Download as PDF, PPTX







![Docker on Marathon { "id": "basic-3", "cmd": "python3 -m http.server 8080", "cpus": 0.5, "mem": 32.0, "container": { "type": "DOCKER", "docker": { "image": "python:3", "network": "BRIDGE", "portMappings": [ { "containerPort": 8080, "hostPort": 0 } ] } } } 15](https://image.slidesharecdn.com/realtime-151002213545-lva1-app6891/75/Big-Data-Open-Source-Security-LLC-Realtime-log-analysis-with-Mesos-Docker-Kafka-Spark-Cassandra-and-Solr-at-scale-15-2048.jpg)


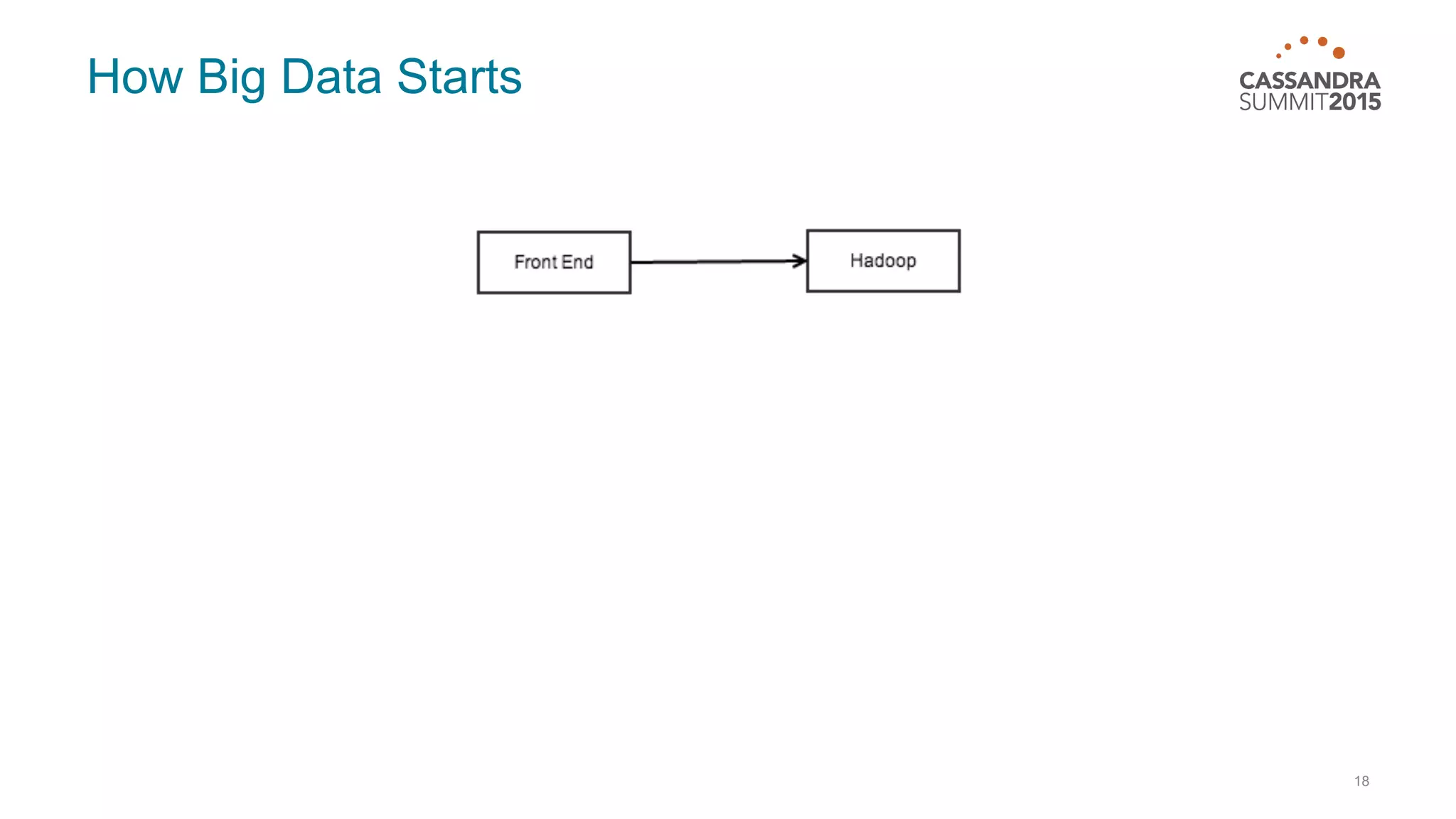
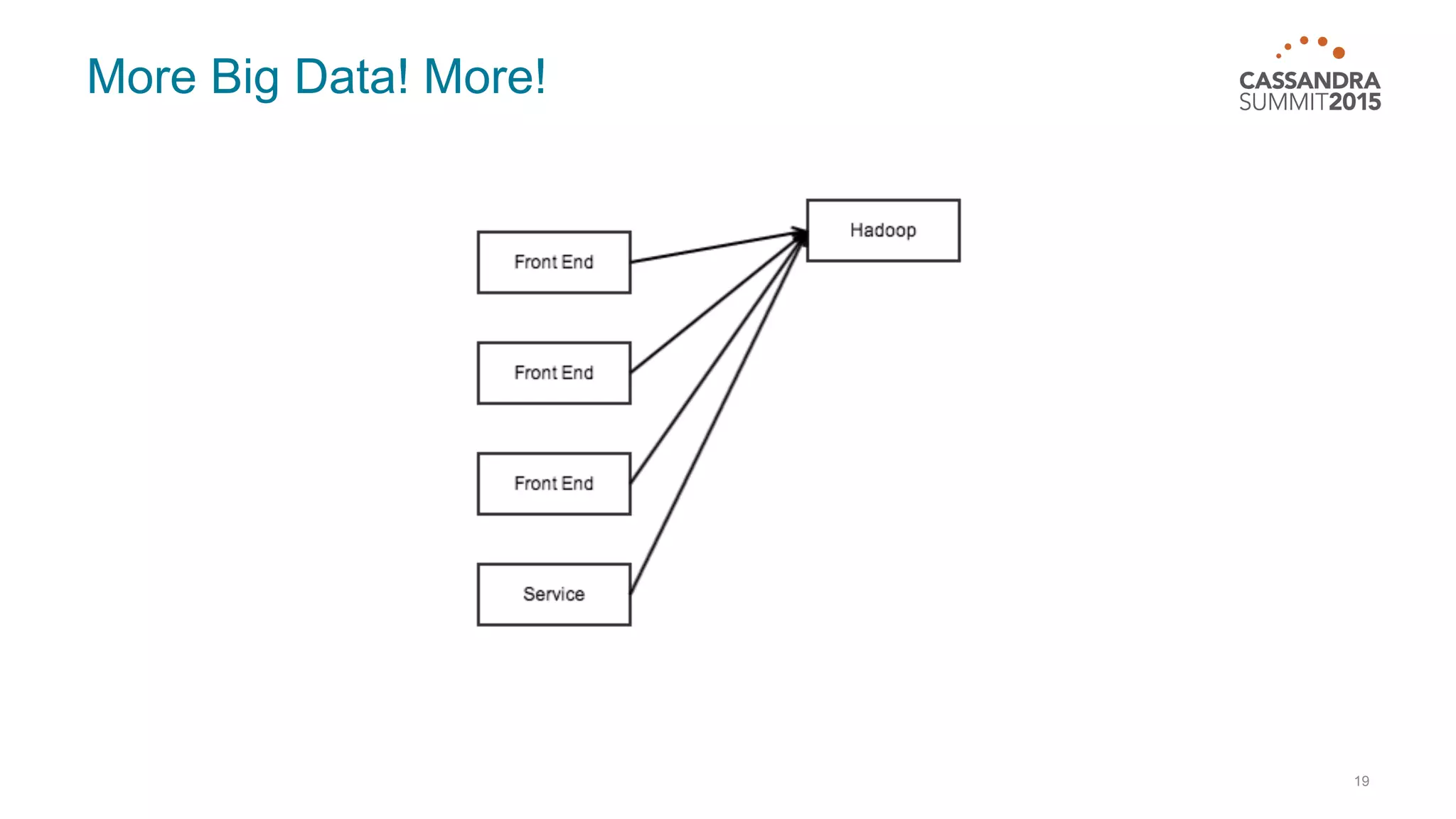
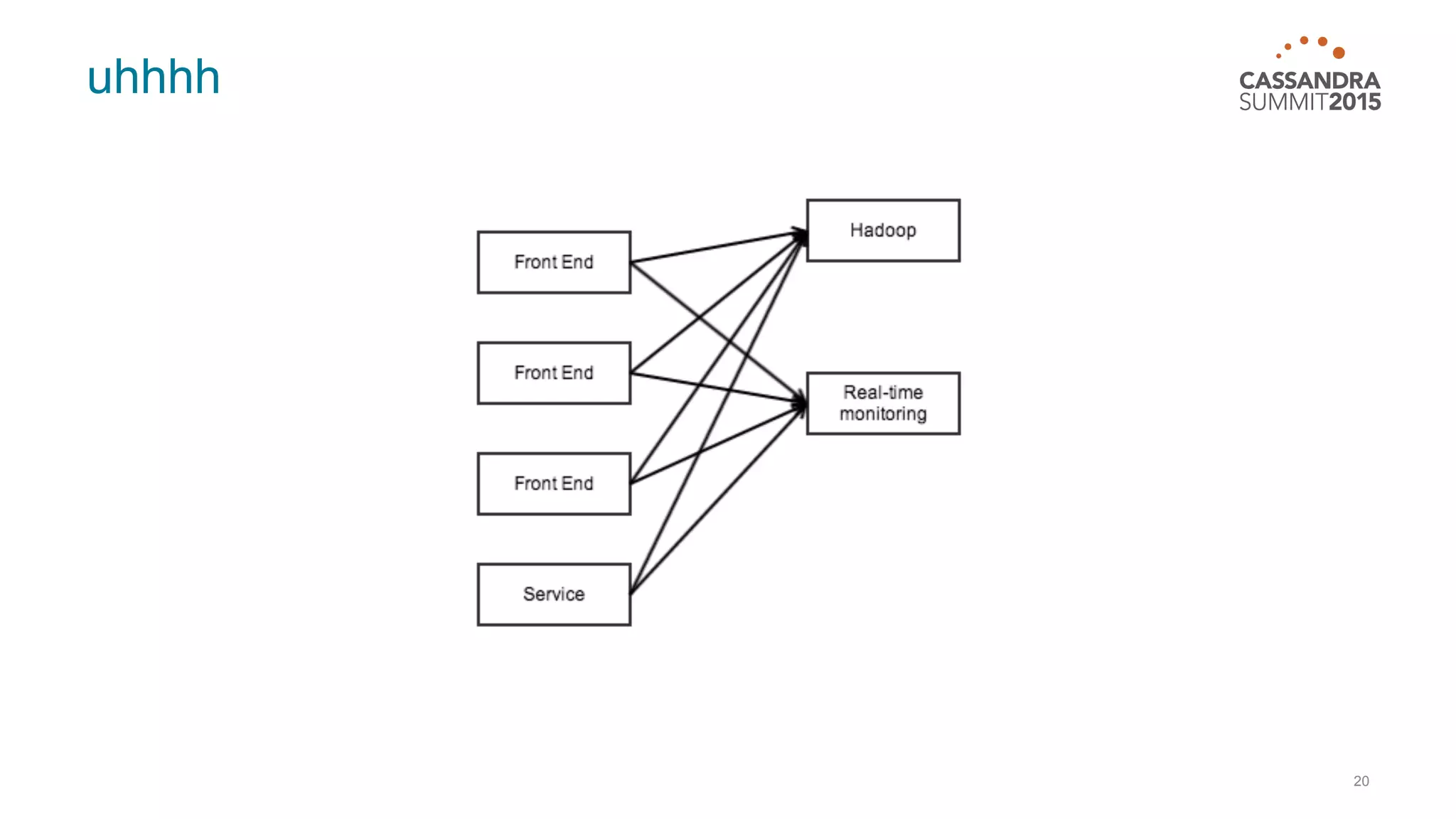
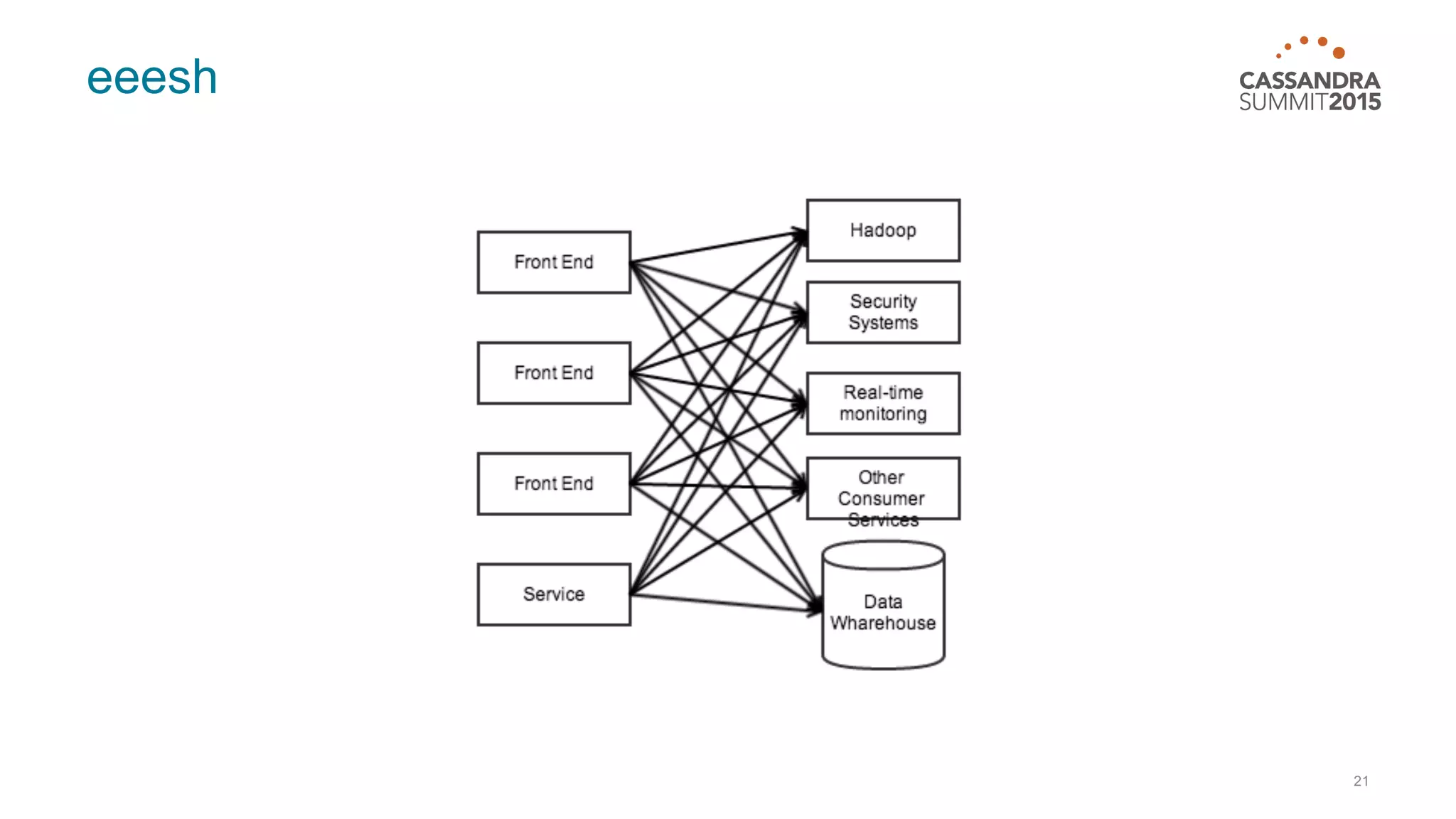
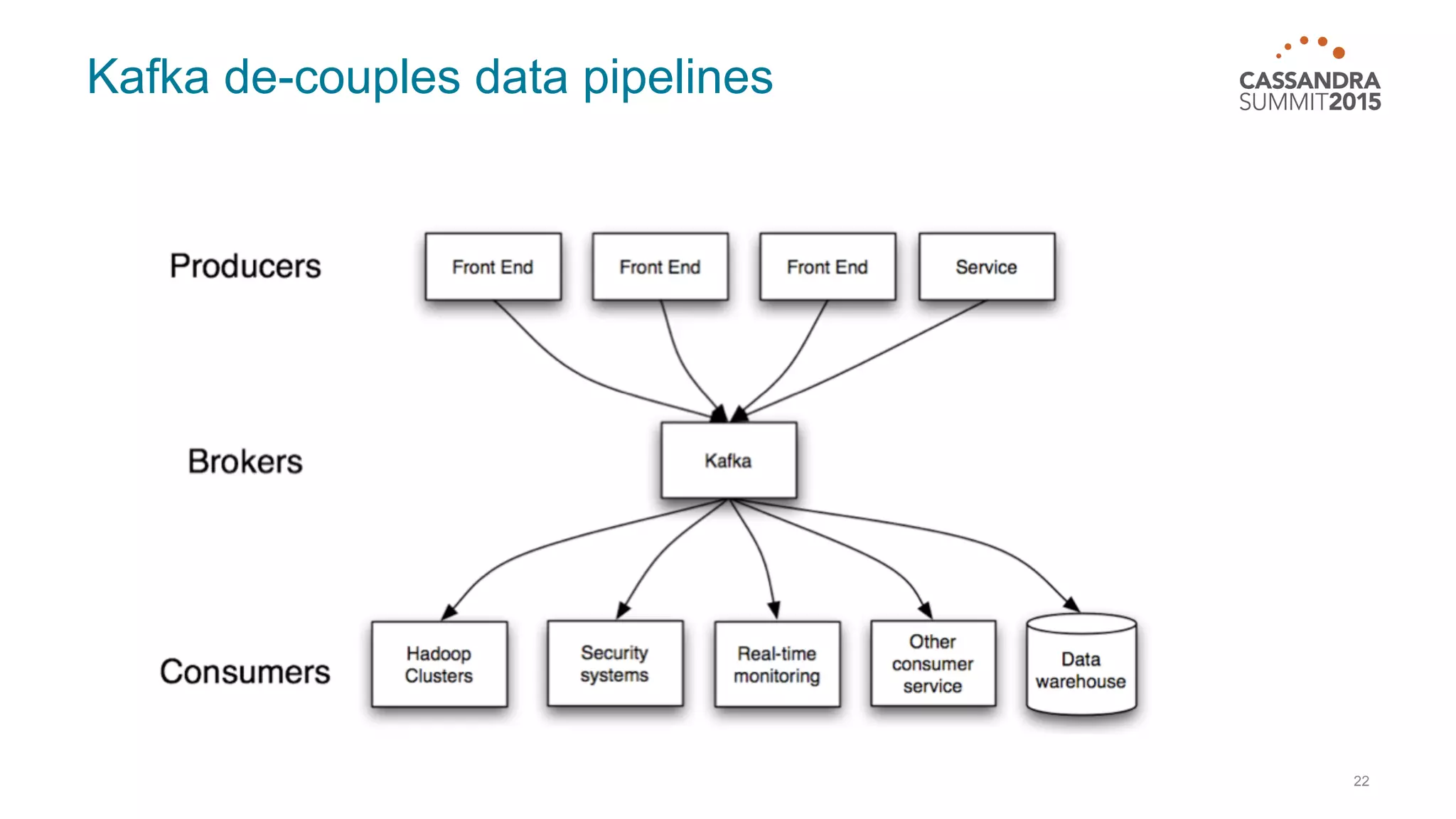
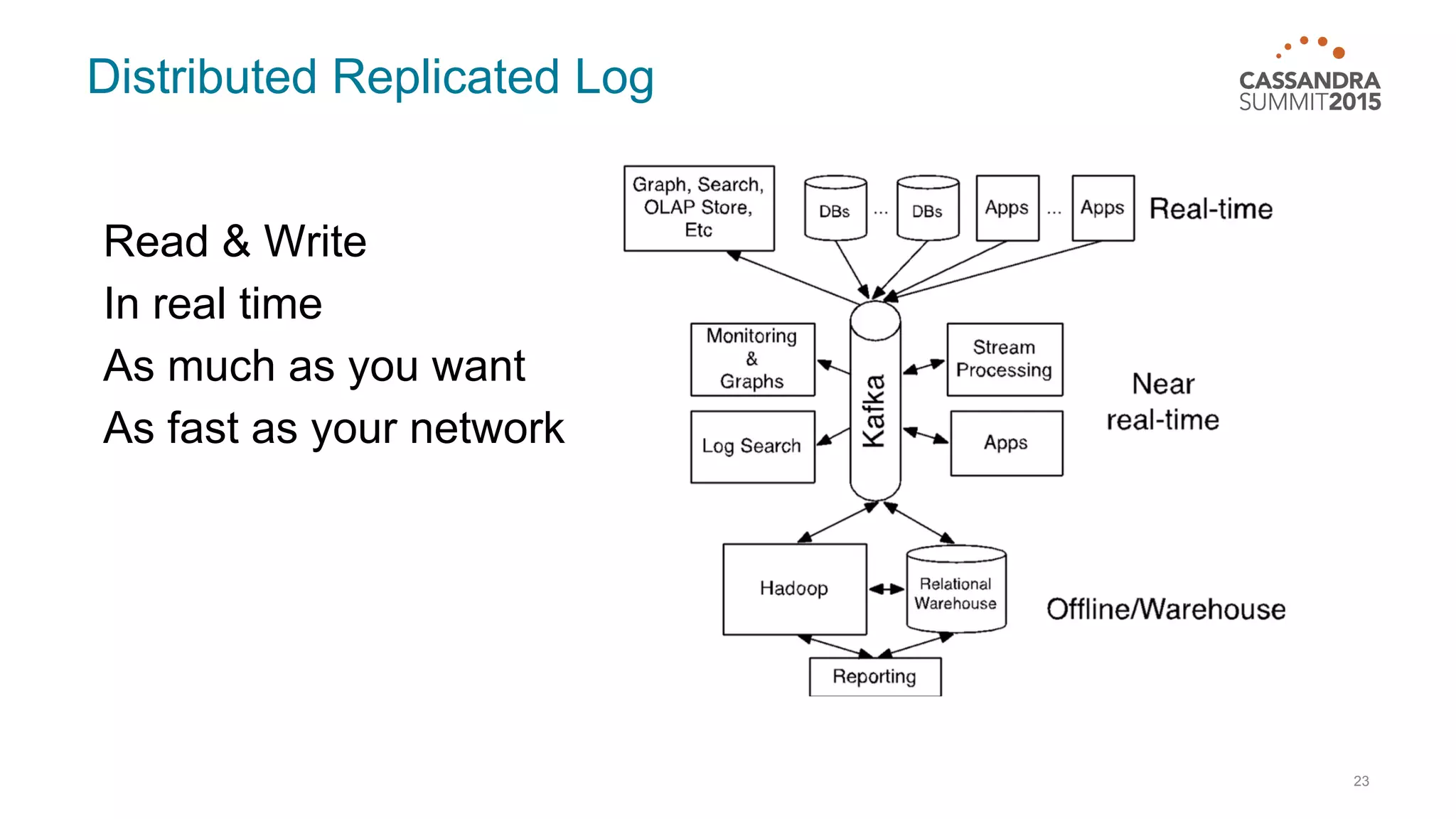
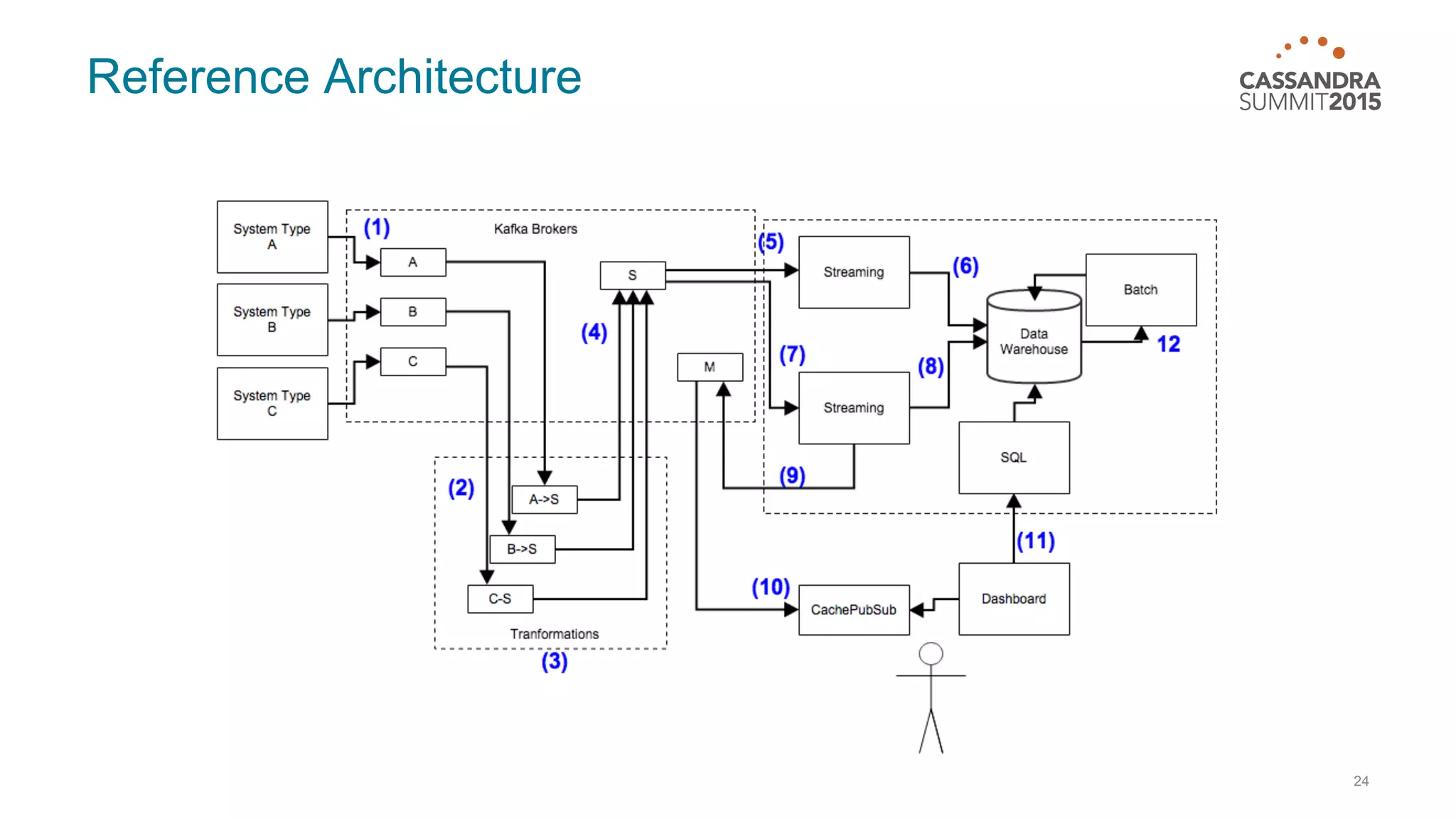
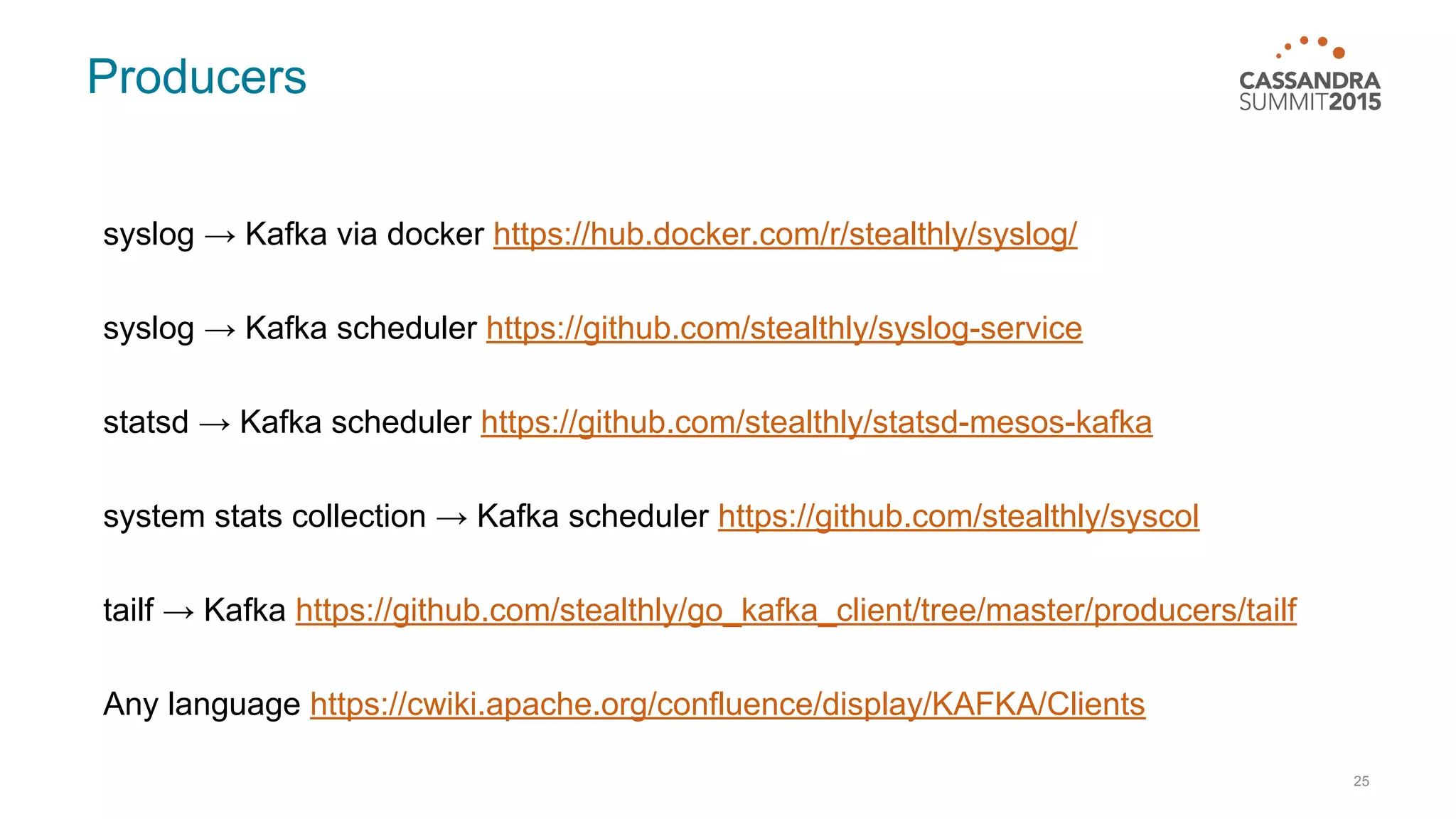
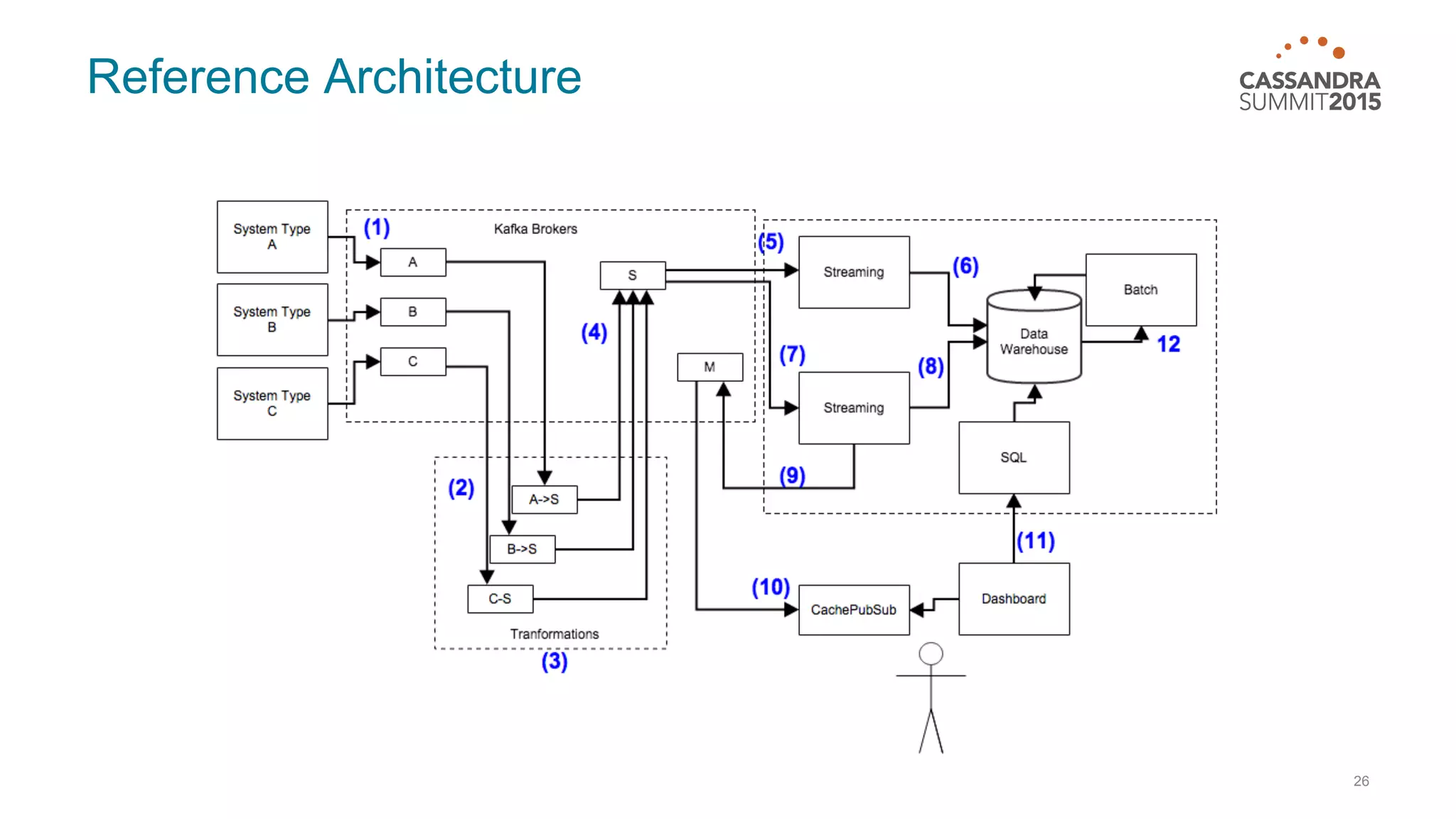
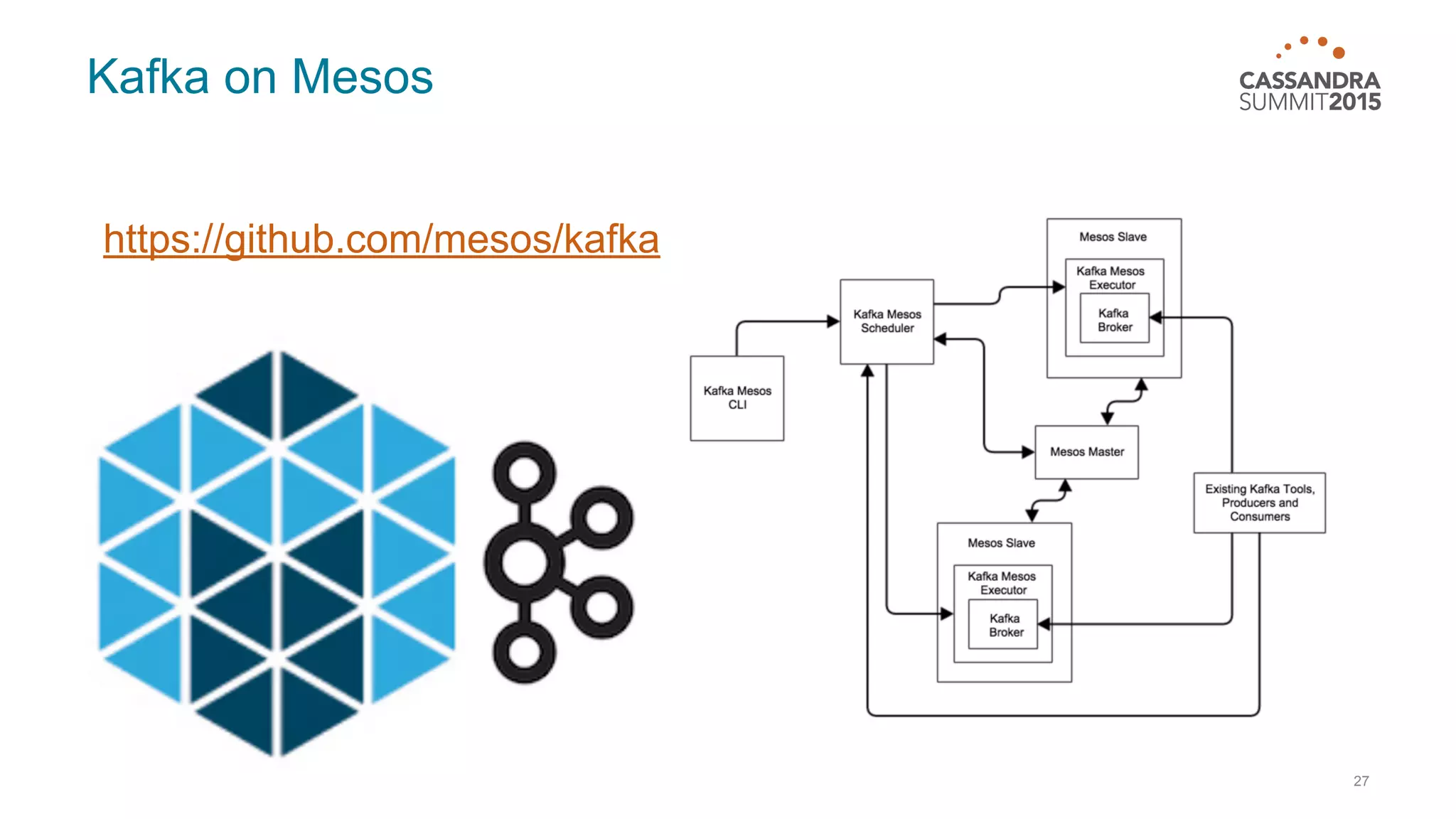


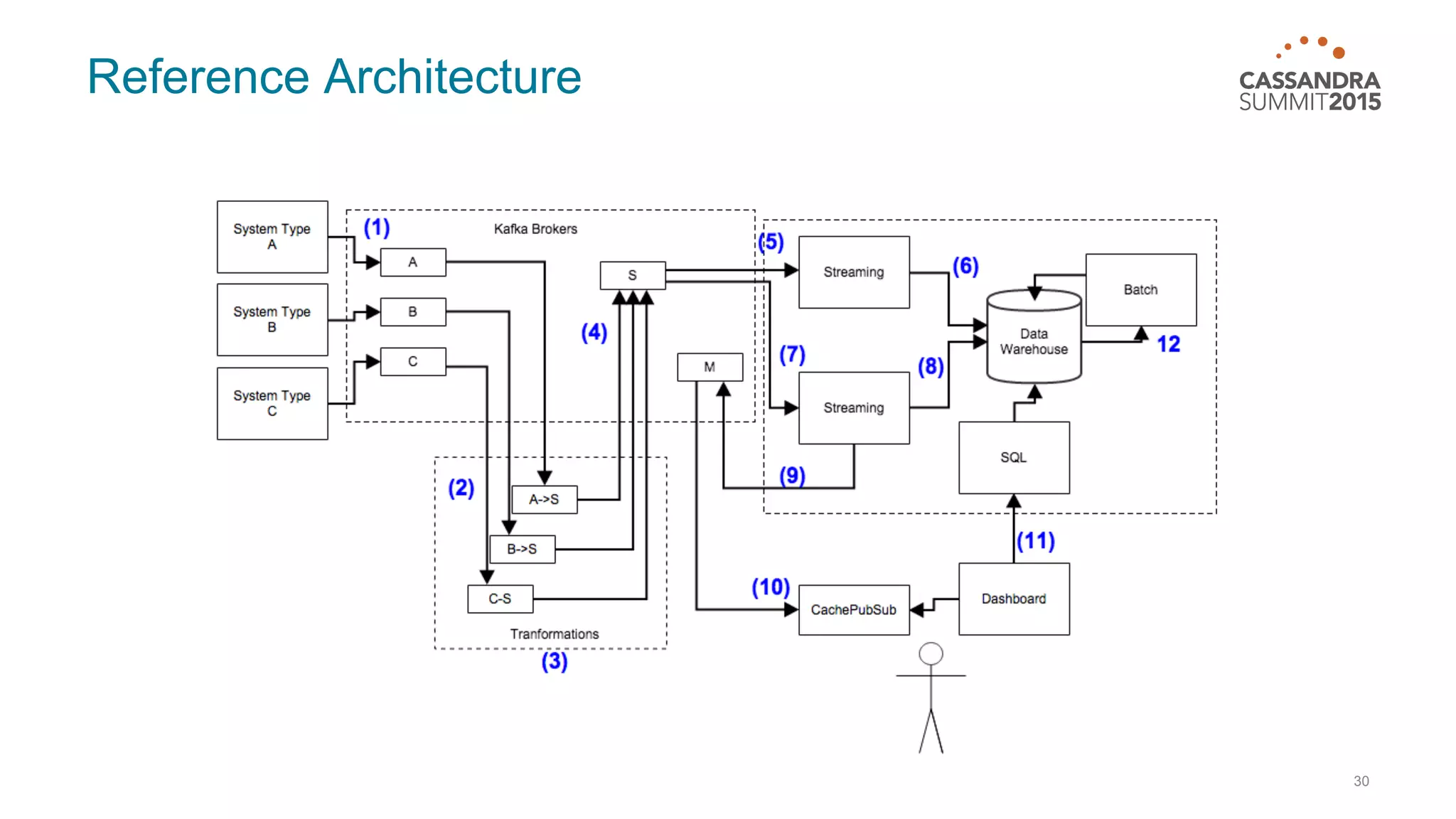


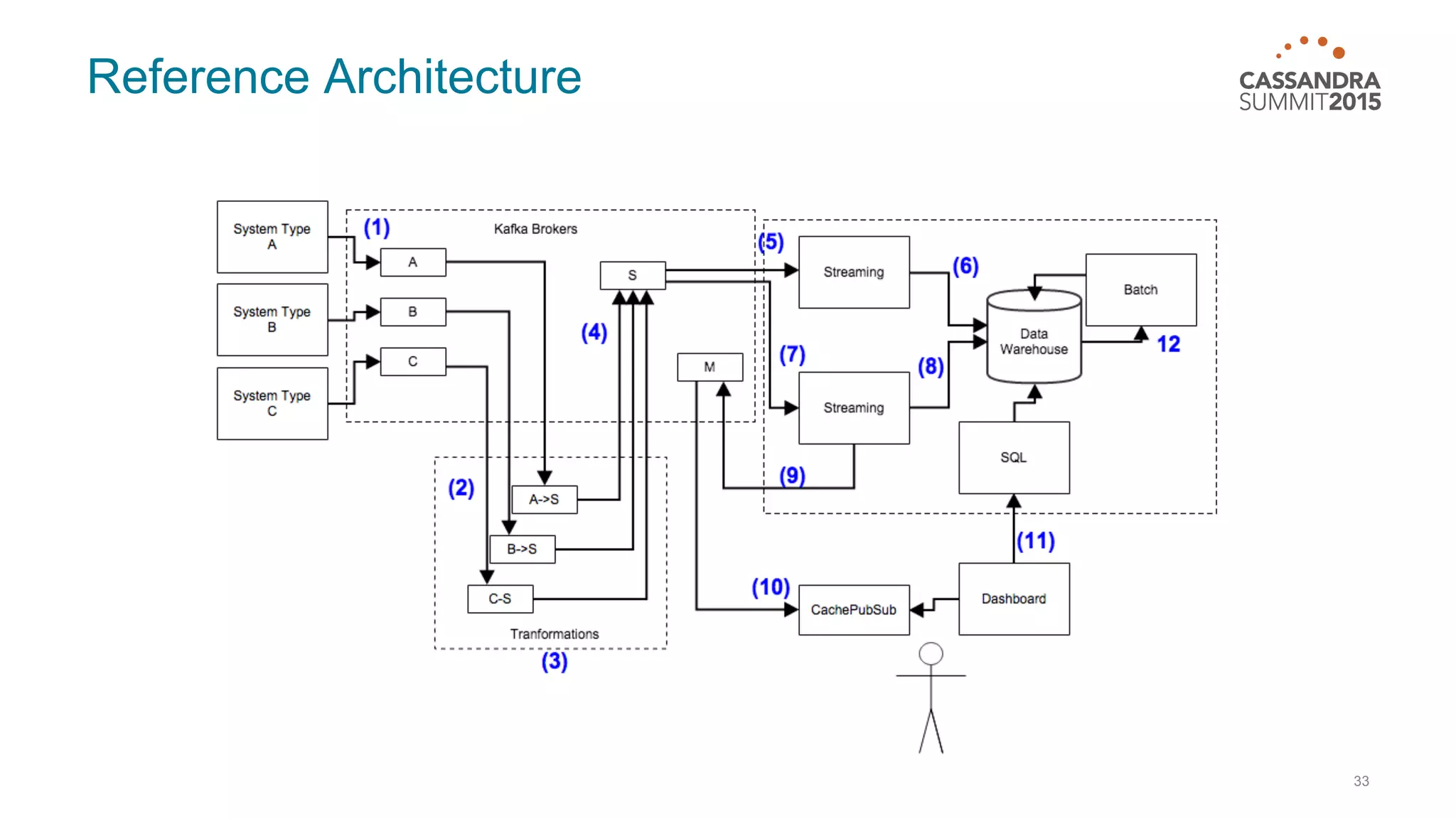





This document discusses real-time log analysis using Mesos, Docker, Kafka, Spark, Cassandra and Solr at scale. It provides an overview of the architecture, describing how data from various sources like syslog can be ingested into Kafka via Docker producers. It then discusses consuming from Kafka to write to Cassandra in real-time and running Spark jobs on Cassandra data. The document uses these open source tools together in a reference architecture to enable real-time analytics and search capabilities on streaming data.