Download as PDF, PPTX























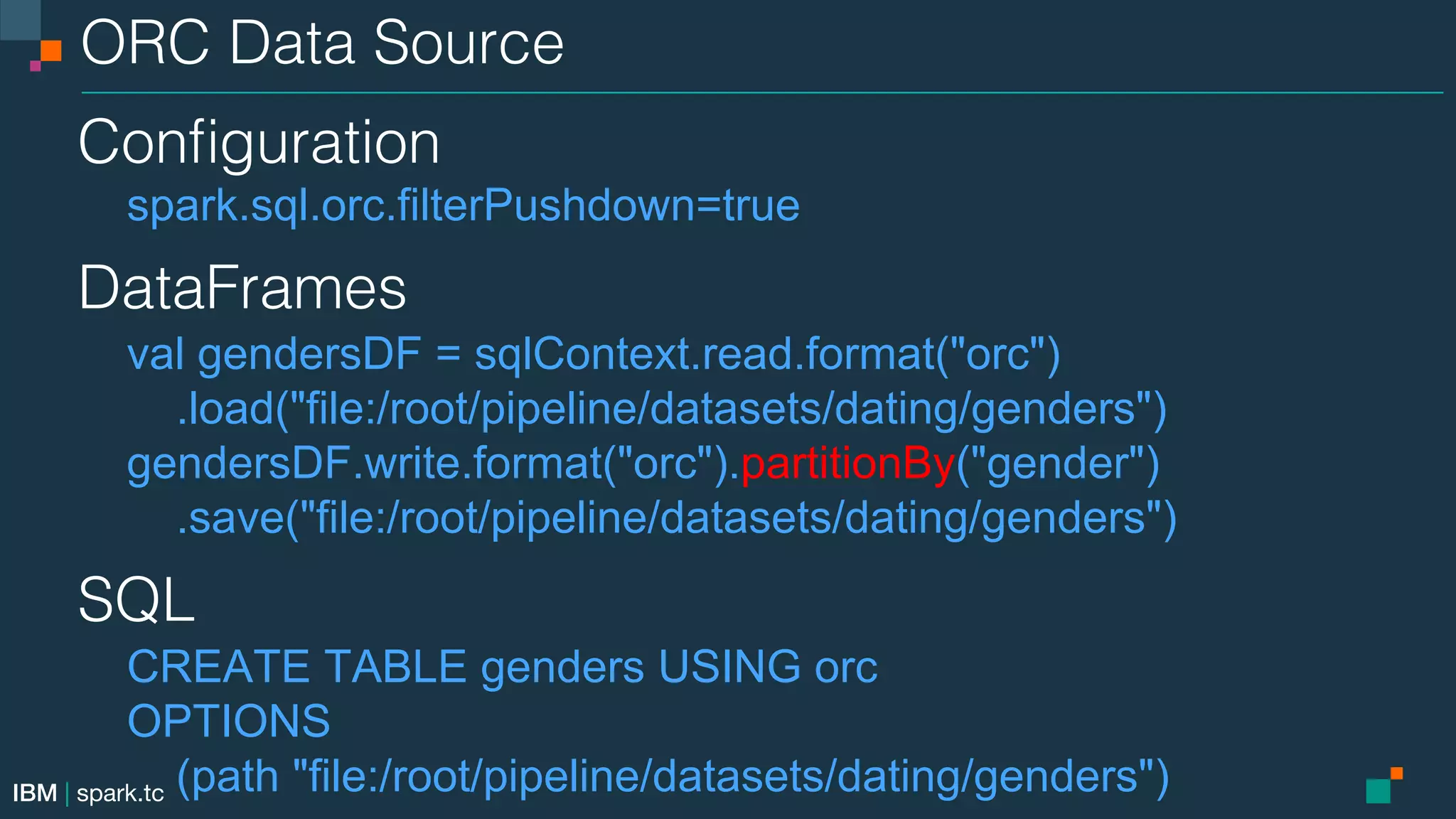
![IBM | spark.tc Parquet Data Source! Configuration! spark.sql.parquet.filterPushdown=true! spark.sql.parquet.mergeSchema=true spark.sql.parquet.cacheMetadata=true! spark.sql.parquet.compression.codec=[uncompressed,snappy,gzip,lzo] DataFrames! val gendersDF = sqlContext.read.format("parquet") .load("file:/root/pipeline/datasets/dating/genders.parquet")! gendersDF.write.format("parquet").partitionBy("gender") .save("file:/root/pipeline/datasets/dating/genders.parquet") SQL! CREATE TABLE genders USING parquet OPTIONS (path "file:/root/pipeline/datasets/dating/genders.parquet")](https://image.slidesharecdn.com/advancedapachesparkmeetupdatasourcesapicassandrasparkconnectoroct062015-151007054113-lva1-app6891/75/Advanced-Apache-Spark-Meetup-Data-Sources-API-Cassandra-Spark-Connector-Spark-1-5-1-Zeppelin-0-6-0-31-2048.jpg)


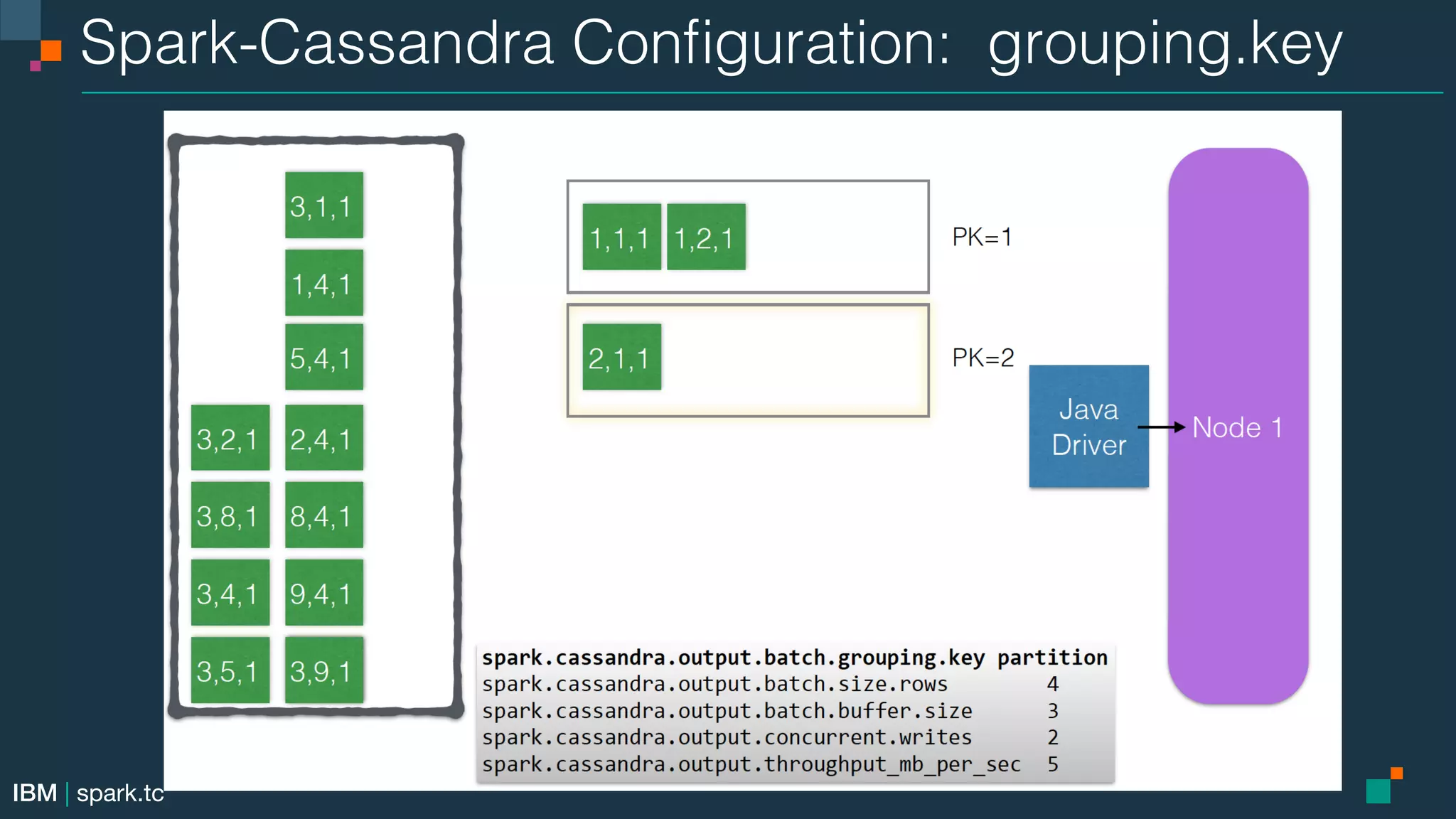


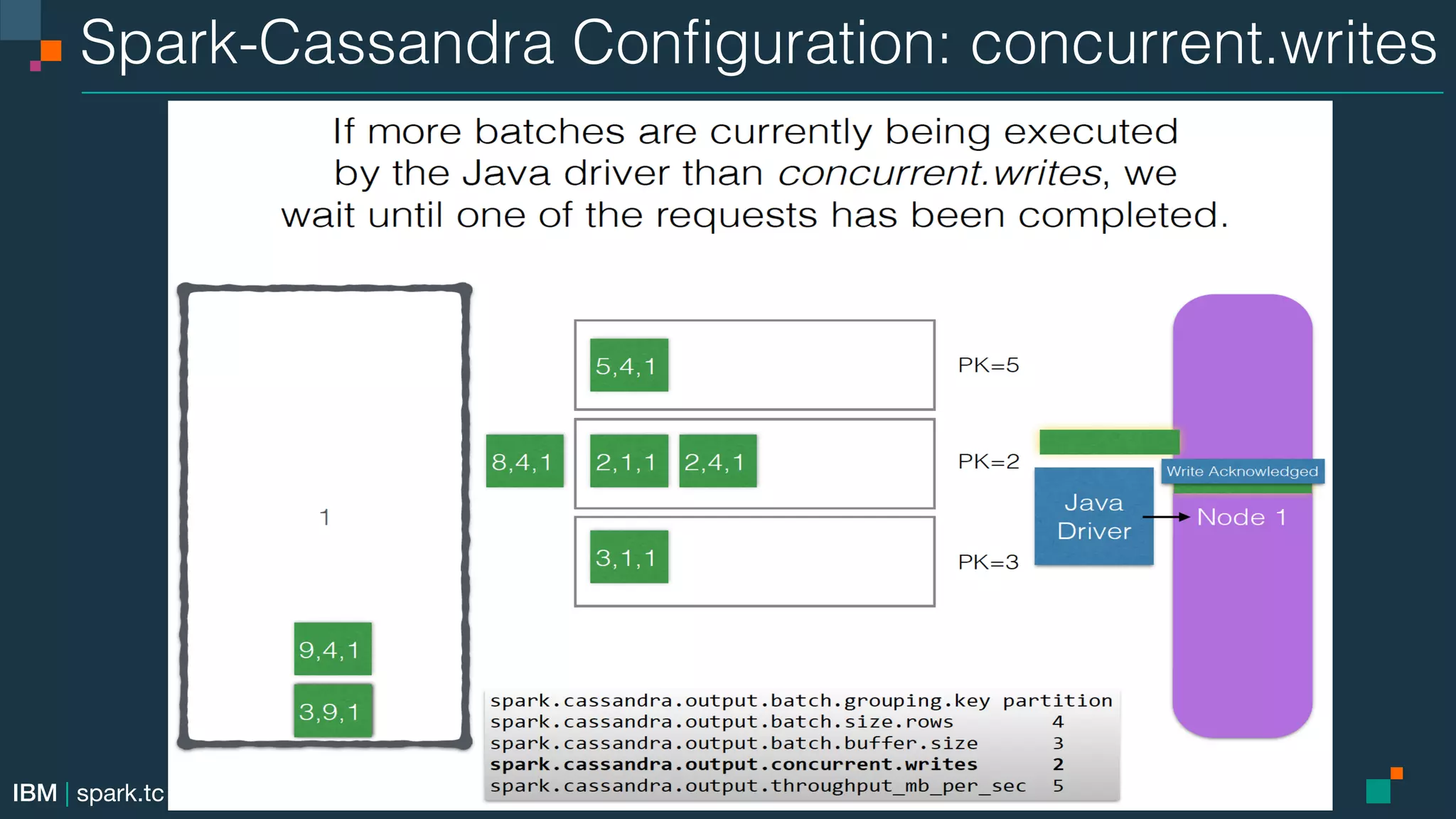

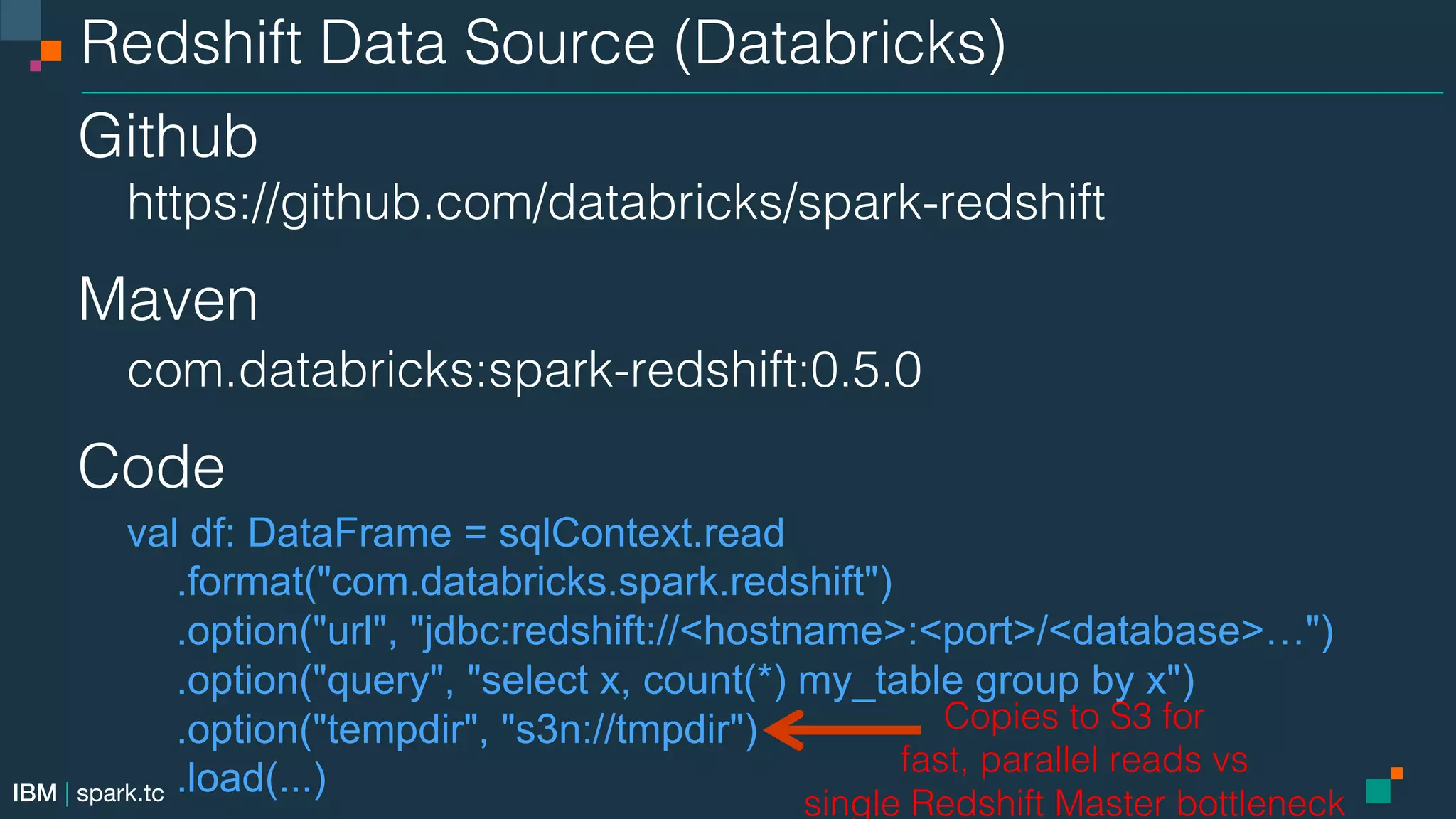







This document summarizes an advanced Apache Spark meetup. It includes announcements from the meetup organizer and details about upcoming meetups on Spark SQL, DataFrames, the Catalyst optimizer, and data sources. Performance tuning tips for Spark SQL are also provided.