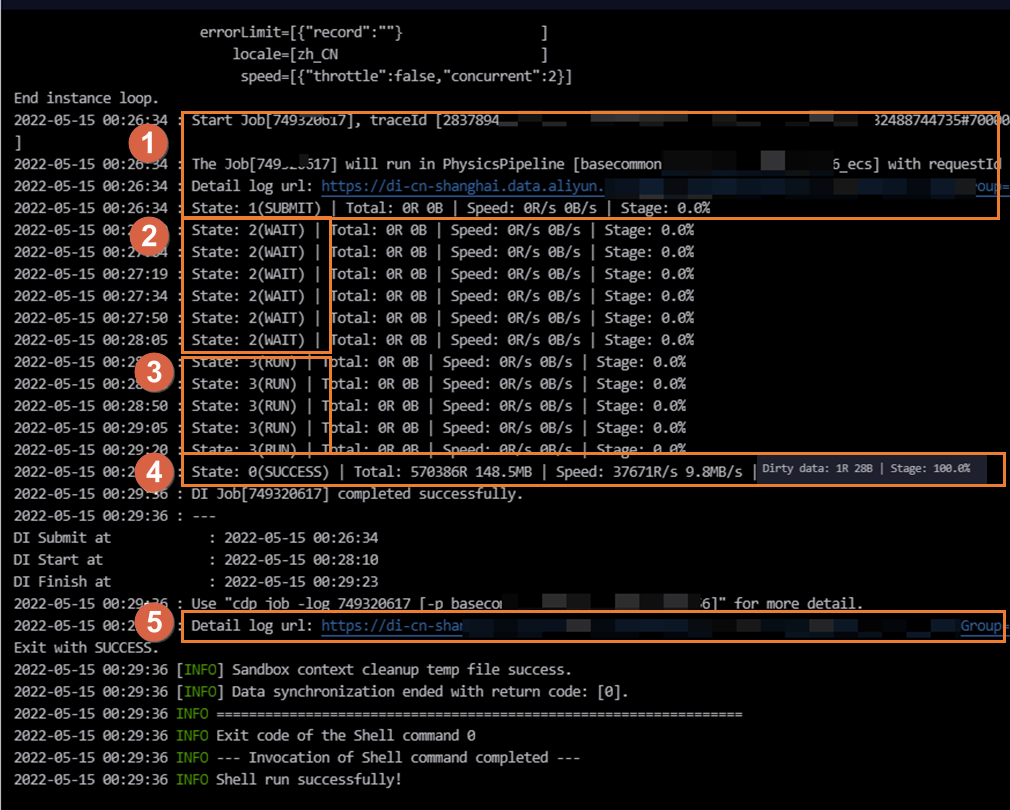
Area | Parameter | Description |
Submit instance (Area ①) | SUBMIT: The `SUBMIT` status indicates that the sync task has been submitted from the CDN mapping system to the resource group for Data Integration task execution. This means the sync task has finished rendering. | The CDN mapping system dispatches the task to a resource group for execution. You can view the Data Integration resource group used by the current task in Area ①. The log output differs depending on the resource group type: If the task runs on the default resource group, the log contains the following information. running in Pipeline[basecommon_ group_xxxxxxxxx]
If the task runs on an exclusive resource group for Data Integration, the log contains the following information. running in Pipeline[basecommon_S_res_group_xxx]
If the task runs on a serverless resource group, the log contains the following information. running in Pipeline[basecommon_Serverless_res_group_xxx]
Note You can also click Detail log url in this area to view the detailed logs for each stage. |
Request resources (Area ②) | WAIT: The `WAIT` status indicates that the sync task is waiting for resources for Data Integration task execution. | If a task waits for a long time for Data Integration resources, other tasks might be using the resources on that resource group. This means that no resources are available for the current task. To resolve this issue, use one of the following solutions: Wait for the tasks that are using the Data Integration resource group to finish and release their resources. Then, run your task again. To identify the tasks that are using the resources, see Scenarios and solutions for slow data synchronization. Find the list of tasks that are using the resources and identify their owners. Coordinate with the owners to reduce task concurrency. Reduce the concurrency of the current sync task. Then, submit and publish the task again. Scale out the resource group for task execution. For more information, see Scale-out and scale-in operations.
|
Start synchronization (Area ③) | RUN: The `RUN` status indicates that the sync task is running. | A batch synchronization task runs in four stages: Pre-preparation The system sends a pre-SQL statement to the database for execution based on your configuration. Not all tasks have a pre-preparation stage. For a MySQL Writer, if you configure a PreSQL statement for the task, the SQL statement is sent to the database and executed in this stage. For a MySQL Reader, if you configure a querySql statement or a data filter (where) clause, these SQL statements are sent to the database and executed in this stage. For example, when you write data to MaxCompute, a task can be configured to Delete Existing Data Before Writing.
Note Use an index field for the filter condition. This helps prevent the SQL statement from taking too long to execute in the database. A long execution time can increase the overall sync time or cause the sync task to time out and fail. Split (shard) task In this stage, the source data is split into multiple subtasks for concurrent batch reading. The splitting rules are as follows: Relational database: Data is split into multiple subtasks based on the splitPk (shard key) that you specify in the interface. The subtasks are then read concurrently in batches. If you do not set a shard key, the data is synchronized using a single concurrent thread. LogHub, DataHub, or MongoDB: Data is split based on the number of shards. The maximum task concurrency cannot exceed the number of shards. Semi-structured storage: Data is split based on the number of files or the data volume. For example, for an OSS task, the maximum concurrency cannot exceed the number of files.
Synchronize data In this stage, the subtasks are synchronized in batches based on your configured concurrency. For a relational database, multiple data retrieval SQL statements are created based on the shard key. These statements are used to retrieve data from the database separately. For more information, see Relationship between batch synchronization concurrency and rate limiting.
Note The actual concurrency during execution may not be the same as the concurrency you set. The data retrieval SQL statements generated from the shard key can cause problems if the shard key is not set correctly. The SQL statements might run for a long time in the database, which increases the overall sync time. They could also time out and cause the sync task to fail. If the database load is high, task execution may also slow down.
Post-preparation The system sends a post-SQL statement to the database for execution based on your configuration. Not all tasks have a post-preparation stage: For a MySQL Writer, if you configure a PostSQL statement for the task, the SQL statement is sent to the database and executed in this stage after data synchronization is complete. The execution time of the PostSQL statement in the database also affects the total running time of the sync task.
|
Execution complete (Area ④) | The task completion status can be one of the following: | If the task fails, a key error message is recorded in the log. You can click the link in Area ⑤ to view the detailed execution process for each stage. If the task succeeds, information such as the total number of synchronized data records and the average synchronization speed is recorded in the log.
Note If dirty data is generated during synchronization, the log shows Dirty data: xxR. The dirty data is not written to the destination. If a large amount of dirty data is generated, this affects the data synchronization speed. If you have requirements for synchronization speed, you must first resolve the dirty data issue. For more information about dirty data, see Features of batch synchronization task configuration. You can control whether dirty data affects normal task execution by configuring the dirty data toleration count. By default, batch synchronization tasks are configured to tolerate dirty data. You can change this setting in the task configuration interface. For information about how to configure a task in the codeless UI, see Configure a task in the codeless UI. For information about how to configure a task in the code editor, see Configure a task in the code editor.
|
Detailed log link (Area ⑤) | Provides a link to the detailed log. | Click the detailed log link to view the detailed logs for each stage of the execution process. |