Download as PDF, PPTX



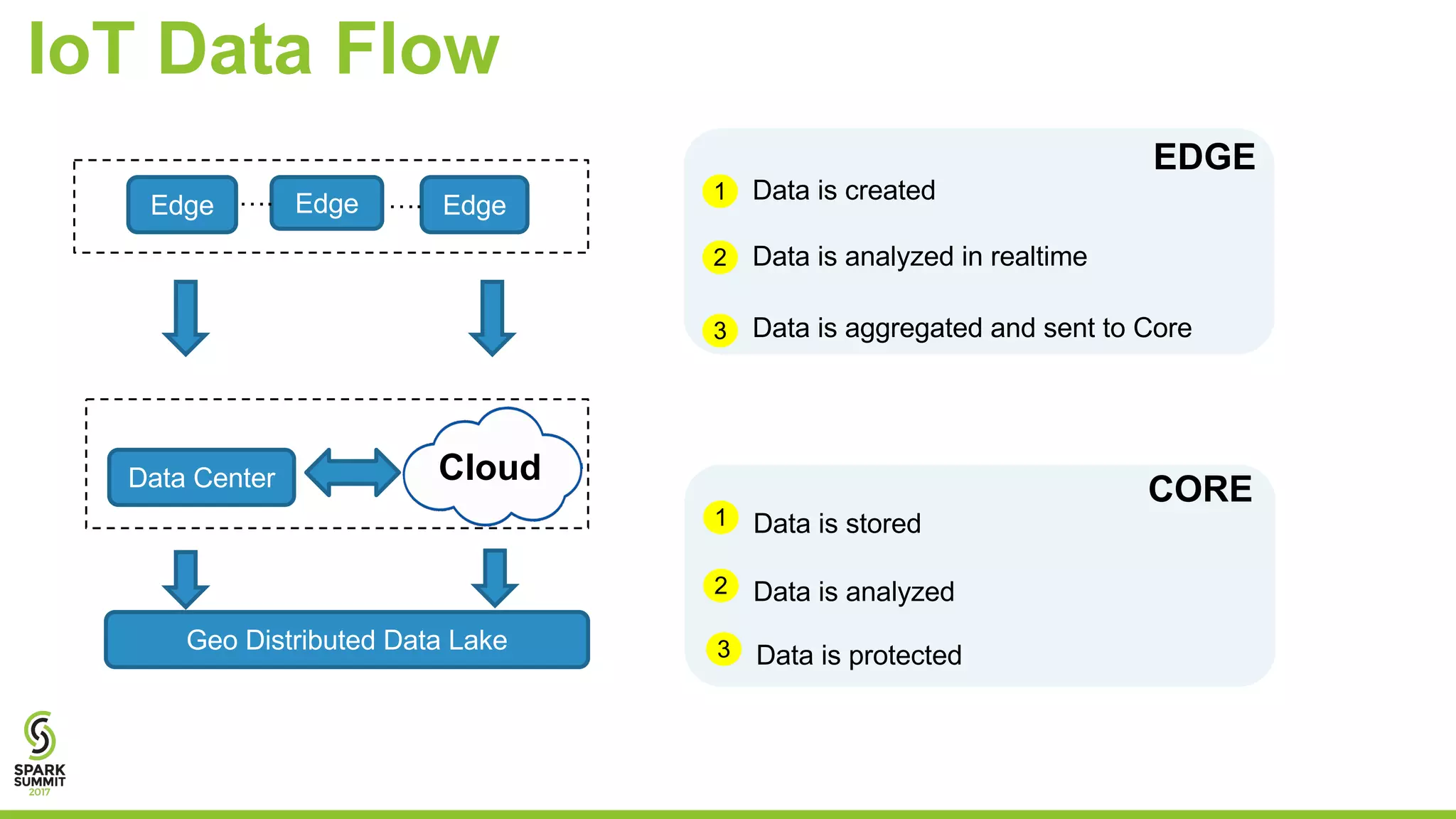


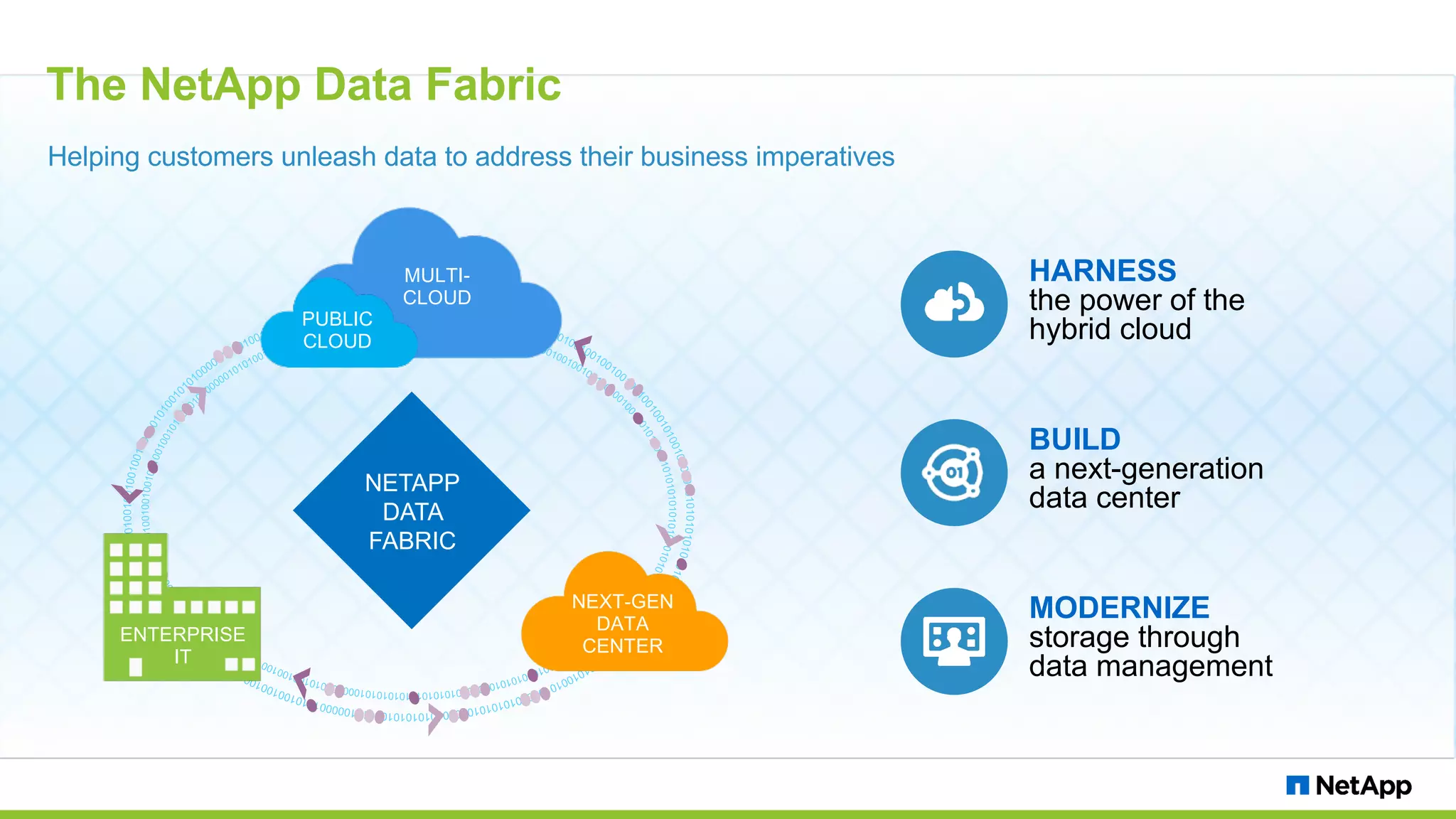
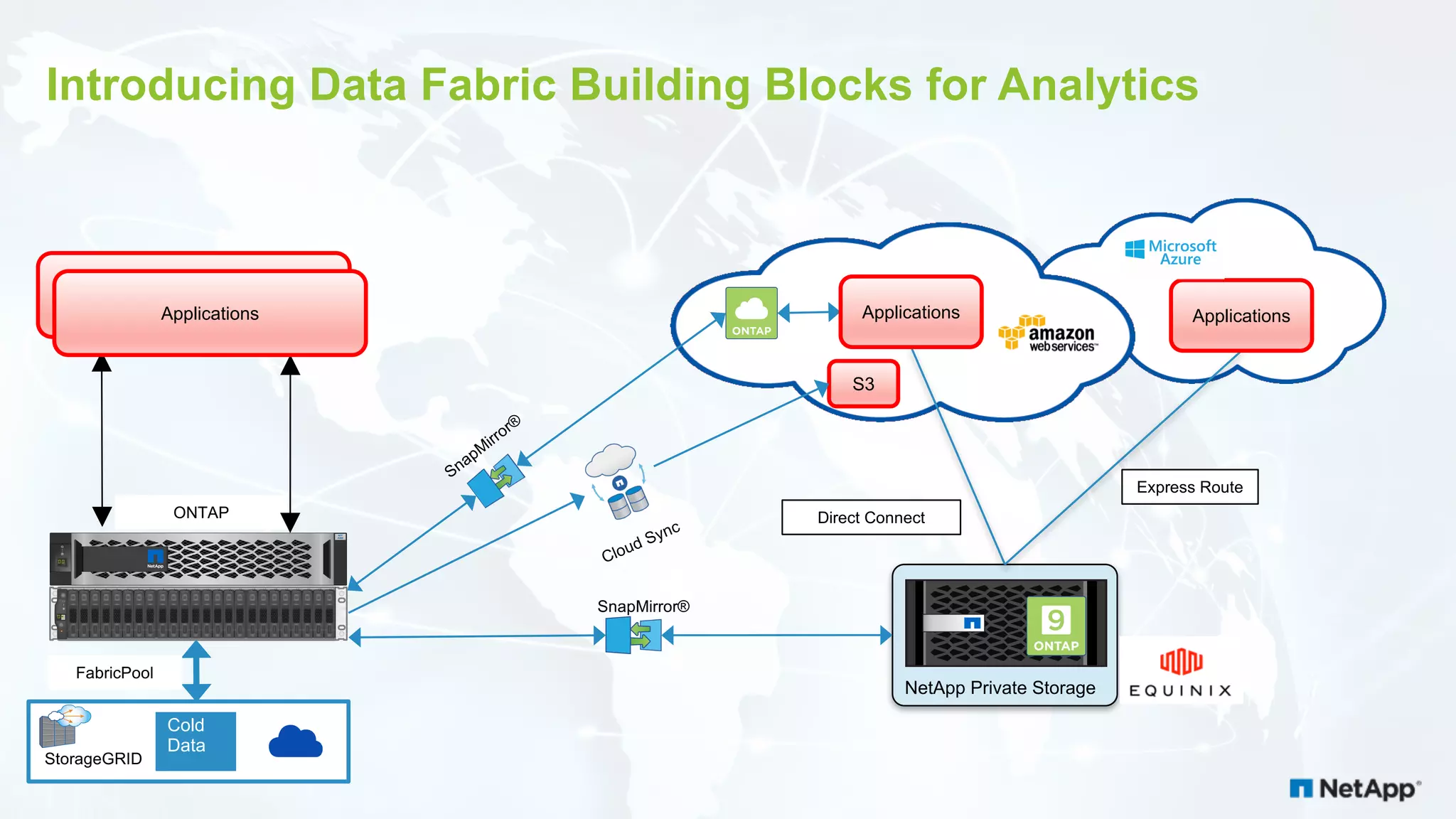
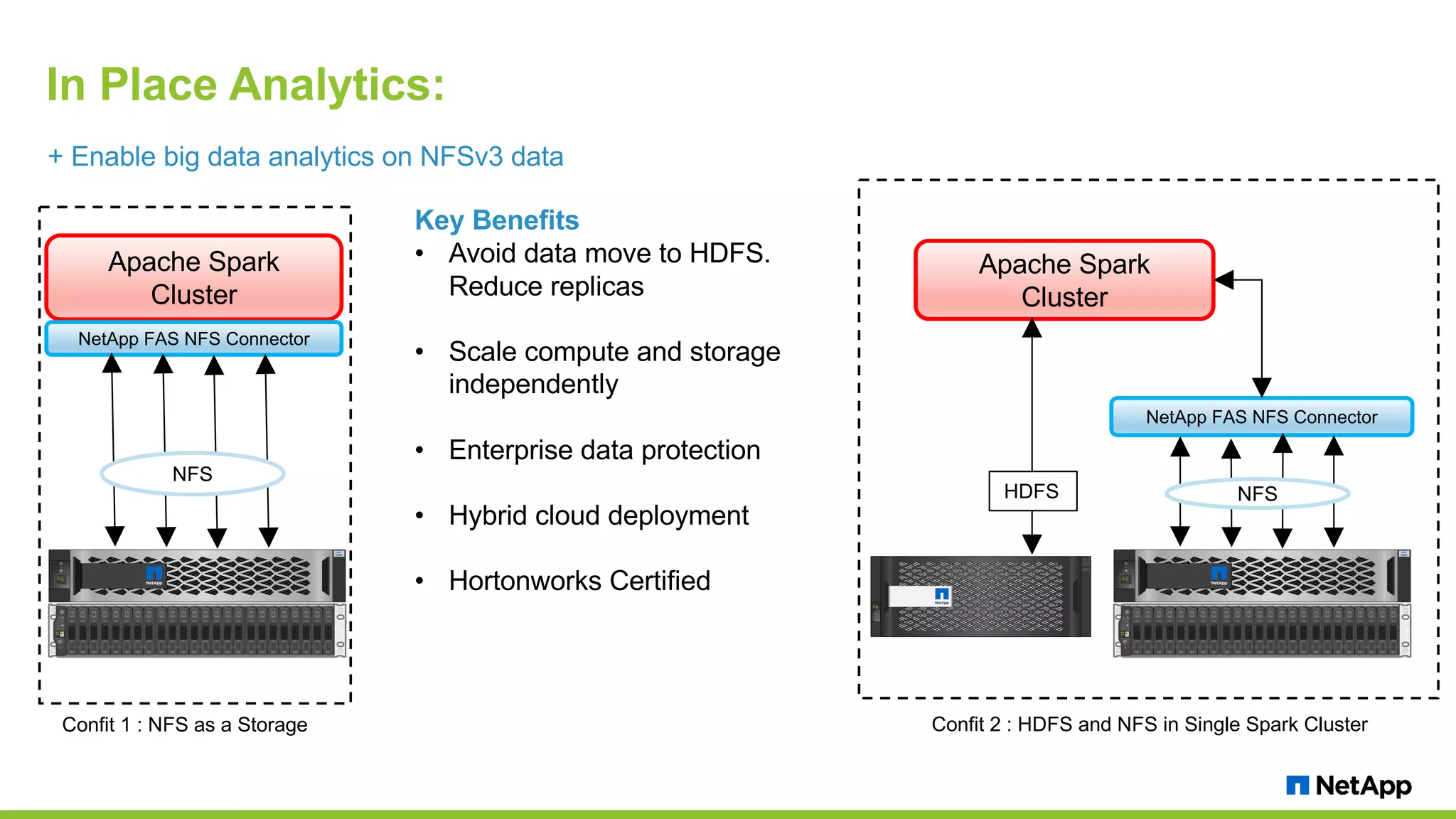
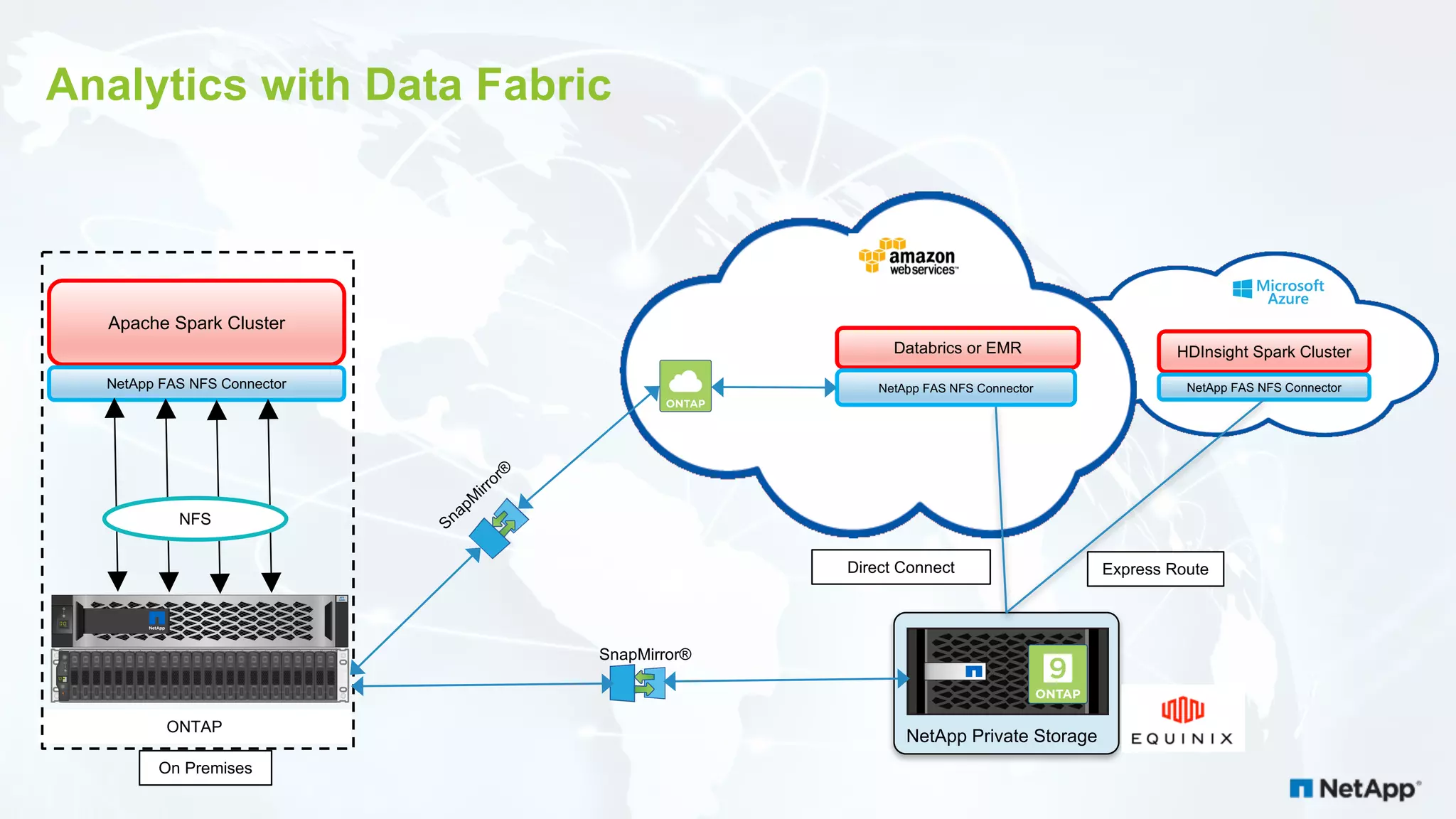


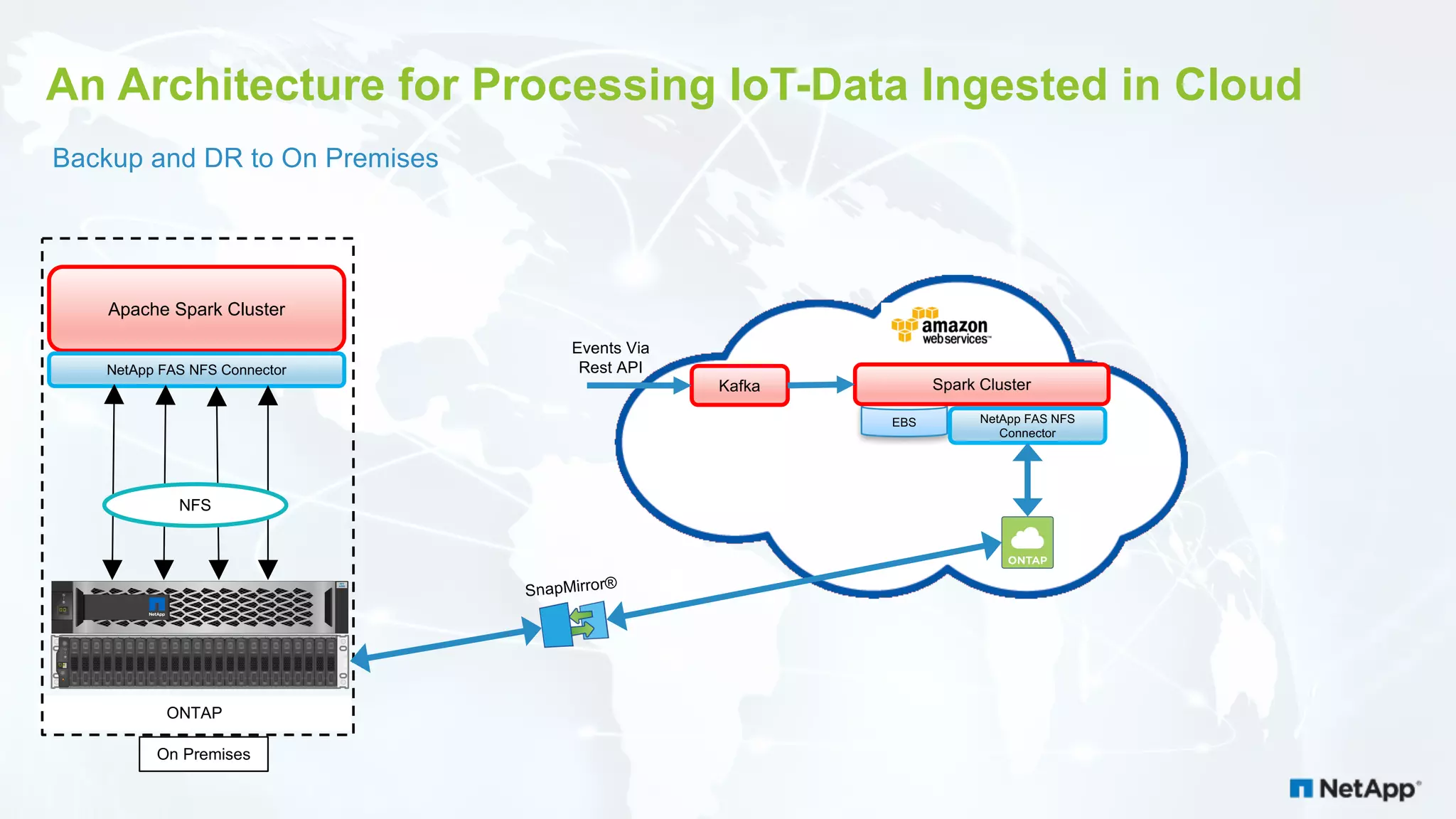

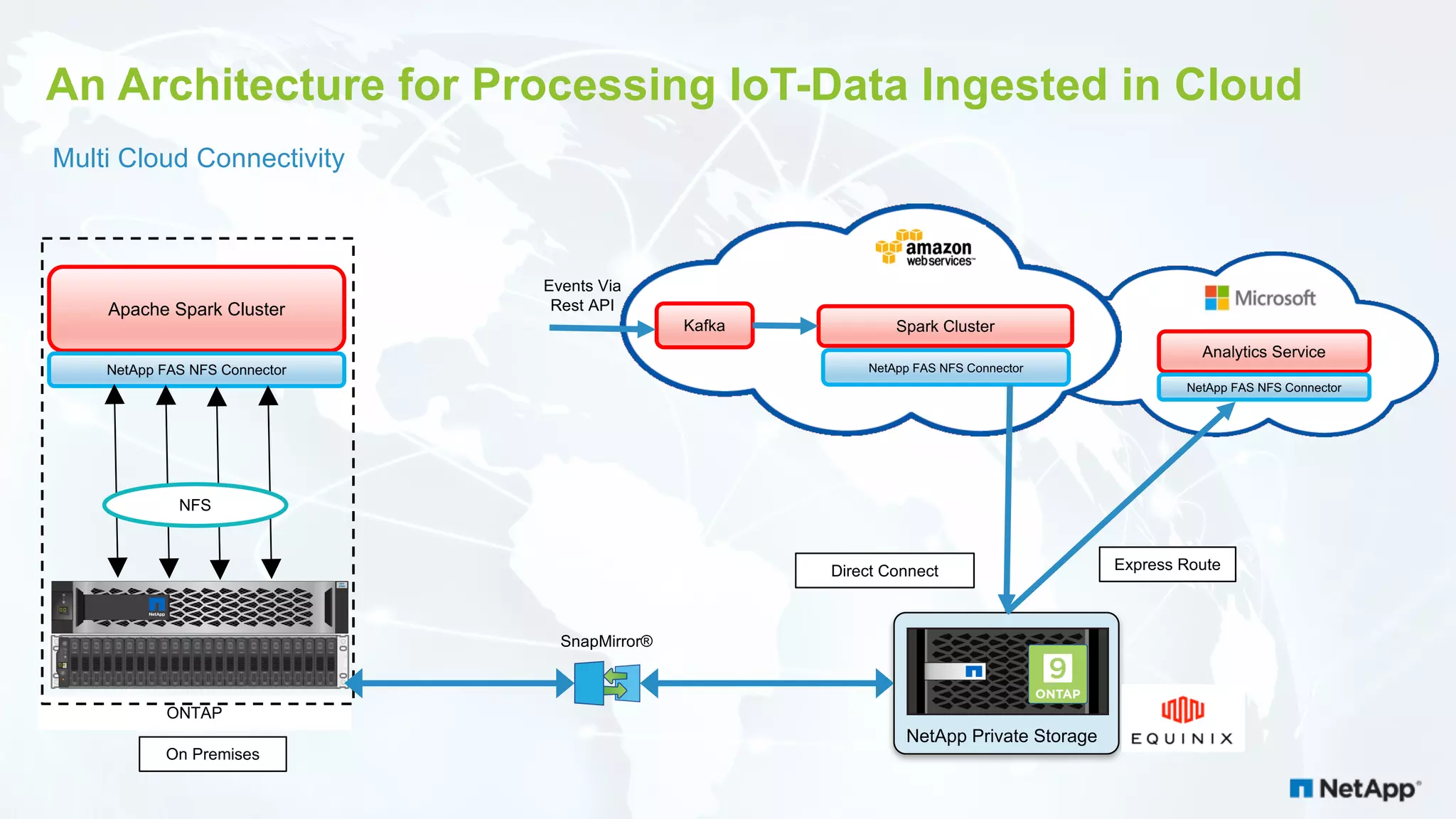

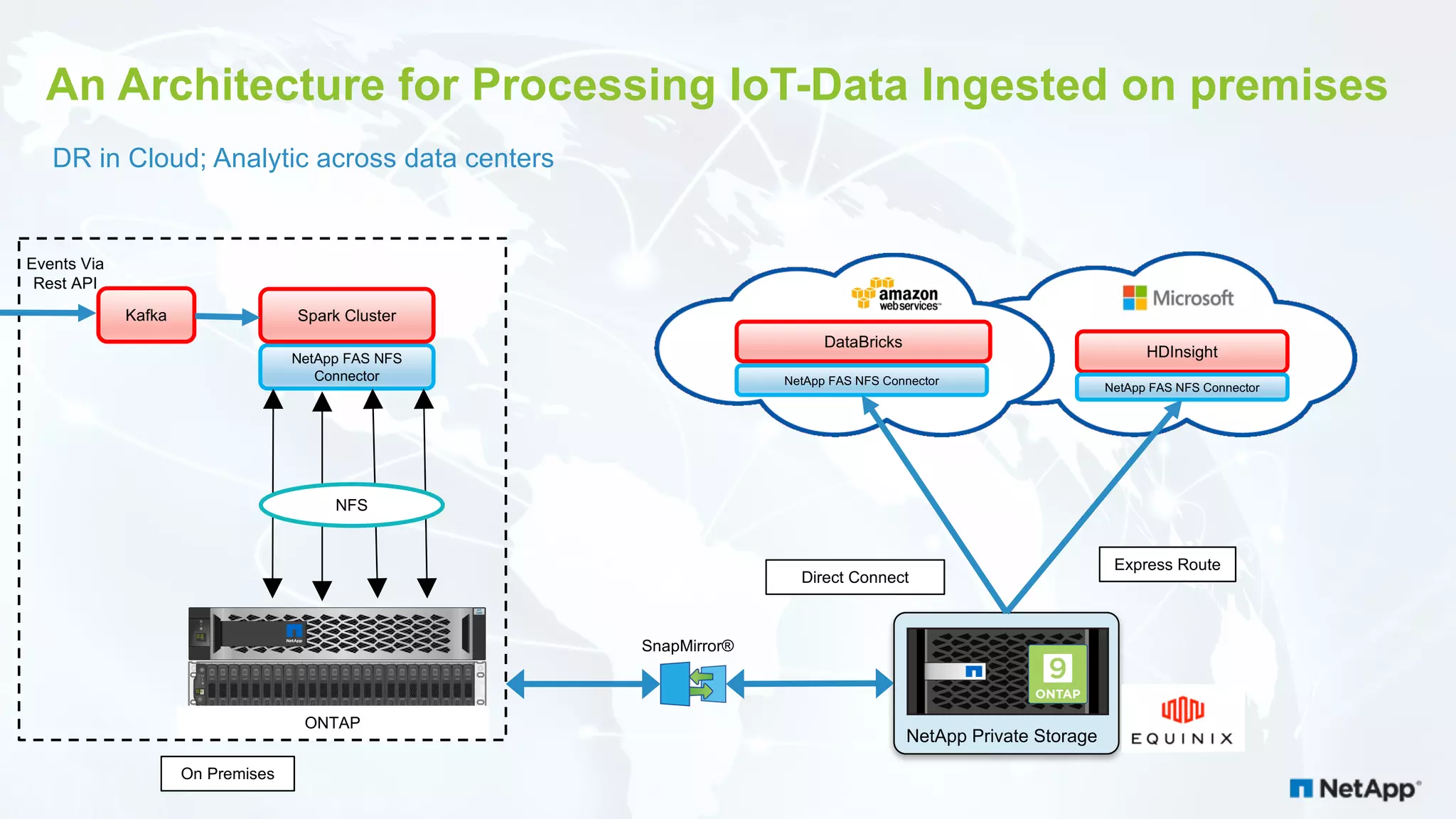

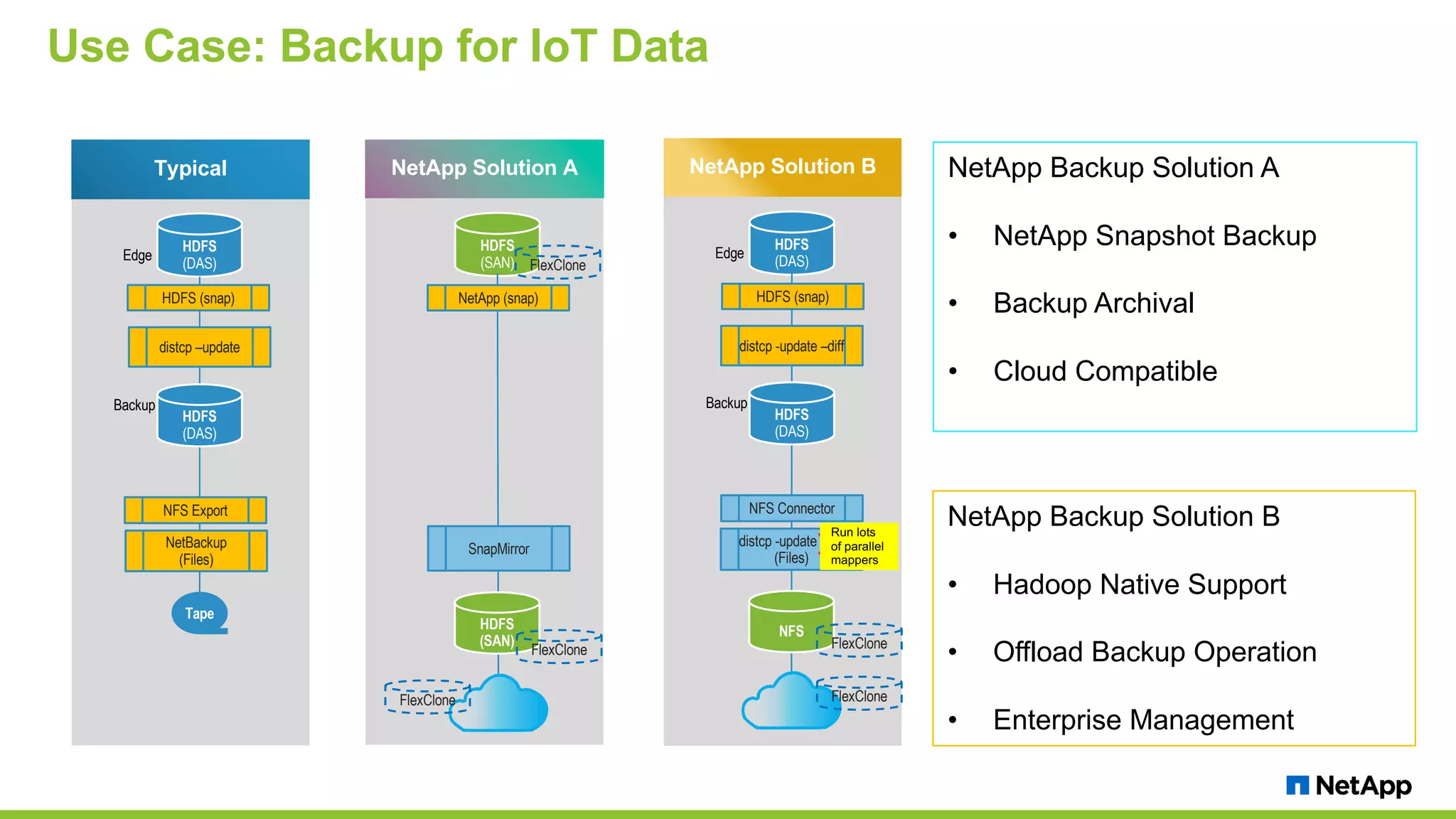

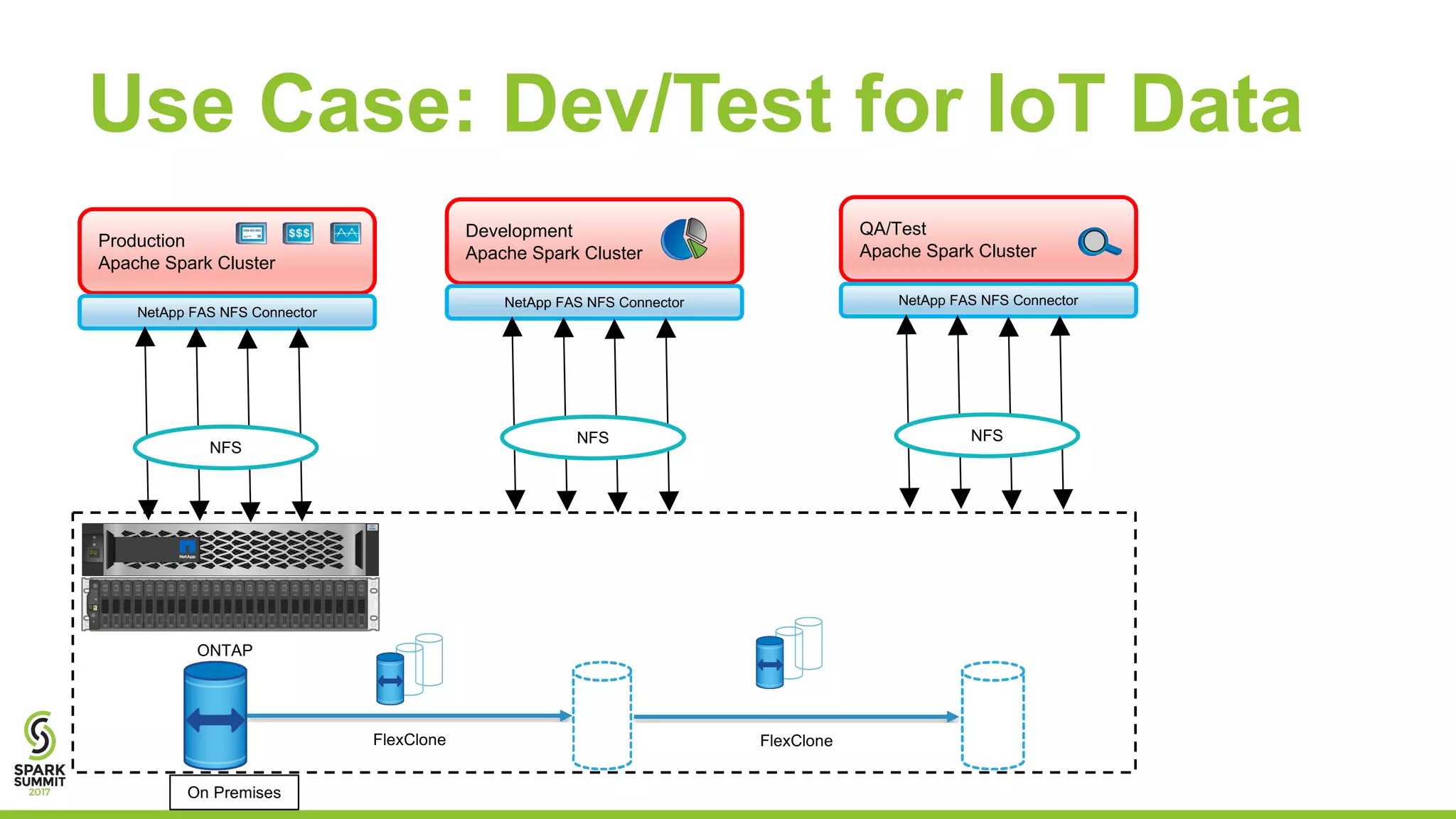

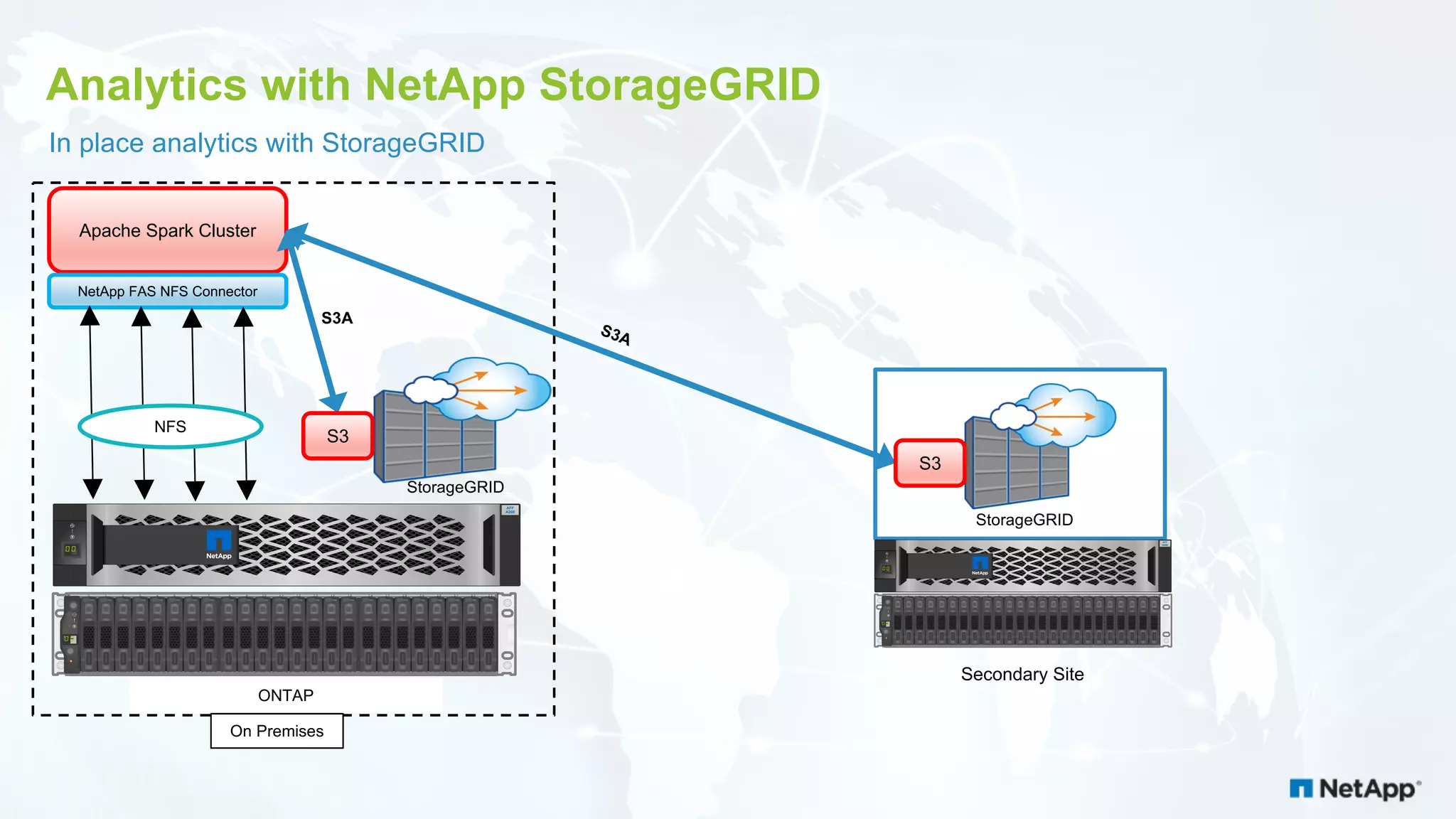
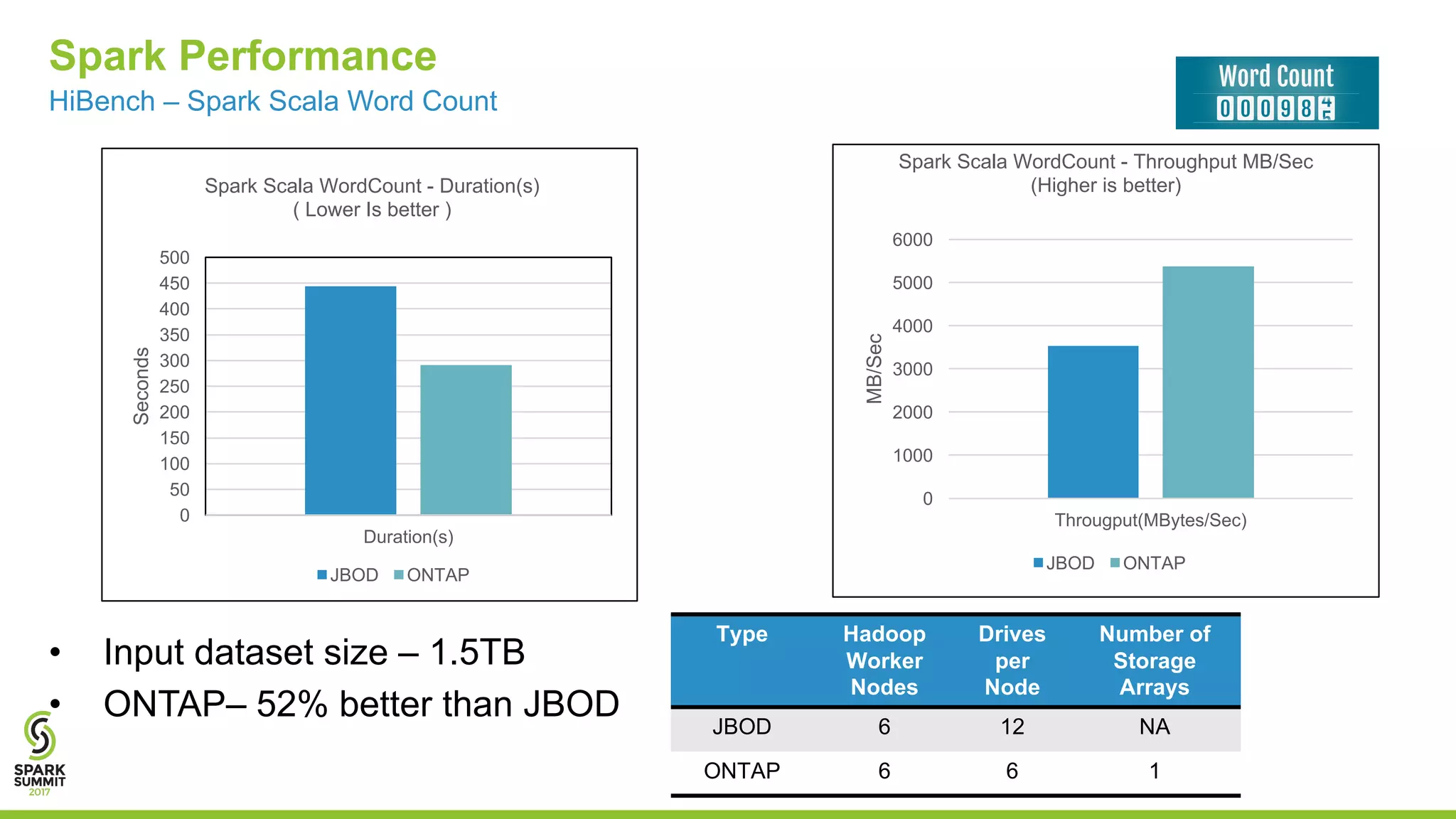





The document discusses the challenges of managing IoT data and explores NetApp's Data Fabric architecture for big data, which helps organizations use hybrid cloud solutions effectively. It presents various customer use cases illustrating how IoT data can be analyzed in real-time and stored across different platforms, emphasizing the importance of data protection and cost management. Additionally, it highlights the benefits of using Apache Spark for analytics and the integration of on-premises and cloud storage solutions.