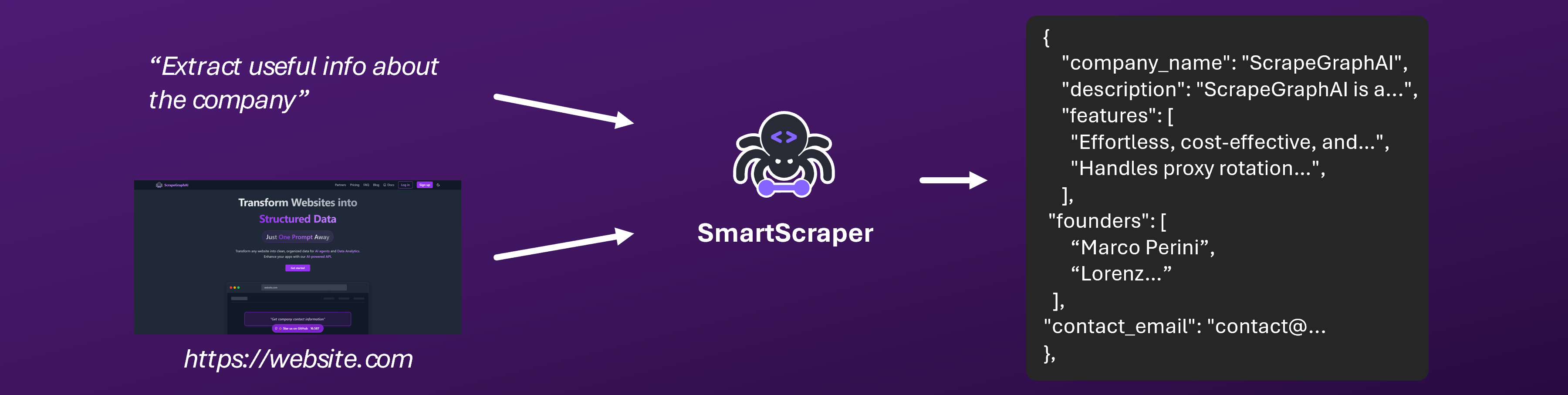
Overview
SmartScraper is our flagship LLM-powered web scraping service that intelligently extracts structured data from any website. Using advanced LLM models, it understands context and content like a human would, making web data extraction more reliable and efficient than ever.Try SmartScraper instantly in our interactive playground - no coding required!
Getting Started
Quick Start
Parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
| apiKey | string | Yes | The ScrapeGraph API Key. |
| websiteUrl | string | Yes | The URL of the webpage that needs to be scraped. |
| prompt | string | Yes | A textual description of what you want to achieve. |
| schema | object | No | The Pydantic or Zod object that describes the structure and format of the response. |
| render_heavy_js | boolean | No | Enable enhanced JavaScript rendering for heavy JS websites (React, Vue, Angular, etc.). Default: false |
| mock | boolean | no | If you want mock data for testing |
| plain_text | boolean | no | If you want result as plain text instead of Json |
Get your API key from the dashboard
Enhanced JavaScript Rendering
For websites that heavily rely on JavaScript frameworks like React, Vue, Angular, or other Single Page Applications (SPAs), enable therender_heavy_js parameter to ensure complete content rendering before extraction. When to Use render_heavy_js
Enable this parameter for: - React/Vue/Angular Applications: Modern web apps built with JavaScript frameworks
- Single Page Applications (SPAs): Sites that load content dynamically via JavaScript
- Heavy JavaScript Sites: Websites with complex client-side rendering
- Dynamic Content: Pages where content appears after JavaScript execution
- Interactive Elements: Sites with JavaScript-dependent content loading
Enhanced JavaScript Rendering Example
Enhanced JavaScript Rendering Example
Here’s how to use
render_heavy_js for modern web applications:cURL
Performance Considerations
- Enhanced Rendering:
render_heavy_js=trueprovides more thorough JavaScript execution - Processing Time: May take slightly longer due to enhanced rendering capabilities
- Use When Needed: Only enable for sites that actually require it to avoid unnecessary overhead
- Default Behavior: Standard rendering works for most websites
Pro Tip: If you’re getting incomplete or missing data from a modern web application, try enabling
render_heavy_js=true to ensure all JavaScript-rendered content is captured.Example Response
Example Response
request_id: Unique identifier for tracking your requeststatus: Current status of the extraction (“completed”, “running”, “failed”)result: The extracted data in structured JSON formaterror: Error message (if any occurred during extraction)
Using Your Own HTML
Using Your Own HTML
Instead of providing a URL, you can optionally pass your own HTML content:This is useful when:
- You already have the HTML content cached
- You want to process modified HTML
- You’re working with dynamically generated content
- You need to process content offline
- You want to pre-process the HTML before extraction
When both
website_url and website_html are provided, website_html takes precedence and will be used for extraction.Key Features
Universal Compatibility
Works with any website structure, including JavaScript-rendered content
AI Understanding
Contextual understanding of content for accurate extraction
Structured Output
Returns clean, structured data in your preferred format
Schema Support
Define custom output schemas using Pydantic or Zod
Use Cases
Content Aggregation
- News article extraction
- Blog post summarization
- Product information gathering
- Research data collection
Data Analysis
- Market research
- Competitor analysis
- Price monitoring
- Trend tracking
AI Training
- Dataset creation
- Training data collection
- Content classification
- Knowledge base building
Want to learn more about our AI-powered scraping technology? Visit our main website to discover how we’re revolutionizing web data extraction.
Other Functionality
Retrieve a previous request
If you know the response id of a previous request you made, you can retrieve all the information.Parameters
| Parameter | Type | Required | Description |
|---|---|---|---|
| apiKey | string | Yes | The ScrapeGraph API Key. |
| requestId | string | Yes | The request ID associated with the output of a previous smartScraper request. |
Custom Schema Example
Define exactly what data you want to extract:Async Support
For applications requiring asynchronous execution, SmartScraper provides comprehensive async support through theAsyncClient: Infinite Scroll Support
SmartScraper can handle infinite scroll pages by automatically scrolling to load more content before extraction. This is perfect for social media feeds, e-commerce product listings, and other dynamic content.Parameters for Infinite Scroll
| Parameter | Type | Required | Description |
|---|---|---|---|
| number_of_scrolls | number | No | Number of times to scroll down to load more content (default: 0) |
Infinite scroll is particularly useful for:
- Social media feeds (Twitter, Instagram, LinkedIn)
- E-commerce product listings
- News websites with continuous scrolling
- Any page that loads content dynamically as you scroll
SmartScraper Endpoint
The SmartScraper endpoint is our core service for extracting structured data from any webpage using advanced language models. It automatically adapts to different website layouts and content types, enabling quick and reliable data extraction.Key Capabilities
- Universal Compatibility: Works with any website structure, including JavaScript-rendered content
- Schema Validation: Supports both Pydantic (Python) and Zod (JavaScript) schemas
- Concurrent Processing: Efficient handling of multiple URLs through async support
- Custom Extraction: Flexible user prompts for targeted data extraction
Endpoint Details
Required Headers
| Header | Description |
|---|---|
| SGAI-APIKEY | Your API authentication key |
| Content-Type | application/json |
Request Body
| Field | Type | Required | Description |
|---|---|---|---|
| website_url | string | Yes* | URL to scrape (*either this or website_html required) |
| website_html | string | No | Raw HTML content to process |
| user_prompt | string | Yes | Instructions for data extraction |
| output_schema | object | No | Pydantic or Zod schema for response validation |
| render_heavy_js | boolean | No | Enable enhanced JavaScript rendering for heavy JS websites (React, Vue, Angular, etc.). Default: false |
| mock | boolean | no | If you want mock data for testing |
Response Format
Best Practices
- Schema Definition:
- Define schemas to ensure consistent data structure
- Use descriptive field names and types
- Include field descriptions for better extraction accuracy
- Async Processing:
- Use async clients for concurrent requests
- Implement proper error handling
- Monitor rate limits and implement backoff strategies
- Error Handling:
- Always wrap requests in try-catch blocks
- Check response status before processing
- Implement retry logic for failed requests
Integration Options
Official SDKs
- Python SDK - Perfect for data science and backend applications
- JavaScript SDK - Ideal for web applications and Node.js
AI Framework Integrations
- LangChain Integration - Use SmartScraper in your LLM workflows
- LlamaIndex Integration - Build powerful search and QA systems
Best Practices
Optimizing Extraction
- Be specific in your prompts
- Use schemas for structured data
- Handle pagination for multi-page content
- Implement error handling and retries
Rate Limiting
- Implement reasonable delays between requests
- Use async clients for better performance
- Monitor your API usage
Example Projects
Check out our cookbook for real-world examples:- E-commerce product scraping
- News aggregation
- Research data collection
- Content monitoring
API Reference
For detailed API documentation, see:Support & Resources
Documentation
Comprehensive guides and tutorials
API Reference
Detailed API documentation
Community
Join our Discord community
GitHub
Check out our open-source projects
Ready to Start?
Sign up now and get your API key to begin extracting data with SmartScraper!