Downloaded 11 times






![Actions Model actions depending on what you want as vertices (Bill)-[:SENT]->(email)-[:TO]->(Jim) OR (Bill)-[:EMAILED]->(Jim) 7](https://image.slidesharecdn.com/graphdatabaseusecasesv2-220912194314-202073e4/75/Advanced-Analytics-Graph-Database-Use-Cases-7-2048.jpg)




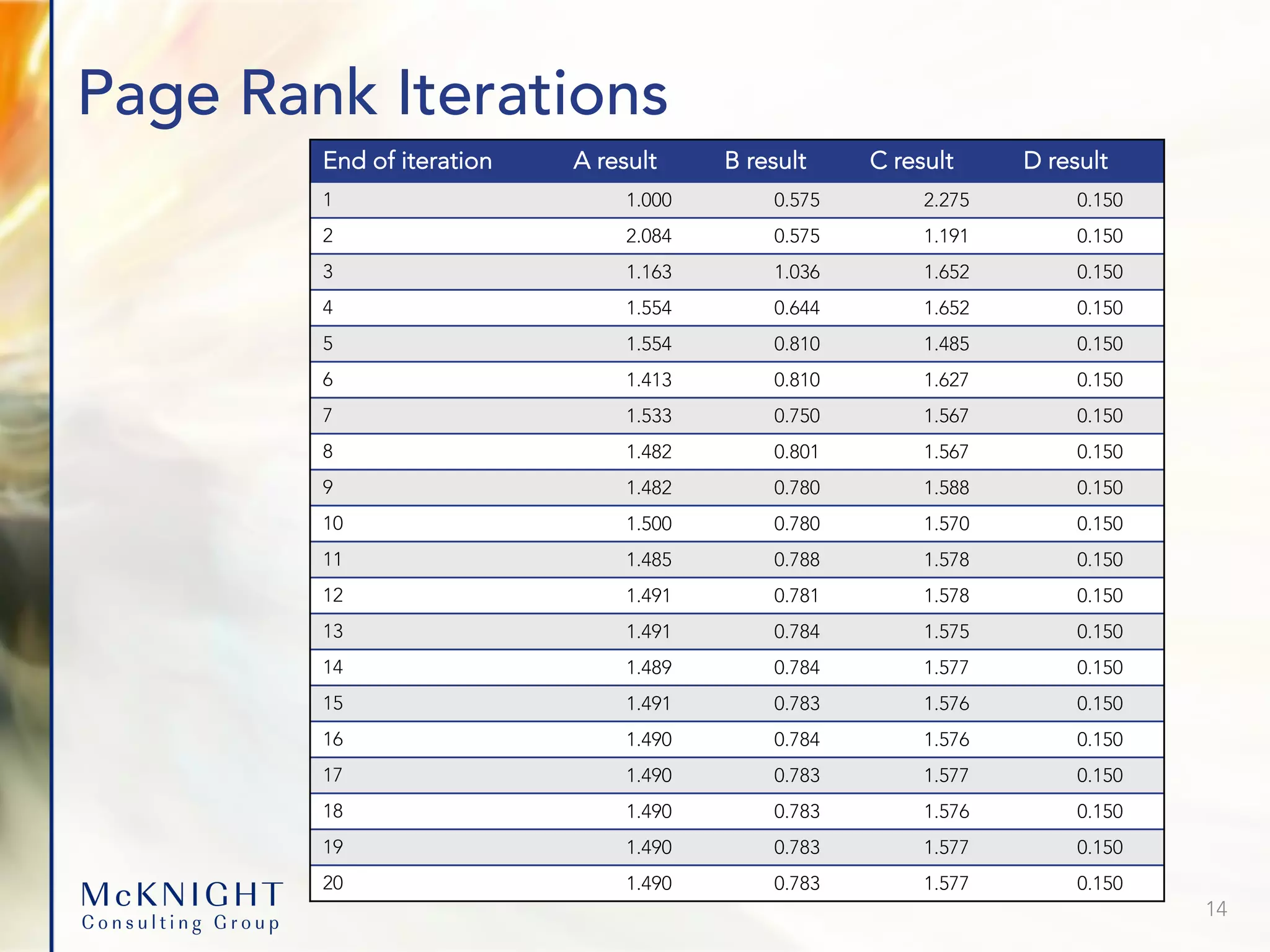


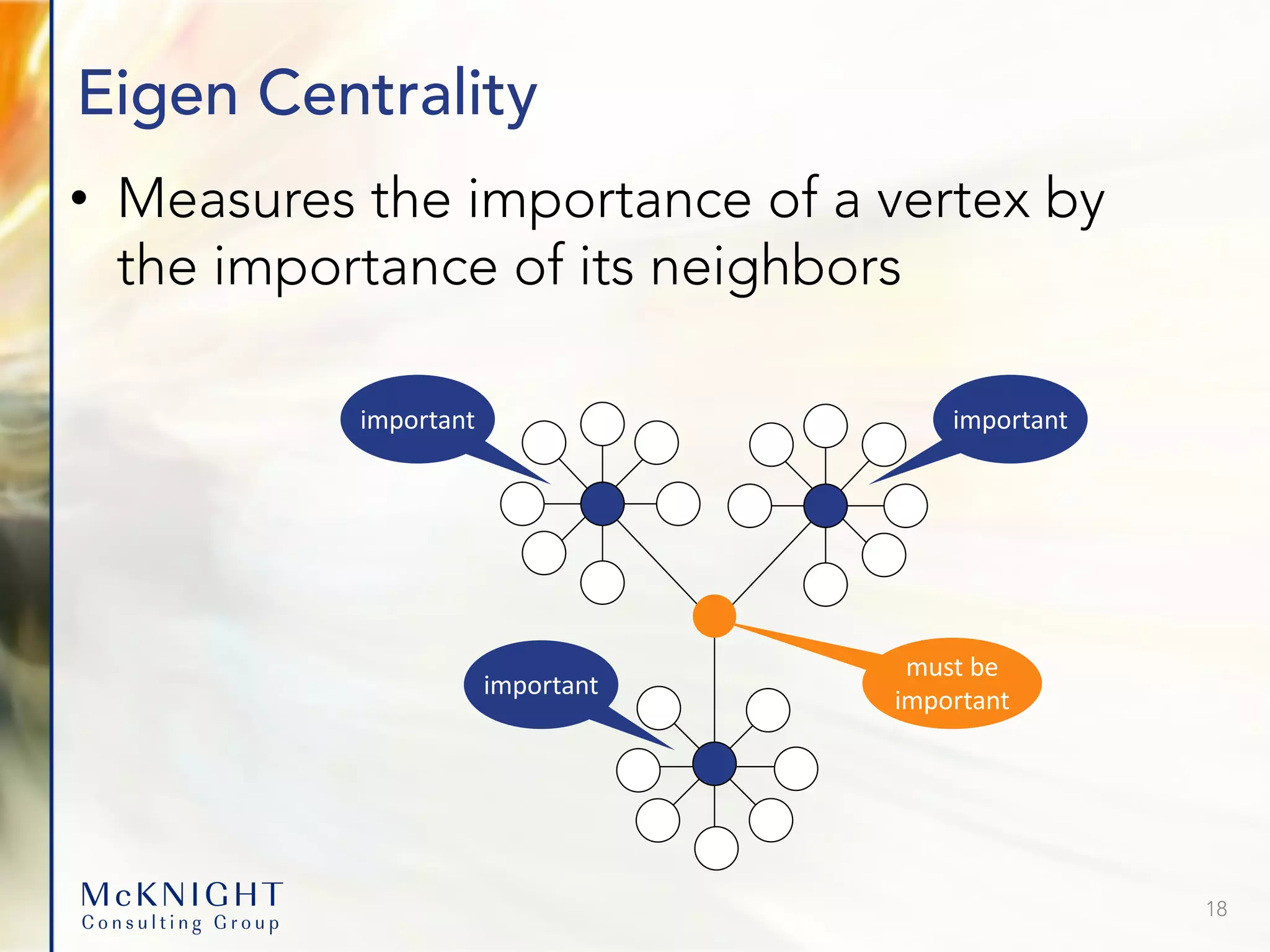
![Clustering Coefficient: Cascading Churn 19 If two people churn, what is the likelihood others will? The two churners affect the central influencer Finally: All contacts churn. An Individual-focused model underestimates churn by 6X. SELECT * FROM LocalClusteringCoefficient( ON Calls as edges PARTITION BY caller_from ON caller_from as vertices PARTITION BY caller_id targetKey(caller_to') directed('f') degreeRange('[3:]') accumulate('personId') );](https://image.slidesharecdn.com/graphdatabaseusecasesv2-220912194314-202073e4/75/Advanced-Analytics-Graph-Database-Use-Cases-19-2048.jpg)









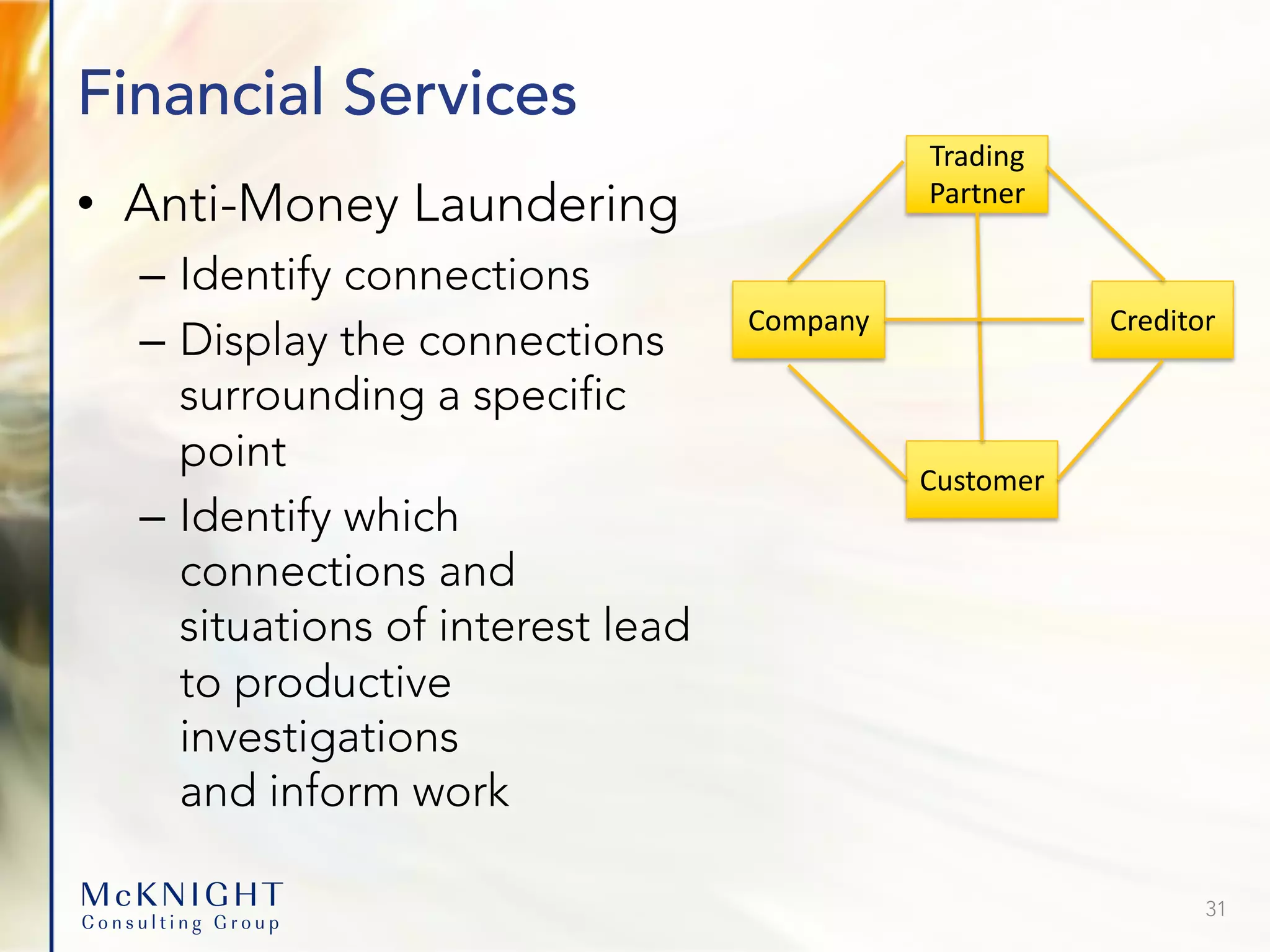



The document presents various use cases for graph databases, emphasizing their efficiency in managing complex relationships and real-time data interactions compared to traditional relational databases. Key topics include analytics trends, master data management, and the applications of graph databases in sectors such as healthcare fraud detection, online shopping, and automotive industries. Overall, the document advocates for reimagining data as graphs to enhance performance and insights across diverse applications.