































![WordCount (Driver) Job job = Job.getInstance(new Configuration()); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordMapper.class); job.setReducerClass(SumReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setJarByClass(WordCount.class); job.submit(); } } import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCount { public static void main(String[] args) throws Exception { if (args.length != 2) { System.out.println("usage: [input] [output]"); System.exit(-1); }](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-44-2048.jpg)
![public class WordCount { public static void main(String[] args) throws Exception { if (args.length != 2) { System.out.println("usage: [input] [output]"); System.exit(-1); } Job job = Job.getInstance(new Configuration()); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordMapper.class); job.setReducerClass(SumReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setJarByClass(WordCount.class); job.submit(); } } Check Input and Output files WordCount (Driver)](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-45-2048.jpg)
![Set output (key, value) types public class WordCount { public static void main(String[] args) throws Exception { if (args.length != 2) { System.out.println("usage: [input] [output]"); System.exit(-1); } Job job = Job.getInstance(new Configuration()); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordMapper.class); job.setReducerClass(SumReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setJarByClass(WordCount.class); job.submit(); } } WordCount (Driver)](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-46-2048.jpg)
![Set Mapper/Reducer classes public class WordCount { public static void main(String[] args) throws Exception { if (args.length != 2) { System.out.println("usage: [input] [output]"); System.exit(-1); } Job job = Job.getInstance(new Configuration()); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordMapper.class); job.setReducerClass(SumReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setJarByClass(WordCount.class); job.submit(); } } WordCount (Driver)](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-47-2048.jpg)
![Set Input/Output format classes public class WordCount { public static void main(String[] args) throws Exception { if (args.length != 2) { System.out.println("usage: [input] [output]"); System.exit(-1); } Job job = Job.getInstance(new Configuration()); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordMapper.class); job.setReducerClass(SumReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setJarByClass(WordCount.class); job.submit(); } } WordCount (Driver)](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-48-2048.jpg)
![Set Input/Output paths public class WordCount { public static void main(String[] args) throws Exception { if (args.length != 2) { System.out.println("usage: [input] [output]"); System.exit(-1); } Job job = Job.getInstance(new Configuration()); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordMapper.class); job.setReducerClass(SumReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setJarByClass(WordCount.class); job.submit(); } } WordCount (Driver)](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-49-2048.jpg)
![Set Driver class public class WordCount { public static void main(String[] args) throws Exception { if (args.length != 2) { System.out.println("usage: [input] [output]"); System.exit(-1); } Job job = Job.getInstance(new Configuration()); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordMapper.class); job.setReducerClass(SumReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setJarByClass(WordCount.class); job.submit(); } } WordCount (Driver)](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-50-2048.jpg)
![Submit the job to the master node public class WordCount { public static void main(String[] args) throws Exception { if (args.length != 2) { System.out.println("usage: [input] [output]"); System.exit(-1); } Job job = Job.getInstance(new Configuration()); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordMapper.class); job.setReducerClass(SumReducer.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setJarByClass(WordCount.class); job.submit(); } } WordCount (Driver)](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-51-2048.jpg)

















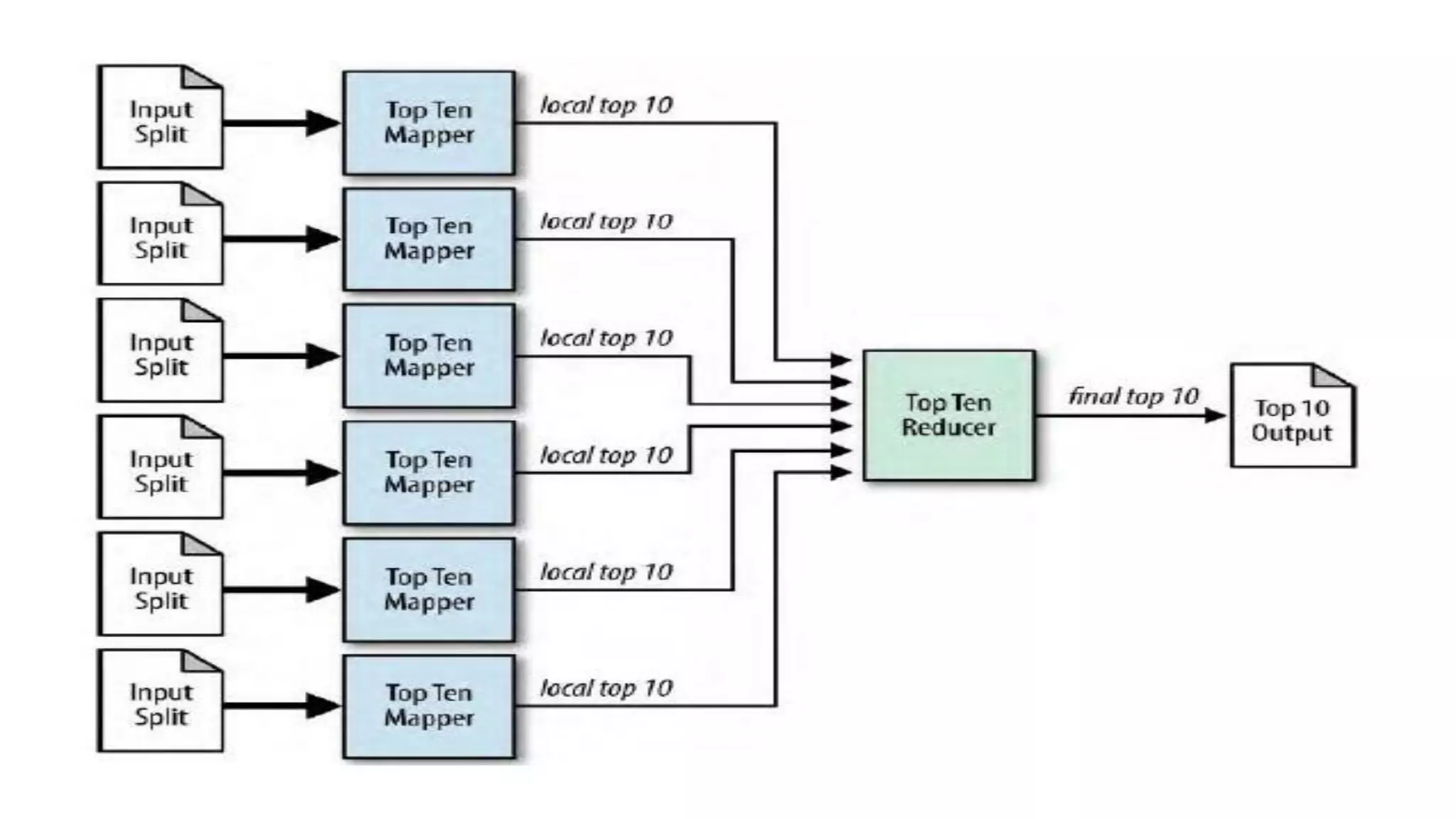
![TopN(Driver) Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); if (otherArgs.length != 2) { System.err.println("Usage: TopN <in> <out>"); System.exit(2); } Job job = Job.getInstance(conf); job.setJobName("Top N"); job.setJarByClass(TopN.class); job.setMapperClass(TopNMapper.class); //job.setCombinerClass(TopNReducer.class); job.setReducerClass(TopNReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(otherArgs[0])); FileOutputFormat.setOutputPath(job, new Path(otherArgs[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } } import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.GenericOptionsParser; import java.io.IOException; import java.util.*; public class TopN { public static void main(String[] args) throws Exception {](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-70-2048.jpg)
![TopNMapper /** * The mapper reads one line at the time, splits it into an array of single words and emits every * word to the reducers with the value of 1. */ public static class TopNMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); private String tokens = "[_|$#<>^=[]*/,;,.-:()?!"']"; @Override public void map(Object key, Text value, Context context) throws IOException, InterruptedException { String cleanLine = value.toString().toLowerCase().replaceAll(tokens, " "); StringTokenizer itr = new StringTokenizer(cleanLine); while (itr.hasMoreTokens()) { word.set(itr.nextToken().trim()); context.write(word, one); } } }](https://image.slidesharecdn.com/bigdataanalyticswithapache-hadoop-150212103110-conversion-gate01/75/Big-data-analytics-with-Apache-Hadoop-71-2048.jpg)








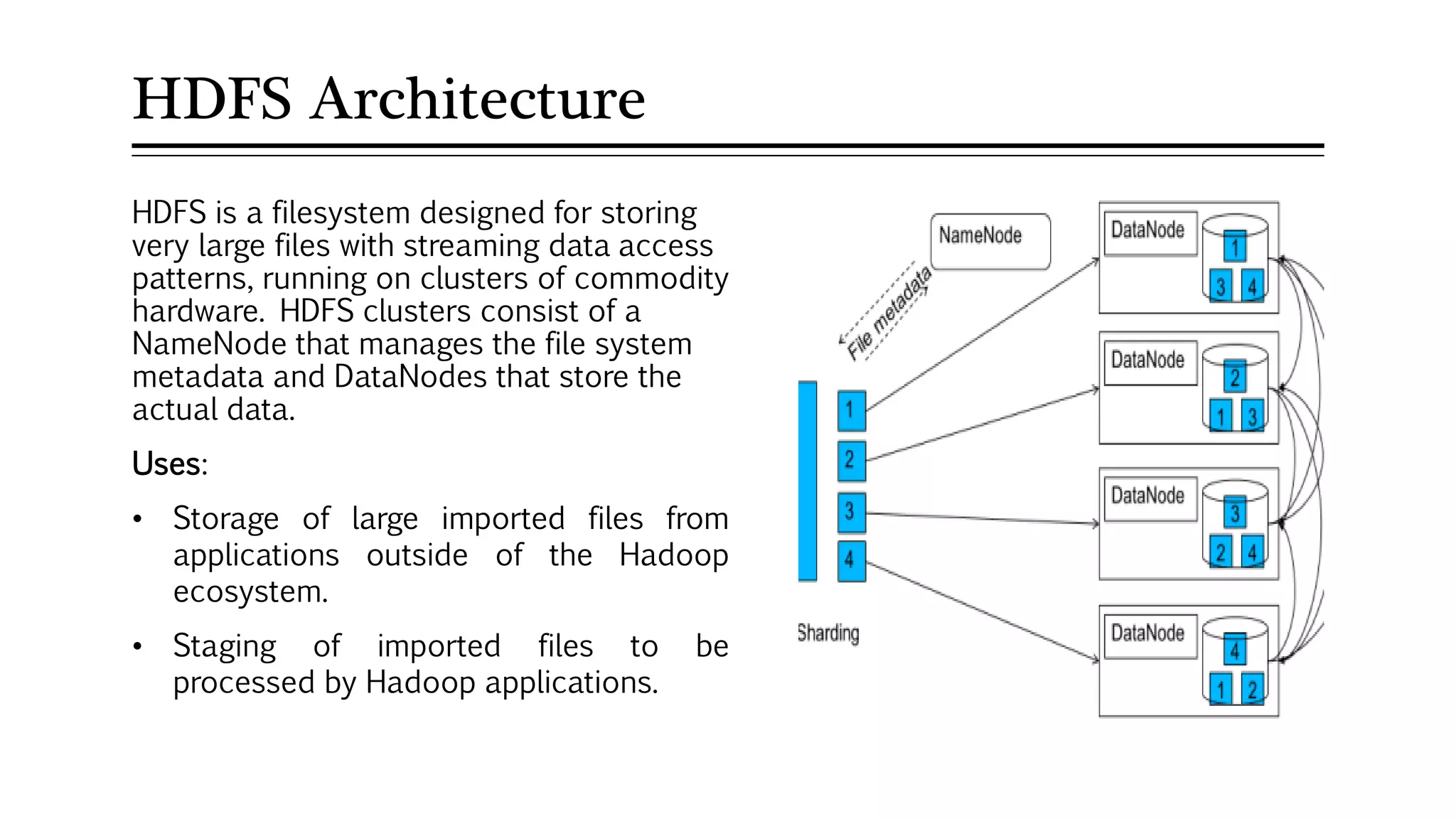
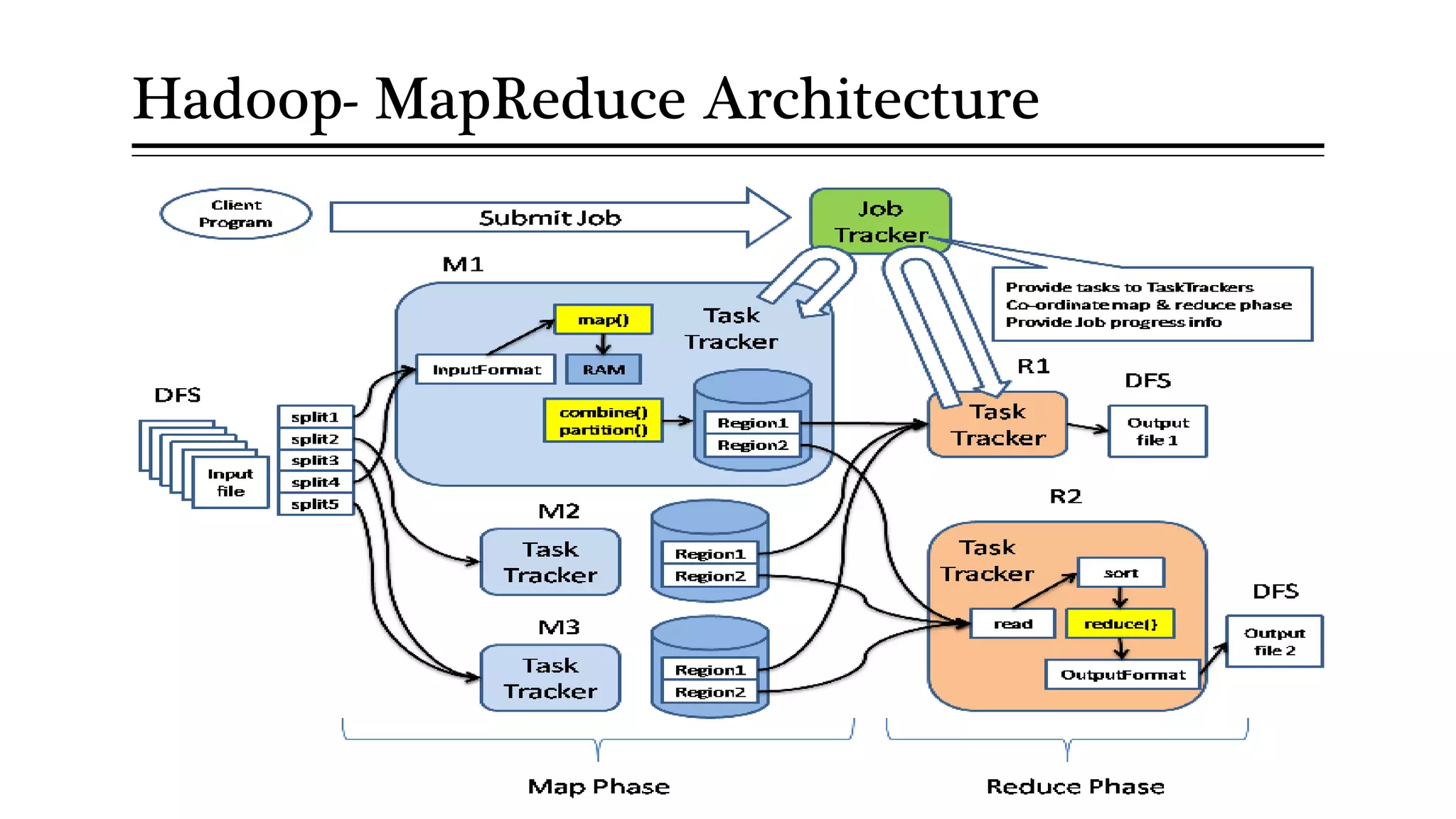
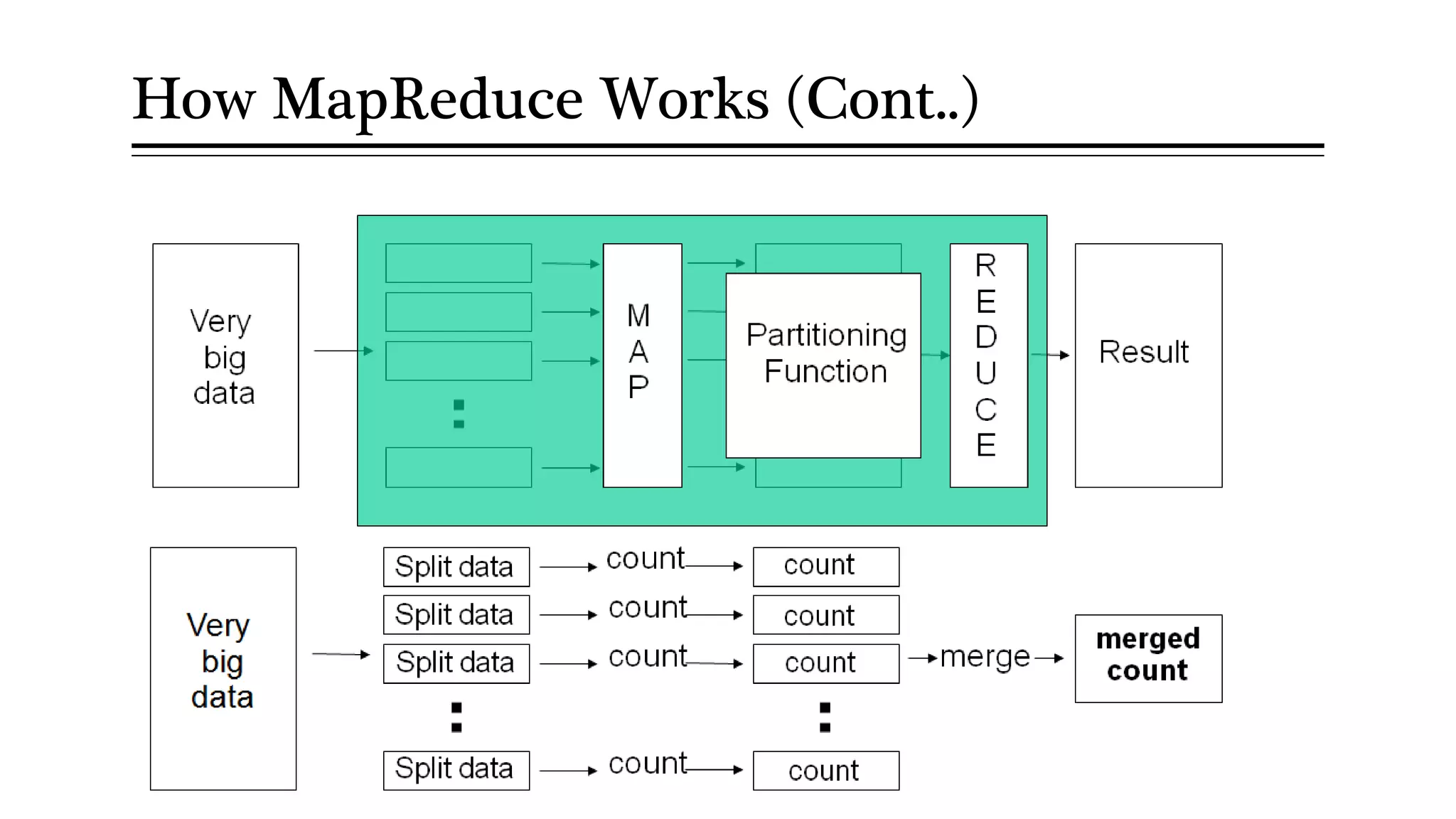
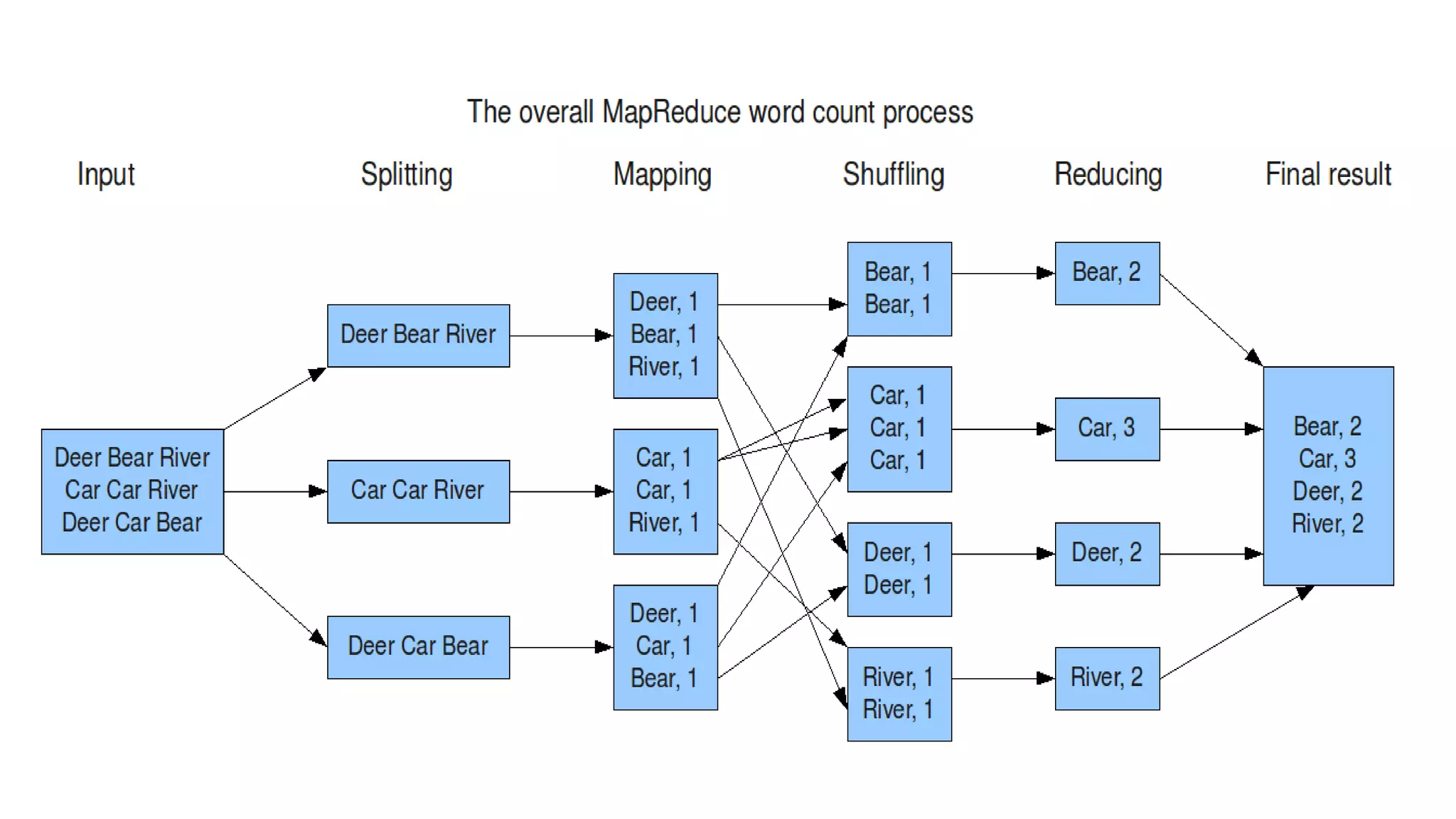
MapReduce allows distributed processing of large datasets across clusters of computers. It works by splitting the input data into independent chunks which are processed by the map function in parallel. The map function produces intermediate key-value pairs which are grouped by the reduce function to form the output data. Fault tolerance is achieved through replication of data across nodes and re-executing failed tasks. This makes MapReduce suitable for efficiently processing very large datasets in a distributed environment.