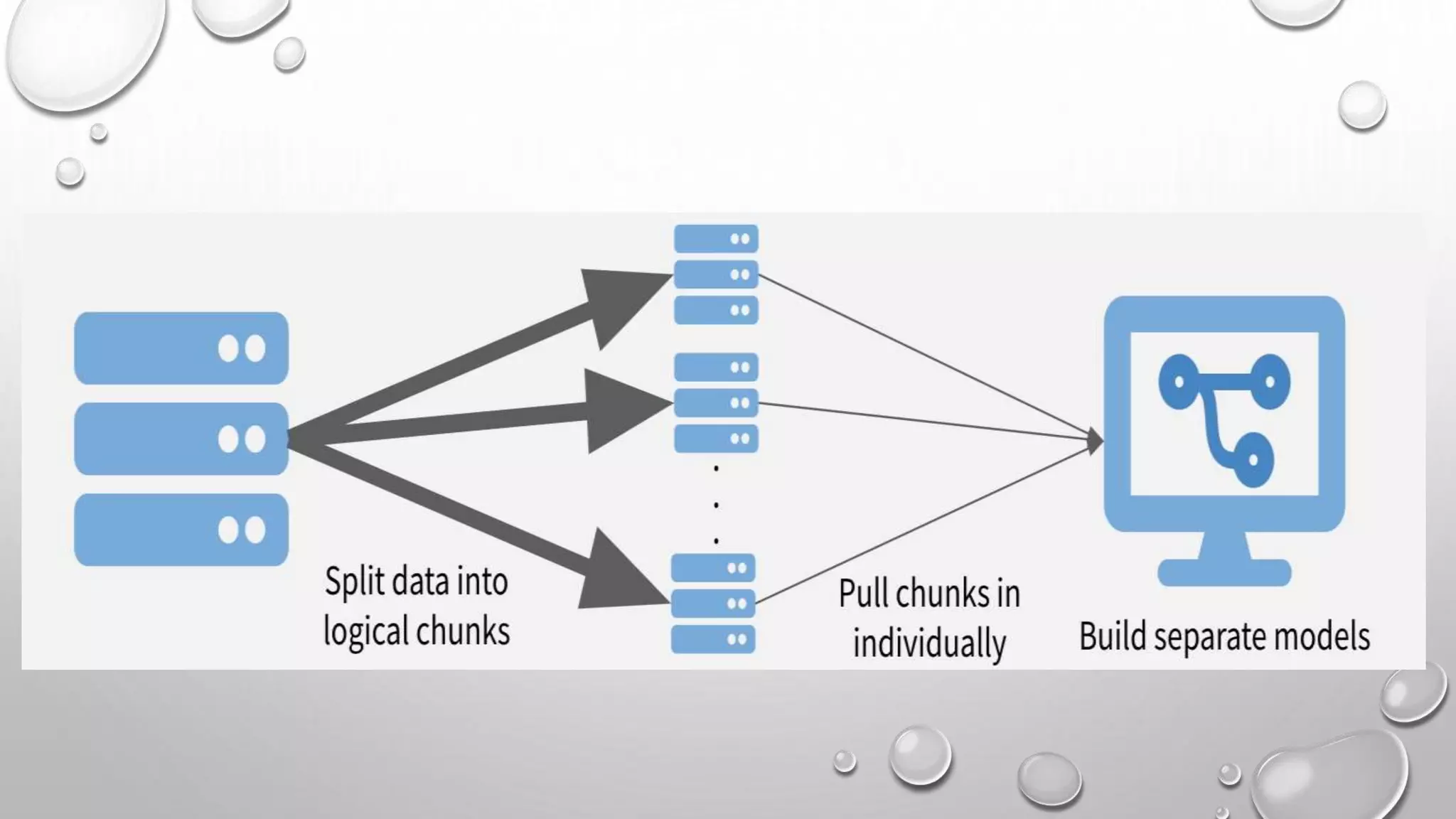
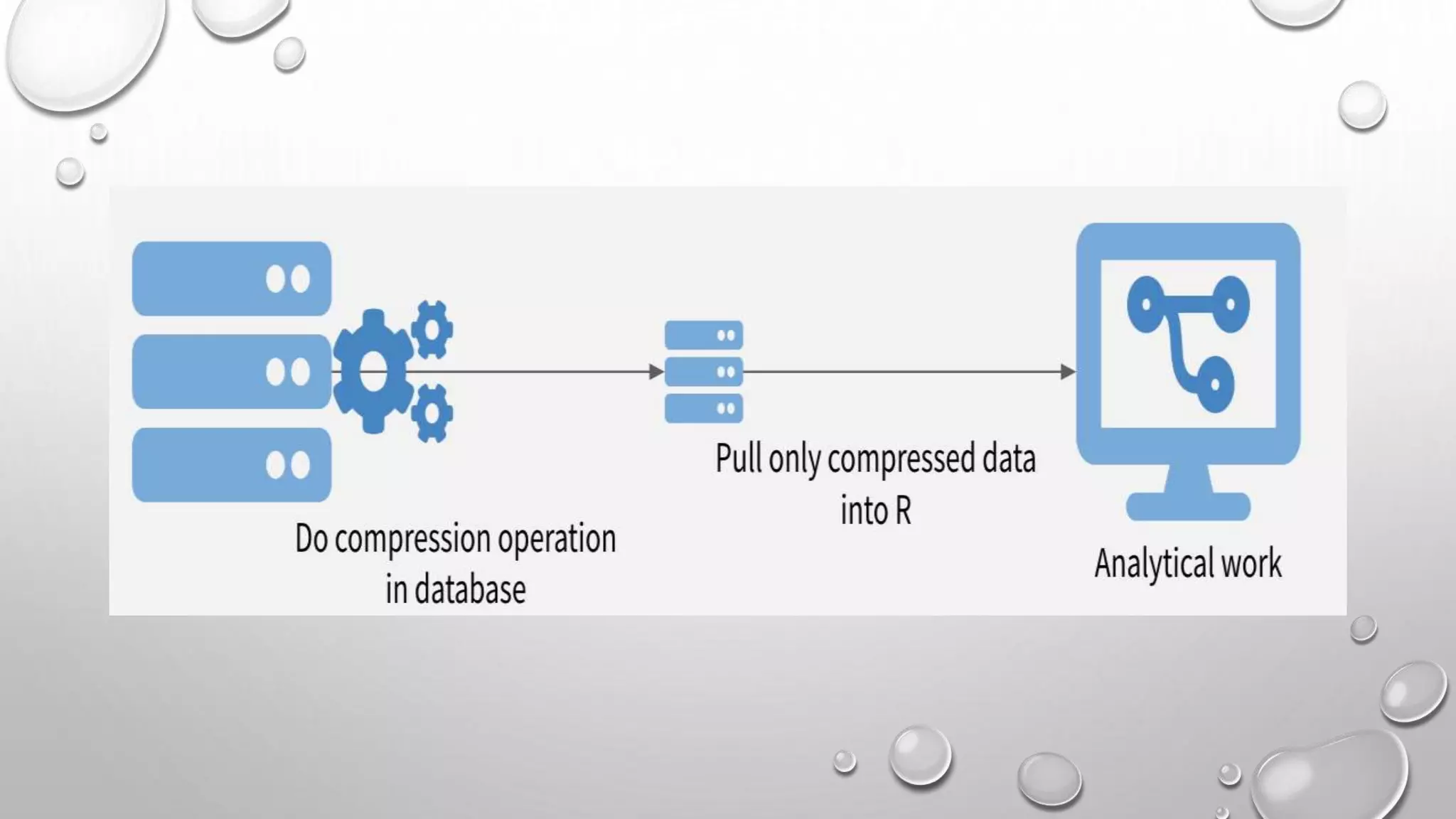
This document discusses three strategies for working with big data: 1. Sample and model - Downsampling the data to thousands or hundreds of thousands of points to create a model while maintaining statistical validity. 2. Chunk and pull - Chunking the data into separable units that can each be operated on serially or in parallel. 3. Push compute to data - Compressing the data on the database and only moving the compressed data to R to take advantage of the database's abilities to quickly summarize and filter large datasets.