Downloaded 32 times


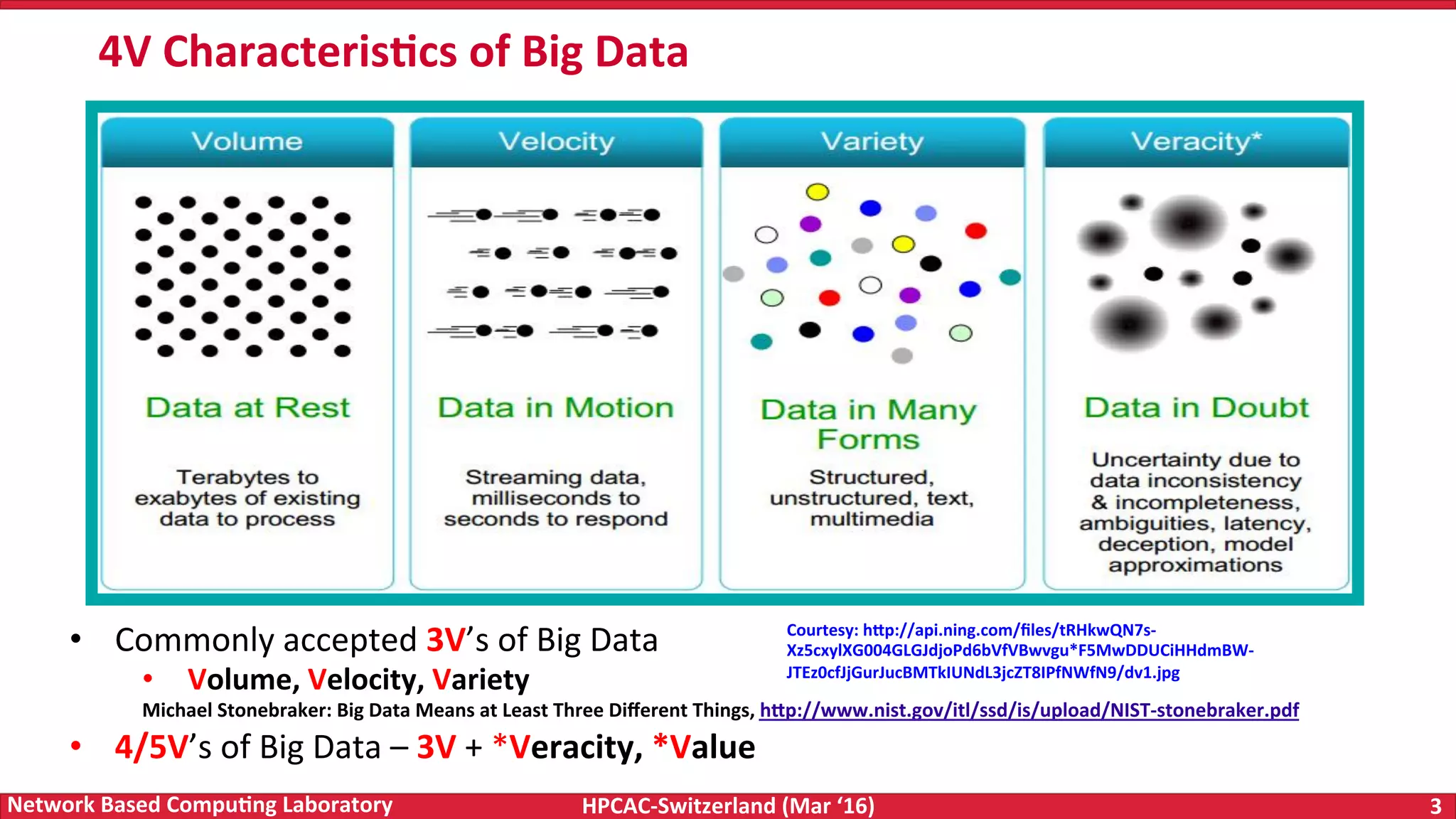
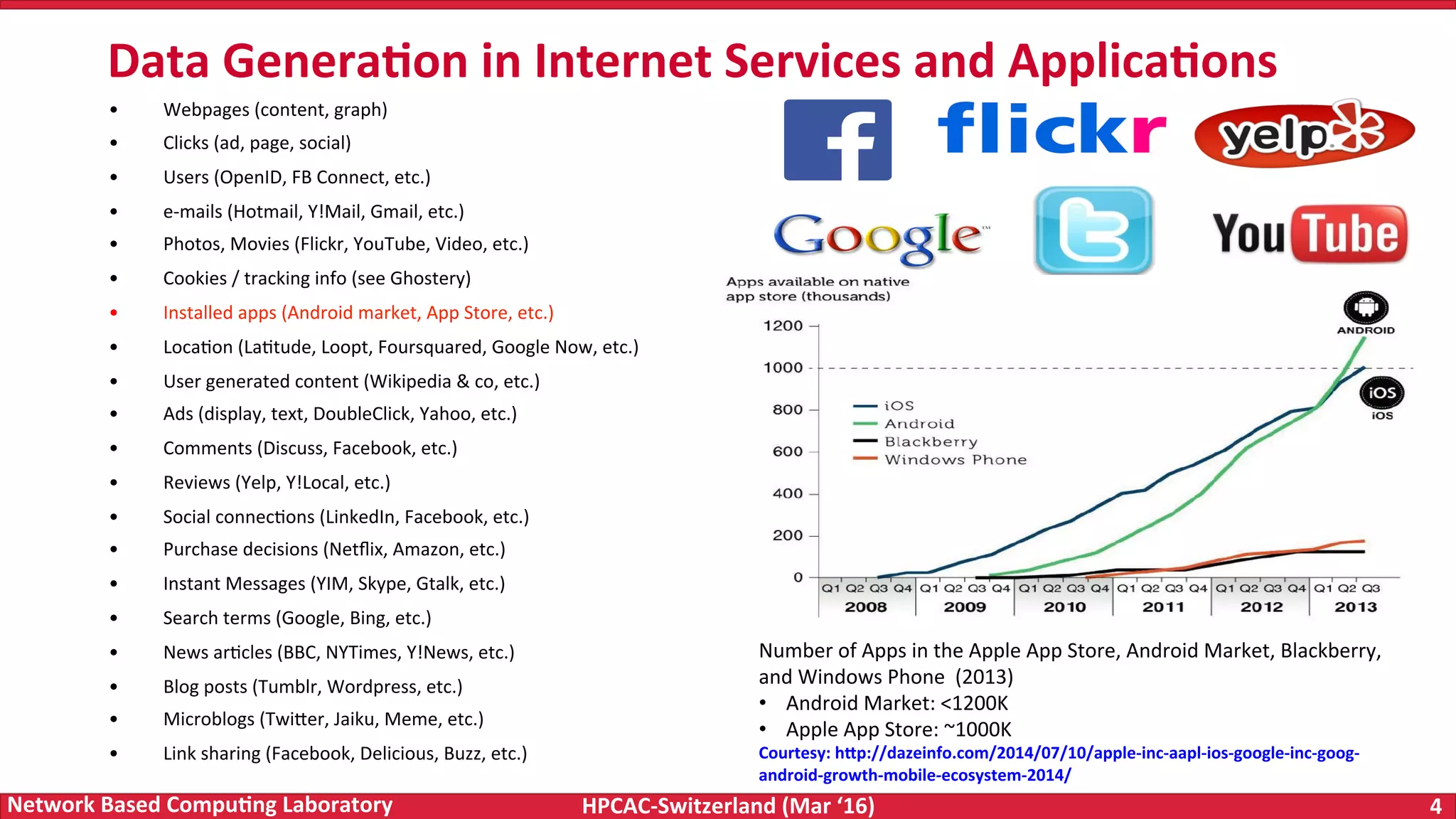



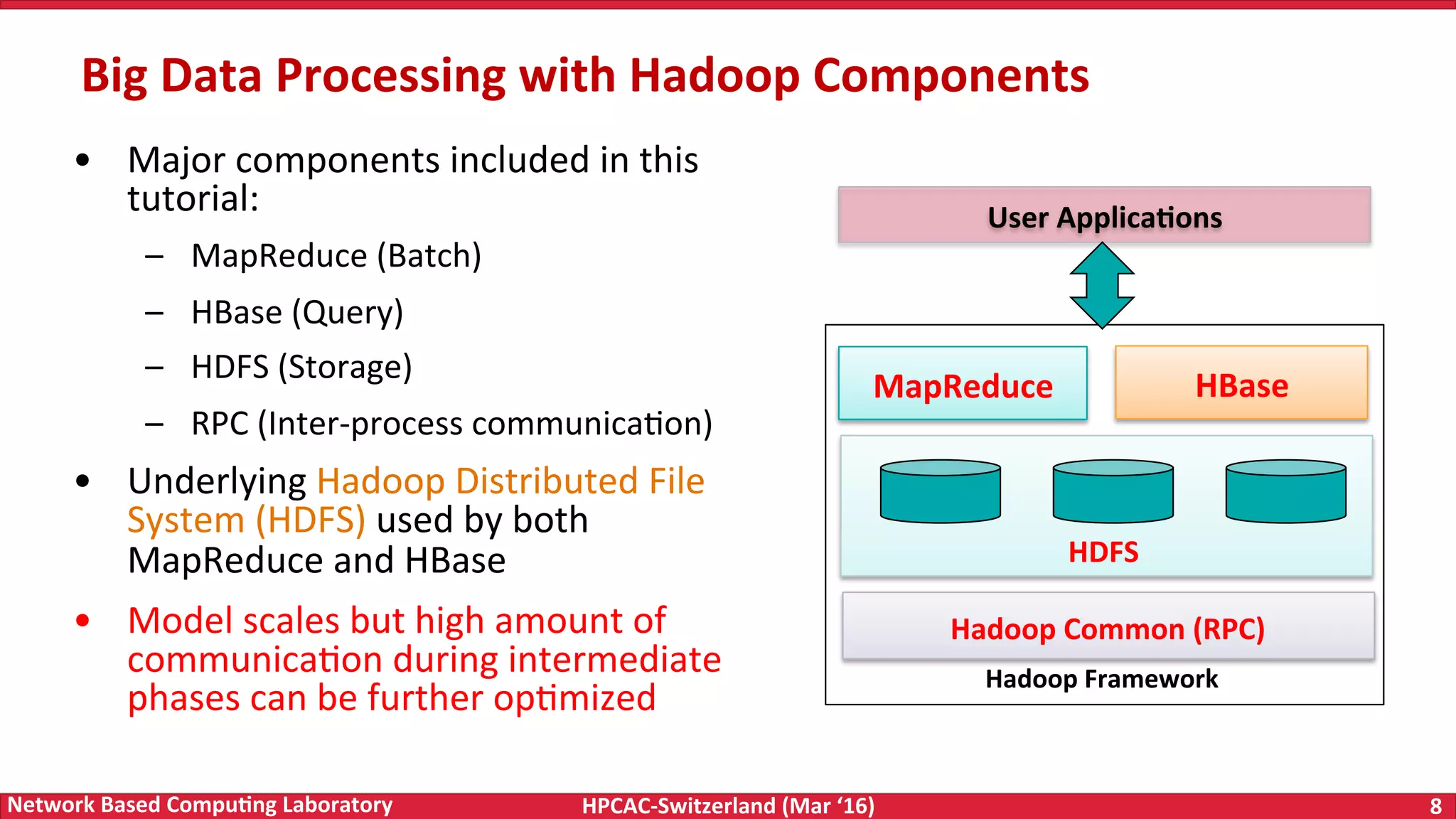
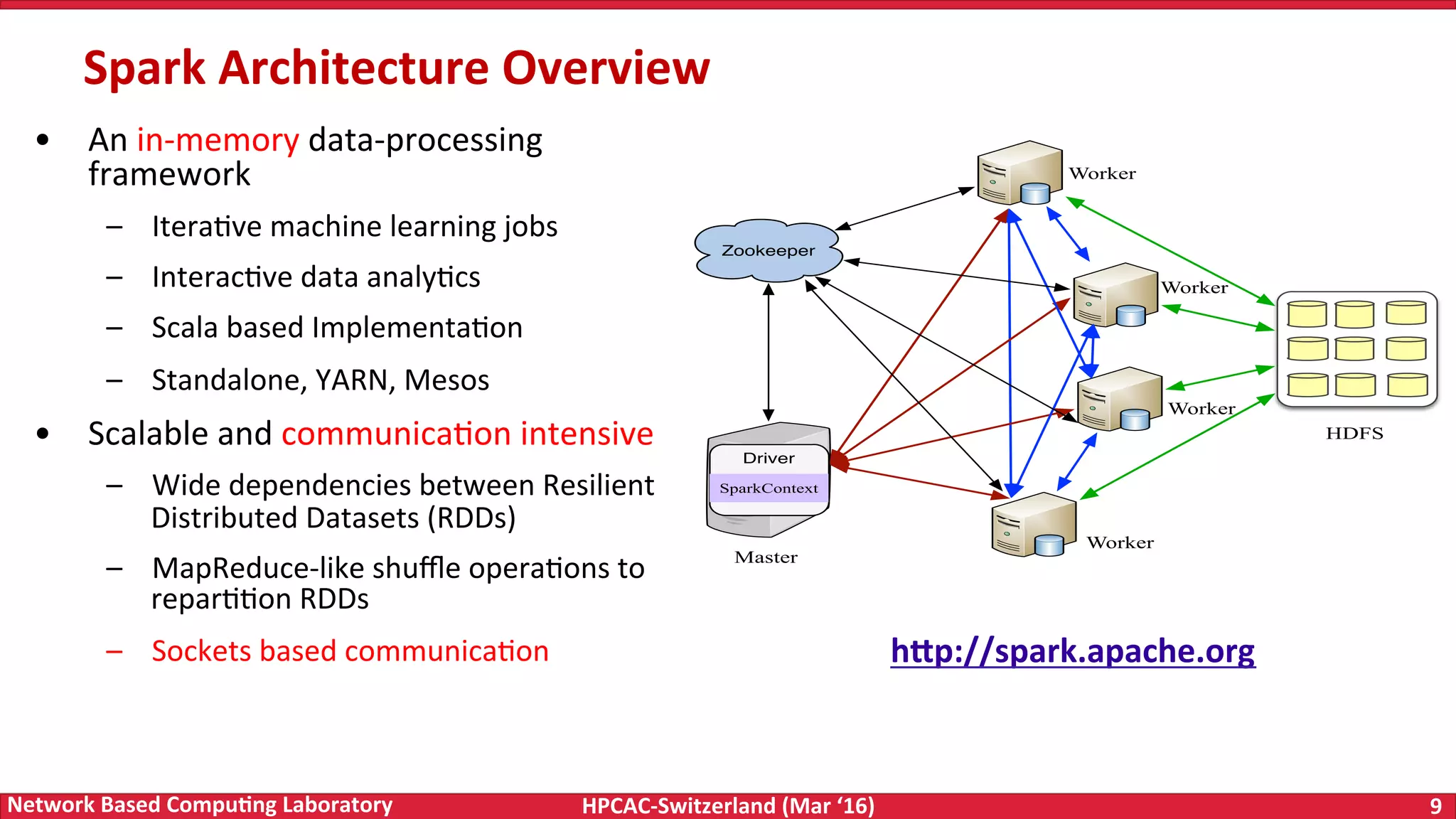
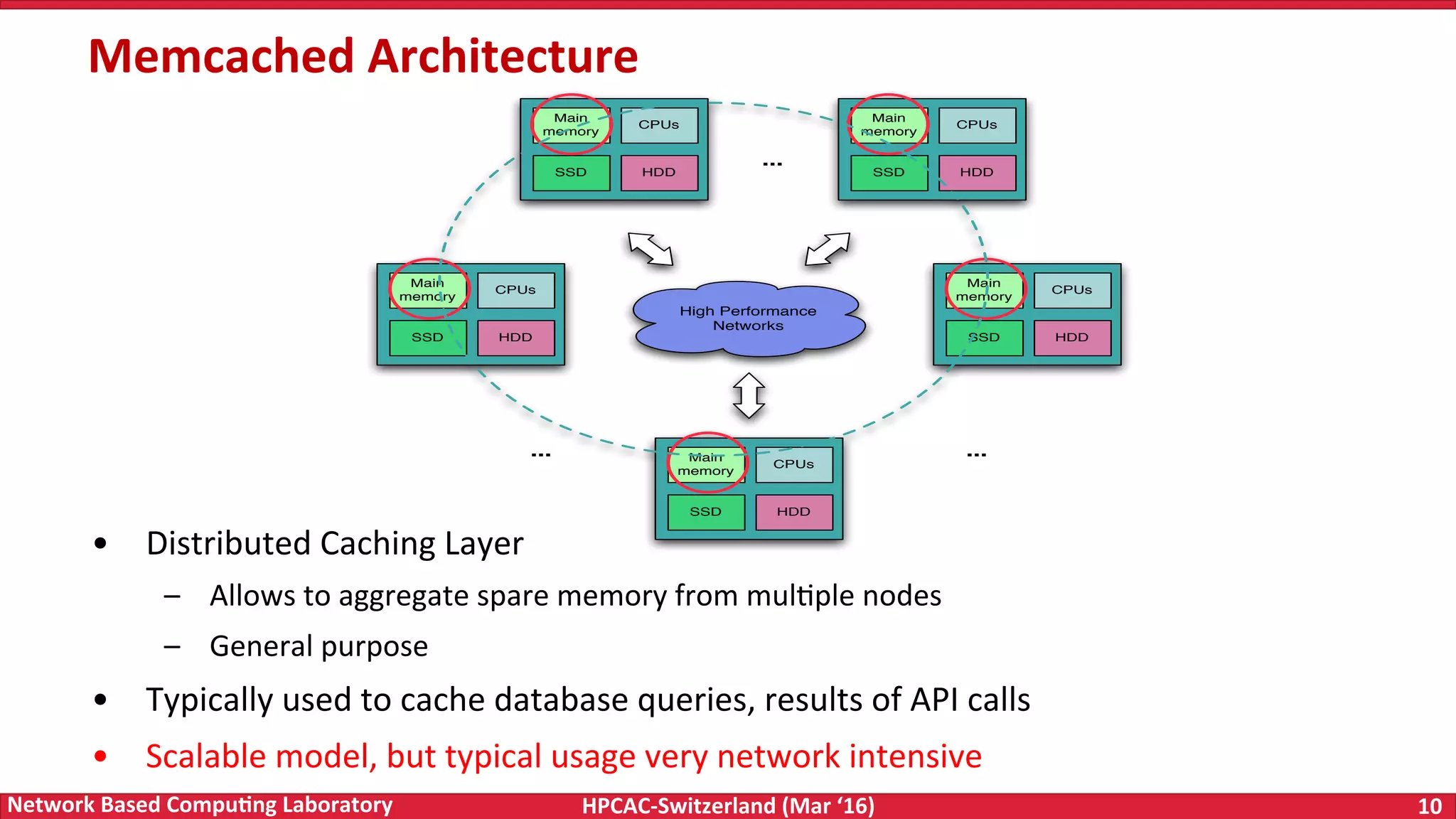
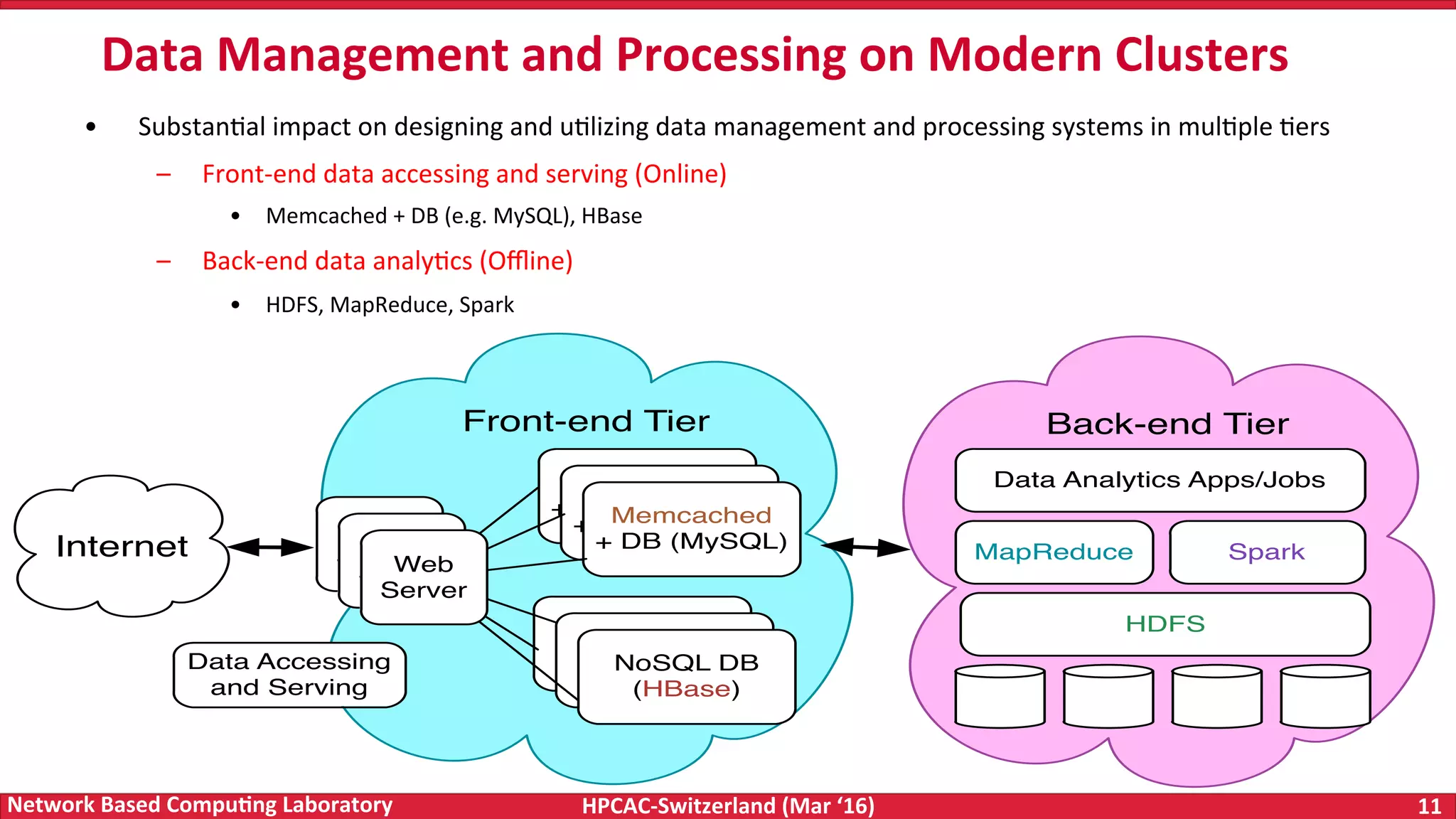

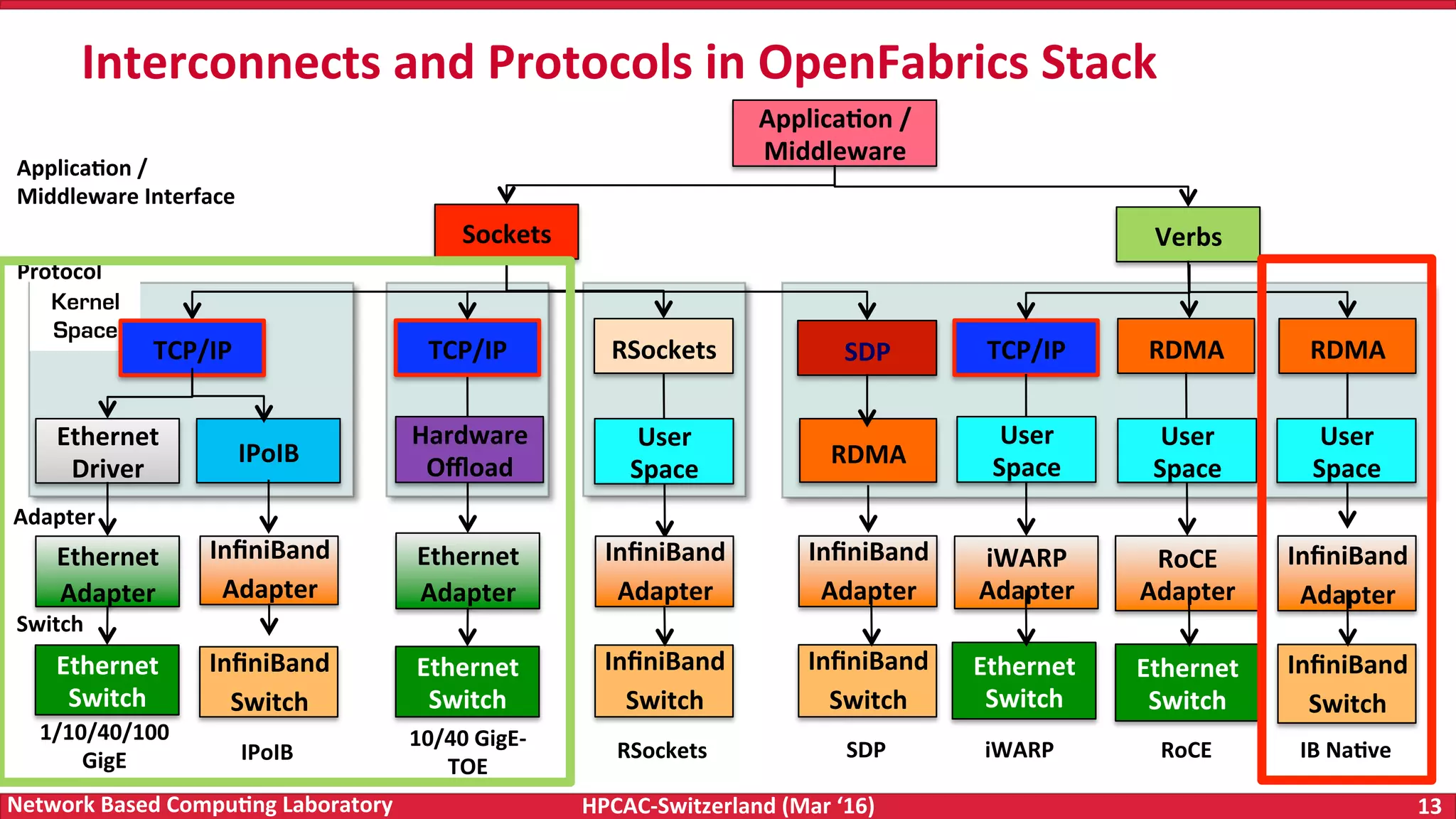
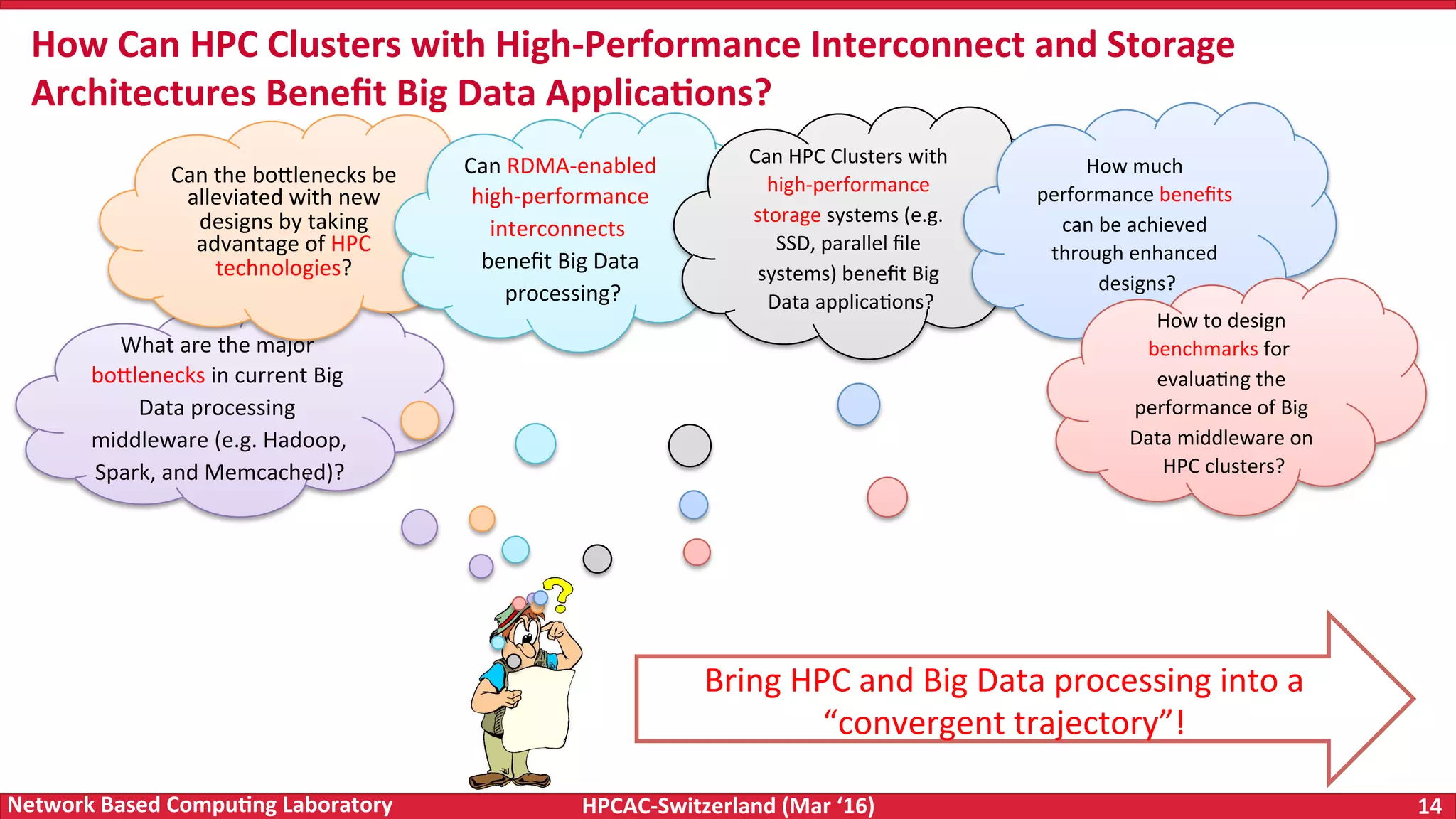
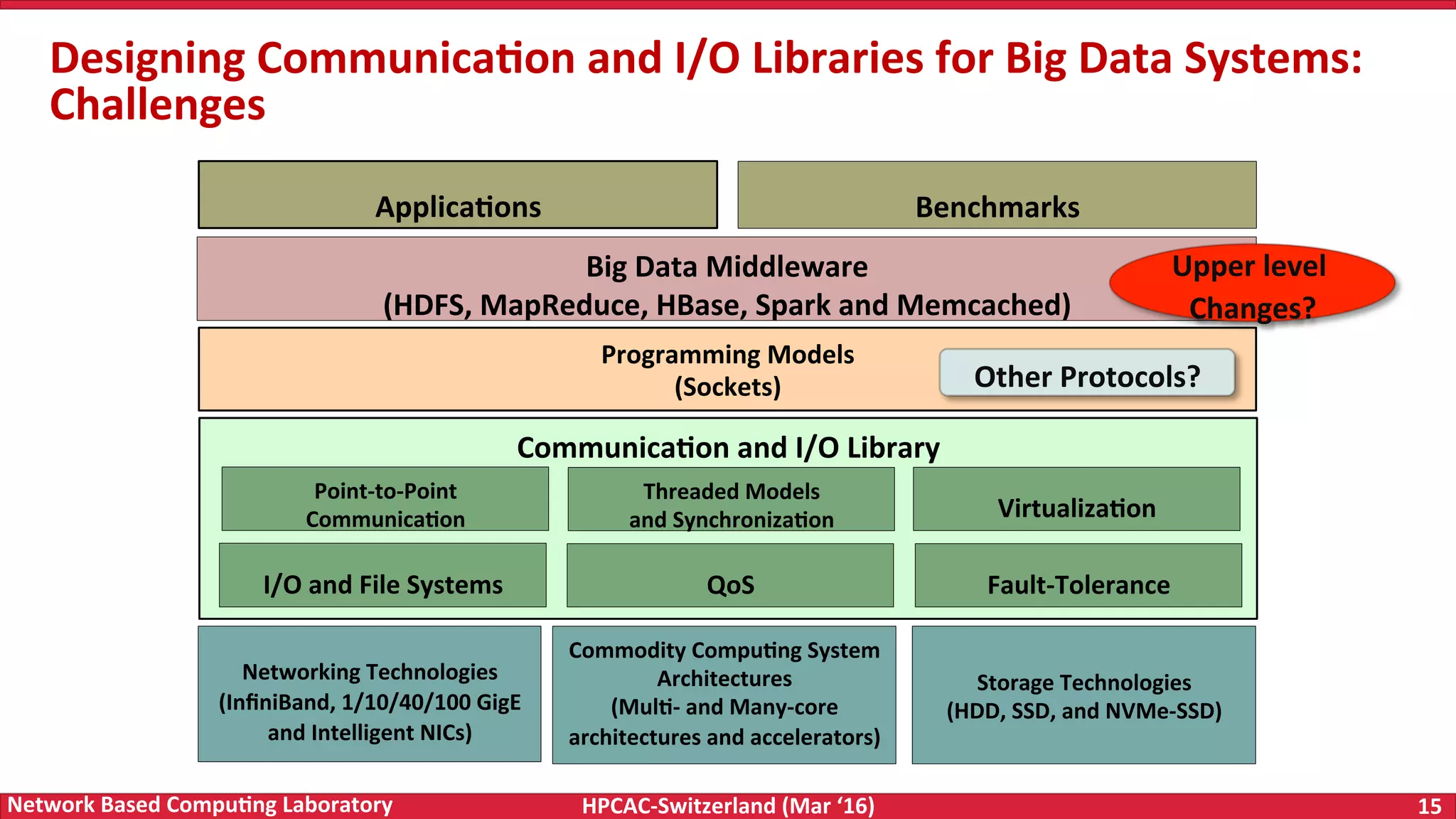
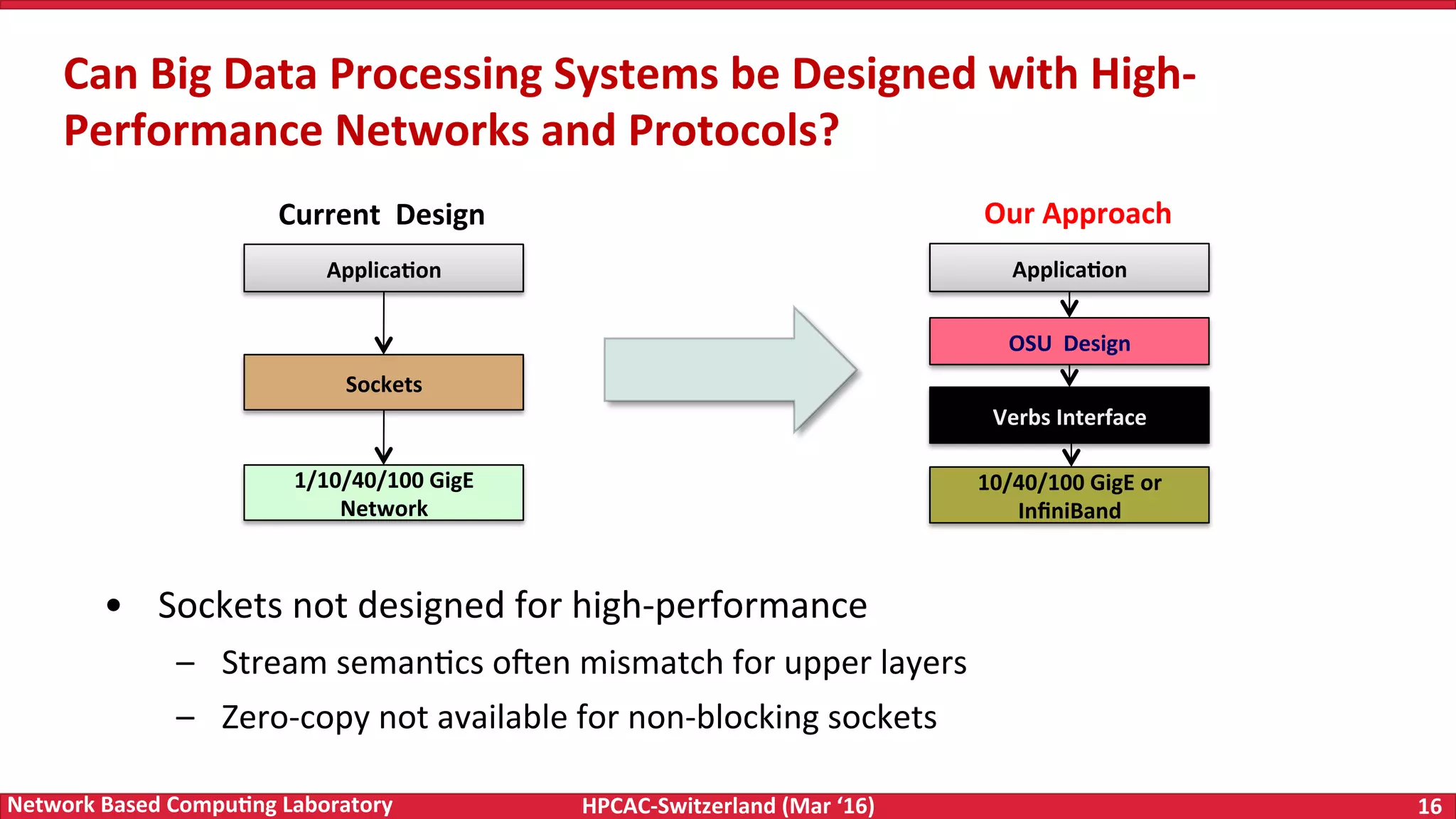







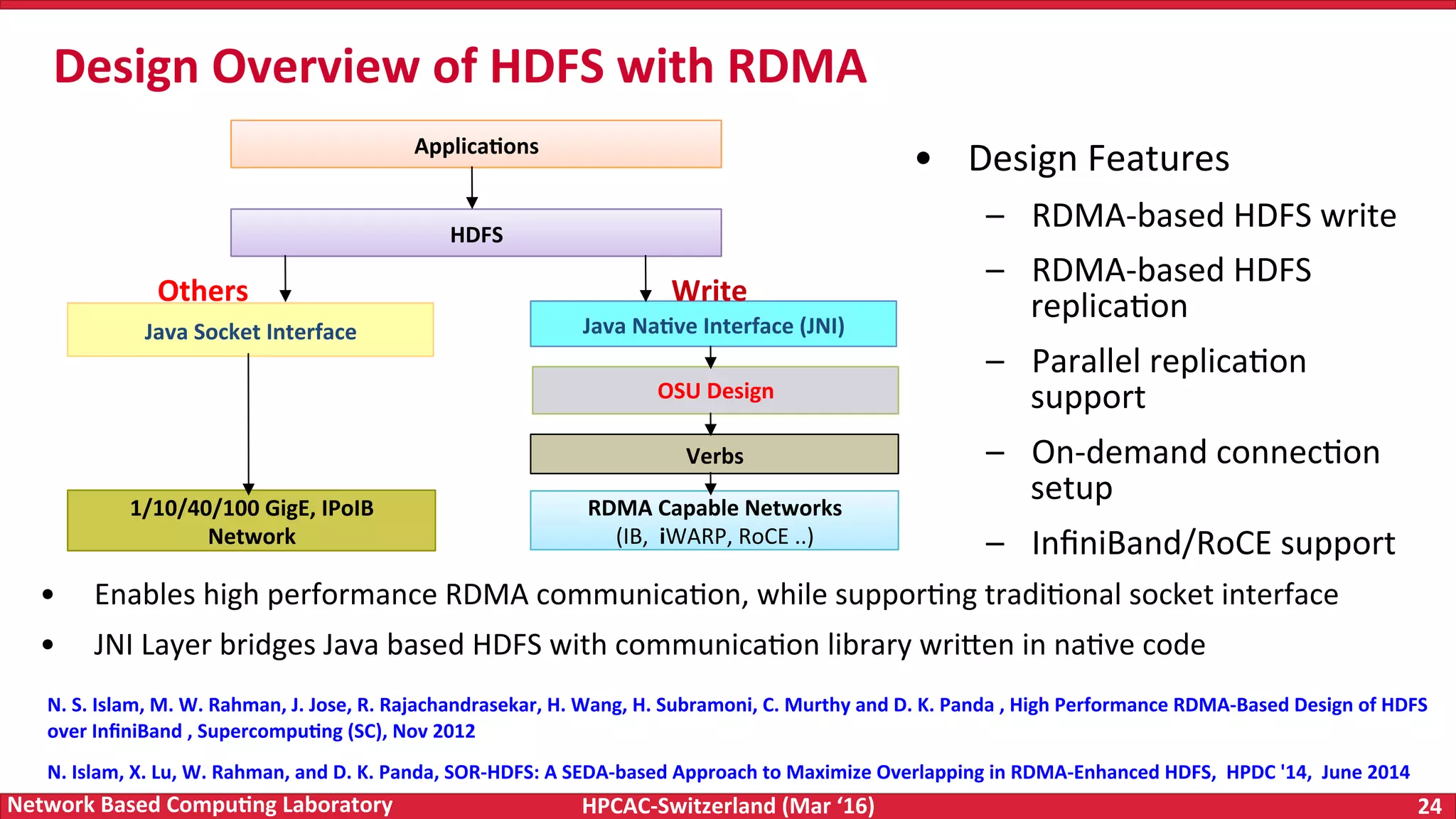
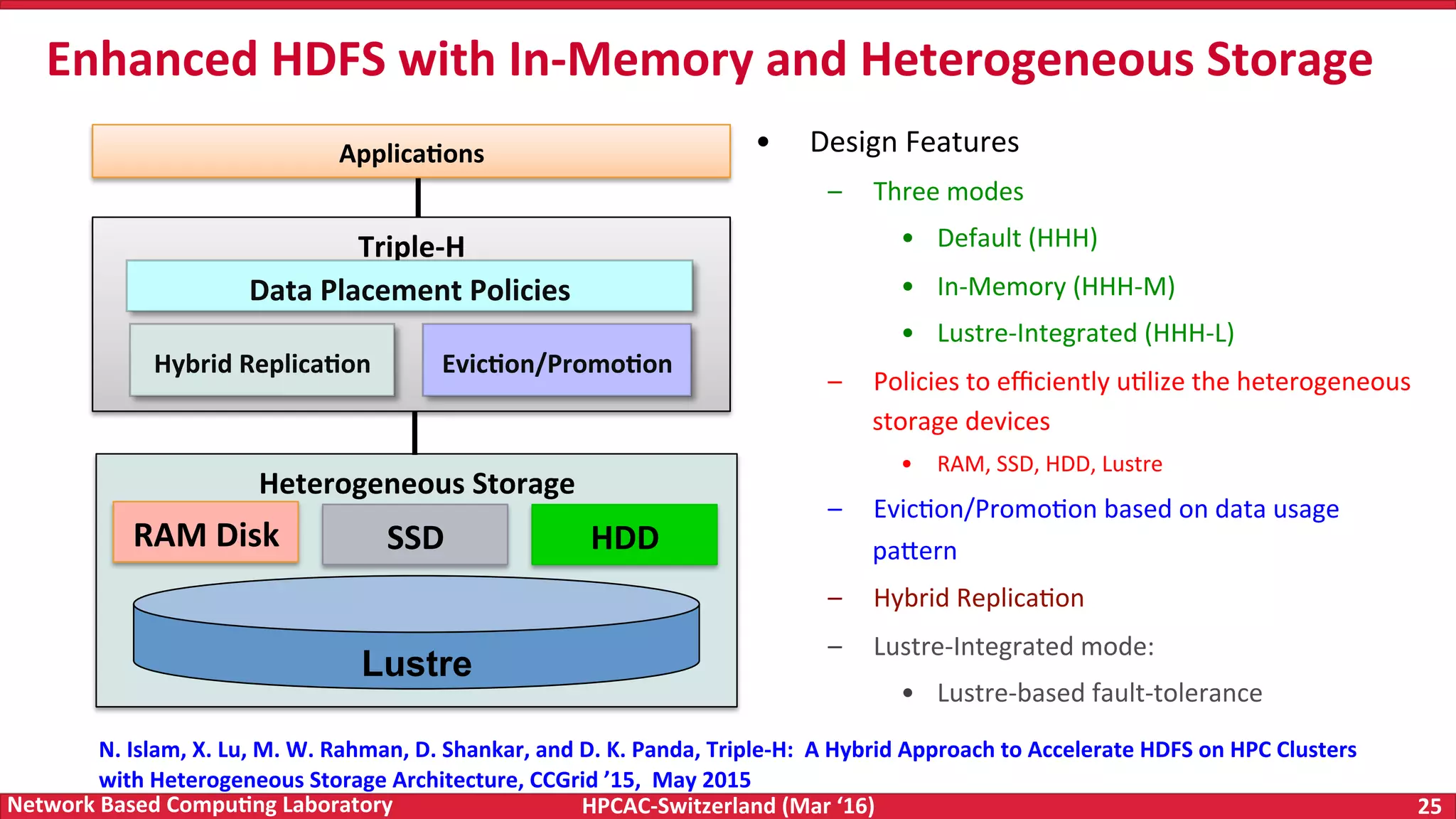
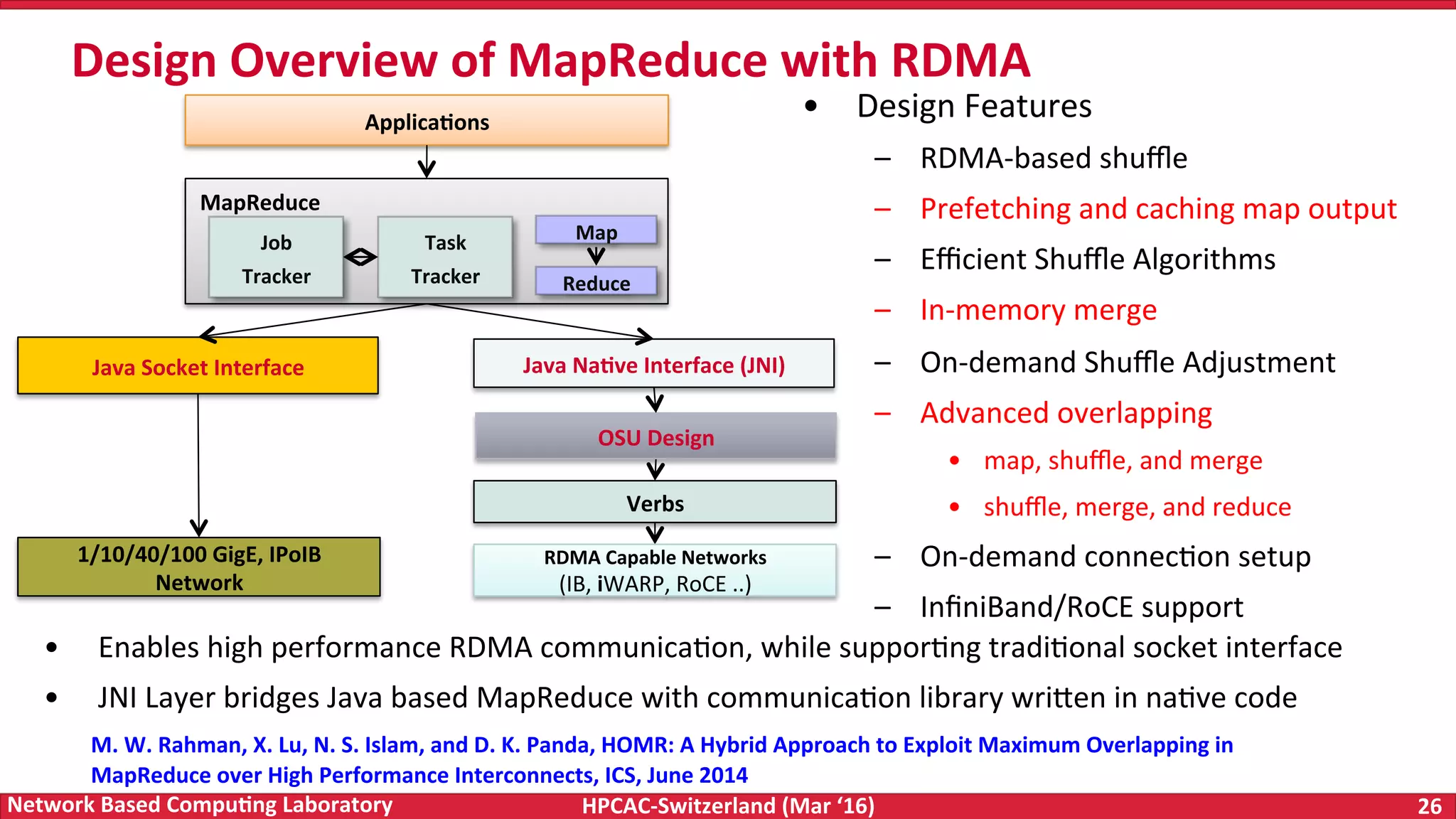
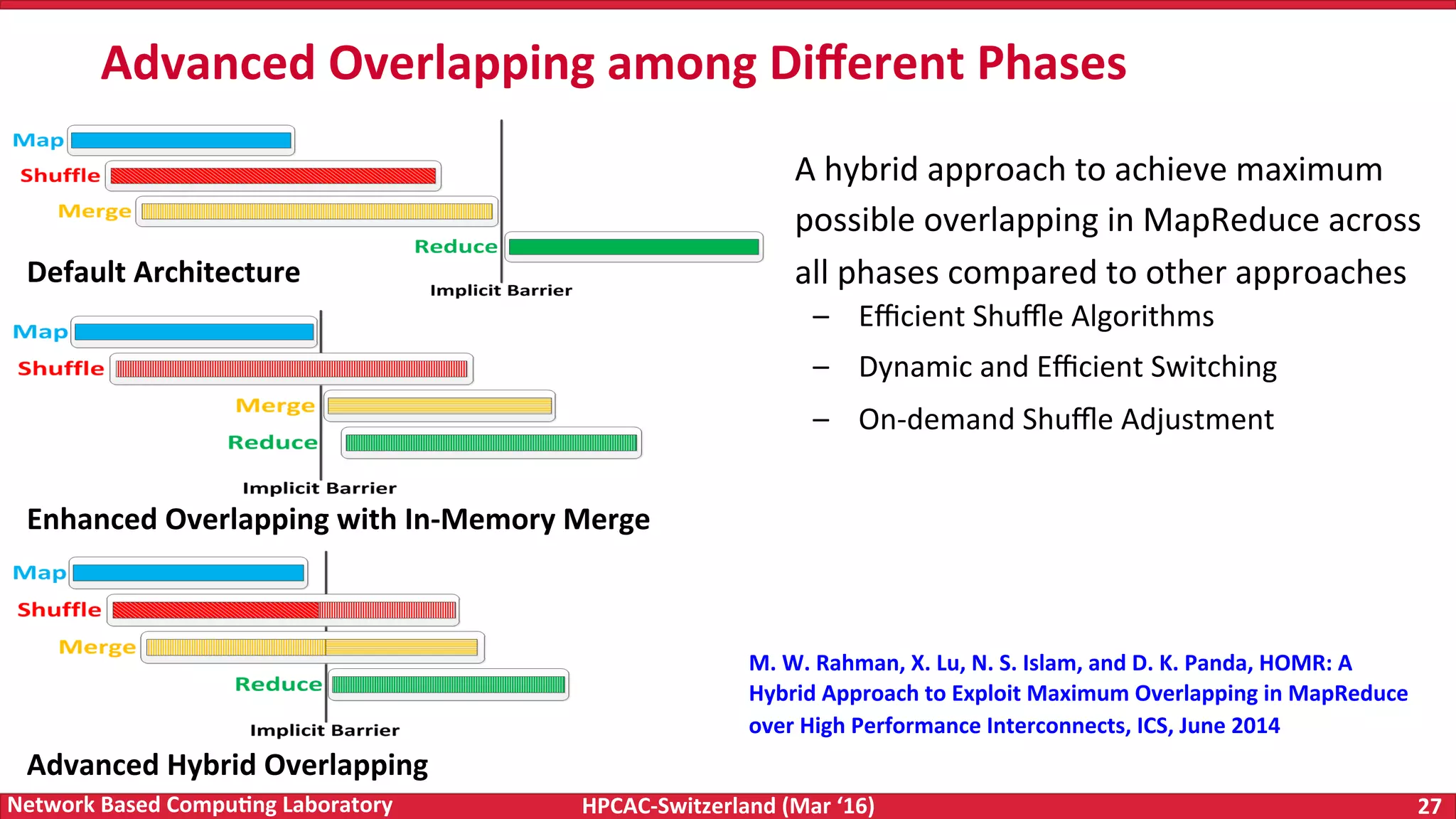
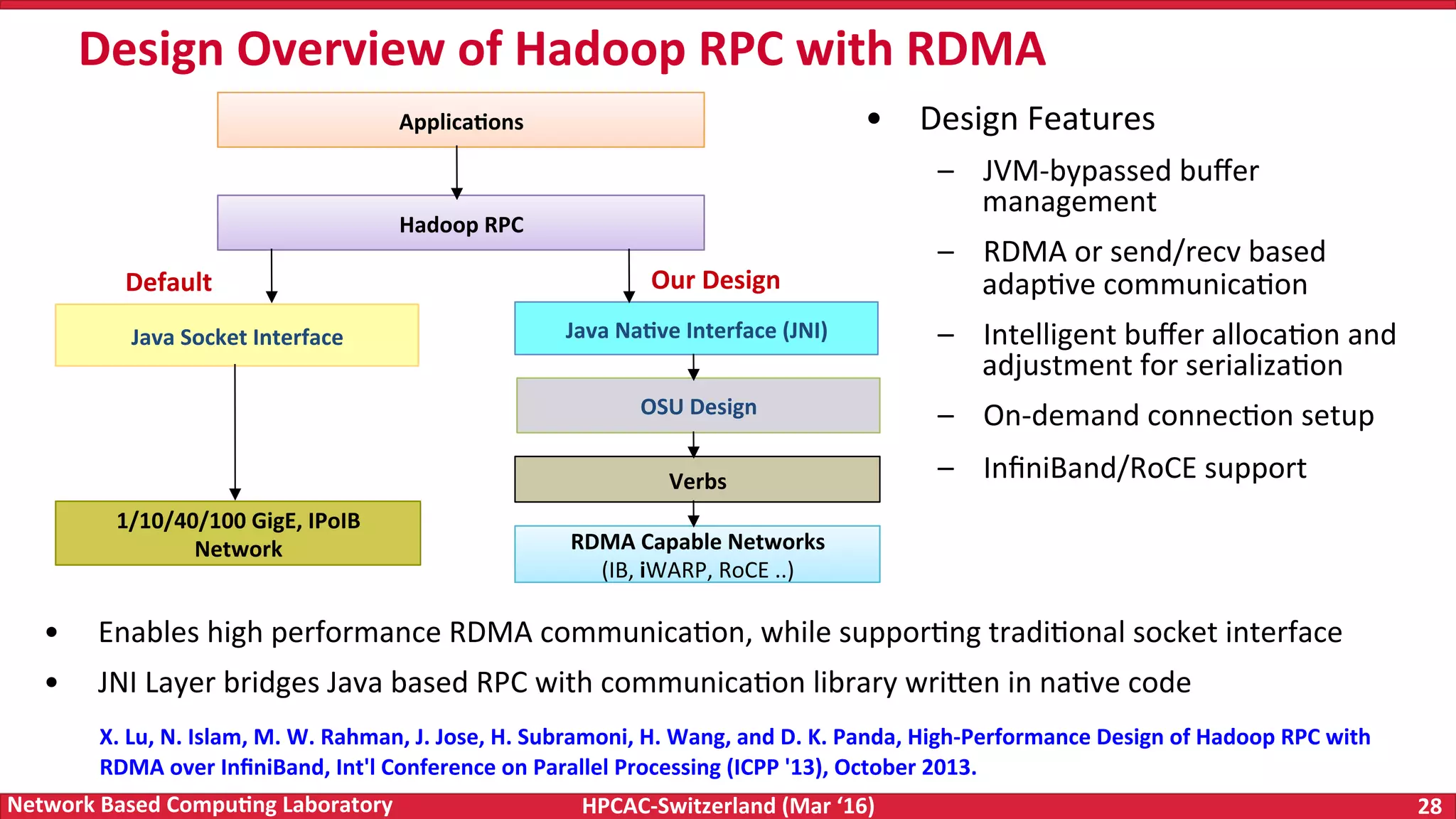
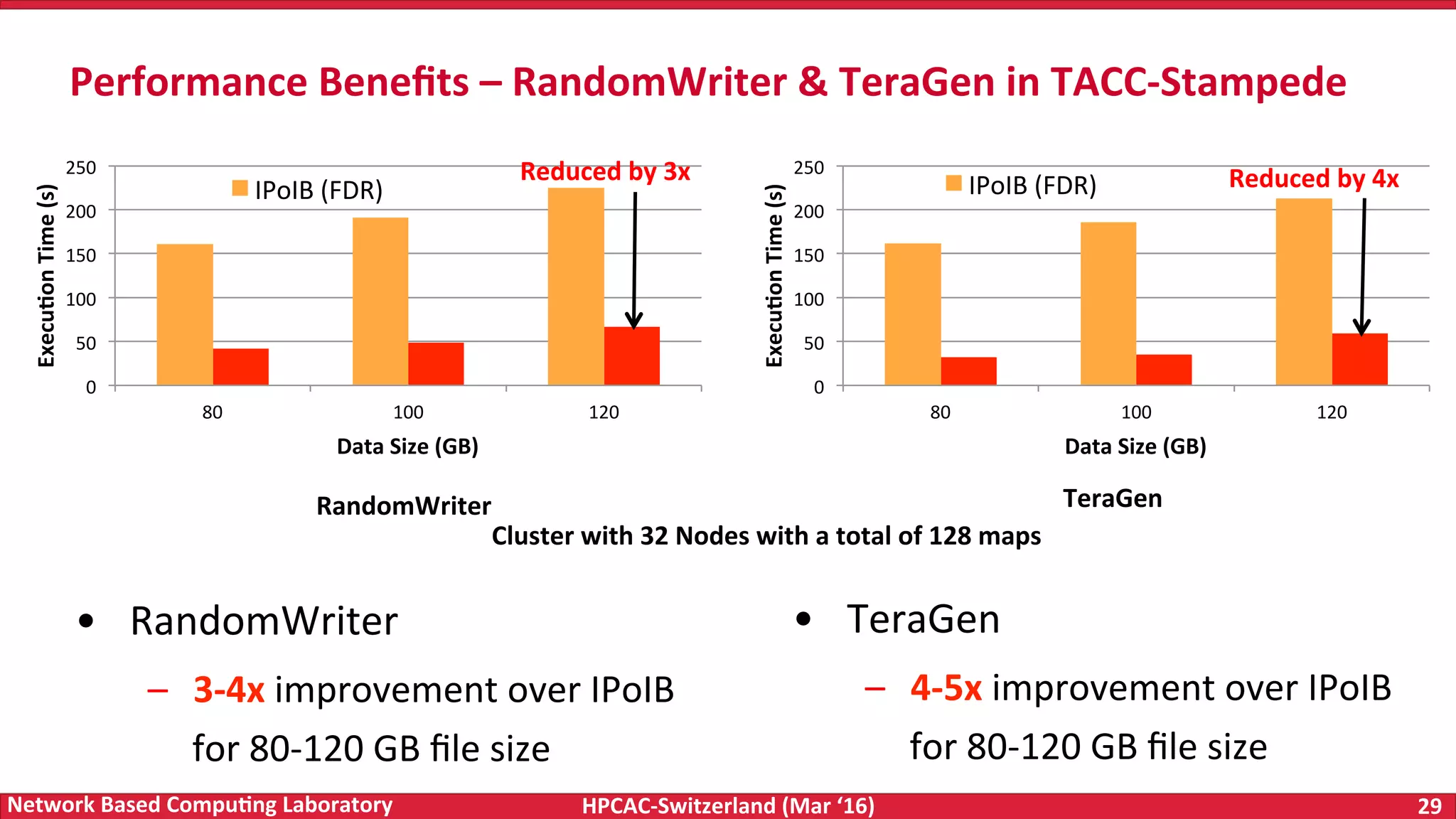
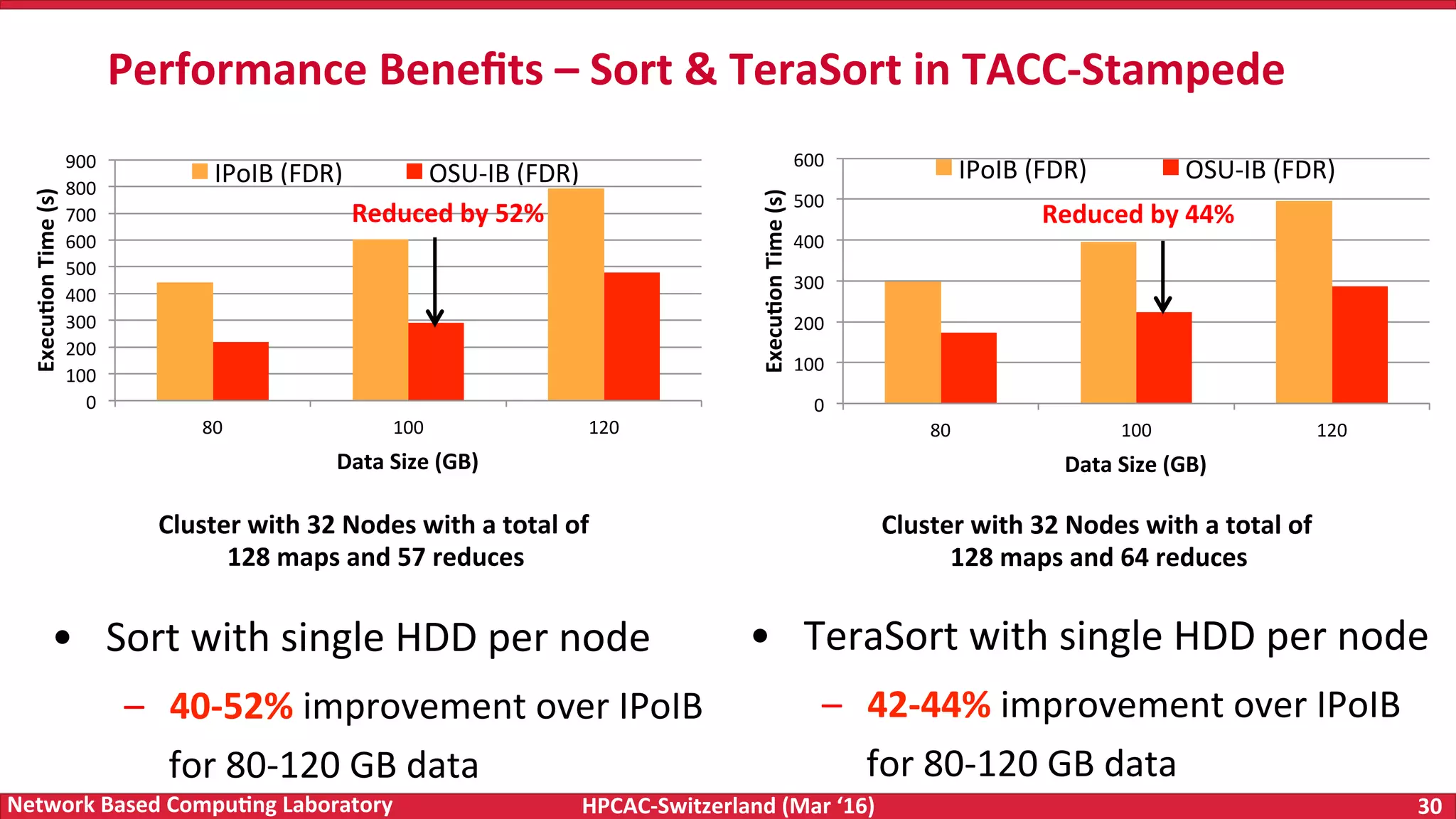
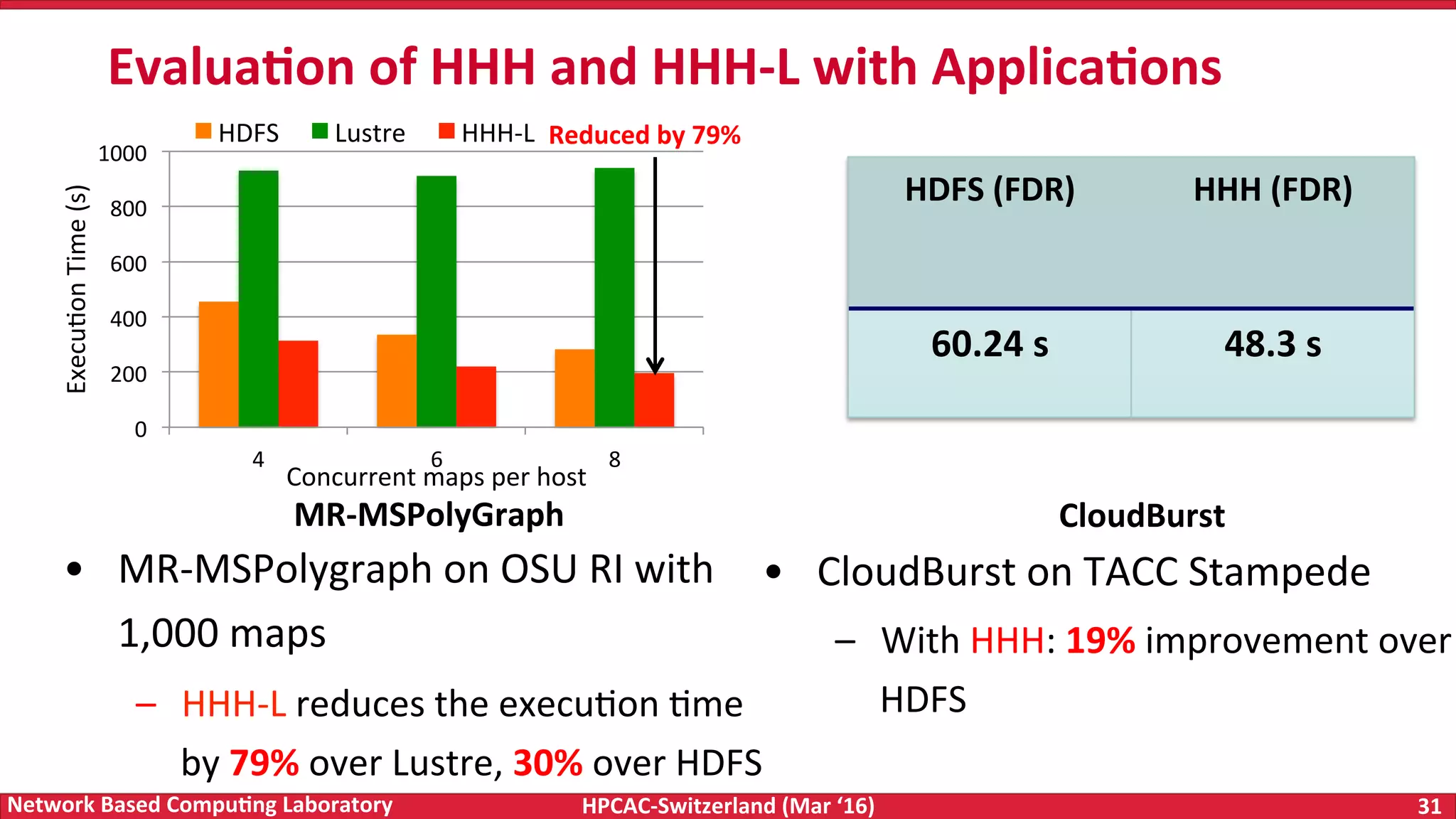
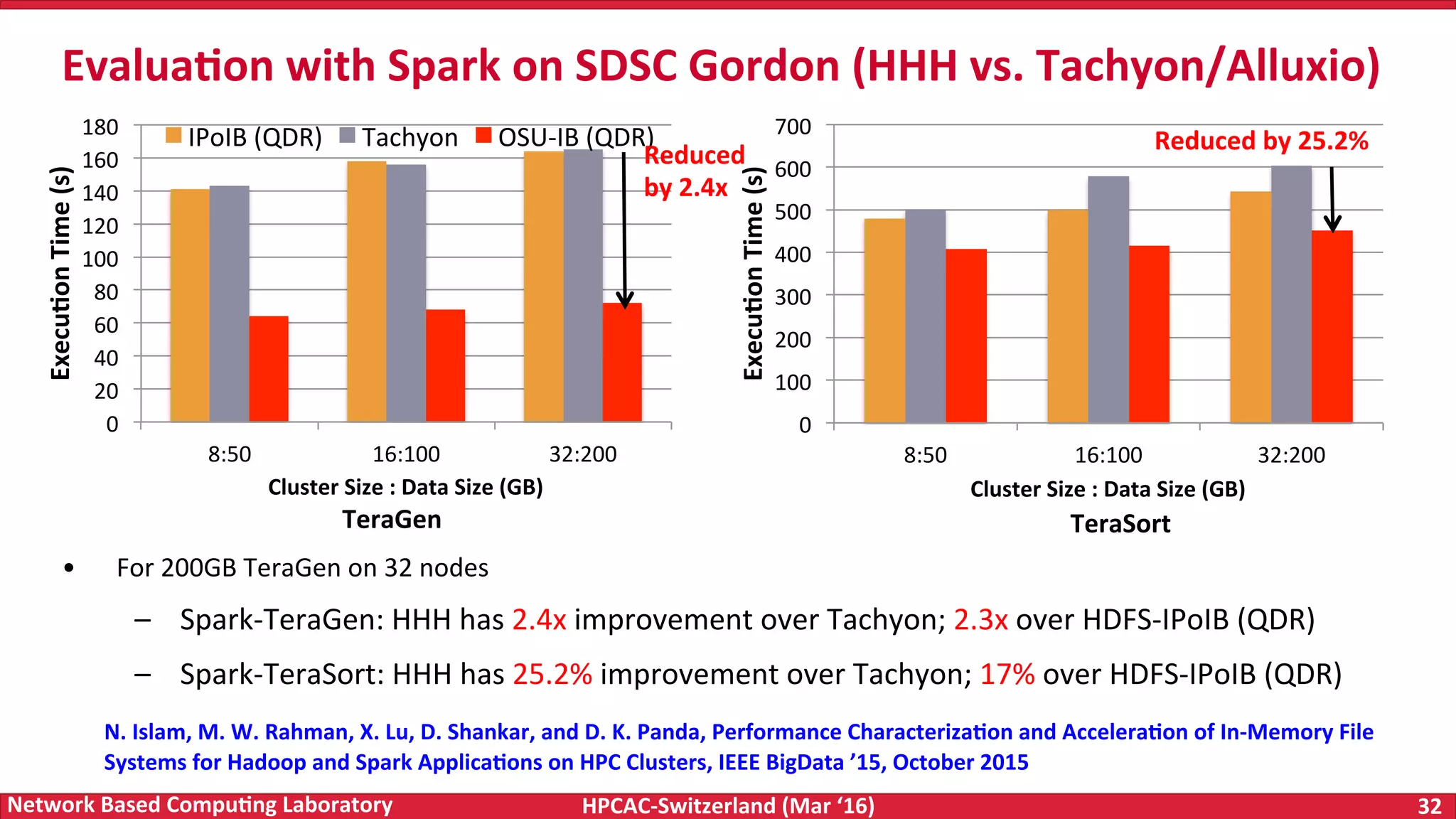
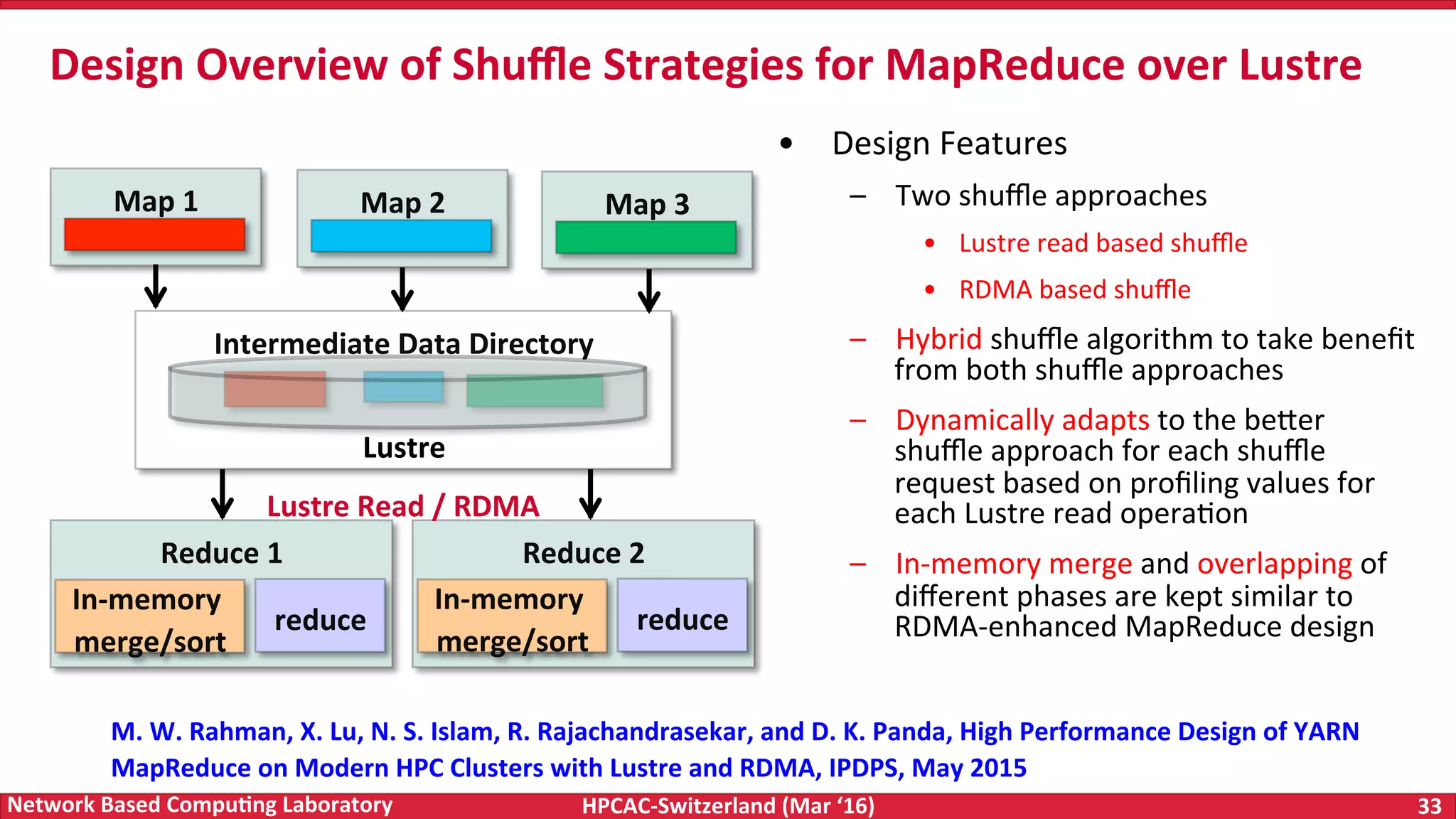
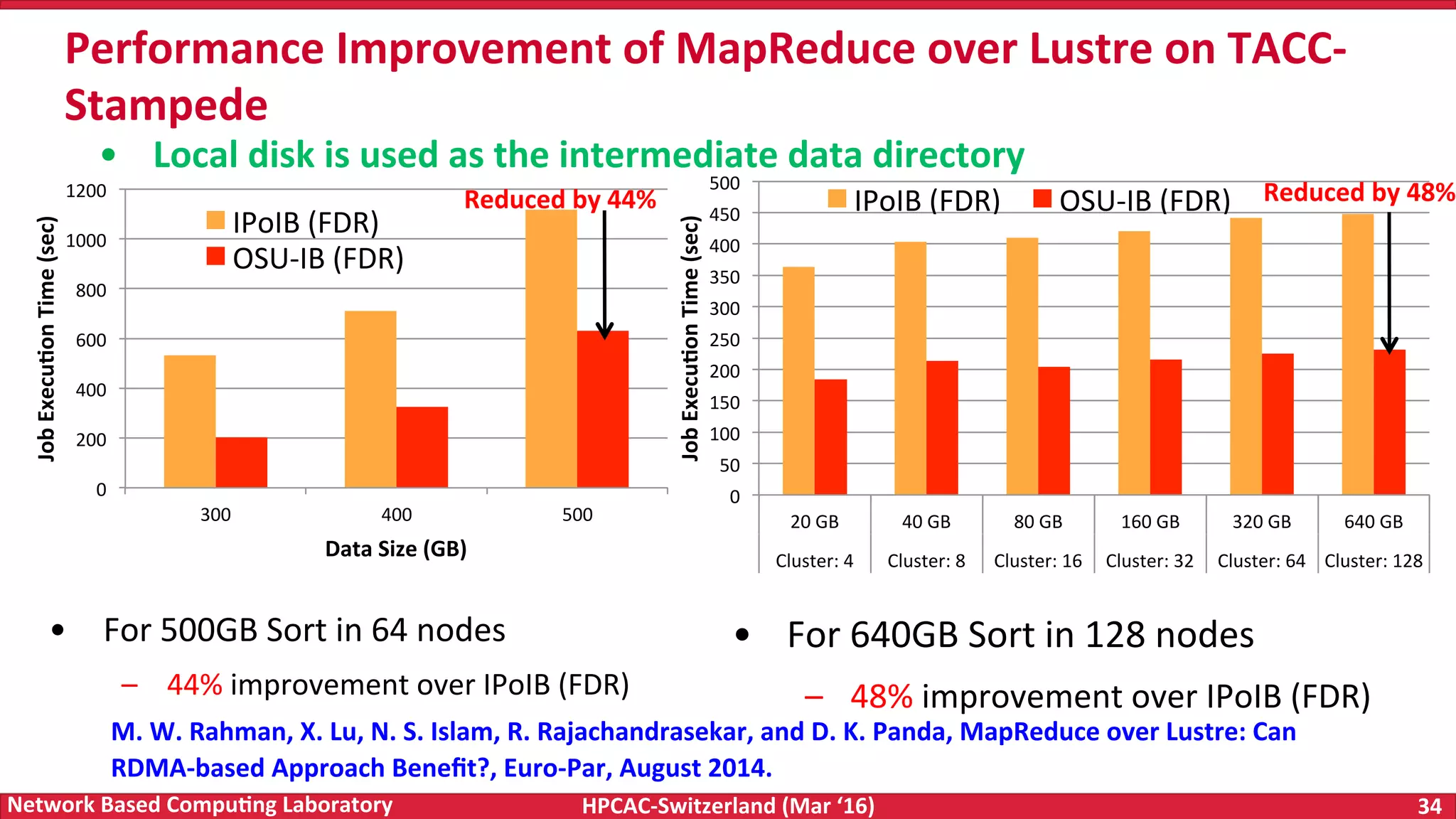
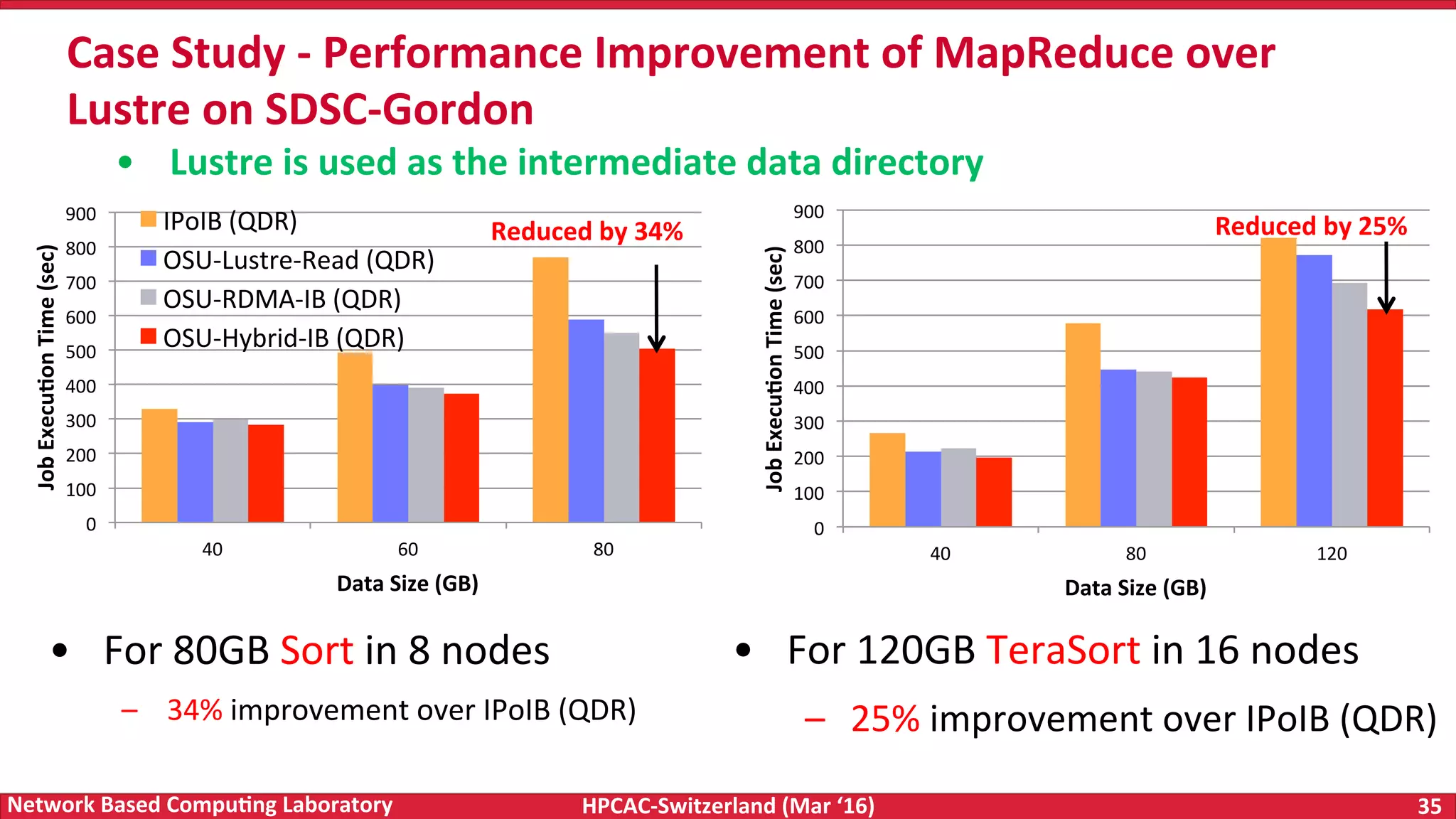

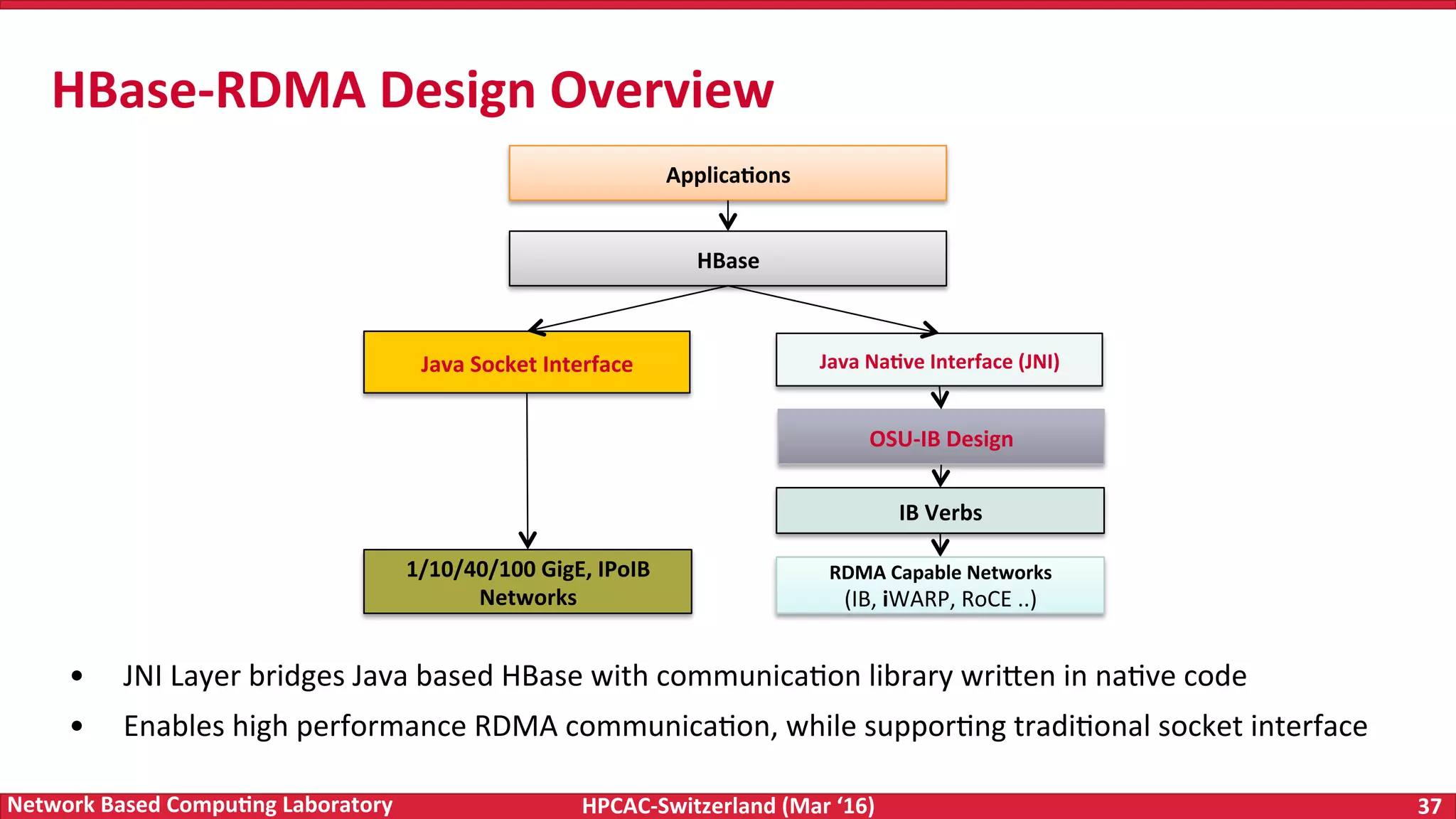
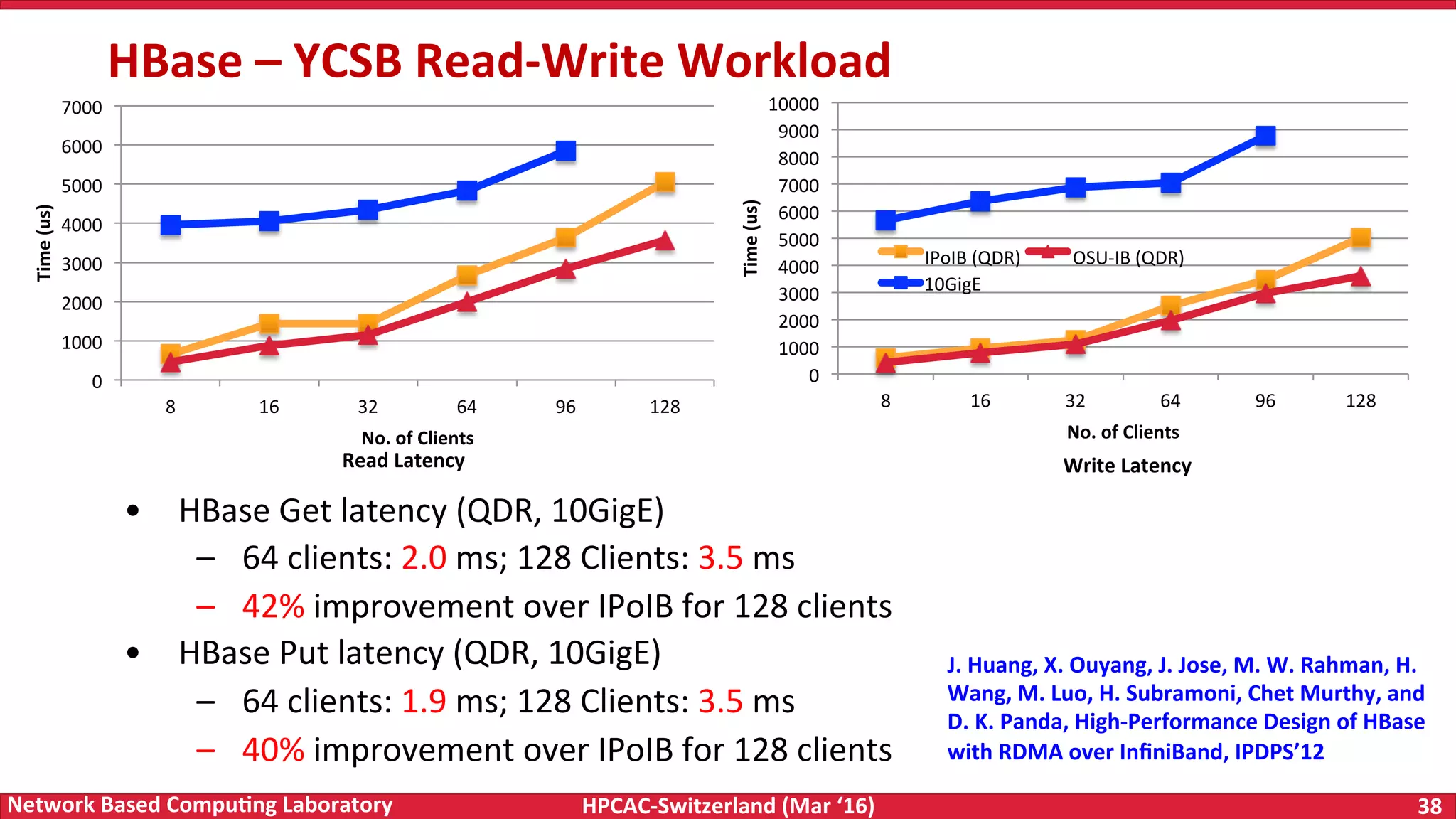

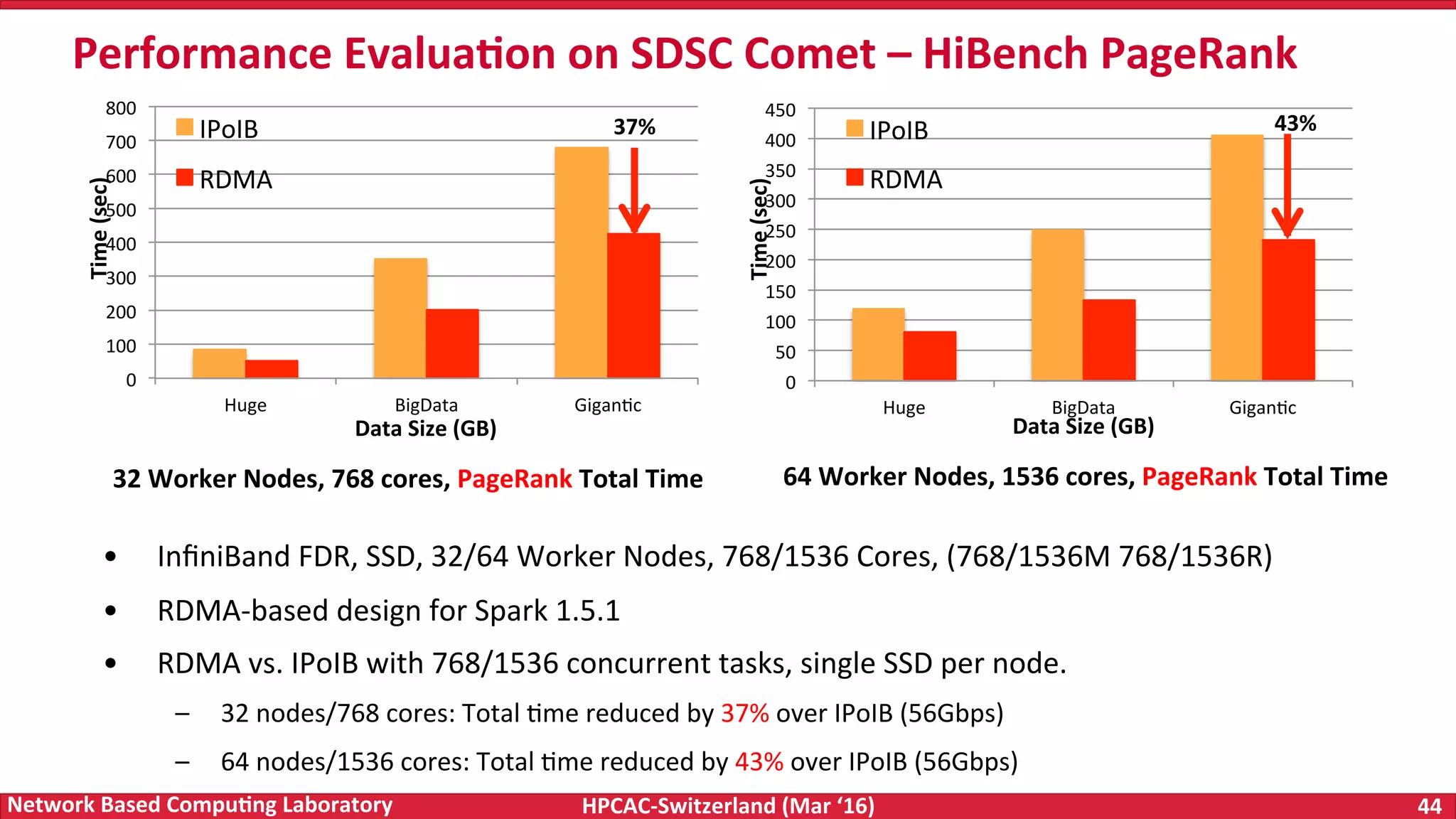

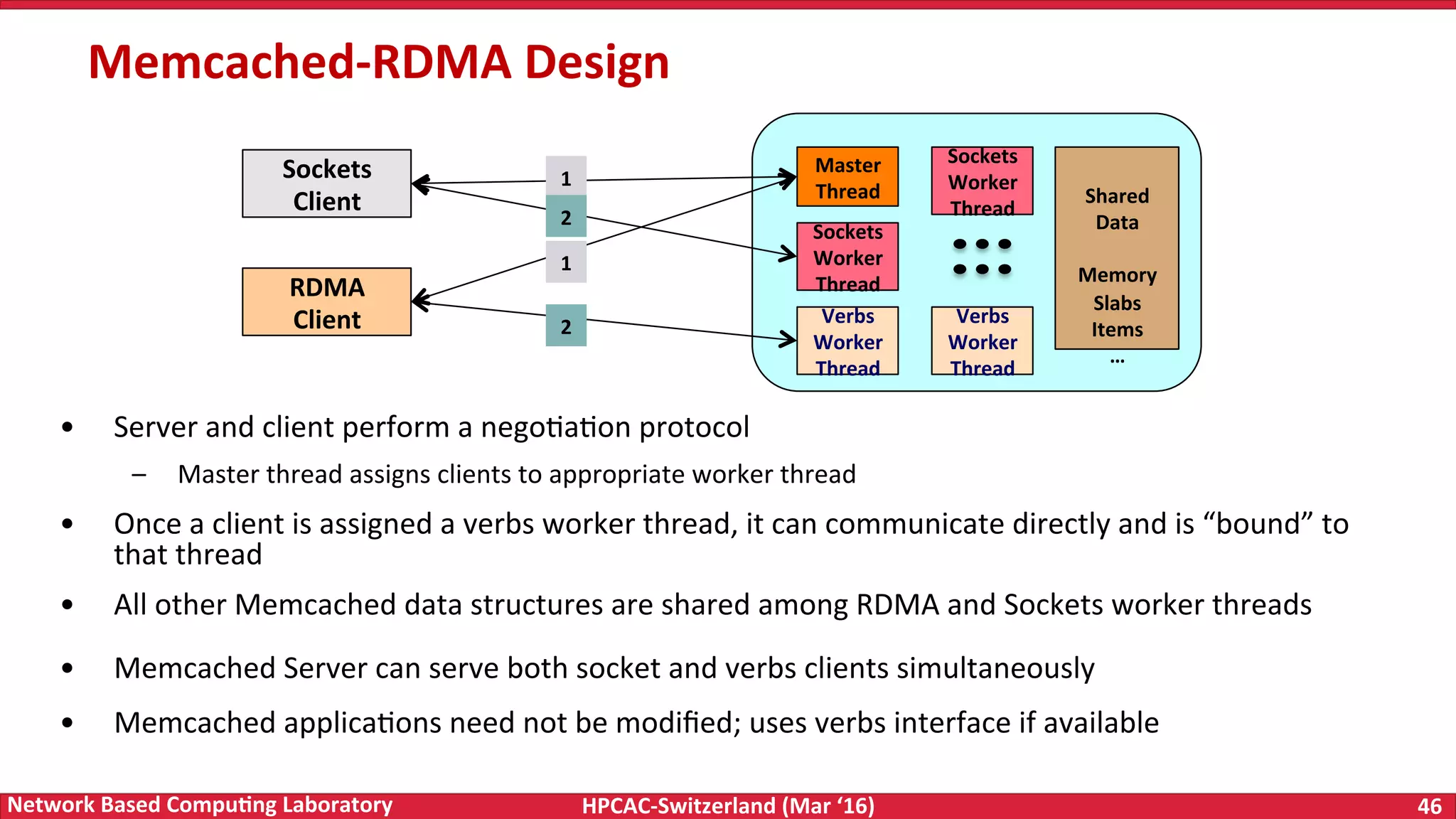
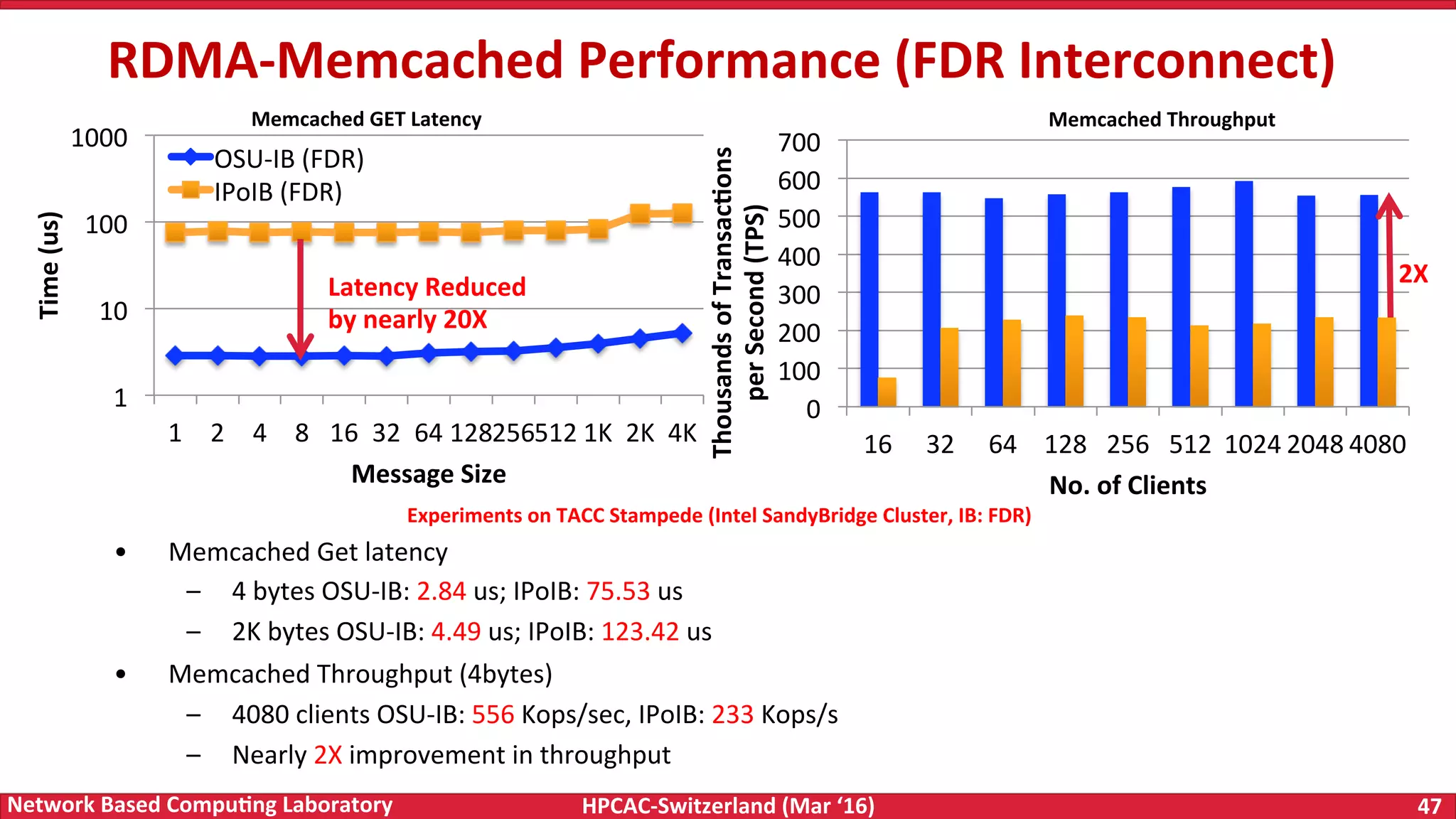
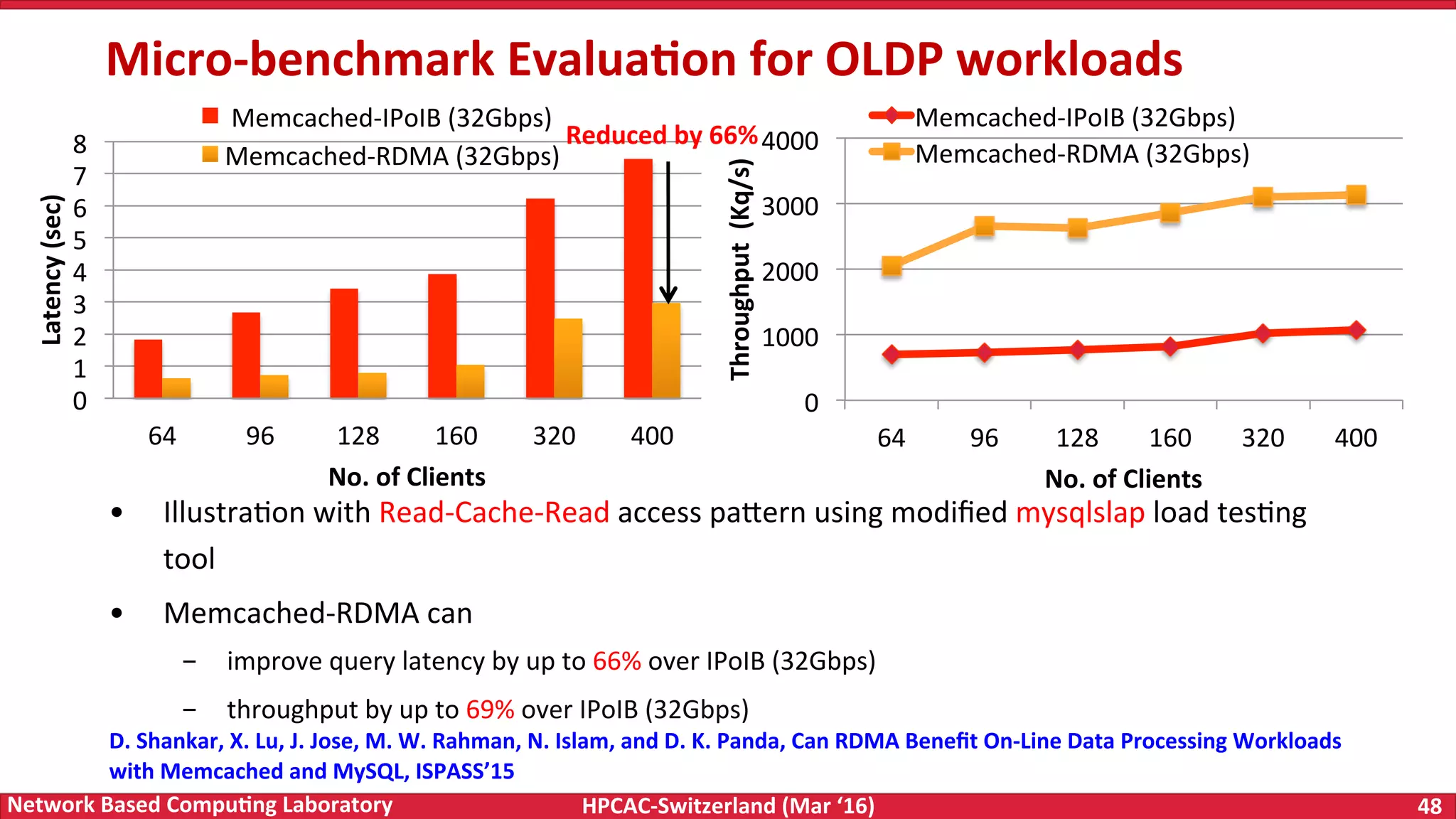
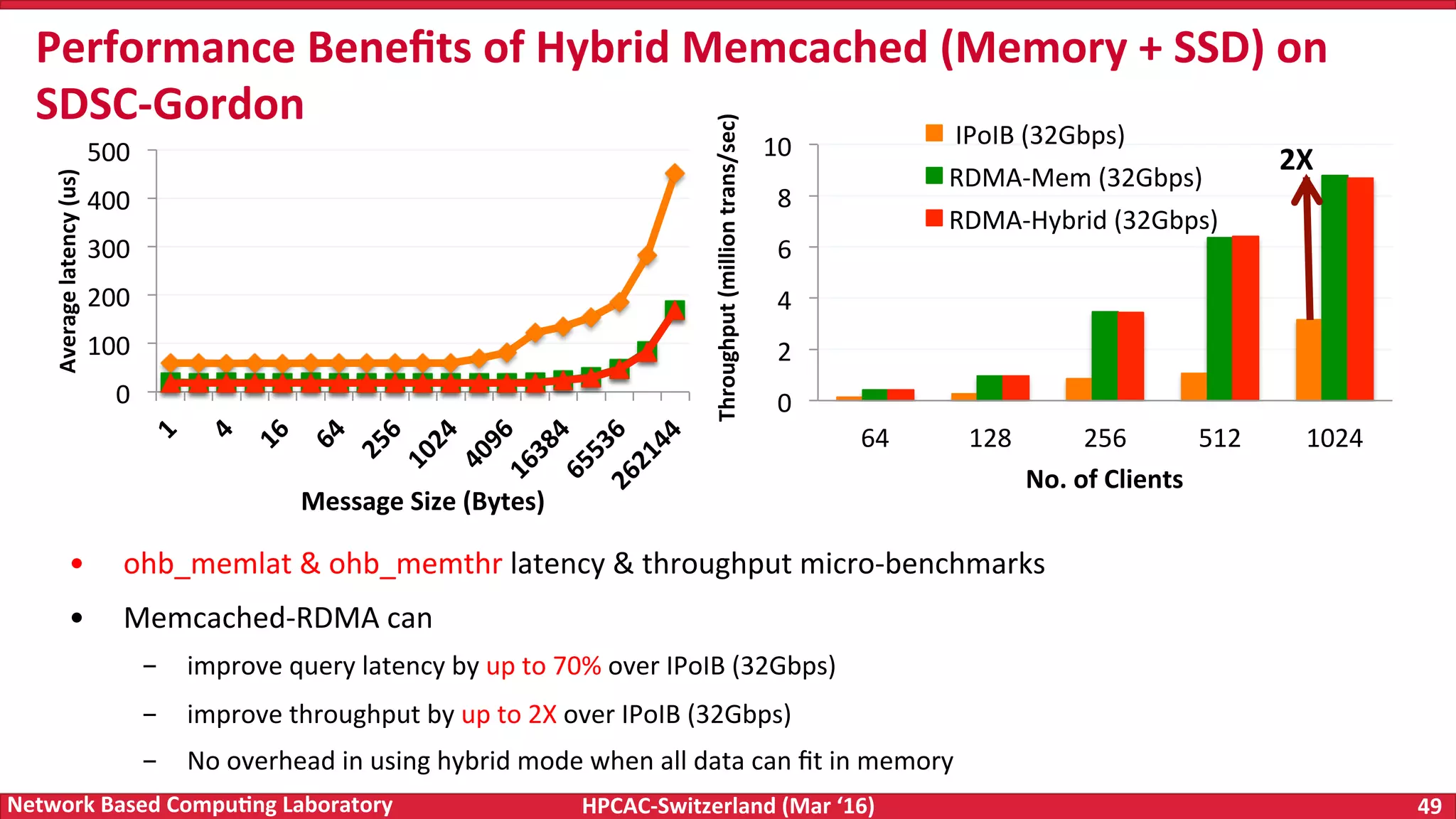

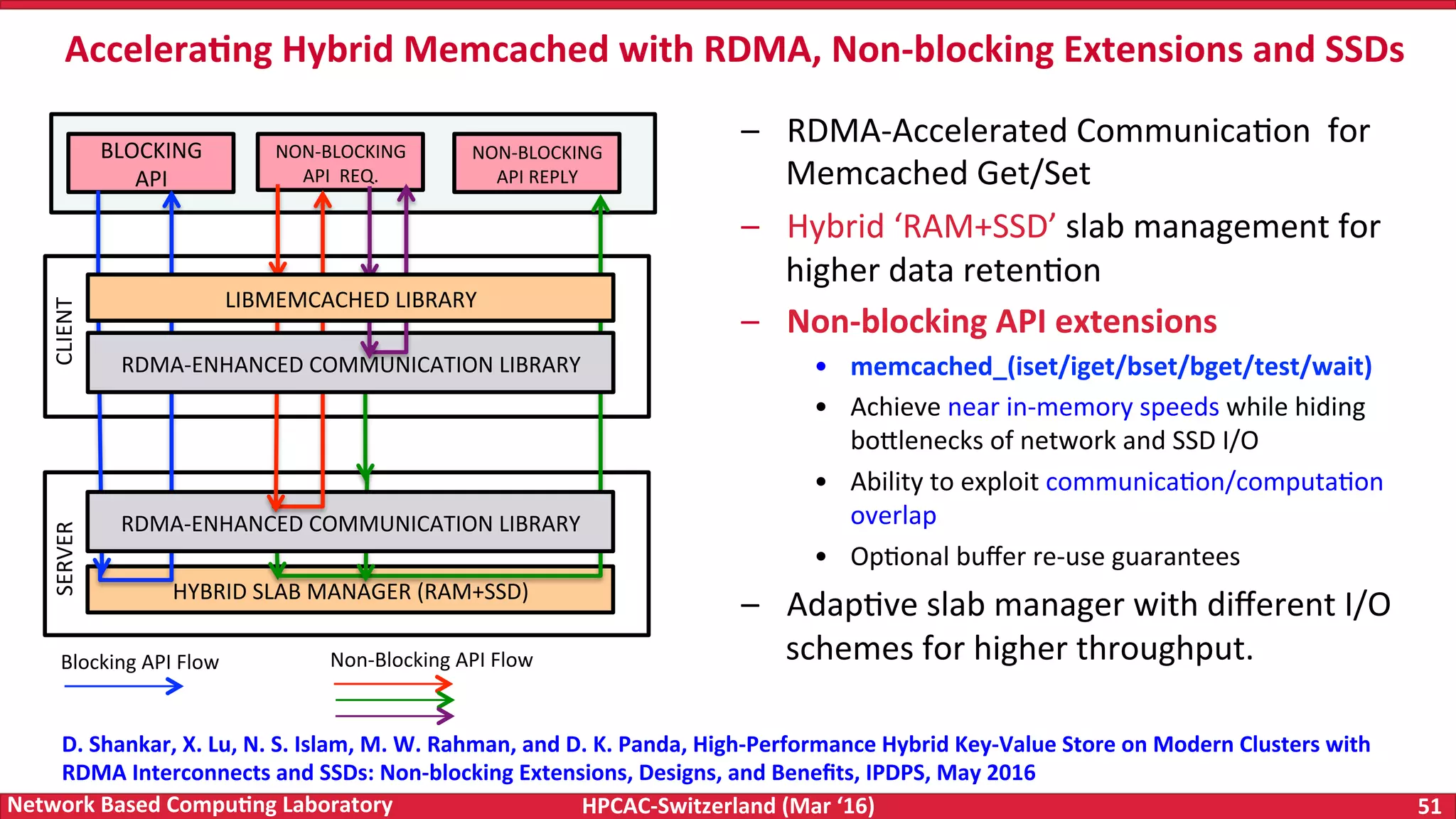
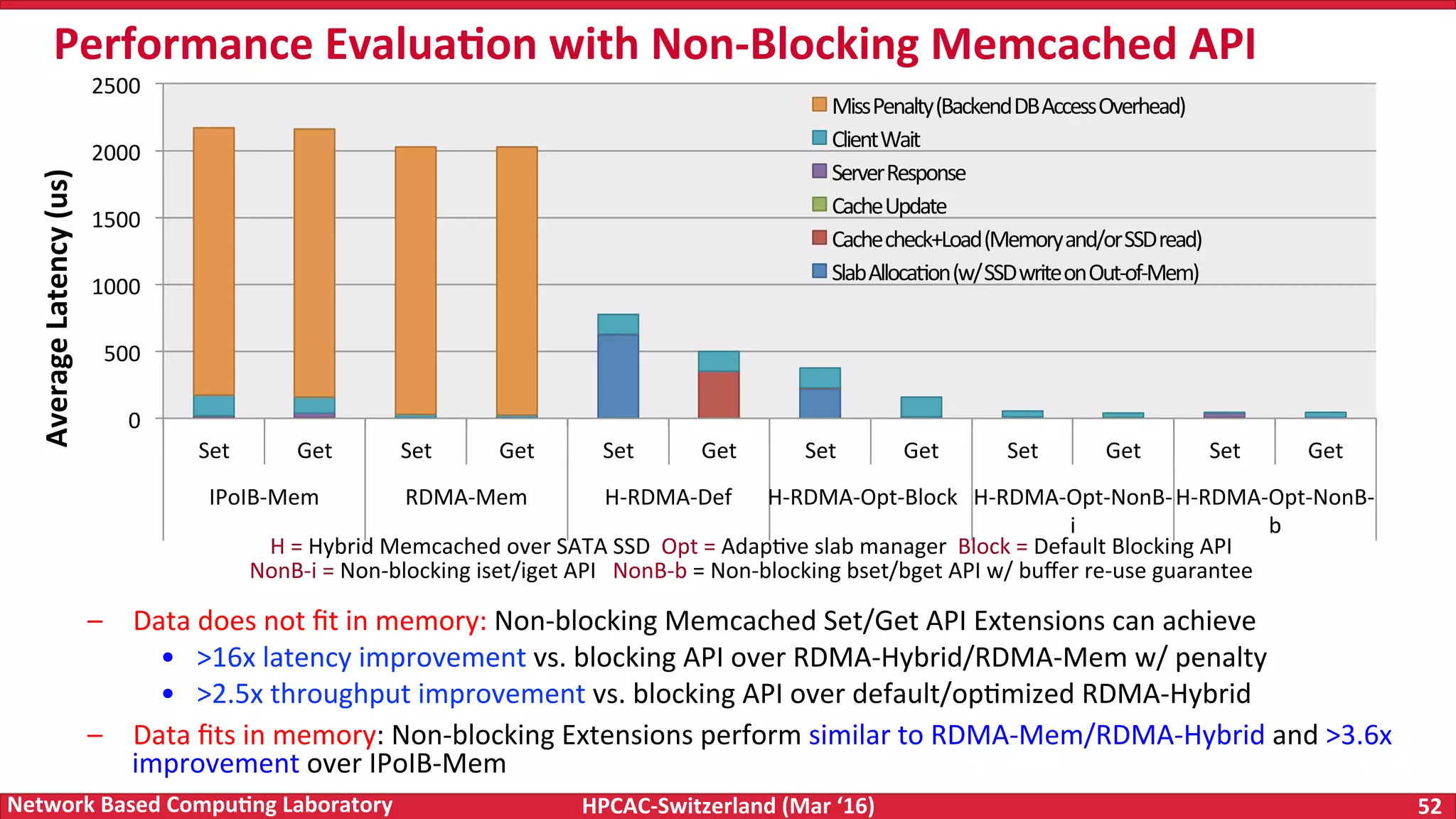

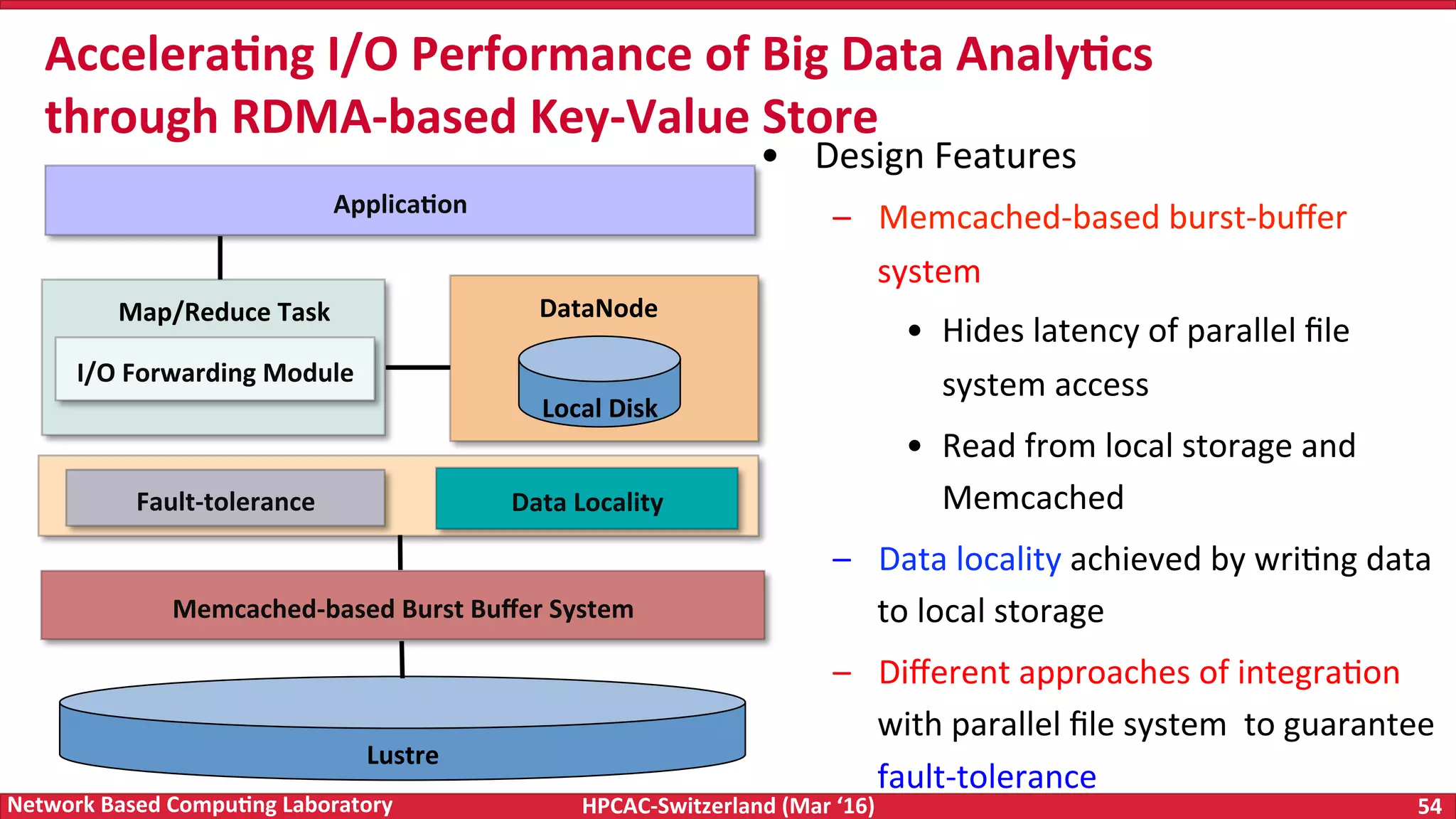
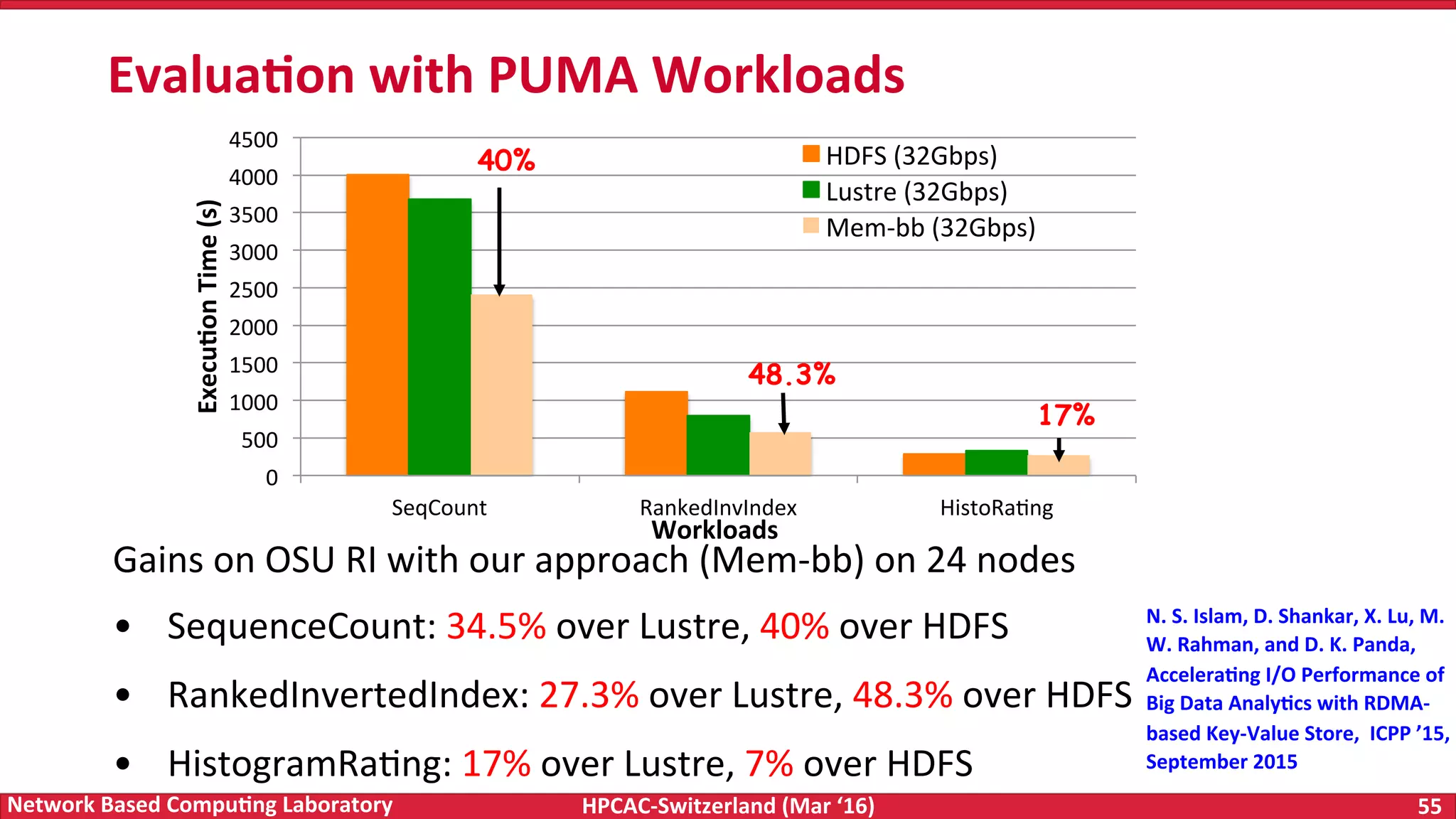


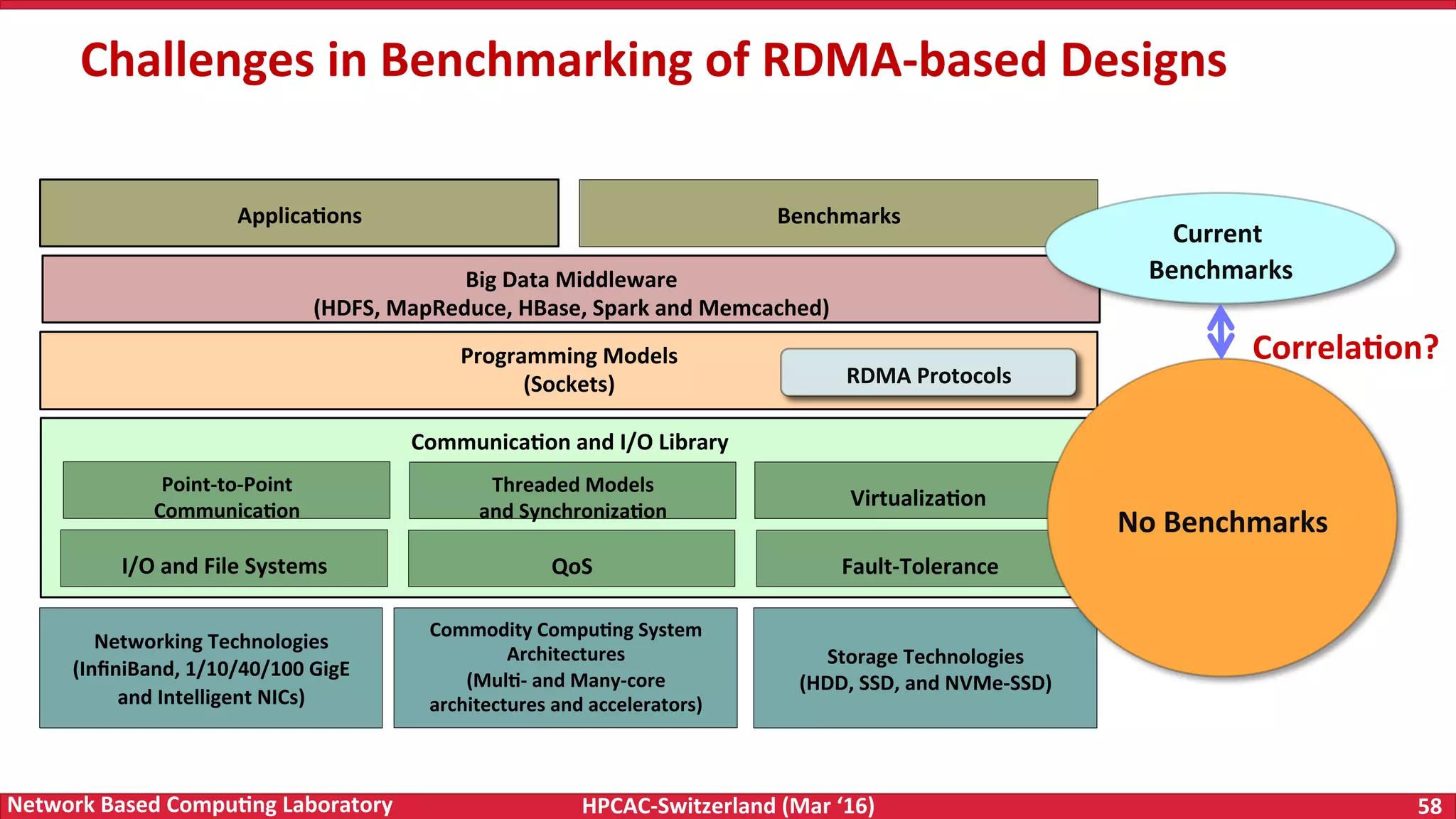

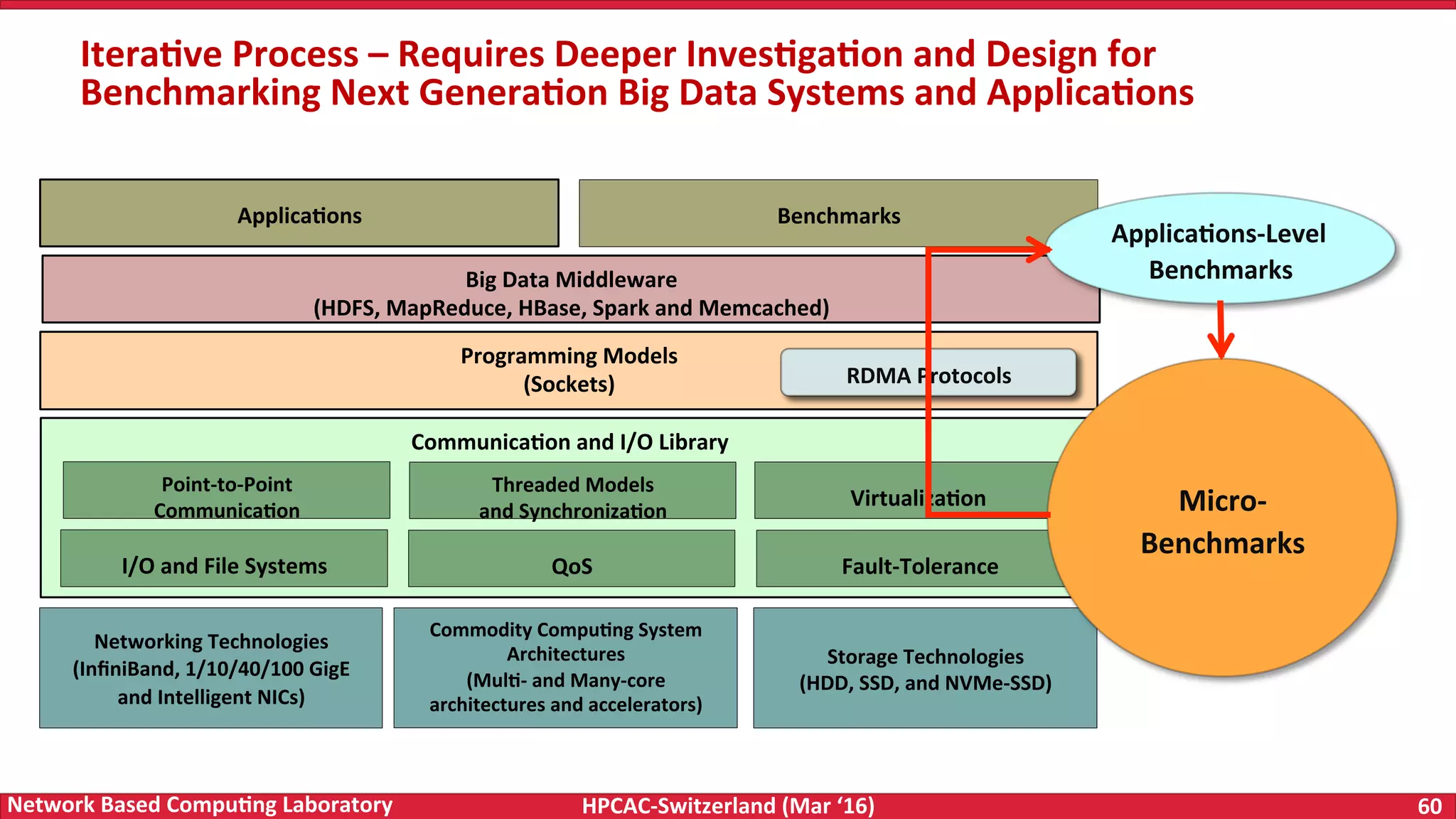








The document discusses the intersection of big data and high-performance computing (HPC), emphasizing the exploding data growth and its significance in business analytics and scientific applications. It explores various technologies, frameworks, and methodologies, specifically how HPC technologies can enhance big data processing, including utilizing RDMA-enabled interconnects and optimizing existing data processing systems like Hadoop and Spark. The presentation underscores the challenges, potential bottlenecks in current big data middleware, and proposes enhancements to improve performance and scalability in data management and processing frameworks.