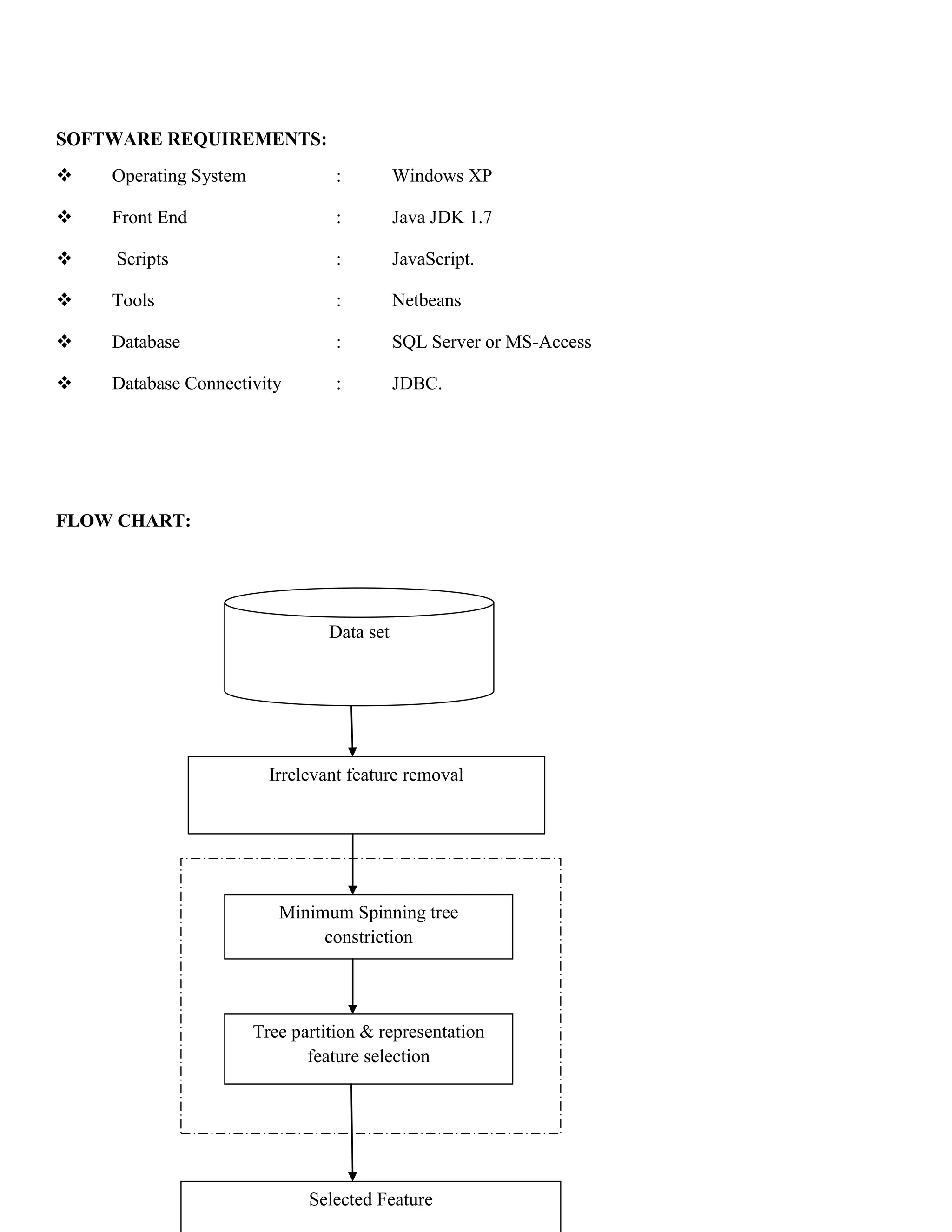
This document presents a novel fast clustering-based feature selection algorithm designed for high-dimensional data, which aims to effectively identify and eliminate irrelevant and redundant features. The algorithm operates in two steps: clustering features using graph-theoretic methods and selecting the most representative features from each cluster, demonstrating improved efficiency and effectiveness compared to existing algorithms. Experimental results indicate that the proposed algorithm significantly enhances the performance of various classifiers across multiple data sets.







![data from the four different aspects of the proportion of selected features, runtime, classification accuracy of a given classifier, and the Win/Draw/Loss record. Generally, the proposed algorithm obtained the best proportion of selected features, the best runtime, and the best classification accuracy for Naive, and RIPPER, and the second best classification accuracy for IB1. The Win/Draw/Loss records confirmed the conclusions. We also found that FAST obtains the rank of 1 for microarray data, the rank of 2 for text data, and the rank of 3 for image data in terms of classification accuracy of the four different types of classifiers, and CFS is a good alternative. At the same time, FCBF is a good alternative for image and text data. Moreover, Consist, and FOCUS-SF are alternatives for text data. For the future work, we plan to explore different types of correlation measures, and study some formal properties of feature space. REFERENCES: [1] H. Almuallim and T.G. Dietterich, “Algorithms for Identifying Relevant Features,” Proc. Ninth Canadian Conf. Artificial Intelligence, pp. 38-45, 1992. [2] H. Almuallim and T.G. Dietterich, “Learning Boolean Concepts in the Presence of Many Irrelevant Features,” Artificial Intelligence, vol. 69, nos. 1/2, pp. 279-305, 1994. [3] A. Arauzo-Azofra, J.M. Benitez, and J.L. Castro, “A Feature Set Measure Based on Relief,” Proc. Fifth Int’l Conf. Recent Advances in Soft Computing, pp. 104-109, 2004. [4] L.D. Baker and A.K. McCallum, “Distributional Clustering of Words for Text Classification,” Proc. 21st Ann. Int’l ACM SIGIR Conf. Research and Development in information Retrieval, pp. 96-103, 1998. [5] R. Battiti, “Using Mutual Information for Selecting Features in Supervised Neural Net Learning,” IEEE Trans. Neural Networks, vol. 5, no. 4, pp. 537-550, July 1994. [6] D.A. Bell and H. Wang, “A Formalism for Relevance and Its Application in Feature Subset Selection,” Machine Learning, vol. 41, no. 2, pp. 175-195, 2000. [7] J. Biesiada and W. Duch, “Features Election for High-Dimensional data a Pearson Redundancy Based Filter,” Advances in Soft Computing, vol. 45, pp. 242-249, 2008.](https://image.slidesharecdn.com/afastclustering-basedfeaturesubsetselectionalgorithmforhigh-dimensionaldata-131008063555-phpapp01/75/DOTNET-2013-IEEE-CLOUDCOMPUTING-PROJECT-A-fast-clustering-based-feature-subset-selection-algorithm-for-high-dimensional-data-9-2048.jpg)
![[8] R. Butterworth, G. Piatetsky-Shapiro, and D.A. Simovici, “On Feature Selection through Clustering,” Proc. IEEE Fifth Int’l Conf. Data Mining, pp. 581-584, 2005. [9] C. Cardie, “Using Decision Trees to Improve Case-Based Learning,” Proc. 10th Int’l Conf. Machine Learning, pp. 25-32, 1993. [10] P. Chanda, Y. Cho, A. Zhang, and M. Ramanathan, “Mining of Attribute Interactions Using Information Theoretic Metrics,” Proc. IEEE Int’l Conf. Data Mining Workshops, pp. 350-355, 2009. [11] S. Chikhi and S. Benhammada, “ReliefMSS: A Variation on a Feature Ranking Relieff Algorithm,” Int’l J. Business Intelligence and Data Mining, vol. 4, nos. 3/4, pp. 375-390, 2009. [12] W. Cohen, “Fast Effective Rule Induction,” Proc. 12th Int’l Conf. Machine Learning (ICML ’95), pp. 115- 123, 1995. [13] M. Dash and H. Liu, “Feature Selection for Classification,” Intelligent Data Analysis, vol. 1, no. 3, pp. 131-156, 1997. [14] M. Dash, H. Liu, and H. Motoda, “Consistency Based Feature Selection,” Proc. Fourth Pacific Asia Conf. Knowledge Discovery and Data Mining, pp. 98-109, 2000. [15] S. Das, “Filters, Wrappers and a Boosting-Based Hybrid for Feature Selection,” Proc. 18th Int’l Conf. Machine Learning, pp. 74- 81, 2001.](https://image.slidesharecdn.com/afastclustering-basedfeaturesubsetselectionalgorithmforhigh-dimensionaldata-131008063555-phpapp01/75/DOTNET-2013-IEEE-CLOUDCOMPUTING-PROJECT-A-fast-clustering-based-feature-subset-selection-algorithm-for-high-dimensional-data-10-2048.jpg)