Downloaded 124 times






















![NumPy Examples 2d array 3d array [439 472 477] [217 205 261 222 245 238] 9.98330639789 2.96677717122](https://image.slidesharecdn.com/columbialecturefeb2020-200214034342/75/Array-computing-and-the-evolution-of-SciPy-NumPy-and-PyData-37-2048.jpg)
![NumPy Slicing (Selection) >>> a[0,3:5] array([3, 4]) >>> a[4:,4:] array([[44, 45], [54, 55]]) >>> a[:,2] array([2,12,22,32,42,52]) 50 51 52 53 54 55 40 41 42 43 44 45 30 31 32 33 34 35 20 21 22 23 24 25 10 11 12 13 14 15 0 1 2 3 4 5 >>> a[2::2,::2] array([[20, 22, 24], [40, 42, 44]])](https://image.slidesharecdn.com/columbialecturefeb2020-200214034342/75/Array-computing-and-the-evolution-of-SciPy-NumPy-and-PyData-38-2048.jpg)














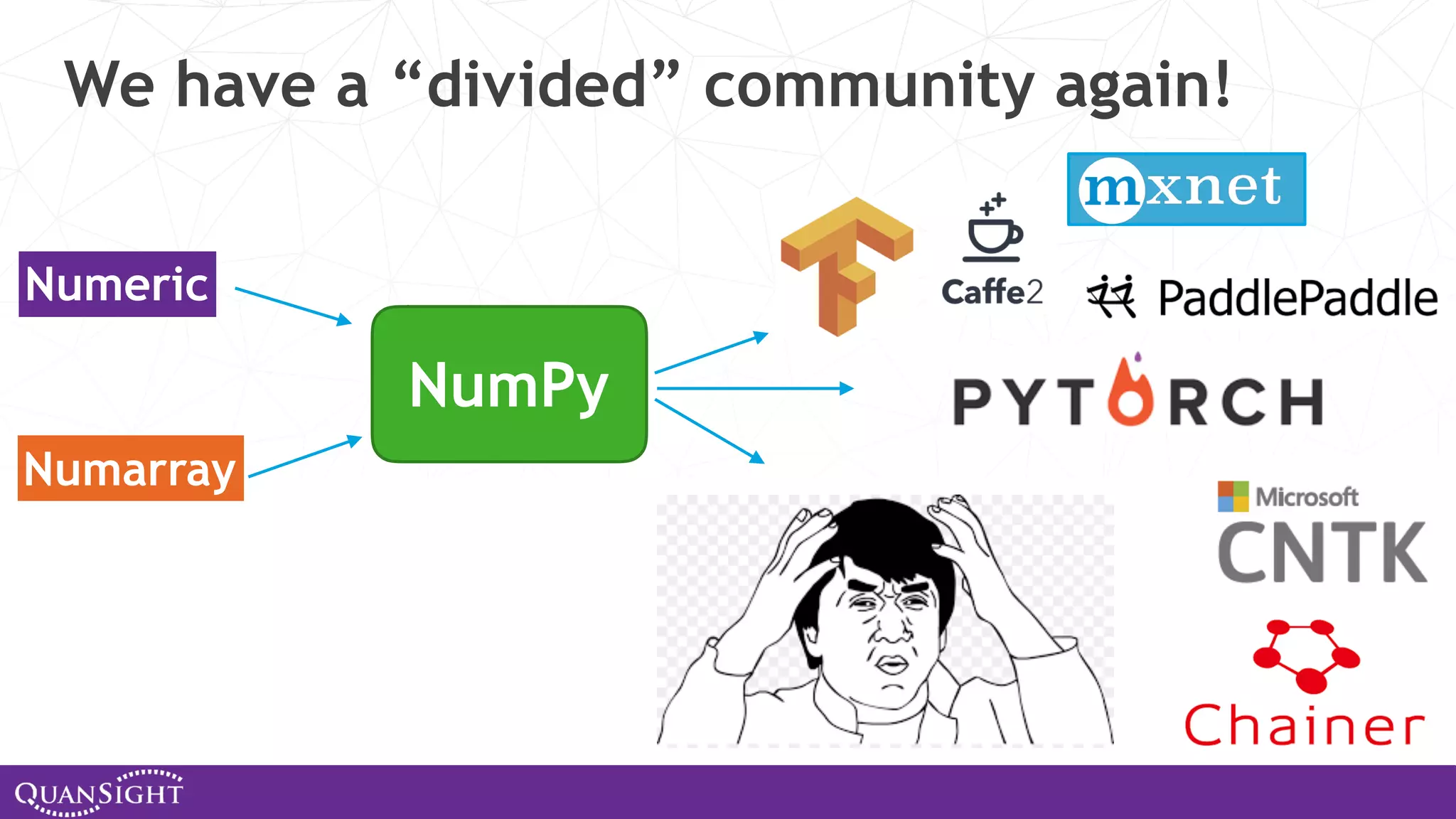
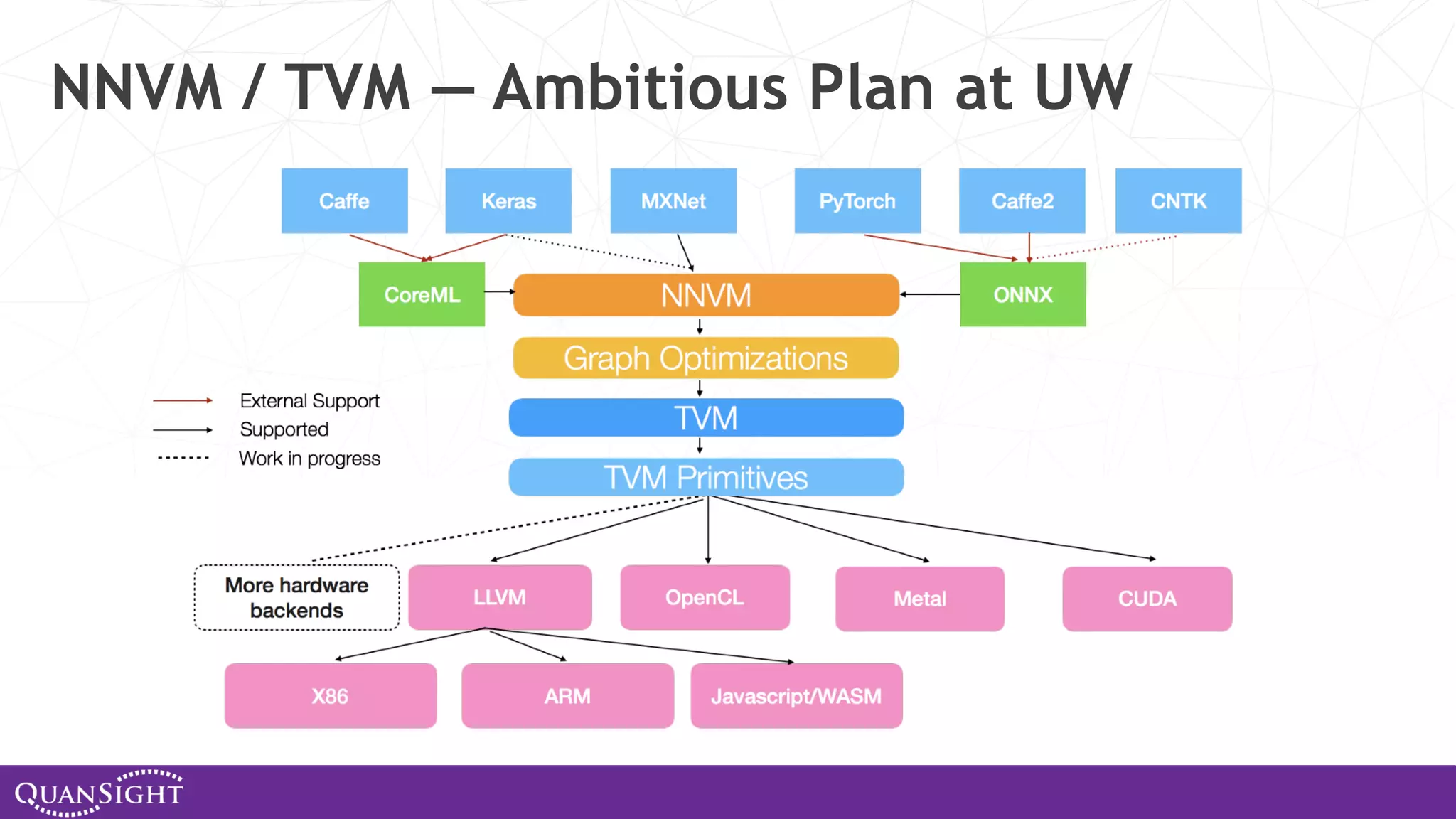
![] https://github.com/josephmisiti/awesome-machine-learning#python-general-purpose http://deeplearning.net/software_links/ http://scikit-learn.org/stable/related_projects.html Explosion of ML Frameworks and libraries TVM/NNVM](https://image.slidesharecdn.com/columbialecturefeb2020-200214034342/75/Array-computing-and-the-evolution-of-SciPy-NumPy-and-PyData-59-2048.jpg)




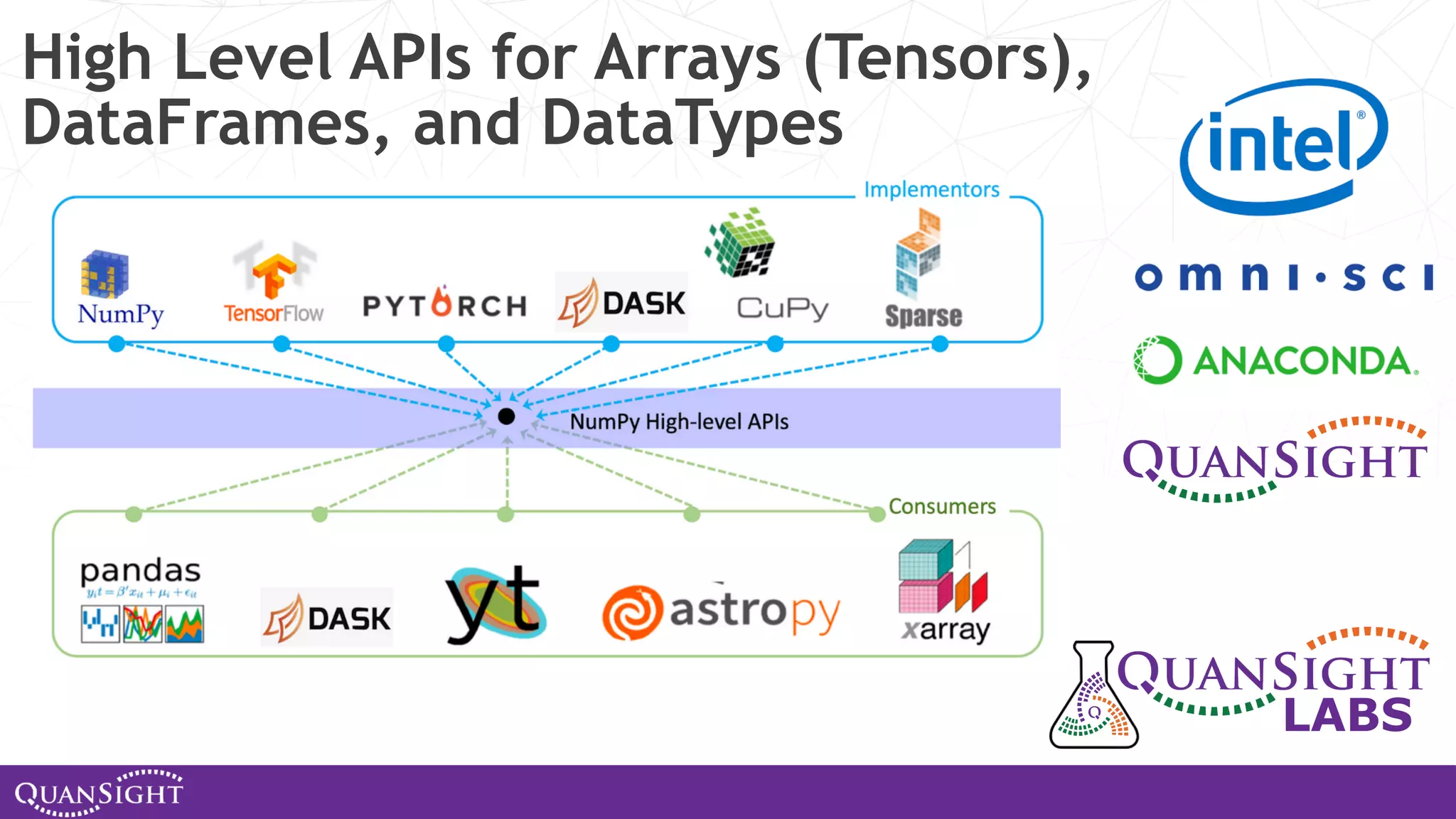



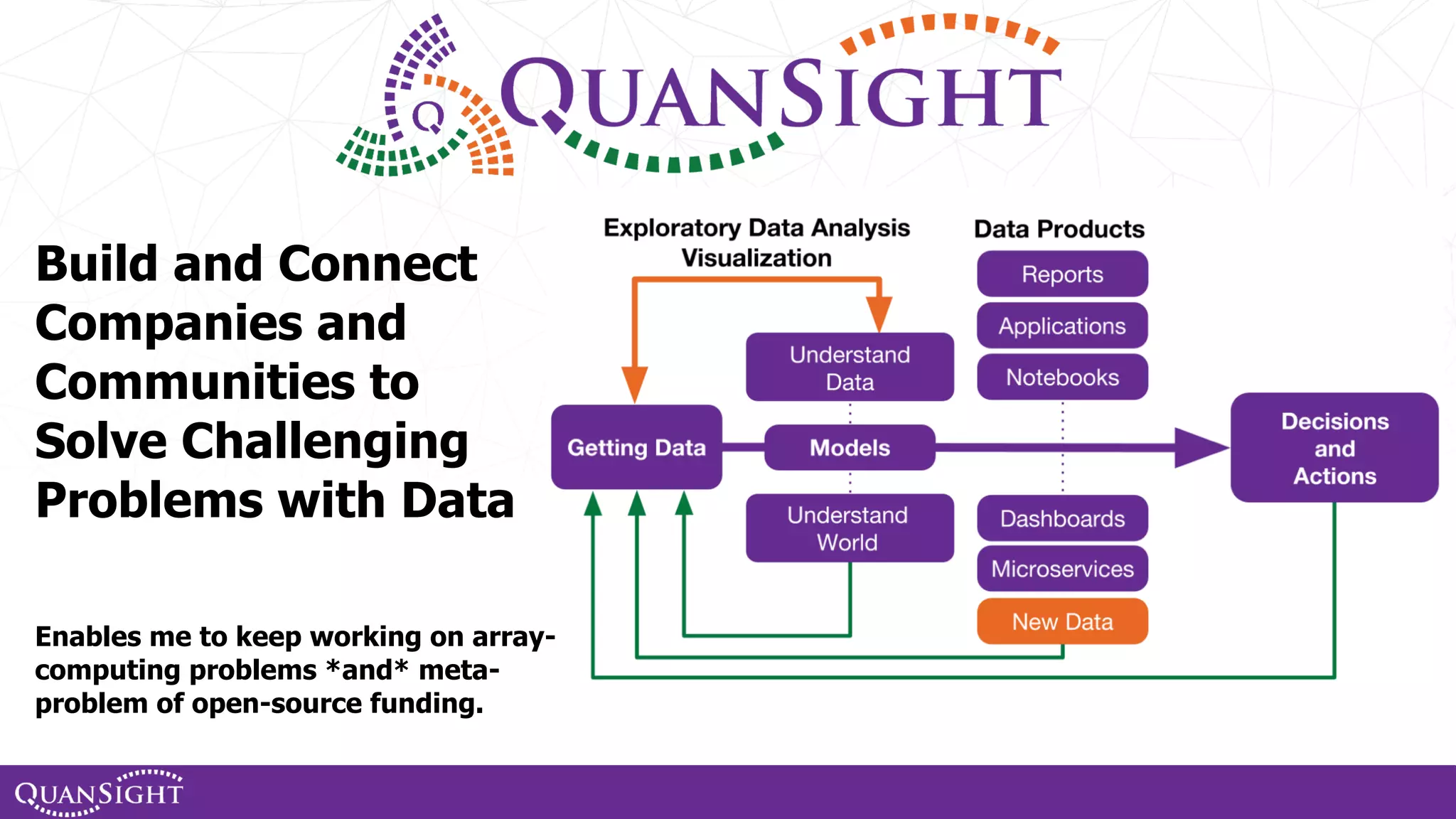




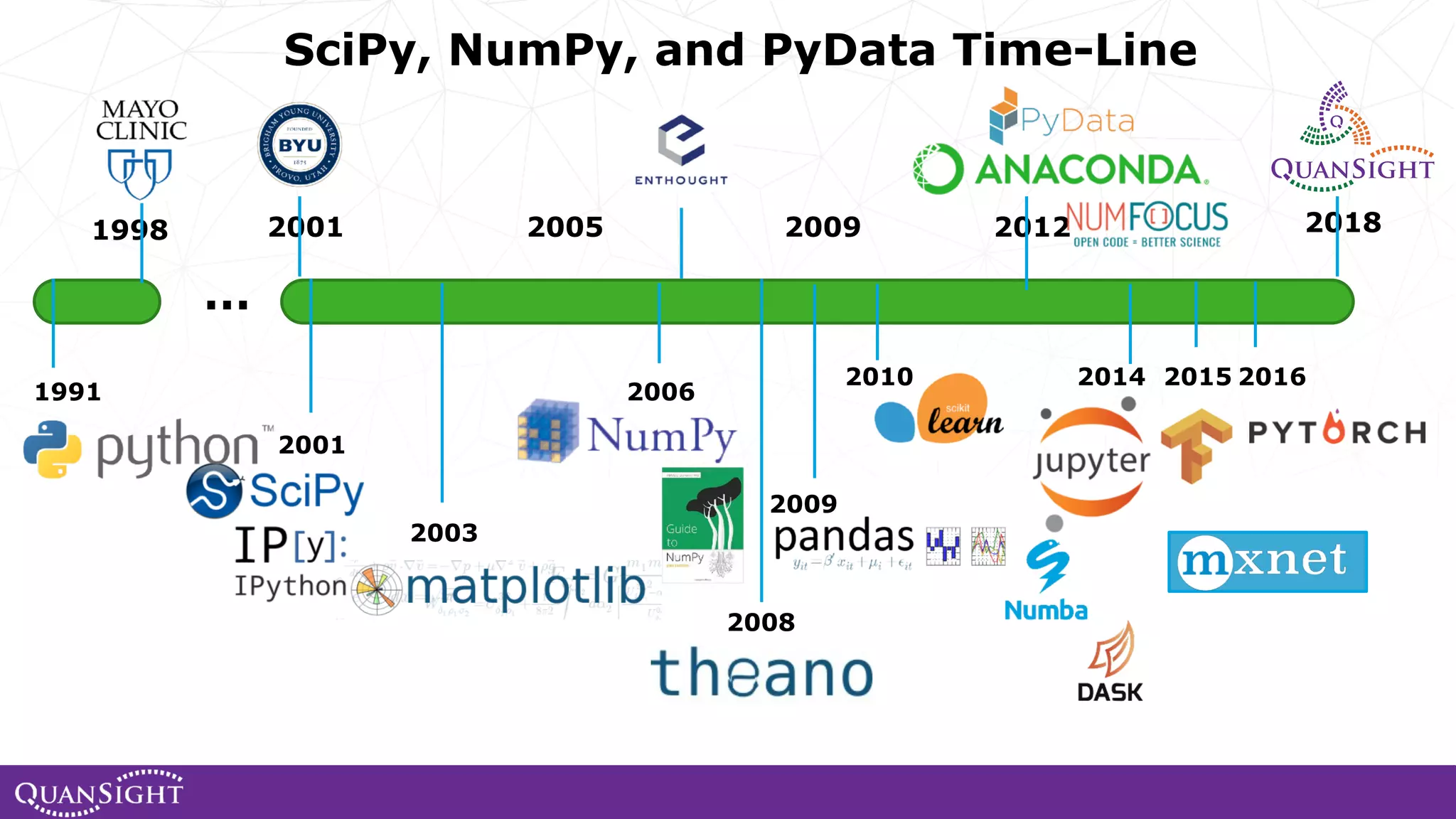
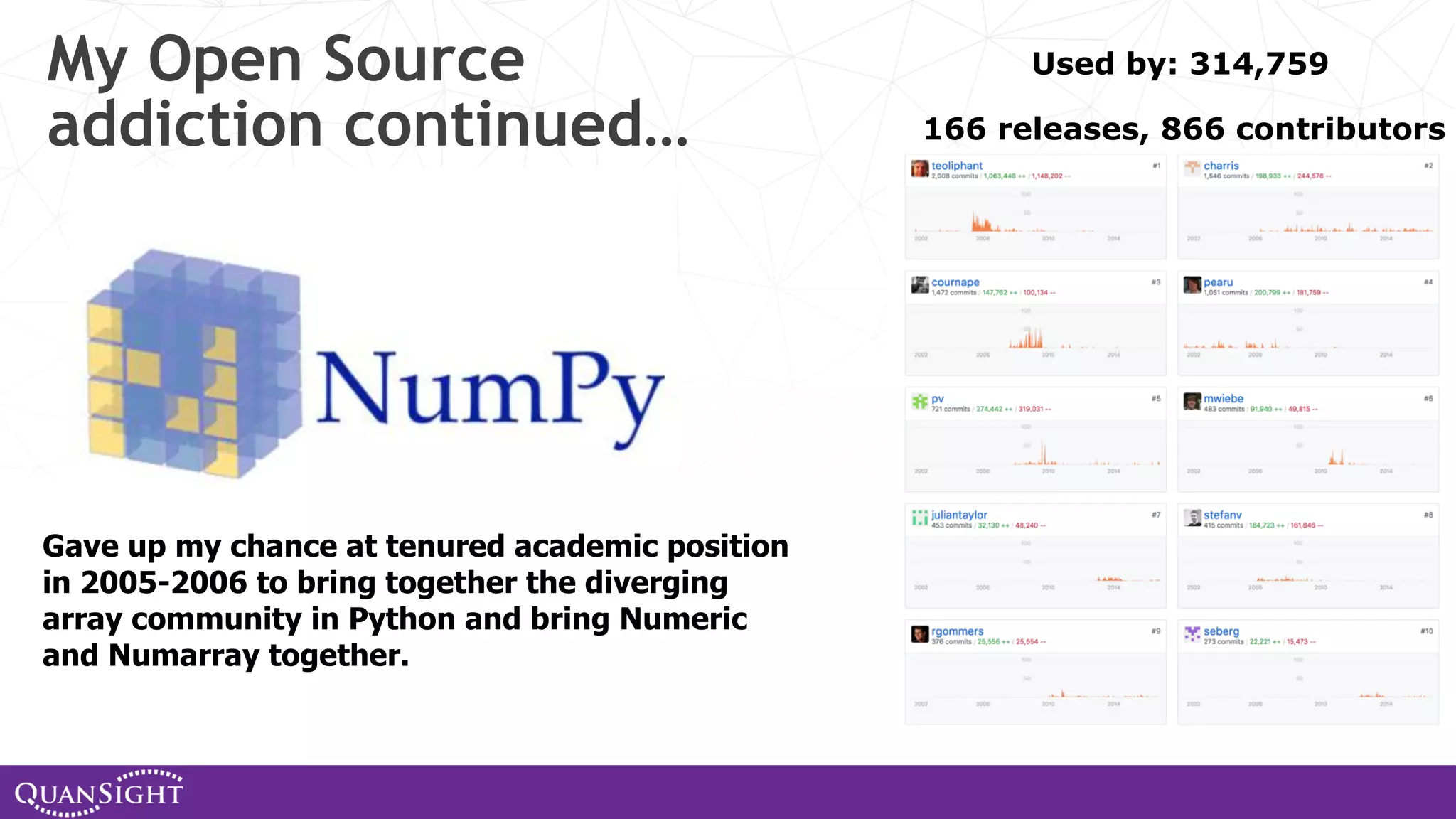
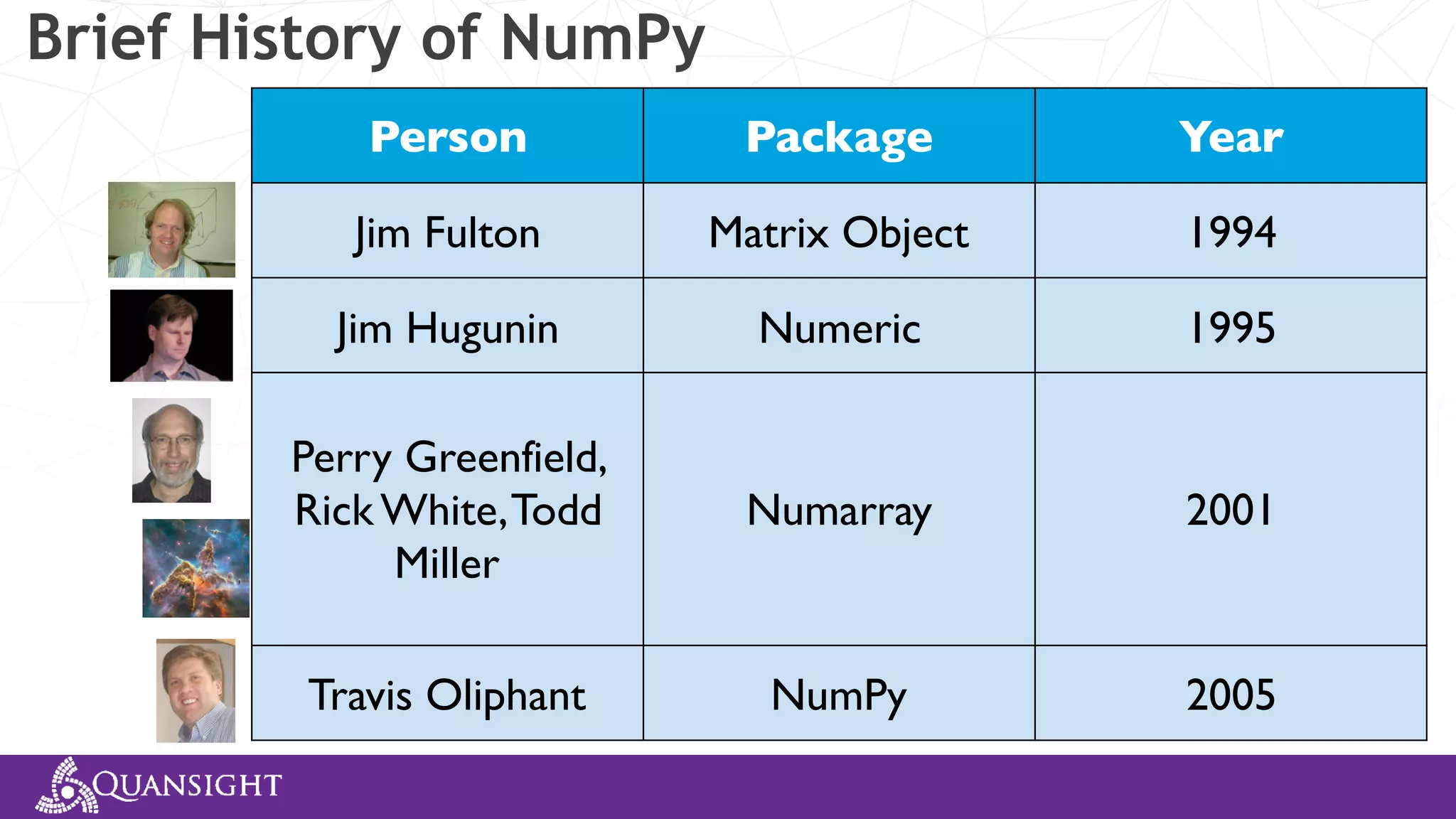
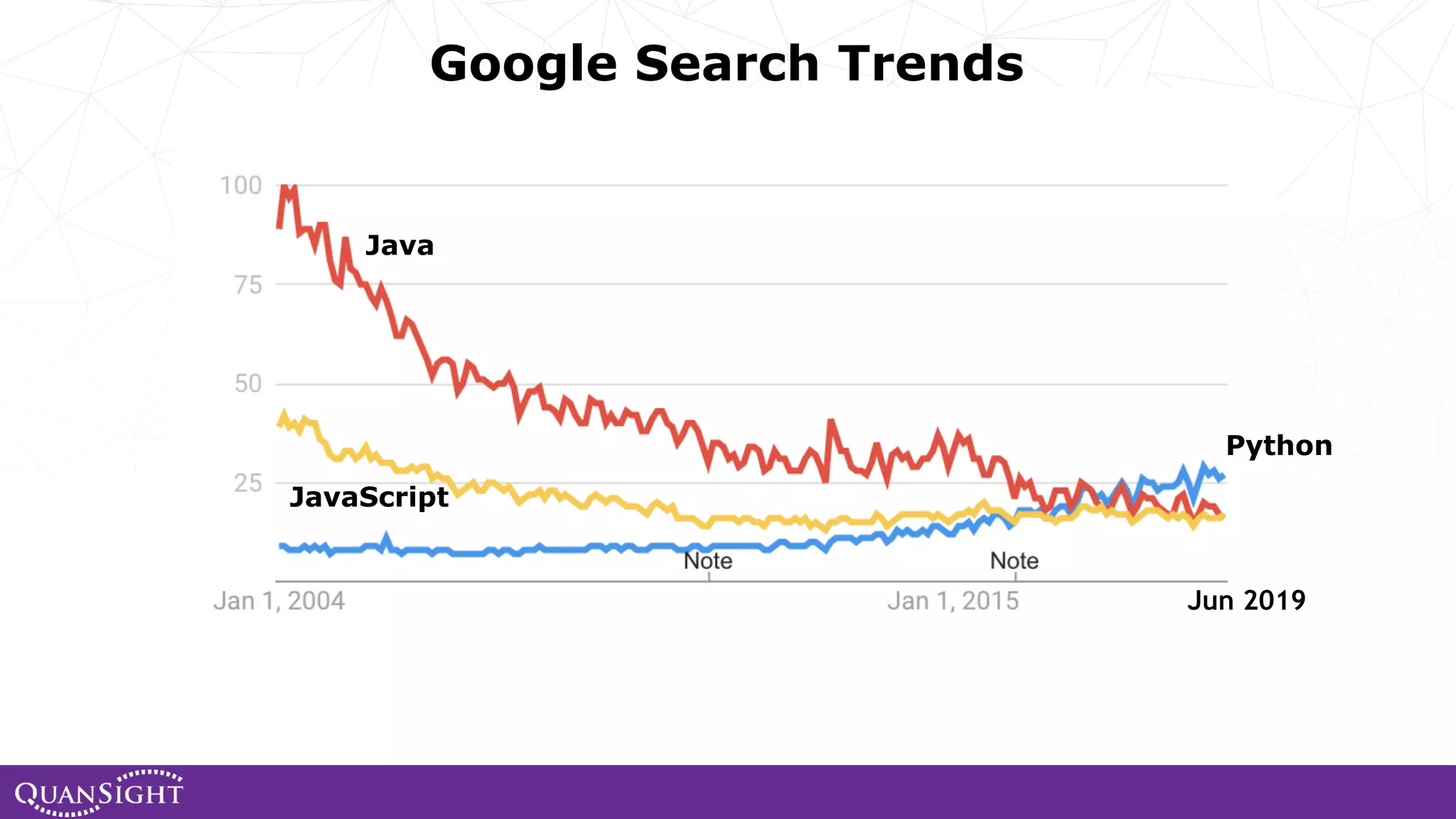
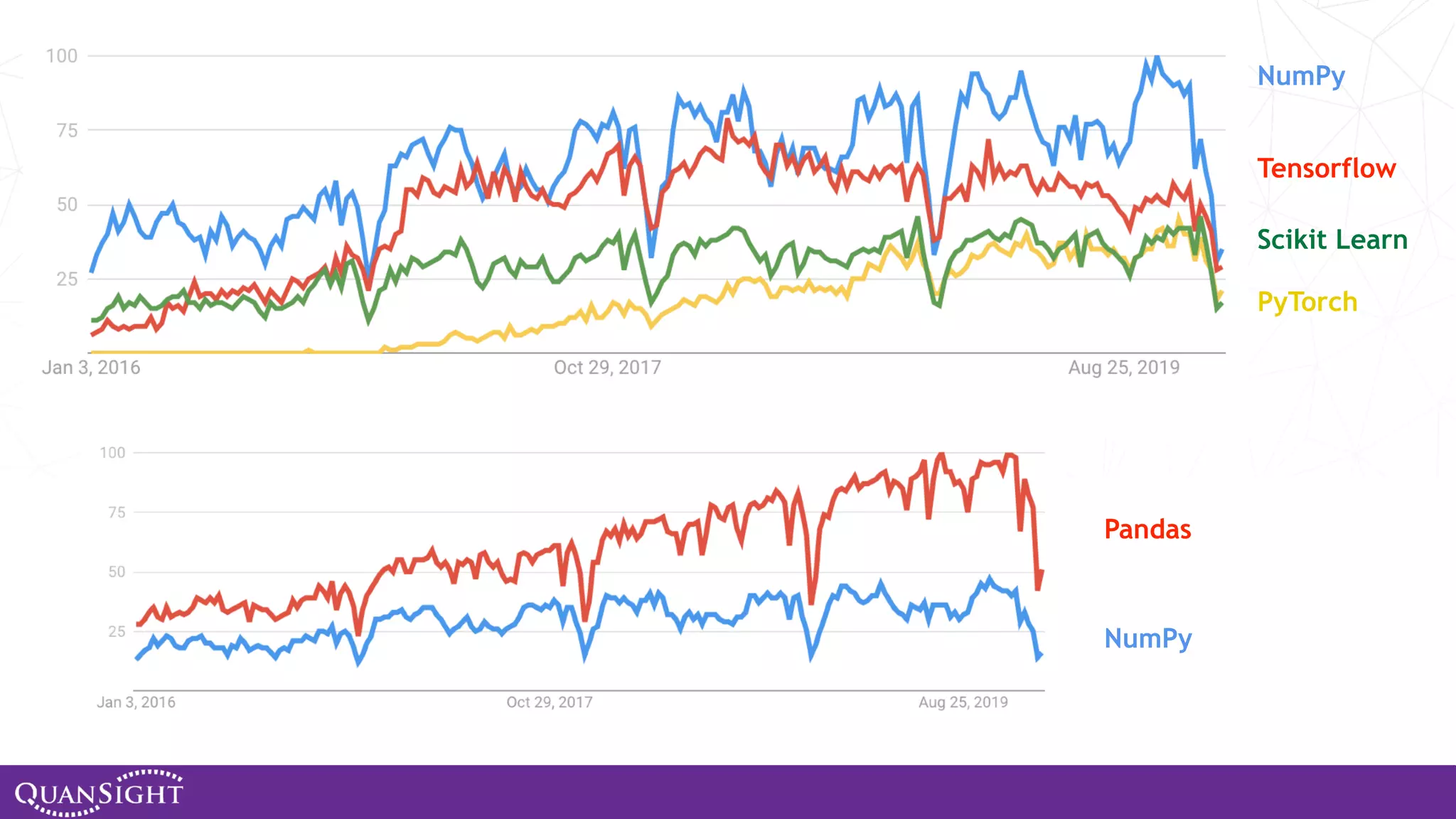
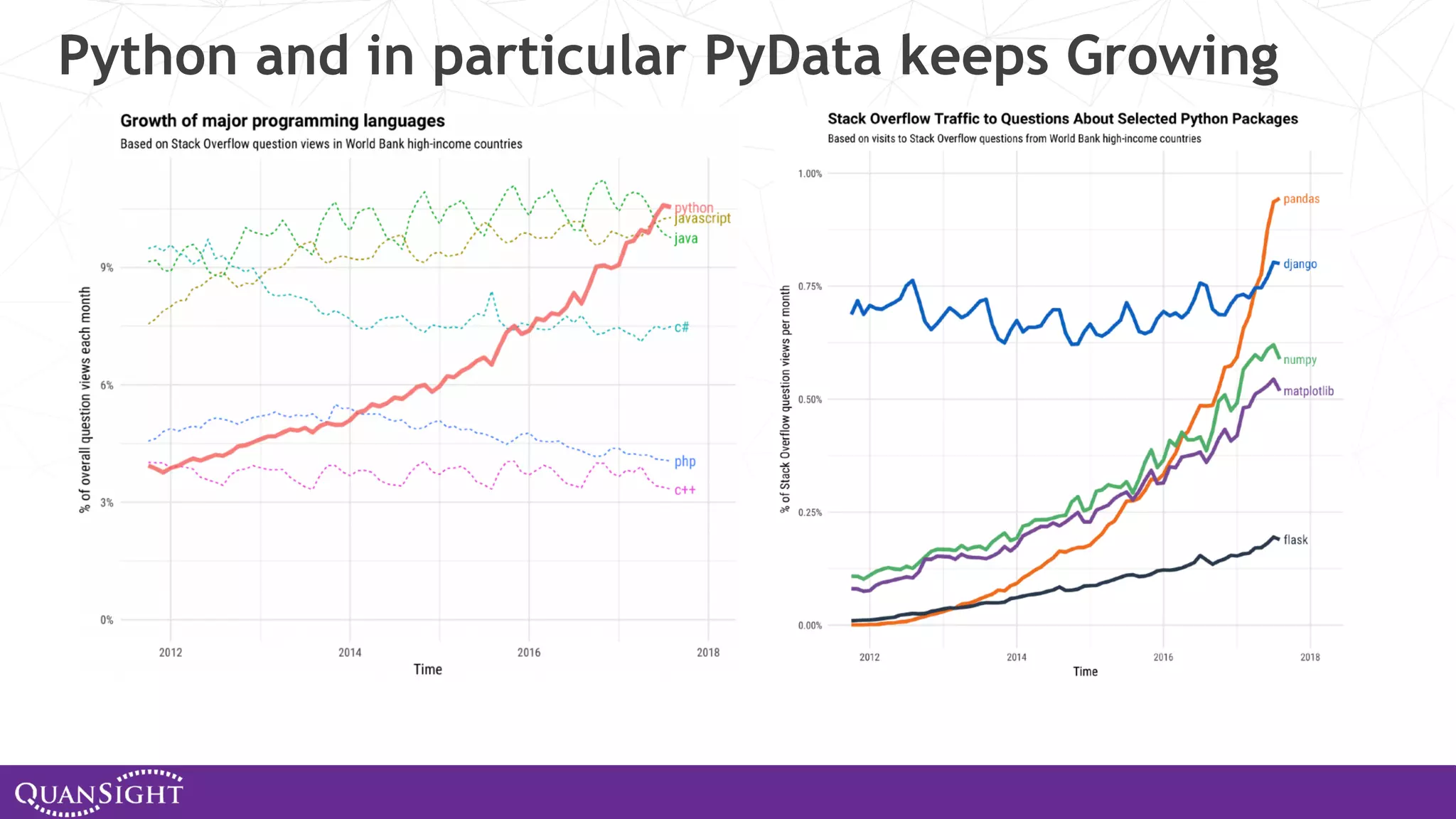
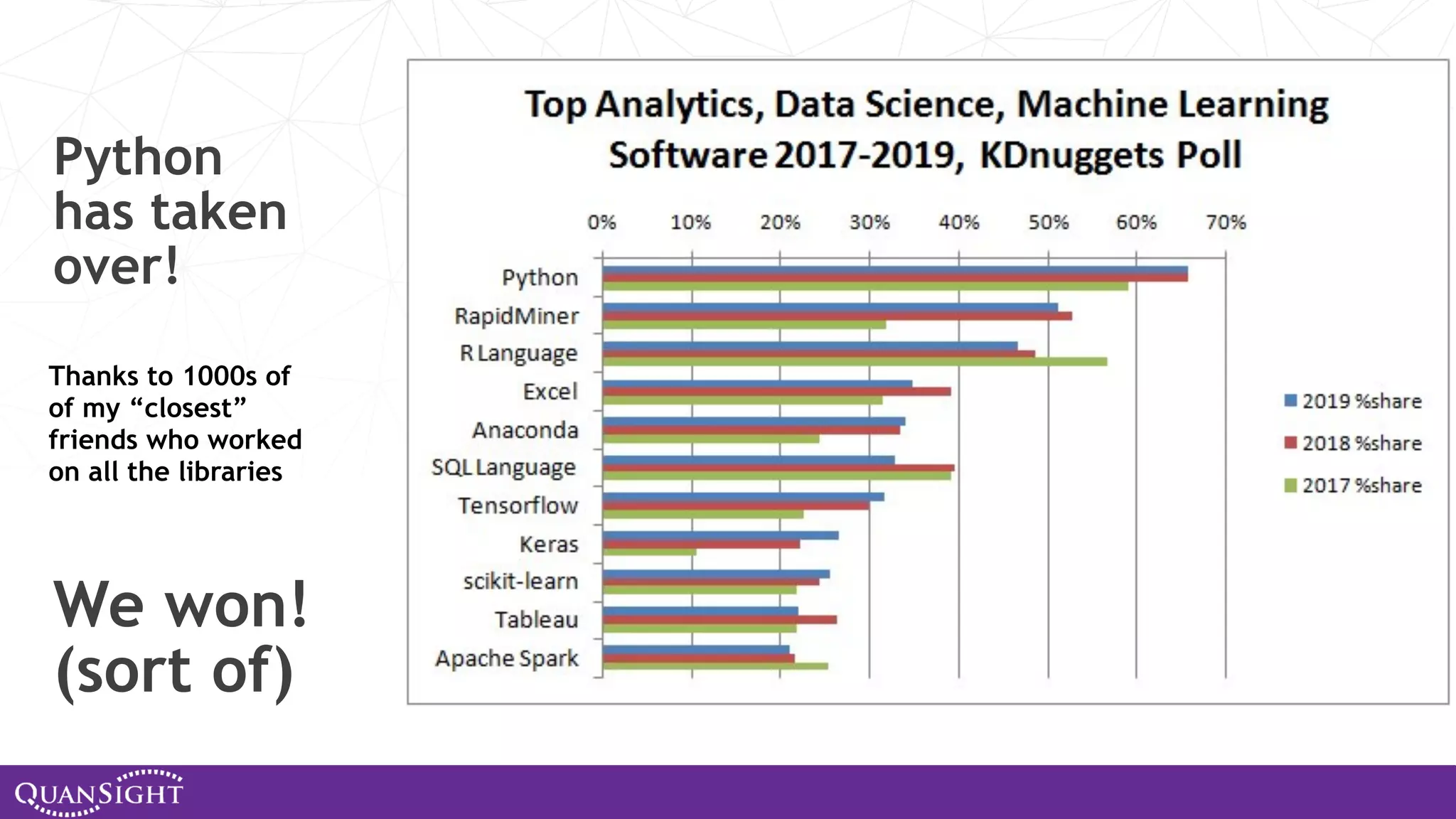
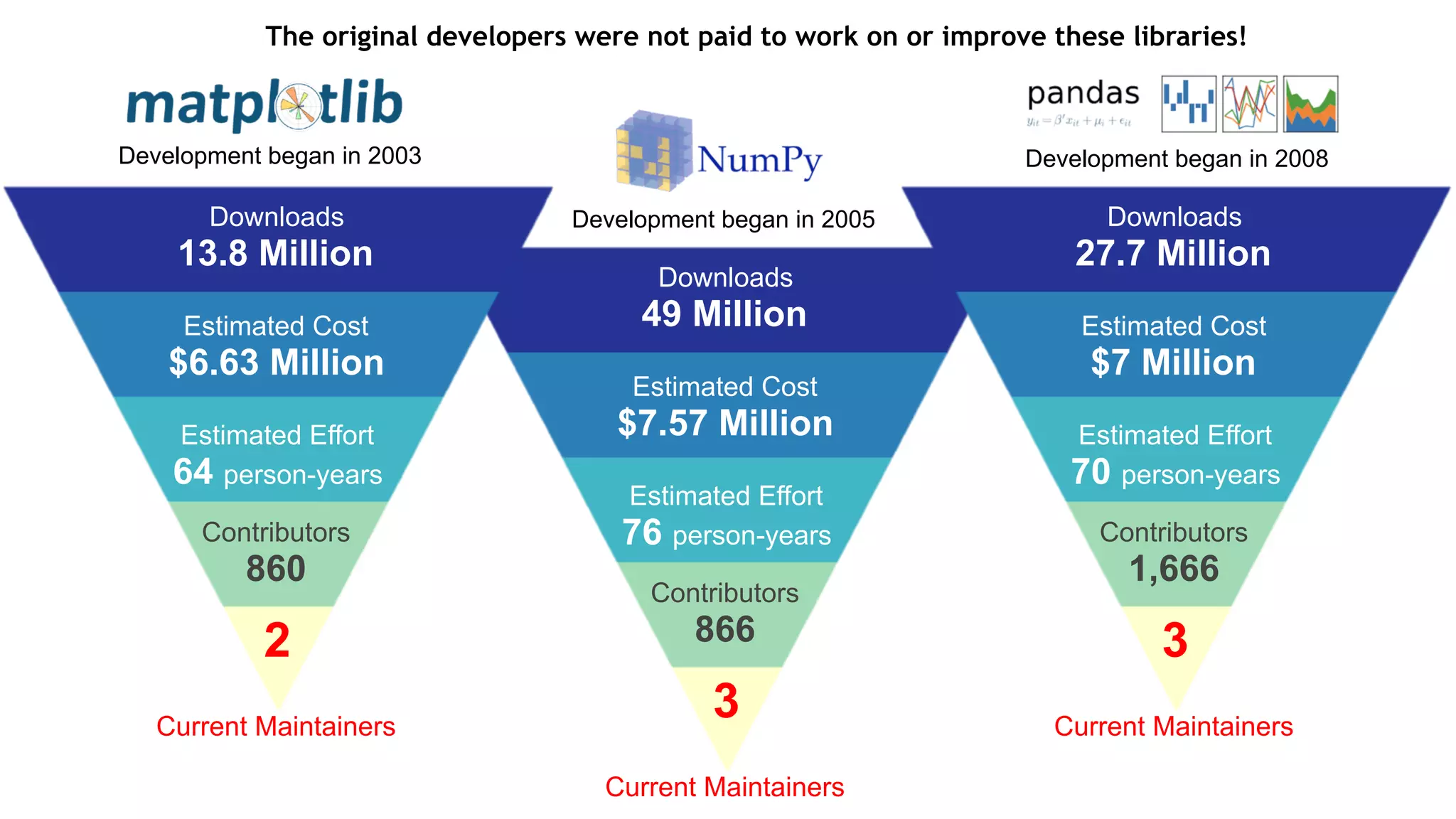
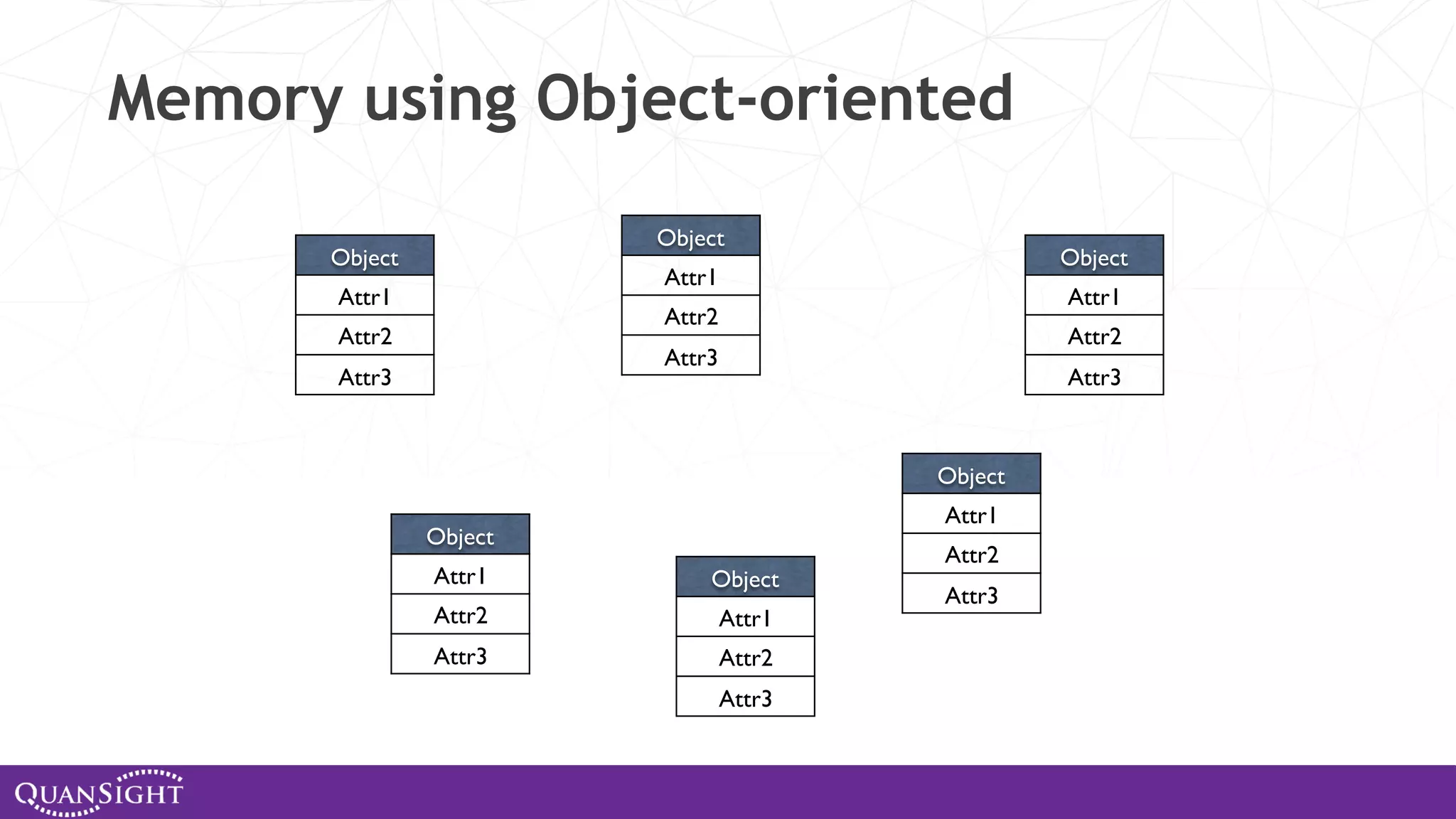
The document outlines the history and evolution of array computing in Python, focusing on the development of libraries such as SciPy and NumPy, which aim to unify the Python scientific computing community. It discusses the importance of open-source contributions, the challenges of sustaining such projects, and the ongoing efforts to improve interoperability and performance in array-oriented programming. Additionally, it highlights the impact of these libraries on machine learning and data science over the years.